
Redes neuronales: así de sencillo (Parte 79): Adición de solicitudes en el contexto de estado (FAQ)

Introducción
La mayoría de los métodos de los que hemos hablado anteriormente analizan el estado del entorno como algo estático y que se ajusta a la definición de un proceso de Markov. Obviamente, completaremos la descripción de las condiciones del entorno con datos históricos para dotar al modelo de la máxima información necesaria, pero el modelo no estimará la dinámica de los cambios de estado. Entre otras cosas, el método DFFT, presentado en el artículo anterior, también se ha desarrollado para la detección de objetos en imágenes estáticas.
Sin embargo, las observaciones de los movimientos de los precios indican que la dinámica de los cambios a veces puede mostrar la fuerza y la dirección del próximo movimiento con suficiente probabilidad. Así que tendrá sentido que nos fijemos en los métodos de detección de objetos en vídeo.
La detección de objetos en vídeo presenta una serie de características y tiene que enfrentarse a los cambios inducidos por el movimiento en las características del objeto que no se encuentran en el dominio de la imagen. Una solución sería utilizar información temporal y combinar características de fotogramas vecinos. En el artículo "FAQ: Feature Aggregated Queries for Transformer-based Video Object Detectors" se propone un nuevo enfoque para la detección de objetos en vídeo. Los autores del artículo mejoran la calidad de las consultas a modelos basados en el Transformer, usando su agregación. Para lograr este objetivo, le proponemos un método práctico de generación y agregación de consultas en función de las características de los fotogramas de entrada. Los amplios resultados experimentales aportados en el artículo confirman la eficacia del método propuesto. Los enfoques del artículo pueden extenderse a una amplia lista de métodos de detección de objetos en imágenes y vídeos para mejorar su rendimiento.
1. El algoritmo Feature Aggregated Queries
Hay que decir que el método FAQ dista mucho de ser el primero en usar la arquitectura del Transformer para detectar objetos en vídeo. Sin embargo, los anteriores detectores de objetos en vídeo que utilizan el Transformer mejoran la representación de las características de los objetos usando la agregación de Query. Una idea ingenua sería promediar las Query de los fotogramas vecinos. Las Query se inicializarán aleatoriamente y se utilizarán durante el proceso de aprendizaje. Las Query vecinas se agregarán en Δ𝑸 para el fotograma actual 𝑰 y se representarán como:
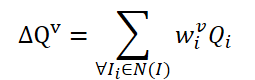
donde w serán los pesos de entrenamiento para la agregación.
La simple idea de crear pesos entrenados se basa en la similitud de coseno de las características del fotograma de entrada. Siguiendo los detectores de objetos existentes en el vídeo, los autores del método FAQ generan pesos de agregación usando la fórmula:
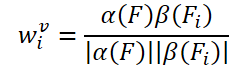
donde α, β son funciones de mapeo, y |⋅|| denota la normalización.
Las características correspondientes del fotograma actual 𝑰 y sus vecinos 𝑰i se denominan como 𝑭 y 𝑭i. Como resultado, la probabilidad de determinar el objeto podría expresarse como:
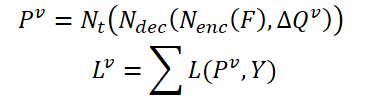
donde 𝑷v será la probabilidad prevista utilizando consultas agregadas Δ𝑸v.
Hay un problema en el módulo de agregación de consultas básico y es que estas consultas 𝑸i vecinas se inicializan aleatoriamente y no se asocian a sus marcos 𝑰i correspondientes. Por lo tanto, las consultas 𝑸i vecinas no proporcionan suficiente información temporal o semántica para eliminar los problemas de degradación del rendimiento causados por el movimiento rápido. Aunque los pesos wi utilizados para la agregación están relacionados con las funciones 𝑭 y 𝑭i, no hay suficientes restricciones sobre el número de estas consultas inicializadas aleatoriamente. Por ello, los autores del método FAQ sugieren actualizar el módulo de agregación de Query a una versión dinámica que añada restricciones a las consultas y pueda ajustar los pesos en función de los fotogramas vecinos. Una idea fácil de implementación sería generar consultas 𝑸i directamente a partir de los atributos 𝑭i del fotograma de entrada. Sin embargo, los experimentos realizados por los autores del método demuestran que este método resulta difícil de entrenar y siempre da los peores resultados. A diferencia de la idea ingenua antes mencionada, los autores del método proponen generar nuevas consultas adaptables a los datos originales partiendo de las Query inicializadas aleatoriamente. En primer lugar, definiremos dos tipos de vectores Query: básicos y dinámicos. Durante los procesos de entrenamiento y explotación, se generarán Query dinámicas a partir de las Query básicas según las características 𝑭i, 𝑭 suministradas a la entrada de los fotogramas como:
![]()
donde M será una función de correspondencia para construir una relación entre la consulta básica Qb y la dinámica Qd según las características 𝑭 y 𝑭i.
En primer lugar, dividiremos las consultas básicas en grupos de r consultas. A continuación, para cada grupo, utilizaremos los mismos pesos 𝑽 para determinar la consulta media ponderada en el grupo actual:
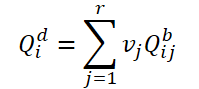
Para crear un vínculo entre las consultas dinámicas 𝑸d y el fotograma 𝑰i correspondiente, los autores del método proponen generar pesos 𝑽 utilizando características globales:
![]()
donde A será una operación de agregación global para cambiar la dimensionalidad del tensor de características y crear características de nivel global,
G será una función de mapeo para proyectar las características globales en la dimensionalidad del tensor Query dinámico.
Así, el proceso de agregación dinámica de consultas basado en las características de los datos originales podrá actualizarse del siguiente modo:
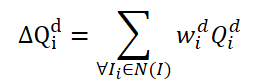
Durante el entrenamiento, los autores del método proponen agregar tanto consultas dinámicas como básicas. Ambos tipos de consultas se agregarán con los mismos pesos; asimismo, se generarán los correspondientes pronósticos 𝑷d y 𝑷b. De este modo se calculará el error de coincidencia bidireccional de ambas previsiones. El hiperparámetro γ se utilizará para equilibrar el efecto de los errores.
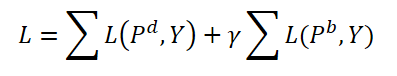
Durante la operación solo se utilizarán consultas 𝑸d dinámicas y sus correspondientes predicciones 𝑷d como resultados finales, lo que solo complicará ligeramente los modelos originales.
A continuación le mostraremos una visualización del método propuesta por los autores.

2. Implementación con MQL5
Tras repasar los aspectos teóricos del método propuesto, ahora pasaremos a la parte práctica de nuestro artículo, donde implementaremos los planteamientos propuestos usando herramientas MQL5.
Como se desprende de la descripción anterior del método FAQ, su principal contribución es la creación del módulo de generación y agregación del tensor dinámico de consultas en el Decodificador Transformer. Y aquí quiero recordar, que los autores del método DFFT se han negado a utilizar el decodificador debido a su ineficiencia. Pues bien, en este artículo añadiremos un Decodificador y evaluaremos su eficacia en las condiciones de uso de las Query dinámicas propuestas por los autores del método FAQ.
2.1 Clase de consultas dinámicas
Para generar consultas dinámicas, crearemos una nueva clase, CNeuronFAQOCL. El nuevo objeto heredará de la clase básica de la capa neuronal de nuestra biblioteca CNeuronBaseOCL.
class CNeuronFAQOCL : public CNeuronBaseOCL { protected: //--- CNeuronConvOCL cF; CNeuronBaseOCL cWv; CNeuronBatchNormOCL cNormV; CNeuronBaseOCL cQd; CNeuronXCiTOCL cDQd; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronFAQOCL(void) {}; ~CNeuronFAQOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronFAQOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Debemos decir aquí que además del conjunto básico de métodos redefinidos en la nueva clase, añadiremos 5 capas neuronales internas, cuyo propósito conoceremos durante la implementación. Declaramos todos los objetos internos como estáticos, lo cual nos permitirá dejar el constructor y el destructor de la clase vacíos.
El objeto de clase se inicializará en el método CNeuronFAQOCL::Init. En los parámetros del método obtendremos todos los parámetros clave para inicializar los objetos internos. Y en el cuerpo del método llamaremos inmediatamente al método homónimo de la clase padre. Como ya sabe, en este método se implementa el control mínimo necesario de los parámetros obtenidos y la inicialización de los objetos heredados.
bool CNeuronFAQOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
No especificaremos ninguna función de activación para nuestra clase.
activation = None;
A continuación, inicializaremos los objetos internos. Y aquí deberemos referirnos a los enfoques de generación dinámica de Query propuestos por los autores del método FAQ. Para generar los pesos de agregación de las Query básicas en función de los atributos de los datos de origen, crearemos 3 capas. En primer lugar, dejaremos que las características de los datos originales pasen por una capa convolucional en la que analizaremos los patrones de los estados del entorno vecinos.
if(!cF.Init(0, 0, OpenCL, 3 * window, window, 8, fmax((int)input_units - 2, 1), optimization_type, batch)) return false; cF.SetActivationFunction(None);
Para mejorar la estabilidad del proceso de entrenamiento y funcionamiento del modelo, normalizaremos los datos obtenidos.
if(!cNormV.Init(8, 1, OpenCL, fmax((int)input_units - 2, 1) * 8, batch, optimization_type)) return false; cNormV.SetActivationFunction(None);
A continuación, comprimiremos los datos hasta el tamaño del tensor de pesos de agregación de la consulta básica. Para que los pesos obtenidos se encuentren en el rango [0,1], utilizaremos la función de activación sigmoidal.
if(!cWv.Init(units_count * window_out, 2, OpenCL, 8, optimization_type, batch)) return false; cWv.SetActivationFunction(SIGMOID);
Según el algoritmo FAQ, tendremos que multiplicar el vector resultante de coeficientes de agregación por una matriz de Query básicas que se generarán aleatoriamente al principio del entrenamiento. En mi aplicación, he decidido ir un poco más allá y formar consultas básicas. Y aquí no se me ha ocurrido nada más original que utilizar una capa neuronal totalmente conectada. Así, suministraremos un vector de coeficientes de agregación a la entrada de la capa, mientras que la matriz de pesos de la capa completamente conectada será el tensor de las consultas básicas entrenadas.
if(!cQd.Init(0, 4, OpenCL, units_count * window_out, optimization_type, batch)) return false; cQd.SetActivationFunction(None);
A continuación vendrá la agregación de las Query dinámicas. Los autores del método FAQ ofrecen en su artículo resultados experimentales con distintos métodos de agregación. Pero la agregación de Query dinámicas mediante la arquitectura del Transformer ha demostrado ser la más eficaz. Según los resultados anteriores, utilizaremos un objeto de la clase CNeuronXCiTOCL para agregar consultas dinámicas.
if(!cDQd.Init(0, 5, OpenCL, window_out, 3, heads, units_count, 3, optimization_type, batch)) return false; cDQd.SetActivationFunction(None);
Y para evitar operaciones innecesarias de copiado de datos, intercambiaremos los búferes de los resultados de nuestra clase y los gradientes de error.
if(Output != cDQd.getOutput()) { Output.BufferFree(); delete Output; Output = cDQd.getOutput(); } if(Gradient != cDQd.getGradient()) { Gradient.BufferFree(); delete Gradient; Gradient = cDQd.getGradient(); } //--- return true; }
Después de inicializar el objeto, procederemos a organizar el proceso de pasada directa en el método CNeuronFAQOCL::feedForward. Aquí todo resulta bastante simple y trivial. En los parámetros del método, obtendremos el puntero a la capa de datos de origen con los parámetros para describir el estado del entorno. Y en el cuerpo del método, llamaremos alternativamente a los métodos similares de pasada directa de objetos internos.
bool CNeuronFAQOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cF.FeedForward(NeuronOCL)) return false;
Primero pasaremos la descripción del entorno por la capa convolucional y normalizaremos los datos resultantes.
if(!cNormV.FeedForward(GetPointer(cF))) return false;
Después generaremos los coeficientes de agregación de la Query básica.
if(!cWv.FeedForward(GetPointer(cNormV))) return false;
Luego crearemos las Query dinámicas.
if(!cQd.FeedForward(GetPointer(cWv))) return false;
Y las agregaremos en el objeto de clase CNeuronXCiTOCL.
if(!cDQd.FeedForward(GetPointer(cQd))) return false; //--- return true; }
Al intercambiar los búferes de datos, los resultados de la capa cDQd interna se reflejarán en el búfer de resultados de nuestra clase CNeuronFAQOCL sin operaciones de copiado innecesarias. Por lo tanto, podemos finalizar tranquilamente el método.
A continuación, crearemos los métodos de pasada inversa CNeuronFAQOCL::calcInputGradients y CNeuronFAQOCL::updateInputWeights De forma similar al método de pasada directa, en estos llamaremos a los métodos del objeto interno homónimo, solo que en orden inverso. Por lo tanto, no entraremos en detalles con su algoritmo en este artículo. Podrá leer el código completo de todos los métodos de la clase de generación de consultas dinámicas CNeuronFAQOCL en el archivo adjunto.
2.2 Clase de Atención Cruzada
El siguiente paso que tendremos que dar es crear una clase de Atención Cruzada. Debemos decir que, como parte de nuestra implementación del método ADAPT, ya hemos creado una capa de atención cruzada CNeuronMH2AttentionOCL. Solo que entonces analizamos las relaciones de las distintas dimensiones de un mismo tensor. Ahora, el reto será un poco diferente. Tendremos que evaluar las dependencias de la Query dinámica generada desde la clase CNeuronFAQOCL respecto al estado comprimido del entorno desde el Codificador de nuestro modelo. En otras palabras, tendremos que evaluar la relación entre 2 tensores diferentes.
Para implementar esta funcionalidad, crearemos la clase CNeuronCrossAttention, que heredará parte de la funcionalidad necesaria de la clase CNeuronMH2AttentionOCL mencionada anteriormente.
class CNeuronCrossAttention : public CNeuronMH2AttentionOCL { protected: uint iWindow_K; uint iUnits_K; CNeuronBaseOCL *cContext; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); virtual bool attentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool AttentionInsideGradients(void); public: CNeuronCrossAttention(void) {}; ~CNeuronCrossAttention(void) { delete cContext; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); //--- virtual int Type(void) const { return defNeuronCrossAttenOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); };
Además del conjunto estándar de métodos redefinidos, aquí podremos notar 2 nuevas variables:
- iWindow_K - tamaño del vector de descripción de un elemento del 2º tensor;
- iUnits_K - número de elementos en la secuencia del 2º tensor.
Además, añadiremos un puntero dinámico a la capa neuronal auxiliar cContext, que, cuando sea necesario, se inicializará como un objeto de los originales. Como este objeto cumple una función auxiliar no obligatoria, el constructor de nuestra clase permanecerá vacío. Pero en el destructor de la clase, eliminaremos el objeto dinámico.
~CNeuronCrossAttention(void) { delete cContext; }
El objeto se inicializará como es habitual en el método CNeuronCrossAttention::Init. En los parámetros del método obtendremos los datos necesarios sobre la arquitectura de la capa a crear. Y en el cuerpo del método, llamaremos al método homónimo de la clase básica de capas neuronales CNeuronBaseOCL::Init.
bool CNeuronCrossAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Nótese que estamos llamando al método de inicialización no de la clase padre directa CNeuronMH2AttentionOCL, sino de la básica CNeuronBaseOCL. Esto se debe a diferencias en la arquitectura de las clases CNeuronCrossAttention y CNeuronMH2AttentionOCL. Por ello, más adelante en el cuerpo del método inicializamos no solo los objetos nuevos, sino también los heredados.
En primer lugar, almacenaremos los parámetros de nuestra capa.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iWindow_K = fmax(window_k, 1); iUnits_K = fmax(units_k, 1); iHeads = fmax(heads, 1); activation = None;
A continuación, inicializaremos la capa de generación de entidades Query.
if(!Q_Embedding.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, optimization_type, batch)) return false; Q_Embedding.SetActivationFunction(None);
Así como las entidades Key y Value.
if(!KV_Embedding.Init(0, 0, OpenCL, iWindow_K, iWindow_K, 2 * iWindowKey * iHeads, iUnits_K, optimization_type, batch)) return false; KV_Embedding.SetActivationFunction(None);
Por favor, no confunda las entidades Query generadas aquí con las consultas dinámicas generadas en la clase CNeuronFAQOCL.
Como parte de la implementación del método FAQ, suministraremos las consultas dinámicas generadas a la entrada de esta clase como datos de entrada. Y aquí podemos decir que la capa Q_Embedding realizará su asignación por cabezas de atención. Pero la capa KV_Embedding generará entidades a partir de la representación comprimida del estado del entorno recibida del Codificador.
Pero volvamos al método de inicialización de nuestra clase. Tras inicializar las capas de generación de entidades, crearemos el búfer de matriz de coeficiente de dependencia Score.
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits_K * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Aquí es donde crearemos una capa de resultados de atención multi-cabeza.
if(!MHAttentionOut.Init(0, 0, OpenCL, iWindowKey * iUnits * iHeads, optimization_type, batch)) return false; MHAttentionOut.SetActivationFunction(None);
Y una capa de agregación de cabezas de atención.
if(!W0.Init(0, 0, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, optimization_type, batch)) return false; W0.SetActivationFunction(None); if(!AttentionOut.Init(0, 0, OpenCL, iWindow * iUnits, optimization_type, batch)) return false; AttentionOut.SetActivationFunction(None);
A continuación, el bloque FeedForward.
if(!FF[0].Init(0, 0, OpenCL, iWindow, iWindow, 4 * iWindow, iUnits, optimization_type, batch)) return false; if(!FF[1].Init(0, 0, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, optimization_type, batch)) return false; for(int i = 0; i < 2; i++) FF[i].SetActivationFunction(None);
Y al final del método de inicialización, organizaremos el intercambio de búferes.
Gradient.BufferFree(); delete Gradient; Gradient = FF[1].getGradient(); //--- return true; }
Tras inicializar la clase, organizaremos la pasada directa como de costumbre. Debemos decir que dentro de esta clase no crearemos nuevos kernels en el lado OpenCL del programa. En este caso, utilizaremos los kernels creados para implementar los procesos de la clase padre. Pero tendremos que hacer algunos pequeños ajustes en los métodos de llamada a los kernels. Por ejemplo, en el método CNeuronCrossAttention::attentionOut, solo cambiaremos los arrays que indican el espacio de tareas y el grupo local en cuanto al tamaño de la secuencia de la entidad Key (en el código se destaca en color rojo)
bool CNeuronCrossAttention::attentionOut(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits_K/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits_K, 1}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, MHAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
El algoritmo completo de pasada directa de nivel superior se describe en el método CNeuronCrossAttention::feedForward. A diferencia del método análogo de la clase padre, este método recibe los punteros a los dos objetos de capas neuronales en sus parámetros, que contienen los datos de los dos tensores para el análisis de las dependencias.
bool CNeuronCrossAttention::feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context) { //--- if(!Q_Embedding.FeedForward(NeuronOCL)) return false; //--- if(!KV_Embedding.FeedForward(Context)) return false;
En el cuerpo del método, primero generaremos entidades a partir de los datos recibidos. Y luego invocaremos el método de atención multi-cabeza.
if(!attentionOut()) return false;
Después agregaremos los resultados de la atención.
if(!W0.FeedForward(GetPointer(MHAttentionOut))) return false;
Y los sumaremos con los datos de origen. A continuación, normalizaremos el resultado dentro de los elementos de la secuencia. En el contexto de la aplicación del método FAQ, la normalización se realizará según consultas dinámicas individuales.
if(!SumAndNormilize(W0.getOutput(), NeuronOCL.getOutput(), AttentionOut.getOutput(), iWindow)) return false;
A continuación, los datos pasarán por el bloque FeedForward.
if(!FF[0].FeedForward(GetPointer(AttentionOut))) return false; if(!FF[1].FeedForward(GetPointer(FF[0]))) return false;
Nuevamente, sumaremos y normalizaremos los datos.
if(!SumAndNormilize(FF[1].getOutput(), AttentionOut.getOutput(), Output, iWindow)) return false; //--- return true; }
Una vez completadas con éxito todas las operaciones anteriores, finalizaremos el método.
Aquí terminaremos la descripción de la puesta en marcha de la pasada directa y pasaremos al organizar la pasada inversa. Aquí también usaremos el kernel creado dentro de la implementación de la clase padre, e introduciremos correcciones puntuales en su método de llamada CNeuronCrossAttention::AttentionInsideGradients.
bool CNeuronCrossAttention::AttentionInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindowKey, iHeads}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_qg, Q_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kvg, KV_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_outg, MHAttentionOut.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kunits, (int)iUnits_K)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
El proceso de distribución del gradiente de error a través de nuestra capa de atención cruzada se organizará en el método CNeuronCrossAttention::calcInputGradients. De forma similar al método de pasada directa, los punteros a las dos capas con dos flujos de información se transmitirán al método en los parámetros.
bool CNeuronCrossAttention::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context) { if(!FF[1].calcInputGradients(GetPointer(FF[0]))) return false; if(!FF[0].calcInputGradients(GetPointer(AttentionOut))) return false;
Debido al intercambio de búferes de datos, el gradiente de error obtenido de la capa posterior pasará inmediatamente al búfer de gradiente de error de la capa 2 del bloque FeedForward. Por lo tanto, no necesitaremos copiar los datos. E inmediatamente llamaremos a los métodos de distribución del gradiente de error de las capas internas del bloque FeedForward.
En este paso, tendremos que sumar el gradiente de error obtenido del bloque FeedForward y la capa neuronal posterior.
if(!SumAndNormilize(FF[1].getGradient(), AttentionOut.getGradient(), W0.getGradient(), iWindow, false)) return false;
A continuación, distribuiremos el gradiente de error entre las cabezas de atención.
if(!W0.calcInputGradients(GetPointer(MHAttentionOut))) return false;
Y llamaremos al método para transmitir el gradiente de error a las entidades Query, Key y Value.
if(!AttentionInsideGradients()) return false;
Luego transmitiremos el gradiente de las entidades Key y Value a la capa de Contexto (al Codificador).
if(!KV_Embedding.calcInputGradients(Context)) return false;
Y de Key a la capa anterior.
if(!Q_Embedding.calcInputGradients(prevLayer)) return false;
Y aquí no nos olvidaremos de sumar los gradientes de error.
if(!SumAndNormilize(prevLayer.getGradient(), W0.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
A continuación, finalizaremos el método.
El método para actualizar los parámetros de los objetos internos de CNeuronCrossAttention::updateInputWeights es bastante sencillo. Se limitará a llamar uno a uno los métodos de los objetos internos homónimos. Le invito a que lo lea por sí mismo en el archivo adjunto. Allí también encontrará métodos para trabajar con archivos, así como el código completo de todos los programas y clases utilizados en la elaboración de este artículo.
Aquí terminamos el trabajo de creación de las nuevas clases y podemos pasar a describir la arquitectura del modelo.
2.3 Arquitectura del modelo
La arquitectura de los modelos se representará, como siempre, en el método CreateDescriptions. Debemos decir que la arquitectura de los modelos la hemos tomado en gran medida de la implementación del método DFFT. Sin embargo, hemos añadido un Decodificador. Y, en consecuencia, el Actor y el Crítico recibirán los datos del Descodificador. Por lo tanto, necesitaremos 4 arrays dinámicos para crear una descripción de los modelos.
bool CreateDescriptions(CArrayObj *dot, CArrayObj *decoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
El modelo de Codificador (dot) se ha heredado del artículo anterior sin modificaciones. Encontrará su descripción aquí.
El descodificador utilizará los datos latentes del Codificador en el nivel de la capa de codificación posicional como datos de entrada.
//--- Decoder decoder.Clear(); //--- Input layer CLayerDescription *po = dot.At(LatentLayer); if(!po || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = po.count * po.window; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Recordemos que en este nivel, eliminaremos las incorporaciones de varios estados del entorno almacenados en la pila local con etiquetas de codificación posicional añadidas. Esencialmente, estos datos contendrán una secuencia de características para describir el estado del entorno detrás de GPTBars de las velas. Lo que podemos identificar con los fotogramas de la serie de vídeo. A partir de estos datos, generaremos Query dinámicas.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFAQOCL; { int temp[] = {QueryCount, po.count}; ArrayCopy(descr.units, temp); } descr.window = po.window; descr.window_out = 16; descr.optimization = ADAM; descr.step = 4; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
E implementaremos la Atención Cruzada.
//--- layer 2 CLayerDescription *encoder = dot.At(dot.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {QueryCount, encoder.count}; ArrayCopy(descr.units, temp); } { int temp[] = {16, encoder.window}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
El actor recibirá los datos del Decodificador.
//--- Actor actor.Clear(); //--- Input layer encoder = decoder.At(decoder.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = encoder.units[0] * encoder.windows[0]; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Luego los combinará con una descripción del estado de la cuenta.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
A continuación, los datos pasarán por 2 capas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y en la salida conferiremos estocasticidad a la política del Actor.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El modelo del Crítico se trasladará sin cambios, salvo que cambiaremos la fuente de los datos originales del Codificador al Decodificador.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(1)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 Asesores para la interacción con el entorno
Para preparar este artículo, hemos recurrido a 3 asesores de interacción con el entorno:
- Research.mq5
- ResearchRealORL.mq5
- Test.mq5
El Asesor Experto "...\Experts\FAQ\ResearchRealORL.mq5" no estará vinculado a la arquitectura de los modelos. Y debido al hecho de que todos los Asesores Expertos son entrenados y probados en el análisis de los mismos datos iniciales de la descripción del entorno, este Asesor Experto se transferirá de artículo a artículo sin el más mínimo cambio. Encontrará la descripción completa de su código y enfoques de uso aquí.
En el código del Asesor Experto "...\Experts\FAQ\Research.mq5" añadiremos el modelo de Decodificador.
CNet DOT; CNet Decoder; CNet Actor;
Por consiguiente, en el método de inicialización, añadiremos la carga de este modelo y su inicialización con parámetros aleatorios si fuera necesario.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; //--- if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; } //--- Decoder.SetOpenCL(DOT.GetOpenCL()); Actor.SetOpenCL(DOT.GetOpenCL()); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Obsérvese que en este caso no utilizaremos el modelo del Crítico. Su funcionalidad no intervendrá en el proceso de interacción con el entorno y la recogida de datos para el entrenamiento.
El propio proceso de interacción con el entorno se organizará en el método OnTick. En el cuerpo del método primero comprobaremos si ha sucedido un evento de apertura de una nueva barra.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Permítanme recordarles que el proceso completo se basa en el análisis de velas cerradas.
Al producirse el evento requerido, primero cargaremos los datos históricos,
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
que transferiremos al búfer que describe el estado actual del entorno.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
A continuación, recopilaremos los datos sobre el estado de la cuenta y las posiciones abiertas.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Después agruparemos los datos obtenidos en el búfer de estado de la cuenta.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
Aquí también añadiremos los armónicos de la marca temporal.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Los datos recogidos se introducirán primero en la entrada del codificador.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Luego los resultados del codificador se transferirán al decodificador.
if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer,(CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Y después al Actor.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } //--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Acto seguido, descargaremos las acciones previstas por el Actor. Y eliminaremos las operaciones opuestas.
vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
A continuación, descodificaremos las acciones de previsión con la ejecución de las acciones comerciales. Primero, con las posiciones largas.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Después, con las posiciones cortas.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Al final del método, guardaremos los resultados de la interacción con el entorno en el búfer de reproducción de experiencias.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
El resto de los métodos del Asesor Experto no han sufrido cambios.
Hemos realizado cambios similares en el Asesor Experto "...\Experts\FAQ\Test.mq5. Podrá leer el código completo de ambos Asesores Expertos en el archivo adjunto.
2.5 Asesor de entrenamiento de modelos
Los modelos se entrenan con el Asesor Experto "...\Experts\FAQ\Study.mq5". Al igual que en los Asesores Expertos anteriores, la estructura del asesor se ha heredado de artículos pasados. En línea con los cambios realizados en la arquitectura del modelo, hemos añadido un Decodificador.
CNet DOT; CNet Decoder; CNet Actor; CNet Critic;
Como podemos ver, el Crítico también participa en el proceso de entrenamiento del modelo.
En el método de inicialización del Asesor Experto, primero cargaremos los datos de entrenamiento.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Y luego intentaremos cargar los modelos pre-entrenados. Si los modelos no pueden cargarse, crearemos modelos nuevos y los inicializaremos con parámetros aleatorios.
//--- load models float temp; if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Decoder.Load(FileName + "Dec.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor) || !Critic.Create(critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; }
Luego trasladaremos todos los modelos a un contexto OpenCL.
OpenCL = DOT.GetOpenCL(); Decoder.SetOpenCL(OpenCL); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
Y luego controlaremos que la arquitectura de los modelos sea correcta.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Después crearemos los búferes de datos auxiliares.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
Y generaremos un evento personalizado para iniciar el proceso de entrenamiento.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
En el método de desinicialización del Asesor Experto, guardaremos los modelos entrenados y vaciaremos la memoria de los objetos dinámicos.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); DOT.Save(FileName + "DOT.nnw", 0, 0, 0, TimeCurrent(), true); Decoder.Save(FileName + "Dec.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
El propio proceso de entrenamiento del modelo se realizará con el método Train. En el cuerpo del método, primero determinaremos la probabilidad de seleccionar trayectorias en función de sus rendimientos.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
A continuación, declararemos las variables locales.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Y crearemos el sistema de ciclos anidados del proceso de entrenamiento.
Recordemos que la arquitectura del Codificador ofrece una capa de incorporación con un búfer interno para acumular datos históricos. Este tipo de decisiones arquitectónicas son muy sensibles a la coherencia histórica de los datos de origen obtenidos. Por lo tanto, organizaremos un sistema de ciclos anidados para entrenar los modelos, donde el ciclo exterior contará el número de paquetes de entrenamiento. Y en un ciclo anidado, los datos de origen se introducirán siguiendo la cronología histórica como parte del paquete de entrenamiento.
En el cuerpo del ciclo externo, muestrearemos la trayectoria y los estados iniciales del paquete de entrenamiento sobre ella.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Luego limpiaremos el búfer interno de acumulación de datos históricos.
DOT.Clear();
Y determinaremos el estado de finalización del paquete de entrenamiento.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
Después organizaremos un ciclo anidado de entrenamiento, en cuyo cuerpo cargaremos primero una descripción histórica del estado del entorno desde el búfer de reproducción de experiencias.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
Con los datos disponibles, realizaremos una pasada directa del Codificador y el Decodificador.
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer, (CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Además, cargaremos la descripción del estado de la cuenta correspondiente desde el búfer de reproducción de experiencias con transferencia de datos al búfer correspondiente
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Aquí es donde añadiremos los armónicos de las marcas temporales.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
El proceso será completamente similar al de los asesores de interacción con el entorno. Solo que no sondearemos el terminal, sino que cargaremos todos los datos desde el búfer de reproducción de la experiencias.
Una vez tengamos los datos, podremos realizar una pasada directa secuencial para el Actor y el Crítico.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(Decoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
La pasada directa irá seguida de una pasada inversa, durante la cual se optimizarán los parámetros de los modelos. En primer lugar, realizaremos una pasada inversa del Actor minimizando los errores hasta las acciones del búfer de reproducción de experiencias.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) ||
El gradiente de error del Actor se transmitirá al Decodificador.
!Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) ||
Este, a su vez, transmitirá el gradiente de error al Codificador. Y aquí debemos señalar que el Decodificador tomará los datos de origen de las dos capas del Codificador, y el gradiente de error lo transmitirá a las dos capas correspondientes. Para actualizar correctamente los parámetros del modelo, primero tendremos que omitir el gradiente de la capa latente.
!DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) ||
Y solo entonces se pasará a través de todo el modelo de Codificador.
!DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A continuación, determinaremos la recompensa de la próxima transición.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result);
Y optimizaremos los parámetros del Crítico, tras lo cual pasaremos el gradiente de error a todos los modelos participantes.
if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient), -1, false) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Al finalizar las operaciones dentro del sistema de ciclos, informaremos al usuario del progreso del entrenamiento y pasaremos a la siguiente iteración.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez completadas con éxito todas las iteraciones del sistema de ciclos de entrenamiento del modelo, eliminaremos el campo de comentarios del gráfico.
Comment("");
Luego enviaremos los resultados del entrenamiento al registro del terminal e iniciaremos el proceso de finalización del Asesor Experto.
PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Con esto concluiremos la descripción de los algoritmos de los programas usados. Podrá leer su código completo en el archivo adjunto. Vamos a pasar ahora a la parte final del artículo: la prueba del trabajo realizado.
3. Simulación
En este artículo, nos hemos familiarizado con el método Feature Aggregated Queries y hemos implementado sus enfoques utilizando las herramientas MQL5. Ahora es el momento de comprobar los resultados del trabajo que hemos hecho. Como siempre, hemos entrenado y probado el modelo con datos históricos del marco temporal H1 de EURUSD. Los modelos se entrenarán en el tramo histórico de los 7 primeros meses de 2023. La prueba del modelo entrenado se realizará con los datos de agosto de 2023.
El modelo considerado en este artículo analizará datos de entrada similares a los modelos de artículos anteriores. Los vectores de acción del Actor y las recompensas por las transiciones de estado completadas también serán idénticos a los de los artículos anteriores. Por lo tanto, podemos usar el búfer de reproducción de experiencias recopilado durante el entrenamiento de los modelos de los artículos anteriores para entrenar los modelos. Para ello, bastará con cambiar el nombre del archivo a "FAQ.bd".
Sin embargo, si usted no tiene un archivo de trabajos anteriores, o por cualquier razón desea crear uno nuevo, le recomiendo que primero haga unas cuantas pasadas utilizando la historia comercial de señales reales, como se describe en el artículo sobre el método RealORL.
A continuación, podrá complementar el búfer de reproducción de experiencias con pasadas aleatorias utilizando el Asesor Experto "...\Experts\FAQ\Research.mq5". Para ello, deberá ejecutar una optimización lenta de este Asesor Experto en el simulador de estrategias de MetaTrader 5 usando los datos históricos del periodo de entrenamiento.
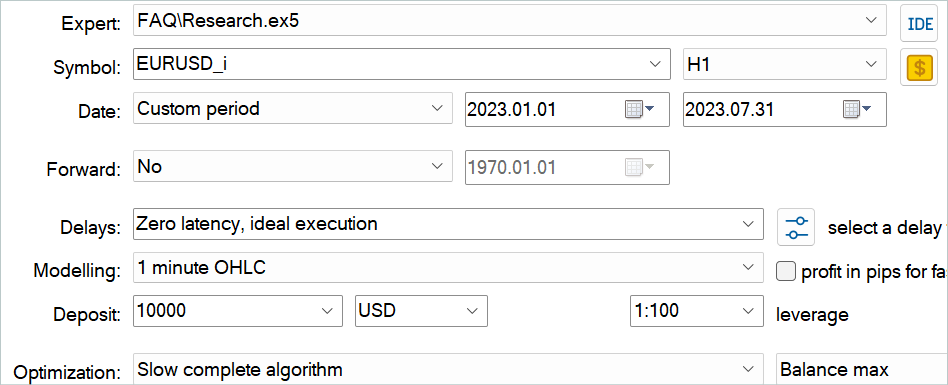
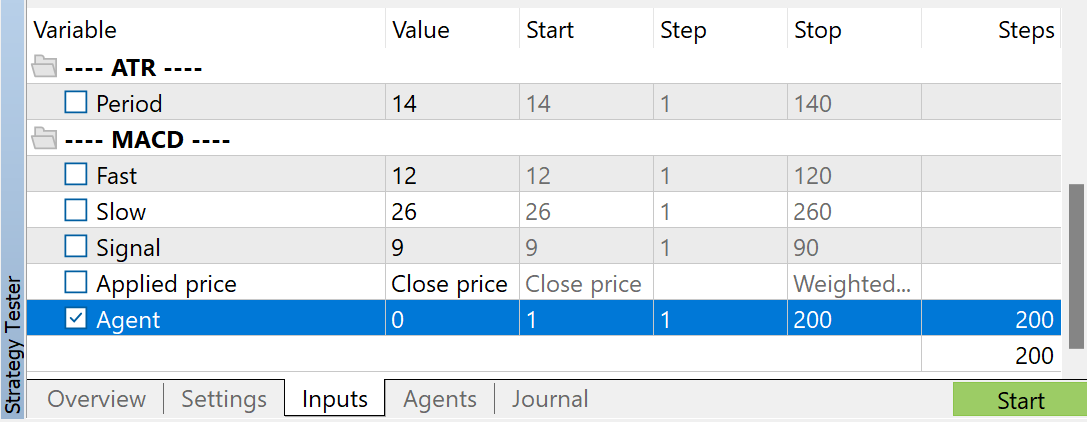
Podrá utilizar cualquier parámetro de los indicadores, pero es muy importante que se utilicen los mismos parámetros para recoger la muestra de entrenamiento y probar el modelo entrenado. También deberá almacenarlos para trabajar con el modelo. Al preparar el artículo, he utilizado los parámetros por defecto de todos los indicadores.
Asimismo, he usado la optimización de parámetros del Agente para regular el número de pasadas a recoger. Este parámetro se añade al Asesor Experto solo para regular las pasadas de optimización y no se utiliza en el código del Asesor Experto.
Tras recoger los datos de entrenamiento, ejecutaremos el Asesor Experto "...\Experts\FAQ\Study.mq5" en el gráfico en tiempo real. En el código del Asesor Experto, los modelos se entrenan utilizando una muestra de entrenamiento recopilada sin operaciones comerciales. Por lo tanto, el funcionamiento del Asesor Experto en el gráfico real no afectará al balance de su cuenta.
Normalmente, utilizo un enfoque iterativo para entrenar los modelos, en el que alterno el entrenamiento de los modelos con la recogida de datos adicionales en la muestra de entrenamiento. Este enfoque resulta notable porque el tamaño de nuestra muestra de entrenamiento es limitado y no es capaz de captar la variedad completa de comportamientos de los Agentes en el entorno. Y durante las siguientes ejecuciones del Asesor Experto "...\Experts\FAQ\Research.mq5", durante la interacción con el entorno, se guiará no por el azar, sino por nuestra política entrenada. De este modo, rellenaremos el búfer de reproducción de experiencias con estados y acciones cercanos a nuestra política. De esta forma, exploraremos un entorno próximo a las acciones de nuestra política, de forma similar al proceso de entrenamiento en línea, lo cual significa que, en el aprendizaje posterior, obtendremos recompensas reales por las acciones en lugar de recompensas interpoladas, y esto ayudará a nuestro Actor a ajustar la política en la dirección correcta.
Para ello, controlaremos periódicamente los resultados del entrenamiento usando datos ajenos a la muestra de entrenamiento.
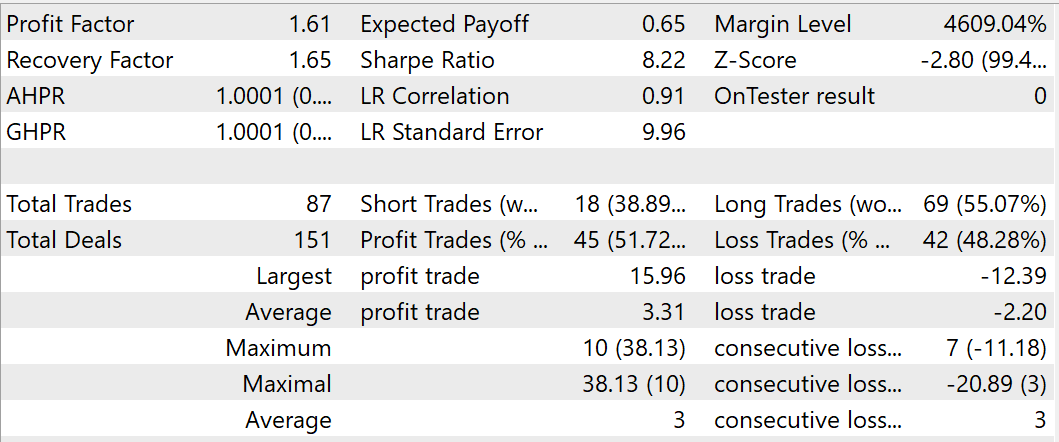
Durante el entrenamiento, hemos logrado que el modelo sea capaz de generar beneficios en la muestra de entrenamiento y en la de prueba. Según los resultados de las pruebas del modelo entrenado para agosto de 2023, se han realizado 87 transacciones, 45 de las cuales se han cerrado con beneficios: eso supone un 51,72%. Además, observamos un exceso de transacciones rentables máximas y medias sobre los indicadores correspondientes de operaciones perdedoras. En conjunto, el periodo de prueba ha alcanzado un factor de beneficio de 1,61 y un factor de recuperación de 1,65.
Conclusión
En este artículo, nos hemos familiarizado con el método de detección de objetos de vídeo Feature Aggregated Queries. Los autores de este método se centran en la inicialización de consultas y su agregación usando como base los datos de origen para detectores basados en la arquitectura del Transformer con el fin de equilibrar la eficacia y el rendimiento del modelo. Asimismo, han desarrollado un módulo de agregación de consultas que amplía su representación a los detectores de objetos. Esto les permite mejorar su rendimiento en las tareas de vídeo.
Además, los autores del método FAQ han ampliado el módulo de agregación de consultas hasta lograr una versión dinámica que puede generar de forma adaptativa inicializaciones de consultas y ajustar los pesos para la agregación de consultas según los datos originales.
El método propuesto es un módulo plug-and-play que puede integrarse en la mayoría de los detectores de objetos modernos basados en el Transformer para resolver problemas de vídeo y otras secuencias temporales.
En la parte práctica de este artículo, hemos implementado los enfoques propuestos utilizando herramientas MQL5. Además, hemos entrenado el modelo con datos históricos reales y lo hemos probado en un periodo de tiempo fuera de la muestra de entrenamiento. Los resultados de nuestras pruebas confirman la eficacia de los planteamientos propuestos. Sin embargo, el periodo de entrenamiento y prueba es demasiado corto para sacar conclusiones de gran alcance. Todos los programas presentados en este documento tienen como único objetivo mostrar y probar los enfoques propuestos.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14394
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso