
Redes neurais de maneira fácil (Parte 76): explorando diversos modos de interação (Multi-future Transformer)

Introdução
A previsão do movimento de preços é um dos componentes chave para construir uma estratégia de negociação bem-sucedida. Por isso, precisamos explorar as possibilidades de criar previsões precisas e multimodais do movimento futuro. Nos artigos anteriores, aprendemos alguns métodos de previsão de movimento de preços. Entre eles, havia multimodais, oferecendo várias opções de desenvolvimento de eventos.
Contudo, raramente se concentram nas futuras possibilidades de interação entre os agentes analisados, o que pode levar à perda de informações e previsão subótima. Além disso, é bastante difícil escalonar os métodos previamente considerados para o caso de vários agentes, pois previsões independentes podem levar a um número exponencial de combinações. A maioria das combinações obtidas é irrealizável devido a previsões contraditórias. Sendo assim, é importante focar na previsão de cenas como um todo, avaliando simultaneamente o estado futuro de vários agentes.
No artigo «Multi-future Transformer: Learning diverse interaction modes for behaviour prediction in autonomous driving» para resolver tais problemas, é proposto o método Multi-future Transformer (MFT). A ideia principal é decompor a distribuição multimodal do futuro em várias distribuições unimodais, permitindo modelar eficientemente diversos modos de interação entre os agentes na cena.
No MFT, as previsões são criadas por uma rede neural com parâmetros fixos em uma única passagem para frente, sem necessidade de amostragem estocástica de variáveis ocultas, pré-definição de vinculações ou execução de um algoritmo iterativo de pós-processamento. Isso permite que o modelo opere de forma determinística e reprodutível.
1. Algoritmo Multi-future Transformer
O principal objetivo do método Multi-future Transformer é prever consistentemente o movimento futuro Y de todos os agentes na cena. Para isso, é analisado o estado dinâmico dos agentes X e a informação contextual M. Assim, a distribuição probabilística geral para captura é P(Y|X,M), que é multimodal como resultado da evolução clara da cena.
Normalmente, é muito difícil modelar diretamente a distribuição multimodal conjunta. E os autores do método introduzem a hipótese de que a distribuição alvo pode ser decomposta em uma mistura de várias distribuições unimodais, e então essas distribuições unimodais são modeladas separadamente, o que é formulado como
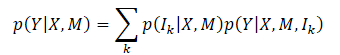
onde Ik — k-ésimo componente do modo;
p(Ik|X,M) — distribuição de probabilidade dos diversos modos;
p(Y|X,M,Ik) — distribuição unimodal fatorizada.
De acordo com esta formulação, o ponto chave do MFT é que a principal diferença entre cada modo da distribuição alvo reside nos diferentes modelos de interação entre os agentes, bem como entre os agentes e o contexto. A modelagem de cada distribuição unimodal pode ser realizada através do estudo dos padrões de interação entre os modos. Intuitivamente, a incerteza futura da cena pode ser basicamente decomposta em duas partes: incerteza de intenção e incerteza de interação.
As intenções não observáveis podem ser bem capturadas através da modelagem da interação entre o agente e o contexto, já que o ponto final da trajetória futura, que representa as intenções do agente, está intimamente ligado ao contexto da cena. Para levar em conta a incerteza de interação, são modelados diferentes modos de interação entre os agentes. Assim, ao capturar conjuntamente a interação agente-agente e a interação agente-contexto, a incerteza futura é minimizada e o desenvolvimento da cena pode ser determinado.
Para alcançar a decomposição descrita acima da distribuição conjunta multimodal, foi desenvolvida a arquitetura geral da abordagem proposta do MFT, que consiste em três partes:
- Codificadores,
- Módulo de interação paralela,
- Cabeçalhos de previsão.
Dois tipos de codificadores são incluídos no modelo:
- o codificador dinâmico do agente é usado para extrair características dos estados dinâmicos observáveis,
- o codificador de segmentos de contexto serve como um módulo de representação de mapa para estudar as características de pontos específicos.
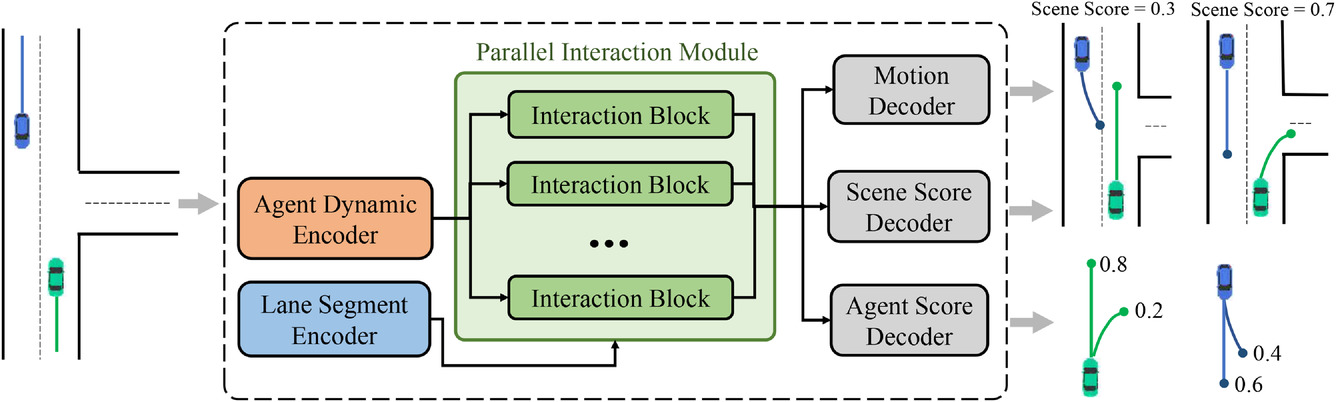
O núcleo do modelo MFT é o módulo de interação paralela, que consiste em vários blocos de interação em estrutura paralela e estuda as características futuras dos movimentos dos agentes para cada modo. Os três cabeçalhos de previsão incluem:
- Decodificador de movimento,
- Decodificador de avaliação do agente,
- Decodificador de avaliação da cena.
Eles são responsáveis por decodificar as trajetórias futuras de cada agente e avaliar os indicadores de confiabilidade para cada trajetória prevista e cada modo da cena. Nesta arquitetura, os caminhos pelos quais os sinais diretos e reversos de cada modo passam são independentes entre si, e cada caminho contém um bloco de interação único, que garante a interação de informações entre os sinais do mesmo modo. Consequentemente, os blocos de interação podem capturar simultaneamente os padrões de interação correspondentes de diferentes modos. Porém, os codificadores e os cabeçalhos de previsão são comuns a cada modo, enquanto os blocos de interação são parametrizados como objetos diferentes. Assim, cada distribuição unimodal, que teoricamente possui diferentes parâmetros, pode ser modelada de uma maneira mais eficiente em termos de parâmetros. Visualização do método pelo autor apresentada abaixo.
As trajetórias percorridas pelos agentes no horizonte histórico podem ser representadas como X={x1,...,xatt}, onde o estado dinâmico em cada passo temporal xt=(x,y,vx,vy,w) contém a posição (x,y), velocidade (vx,vy) e o ângulo de desvio do curso w nesse momento.
Os estados dinâmicos do agente são vistos como um conjunto de pontos em um espaço multidimensional, onde cada ponto é representado pelascoordenadas (x,y), e as outras dimensões são características locais adicionais. Para esses pontos, mantêm-se as propriedades de interação e a estrutura local especificada, pois os estados observáveis do agente interagem entre si e, juntos, formam a trajetória passada do agente. Além disso, outra propriedade importante desses pontos da trajetória é a ordem temporal, que é uma característica implícita em comparação com os pontos estáticos da pista de movimento. Naturalmente, os mesmos pontos da trajetória com a ordem temporal inversa resultam em uma trajetória passada completamente diferente. As propriedades acima mencionadas exigem que o modelo represente os pontos da trajetória não apenas combinando características pontuais, mas também introduzindo informações sobre a ordem temporal. Para esse fim, a codificação posicional absoluta é usada para codificar informações de ordenação. O modelo calcula as características dinâmicas para cada agente da seguinte maneira:
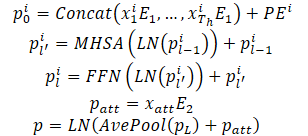
Várias camadas do codificador são empilhadas para melhorar a capacidade do modelo de representar informações dinâmicas. A média é calculada sobre todos os pontos da trajetória do agente para resumir as informações dinâmicas históricas relacionadas a um agente específico.
As características pontuais, correspondentes ao momento atual, também são extraídas para obter informações dinâmicas. Isso proporciona um desempenho semelhante ao de um pool médio. Ao lidar com estados históricos parcialmente observáveis, a estrutura baseada em Self-Attention pode simplesmente mascarar as posições não observadas sem esforços adicionais, evitando assim de forma eficaz a confusão de características causada por preenchimento inválido.
Uma característica distinta da tarefa de previsão de comportamento é a multimodalidade, causada pela incerteza futura da cena. A abordagem geral é usar várias cabeças de resultado para decodificar independentemente as trajetórias futuras de cada agente com base no vetor de características comum. Contudo, esse método tem duas grandes desvantagens:
- a informação sobre o movimento das várias possíveis trajetórias futuras está contida em um único vetor de características com dimensão fixa, o que limita a informação e restringe significativamente a capacidade expressiva do modelo;
- os sinais diretos e inversos de diferentes modos se misturam no processo de interação das características e propagação do gradiente, resultando no problema da confusão de modos, o que prejudica a capacidade de fazer previsões multimodais.
Em vez disso, no MFT, a modelagem da interação é separada em diferentes modos para alcançar um resultado multimodal, estudando o padrão único de interação correspondente a cada modo. Para isso, foi projetado um módulo de interação paralela. Este módulo contém vários blocos de interação paralela, cada um representando um modo específico de desenvolvimento futuro dos eventos. Nesta estrutura, os sinais diretos e reversos dentro de cada modo atravessam o bloco de interação do modo correspondente. Ao mesmo tempo, outros modos não interferem, evitando assim o problema da confusão de modos.
Além disso, cada bloco de interação é parametrizado como um objeto separado, permitindo que o modelo tenha força expressiva suficiente para lidar com grandes diferenças entre os diferentes modos. Em cada bloco de interação, é utilizado o mecanismo Self-Attention para modelar a interação entre os agentes e o mecanismo Cross-Attention para capturar a interação entre os agentes e a cena. Esses dois tipos de funções de interação são adicionados à função dinâmica através de uma conexão residual para obter a função final do movimento futuro para cada agente e modo. O processo descrito acima pode ser representado da seguinte maneira:

A estrutura final do módulo de interação paralela pode ser vista como a paralelização do decodificador Transformer com uma estrutura sequencial. No entanto, a previsão multimodal e a força expressiva aumentada são alcançadas com custos computacionais semelhantes aos do análogo padrão. Os experimentos realizados pelos autores do método confirmam que, em combinação com o uso do erro "o vencedor leva tudo" no nível da cena, o método proposto pode fornecer uma previsão consistente do comportamento de vários agentes. Também foi realizado um estudo para demonstrar a indispensabilidade dos dois tipos de interações modeladas e a justificativa da construção da estrutura modular.
A visualização da estrutura dos módulos pelo autor é apresentada abaixo.

Além de prever a trajetória futura de cada agente, o MFT realiza a avaliação da plausibilidade para cada possível desenvolvimento da cena, bem como para cada trajetória prevista do agente. Para tarefas de planejamento de movimento, os dados de entrada ideais podem ser a previsão multimodal da cena com a respectiva métrica de confiabilidade para cada modo da cena. O algoritmo de planejamento pode calcular diretamente a possível trajetória futura do movimento, considerando todos os agentes vizinhos simultaneamente. Para esse fim, os autores do método desenvolveram cabeçalhos de previsão para as diversas variantes da cena e suas probabilidades.
Para avaliar a probabilidade no nível da cena, é feita a média dos vetores de características de todos os agentes na cena. Isso permite obter uma representação no nível da cena.
Além disso, para prestar atenção especial ao agente, a avaliação da plausibilidade deve ser realizada do ponto de vista do próprio agente. Consequentemente, foi criado um terceiro cabeçalho no modelo para decodificar as avaliações de confiabilidade das trajetórias previstas de cada agente. O processo de decodificação do Multi-future Transformer é formulado da seguinte maneira:
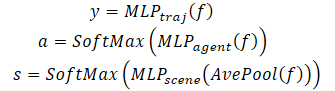
Vale acrescentar que, para decodificar a cena multimodal, é utilizado um decodificador com parâmetros idênticos para todas as possíveis variantes de desenvolvimento dos eventos.
2. Implementação com MQL5
Após considerar os aspectos teóricos do método Multi-future Transformer, passamos à parte prática do nosso artigo. E consideramos uma opção de implementação do método proposto com MQL5.
Do descrito acima do algoritmo Multi-future Transformer pode-se dizer que a principal dificuldade de implementação para nós é o módulo de interação paralela. Em nossa biblioteca já existem camadas de Self-Attention (CNeuronMLMHAttentionOCL) e Cross-Attention (CNeuronMH2AttentionOCL) implementadas. Contudo, mesmo com o uso de várias cabeças de atenção, os fluxos de informação se misturam na propagação para frente e reversa. O que não satisfaz as condições do método Multi-future Transformer.
Bem, começaremos nossa implementação do método com a criação de uma nova classe de camada neural.
2.1. Módulo de interação paralela
O algoritmo do módulo de interação paralela será implementado na classe CNeuronMFTOCL, que será criada como herdeira da classe CNeuronMLMHAttentionOCL.
Vale ressaltar que a escolha da classe pai não é acidental. O fato é que na classe CNeuronMLMHAttentionOCL já existe a funcionalidade de Self-Attention multicamada implementada. Na implementação da nova classe, utilizaremos os trabalhos existentes. Mas, em vez de calcular sequencialmente as camadas do bloco de atenção, faremos previsões de diferentes opções de desenvolvimento de eventos. Além disso, adicionaremos a funcionalidade de Cross-Attention, prevista no algoritmo Multi-future Transformer.
A estrutura da nova classe é apresentada abaixo. Como pode ser observado, além de redefinir os métodos principais, adicionamos mais uma coleção de buffers de dados para transposição de dados, necessária para a implementação do mecanismo de Cross-Attention.
class CNeuronMFTOCL : public CNeuronMLMHAttentionOCL { protected: //--- CCollection cTranspose; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols); virtual bool MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool MHCAInsideGradients(CBufferFloat *q, CBufferFloat *qg, CBufferFloat *kv, CBufferFloat *kvg, CBufferFloat *score, CBufferFloat *aog); public: CNeuronMFTOCL(void) {}; ~CNeuronMFTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronMFTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
A declaração da nova coleção de buffers de dados como estática nos permite deixar o construtor e destrutor da classe “vazios”. E a criação direta de todos os objetos internos da classe é realizada no método de inicialização Init.
bool CNeuronMFTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * features, optimization_type, batch)) return false;
Nos parâmetros, o método recebe todas as informações necessárias para recriar a arquitetura exigida. E no corpo do método, chamamos imediatamente o método análogo da classe base das camadas neurais CNeuronBaseOCL.
Observe que chamamos o método de inicialização não diretamente da classe pai CNeuronMLMHAttentionOCL, mas “por cima” nos dirigimos à classe base das camadas neurais CNeuronBaseOCL. Isso se deve a algumas diferenças na implementação de CNeuronMFTOCL e CNeuronMLMHAttentionOCL.
Se na classe pai CNeuronMLMHAttentionOCL processamos sequencialmente os dados brutos em várias camadas do bloco de atenção e na saída obtivemos um resultado com dimensão semelhante aos dados brutos. Na nova camada CNeuronMFTOCL, geraremos sequencialmente diferentes opções de possível desenvolvimento de eventos. Consequentemente, o resultado do trabalho da camada será múltiplo (de acordo com o número de opções de previsão) do tamanho dos dados brutos. Portanto, precisamos aumentar o buffer de resultados.
Além disso, para evitar cópia excessiva de dados, na classe pai substituímos os buffers de resultados e gradientes da própria camada e da última camada interna. Na implementação da nova classe, essa abordagem é inaceitável, pois precisaremos concatenar os resultados de vários blocos paralelos em um único buffer.
Mas vamos voltar ao nosso método de inicialização. Após a execução bem-sucedida do método de inicialização da classe base das camadas neurais, armazenaremos os parâmetros-chave da arquitetura nas variáveis internas da classe.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(features, 1);
Vale notar que todos os parâmetros são armazenados nas variáveis da classe pai. E há uma pequena discrepância entre o nome da variável e sua funcionalidade: a variável iLayers armazenará o número de opções planejadas. Com o objetivo de utilizar os recursos de maneira mais eficiente, decidi não criar uma variável adicional e "fechar os olhos" para a discrepância entre o nome e a funcionalidade da variável.
Em seguida, calcularemos os principais parâmetros dos nossos blocos.
//--- MHSA uint num = 3 * iWindowKey * iHeads * iUnits; //Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of QKV tensor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of output tensor uint w0 = (iWindowKey + 1) * iHeads * iWindow; //Size W0 tensor
//--- MHCA uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeads * iUnits; //Size of KV tensor uint q_weights = (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of Q tensor uint kv_weights = 2 * (iUnits + 1) * iWindowKey * iHeads; //Size of weights' matrix of KV tensor uint scores_ca = iUnits * iWindow * iHeads; //Size of Score tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
Após a conclusão do trabalho preparatório, realizamos um loop no qual criaremos sequencialmente buffers de dados para cada opção de desenvolvimento de eventos em nosso bloco de interação paralela.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- MHSA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Aqui, criaremos um loop aninhado para criar buffers de propagação para frente e reversa. No corpo do loop aninhado, primeiro criaremos o buffer de embeddings concatenados Query, Key e Value do bloco MHSA. E imediatamente adicionaremos o buffer da matriz de coeficientes Score.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
Adicionaremos o buffer dos resultados da atenção de várias cabeças.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
E na saída do bloco MHSA, criaremos o buffer de união dos resultados das várias cabeças de atenção.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Aqui é importante notar que, para atender aos requisitos do algoritmo MFT, os resultados das cabeças de atenção são combinados apenas dentro de uma opção de interação.
Em seguida, criaremos buffers semelhantes para o bloco Cross-Attention (MHCA). Só que, neste caso, separaremos o buffer de embeddings Query de Key e Value, pois serão usados dados brutos diferentes.
//--- MHCA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cTranspose.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores_ca, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
//--- Initialize multi-heads cross attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Após a criação dos buffers para os blocos de atenção, criaremos os buffers do bloco FeedForward.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
//--- Initialize Feed Forward 2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Acima, criamos buffers de resultados e gradientes de erro de blocos individuais. A seguir, precisaremos criar matrizes de coeficientes de peso treináveis para esses blocos. Vamos criá-los na mesma sequência. Primeiro, geraremos os pesos para os embeddings Query, Key e Value do bloco MHSA.
//--- MHSA //--- Initilize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
E da camada de união das cabeças de atenção.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Repetiremos as operações para o bloco MHCA.
//--- MHCA //--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; for(uint w = 0; w < q_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize KV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float kv = (float)(1 / sqrt(iUnits + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* kv)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
E criaremos as matrizes do bloco FeedForward.
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Depois, organizaremos outro loop aninhado no qual criaremos os buffers dos momentos de atualização das matrizes de coeficientes de peso. Observe que o número de buffers de momentos depende do algoritmo de otimização escolhido.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- MHSA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- MHCA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
Após a inicialização bem-sucedida de todos os buffers de dados necessários, concluímos o trabalho do método com o resultado true.
Como se pode ver acima, criamos um número bastante grande de buffers e é fácil se confundir com eles. Por isso, criaremos uma tabela para navegar pelos buffers de dados.
| id | QKV_Tensors | S_Tensors, AO_Tensors | FF_Tensors | QKV_Weights | FF_Weights |
|---|---|---|---|---|---|
| 0 | Query, Key, Value MHSA | MHSA | MHSA Out | Query, Key, Value MHSA | MHSA W0 |
| 1 | Query MHCA | MHCA | MHCA Out | Query MHCA | MHCA W0 |
| 2 | Key, Value MHCA | Gradient MHSA | FF1 | Key, Value MHCA | FF1 |
| 3 | Gradient Query, Key, Value MHSA | Gradient MHCA | FF2 | Momentum1 Query, Key, Value MHSA | FF2 |
| 4 | Gradient Query MHCA | Gradient MHSA Out | Momentum1 Query MHCA | Momentum1 MHSA W0 | |
| 5 | Gradient Key, Value MHCA | Gradient MHCA Out | Momentum1 Key, Value MHCA | Momentum1 MHCA W0 | |
| 6 | Gradient FF1 | Momentum2 Query, Key, Value MHSA | Momentum1 FF1 | ||
| 7 | Gradient FF2 | Momentum2 Query MHCA | Momentum1 FF2 | ||
| 8 | Momentum2 Key, Value MHCA | Momentum2 MHSA W0 | |||
| 9 | Momentum2 MHCA W0 | ||||
| 10 | Momentum2 FF1 | ||||
| 11 | Momentum2 FF2 |
Após a inicialização da classe CNeuronMFTOCL, passamos à construção do algoritmo de propagação para frente. Vale dizer que, na implementação do algoritmo MFT, não criamos novos kernels no lado do programa OpenCL. Mas, para chamar os kernels criados anteriormente, tivemos que criar alguns métodos no lado do programa principal. Em particular, para nossa classe CNeuronMFTOCL, criamos um método de transposição de matriz. O algoritmo do método replica completamente o método de propagação para frente da camada de transposição. Mas há diferenças nos detalhes. Nos parâmetros, o novo método recebe ponteiros para dois buffers de dados (dados brutos e resultados), bem como os tamanhos da matriz original.
bool CNeuronMFTOCL::Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols) { if(!in || !out) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {rows, cols}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, in.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, out.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("%s %d Error of execution kernel Transpose: %d -> %s", __FUNCTION__, __LINE__, GetLastError(), error); return false; } //--- return true; }
Assim, no corpo do método, verificamos os ponteiros recebidos para os buffers de dados e no espaço das tarefas especificamos os valores dos parâmetros. O próprio algoritmo de chamada do kernel permaneceu inalterado.
Situação semelhante ocorre com o método de propagação para frente MHCA. Nos parâmetros do método, recebemos ponteiros para os buffers de dados. Para comparação, o método CNeuronMH2AttentionOCL::attentionOut não tinha parâmetros e em sua funcionalidade usava objetos internos.
bool CNeuronMFTOCL::MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out) { if(!q || !kv || !score || !out) return false;
No corpo do método, criamos as dimensões do espaço das tarefas.
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindow, iHeads}; uint local_work_size[3] = {1, iWindow, 1};
Passamos os parâmetros para o kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, q.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, kv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, score.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, out.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
E fazemos seu enfileiramento.
if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
O algoritmo de propagação para frente MFT é implementado no método CNeuronMFTOCL::feedForward. Como métodos semelhantes de outras camadas neurais, nos parâmetros, o método recebe um ponteiro para a camada neural anterior. E no corpo do método, verificamos imediatamente a validade do ponteiro recebido.
bool CNeuronMFTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
Em seguida, efetuamos um laço de cálculo sequencial de diferentes opções de interação de agentes.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- MHSA //--- Calculate Queries, Keys, Values CBufferFloat *inputs = NeuronOCL.getOutput(); CBufferFloat *qkv = QKV_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Aqui, primeiro obtemos as entidades Query, Key e Value do bloco MHSA. Depois, definimos a matriz de coeficientes de atenção.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 4); if(IsStopped() || !AttentionScore(qkv, temp, false)) return false;
E geramos o resultado da atenção de várias cabeças.
//--- Multi-heads attention calculation CBufferFloat *out = AO_Tensors.At(i * 4); if(IsStopped() || !AttentionOut(qkv, temp, out)) return false;
O resultado da atenção de várias cabeças será reduzido ao tamanho dos dados brutos. Lembro que a combinação das cabeças de atenção é feita dentro de uma opção de interação de agentes.
//--- Attention out calculation temp = FF_Tensors.At(i * 8); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
O tensor obtido é somado aos dados brutos. Os resultados da operação são normalizados.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
Depois, segue o bloco de cross-attention. Aqui, primeiro definimos a entidade Query.
//--- MHCA inputs = temp; CBufferFloat *q = QKV_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
Em seguida, transpomos os dados brutos e calculamos as entidades Key e Value.
CBufferFloat *tr = cTranspose.At(i * 2); if(IsStopped() || !Transpose(inputs, tr, iUnits, iWindow)) return false;
CBufferFloat *kv = QKV_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), tr, kv, iUnits, 2 * iWindowKey * iHeads, None)) return false;
E definimos os resultados de atenção cruzada multi-cabeça.
//--- Multi-heads cross attention calculation temp = S_Tensors.At(i * 4 + 1); out = AO_Tensors.At(i * 4 + 1); if(IsStopped() || !MHCA(q, kv, temp, out)) return false;
Os resultados obtidos são compactados para o tamanho dos dados brutos.
//--- Cross Attention out calculation temp = FF_Tensors.At(i * 8 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Somamos com os resultados do bloco MHSA e normalizamos os dados.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
Depois efetuamos a transferência de dados através do bloco FeedForward.
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 8 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 8 + 3); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), temp, out, 4 * iWindow, iWindow, activation)) return false;
Os resultados do bloco FeedForward somamos com os resultados do MHCA. Os dados obtidos são normalizados e gravados no buffer de resultados com um deslocamento correspondente à variante de interação analisada.
//--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, Output, iWindow, true, 0, 0, i * inputs.Total())) return false; } //--- return true; }
Em seguida, passamos para a próxima iteração do laço de análise da próxima variante de interação dos agentes na cena.
Após a análise bem-sucedida de todas as variantes de interação dos agentes, concluímos o método com o resultado true.
Se, durante a passagem para frente, for executada a funcionalidade principal da análise das variantes de interação dos agentes na cena e a previsão de possíveis variantes de desenvolvimento de eventos, o treinamento do modelo não é possível sem a implementação de métodos de propagação reversa. É justamente durante a propagação reversa que se realiza a otimização dos parâmetros do modelo para obter resultados ótimos. Assim, após a implementação dos métodos de propagação para frente, passamos para a construção do algoritmo de propagação reversa.
Assim como na propagação para frente, para implementar a propagação reversa, precisaremos criar um método adicional MHCAInsideGradients, cujo algoritmo praticamente duplica o algoritmo CNeuronMH2AttentionOCL::AttentionInsideGradients. A única diferença é que MHCAInsideGradients trabalha não com os objetos internos da classe, mas com buffers recebidos nos parâmetros do método. Acima já foram dados exemplos de tais modificações. E não vamos agora nos deter em uma consideração detalhada do método. Você pode consultar o código em anexo.
O algoritmo de propagação reversa é implementado diretamente no método calcInputGradients, que recebe como parâmetro um ponteiro para o objeto da camada de neurônios anterior.
bool CNeuronMFTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
No corpo do método, verificamos imediatamente a validade do ponteiro recebido. Depois salvamos em variáveis locais os ponteiros para os buffers com os quais todos os blocos de interação paralela trabalharão.
CBufferFloat *out_grad = Gradient; CBufferFloat *inp = prevLayer.getOutput(); CBufferFloat *grad = prevLayer.getGradient();
Após o trabalho preparatório, efetuamos o laço de distribuição dos gradientes de erro através dos blocos de interação paralela.
for(int i = 0; (i < (int)iLayers && !IsStopped()); i++) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), Gradient, FF_Tensors.At(i * 8 + 2), FF_Tensors.At(i * 8 + 6), 4 * iWindow, iWindow, None, i * inp.Total())) return false;
Primeiro, passamos o gradiente de erro através do bloco FeedForward.
CBufferFloat *temp = FF_Tensors.At(i * 8 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(i * 8 + 6), FF_Tensors.At(i * 8 + 1), temp, iWindow, 4 * iWindow, LReLU)) return false;
Lembre-se de que, na propagação para frente, somamos os resultados do bloco FeedForward com a saída do bloco MHCA. Analogamente, passamos o gradiente de erro na direção inversa. Mas desta vez sem normalização.
//--- Sum gradient if(IsStopped() || !SumAndNormilize(Gradient, temp, temp, iWindow, false, i * inp.Total(), 0, 0)) return false; out_grad = temp;
Em seguida, devemos passar o gradiente de erro através do módulo de atenção cruzada. Primeiro, distribuímos o gradiente de erro entre as cabeças de atenção.
//--- MHCA //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out_grad, AO_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3), iWindowKey * iHeads, iWindow, None)) return false;
Depois distribuímos o gradiente de erro para as entidades correspondentes.
if(IsStopped() || !MHCAInsideGradients(QKV_Tensors.At(i * 6 + 1), QKV_Tensors.At(i * 6 + 4), QKV_Tensors.At(i * 6 + 2), QKV_Tensors.At(i * 6 + 5), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3))) return false;
E agora precisamos transpor o gradiente de erro do bloco Key e Value do bloco MHCA.
CBufferFloat *tr = cTranspose.At(i * 2 + 1); if(IsStopped() || !Transpose(QKV_Tensors.At(i * 6 + 5), tr, iWindow, iUnits)) return false;
Primeiro somamos os resultados obtidos entre si.
//--- Sum temp = FF_Tensors.At(i * 8 + 4); if(IsStopped() || !SumAndNormilize(QKV_Tensors.At(i * 6 + 4), tr, temp, iWindow, false)) return false;
E depois com o gradiente de erro na saída do bloco MHCA.
if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Em seguida, temos que executar o gradiente de erro por meio do bloco MHSA. Como no caso da atenção cruzada, primeiro distribuímos o gradiente de erro entre as cabeças de atenção.
//--- MHSA //--- Split gradient to multi-heads out_grad = temp; if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out_grad, AO_Tensors.At(i * 4), AO_Tensors.At(i * 4 + 2), iWindowKey * iHeads, iWindow, None)) return false;
Descemos o gradiente de erro para as entidades correspondentes.
//--- Passing gradient to query, key and value if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 6), QKV_Tensors.At(i * 6 + 3), S_Tensors.At(i * 4), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 1))) return false;
E levamos ao nível dos dados brutos.
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(i * 6 + 3), inp, tr, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Agora precisamos somar o gradiente de erro na entrada e saída do bloco MHSA, e o resultado registrar no buffer de gradientes da camada anterior. Mas há um detalhe aqui. No buffer de gradientes da camada anterior, precisamos registrar a soma dos gradientes de erro de todos os blocos de interação paralela. Por isso, primeiro verificamos o identificador do bloco de interação paralela. Para o primeiro bloco, simplesmente registramos no buffer de gradientes de erro da camada anterior a soma dos gradientes de 2 fluxos. E para os outros blocos de interação paralela, adicionamos os gradientes de erro recebidos aos dados no buffer da camada anterior.
//--- Sum gradients if(i > 0) { if(IsStopped() || !SumAndNormilize(grad, tr, grad, iWindow, false)) return false; if(IsStopped() || !SumAndNormilize(out_grad, grad, grad, iWindow, false)) return false; } else if(IsStopped() || !SumAndNormilize(out_grad, tr, grad, iWindow, false)) return false; } //--- return true; }
E então passamos para a próxima iteração do laço para passar o gradiente de erro pelo próximo bloco de interação paralela.
Após a conclusão bem-sucedida de todas as iterações do laço, concluímos o método com o resultado true.
Acima efetuamos o processo de propagação para frente e a redistribuição do gradiente de erro na classe CNeuronMFTOCL. E para a implementação completa da funcionalidade principal da classe, resta adicionar o método de atualização dos parâmetros treináveis updateInputWeights. O algoritmo deste método é bastante simples. Apenas no laço chamamos o método da classe pai ConvolutuionUpdateWeights, no qual a atualização dos parâmetros de um buffer separado é realizada. E os buffers de dados necessários para o trabalho são passados nos parâmetros do método.
bool CNeuronMFTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(l * 6 + 3), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 3) : QKV_Weights.At(l * 9 + 3)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 6)), iWindow, 3 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 1), QKV_Tensors.At(l * 6 + 4), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 4) : QKV_Weights.At(l * 9 + 4)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 7)), iWindow, iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 2), QKV_Tensors.At(l * 6 + 5), cTranspose.At(l * 2), (optimization == SGD ? QKV_Weights.At(l * 6 + 5) : QKV_Weights.At(l * 9 + 5)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 8)), iUnits, 2 * iWindowKey * iHeads)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12)), FF_Tensors.At(l * 8 + 4), AO_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 8 + 4) : FF_Weights.At(l * 12 + 4)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 8)), iWindowKey * iHeads, iWindow)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 1), FF_Tensors.At(l * 8 + 5), AO_Tensors.At(l * 4 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 5) : FF_Weights.At(l * 12 + 5)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 9)), iWindowKey * iHeads, iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(l * 8 + 6), FF_Tensors.At(l * 8 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 6) : FF_Weights.At(l * 12 + 6)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 10)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 3), FF_Tensors.At(l * 8 + 7), FF_Tensors.At(l * 8 + 2), (optimization == SGD ? FF_Weights.At(l * 8 + 7) : FF_Weights.At(l * 12 + 7)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 11)), 4 * iWindow, iWindow)) return false; } //--- return true; }
Com isso, concluímos a consideração dos métodos de implementação da funcionalidade principal do algoritmo Multi-future Transformer na classe CNeuronMFTOCL. Você pode se familiarizar com a implementação dos métodos auxiliares no anexo. Lá você também encontrará o código completo de todos os programas usados na preparação deste artigo. E passamos à implementação dos EAs de construção e treinamento de modelos.
2.2 Arquitetura dos modelos
Acima construímos a classe de implementação do bloco de interação paralela, cuja arquitetura foi proposta pelos autores do método Multi-future Transformer. Contudo, esta é apenas uma camada do nosso modelo. E agora precisamos descrever a arquitetura completa dos modelos que estamos criando. Na entrada, alimentaremos os "dados brutos". E como resultado do trabalho dos modelos, queremos obter um vetor de ações ótimas do Agente, cuja execução pode gerar lucro ao operar nos mercados financeiros.
Devo dizer que ao construir meu modelo, me afastei um pouco da arquitetura proposta pelos autores do método. E há várias razões para isso.
Primeiro, o método Multi-future Transformer foi proposto para prever a interação de veículos autônomos com o ambiente. Estamos planejando usar nosso modelo para os mercados financeiros. Ambas as tarefas têm suas especificidades, que influenciam a construção dos modelos.
Em segundo lugar, no artigo anterior, dedicamos bastante atenção à otimização do desempenho dos modelos. E eu gostaria de aproveitar a experiência que adquiri. Por isso, usei a arquitetura dos modelos do artigo anterior como "doador". Ao mesmo tempo, fizemos alterações nos modelos de planejamento de trajetória.
Como você sabe, a arquitetura dos modelos de previsão de trajetórias futuras é descrita no método CreateTrajNetDescriptions do arquivo “...\Experts\MFT\Trajectory.mqh”. Nos parâmetros, o método recebe ponteiros para arrays dinâmicos para criar 3 modelos:
- Codificador de estado;
- Decodificador de pontos finais;
- Probabilidades da cena.
Nos artigos anteriores, decidimos não prever a trajetória completa do movimento do preço, mas nos concentramos na previsão dos principais extremos do movimento do preço:
- Close
- High
- Low.
É por esse motivo que, em nosso trabalho, consideramos o estado da dinâmica do movimento dos preços como variantes da cena. E não analisamos as probabilidades das trajetórias finais de agentes individuais.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
No corpo do método, verificamos a atualidade dos ponteiros recebidos nos parâmetros para os objetos e, se necessário, criamos novos.
Primeiro, descrevemos a arquitetura do Codificador, na entrada do qual alimentamos os dados brutos que descrevem o estado atual do ambiente.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Como de costume, os dados recebidos passam pelo processamento inicial na camada de normalização por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Depois criamos o embedding do estado atual e o armazenamos na pilha interna do modelo.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Cada elemento do embedding está associado a um agente separado na cena do ambiente. De acordo com o método MFT, realizaremos a codificação posicional dos dados brutos.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, na arquitetura dos autores do método MFT segue um stack de blocos MHSA. Aqui está minha primeira divergência da arquitetura proposta. Decidi utilizar os avanços do artigo anterior e deixei 2 camadas Crystal-GCN, separadas por uma camada de normalização por lotes.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
Seguido por uma camada MHSA.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Depois, os autores do método sugerem fazer a média dos indicadores da dinâmica de cada agente. No bloco de interação paralela, realiza-se a análise cruzada dos dados com os dados contextuais do mapa. No nosso caso, não há mapa do possível movimento futuro do preço. Em vez disso, usaremos a análise contextual das trajetórias percorridas das características analisadas.
E o próximo em nossa arquitetura é o bloco de cálculos paralelos criado acima. Neste bloco, usamos blocos de Self-Attention e Cross-Attention com 4 cabeças de atenção. Os autores do método utilizaram apenas 1 cabeça de atenção nos blocos de interação paralela. A quantidade de variantes de interação dos agentes é determinada pela constante NForecast.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A seguir, deve-se notar um ponto arquitetônico. Em nossa implementação, construímos a classe CNeuronMFTOCL de tal forma que o resultado de seu trabalho pode ser apresentado na forma de um tensor 3D {quantidade de elementos da sequência, variante de interação, quantidade de agentes}. Esse formato de dados não é muito conveniente para nós para o processamento subsequente, pois precisamos trabalhar com cada variante de interação separadamente. E a localização da variante de interação dentro das dimensões do tensor complica esse trabalho. Desse modo, logo, transpor os dados para trazer a variante da interação dos agentes para a primeira dimensão do tensor.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Assim, na saída do Codificador, obtivemos um tensor {variante da interação dos agentes, número de agentes, comprimento do vetor de descrição da dinâmica do agente}.
Após o Codificador, criamos um modelo de Decodificação dos pontos finais. Na entrada do modelo, vamos alimentar o tensor dos resultados do Codificador.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Lembro que o método MTF prevê o uso de um decodificador com os mesmos parâmetros para todas as variantes de interação dos agentes. Podemos implementar essa abordagem usando uma camada convolucional com o tamanho da janela e o passo igual ao tensor de uma variante de interação dos agentes. Essa etapa será dividida em duas fases. Primeiro, convoluiremos a dinâmica de cada agente individual.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
E então obteremos as variantes da cena para cada variante de interação analisada.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
O modelo de avaliação das probabilidades das cenas previstas permaneceu praticamente inalterado. Como no caso do Decodificador, na entrada do modelo são alimentados os resultados do Codificador.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false;
Que são combinados com as variantes previstas da cena.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; }
Os dados são analisados por duas camadas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
E são normalizados pela função SoftMax.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
A arquitetura dos modelos do Ator foi transferida praticamente sem alterações. Foram feitas apenas pequenas correções na parte do processamento dos resultados do Codificador do estado atual.
Também é importante dizer que as mudanças feitas na arquitetura do modelo praticamente não afetaram os algoritmos de interação com o ambiente e o treinamento dos modelos. Por isso, todos os EA foram transferidos do artigo anterior com mínimas alterações. E, permitam-me, não me deter na descrição de seus algoritmos neste artigo. E com o código completo de todos os programas usados no artigo, você pode se familiarizar no anexo.
3.Teste
Acima, implementamos o algoritmo Multi-future Transformer usando MQL5 e descrevemos a arquitetura dos modelos que nos permitem usar as abordagens propostas para treinar modelos de previsão de múltiplas variantes de movimento futuro dos preços com avaliação de suas probabilidades. E agora é hora de verificar os resultados do nosso trabalho em dados reais no testador de estratégias do MetaTrader 5.
Como sempre, o modelo é treinado e testado em dados históricos do instrumento EURUSD no timeframe H1. O treinamento dos modelos foi realizado em dados históricos dos 7 meses de 2023. E o teste do modelo treinado foi realizado em dados de agosto de 2023.
Gostaria de salientar que para o treinamento do modelo foi usada a amostra de treinamento e o EA de treinamento do artigo anterior. Assim, pode-se observar que a mudança nos resultados obtidos se deve principalmente à mudança na arquitetura do modelo. Claro, não podemos excluir o fator de aleatoriedade, que se manifesta na inicialização inicial do modelo com parâmetros aleatórios. E também na amostragem aleatória de dados do buffer de reprodução de experiência durante o treinamento. Mas a influência desse fator é minimizada com o aumento das épocas de treinamento.
Lembro que no artigo anterior o modelo mostrou um resultado bastante estável, mas um número muito pequeno de negócios. Na nova modelo, observamos um aumento no número de transações mantendo um resultado positivo.
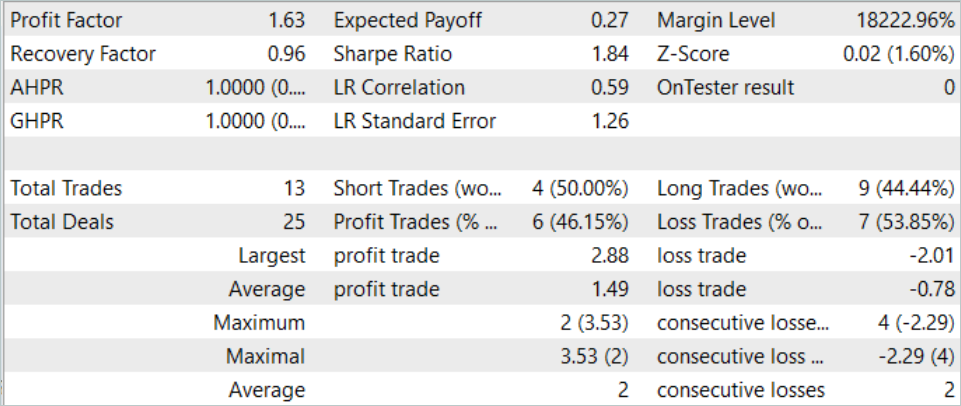
Em agosto de 2023, a modelo realizou 13 transações, das quais 6 foram fechadas com lucro. Como resultado do trabalho da modelo durante o período de teste, foi alcançado um fator de lucro de 1,63.
Considerações finais
Neste artigo, conhecemos outro método de previsão do movimento de preços futuros, o Multi-future Transformer. Uma das características chave deste método é a construção de previsões multimodais do movimento dos agentes com ênfase na interação entre eles e com o ambiente. Isso permite fazer previsões mais precisas do movimento futuro.
Na parte prática, implementamos as abordagens propostas usando MQL5. Treinamos e testamos a modelo em dados reais no testador de estratégias MetaTrader 5. Os resultados obtidos confirmam a eficácia das abordagens propostas. Pode-se notar a diversidade das previsões obtidas, que é alcançada graças ao isolamento das previsões de cada modalidade, mantendo a análise da interação dos agentes.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | EA | EA de treinamento de modelos |
| 4 | Test.mq5 | EA | EA para teste de modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14226
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Redes neurais de maneira fácil (Parte 75): aumentando a produtividade dos modelos de previsão de trajetórias
Redes neurais de maneira fácil (Parte 75): aumentando a produtividade dos modelos de previsão de trajetórias
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso