
Redes neuronales: así de sencillo (Parte 75): Mejora del rendimiento de los modelos de predicción de trayectorias

Introducción
La previsión de la trayectoria de los próximos movimientos de precios desempeña probablemente uno de los papeles clave en el proceso de elaboración de planes de negociación para el horizonte de planificación deseado. La precisión de estas previsiones es fundamental. En un intento de mejorar la calidad de la previsión de trayectorias, complicamos nuestros modelos de previsión de trayectorias.
Sin embargo, este proceso también tiene otra cara de la moneda. Los modelos más complejos requieren más recursos informáticos. Esto significa que aumentan los costes tanto de formación de los modelos como de su funcionamiento. Hay que tener en cuenta el coste de la formación de los modelos. Sin embargo, en cuanto a los costes de explotación, pueden ser aún más críticos. Especialmente cuando se trata de operar en tiempo real utilizando órdenes de mercado en un mercado muy volátil. En estos casos, buscamos métodos para mejorar el rendimiento de nuestros modelos. Idealmente, esta optimización no debería afectar a la calidad de las previsiones de trayectorias futuras.
Los métodos de predicción de trayectorias que hemos tratado en artículos recientes se tomaron prestados del sector de la conducción autónoma de vehículos. Los investigadores del sector se enfrentan al mismo problema. La velocidad de los vehículos exige cada vez más tiempo para tomar decisiones. El uso de modelos costosos para predecir trayectorias y tomar decisiones no sólo conlleva un aumento del tiempo dedicado a la toma de decisiones, sino también del coste del equipo utilizado, ya que requiere la instalación de hardware más caro. En este contexto, sugiero considerar las ideas presentadas en el artículo "Efficient Baselines for Motion Prediction in Autonomous Driving". Sus autores se propusieron construir un modelo "ligero" de previsión de trayectorias y destacan los siguientes logros:
- Identificación de un reto clave en el tamaño de los modelos de predicción de movimiento con implicaciones para la inferencia en tiempo real y el despliegue en dispositivos con recursos limitados.
- Proponer varias líneas de base eficaces para la predicción del tráfico de vehículos que no se basen explícitamente en el análisis exhaustivo de un mapa contextual de alta calidad, sino en información cartográfica previa obtenida en un sencillo paso de preprocesamiento que sirva de guía para la predicción.
- Utilizar menos parámetros y operaciones para lograr un rendimiento competitivo con un menor coste computacional.
1. Técnicas de mejora del rendimiento
Teniendo en cuenta el equilibrio entre los datos de origen analizados y la complejidad del modelo, los autores del método se esfuerzan por lograr resultados competitivos utilizando potentes técnicas de aprendizaje profundo, incluidos mecanismos de atención y redes neuronales gráficas (GNN). Esto reduce el número de parámetros y operaciones en comparación con otros métodos. En concreto, los autores del documento utilizan los siguientes datos como datos de entrada para sus modelos:
- Trayectorias pasadas de los agentes y sus correspondientes interacciones como única entrada al bloque de nivel de base social.
- Que añade una representación simplificada del área de tolerancia del agente como entrada adicional a la base de datos cartográfica.
Así pues, los modelos propuestos no requieren mapas completos de alta calidad ni representaciones rasterizadas de la escena para calcular el contexto físico.
Los autores del método proponen utilizar un algoritmo de preprocesamiento de mapas sencillo pero potente, en el que la trayectoria del agente objetivo se filtra inicialmente. A continuación, calculan el área factible en la que el agente objetivo puede interactuar, teniendo en cuenta únicamente la información geométrica del mapa.
La línea de base social utiliza como entrada las trayectorias pasadas de los obstáculos más significativos como desplazamientos relativos para alimentar el módulo Codificador. A continuación, la información social se calcula mediante una red neuronal gráfica (GNN). En su artículo, los autores del método utilizan la Crystal Graph Convolutional Network (Crystal-GCN) y capas de Multi-Head Self Attention (MHSA) para obtener las interacciones más significativas entre los agentes. Después, en el módulo Decodificador, esta información latente se decodifica utilizando una estrategia autorregresiva, en la que la salida en el i-ésimo paso depende de la anterior.
Una de las características del método propuesto es el análisis de la interacción con agentes que disponen de información a lo largo de todo el horizonte temporal Th = Tobs + Tlen. Al mismo tiempo, se reduce el número de agentes que es necesario considerar en escenarios de tráfico complejos. En lugar de utilizar vistas 2D absolutas desde arriba, la entrada para el agente i es una serie de desplazamientos relativos:
![]()
Los autores del método no limitan ni fijan el número de agentes de la secuencia. Para tener en cuenta los desplazamientos relativos de todos los agentes, se utiliza un LSTM-block, en el que se computa la información temporal de cada agente de la secuencia.
Tras codificar el historial analizado de cada vehículo en secuencia, se calculan las interacciones entre los agentes para obtener la información social más relevante. Para ello, se construye un gráfico de interacción. La capa Crystal-GCN se utiliza para construir un gráfico. A continuación se aplica MHSA para mejorar el aprendizaje de las interacciones agente-agente.
Antes de crear un mecanismo de interacción, los autores del método descomponen la información temporal en escenas adecuadas. Esto tiene en cuenta que cada escenario de movimiento puede tener un número diferente de agentes. El mecanismo de interacción se define como un grafo bidireccional totalmente conectado, en el que las características iniciales de los nodos v<0i están representadas por información temporal latente para cada vehículo hi,out, calculada por el codificador del historial de movimiento. Por otro lado, las aristas desde el nodo k al nodo l están representadas por el vector distancia ek,l entre los agentes correspondientes en un punto del tiempo tobs,len en coordenadas absolutas:
![]()
Dado un grafo de interacciones (nodos y aristas), Crystal-GCN se define como:
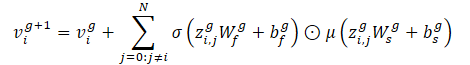
Este operador nos permite incrustar características de borde para actualizar las características de nodo en función de la distancia entre vehículos. Los autores del método utilizan 2 capas de Crystal-GCN con ReLU y normalización por lotes como no linealidades entre capas.
σ y μ son las funciones de activación de sigmoide y softplus, respectivamente. Además, zi,j=(vi‖vj‖ei,j) es una concatenación de características de dos nodos de la capa GNN y la arista correspondiente, N representa el número total de agentes en la escena, y W y b son pesos y desplazamientos de las capas correspondientes.
Tras pasar por el grafo de interacción, cada característica de nodo actualizada v<i contiene información sobre el contexto temporal y social del agente <i. Sin embargo, dependiendo de la posición actual y de la trayectoria pasada, el agente puede necesitar prestar atención a información social específica. Para modelar este método, los autores del método utilizan el mecanismo de Self-Attention multicabezal con 4 cabezales, que se aplica a la matriz de características de nodo actualizada V, que contiene las características del nodo vi como cadenas.
Cada fila de la matriz final de atención social SATT (salida del módulo de atención social, después de los mecanismos GNN y MHSA) representa una característica de interacción del agente <i con los agentes circundantes, teniendo en cuenta la información temporal bajo el capó.
A continuación, los autores del método amplían el modelo básico social utilizando información mínima sobre el mapa a partir de la cual discretizan el área P del agente objetivo como un subconjunto de r puntos seleccionados aleatoriamente {p0, p1. ..pr} alrededor de las líneas centrales plausibles (características de alto nivel y estructuradas), teniendo en cuenta la velocidad y aceleración del agente objetivo en el último fotograma de observación. Se trata de un paso de preprocesamiento del mapa, por lo que el modelo nunca ve el mapa de alta resolución.
Basándose en las leyes de la física, los autores del método tratan el vehículo como una estructura rígida sin cambios bruscos de movimiento entre marcas temporales sucesivas. En consecuencia, al describir la tarea de conducir por una carretera, normalmente los rasgos más importantes se encuentran en una dirección concreta (adelante en el sentido de la marcha). Esto permite obtener una versión simplificada del mapa.
La información sobre trayectorias suele contener ruido asociado al proceso de recogida de datos en el mundo real. Para estimar las variables dinámicas del agente objetivo en el último fotograma de observación tobs,len, los autores del método proponen filtrar primero las observaciones pasadas del agente objetivo utilizando un algoritmo de mínimos cuadrados a lo largo de cada uno de los ejes. Suponen que el agente se mueve con aceleración constante y pueden calcular las características dinámicas (velocidad y aceleración) del agente objetivo. A continuación, calculan el vector de estimaciones de velocidad y aceleración. Además, estos vectores se suman como escalares para obtener una estimación suave, asignando menos peso (mayor factor de olvido λ) a las primeras observaciones. De este modo, las observaciones más recientes desempeñan un papel clave en la determinación del estado cinemático actual del agente:
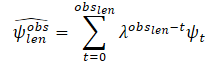
Donde
obslen es el número de fotogramas observados, ψt es la velocidad/aceleración estimada en el fotograma t, λ ∈ (0, 1) es el factor de olvido.
Tras calcular el estado cinemático, se estima la distancia recorrida, suponiendo un modelo físico basado en la aceleración con una velocidad de giro constante en cualquier tiempo t..
A continuación, se procesan estas trayectorias de carril candidatas plausibles para utilizarlas como información física plausible. En primer lugar, encuentran el punto más cercano a la última observación del agente objetivo que representará el punto de partida de una línea central plausible. A continuación, estiman la distancia recorrida a lo largo de las líneas centrales originales. Determinan el índice de punto final p de la línea central m como el punto en el que la distancia acumulada (considerando la distancia euclidiana entre cada punto) es mayor o igual que la desviación precalculada.
A continuación, realizan una interpolación cúbica entre el punto inicial y el punto final de la línea central correspondiente m para obtener pasos en el horizonte de planificación. Los experimentos realizados por los autores del método demuestran que la mejor información a priori, teniendo en cuenta la distancia media y mediana L2 sobre todo el conjunto de validación entre el punto final de la trayectoria verdadera del agente objetivo y los puntos finales de las líneas centrales filtradas, se consigue teniendo en cuenta la velocidad y la aceleración en el estado cinemático y filtrando la entrada mediante el método de los mínimos cuadrados.
Además de estas líneas centrales de alto nivel y estructuradas, los autores del método proponen aplicar distorsiones puntuales a todas las líneas centrales plausibles de acuerdo con la distribución normal N(0, 0,2). Esto discretizará la región plausible P como un subconjunto de r puntos seleccionados aleatoriamente {p0, p1...pr} alrededor de líneas centrales plausibles. Así pueden hacerse una idea general de la zona plausible identificada como rasgos de bajo nivel. Los autores del método utilizan la distribución normal N como término de regularización adicional, en lugar de utilizar los límites de los carriles. Así se evitará el sobreajuste en el módulo de codificación, de forma similar a como se aplica el aumento de datos a las trayectorias anteriores.
Los codificadores de área y de línea central se utilizan para calcular la información cartográfica latente. Procesan características cartográficas de bajo y alto nivel, respectivamente. Cada uno de estos codificadores está representado por un perceptrón multicapa (MLP). En primer lugar, suavizan la información a lo largo de la dimensión de los puntos, alternando la información a lo largo de los ejes de coordenadas. A continuación, el MLP correspondiente (3 capas, con normalización por lotes, ReLU y DropOut en la primera capa) convierte las coordenadas absolutas interpretadas alrededor del origen en información física latente representativa. El contexto físico estático (salida del codificador de regiones) servirá de representación latente común para los distintos modos, mientras que el contexto físico específico ilustrará la información cartográfica específica de cada modo.
El descodificador de trayectorias futuras representa el tercer componente de los modelos básicos propuestos. El módulo consiste en un bloque LSTM que estima recursivamente los movimientos relativos para futuros pasos temporales del mismo modo que se aprendieron los movimientos relativos pasados en el codificador de historial de movimiento. Para el caso base social, el modelo utiliza el contexto social calculado por el módulo de interacción social, prestando atención únicamente a los datos del agente objetivo. El contexto social por sí solo representa todo el tráfico del escenario, representando el vector latente de entrada del predictor autorregresivo LSTM.
Desde el punto de vista del caso base cartográfico para la modalidad m, los autores del método proponen identificar el contexto latente de tráfico como una concatenación de contexto social, contexto físico estático y contexto físico específico, que servirá como vector oculto de entrada del decodificador LSTM.
En relación con los datos originales de un bloque LSTM en el caso social, está representado por los movimientos relativos n pasados codificados del agente objetivo después de la incrustación espacial, mientras que la línea base cartográfica añade el vector de distancia codificado entre la posición absoluta actual del agente objetivo y la línea central actual, así como la marca de tiempo escalar actual t. En ambos casos (social y mapa), los resultados del bloque LSTM se procesan utilizando una capa estándar totalmente conectada.
Tras obtener una previsión relativa en un paso de tiempo t, desplazamos los datos iniciales de la observación pasada de tal forma que llevemos nuestro último movimiento relativo calculado al final del vector, eliminando los primeros datos.
Una vez calculadas las predicciones multimodales, se concatenan y se procesan mediante un MLP residual para ganar confianza (cuanto mayor es la confianza, más probable es el régimen y más se acerca a la verdad).
A continuación se ofrece la visualización original del método presentada por los autores del artículo. Aquí las líneas azules representan información social, y las líneas rojas muestran la transferencia de información sobre la tarjeta.

2. Implementación en MQL5
Hemos examinado los aspectos teóricos del planteamiento propuesto. Ahora vamos a implementarlo usando MQL5. Como puede ver, los autores del método dividieron el modelo en bloques. Cada bloque utiliza un número mínimo de capas. Al mismo tiempo, la simplificación de la arquitectura de los bloques individuales va acompañada de un análisis adicional de los datos utilizando información a priori sobre el entorno analizado. En concreto, se preprocesa el mapa y se filtran las trayectorias pasadas. Esto permite reducir el ruido y el volumen de los datos iniciales, sin perder la calidad de la construcción de trayectorias de previsión.
2.1 Creación de una capa de red convolucional Crystal-GCN
Además, entre los enfoques propuestos encontramos capas neuronales gráficas que no habíamos encontrado antes. En consecuencia, antes de pasar a construir el algoritmo propuesto, crearemos una nueva capa en nuestra biblioteca.
La capa de la red convolucional CrystalGraph propuesta por los autores del método puede representarse mediante la siguiente fórmula:
Esencialmente, aquí vemos la multiplicación elemento a elemento de los resultados del trabajo de 2 capas totalmente conectadas. Uno de ellos es activado por el sigmoide y representa una matriz binaria entrenable de la presencia de conexiones entre los vértices del grafo. La segunda capa se activa mediante la función SoftPlus, que es un análogo suave de ReLU.
Para implementar CrystalGraph Convolutional Network, crearemos una nueva clase CNeuronCGConvOCL heredando la funcionalidad básica de CNeuronBaseOCL.
class CNeuronCGConvOCL : public CNeuronBaseOCL { protected: CNeuronBaseOCL cInputF; CNeuronBaseOCL cInputS; CNeuronBaseOCL cF; CNeuronBaseOCL cS; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCGConvOCL(void) {}; ~CNeuronCGConvOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronCGConvOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Nuestra nueva clase recibe un conjunto estándar de métodos para sobrescribir y funcionalidad básica de la clase padre. Para implementar el algoritmo de convolución de grafos, crearemos 4 capas internas totalmente conectadas:
- 2 para escribir los datos originales y los gradientes de error durante la pasada de retropropagación (cInputF y cInputS).
- 2 para realizar la funcionalidad (cF y cS).
Crearemos todos los objetos internos estáticos, por lo que el constructor y el destructor de la clase permanecerán "vacíos".
En el método de inicialización de nuestra clase Init, llamaremos primero al método correspondiente de la clase padre, que implementa todos los controles necesarios para los datos recibidos del programa externo e inicializa los objetos y variables heredados.
bool CNeuronCGConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; activation = None;
Después inicializamos secuencialmente los objetos internos añadidos llamando a sus métodos de inicialización.
if(!cInputF.Init(numNeurons, 0, OpenCL, window, optimization, batch)) return false; if(!cInputS.Init(numNeurons, 1, OpenCL, window, optimization, batch)) return false; cInputF.SetActivationFunction(None); cInputS.SetActivationFunction(None); //--- if(!cF.Init(0, 2, OpenCL, numNeurons, optimization, batch)) return false; cF.SetActivationFunction(SIGMOID); if(!cS.Init(0, 3, OpenCL, numNeurons, optimization, batch)) return false; cS.SetActivationFunction(LReLU); //--- return true; }
Tenga en cuenta que para las capas internas del registro de datos de origen, especificamos la ausencia de una función de activación. Para las capas funcionales, incluimos las funciones de activación proporcionadas por el algoritmo de la capa creada. La capa CNeuronCGConvOCL en sí no tiene una función de activación.
Después de inicializar el objeto, pasamos a crear un método feedForward. En los parámetros, el método recibe un puntero al objeto de la capa neuronal anterior, cuya salida contiene los datos iniciales.
bool CNeuronCGConvOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !NeuronOCL.getOutput() || NeuronOCL.getOutputIndex() < 0) return false;
En el cuerpo del método, comprobamos inmediatamente la relevancia del puntero recibido.
Después de pasar con éxito el bloque de controles, tenemos que transferir los datos de origen desde el búfer de la capa anterior a los búferes de nuestras 2 capas internas de datos de origen. No olvides que todas las operaciones con nuestras capas neuronales las realizamos en el lado del contexto OpenCL. Por lo tanto, también necesitamos copiar datos a la memoria del contexto OpenCL. Pero iremos un poco más lejos y realizaremos la "copia" sin transferir físicamente los datos. Simplemente sustituiremos el puntero al búfer de resultados en las capas internas y les pasaremos un puntero al búfer de resultados de la capa anterior. Aquí indicamos también la función de activación de la capa anterior.
if(cInputF.getOutputIndex() != NeuronOCL.getOutputIndex()) { if(!cInputF.getOutput().BufferSet(NeuronOCL.getOutputIndex())) return false; cInputF.SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation()); } if(cInputS.getOutputIndex() != NeuronOCL.getOutputIndex()) { if(!cInputS.getOutput().BufferSet(NeuronOCL.getOutputIndex())) return false; cInputS.SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation()); }
Así, al trabajar con capas internas, obtenemos acceso directo al búfer de resultados de la capa anterior sin copiar físicamente los datos. Hemos implementado la tarea de transferencia de datos con recursos mínimos. Además, eliminamos la creación de dos búferes adicionales en el contexto OpenCL, optimizando así el uso de memoria.
A continuación, nos limitamos a llamar a métodos feed-forward para las capas funcionales internas.
if(!cF.FeedForward(GetPointer(cInputF))) return false; if(!cS.FeedForward(GetPointer(cInputS))) return false;
Como resultado de estas operaciones, obtuvimos matrices de contexto y conexiones gráficas. A continuación, realizamos su multiplicación por elementos. Para realizar esta operación utilizamos el núcleo Dropout, que creamos para la multiplicación elemento a elemento de los datos originales por una máscara. En nuestro caso, tenemos un fondo diferente para la misma operación matemática.
Pasemos los parámetros necesarios y los datos iniciales al núcleo.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = int(Neurons() + 3) / 4; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_input, cF.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_map, cS.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_out, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Dropout, def_k_dout_dimension, Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_Dropout, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Después lo ponemos en la cola de ejecución.
El siguiente paso es implementar la funcionalidad de retropropagación. Aquí empezaremos creando un núcleo en el lado OpenCL del programa. La cuestión es que la distribución del gradiente de error de la capa anterior comienza con su transferencia a las capas internas de acuerdo con su influencia en el resultado final. Para ello, tenemos que multiplicar el gradiente de error resultante por los resultados del paso feed-forward de la segunda capa funcional. Para evitar llamar dos veces al kernel de multiplicación por elementos utilizado anteriormente, crearemos un nuevo kernel en el que obtendremos gradientes de error para ambas capas en 1 pasada.
En los parámetros del kernel CGConv_HiddenGradient, pasaremos punteros a 5 buffers de datos y los tipos de funciones de activación de ambas capas.
__kernel void CGConv_HiddenGradient(__global float *matrix_g,///<[in] Tensor of gradients at current layer __global float *matrix_f,///<[in] Previous layer Output tensor __global float *matrix_s,///<[in] Previous layer Output tensor __global float *matrix_fg,///<[out] Tensor of gradients at previous layer __global float *matrix_sg,///<[out] Tensor of gradients at previous layer int activationf,///< Activation type (#ENUM_ACTIVATION) int activations///< Activation type (#ENUM_ACTIVATION) ) { int i = get_global_id(0);
Lanzaremos el núcleo en un espacio de tareas unidimensional basado en el número de neuronas de nuestras capas. En el cuerpo del núcleo determinamos inmediatamente el desplazamiento en los búferes de datos hasta el elemento que se está analizando basándonos en el identificador del hilo.
A continuación, para reducir las operaciones "intensivas" de acceso a la memoria global de la GPU, almacenaremos los datos del elemento analizado en variables locales, a las que se accede muchas veces más rápido.
float grad = matrix_g[i]; float f = matrix_f[i]; float s = matrix_s[i];
En este punto, tenemos todos los datos necesarios para calcular los gradientes de error en ambas capas, y los calculamos.
float sg = grad * f; float fg = grad * s;
Pero antes de escribir los valores obtenidos en los elementos de las memorias intermedias de datos globales, necesitamos ajustar los gradientes de error encontrados a las funciones de activación correspondientes.
switch(activationf) { case 0: f = clamp(f, -1.0f, 1.0f); fg = clamp(fg + f, -1.0f, 1.0f) - f; fg = fg * max(1 - pow(f, 2), 1.0e-4f); break; case 1: f = clamp(f, 0.0f, 1.0f); fg = clamp(fg + f, 0.0f, 1.0f) - f; fg = fg * max(f * (1 - f), 1.0e-4f); break; case 2: if(f < 0) fg *= 0.01f; break; default: break; }
switch(activations) { case 0: s = clamp(s, -1.0f, 1.0f); sg = clamp(sg + s, -1.0f, 1.0f) - s; sg = sg * max(1 - pow(s, 2), 1.0e-4f); break; case 1: s = clamp(s, 0.0f, 1.0f); sg = clamp(sg + s, 0.0f, 1.0f) - s; sg = sg * max(s * (1 - s), 1.0e-4f); break; case 2: if(s < 0) sg *= 0.01f; break; default: break; }
Al final de la operación del núcleo, guardamos los resultados de las operaciones en los elementos correspondientes de las memorias intermedias de datos globales.
matrix_fg[i] = fg; matrix_sg[i] = sg; }
Después de crear el núcleo, volvemos a trabajar en los métodos de nuestra clase. La distribución del gradiente de error se implementa en el método calcInputGradients, en cuyos parámetros pasaremos un puntero al objeto de la capa anterior. En el cuerpo del método, comprobamos inmediatamente la relevancia del puntero recibido.
bool CNeuronCGConvOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer || !prevLayer.getGradient() || prevLayer.getGradientIndex() < 0) return false;
A continuación, tenemos que llamar al núcleo descrito anteriormente para distribuir el gradiente a través de las capas internas CGConv_HiddenGradient. En primer lugar, definimos el espacio de tareas.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = Neurons();
A continuación, pasamos los parámetros necesarios al núcleo.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_f, cF.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_fg, cF.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_s, cS.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_sg, cS.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_g, getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CGConv_HiddenGradient, def_k_cgc_activationf, cF.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CGConv_HiddenGradient, def_k_cgc_activations, cS.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Coloca el núcleo en la cola de ejecución.
if(!OpenCL.Execute(def_k_CGConv_HiddenGradient, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
A continuación, tenemos que propagar el gradiente de error a través de las capas internas totalmente conectadas. Para ello, llamamos a sus métodos correspondientes.
if(!cInputF.calcHiddenGradients(GetPointer(cF))) return false; if(!cInputS.calcHiddenGradients(GetPointer(cS))) return false;
En esta fase tenemos los resultados de 2 flujos de gradientes de error en 2 capas internas de los datos originales. Simplemente los sumamos y transferimos el resultado al nivel de la capa anterior.
if(!SumAndNormilize(cF.getOutput(), cS.getOutput(), prevLayer.getOutput(), 1, false)) return false; //--- return true; }
Tenga en cuenta que en este caso no tenemos en cuenta explícitamente la función de activación de la capa anterior en ningún lugar. Esto es importante para la correcta transmisión del gradiente de error. Pero aquí hay un matiz. Todas nuestras clases de capas neuronales están construidas de tal forma que el ajuste de la derivada de la función de activación se realiza antes de propagar el gradiente al buffer de la capa anterior. A estos efectos, durante el paso feed-forward, especificamos la función de activación de la capa anterior para nuestras capas internas de los datos de origen. Así, cuando el gradiente de error se propagó a través de nuestras capas funcionales internas, ajustamos inmediatamente el gradiente de error a la derivada de la función de activación, que es la misma para los gradientes de ambas corrientes. En la salida sumamos los gradientes de error ya ajustados por la derivada de la función de activación.
El algoritmo del segundo método de retropropagación (actualización de la matriz de pesos updateInputWeights) es bastante sencillo. Aquí nos limitamos a llamar a los métodos correspondientes de las capas funcionales internas.
bool CNeuronCGConvOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cF.UpdateInputWeights(cInputF.AsObject())) return false; if(!cS.UpdateInputWeights(cInputS.AsObject())) return false; //--- return true; }
La implementación del resto de métodos de nuestra clase CNeuronCGConvOCL, en mi opinión, no tiene especial interés. En ellos utilicé los algoritmos habituales para los métodos correspondientes, que ya se han descrito muchas veces en esta serie de artículos. Los encontrará en el archivo adjunto. Allí también encontrará el código completo de todos los programas utilizados al escribir el artículo. Pasemos ahora a la aplicación de los enfoques propuestos en la construcción de la arquitectura de los modelos y su entrenamiento.
2.2 Arquitectura modelo
Para crear la arquitectura de los modelos, utilizaremos modelos de los artículos anteriores, manteniendo la estructura de los datos originales. Esto se hace a propósito. En la estructura ADAPT, también puede seleccionar un módulo codificador, que se presenta como Codificación de características. También incluye un bloque de atención social de capas sucesivas de atención multicabezal. El bloque de predicción del punto final puede compararse con las líneas centrales propuestas. El bloque de confianza es similar a la predicción de probabilidades de trayectoria. Esto hace que trabajar con los nuevos modelos sea aún más interesante.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Empecemos por el modelo de codificador. Alimentamos el modelo con datos brutos sobre el estado del entorno.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos fuente brutos se preprocesan en la unidad de normalización de datos por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, en lugar del bloque LSTM propuesto por los autores, dejé la capa Embedding con codificación posicional, ya que este enfoque nos permite guardar y analizar una historia más profunda.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
También incluí un bloque de atención social en el modelo del codificador. De acuerdo con el método original, consta de 2 capas consecutivas de convolución de gráficos, separadas por una capa de normalización por lotes.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
La salida del bloque de atención social utiliza 1 capa de atención multicabezal.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
En nuestro caso, no existe un mapa del entorno del que podamos deducir analíticamente algunas de las opciones más probables para el próximo movimiento de los precios. Por lo tanto, en lugar de las líneas centrales, dejamos el bloque de predicción del punto final. Utilizará los resultados del bloque de atención social como datos de origen.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (prev_count * prev_wout); descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Pero primero tenemos que preprocesar los datos en una capa totalmente conectada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
A continuación, utilizaremos el bloque LSTM, tal y como proponen los autores del método para el bloque de decodificación de trayectorias.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 3 * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
A la salida del bloque, generamos una representación multimodal de los puntos finales para un número determinado de opciones.
El modelo de predicción de las probabilidades de elegir trayectorias se mantuvo sin cambios. Alimentamos el modelo con los resultados de los 2 modelos anteriores.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false; //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; }
Procéselos con un bloque de capas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Traduce los resultados al área de probabilidades utilizando la capa SoftMax.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Como en el trabajo anterior, no intentaremos predecir la trayectoria detallada de los movimientos de precios. Nuestro principal objetivo es obtener beneficios en los mercados financieros. Por lo tanto, entrenaremos un modelo Actor capaz de generar políticas de comportamiento óptimas basadas en los puntos finales de movimiento de precios previstos.
La arquitectura del modelo está completamente copiada del artículo anterior y se presenta en el archivo adjunto en el método CreateDescriptions en el archivo "...\Experts\BaseLines\Trajectory.mqh". Su descripción detallada se presenta en el anterior artículo.
2.3 Modelo de entrenamiento
Como se desprende de la arquitectura presentada de los modelos, la secuencia de su utilización en los EAs que interactúan con el entorno no ha variado. Por lo tanto, en este artículo no nos detendremos en la consideración de los algoritmos de los programas de recogida de datos de entrenamiento y de prueba de los modelos entrenados. Pasamos directamente al asesor de entrenamiento del modelo. Como en el artículo anterior, todos los modelos se entrenan en un EA "...\Experts\BaseLines\Study.mq5"
En el método de inicialización del EA, primero cargamos una base de datos de ejemplos para los modelos de entrenamiento.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
A continuación, cargamos los modelos preentrenados y, si es necesario, creamos otros nuevos.
//--- load models float temp; if(!BLEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !BLEndpoints.Load(FileName + "Endp.nnw", temp, temp, temp, dtStudied, true) || !BLProbability.Load(FileName + "Prob.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *encoder = new CArrayObj(); CArrayObj *endpoint = new CArrayObj(); CArrayObj *prob = new CArrayObj(); if(!CreateTrajNetDescriptions(encoder, endpoint, prob)) { delete endpoint; delete prob; delete encoder; return INIT_FAILED; } if(!BLEncoder.Create(encoder) || !BLEndpoints.Create(endpoint) || !BLProbability.Create(prob)) { delete endpoint; delete prob; delete encoder; return INIT_FAILED; } delete endpoint; delete prob; delete encoder; }
if(!StateEncoder.Load(FileName + "StEnc.nnw", temp, temp, temp, dtStudied, true) || !EndpointEncoder.Load(FileName + "EndEnc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *endpoint = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); if(!CreateDescriptions(actor, endpoint, encoder)) { delete actor; delete endpoint; delete encoder; return INIT_FAILED; } if(!Actor.Create(actor) || !StateEncoder.Create(encoder) || !EndpointEncoder.Create(endpoint)) { delete actor; delete endpoint; delete encoder; return INIT_FAILED; } delete actor; delete endpoint; delete encoder; //--- }
A continuación, transferimos todos los modelos a un único contexto OpenCL.
OpenCL = Actor.GetOpenCL(); StateEncoder.SetOpenCL(OpenCL); EndpointEncoder.SetOpenCL(OpenCL); BLEncoder.SetOpenCL(OpenCL); BLEndpoints.SetOpenCL(OpenCL); BLProbability.SetOpenCL(OpenCL);
Y controlar la arquitectura de los modelos.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
BLEndpoints.getResults(Result); if(Result.Total() != 3 * NForecast) { PrintFormat("The scope of the Endpoints does not match forecast endpoints (%d <> %d)", 3 * NForecast, Result.Total()); return INIT_FAILED; }
BLEncoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Al final del método, creamos buffers de datos auxiliares y generamos un evento personalizado para el inicio del entrenamiento del modelo.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
En el método de desinicialización, guardamos los modelos entrenados y vaciamos la memoria de objetos dinámicos.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); StateEncoder.Save(FileName + "StEnc.nnw", 0, 0, 0, TimeCurrent(), true); EndpointEncoder.Save(FileName + "EndEnc.nnw", 0, 0, 0, TimeCurrent(), true); BLEncoder.Save(FileName + "Enc.nnw", 0, 0, 0, TimeCurrent(), true); BLEndpoints.Save(FileName + "Endp.nnw", 0, 0, 0, TimeCurrent(), true); BLProbability.Save(FileName + "Prob.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
El proceso de entrenamiento del modelo se realiza mediante el método "Train". En el cuerpo del método, primero generamos un vector de probabilidades para elegir trayectorias.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Después creamos variables locales.
vector<float> result, target; matrix<float> targets, temp_m; bool Stop = false; //--- uint ticks = GetTickCount();
Crear un sistema de bucles de entrenamiento de modelos.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
En el cuerpo del bucle externo, muestreamos la trayectoria desde el búfer de repetición de la experiencia y el estado del inicio del aprendizaje sobre ella.
Aquí determinaremos el último estado del paquete de entrenamiento en la trayectoria seleccionada y borraremos los búferes de datos recurrentes.
BLEncoder.Clear(); BLEndpoints.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
En el cuerpo del bucle anidado, tomamos un estado ambiental del búfer de repetición de la experiencia y ejecutamos pases feed-forward de los modelos de predicción de punto final y sus probabilidades.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- Trajectory if(!BLEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!BLEndpoints.feedForward((CNet*)GetPointer(BLEncoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!BLProbability.feedForward((CNet*)GetPointer(BLEncoder), -1, (CNet*)GetPointer(BLEndpoints))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Como puede ver, las operaciones descritas no difieren mucho de las del artículo anterior. Pero habrá cambios. Se referirán concretamente a la transferencia de conocimientos a priori al modelo durante el proceso de entrenamiento. Porque al utilizar conocimientos a priori sobre el entorno, los autores del método se esfuerzan por aumentar la precisión de las previsiones simplificando al mismo tiempo la arquitectura de los propios modelos.
De hecho, existen varios enfoques para transferir conocimientos a priori a un modelo. Podemos preprocesar los datos brutos para comprimirlos y hacerlos más informativos. Así lo propusieron los autores del método de las líneas centrales.
También podemos utilizar conocimientos a priori a la hora de generar valores objetivo en el proceso de entrenamiento de modelos. Esto ayudará al modelo a prestar más atención a los objetos más significativos de los datos de origen. Por supuesto, es posible utilizar ambos enfoques simultáneamente.
A efectos de este artículo, utilizaremos el segundo enfoque. Para preparar los valores objetivo para el entrenamiento del modelo de predicción de extremos, primero recopilaremos los datos de movimientos de precios próximos del buffer de repetición.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(target.Size() > BarDescr) { matrix<float> temp(1, target.Size()); temp.Row(target, 0); temp.Reshape(target.Size() / BarDescr, BarDescr); temp.Resize(temp.Rows(), 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } target = targets.Col(0).CumSum(); targets.Col(target, 0); targets.Col(target + targets.Col(1), 1); targets.Col(target + targets.Col(2), 2);
Como ejemplo de conocimiento a priori, utilizaremos las señales del indicador MACD. Los datos de nuestra línea principal se almacenan en el elemento 7 de la matriz que describe el estado del entorno. El valor de la línea de señal está en el elemento 8 de la misma matriz. Si la línea de señal está por encima de la línea principal, consideramos que la tendencia actual es alcista. De lo contrario, bajista.
int direct = (Buffer[tr].States[i].state[8] >= Buffer[tr].States[i].state[7] ? 1 : -1);
Estoy de acuerdo en que este enfoque es bastante simplificado y podríamos utilizar más señales e indicadores para identificar tendencias. Pero precisamente esta simplicidad proporcionará un claro ejemplo de aplicación en el marco del artículo y nos permitirá evaluar el impacto del planteamiento. Le sugiero que utilice enfoques más globales en sus proyectos para obtener resultados óptimos.
Tras determinar la dirección de la tendencia, determinamos el extremo en esta dirección. También limitamos la matriz del próximo movimiento del precio al extremo encontrado.
ulong extr=(direct>0 ? target.ArgMax() : target.ArgMin()); if(extr==0) { direct=-direct; extr=(direct>0 ? target.ArgMax() : target.ArgMin()); } targets.Resize(extr+1, 3);
Cabe señalar aquí que la señal MACD va por detrás de los cambios de tendencia. Por lo tanto, si al determinar el extremo lo encontramos en la primera fila de la matriz, cambiamos la dirección de la tendencia a la opuesta y redefinimos el extremo.
Al utilizar tendencias determinadas mediante el conocimiento a priori del entorno, reducimos en cierta medida la estocasticidad de los valores objetivo que se observaba anteriormente cuando se utilizaba la dirección de la primera vela próxima. En general, esto debería ayudar a nuestro modelo a determinar más correctamente las tendencias y las direcciones futuras del movimiento de los precios.
A partir de la matriz truncada del próximo movimiento de precios, determinamos los valores objetivo por el extremo del próximo movimiento de precios.
if(direct >= 0) { target = targets.Max(AXIS_HORZ); target[2] = targets.Col(2).Min(); } else { target = targets.Min(AXIS_HORZ); target[1] = targets.Col(1).Max(); }
Como antes, determinamos la predicción más precisa del modelo a partir de todo el espacio multimodal de puntos finales y, en una ejecución de retropropagación, ajustamos sólo la predicción seleccionada.
BLEndpoints.getResults(result); targets.Reshape(1, result.Size()); targets.Row(result, 0); targets.Reshape(NForecast, 3); temp_m = targets; for(int i = 0; i < 3; i++) temp_m.Col(temp_m.Col(i) - target[i], i); temp_m = MathPow(temp_m, 2.0f); ulong pos = temp_m.Sum(AXIS_VERT).ArgMin(); targets.Row(target, pos); Result.AssignArray(targets);
Los valores objetivo preparados de este modo nos permiten actualizar los parámetros del modelo de predicción del punto final y el estado ambiental inicial Encoder.
if(!BLEndpoints.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!BLEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Aquí ajustamos los modelos de previsión probabilística. Pero no transmitimos el gradiente de error de este modelo al modelo de predicción del punto final o al Codificador.
bProbs.AssignArray(vector<float>::Zeros(NForecast)); bProbs.Update((int)pos, 1); bProbs.BufferWrite(); if(!BLProbability.backProp(GetPointer(bProbs), GetPointer(BLEndpoints))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
El siguiente paso es entrenar la política del Actor. Aquí preparamos primero la información sobre el estado de la cuenta y las posiciones abiertas.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
A continuación, creamos Embeddings (Incrustaciones) de estados y puntos finales previstos.
//--- State embedding if(!StateEncoder.feedForward((CNet *)GetPointer(BLEncoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Endpoint embedding if(!EndpointEncoder.feedForward((CNet *)GetPointer(BLEndpoints), -1, (CNet*)GetPointer(BLProbability))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Nótese que, a diferencia de trabajos anteriores, utilizamos los resultados del pase feed-forward por encima de los modelos entrenados para generar la incrustación de los puntos finales predictivos, en lugar de los valores objetivo. Esto nos permitirá adaptar el rendimiento del Actor a los resultados del modelo de predicción de puntos finales.
Una vez preparadas las incrustaciones, realizamos un paso feed-forward a través del modelo Actor.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(StateEncoder), -1, (CNet*)GetPointer(EndpointEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
La ejecución satisfactoria del paso hacia delante va seguida de un paso hacia atrás que actualiza los parámetros del modelo. Aquí, al preparar los valores objetivo para entrenar el modelo de actor, también añadiremos algunos conocimientos a priori. En concreto, antes de abrir una operación en un sentido u otro, comprobaremos los valores de los indicadores RSI y CCI, que se almacenan en los elementos 4º y 5º de la matriz de descripción del estado del entorno, respectivamente.
if(direct > 0) { if(Buffer[tr].States[i].state[4] > 30 && Buffer[tr].States[i].state[5] > -100 ) { float tp = float(target[1] / _Point / MaxTP); result[1] = tp; int sl = int(MathMax(MathMax(target[1] / 3, -target[2]) / _Point, MaxSL / 10)); result[2] = float(sl) / MaxSL; result[0] = float(MathMax(risk / (value * sl), 0.01)) + FLT_EPSILON; } }
else { if(Buffer[tr].States[i].state[4] < 70 && Buffer[tr].States[i].state[5] < 100 ) { float tp = float((-target[2]) / _Point / MaxTP); result[4] = tp; int sl = int(MathMax(MathMax((-target[2]) / 3, target[1]) / _Point, MaxSL / 10)); result[5] = float(sl) / MaxSL; result[3] = float(MathMax(risk / (value * sl), 0.01)) + FLT_EPSILON; } }
Tenga en cuenta que en este caso no estamos comprobando explícitamente las señales del indicador MACD, puesto que ya se han tenido en cuenta a la hora de determinar la dirección del próximo movimiento directo.
Con estos valores objetivo preparados, podemos ejecutar una pasada de retropropagación a través del modelo Actor compuesto.
Result.AssignArray(result); if(!Actor.backProp(Result, (CNet *)GetPointer(EndpointEncoder)) || !StateEncoder.backPropGradient(GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !EndpointEncoder.backPropGradient((CNet*)GetPointer(BLProbability)) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Utilizamos el gradiente de error del Actor para actualizar los parámetros del Codificador, pero no actualizamos el modelo de predicción del punto final.
if(!BLEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Al final de las operaciones dentro del sistema de bucles, sólo tenemos que informar al usuario sobre el progreso del proceso de formación.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Endpoints", percent, BLEndpoints.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Probability", percent, BLProbability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez finalizado el proceso de entrenamiento del modelo, borramos el campo de comentarios del gráfico. Envía los resultados del entrenamiento del modelo al registro e inicia el proceso de finalización del EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Endpoints", BLEndpoints.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", BLProbability.getRecentAverageError()); ExpertRemove(); //--- }
Con esto concluye nuestra consideración de los algoritmos para implementar los enfoques básicos propuestos para optimizar los modelos de predicción de trayectorias. En el archivo adjunto encontrará el código completo de todos los programas utilizados.
3. Pruebas
Hemos implementado enfoques básicos para optimizar los modelos de previsión de trayectorias utilizando MQL5. En concreto, hemos creado una capa de convolución de grafos y aplicado enfoques para utilizar conocimientos a priori sobre el entorno a la hora de fijar objetivos durante el entrenamiento del modelo. Así se ha reducido el número de capas de los modelos, lo que potencialmente debería reducir su complejidad y aumentar la velocidad de su funcionamiento. Evaluamos el impacto de los enfoques propuestos en el proceso de entrenamiento y prueba de los modelos entrenados con datos reales en el probador de estrategias de MetaTrader 5.
Como antes, el entrenamiento y las pruebas de los modelos se realizan sobre los 7 primeros meses de 2023 del EURUSD H1.
Al construir la arquitectura de los modelos, ya mencionamos la preservación de la estructura de datos de origen. Esto nos permitió utilizar en el entrenamiento el búfer de repetición de experiencias recogido en artículos anteriores. Simplemente cambiamos el nombre del archivo de datos recogidos previamente a BaseLines.bd. Si desea crear un nuevo conjunto de datos de entrenamiento, puede utilizar cualquiera de los métodos discutidos anteriormente utilizando EAs de interacción ambiental.
El proceso de generación de valores objetivo durante el proceso de entrenamiento del modelo nos permitió utilizar el conjunto de datos de entrenamiento hasta obtener resultados óptimos sin necesidad de actualizarlo y complementarlo.
Sin embargo, los resultados de la formación no fueron tan prometedores como se esperaba. Al probar los modelos entrenados, aumentamos el periodo de prueba de 1 a 3 meses.


Pues bien, hemos conseguido obtener un modelo capaz de generar beneficios tanto en las muestras de entrenamiento como en las de prueba. Además, el modelo resultante demostró una buena estabilidad con un factor de beneficio de 1,4. Tras entrenarse con datos históricos durante 7 meses, el modelo es capaz de generar beneficios durante al menos 3 meses. Esto puede indicar que el modelo fue capaz de identificar predictores bastante estables.
Sin embargo, el modelo era bastante deficiente en cuanto al número de operaciones. 11 operaciones realizadas en 3 meses es muy poco. Este no es el resultado que queríamos conseguir.
Conclusión
En este artículo, examinamos enfoques básicos para optimizar el rendimiento de los modelos de predicción de trayectorias. La aplicación de los enfoques propuestos permite entrenar modelos capaces de identificar predictores realmente significativos en los datos de origen. Esto permite un funcionamiento estable durante un periodo de tiempo bastante largo después del entrenamiento.
Sin embargo, nuestros resultados indican un fuerte conservadurismo en las decisiones tomadas por los modelos. Esto se refleja en un número muy reducido de acuerdos realizados. Por tanto, es en esta dirección en la que tenemos que seguir investigando.
Referencias
Programas utilizados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor experto | Colección de ejemplos |
| 2 | ResearchRealORL.mq5 | Asesor experto | EA para la recolección de ejemplos utilizando el método Real-ORL |
| 3 | Study.mq5 | Asesor experto | EA para el entrenamiento del modelo |
| 4 | Test.mq5 | Asesor experto | EA para la prueba del modelo |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema |
| 6 | NeuroNet.mqh | Biblioteca de clases | Una biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Código base | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14187
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso