ニューラルネットワークが簡単に(第77回):Cross-Covariance Transformer (XCiT)

はじめに
Transformerは、様々なシーケンスを分析する問題を解決する上で大きな可能性を示しています。Transformerの基礎となるSelf-Attention操作は、シーケンス内のすべてのトークン間のグローバルな相互作用を提供します。これにより、分析されたシーケンス全体における相互依存関係を評価することができます。ただし、計算時間とメモリ使用量の点で二次時間計算量が伴い、長いシーケンスにアルゴリズムを適用することは難しくなっています。
この問題を解決するために、論文「XCiT:Cross-Covariance Image Transformers」では、Self-Attentionの「転置」バージョンを提案しています。これは、トークンではなく、特徴量チャネルを通して動作するもので、ここでの相互作用はキーとクエリ間の相互共分散行列に基づいています。その結果、トークン数に対して線形時間計算量を持つ交差共分散注意(cross-covariance attention: XCA)が得られ、大規模なデータ列を効率的に処理できるようになりました。XCAに基づく交差共分散画像変換器(Cross-covariance image transformer: XCiT)は、従来の変換器の精度と畳み込みアーキテクチャのスケーラビリティを兼ね備えています。この論文では、XCiTの有効性と汎用性が実験的に確認されています。発表された実験では、画像分類、物体検出、インスタンス分割など、いくつかの視覚ベンチマークで優れた結果が示されました。
1.XCiTアルゴリズム
この手法の著者は、相互共分散に基づくSelf-Attention関数を提案しています。これは、古典的なSelf-Attentionトークンのようにトークン次元に沿ってではなく、特徴量次元に沿って動作します。Query、Key、Valueの定義を使用すると、XCA関数は次のように定義されます。
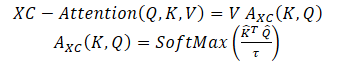
ここで、各出力トークン埋め込みは、Vにおける対応するトークン埋め込みのdv 個の特徴量の凸組合せです。Attentionの重みAは、相互共分散行列に基づいて計算されます。
相互共分散行列に基づく新しいAttention関数を構築することに加え、この方法の著者は、正規化行列QとKの長さNの各列が単位ノルムとなるようにL2正規化することで、Query行列とKey行列の大きさを制限することを提案しています。サイズd*dのAttention係数の相互共分散行列の各要素は、[-1, 1]の範囲にありました。この手法の著者は、ノルムの制御は、特にトークンの数が変化する学習において、学習の安定性を著しく高めると述べています。しかし、ノルムを制限すると、自由度がなくなるため、操作の表現力が低下します。そこで著者は、SoftMax関数による正規化をおこなう前に、内積をスケーリングする訓練可能な温度パラメータτを導入し、Attentionの重みをよりシャープに、あるいはより均一に分布させることを可能にしました。
さらに、この手法の著者は、互いに影響し合う特徴量の数を制限しています。彼らは、Multi-Head Self-Attentionトークンのように、それらをh個のグループ、つまり「ヘッド」に分けることを提案しています。各ヘッドについて、このメソッドの著者は別々にXCAを適用しています。
各ヘッドについて、ソースデータの投影XからQuery、Key、Valueへの重み行列を別々に訓練します。対応する重み行列は、次元{h * d * dq}、Wk — {h * d * dk}およびWv — {h * d * dv} \)のテンソルWqに収集されます。dk = dq = dv = d/hが設定されています。
Attentionをヘッドに制限することには、2つのメリットがあります。
- Attentionの重みを使った値の集計計算量は、係数hによって軽減されます。
- さらに重要なことに、この手法の著者は、ブロック対角行列のバージョンの方が最適化が容易であり、一般的に結果が改善されることを実証しています。
h個のヘッドを持つ古典的なSelf-Attentionトークンは、時間計算量がO(N^2 * d)、メモリがO(hN^2 + Nd)です。二次時間計算量のため、トークンの数が多いシーケンスに対してSelf-Attentionトークンをスケールすることには問題があります。提案されたXCAの計算量O(Nd^2/h)はトークン数に対して線形にスケールするため、この欠点を克服しています。メモリ計算量はO(d^2 / h + Nd)です。
したがって、著者が提案するXCAモデルは、トークンの数Nが大きく、特徴量次元dが比較的小さい場合、特に特徴量をh個のヘッドに分割する場合に、はるかに優れたスケーリングを実現します。
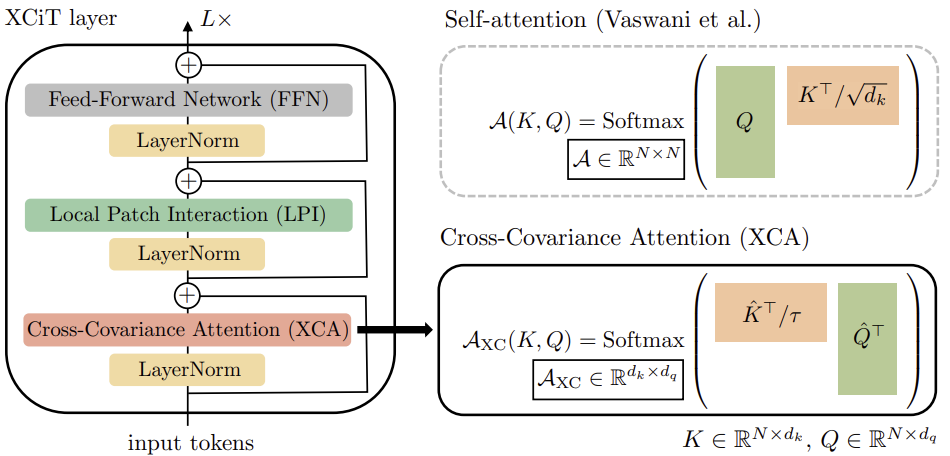
Cross-Covariance Transformer images (XCiT)を構築するために、この手法の著者は、層間で同じ空間解像度を維持する円柱アーキテクチャを提案しています。これらは、Cross-Covariance Attentionブロック(XCA)と、それに続く2つの追加モジュールを組み合わせたもので、各モジュールの前に層内で正規化がおこなわれます。
XCAブロックでは、パッチ間の通信は共有統計情報によって間接的にのみおこなわれます。パッチ間の明示的なコミュニケーションを提供するために、この手法の著者は、各XCAブロックの後に単純なローカルパッチ相互作用ブロック(LPI)を追加しています。LPIは2つの畳み込み層と、その間のバッチ正規化層で構成されます。第1層の活性化関数として、彼らはGELUを使用することを提案しています。その深いブロック構造により、LPIはパラメータのオーバーヘッドを無視でき、帯域幅とメモリのオーバーヘッドも非常に限られています。
Transformerモデルで一般的なように、点順畳み込み層を持つフィードフォワードネットワーク(FFN)が次に追加されます。この層は、4dの隠れブロックを持つ1つの隠れ層を持ちます。XCAブロック内では特徴量間の相互作用はグループ内で制限され、LPIブロック内では特徴量間の相互作用はありませんが、FFNではすべての特徴量との相互作用が可能です。
Self-Attentionトークンに含まれるAttentionマップとは異なり、XCiTの共分散ブロックは、入力シーケンスの解像度に関係なく、固定されたサイズを持っています。SoftMaxは常に同じ要素数で動作するため、解像度の異なる画像を扱う際にXCiTモデルの動作が良くなるのはこのためかもしれません。XCiTは、入力トークンによる加法正弦位置符号化を含みます。
以下に、著者によるアルゴリズムの視覚化を示します。
2.MQL5を使用した実装
Cross-Covariation Transformer (XCiT)の理論的側面を検討した後は、MQL5を使用した提案アプローチの実用的な実装に移ります。
2.1 Cross-Covariance Transformerクラス
XCiTブロックアルゴリズムを実装するために、新しいニューラル層クラスCNeuronXCiTOCLを作成します。親クラスとして、一般的なMulti-Head Multi-Layer AttentionクラスCNeuronMLMHAttentionOCLを使用します。また、新しいクラスはビルトインのマルチ層アーキテクチャーで作成されます。
class CNeuronXCiTOCL : public CNeuronMLMHAttentionOCL { protected: //--- uint iLPIWindow; uint iLPIStep; uint iBatchCount; //--- CCollection cLPI; CCollection cLPI_Weights; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out); virtual bool BatchNorm(CBufferFloat *inputs, CBufferFloat *options, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog); virtual bool BatchNormInsideGradient(CBufferFloat *inputs, CBufferFloat *inputs_g, CBufferFloat *options, CBufferFloat *out, CBufferFloat *out_g, ENUM_ACTIVATION activation); virtual bool BatchNormUpdateWeights(CBufferFloat *options, CBufferFloat *out_g); public: CNeuronXCiTOCL(void) {}; ~CNeuronXCiTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
新しいクラスでは、親クラスのツールを最大限に活用するようにしたいのですが、それでも大幅な補強が必要になるでしょう。まず、LPIブロックのバッファコレクションを追加します。
- cLPI:結果バッファと勾配バッファ
- cLPI_Weights:重み行列とモーメンタム行列
さらに、LPIブロックには追加の定数が必要です。
- iLPIWindow:ブロックの第1層の畳み込みウィンドウ
- iLPIStep:ブロックの第1層の畳み込みウィンドウのステップ
- iBatchCount:ブロックバッチ正規化層で実行された操作の数
畳み込みパラメータは第1層でのみ指定します。第2層では、ソースデータ層のサイズに達する必要があるからです。というのも、この手法の著者は、直前のXCAブロックの結果にデータを追加して正規化することを提案しているからです。
このクラスでは、追加されたオブジェクトはすべて静的に宣言されているので、層のコンストラクタとデストラクタは空にしておきます。層の主な初期化はInitメソッドで実装されています。パラメータでは、メソッドは内部オブジェクトの初期化に必要なすべてのパラメータを受け取ります。
bool CNeuronXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッド本体では、受け取ったパラメータの制御ブロックは編成しません。その代わりに、すべてのニューラル層の基本クラスの初期化メソッドを呼び出します。この基本クラスはすでに必要最小限のコントロールを実装しており、継承されたオブジェクトを初期化します。
ここで注意しなければならないのは、親クラスではなく、基本クラスのメソッドを呼び出しているということです。これは、作成する内部層バッファのサイズとその数が異なるためです。したがって、同じ作業を二度おこなう必要がないように、新しい初期化メソッドの本体内ですべてのバッファを初期化することにします。
まず、主要なパラメータをローカル変数に保存します。
iWindow = fmax(window, 1); iUnits = fmax(units_count, 1); iHeads = fmax(fmin(heads, iWindow), 1); iWindowKey = fmax((window + iHeads - 1) / iHeads, 1); iLayers = fmax(layers, 1); iLPIWindow = fmax(lpi_window, 1); iLPIStep = 1;
シーケンスの1要素の記述ベクトルのサイズとAttentionヘッドの数に基づいて、内部エンティティの次元を再計算することに注意してください。これはXCiT法の著者によって提案されたものです。
次に、各ブロックのバッファの主な次元を決定します。
//--- XCA uint num = 3 * iWindowKey * iHeads * iUnits; // Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; // Size of weights' matrix of // QKV tensor uint scores = iWindowKey * iWindowKey * iHeads; // Size of Score tensor uint out = iWindow * iUnits; // Size of output tensor
//--- LPI uint lpi1_num = iWindow * iHeads * iUnits; // Size of LPI1 tensor uint lpi1_weights = (iLPIWindow + 1) * iHeads; // Size of weights' matrix of // LPI1 tensor uint lpi2_weights = (iHeads + 1) * 2; // Size of weights' matrix of // LPI2 tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; // Size of weights' matrix 1-st // feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; // Size of weights' matrix 2-nd // feed forward layer
その後、内部層の数に等しい反復回数でループを構成します。
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL;
ループの本体では、まず中間結果とその勾配のバッファを作成します。そのために、入れ子のループを作ります。ループの最初の反復では、中間結果のバッファを作成します。2回目の反復では、対応する誤差勾配のバッファを作成します。
for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Query、Key、Valueを1つの連結バッファにまとめてみましょう。これにより、並列スレッドのすべてのAttentionヘッドに対して、1回のパスですべてのエンティティの値を生成できるようになります。
次に、XCA係数の縮小バッファを作成します。
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
Attentionブロックは結果バッファで終了します。
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
エンティティのサイズを計算する方法の著者が提案したアプローチにより、Attentionブロックの次元を縮小する層を取り除くことができます。
次にLPIブロックのバッファを作成します。ここでは、最初の畳み込み層の結果のバッファを作成します。
//--- LPI //--- Initilize LPI tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI1 return false;
続いて、バッチ正規化結果のバッファが続きます。
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI Normalize return false;
ブロックは第2畳み込み層の結果バッファで終わります。
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI2 return false;
最後に、フィードフォワードブロックの結果のバッファを作成します。
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
ブロックの2層目の結果バッファのニュアンスに注目してください。このバッファは中間データ用にのみ作成します。最後の内部層では、新しいバッファは作成せず、以前に作成した層の結果バッファのポインタを保存するだけです。
//--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
同じ順番で重み行列バッファを作成します。
//--- XCiT //--- Initialize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initialize LPI1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi1_weights)) return false; for(uint w = 0; w < lpi1_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Normalization int count = (int)lpi1_num * (optimization_type == SGD ? 7 : 9); temp = new CBufferFloat(); if(!temp.BufferInit(count, 0.0f)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initialize LPI2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi2_weights)) return false; for(uint w = 0; w < lpi2_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initialize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
訓練可能な重み行列を初期化した後、モデルの学習過程でモーメンタムを記録するためのバッファを作成します。しかしここでは、バッチ正規化層のパラメータバッファに注意を払う必要があります。それはすでにパラメータとそのモーメンタムを考慮しています。したがって、指定された層のモーメンタムバッファは作成しません。
さらに、必要なモーメンタムバッファの数は最適化方法によって異なります。この特徴を考慮するため、最適化方法によって反復回数が異なるループでバッファを作成します。
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- LPI temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi2_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } iBatchCount = 1; //--- return true; }
必要なバッファの作成に成功したら、メソッドを終了し、操作の論理結果を呼び出し元に返します。
これでクラスの初期化が完了しました。次に、XCiT法のフィードフォワードアルゴリズムの説明に進みます。前述のように、提案された方法の実装には大きな変更が必要となります。フィードフォワードパスを実装するためには、XCAアルゴリズムを実装するOpenCLプログラム側にカーネルを作成する必要があります。
親クラスのConvolutionForwardから継承したメソッドで実体を受け取っていることに注意してください。つまり、カーネルは生成されたQuery、Key、Valueの各エンティティですでに動作しています。それらを1つのバッファとしてカーネルに転送します。これらに加えて、カーネルパラメータでは、さらにAttention係数とAttentionブロック結果の2つのデータバッファへのポインタを渡します。
__kernel void XCiTFeedForward(__global float *qkv, __global float *score, __global float *out) { const size_t d = get_local_id(0); const size_t dimension = get_local_size(0); const size_t u = get_local_id(1); const size_t units = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
3次元のタスク空間でカーネルを起動します。
- 1つのエンティティ要素の次元
- 配列の長さ
- Attenetionヘッド数
最初の2つの次元に関しては、ローカルワーキンググループにまとめるます。
中間データを書き込み、ワーキンググループ内で情報を交換するために、2つのローカル2次元配列を宣言しましょう。
const uint ls_u = min((uint)units, (uint)LOCAL_ARRAY_SIZE); const uint ls_d = min((uint)dimension, (uint)LOCAL_ARRAY_SIZE); __local float q[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE]; __local float k[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE];
XCAの分析作業を始める前に、この手法の著者が提案したように、QueryとKeyのエンティティを正規化する必要があります。
そのために、まずグループ内の各パラメータのベクトルの大きさを計算します。
//--- Normalize Query and Key for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { float q_val = 0; float k_val = 0; //--- if(d < ls_d && (cur_d + d) < dimension && u < ls_u) { for(int count = u; count < units; count += ls_u) { int shift = count * dimension * heads * 3 + dimension * h + cur_d + d; q_val += pow(qkv[shift], 2.0f); k_val += pow(qkv[shift + dimension * heads], 2.0f); } q[u][d] = q_val; k[u][d] = k_val; } barrier(CLK_LOCAL_MEM_FENCE);
uint count = ls_u; do { count = (count + 1) / 2; if(d < ls_d) { if(u < ls_u && u < count && (u + count) < units) { float q_val = q[u][d] + q[u + count][d]; float k_val = k[u][d] + k[u + count][d]; q[u + count][d] = 0; k[u + count][d] = 0; q[u][d] = q_val; k[u][d] = k_val; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
次に、配列の各要素を、対応する次元に沿ったベクトルサイズの平方根で割ります。
int shift = u * dimension * heads * 3 + dimension * h + cur_d; qkv[shift] = qkv[shift] / sqrt(q[0][d]); qkv[shift + dimension * heads] = qkv[shift + dimension * heads] / sqrt(k[0][d]); barrier(CLK_LOCAL_MEM_FENCE); }
エンティティが正規化されたので、依存係数の定義に移ることができます。そのために、Query行列とKey行列を掛け合わせます。同時に、得られた値の指数をとり、それらを合計します。
//--- Score int step = dimension * heads * 3; for(int cur_r = 0; cur_r < dimension; cur_r += ls_u) { for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { if(u < ls_d && d < ls_d) q[u][d] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- if((cur_r + u) < ls_d && (cur_d + d) < ls_d) { int shift_q = dimension * h + cur_d + d; int shift_k = dimension * (heads + h) + cur_r + u; float scr = 0; for(int i = 0; i < units; i++) scr += qkv[shift_q + i * step] * qkv[shift_k + i * step]; scr = exp(scr); score[(cur_r + u)*dimension * heads + dimension * h + cur_d + d] = scr; q[u][d] += scr; } } barrier(CLK_LOCAL_MEM_FENCE);
int count = ls_d; do { count = (count + 1) / 2; if(u < ls_d) { if(d < ls_d && d < count && (d + count) < dimension) q[u][d] += q[u][d + count]; if(d + count < ls_d) q[u][d + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
次に依存係数を正規化します。
if((cur_r + u) < ls_d) score[(cur_r + u)*dimension * heads + dimension * h + d] /= q[u][0]; barrier(CLK_LOCAL_MEM_FENCE); }
カーネル演算の最後に、Valueテンソルに依存係数を掛けます。この操作の結果は、XCA Attentionブロックの結果バッファに保存されます。
int shift_out = dimension * (u * heads + h) + d; int shift_s = dimension * (heads * d + h); int shift_v = dimension * (heads * (u * 3 + 2) + h); float sum = 0; for(int i = 0; i < dimension; i++) sum += qkv[shift_v + i] * score[shift_s + i]; out[shift_out] = sum; }
OpenCLプログラム側でカーネルを作成した後、メインプログラム側でクラスの操作に移ります。ここではまずCNeuronXCiTOCL::XCiTメソッドを作成し、作成したカーネルを呼び出すアルゴリズムを実装します。
bool CNeuronXCiTOCL::XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out) { if(!OpenCL || !qkv || !score || !out) return false;
メソッドのパラメータには、使用する3つのデータバッファへのポインタを渡します。メソッド本体では、受け取ったポインタが適切かどうかを即座に確認します。
次に、タスク空間とその中のオフセットを定義します。
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads}; uint local_work_size[3] = {iWindowKey, iUnits, 1};
前述したように、最初の2つの次元に沿ってスレッドを作業グループにまとめます。
次に、データバッファへのポインタをカーネルに渡します。
if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_score, score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_out, out.GetIndex())) return false;
カーネルを実行キューに入れます。
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); Print(error); return false; } //--- return true; }
上記のメソッドに加えて、バッチ正規化層のためのフィードフォワードメソッドCNeuronXCiTOCL ::BatchNormを作成します。そのアルゴリズム全体は、CNeuronBatchNormOCL::feedForwardメソッドから完全に転送されます。今はそのアルゴリズムを検討することにはこだわらず、直接、CNeuronXCiTOCL::feedForwardメソッドの分析に移りましょう。これは、XCiTブロックの順伝播アルゴリズムの一般的な概要を表しています。
bool CNeuronXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
パラメータでは、このメソッドは初期データを提供する前の層のオブジェクトへのポインタを受け取ります。メソッド本体では、受け取ったポインタの妥当性を即座に確認します。
コントロールポイントの通過に成功したら、内部層を通るループを作ります。このループの本体で、メソッドのアルゴリズム全体を構築します。
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
ここではまず、Query、Key、Valueのエンティティを作成します。その後、XCAメソッドを呼び出します。
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(qkv, temp, out)) return false;
Attentionの結果は元のデータに加えられ、その結果得られた値は正規化されます。
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
次はLPIブロックです。まず、ブロックの第1層の作業を整理しましょう。
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false;
次に、第1層の結果を正規化します。
out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false;
正規化した結果をブロックの第2層に渡します。
temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() ||!ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false;
そして結果をまとめ、再び正規化します。
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
フィードフォワードブロックを整理します。
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false;
層の出力では、各ブロックの結果をまとめ、正規化します。
//--- Sum and normalize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
以上で、新しいCross-Covariance Transformer層CNeuronXCiTOCLのフィードフォワードパスの実装を終了します。次に、バックプロパゲーションアルゴリズムの構築に移ります。ここでもOpenCLプログラムに戻り、別のカーネルを作成しなければなりません。XCiTInsideGradientsカーネルでXCAブロックのバックプロパゲーションアルゴリズムを構築します。カーネルへのパラメータには、4つのデータバッファへのポインタを渡します。
- qkv:Query、Key、Valueエンティティの連結ベクトル
- qkv_g:Query,Key、Valueエンティティの誤差勾配を連結したベクトル
- scores:依存係数の行列
- gradient:XCAAttentionブロックの出力における誤差勾配のテンソル
__kernel void XCiTInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const int q = get_global_id(0); const int d = get_global_id(1); const int h = get_global_id(2); const int units = get_global_size(0); const int dimension = get_global_size(1); const int heads = get_global_size(2);
3次元のタスク空間でカーネルを立ち上げる予定です。カーネル本体では、スレッドとタスク空間を識別します。次に、データバッファ内の分析対象要素へのオフセットを決定します。
const int shift_q = dimension * (heads * 3 * q + h); const int shift_k = dimension * (heads * (3 * q + 1) + h); const int shift_v = dimension * (heads * (3 * q + 2) + h); const int shift_g = dimension * (heads * q + h); int shift_score = dimension * h; int step_score = dimension * heads;
バックプロパゲーションアルゴリズムに従って、まずValueテンソルの誤差勾配を決定します。
//--- Calculating Value's gradients float sum = 0; for(int i = 0; i < dimension; i ++) sum += gradient[shift_g + i] * scores[shift_score + d + i * step_score]; qkv_g[shift_v + d] = sum;
次に、Queryの誤差勾配を定義します。ここではまず、係数行列の対応するベクトルの誤差勾配を決定しなければなりません。その結果生じる誤差勾配をSoftMax関数の微分に合わせます。この場合のみ、必要な誤差勾配を得ることができます。
//--- Calculating Query's gradients float grad = 0; float val = qkv[shift_v + d]; for(int k = 0; k < dimension; k++) { float sc_g = 0; float sc = scores[shift_score + k]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_score + v] * val * gradient[shift_g + v * dimension] * ((float)(k == v) - sc); grad += sc_g * qkv[shift_k + k]; } qkv_g[shift_q] = grad;
Keyテンソルの場合、誤差勾配は同様に決定されますが、ベクトルの垂直方向に決定されます。
//--- Calculating Key's gradients grad = 0; float out_g = gradient[shift_g]; for(int scr = 0; scr < dimension; scr++) { float sc_g = 0; int shift_sc = scr * dimension * heads; float sc = scores[shift_sc + d]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_sc + v] * out_g * qkv[shift_v + v] * ((float)(d == v) - sc); grad += sc_g * qkv[shift_q + scr]; } qkv_g[shift_k + d] = grad; }
カーネルを構築した後は、メインプログラムの側でクラスを扱う作業に戻ります。ここでは、CNeuronXCiTOCL::XCiTInsideGradientsメソッドを作成します。このメソッドは、パラメータとして、必要なデータバッファへのポインタを受け取ります。
bool CNeuronXCiTOCL::XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog) { if(!OpenCL || !qkv || !qkvg || !score || !aog) return false;
メソッド本体では、受け取ったポインタが適切かどうかを即座に確認します。
そして、3次元の問題空間を定義しますが、今回はワークグループを定義しません。
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads};
データバッファへのポインタをカーネルにパラメータとして渡します。
if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv_g, qkvg.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_scores,score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_gradient,aog.GetIndex())) return false;
準備作業が終わったら、あとはカーネルを実行キューに入れるだけです。
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
ディスパッチメソッドCNeuronXCiTOCL::calcInputGradientsで収集されたXCiTブロックの完全な後方アルゴリズムです。このメソッドは、パラメータとして、前の層のオブジェクトへのポインタを受け取ります。
bool CNeuronXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
メソッド本体では、受け取ったポインタの有効性を即座に確認します。制御点の通過に成功したら、誤差勾配の伝搬を伴う内部層の逆反復のループを構成します。
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 4:6)+1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false;
ループ本体では、まず誤差勾配をFeedForwardブロックに通します。
CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
ダイレクトパスの間に、ブロックの結果をオリジナルデータに加えたことを思い出してください。同様に、誤差勾配を2つのスレッドに伝播させます。
//--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
次に、LPIブロックを通して誤差勾配を伝播させます。
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false;
誤差勾配を再度追加します。
temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
その後、AttentionブロックXCAを通して誤差勾配を伝播させます。
out_grad = temp; //--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
ソースデータの勾配バッファに転送します。
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 3 * iWindowKey * iHeads, None)) return false;
2本目のストリームに沿って誤差の勾配をつけることをお忘れなく。
//--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow)) return false; if(i > 0) out_grad = temp; } //--- return true; }
上記では、誤差勾配を内部層に伝播し、前のニューラル層に転送するアルゴリズムを実装しました。バックプロパゲーションの最後に、モデルのパラメータを更新する必要があります。
新しいCross-Covariance Transformer層のパラメータの更新は、CNeuronXCiTOCL::updateInputWeightsメソッドで実装されています。他のニューラル層の同様のメソッドと同様に、このメソッドもパラメータで前の層のニューラル層へのポインタを受け取ります。
bool CNeuronXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput();
そしてメソッド本体では、受け取ったポインタの妥当性を確認します。
誤差勾配の分布と同様に、内層を通るループでパラメータを更新します。
for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization==SGD ? QKV_Weights.At(l*2+1):QKV_Weights.At(l*3+1)), (optimization==SGD ? NULL : QKV_Weights.At(l*3+2)), iWindow, 3 * iWindowKey * iHeads)) return false;
まず、Query、Key、Valueエンティティの形成行列のパラメータを更新します。
次に、LPIブロックのパラメータを更新します。このブロックには2つの畳み込み層とバッチ正規化層があります。
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization==SGD ? cLPI_Weights.At(l*5+3):cLPI_Weights.At(l*7+3)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization==SGD ? cLPI_Weights.At(l*5+4):cLPI_Weights.At(l*7+4)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
メソッドの最後には、FeedForwardブロックのパラメータを更新するブロックがあります。
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization==SGD ? FF_Weights.At(l*4+2):FF_Weights.At(l*6+2)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization==SGD ? FF_Weights.At(l*4+3):FF_Weights.At(l*6+3)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
これにより、Cross-Covariance Transformer層CNeuronXCiTOCLのフィードフォワードとバックプロパゲーションのアルゴリズムの実装が完了しました。クラスの完全な運用を可能にするには、いくつかの補助メソッドを追加する必要があります。その中にファイルメソッド(SaveとLoad)があります。これらのメソッドのアルゴリズムは複雑ではなく、XCiTメソッドに特化したユニークな側面はありません。したがって、この記事ではそれらのアルゴリズムの説明には触れません。添付ファイルにはクラスの全コードが含まれているので、ご自分でお勉強ください。添付ファイルには、この記事で使用したすべてのプログラムも含まれています。
2.2 モデルアーキテクチャ
次に、モデルの訓練とテストのためのエキスパートアドバイザーを構築します。ここで言っておかなければならないのは、この手法の著者はその論文の中で、モデルの具体的なアーキテクチャを提示していないということです。基本的に、提案されたCross-Covariance Transformerは、どのようなモデルにおいても、先に検討した古典的なTransformerを置き換えることができます。したがって、実験の一環として、以前の記事のモデルを使用し、CNeuronMLMHAttentionOCL層をCNeuronXCiTOCLに置き換えます。
しかし、ここで正直にならなければなりません。前回の記事では、Attentionブロックを使い分けました。特にCNeuronMFTOCLの使用に重点を置きました。CNeuronMFTOCLはそのアーキテクチャ上の特徴から、CNeuronXCiTOCLと置き換えることはできません。
しかし、層を1つでも入れ替えることで、その変化をどうにか評価することができます。
というわけで、テストモデルの最終的なアーキテクチャは以下のようになります。
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
1バーを記述した「生」のソースデータは、環境エンコーダーのソースデータ層に供給されます。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
受信したデータはバッチ正規化層で処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
正規化されたデータから環境状態の埋め込みが生成され、内部スタックに追加されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
ここでは、位置情報のエンコードも追加しています。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
続いて、層間のバッチ正規化を伴うグラフブロックが続きます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
次に、新しいCross-Covariation Transformer層を追加します。配列要素数とソースデータウィンドウは変更しませんでした。指定されたパラメータは、初期データのテンソルによって決定されます。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronXCiTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 3; descr.layers = 1; descr.batch = MathMax(1000, GPTBars); descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
この場合、4つのAttentionヘッドを使用します。
この手法の著者は、1つのシーケンス要素の記述ベクトルのサイズを整数分割して、注目ヘッドの数ごとにエンティティベクトルのサイズを決定することを提案しています。このオプションでは、descr.window_outパラメータは使用されません。そこで、この事実を利用して、最初のLPI層のウィンドウのサイズをこのパラメータで指定してみましょう。また、LPIブロックのデータを正規化するためのバッチサイズも示しています。
エンコーダーに続いてMFTブロックがあります。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
テンソルを適切な形に変換するために転置します。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
環境エンコーダーとMFTの結果は、最も可能性の高いエンドポイントをデコードするために使用されます。
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
次はその確率の推定値です。
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false; //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
ActorモデルはAttention層を使用しませんでした。そのため、モデルはそのままコピーされました。また、添付ファイルで全モデルの完全なアーキテクチャを熟知することができます。
環境状態エンコーダーのアーキテクチャーにおいて、1つの層を置き換えたとしても、モデルの訓練とテストのプロセスの構成には影響しないことにご注意ください。したがって、すべての訓練EAと環境相互作用EAは、変更されることなくコピーされています。私見ですが、こうしてテスト結果を見る方が面白いです。他の条件が同じであれば、モデルアーキテクチャの層を置き換えることの影響を最も正直に評価できるからです。
また、ここで使用されているすべてのプログラムの完全なコードは添付ファイルにあります。次に、構築されたCross-Covariance Transformer層CNeuronXCiTOCLのテストに移ります。
3.テスト
論文「XCiT:Cross-Covariance Image Transformers」で発表されたアルゴリズムに基づき、新しいCross-Covariance TransformerクラスCNeuronXCiTOCLを構築するためにかなりの作業をおこないました。前述したように、前回の記事のEAをそのままの形で使用することにしました。したがって、モデルを訓練するには、以前に収集した訓練データセットを使用することができます。ファイル名を「MFT.bd」から「XCiT.bd」に変更してみましょう。
以前に収集した訓練データセットがない場合は、モデルを訓練する前に収集する必要があります。過去の経験を活かした新しい課題の解決」稿で紹介した方法で、まずは実際の信号からデータを収集することをお勧めします。そして、ストラテジーテスターでEA「...\Experts\XCiT\Research.mq5」のランダムパスで訓練データセットを補完してください。
モデルの訓練は、訓練データを収集した後、EA"...\Experts\XCiT\Study.mq5"でおこないます。
前回と同様、モデルはEURUSD H1の履歴データで学習されます。すべての指標はデフォルトのパラメータで使用されています。
モデルは2023年の最初の7ヶ月間の履歴データで訓練されます。ここで、提案されたアプローチの有効性をテストした最初の結果にすぐに気づくことができます。訓練プロセスでは、同じ訓練反復をおこないながら、ほぼ2%の時間コストの削減が見られます。
訓練済みモデルの有効性は、2023年8月の履歴データを用いて評価されました。テスト期間は訓練データセットに含まれませんが、訓練期間の直後に続きます。訓練したモデルをテストした結果、前回の記事に近い結果が得られました。
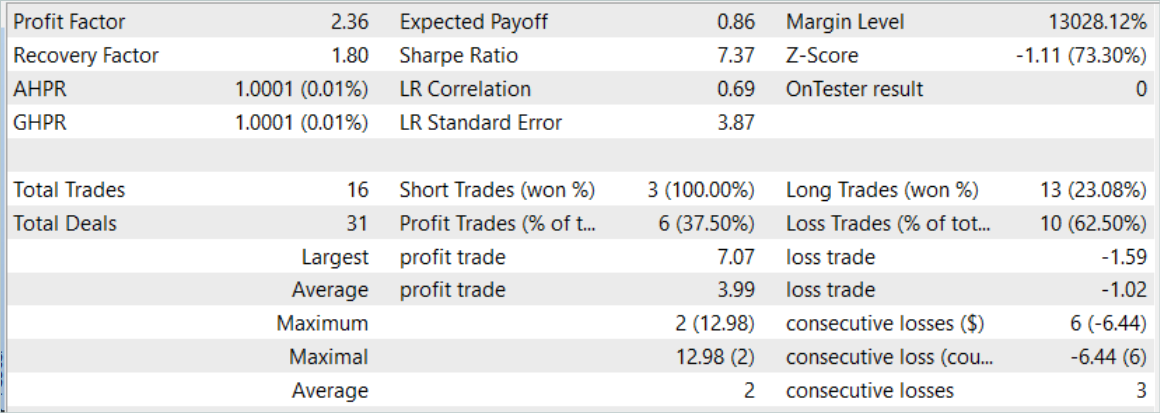
しかし、取引回数のわずかな増加の裏には、プロフィットファクターの増加があります。
結論
この記事では、Transformerと畳み込みアーキテクチャーの長所を併せ持つ、Cross-Covariance Transformer (XCiT)の新アーキテクチャーに触れました。様々な長さのシーケンスを処理する際に、高い精度とスケーラビリティを提供します。小さなトークンサイズで大きなシーケンスを解析する場合、ある程度の効率が得られます。
XCiTは、シーケンス要素の特徴量間のグローバルな相互作用を効率的にモデル化するためにXCAアーキテクチャを使用しており、長いトークンのシーケンスをうまく処理することができます。
この手法の著者は、画像分類、物体検出、意味的セグメンテーションなど、いくつかの視覚タスクにおけるXCiTの高い効率を実験的に確認しています。
本稿の実践編では、MQL5を使って提案手法を実装しました。モデルは実際の履歴データに基づいて訓練およびテストされました。訓練プロセスでは、同じ訓練反復回数で訓練時間がわずかに短縮されました。これは、モデルの層を1つだけ入れ替えることで実現しました。
訓練済みモデルの効率がわずかに向上していることは、提案アーキテクチャの汎化能力が向上していることを示しているのかもしれません。
金融市場での取引はハイリスクな投資であることをお忘れなく。記事で紹介されているプログラムはすべて情報提供のみを目的としており、実際の取引に最適化されたものではありません。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルをテストするEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14276
 ニューラルネットワークが簡単に(第76回):Multi-future Transformerで多様な相互作用パターンを探る
ニューラルネットワークが簡単に(第76回):Multi-future Transformerで多様な相互作用パターンを探る
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索