Neuronale Netze leicht gemacht (Teil 77): Cross-Covariance Transformer (XCiT)

Einführung
Transformatoren zeigen ein großes Potenzial bei der Lösung von Problemen der Analyse verschiedener Sequenzen. Die Operation Selbstaufmerksamkeit (Self-Attention), die den Transformatoren zugrunde liegt, ermöglicht globale Interaktionen zwischen allen Token in der Sequenz. Damit ist es möglich, Abhängigkeiten innerhalb der gesamten analysierten Sequenz zu bewerten. Dies ist jedoch mit einer quadratischen Komplexität in Bezug auf Rechenzeit und Speicherverbrauch verbunden, was die Anwendung des Algorithmus auf lange Sequenzen erschwert.
Um dieses Problem zu lösen, haben die Autoren des Artikels „XCiT: Cross-Covariance Image Transformers“ eine „transponierte“ Version von Selbstaufmerksamkeit (Self-Attention) vorgeschlagen, die über Merkmalskanäle statt über Token funktioniert, wobei die Interaktionen auf einer Kreuzkovarianzmatrix zwischen Schlüsseln und Abfragen basieren. Das Ergebnis ist eine Kreuzkovarianz-Aufmerksamkeit (XCA) mit linearer Komplexität in der Anzahl der Token, die eine effiziente Verarbeitung großer Datensequenzen ermöglicht. Der auf XCA basierende Cross-Covariance Image Transformer (XCiT) kombiniert die Genauigkeit herkömmlicher Transformatoren mit der Skalierbarkeit von Faltungsarchitekturen. Diese Arbeit bestätigt experimentell die Wirksamkeit und Allgemeinheit von XCiT. Die vorgestellten Experimente zeigen hervorragende Ergebnisse bei verschiedenen visuellen Benchmarks, einschließlich Bildklassifizierung, Objekterkennung und Instanzsegmentierung.
1. Der Algorithmus XCiT
Die Autoren der Methode schlagen eine auf der Kreuzkovarianz basierende Selbstaufmerksamkeits-Funktion vor, die entlang der Merkmalsdimension arbeitet und nicht entlang der Token-Dimension, wie bei den klassischen Token der Selbstaufmerksamkeit. Unter Verwendung der Definitionen für Abfrage, Schlüssel und Wert (Query, Key, Value, Q,K,V) wird die Aufmerksamkeitsfunktion der Kreuzkovarianz wie folgt definiert:
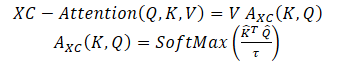
wobei jede Ausgangs-Token-Einbettung eine konvexe Kombination der dv Merkmale ihrer entsprechenden Token-Einbettung in V ist. Die Aufmerksamkeitsgewichte A werden auf der Grundlage der Kreuzkovarianzmatrix berechnet.
Zusätzlich zum Aufbau einer neuen Aufmerksamkeitsfunktion, die auf der Kreuzkovarianzmatrix basiert, schlagen die Autoren der Methode vor, die Größe der Abfrage- und Schlüsselmatrizen durch L2-Normalisierung zu beschränken, sodass jede Spalte der Länge N der normalisierten Matrizen Q und K eine Einheitsnorm hat. Jedes Element der Kreuzkovarianzmatrix der Aufmerksamkeitskoeffizienten der Größe d*d lag im Bereich [-1, 1]. Die Autoren der Methode stellen fest, dass die Normkontrolle die Stabilität des Lernens deutlich erhöht, insbesondere beim Lernen mit einer variablen Anzahl von Token. Durch die Einschränkung der Norm wird jedoch die Darstellungskraft des Vorgangs durch den Wegfall von Freiheitsgraden verringert. Daher führen die Autoren einen trainierbaren Temperaturparameter τ ein, der die inneren Produkte skaliert, bevor sie durch die SoftMax-Funktion normalisiert werden, was eine schärfere oder gleichmäßigere Verteilung der Aufmerksamkeitsgewichte ermöglicht.
Darüber hinaus begrenzen die Autoren der Methode die Anzahl der Merkmale, die miteinander interagieren. Sie schlagen vor, sie in h Gruppen oder „Köpfe“ (heads) aufzuteilen, ähnlich wie die mehrköpfigen Selbstaufmerksamkeitsmarken. Für jeden Kopf wenden die Autoren der Methode separat die Kreuzkovarianz an.
Für jeden Kopf trainieren sie separate Gewichtsmatrizen der Quelldatenprojektion X auf Anfrage, Schlüssel und Wert. Die entsprechenden Gewichtsmatrizen werden in Tensoren Wq der Dimensionen {h * d * dq}, Wk — {h * d * dk} и Wv — {h * d * dv} \) erfasst. Sie legen dk = dq = dv = d/h fest.
Die Beschränkung der Aufmerksamkeit auf die Köpfe hat zwei Vorteile:
- Die Komplexität der Aggregation von Werten mit Aufmerksamkeitsgewichten wird um den Faktor h reduziert;
- Noch wichtiger ist, dass die Autoren der Methode empirisch nachweisen, dass die Version mit blockdiagonaler Matrix einfacher zu optimieren ist und im Allgemeinen zu besseren Ergebnissen führt.
Die klassischen Token der Selbstaufmerksamkeit mit h Köpfen haben eine Zeitkomplexität O(N^2 * d) und einen Speicher O(hN^2 + Nd). Aufgrund der quadratischen Komplexität ist es problematisch, Token der Selbstaufmerksamkeit für Sequenzen mit einer großen Anzahl von Token zu skalieren. Die vorgeschlagene Kreuzkovarianz-Aufmerksamkeit überwindet diesen Nachteil, da ihre Berechnungskomplexität O(Nd^2/h) linear mit der Anzahl der Token skaliert. Das Gleiche gilt für die Speicherkomplexität O(d^2 / h + Nd).
Daher skaliert das von den Autoren vorgeschlagene XCA-Modell viel besser in Fällen, in denen die Anzahl der Token N groß und die Merkmalsdimension d relativ klein ist, insbesondere wenn die Merkmale in h Köpfe aufgeteilt werden
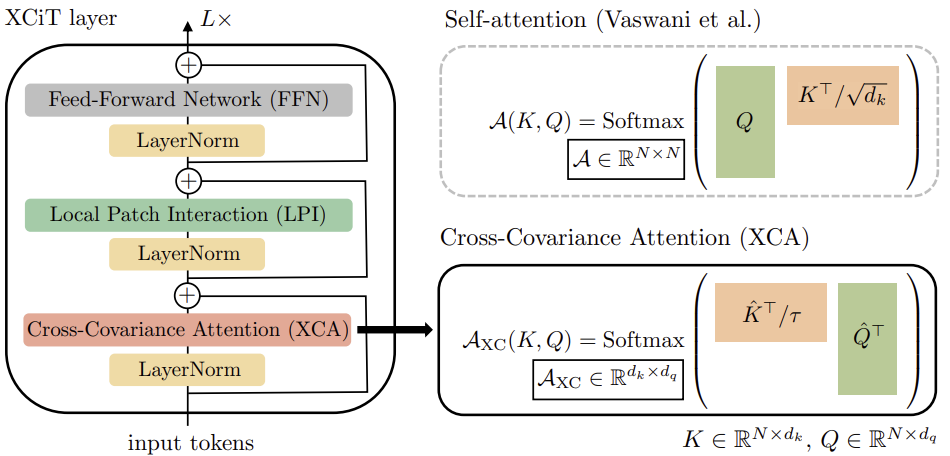
Für die Erstellung von Kreuzkovarianz-Transformer-Bildern (XCiT) schlagen die Autoren der Methode eine säulenartige Architektur vor, bei der die räumliche Auflösung in allen Schichten gleich bleibt. Sie kombinieren den Kreuzkovarianz-Aufmerksamkeit Block (XCA) mit 2 weiteren Modulen, denen jeweils eine Normalisierung innerhalb der Schicht vorausgeht.
Im XCA-Block erfolgt die Kommunikation zwischen den Patches nur indirekt über gemeinsame Statistiken. Um eine explizite Kommunikation zwischen Patches zu ermöglichen, fügen die Autoren der Methode nach jedem XCA-Block einen einfachen lokalen Patch-Interaktionsblock (LPI) ein. LPI besteht aus zwei Faltungsschichten und einer Batch-Normalisierungsschicht dazwischen. Als Aktivierungsfunktion für die erste Schicht schlagen sie GELU vor. Aufgrund seiner tiefen Blockstruktur hat LPI einen vernachlässigbaren Parameter-Overhead und einen sehr geringen Bandbreiten- und Speicher-Overhead.
Wie bei Transformatormodellen üblich, wird als Nächstes ein Vorwärtsdurchgangs-Netz (Feed-Forward Network, FFN) mit punktweisen Faltungsschichten hinzugefügt, das eine versteckte Schicht mit 4d versteckten Blöcken hat. Während die Interaktionen zwischen den Merkmalen innerhalb des XCA-Blocks auf Gruppen beschränkt sind und es keine Interaktion zwischen den Merkmalen im LPI-Block gibt, erlaubt FFN die Interaktion mit allen Merkmalen.
Im Gegensatz zur Aufmerksamkeitskarte, die in Selbstaufmerksamkeits-Token enthalten ist, haben die Kovarianzblöcke in XCiT eine feste Größe, unabhängig von der Auflösung der Eingabesequenz. SoftMax arbeitet immer mit der gleichen Anzahl von Elementen, was vielleicht erklärt, warum sich XCiT-Modelle bei der Arbeit mit Bildern unterschiedlicher Auflösung besser verhalten. XCiT beinhaltet eine additive Sinus-Positionskodierung mit Eingabe-Token.
Im Folgenden wird die Visualisierung des Algorithmus durch die Autoren vorgestellt.
2. Implementierung mit MQL5
Nach der Betrachtung der theoretischen Aspekte des Kreuzkovarianz-Transformer (XCiT) gehen wir zur praktischen Umsetzung der vorgeschlagenen Ansätze mit MQL5 über.
2.1 Kreuzkovarianz-Transformatorenklasse
Um den XCiT-Block-Algorithmus zu implementieren, erstellen wir eine neue neuronale Schichtklasse CNeuronXCiTOCL. Als übergeordnete Klasse wird die allgemeine mehrköpfige mehrschichtige Aufmerksamkeitsklasse CNeuronMLMHAttentionOCL verwendet. Die neue Klasse wird auch mit der eingebauten Multi-Layer-Architektur erstellt.
class CNeuronXCiTOCL : public CNeuronMLMHAttentionOCL { protected: //--- uint iLPIWindow; uint iLPIStep; uint iBatchCount; //--- CCollection cLPI; CCollection cLPI_Weights; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out); virtual bool BatchNorm(CBufferFloat *inputs, CBufferFloat *options, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog); virtual bool BatchNormInsideGradient(CBufferFloat *inputs, CBufferFloat *inputs_g, CBufferFloat *options, CBufferFloat *out, CBufferFloat *out_g, ENUM_ACTIVATION activation); virtual bool BatchNormUpdateWeights(CBufferFloat *options, CBufferFloat *out_g); public: CNeuronXCiTOCL(void) {}; ~CNeuronXCiTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Ich möchte anmerken, dass wir in der neuen Klasse die Werkzeuge der übergeordneten Klasse maximal nutzen werden. Wir werden jedoch noch erhebliche Ergänzungen vornehmen müssen. Zunächst werden wir Puffersammlungen für den LPI-Block hinzufügen:
- cLPI – Ergebnis- und Gradientenpuffer;
- cLPI_Weights – Gewichts- und Impulsmatrizen.
Darüber hinaus benötigen wir für den LPI-Block zusätzliche Konstanten:
- iLPIWindow – Faltungsfenster für die erste Schicht des Blocks;
- iLPIStep – Schritt des Faltungsfensters für die erste Schicht des Blocks;
- iBatchCount – die Anzahl der in der Block-Batch-Normalisierungsschicht durchgeführten Operationen.
Wir geben die Faltungsparameter nur in der ersten Schicht an. Denn in der zweiten Ebene müssen wir die Größe der Quelldatenebene erreichen. Denn die Autoren der Methode schlagen vor, die Daten mit den Ergebnissen des vorherigen XCA-Blocks zu ergänzen und zu normalisieren.
In dieser Klasse werden alle hinzugefügten Objekte als statisch deklariert, sodass wir den Konstruktor und den Destruktor der Ebene leer lassen. Die primäre Initialisierung der Schicht wird in der Methode Init durchgeführt. Als Parameter erhält die Methode alle Parameter, die zur Initialisierung interner Objekte benötigt werden.
bool CNeuronXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Im Hauptteil der Methode wird kein Kontrollblock für die empfangenen Parameter eingerichtet. Stattdessen rufen wir die Initialisierungsmethode der Basisklasse aller neuronalen Schichten auf, die bereits die minimal erforderlichen Steuerelemente implementiert und geerbte Objekte initialisiert.
Hier ist zu beachten, dass wir die Methode der Basisklasse aufrufen, nicht die der übergeordneten Klasse. Dies ist darauf zurückzuführen, dass die Größe der von uns erstellten internen Schichtpuffer und deren Anzahl unterschiedlich sind. Um zu vermeiden, dass dieselbe Arbeit zweimal ausgeführt werden muss, werden wir daher alle Puffer im Hauptteil unserer neuen Initialisierungsmethode initialisieren.
Zunächst speichern wir die wichtigsten Parameter in lokalen Variablen.
iWindow = fmax(window, 1); iUnits = fmax(units_count, 1); iHeads = fmax(fmin(heads, iWindow), 1); iWindowKey = fmax((window + iHeads - 1) / iHeads, 1); iLayers = fmax(layers, 1); iLPIWindow = fmax(lpi_window, 1); iLPIStep = 1;
Bitte beachten Sie, dass wir die Dimensionen der internen Entitäten auf der Grundlage der Größe des Beschreibungsvektors eines Elements der Sequenz und der Anzahl der Aufmerksamkeitsköpfe neu berechnen. Dies wird von den Autoren der XCiT-Methode vorgeschlagen.
Als Nächstes bestimmen wir die Hauptabmessungen der Puffer in jedem Block.
//--- XCA uint num = 3 * iWindowKey * iHeads * iUnits; // Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; // Size of weights' matrix of // QKV tensor uint scores = iWindowKey * iWindowKey * iHeads; // Size of Score tensor uint out = iWindow * iUnits; // Size of output tensor
//--- LPI uint lpi1_num = iWindow * iHeads * iUnits; // Size of LPI1 tensor uint lpi1_weights = (iLPIWindow + 1) * iHeads; // Size of weights' matrix of // LPI1 tensor uint lpi2_weights = (iHeads + 1) * 2; // Size of weights' matrix of // LPI2 tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; // Size of weights' matrix 1-st // feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; // Size of weights' matrix 2-nd // feed forward layer
Danach organisieren wir eine Schleife mit der Anzahl der Iterationen, die der Anzahl der internen Schichten entspricht.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL;
Im Hauptteil der Schleife werden zunächst Puffer für Zwischenergebnisse und deren Gradienten angelegt. Hierfür erstellen wir eine verschachtelte Schleife. In der ersten Iteration der Schleife erstellen wir Puffer mit Zwischenergebnissen. In der zweiten Iteration erstellen wir die Puffer für die entsprechenden Fehlergradienten.
for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Kombinieren wir Abfrage, Schlüssel und Wert in einem verketteten Puffer. Dies ermöglicht es uns, die Werte aller Entitäten in einem Durchgang für alle Aufmerksamkeitsköpfe in parallelen Threads zu erzeugen.
Als Nächstes erstellen wir einen reduzierten Puffer von Kreuzkovarianz-Aufmerksamkeitskoeffizienten.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
Der Aufmerksamkeitsblock endet mit seinem Ergebnispuffer.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
Der von den Autoren der Methode zur Berechnung der Größe von Entitäten vorgeschlagene Ansatz ermöglicht es uns, die Ebene der Reduzierung der Dimension des Aufmerksamkeitsblocks zu entfernen.
Als Nächstes erstellen wir die Puffer des LPI-Blocks. Hier erstellen wir einen Puffer mit den Ergebnissen der ersten Faltungsschicht.
//--- LPI //--- Initilize LPI tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI1 return false;
Danach folgt ein Puffer mit den Ergebnissen der Chargennormalisierung.
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI Normalize return false;
Der Block endet mit dem Ergebnispuffer der zweiten Faltungsschicht.
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI2 return false;
Schließlich erstellen wir die Puffer des Vorwärtdurchgangs-Blockergebnisses.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Achten Sie auf die Nuance beim Ergebnispuffer der zweiten Schicht des Blocks. Wir erstellen diesen Puffer nur für Zwischendaten. Für die letzte innere Schicht erstellen wir keine neuen Puffer, sondern speichern nur einen Zeiger auf den zuvor erstellten Ergebnispuffer unserer Schicht.
//--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Die Puffer für die Gewichtsmatrix werden in der gleichen Reihenfolge erstellt.
//--- XCiT //--- Initialize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initialize LPI1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi1_weights)) return false; for(uint w = 0; w < lpi1_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Normalization int count = (int)lpi1_num * (optimization_type == SGD ? 7 : 9); temp = new CBufferFloat(); if(!temp.BufferInit(count, 0.0f)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initialize LPI2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi2_weights)) return false; for(uint w = 0; w < lpi2_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initialize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Nach der Initialisierung der trainierbaren Gewichtsmatrizen erstellen wir Puffer, um die Momente während des Modelltrainings aufzuzeichnen. Hier sollten Sie jedoch auf den Parameterpuffer der Batch-Normalisierungsschicht achten. Sie berücksichtigt bereits die Parameter und ihre Momente. Daher werden für die angegebene Ebene keine Impulspuffer erstellt.
Darüber hinaus hängt die Anzahl der erforderlichen Impulspuffer von der Optimierungsmethode ab. Um diese Eigenschaft zu berücksichtigen, werden wir Puffer in einer Schleife anlegen, deren Anzahl der Iterationen von der Optimierungsmethode abhängt.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- LPI temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi2_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } iBatchCount = 1; //--- return true; }
Nachdem alle erforderlichen Puffer erfolgreich erstellt wurden, beenden wir die Methode und geben das logische Ergebnis der Operationen an den Aufrufer zurück.
Wir haben die Initialisierung der Klasse abgeschlossen. Fahren wir nun mit der Beschreibung des Vorwärtsdurchgangs-Algorithmus der XCiT-Methode fort. Wie bereits erwähnt, wird die Umsetzung der vorgeschlagenen Methode erhebliche Änderungen erfordern. Um den Feed-Forward-Pass zu implementieren, müssen wir einen Kernel auf der Seite des OpenCL-Programms erstellen, um den XCA-Algorithmus zu implementieren.
Bitte beachten Sie, dass wir die Entitäten in einer von der übergeordneten Klasse ConvolutionForward geerbten Methode erhalten. Unser Kernel arbeitet also bereits mit den generierten Entitäten Abfrage, Schlüssel und Wert, die wir als einen einzigen Puffer an den Kernel übertragen. Zusätzlich zu diesen Parametern werden in den Kernel-Parametern Zeiger auf zwei weitere Datenpuffer übergeben: Aufmerksamkeitskoeffizienten und Aufmerksamkeitsblockergebnisse.
__kernel void XCiTFeedForward(__global float *qkv, __global float *score, __global float *out) { const size_t d = get_local_id(0); const size_t dimension = get_local_size(0); const size_t u = get_local_id(1); const size_t units = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
Wir werden den Kernel in einem 3-dimensionalen Aufgabenraum starten:
- Dimension eines Entitätselements;
- Sequenzlänge;
- Anzahl der Aufmerksamkeitsköpfe.
Die ersten beiden Dimensionen werden wir in lokalen Arbeitsgruppen zusammenfassen.
Wir deklarieren zwei lokale 2-dimensionale Arrays zum Schreiben von Zwischendaten und zum Austausch von Informationen innerhalb der Arbeitsgruppe.
const uint ls_u = min((uint)units, (uint)LOCAL_ARRAY_SIZE); const uint ls_d = min((uint)dimension, (uint)LOCAL_ARRAY_SIZE); __local float q[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE]; __local float k[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE];
Bevor wir mit der Analyse der Kreuzkovarianz-Aufmerksamkeit beginnen, müssen wir die Entitäten Abfrage und Schlüssel normalisieren, wie von den Autoren der Methode vorgeschlagen.
Zu diesem Zweck werden zunächst die Größen der Vektoren für jeden Parameter innerhalb der Gruppe berechnet.
//--- Normalize Query and Key for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { float q_val = 0; float k_val = 0; //--- if(d < ls_d && (cur_d + d) < dimension && u < ls_u) { for(int count = u; count < units; count += ls_u) { int shift = count * dimension * heads * 3 + dimension * h + cur_d + d; q_val += pow(qkv[shift], 2.0f); k_val += pow(qkv[shift + dimension * heads], 2.0f); } q[u][d] = q_val; k[u][d] = k_val; } barrier(CLK_LOCAL_MEM_FENCE);
uint count = ls_u; do { count = (count + 1) / 2; if(d < ls_d) { if(u < ls_u && u < count && (u + count) < units) { float q_val = q[u][d] + q[u + count][d]; float k_val = k[u][d] + k[u + count][d]; q[u + count][d] = 0; k[u + count][d] = 0; q[u][d] = q_val; k[u][d] = k_val; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Anschließend wird jedes Element der Folge durch die Quadratwurzel der Vektorgröße in der entsprechenden Dimension geteilt.
int shift = u * dimension * heads * 3 + dimension * h + cur_d; qkv[shift] = qkv[shift] / sqrt(q[0][d]); qkv[shift + dimension * heads] = qkv[shift + dimension * heads] / sqrt(k[0][d]); barrier(CLK_LOCAL_MEM_FENCE); }
Da unsere Entitäten nun normalisiert sind, können wir mit der Definition von Abhängigkeitskoeffizienten fortfahren. Dazu multiplizieren wir die Matrizen Abfrage und Schlüssel. Gleichzeitig nehmen wir den Exponenten des erhaltenen Wertes und summieren ihn auf.
//--- Score int step = dimension * heads * 3; for(int cur_r = 0; cur_r < dimension; cur_r += ls_u) { for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { if(u < ls_d && d < ls_d) q[u][d] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- if((cur_r + u) < ls_d && (cur_d + d) < ls_d) { int shift_q = dimension * h + cur_d + d; int shift_k = dimension * (heads + h) + cur_r + u; float scr = 0; for(int i = 0; i < units; i++) scr += qkv[shift_q + i * step] * qkv[shift_k + i * step]; scr = exp(scr); score[(cur_r + u)*dimension * heads + dimension * h + cur_d + d] = scr; q[u][d] += scr; } } barrier(CLK_LOCAL_MEM_FENCE);
int count = ls_d; do { count = (count + 1) / 2; if(u < ls_d) { if(d < ls_d && d < count && (d + count) < dimension) q[u][d] += q[u][d + count]; if(d + count < ls_d) q[u][d + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Dann normalisieren wir die Abhängigkeitskoeffizienten.
if((cur_r + u) < ls_d) score[(cur_r + u)*dimension * heads + dimension * h + d] /= q[u][0]; barrier(CLK_LOCAL_MEM_FENCE); }
Am Ende der Kerneloperationen multiplizieren wir den Wertetensor mit den Abhängigkeitskoeffizienten. Das Ergebnis dieser Operation wird im Ergebnispuffer des XCA-Aufmerksamkeitsblocks gespeichert.
int shift_out = dimension * (u * heads + h) + d; int shift_s = dimension * (heads * d + h); int shift_v = dimension * (heads * (u * 3 + 2) + h); float sum = 0; for(int i = 0; i < dimension; i++) sum += qkv[shift_v + i] * score[shift_s + i]; out[shift_out] = sum; }
Nachdem wir den Kernel auf der Seite des OpenCL-Programms erstellt haben, gehen wir zu den Operationen in unserer Klasse auf der Seite des Hauptprogramms über. Hier erstellen wir zunächst die Methode CNeuronXCiTOCL::XCiT, in der wir den Algorithmus zum Aufruf des erstellten Kerns implementieren.
bool CNeuronXCiTOCL::XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out) { if(!OpenCL || !qkv || !score || !out) return false;
In den Methodenparametern übergeben wir Zeiger auf die 3 verwendeten Datenpuffer. Im Methodenkörper wird sofort geprüft, ob die empfangenen Zeiger relevant sind.
Dann definieren wir den Aufgabenraum und die Offsets in diesem Raum.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads}; uint local_work_size[3] = {iWindowKey, iUnits, 1};
Wie bereits erwähnt, fassen wir die Themen in Arbeitsgruppen zusammen, die sich an den ersten beiden Dimensionen orientieren.
Als Nächstes werden Zeiger auf Datenpuffer an den Kernel übergeben.
if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_score, score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_out, out.GetIndex())) return false;
Den Kernel stellen wir in die Ausführungswarteschlange.
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); Print(error); return false; } //--- return true; }
Zusätzlich zu der oben beschriebenen Methode werden wir eine Vorwärtsdurchgangs-Methode für die Batch-Normalisierungsschicht CNeuronXCiTOCL::BatchNorm erstellen, deren gesamter Algorithmus vollständig von der Methode CNeuronBatchNormOCL::feedForward übernommen wird. Aber wir wollen uns jetzt nicht damit aufhalten, seinen Algorithmus zu betrachten. Gehen wir direkt zur Analyse der Methode CNeuronXCiTOCL::feedForward über, die den allgemeinen Rahmen des Vorwärtsdurchgangsalgorithmus im XCiT-Block darstellt.
bool CNeuronXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
In den Parametern erhält die Methode einen Zeiger auf das Objekt der vorherigen Schicht, das die Ausgangsdaten liefert. Im Hauptteil der Methode wird sofort die Relevanz des empfangenen Zeigers geprüft.
Nach erfolgreichem Passieren des Kontrollpunkts erstellen wir eine Schleife durch die internen Ebenen. Im Hauptteil dieser Schleife wird der gesamte Algorithmus der Methode konstruiert.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Hier bilden wir zunächst unsere Entitäten Abfrage, Schlüssel und Wert. Dann nennen wir unsere Kreuzkovarianz-Aufmerksamkeitsmethode.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(qkv, temp, out)) return false;
Die Aufmerksamkeitsergebnisse werden zu den Originaldaten addiert und die resultierenden Werte werden normalisiert.
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Als Nächstes kommt der LPI-Block. Lassen Sie uns zunächst die Arbeit der ersten Schicht des Blocks organisieren.
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false;
Dann normalisieren wir die Ergebnisse der ersten Ebene.
out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false;
Das normalisierte Ergebnis wird an die zweite Schicht des Blocks weitergegeben.
temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() ||!ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false;
Dann fassen wir die Ergebnisse zusammen und normalisieren sie erneut.
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Organisieren wir den Vorwärtsdurchgangs-Block.
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false;
Am Ausgang der Schicht fassen wir die Ergebnisse der Blöcke zusammen und normalisieren sie.
//--- Sum and normalize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
Damit ist die Implementierung des Vorwärtsdurchgang unserer neuen Kreuzkovarianz-Transformatorschicht CNeuronXCiTOCL abgeschlossen. Als Nächstes gehen wir zum Aufbau des Rückwärtsdurchgangs-Algorithmus über. Auch hier müssen wir zum OpenCL-Programm zurückkehren und einen weiteren Kernel erstellen. Wir werden den Rückwärtsdurchgangs-Algorithmus des XCA-Blocks im Kernel XCiTInsideGradients aufbauen. In den Parametern für den Kernel übergeben wir Zeiger auf 4 Datenpuffer:
- qkv – verketteter Vektor von Abfrage-, Schlüssel- und Wertentitäten;
- qkv_g – verketteter Vektor der Fehlergradienten von Abfrage-, Schlüssel- und Wertentitäten;
- scores – Matrix der Abhängigkeitskoeffizienten;
- gradient – Tensor der Fehlergradienten am Ausgang des XCA-Aufmerksamkeitsblocks.
__kernel void XCiTInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const int q = get_global_id(0); const int d = get_global_id(1); const int h = get_global_id(2); const int units = get_global_size(0); const int dimension = get_global_size(1); const int heads = get_global_size(2);
Wir planen den Start des Kernels in einem 3-dimensionalen Aufgabenraum. Im Hauptteil des Kernels werden der Thread- und der Taskraum identifiziert. Dann bestimmen wir den Offset in den Datenpuffern zu den analysierten Elementen.
const int shift_q = dimension * (heads * 3 * q + h); const int shift_k = dimension * (heads * (3 * q + 1) + h); const int shift_v = dimension * (heads * (3 * q + 2) + h); const int shift_g = dimension * (heads * q + h); int shift_score = dimension * h; int step_score = dimension * heads;
Nach dem Rückwärtsdurchgangs-Algorithmus bestimmen wir zunächst den Fehlergradienten auf dem Wertetensor.
//--- Calculating Value's gradients float sum = 0; for(int i = 0; i < dimension; i ++) sum += gradient[shift_g + i] * scores[shift_score + d + i * step_score]; qkv_g[shift_v + d] = sum;
Als Nächstes definieren wir den Fehlergradienten für die Abfrage. Hier müssen wir zunächst den Fehlergradienten auf dem entsprechenden Vektor der Koeffizientenmatrix bestimmen. Anschließend werden die resultierenden Fehlergradienten an die Ableitung der SoftMax-Funktion angepasst. Nur in diesem Fall können wir den erforderlichen Fehlergradienten erhalten.
//--- Calculating Query's gradients float grad = 0; float val = qkv[shift_v + d]; for(int k = 0; k < dimension; k++) { float sc_g = 0; float sc = scores[shift_score + k]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_score + v] * val * gradient[shift_g + v * dimension] * ((float)(k == v) - sc); grad += sc_g * qkv[shift_k + k]; } qkv_g[shift_q] = grad;
Für den Schlüssel-Tensor wird der Fehlergradient auf ähnliche Weise bestimmt, allerdings in der senkrechten Richtung der Vektoren.
//--- Calculating Key's gradients grad = 0; float out_g = gradient[shift_g]; for(int scr = 0; scr < dimension; scr++) { float sc_g = 0; int shift_sc = scr * dimension * heads; float sc = scores[shift_sc + d]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_sc + v] * out_g * qkv[shift_v + v] * ((float)(d == v) - sc); grad += sc_g * qkv[shift_q + scr]; } qkv_g[shift_k + d] = grad; }
Nachdem wir den Kernel erstellt haben, kehren wir zur Arbeit mit unserer Klasse auf der Seite des Hauptprogramms zurück. Hier erstellen wir die Methode CNeuronXCiTOCL::XCiTInsideGradients. In den Parametern erhält die Methode Zeiger auf die benötigten Datenpuffer.
bool CNeuronXCiTOCL::XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog) { if(!OpenCL || !qkv || !qkvg || !score || !aog) return false;
Im Methodenkörper wird sofort geprüft, ob die empfangenen Zeiger relevant sind.
Dann definieren wir einen 3-dimensionalen Problemraum. Aber dieses Mal definieren wir keine Arbeitsgruppen.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads};
Wir übergeben Zeiger auf Datenpuffer als Parameter an den Kernel.
if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv_g, qkvg.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_scores,score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_gradient,aog.GetIndex())) return false;
Nach Abschluss der vorbereitenden Arbeiten müssen wir den Kernel nur noch in die Ausführungswarteschlange stellen.
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Der vollständige Rückwärtsalgorithmus des XCiT-Blocks, der in der Dispatch-Methode CNeuronXCiTOCL::calcInputGradients zusammengefasst ist. In ihren Parametern erhält die Methode einen Zeiger auf das Objekt der vorherigen Ebene.
bool CNeuronXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
Im Hauptteil der Methode wird sofort die Gültigkeit des empfangenen Zeigers überprüft. Nach erfolgreichem Passieren des Kontrollpunkts organisieren wir eine Schleife der umgekehrten Iteration durch die internen Schichten mit der Fortpflanzung des Fehlergradienten.
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 4:6)+1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false;
Im Hauptteil der Schleife wird zunächst der Fehlergradient durch den Vorwärtsdurchgangs-Block geleitet.
CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
Ich möchte Sie daran erinnern, dass wir beim direkten Durchlauf die Ergebnisse der Blöcke mit den Originaldaten addiert haben. In ähnlicher Weise propagieren wir den Fehlergradienten über 2 Threads.
//--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Als Nächstes propagieren wir den Fehlergradienten durch den LPI-Block.
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false;
Fügen wir die Fehlergradienten erneut hinzu.
temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Danach propagieren wir den Fehlergradienten durch den Aufmerksamkeitsblock XCA.
out_grad = temp; //--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
Übertragen wir sie in den Quelldaten-Gradientenpuffer.
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Vergessen Sie nicht, einen Fehlergradienten entlang des zweiten Stroms hinzuzufügen.
//--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow)) return false; if(i > 0) out_grad = temp; } //--- return true; }
Oben haben wir einen Algorithmus für die Weitergabe des Fehlergradienten an die internen Schichten und seine Übertragung an die vorherige neuronale Schicht implementiert. Am Ende der Rückwärtsdurchgang müssen wir die Modellparameter aktualisieren.
Die Aktualisierung der Parameter unserer neuen Kreuzkovarianz-Transformationsschicht ist in der Methode CNeuronXCiTOCL::updateInputWeights implementiert. Wie ähnliche Methoden anderer neuronaler Schichten erhält die Methode in ihren Parametern einen Zeiger auf die neuronale Schicht der vorherigen Schicht.
bool CNeuronXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput();
Und im Hauptteil der Methode wird die Relevanz des empfangenen Zeigers geprüft.
Ähnlich wie bei der Verteilung des Fehlergradienten werden wir die Parameter in einer Schleife durch die inneren Schichten aktualisieren.
for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization==SGD ? QKV_Weights.At(l*2+1):QKV_Weights.At(l*3+1)), (optimization==SGD ? NULL : QKV_Weights.At(l*3+2)), iWindow, 3 * iWindowKey * iHeads)) return false;
Zunächst aktualisieren wir die Parameter der Formationsmatrizen für die Entitäten Abfrage, Schlüssel und Wert.
Als Nächstes aktualisieren wir die Parameter des LPI-Blocks. Dieser Block enthält 2 Faltungsschichten und eine Batch-Normalisierungsschicht.
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization==SGD ? cLPI_Weights.At(l*5+3):cLPI_Weights.At(l*7+3)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization==SGD ? cLPI_Weights.At(l*5+4):cLPI_Weights.At(l*7+4)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
Am Ende der Methode steht der Block, der die Parameter des Vorwärtsdurchgangs-Blocks aktualisiert.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization==SGD ? FF_Weights.At(l*4+2):FF_Weights.At(l*6+2)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization==SGD ? FF_Weights.At(l*4+3):FF_Weights.At(l*6+3)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
Damit ist die Implementierung der Vorwärtsdurchgangs- und Rückwärtsdurchgangs-Algorithmen unserer Kreuzkovarianz-Transformer-Schicht CNeuronXCiTOCL abgeschlossen. Um die volle Funktionsweise der Klasse zu ermöglichen, müssen wir noch einige Hilfsmethoden hinzufügen. Dazu gehören die Dateimethoden (Speichern und Laden). Der Algorithmus dieser Methoden ist nicht kompliziert und enthält keine einzigartigen Aspekte, die sich speziell auf die XCiT-Methode beziehen. Daher werde ich mich in diesem Artikel nicht mit der Beschreibung ihrer Algorithmen befassen. Der Anhang enthält den vollständigen Code der Klasse, sodass Sie ihn selbst studieren können. Der Anhang enthält auch alle in diesem Artikel verwendeten Programme.
2.2 Modellarchitektur
Wir fahren fort mit der Erstellung von Expert Advisors zum Trainieren und Testen der Modelle. Es muss an dieser Stelle gesagt werden, dass die Autoren der Methode in ihrem Papier keine spezifische Architektur der Modelle vorgestellt haben. Im Wesentlichen kann der vorgeschlagene Kreuzkovarianz-Transformator den klassischen Transformator, den wir zuvor betrachtet haben, in jedem Modell ersetzen. Daher können wir als Teil des Experiments das Modell aus den vorherigen Artikeln nehmen und die Schicht CNeuronMLMHAttentionOCL durch CNeuronXCiTOCL ersetzen.
Aber wir müssen hier ehrlich sein. Im vorherigen Artikel haben wir verschiedene Aufmerksamkeitsblöcke verwendet. Wir haben uns besonders auf die Verwendung von CNeuronMFTOCL konzentriert, das aufgrund seiner architektonischen Eigenschaften nicht durch CNeuronXCiTOCL ersetzt werden kann.
Wenn wir jedoch auch nur eine Schicht austauschen, können wir die Veränderungen irgendwie bewerten.
Die endgültige Architektur unseres Testmodells sieht also wie folgt aus.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
„Rohe“ Quelldaten, die 1 Balken beschreiben, werden in die Quelldatenschicht des Umweltmessgeräts eingespeist.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die empfangenen Daten werden in der Batch-Normalisierungsschicht verarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Aus den normalisierten Daten wird eine Einbettung des Umgebungszustands erzeugt und dem internen Stapel hinzugefügt.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Hier fügen wir auch die Kodierung von Positionsdaten hinzu.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Es folgt ein Diagrammblock mit Stapelnormalisierung zwischen den Ebenen.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes fügen wir unsere neue Ebene Kreuzkovariation-Transformer hinzu. Die Anzahl der Sequenzelemente und der Quelldatenfenster wurde nicht verändert. Die angegebenen Parameter werden durch den Tensor der Ausgangsdaten bestimmt.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronXCiTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 3; descr.layers = 1; descr.batch = MathMax(1000, GPTBars); descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
In diesem Fall verwenden wir 4 Aufmerksamkeitsköpfe.
Die Autoren der Methode schlagen vor, eine ganzzahlige Aufteilung der Größe des Beschreibungsvektors eines Sequenzelements zu verwenden, um die Größe des Entity-Vektors entsprechend der Anzahl der Attention Heads zu bestimmen. Bei dieser Option wird unser Parameter descr.window_out nicht verwendet. Machen wir uns diese Tatsache zunutze und geben wir die Größe des Fensters der ersten LPI-Ebene in diesem Parameter an. Wir geben auch die Losgröße zur Normalisierung der Daten im LPI-Block an.
Auf den Encoder folgt der MFT-Block.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Wir transponieren den Tensor, um ihn in die richtige Form zu bringen.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Die Ergebnisse des Umgebungscodierers und der MFT werden zur Dekodierung der wahrscheinlichsten Endpunkte verwendet.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Und ihre Wahrscheinlichkeitsschätzungen.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false; //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Das Akteursmodell verwendete keine Aufmerksamkeitsebenen. Daher wurde das Modell ohne Änderungen übernommen. Und Sie können sich in der Anlage mit der kompletten Architektur aller Modelle vertraut machen.
Es ist zu beachten, dass das Ersetzen einer Schicht in der Architektur des Umgebungszustands-Encoders keinen Einfluss auf die Organisation der Modelltrainings- und Testprozesse hat. Daher wurden alle EAs für Ausbildung und Umweltinteraktion ohne Änderungen übernommen. Meiner Meinung nach ist es auf diese Weise interessanter, die Testergebnisse zu sehen. Denn wenn alle anderen Dinge gleich bleiben, können wir die Auswirkungen des Austauschs einer Schicht in der Modellarchitektur am ehrlichsten beurteilen.
Und im Anhang finden Sie den vollständigen Code aller hier verwendeten Programme. Wir gehen nun dazu über, die konstruierte Kreuzkovarianz-Transformer-Schicht CNeuronXCiTOCL zu testen.
3. Tests
Wir haben umfangreiche Arbeit geleistet, um eine neue Klasse für den Kreukovarianz-Transformer CNeuronXCiTOCL zu entwickeln, die auf dem Algorithmus basiert, der in dem Papier „ Cross-Covariance Image Transformers“. Wie bereits erwähnt, haben wir uns entschieden, den Expert Advisor aus dem vorherigen Artikel in unveränderter Form zu verwenden. Daher können wir zum Trainieren der Modelle den zuvor gesammelten Trainingsdatensatz verwenden. Benennen wir einfach die Datei „MFT.bd“ in „XCiT.bd“ um.
Wenn Sie nicht über einen zuvor gesammelten Trainingsdatensatz verfügen, müssen Sie diesen vor dem Training des Modells sammeln. Ich empfehle, zunächst Daten von echten Signalen zu sammeln, indem Sie die in dem Artikel „Nutzung früherer Erfahrungen zur Lösung neuer Probleme“ beschriebene Methode anwenden. Dann sollten Sie den Trainingsdatensatz mit zufälligen Durchläufen des EA „...\Experts\XCiT\Research.mq5“ im Strategie-Tester ergänzen.
Die Modelle werden in dem EA „...\Experts\XCiT\Study.mq5“ trainiert, nachdem die Trainingsdaten gesammelt wurden.
Wie zuvor wird das Modell mit historischen EURUSD-H1-Daten trainiert. Alle Indikatoren werden mit Standardparametern verwendet.
Das Modell wurde mit historischen Daten für die ersten 7 Monate des Jahres 2023 trainiert. Hier können wir sofort die ersten Ergebnisse der Prüfung der Wirksamkeit der vorgeschlagenen Ansätze feststellen. Während des Trainingsprozesses können wir eine Reduzierung des Zeitaufwands um fast 2 % feststellen, während wir die gleichen Trainingsiterationen haben.
Die Wirksamkeit des trainierten Modells wurde anhand historischer Daten für August 2023 bewertet. Der Testzeitraum ist nicht im Trainingsdatensatz enthalten. Sie erfolgt jedoch unmittelbar nach der Trainingszeit. Die Ergebnisse der Tests des trainierten Modells entsprechen in etwa denen, die im vorherigen Artikel vorgestellt wurden.
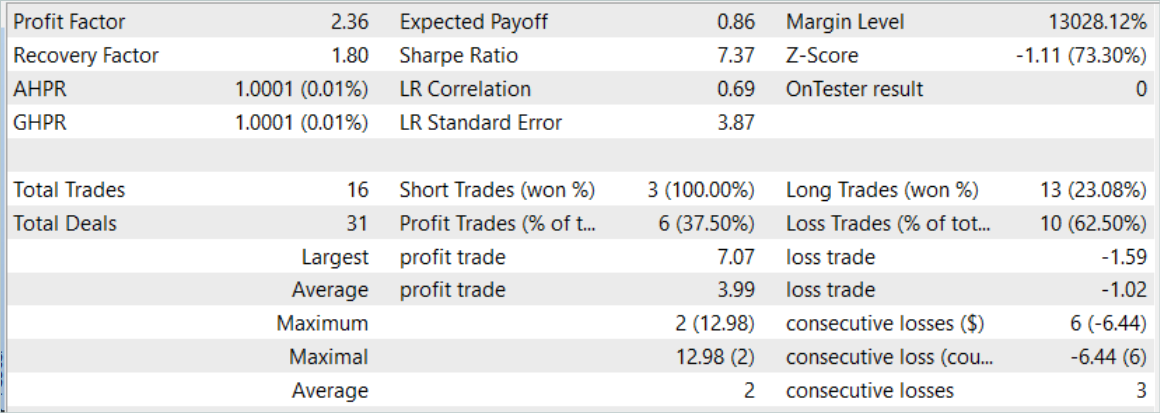
Hinter einem leichten Anstieg der Anzahl der Handelsgeschäfte steht jedoch ein Anstieg des Gewinnfaktors.
Schlussfolgerung
In diesem Artikel haben wir uns mit der neuen Architektur des Kreuzkovarianz-Transformer (XCiT) vertraut gemacht, die die Vorteile von Transformers und Faltungs-Architekturen kombiniert. Es bietet hohe Genauigkeit und Skalierbarkeit bei der Verarbeitung von Sequenzen unterschiedlicher Länge. Eine gewisse Effizienz wird erreicht, wenn große Sequenzen mit kleinen Tokengrößen analysiert werden.
XCiT verwendet eine Kreuzkovarianz-Aufmerksamkeits-Architektur zur effizienten Modellierung globaler Interaktionen zwischen Merkmalen von Sequenzelementen, wodurch lange Token-Sequenzen erfolgreich verarbeitet werden können.
Die Autoren der Methode bestätigen experimentell die hohe Effizienz von XCiT bei verschiedenen visuellen Aufgaben, darunter Bildklassifikation, Objekterkennung und semantische Segmentierung.
Im praktischen Teil unseres Artikels haben wir die vorgeschlagenen Methoden mit MQL5 umgesetzt. Das Modell wurde anhand realer historischer Daten trainiert und getestet. Während des Trainingsprozesses hatten wir eine leichte Reduzierung der Trainingszeitraum für die gleiche Anzahl von Trainingsiterationen. Dies wurde erreicht, indem nur eine Schicht des Modells ersetzt wurde.
Ein leichter Anstieg der Effizienz des trainierten Modells kann auf eine bessere Generalisierungsfähigkeit der vorgeschlagenen Architektur hindeuten.
Vergessen Sie bitte nicht, dass der Handel an den Finanzmärkten eine hochriskante Investition ist. Alle in diesem Artikel vorgestellten Programme dienen nur zu Informationszwecken und sind nicht für den realen Handel optimiert.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modelltraining EA |
| 4 | Test.mq5 | Expert Advisor | Modelltraining EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14276
 Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
 Neuronale Netze leicht gemacht (Teil 76): Erforschung verschiedener Interaktionsmuster mit Multi-Future Transformer
Neuronale Netze leicht gemacht (Teil 76): Erforschung verschiedener Interaktionsmuster mit Multi-Future Transformer
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.