Redes neuronales: así de sencillo (Parte 77): Transformador de covarianza cruzada (XCiT)

Introducción
Los transformadores muestran un gran potencial para resolver problemas de análisis de diversas secuencias. La operación Self-Attention que subyace a los transformadores, proporciona interacciones globales entre todos los tokens de la secuencia. Esto permite evaluar las interdependencias dentro de toda la secuencia analizada. Sin embargo, esto conlleva una complejidad cuadrática en términos de tiempo de cálculo y uso de memoria, lo que dificulta la aplicación del algoritmo a secuencias largas.
Para resolver este problema, los autores del artículo "XCiT: Cross-Covariance Image Transformers" sugirieron una versión "transpuesta" de Self-Attention, que opera a través de canales de características en lugar de fichas, donde las interacciones se basan en una matriz de covarianza cruzada entre claves y consultas. El resultado es una atención de covarianza cruzada (XCA, Cross-Covariance Attention) con una complejidad lineal en el número de tokens, lo que permite un procesamiento eficaz de grandes secuencias de datos. El transformador de imagen de covarianza cruzada (XCiT), basado en XCA, combina la precisión de los transformadores convencionales con la escalabilidad de las arquitecturas convolucionales. Ese artículo confirma experimentalmente la eficacia y generalidad de XCiT. Los experimentos presentados demuestran excelentes resultados en varias pruebas visuales, como la clasificación de imágenes, la detección de objetos y la segmentación de instancias.
1. Algoritmo XCiT
Los autores del método proponen la función Self-Attention basada en la covarianza cruzada, que opera a lo largo de la dimensión del rasgo en lugar de a lo largo de la dimensión del token, como en los tokens clásicos de Self-Attention. Utilizando las definiciones Query, Key y Value, la función de atención de la covarianza cruzada se define como:
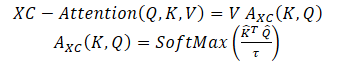
Donde cada incrustación de token de salida es una combinación convexa de las características dv de su correspondiente incrustación de token en V. Los pesos de atención A se calculan a partir de la matriz de covarianzas cruzadas.
Además de construir una nueva función de atención basada en la matriz de covarianza cruzada, los autores del método proponen restringir la magnitud de las matrices Query y Key normalizándolas en L2 de forma que cada columna de longitud N de las matrices normalizadas Q y K tuviera norma unitaria. Cada elemento de la matriz de covarianzas cruzadas de los coeficientes de atención de tamaño d*d estaba en el intervalo [-1, 1]. Los autores del método afirman que el control de normas aumenta significativamente la estabilidad del aprendizaje, especialmente cuando se aprende con un número variable de fichas. Sin embargo, restringir la norma reduce el poder de representación de la operación al eliminar grados de libertad. Por ello, los autores introducen un parámetro de temperatura entrenable τ que escala los productos internos antes de realizar la normalización mediante la función SoftMax, permitiendo una distribución más nítida o uniforme de los pesos de atención.
Además, los autores del método limitan el número de características que interactúan entre sí. Proponen dividirlos en grupos de h, o "cabezas" (heads), similares a los tokens de Self-Attention de varias cabezas. Para cada cabeza, los autores del método aplican por separado la atención a la covarianza cruzada.
Para cada cabeza, entrenan matrices de pesos separadas de proyección de datos de origen X a Query, Key y Value. Las matrices de pesos correspondientes se recogen en tensores Wq de dimensiones {h * d * dq}, Wk - {h * d * dk} и Wv — {h * d * dv} \). Establecen dk = dq = dv = d/h.
Restringir la atención a las cabezas tiene dos ventajas:
- La complejidad de agregar valores con pesos de atención se reduce en un factor h;
- Y lo que es más importante, los autores del método demuestran empíricamente que la versión de matriz diagonal en bloque es más fácil de optimizar y, en general, conduce a mejores resultados.
Los tokens de Self-Attention clásicos con h cabezas tienen una complejidad temporal de O(N^2 * d) y una complejidad de memoria de O(hN^2 + Nd). Debido a la complejidad cuadrática, es problemático escalar los tokens de Self-Attention para secuencias con un gran número de tokens. La atención de covarianza cruzada propuesta supera este inconveniente porque su complejidad computacional O(Nd^2/h) escala linealmente con el número de fichas. Lo mismo ocurre con la complejidad de memoria O(d^2 / h + Nd).
Por lo tanto, el modelo XCA propuesto por los autores escala mucho mejor en los casos en que el número de tokens N es grande, y la dimensión de rasgo d es relativamente pequeña, especialmente cuando se dividen los rasgos en h cabezas.
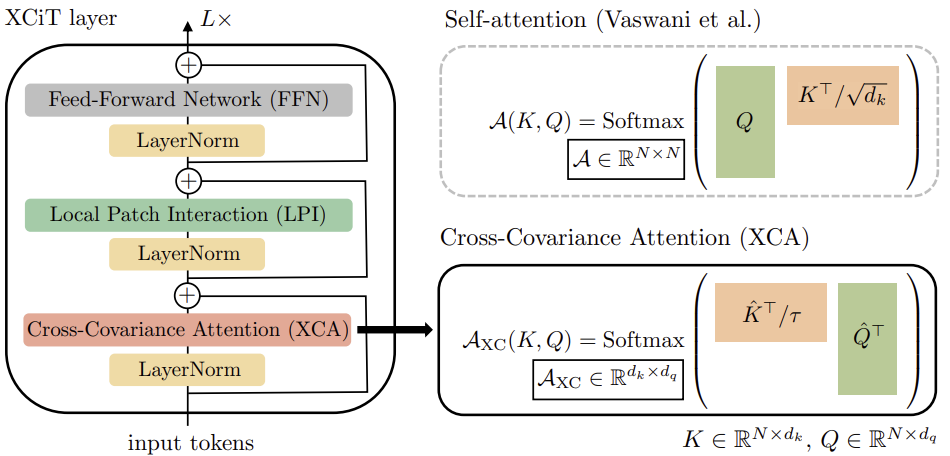
Para construir imágenes del transformador de covarianza cruzada (XCiT), los autores del método proponen una arquitectura columnar que mantiene la misma resolución espacial en todas las capas. Combinan el bloque de atención a la covarianza cruzada (XCA) con 2 módulos adicionales posteriores, cada uno de los cuales va precedido de una normalización dentro de la capa.
En el bloque XCA, la comunicación entre parches se realiza sólo indirectamente a través de estadísticas compartidas. Para proporcionar una comunicación explícita entre parches, los autores del método añaden un bloque simple de interacción local entre parches (LPI) después de cada bloque XCA. LPI consta de dos capas convolucionales y una capa de normalización por lotes entre ellas. Como función de activación de la primera capa, sugieren utilizar GELU. Debido a su profunda estructura de bloques, LPI tiene una sobrecarga de parámetros insignificante y una sobrecarga de ancho de banda y memoria muy limitada.
Como es común en los modelos de transformadores, se añade a continuación una Red Neuronal Feed-Forward (FFN, Feed-Forward Network) con capas convolucionales punto a punto, que tiene una capa oculta con bloques ocultos de 4d. Mientras que las interacciones entre rasgos están limitadas en grupos dentro del bloque XCA, y no hay interacción entre los rasgos en el bloque LPI, FFN permite la interacción con todos los rasgos.
A diferencia del mapa de atención incluido en los tokens de Self-Attention, los bloques de covarianza en XCiT tienen un tamaño fijo, independientemente de la resolución de la secuencia de entrada. SoftMax trabaja siempre con el mismo número de elementos, lo que puede explicar por qué los modelos XCiT se comportan mejor cuando se trabaja con imágenes de diferentes resoluciones. XCiT incluye codificación posicional senoidal aditiva con tokens de entrada.
A continuación se presenta la visualización del algoritmo por parte de los autores.
2. Implementación en MQL5
Tras considerar los aspectos teóricos del Transformador de Variación Cruzada (XCiT), pasamos a la implementación práctica de los enfoques propuestos utilizando MQL5.
2.1 Clase del Transformador de Variación Cruzada (XCiT)
Para implementar el algoritmo de bloques XCiT, crearemos una nueva clase de capa neuronal CNeuronXCiTOCL. Como clase base, usaremos la clase común de atención multi-cabeza y multi-capa CNeuronMLMHAttentionOCL. La nueva clase también se creará con la arquitectura multicapa incorporada.
class CNeuronXCiTOCL : public CNeuronMLMHAttentionOCL { protected: //--- uint iLPIWindow; uint iLPIStep; uint iBatchCount; //--- CCollection cLPI; CCollection cLPI_Weights; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out); virtual bool BatchNorm(CBufferFloat *inputs, CBufferFloat *options, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog); virtual bool BatchNormInsideGradient(CBufferFloat *inputs, CBufferFloat *inputs_g, CBufferFloat *options, CBufferFloat *out, CBufferFloat *out_g, ENUM_ACTIVATION activation); virtual bool BatchNormUpdateWeights(CBufferFloat *options, CBufferFloat *out_g); public: CNeuronXCiTOCL(void) {}; ~CNeuronXCiTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Me gustaría señalar que en la nueva clase haremos el máximo uso de las herramientas de la clase base. Sin embargo, aún tendremos que hacer adiciones significativas. En primer lugar, añadiremos colecciones de búferes para el bloque LPI:
- cLPI – Búferes de resultado y gradiente;
- cLPI_Weights – Matrices de peso y de impulso (momentum).
Además, para el bloque LPI necesitamos constantes adicionales:
- iLPIWindow – Ventana de convolución para la primera capa del bloque;
- iLPIStep – Paso de la ventana de convolución para la primera capa del bloque;
- iBatchCount – El número de operaciones realizadas en la capa de normalización por lotes de bloques.
Especificamos los parámetros de convolución sólo en la primera capa. Ya que en la segunda capa necesitamos alcanzar el tamaño de la capa de datos de origen. Porque los autores del método proponen añadir y normalizar los datos con los resultados del bloque XCA anterior.
En esta clase, todos los objetos añadidos se declaran estáticos, por lo que dejamos vacíos el constructor y el destructor de la capa. La inicialización primaria de la capa se implementa en el método Init. En parámetros, el método recibe todos los parámetros necesarios para inicializar los objetos internos.
bool CNeuronXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
En el cuerpo del método, no organizamos un bloque de control para los parámetros recibidos. En su lugar, llamamos al método de inicialización de la clase base de todas las capas neuronales, que ya implementa los controles mínimos necesarios e inicializa los objetos heredados.
Lo que hay que señalar aquí es que estamos llamando al método de la clase base, no a la clase padre. Esto se debe a que los tamaños de los búferes internos de capa que creamos y su número serán diferentes. Por lo tanto, para evitar la necesidad de realizar el mismo trabajo dos veces, inicializaremos todos los buffers en el cuerpo de nuestro nuevo método de inicialización.
En primer lugar, guardamos los parámetros principales en variables locales.
iWindow = fmax(window, 1); iUnits = fmax(units_count, 1); iHeads = fmax(fmin(heads, iWindow), 1); iWindowKey = fmax((window + iHeads - 1) / iHeads, 1); iLayers = fmax(layers, 1); iLPIWindow = fmax(lpi_window, 1); iLPIStep = 1;
Tenga en cuenta que recalculamos las dimensiones de las entidades internas en función del tamaño del vector de descripción de un elemento de la secuencia y del número de cabezas de atención. Así lo sugieren los autores del método XCiT.
A continuación, determinamos las dimensiones principales de los búferes de cada bloque.
//--- XCA uint num = 3 * iWindowKey * iHeads * iUnits; // Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; // Size of weights' matrix of // QKV tensor uint scores = iWindowKey * iWindowKey * iHeads; // Size of Score tensor uint out = iWindow * iUnits; // Size of output tensor
//--- LPI uint lpi1_num = iWindow * iHeads * iUnits; // Size of LPI1 tensor uint lpi1_weights = (iLPIWindow + 1) * iHeads; // Size of weights' matrix of // LPI1 tensor uint lpi2_weights = (iHeads + 1) * 2; // Size of weights' matrix of // LPI2 tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; // Size of weights' matrix 1-st // feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; // Size of weights' matrix 2-nd // feed forward layer
Después organizamos un bucle con el número de iteraciones igual al número de capas internas.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL;
En el cuerpo del bucle, primero creamos buffers de resultados intermedios y sus gradientes. Para ello, creamos un bucle anidado. En la primera iteración del bucle, creamos buffers de resultados intermedios. En la segunda iteración, creamos los búferes de los gradientes de error correspondientes.
for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Combinemos Query, Key y Value en un buffer concatenado. Esto nos permitirá generar los valores de todas las entidades en una sola pasada para todas las cabezas de atención en hilos paralelos.
A continuación, creamos un buffer reducido de coeficientes de atención de covarianza cruzada.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
El bloque de atención termina con su búfer de resultados.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
El enfoque propuesto por los autores del método para calcular el tamaño de las entidades permite eliminar la capa de reducción de la dimensión del bloque de atención.
A continuación creamos los búferes del bloque LPI. Aquí creamos un buffer de los resultados de la primera capa de convolución.
//--- LPI //--- Initilize LPI tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI1 return false;
A continuación, se almacenan los resultados de la normalización por lotes.
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI Normalize return false;
El bloque termina con el búfer de resultados de la segunda capa convolucional.
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI2 return false;
Por último, creamos los búferes del resultado del bloque FeedForward.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Presta atención a la diferencia con el búfer de resultados de la segunda capa del bloque. Creamos este búfer sólo para los datos intermedios. Para la última capa interna, no creamos nuevos búferes, sino que sólo guardamos un puntero al búfer de resultados previamente creado de nuestra capa.
//--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Crearemos los búferes de la matriz de pesos en el mismo orden.
//--- XCiT //--- Initialize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initialize LPI1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi1_weights)) return false; for(uint w = 0; w < lpi1_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Normalization int count = (int)lpi1_num * (optimization_type == SGD ? 7 : 9); temp = new CBufferFloat(); if(!temp.BufferInit(count, 0.0f)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initialize LPI2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi2_weights)) return false; for(uint w = 0; w < lpi2_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initialize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Tras inicializar las matrices de pesos entrenables, creamos búferes para registrar los momentos durante el proceso de entrenamiento del modelo. Pero aquí hay que prestar atención al búfer de parámetros de la capa batch normalization (normalización por lotes). Ya tiene en cuenta los parámetros y sus impulsos (momentums). Por lo tanto, no crearemos búferes de impulso para la capa especificada.
Además, el número de búferes de impulso necesarios depende del método de optimización. Para tener en cuenta esta característica, crearemos búferes en un bucle cuyo número de iteraciones dependerá del método de optimización.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- LPI temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi2_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } iBatchCount = 1; //--- return true; }
Después de crear exitosamente todos los búferes necesarios, finalizamos el método y devolvemos el resultado lógico de las operaciones al que lo llamó.
Hemos completado la inicialización de la clase. Pasemos ahora a la descripción del algoritmo "feed-forward" del método XCiT. Como ya se ha dicho, la aplicación del método propuesto requerirá cambios significativos. Para implementar el pase hacia adelante (feed-forward pass), necesitamos crear un kernel en el lado del programa de OpenCL para implementar el algoritmo XCA.
Ten en cuenta que recibimos las entidades en un método heredado de la clase padre ConvolutionForward. Así, nuestro kernel ya trabaja con las entidades Query, Key y Value generadas, que transferimos al kernel como un único búfer. Además de ellos, en los parámetros del núcleo pasamos punteros a otros dos búferes de datos: coeficientes de atención y resultados de bloques de atención.
__kernel void XCiTFeedForward(__global float *qkv, __global float *score, __global float *out) { const size_t d = get_local_id(0); const size_t dimension = get_local_size(0); const size_t u = get_local_id(1); const size_t units = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
Lanzaremos el núcleo (kernel) en un espacio de tareas tridimensional:
- Dimensión de un elemento de entidad;
- Longitud de la secuencia;
- Número de cabezas de atención.
En cuanto a las dos primeras dimensiones, las combinaremos en grupos de trabajo locales.
Declaremos dos matrices locales bidimensionales para escribir datos intermedios e intercambiar información dentro del grupo de trabajo.
const uint ls_u = min((uint)units, (uint)LOCAL_ARRAY_SIZE); const uint ls_d = min((uint)dimension, (uint)LOCAL_ARRAY_SIZE); __local float q[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE]; __local float k[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE];
Antes de empezar a trabajar en el análisis de la atención a la covarianza cruzada, necesitamos normalizar las entidades Query y Key, tal y como proponen los autores del método.
Para ello, primero calculamos los tamaños de los vectores de cada parámetro dentro del grupo.
//--- Normalize Query and Key for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { float q_val = 0; float k_val = 0; //--- if(d < ls_d && (cur_d + d) < dimension && u < ls_u) { for(int count = u; count < units; count += ls_u) { int shift = count * dimension * heads * 3 + dimension * h + cur_d + d; q_val += pow(qkv[shift], 2.0f); k_val += pow(qkv[shift + dimension * heads], 2.0f); } q[u][d] = q_val; k[u][d] = k_val; } barrier(CLK_LOCAL_MEM_FENCE);
uint count = ls_u; do { count = (count + 1) / 2; if(d < ls_d) { if(u < ls_u && u < count && (u + count) < units) { float q_val = q[u][d] + q[u + count][d]; float k_val = k[u][d] + k[u + count][d]; q[u + count][d] = 0; k[u + count][d] = 0; q[u][d] = q_val; k[u][d] = k_val; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
A continuación, dividimos cada elemento de la secuencia por la raíz cuadrada del tamaño del vector a lo largo de la dimensión correspondiente.
int shift = u * dimension * heads * 3 + dimension * h + cur_d; qkv[shift] = qkv[shift] / sqrt(q[0][d]); qkv[shift + dimension * heads] = qkv[shift + dimension * heads] / sqrt(k[0][d]); barrier(CLK_LOCAL_MEM_FENCE); }
Ahora que nuestras entidades están normalizadas, podemos pasar a definir los coeficientes de dependencia. Para ello, multiplicamos las matrices Query y Key. Al mismo tiempo, tomamos el exponente del valor obtenido y los sumamos.
//--- Score int step = dimension * heads * 3; for(int cur_r = 0; cur_r < dimension; cur_r += ls_u) { for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { if(u < ls_d && d < ls_d) q[u][d] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- if((cur_r + u) < ls_d && (cur_d + d) < ls_d) { int shift_q = dimension * h + cur_d + d; int shift_k = dimension * (heads + h) + cur_r + u; float scr = 0; for(int i = 0; i < units; i++) scr += qkv[shift_q + i * step] * qkv[shift_k + i * step]; scr = exp(scr); score[(cur_r + u)*dimension * heads + dimension * h + cur_d + d] = scr; q[u][d] += scr; } } barrier(CLK_LOCAL_MEM_FENCE);
int count = ls_d; do { count = (count + 1) / 2; if(u < ls_d) { if(d < ls_d && d < count && (d + count) < dimension) q[u][d] += q[u][d + count]; if(d + count < ls_d) q[u][d + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
A continuación, normalizamos los coeficientes de dependencia.
if((cur_r + u) < ls_d) score[(cur_r + u)*dimension * heads + dimension * h + d] /= q[u][0]; barrier(CLK_LOCAL_MEM_FENCE); }
Al final de las operaciones del núcleo, multiplicamos el tensor Value por los coeficientes de dependencia. El resultado de esta operación se guardará en el búfer de resultados del bloque de atención XCA.
int shift_out = dimension * (u * heads + h) + d; int shift_s = dimension * (heads * d + h); int shift_v = dimension * (heads * (u * 3 + 2) + h); float sum = 0; for(int i = 0; i < dimension; i++) sum += qkv[shift_v + i] * score[shift_s + i]; out[shift_out] = sum; }
Después de crear el núcleo en el lado del programa OpenCL, pasamos a las operaciones de nuestra clase en el lado del programa principal. Aquí creamos primero el método CNeuronXCiTOCL::XCiT, en el que implementamos el algoritmo para llamar al núcleo creado.
bool CNeuronXCiTOCL::XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out) { if(!OpenCL || !qkv || !score || !out) return false;
En los parámetros del método, pasamos punteros a los 3 búferes de datos utilizados. En el cuerpo del método, comprobamos inmediatamente si los punteros recibidos son relevantes.
A continuación, definimos el espacio de tareas y los desplazamientos en él.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads}; uint local_work_size[3] = {iWindowKey, iUnits, 1};
Como ya se ha mencionado, combinamos los hilos en grupos de trabajo según las dos primeras dimensiones.
A continuación, pasamos los punteros a los búferes de datos al núcleo.
if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_score, score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_out, out.GetIndex())) return false;
Coloca el núcleo en la cola de ejecución.
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); Print(error); return false; } //--- return true; }
Además del método descrito anteriormente, crearemos un método feed-forward para la capa de normalización por lotes CNeuronXCiTOCL::BatchNorm, cuyo algoritmo completo se transfiere íntegramente desde el método CNeuronBatchNormOCL::feedForward. Pero no nos detendremos ahora en considerar su algoritmo. Pasemos directamente al análisis del método CNeuronXCiTOCL::feedForward, que representa el esquema general del algoritmo de propagación hacia delante en el bloque XCiT.
bool CNeuronXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
En los parámetros, el método recibe un puntero al objeto de la capa anterior, que proporciona los datos iniciales. En el cuerpo del método, comprobamos inmediatamente la relevancia del puntero recibido.
Después de pasar con éxito el punto de control, creamos un bucle a través de las capas internas. En el cuerpo de este bucle, construiremos el algoritmo completo del método.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Aquí formamos primero nuestras entidades Query, Key y Value. Entonces llamamos a nuestro método de atención de covarianza cruzada.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(qkv, temp, out)) return false;
Los resultados de la atención se suman a los datos originales y los valores resultantes se normalizan.
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
A continuación viene el bloque LPI. En primer lugar, vamos a organizar el trabajo de la primera capa del bloque.
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false;
A continuación, normalizamos los resultados de la primera capa.
out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false;
Pasamos el resultado normalizado a la segunda capa del bloque.
temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() ||!ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false;
A continuación, volvemos a resumir y normalizar los resultados.
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Organice el bloque FeedForward.
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false;
A la salida de la capa, resumimos y normalizamos los resultados de los bloques.
//--- Sum and normalize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
Esto concluye la implementación del paso feed-forward de nuestra nueva capa transformadora de covarianza cruzada CNeuronXCiTOCL. A continuación, pasamos a construir el algoritmo de retropropagación. Aquí también tenemos que volver al programa OpenCL y crear otro núcleo. Construiremos el algoritmo de retropropagación del bloque XCA en el núcleo XCiTInsideGradients. En los parámetros del núcleo, pasamos punteros a 4 búferes de datos:
- qkv – Vector concatenado de entidades Query, Key y Value;
- qkv_g – Vector concatenado de gradientes de error de las entidades Query, Key y Value;
- scores – Matriz de coeficientes de dependencia;
- gradient – Tensor de gradientes de error a la salida del bloque de atención XCA.
__kernel void XCiTInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const int q = get_global_id(0); const int d = get_global_id(1); const int h = get_global_id(2); const int units = get_global_size(0); const int dimension = get_global_size(1); const int heads = get_global_size(2);
Planeamos lanzar el núcleo en un espacio de tareas tridimensional. En el cuerpo del núcleo, identificamos el hilo y el espacio de tareas. A continuación, determinamos el desplazamiento en los búferes de datos hacia los elementos analizados.
const int shift_q = dimension * (heads * 3 * q + h); const int shift_k = dimension * (heads * (3 * q + 1) + h); const int shift_v = dimension * (heads * (3 * q + 2) + h); const int shift_g = dimension * (heads * q + h); int shift_score = dimension * h; int step_score = dimension * heads;
Según el algoritmo de retropropagación, primero determinamos el gradiente de error en el tensor Value.
//--- Calculating Value's gradients float sum = 0; for(int i = 0; i < dimension; i ++) sum += gradient[shift_g + i] * scores[shift_score + d + i * step_score]; qkv_g[shift_v + d] = sum;
A continuación, definimos el gradiente de error para Query. Aquí tenemos que determinar primero el gradiente de error en el vector correspondiente de la matriz de coeficientes. A continuación, ajuste los gradientes de error resultantes a la derivada de la función SoftMax. Sólo en este caso podemos obtener el gradiente de error requerido.
//--- Calculating Query's gradients float grad = 0; float val = qkv[shift_v + d]; for(int k = 0; k < dimension; k++) { float sc_g = 0; float sc = scores[shift_score + k]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_score + v] * val * gradient[shift_g + v * dimension] * ((float)(k == v) - sc); grad += sc_g * qkv[shift_k + k]; } qkv_g[shift_q] = grad;
Para el tensor Key, el gradiente de error se determina de forma similar, pero en la dirección perpendicular de los vectores.
//--- Calculating Key's gradients grad = 0; float out_g = gradient[shift_g]; for(int scr = 0; scr < dimension; scr++) { float sc_g = 0; int shift_sc = scr * dimension * heads; float sc = scores[shift_sc + d]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_sc + v] * out_g * qkv[shift_v + v] * ((float)(d == v) - sc); grad += sc_g * qkv[shift_q + scr]; } qkv_g[shift_k + d] = grad; }
Después de construir el núcleo, volvemos a trabajar con nuestra clase en el lado del programa principal. Aquí creamos el método CNeuronXCiTOCL::XCiTInsideGradients. Aquí creamos el método CNeuronXCiTOCL::XCiTInsideGradients.
bool CNeuronXCiTOCL::XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog) { if(!OpenCL || !qkv || !qkvg || !score || !aog) return false;
En el cuerpo del método, comprobamos inmediatamente si los punteros recibidos son relevantes.
A continuación, definimos un espacio de problemas tridimensional. Pero esta vez no definimos grupos de trabajo.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads};
Pasamos punteros a búferes de datos como parámetros al núcleo.
if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv_g, qkvg.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_scores,score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_gradient,aog.GetIndex())) return false;
Una vez completado el trabajo preparatorio, sólo tenemos que poner el núcleo en la cola de ejecución.
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
El algoritmo hacia atrás completo del bloque XCiT recogido en el método de envío CNeuronXCiTOCL::calcInputGradients. En sus parámetros, el método recibe un puntero al objeto de la capa anterior.
bool CNeuronXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
En el cuerpo del método, comprobamos inmediatamente la validez del puntero recibido. Después de pasar con éxito el punto de control, organizamos un bucle de la iteración inversa a través de las capas internas con la propagación del gradiente de error.
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 4:6)+1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false;
En el cuerpo del bucle, primero pasaremos el gradiente de error a través del bloque FeedForward.
CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
Permítanme recordarles que durante el pase directo, sumamos los resultados de los bloques con los datos originales. Del mismo modo, propagamos el gradiente de error a través de 2 hilos.
//--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
A continuación propagamos el gradiente de error a través del bloque LPI.
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false;
Añade de nuevo los gradientes de error.
temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Después, propagamos el gradiente de error a través del bloque de atención XCA.
out_grad = temp; //--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
Transfiérelo al búfer de gradiente de datos de origen.
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 3 * iWindowKey * iHeads, None)) return false;
No olvides agregar un gradiente de error a lo largo del segundo flujo.
//--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow)) return false; if(i > 0) out_grad = temp; } //--- return true; }
Arriba, implementamos un algoritmo para propagar el gradiente de error a las capas internas y transferirlo a la capa neuronal anterior. Al final de las operaciones de retropropagación, debemos actualizar los parámetros del modelo.
La actualización de los parámetros de nuestra nueva capa Cross-Covariance Transformer se implementa en el método CNeuronXCiTOCL::updateInputWeights. Al igual que los métodos similares de otras capas neuronales, el método recibe en sus parámetros un puntero a la capa neuronal de la capa anterior.
bool CNeuronXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput();
Y en el cuerpo del método, comprobamos la relevancia del puntero recibido.
De forma similar a la distribución del gradiente de error, actualizaremos los parámetros en un bucle a través de las capas internas.
for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization==SGD ? QKV_Weights.At(l*2+1):QKV_Weights.At(l*3+1)), (optimization==SGD ? NULL : QKV_Weights.At(l*3+2)), iWindow, 3 * iWindowKey * iHeads)) return false;
En primer lugar, actualizamos los parámetros de las matrices de formación de las entidades Query, Key y Value.
A continuación, actualizamos los parámetros del bloque LPI. Este bloque contiene 2 capas convolucionales y una capa de normalización por lotes.
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization==SGD ? cLPI_Weights.At(l*5+3):cLPI_Weights.At(l*7+3)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization==SGD ? cLPI_Weights.At(l*5+4):cLPI_Weights.At(l*7+4)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
Al final del método, tenemos el bloque que actualiza los parámetros del bloque FeedForward.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization==SGD ? FF_Weights.At(l*4+2):FF_Weights.At(l*6+2)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization==SGD ? FF_Weights.At(l*4+3):FF_Weights.At(l*6+3)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
Con esto, completamos la implementación de los algoritmos de pase hacia adelante (feed-forward) y retropropagación de nuestra capa Cross-Covariance Transformer CNeuronXCiTOCL. Para habilitar el funcionamiento completo de la clase, aún necesitamos agregar varios métodos auxiliares. Entre ellos se encuentran los métodos de archivo (Save y Load). El algoritmo de estos métodos no es complicado y no contiene aspectos únicos que se relacionen específicamente con el método XCiT. Por lo tanto, no me detendré en la descripción de sus algoritmos en este artículo. El archivo adjunto contiene el código completo de la clase, para que pueda estudiarlo usted mismo. El archivo adjunto también contiene todos los programas utilizados en este artículo.
2.2 Arquitectura del modelo
Pasamos a construir Asesores Expertos para entrenar y probar los modelos. Hay que decir aquí que, en su artículo, los autores del método no presentaron una arquitectura específica de los modelos. Esencialmente, el transformador de covarianza cruzada propuesto puede sustituir al transformador clásico que hemos considerado anteriormente en cualquier modelo. Por lo tanto, como parte del experimento, podemos tomar el modelo de los artículos anteriores y sustituir la capa CNeuronMLMHAttentionOCL por CNeuronXCiTOCL.
Pero tenemos que ser sinceros. En el artículo anterior, utilizamos diferentes bloques de atención. Nos centramos especialmente en el uso de CNeuronMFTOCL, que, debido a sus características arquitectónicas, no puede sustituirse por CNeuronXCiTOCL.
Sin embargo, sustituir aunque sólo sea una capa nos permite evaluar de algún modo los cambios.
Así, la arquitectura final de nuestro modelo de pruebas es la siguiente.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Los datos de origen "brutos" que describen 1 barra se introducen en la capa de datos de origen del codificador ambiental.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos recibidos se procesan en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Se genera una incrustación de estado ambiental a partir de los datos normalizados y se añade a la pila interna.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Aquí también añadimos la codificación de datos posicionales.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
A esto le sigue un bloque gráfico con normalización por lotes entre capas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, añadimos nuestra nueva capa Cross-Covariation Transformer. No hemos modificado el número de elementos de secuencia ni las ventanas de datos de origen. Los parámetros especificados vienen determinados por el tensor de los datos iniciales.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronXCiTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 3; descr.layers = 1; descr.batch = MathMax(1000, GPTBars); descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
En este caso, utilizamos 4 cabezas de atención.
Los autores del método proponen utilizar una división entera del tamaño del vector de descripción de un elemento de la secuencia para determinar el tamaño del vector de entidades por el número de cabezas de atención. Con esta opción, nuestro parámetro descr.window_out no se utiliza. Así pues, aprovechemos este hecho y especifiquemos el tamaño de la ventana de la primera capa LPI en este parámetro. También indicamos el tamaño del lote para normalizar los datos en el bloque LPI.
Al codificador le sigue el bloque MFT.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Transponemos el tensor para convertirlo en la forma adecuada.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Los resultados del codificador ambiental y de la MFT se utilizan para descodificar los puntos finales más probables.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Y sus estimaciones de probabilidad.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false; //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
El modelo Actor no utilizaba capas de atención. Por lo tanto, el modelo se copió sin cambios. Y puede familiarizarse con la arquitectura completa de todos los modelos en el archivo adjunto.
Nótese que la sustitución de una capa en la arquitectura del codificador de estados ambientales no afecta a la organización de los procesos de entrenamiento y prueba del modelo. Por lo tanto, todos los EA de formación e interacción con el entorno se han copiado sin cambios. En mi opinión, así es más interesante ver los resultados de las pruebas. Porque en igualdad de condiciones, podemos evaluar con mayor honestidad el impacto de la sustitución de una capa en la arquitectura del modelo.
En el archivo adjunto encontrará el código completo de todos los programas utilizados. Pasamos a probar la capa CNeuronXCiTOCL construida del transformador de covarianza cruzada.
3. Pruebas
Hemos realizado un trabajo bastante importante para construir una nueva clase de transformadores de covarianza cruzada CNeuronXCiTOCL basada en el algoritmo presentado en el artículo "XCiT: Cross-Covariance Image Transformers". Como se mencionó anteriormente, hemos decidido utilizar el Asesor Experto del article anterior sin cambios. Por lo tanto, para entrenar los modelos, podemos utilizar el conjunto de datos de entrenamiento recogidos previamente. Cambiemos el nombre del archivo "MFT.bd" por "XCiT.bd".
Si no dispone de un conjunto de datos de entrenamiento previamente recopilados, deberá recopilarlos antes de entrenar el modelo. Recomiendo recopilar primero datos de señales reales utilizando el método descrito en el artículo "Utilizamos la experiencia adquirida para afrontar nuevos retos". A continuación, debe complementar el conjunto de datos de entrenamiento con pases aleatorios del EA "...\Experts\XCiT\Research.mq5" en el probador de estrategias.
Los modelos se entrenan en el EA "...\Experts\XCiT\Study.mq5" tras recopilar los datos de entrenamiento.
Como antes, el modelo se entrena con datos históricos del EURUSD H1. Todos los indicadores se utilizan con los parámetros por defecto.
El modelo se entrena con datos históricos de los 7 primeros meses de 2023. Aquí podemos observar inmediatamente los primeros resultados de las pruebas de eficacia de los enfoques propuestos. Durante el proceso de entrenamiento, podemos observar una reducción en los costos de tiempo de casi un 2% mientras mantenemos el mismo número de iteraciones de entrenamiento.
La eficacia del modelo entrenado se evaluó utilizando datos históricos para agosto de 2023. El periodo de prueba no se incluye en el conjunto de datos de formación. Sin embargo, esto ocurre directamente después del período de entrenamiento. Basándonos en los resultados de las pruebas del modelo entrenado, obtuvimos resultados cercanos a los presentados en el artículo anterior.
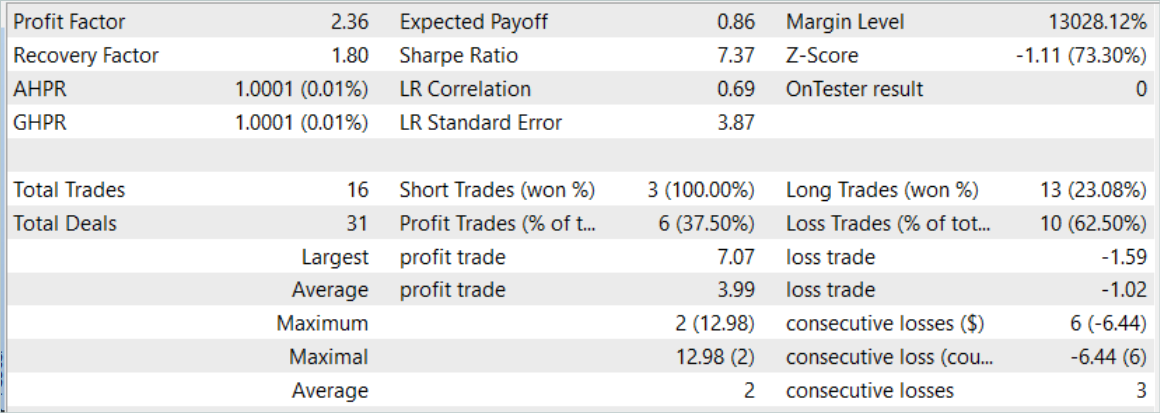
Sin embargo, tras un ligero aumento del número de operaciones hay un aumento del factor de beneficio.
Conclusión
En este artículo, nos familiarizamos con la nueva arquitectura del Transformador de Covarianza Cruzada (XCiT), que combina las ventajas de los Transformadores y las arquitecturas Convolucionales. Ofrece una gran precisión y escalabilidad al procesar secuencias de longitudes variables. Se consigue cierta eficacia cuando se analizan secuencias grandes con tamaños de token pequeños.
XCiT utiliza una arquitectura de Atención de Covarianza Cruzada para modelar eficientemente interacciones globales entre características de elementos de secuencia, lo que le permite manejar con éxito largas secuencias de tokens.
Los autores del método confirman experimentalmente la alta eficiencia de XCiT en varias tareas visuales, incluyendo clasificación de imágenes, detección de objetos y segmentación semántica.
En la parte práctica de nuestro artículo, implementamos los métodos propuestos utilizando MQL5. El modelo se entrenó y probó con datos históricos reales. Durante el proceso de entrenamiento, tuvimos una ligera reducción del tiempo de entrenamiento para el mismo número de iteraciones entrenadas. Esto se consiguió sustituyendo sólo una capa del modelo.
Un ligero aumento de la eficacia del modelo entrenado puede indicar una mejor capacidad de generalización de la arquitectura propuesta.
No olvide que operar en los mercados financieros es una inversión de alto riesgo. Todos los programas presentados en el artículo se proporcionan únicamente con fines informativos y no están optimizados para el comercio real.
Referencias
Programas utilizados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor experto | Colección de ejemplos |
| 2 | ResearchRealORL.mq5 | Asesor experto | EA para la recolección de ejemplos utilizando el método Real-ORL |
| 3 | Study.mq5 | Asesor experto | EA para el entrenamiento del modelo |
| 4 | Test.mq5 | Asesor experto | EA para la prueba del modelo |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema |
| 6 | NeuroNet.mqh | Biblioteca de clases | Una biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Código base | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14276
 Redes neuronales: así de sencillo (Parte 76): Exploración de diversos patrones de interacción con Multi-future Transformer
Redes neuronales: así de sencillo (Parte 76): Exploración de diversos patrones de interacción con Multi-future Transformer
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso