
Redes neuronales: así de sencillo (Parte 76): Exploración de diversos patrones de interacción con Multi-future Transformer

Introducción
Predecir los próximos movimientos de los precios es uno de los requisitos clave para construir una estrategia de negociación con éxito. Por lo tanto, tenemos que explorar las posibilidades de crear previsiones precisas y multimodales del movimiento futuro. En artículos anteriores, nos familiarizamos con algunos métodos para predecir los movimientos de los precios. Entre ellas, las multimodales, que ofrecían diversas variantes de desarrollo del evento.
Sin embargo, todos ellos rara vez se centran en las posibilidades futuras de interacción entre los agentes analizados, lo que puede llevar a una pérdida de información y a una previsión subóptima. Además, es bastante difícil escalar los métodos discutidos anteriormente en caso de que tengamos múltiples agentes, ya que las predicciones independientes pueden dar lugar a un número exponencial de combinaciones. La mayoría de las combinaciones resultantes no son viables debido a predicciones contradictorias. Por ello, es importante centrarse en la predicción de escenas en su conjunto, estimando el estado futuro de múltiples agentes simultáneamente.
Los autores del artículo "Multi-future Transformer: Learning diverse interaction modes for behavior prediction in autonomous driving" sugieren utilizar el método Multi-future Transformer (MFT) para resolver este tipo de problemas. Su idea principal es descomponer la distribución multimodal del futuro en varias distribuciones unimodales, lo que permite simular eficazmente varios modelos de interacción entre agentes en la escena.
En la MFT, las previsiones son generadas por una red neuronal con parámetros fijos en una sola pasada, sin necesidad de muestrear estocásticamente variables latentes, predeterminar anclajes o ejecutar un algoritmo iterativo de postprocesamiento. Esto permite que el modelo funcione de forma determinista y repetible.
1. Algoritmo Transformador Multifuturo
El objetivo principal del método MFT (Multi-future Transformer), es predecir de forma consistente el movimiento Y futuro de todos los agentes de la escena. Para ello, analiza el estado dinámico de los agentes X y la información contextual M. Así, la distribución de probabilidad global a capturar es P(Y|X,M), que es multimodal como resultado de la clara evolución de la escena.
Suele ser muy difícil modelizar directamente la distribución multimodal conjunta. Los autores del método introducen el supuesto de que la distribución objetivo puede descomponerse en una mezcla de varias distribuciones unimodales y, a continuación, estas distribuciones unimodales se modelan por separado, lo que se formula como
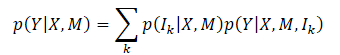
donde Ik representa el k-ésimo componente de modo;
p(Ik|X,M) es la distribución de probabilidad de los distintos modos;
p(Y|X,M,Ik) representa la distribución unimodal factorizada.
Bajo esta formulación, el punto clave en la MFT es que la principal diferencia entre cada modo de distribución objetivo reside en los diferentes modelos de interacción entre agentes, y entre agentes y contexto. El modelado de cada distribución unimodal puede realizarse estudiando los patrones de las interacciones modo-correspondencia. Intuitivamente, la incertidumbre de la escena futura puede descomponerse principalmente en dos partes: incertidumbre de intención e incertidumbre de interacción.
Las intenciones no observables pueden captarse bien modelando la interacción entre el agente y el contexto, ya que el punto final de la trayectoria futura, que representa las intenciones del agente, está estrechamente relacionado con el contexto de la escena. Para tener en cuenta la incertidumbre de la interacción, se modelan distintos modos de interacción entre los agentes. Así, al capturar conjuntamente las interacciones entre agentes y entre agentes y contextos, se minimiza la incertidumbre futura y se puede determinar la evolución de una escena.
Para lograr la descomposición de la distribución conjunta multimodal descrita anteriormente, se diseñó la arquitectura general del enfoque MFT propuesto. Está compuesto por tres partes:
- Codificadores
- Módulo de interacción paralela
- Cabeceras de predicción
El modelo incluye dos tipos de codificadores:
- El codificador de agentes dinámicos se utiliza para extraer características de los estados dinámicos observados,
- El codificador de segmentos contextuales sirve como visor de mapas para aprender funciones puntuales para puntos de franja.
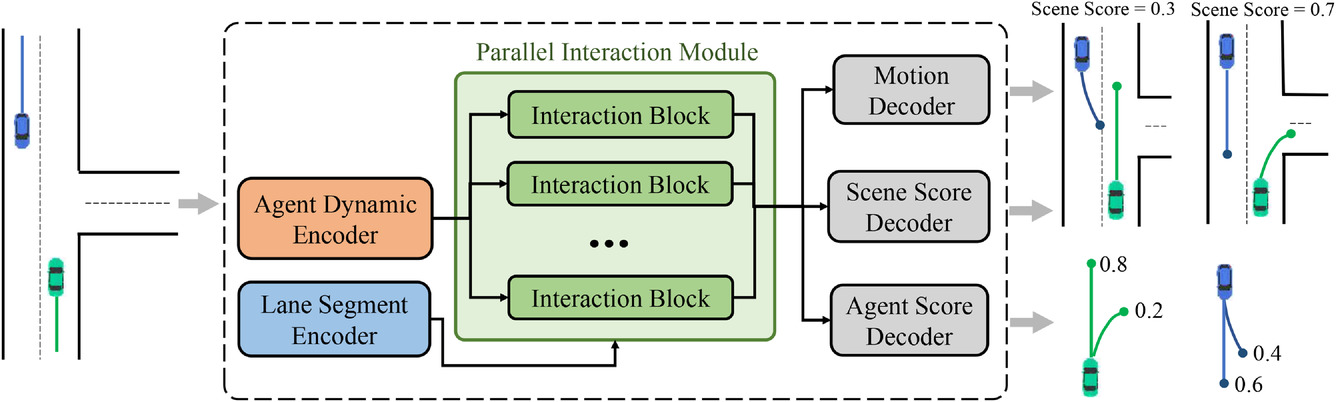
El núcleo del modelo MFT es un módulo de interacción paralela, que consta de varios bloques de interacción en una estructura paralela y estudia las características futuras del movimiento de los agentes para cada modo. Las tres cabeceras de predicción incluyen:
- Descodificador de movimiento,
- Descodificador de puntuación de agentes,
- Descodificador de puntuación de escenas.
Se encargan de descodificar las trayectorias futuras de cada agente y de estimar las puntuaciones de confianza para cada trayectoria prevista y cada modo de escena. En esta arquitectura, los caminos por los que pasan las señales feed-forward y la retropropagación de cada modo son independientes entre sí, y cada camino contiene un bloque de interacción único que proporciona interacción de información entre señales del mismo modo. Por lo tanto, las unidades de interacción pueden captar simultáneamente los patrones de interacción correspondientes a los distintos modos. Sin embargo, los codificadores y las cabeceras de predicción son comunes a cada modo, mientras que los bloques de interacción se parametrizan como objetos diferentes. Por lo tanto, cada distribución unimodal, que teóricamente tiene parámetros diferentes, puede modelarse de una forma más eficiente en cuanto a parámetros. A continuación se muestra la visualización original del método.
Las trayectorias observadas de los agentes en el horizonte histórico pueden representarse como X={x1,.... ,xatt}, donde el estado dinámico en cada paso temporal xt=(x,y,vx,vy, w) contiene la posición (x,y), la velocidad (vx,vy), y el ángulo de viraje w en ese momento.
Los estados dinámicos de un agente se consideran como un conjunto de puntos en un espacio multidimensional, donde cada punto está representado por coordenadas (x,y), y otras dimensiones representan características locales adicionales. Para estos puntos, se conservan las propiedades de interacción y la estructura local dada, ya que los estados observados del agente interactúan entre sí y juntos forman la trayectoria observada del agente. Además, otra propiedad importante de estos puntos de trayectoria es el orden temporal, que es una característica implícita en comparación con los puntos de trayectoria estáticos. Naturalmente, los mismos puntos de trayectoria con un orden temporal inverso conducen a una trayectoria observada completamente distinta. Las propiedades anteriores exigen que el modelo represente los puntos de la trayectoria no sólo combinando características puntuales, sino también introduciendo información de orden temporal. Para ello, se utiliza la codificación posicional absoluta para codificar la información de ordenación. El modelo calcula las características dinámicas de cada agente del siguiente modo:
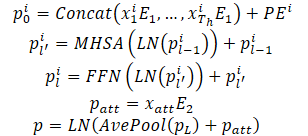
Se apilan varias capas codificadoras para mejorar la capacidad del modelo de representar información dinámica. El promediado se realiza sobre todos los puntos de la trayectoria de un agente para resumir la información dinámica histórica relacionada con un agente específico.
También se extrajeron características puntuales correspondientes al momento actual para obtener información dinámica. Esto proporciona un rendimiento similar al de la piscina media. Cuando se trata de estados históricos parcialmente observables, un marco basado en la autoatención puede simplemente enmascarar las posiciones no observables sin esfuerzo adicional, evitando así eficazmente la confusión de características causada por el relleno no válido.
Una característica distintiva de la tarea de predicción del comportamiento es la multimodalidad causada por la incertidumbre de la escena futura. Un enfoque habitual consiste en utilizar varias cabeceras de resultados para descodificar de forma independiente las trayectorias futuras de cada agente basándose en un vector de características común. Sin embargo, este método tiene dos desventajas principales:
- La información de movimiento de varias trayectorias futuras posibles está contenida en un vector de características con una dimensión fija, lo que conduce a una información limitada y limita significativamente las capacidades expresivas del modelo;
- Las señales de avance y retroceso de los distintos modos se mezclan mediante la interacción de características y la propagación de gradientes, lo que provoca el problema de confusión de modos que degrada la capacidad de realizar predicciones multimodales.
En cambio, en MFT, el modelado de la interacción se divide en diferentes modos para lograr un resultado multimodal mediante el aprendizaje del patrón de interacción único correspondiente a cada modo. Para ello, se diseñó un módulo de interacción paralelo. Este módulo contiene varios bloques de interacción paralela, cada uno de los cuales representa un determinado modo de desarrollo futuro de los acontecimientos. En esta estructura, las señales de avance y retroceso intra-modo atraviesan el bloque de interacción del modo correspondiente. Al mismo tiempo, los demás modos no interfieren, lo que evita el problema de la confusión de modos.
Además, cada bloque de interacción se parametriza como un objeto independiente, lo que permite que el modelo tenga suficiente poder expresivo para hacer frente a la gran variación entre los distintos modos. Cada bloque de interacción utiliza un mecanismo Self-Attention para modelar la interacción entre agentes y el mecanismo "Cross-Attention" para capturar la interacción entre agentes y la escena. Estos dos tipos de características de interacción se añaden a la característica dinámica a través de la conexión residual para obtener la función final de movimiento próximo para cada agente y modo. El proceso anterior puede describirse del siguiente modo:

La estructura final del módulo de interacción paralela puede verse como una paralelización del decodificador "Transformer" con una estructura en serie. Sin embargo, la predicción multimodal y la mayor capacidad expresiva se consiguen con un coste computacional similar al de su homólogo estándar. Los experimentos realizados por los autores del método confirman que, en combinación con el uso de la estrategia de pérdidas del tipo "el ganador se lo lleva todo" a nivel de escena, el método propuesto puede proporcionar una predicción coherente del comportamiento de varios agentes. También se realizó un estudio para demostrar la indispensabilidad de los dos tipos de interacciones modeladas y la razonabilidad del diseño de la estructura del módulo.
A continuación se presenta la visualización de los autores de la estructura del módulo.

Además de predecir la trayectoria futura de cada agente, MFT ejecuta una estimación de probabilidad para cada posible desarrollo de la escena, así como para cada trayectoria predicha del agente. Para las tareas de planificación del movimiento, la entrada ideal sería una predicción multimodal de la escena con una puntuación de confianza adecuada para cada modo de escena. El algoritmo de planificación puede calcular directamente la posible trayectoria de movimiento futura considerando simultáneamente todos los agentes vecinos. Para ello, los autores del método desarrollaron cabezales de predicción de varias escenas y sus probabilidades.
Para estimar la probabilidad a nivel de escena, se promedian los vectores de características de todos los agentes de la escena. Esto nos permite obtener una visión a nivel de escena.
Además, para prestar especial atención al agente, la estimación de la probabilidad debe realizarse desde el punto de vista del propio agente. En consecuencia, se crea una tercera cabecera de modelo para descodificar las estimaciones de confianza de las trayectorias previstas de cada agente. El proceso de descodificación del transformador multifuturo se formula del siguiente modo:
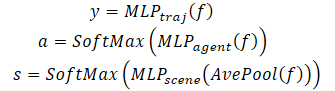
Obsérvese que para descodificar una escena multimodal se utiliza un descodificador con los mismos parámetros para todos los escenarios posibles.
2. Implementación en MQL5
Tras considerar los aspectos teóricos del método transformador multifuturo, pasemos a la parte práctica de nuestro artículo. Veamos cómo implementar el algoritmo en MQL5.
De la descripción anterior del algoritmo transformador multifuturo, podemos decir que la principal dificultad de implementación para nosotros es el módulo de interacción paralela. Nuestra biblioteca ya ha implementado previamente las capas multicabezal Self-Attention (CNeuronMLMHAttentionOCL) y Cross-Attention (CNeuronMH2AttentionOCL). Sin embargo, aunque se utilicen varias cabezas de atención, los flujos de datos en ellas se mezclan durante los pases hacia delante y hacia atrás. Esto no satisface las condiciones del método transformador multifuturo.
Por lo tanto, comenzaremos nuestra implementación del método creando una clase de una nueva capa neuronal.
2.1. Módulo de interacción paralela
Implementamos el algoritmo del módulo de interacción paralela en la clase CNeuronMFTOCL, que heredamos de CNeuronMLMHAttentionOCL.
Esta clase fue elegida como padre a propósito. CNeuronMLMHAttentionOCL ya contiene una funcionalidad implementada del algoritmo multicapa Self-Attention. Utilizamos el código existente para implementar la nueva clase. Pero en lugar de calcular secuencialmente las capas del bloque de atención, predeciremos varios escenarios. Además, añadiremos la funcionalidad Cross-Attention que proporciona el algoritmo MFT (Multi-future Transformer).
A continuación se muestra la estructura de la nueva clase. Como puedes ver, además de redefinir los métodos principales, estamos añadiendo otra colección de búferes de datos para la transposición de datos, que necesitaremos para implementar el mecanismo Cross-Attention.
class CNeuronMFTOCL : public CNeuronMLMHAttentionOCL { protected: //--- CCollection cTranspose; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols); virtual bool MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool MHCAInsideGradients(CBufferFloat *q, CBufferFloat *qg, CBufferFloat *kv, CBufferFloat *kvg, CBufferFloat *score, CBufferFloat *aog); public: CNeuronMFTOCL(void) {}; ~CNeuronMFTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronMFTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Declarar una nueva colección de búferes de datos como estática nos permite dejar el constructor y el destructor de la clase "vacíos". Inicializamos la clase y los objetos internos en el método Init.
bool CNeuronMFTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * features, optimization_type, batch)) return false;
En los parámetros, el método recibe toda la información necesaria para recrear la arquitectura requerida. En el cuerpo del método, llamamos al método relevante de la clase base de la capa neuronal CNeuronBaseOCL.
Tenga en cuenta que no estamos llamando al método de inicialización de la clase padre directa CNeuronMLMHAttentionOCL. En su lugar, nos dirigimos a la clase base de las capas neuronales CNeuronBaseOCL. Esto se debe a algunas diferencias en la implementación de CNeuronMFTOCL y CNeuronMLMHAttentionOCL.
En la clase base CNeuronMLMHAttentionOCL procesamos secuencialmente los datos de origen en varias capas del bloque de atención y, al final, obtuvimos un resultado con una dimensión similar a la de los datos de origen. Ahora, en la nueva capa CNeuronMFTOCL, generaremos sistemáticamente varios patrones para posibles desarrollos. En consecuencia, el resultado de la capa será un múltiplo (por el número de opciones de previsión) del tamaño de los datos originales. Por lo tanto, tenemos que aumentar el búfer de resultados.
Además, para evitar la copia innecesaria de datos, en la clase base sustituimos el buffer de resultados y gradientes de la propia capa y de la última capa interna. En la implementación de la nueva clase, este enfoque es inaceptable, ya que tenemos que concatenar los resultados de varios bloques paralelos en un único búfer.
Volvamos a nuestro método de inicialización. Tras ejecutar con éxito el método de inicialización de la clase base de la capa neuronal, guardamos los parámetros clave de la arquitectura en variables internas de la clase.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(features, 1);
Tenga en cuenta que guardamos todos los parámetros en variables de la clase base. Aquí tenemos una ligera desviación entre el nombre de la variable y su funcionalidad: la variable iLayers almacenará el número de opciones previstas. Para utilizar los recursos de forma más eficiente, decidí no crear una variable adicional e "ignorar" la discrepancia entre el nombre y la funcionalidad de la variable.
A continuación, calcularemos los principales parámetros de nuestros bloques.
//--- MHSA uint num = 3 * iWindowKey * iHeads * iUnits; //Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of QKV tensor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of output tensor uint w0 = (iWindowKey + 1) * iHeads * iWindow; //Size W0 tensor
//--- MHCA uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeads * iUnits; //Size of KV tensor uint q_weights = (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of Q tensor uint kv_weights = 2 * (iUnits + 1) * iWindowKey * iHeads; //Size of weights' matrix of KV tensor uint scores_ca = iUnits * iWindow * iHeads; //Size of Score tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
Tras completar el trabajo preparatorio, organizaremos un bucle en el que crearemos secuencialmente búferes de datos para cada escenario de nuestro bloque de interacción paralelo.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- MHSA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Aquí crearemos un bucle anidado para crear buffers de paso hacia delante y hacia atrás. En el cuerpo del bucle anidado, primero creamos un búfer de Query, Key y Value incrustados concatenados del bloque MHSA. También añadimos un búfer para la matriz "Score".
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
Añade un búfer de resultados de atención múltiple.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
A la salida del bloque MHSA, creamos un buffer para combinar los resultados de diferentes cabezas de atención.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Cabe señalar aquí que para satisfacer los requisitos del algoritmo MFT, los resultados de los cabezales de atención se combinan sólo dentro de un modo de interacción.
A continuación creamos buffers similares para el bloque Cross-Attention (MHCA). Sin embargo, ahora separamos el búfer de incrustación Query de Key y Value, ya que se utilizarán datos de origen diferentes.
//--- MHCA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cTranspose.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores_ca, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
//--- Initialize multi-heads cross attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Después de crear los buffers para los bloques de atención, creamos los buffers del bloque FeedForward.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
//--- Initialize Feed Forward 2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Hemos creado buffers con los resultados y los gradientes de error de los distintos bloques. A continuación, tenemos que crear matrices de pesos entrenables para estos bloques. Los creamos en la misma secuencia. En primer lugar, generamos pesos para las incrustaciones Query, Key y Value del bloque MHSA.
//--- MHSA //--- Initilize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
Y una capa para combinar cabezales de atención.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Repita las operaciones para el bloque MHCA.
//--- MHCA //--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; for(uint w = 0; w < q_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize KV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float kv = (float)(1 / sqrt(iUnits + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* kv)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Crear matrices para el bloque FeedForward.
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Después implementamos otro bucle anidado, en el que creamos buffers para actualizar las matrices de pesos. Tenga en cuenta que el número de buffers de momentos depende del algoritmo de optimización elegido.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- MHSA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- MHCA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
Después de inicializar con éxito todos los búferes de datos necesarios, salimos del método con el resultado true.
Hemos creado muchos búferes. Para no confundirnos, vamos a crear una tabla de navegación de búfer de datos.
| ID | QKV_Tensors | S_Tensors, AO_Tensors | FF_Tensors | QKV_Weights | FF_Weights |
|---|---|---|---|---|---|
| 0 | Query, Key, Value MHSA | MHSA | MHSA Out | Query, Key, Value MHSA | MHSA W0 |
| 1 | Query MHCA | MHCA | MHCA Out | Query MHCA | MHCA W0 |
| 2 | Key, Value MHCA | Gradient MHSA | FF1 | Key, Value MHCA | FF1 |
| 3 | Gradient Query, Key, Value MHSA | Gradient MHCA | FF2 | Momentum1 Query, Key, Value MHSA | FF2 |
| 4 | Gradient Query MHCA | Gradient MHSA Out | Momentum1 Query MHCA | Momentum1 MHSA W0 | |
| 5 | Gradient Key, Value MHCA | Gradient MHCA Out | Momentum1 Key, Value MHCA | Momentum1 MHCA W0 | |
| 6 | Gradient FF1 | Momentum2 Query, Key, Value MHSA | Momentum1 FF1 | ||
| 7 | Gradient FF2 | Momentum2 Query MHCA | Momentum1 FF2 | ||
| 8 | Momentum2 Key, Value MHCA | Momentum2 MHSA W0 | |||
| 9 | Momentum2 MHCA W0 | ||||
| 10 | Momentum2 FF1 | ||||
| 11 | Momentum2 FF2 |
Tras la inicialización de la clase CNeuronMFTOCL, pasamos a construir un algoritmo feed-forward. Al implementar el algoritmo MFT, no creamos nuevos núcleos en el lado del programa OpenCL. Sin embargo, para llamar a los núcleos creados previamente, tuvimos que crear algunos métodos en el lado del programa principal. En particular, para nuestra clase CNeuronMFTOCL, hemos creado un método de transposición de matrices. El algoritmo del método es similar al "feed-forward" del layer de transposición. Sin embargo, hay diferencias en los detalles. En los parámetros, el nuevo método recibe punteros a 2 búferes de datos (datos de origen y resultados), así como los tamaños de la matriz original.
bool CNeuronMFTOCL::Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols) { if(!in || !out) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {rows, cols}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, in.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, out.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("%s %d Error of execution kernel Transpose: %d -> %s", __FUNCTION__, __LINE__, GetLastError(), error); return false; } //--- return true; }
En consecuencia, en el cuerpo del método, comprobamos los punteros recibidos a los búferes de datos e indicamos los valores de los parámetros en la dimensión del espacio de tareas. El algoritmo de llamada al núcleo no ha cambiado.
La situación con el método de avance MHCA es similar. En los parámetros del método recibimos punteros a búferes de datos. El método CNeuronMH2AttentionOCL::attentionOut no tenía parámetros y utilizaba objetos internos en su funcionalidad.
bool CNeuronMFTOCL::MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out) { if(!q || !kv || !score || !out) return false;
En el cuerpo del método, creamos las dimensiones del espacio de tareas.
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindow, iHeads}; uint local_work_size[3] = {1, iWindow, 1};
Pasamos los parámetros al núcleo.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, q.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, kv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, score.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, out.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Añádelo a la cola.
if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
El algoritmo de avance del MFT está implementado en el método CNeuronMFTOCL::feedForward. Al igual que los métodos similares de otras capas neuronales, el método recibe en sus parámetros un puntero a la capa neuronal anterior. En el cuerpo del método, comprobamos inmediatamente la relevancia del puntero recibido.
bool CNeuronMFTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
A continuación, organizamos un bucle de cálculo secuencial de varios modos de interacción entre agentes.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- MHSA //--- Calculate Queries, Keys, Values CBufferFloat *inputs = NeuronOCL.getOutput(); CBufferFloat *qkv = QKV_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Aquí obtenemos primero las entidades Query, Key y Value del bloque MHSA. A continuación definimos la matriz de coeficientes de atención.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 4); if(IsStopped() || !AttentionScore(qkv, temp, false)) return false;
Generar el resultado de la autoatención multicéfala.
//--- Multi-heads attention calculation CBufferFloat *out = AO_Tensors.At(i * 4); if(IsStopped() || !AttentionOut(qkv, temp, out)) return false;
Reducimos el resultado de la atención multicabezal al tamaño de los datos originales. Permítanme recordarles que los cabezales de atención se combinan en el marco de una variante de interacción entre agentes.
//--- Attention out calculation temp = FF_Tensors.At(i * 8); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Sumamos el tensor resultante con los datos originales y normalizamos el resultado de la operación.
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
A continuación viene el bloque de atención cruzada (Cross-attention). Aquí definimos primero la entidad Query.
//--- MHCA inputs = temp; CBufferFloat *q = QKV_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
A continuación, transponemos los datos originales y calculamos las entidades Key y Value.
CBufferFloat *tr = cTranspose.At(i * 2); if(IsStopped() || !Transpose(inputs, tr, iUnits, iWindow)) return false;
CBufferFloat *kv = QKV_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), tr, kv, iUnits, 2 * iWindowKey * iHeads, None)) return false;
Determinar los resultados de la atención cruzada multicabezal.
//--- Multi-heads cross attention calculation temp = S_Tensors.At(i * 4 + 1); out = AO_Tensors.At(i * 4 + 1); if(IsStopped() || !MHCA(q, kv, temp, out)) return false;
Los resultados obtenidos se comprimen al tamaño de los datos originales.
//--- Cross Attention out calculation temp = FF_Tensors.At(i * 8 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Añádelo a los resultados del bloque MHSA y normaliza los datos.
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
A continuación, organizamos la propagación de datos a través del bloque FeedForward.
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 8 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 8 + 3); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), temp, out, 4 * iWindow, iWindow, activation)) return false;
Los resultados de la operación de bloque FeedForward se añaden a los resultados de MHCA. Los datos recibidos se normalizan y se escriben en el búfer de resultados con un desplazamiento correspondiente al modo de interacción analizado.
//--- Sum and normalize out if(IsStopped() || !SumAndNormilize(out, inputs, Output, iWindow, true, 0, 0, i * inputs.Total())) return false; } //--- return true; }
A continuación, pasamos al siguiente bucle de iteración para analizar el siguiente modo de interacción entre agentes en la escena.
Tras analizar con éxito todos los modos de interacción entre agentes, completamos el método con el resultado true.
Durante el paso feed-forward, realizamos la funcionalidad básica de analizar los modos de interacción de los agentes en la escena y predecir posibles variantes para eventos posteriores. Por lo tanto, el entrenamiento del modelo no es posible sin aplicar métodos de retropropagación. Durante el paso de retropropagación se optimizan los parámetros del modelo para obtener mejores resultados. Por lo tanto, después de implementar los métodos feed-forward, pasamos a construir el algoritmo de retropropagación.
Al igual que con el paso feed-forward, para implementar el paso de retropropagación necesitaremos crear un método adicional MHCAInsideGradients. Su algoritmo es casi completamente similar al algoritmo de CNeuronMH2AttentionOCL::AttentionInsideGradients. La única diferencia es que MHCAInsideGradients no trabaja con objetos internos de la clase, sino con buffers recibidos en parámetros de métodos. Ya hemos visto ejemplos de este tipo de modificaciones anteriormente en este artículo. Por lo tanto, no nos detendremos ahora en un examen detallado del método. Puede encontrar el código completo en el archivo adjunto.
El algoritmo de paso de retropropagación se implementa en el método calcInputGradients. En los parámetros, el método recibe un puntero al objeto de la capa neuronal anterior.
bool CNeuronMFTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
En el cuerpo del método, comprobamos inmediatamente la validez del puntero recibido. Después guardamos punteros a buffers en variables locales, con los que funcionarán todos los bloques de interacción paralela.
CBufferFloat *out_grad = Gradient; CBufferFloat *inp = prevLayer.getOutput(); CBufferFloat *grad = prevLayer.getGradient();
Una vez finalizado el trabajo preparatorio, organizamos un bucle para propagar los gradientes de error a través de bloques separados de interacción paralela.
for(int i = 0; (i < (int)iLayers && !IsStopped()); i++) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), Gradient, FF_Tensors.At(i * 8 + 2), FF_Tensors.At(i * 8 + 6), 4 * iWindow, iWindow, None, i * inp.Total())) return false;
Aquí propagamos primero el gradiente de error a través del bloque FeedForward.
CBufferFloat *temp = FF_Tensors.At(i * 8 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(i * 8 + 6), FF_Tensors.At(i * 8 + 1), temp, iWindow, 4 * iWindow, LReLU)) return false;
En el paso feed-forward, los resultados de la operación del bloque FeedForward se añadieron a la salida del bloque MHCA. Del mismo modo, propagamos el gradiente de error en la dirección opuesta. Sin embargo, esta vez no realizamos la normalización.
//--- Sum gradient if(IsStopped() || !SumAndNormilize(Gradient, temp, temp, iWindow, false, i * inp.Total(), 0, 0)) return false; out_grad = temp;
A continuación, tenemos que propagar el gradiente de error a través del módulo de atención cruzada. Aquí, primero propagamos el gradiente de error a través de las cabezas de atención.
//--- MHCA //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out_grad, AO_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3), iWindowKey * iHeads, iWindow, None)) return false;
A continuación, propagamos el gradiente de error a las entidades correspondientes.
if(IsStopped() || !MHCAInsideGradients(QKV_Tensors.At(i * 6 + 1), QKV_Tensors.At(i * 6 + 4), QKV_Tensors.At(i * 6 + 2), QKV_Tensors.At(i * 6 + 5), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3))) return false;
Ahora necesitamos transponer el gradiente de error de Key y Value del bloque MHCA.
CBufferFloat *tr = cTranspose.At(i * 2 + 1); if(IsStopped() || !Transpose(QKV_Tensors.At(i * 6 + 5), tr, iWindow, iUnits)) return false;
En primer lugar, resumimos los resultados obtenidos.
//--- Sum temp = FF_Tensors.At(i * 8 + 4); if(IsStopped() || !SumAndNormilize(QKV_Tensors.At(i * 6 + 4), tr, temp, iWindow, false)) return false;
Luego les añadimos el gradiente de error a la salida del bloque MHCA.
if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Después tenemos que propagar el gradiente de error a través del bloque MHSA. Al igual que con la atención cruzada, primero distribuimos el gradiente de error entre los cabezales de atención.
//--- MHSA //--- Split gradient to multi-heads out_grad = temp; if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out_grad, AO_Tensors.At(i * 4), AO_Tensors.At(i * 4 + 2), iWindowKey * iHeads, iWindow, None)) return false;
Propagar el gradiente de error a las entidades correspondientes.
//--- Passing gradient to query, key and value if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 6), QKV_Tensors.At(i * 6 + 3), S_Tensors.At(i * 4), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 1))) return false;
Propagar hasta el nivel de datos de origen.
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(i * 6 + 3), inp, tr, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Ahora necesitamos sumar el gradiente de error en la entrada y salida del bloque MHSA y escribir el resultado en el buffer de gradiente de la capa anterior. Pero hay un punto. Necesitamos escribir la suma de los gradientes de error de todos los bloques de interacción paralela en el buffer de gradiente de la capa anterior. Por lo tanto, primero comprobamos el identificador del bloque de interacción paralelo. Para el primer bloque, simplemente escribimos la suma de los gradientes de 2 hilos en el buffer de gradiente de los errores de la capa anterior. Para los bloques restantes de interacción paralela, añadimos los gradientes de error resultantes a los datos del búfer de la capa anterior.
//--- Sum gradients if(i > 0) { if(IsStopped() || !SumAndNormilize(grad, tr, grad, iWindow, false)) return false; if(IsStopped() || !SumAndNormilize(out_grad, grad, grad, iWindow, false)) return false; } else if(IsStopped() || !SumAndNormilize(out_grad, tr, grad, iWindow, false)) return false; } //--- return true; }
Entonces pasamos a la siguiente iteración del bucle para pasar el gradiente de error a través del siguiente bloque de interacción paralela.
Después de completar con éxito todas las iteraciones del bucle, terminamos el método con 'true'.
Hemos organizado el paso feed-forward y la retropropagación del gradiente de error en la clase CNeuronMFTOCL. Para completar la implementación de la funcionalidad principal de la clase, necesitamos añadir un método para actualizar los parámetros de pesaje "updateInputWeights". El algoritmo del método es bastante sencillo. En un bucle, llamamos al método de la clase base ConvolutionUpdateWeights, en el que se actualizan los parámetros de un buffer independiente. Los búferes de datos necesarios para el funcionamiento se pasan en los parámetros del método.
bool CNeuronMFTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(l * 6 + 3), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 3) : QKV_Weights.At(l * 9 + 3)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 6)), iWindow, 3 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 1), QKV_Tensors.At(l * 6 + 4), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 4) : QKV_Weights.At(l * 9 + 4)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 7)), iWindow, iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 2), QKV_Tensors.At(l * 6 + 5), cTranspose.At(l * 2), (optimization == SGD ? QKV_Weights.At(l * 6 + 5) : QKV_Weights.At(l * 9 + 5)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 8)), iUnits, 2 * iWindowKey * iHeads)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12)), FF_Tensors.At(l * 8 + 4), AO_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 8 + 4) : FF_Weights.At(l * 12 + 4)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 8)), iWindowKey * iHeads, iWindow)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 1), FF_Tensors.At(l * 8 + 5), AO_Tensors.At(l * 4 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 5) : FF_Weights.At(l * 12 + 5)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 9)), iWindowKey * iHeads, iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(l * 8 + 6), FF_Tensors.At(l * 8 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 6) : FF_Weights.At(l * 12 + 6)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 10)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 3), FF_Tensors.At(l * 8 + 7), FF_Tensors.At(l * 8 + 2), (optimization == SGD ? FF_Weights.At(l * 8 + 7) : FF_Weights.At(l * 12 + 7)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 11)), 4 * iWindow, iWindow)) return false; } //--- return true; }
Esto concluye la implementación de la funcionalidad principal del algoritmo MFT (Multi-future Transformer) en la clase CNeuronMFTOCL. Puedes familiarizarte con la implementación de los métodos auxiliares utilizando los códigos del archivo adjunto. Allí también encontrará el código completo de todos los programas utilizados al escribir el artículo. Ahora pasamos a la aplicación de Asesores Expertos para construir y entrenar los modelos.
2.2 Arquitectura modelo
Hemos construido una clase para un algoritmo de bloques de interacción paralela, que fue propuesto por los autores del método Multi-future Transformer. Sin embargo, esto es sólo una capa de nuestro modelo. Ahora tenemos que describir la arquitectura completa de los modelos creados. Los modelos se alimentarán de datos fuente sin procesar. Como resultado del trabajo de los modelos, necesitamos obtener un vector de acciones óptimas del Agente, cuya aplicación puede reportar beneficios cuando se trabaja en los mercados financieros.
Debo decir que al construir mi modelo, me desvié un poco de la arquitectura propuesta por los autores del método. Hay varias razones para ello.
En primer lugar, se propuso el método Multi-future Transformer para predecir la interacción de los vehículos autónomos con el entorno. Tenemos previsto utilizar nuestro modelo para los mercados financieros. Ambas tareas tienen sus propias especificidades, que dejan huella en la construcción de los modelos.
En segundo lugar, en el anterior artículo, prestamos mucha atención a la optimización del rendimiento del modelo. Me gustaría aprovechar la experiencia adquirida. Por lo tanto, he utilizado el modelo de arquitectura del artículo anterior como donante. Se han introducido cambios en los modelos de planificación de trayectorias.
La arquitectura de los modelos de predicción de trayectorias futuras se describe en el método CreateTrajNetDescriptions del archivo "...\Experts\MFT\Trajectory.mqh". En los parámetros, el método recibe punteros a matrices dinámicas para crear 3 modelos:
- Estado del codificador
- Descodificador de extremos
- Probabilidades de escena
En artículos anteriores, decidimos no predecir la trayectoria completa del movimiento de los precios, sino que nos concentramos en predecir los principales extremos del movimiento de los precios:
- Close
- High
- Low
Por lo tanto, en nuestro trabajo consideramos el estado de la dinámica del movimiento de los precios como variantes de la escena. No analizamos las probabilidades de las trayectorias finales de los agentes individuales.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
En el cuerpo del método, comprobamos la pertinencia de los punteros a objetos recibidos en los parámetros y, si es necesario, creamos otros nuevos.
En primer lugar, describimos la arquitectura del codificador, al que alimentamos con datos iniciales brutos que describen el estado actual del entorno.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Como es habitual, los datos recibidos se preprocesan en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Después creamos una incrustación del estado actual y la guardamos en la pila interna del modelo.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Cada elemento incrustado se asocia a un agente distinto de la escena ambiental. Según el método MFT, implementaremos la codificación posicional de los datos de origen.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Más adelante en la arquitectura del método MFT original viene una pila de bloques MHSA. He aquí mi primera desviación de la arquitectura propuesta. Decidí utilizar el trabajo del artículo anterior y dejé 2 capas Crystal-GCN separadas por una capa de normalización de lotes.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
Le sigue una capa de MHSA.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, los autores del método proponen promediar la dinámica de cada agente. Aquí, en el bloque de interacción paralela, realizan análisis cruzados de datos con datos de mapas contextuales. En nuestro caso, no existe un mapa de posibles movimientos de precios próximos. En su lugar, utilizaremos el análisis contextual de las trayectorias de los rasgos analizados.
Lo siguiente en nuestra arquitectura es el bloque de computación paralela creado anteriormente. En este bloque, utilizamos los bloques Self-Attention y Cross-Attention con 4 cabezales de atención. Los autores del método utilizaron en su trabajo sólo 1 cabezal de atención en bloques de interacción paralelos. El número de modos de interacción de los agentes viene determinado por la constante NForecast.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Preste atención al siguiente punto arquitectónico. En nuestra implementación, construimos la clase CNeuronMFTOCL de tal forma que sus resultados pueden representarse como un tensor tridimensional {número de elementos de secuencia, modo de interacción, número de agentes}. Este formato de datos no es muy cómodo para el procesamiento posterior, ya que entonces tenemos que trabajar con cada modo de interacción individual. La ubicación del modo de interacción dentro de las dimensiones del tensor complica este trabajo. Por lo tanto, transponemos los datos para trasladar el modo de interacción del agente a la primera dimensión del tensor.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Así, a la salida del codificador recibimos el tensor {modo de interacción del agente, número de agentes, longitud del vector que describe la dinámica del agente}.
Después del codificador, creamos el modelo de decodificador de punto final. Introducimos en el modelo el tensor de los resultados del codificador.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Permítanme recordarles que el método MTF requiere el uso de un descodificador con los mismos parámetros para todos los modos de interacción de los agentes. Podemos implementar un enfoque similar utilizando una capa convolucional con un tamaño de ventana y un paso igual al tensor de un modo de interacción del agente. Dividiremos esta etapa en 2 fases. Primero colapsamos la dinámica de cada agente individual.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Y luego tenemos opciones de escena para cada modo de interacción analizado.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
El modelo para evaluar las probabilidades de las distintas escenas previstas se mantuvo prácticamente sin cambios. Como en el caso del descodificador, los resultados del codificador se introducen en el modelo.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false;
Se combinan con opciones de escenas predictivas.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; }
Los datos se analizan mediante 2 capas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Y se normaliza mediante la función SoftMax.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
La arquitectura de los modelos Actor es prácticamente la misma. Sólo tuve que hacer pequeñas modificaciones en cuanto al procesamiento de los resultados del codificador de estado actual.
También hay que señalar que los cambios introducidos en la arquitectura del modelo no tuvieron prácticamente ninguna repercusión en los algoritmos de interacción con el entorno y de entrenamiento del modelo. Por tanto, todos los EAs han sido copiados del anterior artículos con mínimas ediciones. Por lo tanto, no me detendré en la descripción de sus algoritmos en el marco de este artículo. De todas formas, puedes encontrar el código completo de todos los programas utilizados en el artículo en el archivo adjunto.
3. Pruebas
Hemos implementado el algoritmo Multi-future Transformer utilizando herramientas MQL5 y descrito la arquitectura de modelos que nos permiten utilizar los enfoques propuestos para entrenar modelos de predicción de varias opciones para el próximo movimiento de precios con una evaluación de la probabilidad de su implementación. Ahora es el momento de comprobar los resultados de nuestro trabajo con datos reales en el probador de estrategias de MetaTrader 5.
Como siempre, el modelo se entrena y se prueba utilizando datos históricos del EURUSD H1. Los datos de los 7 primeros meses de 2023 se utilizan para entrenar los modelos. Para probar el modelo entrenado, utilizamos datos históricos de agosto de 2023.
Para entrenar el modelo, utilicé el conjunto de datos de entrenamiento y el EA de entrenamiento del artículo anterior. Por lo tanto, puede observarse que los cambios en los resultados obtenidos se deben principalmente a un cambio en la arquitectura del modelo. Por supuesto, no podemos excluir el factor de aleatoriedad introducido por la inicialización del modelo con parámetros aleatorios. Además, el muestreo de datos del búfer de repetición de experiencias durante el proceso de entrenamiento también es aleatorio. Pero la influencia de este factor se minimiza al aumentar las épocas de entrenamiento.
En el artículo anterior, el modelo mostraba un resultado bastante estable, pero tiene un número muy reducido de operaciones. En el nuevo modelo, se observa un aumento del número de operaciones al tiempo que se mantiene un resultado positivo.
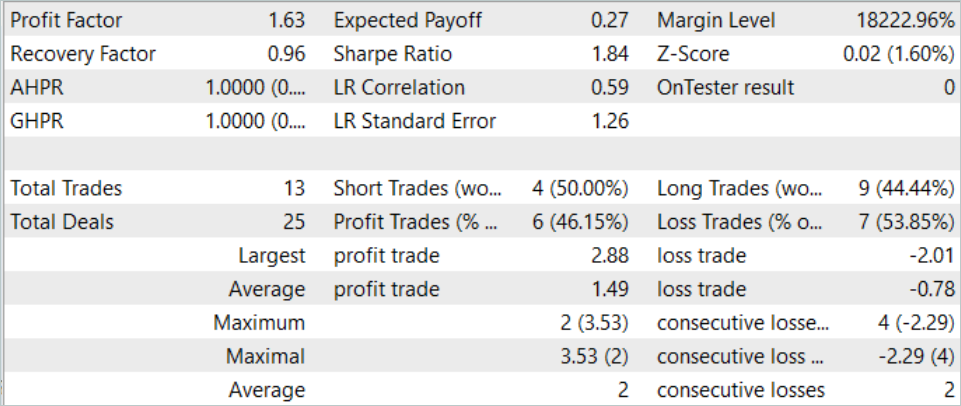
Durante el mes de agosto de 2023, el modelo ejecutó 13 operaciones, 6 de las cuales se cerraron con beneficio. El modelo arrojó un factor de beneficio de 1,63 durante el periodo de prueba.
Conclusión
En este artículo, nos familiarizamos con otro método para predecir el próximo movimiento de precios - Multi-future Transformer. Una de las características clave de este método es la construcción de previsiones multimodales para el movimiento de los agentes, haciendo hincapié en su interacción entre sí y con la escena ambiental. Esto nos permite hacer previsiones más precisas de los próximos movimientos.
En la parte práctica, implementamos los enfoques propuestos utilizando MQL5. Entrenamos y probamos el modelo utilizando datos reales en el probador de estrategias de MetaTrader 5. Los resultados obtenidos confirman la eficacia de los planteamientos propuestos. Podemos observar la diversidad de las previsiones obtenidas, que se consigue gracias al aislamiento de las previsiones de las modalidades individuales manteniendo el análisis de la interacción de los agentes.
Referencias
Programas utilizados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor experto | Colección de ejemplos |
| 2 | ResearchRealORL.mq5 | Asesor experto | EA para la recolección de ejemplos utilizando el método Real-ORL |
| 3 | Study.mq5 | Asesor experto | EA para el entrenamiento del modelo |
| 4 | Test.mq5 | Asesor experto | EA para la prueba del modelo |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema |
| 6 | NeuroNet.mqh | Biblioteca de clases | Una biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Código base | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14226
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso