
Redes neuronales: así de sencillo (Parte 81): Razonamiento de movimiento guiado por el contexto de grueso a fino (CCMR, Coarse-to-Fine Context-Guided Motion Reasoning)

Introducción
Como parte de esta serie, nos familiarizamos con diversos métodos para analizar el estado del medio ambiente y algoritmos para utilizar los datos obtenidos. Utilizamos modelos convolucionales para encontrar patrones estables en datos históricos de movimientos de precios. También utilizamos modelos de atención para encontrar dependencias entre distintos estados ambientales locales. Siempre evaluamos el estado del medio ambiente como una determinada sección transversal en un momento dado. Sin embargo, nunca hemos evaluado la dinámica de los indicadores medioambientales. Supusimos que el modelo, en el proceso de análisis y comparación de las condiciones ambientales, prestaría atención de algún modo a los cambios clave. Pero no utilizamos una representación cuantitativa explícita de dicha dinámica.
Sin embargo, en el campo de la visión por ordenador, existe un problema fundamental de estimación del flujo óptico. La solución a este problema proporciona información sobre el movimiento de los objetos en la escena. Para resolver este problema, se han propuesto una serie de algoritmos interesantes que ahora se utilizan ampliamente. Los resultados de la estimación del flujo óptico se utilizan en diversos campos, desde la conducción autónoma hasta el seguimiento y la vigilancia de objetos.
La mayoría de los enfoques actuales utilizan redes neuronales convolucionales, pero carecen de contexto global. Esto dificulta el razonamiento sobre oclusiones de objetos o grandes desplazamientos. Un enfoque alternativo es utilizar transformadores y otras técnicas de atención. Permiten ir mucho más allá del campo receptivo fijo de las CNN clásicas.
Un método especialmente interesante, denominado CCMR, se presentó en el artículo «CCMR: High Resolution Optical Flow Estimation via Coarse-to-Fine Context-Guided Motion Reasoning». Se trata de un enfoque para la estimación del flujo óptico que combina las ventajas de los métodos orientados a la atención de los conceptos de agregación de movimiento y los enfoques multiescala de alta resolución. El método CCMR integra de forma coherente conceptos de agrupación de movimientos basados en el contexto en un marco de estimación de grano grueso de alta resolución. Esto permite obtener campos de flujo detallados que también proporcionan una gran precisión en las zonas ocluidas. En este contexto, los autores del método proponen una estrategia de agrupación del movimiento en dos etapas, en la que primero se calculan las características contextuales globales de autoatención y luego se utilizan para guiar las características de movimiento de forma iterativa en todas las escalas. Así, el razonamiento dirigido al contexto sobre el movimiento basado en XCiT proporciona procesamiento en todas las escalas de grano grueso. Los experimentos realizados por los autores del método demuestran el buen rendimiento del enfoque propuesto y las ventajas de sus conceptos básicos.
1. El algoritmo CCMR
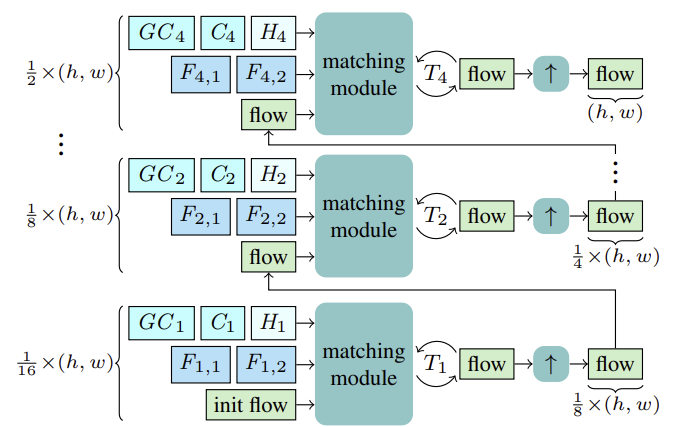
El método CCMR estima el flujo óptico mediante actualizaciones recurrentes a escala gruesa y fina utilizando una Unidad Recurrente Cerrada (GRU, Gated Recurrent Unit) común. Antes de comenzar con la estimación, para cada escala S, se calculan las características Fs,1, Fs,2 para el emparejamiento. Además, se calculan las características de contexto Cs y, a partir de ellas, las características de contexto global GCs, así como el estado oculto inicial Hs para la escala actual del bloque recurrente a partir del estado de referencia I1.
Partiendo de la escala más gruesa de 1/16, el flujo se calcula a partir de las características anteriores F1,1, F1,2, C1, GC1, H1. Después de T1 actualizaciones recurrentes del flujo, el flujo estimado se remuestrea utilizando un remuestreador convexo X2 compartido, donde el flujo sirve como inicialización para el proceso de emparejamiento a la siguiente escala más fina. Este proceso continúa hasta que el flujo se calcula a la escala 1/2 más fina y se amplía a la resolución original.
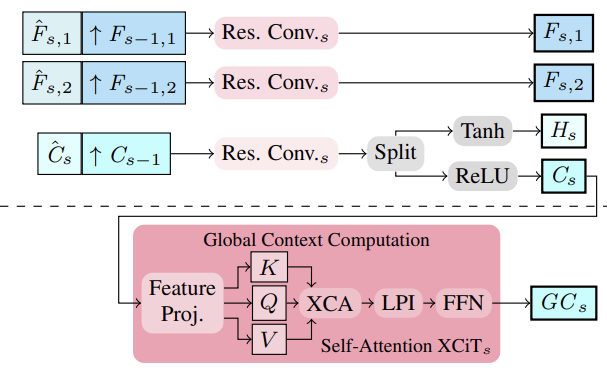
Los autores del método propusieron extraer características multiescala de la imagen y del contexto mediante un extractor de características. Para ello, se calculan características intermedias de arriba abajo y, a continuación, para obtener características multiescala, se potencian semánticamente características más estructuradas y finas Fs,1,Fs, 2 y Cs se potencian semánticamente combinándolas con características más profundas y de escala más gruesa Fs-1, 1,Fs-1,2 y Cs-1 para S∈ {2, 3, 4}. Por lo tanto, la consolidación se realiza apilando las características más gruesas sobremuestreadas y las características más finas intermedias y su agregación.
A partir de las características contextuales Cs multiescala, se calculan las características contextuales globales. Aquí el objetivo es obtener características más significativas, que luego se utilizan para controlar el movimiento. Para ello, la agregación de características contextuales C<s se realiza mediante estadísticas de canal utilizando la capa XCiT, que garantiza una complejidad lineal con respecto al número de tokens. Esta elección arquitectónica permite la posible agregación de contextos en todas las escalas gruesas y finas durante la estimación. Es importante señalar que el enfoque de CCMR propuesto por los autores para el uso de XCiT es diferente de su enfoque original, en el que la capa XCiT se aplica en realidad a una representación más gruesa de sus datos de entrada, implementada a través de un parcheado explícito, y luego remuestreada de nuevo a la resolución original. En CCMR, por el contrario, la capa XCiT se aplica directamente a las características en todas las escalas gruesas y finas utilizando contenido específico de escala. Para calcular el contexto global, primero se añade la codificación posicional a las características de contexto Cs. A continuación, se normaliza la capa. En esta etapa, para implementar la autoatención, todas las características Query, Key y Value se calculan a partir de Csp. Antes de aplicar el paso de atención a la covarianza cruzada, los canales KCs, QCs, VCs se remodelan en cabezas h. La atención de la covarianza cruzada se calcula entonces como XCA(KCs, QCs, VCs). Después, se aplica una capa de interacción de parche local (LPI) y, a continuación, el bloque FFN.
Mientras que la atención de covarianza cruzada proporciona interacciones globales entre canales en cada cabeza, los módulos LPI y FFN proporcionan interacciones espaciales explícitas entre fichas localmente y conexiones entre todos los canales, respectivamente.
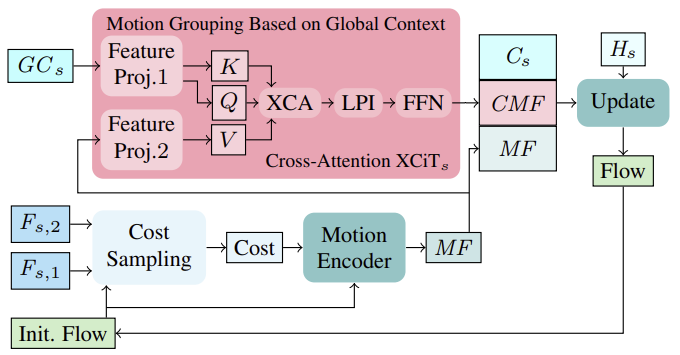
En primer lugar, basándose en el flujo inicial en la primera iteración (o en el flujo actualizado en iteraciones posteriores), se calculan los costes de coincidencia de vecindad a partir de las características de la imagen (Fs,1, Fs,2). Los costes calculados, junto con la estimación del flujo actual, se procesan a continuación a través de un codificador de movimiento, que emite características de movimiento que son utilizadas en última instancia por la GRU para calcular una actualización del hilo.
Al calcular actualizaciones iterativas del flujo, la incorporación de características de movimiento agregadas globalmente y basadas en características contextuales puede ayudar a resolver ambigüedades en regiones ocluidas. Esto es lógico porque el movimiento de los píxeles ocluidos de un objeto parcialmente no ocluido puede inferirse normalmente a partir del movimiento de sus píxeles no ocluidos. Para agregar las características de movimiento en una única escala, los autores del método siguen su eficaz estrategia basada en las estadísticas globales del canal a partir del cálculo del contexto global, que se realiza en todas las escalas gruesas y finas. La agrupación del movimiento se realiza mediante una capa de atención cruzada XCiT aplicada a las características contextuales globales GCs y a las características de movimiento MF. Así, calculamos Query y Key a partir de características contextuales globales GCs y Value a partir de características de movimiento directamente en cada escala sin partición explícita en parches. Tras aplicar XCA, LPI y FFN a la consulta, la clave y el valor del contexto, se combinan las características de movimiento impulsadas por el contexto (CMF), las características de movimiento impulsadas por el contexto Cs y las características de movimiento iniciales MFs y se pasan a través de un bloque recurrente para calcular iterativamente el flujo de actualización.
Tenga en cuenta que el uso de la atención cruzada de tokens para realizar la agregación de movimiento en esquemas de grano grueso y fino no es práctico en términos de uso de memoria.
A continuación se ofrece la visualización original del método CCMR presentada por sus autores.
2. Implementación en MQL5
Tras considerar los aspectos teóricos del método CCMR, pasamos a la parte práctica de nuestro artículo, en la que implementamos los enfoques propuestos utilizando MQL5. Como puede ver, la arquitectura propuesta es bastante compleja. Por ello, decidí dividir la aplicación de los algoritmos propuestos en varios bloques.
2.1 Bloque convolucional de bucle cerrado
Empezaremos con el bloque convolucional de bucle cerrado. Para implementarlo, vamos a crear la clase CResidualConv, que heredará la funcionalidad básica de la clase de capa totalmente conectada CNeuronBaseOCL.
A continuación se muestra la estructura de la nueva clase. Como puede ver, contiene un conjunto familiar de métodos.
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
La funcionalidad de la clase utilizará 3 bloques de una capa convolucional y normalización por lotes. Todas las capas internas se declaran estáticas, lo que nos permite dejar vacíos el constructor y el destructor de la clase.
La inicialización de un objeto de clase se realiza en el método Init. En los parámetros del método, pasaremos constantes que definen la arquitectura de la clase.
bool CResidualConv::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
En el cuerpo del método, utilizamos el método del mismo nombre de la clase padre para controlar los parámetros recibidos e inicializar los objetos heredados.
Después de que el método de la clase padre se ejecute correctamente, inicializamos los objetos internos.
if(!cConvs[0].Init(0, 0, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[0].Init(0, 1, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[0].SetActivationFunction(LReLU);
Para extraer características del estado analizado del entorno, utilizamos 2 bloques de capa convolucional secuencial y normalización por lotes con la función LReLU para crear no linealidad entre ellos.
if(!cConvs[1].Init(0, 2, OpenCL, window_out, window_out, window_out, count, optimization, iBatch)) return false; if(!cNorm[1].Init(0, 3, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[1].SetActivationFunction(None);
Utilizamos el tercer bloque de capa convolucional y la normalización por lotes (sin función de activación) para escalar los datos originales al tamaño de los resultados de nuestra CResidualConv. Esto nos permitirá implementar un segundo flujo de datos.
if(!cConvs[2].Init(0, 4, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[2].Init(0, 5, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[2].SetActivationFunction(None);
Crear 2 flujos de datos paralelos nos obliga a transmitir el gradiente de error en flujos paralelos similares. Utilizamos una capa interna auxiliar para sumar los gradientes de error.
if(!cTemp.Init(0, 6, OpenCL, window * count, optimization, batch)) return false;
Para evitar la copia innecesaria de datos, sustituimos los búferes de datos.
cNorm[1].SetGradientIndex(getGradientIndex()); cNorm[2].SetGradientIndex(getGradientIndex()); SetActivationFunction(None); iWindowOut = (int)window_out; //--- return true; }
Implementamos la funcionalidad feed-forward en el método CResidualConv::feedForward. En los parámetros del método, recibimos un puntero a la capa neuronal anterior.
bool CResidualConv::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cConvs[0].FeedForward(NeuronOCL)) return false; if(!cNorm[0].FeedForward(GetPointer(cConvs[0]))) return false;
En el cuerpo del método, no organizamos una comprobación del puntero recibido, puesto que dicha comprobación ya está implementada en los métodos pertinentes de las capas internas. Por lo tanto, procedemos inmediatamente a llamar a los métodos feed-forward para las capas internas.
if(!cConvs[1].FeedForward(GetPointer(cNorm[0]))) return false; if(!cNorm[1].FeedForward(GetPointer(cConvs[1]))) return false;
Como se ha mencionado anteriormente, utilizamos los datos recibidos de la capa neuronal anterior para el paso feed-forward de los bloques 1 y 3.
if(!cConvs[2].FeedForward(NeuronOCL)) return false; if(!cNorm[2].FeedForward(GetPointer(cConvs[2]))) return false;
A continuación, sumamos y normalizamos sus resultados.
if(!SumAndNormilize(cNorm[1].getOutput(), cNorm[2].getOutput(), Output, iWindowOut, true)) return false; //--- return true; }
El proceso inverso de retropropagación de gradiente de error se implementa en el método CResidualConv::calcInputGradients. Su algoritmo es bastante similar al método feed-forward. Simplemente llamamos a los métodos del mismo nombre en las capas internas, pero en el orden inverso.
bool CResidualConv::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cNorm[2].calcInputGradients(GetPointer(cConvs[2]))) return false; if(!cConvs[2].calcInputGradients(GetPointer(cTemp))) return false; //--- if(!cNorm[1].calcInputGradients(GetPointer(cConvs[1]))) return false; if(!cConvs[1].calcInputGradients(GetPointer(cNorm[0]))) return false; if(!cNorm[0].calcInputGradients(prevLayer)) return false;
Hay que tener en cuenta aquí que, al sustituir los búferes de datos, eliminamos la copia inicial de los gradientes de error en las capas internas. A la capa anterior, transferimos la suma de los gradientes de error de 2 flujos de datos.
if(!SumAndNormilize(prevLayer.getGradient(), cTemp.getGradient(), prevLayer.getGradient(), iWindowOut, false)) return false; //--- return true; }
El método CResidualConv::updateInputWeights para actualizar los parámetros de la clase se organiza de forma similar. Te sugiero que te familiarices con él utilizando el código adjunto. A continuación se adjunta el código completo de la clase CResidualConv y todos sus métodos. El archivo adjunto también incluye el código completo de todos los programas utilizados en la preparación del artículo. Ahora pasamos a considerar el algoritmo para construir el siguiente bloque: el codificador de características.
2.2 El codificador de características
El algoritmo Feature Encoder propuesto por los autores del método CCMR se implementará en la clase CCCMREncoder, que también hereda de la clase base de la capa neuronal totalmente conectada CNeuronBaseOCL.
class CCCMREncoder : public CNeuronBaseOCL { protected: CResidualConv cResidual[6]; CNeuronConvOCL cInput; CNeuronBatchNormOCL cNorm; CNeuronConvOCL cOutput; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CCCMREncoder(void) {}; ~CCCMREncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defCCMREncoder; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
En esta clase, utilizamos una capa convolucional para proyectar los datos originales cInput, cuyos resultados normalizamos con la capa de normalización por lotes cNorm. También utilizamos la capa convolucional de la proyección de resultados de la operación del codificador cSalida. Dado que utilizamos una capa de proyección de los datos de origen y los resultados, podemos establecer la extracción de características en cascada a varias escalas sin referencia al tamaño de los datos de origen ni al número deseado de características.
Los procesos de escalado de datos y extracción de características se realizan en varios bloques convolucionales secuenciales de bucle cerrado, que por comodidad hemos combinado en la matriz cResidual.
Como en la clase anterior, declaramos estáticos todos los objetos internos de la clase, lo que nos permite dejar vacíos el constructor y el destructor de la clase.
La inicialización de los objetos de la clase se realiza en el método CCCMREncoder::Init. El algoritmo de este método sigue una lógica ya conocida. En parámetros, el método recibe constantes de arquitectura de clase.
bool CCCMREncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
En el cuerpo del método, primero llamamos al método correspondiente de la clase padre, que comprueba los parámetros recibidos e inicializa los objetos heredados. Controlamos el resultado del método de la clase padre utilizando el resultado lógico de su finalización.
A continuación, inicializamos el bloque para escalar y normalizar los datos de origen. A partir de los resultados de su funcionamiento, se prevé obtener una representación de un único estado del entorno en forma de descripción de 32 parámetros.
if(!cInput.Init(0, 0, OpenCL, window, window, 32, count, optimization, iBatch)) return false; if(!cNorm.Init(0, 1, OpenCL, 32 * count, iBatch, optimization)) return false; cNorm.SetActivationFunction(LReLU);
A continuación, creamos una cascada de escalado de datos con el número de características {32, 64, 128}.
if(!cResidual[0].Init(0, 2, OpenCL, 32, 32, count, optimization, iBatch)) return false; if(!cResidual[1].Init(0, 3, OpenCL, 32, 32, count, optimization, iBatch)) return false;
if(!cResidual[2].Init(0, 4, OpenCL, 32, 64, count, optimization, iBatch)) return false; if(!cResidual[3].Init(0, 5, OpenCL, 64, 64, count, optimization, iBatch)) return false;
if(!cResidual[4].Init(0, 6, OpenCL, 64, 128, count, optimization, iBatch)) return false; if(!cResidual[5].Init(0, 7, OpenCL, 128, 128, count, optimization, iBatch)) return false;
Y, por último, llevamos la dimensión de los datos a la escala especificada por el usuario.
if(!cOutput.Init(0, 8, OpenCL, 128, 128, window_out, count, optimization, iBatch)) return false;
Para eliminar las operaciones de copia innecesarias de los resultados de las operaciones en bloque y los gradientes de error, sustituimos los búferes de datos.
if(Output != cOutput.getOutput()) { if(!!Output) delete Output; Output = cOutput.getOutput(); } //--- if(Gradient != cOutput.getGradient()) { if(!!Gradient) delete Gradient; Gradient = cOutput.getGradient(); } //--- return true; }
No olvide controlar el proceso de las operaciones en cada paso. A continuación, informamos a la persona que llama sobre los resultados del método con un valor lógico.
Ahora creamos un algoritmo de paso feed-forward en el método CCCMREncoder::feedForward. En los parámetros del método, como siempre, recibimos un puntero al objeto de la capa anterior. La comprobación de la pertinencia del puntero recibido se realiza en el cuerpo de los métodos para el paso de objetos anidados.
bool CCCMREncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cInput.FeedForward(NeuronOCL)) return false; if(!cNorm.FeedForward(GetPointer(cInput))) return false;
En primer lugar, escalamos y normalizamos los datos originales. A continuación, someteremos los datos a una cascada de escalado con extracción de características.
Obsérvese que el primer bloque convolucional de bucle cerrado recibe sus datos iniciales de la capa de normalización por lotes, y los siguientes del bloque anterior de la matriz. Esto nos permite iterar a través de bloques en un bucle.
if(!cResidual[0].FeedForward(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].FeedForward(GetPointer(cResidual[i - 1]))) return false;
Escalamos el resultado de las operaciones a un tamaño determinado.
if(!cOutput.FeedForward(GetPointer(cResidual[5]))) return false; //--- return true; }
El gradiente de error se propaga a través de los objetos internos del Encoder en orden inverso.
bool CCCMREncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cInput.UpdateInputWeights(NeuronOCL)) return false; if(!cNorm.UpdateInputWeights(GetPointer(cInput))) return false; if(!cResidual[0].UpdateInputWeights(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].UpdateInputWeights(GetPointer(cResidual[i - 1]))) return false; if(!cOutput.UpdateInputWeights(GetPointer(cResidual[5]))) return false; //--- return true; }
En este artículo no nos detendremos en la descripción de todos los métodos de la clase. Tienen una estructura de bloques similar de llamada secuencial a los métodos correspondientes de los objetos internos. Puede estudiar la estructura utilizando el código completo que se adjunta a continuación. Si tienes alguna pregunta sobre el código, estaré encantado de responderte en el foro o en mensajes privados. Elija el formato de comunicación que prefiera.
2.3 Agrupamiento dinámico del contexto global
Para agrupar el contexto global teniendo en cuenta la dinámica de los cambios en los rasgos, los autores del método CCRM propusieron utilizar un bloque de atención cruzada XCiT. En este bloque, las entidades Query y Key se forman a partir de características del contexto global. Value se forma a partir de la dinámica de las características ambientales formadas de 2 estados posteriores. Este uso del bloque es algo diferente del que hemos considerado anteriormente. Para aplicar la opción propuesta de utilizar el bloque, tenemos que hacer algunas modificaciones.
Vamos a crear una nueva clase CNeuronCrossXCiTOCL, que heredará la mayor parte de la funcionalidad de la implementación anterior del método XCiT.
class CNeuronCrossXCiTOCL : public CNeuronXCiTOCL { protected: CCollection cConcat; CCollection cValue; CCollection cV_Weights; CBufferFloat TempBuffer; uint iWindow2; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool Concat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool DeConcat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); public: CNeuronCrossXCiTOCL(void) {}; ~CNeuronCrossXCiTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion); //--- virtual int Type(void) const { return defNeuronCrossXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Ten en cuenta que en esta implementación, he intentado utilizar al máximo la funcionalidad creada anteriormente. Se han añadido a la estructura de clases 3 colecciones de búferes de datos y un búfer auxiliar para almacenar datos intermedios.
Como antes, todos los objetos internos se declaran estáticos, por lo que el constructor y el destructor de la clase están «vacíos».
La inicialización de todos los objetos de la clase se realiza en el método CNeuronCrossXCiTOCL::Init.
bool CNeuronCrossXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronXCiTOCL::Init(numOutputs, myIndex, open_cl, window1, lpi_window, heads, units_count, layers, optimization_type, batch)) return false;
En los parámetros, el método recibe los parámetros principales que determinan la arquitectura de toda la clase y sus objetos internos. En el cuerpo de la clase, llamamos al método correspondiente de la clase padre, que comprueba los parámetros recibidos e inicializa todos los objetos heredados.
Una vez ejecutado con éxito el método de la clase padre, definimos los parámetros de los buffers para escribir entidades Value y sus gradientes de error. También definimos matrices de generación de pesos para la entidad especificada.
//--- Cross XCA iWindow2 = fmax(window2, 1); uint num = iWindowKey * iHeads * iUnits; //Size of V tensor uint v_weights = (iWindow2 + 1) * iWindowKey * iHeads; //Size of weights' matrix of V tensor
A continuación, organizamos un bucle por el número de XCiT capas internas de atención cruzada y creamos los búferes necesarios en el cuerpo del bucle. En primer lugar, añadimos un búfer para escribir las entidades de valor generadas y los gradientes de error correspondientes.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize V tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cValue.Add(temp)) return false;
En la clase padre CNeuronXCiTOCL, utilizamos un buffer concatenado de entidades Query, Key y Value. Para poder seguir utilizando la funcionalidad heredada, vamos a concatenar las entidades especificadas de 2 fuentes en un búfer de colección cConcat.
//--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(3 * num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cConcat.Add(temp)) return false; }
El siguiente paso es crear los buffers de la matriz de pesos para generar la entidad Value.
//--- XCiT //--- Initilize V weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(v_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < v_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false;
Búferes de momentos para el proceso de optimización de la matriz de pesos especificada.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(v_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false; } }
A continuación, inicializamos el búfer intermedio de almacenamiento de datos.
TempBuffer.BufferInit(iWindow2 * iUnits, 0); if(!TempBuffer.BufferCreate(OpenCL)) return false; //--- return true; }
No olvide controlar el proceso de las operaciones en cada paso.
El método feed-forward CNeuronCrossXCiTOCL::feedForward fue copiado en gran parte de la clase padre. Sin embargo, las características de la atención cruzada requieren su redefinición. En concreto, para aplicar la atención cruzada, necesitamos dos fuentes de datos iniciales.
bool CNeuronCrossXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(!NeuronOCL || !Motion) return false;
En el cuerpo del método, comprobamos la relevancia de los punteros recibidos a los objetos de datos de origen y organizamos un bucle a través de las capas internas.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 2 * iWindowKey * iHeads, None)) return false;
En el cuerpo del bucle, primero generamos las entidades Query y Key a partir de los datos de la capa neuronal anterior. Se supone que en este flujo de información recibimos el contexto global GC<s.
Tenga en cuenta que estamos utilizando buffers de las colecciones heredadas QKV_Tensors y QKV_Weights. Sin embargo, sólo generamos 2 entidades. Esto puede verse en el número de filtros de convolución «2 * iWindowKey * iHeads».
Del mismo modo, generamos la tercera entidad Value, pero basándonos en otros datos iniciales.
CBufferFloat *v = cValue.At(i * 2); if(IsStopped() || !ConvolutionForward(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), Motion, v, iWindow, iWindowKey * iHeads, None)) return false;
Como se ha mencionado anteriormente, para poder utilizar la funcionalidad heredada, concatenamos las 3 entidades en un único tensor.
if(IsStopped() || !Concat(qkv, v, cConcat.At(2 * i), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
Entonces usamos la funcionalidad heredada, pero hay una cosa. En esta aplicación, el número de elementos de la secuencia en ambos flujos es idéntico. Porque en el nivel superior, generamos ambos flujos a partir de los mismos datos de origen. Teniendo esto en cuenta, no he incluido una comprobación de igualdad de longitud de secuencia. Pero para el correcto funcionamiento de las funciones posteriores, este cumplimiento es fundamental. Por lo tanto, si desea utilizar esta clase por separado, asegúrese de que las longitudes de ambas secuencias son iguales.
Determinemos los resultados de la atención multicabeza.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(cConcat.At(2 * i), temp, out)) return false;
Suma y normaliza los flujos de datos.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
A continuación, un bloque de interacción local. A continuación, se suman y normalizan los flujos.
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false; out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false; temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false; //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Luego viene el bloque FeedForward.
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false; //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
Después de iterar con éxito a través de todas las capas neuronales internas, completamos el método.
Tenga en cuenta que, en este método, se utiliza un búfer de los datos originales de dinámica de características para todas las capas neuronales internas. Еl contexto global cambia gradualmente y se transforma en el contexto global guiado por el contexto Context-guided Motion Features (CMF).
El proceso de propagación del gradiente de error a través de los objetos internos se implementa de forma similar en orden inverso. Su algoritmo se describe en el método CNeuronCrossXCiTOCL::calcInputGradients. En los parámetros, el método recibe punteros a 2 objetos de datos de origen con búferes de los gradientes de error correspondientes que tenemos que rellenar.
bool CNeuronCrossXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion) { if(!prevLayer || !Motion) return false;
En el cuerpo del método, primero comprobamos la relevancia de los punteros recibidos. A continuación, organizamos un bucle a través de las capas internas en orden inverso.
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
En el cuerpo del bucle, primero propagamos el gradiente de error a través del bloque FeedForward.
Permítanme recordarles que durante el paso feed-forward, sumamos y normalizamos los datos de entrada y salida de cada bloque. En consecuencia, durante el paso de retropropagación, también necesitamos propagar un gradiente de error a lo largo de ambos flujos de datos. Por lo tanto, después de propagar el gradiente de error a través del bloqueFeedForward, tenemos que sumar los gradientes de error de los dos flujos.
//--- Sum gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
De forma similar, propagamos el gradiente de error a través del bloque de interacción local y sumamos el gradiente de error sobre dos flujos de datos.
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false; temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
El último paso consiste en propagar el gradiente de error a través del bloque de atención.
//--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(cConcat.At(i * 2), cConcat.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
Sin embargo, aquí obtenemos un buffer concatenado de gradientes de error para 3 entidades:Query, Key y Value. Pero recordemos que las entidades se generaron a partir de varias fuentes de datos. Tenemos que distribuir el gradiente de error en ellos. Primero dividimos un búfer en 2.
if(IsStopped() || !DeConcat(QKV_Tensors.At(i * 2 + 1), cValue.At(i * 2 + 1), cConcat.At(i * 2 + 1), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
A continuación, llamamos a métodos para propagar gradientes a los datos de origen correspondientes. Podemos utilizar la funcionalidad heredada para Query y Key. Sin embargo, las cosas son un poco más complicadas para Value.
//--- CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false;
Durante el pase de avance, hice hincapié en que para todas las capas utilizamos una memoria intermedia de la dinámica de los cambios de rasgos. Pasar directamente el gradiente de error al búfer de gradiente del objeto de datos de origen simplemente los sobrescribirá y borrará los datos previamente escritos de otras capas internas. Por lo tanto, escribiremos los datos directamente sólo en la primera iteración (la última capa interna).
if(i > 0) out_grad = temp; if(i == iLayers - 1) { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), Motion.getGradient(), iWindow, iWindowKey * iHeads, None)) return false; }
En otros casos, utilizaremos un búfer auxiliar para almacenar datos temporales y luego sumaremos los gradientes nuevos y los acumulados anteriormente.
else { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), GetPointer(TempBuffer), iWindow, iWindowKey * iHeads, None)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(TempBuffer), Motion.getGradient(), Motion.getGradient(), iWindow2, false)) return false; }
Suma los gradientes de error sobre los 2 flujos de datos y pasa a la siguiente iteración del bucle.
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false; if(i > 0) out_grad = temp; } //--- return true; }
Después de pasar con éxito el gradiente de error a través de todas las capas internas, terminamos el método.
Tras distribuir el gradiente de error entre todos los objetos internos y los datos de origen en función de su influencia en el resultado final, tenemos que ajustar los parámetros del modelo para minimizar el error. Este proceso se organiza en el método CNeuronCrossXCiTOCL::updateInputWeights. De forma similar a los 2 métodos discutidos anteriormente, actualizamos los parámetros de los objetos internos en un bucle a través de capas neuronales internas.
bool CNeuronCrossXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization == SGD ? QKV_Weights.At(l * 2 + 1) : QKV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : QKV_Weights.At(l * 3 + 2)), iWindow, 2 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cV_Weights.At(l * (optimization == SGD ? 2 : 3)), cValue.At(l * 2 + 1), inputs, (optimization == SGD ? cV_Weights.At(l * 2 + 1) : cV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : cV_Weights.At(l * 3 + 2)), iWindow, iWindowKey * iHeads)) return false;
Primero actualizamos los parámetros para generar las entidades Query, Key y Value. A continuación, el bloque de comunicación local LPI.
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization == SGD ? cLPI_Weights.At(l * 5 + 3) : cLPI_Weights.At(l * 7 + 3)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization == SGD ? cLPI_Weights.At(l * 5 + 4) : cLPI_Weights.At(l * 7 + 4)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
Completamos el proceso con un bloque FeedForward.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization == SGD ? FF_Weights.At(l * 4 + 2) : FF_Weights.At(l * 6 + 2)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 4 + 3) : FF_Weights.At(l * 6 + 3)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
Con esto concluye la descripción de los métodos de la clase CNeuronCrossXCiTOCL. Dentro del ámbito de este artículo, no podemos detenernos en detalle en todos los métodos de la clase. Puede estudiarlos usted mismo utilizando el código del archivo adjunto. Los archivos adjuntos incluyen el código completo de todas las clases y sus métodos. También contienen todos los programas utilizados en la preparación del artículo.
2.4 Implementación del algoritmo CCMR
Hemos trabajado bastante para implantar nuevas clases. Sin embargo, han sido trabajos preparatorios. Ahora procedemos a poner en práctica nuestra visión del algoritmo CCMR. Tenga en cuenta que esta es nuestra visión de los planteamientos propuestos. Puede diferir de la representación original. No obstante, intentamos aplicar los planteamientos propuestos para resolver nuestros problemas.
Para implementar el método, vamos a crear la clase CNeuronCCMROCL, que heredará la funcionalidad básica de la clase CNeuronBaseOCL. A continuación se muestra la estructura de la nueva clase.
class CNeuronCCMROCL : public CNeuronBaseOCL { protected: CCCMREncoder FeatureExtractor; CNeuronBaseOCL PrevFeatures; CNeuronBaseOCL Motion; CNeuronBaseOCL Temp; CCCMREncoder LocalContext; CNeuronXCiTOCL GlobalContext; CNeuronCrossXCiTOCL MotionContext; CNeuronLSTMOCL RecurentUnit; CNeuronConvOCL UpScale; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCCMROCL(void) {}; ~CNeuronCCMROCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronCCMROCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag virtual bool Clear(void); };
Aquí puedes ver el conjunto tradicional de métodos y una serie de objetos, la mayoría de los cuales fueron creados anteriormente. Creamos 2 instancias de objetos de clase CCCMREncoder para extraer características del entorno y del contexto local (FeatureExtractor y LocalContext, respectivamente).
La instancia del objeto CNeuronXCiTOCL se utiliza para obtener el contexto global (GlobalContext). Usando CNeuronCrossXCiTOCL, lo ajustamos teniendo en cuenta la dinámica de las características a CMF (MotionContext).
Para implementar las conexiones recurrentes, en lugar de GRU, utilizamos un bloque LSTM (CNeuronLSTMOCL RecurrentUnit).
Nos familiarizaremos con la funcionalidad de todos los objetos internos con más detalle durante la implementación de los métodos de la clase.
Como antes, declaramos que todos los objetos internos de la clase son estáticos. Por lo tanto, el constructor y el destructor de la clase permanecen «vacíos».
Los objetos internos de la clase se inicializan con el método CNeuronCCMROCL::Init.
bool CNeuronCCMROCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
En los parámetros del método, obtenemos las constantes clave de la arquitectura de la clase. En el cuerpo del método, llamamos inmediatamente al método correspondiente de la clase padre, en el que se comprueban los parámetros recibidos y se inicializan los objetos heredados.
Después de ejecutar con éxito el método de la clase padre, pasamos a inicializar los objetos internos. En primer lugar, inicializamos el Feature Encoder del estado actual del entorno.
if(!FeatureExtractor.Init(0, 0, OpenCL, window, 16, count, optimization, iBatch)) return false;
Para estimar el flujo, el método CCMR utiliza instantáneas de 2 estados consecutivos del sistema. Sin embargo, nosotros abordamos esta cuestión desde un ángulo ligeramente distinto. En cada iteración del paso de avance, generamos características de sólo 1 estado ambiental y lo guardamos en el buffer local PrevFeatures. Utilizamos el valor de este búfer para estimar el flujo dinámico en la siguiente pasada de avance. Inicializamos los objetos de la memoria intermedia local del estado anterior y los cambios en las características.
if(!PrevFeatures.Init(0, 1, OpenCL, 16 * count, optimization, iBatch)) return false; if(!Motion.Init(0, 2, OpenCL, 16 * count, optimization, iBatch)) return false;
Para evitar la copia innecesaria de datos, organizamos la sustitución de búferes.
if(Motion.getGradientIndex() != FeatureExtractor.getGradientIndex())
Motion.SetGradientIndex(FeatureExtractor.getGradientIndex());
A continuación, basándonos en el estado actual del entorno, generamos características de contexto utilizando el codificador LocalContext. Hay que señalar aquí que estamos utilizando un conjunto de datos de origen en 2 flujos de datos. En consecuencia, necesitamos obtener el gradiente de error a partir de 2 flujos. Para permitir la suma de gradientes, crearemos un búfer de datos local.
if(!Temp.Init(0, 3, OpenCL, window * count, optimization, iBatch)) return false; if(!LocalContext.Init(0, 4, OpenCL, window, 16, count, optimization, iBatch)) return false;
Los mecanismos de atención nos permitirán agrupar los contextos locales en un contexto global.
if(!GlobalContext.Init(0, 5, OpenCL, 16, 3, 4, count, 4, optimization, iBatch)) return false;
El contexto global se ajusta entonces a la dinámica del flujo.
if(!MotionContext.Init(0, 6, OpenCL, 16, 16, 3, 4, count, 4, optimization, iBatch)) return false;
Por último, actualizamos el flujo en el bloque recurrente.
if(!RecurentUnit.Init(0, 7, OpenCL, 16 * count, optimization, iBatch) || !RecurentUnit.SetInputs(16 * count)) return false;
Para reducir el tamaño del modelo, utilizamos objetos internos de un estado bastante comprimido. Sin embargo, el usuario puede necesitar datos en una dimensión diferente. Para ajustar los resultados al tamaño deseado, utilizaremos una capa de escalado.
if(!UpScale.Init(0, 8, OpenCL, 16, 16, window_out, count, optimization, iBatch)) return false;
Para evitar la copia innecesaria de datos, organizamos la sustitución de los búferes de datos.
if(UpScale.getGradientIndex() != getGradientIndex()) SetGradientIndex(UpScale.getGradientIndex()); if(UpScale.getOutputIndex() != getOutputIndex()) Output.BufferSet(UpScale.getOutputIndex()); //--- return true; }
El algoritmo feed-forward se implementa en el método CNeuronCCMROCL::feedForward. En los parámetros, el método feed-forward recibe un puntero al objeto de capa anterior que contiene los datos originales.
bool CNeuronCCMROCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Delta Features if(!SumAndNormilize(FeatureExtractor.getOutput(), FeatureExtractor.getOutput(), PrevFeatures.getOutput(), 1, false, 0, 0, 0, -0.5f)) return false;
En el cuerpo del método, antes de iniciar cualquier operación, transferimos el contenido de la memoria intermedia de resultados del codificador de señales de estado ambiental a la memoria intermedia de estado anterior. Antes de que comiencen las iteraciones, la memoria intermedia contiene los resultados de la pasada anterior.
Tenga en cuenta que, al transferir los datos, cambiamos el signo del atributo de la característica por el opuesto.
Una vez guardados los datos, pasamos por el codificador de estados.
if(!FeatureExtractor.FeedForward(NeuronOCL)) return false;
Después de pasar con éxito el feed-forward de FeatureExtractor, tenemos características de 2 condiciones posteriores y podemos determinar la desviación. Para simplificar, tomaremos simplemente la diferencia de características. Al guardar el estado anterior, hemos cambiado prudentemente el signo de las características. Ahora, para obtener la diferencia de estados, podemos sumar el contenido de los buffers.
if(!SumAndNormilize(FeatureExtractor.getOutput(), PrevFeatures.getOutput(), Motion.getOutput(), 1, false, 0, 0, 0, 1.0f)) return false;
El siguiente paso consiste en generar características contextuales locales.
if(!LocalContext.FeedForward(NeuronOCL)) return false;
Extraigamos el contexto global.
if(!GlobalContext.FeedForward(GetPointer(LocalContext))) return false;
Y ajustarlo a la dinámica de los cambios.
if(!MotionContext.FeedForward(GetPointer(GlobalContext), Motion.getOutput())) return false;
A continuación, ajustamos el flujo en el bloque recurrente.
//--- Flow if(!RecurentUnit.FeedForward(GetPointer(MotionContext))) return false;
Escala los datos al tamaño deseado.
if(!UpScale.FeedForward(GetPointer(RecurentUnit))) return false; //--- return true; }
Durante la aplicación, no olvide controlar el proceso en cada paso.
El algoritmo de retropropagación se implementa en el método CNeuronCCMROCL::calcInputGradients. Al igual que los métodos del mismo nombre en otras clases, los parámetros del método proporcionan un índice al objeto de la capa anterior. En el cuerpo del método, llamamos secuencialmente a los métodos correspondientes de los objetos internos. Sin embargo, la secuencia de objetos será la inversa a la del paso directo.
bool CNeuronCCMROCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!UpScale.calcInputGradients(GetPointer(RecurentUnit))) return false;
Primero propagamos el gradiente de error a través de la capa de escalado. A continuación, a través del bloque recurrente.
if(!RecurentUnit.calcInputGradients(GetPointer(MotionContext))) return false;
A continuación, propagamos el gradiente de error secuencialmente a través de todas las etapas de la transformación de contexto.
if(!MotionContext.calcInputGradients(GetPointer(GlobalContext), GetPointer(Motion))) return false; if(!GlobalContext.calcInputGradients(GetPointer(LocalContext))) return false; if(!LocalContext.calcInputGradients(GetPointer(Temp))) return false;
Con la sustitución de los búferes de datos, el gradiente de error de la dinámica de características se transfiere al codificador de características de estado. Propagamos el gradiente de error a través del Encoder al buffer de la capa anterior.
if(!FeatureExtractor.calcInputGradients(prevLayer)) return false;
Añadir gradiente de error del codificador de contexto.
if(!SumAndNormilize(prevLayer.getGradient(), Temp.getGradient(), prevLayer.getGradient(), 1, false, 0, 0, 0, 1.0f)) return false; //--- return true; }
El método para actualizar los parámetros del modelo no es difícil. Actualizamos secuencialmente los parámetros de los objetos internos.
bool CNeuronCCMROCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!FeatureExtractor.UpdateInputWeights(NeuronOCL)) return false; if(!LocalContext.UpdateInputWeights(NeuronOCL)) return false; if(!GlobalContext.UpdateInputWeights(GetPointer(LocalContext))) return false; if(!MotionContext.UpdateInputWeights(GetPointer(GlobalContext), Motion.getOutput())) return false; if(!RecurentUnit.UpdateInputWeights(GetPointer(MotionContext))) return false; if(!UpScale.UpdateInputWeights(GetPointer(RecurentUnit))) return false; //--- return true; }
Tenga en cuenta que esta clase contiene un bloque recurrente y un búfer para guardar el estado anterior. Por lo tanto, necesitamos redefinir el método para borrar el componente recurrente CNeuronCCMROCL::Clear. Aquí llamamos al método de bloque recurrente del mismo nombre y llenamos el búfer de resultados de FeatureExtractor con valores cero.
bool CNeuronCCMROCL::Clear(void) { if(!RecurentUnit.Clear()) return false; //--- CBufferFloat *temp = FeatureExtractor.getOutput(); temp.BufferInit(temp.Total(), 0); if(!temp.BufferWrite()) return false; //--- return true; }
Ten en cuenta que estamos borrando el buffer de resultados del Encoder, no el buffer de estado anterior. Al principio del método de paso de avance, copiamos los datos del búfer de resultados del codificador al búfer de estado anterior.
Con esto concluyen los principales métodos de aplicación de los enfoques CCMR. Hemos trabajado bastante, pero el tamaño del artículo es limitado. Por lo tanto, le sugiero que se familiarice con el algoritmo de métodos auxiliares en el archivo adjunto. Allí encontrarás el código completo de todas las clases y sus métodos para implementar los enfoques CCMR. Además, en el archivo adjunto encontrará el código completo de todos los programas utilizados en la preparación del artículo. Y pasamos a considerar la arquitectura de entrenamiento del modelo.
2.5. Arquitectura del modelo
Pasando a la descripción de la arquitectura del modelo, me gustaría mencionar que los planteamientos del CCMR afectaban únicamente al codificador de estados ambientales.
La arquitectura de los modelos que entrenaremos se proporciona en el método CreateDescriptions, en cuyos parámetros proporcionaremos 3 arreglos dinámicos para registrar la arquitectura del codificador (Encoder), el actor (Actor) y el crítico (Critic).
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
En el cuerpo del método, comprobamos los punteros recibidos y, si es necesario, creamos nuevas instancias de objetos.
Alimentamos el codificador con datos brutos del estado actual del entorno.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos recibidos se preprocesan en una capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Después, formamos una pila de incrustaciones de estado.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Añadimos codificación posicional a las incrustaciones resultantes.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Y el último en la arquitectura del codificador es el nuevo bloque CNeuronCCMROCL, que en sí mismo es bastante complejo y requiere procesamiento adicional.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCCMROCL; descr.count = prev_count; descr.window = prev_wout; descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Utilizo aquí las arquitecturas Actor y Critic de los anteriores artículos sin cambios. Puede encontrar la descripción detallada de la arquitectura del modelo aquí. Además, en el anexo se presenta la arquitectura completa de los modelos. Ahora pasamos a la fase final para comprobar el trabajo realizado.
3. Prueba
En las secciones anteriores de este artículo, nos familiarizamos con el método CCMR e implementamos los enfoques propuestos utilizando MQL5. Ahora es el momento de probar en la práctica los resultados del trabajo realizado anteriormente. Como siempre, utilizamos datos históricos del EURUSD, marco temporal H1, para entrenar y probar los modelos. Los modelos se entrenan con datos históricos de los 7 primeros meses de 2023. Para probar el modelo entrenado en el Probador de Estrategias de MetaTrader 5, utilizo datos históricos de agosto de 2023.
En este artículo, he entrenado el modelo utilizando el conjunto de datos de entrenamiento recopilados como parte de los artículos anteriores. Durante el proceso de entrenamiento, conseguí obtener un modelo capaz de generar beneficios en el conjunto de entrenamiento.
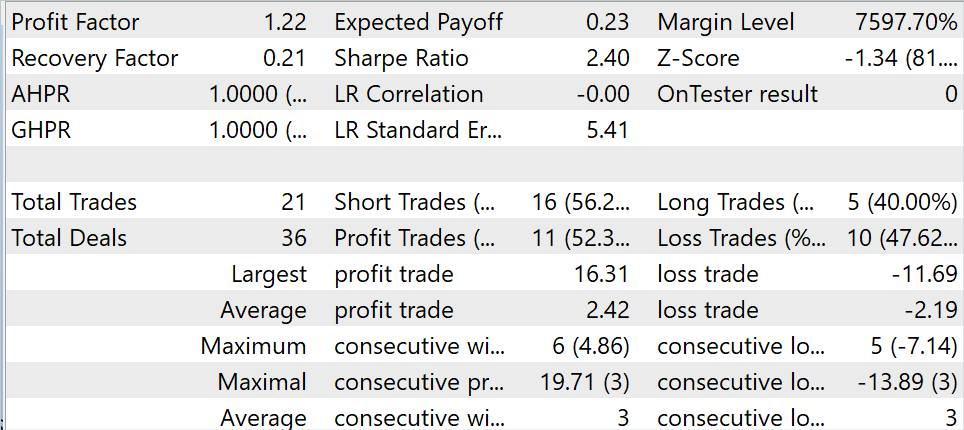
Durante el periodo de prueba, el modelo realizó 21 transacciones, el 52,3% de las cuales se cerraron con beneficio. Tanto el máximo como la media de las operaciones rentables superan los valores correspondientes a las operaciones perdedoras. El resultado fue un factor de beneficio de 1.22.
Conclusión
En este artículo, discutimos un método de estimación del flujo óptico llamado CCMR, que combina las ventajas de los conceptos de agregación de movimiento basada en el contexto y un enfoque multiescala de grueso a fino. Esto produce mapas de flujo detallados que también son muy precisos en zonas obstruidas.
Los autores del método propusieron una estrategia de agrupación de movimientos en dos fases, en la que primero se calculan las características del contexto global. A continuación, se utilizan para guiar iterativamente las características del movimiento a todas las escalas. Esto permite a los algoritmos basados en XCiT procesar todas las escalas, de gruesa a fina, conservando el contenido específico de cada escala.
En la parte práctica del artículo, implementamos los enfoques propuestos utilizando MQL5. Entrenamos y probamos el modelo utilizando datos reales en el Probador de Estrategias de MetaTrader 5. Los resultados obtenidos sugieren la eficacia de los planteamientos propuestos.
No obstante, le recuerdo que todos los programas presentados en el artículo son de carácter informativo y sólo pretenden demostrar los enfoques propuestos.
Referencias
Programas utilizados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor experto | Colección de ejemplos |
| 2 | ResearchRealORL.mq5 | Asesor experto | EA para la recolección de ejemplos utilizando el método Real-ORL |
| 3 | Study.mq5 | Asesor experto | EA para el entrenamiento del modelo |
| 4 | Test.mq5 | Asesor experto | EA para la prueba del modelo |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema |
| 6 | NeuroNet.mqh | Biblioteca de clases | Una biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Código base | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14505
 Utilizando redes neuronales en MetaTrader
Utilizando redes neuronales en MetaTrader
 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso