Redes neurais de maneira fácil (Parte 77): Cross-Covariance Transformer (XCiT)

Introdução
Os transformadores demonstram grande potencial na resolução de tarefas de análise de diversas sequências. A operação Self-Attention, que está na base dos transformadores, garante interações globais entre todos os tokens na sequência. Isso permite avaliar as interdependências dentro da sequência analisada. No entanto, isso vem acompanhado de complexidade quadrática em termos de tempo de computação e uso de memória, dificultando a aplicação do algoritmo a sequências longas.
Para resolver esse problema, os autores do artigo "XCiT: Cross-Covariance Image Transformers" propuseram uma versão "transposta" do Self-Attention, que atua através dos canais de características, em vez de tokens, onde as interações são baseadas na matriz de cross-covariance entre chaves e consultas. O resultado é a atenção de cross-covariance (XCA) com complexidade linear em relação ao número de tokens, permitindo processar eficientemente grandes sequências de dados. O transformador de imagens de cross-covariance (XCiT), baseado no XCA, combina a precisão dos transformadores convencionais com a escalabilidade das arquiteturas convolucionais. No artigo original, a eficácia e a generalidade do XCiT são confirmadas experimentalmente. Os experimentos apresentados demonstram excelentes resultados em vários benchmarks visuais, incluindo classificação de imagens, detecção de objetos e segmentação de instâncias.
1. Algoritmo XCiT
Os autores do método propõem uma função Self-Attention baseada em cross-covariance, que atua ao longo da dimensão das características, em vez de ao longo da dimensão dos tokens, como no clássico Self-Attention de tokens. Usando as definições Query, Key e Value, a função de atenção baseada em cross-covariance é definida da seguinte forma:
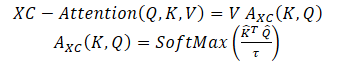
onde cada incorporação de token de saída é uma combinação convexa de dv características da sua respectiva incorporação de token em V. Os pesos de atenção A são calculados com base na matriz de cross-covariance.
Além de construir uma nova função de atenção baseada na matriz de cross-covariance, os autores do método propõem limitar a magnitude dos valores das matrizes Query e Key por meio da normalização L2, de modo que cada coluna das matrizes normalizadas N Q e K tenha norma unitária. E cada elemento da matriz de coeficientes de atenção de cross-covariance, de tamanho d * d, esteja no intervalo [−1, 1]. Os autores do método afirmam que o controle da norma aumenta significativamente a estabilidade do treinamento, especialmente no treinamento com número variável de tokens. No entanto, a limitação da norma reduz o poder representativo da operação, removendo graus de liberdade. Portanto, os autores introduzem um parâmetro de temperatura treinável τ, que escala os produtos escalares antes de executar a normalização SoftMax, permitindo obter uma distribuição de pesos de atenção mais nítida ou mais uniforme.
Além disso, os autores do método limitam o número de características que interagem entre si. Eles propõem dividi-las em h grupos, ou "cabeças", semelhante ao Self-Attention multi-cabeça de tokens. Os autores aplicam a atenção de cross-covariance separadamente para cada cabeça.
Para cada cabeça, são treinadas matrizes de pesos de projeção dos dados brutos X para Query, Key e Value. As matrizes de pesos correspondentes são reunidas em tensores Wq de dimensão {h * d * dq}, Wk — {h * d * dk} e Wv — {h * d * dv} \). Estabelece-se dk = dq = dv = d/h.
Limitar a atenção dentro das cabeças traz duas vantagens:
- A complexidade da agregação dos valores com os pesos de atenção diminui por um fator de h;
- mais importante, os autores demonstram empiricamente que a versão com matriz bloco-diagonal é mais fácil de otimizar e geralmente resulta em melhores resultados.
O Self-Attention clássico de tokens com h cabeças tem complexidade temporal de O(N^2 * d) e memória de O(hN^2 + Nd). Devido à complexidade quadrática, é problemático escalar o Self-Attention de tokens para sequências com grande número de tokens. A atenção de cross-covariance proposta supera essa limitação, pois sua complexidade computacional O(Nd^2 / h) escala linearmente com o número de tokens, assim como a complexidade de memória O(d^2 / h + Nd).
Consequentemente, o modelo XCA proposto pelos autores escala muito melhor em casos onde o número de tokens N é grande, e a dimensionalidade das características d é relativamente pequena, especialmente ao dividir as características em h cabeças.
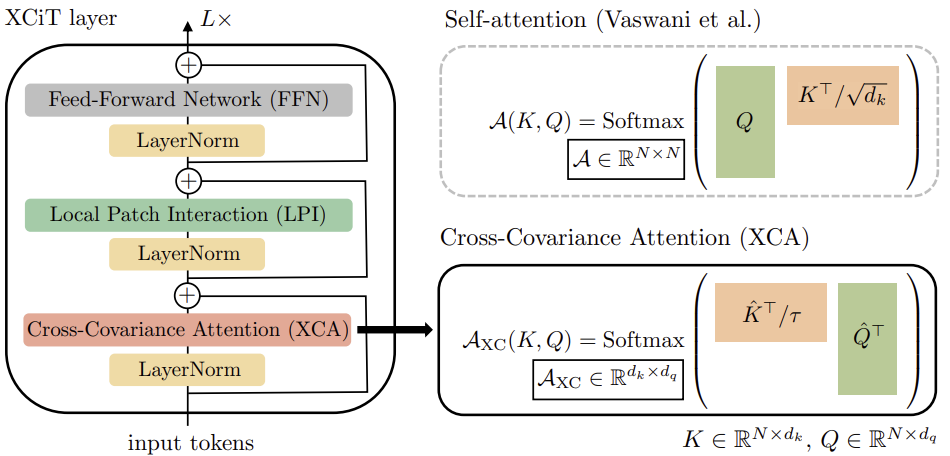
Para construir o Cross-Covariance Transformer de imagens (XCiT), os autores propõem uma arquitetura colunar que mantém a mesma resolução espacial em todas as camadas. Eles combinam o bloco de Cross-Covariance Attention (XCA) com dois módulos adicionais subsequentes, cada um precedido por normalização de camada.
No bloco XCA, a comunicação entre patches ocorre apenas indiretamente através de estatísticas compartilhadas. Para assegurar uma comunicação explícita entre patches, os autores adicionam um simples bloco de interação local de patches (LPI) após cada bloco XCA. LPI consiste em duas camadas convolucionais com uma camada de normalização em lote entre elas. Como função de ativação da primeira camada, propõe-se GELU. Devido à sua estrutura profunda, o bloco LPI tem sobrecarga de parâmetros insignificante, bem como sobrecarga muito limitada em termos de largura de banda e uso de memória.
Como de costume em modelos de transformadores, uma rede de propagação para frente (FFN) com camadas convolucionais pontuais é adicionada a seguir, possuindo uma camada oculta com 4d blocos ocultos. Enquanto a interação entre características é limitada em grupos no bloco XCA, e no bloco LPI não há interação entre características, o FFN permite interação entre todas as características.
Ao contrário do mapa de atenção incluído no Self-Attention de tokens, os blocos de covariância em XCiT têm tamanho fixo, independentemente da resolução da sequência de entrada. SoftMax sempre opera com o mesmo número de elementos, o que pode explicar porque os modelos XCiT se comportam melhor ao trabalhar com imagens de resoluções variadas. XCiT inclui uma codificação posicional senoidal aditiva com tokens de entrada.
A visualização autoral do algoritmo é apresentada abaixo.
2. Implementação em MQL5
Após conhecer os aspectos teóricos do Cross-Covariance Transformer (XCiT), passamos à implementação prática dos métodos propostos utilizando MQL5.
2.1 Classe do Cross-Covariance Transformer
Para implementar o algoritmo do bloco XCiT, criaremos uma nova classe de camada neural CNeuronXCiTOCL. Usaremos como classe pai a classe de atenção multi-cabeça multi-camada clássica CNeuronMLMHAttentionOCL. Também criaremos a nova classe com uma arquitetura multi-camada integrada.
class CNeuronXCiTOCL : public CNeuronMLMHAttentionOCL { protected: //--- uint iLPIWindow; uint iLPIStep; uint iBatchCount; //--- CCollection cLPI; CCollection cLPI_Weights; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out); virtual bool BatchNorm(CBufferFloat *inputs, CBufferFloat *options, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog); virtual bool BatchNormInsideGradient(CBufferFloat *inputs, CBufferFloat *inputs_g, CBufferFloat *options, CBufferFloat *out, CBufferFloat *out_g, ENUM_ACTIVATION activation); virtual bool BatchNormUpdateWeights(CBufferFloat *options, CBufferFloat *out_g); public: CNeuronXCiTOCL(void) {}; ~CNeuronXCiTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Desde já, informo que na nova classe usaremos ao máximo as ferramentas da classe pai. No entanto, ainda serão necessárias melhorias significativas. Primeiramente, adicionaremos coleções de buffers para o bloco LPI:
- cLPI — buffers de resultados e gradientes;
- cLPI_Weights — matrizes de pesos e momentos.
Além disso, para o bloco LPI, serão necessárias constantes adicionais:
- iLPIWindow — janela de convolução da primeira camada do bloco;
- iLPIStep — passo da janela de convolução da primeira camada do bloco;
- iBatchCount — número de operações realizadas na camada de normalização em lote do bloco.
Especificamos os parâmetros de convolução apenas na primeira camada. Na segunda camada, precisamos retornar ao tamanho da camada de dados brutos. Afinal, os autores do método propõem a soma e normalização dos dados com os resultados do bloco anterior XCA.
Nesta classe, todos os objetos adicionados são declarados como estáticos, então o construtor e o destrutor da camada são deixados vazios. A inicialização inicial da camada é realizado no método Init. Nos parâmetros, o método recebe todos os parâmetros necessários para inicializar os objetos internos.
bool CNeuronXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
No corpo do método, não definimos o controle dos parâmetros recebidos. Em vez disso, chamamos o método de inicialização da classe base de todas as camadas neurais, no qual já estão implementados os controles mínimos necessários e a inicialização dos objetos herdados.
É importante observar que chamamos o método da classe base, e não da classe pai. Isso se deve ao fato de que os tamanhos e a quantidade dos buffers das camadas internas que estamos criando serão diferentes. Portanto, para não realizar o mesmo trabalho duas vezes, inicializaremos todos os buffers no corpo do nosso novo método de inicialização.
Primeiramente, salvaremos os principais parâmetros em variáveis locais.
iWindow = fmax(window, 1); iUnits = fmax(units_count, 1); iHeads = fmax(fmin(heads, iWindow), 1); iWindowKey = fmax((window + iHeads - 1) / iHeads, 1); iLayers = fmax(layers, 1); iLPIWindow = fmax(lpi_window, 1); iLPIStep = 1;
Note que recalculamos as dimensões das entidades internas com base no tamanho do vetor de descrição de um elemento da sequência e no número de cabeças de atenção. Como proposto pelos autores do método XCiT.
Em seguida, definiremos as principais dimensões dos buffers em cada bloco.
//--- XCA uint num = 3 * iWindowKey * iHeads * iUnits; // Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; // Size of weights' matrix of // QKV tensor uint scores = iWindowKey * iWindowKey * iHeads; // Size of Score tensor uint out = iWindow * iUnits; // Size of output tensor
//--- LPI uint lpi1_num = iWindow * iHeads * iUnits; // Size of LPI1 tensor uint lpi1_weights = (iLPIWindow + 1) * iHeads; // Size of weights' matrix of // LPI1 tensor uint lpi2_weights = (iHeads + 1) * 2; // Size of weights' matrix of // LPI2 tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; // Size of weights' matrix 1-st // feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; // Size of weights' matrix 2-nd // feed forward layer
Após isso, fazemos um ciclo pelo número de camadas internas.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL;
No corpo do ciclo, criaremos primeiro buffers de resultados intermediários e seus gradientes. Para isso, criaremos um ciclo aninhado. Na primeira iteração do ciclo, criaremos buffers de resultados intermediários. E na segunda, os gradientes de erro correspondentes.
for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Query, Key e Value serão combinados em um único buffer concatenado. Isso nos permitirá gerar os valores de todas as entidades em uma única passagem para todas as cabeças de atenção em fluxos paralelos.
Em seguida, criaremos um buffer reduzido para os coeficientes de atenção cross-covariance.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
O bloco de atenção é concluído pelo buffer de seus resultados.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
A abordagem proposta pelos autores do método, com o cálculo do tamanho das entidades, nos permite dispensar a camada de redução de dimensionalidade do bloco de atenção.
Depois, criamos buffers para o bloco LPI. Aqui, criamos o buffer dos resultados da primeira camada convolucional.
//--- LPI //--- Initilize LPI tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI1 return false;
Depois vem o buffer dos resultados da normalização por lote.
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI Normalize return false;
E o bloco é finalizado pelo buffer dos resultados da segunda camada convolucional.
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI2 return false;
Por fim, criaremos os buffers dos resultados do bloco FeedForward.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Observe o detalhe com o buffer dos resultados da segunda camada do bloco. Esse buffer é criado apenas para os dados intermediários. Para a última camada interna, não criamos novos buffers, apenas salvamos o ponteiro para o buffer de resultados criado anteriormente para a nossa camada.
//--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Na mesma ordem, criaremos os buffers das matrizes de pesos.
//--- XCiT //--- Initilize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize LPI1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi1_weights)) return false; for(uint w = 0; w < lpi1_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Normalization int count = (int)lpi1_num * (optimization_type == SGD ? 7 : 9); temp = new CBufferFloat(); if(!temp.BufferInit(count, 0.0f)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initilize LPI2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi2_weights)) return false; for(uint w = 0; w < lpi2_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Após a inicialização das matrizes de coeficientes de peso treináveis, criaremos buffers para armazenar momentos durante o treinamento dos modelos. Mas aqui devemos prestar atenção ao buffer dos parâmetros da camada de normalização por lote. Nele, já são considerados os parâmetros e seus momentos. Portanto, para essa camada, não criaremos buffers de momentos.
Além disso, a quantidade de buffers de momentos necessários depende do método de otimização. Para considerar essa característica, criaremos buffers em um ciclo, cujo número de iterações depende do método de otimização.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- LPI temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi2_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } iBatchCount = 1; //--- return true; }
Após a criação bem-sucedida de todos os buffers necessários, concluímos o método e retornamos o resultado lógico da execução das operações para o programa chamador.
Após inicializar a classe, passamos à descrição do algoritmo de propagação para frente do método XCiT. Como mencionado anteriormente, a implementação do método proposto exigirá mudanças significativas. E para a implementação da propagação para frente, precisamos criar um kernel no lado do programa OpenCL para implementar o algoritmo XCA.
Aqui, devemos dizer que as próprias entidades são obtidas no método ConvolutionForward herdado da classe pai. E nosso kernel já funciona com as entidades formadas Query, Key e Value, que passamos para o kernel em um único buffer. Além disso, nos parâmetros do kernel, passaremos ponteiros para mais 2 buffers de dados: coeficientes de atenção e resultados do bloco de atenção.
__kernel void XCiTFeedForward(__global float *qkv, __global float *score, __global float *out) { const size_t d = get_local_id(0); const size_t dimension = get_local_size(0); const size_t u = get_local_id(1); const size_t units = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
O kernel será executado em um espaço de tarefas tridimensional:
- dimensão de um elemento das entidades;
- comprimento da sequência;
- número de cabeças de atenção.
As duas primeiras dimensões serão combinadas em grupos de trabalho locais.
Imediatamente declaramos 2 arrays bidimensionais locais para registrar dados intermediários e trocar informações dentro do grupo de trabalho.
const uint ls_u = min((uint)units, (uint)LOCAL_ARRAY_SIZE); const uint ls_d = min((uint)dimension, (uint)LOCAL_ARRAY_SIZE); __local float q[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE]; __local float k[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE];
Antes de começar a analisar a atenção cross-covariance, precisamos normalizar as entidades Query e Key, conforme proposto pelos autores do método.
Para isso, primeiro, no âmbito do grupo, calculamos os tamanhos dos vetores para cada parâmetro.
//--- Normalize Query and Key for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { float q_val = 0; float k_val = 0; //--- if(d < ls_d && (cur_d + d) < dimension && u < ls_u) { for(int count = u; count < units; count += ls_u) { int shift = count * dimension * heads * 3 + dimension * h + cur_d + d; q_val += pow(qkv[shift], 2.0f); k_val += pow(qkv[shift + dimension * heads], 2.0f); } q[u][d] = q_val; k[u][d] = k_val; } barrier(CLK_LOCAL_MEM_FENCE);
uint count = ls_u; do { count = (count + 1) / 2; if(d < ls_d) { if(u < ls_u && u < count && (u + count) < units) { float q_val = q[u][d] + q[u + count][d]; float k_val = k[u][d] + k[u + count][d]; q[u + count][d] = 0; k[u + count][d] = 0; q[u][d] = q_val; k[u][d] = k_val; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Depois, dividimos cada elemento da sequência pela raiz quadrada do tamanho do vetor na dimensão correspondente.
int shift = u * dimension * heads * 3 + dimension * h + cur_d; qkv[shift] = qkv[shift] / sqrt(q[0][d]); qkv[shift + dimension * heads] = qkv[shift + dimension * heads] / sqrt(k[0][d]); barrier(CLK_LOCAL_MEM_FENCE); }
Agora, com nossas entidades normalizadas, podemos prosseguir para determinar os coeficientes de dependência. Para isso, multiplicamos as matrizes Query e Key. Em seguida, tomamos a exponencial do valor obtido e somamos.
//--- Score int step = dimension * heads * 3; for(int cur_r = 0; cur_r < dimension; cur_r += ls_u) { for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { if(u < ls_d && d < ls_d) q[u][d] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- if((cur_r + u) < ls_d && (cur_d + d) < ls_d) { int shift_q = dimension * h + cur_d + d; int shift_k = dimension * (heads + h) + cur_r + u; float scr = 0; for(int i = 0; i < units; i++) scr += qkv[shift_q + i * step] * qkv[shift_k + i * step]; scr = exp(scr); score[(cur_r + u)*dimension * heads + dimension * h + cur_d + d] = scr; q[u][d] += scr; } } barrier(CLK_LOCAL_MEM_FENCE);
int count = ls_d; do { count = (count + 1) / 2; if(u < ls_d) { if(d < ls_d && d < count && (d + count) < dimension) q[u][d] += q[u][d + count]; if(d + count < ls_d) q[u][d + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Depois, normalizamos os coeficientes de dependência.
if((cur_r + u) < ls_d) score[(cur_r + u)*dimension * heads + dimension * h + d] /= q[u][0]; barrier(CLK_LOCAL_MEM_FENCE); }
Ao final das operações do kernel, multiplicamos o tensor Value pelos coeficientes de dependência. O resultado dessa operação é armazenado no buffer de resultados do bloco de atenção XCA.
int shift_out = dimension * (u * heads + h) + d; int shift_s = dimension * (heads * d + h); int shift_v = dimension * (heads * (u * 3 + 2) + h); float sum = 0; for(int i = 0; i < dimension; i++) sum += qkv[shift_v + i] * score[shift_s + i]; out[shift_out] = sum; }
Após criar o kernel no lado do programa OpenCL, passamos a trabalhar na nossa classe no lado do programa principal. Aqui, criamos primeiro o método CNeuronXCiTOCL::XCiT, no qual implementamos o algoritmo de chamada do kernel criado.
bool CNeuronXCiTOCL::XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out) { if(!OpenCL || !qkv || !score || !out) return false;
Nos parâmetros do método, passamos ponteiros para 3 buffers de dados usados. No corpo do método, verificamos imediatamente a validade dos ponteiros recebidos.
Em seguida, definimos o espaço de tarefas e seus deslocamentos.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads}; uint local_work_size[3] = {iWindowKey, iUnits, 1};
Como mencionado anteriormente, agrupamos os fluxos em grupos de trabalho pelas duas primeiras dimensões.
Depois, passamos os ponteiros dos buffers de dados para o kernel.
if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_score, score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_out, out.GetIndex())) return false;
E colocamos o kernel na fila de execução.
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); Print(error); return false; } //--- return true; }
Além do método descrito acima, criamos o método de propagação para frente da camada de normalização por lote CNeuronXCiTOCL::BatchNorm, cujo algoritmo é completamente transferido do método CNeuronBatchNormOCL::feedForward. Mas não vamos nos deter na análise do algoritmo dele agora. Vamos passar diretamente à análise do método CNeuronXCiTOCL::feedForward, que representa o esquema geral do algoritmo de propagação para frente no bloco XCiT.
bool CNeuronXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
Nos parâmetros, o método recebe um ponteiro para o objeto da camada anterior, que nos fornece os dados brutos. No corpo do método, verificamos imediatamente a validade do ponteiro recebido.
Após passar com sucesso pelo ponto de controle, criamos um ciclo para percorrer as camadas internas. É no corpo deste ciclo que construímos todo o algoritmo do método.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Aqui, primeiro formamos nossas entidades Query, Key e Value. Em seguida, chamamos nosso método de atenção cross-covariance.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(qkv, temp, out)) return false;
Os resultados da atenção são somados aos dados brutos e normalizamos os valores obtidos.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Depois vem o bloco LPI. Primeiro, realizamos o trabalho da primeira camada do bloco.
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false;
Normalizamos os resultados da primeira camada.
out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false;
E passamos para a segunda camada do bloco.
temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() ||!ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false;
Repetimos a soma e normalização dos resultados.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Elaboramos o trabalho do bloco FeedForward.
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false;
E na saída da camada, somamos e normalizamos os resultados dos blocos.
//--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
Assim, concluímos o trabalho na implementação da propagação da nossa nova camada Cross-Covariance Transformer CNeuronXCiTOCL. E passamos a construir o algoritmo de propagação reversa. Aqui, também precisamos voltar ao programa OpenCL e criar mais um kernel. O algoritmo de propagação reversa do bloco XCA será construído no kernel XCiTInsideGradients. Nos parâmetros do kernel, passaremos ponteiros para 4 buffers de dados:
- qkv — o vetor concatenado das entidades Query, Key e Value;
- qkv_g — o vetor concatenado dos gradientes de erro das entidades Query, Key e Value;
- scores — a matriz de coeficientes de dependência;
- gradient — o tensor dos gradientes de erro na saída do bloco de atenção XCA.
__kernel void XCiTInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const int q = get_global_id(0); const int d = get_global_id(1); const int h = get_global_id(2); const int units = get_global_size(0); const int dimension = get_global_size(1); const int heads = get_global_size(2);
O kernel será executado em um espaço de tarefas tridimensional. No corpo do kernel, identificamos imediatamente o fluxo e o espaço de tarefas. Em seguida, determinamos o deslocamento nos buffers de dados para os elementos analisados.
const int shift_q = dimension * (heads * 3 * q + h); const int shift_k = dimension * (heads * (3 * q + 1) + h); const int shift_v = dimension * (heads * (3 * q + 2) + h); const int shift_g = dimension * (heads * q + h); int shift_score = dimension * h; int step_score = dimension * heads;
De acordo com o algoritmo de propagação reversa, primeiro determinamos o gradiente de erro no tensor Value.
//--- Calculating Value's gradients float sum = 0; for(int i = 0; i < dimension; i ++) sum += gradient[shift_g + i] * scores[shift_score + d + i * step_score]; qkv_g[shift_v + d] = sum;
Depois, determinamos o gradiente de erro para Query. Aqui, precisamos primeiro determinar o gradiente de erro no vetor correspondente da matriz de coeficientes. Depois, corrigir os gradientes de erro obtidos pela derivada da função SoftMax. Somente assim podemos obter o gradiente de erro necessário.
//--- Calculating Query's gradients float grad = 0; float val = qkv[shift_v + d]; for(int k = 0; k < dimension; k++) { float sc_g = 0; float sc = scores[shift_score + k]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_score + v] * val * gradient[shift_g + v * dimension] * ((float)(k == v) - sc); grad += sc_g * qkv[shift_k + k]; } qkv_g[shift_q] = grad;
Para o tensor Key, o gradiente de erro é determinado de forma semelhante, mas na direção perpendicular dos vetores.
//--- Calculating Key's gradients grad = 0; float out_g = gradient[shift_g]; for(int scr = 0; scr < dimension; scr++) { float sc_g = 0; int shift_sc = scr * dimension * heads; float sc = scores[shift_sc + d]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_sc + v] * out_g * qkv[shift_v + v] * ((float)(d == v) - sc); grad += sc_g * qkv[shift_q + scr]; } qkv_g[shift_k + d] = grad; }
Após construir o kernel, voltamos ao trabalho com a nossa classe no lado do programa principal. Aqui, criamos o método CNeuronXCiTOCL::XCiTInsideGradients. Nos parâmetros, o método recebe ponteiros para os buffers de dados necessários.
bool CNeuronXCiTOCL::XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog) { if(!OpenCL || !qkv || !qkvg || !score || !aog) return false;
No corpo do método, verificamos imediatamente a validade dos ponteiros recebidos.
Depois, determinamos o espaço de tarefas tridimensional. Só que desta vez, não definimos grupos de trabalho.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads};
Passamos os ponteiros dos buffers de dados para os parâmetros do kernel.
if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv_g, qkvg.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_scores,score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_gradient,aog.GetIndex())) return false;
Após o trabalho preparatório, resta apenas colocar o kernel na fila de execução.
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
O algoritmo completo do bloco reverso XCiT é montado no método dispatcher CNeuronXCiTOCL::calcInputGradients. Nos parâmetros, o método recebe um ponteiro para o objeto da camada anterior.
bool CNeuronXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
No corpo do método, verificamos imediatamente a validade do ponteiro recebido. Após passar pelo ponto de controle com sucesso, preparamos um ciclo de iteração reversa das camadas internas com a passagem do gradiente de erro.
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 4:6)+1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false;
No corpo do ciclo, primeiro passamos o gradiente de erro pelo bloco FeedForward.
CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
Lembro que na passagem direta somamos os resultados dos blocos com os dados brutos. Da mesma forma, passamos o gradiente de erro por 2 fluxos.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Depois, passamos o gradiente de erro pelo bloco LPI.
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false;
Novamente, somamos os gradientes de erro.
temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Em seguida, passamos o gradiente de erro pelo bloco de atenção XCA.
out_grad = temp; //--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
E passamos para o buffer de gradientes dos dados brutos.
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 3 * iWindowKey * iHeads, None)) return false;
E não esquecemos de adicionar o gradiente do erro pelo segundo fluxo.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow)) return false; if(i > 0) out_grad = temp; } //--- return true; }
Acima, implementamos o algoritmo de propagação do gradiente de erro para as camadas internas e sua transmissão para a camada neural anterior. E ao finalizar as operações de propagação reversa, precisamos atualizar os parâmetros do modelo.
A atualização dos parâmetros da nossa nova camada do Cross-Covariance Transformer é realizada no método CNeuronXCiTOCL::updateInputWeights. Como métodos análogos de outras camadas neurais, nos parâmetros, o método recebe um ponteiro para a camada neural da camada anterior.
bool CNeuronXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput();
E no corpo do método, verificamos a relevância do ponteiro recebido.
Assim como na distribuição do gradiente de erro, as atualizações dos parâmetros serão realizadas no laço iterando pelas camadas internas.
for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization==SGD ? QKV_Weights.At(l*2+1):QKV_Weights.At(l*3+1)), (optimization==SGD ? NULL : QKV_Weights.At(l*3+2)), iWindow, 3 * iWindowKey * iHeads)) return false;
Primeiro, atualizamos os parâmetros das matrizes de formação das entidades Query, Key e Value.
Depois, atualizamos os parâmetros do bloco LPI. Este bloco contém 2 camadas convolucionais e uma camada de normalização por lotes.
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization==SGD ? cLPI_Weights.At(l*5+3):cLPI_Weights.At(l*7+3)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization==SGD ? cLPI_Weights.At(l*5+4):cLPI_Weights.At(l*7+4)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
E o método é finalizado com o bloco de atualização dos parâmetros do bloco FeedForward.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization==SGD ? FF_Weights.At(l*4+2):FF_Weights.At(l*6+2)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization==SGD ? FF_Weights.At(l*4+3):FF_Weights.At(l*6+3)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
Com isso, finalizamos o trabalho no que toca aos métodos de propagação para frente e reversa da nossa classe Cross-Covariance Transformer CNeuronXCiTOCL. Para o pleno funcionamento da classe, ainda é necessário adicionar alguns métodos auxiliares. Entre eles, métodos para trabalhar com arquivos (Save e Load). O algoritmo desses métodos não é complicado e não contém elementos únicos relacionados ao método XCiT. Portanto, não irei me deter na descrição dos seus algoritmos neste artigo. E sugiro que você os examine de forma independente no anexo. Lá você pode encontrar o código completo da classe apresentada. Bem como todos os programas usados na preparação deste artigo.
2.2 Arquitetura dos modelos
E passamos para a construção de EAs para treinamento e teste de modelos. Aqui é importante mencionar que os autores do método não apresentaram uma arquitetura específica de modelos. Na verdade, o Cross-Covariance Transformer proposto pode substituir o clássico Transformer em qualquer modelo. Consequentemente, no experimento, podemos pegar um modelo do artigo anterior e substituir a camada CNeuronMLMHAttentionOCL pela CNeuronXCiTOCL.
Claro, devemos ser honestos aqui. No trabalho anterior, usamos diferentes blocos de atenção. E o foco foi no uso do CNeuronMFTOCL, que devido às características arquitetônicas, não pode ser substituído pelo CNeuronXCiTOCL.
No entanto, substituir apenas uma camada nos permite, em certa medida, avaliar as mudanças introduzidas.
Assim, a arquitetura final do modelo testado é a seguinte.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Os dados brutos de descrição de 1 barra são enviados para a camada de dados brutos do codificador do estado do ambiente.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados obtidos são processados na camada de normalização por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Dos dados normalizados, é formado o embedding do estado do ambiente e adicionado ao stack interno.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Aqui, também adicionamos a codificação posicional dos dados.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Após o qual vem o bloco de grafos com normalização por lotes entre as camadas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
E então adicionamos nossa nova camada do Cross-Covariance Transformer. O número de elementos da sequência e a janela de dados brutos permanecem inalterados. Os parâmetros especificados são determinados pelo tensor de dados brutos.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronXCiTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 3; descr.layers = 1; descr.batch = MathMax(1000, GPTBars); descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Neste caso, usamos 4 cabeças de atenção.
Lembro que os autores do método sugerem determinar o tamanho do vetor das entidades usando a divisão inteira do tamanho do vetor de descrição de um elemento da sequência pelo número de cabeças de atenção. Dessa forma, liberamos o parâmetro descr.window_out. Aproveitaremos esse fato e indicaremos neste parâmetro o tamanho da janela da primeira camada do LPI. Também indicaremos o tamanho do lote para a normalização dos dados no bloco LPI.
Após o codificador, vem o bloco MFT.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
E transpondo o tensor para a forma correspondente.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Os resultados do codificador do estado do ambiente e do MFT são usados para decodificar os pontos finais mais prováveis.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
E avaliar suas probabilidades.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false; //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Na modelo Actor, não foram usadas camadas de atenção. Portanto, o modelo foi completamente transferido sem alterações. E a arquitetura completa de todos os modelos pode ser encontrada no anexo.
Deve-se dizer imediatamente que a substituição de uma camada na arquitetura do codificador do estado do ambiente não afeta a preparação do processo de treinamento e teste dos modelos. Portanto, todos os EAs de treinamento e interação com o ambiente foram transferidos sem alterações. A meu ver, isso aumenta o interesse pelos resultados do teste. Pois, mantendo todas as outras condições iguais, podemos avaliar de forma mais justa o impacto da substituição da camada na arquitetura do modelo.
O código completo de todos os programas utilizados na preparação deste artigo pode ser encontrado no anexo. Agora passamos ao teste da camada construída do Cross-Covariance Transformer CNeuronXCiTOCL.
3. Teste
Acima, foi realizado um grande trabalho na construção da nova classe do Cross-Covariance Transformer CNeuronXCiTOCL, proposta no artigo "XCiT: Cross-Covariance Image Transformers". Como mencionado anteriormente, transferimos completamente o EA do artigo anterior. Portanto, podemos usar o conjunto de dados de treinamento coletado anteriormente para treinar os modelos. Para isso, renomeamos o arquivo "MFT.bd" para "XCiT.bd".
Se você não possui um conjunto de dados de treinamento coletado anteriormente, é necessário coletá-lo antes de treinar o modelo. Recomendo primeiro coletar dados de sinais reais usando o método descrito no artigo "Uso de experiências passadas para resolver novas tarefas". E então completar o conjunto de dados de treinamento com passagens aleatórias do EA "...\Experts\XCiT\Research.mq5" no testador de estratégias.
O treinamento dos modelos é realizado no EA "...\Experts\XCiT\Study.mq5" após a coleta dos dados de treinamento.
Como anteriormente, o modelo é treinado em dados históricos do instrumento EURUSD, time frame H1. Os parâmetros de todos os indicadores analisados são usados por padrão.
O treinamento do modelo foi realizado em dados históricos dos primeiros 7 meses de 2023. Aqui podemos observar os primeiros resultados de verificação da eficácia dos métodos propostos. Durante o treinamento, houve uma redução no tempo gasto em quase 2%, mantendo o número de iterações de treinamento.
A avaliação da eficácia do modelo treinado foi feita em dados históricos de agosto de 2023. O período de teste não faz parte do conjunto de treinamento, mas segue diretamente o período de treinamento. Os resultados dos testes do modelo treinado foram próximos aos anteriores.
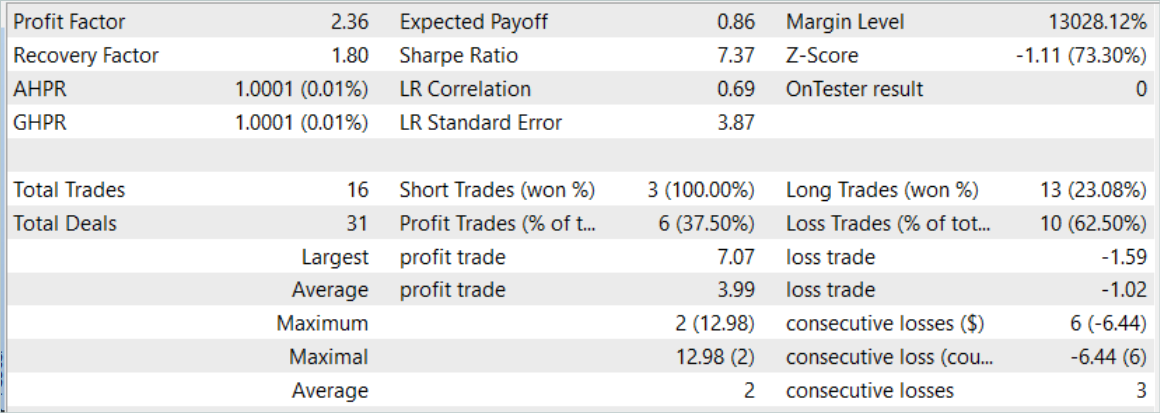
No entanto, o pequeno aumento no número de negociações também esconde um aumento no coeficiente do fator de lucro.
Considerações finais
Neste artigo, conhecemos a nova arquitetura do Cross-Covariance Transformer (XCiT), que combina as vantagens dos Transformadores e das arquiteturas Convolucionais. Ela oferece alta precisão e escalabilidade no processamento de sequências de diferentes comprimentos. Uma pequena eficiência é alcançada na análise de grandes sequências com um tamanho pequeno de tokens.
XCiT usa a arquitetura de atenção Cross-Covariance para modelar de maneira eficiente as interações globais entre as características dos elementos da sequência, permitindo lidar com sequências longas de tokens.
Os autores do método confirmam experimentalmente a alta eficácia do XCiT em várias tarefas visuais, incluindo classificação de imagens, detecção de objetos e segmentação semântica.
Na parte prática do nosso artigo, implementamos os métodos propostos utilizando MQL5. Realizamos o treinamento e teste do modelo em dados históricos reais. Durante o treinamento, notou-se uma ligeira redução no tempo de treinamento, mantendo o número de iterações de treinamento. No entanto, substituímos apenas uma camada no modelo.
E o pequeno aumento na eficácia do modelo treinado pode indicar uma melhor capacidade de generalização da arquitetura proposta.
Lembro que o trading nos mercados financeiros envolve investimentos de alto risco. Todos os programas apresentados no artigo são apenas para fins informativos e não são otimizados para trading real.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | EA | EA de treinamento de Modelos |
| 4 | Test.mq5 | EA | EA para teste de modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14276
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso