
ニューラルネットワークが簡単に(第76回):Multi-future Transformerで多様な相互作用パターンを探る

はじめに
今後の値動きを予測することは、取引戦略を成功させるための重要な前提条件の1つです。したがって、正確でマルチモーダルな将来の運動予測の可能性を探る必要があります。前回の記事では、値動きを予測するためのいくつかの方法について学びました。その中には、複数のイベント展開のバリエーションを提供するマルチモーダルなものもありました。
しかし、これらはいずれも、分析対象エージェント間の相互作用の将来的な可能性に焦点を当てることはほとんどなく、情報の損失や最適とは言えない予測につながる可能性があります。さらに、複数のエージェントがある場合、独立した予測は指数関数的な数の組み合わせにつながるため、これまで議論されてきた方法を拡張することは非常に困難です。その結果の組み合わせのほとんどは、相反する予測のために実現不可能です。したがって、複数のエージェントの将来の状態を同時に推定し、シーン全体を予測することに重点を置くことが重要です。
「Multi-future Transformer:Learning diverse interaction modes for behavior prediction in autonomous driving」稿の著者は、このような問題を解決するために、Multi-future Transformer (MFT)法を用いることを提案しています。その主なアイデアは、未来のマルチモーダル分布をいくつかのユニモーダル分布に分解することで、シーンのエージェント間の相互作用のさまざまなモデルを効果的にシミュレートすることができるというものです。
MFTでは、潜在変数を確率的にサンプリングしたり、アンカーを事前に決定したり、反復的な後処理アルゴリズムを実行したりする必要がなく、固定パラメータを持つニューラルネットワークによって、1回のフィードフォワードパスで予測が生成されます。これにより、モデルは決定論的で再現可能な方法で動作します。
1.Multi-future Transformerアルゴリズム
Multi-future Transformer法の主な目標は、シーン内のすべてのエージェントの将来の動きYを一貫して予測することです。そのために、エージェントの動的状態Xとコンテキスト情報Mを分析します。したがって、捕捉する全体的な確率分布はP(Y|X,M)です。これは、シーンの明確な進化の結果としてマルチモーダルです。
通常、多峰性の共同分布を直接モデル化するのは非常に難しいです。この手法の著者は、目標分布が複数の単峰性分布の混合に分解できるという仮定を導入し、これらの単峰性分布を別々にモデル化します。これは次のように定式化されます。
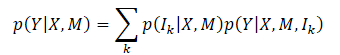
ここで、Ikはk番目のモード成分
p(Ik|X,M)は異なるモードの確率分布
p(Y|X,M,Ik)は 因数分解された単峰分布
この定式化の下で、MFTの重要な点は、各目標分布モード間の主な違いは、エージェント間およびエージェントとコンテキストの間の相互作用モデルの違いにあるということです。各単峰分布のモデリングは、モード対応相互作用のパターンを研究することで実現できます。直感的には、未来の場面の不確実性は主に意図の不確実性と相互作用の不確実性の2つに分解できます。
エージェントの意図を表す未来の軌跡のエンドポイントは、シーンのコンテキストと密接に関係しているため、観測不可能な意図は、エージェントとコンテキストの間の相互作用をモデル化することでうまく捉えることができます。相互作用の不確実性を考慮するため、エージェント間のさまざまな相互作用モードがモデル化されます。このように、エージェント間の相互作用だけでなく、エージェントとコンテキストの相互作用も共同で捉えることで、将来の不確実性を最小化し、シーンの進化を決定することができます。
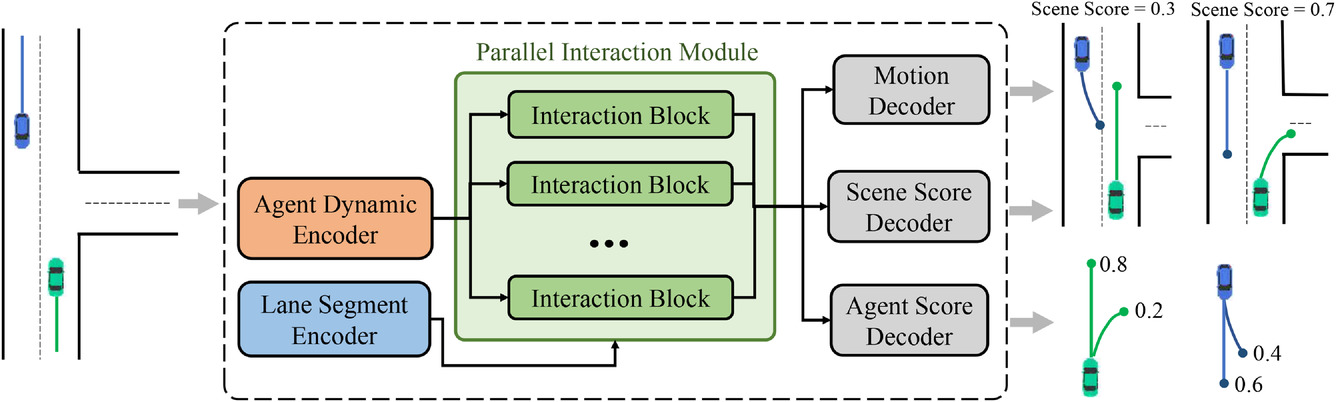
上述したマルチモーダルジョイント分布分解を実現するために、提案されたMFTアプローチの一般的なアーキテクチャが設計されました。これは、3つの部分から構成されています。
- エンコーダー
- 並列相互作用モジュール
- 予測ヘッダー
このモデルには2種類のエンコーダーが搭載されています。
- ダイナミックエージェントエンコーダーは、観測された動的状態から特徴を抽出するために使用される
- コンテキストセグメントエンコーダーは、縞模様の点ごとの関数を学習するマップビューアとして機能する
MFTモデルの核となるのは並列相互作用モジュールであり、並列構造の複数の相互作用ブロックから構成され、各モードにおけるエージェントの動きの将来的な特徴を研究します。3つの予測ヘッダーは以下の通りです。
- モーションデコーダー
- エージェントスコアデコーダー
- シーンスコアデコーダー
これらは、各エージェントの将来の軌道をデコードし、予測された軌道とシーンモードごとに信頼スコアを推定する役割を担います。このアーキテクチャでは、各モードのフィードフォワード信号とバックプロパゲーション信号が通る経路は互いに独立しており、各経路には同じモードの信号間の情報相互作用を提供する固有の相互作用ブロックが含まれています。したがって、相互作用ユニットは、異なるモードの対応する相互作用パターンを同時に捉えることができます。ただし、エンコーダーと予測ヘッダーは各モードに共通で、相互作用ブロックは異なるオブジェクトとしてパラメータ化されています。したがって、理論的には異なるパラメータを持つ一峰性分布を、よりパラメータ効率の良い方法でモデル化することができます。この手法の元の視覚化を以下に示します。
地平線上のエージェントの履歴的に観測された軌跡はX={x1,...,xatt}で表すことができます。ここで、各タイムステップの動的状態xt=(x,y,vx,vy,w)には、その時点での位置 (x,y)、速度(vx,vy)、およびヨー角wが含まれます。
エージェントの動的な状態は、多次元空間の点の集合とみなされ、各点は座標(x,y)で表され、 他の次元は追加の局所的な特徴を表します。これらのポイントでは、エージェントの観測された状態が相互に作用し、エージェントの観測された軌道を形成するため、相互作用の特性と与えられた局所的な構造が保持されます。さらに、これらの軌跡点のもう1つの重要な特性は、静的なレーン点に比べて暗黙的な特徴である時間的順序です。当然ながら、同じ軌跡でも時間順が逆であれば、観測される軌跡はまったく異なるものになります。以上の性質から、モデルは点特徴量の組み合わせだけでなく、時間的な順序情報を導入して軌跡点を表現する必要があります。この目的のために、絶対位置符号化が順序情報をエンコードするために使用されます。モデルは各エージェントの動的特徴を以下のように計算します。
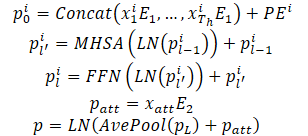
動的な情報を表現するモデルの能力を向上させるために、複数のエンコーダー層が積み重ねられています。平均化は、特定のエージェントに関連する過去の動的情報を要約するために、エージェントの軌道のすべてのポイントにわたって実行されます。
また、動的な情報を得るために、現在の瞬間に対応する点の特徴量も抽出されました。これにより、平均的なプールと同様のパフォーマンスが得られます。部分的に観測可能な履歴状態を扱う場合、Self-Attentionベースのフレームワークは、追加的な努力なしに、観測不可能な位置を単純にマスクすることができ、それによって無効なパディングによって引き起こされる特徴の混乱を効果的に回避することができます。
行動予測タスクの特徴は、未来のシーンの不確実性に起因するマルチモーダル性です。一般的なアプローチは、複数の結果ヘッダを使用して、共通の特徴ベクトルに基づいて各エージェントの将来の軌道を独立にデコードすることです。しかし、この手法には主に2つの欠点があります。
- 将来起こりうる様々な軌跡の運動情報は、固定次元の1つの特徴ベクトルに含まれるため、情報量が制限され、モデルの表現力が著しく制限される
- 異なるモードからの前方信号と後方信号は、特徴の相互作用と勾配伝搬によって混合され、マルチモーダル予測の能力を低下させるモード混同問題につながる
その代わりにMFTでは、相互作用のモデリングをさまざまなモードに分け、それぞれのモードに対応する独自の相互作用パターンを学習することで、マルチモーダルな結果を実現します。この目的のために、並列相互作用モジュールが設計されました。このモジュールには、並列に相互作用するいくつかのブロックがあり、それぞれが将来の出来事のある発展様式を表しています。この構造では、モード内順方向信号と逆方向信号は、対応するモードの相互作用ブロックを横切ります。同時に、他のモードが干渉することもないため、モード混同の問題も回避できます。
加えて、各相互作用ブロックは独立したオブジェクトとしてパラメータ化されているため、異なるモード間の大きな変動に対処するのに十分な表現力をモデルに持たせることができます。各相互作用ブロックは、エージェント間の相互作用をモデル化するためにSelf-Attentionメカニズムを使用し、エージェントとシーン間の相互作用をキャプチャするためにCross-Attentionメカニズムを使用します。これらの2種類の相互作用特徴量は、残差接続によって動的特徴量に追加され、各エージェントとモードの最終的な次期運動関数を得ます。上記のプロセスは次のように説明できます。

並列相互作用モジュールの最終的な構造は、Transformerデコーダーをシリアル構造で並列化したものと見ることができます。しかし、マルチモーダル予測と表現力の向上は、標準的なものと比べて同程度の計算コストで達成されます。本手法の著者がおこなった実験では、シーンレベルでの勝者総取りの損失戦略を併用することで、提案手法が複数のエージェントの行動を一貫して予測できることが確認されました。また、モデル化された2種類の相互作用の不可欠性と、モジュール構造設計の合理性を実証するための研究もおこなわれました。
筆者によるモジュール構造の可視化を以下に示します。

各エージェントの将来の軌道を予測することに加え、MFTはシーンの可能な展開ごとに、またエージェントの予測された軌道ごとに尤度推定を実行します。運動計画タスクにとって理想的な入力は、各シーンモードに対して適切な信頼スコアを持つマルチモーダルなシーン予測です。計画アルゴリズムは、すべての隣接エージェントを同時に考慮することで、将来可能な運動軌道を直接計算することができます。この目的のために、この手法の著者は、さまざまなシーンとその確率を予測するためのヘッドを開発しました。
シーンレベルでの確率を推定するために、シーン内のすべてのエージェントの特徴ベクトルが平均化されます。これにより、シーンレベルの視点を得ることができます。
また、エージェントに特別な注意を払うために、エージェント自身の視点から尤度推定をおこなう必要があります。その結果、各エージェントの予測軌道の信頼度推定値をデコードするために、3つ目のモデルヘッダーが作成されます。Multi-future Transformerのデコーディングプロセスは以下のように定式化されます。
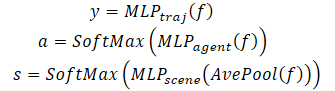
マルチモーダルなシーンをデコードするには、すべての可能なシナリオに対して同じパラメータを持つデコーダを使用することに注意してください。
2.MQL5を使用した実装
Multi-future Transformer法の理論的側面を検討した後は、実践的な部分に話を移しましょう。MQL5でアルゴリズムを実装する方法を考えてみましょう。
上にあるMulti-future Transformerアルゴリズムの説明から、私たちにとっての主な実装上の課題は並列相互作用モジュールであると言えます。ライブラリでは、すでにMulti-Head Self-Attention (CNeuronMLMHAttentionOCL)とCross-Attention (CNeuronMH2AttentionOCL)層を実装しています。しかし、複数の注目ヘッドを使用する場合でも、フォワードパスとバックワードパスの間に、その中のデータフローが混在します。これではMulti-future Transformer法の条件を満たしません。
そこで、新しいニューラル層のクラスを作成することから、このメソッドの実装を始めることにします。
2.1.並列相互作用モジュール
並列相互作用モジュールのアルゴリズムは、CNeuronMLMHAttentionOCLから継承したCNeuronMFTOCLクラスに実装しています。
このクラスは意図的に親として選ばれました。CNeuronMLMHAttentionOCLには、多層Self-Attentionアルゴリズムの実装機能がすでに含まれています。新しいクラスの実装には既存のコードを使用します。しかし、Attentionブロックの層を逐次計算するのではなく、様々なシナリオを予測します。さらに、Multi-future Transformerアルゴリズムが提供するCross-Attention機能を追加します。
新しいクラスの構造体を以下に示します。ご覧のように、主要メソッドの再定義に加えて、Cross-Attentionメカニズムを実装するために必要となる、データ移行のためのデータバッファのコレクションを追加しています。
class CNeuronMFTOCL : public CNeuronMLMHAttentionOCL { protected: //--- CCollection cTranspose; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols); virtual bool MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool MHCAInsideGradients(CBufferFloat *q, CBufferFloat *qg, CBufferFloat *kv, CBufferFloat *kvg, CBufferFloat *score, CBufferFloat *aog); public: CNeuronMFTOCL(void) {}; ~CNeuronMFTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronMFTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
新しいデータバッファのコレクションをstaticとして宣言することで、クラスのコンストラクタとデストラクタを「空」のままにすることができます。Initメソッドでクラスと内部オブジェクトを初期化します。
bool CNeuronMFTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * features, optimization_type, batch)) return false;
パラメータには、必要なアーキテクチャを再現するために必要なすべての情報を受け取ります。メソッド本体では、ニューラル層基本クラスCNeuronBaseOCLの関連メソッドを呼び出します。
直接の親クラスCNeuronMLMHAttentionOCLの初期化メソッドを呼び出していないことに注意してください。その代わりに、ニューラル層の基本クラスCNeuronBaseOCLに目を向けます。これは、CNeuronMFTOCLとCNeuronMLMHAttentionOCLの実装に若干の違いがあるためです。
CNeuronMLMHAttentionOCLの親クラスでは、Attentionブロックのいくつかの層でソースデータを順次処理し、出力ではソースデータと同様の次元の結果を得ました。新しいCNeuronMFTOCL層では、可能性のある展開のために様々なパターンを一貫して生成していきます。したがって、層の結果は、元データのサイズの(予測オプション数の)倍数となります。したがって、結果バッファを増やす必要があります。
さらに、不必要なデータのコピーを避けるために、親クラスでは、層自身と最後の内部層の結果とグラデーションのバッファを置き換えました。新しいクラスを実装する場合、このアプローチは受け入れられません。なぜなら、複数の並列ブロックの結果を1つのバッファに連結しなければならないからです。
初期化メソッドに戻りましょう。ニューラル層ベースクラスの初期化メソッドを正常に実行した後、アーキテクチャーの主要なパラメータを内部クラス変数に保存します。
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(features, 1);
すべてのパラメータを親クラスの変数に保存することに注意してください。ここでは、変数名とその機能との間に若干のずれがあります。iLayers変数は、計画されたオプションの数を格納します。リソースをより効率的に使用するために、私は追加の変数を作らず、変数名と機能の不一致を「無視」することにしました。
次に、ブロックの主要なパラメータを計算します。
//--- MHSA uint num = 3 * iWindowKey * iHeads * iUnits; //Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of QKV tensor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of output tensor uint w0 = (iWindowKey + 1) * iHeads * iWindow; //Size W0 tensor
//--- MHCA uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeads * iUnits; //Size of KV tensor uint q_weights = (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of Q tensor uint kv_weights = 2 * (iUnits + 1) * iWindowKey * iHeads; //Size of weights' matrix of KV tensor uint scores_ca = iUnits * iWindow * iHeads; //Size of Score tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
準備作業を終えたら、並列相互作用ブロックの各シナリオのデータバッファを順次作成するループを編成します。
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- MHSA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
ここでは、入れ子になったループを作成し、フォワードパスとバックワードパスのバッファを作成します。入れ子になったループの本体では、まずMHSAブロックのQuery、Key、Valueの埋め込みを連結したバッファを作成します。また、「Score」行列用のバッファも追加した。
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
Multi-Head Attentionのバッファを追加します。
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
MHSAブロックの出力では、異なるAttentionヘッドの結果を組み合わせるためのバッファを作成します。
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
ここで注意しなければならないのは、MFTアルゴリズムの要件を満たすために、Attentionヘッドの結果は1つの相互作用モード内でのみ組み合わされるということです。
次に、 Cross-Attentionブロック(MHCA)用に同様のバッファを作成します。しかし、ここでは、異なるソースデータが使用されるため、Query埋め込みバッファをKeyとValueから分離します。
//--- MHCA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cTranspose.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores_ca, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
//--- Initialize multi-heads cross attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Attentionブロックのバッファを作成した後、FeedForwardブロックのバッファを作成します。
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
//--- Initialize Feed Forward 2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
個々のブロックの結果と誤差勾配のバッファを作成しました。次に、これらのブロックに対して学習可能な重みの行列を作成する必要があります。同じ順序で作ります。まず、MHSAブロックのQuery、Key、Valueの埋め込みに対する重みを生成します。
//--- MHSA //--- Initilize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
そして、Attentionヘッドを組み合わせるための層を生成します。
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
MHCAブロックの操作を繰り返します。
//--- MHCA //--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; for(uint w = 0; w < q_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize KV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float kv = (float)(1 / sqrt(iUnits + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* kv)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
FeedForwardブロック用の行列を作成します。
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
その後、別の入れ子ループを実装し、重み行列を更新するためのバッファを作成します。モーメントバッファの数は、選択された最適化アルゴリズムに依存することに注意してください。
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- MHSA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- MHCA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
必要なデータバッファの初期化に成功したら、trueの結果とともにメソッドを終了します。
多くのバッファを作成してきたので、混乱しないように、データバッファナビゲーションの表を作成しましょう。
| ID | QKV_Tensors | S_Tensors、 AO_Tensors | FF_Tensors | QKV_Weights | FF_Weights |
|---|---|---|---|---|---|
| 0 | Query、Key、Value MHSA | MHSA | MHSA Out | Query、Key、Value MHSA | MHSA W0 |
| 1 | Query MHCA | MHCA | MHCA Out | Query MHCA | MHCA W0 |
| 2 | Key、Value MHCA | Gradient MHSA | FF1 | Key、Value MHCA | FF1 |
| 3 | Gradient Query、Key、Value MHSA | Gradient MHCA | FF2 | Momentum1 Query、Key、Value MHSA | FF2 |
| 4 | Gradient Query MHCA | Gradient MHSA Out | Momentum1 Query MHCA | Momentum1 MHSA W0 | |
| 5 | Gradient Key, Value MHCA | Gradient MHCA Out | Momentum1 Key, Value MHCA | Momentum1 MHCA W0 | |
| 6 | Gradient FF1 | Momentum2 Query, Key, Value MHSA | Momentum1 FF1 | ||
| 7 | Gradient FF2 | Momentum2 Query MHCA | Momentum1 FF2 | ||
| 8 | Momentum2 Key, Value MHCA | Momentum2 MHSA W0 | |||
| 9 | Momentum2 MHCA W0 | ||||
| 10 | Momentum2 FF1 | ||||
| 11 | Momentum2 FF2 |
CNeuronMFTOCLクラスの初期化の後、フィードフォワードアルゴリズムの構築に移ります。MFTアルゴリズムを実装する際、OpenCLプログラム側では新しいカーネルを作成しませんでした。しかし、先に作成したカーネルを呼び出すには、メインプログラムの側でいくつかのメソッドを作成しなければなりませんでした。特にCNeuronMFTOCLクラスでは、行列の転置メソッドを作成しました。このメソッドのアルゴリズムは、転置層のフィードフォワードパスに似ています。ただし、細部には違いがあります。パラメータにおいて、新しいメソッドは、2つのデータバッファ(ソースデータと結果)へのポインタと、元の行列のサイズを受け取ります。
bool CNeuronMFTOCL::Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols) { if(!in || !out) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {rows, cols}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, in.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, out.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("%s %d Error of execution kernel Transpose: %d -> %s", __FUNCTION__, __LINE__, GetLastError(), error); return false; } //--- return true; }
したがって、メソッド本体では、受け取ったデータバッファへのポインタを確認し、タスク空間次元のパラメータから値を示します。カーネル呼び出しのアルゴリズム自体に変更はありませんでした。
MHCAフィードフォワードメソッドの場合も状況は似ています。メソッドのパラメータで、データバッファへのポインタを受け取ります。CNeuronMH2AttentionOCL::attentionOutメソッドはパラメータを持たず、その機能で内部オブジェクトを使用していました。
bool CNeuronMFTOCL::MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out) { if(!q || !kv || !score || !out) return false;
メソッドの本体では、タスク空間の次元を作成します。
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindow, iHeads}; uint local_work_size[3] = {1, iWindow, 1};
パラメータをカーネルに渡します。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, q.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, kv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, score.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, out.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
キューに追加します。
if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
MFTフィードフォワードアルゴリズムは、CNeuronMFTOCL::feedForwardメソッドに実装されています。他のニューラル層の同様のメソッドと同様に、このメソッドもパラメータで前のニューラル層へのポインタを受け取ります。メソッド本体では、受け取ったポインタの妥当性を即座に確認します。
bool CNeuronMFTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
次に、エージェント間の相互作用のための様々なモードの逐次計算のループを整理します。
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- MHSA //--- Calculate Queries, Keys, Values CBufferFloat *inputs = NeuronOCL.getOutput(); CBufferFloat *qkv = QKV_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
ここではまず、MHSAブロックのQuery、Key、Valueエンティティを取得します。次に、Attention係数の行列を定義します。
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 4); if(IsStopped() || !AttentionScore(qkv, temp, false)) return false;
Multi-Head Self-Attentionの結果を生成します。
//--- Multi-heads attention calculation CBufferFloat *out = AO_Tensors.At(i * 4); if(IsStopped() || !AttentionOut(qkv, temp, out)) return false;
Multi-Head Attentionの結果を元データのサイズに縮小します。Attentionヘッドは、エージェントの相互作用の1つの変形の枠組みの中で組み合わされていることを思い出してください。
//--- Attention out calculation temp = FF_Tensors.At(i * 8); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
得られたテンソルを元のデータと合計し、演算結果を正規化します。
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
次にCross-Attentionブロックです。ここではまず、Queryエンティティを定義します。
//--- MHCA inputs = temp; CBufferFloat *q = QKV_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
次に、元のデータを転置し、Keyと Valueのエンティティを計算します。
CBufferFloat *tr = cTranspose.At(i * 2); if(IsStopped() || !Transpose(inputs, tr, iUnits, iWindow)) return false;
CBufferFloat *kv = QKV_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), tr, kv, iUnits, 2 * iWindowKey * iHeads, None)) return false;
Multi-Head Cross-Attentionの結果を見極めます。
//--- Multi-heads cross attention calculation temp = S_Tensors.At(i * 4 + 1); out = AO_Tensors.At(i * 4 + 1); if(IsStopped() || !MHCA(q, kv, temp, out)) return false;
得られた結果は元データのサイズに圧縮されます。
//--- Cross Attention out calculation temp = FF_Tensors.At(i * 8 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
これをMHSAブロックの結果に加え、データを正規化します。
//--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
次に、FeedForwardブロックを介してデータの伝播を整理します。
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 8 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 8 + 3); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), temp, out, 4 * iWindow, iWindow, activation)) return false;
FeedForwardのブロック演算結果は、MHCAの結果に追加されます。受信されたデータは正規化され、分析された相互作用モードに対応するオフセットを伴って結果バッファに書き込まれます。
//--- Sum and normalize out if(IsStopped() || !SumAndNormilize(out, inputs, Output, iWindow, true, 0, 0, i * inputs.Total())) return false; } //--- return true; }
次に、シーン上のエージェント間の相互作用の次のモードを分析するために、次の反復ループに移ります。
エージェント間の相互作用に関するすべてのモードの分析に成功した後、結果をtrueとしてメソッドを完了します。
フィードフォワードパスの間、シーン上のエージェントの相互作用のモードを分析し、さらなるイベントの可能なバリエーションを予測するという基本的な機能を実行します。そのため、バックプロパゲーションの手法を導入しない限り、モデルの訓練は不可能です。バックプロパゲーションパスの間に、より良い結果を得るためにモデルパラメータが最適化されます。したがって、フィードフォワード法を実装した後、バックプロパゲーションアルゴリズムの構築に移ります。
フィードフォワードパスと同様に、バックプロパゲーションパスを実装するには、追加のメソッドMHCAInsideGradientsを作成する必要があります。このアルゴリズムは、CNeuronMH2AttentionOCL::AttentionInsideGradientsのアルゴリズムとほぼ完全に似ています。唯一の違いは、MHCAInsideGradientsは内部クラスオブジェクトではなく、メソッドパラメータで受け取ったバッファを扱うことです。この記事の前半ではそのような改造の例をすでに見てきたので、今はメソッドについての詳細な考察には立ち入りません。すべてのコードは添付ファイルにあります。
バックプロパゲーションのアルゴリズムはcalcInputGradientsメソッドに実装されています。パラメータで、メソッドは前のニューラル層のオブジェクトへのポインタを受け取ります。
bool CNeuronMFTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
メソッド本体では、受け取ったポインタの有効性を即座に確認します。その後、バッファへのポインタをローカル変数に保存します。すべての並列相互作用ブロックはここで操作されます。
CBufferFloat *out_grad = Gradient; CBufferFloat *inp = prevLayer.getOutput(); CBufferFloat *grad = prevLayer.getGradient();
準備作業を終えたら、並列相互作用の別々のブロックを通して誤差勾配を伝播させるループを組織します。
for(int i = 0; (i < (int)iLayers && !IsStopped()); i++) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), Gradient, FF_Tensors.At(i * 8 + 2), FF_Tensors.At(i * 8 + 6), 4 * iWindow, iWindow, None, i * inp.Total())) return false;
ここではまず、FeedForwardブロックを通して誤差勾配を伝播させます。
CBufferFloat *temp = FF_Tensors.At(i * 8 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(i * 8 + 6), FF_Tensors.At(i * 8 + 1), temp, iWindow, 4 * iWindow, LReLU)) return false;
フィードフォワードパスでは、FeedForwardの演算結果がMHCAブロックの出力に加えられました。同様に、誤差勾配を逆方向に伝播させます。ただし、今回は正規化はおこないません。
//--- Sum gradient if(IsStopped() || !SumAndNormilize(Gradient, temp, temp, iWindow, false, i * inp.Total(), 0, 0)) return false; out_grad = temp;
次に、Cross-Attentionモジュールを通して誤差勾配を伝播させる必要があります。ここではまず、Attention-Head全体に誤差勾配を伝播させます。
//--- MHCA //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out_grad, AO_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3), iWindowKey * iHeads, iWindow, None)) return false;
そして、誤差の勾配を対応するエンティティに伝播させます。
if(IsStopped() || !MHCAInsideGradients(QKV_Tensors.At(i * 6 + 1), QKV_Tensors.At(i * 6 + 4), QKV_Tensors.At(i * 6 + 2), QKV_Tensors.At(i * 6 + 5), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3))) return false;
ここで、MHCAブロックのKeyとValueから誤差勾配を転置する必要があります。
CBufferFloat *tr = cTranspose.At(i * 2 + 1); if(IsStopped() || !Transpose(QKV_Tensors.At(i * 6 + 5), tr, iWindow, iUnits)) return false;
まず、得られた結果を総括します。
//--- Sum temp = FF_Tensors.At(i * 8 + 4); if(IsStopped() || !SumAndNormilize(QKV_Tensors.At(i * 6 + 4), tr, temp, iWindow, false)) return false;
次に、MHCAブロックの出力における誤差勾配を加えます。
if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
その後、MHSAブロックを通して誤差勾配を伝播させる必要があります。Cross-Attentionと同様に、まずAttention-Headに誤差勾配を分散させます。
//--- MHSA //--- Split gradient to multi-heads out_grad = temp; if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out_grad, AO_Tensors.At(i * 4), AO_Tensors.At(i * 4 + 2), iWindowKey * iHeads, iWindow, None)) return false;
誤差勾配を対応するエンティティに伝播します。
//--- Passing gradient to query, key and value if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 6), QKV_Tensors.At(i * 6 + 3), S_Tensors.At(i * 4), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 1))) return false;
ソースデータレベルまで伝播します。
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(i * 6 + 3), inp, tr, iWindow, 3 * iWindowKey * iHeads, None)) return false;
ここで、MHSAブロックの入力と出力で誤差勾配を加算し、その結果を前の層の勾配バッファに書き込む必要があります。ただ、1点だけ。すべての並列相互作用ブロックからの誤差勾配の合計を、前の層の勾配バッファに書き込む必要があります。そこで、まず並列相互作用ブロックの識別子を確認します。最初のブロックでは、単純に2つのスレッドからの勾配の合計を、前の層の誤差の勾配バッファに書き込みます。並列相互作用の残りのブロックについては、結果の誤差勾配を前の層のバッファのデータに加えます。
//--- Sum gradients if(i > 0) { if(IsStopped() || !SumAndNormilize(grad, tr, grad, iWindow, false)) return false; if(IsStopped() || !SumAndNormilize(out_grad, grad, grad, iWindow, false)) return false; } else if(IsStopped() || !SumAndNormilize(out_grad, tr, grad, iWindow, false)) return false; } //--- return true; }
そして、ループの次の反復に移り、誤差勾配を次の並列相互作用のブロックに渡します。
ループのすべての反復が成功したら、メソッドをtrueで終了します。
CNeuronMFTOCLクラスでは、フィードフォワードパスと誤差勾配のバックプロパゲーションを整理しました。クラスの主要機能の実装を完成させるには、計量パラメータを更新するメソッドを追加する必要があります。このメソッドのアルゴリズムは非常にシンプルです。ループの中で、親クラスのメソッド ConvolutionUpdateWeightsを呼び出します。ここでは、別のバッファのパラメータが更新されます。操作に必要なデータバッファは、メソッドのパラメータで渡されます。
bool CNeuronMFTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(l * 6 + 3), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 3) : QKV_Weights.At(l * 9 + 3)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 6)), iWindow, 3 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 1), QKV_Tensors.At(l * 6 + 4), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 4) : QKV_Weights.At(l * 9 + 4)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 7)), iWindow, iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 2), QKV_Tensors.At(l * 6 + 5), cTranspose.At(l * 2), (optimization == SGD ? QKV_Weights.At(l * 6 + 5) : QKV_Weights.At(l * 9 + 5)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 8)), iUnits, 2 * iWindowKey * iHeads)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12)), FF_Tensors.At(l * 8 + 4), AO_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 8 + 4) : FF_Weights.At(l * 12 + 4)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 8)), iWindowKey * iHeads, iWindow)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 1), FF_Tensors.At(l * 8 + 5), AO_Tensors.At(l * 4 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 5) : FF_Weights.At(l * 12 + 5)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 9)), iWindowKey * iHeads, iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(l * 8 + 6), FF_Tensors.At(l * 8 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 6) : FF_Weights.At(l * 12 + 6)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 10)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 3), FF_Tensors.At(l * 8 + 7), FF_Tensors.At(l * 8 + 2), (optimization == SGD ? FF_Weights.At(l * 8 + 7) : FF_Weights.At(l * 12 + 7)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 11)), 4 * iWindow, iWindow)) return false; } //--- return true; }
以上で、CNeuronMFTOCLクラスにおけるMulti-future Transformerアルゴリズムの主要機能の実装を終了します。添付のコードを使って、補助メソッドの実装に慣れてください。また、記事執筆時に使用したすべてのプログラムの完全なコードも掲載されています。次に、モデルの構築と訓練のためのエキスパートアドバイザーの実装に進みます。
2.2 モデルアーキテクチャ
Multi-future Transformer法の著者によって提案された並列相互作用ブロックアルゴリズムのクラスを構築しました。ただし、これは私たちのモデルの1つの層に過ぎません。次に、作成したモデルの完全なアーキテクチャを説明する必要があります。モデルには生のソースデータが供給されます。モデルの作業の結果として、エージェントの最適なアクションのベクトルを得る必要があります。これを実装すると、金融市場で活動する際に利益をもたらすことができます。
モデルを構築する際、このメソッドの著者が提案したアーキテクチャから少し外れたと言わなければなりません。これにはいくつかの理由があります。
まず、Multi-future Transformer法は、自律走行車と環境との相互作用を予測するために提案されましたが、私たちは、このモデルを金融市場に使用する予定です。どちらの作業にもそれぞれの特殊性があり、それがモデル作りに影響を与えています。
次に、前回の記事では、モデルのパフォーマンスを最適化することに多くの注意を払いました。そこで得られた経験を生かしたいのです。そよって、前回の記事のモデルアーキテクチャに貢献してもらいました。軌道計画モデルに変更が加えられました。
将来の軌道を予測するモデルのアーキテクチャは、ファイル「...\Experts\MFT\Trajectory.mqh」のCreateTrajNetDescriptionsメソッドに記述されています。このメソッドはパラメータに3つのモデルを作成するための動的配列へのポインタを受け取ります。
- ステータスエンコーダー
- エンドポイントデコーダー
- シーンの確率
前回の記事では、値動きの全軌跡を予測するのではなく、主な値動きの極値を予測することに集中することにしました。
- 終値
- 高値
- 安値
したがって、ここでの作業では、値動きのダイナミクスの状態をシーンのバリエーションとして考えました。個々のエージェントの最終的な軌道の確率は分析しません。
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
メソッド本体では、パラメータで受け取ったオブジェクトポインタの妥当性を確認し、必要であれば新しいポインタを作成します。
まず、エンコーダーのアーキテクチャーを説明しました。エンコーダーは、環境の現在の状態を表す生の初期データを入力します。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
通常通り、受信したデータはバッチ正規化層で前処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
その後、現在の状態の埋め込みを作成し、モデルの内部スタックに保存します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
各埋め込み要素は、環境シーン内の別々のエージェントに関連しています。MFTメソッドに従い、ソースデータの位置符号化を実施します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
元のMFTメソッドのアーキテクチャには、さらにMHSAブロックのスタックがあります。私が提案したアーキテクチャーからの最初の逸脱はここです。前回の記事を参考に、2つのCrystal-GCN層をバッチ正規化層で区切ることにしたということです。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
続いてMHSAの層が続きます。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次に、この手法の著者は、各エージェントのダイナミクスを平均化することを提案します。ここでは、並列相互作用ブロックで、文脈マップデータとデータのクロス分析をおこないます。私たちの場合、今後起こりうる値動きのマップはありません。その代わりに、分析した特徴の軌跡の文脈分析を用います。
このアーキテクチャの次に来るのは、上で作成した並列コンピューティングブロックです。このブロックでは、4つのAttentionヘッドを持つSelf-AttentionブロックとCross-Attentionブロックを使用します。この手法の著者は、並列の相互作用ブロックに1つのAttention-Headだけを使用しました。エージェントの相互作用モードの数はNForecast定数によって決定されます。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
以下の建築上のポイントに注目してください。私たちの実装では、CNeuronMFTOCLクラスの結果を3次元テンソル{配列要素数、相互作用モード、エージェント数}として表現できるように構築しました。このデータ形式はその後の処理にはあまり便利ではありません。個々の相互作用モードを扱う必要があるためです。相互作用モードがテンソル次元の内側にあることが、この作業を複雑にしています。そこで、エージェントの相互作用モードをテンソルの1次元目に移動させるために、データをさらに転置します。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
したがって、エンコーダーの出力には、{エージェントの相互作用モード、エージェントの数、エージェントのダイナミクスを記述するベクトルの長さ}というテンソルを受け取ります。
エンコーダーの次に、エンドポイントデコーダーモデルを作成します。エンコーダーの結果のテンソルをモデルに入力します。
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
MTF手法では、すべてのエージェント相互作用モードに対して同じパラメータを持つデコーダーを使用する必要があることを思い出してください。私たちは、1つのエージェント相互作用モードのテンソルに等しいウィンドウサイズとステップを持つ畳み込み層を使用して、同様のアプローチを実装することができます。この段階を2つに分けます。まず、個々のエージェントのダイナミクスを崩壊させます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
そして、分析された相互作用モードごとにシーンオプションが用意されています。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
個々の予測シーンの確率を評価するモデルはほとんど変わっていません。デコーダーの場合と同様に、エンコーダーの結果がモデルに入力されます。
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false;
これらは予測シーンオプションと組み合わされます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; }
データは2つの全結合層で分析されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
そしてSoftMax関数によって正規化されます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Actorモデルのアーキテクチャはほとんど同じです。現在の状態のエンコーダーの結果を処理するという点では、ちょっとした修正を加えるだけでした。
また、モデルアーキテクチャに加えられた変更は、環境との相互作用やモデル訓練のアルゴリズムにはほとんど影響を及ぼさなかったことにも注目すべきです。したがって、すべてのEAは、以前の記事から最小限の編集を加えてコピーされています。したがって、この記事の枠組みでは、彼らのアルゴリズムの説明には触れないことにします。いずれにせよ、この記事で使用したすべてのプログラムの完全なコードは添付ファイルにあります。
3.テスト
MQL5ツールを使用してMulti-future Transformerアルゴリズムを実装し、提案されたアプローチを使用して、今後の値動きに関するいくつかの選択肢を予測するモデルを訓練し、それらの実装の確率を評価することを可能にするモデルのアーキテクチャについて説明しました。それではいよいよ、MetaTrader 5のストラテジーテスターで、実際のデータを使って作業結果を確認してみましょう。
いつものように、モデルはEURUSD H1の履歴データを使用して訓練およびテストされています。モデルの訓練には、2023年の最初の7ヶ月間のデータが使用されます。訓練済みモデルをテストするために、2023年8月からの履歴データを使用します。
モデルを訓練するために、前回の記事の訓練データセットと訓練EAを使用しました。したがって、得られた結果の変化は、主にモデルアーキテクチャの変更によるものであることがわかります。もちろん、ランダムなパラメータを持つモデルの初期化によってもたらされるランダム性の要因を排除することはできません。さらに、訓練過程における経験再生バッファからのデータのサンプリングもランダムですが、訓練エポックが増えるにつれて、この要因の影響は最小になります。
前回の記事では、このモデルはかなり安定した結果を示しましたが、取引回数は非常に少なくなっています。新モデルでは、プラスの結果を維持しながら取引回数が増加しています。
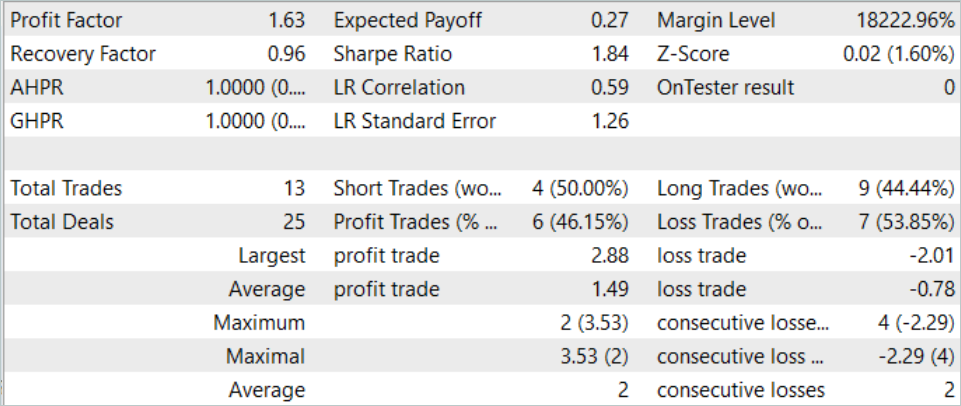
2023年8月中、このモデルは13回の取引をおこない、うち6回は利益で決済されました。テスト期間中のプロフィットファクターは1.63でした。
結論
この記事では、今後の値動きを予測するもう1つの手法であるMulti-future Transformerを紹介しました。この手法の主な特徴の1つは、エージェント同士の相互作用や環境シーンとの相互作用に重点を置きながら、エージェントの移動に関するマルチモーダルな予測を構築することです。これにより、今後の動きをより正確に予測することができます。
実用的な部分では、MQL5を用いて提案されたアプローチを実装しました。MetaTrader 5のストラテジーテスターで実際のデータを使ってモデルを訓練し、テストした。得られた結果から、提案されたアプローチの有効性が確認されました。エージェントの相互作用の分析を維持しながら、個々のモダリティの予測を分離することで、得られた予測の多様性に注目することができます。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルをテストするEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14226
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索