
Redes neuronales: así de sencillo (Parte 84): Normalización reversible (RevIN)

Introducción
En el artículo anterior nos familiarizamos con el Conformerdesarrollado para la previsión meteorológica. Un método muy interesante. Y al probar el modelo entrenado no obtuvimos malos resultados. Pero, ¿lo hemos hecho todo bien? ¿O es posible obtener resultados mejores? Echemos un vistazo al proceso de entrenamiento. Resulta fácil ver que claramente no estamos usando el modelo para predecir los próximos indicadores de series temporales más probables para el fin previsto. Suministrando a la entrada del modelo datos de origen de la secuencia temporal, lo entrenaremos recorriendo el gradiente de error de los modelos que utilizan los resultados de la predicción. Primero del Crítico.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y luego del Actor.
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y nuevamente del Actor, mientras ajusta su política para reflejar la rentabilidad de las transacciones.
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), -1, -1, false) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Obviamente, no hay nada malo en ello, es una práctica muy utilizada a la hora de entrenar diferentes modelos. Sin embargo, en este caso, nuestro objetivo al entrenar el modelo de Codificador del estado del entorno inicial no será predecir los estados posteriores, sino extraer características individuales para optimizar el rendimiento de los modelos posteriores.
Por supuesto, nuestra principal preocupación será encontrar la política óptima del Actor. Y, a primera vista, no hay nada de malo en adaptar el modelo de Codificador a los fines del Actor. Pero en ese caso, el Codificador resolverá un problema ligeramente distinto. En la práctica, se convertirá en un bloque de modelos posteriores. Y su arquitectura podría no ser la óptima para la tarea que se está realizando.
Además, al entrenar el Codificador con los gradientes de error de 3 tareas diferentes, podemos encontrarnos con un problema en el que los gradientes de las tareas individuales serán multidireccionales. En tal caso, el modelo buscará un término medio que cumpla al máximo todas las tareas, y es muy probable que esa solución esté muy lejos de ser óptima.
A mi juicio, resulta obvio que la lógica estructurada del uso de modelos debe aplicarse también en el proceso de entrenamiento. Y en un paradigma así, tendremos que enseñar al Codificador a predecir estados del entorno posteriores. Precisamente en el Codificador se utilizarán los enfoques del Conformer. Y luego entrenaremos las políticas del Actor considerando los estados del entorno pronosticados.
En teoría, todo está claro. Y en la aplicación práctica nos enfrentamos a una discontinuidad significativa en las distribuciones de las características individuales de la descripción del estado del entorno. Al obtener datos "en bruto" similares que describen el estado del entorno como entrada al modelo, los normalizaremos para llevarlos a una forma comparable. Pero, ¿cómo se obtienen valores tan distintos en la salida del modelo?
Querría recordarle que ya nos hemos encontrado con un problema similar al entrenar distintos modelos de autocodificadores. Entonces encontramos una salida al usar los datos de origen tras la normalización como objetivos. Sin embargo, en este caso necesitamos datos que describan estados del entorno posteriores diferentes de los datos originales. Uno de los métodos para resolver este problema se propuso en el artículo "Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift".
Los autores del artículo proponen un método de normalización y desnormalización sencillo pero eficaz: la normalización instantánea reversible (RevIN), que primero normaliza las secuencias de entrada y luego desnormaliza las secuencias de salida del modelo para resolver problemas de previsión de series temporales que impliquen el desplazamiento distribucional. RevIN está estructurado simétricamente para retornar la información de la distribución original a la salida del modelo mediante el escalado y el desplazamiento de la salida en la capa de desnormalización en una cantidad equivalente al desplazamiento y escalado de los datos originales en la capa de normalización.
RevIN es una capa flexible y entrenable que puede aplicarse a cualquier capa elegida aleatoriamente, suprimiendo de forma eficaz la información no estacionaria (media y varianza de una instancia) en una capa y restaurándola en otra capa de posición casi simétrica, como las capas de entrada y salida.
1. Algoritmo RevIN
Para familiarizarnos con el algoritmo RevIN, analizaremos el problema de la previsión de series temporales multivariantes en tiempo discreto para un conjunto de datos de entrada X = {xi}i=[1..N] y los datos objetivo correspondientes Y = {yi}i=[1..N], donde N denotará el número de elementos de la secuencia.
Supondremos que K, Tx y Ty son el número de variables, la longitud de la secuencia de entrada y la longitud de predicción del modelo, respectivamente. Dada una secuencia de entrada Xi ∈ RK*Tx, nuestro objetivo será resolver el problema de previsión de series temporales, que consistirá en predecir los valores posteriores de Yi ∈ RK*Ty En RevIN, la longitud de la secuencia de entrada Tx y la longitud del pronóstico Ty pueden diferir, ya que las observaciones se normalizarán y desnormalizarán a lo largo de la dimensión temporal. El método propuesto, RevIN, consta de capas de normalización y desnormalización estructuradas simétricamente. Primero normalizaremos los datos de origen Xi utilizando su media y su desviación estándar, lo cual se acepta ampliamente como normalización instantánea. La media y la desviación típica se calcularán para cada instancia Xi de los datos de origen del siguiente modo:
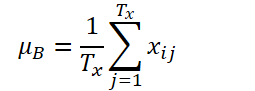
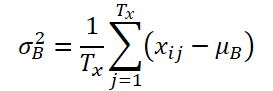

Las secuencias normalizadas pueden tener una media y una desviación típica más coherentes si reducimos la información no estacionaria. Como resultado, la capa de normalización permitirá al modelo predecir con precisión la dinámica local dentro de una secuencia cuando se dan datos de entrada con distribuciones de media y desviación estándar coherentes.
El modelo tomará como entrada los datos transformados y pronosticará sus valores futuros. Sin embargo, los datos de entrada tienen estadísticas diferentes en comparación con la distribución original, y observando solo la entrada normalizada, nos será difícil captar la distribución original de los datos de entrada. Así, para simplificar esta tarea para el modelo, retornaremos explícitamente las propiedades no estacionarias eliminadas de los datos de entrada a la salida del modelo invirtiendo la normalización en el posicionamiento simétrico en la capa de salida. El paso de desnormalización puede retornar la salida del modelo al valor original de la serie temporal. Como consecuencia, desnormalizaremos la salida del modelo aplicando operaciones de normalización inversa:

Las mismas medidas estadísticas usadas en el paso de normalización se aplicarán para el escalado y el desplazamiento. Ahora ŷi será la predicción final del modelo.
Con solo añadirse a posiciones prácticamente simétricas de la red, RevIN puede reducir eficazmente la divergencia distributiva en los datos de series temporales. Es similar a la capa de normalización entrenada, aplicable a redes neuronales profundas arbitrarias. De hecho, el método propuesto supone una capa flexible y entrenable que puede aplicarse a cualquier capa elegida arbitrariamente, incluso a capas múltiples. Los autores del método confirman su eficacia como capa flexible añadiéndola a las capas intermedias en varios modelos. Sin embargo, RevIN es más eficaz cuando se aplica a capas prácticamente simétricas de la estructura Codificador-decodificador. En un modelo típico de previsión de series temporales, la frontera entre el Codificador y el decodificador no suele estar clara. Por lo tanto, los autores del método aplican RevIN a las capas de entrada y salida del modelo, ya que pueden verse como una estructura Codificador-Decodificador que genera valores posteriores basados en los datos de entrada.
La variante de autor de RevIN se muestra más abajo.

2. Implementación con MQL5
Tras considerar los aspectos teóricos del método, vamos a pasar a la aplicación práctica de los planteamientos propuestos utilizando herramientas MQL5.
A partir de la descripción teórica del método presentada anteriormente, resulta fácil ver que la normalización de los datos originales propuesta por los autores del método repite completamente el algoritmo de la capa de normalización por lotes que implementamos anteriormente CNeuronBatchNormOCL. Por lo tanto, podemos usar una clase existente para normalizar los datos. Pero para desnormalizar los datos, tendremos que crear una nueva capa neuronal CNeuronRevINDenormOCL.
2.1 Creación de una nueva capa de desnormalización
Resulta bastante obvio que los objetos usados en la desnormalización de datos se utilizarán en el proceso de normalización de datos. Por ello, crearemos una nueva capa CNeuronRevINDenormOCL como heredera de la capa de normalización CNeuronBatchNormOCL.
class CNeuronRevINDenormOCL : public CNeuronBatchNormOCL { protected: int iBatchNormLayer; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronRevINDenormOCL(void) : iBatchNormLayer(-1) {}; ~CNeuronRevINDenormOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, int NormLayer, CNeuronBatchNormOCL *normLayer); virtual int GetNormLayer(void) { return iBatchNormLayer; } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronRevInDenormOCL; } virtual CLayerDescription* GetLayerInfo(void); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) { return true; } };
Debemos señalar de entrada que el algoritmo del método RevIN prevé la utilización de los parámetros formados en la fase de normalización para la desnormalización. La lógica aquí es que en la etapa de normalización, analizaremos la distribución de los datos originales. A continuación, convertiremos los datos de origen en un formato comparable eliminando las "discontinuidades". Además, el modelo funcionará con datos normalizados. En la salida del modelo, desnormalizaremos los datos retornando los parámetros de distribución de los datos originales. Así, esperaremos que la salida del modelo sean datos predictivos en la distribución "natural" de los datos de entrada.
Obviamente, los parámetros del modelo no se actualizarán en la fase de desnormalización. Por lo tanto, sobrescribiremos los métodos para actualizar los parámetros del modelo con "stubs vacíos" en la estructura de la clase. No obstante, aún tenemos que aplicar el algoritmo de pasada directa y de distribución del gradiente de error. Pero lo primero es lo primero.
En esta clase, no declararemos ningún objeto interno adicional. Por consiguiente, el constructor y el destructor de la clase permanecerán vacíos. Sin embargo, crearemos una variable para registrar el ID de la capa de normalización en el modelo iBatchNormLayer. Y luego crearemos un método público para conseguir el valor de esta variable GetNormLayer(void).
El objeto de nuestra nueva clase se inicializará en el método CNeuronRevINDenormOCL::Init. En los parámetros, el método obtendrá toda la información necesaria para inicializar correctamente los objetos y variables internos. Y aquí debemos decir que existe una diferencia muy sustancial respecto a los métodos similares de las capas neuronales consideradas anteriormente. La cuestión es que en los parámetros del método, además de las constantes, transmitiremos un puntero al objeto de capa de normalización por lotes CNeuronBatchNormOCL.
bool CNeuronRevINDenormOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, int NormLayer, CNeuronBatchNormOCL *normLayer) { if(NormLayer > 0) { if(!normLayer) return false; if(normLayer.Type() != defNeuronBatchNormOCL) return false; if(BatchOptions == normLayer.BatchOptions) BatchOptions = NULL; if(!CNeuronBatchNormOCL::Init(numOutputs, myIndex, open_cl, numNeurons, normLayer.iBatchSize, normLayer.Optimization())) return false; if(!!BatchOptions) delete BatchOptions; BatchOptions = normLayer.BatchOptions; }
Otra diferencia fundamental radicará en el cuerpo del método. Aquí, crearemos un algoritmo de ramificación según el ID de la capa de normalización por lotes resultante. Si es mayor que "0", comprobaremos también el puntero resultante de la capa de normalización por lotes. Además, comprobaremos el tipo del objeto recibido. Después llamaremos al método homónimo de la clase padre. Y solo después de pasar con éxito todos los puntos de control especificados, realizaremos un intercambio del búfer de parámetros de optimización.
Tenga en cuenta que no copiaremos los datos, sino que cambiaremos completamente el puntero al objeto de búfer. De este modo, trabajaremos con parámetros de normalización siempre actualizados durante el entrenamiento del modelo.
La segunda rama del algoritmo está diseñada para inicializar un objeto de clase vacío mientras se carga un modelo previamente guardado. Aquí nos limitaremos a llamar al método homónimo de la clase padre con unos parámetros mínimos
else if(!CNeuronBatchNormOCL::Init(numOutputs, myIndex, open_cl, numNeurons, 0, ADAM)) return false;
Y después, independientemente del camino elegido, guardaremos el identificador de la capa de normalización por lotes resultante y finalizaremos el método.
iBatchNormLayer = NormLayer; //--- return true; }
2.2 Organización de la pasada directa
Comenzaremos implementando el algoritmo de pasada directa creando el kernel RevInFeedForward en el lado OpenCL del programa. De forma similar a la implementación del algoritmo de la capa de normalización por lotes, planeamos ejecutar este kernel en un espacio de tareas unidimensional.
En los parámetros del kernel, transmitiremos los punteros a 3 búferes de datos: los datos de origen, los parámetros de normalización y los resultados. Y también 2 constantes: el tamaño del búfer de parámetros del paquete de normalización y el tipo de optimización de parámetros.
__kernel void RevInFeedForward(__global float *inputs, __global float *options, __global float *output, int options_size, int optimization) { int n = get_global_id(0);
Recordemos que el tamaño del búfer de parámetros de normalización dependerá del algoritmo de optimización de parámetros elegido. Este búfer tendrá la siguiente estructura

En el cuerpo del kernel, identificaremos el flujo analizado en el espacio de tareas. Y determinaremos inmediatamente el desplazamiento en los búferes con respecto a los datos analizados. En los búferes de origen y de resultado, el desplazamiento será igual al ID del flujo. Y determinaremos el desplazamiento en el búfer de parámetros de optimización según la estructura de búfer dada y el método de optimización de parámetros especificado.
int shift = (n * optimization == 0 ? 7 : 9) % options_size;
Además, aquí deberemos considerar que el número de estados del entorno a analizar puede diferir de la profundidad de nuestra predicción. En este caso, partiremos del supuesto de que se preservará la estructura de los estados del entorno analizados y previstos. En otras palabras, el número y el orden de los parámetros analizados de la descripción del estado del entorno 1 se conservarán íntegramente a la hora de predecir los estados posteriores. Por lo tanto, para determinar el desplazamiento en el búfer de parámetros de normalización, tomaremos el resto de dividir el desplazamiento calculado, teniendo en cuenta el flujo analizado y la estructura del búfer, por el tamaño del búfer de parámetros de normalización.
El siguiente paso consistirá en extraer los datos de los búferes globales en las variables locales.
float mean = options[shift]; float variance = options[shift + 1]; float k = options[shift + 3];
A continuación, calcularemos el valor desnormalizado del parámetro previsto.
float res = 0; if(k != 0) res = sqrt(variance) * (inputs[n] - options[shift + 4]) / k + mean; if(isnan(res)) res = 0;
El resultado de las operaciones se escribirá en el elemento correspondiente del búfer de resultados.
output[n] = res; }
Después de implementar el algoritmo de desnormalización de datos en el lado OpenCL del programa, tendremos que organizar la llamada del kernel creado desde el programa principal. Para ello, redefiniremos el método CNeuronRevINDenormOCL::feedForward.
bool CNeuronRevINDenormOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false; //--- PrevLayer = NeuronOCL; //--- if(!BatchOptions) iBatchSize = 0; if(iBatchSize <= 1) { activation = (ENUM_ACTIVATION)NeuronOCL.Activation(); return true; }
Al igual que el método homónimo de la clase padre, en sus parámetros el método obtendrá un puntero al objeto de la capa anterior que contiene los datos de origen para nosotros.
En el cuerpo del método comprobaremos inmediatamente el puntero obtenido y lo guardaremos en la variable correspondiente.
A continuación, comprobaremos el tamaño del paquete de normalización. Y si no supera "1", lo evaluaremos como una falta de normalización y transmitiremos los datos de la capa anterior sin cambios. Obviamente, no copiaremos los datos al completo: solo copiaremos el identificador de la función de activación. Y al acceder al búfer de resultado o gradiente, retornaremos punteros a los búferes de la capa anterior. Esta funcionalidad ya se ha implementado en la clase padre.
A continuación, implementaremos un algoritmo para colocar directamente el kernel en la cola de ejecución. En primer lugar, definiremos el espacio de tareas.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Después transmitiremos los parámetros necesarios al kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffinputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffoptions, BatchOptions.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffoutput, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_RevInFeedForward, def_k_revffoptions_size, (int)BatchOptions.Total())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_RevInFeedForward, def_k_revffoptimization, (int)optimization)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Y enviaremos el kernel a la cola de ejecución.
if(!OpenCL.Execute(def_k_RevInFeedForward, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
En este caso, además, deberemos necesariamente supervisar el progreso de las operaciones en cada paso.
2.3 Algoritmo de distribución del gradiente de error
Tras implementar la pasada directa, tendremos que implementar el algoritmo de pasada inversa. Como ya hemos mencionado, esta capa no contendrá parámetros entrenables. Más concretamente, utilizará los parámetros entrenados en la fase de normalización. Como consecuencia, todos los métodos de actualización de los parámetros se sustituirán por métodos "stub".
Sin embargo, la capa está implicada en algoritmos de pasada inversa y el gradiente de error pasa a través de ella a la capa neuronal anterior. Al igual que antes, primero crearemos el kernel RevInHiddenGraddient en el lado OpenCL del programa. Esta vez, el número de parámetros del kernel ha aumentado. Transmitiremos 4 punteros a búferes de datos: los búferes de los resultados y gradientes de error de la capa anterior, los parámetros de optimización y el gradiente de error a nivel de resultados de la capa actual. Y 3 constantes: el tamaño del búfer del parámetro de normalización, el tipo de optimización del parámetro y la función de activación de la capa anterior.
__kernel void RevInHiddenGraddient(__global float *inputs, __global float *inputs_gr, __global float *options, __global float *output_gr, int options_size, int optimization, int activation) { int n = get_global_id(0); int shift = (n * optimization == 0 ? 7 : 9) % options_size;
En el cuerpo del kernel, primero identificaremos el flujo que se va a analizar y determinaremos los desplazamientos en los búferes de datos. El algoritmo para determinar el desplazamiento en los búferes se ha descrito anteriormente al construir el kernel de pasada directa.
A continuación, cargaremos los datos de los búferes de datos globales en variables locales.
float variance = options[shift + 1]; float inp = inputs[n]; float k = options[shift + 3];
Y corregiremos el gradiente de error usando la derivada de la función de desnormalización. Aquí cabe señalar que en la etapa de desnormalización todos los parámetros de normalización son constantes y la derivada de la función se simplifica notablemente.
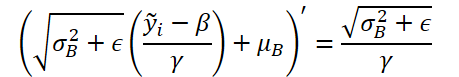
Ahora implementaremos la función presentada en el código.
float res = 0; if(k != 0) res = sqrt(variance) * output_gr[n] / k; if(isnan(res)) res = 0;
A continuación, ajustaremos el gradiente de error mediante la derivada de la función de activación de la capa neuronal anterior.
switch(activation) { case 0: res = clamp(res + inp, -1.0f, 1.0f) - inp; res = res * (1 - pow(inp == 1 || inp == -1 ? 0.99999999f : inp, 2)); break; case 1: res= clamp(res + inp, 0.0f, 1.0f) - inp; res = res * (inp == 0 || inp == 1 ? 0.00000001f : (inp * (1 - inp))); break; case 2: if(inp < 0) res *= 0.01f; break; default: break; }
El resultado de las operaciones se almacenará en el elemento correspondiente del búfer del gradiente de error de la capa neuronal anterior.
//---
inputs_gr[n] = res;
}
El siguiente paso consistirá en implementar la llamada a este kernel en el lado del programa principal. Esta funcionalidad se realizará en el método CNeuronRevINDenormOCL::calcInputGradients, mientras que el algoritmo de colocación del kernel en la cola de ejecución será completamente igual al descrito anteriormente para el método de pasada directa. Por lo tanto, no nos detendremos ahora en su análisis detallado.
Tampoco consideraremos con detalle los métodos auxiliares de la clase. Su algoritmo es bastante sencillo y está disponible para que el lector lo analice por su cuenta en el archivo adjunto, donde encontrará el código completo de todos los métodos de la nueva clase y de las creadas anteriormente. Allí también podrá informarse de todos los programas usados en la elaboración del artículo.
2.4 Modificaciones puntuales en clases de alto nivel
Debemos decir unas palabras sobre la realización de correcciones puntuales en los métodos de las clases de alto nivel causadas por las particularidades de nuestra nueva clase CNeuronRevINDenormOCL. Y en primer lugar nos referiremos a la inicialización y carga de objetos de esta clase.
Al describir el método para inicializar un objeto de nuestra clase CNeuronRevINDenormOCL, mencionamos las peculiaridades de transmisión de los punteros a un objeto de la capa de normalización de datos. Aquí debemos entender que al momento de describir la arquitectura del modelo no tenemos un puntero a este objeto por una simple razón: este objeto no ha sido creado todavía. Solo podemos especificar el número de secuencia de la capa. Lo sabemos por la arquitectura del modelo descrito.
Sin embargo, sabemos claramente que la capa de normalización es anterior a la capa de desnormalización. Todavía puede haber un número aleatorio de capas neuronales entre ellas. Por lo tanto, en el momento en que se crea el objeto de capa de desnormalización, ya debería haber una capa de normalización creada en el modelo. Y podremos acceder a ella, pero solo dentro del modelo, dado que el acceso a las capas neuronales individuales está cerrado a programas externos.
Por lo tanto, en el método CNet::Create crearemos un bloque aparte para inicializar el objeto de capa de desnormalización CNeuronRevINDenormOCL.
case defNeuronRevInDenormOCL: if(desc.layers>=layers.Total()) { delete temp; return false; }
Aquí comprobaremos primero que la capa con el identificador especificado ya ha sido creada en nuestro modelo.
A continuación, comprobaremos el tipo de la capa especificada. Debería ser una capa de normalización por lotes.
if(((CLayer *)layers.At(desc.layers)).At(0).Type()!=defNeuronBatchNormOCL) { delete temp; return false; }
Y solo después de pasar con éxito los controles especificados crearemos un nuevo objeto.
revin = new CNeuronRevINDenormOCL(); if(!revin) { delete temp; return false; }
Luego lo iniciaremos.
if(!revin.Init(outputs, 0, opencl, desc.count, desc.layers, ((CLayer *)layers.At(desc.layers)).At(0))) { delete temp; delete revin; return false; }
Y lo añadiremos al array de objetos.
if(!temp.Add(revin)) { delete temp; delete revin; return false; } break;
Además, también hay un matiz a la hora de cargar un modelo previamente entrenado. Como ya sabe, en el método de inicialización de nuestra nueva clase, hemos creado un algoritmo de ramificación según el ID de la capa de normalización. Esto se ha hecho considerando el proceso de bootstrapping del modelo previamente entrenado. La cuestión es que antes de cargar un objeto necesitaremos crear su "dummy". Esta funcionalidad se implementará en el método CLayer::CreateElement. Y lo difícil del momento es que no conoceremos el ID de la capa de normalización antes de cargar los datos. Por ello, especificaremos "-1" como identificador y "NULL" en lugar de un puntero al objeto.
case defNeuronRevInDenormOCL: if(CheckPointer(OpenCL) == POINTER_INVALID) return false; revin = new CNeuronRevINDenormOCL(); if(CheckPointer(revin) == POINTER_INVALID) result = false; if(revin.Init(iOutputs, index, OpenCL, 1, -1, NULL)) { m_data[index] = revin; return true; } delete revin; break;
Y luego en el proceso de carga todos los datos se cargarán en objetos internos y variables de nuestra clase. Pero aquí también existe otro matiz. Durante el proceso de carga de datos, obtendremos los parámetros de normalización almacenados tras el preentrenamiento del modelo. Sin embargo, no estamos contentos con eso. Para seguir entrenando el modelo y hacerlo funcionar, necesitaremos sincronizar los parámetros entre las capas de normalización y desnormalización. De lo contrario, tendremos un desfase entre las distribuciones de los datos de origen y nuestras predicciones. Así iremos al método CNet::Load y después de cargar la siguiente capa neuronal, comprobaremos su tipo.
bool CNet::Load(const int file_handle) { ........ ........ //--- read array length num = FileReadInteger(file_handle, INT_VALUE); //--- read array if(num != 0) { for(i = 0; i < num; i++) { //--- create new element CLayer *Layer = new CLayer(0, file_handle, opencl); if(!Layer.Load(file_handle)) break; if(Layer.At(0).Type() == defNeuronRevInDenormOCL) { CNeuronRevINDenormOCL *revin = Layer.At(0); int l = revin.GetNormLayer(); if(!layers.At(l)) { delete Layer; break; }
Si se detecta una capa de desnormalización CNeuronRevINDenormOCL, solicitaremos el puntero a la capa de normalización y comprobaremos si dicha capa está cargada.
También comprobaremos el tipo de esta capa.
CNeuronBaseOCL *neuron = ((CLayer *)layers.At(l)).At(0); if(neuron.Type() != defNeuronBatchNormOCL) { delete Layer; break; }
Y después de pasar con éxito los puntos de control especificados, inicializaremos el objeto de capa transmitiendo el puntero a la capa de normalización correspondiente.
if(!revin.Init(revin.getConnections(), 0, opencl, revin.Neurons(), l, neuron)) { delete Layer; break; } } if(!layers.Add(Layer)) break; } } FileClose(file_handle); //--- result return (layers.Total() == num); }
Y luego siguiendo el algoritmo creado previamente.
El código completo de todas las clases y sus métodos, así como todos los programas usados en la preparación del artículo, se encuentran en el archivo adjunto.
2.5 Arquitectura de los modelos entrenados
Arriba hemos implementado los enfoques propuestos por los autores del método RevIN usando herramientas MQL5. Ahora es el momento de incorporarlos a la arquitectura de nuestros modelos. Como ya hemos comentado, usaremos la desnormalización en el modelo del Codificador para poder entrenarlo y predecir directamente los estados del entorno posteriores. Definiremos el número de estados del entorno previstos (en nuestro caso, las velas posteriores) según la constante NForecast.
#define NForecast 6 //Number of forecast
Como estamos planeando entrenar el Codificador aparte del Actor y del Crítico, pondremos la descripción de la arquitectura del Codificador en el método separado CreateEncoderDescriptions. En los parámetros a los que transmitiremos solo un puntero al array dinámico para preservar la arquitectura del modelo creado. Nótese aquí que nuestra implementación de la clase CNeuronRevINDenormOCL no permite que el Decodificador sea un modelo separado.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
En el cuerpo del método comprobaremos el puntero recibido y, si es necesario, crearemos una nueva instancia del objeto de array dinámico.
Al igual que antes, suministraremos a la entrada del modelo datos de entrada "brutos" que describan el estado del entorno.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos obtenidos se someterán a un procesamiento inicial en la capa de normalización por lotes, y luego recordaremos el número de secuencia de la capa.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Tras normalizar los datos originales, crearemos una incorporación de los mismos con una adición a la pila interna.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {4, 1, 1, 1, 2}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count * 5; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, añadiremos la codificación posicional de los datos.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout * 5; if(!encoder.Add(descr)) { delete descr; return false; }
Luego suministraremos los datos así preparados a la entrada de un bloque de 5 capas CNeuronConformer.
//--- layer 5-10 for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 5; if(!encoder.Add(descr)) { delete descr; return false; } }
Para validar el método, utilizaremos como decodificador una capa totalmente conectada con un número correspondiente de elementos. No obstante, le recomendamos utilizar un decodificador con una arquitectura más sofisticada para mejorar la calidad de la predicción,
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NForecast*BarDescr; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
dado que trabajamos con datos normalizados y suponemos que su varianza se aproximará a "1" y su media a "0". A continuación, utilizaremos la tangente hiperbólica (tanh) como función de activación a la salida del decodificador. Como sabemos, su rango de valores va de "-1" a "1".
Y, por último, desnormalizaremos los valores previstos.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Para finalizar la descripción de la arquitectura de los modelos, le propongo analizar directamente la construcción del Actor y del Crítico. La arquitectura de los modelos especificados se describirá en el método CreateDescriptions. Toma mucho prestado del artículo anterior, pero hay un matiz reseñable.
En sus parámetros, el método obtiene los punteros a 2 arrays dinámicos.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
En el cuerpo del método comprobaremos los punteros obtenidos y, de ser necesario, crearemos nuevas instancias del objeto.
Luego suministraremos a la entrada del Actor un tensor que describe el estado de la cuenta y las posiciones abiertas.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Generaremos una incorporación de la representación dada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y luego vendrá el bloque de Atención Cruzada, que analizará el estado actual de la cuenta según los estados del entorno previstos.
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
Y finalizará el modelo del Actor con un bloque de toma de decisiones de la política estocástica.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Construiremos el modelo del Crítico de forma similar, solo que en lugar de describir el estado de la cuenta, el Crítico analizará las acciones del Actor en el contexto de los estados del entorno previstos.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } }
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Y en la salida del Crítico, obtendremos una evaluación clara, y no estocástica, de las acciones del Agente.
2.6 Programas de entrenamiento de los modelos
Tras describir la arquitectura de los modelos entrenados, procederemos a crear programas para entrenarlos directamente. Para entrenar el Codificador, crearemos el asesor experto "...\Experts\RevIN\StudyEncoder.mq5". La arquitectura de la construcción del EA la hemos tomado de artículos anteriores, así que se ha analizado muchas veces en los artículos de esta serie. Por consiguiente, solo nos centraremos en el método de entrenamiento directo del modelo Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
En el cuerpo del método, generaremos, como de costumbre, un vector de probabilidades de selección de trayectorias según sus rendimientos. Debemos decir que para predecir los futuros estados del entorno, todas las pasadas serán iguales, ya que el Codificador no analiza el estado de las cuentas y las posiciones abiertas. No obstante, dejaremos esta funcionalidad por si el búfer de reproducción contiene la experiencia de pasadas en diferentes intervalos históricos.
A continuación, prepararemos las variables locales y organizaremos un sistema de ciclos de entrenamiento del modelo.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - batch)); if(state <= 0) { iter--; continue; } Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - NForecast);
En el cuerpo del ciclo externo, muestrearemos una trayectoria del búfer de repetición de experiencias y el estado del inicio del entrenamiento sobre ella. A continuación, determinaremos el estado final del paquete de entrenamiento y borraremos la pila interna del modelo. Luego organizaremos un ciclo de entrenamiento anidado en el segmento de datos históricos seleccionado.
for(int i = state; i < end && !IsStopped() && !Stop; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Aquí, primero cargaremos el estado analizado de la muestra de entrenamiento. Lo transferiremos al búfer de datos. Y realizaremos una pasada directa del Codificador llamando al método correspondiente de nuestro modelo.
En la siguiente etapa, tendremos que preparar los datos objetivo. Para ello, organizaremos otro ciclo anidado en el que tomaremos el número necesario de estados posteriores de la muestra de entrenamiento y los añadiremos a la búfer de datos.
//--- Collect target data bState.Clear(); for(int fst = 1; fst <= NForecast; fst++) { if(!bState.AddArray(Buffer[tr].States[i + fst].state)) break; }
Una vez recogidos los valores objetivo, podremos realizar una pasada inversa del Codificador para minimizar el error entre los valores predichos y los valores objetivo.
if(!Encoder.backProp(GetPointer(bState), (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y luego solo tendremos que informar al usuario sobre el progreso del proceso de entrenamiento y pasar a la siguiente iteración.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez completadas con éxito todas las iteraciones de entrenamiento, eliminaremos el campo de comentarios.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Luego enviaremos la información sobre los resultados obtenidos del entrenamiento al registro e inicializaremos la finalización del asesor experto.
El entrenamiento del modelo para predecir futuros estados del entorno es útil. Pero nuestro objetivo es entrenar la política del Actor. Y el siguiente paso será crear el asesor de entrenamiento del Actor y el Crítico "...\Experts\RevIN\Study.mq5". El EA se basará en la misma arquitectura, por lo que solo nos referiremos a cambios puntuales.
En primer lugar, durante la inicialización del EA, la ausencia de un Codificador preentrenado generará un error de inicialización incorrecta del programa.
int OnInit() { //--- ........ ........ //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Error of load Encoder: %d", GetLastError()); return INIT_FAILED; } ........ ........ //--- return(INIT_SUCCEEDED); }
En segundo lugar, el Codificador de este modelo no se entrenará y, por tanto, no se almacenará.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
También hay un matiz a considerar cuando utilizamos el Codificador como fuente de datos de entrada para el Actor y el Crítico. Al principio de este artículo hablábamos de la importancia de usar datos normalizados para el entrenamiento y la explotación de modelos. Por el contrario, la capa de desnormalización en la salida del Codificador retornará nuestras predicciones a la distribución de los datos originales, lo cual las hace incomparables.
Sin embargo, hace tiempo que implementamos la funcionalidad de acceder a las capas ocultas del modelo para extraer datos. Y utilizamos esta funcionalidad para obtener datos predictivos normalizados de la penúltima capa del Codificador. Son estos datos los que usaremos como entrada para el Actor y el Crítico. Especificaremos el puntero a la capa requerida en la constante LatentLayer.
#define LatentLayer 11
Entonces la llamada de la pasada directa del Crítico tomará la forma:
if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
o
if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
En consecuencia, escribiremos la llamada directa a la pasada del Actor como
if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y no olvidaremos especificar el ID de capa al llamar a los métodos de pasada inversa de nuestros modelos.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder),LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Hemos introducido los mismos cambios puntuales en los asesores de interacción con el entorno. Pero le sugiero que se familiarice con ellos. El código completo de todos los programas utilizados en la elaboración de este artículo figurará en el anexo.
3. Simulación
Una vez creados todos los programas necesarios, podemos pasar a entrenar y probar los modelos, lo cual nos permitirá evaluar la eficacia de las soluciones propuestas.
Como de costumbre, entrenaremos y probaremos los modelos con datos históricos reales de EURUSD y el marco temporal H1.
El tiempo no se detiene. Y con ello se enriquece nuestra base de datos históricos. Al preparar este artículo, decidí ampliar el intervalo histórico de la muestra de entrenamiento a todo el año 2023. Al mismo tiempo, validaremos los modelos entrenados con los datos de enero de 2024.
Para crear la muestra de entrenamiento inicial, hemos usado el marco Real-ORL. Su descripción detallada puede encontrarse en el enlace. Hemos descargado los datos comerciales de 20 señales reales. Y también iniciado el asesor de experto "...\Experts\RevIN\ResearchRealORL.mq5" en el modo de optimización lenta.


Como resultado, hemos obtenido 20 trayectorias. Y no todas son rentables.

En este paso, primero iniciaremos el entrenamiento del Codificador. Y tras su finalización, ejecutaremos el entrenamiento inicial del Actor y del Crítico. Y decimos inicial porque 20 trayectorias son muy pocas para obtener una política de Actor óptima.
En el siguiente paso, aumentaremos nuestra muestra de entrenamiento. Para ello, en el modo de optimización lenta ejecutaremos el asesor experto "...\Experts\RevIN\Research.mq5", que comprobará la política del Actor actual con los datos históricos reales del periodo de entrenamiento y añadirá pasadas a nuestra muestra de entrenamiento.

No hay que esperar resultados extraordinarios en esta fase. Un resultado negativo también supone un resultado. Además de una buena experiencia para seguir entrenando el modelo. Además, dicha iteración permite conocer mejor el entorno en el ámbito de actuación de la actual política de Actor.
Tras varias iteraciones de entrenamiento de la política de Actor y la recopilación de datos adicionales con la muestra de entrenamiento, hemos podido entrenar un modelo capaz de generar beneficios tanto en la muestra de entrenamiento como en la de prueba.


Durante el periodo de prueba, el asesor experto ha realizado 424 transacciones, 210 de las cuales se han cerrado con beneficios. Esto supone un 49,53%. Sin embargo, gracias a que las transacciones rentables máximas y medias han superado en indicadores similares a las transacciones perdedoras, hemos logrado obtener beneficios en general durante el periodo de prueba. Al mismo tiempo, la reducción máxima del balance y de la equidad ha mostrado resultados cercanos (9,14% y 10,36% respectivamente). El factor de beneficio para el periodo de prueba ha sido de 1,25, mientras que el ratio de Sharpe ha alcanzado el 3,38.
Conclusión
En este artículo nos hemos familiarizado con el método RevIN, que supone un paso importante en el desarrollo de las técnicas de normalización y desnormalización. Especialmente para los modelos de aprendizaje profundo en el contexto de la previsión de series temporales, permite conservar y recuperar la información estadística de las series temporales, lo cual resulta fundamental para realizar previsiones precisas. RevIN ha mostrado su capacidad de adaptación a los cambios en la dinámica de los datos a lo largo del tiempo. Esto lo convierte en una herramienta eficaz para tratar los cambios de distribución en las series temporales.
Una de las ventajas importantes de RevIN es su flexibilidad y aplicabilidad a distintos modelos de aprendizaje profundo. Puede implementarse fácilmente en diferentes arquitecturas de redes neuronales e incluso aplicarse a múltiples capas, ofreciendo una calidad de predicción estable.
En la parte práctica del artículo, hemos implementado los enfoques propuestos usando herramientas MQL5. Hemos entrenado los modelos con datos históricos reales, y los hemos probado con nuevos datos fuera de la muestra de entrenamiento.
Los resultados de las pruebas han mostrado la capacidad de los modelos entrenados para realizar generalizaciones a partir de los datos de la muestra de entrenamiento y generar rendimientos tanto dentro como fuera de los datos históricos de la muestra de entrenamiento.
No obstante, conviene recordar que todos los programas presentados en este artículo tienen carácter demostrativo y solo pretenden poner a prueba los planteamientos propuestos.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de cobros de ejemplo Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | StudyEncoder.mq5 | Asesor | Asesor de entrenamiento del Codificador |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14673
 Utilizando redes neuronales en MetaTrader
Utilizando redes neuronales en MetaTrader
 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso