
Redes neuronales: así de sencillo (Parte 83): Algoritmo de convertidor espacio-temporal de atención constante (Conformer)

Introducción
El comportamiento impredecible de los mercados financieros puede compararse, sin lugar a dudas, con la volatilidad del tiempo. Sin embargo, la humanidad ha hecho bastante en el campo de la predicción de fenómenos meteorológicos. Y, en la actualidad, observamos con bastante confianza las previsiones meteorológicas facilitadas por los meteorólogos. ¿Podemos usar sus conclusiones para predecir el "tiempo" en los mercados financieros? En este artículo, le presentaremos el complejo algoritmo del convertidor espacio-temporal de atención constante Conformer, desarrollado con fines de previsión meteorológica y presentado en el artículo "Conformer: Embedding Continuous Attention in Vision Transformer for Weather Forecasting". En su artículo, los autores del método proponen el algoritmo Continuous Attention. Y lo combinan con los que comentamos en el artículo anterior ODE neuronal.
1. El algoritmo Conformer
El Conformer analiza el cambio climático a lo largo del tiempo, manteniendo la continuidad en el mecanismo de atención multicabeza. El mecanismo de atención se codifica como una función diferenciable en la arquitectura del transformador para modelizar dinámicas meteorológicas complejas.
Inicialmente, los autores del método tenían la tarea de construir un modelo que recibiera como entrada datos meteorológicos en la forma (XN*W*H, T). Aquí N representa el número de variables meteorológicas como la temperatura, la velocidad del viento, la presión, etc., mientras que W*H se refiere a la resolución espacial de la variable. T es el tiempo a lo largo del cual evoluciona el sistema. El modelo toma las variables meteorológicas en el momento t, estudia la evolución del sistema espacio-temporal y pronostica el tiempo en el siguiente paso temporal t+1.
![]()
Como las condiciones meteorológicas cambian constantemente a lo largo del tiempo, también será importante captar los cambios constantes en los datos ofrecidos para un tiempo fijo. La idea es aprender una representación latente continua de los datos meteorológicos usando solucionadores de ecuaciones diferenciales. Así, el modelo no solo predice el valor de la variable meteorológica en el momento "T", sino que la integral definida también analiza los cambios de la variable meteorológica, como la temperatura, desde el punto temporal inicial hasta el punto temporal "T". Podemos visualizar el sistema como:
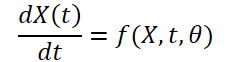
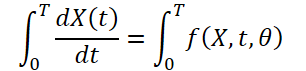
![]()
La información meteorológica es muy variable y resulta difícil de predecir tanto temporal como espacialmente. Las derivadas temporales de cada variable meteorológica se calculan para preservar la dinámica meteorológica y posibilitar una mejor extracción de características a partir de datos discretos. Los autores del método realizan un muestreo diferenciado a nivel de píxeles para captar los cambios continuos de los fenómenos meteorológicos a lo largo del tiempo.
La normalización de la derivación es uno de los pasos más importantes para garantizar la estabilidad del comportamiento del modelo de aprendizaje profundo. En su artículo, los autores del método amplían la idea de normalización como elementos independientes de la arquitectura del modelo. Asimismo, investigan el papel de la normalización cuando se aplica directamente a las derivadas. El trabajo del autor investiga el efecto sobre el resultado del modelo de los dos métodos de normalización más comunes y de la capa de pre-diferenciación para mostrar sus ventajas en sistemas continuos.
La atención es uno de los componentes clave de la arquitectura del Transformer. Se basa en la idea de identificar los bloques de datos de entrada más importantes en la etapa final de la previsión. A pesar de su éxito en diversas tareas, el Transformer sigue estando limitado en su capacidad de aprender a integrar información para sistemas muy dinámicos, como la previsión meteorológica. Los autores del método de Conformer desarrollan un mecanismo de Continuous Attention para modelizar cambios de estado continuos en las variables meteorológicas. En primer lugar, los autores del método sustituyen el análisis de las dependencias entre los elementos del estado inicial por la atención entre los parámetros correspondientes de diferentes estados del entorno. Esto nos permitirá calcular el espacio de incorporación contextual para cada variable meteorológica que cambia con el tiempo. Este paso garantizará que el modelo maneje la misma variable en diferentes estados del paquete en lugar de acceder a bloques en el mismo estado del entorno. La transformación de variables se aprende asignando a cada variable su propio Query, Key y Value para cada muestra de datos de origen, de forma similar a como se hace en un estado del entorno. El mecanismo de atención calcula las estimaciones de la dependencia entre variables de diferentes muestras (en las mismas posiciones de variable). De forma similar a los mecanismos de atención tradicionales, los pesos de dependencia obtenidos para distintos paquetes pueden usarse para añadir o ponderar la información asociada a estas variables.
Dicha modificación permite al modelo captar relaciones o dependencias entre las mismas variables meteorológicas en diferentes estados del entorno. Esto ha demostrado su utilidad en un escenario de previsión meteorológica en el que el modelo es capaz de representar las características en evolución continua de cada variable meteorológica. Para garantizar un aprendizaje continuo, los autores del método introducen derivadas en el mecanismo de Continuous Attention. Las ecuaciones diferenciales representan la dinámica de un sistema físico a lo largo del tiempo y consideran los valores de los datos faltantes. Los autores del método combinan un mecanismo de atención con un paradigma de aprendizaje basado en ecuaciones diferenciales para modelizar el cambio atmosférico en sus características espaciales y temporales. Además, este planteamiento elimina la limitación de modelado de complejas ecuaciones físicas en los modelos. Y en lugar de hacer predicciones solo para un momento concreto, el Conformer estudia los cambios transitorios de un paso temporal al siguiente, lo cual resulta importante para captar cambios meteorológicos sin precedentes.
Para calcular Continuous Attention, los autores del método proponen calcular las similitudes derivadas para las mismas variables en cada muestra de datos. Supongamos que tenemos 2 muestras de datos de origen de tamaño (N*W*H). Las denotaremos como X0 y X1 para el tiempo t0 y t1, respectivamente. Cada variable tiene sus propios tensores Q, K y V en ambas muestras. Continuous Attention se calculará del siguiente modo:
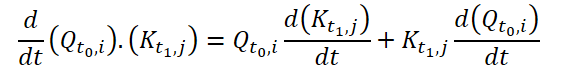
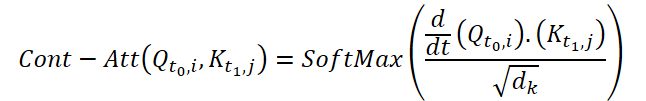
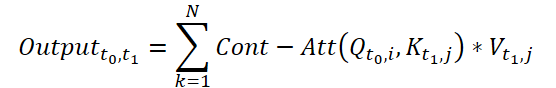
El resultado obtenido será la suma ponderada según la atención de los valores de variables similares en los datos de origen en un momento determinado t0 y t1. El proceso presentado calculará la atención entre variables similares en los datos de origen en todos los pasos temporales, lo cual permitirá al modelo captar las relaciones o interacciones entre variables a lo largo de toda la secuencia de muestras originales.
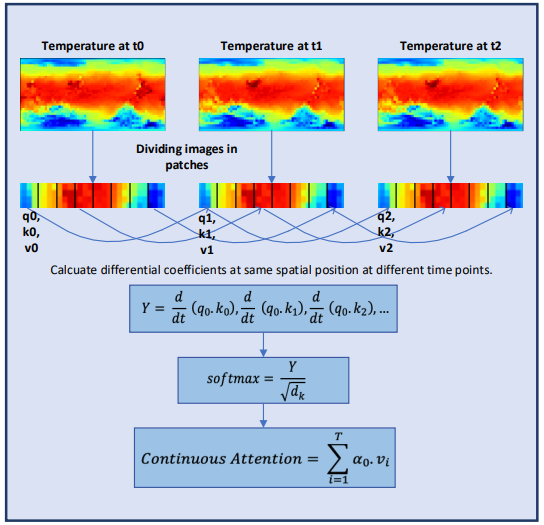
Para aprender aún mejor las características continuas de la información meteorológica, los autores del Conformer añaden capas al modelo Neural ODE. Como los solucionadores de tamaño adaptable tienen mayor precisión que los de tamaño fijo, los autores del método han elegido el método Dormand-Prince (Dopri5). Esto nos permitirá estudiar los cambios meteorológicos más pequeños posibles a lo largo del tiempo. El hilo de trabajo completo del Conformer y la colocación de las capas de Neural ODE se muestran en la visualización del autor del método que aparece a continuación.
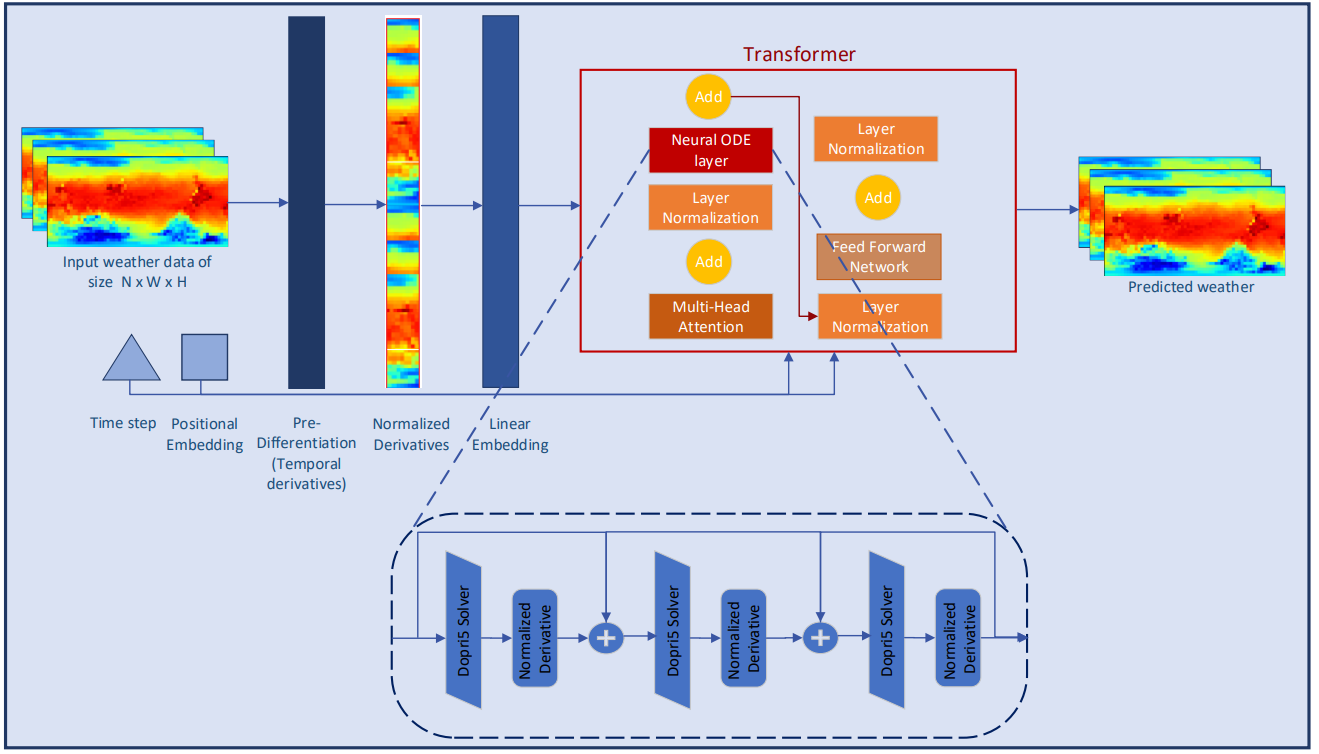
2. Implementación con MQL5
Tras considerar los aspectos teóricos de los métodos de Conformer, pasaremos a la aplicación práctica de los enfoques propuestos utilizando herramientas MQL5. Implementaremos la funcionalidad principal en una nueva clase CNeuronConformer, que crearemos heredando la clase básica de la capa neuronal CNeuronBaseOCL.
2.1 Arquitectura de la clase CNeuronConformer
En la estructura de la clase CNeuronConformer observamos los métodos ya conocidos redefinidos en todas las clases de implementación de los métodos de atención. Sin embargo, Continuous Attention es tan diferente de los métodos de atención comentados anteriormente que hemos decidido implementar el algoritmo completamente desde cero. No obstante, en esta aplicación usaremos desarrollos de trabajos anteriores.
Introduciremos 5 variables para registrar los parámetros básicos de la arquitectura de capas:
- iWindow - tamaño del vector de descripción de un parámetro en el tensor de datos iniciales;
- iDimension - dimensionalidad del vector de una entidad Query, Key, Value;
- iHeads - número de cabezas de atención;
- iVariables - número de parámetros que describen un estado del entorno;
- iCount - número de estados del entorno analizados (longitud de la secuencia inicial de datos).
Para generar las entidades Query, Key y Value, usaremos la capa de convolución cQKV, como ya hemos hecho anteriormente en casos similares. Este enfoque nos permitirá realizar la paralelización de las 3 entidades. Escribiremos las derivadas temporales de las entidades en la capa neuronal básica cdQKV.
Almacenaremos los coeficientes de dependencia, de forma similar al algoritmo Transformer nativo, en la matriz Score. Pero en esta implementación, no crearemos una copia de la matriz en el lado del programa principal. Crearemos un búfer en el contexto de OpenCL. Y en la variable local iScore de la clase CNeuronConformer, almacenaremos el puntero al búfer.
Asimismo, almacenaremos los resultados de la atención multicabeza en los búferes de la capa neuronal básica cAttentionOut. Y reduciremos la dimensionalidad de los datos obtenidos utilizando la capa de convolución cW0.
Según el algoritmo de Conformer, al bloque de atención le seguirá un bloque de capas neuronales de ecuaciones diferenciales ordinarias. Luego crearemos un array cNODE para ellas. Del mismo modo, para el bloque FeedForward, crearemos el array cFF.
class CNeuronConformer : public CNeuronBaseOCL { protected: //--- int iWindow; int iDimension; int iHeads; int iVariables; int iCount; //--- CNeuronConvOCL cQKV; CNeuronBaseOCL cdQKV; int iScore; CNeuronBaseOCL cAttentionOut; CNeuronConvOCL cW0; CNeuronNODEOCL cNODE[3]; CNeuronConvOCL cFF[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool attentionOut(void); //--- virtual bool AttentionInsideGradients(void); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronConformer(void) {}; ~CNeuronConformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint variables, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronConformerOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual void SetOpenCL(COpenCLMy *obj); virtual CLayerDescription* GetLayerInfo(void); };
Después declararemos todos los objetos internos de la clase como estáticos. Y esto nos permitirá dejar el constructor y el destructor de la clase "vacíos", mientras que la inicialización del objeto de clase según los requisitos del usuario se realizará en el método Init. En los parámetros del método transmitiremos los parámetros básicos de la arquitectura del objeto.
bool CNeuronConformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint variables, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * variables * units_count, optimization_type, batch)) return false;
En el cuerpo del método llamaremos directamente al método homónimo de la clase padre, que realiza el control mínimo necesario de los parámetros recibidos y la inicialización de los objetos heredados. Sabremos sobre los resultados de la ejecución de los controles y la inicialización a partir del resultado lógico devuelto por el método.
A continuación, inicializaremos la capa interna cQKV, que sirve para generar las entidades Query, Key y Value. Tenga en cuenta que el método Conformer prevé la creación de entidades para cada variable individual. Por lo tanto, el tamaño de la ventana de convolución y el tamaño del paso serán iguales a la longitud del vector de incorporación de una variable. En este caso, el número de elementos de la convolución será igual al producto del número de variables que describen un estado del entorno por el número de dichos estados que hay que analizar. El número de filtros de convolución será igual a 3 productos de la longitud de una entidad por el número de cabezas de atención.
if(!cQKV.Init(0, 0, OpenCL, window, window, 3 * window_key * heads, variables * units_count, optimization, iBatch)) return false;
Después de pasar con éxito los 2 métodos anteriores, almacenaremos los parámetros obtenidos en las variables internas.
iWindow = int(fmax(window, 1)); iDimension = int(fmax(window_key, 1)); iHeads = int(fmax(heads, 1)); iVariables = int(fmax(variables, 1)); iCount = int(fmax(units_count, 1));
Luego inicializaremos la capa interna para registrar las derivadas temporales parciales.
if(!cdQKV.Init(0, 1, OpenCL, 3 * iDimension * iHeads * iVariables * iCount, optimization, iBatch)) return false;
Y crearemos un búfer de coeficientes de atención.
iScore = OpenCL.AddBuffer(sizeof(float) * iCount * iHeads * iVariables * iCount, CL_MEM_READ_WRITE); if(iScore < 0) return false;
Con la inicialización de las capas internas cAttentionOut y cW0 completaremos el trabajo de preparación de los objetos del bloque de atención.
if(!cAttentionOut.Init(0, 2, OpenCL, iDimension * iHeads * iVariables * iCount, optimization, iBatch)) return false; if(!cW0.Init(0, 3, OpenCL, iDimension * iHeads, iDimension * iHeads, iWindow, iVariables * iCount, optimization, iBatch)) return false;
Aquí debemos señalar que a la salida del bloque de atención, la dimensionalidad de los datos deberá corresponderse con la dimensionalidad de los datos de origen recibidos. Al mismo tiempo, como el algoritmo de Conformer prevé el análisis de dependencias dentro de una variable pero en diferentes estados del entorno, también realizaremos la reducción de la dimensionalidad dentro de variables separadas.
Todas las capas neuronales de ecuaciones diferenciales ordinarias usadas tienen la misma arquitectura. Esto nos permitirá inicializarlos en un ciclo.
for(int i = 0; i < 3; i++) if(!cNODE[i].Init(0, 4 + i, OpenCL, iWindow, iVariables, iCount, optimization, iBatch)) return false;
Y nos quedará inicializar los objetos del bloque FeedForward.
if(!cFF[0].Init(0, 7, OpenCL, iWindow, iWindow, 4 * iWindow, iVariables * iCount, optimization, iBatch)) return false; if(!cFF[1].Init(0, 8, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iVariables * iCount, optimization, iBatch)) return false;
Antes de que el método finalice, organizaremos la sustitución del puntero del búfer de gradiente de nuestra clase por el búfer de gradiente de la última capa del bloque FeedForward. Esta técnica permite evitar el copiado innecesario de datos, y ya la hemos utilizado muchas veces en la implementación de muchos métodos.
if(getGradientIndex() != cFF[1].getGradientIndex()) SetGradientIndex(cFF[1].getGradientIndex()); //--- return true; }
2.2 Implementación de la pasada directa
Después de inicializar la instancia de la clase, procederemos a implementar el algoritmo de pasada directa. Y aquí deberemos prestar atención al algoritmo de Continuous Attention propuesto por los autores del método Conformer. Este usa derivadas parciales de las entidades Query y Key.
Obviamente, en la fase de entrenamiento del modelo, no dispondremos más que de la aproximación más cercana de la función de dependencia de estas entidades respecto al tiempo. Por lo tanto, abordaremos la cuestión de la definición de las derivadas desde un ángulo distinto. En primer lugar, deberemos recordar el significado geométrico de la derivada de una función. Y este establece que la derivada de una función sobre el argumento en un punto concreto es el ángulo de inclinación de la recta tangente al gráfico de la función en ese punto y muestra el cambio aproximado (para una función lineal, el exacto) en el valor de la función cuando el argumento se modifica en 1.
En nuestros datos de origen, obtendremos los estados del entorno con un paso de tiempo fijo que será igual al marco temporal analizado. Para simplificar nuestra aplicación, no consideraremos el marco temporal específico y equipararemos el paso de tiempo entre 2 estados sucesivos a "1". Así, podremos obtener alguna aproximación de la derivada de la función analíticamente tomando el cambio medio en el valor de la función a lo largo de 2 transiciones sucesivas entre los estados del anterior al actual y del actual al siguiente.
Implementaremos el mecanismo propuesto en el lado del contexto OpenCL en el kernel TimeDerivative. En los parámetros del kernel, pasaremos los punteros a 2 búferes: el de datos de origen y el de resultados. Así como la dimensionalidad de una sola entidad.
__kernel void TimeDerivative(__global float *qkv, __global float *dqkv, int dimension) { const size_t pos = get_global_id(0); const size_t variable = get_global_id(1); const size_t head = get_global_id(2); const size_t total = get_global_size(0); const size_t variables = get_global_size(1); const size_t heads = get_global_size(2);
Planeamos ejecutar el kernel en 3 dimensiones:
- El número de estados del entorno que deben analizarse;
- El número de variables que describen un estado del entorno;
- El número de cabezas de atención.
En el cuerpo del kernel, identificaremos directamente el hilo actual en las 3 dimensiones. A continuación, determinamos los desplazamientos en los búferes de las entidades que deben procesarse. Por comodidad, utilizaremos un búfer de datos de origen y resultados del mismo tamaño. Por consiguiente, los desplazamientos también resultarán idénticos.
const int shift = 3 * heads * variables * dimension; const int shift_query = pos * shift + (3 * variable * heads + head) * dimension; const int shift_key = shift_query + heads * dimension;
Después organizaremos el cálculo de las desviaciones en un ciclo con una enumeración de todos los elementos de una misma entidad. Primero determinaremos la derivación para Query de forma analítica.
for(int i = 0; i < dimension; i++) { //--- dQ/dt { int count = 0; float delta = 0; float value = qkv[shift_query + i]; if(pos > 0) { delta = value - qkv[shift_query + i - shift]; count++; } if(pos < (total - 1)) { delta += qkv[shift_query + i + shift] - value; count++; } if(count > 0) dqkv[shift_query + i] = delta / count; }
Aquí deberemos prestar atención a los casos especiales del primer y el último elemento de la secuencia. En los estados anteriores solo tendremos una transición. No queremos complicar el algoritmo, así que solo usaremos los datos disponibles.
Del mismo modo, también calcularemos las derivadas para Key.
//--- dK/dt { int count = 0; float delta = 0; float value = qkv[shift_key + i]; if(pos > 0) { delta = value - qkv[shift_key + i - shift]; count++; } if(pos < (total - 1)) { delta += qkv[shift_key + i + shift] - value; count++; } if(count > 0) dqkv[shift_key + i] = delta / count; } } }
Una vez determinadas las derivadas temporales parciales, dispondremos de todos los datos necesarios para ejecutar Continuous Attention. En el lado del contexto OpenCL, implementaremos el algoritmo propuesto en el kernel FeedForwardContAtt. En los parámetros del kernel transmitiremos los punteros a los 4 búferes de datos: 2 búferes de datos de origen (las entidades y sus derivadas), un búfer de matriz de coeficientes de dependencia y un búfer de resultados de atención multicabeza. Además, transmitiremos 2 constantes en los parámetros del kernel: la dimensionalidad del vector de entidades y el número de cabezas de atención.
__kernel void FeedForwardContAtt(__global float *qkv, __global float *dqkv, __global float *score, __global float *out, int dimension, int heads) { const size_t query = get_global_id(0); const size_t key = get_global_id(1); const size_t variable = get_global_id(2); const size_t queris = get_global_size(0); const size_t keis = get_global_size(1); const size_t variables = get_global_size(2);
En el cuerpo del kernel, como siempre, primero identificaremos el hilo actual en todas las dimensiones del espacio de tareas. En este caso, se utilizaremos un espacio de tareas tridimensional con la creación de grupos locales dentro de una única consulta para una única variable.
Aquí también declararemos un array local para los datos intermedios.
const uint ls_score = min((uint)keis, (uint)LOCAL_ARRAY_SIZE); __local float local_score[LOCAL_ARRAY_SIZE];
Y luego organizaremos un ciclo con iteraciones según el número de cabezas de atención. En el cuerpo del ciclo, realizaremos secuencialmente análisis de datos en todas las cabezas de atención.
for(int head = 0; head < heads; head++) { const int shift = 3 * heads * variables * dimension; const int shift_query = query * shift + (3 * variable * heads + head) * dimension; const int shift_key = key * shift + (3 * variable * heads + heads + head) * dimension; const int shift_out = dimension * (heads * (query * variables + variable) + head); int shift_score = keis * (heads * (query * variables + variable) + head) + key;
En primer lugar, determinaremos el desplazamiento en los búferes de datos hacia los elementos analizados. A continuación, calcularemos los coeficientes de dependencia. La determinación de estos coeficientes se realizará en 3 etapas. Primero calcularemos los valores exponenciales de d/dt(Q.K) y los almacenaremos en el elemento correspondiente del búfer de coeficientes de dependencia. Los cálculos se realizarán en hilos paralelos del mismo grupo de trabajo.
//--- Score float scr = 0; for(int d = 0; d < dimension; d++) scr += qkv[shift_query + d] * dqkv[shift_key + d] + qkv[shift_key + d] * dqkv[shift_query + d]; scr = exp(min(scr / sqrt((float)dimension), 30.0f)); score[shift_score] = scr; barrier(CLK_LOCAL_MEM_FENCE);
En el segundo paso, recopilaremos la suma de todos los valores obtenidos.
if(key < ls_score) { local_score[key] = scr; for(int k = ls_score + key; k < keis; k += ls_score) local_score[key] += score[shift_score + k]; } barrier(CLK_LOCAL_MEM_FENCE); //--- int count = ls_score; do { count = (count + 1) / 2; if(key < count) { if((key + count) < keis) { local_score[key] += local_score[key + count]; local_score[key + count] = 0; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Y en el tercer paso, normalizaremos los coeficientes de dependencia.
score[shift_score] /= local_score[0];
barrier(CLK_LOCAL_MEM_FENCE);
Y al final de las iteraciones del ciclo, calcularemos el valor de los resultados del bloque de atención según las relaciones de dependencia definidas con anterioridad.
shift_score -= key; for(int d = key; d < dimension; d += keis) { float sum = 0; int shift_value = (3 * variable * heads + 2 * heads + head) * dimension + d; for(int v = 0; v < keis; v++) sum += qkv[shift_value + v * shift] * score[shift_score + v]; out[shift_out + d] = sum; } barrier(CLK_LOCAL_MEM_FENCE); } //--- }
Después de crear los kernels de la implementación del algoritmo de Continuous Attention en el lado del contexto OpenCL, tendremos que implementar la llamada de los kernels creados anteriormente desde el programa principal. Para ello, añadiremos el método attentionOut a nuestra clase CNeuronConformer.
No hemos dividido la llamada al kernel en métodos separados. Al fin y al cabo, se llamarán secuencialmente, mientras que la división del algoritmo en el lado OpenCL del programa se deberá a la diferencia en el espacio de tareas.
Como este método se creará solo para ser llamado dentro de la clase, su algoritmo se construirá enteramente sobre el uso de objetos y variables internas. Esto ha permitido eliminar por completo los parámetros del método.
bool CNeuronConformer::attentionOut(void) { if(!OpenCL) return false;
En el cuerpo del método, comprobaremos la relevancia del puntero al contexto OpenCL. Después, haremos los preparativos para llamar el primer kernel de definiciones de entidades derivadas.
En primer lugar, definiremos el espacio de tareas.
bool CNeuronConformer::attentionOut(void) { if(!OpenCL) return false; //--- Time Derivative { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iVariables, iHeads};
A continuación, transmitiremos los parámetros al kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_TimeDerivative, def_k_tdqkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_TimeDerivative, def_k_tddqkv, cdQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_TimeDerivative, def_k_tddimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Y pondremos el kernel en la cola de ejecución.
if(!OpenCL.Execute(def_k_TimeDerivative, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } }
El algoritmo general para colocar el segundo kernel en la cola de ejecución será similar, solo que añadiremos el espacio de tareas del grupo de trabajo.
//--- MH Attention Out { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iCount, iVariables}; uint local_work_size[3] = {1, iCount, 1};
Además, aumentará el número de parámetros que debemos transmitir.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardContAtt, def_k_caqkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardContAtt, def_k_cadqkv, cdQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardContAtt, def_k_cascore, iScore)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardContAtt, def_k_caout, cAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardContAtt, def_k_cadimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardContAtt, def_k_caheads, int(iHeads))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Una vez realizado el trabajo preparatorio, el kernel se colocará en la cola de ejecución.
if(!OpenCL.Execute(def_k_FeedForwardContAtt, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
Sin embargo, la llamada a 2 kernels solo implementará una parte del método de Conformer propuesto. Más concretamente, la parte principal de Continuous Attention. Describiremos el algoritmo completo de la pasada directa de nuestra clase en el método CNeuronConformer::feedForward. De forma similar a los métodos homónimos de las clases creadas anteriormente, en los parámetros, el método feedForward recibirá el puntero al objeto de la capa anterior que contiene los datos de origen para nuestra clase.
bool CNeuronConformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Generate Query, Key, Value if(!cQKV.FeedForward(NeuronOCL)) return false;
En el cuerpo del método, primero llamaremos al método de pasada directa de la capa interna cQKV para formar los tensores de las entidades Query, Key y Value. Después de eso, llamaremos al método creado anteriormente de la llamada de los kernels del mecanismo de Continuous Attention.
//--- MH Continuas Attention if(!attentionOut()) return false;
A continuación, redimensionaremos los resultados de la atención multicabeza resultante. El tensor resultante se añadirá a los datos de origen y se normalizará dentro de las variables individuales.
if(!cW0.FeedForward(GetPointer(cAttentionOut))) return false; if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cW0.getOutput(), iDimension, true, 0, 0, 0, 1)) return false;
Detrás del bloque de Continuous Attention, el algoritmo de Conformer proporcionará un bloque de solucionadores de ecuaciones diferenciales ordinarias. Tendremos que organizar su llamada en un ciclo. A continuación sumaremos los tensores a la entrada y a la salida del bloque. Y normalizaremos el resultado.
//--- Neural ODE CNeuronBaseOCL *prev = GetPointer(cW0); for(int i = 0; i < 3; i++) { if(!cNODE[i].FeedForward(prev)) return false; prev = GetPointer(cNODE[i]); } if(!SumAndNormilize(prev.getOutput(), cW0.getOutput(), prev.getOutput(), iDimension, true, 0, 0, 0, 1)) return false;
Al final del método de pasada directa, realizaremos una pasa directa del bloque FeedForward seguido de la suma y normalización de los resultados.
//--- Feed Forward for(int i = 0; i < 2; i++) { if(!cFF[i].FeedForward(prev)) return false; prev = GetPointer(cFF[i]); } if(!SumAndNormilize(prev.getOutput(), cNODE[2].getOutput(), getOutput(), iDimension, true, 0, 0, 0, 1)) return false; //--- return true; }
Con esto concluiremos nuestro trabajo sobre la aplicación del algoritmo de pasada directa. Pero para entrenar los modelos también necesitaremos implementar la pasada inversa con la distribución del gradiente de error a todos los elementos según su influencia en el resultado final y la corrección de los parámetros del modelo en la dirección de la reducción del error global del modelo.
2.3 Organización de la pasada inversa
La aplicación del algoritmo de pasada inversa también requerirá la creación de nuevos kernels. Y en primer lugar tendremos que crear un kernel de distribución del gradiente de error a través del bloque Continuous Attention - HiddenGradientContAtt. En los parámetros del kernel transmitiremos los punteros a 6 búferes de datos y 1 constante.
__kernel void HiddenGradientContAtt(__global float *qkv, __global float *qkv_g, __global float *dqkv, __global float *dqkv_g, __global float *score, __global float *out_g, int dimension) { const size_t pos = get_global_id(0); const size_t variable = get_global_id(1); const size_t head = get_global_id(2); const size_t total = get_global_size(0); const size_t variables = get_global_size(1); const size_t heads = get_global_size(2);
De forma similar al kernel de pasada directa, implementaremos la pasada inversa en un espacio de tareas tridimensional, pero sin agrupación en grupos de trabajo. En el cuerpo del kernel, identificaremos inmediatamente el hilo en todas las dimensiones del espacio de tareas.
El algoritmo kernel posterior puede dividirse en 3 partes según el objeto de atribución del gradiente de error. En el primer bloque, distribuiremos el gradiente de error a la entidad Value.
//--- Value gradient { const int shift_value = dimension * (heads * (3 * variables * pos + 3 * variable + 2) + head); const int shift_out = dimension * (head + variable * heads); const int shift_score = total * (variable * heads + head); const int step_out = variables * heads * dimension; const int step_score = variables * heads * total; //--- for(int d = 0; d < dimension; d++) { float sum = 0; for(int g = 0; g < total; g++) sum += out_g[shift_out + g * step_out + d] * score[shift_score + g * step_score]; qkv_g[shift_value + d] = sum; } }
En primer lugar, determinaremos el desplazamiento en los búferes de datos hacia los elementos analizados. Y luego, en un sistema de ciclos, recopilaremos los gradientes de error en todos los elementos dependientes y en todos los elementos del vector de entidad.
En el segundo bloque, distribuiremos los gradientes de error hasta Query. Aquí, sin embargo, el algoritmo será un poco más complicado.
//--- Query gradient { const int shift_out = dimension * (heads * (pos * variables + variable) + head); const int step = 3 * variables * heads * dimension; const int shift_query = dimension * (3 * heads * variable + head) + pos * step; const int shift_key = dimension * (heads * (3 * variable + 1) + head); const int shift_value = dimension * (heads * (3 * variable + 2) + head); const int shift_score = total * (heads * (pos * variables + variable) + head);
Al igual que en el primer bloque, primero determinamos el desplazamiento a los elementos analizados en los búferes de datos. Después de lo cual, primero tendremos que distribuir el gradiente a la matriz de coeficientes de dependencia y ajustarlo usando la derivada de la función SoftMax.
//--- Score gradient for(int k = 0; k < total; k++) { float score_grad = 0; float scr = score[shift_score + k]; for(int v = 0; v < total; v++) { float grad = 0; for(int d = 0; d < dimension; d++) grad += qkv[shift_value + v * step + d] * out_g[shift_out + d]; score_grad += score[shift_score + v] * grad * ((float)(pos == v) - scr); } score_grad /= sqrt((float)dimension);
Y solo entonces podremos distribuir el gradiente de error a la entidad Query. Sin embargo, a diferencia del algoritmo de Transformer nativo, en este caso distribuiremos también el gradiente de error a las correspondientes entidades Query derivadas según el tiempo.
//--- Query gradient for(int d = 0; d < dimension; d++) { if(k == 0) { dqkv_g[shift_query + d] = score_grad * qkv[shift_key + k * step + d]; qkv_g[shift_query + d] = score_grad * dqkv[shift_key + k * step + d]; } else { dqkv_g[shift_query + d] += score_grad * qkv[shift_key + k * step + d]; qkv_g[shift_query + d] += score_grad * dqkv[shift_key + k * step + d]; } } } }
La distribución del gradiente de error a la entidad Key y su derivada parcial se realizará de forma similar. Solo que en la matriz de coeficientes de dependencia, pasaremos por una dimensión diferente.
//--- Key gradient { const int shift_key = dimension * (heads * (3 * variables * pos + 3 * variable + 1) + head); const int shift_out = dimension * (heads * variable + head); const int step_out = variables * heads * dimension; const int step = 3 * variables * heads * dimension; const int shift_query = dimension * (3 * heads * variable + head); const int shift_value = dimension * (heads * (3 * variable + 2) + head) + pos * step; const int shift_score = total * (heads * variable + head); const int step_score = variables * heads * total; //--- Score gradient for(int q = 0; q < total; q++) { float score_grad = 0; float scr = score[shift_score + q * step_score]; for(int g = 0; g < total; g++) { float grad = 0; for(int d = 0; d < dimension; d++) grad += qkv[shift_value + d] * out_g[shift_out + d + g * step_out]; score_grad += score[shift_score + q * step_score + g] * grad * ((float)(q == pos) - scr); } score_grad /= sqrt((float)dimension); //--- Key gradient for(int d = 0; d < dimension; d++) { if(q == 0) { dqkv_g[shift_key + d] = score_grad * qkv[shift_query + q * step + d]; qkv_g[shift_key + d] = score_grad * dqkv[shift_query + q * step + d]; } else { qkv_g[shift_key + d] += score_grad * dqkv[shift_query + q * step + d]; dqkv_g[shift_key + d] += score_grad * qkv[shift_query + q * step + d]; } } } } }
Como podemos ver, en el kernel anterior hemos distribuido el gradiente de error tanto a las propias entidades como a sus derivadas. Recordemos que estamos calculando las derivadas temporales parciales de forma analítica a partir de los valores de las propias entidades para distintos estados del entorno. Lógicamente, también podremos transferir el gradiente de error de forma similar. Este algoritmo lo implementaremos en el kernel HiddenGradientTimeDerivative.
__kernel void HiddenGradientTimeDerivative(__global float *qkv_g, __global float *dqkv_g, int dimension) { const size_t pos = get_global_id(0); const size_t variable = get_global_id(1); const size_t head = get_global_id(2); const size_t total = get_global_size(0); const size_t variables = get_global_size(1); const size_t heads = get_global_size(2);
Los parámetros del kernel y el espacio de tareas son similares a los de la pasada directa, solo que en lugar de búferes de resultados, utilizaremos búferes de gradiente de error.
En el cuerpo del método, identificaremos inmediatamente el hilo en todas las dimensiones del espacio de tareas utilizado. A continuación, determinaremos el desplazamiento en los búferes de datos.
const int shift = 3 * heads * variables * dimension; const int shift_query = pos * shift + (3 * variable * heads + head) * dimension; const int shift_key = shift_query + heads * dimension;
De forma similar al cálculo de las derivadas, realizaremos la distribución de los gradientes de error.
for(int i = 0; i < dimension; i++) { //--- dQ/dt { int count = 0; float grad = 0; float current = dqkv_g[shift_query + i]; if(pos > 0) { grad += current - dqkv_g[shift_query + i - shift]; count++; } if(pos < (total - 1)) { grad += dqkv_g[shift_query + i + shift] - current; count++; } if(count > 0) grad /= count; qkv_g[shift_query + i] += grad; }
//--- dK/dt { int count = 0; float grad = 0; float current = dqkv_g[shift_key + i]; if(pos > 0) { grad += current - dqkv_g[shift_key + i - shift]; count++; } if(pos < (total - 1)) { grad += dqkv_g[shift_key + i + shift] - current; count++; } if(count > 0) grad /= count; qkv_g[shift_key + i] += dqkv_g[shift_key + i] + grad; } } }
Estos kernels se llamarán en el lado del programa principal en el método CNeuronConformer::AttentionInsideGradients. Su algoritmo será similar al método de pasada directa correspondiente, solo que la llamada al kernel se realizará en orden inverso. En primer lugar, colocaremos el kernel de distribución del gradiente en la cola de ejecución a través del bloque Continuous Attention.
bool CNeuronConformer::AttentionInsideGradients(void) { if(!OpenCL) return false; //--- MH Attention Out Gradient { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iVariables, iHeads};
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcaqkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcaqkv_g, cQKV.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcadqkv, cdQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcadqkv_g, cdQKV.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcascore, iScore)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcaout_g, cAttentionOut.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientContAtt, def_k_hgcadimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.Execute(def_k_HiddenGradientContAtt, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } }
Y luego añadiremos el gradiente de error de las derivadas parciales.
//--- Time Derivative Gradient { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iVariables, iHeads};
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HGTimeDerivative, def_k_tdqkv, cQKV.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HGTimeDerivative, def_k_tddqkv, cdQKV.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HGTimeDerivative, def_k_tddimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.Execute(def_k_HGTimeDerivative, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
Una vez terminado el trabajo preparatorio, ensamblaremos todo el algoritmo de distribución del gradiente de error en el método CNeuronConformer::calcInputGradients, en cuyos parámetros obtendremos el puntero al objeto de la capa anterior. A él le deberemos transferir el gradiente de error.
bool CNeuronConformer::calcInputGradients(CNeuronBaseOCL *prevLayer) { //--- Feed Forward Gradient if(!cFF[1].calcInputGradients(GetPointer(cFF[0]))) return false; if(!cFF[0].calcInputGradients(GetPointer(cNODE[2]))) return false; if(!SumAndNormilize(Gradient, cNODE[2].getGradient(), cNODE[2].getGradient(), iDimension, false)) return false;
Gracias al intercambio de búferes de gradiente que hemos organizado, la capa posterior nos ha transmitido el gradiente de error directamente al búfer de la última capa interna en el bloque FeedForward. Y ahora, sin operaciones de copiado innecesarias, llamaremos secuencialmente a los métodos de pasada inversa de objetos del bloque FeedForward.
Permítanme recordarles que durante el pasada directa hemos sumado el valor de los búferes en la entrada y la salida del bloque FeedForward. Del mismo modo, sumaremos los gradientes de error. Y transmitiremos el resultado obtenido a la salida del bloque de capas de ecuaciones diferenciales ordinarias. Después organizaremos un ciclo de iteración inversa de las capas internas del bloque Neural ODE y la distribución del gradiente de error en ellas.
//--- Neural ODE Gradient CNeuronBaseOCL *prev = GetPointer(cNODE[1]); for(int i = 2; i > 0; i--) { if(!cNODE[i].calcInputGradients(prev)) return false; prev = GetPointer(cNODE[i - 1]); } if(!cNODE[0].calcInputGradients(GetPointer(cW0))) return false; if(!SumAndNormilize(cW0.getGradient(), cNODE[2].getGradient(), cW0.getGradient(), iDimension, false)) return false;
Aquí también sumaremos los gradientes de error a la entrada y a la salida del bloque.
En primer lugar, durante la propagación directa, y en último, durante la propagación inversa, en el bloque Continuous Attention distribuiremos el gradiente de error entre las cabezas de atención.
//--- MH Attention Gradient if(!cW0.calcInputGradients(GetPointer(cAttentionOut))) return false;
A continuación, distribuiremos el gradiente de error a través del bloque de atención.
if(!AttentionInsideGradients()) return false;
Y bajaremos el gradiente de error al nivel de la capa anterior.
//--- Query, Key, Value Graddients if(!cQKV.calcInputGradients(prevLayer)) return false;
Al final del método, sumaremos el gradiente de error a la entrada y a la salida del bloque de atención.
if(!SumAndNormilize(cW0.getGradient(), prevLayer.getGradient(), prevLayer.getGradient(), iDimension, false)) return false; //--- return true; }
Tras distribuir el gradiente de error entre todos los objetos según su influencia en el resultado final, procederemos a optimizar los parámetros para reducir el error global de los modelos.
Aquí debemos decir que todos los parámetros entrenados de nuestra clase CNeuronConformer se hallan en las capas neuronales internas. Por lo tanto, para actualizar los parámetros del modelo, solo tendremos que llamar a los métodos de los objetos internos homónimos uno por uno.
bool CNeuronConformer::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { //--- MH Attention if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; if(!cW0.UpdateInputWeights(GetPointer(cAttentionOut))) return false;
//--- Neural ODE CNeuronBaseOCL *prev = GetPointer(cW0); for(int i = 0; i < 3; i++) { if(!cNODE[i].UpdateInputWeights(prev)) return false; prev = GetPointer(cNODE[i]); }
//--- Feed Forward for(int i = 0; i < 2; i++) { if(!cFF[i].UpdateInputWeights(prev)) return false; prev = GetPointer(cFF[i]); } //--- return true; }
Con esto concluirá nuestra consideración de los métodos de la nueva clase CNeuronConformer, en la que hemos implementado los principales enfoques propuestos por los autores del método Conformer. Lamentablemente, el formato del artículo no nos permite detenernos en los métodos auxiliares de la clase con más detalle. Le sugiero que se familiarice con ellos en el anexo. También encontrará el código completo de todos los programas usados en la elaboración del artículo. Continuemos.
2.4 Arquitectura de los modelos entrenados
Y antes de pasar a la arquitectura de los modelos entrenados, querríamos recordarles que el método Conformer implica el análisis de parámetros individuales de la descripción del entorno. Por consiguiente, en el procesamiento inicial de los datos de origen, tendremos que crear una incorporación para cada parámetro analizado.
En primer lugar, echaremos un vistazo a la estructura de los datos analizados.
......... ......... sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; ........ ........
En nuestra aplicación, hemos dividido los datos de origen del siguiente modo:
- Descripción de la última vela (4 elementos)
- RSI (1 elemento)
- CCI (1 elemento)
- ATF (1 elemento)
- MACD (2 elementos)
Esta división supone solo nuestra visión. Usted podrá utilizar una división diferente en su trabajo. No obstante, deberá reflejarse en la arquitectura de los modelos entrenados.
Así, la arquitectura de los modelos entrenados se describirá en el método CreateDescriptions. En los parámetros, el método obtendrá los 3 punteros a los arrays dinámicos para transmitir la arquitectura de los 3 modelos.
En el cuerpo del método comprobaremos primero los punteros recibidos y, si es necesario, crearemos nuevos objetos de array dinámicos.
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Luego transmitiremos los datos de descripción sin procesar del estado actual del entorno a la entrada del modelo del Codificador.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos obtenidos se someterán a un procesamiento primario en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, crearemos las incorporaciones de los parámetros de estado actuales según la estructura presentada anteriormente.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {4, 1, 1, 1, 2}; ArrayCopy(descr.windows, temp); }
Tenga en cuenta que en las arquitecturas de incorporación comentadas anteriormente, hemos especificado un tamaño de ventana igual al tamaño de los datos de origen. Al hacerlo, hemos creado una incorporación de un estado independiente. Sin embargo, en este caso, partiremos del análisis de la descripción de la última barra con la división de los parámetros en los bloques anteriores. No obstante, si analizamos más de una barra o se da otra configuración de datos, esto debería reflejarse en el tamaño de las ventanas de los datos analizados.
prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
La capa de convolución posterior completará el proceso de generación de las incorporaciones de los datos de origen.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count * 5; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Después añadiremos a las incorporaciones los armónicos de la codificación de la posición.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout * 5; if(!encoder.Add(descr)) { delete descr; return false; }
Y al final del modelo codificador crearemos un bloque de 5 capas de Conformer consecutivas. A continuación, especificaremos los parámetros de la capa de la misma manera que las otras capas de atención. E indicaremos el número de variables analizadas en descr.layers.
for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 5; if(!encoder.Add(descr)) { delete descr; return false; } }
En el núcleo del modelo del Actor, como antes, habrá una capa de atención cruzada que evaluará las dependencias entre el estado actual de la cuenta y una representación comprimida del estado actual del entorno obtenida del Codificador.
A la entrada del modelo, suministraremos primero una descripción del estado de la cuenta.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Lo convertiremos en incorporación.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y añadiremos un bloque de 3 capas de atención cruzada.
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, GPTBars * 5}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
A partir de los datos obtenidos del bloque de atención cruzada formaremos la política estocástica del Actor.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El modelo del Crítico seguirá una estructura similar, solo que en lugar del estado de la cuenta, asignará las acciones del Actor al estado del entorno.
Luego introduciremos en la entrada del modelo las acciones generadas del Actor.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Que se convertirán en una incorporación.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Y después tendremos un bloque de atención cruzada de 3 capas.
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, GPTBars * 5}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } }
La evaluación directa de las acciones se realizará en el bloque del perceptrón.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.5 Entrenamiento de los modelos
Los cambios que hemos hecho no afectan al proceso de interacción con el entorno. Esto nos ha permitido utilizar el asesor experto "...\Conformer\Research.mq5" sin cambios para recopilar los datos de entrenamiento primarios y luego actualizar la muestra de entrenamiento. Además, a pesar de los cambios en el enfoque del análisis de los datos de origen, hemos dejado inalterada la estructura de los datos, lo cual nos permite utilizar muestras de entrenamiento recogidas previamente en el proceso de entrenamiento del modelo.
No obstante, hemos realizado algunos cambios en el proceso de entrenamiento del modelo que se reflejarán en el algoritmo del asesor experto "...\Conformer\Study.mq5". En el ámbito de este artículo, solo consideraremos el método de entrenamiento directo de los modelos Train.
Al igual que antes, al principio del método, generaremos un vector de probabilidades de selección de trayectorias según sus rendimientos. Los pasadas más rentables obtendrán una mayor probabilidad cuando se muestrean durante el entrenamiento del modelo.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
A continuación, inicializaremos las variables locales.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Y crearemos un sistema de ciclos anidados de entrenamiento de modelos. En el cuerpo del ciclo externo, muestrearemos una trayectoria del búfer de repetición de experiencias y el estado inicial de entrenamiento en él.
int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Después limpiaremos los búferes recurrentes del Codificador y determinaremos el estado final del paquete de entrenamiento.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
Una vez realizado el trabajo preparatorio, organizaremos un ciclo anidado de iteración directa de los estados entrenados.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
En el cuerpo del ciclo, primero cargaremos el estado del entorno desde el búfer de reproducción de experiencias y lo analizaremos en nuestro codificador, llamando al método de pasada directa.
A continuación, cargaremos las acciones del Actor desde el búfer de repetición de experiencias y haremos que nuestro Crítico las evalúe.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite(); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Asimismo, ajustamos inmediatamente la estimación del Crítico hacia la recompensa real del búfer de repetición de experiencias.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); Critic.TrainMode(true); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
También transmitiremos el gradiente de error del Crítico al Codificador para optimizar el análisis del entorno.
En el siguiente paso, cargaremos desde el búfer de repetición de experiencias una descripción del estado de la cuenta correspondiente a la condición del entorno analizada.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
A partir de estos datos, generaremos la acción del Actor según su política actual.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y la evaluaremos según nuestro Crítico.
if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
El ajuste de la política del Actor se realizará en 2 etapas. Primero ajustaremos la política para minimizar la desviación de las acciones reales del Agente. Esto nos permitirá mantener la política del Actor en una distribución cercana a nuestra muestra de entrenamiento.
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
En el segundo paso, ajustaremos la política del Actor según la evaluación de sus acciones por parte del Crítico. Para ello, desactivaremos el modo de aprendizaje del Crítico y haremos pasar por él el gradiente de error hasta el Actor. A continuación, ajustaremos la política en la dirección del gradiente de error resultante.
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), -1, -1, false) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Nótese que en ambos casos de ajuste de la política del Actor, transmitimos el gradiente de error a nuestro Codificador y ajustamos "su visión" del entorno. De este modo pretendemos que los análisis del entorno sean lo más informativos posible.
Una vez actualizados los parámetros de todos los modelos, bastará con informar al usuario del progreso del proceso de entrenamiento y pasar a la siguiente iteración del sistema de ciclos.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
El proceso de entrenamiento se repetirá hasta que se enumeren por completo todas las iteraciones del sistema de ciclos. Y una vez completado con éxito el proceso de entrenamiento, borraremos la casilla de comentarios del gráfico.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Luego mostraremos los resultados del proceso de entrenamiento del modelo e inicializaremos la finalización del asesor de entrenamiento.
Con esto concluiremos el análisis de los algoritmos de los programas utilizados en el artículo. Podrá ver su código completo en el archivo adjunto.
3. Simulación
En el marco de este artículo, nos hemos familiarizado con el método Conformer e implementado los enfoques propuestos utilizando las herramientas MQL5. Ahora tenemos la oportunidad de entrenar el modelo con el método propuesto y probarlo con datos reales.
Como de costumbre, entrenaremos y probaremos el modelo utilizando el simulador de estrategias de MetaTrader 5 con datos históricos reales de EURUSD y el marco temporal H1. Utilizaremos los datos históricos de los 7 primeros meses de 2023 para entrenar los modelos, mientras que las pruebas del modelo entrenado se realizarán con datos históricos de agosto de 2023.
Para preparar este artículo, hemos entrenado el modelo con una muestra recogida para el entrenamiento de los modelos de los artículos anteriores de esta serie.
Debo decir que el cambio de la arquitectura de los modelos y el algoritmo del proceso de entrenamiento ha aumentado ligeramente el coste por iteración. Sin embargo, los enfoques propuestos muestran estabilidad en el proceso de entrenamiento, lo que en mi opinión reduce el número de repeticiones necesarias para entrenar el modelo.
En el proceso de entrenamiento, hemos obtenido un modelo capaz de generar beneficios tanto con los datos de entrenamiento como con los de prueba.


Durante el periodo de prueba, el modelo ha realizado 34 transacciones, 18 de las cuales se cerraron con beneficios, lo cual supone un 52,94% de transacciones rentables. La media de las transacciones rentables es un 52,47% superior a la media de las transacciones perdedoras, y la transacción rentable máxima es más de 2 veces superior a la transacción similar no rentable. En conjunto, el modelo ha mostrado un factor de beneficio de 1,72 y en el gráfico de balance vemos una tendencia al alza. La reducción máxima de equidad ha sido del 17,12% y para el balance, del 8,96%.
Conclusión
En el presente artículo, nos hemos familiarizado con el algoritmo complejo del convertidor espacio-temporal de atención constante Conformer, desarrollado para pronosticar el tiempo atmosférico y presentado en el artículo "Conformer: Embedding Continuous Attention in Vision Transformer for Weather Forecasting". Los autores del método proponen el algoritmo Continuous Attention y lo combinan con Neural ODE.
En la parte práctica de nuestro artículo, hemos implementado los enfoques propuestos usando herramientas MQL5. Asimismo, hemos ejecutado el entrenamiento y las pruebas de los modelos creados. Los resultados de las pruebas resultan bastante alentadores. El modelo ha sido capaz de generar beneficios tanto en la muestra de entrenamiento como en la de prueba.
No obstante, debemos recordar que todos los programas presentados en este artículo son meramente informativos y solo pretenden mostrar los planteamientos propuestos.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de cobros de ejemplo Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14615
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso