
Neuronale Netze leicht gemacht (Teil 76): Erforschung verschiedener Interaktionsmuster mit Multi-Future Transformer

Einführung
Die Vorhersage bevorstehender Kursbewegungen ist eine der wichtigsten Voraussetzungen für den Aufbau einer erfolgreichen Handelsstrategie. Daher müssen wir die Möglichkeiten zur Erstellung präziser und multimodaler Prognosen für künftige Bewegungen untersuchen. In früheren Artikeln haben wir einige Methoden zur Vorhersage von Kursbewegungen kennen gelernt. Darunter waren auch multimodale, die mehrere Varianten der Ereignisentwicklung anbieten.
Allerdings konzentrieren sich alle selten auf die zukünftigen Möglichkeiten der Interaktion zwischen den analysierten Akteuren, was zu Informationsverlusten und suboptimalen Prognosen führen kann. Darüber hinaus ist es recht schwierig, die zuvor erörterten Methoden zu skalieren, wenn wir mehrere Agenten haben, da unabhängige Vorhersagen zu einer exponentiellen Anzahl von Kombinationen führen können. Die meisten der daraus resultierenden Kombinationen sind aufgrund widersprüchlicher Vorhersagen nicht durchführbar. Daher ist es wichtig, sich auf die Vorhersage von Szenen als Ganzes zu konzentrieren und den zukünftigen Zustand mehrerer Agenten gleichzeitig zu schätzen.
Die Autoren des Artikels „Multi-future Transformer: Learning diverse interaction modes for behavior prediction in autonomous driving“ schlagen vor, die Methode des Multi-Future-Transformers (MFT) zur Lösung solcher Probleme zu verwenden. Die Hauptidee besteht darin, die multimodale Verteilung der Zukunft in mehrere unimodale Verteilungen zu zerlegen, was es ermöglicht, verschiedene Modelle der Interaktion zwischen Agenten auf der Szene effektiv zu simulieren.
Bei der MFT werden die Prognosen von einem neuronalen Netz mit festen Parametern in einem einzigen Vorwärtsdurchgang erstellt, ohne dass stochastische Stichproben latenter Variablen, vorab festgelegte Anker oder ein iterativer Nachbearbeitungsalgorithmus erforderlich sind. Dies ermöglicht es dem Modell, auf deterministische, wiederholbare Weise zu arbeiten.
1. Der Algorithmus Multi-Future-Transformer
Das Hauptziel der Methode des Multi-Future-Transformers ist die konsistente Vorhersage der zukünftigen Bewegung Y aller Agenten in der Szene. Zu diesem Zweck werden der dynamische Zustand der Agenten X und die Kontextinformationen M analysiert. Die zu erfassende Gesamtwahrscheinlichkeitsverteilung ist also P(Y|X,M), die aufgrund der eindeutigen Entwicklung der Szene multimodal ist.
Es ist in der Regel sehr schwierig, eine gemeinsame multimodale Verteilung direkt zu modellieren. Die Autoren der Methode gehen von der Annahme aus, dass die Zielverteilung in eine Mischung aus mehreren unimodalen Verteilungen zerlegt werden kann, und modellieren diese unimodalen Verteilungen dann separat, was wie folgt formuliert wird:
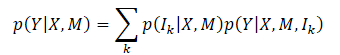
wobei Ik die k-te Moduskomponente darstellt;
p(Ik|X,M) ist die Wahrscheinlichkeitsverteilung der verschiedenen Modi;
p(Y|X,M,Ik) repräsentiert die faktorisierte, unimodale Verteilung.
Der entscheidende Punkt bei MFT besteht nach dieser Formulierung darin, dass der Hauptunterschied zwischen den einzelnen Zielverteilungsmodi in den unterschiedlichen Interaktionsmodellen zwischen Agenten und zwischen Agenten und Kontext liegt. Die Modellierung jeder unimodalen Verteilung kann durch die Untersuchung der Muster von Modus-Korrespondenz-Wechselwirkungen erfolgen. Intuitiv lässt sich die Unsicherheit der zukünftigen Szene hauptsächlich in zwei Teile zerlegen: Unsicherheit der Absicht und Unsicherheit der Interaktion.
Unbeobachtbare Absichten können durch die Modellierung der Interaktion zwischen dem Agenten und dem Kontext gut erfasst werden, da der Endpunkt der zukünftigen Trajektorie, der die Absichten des Agenten darstellt, eng mit dem Kontext der Szene verbunden ist. Um der Unsicherheit der Interaktion Rechnung zu tragen, werden verschiedene Arten der Interaktion zwischen Agenten modelliert. Durch die gemeinsame Erfassung von Agenten-Agenten-Interaktionen sowie von Agenten-Kontext-Interaktionen wird die zukünftige Unsicherheit minimiert und die Entwicklung einer Szene kann bestimmt werden.
Um die oben beschriebene multimodale Zerlegung der gemeinsamen Verteilung zu erreichen, wurde die allgemeine Architektur des vorgeschlagenen MFT-Ansatzes entwickelt. Sie besteht aus drei Teilen:
- Encoders
- Modul für parallele Interaktion
- Vorhersage-Kopfzeilen
Das Modell umfasst zwei Arten von Encoders:
- Der dynamische Agentenkodierer wird verwendet, um Merkmale aus beobachteten, dynamischen Zuständen zu extrahieren,
- Der Kontext-Segment-Encoder dient als Kartenbetrachter zum Erlernen punktweiser Funktionen für Streifenpunkte.
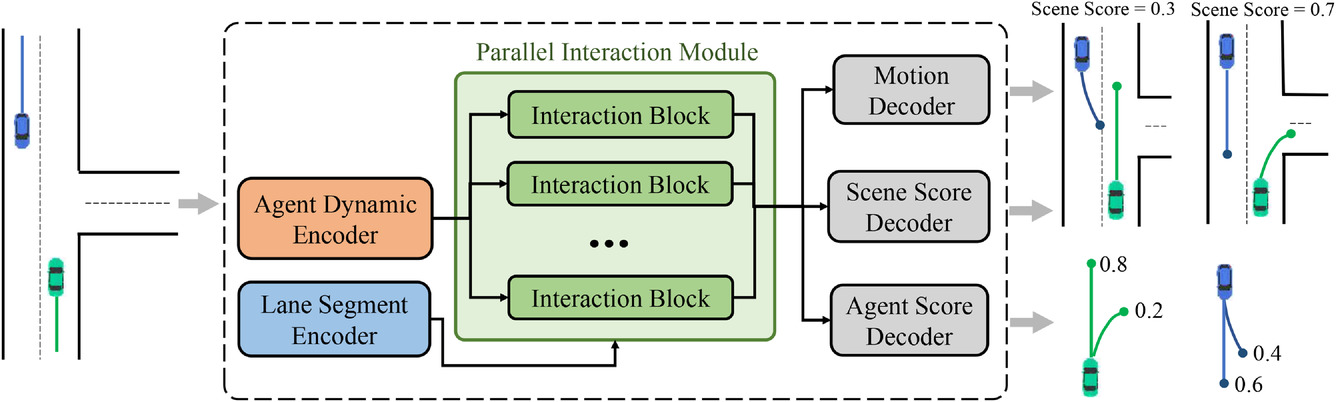
Das Kernstück des MFT-Modells ist ein paralleles Interaktionsmodul, das aus mehreren Interaktionsblöcken in einer parallelen Struktur besteht und die zukünftigen Merkmale der Bewegung von Agenten für jeden Modus untersucht. Zu den drei Vorhersageköpfen gehören:
- Bewegungsdecoder,
- Decoder für die Agenten-Werte,
- Decoder für die Szenenbewertung.
Sie sind für die Dekodierung zukünftiger Trajektorien für jeden Agenten und die Schätzung der Vertrauenswerte für jede vorhergesagte Trajektorie und jeden Szenenmodus verantwortlich. Bei dieser Architektur sind die Pfade, auf denen die Signale vom Vorwärts- und Rückwärtsdurchgang der einzelnen Modi verlaufen, voneinander unabhängig, und jeder Pfad enthält einen einzigartigen Interaktionsblock, der eine Informationsinteraktion zwischen den Signalen desselben Modus ermöglicht. Daher können die Interaktionseinheiten gleichzeitig die entsprechenden Interaktionsmuster verschiedener Modi erfassen. Kodierer und Vorhersagekopfzeilen sind jedoch allen Modi gemeinsam, während Interaktionsblöcke als unterschiedliche Objekte parametrisiert sind. Daher kann jede unimodale Verteilung, die theoretisch unterschiedliche Parameter hat, auf eine parameter-effizientere Weise modelliert werden. Die original Visualisierung der Methode ist unten dargestellt.
Die beobachteten Trajektorien der Agenten auf dem historischen Horizont können als X={x1,...,xatt} dargestellt werden, wobei der dynamische Zustand zu jedem Zeitschritt xt=(x,y,vx,vy,w) die Position (x,y) umfasst, die Geschwindigkeit (vx,vy) und Gierwinkel w zu diesem Zeitpunkt enthält.
Die dynamischen Zustände eines Agenten werden als eine Menge von Punkten in einem mehrdimensionalen Raum betrachtet, wobei jeder Punkt durch Koordinaten (x,y) dargestellt wird und andere Dimensionen zusätzliche lokale Merkmale darstellen. Für diese Punkte bleiben die Interaktionseigenschaften und die gegebene lokale Struktur erhalten, da die beobachteten Zustände des Agenten miteinander interagieren und zusammen die beobachtete Trajektorie des Agenten bilden. Eine weitere wichtige Eigenschaft dieser Trajektorienpunkte ist die zeitliche Ordnung, die im Vergleich zu statischen Fahrspurpunkten ein implizites Merkmal darstellt. Natürlich führen die gleichen Punkte der Trajektorie in umgekehrter zeitlicher Reihenfolge zu einer völlig anderen beobachteten Trajektorie. Die oben genannten Eigenschaften erfordern, dass das Modell Trajektorienpunkte nicht nur durch die Kombination von Punktmerkmalen, sondern auch durch die Einführung von Informationen über die zeitliche Reihenfolge darstellt. Zu diesem Zweck wird die absolute Positionskodierung verwendet, um Auftragsinformationen zu kodieren. Das Modell berechnet die dynamischen Merkmale für jeden Agenten wie folgt:
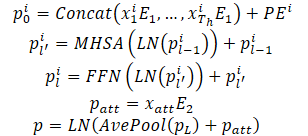
Um die Fähigkeit des Modells, dynamische Informationen darzustellen, zu verbessern, werden mehrere Encoderschichten übereinander gelegt. Die Mittelwertbildung wird über alle Punkte der Trajektorie eines Agenten durchgeführt, um die historischen dynamischen Informationen zu einem bestimmten Agenten zusammenzufassen.
Um dynamische Informationen zu erhalten, wurden auch Punktmerkmale extrahiert, die dem aktuellen Zeitpunkt entsprechen. Dies entspricht in etwa der Leistung eines durchschnittlichen Pools. Beim Umgang mit teilweise beobachtbaren historischen Zuständen kann ein auf Selbstbeobachtung basierender Rahmen unbeobachtbare Positionen ohne zusätzlichen Aufwand einfach ausblenden, wodurch eine durch ungültige Auffüllungen verursachte Merkmalsverwirrung wirksam vermieden wird.
Ein charakteristisches Merkmal der Verhaltensvorhersage ist die Multimodalität, die durch die Ungewissheit der zukünftigen Szene verursacht wird. Ein gängiger Ansatz besteht darin, mehrere Ergebnisköpfe zu verwenden, um die zukünftigen Trajektorien der einzelnen Agenten unabhängig voneinander auf der Grundlage eines gemeinsamen Merkmalsvektors zu dekodieren. Diese Methode hat jedoch zwei wesentliche Nachteile:
- Die Bewegungsinformationen verschiedener möglicher zukünftiger Trajektorien sind in einem Merkmalsvektor mit einer festen Dimension enthalten, was zu einer begrenzten Information führt und die Aussagekraft des Modells erheblich einschränkt;
- Die Vorwärts- und Rückwärtssignale aus verschiedenen Modi werden durch die Interaktion von Merkmalen und die Ausbreitung von Gradienten vermischt, was zu dem Problem der Modusverwechslung führt, das die Fähigkeit, multimodale Vorhersagen zu treffen, beeinträchtigt.
Stattdessen wird bei MFT die Interaktionsmodellierung in verschiedene Modi unterteilt, um ein multimodales Ergebnis zu erzielen, indem das einzigartige Interaktionsmuster, das jedem Modus entspricht, gelernt wird. Zu diesem Zweck wurde ein paralleles Interaktionsmodul entwickelt. Dieses Modul enthält mehrere Blöcke mit paralleler Interaktion, von denen jeder eine bestimmte Art der zukünftigen Entwicklung von Ereignissen darstellt. Bei dieser Struktur kreuzen die Vorwärts- und Rückwärtssignale innerhalb des Modus den Interaktionsblock des entsprechenden Modus. Gleichzeitig werden andere Modi nicht gestört, wodurch das Problem der Modusverwechslung vermieden wird.
Darüber hinaus wird jeder Interaktionsblock als separates Objekt parametrisiert, sodass das Modell über eine ausreichende Ausdruckskraft verfügt, um die großen Unterschiede zwischen den verschiedenen Modi zu bewältigen. Jeder Interaktionsblock verwendet einen Selbstaufmerksamkeits-Mechanismus, um die Interaktion zwischen Agenten zu modellieren, und den Cross-Attention-Mechanismus, um die Interaktion zwischen Agenten und der Szene zu erfassen. Diese beiden Arten von Interaktionsmerkmalen werden dem dynamischen Merkmal durch eine Restverbindung hinzugefügt, um die endgültige kommende Bewegungsfunktion für jeden Agenten und Modus zu erhalten. Der oben beschriebene Prozess kann wie folgt beschrieben werden:

Die endgültige Struktur des parallelen Interaktionsmoduls kann als Parallelisierung des Transformer-Decoders mit einer seriellen Struktur betrachtet werden. Die multimodale Vorhersage und die gesteigerte Aussagekraft werden jedoch bei ähnlichem Rechenaufwand wie bei der Standardvariante erreicht. Die von den Autoren der Methode durchgeführten Experimente bestätigen, dass die vorgeschlagene Methode in Kombination mit der Verwendung der Winner-take-all-Verluststrategie auf Szenenebene eine konsistente Vorhersage des Verhaltens mehrerer Agenten ermöglicht. Außerdem wurde eine Studie durchgeführt, um die Unverzichtbarkeit der beiden Arten von modellierten Interaktionen und die Sinnhaftigkeit der Modulstruktur zu demonstrieren.
Im Folgenden wird die von den Autoren entwickelte Visualisierung der Modulstruktur vorgestellt.

Zusätzlich zur Vorhersage der zukünftigen Trajektorie jedes Agenten führt MFT eine Likelihood-Schätzung für jede mögliche Entwicklung der Szene sowie für jede vorhergesagte Trajektorie des Agenten durch. Für Bewegungsplanungsaufgaben wäre die ideale Eingabe eine multimodale Szenenvorhersage mit einer angemessenen Vertrauensbewertung für jeden Szenenmodus. Der Planungsalgorithmus kann die mögliche zukünftige Bewegungsbahn direkt berechnen, indem er alle benachbarten Agenten gleichzeitig berücksichtigt. Zu diesem Zweck haben die Autoren der Methode Köpfe zur Vorhersage verschiedener Szenen und deren Wahrscheinlichkeiten entwickelt.
Um die Wahrscheinlichkeit auf der Ebene der Szene zu schätzen, werden die Merkmalsvektoren aller Agenten in der Szene gemittelt. So erhalten wir einen Überblick über die Szene.
Um dem Agenten besondere Aufmerksamkeit zu schenken, sollte die Wahrscheinlichkeitsschätzung außerdem aus der Sicht des Agenten selbst erfolgen. Folglich wird ein dritter Modellkopf erstellt, um die Konfidenzschätzungen der vorhergesagten Trajektorien der einzelnen Agenten zu dekodieren. Der Dekodierungsprozess des Multi-Future-Transformers wird wie folgt formuliert:
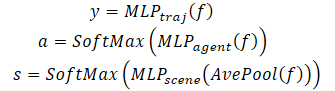
Beachten Sie, dass zur Dekodierung einer multimodalen Szene ein Dekoder mit denselben Parametern für alle möglichen Szenarien verwendet wird.
2. Implementierung mit MQL5
Nachdem wir uns mit den theoretischen Aspekten der Multi-Future-Transformer-Methode beschäftigt haben, kommen wir nun zum praktischen Teil unseres Artikels. Betrachten wir nun, wie der Algorithmus in MQL5 implementiert werden kann.
Aus der obigen Beschreibung des Multi-Future-Transformer-Algorithmus geht hervor, dass die Hauptschwierigkeit bei der Implementierung das parallele Interaktionsmodul ist. Unsere Bibliothek hat bereits zuvor mehrköpfige Selbstaufmerksamkeit(CNeuronMLMHAttentionOCL) und Kreuzaufmerksamkeit (CNeuronMH2AttentionOCL) Schichten implementiert. Aber auch bei der Verwendung mehrerer Aufmerksamkeitsköpfe werden die Datenströme bei Vorwärts- und Rückwärtsdurchläufen vermischt. Dies entspricht nicht den Bedingungen der Multi-Future-Transformer-Methode.
Daher beginnen wir unsere Implementierung der Methode mit der Erstellung einer Klasse für eine neue neuronale Schicht.
2.1. Modul für parallele Interaktion
Wir implementieren den Algorithmus des parallelen Interaktionsmoduls in der Klasse CNeuronMFTOCL, die wir von CNeuronMLMHAttentionOCL erben.
Diese Klasse wurde absichtlich als Elternteil ausgewählt. CNeuronMLMHAttentionOCL enthält bereits eine implementierte Funktionalität des mehrschichtigen Selbstaufmerksamkeits-Algorithmus. Bei der Implementierung der neuen Klasse wird der vorhandene Code verwendet. Anstatt jedoch die Schichten des Aufmerksamkeitsblocks nacheinander zu berechnen, werden wir verschiedene Szenarien vorhersagen. Außerdem werden wir die Kreuz-Aufmerksamkeit-Funktionalität hinzufügen, die der Multi-Future-Transformer-Algorithmus bietet.
Die Struktur der neuen Klasse ist unten dargestellt. Wie Sie sehen, fügen wir neben der Neudefinition der Hauptmethoden eine weitere Sammlung von Datenpuffern für die Datentransposition hinzu, die wir benötigen, um den Cross-Attention-Mechanismus zu implementieren.
class CNeuronMFTOCL : public CNeuronMLMHAttentionOCL { protected: //--- CCollection cTranspose; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols); virtual bool MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool MHCAInsideGradients(CBufferFloat *q, CBufferFloat *qg, CBufferFloat *kv, CBufferFloat *kvg, CBufferFloat *score, CBufferFloat *aog); public: CNeuronMFTOCL(void) {}; ~CNeuronMFTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronMFTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Wenn wir eine neue Sammlung von Datenpuffern als statisch deklarieren, können wir den Konstruktor und den Destruktor der Klasse „leer“ lassen. Wir initialisieren die Klasse und die internen Objekte in der Init-Methode.
bool CNeuronMFTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * features, optimization_type, batch)) return false;
In den Parametern erhält die Methode alle notwendigen Informationen, um die gewünschte Architektur nachzubilden. Im Hauptteil der Methode rufen wir die entsprechende Methode der Basisklasse der neuronalen Schicht CNeuronBaseOCL auf.
Bitte beachten Sie, dass wir nicht die Initialisierungsmethode der direkten Elternklasse CNeuronMLMHAttentionOCL aufrufen. Stattdessen wenden wir uns einer höheren Klasse zu – der Basisklasse der neuronalen Schichten CNeuronBaseOCL. Dies ist auf einige Unterschiede in der Implementierung von CNeuronMFTOCL und CNeuronMLMHAttentionOCL zurückzuführen.
In der übergeordneten Klasse CNeuronMLMHAttentionOCL haben wir die Quelldaten nacheinander in mehreren Schichten des Aufmerksamkeitsblocks verarbeitet und am Ausgang ein Ergebnis mit einer ähnlichen Dimension wie die Quelldaten erhalten. In der neuen Schicht CNeuronMFTOCL werden wir nun konsequent verschiedene Muster für mögliche Entwicklungen generieren. Dementsprechend wird das Ergebnis der Ebene ein Vielfaches (der Anzahl der Vorhersageoptionen) der Größe der ursprünglichen Daten sein. Deshalb müssen wir den Ergebnispuffer erhöhen.
Um unnötiges Kopieren von Daten zu vermeiden, haben wir außerdem in der übergeordneten Klasse den Puffer für Ergebnisse und Gradienten der Ebene selbst und der letzten internen Ebene ersetzt. Bei der Implementierung der neuen Klasse ist dieser Ansatz inakzeptabel, da wir die Ergebnisse mehrerer paralleler Blöcke in einem einzigen Puffer zusammenfassen müssen.
Kehren wir zu unserer Initialisierungsmethode zurück. Nach erfolgreicher Ausführung der Initialisierungsmethode für die Basisklasse der neuronalen Schicht speichern wir die wichtigsten Parameter der Architektur in internen Klassenvariablen.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(features, 1);
Bitte beachten Sie, dass wir alle Parameter in Variablen der übergeordneten Klasse speichern. Hier gibt es eine kleine Abweichung zwischen dem Namen der Variablen und ihrer Funktionalität: Die Variable iLayers speichert die Anzahl der geplanten Optionen. Um die Ressourcen effizienter zu nutzen, habe ich beschlossen, keine zusätzliche Variable zu erstellen und die Diskrepanz zwischen dem Namen und der Funktionalität der Variablen zu „ignorieren“.
Als Nächstes werden wir die wichtigsten Parameter unserer Blöcke berechnen.
//--- MHSA uint num = 3 * iWindowKey * iHeads * iUnits; //Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of QKV tensor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of output tensor uint w0 = (iWindowKey + 1) * iHeads * iWindow; //Size W0 tensor
//--- MHCA uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeads * iUnits; //Size of KV tensor uint q_weights = (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of Q tensor uint kv_weights = 2 * (iUnits + 1) * iWindowKey * iHeads; //Size of weights' matrix of KV tensor uint scores_ca = iUnits * iWindow * iHeads; //Size of Score tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
Nach Abschluss der vorbereitenden Arbeiten werden wir eine Schleife organisieren, in der wir nacheinander Datenpuffer für jedes Szenario in unserem parallelen Interaktionsblock erstellen.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- MHSA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Hier werden wir eine verschachtelte Schleife erstellen, um Vorwärts- und Rückwärtspuffer zu erzeugen. Im Hauptteil der geschachtelten Schleife erstellen wir zunächst einen Puffer mit den verketteten Abfrage-, Schlüssel- und Werteinbettungen des MHSA-Blocks. Wir fügen auch einen Puffer für die Matrix ‚Score‘ hinzu.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
Fügen wir einen Puffer für mehrköpfige Aufmerksamkeitsergebnisse hinzu.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
Am Ausgang des MHSA-Blocks legen wir einen Puffer an, in dem wir die Ergebnisse der verschiedenen Aufmerksamkeitsköpfe kombinieren.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Um den Anforderungen des MFT-Algorithmus gerecht zu werden, werden die Ergebnisse der Aufmerksamkeitsköpfe nur innerhalb eines Interaktionsmodus kombiniert.
Als Nächstes erstellen wir ähnliche Puffer für den Kreuz-Aufmerksamkeits-Block (MHCA). Jetzt trennen wir jedoch den Abfrage-Einbettungspuffer vom Schlüssel und Wert, da unterschiedliche Quelldaten verwendet werden.
//--- MHCA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cTranspose.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores_ca, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
//--- Initialize multi-heads cross attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Nachdem wir die Puffer für die Aufmerksamkeitsblöcke erstellt haben, erstellen wir die Puffer für die Blöcke von „FeedForward“.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
//--- Initialize Feed Forward 2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Wir haben Puffer für die Ergebnisse und Fehlergradienten der einzelnen Blöcke erstellt. Als Nächstes müssen wir Matrizen mit trainierbaren Gewichten für diese Blöcke erstellen. Wir erstellen sie in der gleichen Reihenfolge. Zunächst erzeugen wir Gewichte für die Abfrage-, Schlüssel- und Werteinbettungen des MHSA-Blocks.
//--- MHSA //--- Initilize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
Und eine Ebene für die Kombination von Aufmerksamkeitsköpfen.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Wiederholen Sie die Vorgänge für den MHCA-Block.
//--- MHCA //--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; for(uint w = 0; w < q_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize KV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float kv = (float)(1 / sqrt(iUnits + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* kv)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Erstellen wir die Matrizen für den Vorwärtsdurchgang-Block.
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Danach implementieren wir eine weitere verschachtelte Schleife, in der wir Puffer für die Aktualisierung der Gewichtsmatrizen anlegen. Beachten Sie, dass die Anzahl der Momentpuffer von dem gewählten Optimierungsalgorithmus abhängt.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- MHSA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- MHCA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
Nachdem alle erforderlichen Datenpuffer erfolgreich initialisiert wurden, verlassen wir die Methode mit dem Ergebnis true.
Wir haben eine Menge Puffer erstellt. Um nicht durcheinander zu kommen, legen wir eine Navigationstabelle für den Datenpuffer an.
| id | QKV_Tensoren | S_Tensoren, AO_Tensoren | FF_Tensoren | QKV_Gewichte | FF_Gewichte |
|---|---|---|---|---|---|
| 0 | Query, Key, Value MHSA | MHSA | MHSA Out | Query, Key, Value MHSA | MHSA W0 |
| 1 | Query MHCA | MHCA | MHCA Out | Query MHCA | MHCA W0 |
| 2 | Key, Value MHCA | Gradient MHSA | FF1 | Key, Value MHCA | FF1 |
| 3 | Gradient Query, Key, Value MHSA | Gradient MHCA | FF2 | Momentum1 Query, Key, Value MHSA | FF2 |
| 4 | Gradient Query MHCA | Gradient MHSA Out | Momentum1 Query MHCA | Momentum1 MHSA W0 | |
| 5 | Gradient Key, Value MHCA | Steigung MHCA Out | Momentum1 Key, Value MHCA | Momentum1 MHCA W0 | |
| 6 | Gradient FF1 | Momentum2 Query, Key, Value MHSA | Momentum1 FF1 | ||
| 7 | Gradient FF2 | Momentum2 Query MHCA | Momentum1 FF2 | ||
| 8 | Momentum2 Key, Value MHCA | Momentum2 MHSA W0 | |||
| 9 | Momentum2 MHCA W0 | ||||
| 10 | Momentum2 FF1 | ||||
| 11 | Momentum2 FF2 |
Nach der Initialisierung der Klasse CNeuronMFTOCL gehen wir zur Konstruktion eines Vorwärtsdurchgangs-Algorithmus über. Bei der Implementierung des MFT-Algorithmus haben wir keine neuen Kernel auf der OpenCL-Programmseite erstellt. Um die zuvor erstellten Kernel aufzurufen, mussten wir jedoch einige Methoden auf der Seite des Hauptprogramms erstellen. Insbesondere haben wir für unsere Klasse CNeuronMFTOCL eine Methode zur Matrixtransposition entwickelt. Der Algorithmus der Methode ähnelt dem Vorwärtsdurchgangs-Algorithmus der Transpositionsschicht. Allerdings gibt es Unterschiede im Detail. In den Parametern erhält die neue Methode Zeiger auf 2 Datenpuffer (Quelldaten und Ergebnisse) sowie die Größen der ursprünglichen Matrix.
bool CNeuronMFTOCL::Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols) { if(!in || !out) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {rows, cols}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, in.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, out.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("%s %d Error of execution kernel Transpose: %d -> %s", __FUNCTION__, __LINE__, GetLastError(), error); return false; } //--- return true; }
Dementsprechend überprüfen wir im Hauptteil der Methode die empfangenen Zeiger auf Datenpuffer und geben die Werte der Parameter in der Dimension des Aufgabenraums an. Der Algorithmus für den Kernelaufruf selbst blieb unverändert.
Ähnlich verhält es sich mit der MHCA-Vorwärtsmethode. In den Methodenparametern erhalten wir Zeiger auf Datenpuffer. Die CNeuronMH2AttentionOCL::attentionOut Methode hatte keine Parameter und verwendete interne Objekte in ihrer Funktionalität.
bool CNeuronMFTOCL::MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out) { if(!q || !kv || !score || !out) return false;
Im Hauptteil der Methode werden die Dimensionen des Aufgabenraums festgelegt.
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindow, iHeads}; uint local_work_size[3] = {1, iWindow, 1};
Wir übergeben die Parameter an den Kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, q.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, kv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, score.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, out.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Fügen wir es der Warteschlange hinzu.
if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Der MFT-Vorwärts-Algorithmus ist in der Methode CNeuronMFTOCL::feedForward implementiert. Wie ähnliche Methoden anderer neuronaler Schichten erhält die Methode in ihren Parametern einen Zeiger auf die vorherige neuronale Schicht. Im Hauptteil der Methode wird sofort die Relevanz des empfangenen Zeigers geprüft.
bool CNeuronMFTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
Als Nächstes organisieren wir eine Schleife der sequentiellen Berechnung verschiedener Modi für die Interaktion zwischen Agenten.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- MHSA //--- Calculate Queries, Keys, Values CBufferFloat *inputs = NeuronOCL.getOutput(); CBufferFloat *qkv = QKV_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Hier erhalten wir zunächst die Entitäten Abfrage, Schlüssel und Wert des MHSA-Blocks. Dann definieren wir die Matrix der Aufmerksamkeitskoeffizienten.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 4); if(IsStopped() || !AttentionScore(qkv, temp, false)) return false;
Erzeugen Sie das Ergebnis der vielköpfigen Selbstaufmerksamkeit.
//--- Multi-heads attention calculation CBufferFloat *out = AO_Tensors.At(i * 4); if(IsStopped() || !AttentionOut(qkv, temp, out)) return false;
Wir reduzieren das Ergebnis der mehrköpfigen Aufmerksamkeit auf die Größe der ursprünglichen Daten. Ich möchte Sie daran erinnern, dass die Aufmerksamkeitsköpfe im Rahmen einer Variante der Agenteninteraktion kombiniert werden.
//--- Attention out calculation temp = FF_Tensors.At(i * 8); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Wir summieren den resultierenden Tensor mit den Originaldaten und normalisieren das Ergebnis der Operation.
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
Als Nächstes kommt der Kreuz-Aufmerksamkeits-Block. Hier definieren wir zunächst die Entität Abfrage.
//--- MHCA inputs = temp; CBufferFloat *q = QKV_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
Dann transponieren wir die ursprünglichen Daten und berechnen die Entitäten Schlüssel und Wert.
CBufferFloat *tr = cTranspose.At(i * 2); if(IsStopped() || !Transpose(inputs, tr, iUnits, iWindow)) return false;
CBufferFloat *kv = QKV_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), tr, kv, iUnits, 2 * iWindowKey * iHeads, None)) return false;
Ermittelung der Ergebnisse der mehrköpfigen Kreuz-Aufmerksamkeit.
//--- Multi-heads cross attention calculation temp = S_Tensors.At(i * 4 + 1); out = AO_Tensors.At(i * 4 + 1); if(IsStopped() || !MHCA(q, kv, temp, out)) return false;
Die erhaltenen Ergebnisse werden auf die Größe der Originaldaten komprimiert.
//--- Cross Attention out calculation temp = FF_Tensors.At(i * 8 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Addieren wir dies zu den Ergebnissen des MHSA-Blocks und normalisieren die Daten.
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
Dann organisieren wir die Datenweitergabe durch den FeedForward-Block.
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 8 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 8 + 3); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), temp, out, 4 * iWindow, iWindow, activation)) return false;
Die Ergebnisse der Blockoperationen von FeedForward werden den MHCA-Ergebnissen hinzugefügt. Die empfangenen Daten werden normalisiert und mit einem Offset, der dem analysierten Interaktionsmodus entspricht, in den Ergebnispuffer geschrieben.
//--- Sum and normalize out if(IsStopped() || !SumAndNormilize(out, inputs, Output, iWindow, true, 0, 0, i * inputs.Total())) return false; } //--- return true; }
Anschließend gehen wir zur nächsten Iterationsschleife über, um die nächste Art der Interaktion zwischen den Agenten auf der Szene zu analysieren.
Nachdem wir erfolgreich alle Modi für die Interaktion zwischen Agenten analysiert haben, schließen wir die Methode mit dem Ergebnis true ab.
Während des Vorwärtsdurchgangs führen wir die grundlegende Funktion der Analyse der Modi für die Interaktion von Agenten auf der Szene und die Vorhersage möglicher Varianten für weitere Ereignisse durch. Daher ist das Modelltraining ohne die Anwendung von Rückwärtsdurchgangs-Methoden nicht möglich. Während des Rückwärtsdurchgangs werden die Modellparameter optimiert, um bessere Ergebnisse zu erzielen. Nach der Implementierung der Vorwärtsdurchgangs-Methoden gehen wir daher dazu über, den Rückwärtsdurchgangs-Algorithmus zu entwickeln.
Wie beim Vorwärtsdurchgang müssen wir auch für die Implementierung des Rückwärtsdurchgangs eine zusätzliche Methode MHCAInsideGradients erstellen. Sein Algorithmus gleicht dem Algorithmus von CNeuronMH2AttentionOCL::AttentionInsideGradients fast vollständig. Der einzige Unterschied ist, dass MHCAInsideGradients nicht mit klasseninternen Objekten arbeitet, sondern mit Puffern, die in Methodenparametern empfangen werden. Beispiele für solche Änderungen haben wir bereits weiter oben in diesem Artikel gesehen. Daher werden wir uns jetzt nicht mit einer detaillierten Betrachtung der Methode befassen. Den vollständigen Code finden Sie im Anhang.
Der Rückwärtsdurchgangs-Algorithmus ist in der Methode calcInputGradients implementiert. In den Parametern erhält die Methode einen Zeiger auf das Objekt der vorherigen neuronalen Schicht.
bool CNeuronMFTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
Im Hauptteil der Methode wird sofort die Gültigkeit des empfangenen Zeigers überprüft. Danach speichern wir Zeiger auf Puffer in lokalen Variablen, mit denen alle parallelen Interaktionsblöcke arbeiten werden.
CBufferFloat *out_grad = Gradient; CBufferFloat *inp = prevLayer.getOutput(); CBufferFloat *grad = prevLayer.getGradient();
Nach Abschluss der vorbereitenden Arbeiten organisieren wir eine Schleife, um Fehlergradienten durch separate Blöcke mit paralleler Interaktion zu propagieren.
for(int i = 0; (i < (int)iLayers && !IsStopped()); i++) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), Gradient, FF_Tensors.At(i * 8 + 2), FF_Tensors.At(i * 8 + 6), 4 * iWindow, iWindow, None, i * inp.Total())) return false;
Hier propagieren wir zunächst den Fehlergradienten durch den Vorwärtsdurchgangs-Block.
CBufferFloat *temp = FF_Tensors.At(i * 8 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(i * 8 + 6), FF_Tensors.At(i * 8 + 1), temp, iWindow, 4 * iWindow, LReLU)) return false;
Im Vorwärtsdurchgang wurden die Ergebnisse des Vorwärtsdurchgangs-Blocks zum Ausgang des MHCA-Blocks hinzugefügt. In ähnlicher Weise pflanzen wir den Fehlergradienten in die entgegengesetzte Richtung fort. Dieses Mal führen wir jedoch keine Normalisierung durch.
//--- Sum gradient if(IsStopped() || !SumAndNormilize(Gradient, temp, temp, iWindow, false, i * inp.Total(), 0, 0)) return false; out_grad = temp;
Als Nächstes müssen wir den Fehlergradienten durch das Cross-Attention-Modul propagieren. Hier propagieren wir zunächst den Fehlergradienten über die Aufmerksamkeitsköpfe hinweg.
//--- MHCA //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out_grad, AO_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3), iWindowKey * iHeads, iWindow, None)) return false;
Dann übertragen wir den Fehlergradienten auf die entsprechenden Einheiten.
if(IsStopped() || !MHCAInsideGradients(QKV_Tensors.At(i * 6 + 1), QKV_Tensors.At(i * 6 + 4), QKV_Tensors.At(i * 6 + 2), QKV_Tensors.At(i * 6 + 5), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3))) return false;
Nun müssen wir den Fehlergradienten aus Schlüssel und Wert des MHCA-Blocks transponieren.
CBufferFloat *tr = cTranspose.At(i * 2 + 1); if(IsStopped() || !Transpose(QKV_Tensors.At(i * 6 + 5), tr, iWindow, iUnits)) return false;
Wir fassen zunächst die erzielten Ergebnisse zusammen.
//--- Sum temp = FF_Tensors.At(i * 8 + 4); if(IsStopped() || !SumAndNormilize(QKV_Tensors.At(i * 6 + 4), tr, temp, iWindow, false)) return false;
Dann addieren wir zu ihnen den Fehlergradienten am Ausgang des MHCA-Blocks.
if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Danach müssen wir den Fehlergradienten durch den MHSA-Block propagieren. Wie bei der Kreuzaufmerksamkeit verteilen wir zunächst den Fehlergradienten auf die Aufmerksamkeitsköpfe.
//--- MHSA //--- Split gradient to multi-heads out_grad = temp; if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out_grad, AO_Tensors.At(i * 4), AO_Tensors.At(i * 4 + 2), iWindowKey * iHeads, iWindow, None)) return false;
Wir übertragen den Fehlergradienten auf die entsprechenden Einheiten.
//--- Passing gradient to query, key and value if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 6), QKV_Tensors.At(i * 6 + 3), S_Tensors.At(i * 4), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 1))) return false;
Weitergabe bis zur Ebene der Quelldaten.
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(i * 6 + 3), inp, tr, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Nun müssen wir den Fehlergradienten am Eingang und Ausgang des MHSA-Blocks addieren und das Ergebnis in den Gradientenpuffer der vorherigen Schicht schreiben. Aber es gibt einen Punkt. Wir müssen die Summe der Fehlergradienten aus allen parallelen Interaktionsblöcken in den Gradientenpuffer der vorherigen Schicht schreiben. Daher überprüfen wir zunächst die Kennung des parallelen Interaktionsblocks. Für den ersten Block schreiben wir einfach die Summe der Gradienten von 2 Threads in den Gradientenpuffer der Fehler der vorherigen Schicht. Bei den verbleibenden Blöcken der parallelen Interaktion addieren wir die resultierenden Fehlergradienten zu den Daten im Puffer der vorherigen Schicht.
//--- Sum gradients if(i > 0) { if(IsStopped() || !SumAndNormilize(grad, tr, grad, iWindow, false)) return false; if(IsStopped() || !SumAndNormilize(out_grad, grad, grad, iWindow, false)) return false; } else if(IsStopped() || !SumAndNormilize(out_grad, tr, grad, iWindow, false)) return false; } //--- return true; }
Dann gehen wir zur nächsten Iteration der Schleife über, um den Fehlergradienten durch den nächsten Block der parallelen Interaktion zu leiten.
Nachdem alle Iterationen der Schleife erfolgreich abgeschlossen wurden, beenden wir die Methode mit „true“.
Wir haben den Vorwärtsdurchgang und den Rückwärtsdurchgang des Fehlergradienten in der Klasse CNeuronMFTOCL organisiert. Um die Implementierung der Hauptfunktionalität der Klasse zu vervollständigen, müssen wir eine Methode zur Aktualisierung der Wägeparameter updateInputWeights hinzufügen. Der Algorithmus der Methode ist recht einfach. In einer Schleife rufen wir die Methode der übergeordneten Klasse ConvolutionUpdateWeights auf, in der die Parameter eines separaten Puffers aktualisiert werden. Die für den Betrieb notwendigen Datenpuffer werden in den Methodenparametern übergeben.
bool CNeuronMFTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(l * 6 + 3), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 3) : QKV_Weights.At(l * 9 + 3)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 6)), iWindow, 3 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 1), QKV_Tensors.At(l * 6 + 4), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 4) : QKV_Weights.At(l * 9 + 4)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 7)), iWindow, iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 2), QKV_Tensors.At(l * 6 + 5), cTranspose.At(l * 2), (optimization == SGD ? QKV_Weights.At(l * 6 + 5) : QKV_Weights.At(l * 9 + 5)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 8)), iUnits, 2 * iWindowKey * iHeads)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12)), FF_Tensors.At(l * 8 + 4), AO_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 8 + 4) : FF_Weights.At(l * 12 + 4)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 8)), iWindowKey * iHeads, iWindow)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 1), FF_Tensors.At(l * 8 + 5), AO_Tensors.At(l * 4 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 5) : FF_Weights.At(l * 12 + 5)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 9)), iWindowKey * iHeads, iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(l * 8 + 6), FF_Tensors.At(l * 8 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 6) : FF_Weights.At(l * 12 + 6)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 10)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 3), FF_Tensors.At(l * 8 + 7), FF_Tensors.At(l * 8 + 2), (optimization == SGD ? FF_Weights.At(l * 8 + 7) : FF_Weights.At(l * 12 + 7)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 11)), 4 * iWindow, iWindow)) return false; } //--- return true; }
Damit ist die Implementierung der Hauptfunktionalität des Multi-Future-Transformer-Algorithmus in der Klasse CNeuronMFTOCL abgeschlossen. Sie können sich mit der Implementierung von Hilfsmethoden anhand der Codes im Anhang vertraut machen. Dort finden Sie auch den vollständigen Code aller Programme, die beim Schreiben des Artikels verwendet wurden. Wir gehen nun zur Implementierung von Expert Advisors für den Aufbau und das Training der Modelle über.
2.2 Modellarchitektur
Wir haben eine Klasse für einen parallelen Interaktionsblock-Algorithmus entwickelt, der von den Autoren der Multi-Future-Transformer-Methode vorgeschlagen wurde. Dies ist jedoch nur eine Ebene unseres Modells. Nun müssen wir die gesamte Architektur der erstellten Modelle beschreiben. Die Modelle werden mit rohen Quelldaten gefüttert. Als Ergebnis der Arbeit der Modelle müssen wir einen Vektor optimaler Aktionen des Agenten erhalten, deren Umsetzung bei der Arbeit auf den Finanzmärkten Gewinn bringen kann.
Ich muss sagen, dass ich beim Aufbau meines Modells ein wenig von der von den Autoren der Methode vorgeschlagenen Architektur abgewichen bin. Hierfür gibt es mehrere Gründe.
Zunächst wurde die Methode Multi-Future-Transformer vorgeschlagen, um die Interaktion von autonomen Fahrzeugen mit der Umwelt vorherzusagen. Wir planen, unser Modell für die Finanzmärkte zu verwenden. Beide Aufgaben haben ihre eigenen Besonderheiten, die sich auf die Konstruktion der Modelle auswirken.
Zweitens haben wir im vorigen Artikel der Optimierung der Modellleistung große Aufmerksamkeit gewidmet. Ich möchte die gewonnenen Erfahrungen nutzen. Deshalb habe ich die Modellarchitektur aus dem vorherigen Artikel als Spender verwendet. Es wurden Änderungen an den Modellen zur Planung der Trajektorie vorgenommen.
Die Architektur der Modelle zur Vorhersage künftiger Trajektorien wird in der Methode CreateTrajNetDescriptions in der Datei „...\Experts\MFT\Trajectory.mqh“ beschrieben. In den Parametern erhält die Methode Zeiger auf dynamische Arrays zur Erstellung von 3 Modellen:
- Status-Encoder
- Endpunkt-Decoder
- Wahrscheinlichkeiten der Umgebung
In früheren Artikeln haben wir beschlossen, nicht den gesamten Verlauf der Kursbewegung vorherzusagen, sondern uns auf die Vorhersage der wichtigsten Extrema der Kursbewegung zu konzentrieren:
- Close
- High
- Low
Daher betrachten wir in unserer Arbeit den Zustand der Preisbewegungsdynamik als Varianten der Szene. Wir analysieren nicht die Wahrscheinlichkeiten der endgültigen Trajektorien der einzelnen Agenten.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Im Hauptteil der Methode prüfen wir die Relevanz der in den Parametern erhaltenen Objektzeiger und erstellen gegebenenfalls neue.
Zunächst haben wir die Architektur des Encoders beschrieben, den wir mit den rohen Ausgangsdaten füttern, die den aktuellen Zustand der Umgebung beschreiben.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Wie üblich werden die empfangenen Daten in der Batch-Normalisierungsschicht vorverarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Danach erstellen wir eine Einbettung des aktuellen Zustands und speichern sie im internen Stapel des Modells.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Jedes Einbettungselement ist mit einem separaten Akteur in der Umgebungsszene verbunden. Gemäß der MFT-Methode werden wir eine Positionskodierung der Quelldaten vornehmen.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Zur Architektur der ursprünglichen MFT-Methode gehört auch ein Stapel von MHSA-Blöcken. Hier ist meine erste Abweichung von der vorgeschlagenen Architektur. Ich beschloss, die Arbeit des vorherigen Artikels zu verwenden und ließ 2 Schichten Crystal-GCN übrig, die durch eine Batch-Normalisierungsschicht getrennt sind.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
Darauf folgt eine MHSA-Ebene.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes schlagen die Autoren der Methode vor, die Dynamik der einzelnen Agenten zu mitteln. Hier, im parallelen Interaktionsblock, führen sie eine Kreuzanalyse der Daten mit kontextuellen Kartendaten durch. In unserem Fall gibt es keine Karte der möglichen kommenden Preisbewegung. Stattdessen werden wir eine kontextbezogene Analyse der Trajektorien der analysierten Merkmale durchführen.
Als Nächstes kommt in unserer Architektur der oben beschriebene Block für parallele Berechnungen. In diesem Block verwenden wir Selbstaufmerksamkeits- und Kreuzaufmerksamkeitsblöcke mit 4 Aufmerksamkeitsköpfen. Die Autoren der Methode verwendeten in ihrer Arbeit nur einen Aufmerksamkeitskopf in parallelen Interaktionsblöcken. Die Anzahl der Agenteninteraktionsmodi wird durch die Konstante NForecast bestimmt.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Bitte beachten Sie den folgenden architektonischen Punkt. In unserer Implementierung haben wir die Klasse CNeuronMFTOCL so aufgebaut, dass ihre Ergebnisse als 3-dimensionaler Tensor {Anzahl der Sequenzelemente, Interaktionsmodus, Anzahl der Agenten} dargestellt werden können. Dieses Datenformat ist für die Weiterverarbeitung nicht sehr praktisch, da wir dann mit jedem einzelnen Interaktionsmodus arbeiten müssen. Die Lage des Wechselwirkungsmodus innerhalb der Tensordimensionen erschwert diese Arbeit. Daher transponieren wir die Daten weiter, um den Agenteninteraktionsmodus in die erste Dimension des Tensors zu verschieben.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Am Ausgang des Encoders erhalten wir also den Tensor {Agenteninteraktionsmodus, Anzahl der Agenten, Länge des Vektors, der die Dynamik des Agenten beschreibt}.
Nach dem Encoder erstellen wir das Endpoint-Decoder-Modell. Wir speisen den Tensor der Encoder-Ergebnisse in das Modell ein.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Ich möchte Sie daran erinnern, dass die MTF-Methode die Verwendung eines Decoders mit den gleichen Parametern für alle Agenteninteraktionsmodi erfordert. Wir können einen ähnlichen Ansatz mit einer Faltungsschicht mit einer Fenstergröße und einem Schritt, der dem Tensor eines Agenteninteraktionsmodus entspricht, umsetzen. Wir werden diese Phase in 2 Stufen unterteilen. Zunächst kollabieren wir die Dynamik jedes einzelnen Agenten.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Und dann erhalten wir Szenenoptionen für jeden analysierten Interaktionsmodus.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Das Modell zur Bewertung der Wahrscheinlichkeiten einzelner vorhergesagter Szenen blieb nahezu unverändert. Wie im Falle des Decoders werden die Ergebnisse des Encoders in das Modell eingespeist.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false;
Sie werden mit prädiktiven Szenenoptionen kombiniert.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; }
Die Daten werden von 2 vollständig verbundenen Schichten analysiert.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Und wird durch die SoftMax-Funktion normalisiert.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Die Architektur der Actor-Modelle ist nahezu identisch. Ich musste nur geringfügige Änderungen bei der Verarbeitung der Ergebnisse des Current State Encoders vornehmen.
Es ist auch anzumerken, dass die Änderungen an der Modellarchitektur praktisch keine Auswirkungen auf die Algorithmen für die Interaktion mit der Umwelt und das Modelltraining hatten. Daher wurden alle EAs aus den vorherigen Artikeln mit minimalen Änderungen übernommen. Daher werde ich mich im Rahmen dieses Artikels nicht mit der Beschreibung ihrer Algorithmen befassen. Den vollständigen Code aller im Artikel verwendeten Programme finden Sie im Anhang.
3. Tests
Wir haben den Multi-Future-Transformer-Algorithmus mit Hilfe von MQL5-Tools implementiert und die Architektur der Modelle beschrieben, die es uns ermöglichen, die vorgeschlagenen Ansätze zu nutzen, um Modelle für die Vorhersage mehrerer Optionen für die kommende Preisbewegung mit einer Bewertung der Wahrscheinlichkeit ihrer Umsetzung zu trainieren. Nun ist es an der Zeit, die Ergebnisse unserer Arbeit an realen Daten im MetaTrader 5 Strategietester zu überprüfen.
Wie immer wird das Modell anhand historischer EURUSD-H1-Daten trainiert und getestet. Die Daten für die ersten 7 Monate des Jahres 2023 werden zum Trainieren der Modelle verwendet. Um das trainierte Modell zu testen, verwenden wir historische Daten vom August 2023.
Um das Modell zu trainieren, habe ich den Trainingsdatensatz und die Trainings-EA aus dem vorherigen Artikel verwendet. Es kann also festgestellt werden, dass die Veränderungen der erzielten Ergebnisse hauptsächlich auf eine Änderung der Modellarchitektur zurückzuführen sind. Natürlich können wir den Zufallsfaktor nicht ausschließen, der durch die anfängliche Initialisierung des Modells mit zufälligen Parametern eingeführt wird. Darüber hinaus erfolgt die Auswahl der Daten aus dem Erfahrungswiedergabepuffer während des Trainingsprozesses ebenfalls nach dem Zufallsprinzip. Der Einfluss dieses Faktors wird jedoch mit zunehmender Anzahl von Trainingsepochen minimiert.
Im vorangegangenen Artikel zeigte das Modell ein recht stabiles Ergebnis, hatte aber eine sehr geringe Anzahl von Trades. Bei dem neuen Modell steigt die Zahl der Abschlüsse bei gleichbleibend positivem Ergebnis.
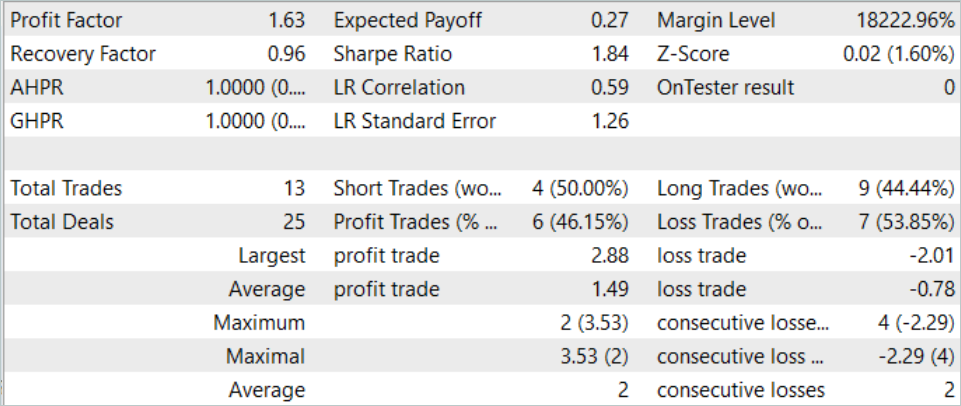
Im August 2023 führte das Modell 13 Handelsgeschäfte aus, von denen 6 mit Gewinn abgeschlossen wurden. Das Modell ergab für den Testzeitraum einen Gewinnfaktor von 1,63.
Schlussfolgerung
In diesem Artikel haben wir eine weitere Methode zur Vorhersage der kommenden Kursbewegung kennengelernt – den Multi-Future-Transformer. Eines der Hauptmerkmale dieser Methode ist die Erstellung multimodaler Prognosen für die Bewegung der Agenten, wobei der Schwerpunkt auf ihrer Interaktion untereinander und mit der Umgebung liegt. Auf diese Weise können wir genauere Vorhersagen über kommende Bewegungen machen.
Im praktischen Teil haben wir die vorgeschlagenen Ansätze mit MQL5 umgesetzt. Wir haben das Modell mit realen Daten im MetaTrader 5 Strategie-Tester trainiert und getestet. Die erzielten Ergebnisse bestätigen die Wirksamkeit der vorgeschlagenen Ansätze. Wir können die Vielfalt der erhaltenen Prognosen feststellen, die durch die Isolierung der Prognosen der einzelnen Modalitäten erreicht wird, während die Analyse der Agenteninteraktion beibehalten wird.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modelltraining EA |
| 4 | Test.mq5 | Expert Advisor | Modelltraining EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14226
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.