
Características del Wizard MQL5 que debe conocer (Parte 12): Polinomio de Newton
Introducción
El análisis de series temporales desempeña un papel importante no sólo como apoyo al análisis fundamental, sino que en mercados muy líquidos como el de divisas, puede ser el principal impulsor de las decisiones sobre cómo posicionarse en los mercados. Los indicadores técnicos tradicionales han tendido a ir muy por detrás del mercado, lo que les ha hecho perder el favor de la mayoría de los operadores, dando lugar al surgimiento de alternativas, de las cuales la más predominante en estos momentos son las redes neuronales. Pero, ¿qué pasa con la interpolación polinómica?
Presentan algunas ventajas, principalmente por ser fáciles de entender y aplicar, ya que presentan explícitamente la relación entre las observaciones pasadas y las previsiones futuras en una ecuación sencilla. Esto ayuda a comprender cómo influyen los datos pasados en los valores futuros, lo que a su vez permite desarrollar conceptos amplios y posibles teorías sobre el comportamiento de las series temporales estudiadas.
Además, al ser adaptables tanto a relaciones lineales como cuadráticas, son flexibles a diversas series temporales y, quizá más pertinente para los operadores, capaces de hacer frente a distintos tipos de mercado (por ejemplo, mercados con oscilaciones frente a mercados con tendencias o volátiles frente a mercados en calma).
Además, no suelen consumir muchos recursos informáticos y son relativamente ligeras si se comparan con enfoques alternativos como las redes neuronales. De hecho, el modelo o modelos examinados en este artículo no tienen requisitos de almacenamiento del tipo que necesitaría, por ejemplo, una red neuronal en la que, dependiendo de su arquitectura, es necesario almacenar los pesos y sesgos óptimos después de cada sesión de entrenamiento.
Así, formalmente el polinomio de interpolación de Newton N(x) viene definido por la ecuación:

Donde todos los 'x j' son únicos en la serie y 'a j' es la suma de las diferencias divididas, mientras que 'n j' (x) es la suma del producto de los coeficientes de la base para 'x', que se representa formalmente de la siguiente manera:

Las fórmulas de las diferencias divididas y de los coeficientes de base pueden consultarse fácilmente de forma independiente, pero vamos a intentar desglosar aquí sus definiciones de la forma más informal posible.
Las diferencias divididas son un proceso de división repetitivo que establece coeficientes para 'x' en cada exponente hasta que se agotan todos los exponentes de 'x' del conjunto de datos proporcionado. Para ilustrarlo, consideremos el ejemplo siguiente de tres puntos de datos:
(1,2), (3,4) y (5,6)
Para utilizar la diferencia dividida, todos los valores 'x' deben ser únicos. El número de puntos de datos proporcionados infiere el mayor exponente de 'x' en el polinomio de forma Newton que se obtiene. Si tuviéramos sólo 2 puntos, por ejemplo, entonces nuestra ecuación sería simplemente lineal en la forma:
y = mx + c.
Lo que implica que nuestro máximo exponente es uno. Por lo tanto, para nuestro ejemplo de tres puntos, el exponente más alto es 2, lo que significa que necesitamos obtener 3 coeficientes diferentes para nuestro polinomio derivado.
Obtener cada uno de estos 3 coeficientes es un proceso iterativo, paso a paso, hasta llegar al tercero. Hay fórmulas en los enlaces compartidos más arriba, pero probablemente la mejor manera de entenderlo sería utilizando una tabla como la que se muestra a continuación:
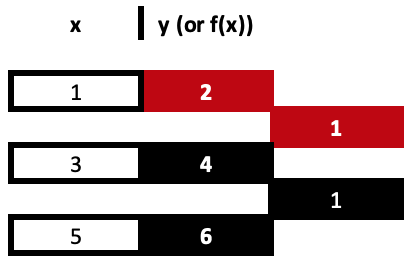
Así, nuestra primera columna de diferencias divididas se obtiene de dividir la diferencia entre los valores 'y' y el cambio en los respectivos valores 'x'. Recuerde que todos los valores 'x' deben ser únicos. Estos cálculos son muy sencillos y directos, aunque es más fácil seguirlos a partir de una tabla como la que se muestra arriba que con las fórmulas típicas a las que se hace referencia en los enlaces compartidos. Ambos enfoques conducen al mismo resultado.
= (4 - 2) / (3 - 1)
Nos da nuestro primer coeficiente, 1.
= (6 - 4) / (5 - 3)
Nos da el segundo coeficiente de valor similar. Los coeficientes están resaltados en rojo.
En nuestro ejemplo con 3 puntos de datos, el valor final obtendría sus diferencias en 'y' a partir de los valores recién calculados, pero sus denominadores en 'x' serían los dos valores extremos de la serie en 'x', ya que su diferencia será el divisor.
Así que nuestra tabla se completaría de la siguiente manera:

Con nuestra tabla completa anterior, tenemos 3 valores derivados pero sólo 2 de ellos se utilizan para obtener los coeficientes. Esto nos lleva, por lo tanto, a las sumas de productos de los 'polinomios base'. Aunque suene extravagante, en realidad es más sencillo que las diferencias divididas. Así que, para ilustrar esto, basándonos en nuestros coeficientes derivados de la tabla anterior, nuestra ecuación para los tres puntos sería:
y = 2 + 1*(x – 1) + 0*(x – 1)*(x – 3)
Esto resulta en:
y = x + 1
Los paréntesis añadidos son todo lo que constituye la base de los polinomios. El valor 'x n' es simplemente el valor 'x' respectivo de cada punto de datos muestreado. Ahora volvamos a los coeficientes y observaremos que, por regla general, sólo utilizamos los valores superiores de la tabla para anteponer estos valores de corchete y, a medida que avanzamos hacia la derecha obteniendo columnas más cortas en la tabla, los valores superiores anteponen secuencias de corchete más largas hasta que se consideran todos los puntos de datos proporcionados. Como ya se ha mencionado, cuantos más puntos de datos haya que interpolar, más exponentes de 'x y', por tanto, más columnas tendremos en nuestra tabla de derivadas.
Antes de pasar a la aplicación, veamos otra ilustración atractiva. Suponiendo que tenemos 7 puntos de datos para los precios de los valores donde los valores 'x' son simplemente el índice de barras de precios como se muestra a continuación:
| 0 | 1.25590 |
| 1 | 1.26370 |
| 2 | 1.25890 |
| 3 | 1.25395 |
| 4 | 1.25785 |
| 5 | 1.26565 |
| 6 | 1.26175 |
Nuestra tabla que propaga los valores de los coeficientes se extendería en 8 columnas de la siguiente manera:

Con los coeficientes resaltados en rojo, la ecuación resultante sería la siguiente:
y = 1.2559 + 0.0078*(x – 0) – 0.0063*(x – 0)*(x – 1) + …
Esta ecuación, como es evidente, llega hasta el exponente 6, dados los siete puntos de datos y podría decirse que su función clave podría ser la de pronosticar el siguiente valor introduciendo un nuevo índice 'x' en la ecuación. Si los datos muestreados se "fijan como una serie" entonces el siguiente índice sería -1 de lo contrario sería 8.
Implementación en MQL5:
Implementar esto en MQL5 se puede lograr con un mínimo de codificación aunque cabe mencionar que no pude encontrar ninguna librería que permita ejecutar estas ideas desde instancias de clases precodificadas, por ejemplo.
Para ello, sin embargo, tenemos que hacer básicamente dos cosas. En primer lugar, necesitamos una función para calcular los coeficientes de 'x' de nuestra ecuación a partir de nuestro conjunto de datos muestreados. En segundo lugar, también necesitamos una función que procese un valor previsto utilizando nuestra ecuación cuando se le presente un valor 'x'. Todo parece bastante sencillo, pero si tenemos en cuenta que queremos hacerlo de forma escalable, hay que tener en cuenta algunas advertencias en los pasos de procesamiento.
Antes de entrar en materia, ¿qué se entiende por "forma escalable"? Con esto me refiero simplemente a funciones que pueden utilizar diferencias divididas para obtener coeficientes para conjuntos de datos cuyo tamaño no está predeterminado. Puede parecer obvio, pero si consideramos nuestro primer ejemplo con 3 puntos de datos, la implementación en MQL5 para obtener los coeficientes se detalla más abajo.
El siguiente listado simplemente sigue las ecuaciones para obtener la diferencia dividida para los dos pares dentro de los datos muestreados e itera este procedimiento para obtener también el último valor. Ahora bien, si tuviéramos una muestra de 4 puntos de datos, la interpolación de su ecuación requeriría una función diferente, ya que tenemos que dar más pasos que los mostrados en el ejemplo anterior de 3 puntos.
Por lo tanto, si tenemos una función escalable, sería capaz de manejar 'n' conjuntos de datos de tamaño y la salida de 'n-1' coeficientes. De ello da cuenta el siguiente listado:
//+------------------------------------------------------------------+ //| INPUT PARAMETERS | //| X - vector with x values of sampled data | //| Y - vector with y values of sampled data | //| OUTPUT PARAMETERS | //| W - vector with coefficients. | | //+------------------------------------------------------------------+ void Cnewton::Set(vector &W, vector &X, vector &Y) { vector _w[]; ArrayResize(_w, int(X.Size() - 1)); int _x_scale = 1; int _y_scale = int(X.Size() - 1); for(int i = 0; i < int(X.Size() - 1); i++) { _w[i].Init(_y_scale); for(int ii = 0; ii < _y_scale; ii++) { if(X[ii + _x_scale] != X[ii]) { if(i == 0) { _w[i][ii] = (Y[ii + 1] - Y[ii]) / (X[ii + _x_scale] - X[ii]); } else if(i > 0) { _w[i][ii] = (_w[i - 1][ii + 1] - _w[i - 1][ii]) / (X[ii + _x_scale] - X[ii]); } } else { printf(__FUNCSIG__ + " ERR!, identical X value: " + DoubleToString(X[ii + _x_scale]) + ", at: " + IntegerToString(ii + _x_scale) + ", and: " + IntegerToString(ii)); return; } } _x_scale++; _y_scale--; W[i + 1] = _w[i][0]; if(_y_scale <= 0) { break; } } }
Esta función opera utilizando dos bucles anidados y dos enteros que rastrean los índices para los valores de 'x' e 'y'. Puede que no sea la forma más eficiente de implementarlo, pero funciona y, a falta de una biblioteca estándar que lo implemente, animo a explorarlo e incluso a mejorarlo en función del caso de uso.
La función para procesar la siguiente 'y' dada una entrada 'x' y todos los coeficientes de nuestras ecuaciones también se comparte a continuación:
//+------------------------------------------------------------------+ //| INPUT PARAMETERS | //| W - vector with pre-computed coefficients | //| X - vector with x values of sampled data | //| XX - query x value with unknown y | //| OUTPUT PARAMETERS | //| YY - solution for unknown y. | //+------------------------------------------------------------------+ void Cnewton::Get(vector &W, vector &X, double &XX, double &YY) { YY = W[0]; for(int i = 1; i < int(W.Size()); i++) { double _y = W[i]; for(int ii = 0; ii < i; ii++) { _y *= (XX - X[ii]); } YY += _y; } }
Esto también es más sencillo que nuestra función anterior, aunque también tiene un bucle anidado; lo único que estamos haciendo es rastrear los coeficientes que obtuvimos en la función de conjunto y asignarlos a su polinomio base de Newton correspondiente.
Aplicaciones:
Las aplicaciones de esto pueden ser muy variadas y para este artículo consideraremos cómo esto puede ser útil como una señal, un método de trailing stop, y un método de gestión de dinero. Antes de codificar esto normalmente es una buena idea tener una clase base con las dos funciones que implementan la interpolación, cuyo código se lista arriba. Para tal clase, su interfaz será la siguiente:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Cnewton { private: public: Cnewton(); ~Cnewton(); void Set(vector &W, vector &X, vector &Y); void Get(vector &W, vector &X, double &XX, double &YY); };
Señal
Los archivos de la clase de señales de experto estándar proporcionados en la biblioteca de MQL5, como siempre, sirven como una guía útil para desarrollar una implementación personalizada. En nuestro caso, la primera opción obvia para los datos de muestra de entrada, para generar el polinomio, serían los precios de cierre de los valores sin procesar. Para generar un polinomio basado en los precios de cierre, primero rellenaríamos los vectores 'x' e 'y' con los índices de barras de precios y los precios de cierre reales, respectivamente. Estos dos vectores son las entradas clave de nuestra función "set", responsable de obtener los coeficientes. Como nota al margen, estamos utilizando simplemente los índices de las barras de precios para 'x' en nuestra señal, pero es posible usar alternativas como las sesiones en un día de trading, o en una semana de trading, siempre que, por supuesto, ninguno de estos se repita en la muestra de datos, es decir, que todos aparezcan solo una vez. Por ejemplo, si tu día de trading tiene 4 sesiones, entonces no puedes proporcionar más de 4 puntos de datos y los índices de sesión 0, 1, 2 y 3 solo pueden aparecer una vez dentro del conjunto de datos.
Después de rellenar nuestros vectores 'x' e 'y', llamar a la función 'set' debería proporcionar los coeficientes preliminares a nuestra ecuación polinómica. Si ejecutamos esta ecuación con estos coeficientes y el siguiente valor de 'x' utilizando la función "get", obtenemos la proyección de cuál será el próximo valor de 'y'. Dado que nuestros valores de entrada y en la función "set" eran precios de cierre, estaríamos buscando obtener el siguiente precio de cierre. El código para ello se comparte a continuación:
double _xx = -1.0;//m_length + 1.0, double _yy = 0.0; __N.Get(_w, _xx, _yy);
Además de obtener el siguiente precio de cierre proyectado, las funciones de comprobación de apertura de la clase de señal experta suelen dar como resultado un número entero que está en el rango de 0 - 100 como señal de lo fuerte que es la señal de compra o venta. En nuestro caso, por lo tanto, necesitamos encontrar una forma de representar el precio de cierre proyectado como un simple número entero que se ajuste a este rango.
Para obtener esta normalización, el cambio de precio de cierre previsto se expresa como porcentaje del rango de precios máximo y mínimo actual. A continuación, este porcentaje se expresa como un número entero comprendido entre 0 y 100. Esto implica que las variaciones negativas del precio de cierre en la función "comprobar si hay posiciones largas abiertas" serán automáticamente cero, y lo mismo ocurrirá con las variaciones positivas de las previsiones en la función "comprobar si hay posiciones cortas abiertas".
m_high.Refresh(-1); m_low.Refresh(-1); m_close.Refresh(-1); int _i = StartIndex(); double _h = m_high.GetData(m_high.MaxIndex(_i,m_length)); double _l = m_low.GetData(m_low.MinIndex(_i,m_length)); double _c = m_close.GetData(0); // if(_yy > _c) { _result = int(round(((_yy - _c) / (fmax(_h, fmax(_yy, _c)) - fmin(fmin(_yy, _c), _l))) * 100.0)); }
Al hacer previsiones mediante la ecuación polinómica, la única variable que utilizamos es la duración del periodo de retrospección (que fija el tamaño de los datos de muestreo). Esta variable se denomina "m_length". Si ejecutamos optimizaciones sólo para este parámetro para el símbolo EURJPY en el marco temporal de 1 hora durante el año 2023, obtendremos los siguientes informes.


Un recorrido completo a lo largo de todo el año nos da esta imagen de equidad:

Trailing Stop
Además de la clase de señal experta, podemos montar un asesor experto con el asistente seleccionando también un método para fijar y ajustar el trailing stop de las posiciones abiertas. En la biblioteca se proporcionan métodos que utilizan el SAR Parabólico y medias móviles, y en general, su número es mucho menor que el de la biblioteca de señales. Si queremos mejorar este recuento añadiendo una clase que utilice el polinomio de Newton, entonces podría decirse que nuestros datos muestreados tendrían que ser rangos de barras de precios.
Si seguimos los mismos pasos que tomamos anteriormente al proyectar el próximo precio de cierre, con el cambio principal siendo los datos del vector y, que en este caso serán los rangos de las barras de precios, entonces nuestro código será el siguiente:
//+------------------------------------------------------------------+ //| Checking trailing stop and/or profit for long position. | //+------------------------------------------------------------------+ bool CTrailingNP::CheckTrailingStopLong(CPositionInfo *position, double &sl, double &tp) { //--- check ... //--- m_high.Refresh(-1); m_low.Refresh(-1); vector _x, _y; _x.Init(m_length); _y.Init(m_length); for(int i = 0; i < m_length; i++) { _x[i] = i; _y[i] = (m_high.GetData(StartIndex()+i)-m_low.GetData(StartIndex()+i)); } vector _w; _w.Init(m_length); _w[0] = _y[0]; __N.Set(_w, _x, _y); double _xx = -1.0; double _yy = 0.0; __N.Get(_w, _x, _xx, _yy); //--- ... //--- return(sl != EMPTY_VALUE); }
A continuación, se utiliza una proporción de este rango de barras de previsión para fijar el tamaño del Stop Loss de la posición. La proporción utilizada es un parámetro optimizable llamado ‘m_stop_level’ y, antes de establecer el nuevo Stop Loss, añadimos la distancia mínima de stop a este delta para evitar errores del bróker. Esta normalización se recoge en el siguiente código:
//+------------------------------------------------------------------+ //| Checking trailing stop and/or profit for long position. | //+------------------------------------------------------------------+ bool CTrailingNP::CheckTrailingStopLong(CPositionInfo *position, double &sl, double &tp) { //--- check ... //--- sl = EMPTY_VALUE; tp = EMPTY_VALUE; delta = (m_stop_level * _yy) + (m_symbol.Point() * m_symbol.StopsLevel()); //--- if(price - base > delta) { sl = price - delta; } //--- return(sl != EMPTY_VALUE); }
Si montamos un experto a través del asistente de MQL5 (Wizard MQL5) que utiliza la clase de señal experta Awesome Oscillator de la biblioteca, e intentamos optimizar sólo para la longitud polinómica ideal, para el mismo símbolo, marco temporal y periodo de 1 año que el anterior, obtenemos el siguiente informe como nuestro mejor caso:


Los resultados son, en el mejor de los casos, mediocres. Curiosamente, si como control ejecutamos el mismo Asesor Experto pero con un Trailing Stop basado en una media móvil, obtendremos "mejores" resultados, como se indica en los informes siguientes:


Estos mejores resultados pueden atribuirse a que se han optimizado más parámetros en lugar de sólo el que teníamos con el polinomio y, de hecho, el emparejamiento con una señal experta diferente podría producir resultados radicalmente distintos. No obstante, a efectos de experimentos de control, estos informes podrían servir de guía sobre el potencial del polinomio de Newton en la gestión de "stop losses" de posiciones abiertas.
Gestión del dinero
Por último, consideraremos cómo los polinomios de Newton pueden ayudar en el dimensionamiento de la posición, que se gestiona mediante el tercer tipo de clases incorporadas al asistente, denominadas "CExpertMoney". Entonces, ¿como podría nuestro polinomio ayudar con esto?. Ciertamente hay muchas direcciones que se pueden tomar para llegar a un mejor uso, sin embargo vamos a considerar los cambios en el rango de barras como un indicador de la volatilidad y por lo tanto una guía de cómo debemos ajustar el tamaño de una posición de margen fijo. Nuestra tesis simple será que si estamos pronosticando un aumento en el rango de la barra de precios, entonces disminuiríamos proporcionalmente el tamaño de nuestra posición, sin embargo, si no está aumentando, entonces no hacemos nada. No habrá aumentos debido a las caídas previstas de la volatilidad.
Nuestro código fuente que nos ayuda con esto está a continuación, con las secciones similares a las que hemos cubierto arriba editadas.
//+------------------------------------------------------------------+ //| Optimizing lot size for open. | //+------------------------------------------------------------------+ double CMoneySizeOptimized::Optimize(double lots) { double lot = lots; //--- 0 factor means no optimization if(m_decrease_factor > 0) { m_high.Refresh(-1); m_low.Refresh(-1); vector _x, _y; _x.Init(m_length); _y.Init(m_length); for(int i = 0; i < m_length; i++) { _x[i] = i; _y[i] = (m_high.GetData(StartIndex() + i) - m_low.GetData(StartIndex() + i)) - (m_high.GetData(StartIndex() + i + 1) - m_low.GetData(StartIndex() + i + 1)); } vector _w; _w.Init(m_length); _w[0] = _y[0]; __N.Set(_w, _x, _y); double _xx = -1.0; double _yy = 0.0; __N.Get(_w, _x, _xx, _yy); //--- if(_yy > 0.0) { double _range = (m_high.GetData(StartIndex()) - m_low.GetData(StartIndex())); _range += (m_decrease_factor*m_symbol.Point()); _range += _yy; lot = NormalizeDouble(lot*(1.0-(_yy/_range)), 2); } } //--- normalize and check limits ... //--- return(lot); }
Una vez más, si realizamos optimizaciones ÚNICAMENTE para el período de retroceso del polinomio en un asesor experto que utiliza la misma clase de señales que teníamos con el asesor experto de Trailing para el mismo símbolo, marco temporal y período, obtenemos los siguientes informes:


Este asesor experto no tenía ningún método de Trailing Stop seleccionado en el asistente y, en esencia, utiliza las señales sin procesar del Awesome Oscillator con los únicos cambios que se producen en la disminución del tamaño de la posición si se prevé volatilidad.
Como control utilizamos la clase de gestión monetaria incorporada "size optimized" en un experto con señal similar y también sin Trailing Stop. Este experto permite ajustar sólo el factor de disminución que forma un denominador a una fracción que reduce el tamaño de la posición en proporción a las pérdidas sufridas por el asesor experto. Si realizamos pruebas con su mejor configuración, obtendremos los siguientes informes.


Los resultados son claramente "pálidos" en comparación con los que obtuvimos con la gestión monetaria polinómica de Newton, que de nuevo, como vimos con las clases Trailing, no es una acusación per se sobre los expertos optimizados en tamaño de posición, pero para nuestros fines comparativos podría significar que la gestión monetaria basada en el polinomio de Newton, en la forma en que la hemos implementado, es una mejor alternativa.
Conclusión
En conclusión, hemos visto el polinomio de Newton, un método que deriva una ecuación polinómica a partir de un conjunto de unos pocos puntos de datos. Este polinomio, y el muro de números que se consideró en el último artículo, o la máquina de Boltzmann restringida que lo precedió, representan introducciones a ideas que podrían utilizarse de formas que van más allá de lo que se considera dentro de estas series.
Hay una escuela de pensamiento en ciernes que propone ceñirse a los métodos probados y comprobados en el análisis de los mercados y estos artículos no están en contra de eso, per se, pero cuando estamos en una situación en la que todo, desde BTC, a las acciones, a los bonos e incluso las materias primas, está bastante correlacionado, ¿podría ser esto un presagio de eventos sistémicos? Es fácil descartar una ventaja en tiempos de dinero fácil, por lo que estas series pueden considerarse un medio de defender enfoques nuevos y a menudo poco apreciados que podrían proporcionar un seguro muy necesario mientras todos nos adentramos en lo desconocido.
Los polinomios de Newton tienen limitaciones, como se muestra en los informes de pruebas anteriores, y esto se debe principalmente a su incapacidad para filtrar el ruido blanco, lo que implica que tienen potencial para funcionar bien cuando se combinan con otros indicadores que se ocupan de esto. El asistente MQL5 permite emparejar varias señales en un único asesor experto, de modo que se puede utilizar un filtro o incluso varios filtros para obtener una señal experta mejor. La clase Trailing y los módulos de gestión monetaria no lo permiten, por lo que habría que hacer más pruebas para encontrar qué clases Trailing y de gestión monetaria funcionan mejor con la señal.
Así pues, la incapacidad para filtrar el ruido blanco puede atribuirse a la tendencia de los polinomios a sobreajustar los datos muestreados captando todos los meneos en lugar de procesar los patrones subyacentes. Esto suele denominarse "ruido de memorización" y provoca un rendimiento deficiente en datos fuera de muestra. Las series temporales financieras suelen tener también propiedades estadísticas cambiantes (media, varianza... ) y una dinámica no lineal en la que los cambios bruscos de precio pueden ser la norma. Los polinomios de Newton, basados en curvas polinómicas suaves, tienen dificultades para captar esas complejidades. Por último, su incapacidad para incorporar el sentimiento económico y las variables fundamentales implica que deben combinarse con indicadores financieros adecuados, como se ha mencionado anteriormente.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/14273
 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
 Redes neuronales: así de sencillo (Parte 76): Exploración de diversos patrones de interacción con Multi-future Transformer
Redes neuronales: así de sencillo (Parte 76): Exploración de diversos patrones de interacción con Multi-future Transformer
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso