
Neuronale Netze leicht gemacht (Teil 84): Umkehrbare Normalisierung (RevIN)

Einführung
Im vorigen Artikel haben wir die Methode Conformer vorgestellt, die ursprünglich für die Wettervorhersage entwickelt wurde. Dies ist eine sehr interessante Methode. Beim Testen des trainierten Modells erzielten wir ein ziemlich gutes Ergebnis. Aber haben wir alles richtig gemacht? Ist es möglich, ein besseres Ergebnis zu erzielen? Schauen wir uns den Lernprozess an. Es ist leicht zu erkennen, dass das Modell zur Vorhersage der nächstwahrscheinlichen Indikatoren der Zeitreihe eindeutig nicht für den vorgesehenen Zweck verwendet wird. Indem wir das Modell mit Eingabedaten aus einer Zeitreihe fütterten, trainierten wir es, indem wir den Fehlergradienten von Modellen unter Verwendung der Vorhersageergebnisse fortpflanzten. Wir haben mit den Ergebnissen der Kritiker begonnen.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Dann die Ergebnisse des Akteurs.
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Und wieder einmal Daten aus dem Akteur, bei der Anpassung der Politik für die Rentabilität der Operationen.
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), -1, -1, false) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Daran ist natürlich nichts auszusetzen. Dies ist eine weit verbreitete Praxis bei der Ausbildung verschiedener Modelle. In diesem Fall konzentrieren wir uns beim Training des Encoder-Modells des anfänglichen Umgebungszustands jedoch nicht auf die Vorhersage nachfolgender Zustände, sondern auf die Identifizierung einzelner Merkmale, die es uns ermöglichen, die Funktionsweise nachfolgender Modelle zu optimieren.
Unsere Hauptaufgabe besteht natürlich darin, die optimale Politik des Akteurs zu finden. Auf den ersten Blick spricht also nichts dagegen, das Encoder-Modell an die Ziele des Akteurs anzupassen. Aber in diesem Fall löst der Encoder ein etwas anderes Problem. In der Praxis wird es zu einem Baustein für nachfolgende Modelle. Seine Architektur ist möglicherweise nicht optimal für die Lösung der erforderlichen Aufgaben.
Beim Training des Encoders mit den Fehlergradienten von 3 verschiedenen Aufgaben kann es außerdem zu dem Problem kommen, dass die Gradienten der einzelnen Aufgaben in unterschiedliche Richtungen verlaufen. In diesem Fall sucht das Modell nach der „goldenen Mitte“, die alle gestellten Aufgaben am besten erfüllt. Es ist durchaus möglich, dass eine solche Lösung weit vom Optimum entfernt ist.
Ich denke, es ist offensichtlich, dass die strukturierte Logik der Verwendung von Modellen auch im Lernprozess umgesetzt werden sollte. In einem solchen Paradigma müssen wir den Encoder so trainieren, dass er spätere Zustände der Umgebung vorhersagen kann. Die Ansätze des Conformers werden genau im Encoder verwendet. Dann trainieren wir die Politik des Akteurs unter Berücksichtigung der vorhergesagten Zustände der Umgebung.
Das ist die Theorie, die ziemlich eindeutig ist. In der praktischen Umsetzung sind wir jedoch mit einer erheblichen Lücke in der Verteilung der einzelnen Merkmale konfrontiert, die den Zustand der Umgebung beschreiben. Wenn wir solche „rohen“ Daten, die den Zustand der Umgebung beschreiben, am Eingang des Modells erhalten, normalisieren wir sie, um sie in eine vergleichbare Form zu bringen. Aber wie erhalten wir unterschiedliche Werte für die Modellausgabe?
Auf ein ähnliches Problem sind wir bereits beim Training verschiedener Autoencoder-Modelle gestoßen. In diesen Fällen haben wir eine Lösung gefunden, indem wir die Originaldaten nach der Normalisierung als Ziele verwendet haben. In diesem Fall benötigen wir jedoch Daten, die spätere Zustände der Umgebung beschreiben, die sich von den Eingabedaten unterscheiden. Eine der Methoden zur Lösung dieses Problems wurde in dem Artikel „Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift“ vorgeschlagen.
Die Autoren des Papiers schlagen eine einfache, aber effektive Methode zur Normalisierung und Denormalisierung vor: die Umkehrbare sofortige Normalisierung (Reversible Instantaneous Normalizationm RevIN). Der Algorithmus normalisiert zunächst die Eingabesequenzen und denormalisiert dann die Ausgabesequenzen des Modells, um Probleme der Zeitreihenprognose im Zusammenhang mit Verteilungsverschiebungen zu lösen. RevIN ist symmetrisch aufgebaut, um die ursprüngliche Verteilungsinformation an die Modellausgabe zurückzugeben, indem die Ausgabe in der Denormalisierungsschicht in einem Umfang skaliert und verschoben wird, der der Verschiebung und Skalierung der Eingabedaten in der Normalisierungsschicht entspricht.
RevIN - ist eine flexible, trainierbare Schicht, die auf beliebig gewählte Schichten angewandt werden kann. Sie unterdrückt effektiv nicht-stationäre Informationen (Mittelwert und Varianz einer Instanz) in einer Schicht und stellt sie in einer anderen Schicht mit nahezu symmetrischer Position wieder her, z. B. in Eingabe- und Ausgabeschichten.
1. Der Algorithmus von RevIN
Um sich mit dem Algorithmus von RevIN vertraut zu machen, betrachten wir das Problem der multivariaten Vorhersage von Zeitreihen in diskreter Zeit für eine Menge von Eingabedaten X = {xi}i=[1..N] und das entsprechende Ziel Y = {yi}i=[1..N], wobei N die Anzahl der Elemente in der Folge bezeichnet.
K, Tx undTy bezeichnendie Anzahl der Variablen, die Länge der Eingabesequenz bzw. die Länge der Modellvorhersage. Angesichts der Eingangssequenz Xi∈ RK*Tx besteht unser Ziel darin, das Problem der Zeitreihenprognose zu lösen, d. h. die nachfolgenden Werte Yi∈ RK*Ty vorherzusagen. Bei RevIN können die Länge der Eingangssequenz Tx und die Länge der Vorhersage Ty unterschiedlich sein, da die Beobachtungen entlang der Zeitdimension normalisiert und denormalisiert werden. Die vorgeschlagene Methode, RevIN, besteht aus symmetrisch strukturierten Normalisierungs- und Denormalisierungsschichten. Zunächst normalisieren wir die Eingabe Xi anhand ihres Mittelwerts und ihrer Standardabweichung, was allgemein als sofortige Normalisierung anerkannt ist. Der Mittelwert und die Standardabweichung werden für jede Eingabeinstanz Xi wie folgt berechnet:
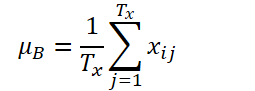
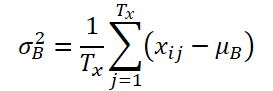

Normalisierte Sequenzen können einen konsistenteren Mittelwert und eine konsistentere Standardabweichung aufweisen, wobei nicht-stationäre Informationen reduziert werden. Infolgedessen ermöglicht die Normalisierungsschicht dem Modell eine genaue Vorhersage der lokalen Dynamik innerhalb der Sequenz, während es Eingaben mit konsistenten Verteilungen in Bezug auf Mittelwert und Varianz erhält.
Das Modell erhält transformierte Daten als Eingabe und sagt zukünftige Werte voraus. Die Eingabedaten haben jedoch eine andere Statistik als die ursprüngliche Verteilung, und wenn man nur die normalisierte Eingabe betrachtet, ist es schwierig, die ursprüngliche Verteilung der Eingabedaten zu erfassen. Um dem Modell diese Aufgabe zu erleichtern, geben wir die aus den Eingabedaten entfernten nicht-stationären Merkmale explizit an die Modellausgabe zurück, indem wir die Normalisierung an einer symmetrischen Stelle, der Ausgabeschicht, umkehren. Der Denormalisierungsschritt kann die Modellausgabe auf den ursprünglichen Zeitreihenwert zurückführen.. Dementsprechend denormalisieren wir die Modellausgabe durch Anwendung der umgekehrten Normalisierungsoperation:

Für die Skalierung und die Verschiebung werden dieselben Statistiken wie bei der Normalisierung verwendet. Nun ist ŷi die endgültige Vorhersage des Modells.
Einfach zu praktisch symmetrischen Positionen im Netzwerk hinzugefügt, kann RevIN effektiv die Verteilungsdivergenz in Zeitreihendaten als trainierbare Normalisierungsschicht reduzieren, die allgemein auf beliebige tiefe neuronale Netzwerke anwendbar ist. Bei der vorgeschlagenen Methode handelt es sich um eine flexible, lernfähige Schicht, die auf beliebig ausgewählte Schichten, sogar auf mehrere Schichten, angewendet werden kann. Die Autoren der Methode bestätigen ihre Wirksamkeit als flexible Schicht, indem sie sie in verschiedenen Modellen zu Zwischenschichten hinzufügen. RevIN ist jedoch am effektivsten, wenn es auf praktisch symmetrische Schichten der Encoder-Decoder-Struktur angewendet wird. In einem typischen Zeitreihenprognosemodell ist die Grenze zwischen Encoder und Decoder oft unklar. Daher wenden die Autoren der Methode RevIN auf die Eingabe- und Ausgabeschichten des Modells an, da diese als eine Encoder-Decoder-Struktur betrachtet werden können, die auf der Grundlage der Eingabedaten nachfolgende Werte erzeugt.
Die originale Visualisierung der RevIN-Methode wird im Folgenden vorgestellt.

2. Implementierung in MQL5
Wir haben uns mit den theoretischen Aspekten der Methode befasst. Nun können wir uns der praktischen Umsetzung der vorgeschlagenen Ansätze mit MQL5 zuwenden.
Aus der oben dargestellten theoretischen Beschreibung der Methode geht hervor, dass die von den Autoren der Methode vorgeschlagene Normalisierung der Ausgangsdaten den Algorithmus der CNeuronBatchNormOCL Batch-Normalisierungsschicht, die wir zuvor implementiert haben. Daher können wir die vorhandene Klasse zur Normalisierung der Daten verwenden. Um jedoch die Daten zu denormalisieren, müssen wir eine neue neuronale Schicht, CNeuronRevINDenormOCL, erstellen.
2.1 Erstellen einer neuen Denormalisierungsschicht
Natürlich werden bei der Denormalisierung der Daten die bei der Normalisierung der Daten verwendeten Objekte verwendet. Aus diesem Grund ist die neue Schicht CNeuronRevINDenormOCL von der Normalisierungsschicht CNeuronBatchNormOCL abgeleitet.
class CNeuronRevINDenormOCL : public CNeuronBatchNormOCL { protected: int iBatchNormLayer; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronRevINDenormOCL(void) : iBatchNormLayer(-1) {}; ~CNeuronRevINDenormOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, int NormLayer, CNeuronBatchNormOCL *normLayer); virtual int GetNormLayer(void) { return iBatchNormLayer; } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronRevInDenormOCL; } virtual CLayerDescription* GetLayerInfo(void); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) { return true; } };
Nach dem Algorithmus der RevIN-Methode sollten wir Parameter verwenden, die in der Normalisierungsphase für die Denormalisierung trainiert wurden. Die Logik dabei ist, dass wir in der Normalisierungsphase die Verteilung der Eingabedaten untersuchen. Danach bringen wir die Eingabedaten in eine vergleichbare Form und entfernen die „Lücken“. Dann arbeitet das Modell mit normalisierten Daten. Am Ausgang des Modells werden die Daten denormalisiert und die Verteilungsparameter der Eingabedaten zurückgegeben. Daher erwarten wir, dass die Modellausgabe vorhergesagte Daten in der „natürlichen“ Verteilung der Eingabedaten enthält.
Beim Schritt der Denormalisierung werden die Modellparameter natürlich nicht aktualisiert. Deshalb überschreiben wir in der Klassenstruktur die Methoden zur Aktualisierung der Modellparameter mit „leeren Stummeln“. Dennoch müssen wir den Vorwärtsdurchgangs-Algorithmus und die Fehlergradientenverteilung implementieren. Aber das Wichtigste zuerst.
In dieser Klasse deklarieren wir keine zusätzlichen internen Objekte. Daher bleiben der Konstruktor und der Destruktor der Klasse leer. Wir erstellen jedoch eine Variable, um die Kennung der Normalisierungsschicht im Modell zu speichern: iBatchNormLayer. Hier erstellen wir auch eine öffentliche Methode, um den Wert dieser Variablen zu erhalten: GetNormLayer(void).
Das Objekt unserer neuen Klasse wird in der Methode CNeuronRevINDenormOCL::Init initialisiert. In den Parametern erhält die Methode alle notwendigen Informationen für eine erfolgreiche Initialisierung der internen Objekte und Variablen. Es sollte hier erwähnt werden, dass es einen sehr bedeutenden Unterschied zu ähnlichen Methoden der zuvor betrachteten neuronalen Schichten gibt. In den Parametern der Methode wird zusätzlich zu den Konstanten ein Zeiger auf das Objekt der Batch-Normalisierungsschicht CNeuronBatchNormOCL übergeben.
bool CNeuronRevINDenormOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, int NormLayer, CNeuronBatchNormOCL *normLayer) { if(NormLayer > 0) { if(!normLayer) return false; if(normLayer.Type() != defNeuronBatchNormOCL) return false; if(BatchOptions == normLayer.BatchOptions) BatchOptions = NULL; if(!CNeuronBatchNormOCL::Init(numOutputs, myIndex, open_cl, numNeurons, normLayer.iBatchSize, normLayer.Optimization())) return false; if(!!BatchOptions) delete BatchOptions; BatchOptions = normLayer.BatchOptions; }
Ein weiterer grundlegender Unterschied liegt im Aufbau der Methode. Hier erstellen wir einen Verzweigungsalgorithmus in Abhängigkeit von der empfangenen Kennung der Stapelnormalisierungsschicht. Wenn er größer als 0 ist, wird der empfangene Zeiger auf die Stapelnormalisierungsschicht überprüft. Wir prüfen auch den Typ des empfangenen Objekts. Danach rufen wir die gleiche Methode der übergeordneten Klasse auf. Erst wenn alle angegebenen Kontrollpunkte erfolgreich durchlaufen wurden, wird der Optimierungsparameterpuffer ersetzt.
Bitte beachten Sie, dass wir keine Daten kopieren. Stattdessen ändern wir den Zeiger auf das Pufferobjekt vollständig. Daher werden wir während des Modelltrainings immer mit relevanten Normalisierungsparametern arbeiten.
Der zweite Zweig des Algorithmus dient der Initialisierung eines leeren Klassenobjekts während des Ladevorgangs eines zuvor gespeicherten Modells. Hier rufen wir einfach dieselbe Methode der übergeordneten Klasse mit minimalen Parametern auf
else if(!CNeuronBatchNormOCL::Init(numOutputs, myIndex, open_cl, numNeurons, 0, ADAM)) return false;
Anschließend speichern wir unabhängig vom gewählten Weg die erhaltene Kennung der Batch-Normalisierungsschicht und schließen die Methode ab.
iBatchNormLayer = NormLayer; //--- return true; }
2.2 Organisation des Vorlaufs
Wir beginnen die Implementierung des Vorwärtsdurchgangs-Algorithmus, indem wir den RevInFeedForward-Kernel auf der Programmseite von OpenCL erstellen. Ähnlich wie bei der Implementierung des Algorithmus für die Batch-Normalisierungsschicht werden wir diesen Kernel in einem eindimensionalen Aufgabenraum starten.
In den Kernel-Parametern werden wir Zeiger auf 3 Datenpuffer übergeben: Quelldaten, Normalisierungsparameter und Ergebnisse. Außerdem werden 2 Konstanten übergeben: die Größe des Puffers mit Normalisierungs-Batch-Parametern und die Art der Parameteroptimierung.
__kernel void RevInFeedForward(__global float *inputs, __global float *options, __global float *output, int options_size, int optimization) { int n = get_global_id(0);
Ich möchte Sie daran erinnern, dass die Größe des Puffers für die Normalisierungsparameter vom gewählten Algorithmus für die Parameteroptimierung abhängt. Dieser Puffer hat die folgende Struktur.

Im Kernelkörper identifizieren wir den Thread im Taskraum. Wir bestimmen auch die Verschiebung in den Puffern bis zu den analysierten Daten. In den Quell- und Ergebnispuffern ist der Offset gleich dem Thread-Identifikator. Die Verschiebung im Optimierungsparameterpuffer wird entsprechend der vorgegebenen Pufferstruktur und der angegebenen Parameteroptimierungsmethode bestimmt.
int shift = (n * optimization == 0 ? 7 : 9) % options_size;
Darüber hinaus müssen wir hier berücksichtigen, dass die Anzahl der analysierten Umgebungszustände von der Tiefe unserer Prognose abweichen kann. In diesem Fall sollten wir die Struktur der analysierten und vorhergesagten Zustände der Umgebung beibehalten. Mit anderen Worten, die Anzahl und Reihenfolge der analysierten Parameter einer Umgebungszustandsbeschreibung bleiben bei der Vorhersage der nachfolgenden Zustände vollständig erhalten. Um die Verschiebung im Puffer für die Normalisierungsparameter zu bestimmen, nehmen wir also den Rest, der sich ergibt, wenn wir die auf der Grundlage des analysierten Threads und der Pufferstruktur berechnete Verschiebung durch die Größe des Puffers für die Normalisierungsparameter teilen.
Der nächste Schritt besteht darin, Daten aus globalen Puffern in lokale Variablen zu extrahieren.
float mean = options[shift]; float variance = options[shift + 1]; float k = options[shift + 3];
Wir berechnen den denormalisierten Wert des vorhergesagten Parameters.
float res = 0; if(k != 0) res = sqrt(variance) * (inputs[n] - options[shift + 4]) / k + mean; if(isnan(res)) res = 0;
Das Ergebnis der Operationen wird in das entsprechende Element des Ergebnispuffers geschrieben.
output[n] = res; }
Nach der Implementierung des Daten-Denormalisierungsalgorithmus auf der OpenCL-Programmseite müssen wir den erstellten Kernel-Aufruf im Hauptprogramm implementieren. Dazu müssen wir die Methode CNeuronRevINDenormOCL::feedForward überschreiben.
bool CNeuronRevINDenormOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false; //--- PrevLayer = NeuronOCL; //--- if(!BatchOptions) iBatchSize = 0; if(iBatchSize <= 1) { activation = (ENUM_ACTIVATION)NeuronOCL.Activation(); return true; }
Wie die gleiche Methode der übergeordneten Klasse erhält auch diese Methode als Parameter einen Zeiger auf das Objekt der vorhergehenden Ebene, das die Eingabedaten enthält.
Im Hauptteil der Methode prüfen wir den empfangenen Zeiger und speichern ihn in der entsprechenden Variablen.
Dann überprüfen wir die Größe der Normalisierungscharge. Wenn der Wert nicht größer als „1“ ist, betrachten wir dies als keine Normalisierung und geben die Daten der vorherigen Schicht unverändert weiter. Natürlich werden wir nicht alle Daten kopieren. Wir kopieren einfach den Identifikator der Aktivierungsfunktion. Beim Zugriff auf den Ergebnis- oder Gradientenpuffer geben wir Zeiger auf die Puffer der vorherigen Schicht zurück. Diese Funktionalität wurde bereits in der übergeordneten Klasse implementiert.
Als Nächstes implementieren wir den Algorithmus, um den Kernel direkt in die Ausführungswarteschlange zu stellen. Hier definieren wir zunächst den Aufgabenraum.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Danach übergeben wir die notwendigen Parameter an den Kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffinputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffoptions, BatchOptions.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffoutput, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_RevInFeedForward, def_k_revffoptions_size, (int)BatchOptions.Total())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_RevInFeedForward, def_k_revffoptimization, (int)optimization)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Senden Sie den Kernel an die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_RevInFeedForward, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Vergessen Sie nicht, die Vorgänge bei jedem Schritt zu kontrollieren.
2.3 Algorithmus der Fehlergradientenausbreitung
Nach der Implementierung des Vorwärtsdurchganges müssen wir den Algorithmus des Rückwärtsdurchgangs implementieren. Wie bereits erwähnt, enthält diese Schicht keine lernbaren Parameter. Dabei werden die in der Normalisierungsphase trainierten Parameter verwendet. Daher werden alle Methoden zur Aktualisierung der Parameter durch „Stummel“ ersetzt.
Die Schicht ist jedoch an Backpropagation-Algorithmen beteiligt, und der Fehlergradient wird über sie an die vorherige neuronale Schicht weitergegeben. Wie zuvor erstellen wir zunächst den RevInHiddenGradient-Kernel auf der Seite des OpenCL-Programms. Diesmal hat sich die Anzahl der Kernelparameter erhöht. Wir übergeben 4 Zeiger auf Datenpuffer: Puffer für Ergebnisse und Fehlergradienten der vorherigen Schicht, Optimierungsparameter und Fehlergradient der aktuellen Schicht-Ergebnisstufe. Außerdem werden 3 Konstanten übergeben: die Größe des Puffers für die Normalisierungsparameter, der Typ der Parameteroptimierung und die Aktivierungsfunktion der vorherigen Schicht.
__kernel void RevInHiddenGraddient(__global float *inputs, __global float *inputs_gr, __global float *options, __global float *output_gr, int options_size, int optimization, int activation) { int n = get_global_id(0); int shift = (n * optimization == 0 ? 7 : 9) % options_size;
Im Kernelkörper wird zunächst der Thread identifiziert und die Verschiebungen in den Datenpuffern bestimmt. Der Algorithmus zur Bestimmung der Pufferverschiebung ist oben im Teil über den Vorwärts-Kernel beschrieben.
Als Nächstes laden wir Daten aus globalen Datenpuffern in lokale Variablen.
float variance = options[shift + 1]; float inp = inputs[n]; float k = options[shift + 3];
Anschließend wird der Fehlergradient durch die Ableitung der Denormalisierungsfunktion angepasst. Dabei ist zu beachten, dass in der Denormalisierungsphase alle Normalisierungsparameter Konstanten sind, während die Ableitung der Funktion erheblich vereinfacht wird.
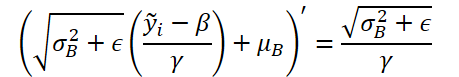
Lassen Sie uns die vorgestellte Funktion in Code umsetzen.
float res = 0; if(k != 0) res = sqrt(variance) * output_gr[n] / k; if(isnan(res)) res = 0;
Danach wird der Fehlergradient durch die Ableitung der Aktivierungsfunktion der vorherigen neuronalen Schicht angepasst.
switch(activation) { case 0: res = clamp(res + inp, -1.0f, 1.0f) - inp; res = res * (1 - pow(inp == 1 || inp == -1 ? 0.99999999f : inp, 2)); break; case 1: res= clamp(res + inp, 0.0f, 1.0f) - inp; res = res * (inp == 0 || inp == 1 ? 0.00000001f : (inp * (1 - inp))); break; case 2: if(inp < 0) res *= 0.01f; break; default: break; }
Wir speichern das Ergebnis der Operationen in dem entsprechenden Element des Fehlergradientenpuffers der vorherigen neuronalen Schicht.
//---
inputs_gr[n] = res;
}
Der nächste Schritt ist die Implementierung des Kernel-Aufrufs auf der Seite des Hauptprogramms. Diese Funktionalität ist in der Methode CNeuronRevINDenormOCL::calcInputGradients implementiert. Der Algorithmus zur Platzierung des Kerns in der Ausführungswarteschlange ist derselbe wie der oben für die Feed-Forward-Methode beschriebene. Daher werden wir sie jetzt nicht im Detail diskutieren.
Außerdem werden wir die Hilfsmethoden der Klasse nicht berücksichtigen. Ihr Algorithmus ist recht einfach, sodass Sie ihn anhand der beigefügten Dateien selbst studieren können. Außerdem enthält der Anhang den vollständigen Code aller Methoden der neuen Klasse und der zuvor erstellten Methoden. Sie können also alle in diesem Artikel verwendeten Programme studieren.
2.4 Punktuelle Bearbeitungen in höherwertigen Klassen
Noch ein paar Worte zu den spezifischen Änderungen an den Methoden der übergeordneten Klassen, die durch die Besonderheiten unserer neuen Klasse CNeuronRevINDenormOCL bedingt sind. Dies betrifft die Initialisierung und das Laden von Objekten dieser Klasse.
Bei der Beschreibung der Methode zur Initialisierung eines Objekts unserer Klasse CNeuronRevINDenormOCL haben wir die Besonderheit der Übergabe eines Zeigers auf ein Objekt der Datennormalisierungsschicht erwähnt. Beachten Sie, dass wir zum Zeitpunkt der Beschreibung der Modellarchitektur keinen Zeiger auf dieses Objekt haben, und zwar aus einem einfachen Grund: Dieses Objekt ist noch nicht erstellt worden. Wir können nur die Ordnungszahl der Schicht angeben, die wir aus der beschriebenen Architektur des Modells kennen.
Wir wissen jedoch genau, dass die Normalisierungsschicht vor der Denormalisierungsschicht kommt. Außerdem kann eine beliebige Anzahl von neuronalen Schichten dazwischen liegen. Das bedeutet, dass zum Zeitpunkt der Erstellung des Denormalisierungsschicht-Objekts bereits eine Normalisierungsschicht im Modell angelegt sein muss. Wir können darauf zugreifen, aber nur innerhalb des Modells. Denn der Zugang zu einzelnen neuronalen Schichten ist für externe Programme gesperrt.
Daher erstellen wir in der Methode CNet::Create einen separaten Block, um das Objekt CNeuronRevINDenormOCL der Denormalisierungsschicht zu initialisieren.
case defNeuronRevInDenormOCL: if(desc.layers>=layers.Total()) { delete temp; return false; }
Hier prüfen wir zunächst, ob in unserem Modell bereits eine Ebene mit dem angegebenen Identifikator angelegt worden ist.
Dann prüfen wir den Typ der angegebenen Ebene. Es sollte sich um eine Batch-Normalisierungsschicht handeln.
if(((CLayer *)layers.At(desc.layers)).At(0).Type()!=defNeuronBatchNormOCL) { delete temp; return false; }
Erst wenn die angegebenen Steuerelemente erfolgreich übergeben wurden, erstellen wir ein neues Objekt.
revin = new CNeuronRevINDenormOCL(); if(!revin) { delete temp; return false; }
Initialisieren es.
if(!revin.Init(outputs, 0, opencl, desc.count, desc.layers, ((CLayer *)layers.At(desc.layers)).At(0))) { delete temp; delete revin; return false; }
Fügen es dem Array von Objekten hinzu.
if(!temp.Add(revin)) { delete temp; delete revin; return false; } break;
Darüber hinaus gibt es eine Nuance beim Laden eines zuvor trainierten Modells. Wie Sie wissen, haben wir in der Initialisierungsmethode unserer neuen Klasse einen Verzweigungsalgorithmus erstellt, der von dem Identifikator der Normalisierungsschicht abhängt. Dies geschah, um das Laden eines vortrainierten Modells zu ermöglichen. Der Punkt ist, dass wir vor dem Laden eines Objekts einen „Rohling“ davon erstellen müssen. Diese Funktion wird in der Methode CLayer::CreateElement ausgeführt. Die Schwierigkeit besteht darin, dass wir vor dem Laden der Daten den Identifikator der Normalisierungsschicht noch nicht kennen. Deshalb geben wir „-1“ als Identifikator und „NULL“ als Objektzeiger an.
case defNeuronRevInDenormOCL: if(CheckPointer(OpenCL) == POINTER_INVALID) return false; revin = new CNeuronRevINDenormOCL(); if(CheckPointer(revin) == POINTER_INVALID) result = false; if(revin.Init(iOutputs, index, OpenCL, 1, -1, NULL)) { m_data[index] = revin; return true; } delete revin; break;
Während des Ladevorgangs werden dann alle Daten in die internen Objekte und Variablen unserer Klasse geladen. Aber auch hier gibt es eine Nuance. Beim Laden der Daten erhalten wir die Normalisierungsparameter, die nach dem Vortraining des Modells gespeichert wurden. Aber das brauchen wir nicht. Um das Modell weiter zu trainieren und zu betreiben, müssen wir die Parameter zwischen der Normalisierungs- und der Denormalisierungsschicht synchronisieren. Andernfalls würde eine Lücke zwischen den Verteilungen der Eingabedaten und unseren Prognosen entstehen. Deshalb rufen wir die Methode CNet::Load auf und überprüfen nach dem Laden der nächsten neuronalen Schicht deren Typ.
bool CNet::Load(const int file_handle) { ........ ........ //--- read array length num = FileReadInteger(file_handle, INT_VALUE); //--- read array if(num != 0) { for(i = 0; i < num; i++) { //--- create new element CLayer *Layer = new CLayer(0, file_handle, opencl); if(!Layer.Load(file_handle)) break; if(Layer.At(0).Type() == defNeuronRevInDenormOCL) { CNeuronRevINDenormOCL *revin = Layer.At(0); int l = revin.GetNormLayer(); if(!layers.At(l)) { delete Layer; break; }
Wenn die Denormalisierungsschicht CNeuronRevINDenormOCL erkannt wird, wird ein Zeiger auf die Normalisierungsschicht angefordert und geprüft, ob eine solche Schicht geladen ist.
Wir überprüfen auch den Typ dieser Schicht.
CNeuronBaseOCL *neuron = ((CLayer *)layers.At(l)).At(0); if(neuron.Type() != defNeuronBatchNormOCL) { delete Layer; break; }
Sobald die angegebenen Kontrollpunkte erfolgreich übergeben wurden, initialisieren wir das Ebenenobjekt, indem wir einen Zeiger auf die entsprechende Normalisierungsebene übergeben.
if(!revin.Init(revin.getConnections(), 0, opencl, revin.Neurons(), l, neuron)) { delete Layer; break; } } if(!layers.Add(Layer)) break; } } FileClose(file_handle); //--- result return (layers.Total() == num); }
Dann folgen wir dem zuvor erstellten Algorithmus.
Den vollständigen Code aller Klassen und ihrer Methoden sowie alle Programme, die bei der Erstellung des Artikels verwendet wurden, finden Sie im Anhang.
2.5 Modellarchitektur für das Training
Wir haben die von den Autoren der Methode RevIN vorgeschlagenen Ansätze mit MQL5 umgesetzt. Nun ist es an der Zeit, sie in die Architektur unserer Modelle einzubinden. Wie bereits erwähnt, werden wir im Encoder-Modell eine Denormalisierung verwenden, um die Fähigkeit zu implementieren, es so zu trainieren, dass es nachfolgende Zustände der Umgebung vorhersagen kann. Wir werden die Anzahl der Vorhersagezustände der Umgebung (in unserem Fall die nachfolgenden Kerzen) in der Konstante NForecast definieren.
#define NForecast 6 //Number of forecast
Da wir planen, den Encoder getrennt von Akteur und Kritiker zu trainieren, werden wir auch die Beschreibung der Encoder-Architektur in eine separate Methode, CreateEncoderDescriptions, verschieben. In den Parametern der Methode wird nur ein Zeiger auf ein dynamisches Array übergeben, um die Architektur des erstellten Modells zu speichern. An dieser Stelle ist anzumerken, dass unsere Implementierung der Klasse CNeuronRevINDenormOCL es nicht erlaubt, den Decoder als separates Modell zuzuordnen.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Im Hauptteil der Methode wird der empfangene Zeiger überprüft und gegebenenfalls eine neue Instanz des dynamischen Array-Objekts erstellt.
Wie zuvor füttern wir das Modell mit „rohen“ Eingangsdaten, die den Zustand der Umgebung beschreiben.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die empfangenen Daten werden in der Batch-Normalisierungsschicht einer Erstverarbeitung unterzogen. Wir müssen die Ordnungszahl der Ebene speichern.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Nach der Normalisierung der Eingabedaten erstellen wir die Dateneinbettung und fügen sie dem internen Stapel hinzu.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {4, 1, 1, 1, 2}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count * 5; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Dann fügen wir die Positionskodierung der Daten hinzu.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout * 5; if(!encoder.Add(descr)) { delete descr; return false; }
Wir übertragen die aufbereiteten Daten in den Block mit 5 Schichten von CNeuronConformer ein.
//--- layer 5-10 for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 5; if(!encoder.Add(descr)) { delete descr; return false; } }
Um die Methode zu testen, verwenden wir eine vollständig verbundene Schicht mit einer angemessenen Anzahl von Elementen als Decoder. Um die Qualität der Vorhersage zu verbessern, empfiehlt es sich jedoch, einen Decoder mit einer komplexeren Architektur zu verwenden.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NForecast*BarDescr; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Wir arbeiten mit normalisierten Daten und nehmen an, dass ihre Varianz nahe bei 1 und ihr Mittelwert nahe bei 0 liegt. Daher verwenden wir den hyperbolischen Tangens (tanh) als Aktivierungsfunktion am Decoderausgang. Wie Sie wissen, reicht der Wertebereich von „-1“ bis „1“.
Und schließlich werden die Prognosewerte denormalisiert.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Um die Beschreibung der Architektur der Modelle zu vervollständigen, betrachten wir die Konstruktionen von Akteur und Kritiker. Die Architektur der angegebenen Modelle wird in der Methode CreateDescriptions beschrieben. Sie ist der im vorigen Artikel beschriebenen sehr ähnlich, aber es gibt eine Nuance.
In den Parametern erhält die Methode Zeiger auf 2 dynamische Arrays.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Im Hauptteil der Methode werden die empfangenen Zeiger überprüft und gegebenenfalls neue Objektinstanzen erstellt.
Wir übertragen den Akteur mit einem Tensor, der den Kontostatus und die offenen Positionen beschreibt.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wir erzeugen eine Einbettung dieser Darstellung.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Dann kommt der Cross-Attention-Block, der den aktuellen Zustand des Kontos mit den vorhergesagten Zuständen der Umgebung vergleicht.
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
Am Ende des Akteursmodells gibt es einen Entscheidungsblock mit einer stochastischen Politik.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Kritikermodell ist auf ähnliche Weise aufgebaut. Nur dass der Kritiker nicht den Zustand des Kontos beschreibt, sondern die Handlungen des Akteurs im Zusammenhang mit den vorhergesagten Zuständen der Umgebung analysiert.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } }
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Der Kritiker gibt uns eine klare, nicht stochastische Bewertung der Handlungen des Agenten.
2.6 Trainingsprogramme des Modells
Nachdem wir die Architektur der trainierten Modelle beschrieben haben, gehen wir zur Erstellung von Programmen über, mit denen sie trainiert werden können. Um den Encoder zu trainieren, erstellen wir einen Expert Advisor: „...\Experts\RevIN\StudyEncoder.mq5“. Die EA-Architektur entspricht derjenigen der vorangegangenen Artikel. Das haben wir in dieser Serie bereits mehrfach besprochen. Daher werden wir uns nur auf die Modellbildungsmethode Train konzentrieren.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Im Hauptteil der Methode generieren wir wie üblich einen Vektor von Wahrscheinlichkeiten für die Auswahl von Trajektorien in Abhängigkeit von ihrer Rentabilität. Für die Vorhersage des künftigen Umgebungszustands sind alle Durchgänge gleich. Da der Encoder keine Analyse von Kontostatus und offene Positionen. Wir entfernen diese Funktion jedoch nicht, wenn es einen Erfahrungswiedergabepuffer gibt, der auf den Durchläufen in verschiedenen historischen Intervallen basiert.
Dann bereiten wir lokale Variablen vor und organisieren ein System von Modelltrainingsschleifen.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - batch)); if(state <= 0) { iter--; continue; } Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - NForecast);
Im Hauptteil der äußeren Schleife werden die Trajektorie aus dem Erfahrungswiedergabepuffer und der Status des Lernbeginns abgerufen. Anschließend wird der Endzustand des Trainingsstapels bestimmt und der interne Modellstapel gelöscht. Danach führen wir einen verschachtelten Lernzyklus für das ausgewählte Segment der historischen Daten durch.
for(int i = state; i < end && !IsStopped() && !Stop; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Hier laden wir zunächst den gewünschten Zustand aus der Trainingsmenge. Wir verschieben sie in den Datenpuffer. Dann führen wir einen Vorwärtsdurchgang des Encoders aus, indem wir die entsprechende Methode unseres Modells aufrufen.
Im nächsten Schritt bereiten wir die Zieldaten vor. Zu diesem Zweck organisieren wir eine weitere verschachtelte Schleife, in der wir die erforderliche Anzahl von Folgezuständen aus der Trainingsstichprobe nehmen und dem Datenpuffer hinzufügen.
//--- Collect target data bState.Clear(); for(int fst = 1; fst <= NForecast; fst++) { if(!bState.AddArray(Buffer[tr].States[i + fst].state)) break; }
Nachdem wir die Zielwerte gesammelt haben, können wir den Encoder-Backpropagation-Durchgang ausführen, um den Fehler zwischen den vorhergesagten und den Zielwerten zu minimieren.
if(!Encoder.backProp(GetPointer(bState), (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Dann informieren wir den Nutzer über den Trainingsfortschritt und gehen zur nächsten Trainingsiteration über.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nachdem alle Trainingsiterationen erfolgreich abgeschlossen wurden, löschen wir das Kommentarfeld.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Wir geben Informationen über die erzielten Trainingsergebnisse in das Protokoll ein und initialisieren die EA-Beendigung.
Die Ausbildung eines Modells zur Vorhersage künftiger Zustände der Umgebung ist nützlich. Unser Ziel ist es jedoch, die Politik des Akteurs zu trainieren. Im nächsten Schritt erstellen wir den Trainings-EA „...\Experts\RevIN\Study.mq5“ für Akteur and Kritiker. Der EA ist nach der gleichen Architektur aufgebaut, sodass wir nur auf die spezifischen Änderungen eingehen werden.
Erstens, während der EA-Initialisierung, wenn es keinen vortrainierten Encoder gibt, generieren wir einen Fehler wegen falscher Programminitialisierung.
int OnInit() { //--- ........ ........ //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Error of load Encoder: %d", GetLastError()); return INIT_FAILED; } ........ ........ //--- return(INIT_SUCCEEDED); }
Zweitens ist der Encoder in diesem Modell nicht trainiert und sollte daher nicht gespeichert werden.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
Außerdem gibt es eine Sache, wenn Sie den Encoder als Quelle für die Eingabedaten für Akteur und Kritiker verwenden. Zu Beginn des Artikels haben wir darüber gesprochen, wie wichtig es ist, normalisierte Daten zum Trainieren und Betreiben von Modellen zu verwenden. Die Denormalisierungsschicht am Ausgang des Encoders hingegen führt unsere Vorhersagen auf die ursprüngliche Datenverteilung zurück, sodass sie nicht vergleichbar sind.
Wir haben jedoch schon vor langer Zeit die Funktion des Zugriffs auf die verborgenen Schichten des Modells implementiert, um Daten zu extrahieren. Wir werden also diese Funktionalität nutzen, um normalisierte vorhergesagte Daten von der vorletzten Schicht des Encoders zu erhalten. Diese Daten werden wir als Ausgangsdaten für den Akteur und den Kritiker verwenden. Der Zeiger auf die gewünschte Ebene wird in der Konstante LatentLayer angegeben.
#define LatentLayer 11
Der Vorwärtsaufruf für den Kritiker kann wie folgt aussehen:
if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
oder
if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Dementsprechend schreiben wir den Vorwärtsaufruf des Akteurs als
if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Vergessen wir nicht, den Layer-Identifikator anzugeben, wenn wir die Backpropagation-Methoden unserer Modelle aufrufen.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder),LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Ich habe ähnliche gezielte Änderungen an den Umgebungsinteraktions-EAs vorgenommen. Sie können sie mit den Codes in den Anhängen selbst überprüfen. Der Anhang enthält den vollständigen Code aller Programme im Anhang.
3. Tests
Nachdem wir alle erforderlichen Programme erstellt haben, können wir die Modelle schließlich trainieren und testen. So können wir die Wirksamkeit der vorgeschlagenen Lösungen bewerten.
Wir trainieren und testen Modelle mit historischen Daten für EURUSD, H1.
Die Zeit bleibt nicht stehen. Mit der Zeit wächst unsere historische Datenbank. Bei der Vorbereitung dieses Artikels habe ich daher beschlossen, das historische Intervall des Trainingsdatensatzes auf das gesamte Jahr 2023 auszudehnen. Die Daten für Januar 2024 werden verwendet, um die trainierten Modelle zu testen.
Zur Erstellung des primären Trainingsdatensatzes habe ich das Real-ORL Framework verwendet. Eine ausführliche Beschreibung finden Sie unter diesem Link. Ich habe Handelsdaten von 20 echten Signalen heruntergeladen. Dann habe ich den EA „...\Experts\RevIN\ResearchRealORL.mq5“ im Modus „Volle Optimierung“ ausgeführt.


Als Ergebnis erhielt ich 20 Trajektorien. Nicht alle von ihnen sind rentabel.

In diesem Schritt beginnen wir zunächst mit dem Training des Encoders. Sobald das Encoder-Training abgeschlossen ist, führen wir das primäre Training für den Akteur und den Kritiker durch. Das liegt vor allem daran, dass 20 Trajektorien zu wenig sind, um die optimale Politik des Akteurs zu erhalten.
Im nächsten Schritt erweitern wir unseren Trainingsdatensatz. Hierfür führen wir im langsamen Volloptimierungsmodus den EA „...\Experts\RevIN\Research.mq5“ aus. Es testet die aktuelle Akteurspolitik auf realen historischen Daten innerhalb des Trainingszeitraums und fügt unserem Trainingsdatensatz Durchgänge hinzu.

In diesem Stadium sollten Sie keine herausragenden Ergebnisse erwarten. Auch ein negatives Ergebnis ist ein Ergebnis. Dies ist auch eine gute Erfahrung für weitere Modellversuche. Darüber hinaus tragen solche Iterationen dazu bei, das Umfeld im Wirkungsbereich der aktuellen Politik des Akteurs zu verstehen.
Nach mehreren Iterationen zum Training der Akteurs-Policy und dem Sammeln zusätzlicher Daten für den Trainingsdatensatz gelang es mir, ein Modell zu trainieren, das sowohl im Trainings- als auch im Testdatensatz Gewinne erzielen konnte.


Während des Testzeitraums tätigte der EA 424 Transaktionen, von denen 210 mit Gewinn abgeschlossen wurden. Dies entspricht 49,53 %. Da jedoch die größten und durchschnittlich profitablen Geschäfte die unprofitablen übersteigen, endete der Testzeitraum mit einem Gewinn. Die Ergebnisse für den maximalen Saldo und die Inanspruchnahme des Eigenkapitals liegen nahe beieinander (9,14 % bzw. 10,36 %). Der Gewinnfaktor für den Testzeitraum betrug 1,25. Die Sharpe Ratio erreichte 3,38.
Schlussfolgerung
In diesem Artikel haben wir uns mit der RevIN-Methode vertraut gemacht, die einen wichtigen Schritt in der Entwicklung von Normalisierungs- und Denormalisierungstechniken darstellt. Sie ist besonders für Deep-Learning-Modelle im Zusammenhang mit Zeitreihenprognosen von Bedeutung. Sie ermöglicht es uns, statistische Informationen über Zeitreihen zu speichern und abzurufen, die für genaue Prognosen entscheidend sind. RevIN zeigt sich robust gegenüber Veränderungen der Datendynamik im Laufe der Zeit. Dies macht sie zu einem wirksamen Instrument für die Lösung des Problems der Verteilungsverschiebung in Zeitreihen.
Einer der wichtigsten Vorteile von RevIN ist seine Flexibilität und Anwendbarkeit auf verschiedene Deep-Learning-Modelle. Es kann leicht in verschiedene neuronale Netzarchitekturen implementiert und sogar auf mehrere Schichten angewandt werden und bietet eine stabile Vorhersagequalität.
Im praktischen Teil des Artikels haben wir die vorgeschlagenen Ansätze mit MQL5 umgesetzt. Wir trainierten die Modelle anhand echter historischer Daten und testeten sie mit neuen Daten, die nicht im Trainingsdatensatz enthalten waren.
Die Testergebnisse zeigten, dass die trainierten Modelle in der Lage sind, die Trainingsdaten zu verallgemeinern und sowohl auf der historischen Trainingsmenge als auch darüber hinaus Gewinne zu erzielen.
Es ist jedoch zu bedenken, dass alle in diesem Artikel vorgestellten Programme Demonstrationscharakter haben und nur dazu dienen, die vorgeschlagenen Ansätze zu testen.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA-Beispielsammlung |
| 2 | ResearchRealORL.mq5 | EA | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | EA | Modelltraining EA |
| 4 | StudyEncoder.mq5 | EA | Encoder Trainings-EA |
| 5 | Test.mq5 | EA | Modeltest-EA |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14673
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.