引文中的依赖性统计(信息论、相关和其他特征选择方法)。
好样的,阿列克谢,我没想到你会是那个让你的名字感到惊讶的人(看在上帝的份上原谅我,但我还是对我们论坛的平均成熟度有一个概念)。
很高兴你和我的方法差不多,降到相互信息I()和以百分之一为单位的粗略估计。的确,我没有使用Kolmogorov-Smirnov检验。而且我花的时间不是几天,而是几个小时(有更多的数据,结论也更可靠)。И...我以一种稍微不同的方式将增量离散化。
我想,这对枢纽来说真的有点太陡了。他们只是IT人员,虽然非常聪明 :)(看看雪儿的 评论,她得到了评级+3,即最高评级)。
我有几个问题要问你--我稍后会亲自写信。在这里,我将暂时观察:突然会有其他有知识的人出现......。
阿列克谢,谢谢你...很高兴你欣赏它,事实上,在看了你的研究成果总结后,我终于燃起了这个想法。
当然,研究的一些具体内容可以改变。我自己长期以来一直在思考如何更好地将数值离散化,并止步于四舍五入这样一个简单的方法。
而且我也已经为欧元兑美元的H1做了分析。从Alpari那里得到了10年(64500条)的报价。在这里,它是。
。")
我还用箭头标记了每周的滞后情况:在我看来,它们在某种程度上很突出。
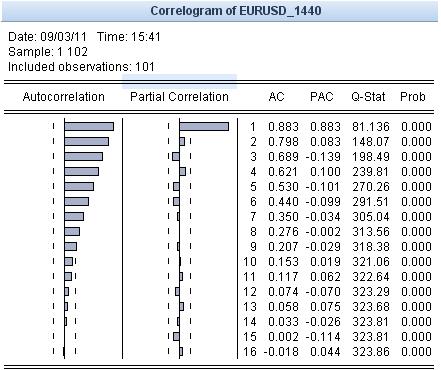
这就是这个系列的自相关函数的样子。
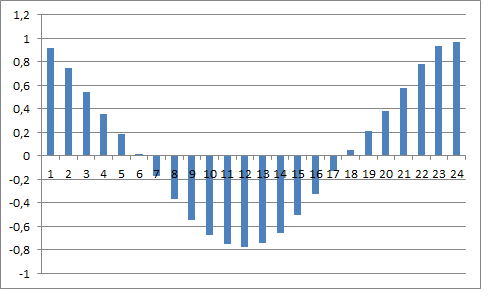
总而言之,你可以看到一个严格的24小时周期性。这也可以讨论。
顺便说一下,我把这里的增量也四舍五入到了10点(因为这样,数据的熵变成了大约2.5比特)。另外,我无法耕耘更多的变量,比如说在潜心研究一年的历史的情况下。Excel把电脑挂得很紧,吞噬了4GB的内存。身体上做不到,尽管这个想法肯定存在。
顺便说一下,卡方给出了大致相同的情况:随着滞后期的增加,每隔24个柱子就有一个体面的标准值峰值。
P.S. 我想强调的是,这里的ACF并不是由回报的数量来计算的,而是由过去的报价传递到零条的平均信息流。如果我们取一个特定的零条进行计算,流向它的信息将被不同地计算。
可以得出结论,在自然金融数据中(至少对于道琼斯指数而言),报价的增量之间存在着统计学上显著的任意关系。也就是说,这样的一系列数据不能被认为是随机的。从理论上讲,存在着预测这种系列的未来值的空间,例如,使用神经网络。
发现这种关系的事实可以用众所周知的事实来解释,即波动性取决于以前的数值。你甚至可以通过你的增量图用肉眼看到它。有一些理论模型可以描述波动率的依赖性--比如ARCH/GARCH。
这就是为什么24小时的周期会在一天内形成--外汇市场上的牛有固定的周期行为。
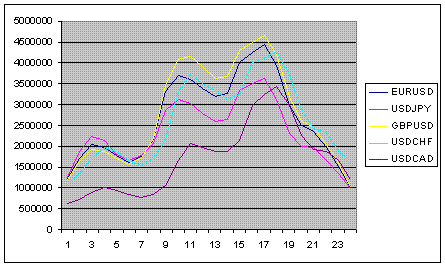
这只是与不同金融中心的开放和关闭时间有关。交易活动的变化。如果你用一枚硬币作为数据源))),那么它就会开始频繁地被抛出,然后同时减少。
此外,还有一个每周的波动周期,但它没有股票市场那么明显。只是每天都有5个的滞后性;)
因此,这不是一个预测报价变化方向的论据(这正是我们感兴趣的)。比较的对象应该是由真实的波动率产生的随机序列(例如,tick volume)。即在生成过程中对分布的依赖性。否则,很多统计学测试 恰恰确定了波动率的依赖性,而不是增量的方差
否则,很多统计测试都是准确地确定波动率的依赖性,而不是对增量的修正。
而这是正确的。我自己也是这样过来的,只是没有把我的想法都贴在这里。
顺便说一下,卡方给出了大致相同的情况:随着滞后期的增加,每隔24个柱子就有一个体面的标准值峰值。
P.S. 我想强调的是,这里的ACF并不是由回报的数量来计算的,而是由过去的报价传递到零条的平均信息流。如果我们取一个特定的零条进行计算,流向它的信息将被不同地计算。
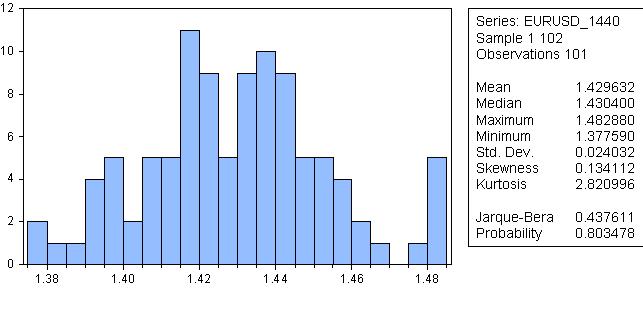
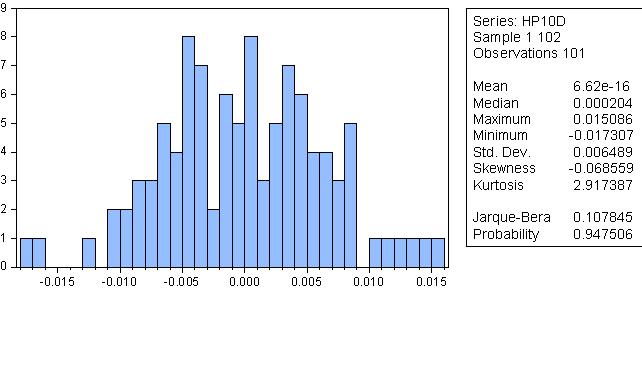
是的,直方图是由相互信息的数值计算出来的,我只是把它拿出来确认周期性的想法。
有什么好讨论的呢?长期以来,盘面周期性是一个众所周知的事实。甚至有完全不懂数学,但懂市场的人也指出了这一点。此外,即使在特定交易大厅的交易时段内,也存在周期性。它本身并不接近于对应该做什么的理解。不过,可以从中提取一点优势。
我理解。我们应该采取一天或更长时间的时间框架。

下午好!
我决定稍微发展一下Alexey(Mathemat)在论坛的一个主题中触及的话题。
我试图用统计学方法搜索一种金融工具的报价中的依赖关系。首先,我采取了道琼斯工业指数,每日数据,并将一系列的系列转换为百分比增量的系列。
这篇文章实际上在这里: http://habrahabr.ru/blogs/data_mining/127394/
我想继续进行外汇报价,我将在这里公布结果。