
Redes neuronales: así de sencillo (Parte 80): Modelo generativo y adversarial del Transformador de grafos (GTGAN)

Introducción
Los modelos que usan capas convolucionales o diversos mecanismos de atención son los más utilizados para analizar el estado inicial del entorno. Sin embargo, las arquitecturas convolucionales carecen de la comprensión necesaria de las dependencias a largo plazo en los datos básicos porque existen sesgos inductivos inherentes. Las arquitecturas basadas en mecanismos de atención permiten codificar relaciones a largo plazo o globales y aprender representaciones muy expresivas de las funciones. Por otra parte, los modelos de convolución de grafos hacen un buen uso de las correlaciones locales y entre vértices vecinos basadas en la topología de los grafos. Por ello, tiene sentido combinar las redes de convolución de grafos y los Transformadores para modelar las interacciones locales y globales con el fin de resolver la búsqueda de estrategias comerciales óptimas.
Recientemente presentado en el artículo "Graph Transformer GANs with Graph Masked Modeling for Architectural Layout Generation", el algoritmo del Modelo generativo y adversarial del Transformador de grafos (GTGAN) combina sucintamente ambos enfoques. Los autores del algoritmo GTGAN resuelven el problema de la creación de un diseño arquitectónico realista de una casa partiendo de un grafo de entrada. El modelo de generador que presentan consta de tres componentes: una red neuronal convolucional de transmisión de mensajes (Conv-MPN), un codificador de Transformador de grafos (GTE) y una cabeza de generación.
Los experimentos cualitativos y cuantitativos sobre tres generaciones complejas de un diseño arquitectónico con restricciones gráficas con tres conjuntos de datos, presentados en el artículo del autor, demuestran que el método en cuestión puede producir resultados superiores a los algoritmos mostrados anteriormente.
1. El algoritmo GTGAN
Para describir el método, tomaremos como ejemplo la creación del plano de una casa. El generador G recibe el vector de ruido de cada habitación y el diagrama de burbujas como datos de entrada. A continuación, genera un plano de la casa en el que se representa cada habitaciónen forma de rectángulo alineado en el eje. Los autores del método representan cada diagrama de burbujas como un grafo en el que cada nodo representa una habitación de un tipo determinado y cada arista representa la contigüidad espacial de las habitaciones. En concreto, se generará un rectángulo para cada habitación. Y las dos habitaciones conectadas en el grafo deberán ser espacialmente adyacentes, mientras que las habitaciones no conectadas deberán ser espacialmente no contiguas.
Dado un diagrama de burbujas, primero generaremos un nodo para cada habitación y lo inicializaremos con un vector de ruido de 128 dimensiones elegido a partir de una distribución normal. A continuación, combinaremos el vector de ruido con un vector one-hot de 10 dimensiones con el tipo de habitación (tr). Por lo tanto, podremos obtener un vector gr de 138 dimensiones para representar el diagrama de burbujas original.
![]()
Obsérvese que los nodos del grafo se utilizarán aquí como datos de entrada del convertidor propuesto.
El bloque convolucional de transmisión de mensajes Conv-MPN es un tensor 3D en el espacio de diseño de salida. De esta forma, aplicaremos una capa general lineal para la ampliación gr en el volumen temático gr,l=1 de tamaño 16×8 ×8, donde l=1 será el objeto extraído de la primera capa Conv-MPN. Luego se muestreará dos veces usando convolución transpuesta para convertirlo en un objeto gr,l=3 de tamaño 16×32×32.
La capa Conv-MPN actualizará el grafo de objetos espaciales usando la transmisión de mensajes convolucionales. En concreto, actualizaremos gr,l=1 en los siguientes pasos:
- Utilizaremos un único GTE para capturar correlaciones a largo plazo entre habitaciones que están conectadas en el grafo de entrada;
- Usaremos otro GTE para capturar las dependencias a largo plazo entre habitaciones no relacionadas en el grafo de entrada;
- Combinaremos las características sobre habitaciones conectadas en el grafo de entrada;
- Combinaremos las funciones en habitaciones no relacionadas;
- Aplicaremos un bloque convolucional (CNN) al objeto fusionado.
Este proceso puede resumirse del siguiente modo:
![]()
donde N(r) denotará conjuntos de habitaciones conectadas y no conectadas; «+» y «;» denotarán la suma de píxeles y la concatenación canal por canal, respectivamente.
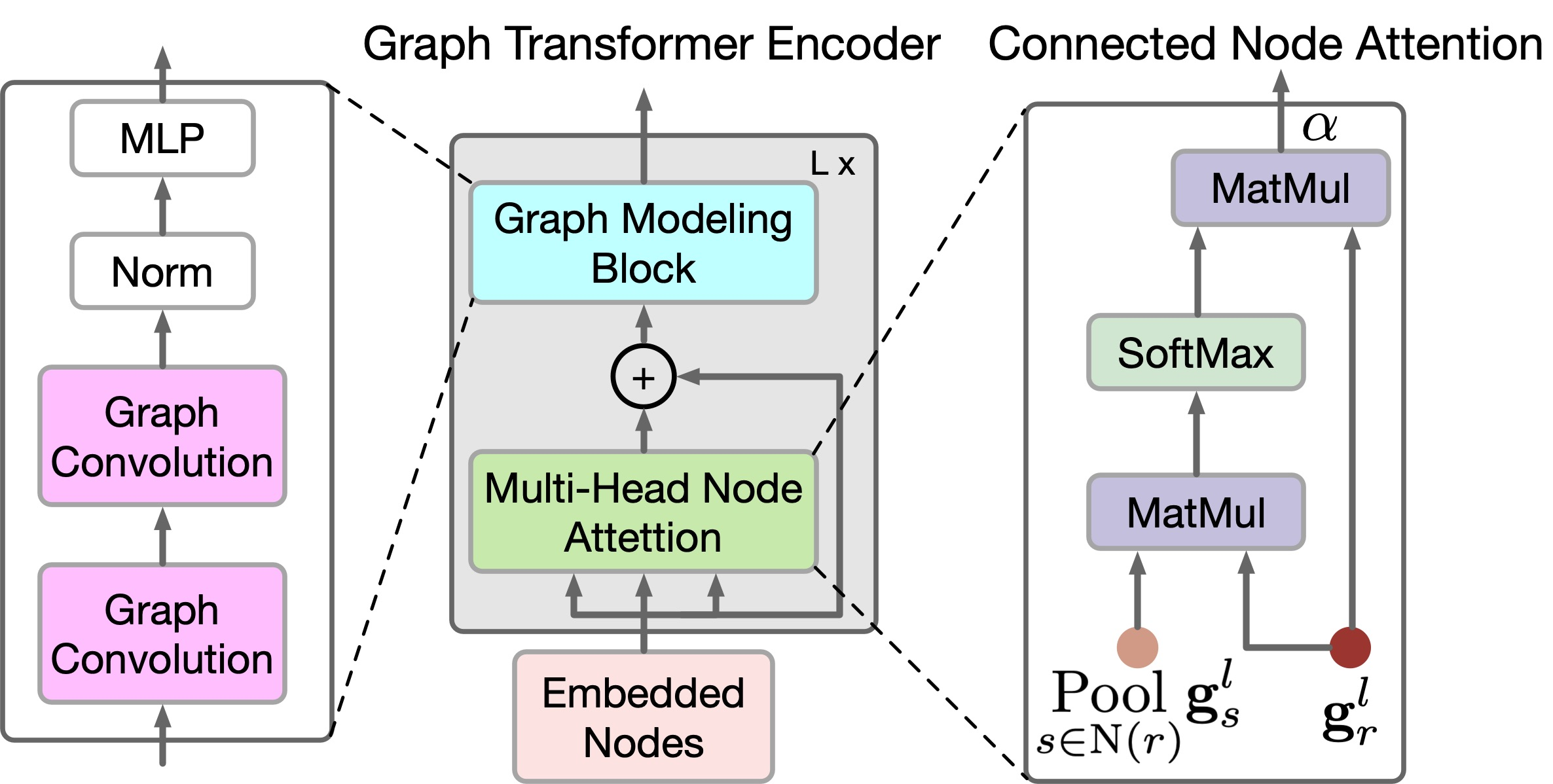
Para captar las relaciones locales y globales entre los nodos del grafo, los autores del método proponen un nuevo codificador GTE. GTE combinará los modelos de Self-Attention de los modelos, el Transformer y Graph Convolution para captar las correlaciones globales y locales, respectivamente. Tenga en cuenta que GTGAN no utiliza la codificación posicional porque el objetivo de la tarea es especificar las posiciones de los nodos en el diseño de la casa generada.
GTGAN amplía la Self-Attention multicabeza a la atención a nodos multicabeza, que pretende captar correlaciones globales entre habitaciones/nodos conectados y dependencias globales entre habitaciones/nodos desconectados. Para ello, los autores del método proponen dos nuevos módulos de atención a los nodos del grafo, a saber, la atención a los nodos conectados (CNA) y la atención a los nodos no conectados (NNA). Ambas unidades comparten la misma arquitectura de red.
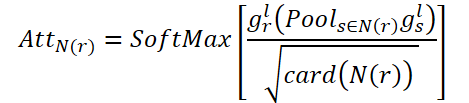
El objetivo de CNA será modelar correlaciones globales entre habitaciones conectadas. AttN(r) medirá la influencia de un nodo sobre otros nodos conectados. A continuación, realizaremos la multiplicación matricial gr,l por la AttN(r) transpuesta. Luego multiplicaremos el resultado por el parámetro de escala ɑ.
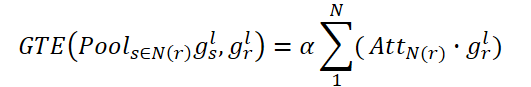
donde ɑ será el parámetro a entrenar.
En este caso, cada nodo conectado en N(r) será una suma ponderada de todos los nodos conectados. De este modo, CNA obtendrá una visión global de la estructura del grafo espacial y podrá ajustar selectivamente las habitaciones según el mapa de atención conectado, mejorando la representación de la distribución de la casa y la coherencia semántica de alto nivel.
Del mismo modo, NNA intentará captar las relaciones globales en habitaciones no relacionadas. En este caso, utilizará su parámetro entrenado ß.
Por último, realizaremos una suma por partes de gr,l para que el objeto de nodo actualizado pueda captar tanto las relaciones espaciales conectadas como las no conectadas.
![]()
Aunque CNA y NNA son útiles para extraer dependencias a largo plazo y globales, resultarán menos eficaces a la hora de recopilar información local de grano fino en estructuras de datos complejas de la casa. Para hacer frente a esta limitación, los autores del método proponen un nuevo bloque de modelización de grafos.
En particular, dadas las características gr,l generadas en la ecuación anterior, se mejorarán aún más las correlaciones locales utilizando redes de grafos convolucionales.
![]()
donde A denotará la matriz de adyacencia del grafo, GC(•) representará la convolución del grafo y P denotará los parámetros a entrenar. σ será la unidad lineal de error gaussiano (GeLU).
El suministro de información sobre las relaciones de los nodos del grafo global ayudará a crear diseños de casas más precisos. Para diferenciar este proceso, los autores del método proponen una nueva función de pérdida basada en la matriz de adyacencia, que se corresponderá con las relaciones espaciales entre los grafos básicos verdadero y generado. Más concretamente, el grafo capturará las relaciones de adyacencia entre cada nodo de las distintas habitaciones y, a continuación, ofrecerá una correspondencia entre la verdad sobre el terreno y los grafos generados mediante la función propuesta de pérdida de coherencia de ciclo. Esta función de pérdida ha sido pensadapara mantener con precisión las relaciones mutuas entre nodos. Por un lado, las partes que no se solapan deberán predecirse como no solapadas. Por otro lado, los nodos vecinos deberán predecirse como nodos vecinos y emparejarse usando coeficientes de proximidad.
A continuación le mostramos la representación de autor de GTGAN.
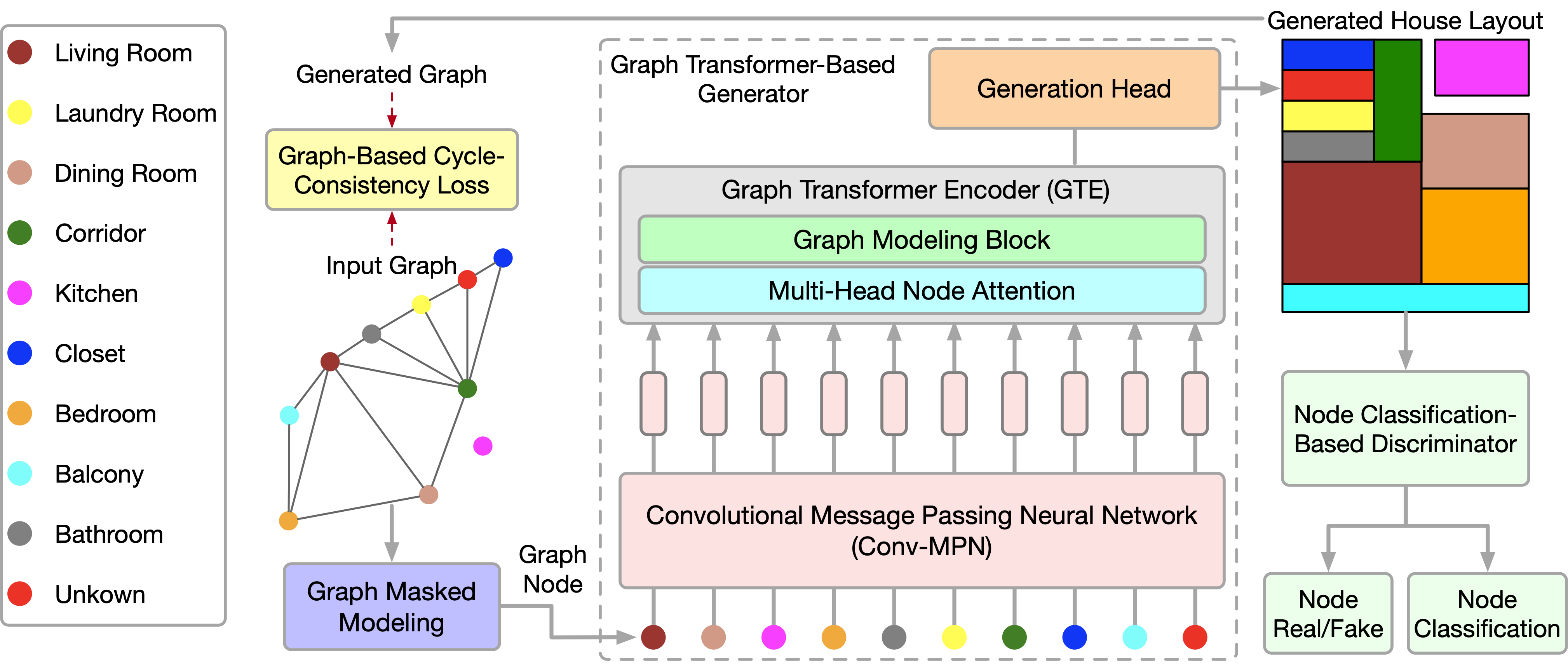
2. Implementación con MQL5
Tras repasar los aspectos teóricos del método GTGAN, abordaremos la parte práctica de nuestro artículo, donde implementaremos los enfoques propuestos utilizando herramientas MQL5.
De entrada, querría llamar su atención sobre la diferencia existente entre las tareas resueltas por los autores del método y por nosotros. No pretendemos generar un gráfico de movimientos de precios. Nuestro objetivo consiste en encontrar la estrategia óptima para el comportamiento del Agente. Y en la salida del modelo queremos obtener la acción óptima del Agente en un estado concreto del entorno. A primera vista, nuestras tareas resultan radicalmente distintas.
Pero si miramos más de cerca la metodología GTGAN, veremos que el enfoque principal de los autores del método se centra en el GTE. Aquí se presta mucha atención tanto a la arquitectura del codificador como a su entrenamiento.
Los autores del método proponen un preentrenamiento del codificador con enmascaramiento aleatorio tanto de nodos como de enlaces. Nos proponen enmascarar hasta el 40% de los datos originales, dejando en cada nodo y arista posibles lagunas en las conexiones vecinas. Para recuperar los datos que faltan, cada incorporación de nodo y arista deberá absorber e interpretar su contexto local. Es decir, cada incorporación deberá comprender los detalles específicos de su entorno inmediato. El enfoque propuesto de enmascaramiento aleatorio de alta relación y la posterior reconstrucción eliminará las limitaciones impuestas por el tamaño y la forma de los subgrafos utilizados para la predicción. Como resultado, se fomentará la incorporación de nodos y aristas para comprender los detalles contextuales locales.
Además, cuando se eliminen nodos o aristas con coeficientes elevados, los nodos y aristas restantes podrán considerarse un conjunto de subgrafos cuya tarea será predecir el grafo completo. Es una tarea de predicción por grafos más compleja que otras tareas de aprendizaje previo autodidacta, que suelen abarcar detalles globales del grafo utilizando grafos más pequeños o contextos como objetivos de predicción. La tarea "intensiva" propuesta de preentrenamiento del enmascaramiento y reordenación de grafos ofrece una perspectiva más amplia para el aprendizaje de incorporaciones superiores de nodos y aristas que pueden capturar detalles complejos tanto a nivel de nodos/aristas individuales como a nivel del grafo completo.
El codificador del sistema propuesto actúa como un puente que transformará los atributos originales de los nodos y aristas visibles y no enmascarados en sus correspondientes incorporaciones en espacios de características ocultas. En este proceso intervendrán los aspectos de nodos y límites del codificador, que incluirán el bloque de modelado de grafos propuesto y el mecanismo de atención a nodos de varias cabezas. Estas características se han diseñado siguiendo el espíritu de la arquitectura del Transformer, un método conocido por su capacidad para modelar eficazmente datos secuenciales. Este bloque ayudará a crear representaciones sólidas que encapsulen la dinámica holística de las relaciones dentro del grafo.
Por lo tanto, y podremos utilizar el codificador propuesto para explorar las dependencias locales y globales en los datos originales. Implementaremos el algoritmo codificador propuesto en una nueva clase CNeuronGTE.
2.1 Clase de Codificador GTE
Crearemos la clase de Codificador GTE CNeuronGTE como heredera de nuestra clase básica de capas neuronales CNeuronBaseOCL. La estructura del Codificador propuesto es tan diferente de las variantes de Transformador previamente discutidas que, a pesar del gran número de capas neuronales previamente creadas que utilizan mecanismos de atención, hemos decidido renunciar a la herencia de una de ellas. Aunque en el proceso usaremos desarrollos creados previamente.
A continuación, mostraremos la estructura de la nueva clase.
class CNeuronGTE : public CNeuronBaseOCL { protected: uint iHeads; ///< Number of heads uint iWindow; ///< Input window size uint iUnits; ///< Number of units uint iWindowKey; ///< Size of Key/Query window //--- CNeuronConvOCL cQKV; CNeuronSoftMaxOCL cSoftMax; int ScoreIndex; CNeuronBaseOCL cMHAttentionOut; CNeuronConvOCL cW0; CNeuronBaseOCL cAttentionOut; CNeuronCGConvOCL cGraphConv[2]; CNeuronConvOCL cFF[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionInsideGradients(void); public: CNeuronGTE(void) {}; ~CNeuronGTE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronGTE; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
Aquí vemos las variables locales que ya conocemos:
- iHeads;
- iWindow;
- iUnits;
- iWindowKey.
Su carga funcional seguirá siendo la misma. Nos familiarizaremos con el propósito de las capas internas durante la implementación de los métodos.
Declararemos todos los objetos internos como estáticos, lo cual nos permitirá dejar el constructor y el destructor de la clase vacíos. Observe que ni siquiera especificaremos el valor de las variables locales en el constructor de la clase.
La inicialización completa de la clase se realizará, como siempre, en el método Init. En los parámetros de este método obtendremos toda la información necesaria para crear una arquitectura de clases correcta, mientras que en el cuerpo del método llamaremos directamente al método homónimo de la clase padre, que realizará el control mínimo necesario de los parámetros iniciales recibidos y la inicialización de los objetos heredados.
bool CNeuronGTE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Una vez ejecutado con éxito el método de la clase padre, guardaremos los datos obtenidos en variables locales.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); activation = None;
E inicializaremos los objetos añadidos. Primero inicializaremos la capa convolucional interna cQKV. En ella planeamos generar una representación de las 3 entidades (Query, Key y Value) en hilos paralelos. El tamaño de la ventana de datos inicial y su paso será igual al tamaño de la descripción de un elemento de la secuencia, mientras que el número de filtros de convolución será igual al producto del tamaño de un vector de descripción de entidad de un elemento de la secuencia multiplicado por el número de cabezas de atención y por 3 (el número de entidades). El número de elementos será igual al tamaño de la secuencia que se va a analizar.
if(!cQKV.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * 3 * iHeads, iUnits, optimization, iBatch)) return false;
Para mejorar la estabilidad del bloque, normalizaremos las entidades generadas mediante la capa SoftMax.
if(!cSoftMax.Init(0, 1, OpenCL, iWindowKey * 3 * iHeads * iUnits, optimization, iBatch)) return false; cSoftMax.SetHeads(3 * iHeads * iUnits);
El siguiente paso consistirá en crear un búfer de coeficientes de dependencia en el contexto de OpenCL. Su tamaño será 2 veces mayor de lo habitual para escribir los coeficientes de los vértices conectados y no conectados por separado.
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits * 2 * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Almacenaremos los resultados de la atención multicabeza en una capa local cMHAttentionOut.
if(!cMHAttentionOut.Init(0, 2, OpenCL, iWindowKey * 2 * iHeads * iUnits, optimization, iBatch)) return false;
Obsérvese que el tamaño de la capa de resultados de atención multicabeza también será 2 veces mayor que la propia capa de implementaciones del Transformer comentadas anteriormente. Esto también se hará para permitir que se registren los datos de los vértices vinculados y no vinculados.
Además, este enfoque nos permitirá no sacar a un funcional separado el entrenamiento de los parámetros de escala ɑ y ß. En su lugar, usaremos la capa funcional W0. Esta combinará las cabezas de atención y la influencia de los vértices conectados y no conectados.
if(!cW0.Init(0, 3, OpenCL, 2 * iWindowKey * iHeads, 2 * iWindowKey* iHeads, iWindow, iUnits, optimization, iBatch)) return false;
Después del bloque de atención, también deberemos sumar los resultados a los datos originales y normalizar los resultados. Escribiremos los valores resultantes en la capa cAttentionOut.
if(!cAttentionOut.Init(0, 4, OpenCL, iWindow * iUnits, optimization, iBatch)) return false;
Después vendrán 2 bloques con 2 capas en cada uno. Serán un bloque de convolución de grafos y FeedForward. Inicializaremos los objetos de los bloques especificados en un ciclo.
for(int i = 0; i < 2; i++) { if(!cGraphConv[i].Init(0, 5 + i, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cFF[i].Init(0, 7 + i, OpenCL, (i == 0 ? iWindow : 4 * iWindow), (i == 0 ? iWindow : 4 * iWindow), (i == 1 ? iWindow : 4 * iWindow), iUnits, optimization, iBatch)) return false; }
Por último, sustituiremos el búfer de gradiente de error.
if(cFF[1].getGradient() != Gradient) { if(!!Gradient) delete Gradient; Gradient = cFF[1].getGradient(); } //--- return true; }
Y finalizaremos el método.
Tras inicializar la clase, comenzaremos a organizar el algoritmo de pasada directa de la clase. Y aquí nos centramos primero en nuestro programa OpenCL, en el que deberemos crear un nuevo kernel GTEFeedForward. Dentro de este kernel, analizaremos las dependencias tanto de los nodos conectados como de los no conectados. En la metodología del método GTGAN, implementaremos la funcionalidad CNA y NNA en el cuerpo del kernel GTEFeedForward.
Pero, antes de pasar a la implementación, deberemos decidir qué nodos consideraremos conectados y cuáles no. Lo primero que deberemos saber es que los nodos de nuestra aplicación son descripciones de los parámetros de una única barra. Hablamos del análisis de series temporales. Por lo tanto, solo las 2 barras siguientes podrán relacionarse directamente. Así, para la barra Xt solo las barras Xt-1 y Xt+1 estarán conectadas. En este caso, además, las barras Xt-1 y Xt+1 no estarán relacionadas entre sí, dado que entre ellas se encuentra la barra Xt.
Este punto ya está decidido, así que ahora pasaremos a la aplicación. El kernel obtendrá los punteros a los búferes de intercambio de datos en los parámetros.
__kernel void GTEFeedForward(__global float *qkv, __global float *score, __global float *out, int dimension) { const size_t cur_q = get_global_id(0); const size_t units_q = get_global_size(0); const size_t cur_k = get_local_id(1); const size_t units_k = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
En el cuerpo del kernel, identificaremos el flujo en el espacio de tareas. En este caso, se tratará de un espacio de tareas tridimensional; una de dichas dimensiones se agrupará en un grupo local.
En el siguiente paso, determinaremos el desplazamiento en los búferes de datos.
int shift_q = dimension * (cur_q + h * units_q); int shift_k = (cur_k + h * units_k + heads * units_q); int shift_v = dimension * (h * units_k + heads * (units_q + units_k)); int shift_score_con = units_k * (cur_q * 2 * heads + h) + cur_k; int shift_score_notcon = units_k * (cur_q * 2 * heads + heads + h) + cur_k; int shift_out_con = dimension * (cur_q + h * units_q); int shift_out_notcon = dimension * (cur_q + units_q * (h + heads));
Aquí también declararemos un array local bidimensional. En la segunda dimensión, declararemos 2 elementos para nodos vinculados y no vinculados.
const uint ls_score = min((uint)units_k, (uint)LOCAL_ARRAY_SIZE); __local float local_score[LOCAL_ARRAY_SIZE][2];
El siguiente paso consistirá en determinar los coeficientes de dependencia. Primero multiplicaremos los correspondientes tensores Query y Key. Luego dividiremos por la raíz de la dimensión y tomaremos el valor exponencial.
//--- Score float scr = 0; for(int d = 0; d < dimension; d ++) scr += qkv[shift_q + d] * qkv[shift_k + d]; scr = exp(min(scr / sqrt((float)dimension), 30.0f));
Y determinaremos si los elementos analizados de la secuencia están conectados y guardaremos el resultado en el elemento de búfer requerido.
if(cur_q == cur_k) { score[shift_score_con] = scr; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = scr; } } else { if(abs(cur_q - cur_k) == 1) { score[shift_score_con] = scr; score[shift_score_notcon] = 0; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = 0; } } else { score[shift_score_con] = 0; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = 0; local_score[cur_k][1] = scr; } } } barrier(CLK_LOCAL_MEM_FENCE);
Ahora podremos hallar la suma de los coeficientes de cada uno de los elementos de la secuencia.
for(int k = ls_score; k < units_k; k += ls_score) { if((cur_k + k) < units_k) { local_score[cur_k][0] += score[shift_score_con + k]; local_score[cur_k][1] += score[shift_score_notcon + k]; } } barrier(CLK_LOCAL_MEM_FENCE); //--- int count = ls_score; do { count = (count + 1) / 2; if(cur_k < count) { if((cur_k + count) < units_k) { local_score[cur_k][0] += local_score[cur_k + count][0]; local_score[cur_k][1] += local_score[cur_k + count][1]; local_score[cur_k + count][0] = 0; local_score[cur_k + count][1] = 0; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); barrier(CLK_LOCAL_MEM_FENCE);
Y llevaremos la suma de las relaciones de dependencia a 1 para cada elemento de la secuencia. Para ello, bastará con dividir el valor de cada elemento por la suma correspondiente.
score[shift_score_con] /= local_score[0][0]; score[shift_score_notcon] /= local_score[0][1]; barrier(CLK_LOCAL_MEM_FENCE);
Una vez hallados los coeficientes de dependencia, podremos determinar los resultados del impacto de los nodos conectados y no conectados.
shift_score_con -= cur_k; shift_score_notcon -= cur_k; for(int d = 0; d < dimension; d += ls_score) { if((cur_k + d) < dimension) { float sum_con = 0; float sum_notcon = 0; for(int v = 0; v < units_k; v++) { sum_con += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_con + v]; sum_notcon += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_notcon + v]; } out[shift_out_con + cur_k + d] = sum_con; out[shift_out_notcon + cur_k + d] = sum_notcon; } } }
Tras completar con éxito todas las iteraciones, finalizaremos el kernel y volveremos a trabajar en el programa principal. Aquí crearemos primero el método AttentionOut de la llamada al kernel que hemos creado antes. Este será un método que se llamará desde otro método de la misma clase. Solo funcionará con objetos internos y no contendrá parámetros.
En el cuerpo del método, primero comprobaremos la relevancia del puntero al objeto de clase de gestión del contexto OpenCL.
bool CNeuronGTE::AttentionOut(void) { if(!OpenCL) return false;
Después, definiremos el espacio de tareas y el tamaño de los grupos de trabajo. En este caso, utilizaremos un espacio de tareas tridimensional con una agrupación unidimensional en grupos de trabajo.
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits, 1};
A continuación, transmitiremos los parámetros necesarios al kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_qkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_out, cAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_GTEFeedForward, def_k_gteff_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Y podremos el kernel en la cola de ejecución.
if(!OpenCL.Execute(def_k_GTEFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
en este caso, además, deberemos necesariamente supervisar el progreso de las operaciones en cada paso. Y una vez finalizado el método, retornaremos el valor lógico de los resultados del método, lo cual nos permitirá controlar el proceso en el programa que realiza la llamada.
Una vez completado el trabajo preparatorio, crearemos el método de pasada directa de nivel superior de nuestra clase CNeuro.nGTE::feedForward. En los parámetros de este método, de forma similar a muchos métodos homónimos de otras clases comentadas anteriormente, obtendremos el puntero al objeto de la capa anterior, cuyo búfer contendrá los datos iniciales para el funcionamiento de nuestro método.
bool CNeuronGTE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.FeedForward(NeuronOCL)) return false;
Sin embargo, en el cuerpo del método no comprobaremos la pertinencia del puntero recibido, sino que llamaremos directamente a un método similar de pasada directa del objeto de entrenamiento de las entidades Query, Key y Value. Todos los controles necesarios ya están implementados en el cuerpo del método llamado. Después de entrenar con éxito las entidades (cosa que podemos juzgar según el resultado del método llamado), normalizaremos los datos obtenidos en la capa SoftMax.
if(!cSoftMax.FeedForward(GetPointer(cQKV))) return false;
A continuación, usaremos el método AttentionOut creado anteriormente y determinaremos el impacto de los vértices conectados y no conectados.
if(!AttentionOut()) return false;
Asimismo, reduciremos la dimensionalidad de los resultados de la atención multicabeza al tensor de los datos originales.
if(!cW0.FeedForward(GetPointer(cMHAttentionOut))) return false;
Luego sumaremos y normalizaremos los datos.
if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cAttentionOut.getOutput(), iWindow, true)) return false;
En este punto, podemos dar por completado el bloque de atención multicabeza y podemos pasar al bloque de convolución de grafos GC. Aquí usaremos 2 capas de CrystalGraph Convolutional Network. Y para implementar la funcionalidad solo tendremos que llamar sistemáticamente a sus métodos de pasada directa.
if(!cGraphConv[0].FeedForward(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].FeedForward(GetPointer(cGraphConv[0]))) return false;
A continuación vendrá el bloque FeedForward.
if(!cFF[0].FeedForward(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].FeedForward(GetPointer(cFF[0]))) return false;
Y al final del método, volveremos a sumar y normalizar los resultados.
if(!SumAndNormilize(cAttentionOut.getOutput(), cFF[1].getOutput(), Output, iWindow, true)) return false; //--- return true; }
Tras poner en práctica el pasada directa, pasaremos a organizar el proceso de pasada inversa. Una vez más, comenzaremos nuestro trabajo creando un nuevo kernel GTEInsideGradients en el lado del programa OpenCL. En los parámetros, el kernel obtendrá los punteros a los búferes de datos necesarios para la trabajar. Y obtendremos todas las dimensiones del espacio de tareas.
__kernel void GTEInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const uint u = get_global_id(0); const uint d = get_global_id(1); const uint h = get_global_id(2); const uint units = get_global_size(0); const uint dimension = get_global_size(1); const uint heads = get_global_size(2);
De forma similar al kernel de pasada directa, ejecutaremos este kernel en un espacio de tareas tridimensional, solo que esta vez sin organizar grupos de trabajo. En el cuerpo del kernel, identificaremos el flujo actual en el espacio de tareas en todas las dimensiones.
A grandes rasgos, podemos dividir el algoritmo de nuestro kernel en 3 bloques:
- Gradiente Value;
- Gradiente Query;
- Gradiente Key.
Organizaremos la pasada inversa en orden inverso a la directa. Y primero definiremos el gradiente de error para la entidad Value. En este bloque, primero definiremos los desplazamientos en los búferes de datos.
//--- Calculating Value's gradients { int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units + u) + d;
A continuación, organizaremos un ciclo para recoger los gradientes de error en los nodos conectados y no conectados. Y almacenaremos el resultado en el elemento correspondiente del búfer global de gradientes de error de entidades qkv_g.
float sum = 0; for(uint i = 0; i <= units; i ++) { sum += gradient[shift_out_con + i * dimension] * scores[shift_score_con + i * step_score]; sum += gradient[shift_out_notcon + i * dimension] * scores[shift_score_notcon + i * step_score]; } qkv_g[shift_v] = sum; }
En el segundo paso, calcularemos los gradientes de error para la entidad Query. Al igual que en el primer bloque, primero calcularemos los desplazamientos en los búferes de datos.
//--- Calculating Query's gradients { int shift_q = dimension * (u + h * units) + d; int shift_out_con = dimension * (h * units + u) + d; int shift_out_notcon = dimension * (u + units * (h + heads)) + d; int shift_score_con = units * h; int shift_score_notcon = units * (heads + h); int shift_v = dimension * (h * units + 2 * heads * units);
El cálculo del gradiente de error, en cambio, será un poco más complicado. La cuestión es que primero deberemos determinar el gradiente de error a nivel de la matriz de coeficientes de dependencia y ajustar su derivada de la función SoftMax. Y solo entonces desplazar el gradiente de error hasta el nivel de la entidad buscada. Para ello, deberemos organizar todo un sistema de ciclos anidados.
float grad = 0; for(int k = 0; k < units; k++) { int shift_k = (k + h * units + heads * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + k]; float sc_notcon = scores[shift_score_notcon + k]; for(int v = 0; v < units; v++) for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_con + dim] * ((float)(k == v) - sc_con); sc_g += scores[shift_score_notcon + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_notcon + dim] * ((float)(k == v) - sc_notcon); } grad += sc_g * qkv[shift_k]; }
Una vez completadas todas las iteraciones del sistema de ciclos, trasladaremos el gradiente de error total al elemento correspondiente del búfer global de datos.
qkv_g[shift_q] = grad; }
En el bloque final de nuestro kernel, determinaremos el gradiente de error para la entidad Key. En esta ocasión, crearemos un algoritmo similar al del bloque anterior. Solo que en este caso tomaremos el gradiente de error de la matriz de coeficientes de dependencia en otra dimensión.
//--- Calculating Key's gradients { int shift_k = (u + (h + heads) * units) + d; int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units); float grad = 0; for(int q = 0; q < units; q++) { int shift_q = dimension * (q + h * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + u + q * step_score]; float sc_notcon = scores[shift_score_notcon + u + q * step_score]; for(int g = 0; g < units; g++) { for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_con + g * dimension + dim] * ((float)(u == g) - sc_con); sc_g += scores[shift_score_notcon + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_notcon + g * dimension+ dim] * ((float)(u == g) - sc_notcon); } } grad += sc_g * qkv[shift_q]; } qkv_g[shift_k] = grad; } }
Para llamar al kernel descrito, crearemos el método CNeuronGTE::AttentionInsideGradients. Su algoritmo será similar al método CNeuronGTE::AttentionOut. Así que no nos detendremos ahora para analizarlo detalladamente. Le sugiero que lo lea por sí mismo en el archivo adjunto, donde encontrará el código completo de todos los programas utilizados en la elaboración de este artículo.
El proceso completo de distribución del gradiente de error, por su parte, se describirá en el método CNeuronGTE::calcInputGradients. En los parámetros, este método recibirá el puntero al objeto de la capa neuronal anterior a la que se debe transmitir el gradiente de error.
bool CNeuronGTE::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cFF[1].calcInputGradients(GetPointer(cFF[0]))) return false;
Aquí vale la pena recordar nuestro enfoque (ya utilizado muchas veces) de intercambio de búferes de datos. Cuando el método de pasada inversa de la capa neuronal posterior está funcionando, obtendremos el gradiente de error directamente en el búfer de la última capa del bloque FeedForward. Por tanto, no deberemos copiar datos innecesariamente. Y en el método de pasada inversa, empezaremos directamente distribuyendo el gradiente de error a través de las capas del bloque FeedForward.
if(!cFF[0].calcInputGradients(GetPointer(cGraphConv[1]))) return false;
A continuación, ejecutaremos de forma similar el gradiente de error a través del bloque de convolución de grafos.
if(!cGraphConv[1].calcInputGradients(GetPointer(cGraphConv[0]))) return false; if(!cGraphConv[1].calcInputGradients(GetPointer(cAttentionOut))) return false;
En este paso, combinaremos el gradiente de error de los 2 flujos.
if(!SumAndNormilize(cAttentionOut.getGradient(), Gradient, cW0.getGradient(), iWindow, false)) return false;
Luego distribuiremos el gradiente de error entre las cabezas de atención.
if(!cW0.calcInputGradients(GetPointer(cMHAttentionOut))) return false;
Y lo pasaremos por el bloque de atención.
if(!AttentionInsideGradients()) return false;
Recordemos que el gradiente de error a través de las 3 entidades (Query, Key, Value) se contiene en 1 búfer concatenado, lo cual nos permitirá procesar todas las entidades en paralelo a la vez. Primero corregiremos el gradiente de error usando la derivada de la función SoftMax que hemos utilizado para normalizar los datos.
if(!cSoftMax.calcInputGradients(GetPointer(cQKV))) return false;
Y luego bajaremos el gradiente de error al nivel de la capa anterior.
if(!cQKV.calcInputGradients(prevLayer)) return false;
Aquí solo deberemos añadir el gradiente de error del segundo flujo de datos.
if(!SumAndNormilize(cW0.getGradient(), prevLayer.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
Luego finalizaremos el método.
Una vez distribuido el gradiente de error, solo tendremos que actualizar los parámetros del modelo para minimizar el error. Todos los parámetros entrenados de nuestra clase se contendrán en los objetos internos. Por lo tanto, para ajustar los parámetros, llamaremos secuencialmente a los métodos correspondientes de los objetos internos.
bool CNeuronGTE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; if(!cW0.UpdateInputWeights(GetPointer(cMHAttentionOut))) return false; if(!cGraphConv[0].UpdateInputWeights(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].UpdateInputWeights(GetPointer(cGraphConv[0]))) return false; if(!cFF[0].UpdateInputWeights(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].UpdateInputWeights(GetPointer(cFF[0]))) return false; //--- return true; }
Con esto concluirá nuestra revisión de los métodos de nuestra nueva clase CNeuronGTE. Le sugiero que se familiarice con todos los métodos de mantenimiento de la clase, incluido el trabajo con archivos, en el archivo adjunto. Ahí, como siempre, encontrará el código completo de todos los programas utilizados en la elaboración de este artículo.
2.2 Arquitectura del modelo
Tras crear una nueva clase, comenzaremos a trabajar en nuestros modelos, implementando su arquitectura y entrenamiento. Aquí debemos recordar que el método GTGAN presupone el entrenamiento previo del Codificador. Por lo tanto, crearemos 2 métodos para implementar la descripción de la arquitectura de los modelos. En el primer método CreateEncoderDescriptions, crearemos las descripciones de la arquitectura del Codificador y el Decodificador utilizadas solo para el entrenamiento previo de las representaciones.
bool CreateEncoderDescriptions(CArrayObj *encoder, CArrayObj *decoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; }
Asimismo, introduciremos la descripción de una vela en la entrada del Codificador.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Luego normalizaremos los datos resultantes utilizando la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, crearemos la incorporación de la última barra y la añadiremos a la pila.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
Cabe destacar aquí que, a diferencia de trabajos anteriores, en los que la incorporación se creaba en una sola capa, nosotros aprovecharemos las sugerencias del método GTGAN en cuanto al bloque de transmisión de mensajes Conv-MPN y dividiremos el proceso de creación de la incorporación en 2 etapas. Y detrás de la capa de incorporación, colocaremos otra capa de convolución que completará el trabajo de generación de incorporaciones de los estados.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, pondremos una capa DropOut para enmascarar los datos mientras entrenamos las representaciones en la fase de entrenamiento previo.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count*prev_wout; descr.probability= 0.4f; descr.activation=None; if(!encoder.Add(descr)) { delete descr; return false; }
En el siguiente paso, nos desviaremos ligeramente del algoritmo propuesto y añadiremos la codificación posicional. Esto se debe a las diferencias significativas en las tareas a realizar.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, añadiremos 8 capas del nuevo codificador en un ciclo.
//--- layer 6 - 14 for(int i = 0; i < 8; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronGTE; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!encoder.Add(descr)) { delete descr; return false; } }
La arquitectura del decodificador será mucho más corta. Asimismo, introduciremos los resultados del codificador en la entrada del modelo.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count * prev_wout; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Y los pasaremos por la capa de convolución.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count=prev_count; descr.window = prev_wout; descr.step=prev_wout; descr.window_out=EmbeddingSize/4; descr.optimization = ADAM; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
Luego los normalizaremos con SoftMax.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
A la salida del decodificador, crearemos una capa totalmente conectada con un número de elementos igual a los resultados de la capa de incorporación.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count*EmbeddingSize/2; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Como resultado, compilaremos un Autocodificador asimétrico a partir de los modelos, que se entrenará con la recuperación de los datos en la pila de la capa de Incorporación. La elección del estado latente de la capa de incorporación no se hará al azar. Durante el entrenamiento, nos gustaría acentuar la atención del Codificador en el conjunto completo de datos históricos, no solo en la última vela.
Describiremos la arquitectura del Actor y del Crítico en el método CreateDescriptions.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
También hemos decidido añadir un poco de espíritu de experimentación a la arquitectura del Actor. Así, suministraremos a la entrada del modelo una descripción del estado actual de la cuenta.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
La capa totalmente conectada nos ofrecerá una cierta incorporación del estado resultante.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A continuación, añadiremos un bloque de 3 capas de atención cruzada, en el que evaluaremos las dependencias entre el estado actual de nuestra cuenta y el estado del entorno.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Los resultados obtenidos se procesarán usando 2 capas completamente conectadas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y en la salida del Actor, generaremos su política estocástica.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El modelo del Crítico se ha mantenido prácticamente inalterado con respecto a los trabajos anteriores. Los resultados del codificador se introducirán en la entrada del modelo.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = GPTBars*EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
A los datos obtenidos se les añadirán las acciones del Actor.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type=defNeuronConcatenate; descr.window=prev_count; descr.step = NActions; descr.count=LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; }
Y crearemos un bloque de decisión de 2 capas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.3 Asesor de entrenamiento para las representaciones
Tras crear la Arquitectura de los modelos, comenzaremos a construir nuestros asesores de entrenamiento. Y el primero que vamos a crear es el asesor experto "...\Experts\GTGAN\StudyEncoder.mq5". La estructura del EA se inspirará en gran medida en trabajos anteriores. Y para reducir la extensión del artículo, nos centraremos únicamente en el método de entrenamiento directo de modelos Train.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
En el cuerpo del método, primero generaremos un vector de probabilidades para seleccionar las pasadas del búfer de reproducción de experiencias basándonos en su rendimiento.
A continuación, declararemos las variables locales.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Luego organizaremos un sistema de ciclos de entrenamiento de modelos. En el cuerpo del ciclo externo, muestrearemos la trayectoria y el estado inicial de entrenamiento sobre ella.
int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - batch)); if(state <= 0) { iter--; continue; }
Después eliminaremos el búfer del Codificador y determinaremos el estado final del paquete de entrenamiento.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total);
Una vez concluido el trabajo preparatorio, organizaremos un ciclo anidado de entrenamiento directo del modelo.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
Aquí cargaremos una descripción del estado actual del entorno desde el búfer de reproducción de experiencias y llamaremos al método de pasada directa del Codificador.
//--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Le seguirá una pasada directa del Decodificador.
if(!Decoder.feedForward((CNet*)GetPointer(Encoder),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tras la pasada directa, tendremos que definir los objetivos de entrenamiento del modelo. El autoaprendizaje del Autocodificador se realizará sobre la recuperación de los datos iniciales. Como ya hemos comentado, utilizaremos el estado oculto de la capa de incorporación en nuestro entrenamiento del modelo de representaciones. Cargaremos estos datos en el búfer local.
Encoder.GetLayerOutput(LatentLayer,Result);
Y los transmitiremos como valores objetivo para optimizar los parámetros de nuestros modelos.
if(!Decoder.backProp(Result,(CBufferFloat*)NULL) || !Encoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Ahora solo tendremos que informar al usuario del progreso del proceso de entrenamiento y pasar a la siguiente iteración del sistema de ciclos.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez finalizado con éxito el proceso de entrenamiento del modelo de representación, borraremos el campo de comentarios en el gráfico.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Decoder", Decoder.getRecentAverageError()); ExpertRemove(); //--- }
Después registraremos los resultados del entrenamiento e inicializaremos el proceso de finalización del EA.
En esta fase, podremos utilizar la muestra de entrenamiento de trabajos anteriores y ejecutar el proceso de entrenamiento del modelo de representación. Y mientras se entrena el modelo, pasaremos a crear el asesor de entrenamiento de la política del Actor.
2.4 Asesor para el entrenamiento de la política del Actor
Para entrenar la política de comportamiento del Actor, crearemos el asesor experto "...\Experts\GTGAN\Study.mq5". Aquí cabe señalar que utilizaremos 3 modelos en el proceso de entrenamiento, y entrenaremos solo 2 (Actor y Crítico). El modelo de Codificador se ha entrenado en la etapa anterior.
CNet Encoder; CNet Actor; CNet Critic;
En el método de inicialización del asesor experto, primero cargaremos la base de ejemplos.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Después intentaremos cargar los modelos pre-entrenados. Y en este caso, el error de carga del Codificador pre-entrenado será crítico para el funcionamiento del programa.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Can't load pretrained Encoder"); return INIT_FAILED; }
Pero cuando el Actor y/o el Crítico no se carguen, crearemos nuevos modelos inicializados con parámetros aleatorios.
if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor) || !Critic.Create(critic)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Luego reuniremos todos los modelos en un único contexto OpenCL.
OpenCL = Encoder.GetOpenCL(); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
Y nos aseguraremos de desactivar el modo de entrenamiento del Codificador.
Encoder.TrainMode(false);
Recordemos que su arquitectura utiliza una capa DropOut que enmascarará aleatoriamente los datos. En el proceso de funcionamiento del modelo, tendremos que desactivar el enmascaramiento, lo cual se logrará desactivando el modo de entrenamiento del modelo.
A continuación, realizaremos el control mínimo necesario de la arquitectura del modelo.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Inicializaremos los búferes de datos auxiliares.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
Y generaremos un evento de inicio del entrenamiento del modelo.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
El propio proceso de entrenamiento del modelo se organizará, como es habitual, en el método Train.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
En el cuerpo del método, al igual que en el EA anterior, primero generaremos el vector de probabilidades de selección de trayectorias del búfer de reproducción de experiencias según su rendimiento. E inicializaremos las variables locales. A continuación, organizaremos un sistema de ciclos de entrenamiento de modelos.
En el cuerpo del ciclo externo, muestrearemos la trayectoria del búfer de reproducción de experiencias y el estado de inicio del proceso de entrenamiento en ella.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand()*MathRand() / MathPow(32767, 2))*(Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Luego borraremos la pila del Codificador y determinaremos el último estado del paquete de entrenamiento.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
Una vez concluido el trabajo preparatorio, organizaremos un ciclo anidado de entrenamiento directo del modelo.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
En el cuerpo del ciclo anidado, cargaremos la descripción del estado de la cuenta analizado desde el búfer de reproducción de experiencias y realizaremos una pasada directa del Codificador.
A continuación, tendremos que cargar la descripción del estado de la cuenta desde el búfer de reproducción de experiencias para realizar una pasada directo del Actor.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Aquí también añadiremos la marca temporal del estado actual.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Y luego realizaremos una pasada directa del Actor.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount),1,false,GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y después del Crítico.
//--- Critic if(!Critic.feedForward((CNet *)GetPointer(Encoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tomaremos los valores objetivo para ambos modelos del búfer de reproducción de experiencias. En primer lugar, realizaremos el pasada inversa del Actor.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y luego del Crítico, transmitiendo el error de gradiente al Actor.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
En ninguno de los casos actualizaremos los parámetros del Codificador.
Una vez completado con éxito la pasada inversa de ambos modelos, informaremos al usuario sobre el progreso del proceso de entrenamiento y pasaremos a la siguiente iteración del sistema de ciclos.
//--- if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez finalizado el proceso de entrenamiento, borraremos el campo de comentarios del gráfico.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Enviaremos los resultados del entrenamiento al registro e iniciaremos el proceso de finalización del Asesor Experto.
Con esto concluiremos nuestra revisión de los programas de entrenamiento de modelos. Los programas de interacción con el entorno los hemos transferido desde el artículo anterior con unos ajustes mínimos. Le sugiero que los lea en el archivo adjunto, donde encontrará el código completo de todos los programas utilizados en la elaboración del artículo.
3. Simulación
En las secciones anteriores de este artículo, nos hemos familiarizado con el nuevo método GTGAN y hemos realizado un trabajo considerable para poner en práctica los enfoques propuestos utilizando herramientas MQL5. En esta parte del artículo, como es habitual, pondremos a prueba el trabajo realizado y evaluaremos los resultados obtenidos sobre datos reales en el Simulador de Estrategias de MetaTrader 5. El entrenamiento y las pruebas de los modelos se han realizado con los datos históricos del marco temporal EURUSD H1. Los modelos se han entrenado con el tramo histórico de los 7 primeros meses de 2023. La prueba del modelo entrenado se ha realizado con datos de agosto de 2023.
Los modelos creados en este artículo trabajan con los datos de origen de forma similar a los modelos de los artículos anteriores. Los vectores de acción del Actor y las recompensas por las transiciones de estado completadas también son idénticos a los de los artículos anteriores. Por lo tanto, para entrenar los modelos, podemos utilizar el búfer de reproducción de experiencias recopilado durante el entrenamiento de los modelos en artículos anteriores Para ello, bastará con cambiar el nombre del archivo a "GTGAN.bd".
El entrenamiento de los modelos se realizará en 2 fases. En primer lugar, entrenaremos el codificador (modelo de vista). Y luego se entrenará la política de comportamiento del Actor. Debemos decir que dividir el proceso de entrenamiento en 2 fases tiene un impacto positivo. Los modelos se entrenan con bastante rapidez y constancia.
A partir de los resultados del entrenamiento, podemos afirmar que el modelo ha aprendido rápidamente a generalizar y seguir la política de acción a partir del búfer de reproducción de experiencias. Desgraciadamente, se han realizado pocas pasadas positivas en el búfer de reproducción de experiencias. Por ello, el modelo ha aprendido una política cercana a la media de la muestra de entrenamiento, lo que, por desgracia, no arroja un resultado positivo. Creo que vale la pena intentar entrenar el modelo con pasadas positivas.
Conclusión
En este trabajo, nos hemos familiarizado con el algoritmo GTGAN, introducido en enero de 2024 para resolver problemas de arquitectura complejos. Para nuestros objetivos, hemos intentado tomar prestados los planteamientos del versátil análisis del estado actual en el codificador GTE, que combina sucintamente la ventaja de los métodos de atención y los modelos de grafos convolucionales.
En la parte práctica del artículo, hemos implementado los enfoques propuestos utilizando las herramientas MQL5 y hemos probado los modelos obtenidos con datos reales en el simulador de estrategias de MetaTrader 5.
Los resultados de las pruebas nos indican que debemos seguir trabajando con los planteamientos propuestos.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de cobros de ejemplo Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | StudyEncoder.mq5 | Asesor | Asesor de entrenamiento del modelo de presentaciones |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14445
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso