
Redes neuronales: así de sencillo (Parte 82): Modelos de ecuaciones diferenciales ordinarias (NeuralODE)

Introducción
Conozcamos una nueva familia de modelos: Ecuaciones diferenciales ordinarias (ODE, Ordinary Differential Equations). En lugar de especificar una secuencia discreta de capas ocultas, parametrizan la derivada del estado oculto mediante una red neuronal. Los resultados del modelo se calculan utilizando una «caja negra», es decir, el solucionador de ecuaciones diferenciales. Estos modelos de profundidad continua utilizan una cantidad constante de memoria y adaptan su estrategia de estimación a cada señal de entrada. Estos modelos se introdujeron por primera vez en el artículo «Neural Ordinary Differential Equations (Ecuaciones diferenciales ordinarias neuronales)». En este artículo, los autores del método demuestran la capacidad de escalar la retropropagación utilizando cualquier solucionador de ecuaciones diferenciales ordinarias (ODE, por sus siglas en inglés) sin necesidad de acceder a sus operaciones internas. Esto permite el entrenamiento de extremo a extremo de las ODEs dentro de modelos más grandes.
1. Algoritmo
El principal desafío técnico al entrenar modelos de ecuaciones diferenciales ordinarias es realizar la diferenciación en modo inverso de la propagación del error utilizando un solucionador ODE. La diferenciación mediante operaciones feed-forward es sencilla, pero requiere grandes cantidades de memoria e introduce errores numéricos adicionales.
Los autores del método proponen tratar el solucionador ODE como una caja negra y calcular los gradientes utilizando el método de sensibilidad conjugada. Con este enfoque, podemos calcular gradientes resolviendo una segunda ODE extendida hacia atrás en el tiempo. Esto es aplicable a todos los solucionadores ODE. Se escala linealmente con el tamaño de la tarea y tiene un bajo consumo de memoria. Además, controla claramente el error numérico.
Consideremos la optimización de la función de pérdida escalar L(), cuyos datos de entrada son los resultados del solucionador ODE:
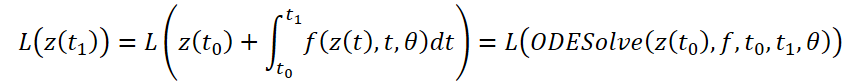
Para optimizar el error L, necesitamos gradientes a lo largo de θ. El primer paso del algoritmo propuesto por los autores del método consiste en determinar cómo depende el gradiente de error del estado oculto z(t) en cada instante a(t)=∂L/∂z(t). Su dinámica viene dada por otra ODE, que puede considerarse un análogo de la regla:
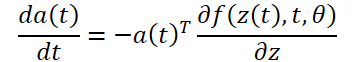
Podemos calcular ∂L/∂z(t) utilizando otra llamada al solucionador ODE. Este solucionador debe trabajar hacia atrás, partiendo del valor inicial ∂L/∂z(t<1). Una de las dificultades es que para resolver esta ODE necesitamos conocer los valores de z(t) a lo largo de toda la trayectoria. Sin embargo, podemos simplemente enumerar z(t) hacia atrás en el tiempo, partiendo de su valor final z(t1).
Para calcular gradientes por parámetros θ, necesitamos determinar la tercera integral, que depende tanto de z(t) como de a(t):.
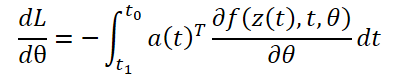
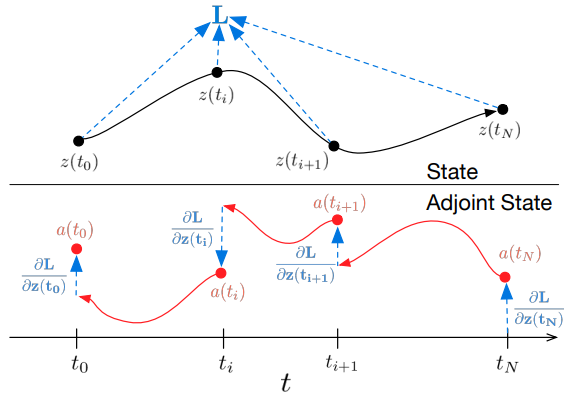
Todas las integrales para resolver 𝐳, 𝐚 y ∂L/∂θ pueden calcularse en una sola llamada de un solucionador ODE que combina el estado original, el conjugado y otras derivadas parciales en un único vector. A continuación se muestra un algoritmo para construir la dinámica necesaria y llamar a un solucionador ODE para calcular todos los gradientes simultáneamente.

La mayoría de los solucionadores ODE tienen la capacidad de calcular el estado z(t) repetidamente. Cuando las pérdidas dependen de estos estados intermedios, la derivada de modo inverso debe descomponerse en una secuencia de soluciones separadas, una entre cada par sucesivo de valores de salida. Para cada observación, el conjugado debe ajustarse en la dirección de la derivada parcial correspondiente ∂L/∂z(t).
Los solucionadores ODE pueden garantizar de forma aproximada que los resultados obtenidos están dentro de una tolerancia dada de la solución verdadera. Cambiar la tolerancia modifica el comportamiento del modelo. El tiempo empleado en una llamada directa es proporcional al número de evaluaciones de la función, por lo que el ajuste de la tolerancia nos ofrece un compromiso entre precisión y coste computacional. Puedes realizar el entrenamiento con alta precisión y luego cambiar a una precisión menor durante la operación.
2. Implementación en MQL5
Para implementar los enfoques propuestos, crearemos una nueva clase CNeuronNODEOCL, que heredará la funcionalidad básica de nuestra capa totalmente conectada CNeuronBaseOCL. A continuación se muestra la estructura de la nueva clase. Además del conjunto básico de métodos, la estructura tiene varios métodos y objetos específicos. Tendremos en cuenta su funcionalidad durante el proceso de implantación.
class CNeuronNODEOCL : public CNeuronBaseOCL { protected: uint iDimension; uint iVariables; uint iLenth; int iBuffersK[]; int iInputsK[]; int iMeadl[]; CBufferFloat cAlpha; CBufferFloat cTemp; CCollection cBeta; CBufferFloat cSolution; CCollection cWeights; //--- virtual bool CalculateKBuffer(int k); virtual bool CalculateInputK(CBufferFloat* inputs, int k); virtual bool CalculateOutput(CBufferFloat* inputs); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool CalculateOutputGradient(CBufferFloat* inputs); virtual bool CalculateInputKGradient(CBufferFloat* inputs, int k); virtual bool CalculateKBufferGradient(int k); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronNODEOCL(void) {}; ~CNeuronNODEOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint variables, uint lenth, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronNODEOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); };
Tenga en cuenta que para poder trabajar con secuencias de varios estados ambientales, descritos por incrustaciones de varias características, creamos un objeto que puede trabajar con datos iniciales presentados en 3 dimensiones:
- iDimension: El tamaño del vector de incrustación de una característica en un estado medioambiental distinto.
- iVariables: El número de características que describen un estado del entorno.
- iLenth: El número de estados del sistema analizados.
La función ODE en nuestro caso estará representada por 2 capas totalmente conectadas con la función de activación ReLU entre ellas. Sin embargo, admitimos que la dinámica de cada característica individual puede diferir. Por lo tanto, para cada atributo, proporcionaremos nuestras propias matrices de ponderación. Este enfoque no nos permite utilizar capas convolucionales como internas, como se hacía anteriormente. Por lo tanto, en nuestra nueva clase, descomponemos las capas internas de la función ODE. Declararemos los búferes de datos que componen las capas internas de datos. A continuación, crearemos kernels y métodos para implementar procesos.
2.1 Feed-forward kernel (núcleo de avance)
Al construir el kernel feed-forward para la función ODE, partimos de las siguientes restricciones:
- Cada estado del entorno se describe mediante el mismo número fijo de características.
- Todas las características tienen el mismo tamaño fijo de incrustación.
Teniendo en cuenta estas restricciones, creamos el kernel FeedForwardNODEF en el lado del programa OpenCL. En los parámetros de nuestro kernel, pasaremos punteros a 3 búferes de datos y 3 variables. El kernel se lanzará en un espacio de tareas tridimensional.
__kernel void FeedForwardNODEF(__global float *matrix_w, ///<[in] Weights matrix __global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_o, ///<[out] Output tensor int dimension, ///< input dimension float step, ///< h int activation ///< Activation type (#ENUM_ACTIVATION) ) { int d = get_global_id(0); int dimension_out = get_global_size(0); int v = get_global_id(1); int variables = get_global_size(1); int i = get_global_id(2); int lenth = get_global_size(2);
En el cuerpo del kernel, primero identificamos el hilo actual en las 3 dimensiones del espacio de tareas. A continuación, determinaremos el desplazamiento en las memorias intermedias de los datos analizados.
int shift = variables * i + v; int input_shift = shift * dimension; int output_shift = shift * dimension_out + d; int weight_shift = (v * dimension_out + d) * (dimension + 2);
Tras el trabajo preparatorio, calculamos los valores del resultado actual en un bucle, multiplicando el vector de datos iniciales por el correspondiente vector de pesos.
float sum = matrix_w[dimension + 1 + weight_shift] + matrix_w[dimension + weight_shift] * step; for(int w = 0; w < dimension; w++) sum += matrix_w[w + weight_shift] * matrix_i[input_shift + w];
Cabe señalar aquí que la función ODE no sólo depende del estado del entorno, sino también de la marca temporal. En este caso, hay una única marca de tiempo para todo el estado ambiental. Para eliminar su duplicación en términos de número de características y longitud de secuencia, no añadimos una marca de tiempo al tensor de datos de origen, sino que simplemente lo pasamos al kernel como parámetro de paso.
A continuación, sólo tenemos que propagar el valor resultante a través de la función de activación y guardar el resultado en el elemento del búfer correspondiente.
if(isnan(sum)) sum = 0; switch(activation) { case 0: sum = tanh(sum); break; case 1: sum = 1 / (1 + exp(-clamp(sum, -20.0f, 20.0f))); break; case 2: if(sum < 0) sum *= 0.01f; break; default: break; } matrix_o[output_shift] = sum; }
2.2 Kernel de retropropagación
Después de implementar el kernel feed-forward, crearemos la funcionalidad inversa en el lado OpenCL del programa, el kernel de distribución de gradiente de error HiddenGradientNODEF.</i0
__kernel void HiddenGradientNODEF(__global float *matrix_w, ///<[in] Weights matrix __global float *matrix_g, ///<[in] Gradient tensor __global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_ig, ///<[out] Inputs Gradient tensor int dimension_out, ///< output dimension int activation ///< Input Activation type (#ENUM_ACTIVATION) ) { int d = get_global_id(0); int dimension = get_global_size(0); int v = get_global_id(1); int variables = get_global_size(1); int i = get_global_id(2); int lenth = get_global_size(2);
Este kernel también se lanzará en un espacio de tareas tridimensional, e identificamos el hilo en el cuerpo del kernel. También determinamos los desplazamientos en los búferes de datos a los elementos analizados.
int shift = variables * i + v; int input_shift = shift * dimension + d; int output_shift = shift * dimension_out; int weight_step = (dimension + 2); int weight_shift = (v * dimension_out) * weight_step + d;
A continuación, sumamos el gradiente de error para el elemento de datos fuente analizado.
float sum = 0; for(int k = 0; k < dimension_out; k ++) sum += matrix_g[output_shift + k] * matrix_w[weight_shift + k * weight_step]; if(isnan(sum)) sum = 0;
Tenga en cuenta que la marca de tiempo es esencialmente una constante para un estado independiente. Por lo tanto, no propagamos el gradiente del error hacia él.
Ajustamos la cantidad resultante mediante la derivada de la función de activación y guardamos el valor resultante en el elemento correspondiente de la memoria intermedia de datos.
float out = matrix_i[input_shift]; switch(activation) { case 0: out = clamp(out, -1.0f, 1.0f); sum = clamp(sum + out, -1.0f, 1.0f) - out; sum = sum * max(1 - pow(out, 2), 1.0e-4f); break; case 1: out = clamp(out, 0.0f, 1.0f); sum = clamp(sum + out, 0.0f, 1.0f) - out; sum = sum * max(out * (1 - out), 1.0e-4f); break; case 2: if(out < 0) sum *= 0.01f; break; default: break; } //--- matrix_ig[input_shift] = sum; }
2.3 Solucionador ODE
Hemos completado la primera fase del trabajo. Veamos ahora el lado del solucionador ODE. Para mi implementación, elegí el método de Dormand-Prince de quinto orden.
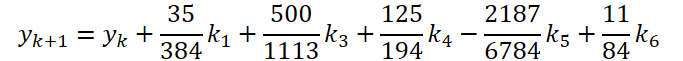
Donde:
![]()
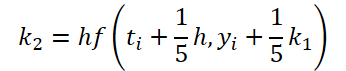
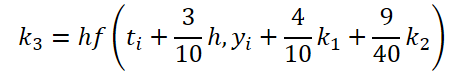
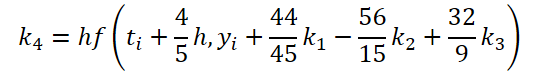
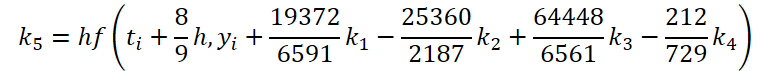
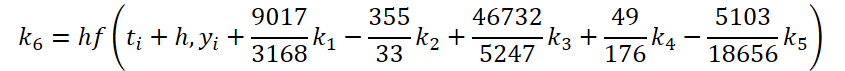
Como se puede ver, la función de resolver y ajustar los datos iniciales para calcular los coeficientes k1..k6 difieren sólo en coeficientes numéricos. Podemos añadir los coeficientes que faltan ki multiplicados por 0, lo que no afectará al resultado. Por lo tanto, para unificar el proceso, crearemos un único kernel FeedForwardNODEInpK en el lado OpenCL del programa. En los parámetros del kernel, pasamos punteros a los búferes de los datos de origen y todos los coeficientes ki. Indicamos los multiplicadores necesarios en el buffer matrix_beta.
__kernel void FeedForwardNODEInpK(__global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_k1, ///<[in] K1 tensor __global float *matrix_k2, ///<[in] K2 tensor __global float *matrix_k3, ///<[in] K3 tensor __global float *matrix_k4, ///<[in] K4 tensor __global float *matrix_k5, ///<[in] K5 tensor __global float *matrix_k6, ///<[in] K6 tenтor __global float *matrix_beta, ///<[in] beta tensor __global float *matrix_o ///<[out] Output tensor ) { int i = get_global_id(0);
Ejecutaremos el kernel en un espacio de tareas unidimensional y calcularemos valores para cada valor individual del búfer de resultados.
Tras identificar el flujo, recogeremos la suma de los productos en un bucle.
float sum = matrix_i[i]; for(int b = 0; b < 6; b++) { float beta = matrix_beta[b]; if(beta == 0.0f || isnan(beta)) continue; //--- float val = 0.0f; switch(b) { case 0: val = matrix_k1[i]; break; case 1: val = matrix_k2[i]; break; case 2: val = matrix_k3[i]; break; case 3: val = matrix_k4[i]; break; case 4: val = matrix_k5[i]; break; case 5: val = matrix_k6[i]; break; } if(val == 0.0f || isnan(val)) continue; //--- sum += val * beta; }
El valor resultante se guarda en el elemento correspondiente de la memoria intermedia de resultados.
matrix_o[i] = sum; }
Para el método de retropropagación, creamos el kernel HiddenGradientNODEInpK, en el que propagamos el gradiente de error en los búferes de datos correspondientes, teniendo en cuenta los mismos coeficientes Beta.
__kernel void HiddenGradientNODEInpK(__global float *matrix_ig, ///<[in] Inputs tensor __global float *matrix_k1g, ///<[in] K1 tensor __global float *matrix_k2g, ///<[in] K2 tensor __global float *matrix_k3g, ///<[in] K3 tensor __global float *matrix_k4g, ///<[in] K4 tensor __global float *matrix_k5g, ///<[in] K5 tensor __global float *matrix_k6g, ///<[in] K6 tensor __global float *matrix_beta, ///<[in] beta tensor __global float *matrix_og ///<[out] Output tensor ) { int i = get_global_id(0); //--- float grad = matrix_og[i]; matrix_ig[i] = grad; for(int b = 0; b < 6; b++) { float beta = matrix_beta[b]; if(isnan(beta)) beta = 0.0f; //--- float val = beta * grad; if(isnan(val)) val = 0.0f; switch(b) { case 0: matrix_k1g[i] = val; break; case 1: matrix_k2g[i] = val; break; case 2: matrix_k3g[i] = val; break; case 3: matrix_k4g[i] = val; break; case 4: matrix_k5g[i] = val; break; case 5: matrix_k6g[i] = val; break; } } }
Tenga en cuenta que también escribimos valores cero en los búferes de datos. Esto es necesario para evitar que se cuenten dos veces los valores guardados anteriormente.
2.4 Kernel de actualización del peso
Para completar la parte del programa OpenCL, crearemos un kernel para actualizar los pesos de la función ODE. Como se puede ver en las fórmulas presentadas anteriormente, la función ODE se utilizará para determinar todos los coeficientes ki Por lo tanto, al ajustar los pesos, debemos recoger el gradiente de error de todas las operaciones. Ninguno de los kernels de actualización de pesos que hemos creado anteriormente funcionaba con tantos buffers de gradiente. Por lo tanto, tenemos que crear un nuevo kernel. Para simplificar el experimento, sólo crearemos el kernel NODEF_UpdateWeightsAdam para actualizar parámetros usando el método Adam, que es el que yo uso más a menudo.
__kernel void NODEF_UpdateWeightsAdam(__global float *matrix_w, ///<[in,out] Weights matrix __global const float *matrix_gk1, ///<[in] Tensor of gradients at k1 __global const float *matrix_gk2, ///<[in] Tensor of gradients at k2 __global const float *matrix_gk3, ///<[in] Tensor of gradients at k3 __global const float *matrix_gk4, ///<[in] Tensor of gradients at k4 __global const float *matrix_gk5, ///<[in] Tensor of gradients at k5 __global const float *matrix_gk6, ///<[in] Tensor of gradients at k6 __global const float *matrix_ik1, ///<[in] Inputs tensor __global const float *matrix_ik2, ///<[in] Inputs tensor __global const float *matrix_ik3, ///<[in] Inputs tensor __global const float *matrix_ik4, ///<[in] Inputs tensor __global const float *matrix_ik5, ///<[in] Inputs tensor __global const float *matrix_ik6, ///<[in] Inputs tensor __global float *matrix_m, ///<[in,out] Matrix of first momentum __global float *matrix_v, ///<[in,out] Matrix of seconfd momentum __global const float *alpha, ///< h const int lenth, ///< Number of inputs const float l, ///< Learning rates const float b1, ///< First momentum multiplier const float b2 ///< Second momentum multiplier ) { const int d_in = get_global_id(0); const int dimension_in = get_global_size(0); const int d_out = get_global_id(1); const int dimension_out = get_global_size(1); const int v = get_global_id(2); const int variables = get_global_id(2);
Como se ha indicado anteriormente, los parámetros del kernel pasan punteros a un gran número de búferes de datos globales. Se les añaden los parámetros estándar del método de optimización seleccionado.
Ejecutaremos el kernel en un espacio de tareas tridimensional, que tiene en cuenta la dimensión de los vectores de incrustación de los datos de origen y los resultados, así como el número de características analizadas. En el cuerpo del kernel, identificamos el flujo en el espacio de tareas a lo largo de las 3 dimensiones. A continuación, determinamos los desplazamientos en los búferes de datos.
const int weight_shift = (v * dimension_out + d_out) * dimension_in; const int input_step = variables * (dimension_in - 2); const int input_shift = v * (dimension_in - 2) + d_in; const int output_step = variables * dimension_out; const int output_shift = v * dimension_out + d_out;
A continuación, en un bucle, recogemos el gradiente de error en todos los estados ambientales.
float weight = matrix_w[weight_shift]; float g = 0; for(int i = 0; i < lenth; i++) { int shift_g = i * output_step + output_shift; int shift_i = i * input_step + input_shift; switch(dimension_in - d_in) { case 1: g += matrix_gk1[shift_g] + matrix_gk2[shift_g] + matrix_gk3[shift_g] + matrix_gk4[shift_g] + matrix_gk5[shift_g] + matrix_gk6[shift_g]; break; case 2: g += matrix_gk1[shift_g] * alpha[0] + matrix_gk2[shift_g] * alpha[1] + matrix_gk3[shift_g] * alpha[2] + matrix_gk4[shift_g] * alpha[3] + matrix_gk5[shift_g] * alpha[4] + matrix_gk6[shift_g] * alpha[5]; break; default: g += matrix_gk1[shift_g] * matrix_ik1[shift_i] + matrix_gk2[shift_g] * matrix_ik2[shift_i] + matrix_gk3[shift_g] * matrix_ik3[shift_i] + matrix_gk4[shift_g] * matrix_ik4[shift_i] + matrix_gk5[shift_g] * matrix_ik5[shift_i] + matrix_gk6[shift_g] * matrix_ik6[shift_i]; break; } }
Y luego ajustamos los pesos según el algoritmo conocido.
float mt = b1 * matrix_m[weight_shift] + (1 - b1) * g; float vt = b2 * matrix_v[weight_shift] + (1 - b2) * pow(g, 2); float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight));
Al final del kernel, guardamos el resultado y los valores auxiliares en los elementos correspondientes de los búferes de datos.
if(delta * g > 0) matrix_w[weight_shift] = clamp(matrix_w[weight_shift] + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[weight_shift] = mt; matrix_v[weight_shift] = vt; }
Esto completa la parte del programa OpenCL. Volvamos a la implementación de nuestra clase CNeuronNODEOCL.
2.5 Método de inicialización de la clase CNeuronNODEOCL.
La inicialización de nuestro objeto de clase se realiza en el método CNeuronNODEOCL::Init. En los parámetros del método, como es habitual, pasaremos los parámetros principales de la arquitectura del objeto.
bool CNeuronNODEOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint variables, uint lenth, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, dimension * variables * lenth, optimization_type, batch)) return false;
En el cuerpo del método, primero llamamos al método relevante de la clase padre, que controla los parámetros recibidos e inicializa los objetos heredados. Podemos conocer el resultado generalizado de realizar operaciones en el cuerpo de la clase padre por el valor lógico devuelto.
A continuación, guardamos los parámetros resultantes de la arquitectura del objeto en variables locales de la clase.
iDimension = dimension; iVariables = variables; iLenth = lenth;
Declarar variables auxiliares y asignarles los valores necesarios.
uint mult = 2; uint weights = (iDimension + 2) * iDimension * iVariables;
Veamos ahora los topes de coeficiente k<i y los datos iniciales ajustados para su cálculo. Como se puede adivinar, los valores de estos búferes de datos se guardan desde el pase de avance hasta el pase de retropropagación. Durante la siguiente pasada de avance, los valores se sobrescriben. Por lo tanto, para guardar recursos, no creamos estos búferes en la memoria principal del programa. Los creamos sólo en el lado OpenCL del contexto. En la clase, sólo creamos arrays para almacenar punteros a ellos. En cada matriz, creamos 3 veces más elementos que k coeficientes se utilizan. Esto es necesario para recoger los gradientes de error.
if(ArrayResize(iBuffersK, 18) < 18) return false; if(ArrayResize(iInputsK, 18) < 18) return false;
Hacemos lo mismo con los valores de cálculo intermedios. Sin embargo, el tamaño de la matriz es menor.
if(ArrayResize(iMeadl, 12) < 12) return false;
Para aumentar la legibilidad del código, crearemos buffers en un bucle.
for(uint i = 0; i < 18; i++) { iBuffersK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; iInputsK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iInputsK[i] < 0) return false; if(i > 11) continue; //--- Initilize Meadl Output and Gradient buffers iMeadl[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iMeadl[i] < 0) return false; }
El siguiente paso es crear matrices de coeficientes de ponderación del modelo de función ODE y momentos para ellos. Como ya se ha mencionado, utilizaremos 2 capas.
//--- Initilize Weights for(int i = 0; i < 2; i++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(weights)) return false; float k = (float)(1 / sqrt(iDimension + 2)); for(uint w = 0; w < weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cWeights.Add(temp)) return false;
for(uint d = 0; d < 2; d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cWeights.Add(temp)) return false; } }
A continuación creamos búferes multiplicadores constantes:
- Paso temporal Alfa
{
float temp_ar[] = {0, 0.2f, 0.3f, 0.8f, 8.0f / 9, 1, 1};
if(!cAlpha.AssignArray(temp_ar))
return false;
if(!cAlpha.BufferCreate(OpenCL))
return false;
}
- Ajustes de los datos de origen:
//--- Beta K1 { float temp_ar[] = {0, 0, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K2 { float temp_ar[] = {0.2f, 0, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K3 { float temp_ar[] = {3.0f / 40, 9.0f / 40, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K4 { float temp_ar[] = {44.0f / 44, -56.0f / 15, 32.0f / 9, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K5 { float temp_ar[] = {19372.0f / 6561, -25360 / 2187.0f, 64448 / 6561.0f, -212.0f / 729, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K6 { float temp_ar[] = {9017 / 3168.0f, -355 / 33.0f, 46732 / 5247.0f, 49.0f / 176, -5103.0f / 18656, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
- Soluciones ODE
{
float temp_ar[] = {35.0f / 384, 0, 500.0f / 1113, 125.0f / 192, -2187.0f / 6784, 11.0f / 84};
if(!cSolution.AssignArray(temp_ar))
return false;
if(!cSolution.BufferCreate(OpenCL))
return false;
}
Al final del método de inicialización, añadimos un búfer local para registrar los valores intermedios.
if(!cTemp.BufferInit(Output.Total(), 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
2.6 Organizar el pase feed-forward
Tras inicializar el objeto de clase, pasamos a organizar el algoritmo feed-forward. Anteriormente, creamos 2 kernels en el lado del programa OpenCL para organizar el paso de avance. Por lo tanto, tenemos que crear métodos para llamarlos. Empezaremos con un método bastante sencillo CalculateInputK que prepara los datos iniciales para calcular los coeficientes k.
bool CNeuronNODEOCL::CalculateInputK(CBufferFloat* inputs, int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
En los parámetros del método, recibimos un puntero al búfer de datos de origen obtenidos de la capa anterior y el índice del coeficiente que se va a calcular. En el cuerpo del método, comprobamos si el índice de coeficiente especificado corresponde a nuestra arquitectura.
Después de pasar con éxito el bloque de control, consideramos el caso especial para k1.
![]()
En este caso, no llamamos a la ejecución del kernel, sino que simplemente copiamos el puntero al búfer de datos de origen.
if(k == 0) { if(iInputsK[k] != inputs.GetIndex()) { OpenCL.BufferFree(iInputsK[k]); iInputsK[k] = inputs.GetIndex(); } return true; }
En el caso general, llamamos al kernel FeedForwardNODEInpK y escribimos los datos de origen ajustados en el búfer apropiado. Para ello, primero definimos un espacio de tareas. En este caso, se trata de un espacio unidimensional.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Pasemos punteros de búfer a los parámetros del kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_beta, ((CBufferFloat *)cBeta.At(k)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_o, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Coloca el kernel en la cola de ejecución.
if(!OpenCL.Execute(def_k_FeedForwardNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Tras ajustar los datos de origen, calculamos el valor de los coeficientes. Este proceso se organiza en el método CalculateKBuffer. Dado que el método sólo funciona con objetos internos, basta con especificar el índice del coeficiente requerido en los parámetros del método para realizar las operaciones.
bool CNeuronNODEOCL::CalculateKBuffer(int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
En el cuerpo del método, comprobamos si el índice resultante coincide con la arquitectura de la clase.
A continuación, definimos un espacio de problemas tridimensional.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iVariables, iLenth};
A continuación, pasamos parámetros al kernel para pasar la primera capa. Aquí utilizamos LReLU para crear no linealidad.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_i, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_o, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_dimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_step, float(cAlpha.At(k)))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_activation, int(LReLU))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Coloca el kernel en la cola de ejecución.
if(!OpenCL.Execute(def_k_FeedForwardNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
El siguiente paso es realizar una pasada de avance de la segunda capa. El espacio de tareas sigue siendo el mismo. Por lo tanto, no modificamos las matrices correspondientes. Tenemos que volver a pasar los parámetros al kernel. Esta vez cambiamos los datos de origen, el peso y los búferes de resultados.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_i, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_o, iBuffersK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Tampoco utilizamos la función de activación.
if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_activation, int(None))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Los demás parámetros no cambian.
if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_dimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_step, cAlpha.At(k))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Envía el kernel a la cola de ejecución.
if(!OpenCL.Execute(def_k_FeedForwardNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
Después de calcular todos los coeficientes k, podemos determinar el resultado de la resolución de ODE. En la práctica, para estos fines utilizaremos el kernel FeedForwardNODEInpK. Su llamada ya ha sido implementada en el método CalcularInputK. Pero en este caso, tenemos que cambiar los búferes de datos utilizados. Por lo tanto, reescribiremos el algoritmo en el método CalculateOutput.
bool CNeuronNODEOCL::CalculateOutput(CBufferFloat* inputs) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
En los parámetros de este método, sólo recibimos un puntero al búfer de datos de origen. En el cuerpo del método, definimos inmediatamente un espacio de problemas unidimensional. A continuación, pasamos punteros a los búferes de datos de origen a los parámetros del kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Para los multiplicadores, indicamos un buffer de coeficientes de resolución ODE.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_beta, cSolution.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Escribimos los resultados en el búfer de resultados de nuestra clase.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_o, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Coloca el kernel en la cola de ejecución.
if(!OpenCL.Execute(def_k_FeedForwardNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Combinamos los valores obtenidos con los datos de origen y los normalizamos.
if(!SumAndNormilize(Output, inputs, Output, iDimension, true, 0, 0, 0, 1)) return false; //--- return true; }
Hemos preparado métodos de llamada a kernels para organizar el proceso de pases de avance. Ahora sólo tenemos que formalizar el algoritmo en el método de nivel superior CNeuronNODEOCL::feedForward.
bool CNeuronNODEOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { for(int k = 0; k < 6; k++) { if(!CalculateInputK(NeuronOCL.getOutput(), k)) return false; if(!CalculateKBuffer(k)) return false; } //--- return CalculateOutput(NeuronOCL.getOutput()); }
En los parámetros, el método recibe un puntero al objeto de la capa anterior. En el cuerpo del método, organizamos un bucle en el que ajustamos secuencialmente los datos de origen y calculamos todos los coeficientes k En cada iteración, controlamos el proceso de realización de las operaciones. Una vez calculados con éxito los coeficientes necesarios, llamamos al método de resolución ODE. Hemos hecho mucho trabajo preparatorio, y así el algoritmo del método de nivel superior resultó ser bastante conciso.
2.7 Organización del paso de retropropagación
El algoritmo feed-forward proporciona el proceso de funcionamiento del modelo. Sin embargo, el entrenamiento del modelo es inseparable del proceso de retropropagación. Durante este proceso, los parámetros entrenados se ajustan para minimizar el error del modelo.
De forma similar a los kernels feed-forward, hemos creado 2 kernels de retropropagación en el lado del programa OpenCL. Ahora, en el lado del programa principal, tenemos que crear métodos para llamar a los kernels de retropropagación. Como estamos implementando un proceso hacia atrás, trabajamos con métodos en la secuencia de la pasada de retropropagación.
Tras recibir el gradiente de error de la capa siguiente, distribuimos el gradiente resultante entre la capa de datos de origen y los coeficientes k. Este proceso se implementa en el método CalculateOutputGradient que llama al kernel HiddenGradientNODEInpK.
bool CNeuronNODEOCL::CalculateOutputGradient(CBufferFloat *inputs) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
En los parámetros del método, recibimos un puntero al búfer del gradiente de error de la capa anterior. En el cuerpo del método, organizamos el proceso de llamada al kernel del programa OpenCL. En primer lugar, definimos un espacio de tareas unidimensional. A continuación, pasamos punteros a búferes de datos y parámetros del kernel.
Tenga en cuenta que los parámetros del kernel HiddenGradientNODEInpK replican completamente los parámetros del kernel FeedForwardNODEInpK. La única diferencia es que el pase de avance utilizaba búferes de los datos de origen y coeficientes k. El paso de retropropagación utiliza buffers de los gradientes correspondientes. Por este motivo, no he redefinido las constantes del búfer del kernel, sino que he utilizado las constantes del paso de avance.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_beta, cSolution.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_o, Gradient.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
También presta atención a lo siguiente. Para registrar k coeficientes, utilizamos buffers con el índice correspondiente en el rango [0, 5]. En este caso, utilizamos buffers con un índice en el rango [6, 11] para registrar los gradientes de error.
Después de pasar con éxito todos los parámetros al kernel, lo ponemos en la cola de ejecución.
if(!OpenCL.Execute(def_k_HiddenGradientNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
A continuación, consideremos el método CalculateInputKGradient, que llama al mismo kernel. La construcción del algoritmo tiene algunos matices a los que debemos prestar especial atención.
El primero son, por supuesto, los parámetros del método. Aquí se añade el índice del coeficiente k.
bool CNeuronNODEOCL::CalculateInputKGradient(CBufferFloat *inputs, int k) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
En el cuerpo del método, definimos el mismo espacio unidimensional de tareas. A continuación, pasamos los parámetros al kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Sin embargo, esta vez, para escribir los gradientes de error de los k coeficientes, utilizamos buffers con un índice en el rango [12, 17]. Esto se debe a la necesidad de acumular gradientes de error para cada coeficiente.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[13])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[14])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[15])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[16])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[17])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Además, utilizamos multiplicadores de la matriz cBeta.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_beta, ((CBufferFloat *)cBeta.At(k)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_o, iInputsK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Después de pasar con éxito todos los parámetros necesarios al kernel, lo ponemos en la cola de ejecución.
if(!OpenCL.Execute(def_k_HiddenGradientNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
A continuación, debemos sumar el gradiente de error actual con el gradiente de error acumulado anteriormente para el coeficiente k correspondiente. Para ello, organizamos un bucle hacia atrás en el que añadimos secuencialmente gradientes de error empezando por el coeficiente k analizado hasta el mínimo.
for(int i = k - 1; i >= 0; i--) { float mult = 1.0f / (i == (k - 1) ? 6 - k : 1); uint global_work_offset[1] = {0}; uint global_work_size[1] = {iLenth * iVariables}; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix1, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix2, iBuffersK[k + 12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix_out, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_dimension, iDimension)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_in1, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_in2, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_out, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_multiplyer, mult)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MatrixSum, 1, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
Tenga en cuenta que sólo sumamos los gradientes de error para k coeficientes con un índice menor que el actual. Esto se debe a que el multiplicador ß para coeficientes con un índice mayor es obviamente igual a 0. Porque tales coeficientes se calculan después del actual y no participan en su determinación. En consecuencia, su gradiente de error es cero. Además, para un entrenamiento más estable, promediamos los gradientes de error acumulados.
El último kernel que participa en la propagación del gradiente de error es el kernel que propaga el gradiente de error a través de la capa interna de la función ODE HiddenGradientNODEF. Se llama en el método CalculateKBufferGradient. En parámetros, el método recibe sólo el índice del coeficiente k para el que se distribuye el gradiente.
bool CNeuronNODEOCL::CalculateKBufferGradient(int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
En el cuerpo del método, comprobamos si el índice resultante se ajusta a la arquitectura del objeto. A continuación, definimos un espacio de problemas tridimensional.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iVariables, iLenth};
Implementa la transferencia de parámetros al kernel. Como estamos distribuyendo el gradiente de error dentro del paso de retropropagación, primero especificamos los buffers de la capa 2 de la función.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_i, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_ig, iMeadl[k * 2 + 1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_g, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_dimension_out, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_activation, int(LReLU))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Coloca el kernel en la cola de ejecución.
if(!OpenCL.Execute(def_k_HiddenGradientNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
En el siguiente paso, si las matrices que definen el espacio de tareas permanecen inalteradas, transferimos los datos de la 1ª capa de la función a los parámetros del kernel.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_i, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_ig, iInputsK[k + 12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_g, iMeadl[k * 2 + 1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_dimension_out, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_activation, int(None))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Llama a la ejecución del kernel.
if(!OpenCL.Execute(def_k_HiddenGradientNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
Hemos creado métodos para llamar a kernels para distribuir el gradiente de error entre objetos de capa. Pero en este estado, sólo son piezas dispersas del programa que no forman un algoritmo único. Tenemos que combinarlos en un todo único. Organizamos el algoritmo general para distribuir el gradiente de error dentro de nuestra clase utilizando el método calcInputGradients.
bool CNeuronNODEOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!CalculateOutputGradient(prevLayer.getGradient())) return false; for(int k = 5; k >= 0; k--) { if(!CalculateKBufferGradient(k)) return false; if(!CalculateInputKGradient(GetPointer(cTemp), k)) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getOutput(), iDimension, false, 0, 0, 0, 1.0f / (k == 0 ? 6 : 1))) return false; } //--- return true; }
En los parámetros, el método recibe un puntero al objeto de la capa anterior, al que tenemos que pasar el gradiente de error. En la primera etapa, distribuimos el gradiente de error obtenido de la capa posterior entre la capa anterior y los coeficientes k según los factores de la solución ODE. Como recordarás, implementamos este proceso en el método CalculateOutputGradient.
A continuación, ejecutamos un bucle hacia atrás para propagar gradientes a través de la función ODE al calcular los coeficientes correspondientes. Aquí primero propagamos el gradiente de error a través de nuestras 2 capas en el método CalculateKBufferGradient. A continuación, distribuimos el gradiente de error resultante entre los coeficientes k correspondientes y los datos iniciales en el método CalculateInputKGradient. Sin embargo, en lugar de un búfer de gradientes de error de la capa anterior, recibimos datos en un búfer temporal. A continuación añadimos el gradiente resultante al acumulado previamente en el buffer de gradiente de la capa anterior mediante el método SumAndNormilize. En la última iteración, promediamos el gradiente de error acumulado.
En esta fase, hemos distribuido completamente el gradiente de error entre todos los objetos que influyen en el resultado en función de su contribución. Todo lo que tenemos que hacer es actualizar los parámetros del modelo. Previamente, para realizar esta funcionalidad, hemos creado el kernel NODEF_UpdateWeightsAdam. Ahora tenemos que organizar una llamada al kernel especificado en el lado del programa principal. Esta funcionalidad se realiza en el método updateInputWeights.
bool CNeuronNODEOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension + 2, iDimension, iVariables};
En los parámetros, el método recibe un puntero al objeto de la capa neuronal anterior, que en este caso es nominal y sólo es necesario para el procedimiento de virtualización del método.
De hecho, durante los pases hacia delante y hacia atrás, utilizamos los datos de la capa anterior. Por lo tanto, los necesitaremos para actualizar los parámetros de la primera capa de la función ODE. Durante el paso de avance, guardamos el puntero al búfer de resultados de la capa anterior en la matriz iInputsK con índice 0. Por lo tanto, vamos a utilizarlo en nuestra aplicación.
En el cuerpo del método, definimos primero un espacio de problemas tridimensional. A continuación, pasamos los parámetros necesarios al kernel. Primero actualizamos los parámetros de la capa 1.
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik1, iInputsK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk1, iMeadl[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik2, iInputsK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk2, iMeadl[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik3, iInputsK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk3, iMeadl[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik4, iInputsK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk4, iMeadl[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik5, iInputsK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk5, iMeadl[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik6, iInputsK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk6, iMeadl[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_m, ((CBufferFloat*)cWeights.At(1)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_v, ((CBufferFloat*)cWeights.At(2)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_alpha, cAlpha.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_lenth, int(iLenth))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Coloca el kernel en la cola de ejecución.
if(!OpenCL.Execute(def_k_NODEF_UpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
A continuación, repetimos las operaciones para organizar el proceso de actualización de los parámetros de la capa 2.
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik1, iMeadl[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk1, iBuffersK[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik2, iMeadl[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk2, iBuffersK[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik3, iMeadl[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk3, iBuffersK[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik4, iMeadl[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk4, iBuffersK[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik5, iMeadl[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk5, iBuffersK[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik6, iMeadl[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk6, iBuffersK[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_m, ((CBufferFloat*)cWeights.At(4)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_v, ((CBufferFloat*)cWeights.At(5)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_alpha, cAlpha.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_lenth, int(iLenth))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_NODEF_UpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
2.8 Operaciones de archivos
Hemos visto métodos para organizar el proceso de la clase principal. Sin embargo, me gustaría decir unas palabras sobre los métodos para trabajar con archivos. Si se observa detenidamente la estructura de los objetos internos de la clase, se puede seleccionar para ser guardada sólo la colección cWeights, que contiene los pesos en los momentos de su ajuste. También puede guardar 3 parámetros que determinan la arquitectura de la clase. Vamos a guardarlos en el método Save.
bool CNeuronNODEOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; if(!cWeights.Save(file_handle)) return false; if(FileWriteInteger(file_handle, int(iDimension), INT_VALUE) < INT_VALUE || FileWriteInteger(file_handle, int(iVariables), INT_VALUE) < INT_VALUE || FileWriteInteger(file_handle, int(iLenth), INT_VALUE) < INT_VALUE) return false; //--- return true; }
En los parámetros, el método recibe un manejador de archivo para guardar los datos. Inmediatamente, en el cuerpo del método, llamamos al método de la clase padre con el mismo nombre. A continuación guardamos la colección y las constantes.
El método de guardado de clases es bastante conciso y permite ahorrar el máximo espacio en disco. Sin embargo, el ahorro tiene un coste en el método de carga de datos.
bool CNeuronNODEOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; if(!cWeights.Load(file_handle)) return false; cWeights.SetOpenCL(OpenCL); //--- iDimension = (int)FileReadInteger(file_handle); iVariables = (int)FileReadInteger(file_handle); iLenth = (int)FileReadInteger(file_handle);
Aquí cargamos primero los datos guardados. A continuación, organizamos el proceso de creación de los objetos que faltan de acuerdo con los parámetros cargados de la arquitectura de objetos.
//--- CBufferFloat *temp = NULL; for(uint i = 0; i < 18; i++) { OpenCL.BufferFree(iBuffersK[i]); OpenCL.BufferFree(iInputsK[i]); //--- iBuffersK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; iInputsK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; if(i > 11) continue; //--- Initilize Output and Gradient buffers OpenCL.BufferFree(iMeadl[i]); iMeadl[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iMeadl[i] < 0) return false; } //--- cTemp.BufferFree(); if(!cTemp.BufferInit(Output.Total(), 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
Esto concluye nuestra discusión de los métodos de nuestra nueva clase CNeuronNODEOCL. En el archivo adjunto encontrará el código completo de todos los métodos y programas utilizados.
2.9 Arquitectura del modelo para el entrenamiento
Hemos creado una nueva clase de capa neuronal basada en el solucionador ODE CNeuronNODEOCL. Vamos a añadir un objeto de esta clase a la arquitectura del Encoder que creamos en el artículo anterior.
Como siempre, la arquitectura de los modelos se especifica en el método CreateDescriptions, en cuyos parámetros pasamos punteros a 3 matrices dinámicas para indicar la arquitectura de los modelos que se están creando.
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
En el cuerpo del método, comprobamos los punteros recibidos y, si es necesario, creamos nuevos objetos de matriz.
Introducimos en el modelo del codificador datos brutos que describen el estado del entorno.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos recibidos se preprocesan en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos recibidos se preprocesan en la capa de normalización por lotes.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Las incrustaciones generadas se complementan con codificación posicional.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, utilizamos una capa de análisis de datos compleja y guiada por el contexto.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCCMROCL; descr.count = prev_count; descr.window = prev_wout; descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Hasta aquí, hemos repetido completamente el modelo de los artículos anteriores. Pero a continuación, vamos a añadir 2 capas de una nueva clase.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronNODEOCL; descr.count = prev_count; descr.window = EmbeddingSize/4; descr.step = 4; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronNODEOCL; descr.count = prev_count; descr.window = EmbeddingSize/4; descr.step = 4; if(!encoder.Add(descr)) { delete descr; return false; }
Los modelos Actor y Critic están copiados del artículo anterior sin cambios. Por lo tanto, no consideraremos estos modelos ahora.
La adición de nuevas capas no afecta a los procesos de interacción con el entorno y entrenamiento del modelo. Por consiguiente, todas las EAs anteriores se utilizan también sin cambios. De nuevo puedes encontrar el código completo de todos los programas en el archivo adjunto. Ahora pasamos a la siguiente fase para comprobar el trabajo realizado.
3. Pruebas
Hemos considerado una nueva familia de modelos de Ecuaciones Diferenciales Ordinarias. Teniendo en cuenta los enfoques propuestos, implementamos la nueva clase CNeuronNODEOCL utilizando MQL5 para organizar la capa neuronal en nuestros modelos. Ahora pasamos a la fase 3 de nuestro trabajo: entrenar y probar los modelos con datos reales en el probador de estrategias de MetaTrader 5.
Al igual que antes, los modelos se entrenan y prueban utilizando datos históricos para EURUSD H1. Entrenamos los modelos fuera de línea. Para ello, recogimos una muestra de entrenamiento de varias 500 trayectorias basadas en datos históricos de los 7 primeros meses de 2023. La mayoría de las trayectorias se recogieron mediante pasadas aleatorias. La proporción de pases rentables es bastante pequeña. Para igualar la rentabilidad media de los pases durante el proceso de entrenamiento, utilizamos el muestreo de trayectorias con priorización en su resultado. Esto permite asignar mayor peso a los pases rentables. Esto aumenta la probabilidad de seleccionar dichos pases.
Los modelos entrenados se probaron en el probador de estrategias utilizando datos históricos de agosto de 2023, con el mismo símbolo y marco temporal. Con este enfoque, podemos evaluar el rendimiento del modelo entrenado en datos nuevos (no incluidos en la muestra de entrenamiento) preservando las estadísticas de los conjuntos de datos de entrenamiento y prueba.
Los resultados de las pruebas sugieren que es posible aprender estrategias que generen beneficios tanto en el periodo de entrenamiento como en el de prueba. A continuación se presentan las capturas de pantalla de las pruebas.


Según los resultados de las pruebas de agosto de 2023, el modelo entrenado realizó 160 operaciones, 84 de las cuales se cerraron con beneficios. Esto equivale al 52,5%. Podemos concluir que la paridad comercial se ha inclinado ligeramente hacia el beneficio. La media de operaciones rentables es un 4% superior a la media de operaciones perdedoras. La serie media de operaciones rentables es igual a la serie media de operaciones perdedoras. La serie máxima rentable por el número de operaciones es igual a la serie máxima perdedora por este parámetro. Sin embargo, la operación rentable máxima y la serie rentable máxima en importe superan variables similares de operaciones perdedoras. Como resultado, durante el periodo de prueba, el modelo mostró un factor de beneficio de 1,15 con un ratio de Sharpe de 2,14.
Conclusión
En este artículo, consideramos una nueva clase de modelos de Ecuaciones Diferenciales Ordinarias (ODE). El uso de ODE como componente de los modelos de aprendizaje automático presenta una serie de ventajas y potencialidades. Permiten modelar procesos dinámicos y cambios en los datos, lo que es especialmente importante para problemas relacionados con series temporales, dinámica de sistemas y previsiones. Las ODEs neuronales pueden integrarse con éxito en diversas arquitecturas de redes neuronales, incluidos los modelos profundos y recurrentes, ampliando el alcance de estos métodos.
En la parte práctica de nuestro artículo, implementamos los enfoques propuestos en MQL5. Entrenamos y probamos el modelo utilizando datos reales en el probador de estrategias de MetaTrader 5. Los resultados de las pruebas se presentan más arriba. Demuestran la eficacia de los planteamientos propuestos para resolver nuestros problemas.
No obstante, le recuerdo que todos los programas presentados en el artículo son de carácter informativo y sólo pretenden demostrar los enfoques propuestos.
Referencias
Programas utilizados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor experto | Colección de ejemplos |
| 2 | ResearchRealORL.mq5 | Asesor experto | EA para la recolección de ejemplos utilizando el método Real-ORL |
| 3 | Study.mq5 | Asesor experto | EA para el entrenamiento del modelo |
| 4 | Test.mq5 | Asesor experto | EA para la prueba del modelo |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema |
| 6 | NeuroNet.mqh | Biblioteca de clases | Una biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Código base | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14569
 Utilizando redes neuronales en MetaTrader
Utilizando redes neuronales en MetaTrader
 Paradigmas de programación (Parte 2): Enfoque orientado a objetos para el desarrollo de EA basados en la dinámica de precios
Paradigmas de programación (Parte 2): Enfoque orientado a objetos para el desarrollo de EA basados en la dinámica de precios
 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso