
Redes neuronales: así de sencillo (Parte 78): Detector de objetos basado en el Transformer (DFFT)

Introducción
En artículos anteriores, nos hemos centrado mucho en la predicción del próximo movimiento de los precios. Hemos analizado los datos históricos, y basándonos en este análisis, hemos intentado predecir el movimiento de precios más probable de varias maneras. Algunas construyen toda una serie de movimientos predictivos e intentan estimar la probabilidad de cada una de las predicciones construidas. Naturalmente, el entrenamiento y funcionamiento de dichos modelos requiere importantes recursos informáticos.
Pero, ¿realmente necesitamos hasta tal punto predecir el movimiento de los precios? Sobre todo porque la precisión de las previsiones resultantes dista mucho de ser la deseable.
Nuestro objetivo final es la obtención de beneficios, cosa que planeamos realizar gracias al eventual éxito comercial de nuestro Agente, que, a su vez, elige las acciones óptimas según las trayectorias de precios previstas que obtengamos.
En consecuencia, un error en la construcción de las trayectorias predictivas conducirá potencialmente a un error aún mayor en la selección de acciones por parte del Agente. Aquí digo "conducirá potencialmente" porque durante el aprendizaje, el Actor puede ajustar los errores de predicción e igualar un poco el error. Sin embargo, esta situación resulta posible con un error de previsión relativamente constante. Si se da un error de previsión estocástico, el error de acción del Agente no hará sino aumentar.
En una situación así, buscaremos formas de minimizar el error. ¿Y si excluimos el paso intermedio de predecir la trayectoria del próximo movimiento de los precios? Así volveremos al enfoque clásico del aprendizaje por refuerzo, y dejaremos que el Actor elija acciones basadas en el análisis de datos históricos. Pero al hacerlo, no daremos un paso atrás, sino más bien hacia los lados.
Hoy les propongo un método interesante, presentado inicialmente para resolver problemas de visión artificial. Se trata del método Decoder-Free Fully Transformer-based (DFFT), presentado en el artículo "Efficient Decoder-free Object Detection with Transformers".
El método DFFT propuesto en este material ofrece una alta eficiencia tanto en la fase de entrenamiento como en la de explotación. Los autores del método simplifican la detección de objetos a un problema de predicción densa de un solo nivel utilizando solo un codificador. Centrar sus esfuerzos en 2 tareas:
- Eliminar el decodificador ineficiente y usar 2 codificadores potentes para preservar la precisión de predicción del mapa de características de un solo nivel;
- Aprender características semánticas de bajo nivel para la tarea de detección con recursos informáticos limitados.
En concreto, los autores del método proponen una nueva arquitectura de transformadores ligera y orientada a la detección que captura eficazmente características de bajo nivel con una rica semántica Los experimentos presentados en el artículo muestran un menor coste computacional y menos épocas de entrenamiento.
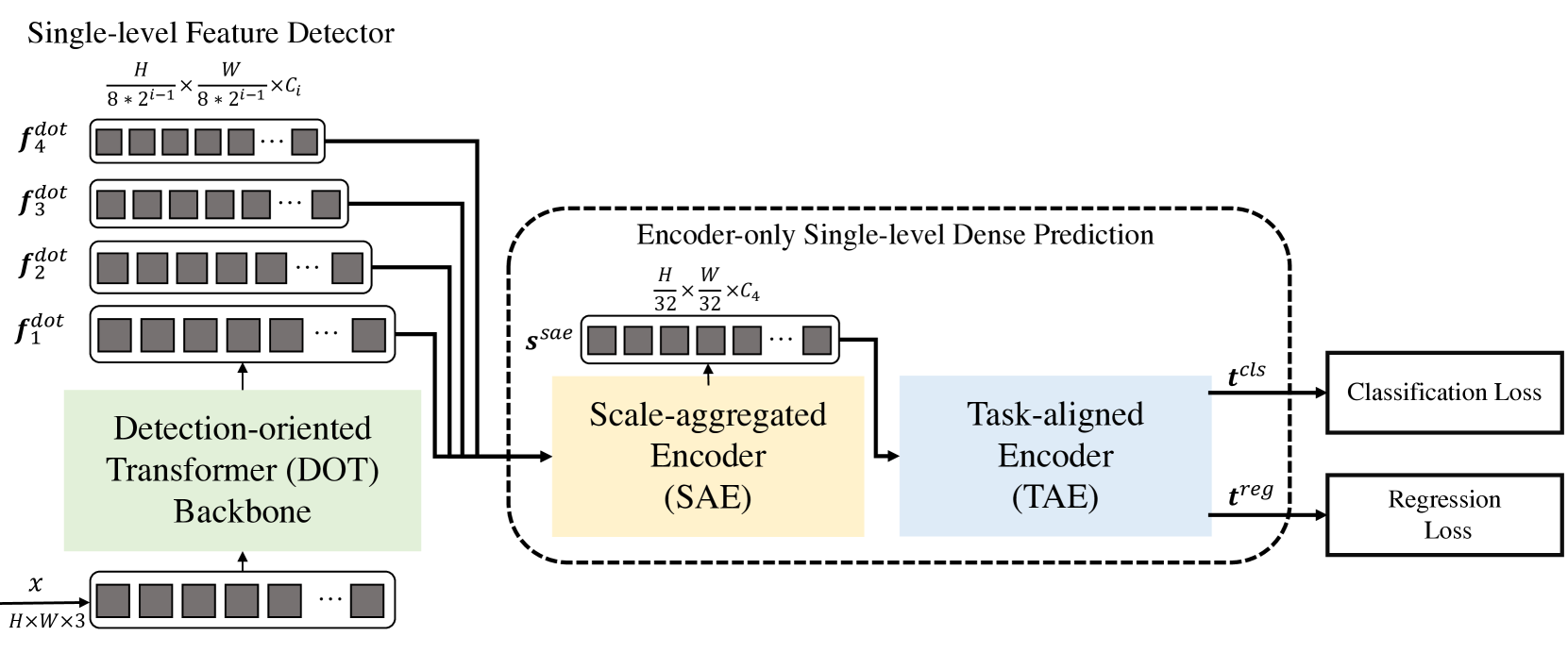
1. Algoritmo DFFT
El métodoDecoder-Free Fully Transformer-based (DFFT) es un eficaz detector de objetos basado enteramente en transformadores sin decodificadores. La columna vertebral del Transformer se centra en la detección de objetos, que extrae a cuatro escalas y envía al siguiente módulo de predicción de densidad de un solo nivel solo para el codificador. El módulo de predicción primero añade el objeto multiescala en un único mapa de objeto utilizando el codificador Scale-Aggregated Encoder.
A continuación, los autores del método proponen usar el Task-Aligned Encoder para alinear simultáneamente las características de las tareas de clasificación y regresión.
El transformador orientado a la detección (Detection-Оriented Тransformer — DOT) está diseñado para la extracción de características multiescala con una semántica estricta. Apila jerárquicamente un módulo de incorporación y cuatro etapas de DOT. El nuevo módulo de atención semánticamente ampliado añade la información semántica de bajo nivel de cada dos etapas DOT consecutivas.
Al procesar mapas de características de alta resolución en predicción densa, los bloques transformadores convencionales reducen el coste computacional sustituyendo la capa de Self-Attention de cabeza múltiple (MSA) por una capa de atención espacial local y Self-Attention multicabeza con ventana desplazada (SW-MSA). Sin embargo, esta estructura reduce el rendimiento de la detección, pues solo extrae objetos multiescala con una semántica de bajo nivel limitada.
Para mitigar este inconveniente, los autores del método DFFT añaden al bloque DOT varios bloques SW-MSA y un bloque de atención global al canal. Obsérvese que cada bloque de atención contiene una capa de atención y una capa FFN.
Los autores del método descubrieron que colocar una capa ligera de atención a través de los canales tras las sucesivas capas espaciales locales de atención puede ayudar a inferir la semántica del objeto en cada escala.
Mientras que el bloque DOT mejora la información semántica de las características de bajo nivel usando la atención global en todos los canales, la semántica puede mejorarse aún más para mejorar la tarea de detección. Para ello, los autores del método proponen un nuevo módulo de atención semántica mejorada (Semantic-Augmented Attention — SAA) que intercambia información semántica entre dos niveles consecutivos de DOT y complementa sus características. El SAA consta de una capa de sobremuestreo y un bloque de atención global por canales. Los autores del método añaden SAA a cada dos bloques consecutivos de DOT. Formalmente, el SAA toma los resultados del bloque DOT actual y de la etapa DOT anterior, y luego retorna una función semántica ampliada que se envía a la siguiente etapa DOT y también contribuye a las características multiescala finales.
En general, la etapa orientada al descubrimiento comprende cuatro capas de DOT, en las que cada etapa comprende una unidad DOT y un módulo SAA (salvo la primera etapa). En particular, la primera etapa contiene una sola unidad DOT y no contiene un módulo SAA, puesto que las entradas del módulo SAA proceden de dos etapas DOT consecutivas. A continuación, se aplica una capa de muestreo descendente para recuperar la dimensión de entrada.
El siguiente módulo está diseñado para mejorar tanto la inferencia como la eficiencia de aprendizaje del modelo DFFT. En primer lugar, se usa un codificador de escala agregada (Scale-Aggregated Encoder — SAE) para añadir objetos multiescala de la columna vertebral DOT en un único mapa de objetos Ssae.
A continuación, se usa un codificador alineado por tarea (Task-Aligned Encoder — TAE) para crear una función de clasificación alineada 𝒕cls y la función de regresión 𝒕reg simultáneamente en la misma cabeza.
El codificador de escala agregada se construye a partir de 3 bloques de SAE. Cada bloque SAE toma dos objetos como datos de entrada y los añade paso a paso en todos los bloques SAE. Los autores del método usan una escala de agregación de objetos finita para equilibrar la precisión de la detección y el coste computacional.
Normalmente, los detectores realizan la clasificación y localización de objetos de forma independiente usando dos ramas separadas (cabezas no relacionadas). Esta estructura de dos ramas no considera la interacción entre las dos tareas y da lugar a predicciones incoherentes. Mientras tanto, cuando se aprenden características para dos tareas en la cabeza conjunta, suele haber conflictos en la cabeza conjunta. Los autores de DFFT proponen usar un codificador orientado a la tarea que ofrece un mejor equilibrio entre el aprendizaje de características interactivas y las características específicas de la tarea mediante la combinación de bloques grupales de atención a través de canales en una cabeza conectada.
Este codificador se compone de dos tipos de bloques de atención por canal En primer lugar, los bloques de atención grupal multinivel entre canales alinean y separan los objetos Ssae agregados en 2 partes. En segundo lugar, la atención global bloquea por los canales la codificación de uno de los dos objetos separados para la tarea de regresión posterior.
En particular, las diferencias entre el bloque grupal de atención del canal y el bloque global de atención del canal son que todas las proyecciones lineales, excepto las proyecciones para los anexos Query/Key/Value en el bloque grupal de atención del canal, se realizan en dos grupos. Así, los rasgos interactúan en las operaciones atencionales mientras que se emiten por separado en las proyecciones de salida.
A continuación se presenta la visualización personalizada del método.
2. Implementación con MQL5
Tras considerar los aspectos teóricos del método Decoder-Free Fully Transformer-based (DFFT), vamos a pasar a la implementación práctica de los enfoques propuestos usando MQL5. Sin embargo, nuestro modelo será ligeramente diferente al del autor, ya que en su construcción estamos considerando las diferencias en las especificidades de las tareas de visión por computadora para las que se propuso el método, y el trabajo en mercados financieros, para el que construimos nuestro modelo.
2.1 Construcciones de bloques DOT
Y entrando ya en materia, conviene señalar que los enfoques propuestos son bastante diferentes de los modelos que hemos construido antes. Entre otras cosas, el bloque DOT se distingue de los bloques de atención que hemos analizado anteriormente. Por ello, comenzaremos nuestro trabajo construyendo una nueva capa neuronal CNeuronDOTOCL. Luego crearemos nuestra nueva capa heredando nuestra clase de capa neuronal básica CNeuronBaseOCL.
De forma similar a otros bloques de atención, añadiremos variables para almacenar los parámetros clave:
- iWindowSize - tamaño de la ventana de un elemento de la secuencia;
- iPrevWindowSize - tamaño de ventana de un elemento de secuencia de la capa anterior;
- iDimension - tamaño del vector de entidades internas Query, Key y Value;
- iUnits - número de elementos de la secuencia;
- iHeads - número de cabezas de atención.
Supongo que se habrá fijado en la variable iPrevWindowSize. Su adición nos permitirá hacer realidad la capacidad de comprimir los datos de capa a capa que ofrece el método DFFT.
Además, para minimizar el trabajo directamente en la nueva clase y maximizar el aprovechamiento de los desarrollos creados previamente, implementaremos parte de la funcionalidad usando capas neuronales anidadas de nuestra biblioteca. Nos familiarizaremos con su funcionalidad durante la implementación de los métodos de pasada directa y inversa.
class CNeuronDOTOCL : public CNeuronBaseOCL { protected: uint iWindowSize; uint iPrevWindowSize; uint iDimension; uint iUnits; uint iHeads; //--- CNeuronConvOCL cProjInput; CNeuronConvOCL cQKV; int iScoreBuffer; CNeuronBaseOCL cRelativePositionsBias; CNeuronBaseOCL MHAttentionOut; CNeuronConvOCL cProj; CNeuronBaseOCL AttentionOut; CNeuronConvOCL cFF1; CNeuronConvOCL cFF2; CNeuronBaseOCL SAttenOut; CNeuronXCiTOCL cCAtten; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool DOT(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool updateRelativePositionsBias(void); virtual bool DOTInsideGradients(void); public: CNeuronDOTOCL(void) {}; ~CNeuronDOTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint dimension, uint heads, uint units_count, uint prev_window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronDOTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
No obstante, en general, la lista de métodos redefinidos será bastante estándar.
En el cuerpo de la clase, utilizaremos objetos estáticos, lo cual nos permitirá dejar el constructor y el destructor de la clase vacíos.
La inicialización de la clase se realizará en el método Init. Transmitiremos toda la información necesaria al método en los parámetros, cuyo control mínimo se implementará en el método de la clase padre del mismo nombre. La inicialización de los objetos heredados también se realizará allí.
bool CNeuronDOTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint dimension, uint heads, uint units_count, uint prev_window, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
A continuación, comprobaremos que el tamaño de los datos originales y los parámetros de la capa actual coincidan. Asimismo, inicializaremos la capa de escalado de datos, si fuera necesario.
if(prev_window != window) { if(!cProjInput.Init(0, 0, OpenCL, prev_window, prev_window, window, units_count, optimization_type, batch)) return false; }
Luego almacenaremos las constantes básicas obtenidas del programa de llamada que definirán la arquitectura de la capa en variables internas de la clase.
iWindowSize = window; iPrevWindowSize = prev_window; iDimension = dimension; iHeads = heads; iUnits = units_count;
Después inicializaremos todos los objetos internos secuencialmente. Primero inicializaremos la capa de generación de entidades Query, Key y Value. Generaremos las 3 entidades en paralelo en el cuerpo de una única capa neuronal cQKV.
if(!cQKV.Init(0, 1, OpenCL, window, window, dimension * heads, units_count, optimization_type, batch)) return false;
A continuación, crearemos un búfer para registrar los coeficientes de dependencia de los objetos iScoreBuffer. Aquí cabe señalar que en el bloque DOT, primero analizaremos la semántica local. Para ello, comprobaremos la dependencia entre un objeto y sus 2 vecinos más próximos. Por consiguiente, definiremos el tamaño del búfer Score como iUnits * iHeads * 3.
Además, los coeficientes almacenados en el búfer se recalcularán en cada pasada directa. Y solo se utilizarán en la siguiente pasada inversa. Por lo tanto, no guardaremos los datos del búfer en el archivo de almacenamiento del modelo. Además, ni siquiera crearemos un búfer en la memoria principal del programa. Todo lo que deberemos hacer es crear un búfer en la memoria contextual OpenCL. En el lado del programa principal, guardaremos solo el puntero del búfer.
//--- iScoreBuffer = OpenCL.AddBuffer(sizeof(float) * iUnits * iHeads * 3, CL_MEM_READ_WRITE); if(iScoreBuffer < 0) return false;
En el mecanismo de Self-Attention con ventanas, a diferencia del transformador clásico, cada token interactuará solo con tokens dentro de una ventana concreta. Esto reducirá significativamente la complejidad computacional. Sin embargo, esta restricción también implicará que los modelos deben tener en cuenta las posiciones relativas de los tokens dentro de la ventana. Para realizar esta funcionalidad, se introducirán los parámetros entrenados cRelativePositionsBias. Para cada par de símbolos (i, j) dentro de una ventana iWindowSize, cRelativePositionsBias contiene un peso que determinará la importancia de la interacción entre estos símbolos según su posición relativa.
Resulta sencillo adivinar que el tamaño de este búfer será igual al tamaño del búfer del coeficiente Score. Sin embargo, para entrenar los parámetros, necesitaremos búferes adicionales además del búfer de los propios valores. Para reducir el número de objetos internos y la legibilidad del código, para cRelativePositionsBias declararemos un objeto de capa neuronal que contendrá todos los búferes adicionales.
if(!cRelativePositionsBias.Init(1, 2, OpenCL, iUnits * iHeads * 3, optimization_type, batch)) return false;
Añadiremos los demás elementos del mecanismo de Self-Attention del mismo modo.
if(!MHAttentionOut.Init(0, 3, OpenCL, iUnits * iHeads * iDimension, optimization_type, batch)) return false; if(!cProj.Init(0, 4, OpenCL, iHeads * iDimension, iHeads * iDimension, window, iUnits, optimization_type, batch)) return false; if(!AttentionOut.Init(0, 5, OpenCL, iUnits * window, optimization_type, batch)) return false; if(!cFF1.Init(0, 6, OpenCL, window, window, 4 * window, units_count, optimization_type,batch)) return false; if(!cFF2.Init(0, 7, OpenCL, window * 4, window * 4, window, units_count, optimization_type, batch)) return false; if(!SAttenOut.Init(0, 8, OpenCL, iUnits * window, optimization_type, batch)) return false;
Como bloque de atención global, utilizaremos la capa CNeuronXCiTOCL.
if(!cCAtten.Init(0, 9, OpenCL, window, MathMax(window / 2, 3), 8, iUnits, 1, optimization_type, batch)) return false;
Para minimizar las operaciones de copiado de datos entre búferes, realizaremos un intercambio de objetos y búferes.
if(!!Output) delete Output; Output = cCAtten.getOutput(); if(!!Gradient) delete Gradient; Gradient = cCAtten.getGradient(); SAttenOut.SetGradientIndex(cFF2.getGradientIndex()); //--- return true; }
Luego finalizaremos el método.
Tras inicializar la clase, pasaremos a construir el algoritmo de pasada directa. Y aquí tendremos que empezar a trabajar con la organización del mecanismo de Self-Attention con ventanas en el lado OpenCL del programa. Para ello, crearemos un kernel DOTFeedForward. En los parámetros al kernel transmitiremos los punteros a 4 búferes de datos:
- qkv - búfer de entidades Query, Key y Value,
- score - búfer de coeficientes de dependencia,
- rpb - búfer de desplazamientos de posición,
- out - búfer de resultados de Self-attention multicabeza con ventanas.
__kernel void DOTFeedForward(__global float *qkv, __global float *score, __global float *rpb, __global float *out) { const size_t d = get_local_id(0); const size_t dimension = get_local_size(0); const size_t u = get_global_id(1); const size_t units = get_global_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
El kernel planeamos ejecutarlo en un espacio de tareas tridimensional. Y en el cuerpo del kernel, identificaremos inmediatamente el hilo en las 3 dimensiones. Cabe señalar aquí que en la primera dimensión de entidades de Query, Key y Value, crearemos un grupo de trabajo con uso compartido del búfer en memoria local.
A continuación, determinaremos los desplazamientos en los búferes de datos antes del inicio de los objetos analizados.
uint step = 3 * dimension * heads; uint start = max((int)u - 1, 0); uint stop = min((int)u + 1, (int)units - 1); uint shift_q = u * step + h * dimension; uint shift_k = start * step + dimension * (heads + h); uint shift_score = u * 3 * heads;
Y luego crearemos un búfer local para el intercambio de datos entre hilos del mismo grupo de trabajo.
const uint ls_d = min((uint)dimension, (uint)LOCAL_ARRAY_SIZE); __local float temp[LOCAL_ARRAY_SIZE][3];
Como ya hemos mencionado, definiremos la semántica local usando los 2 vecinos más próximos al objeto. En primer lugar, determinaremos el impacto de los vecinos en el objeto analizado. Calcularemos las tasas de dependencia dentro del grupo de trabajo. En primer lugar, multiplicaremos los elementos de las entidades Query y Key en hilos paralelos de dos en dos.
//--- Score if(d < ls_d) { for(uint pos = start; pos <= stop; pos++) { temp[d][pos - start] = 0; } for(uint dim = d; dim < dimension; dim += ls_d) { float q = qkv[shift_q + dim]; for(uint pos = start; pos <= stop; pos++) { uint i = pos - start; temp[d][i] = temp[d][i] + q * qkv[shift_k + i * step + dim]; } } barrier(CLK_LOCAL_MEM_FENCE);
Y luego sumaremos los productos resultantes.
int count = ls_d; do { count = (count + 1) / 2; if(d < count && (d + count) < dimension) for(uint i = 0; i <= (stop - start); i++) { temp[d][i] += temp[d + count][i]; temp[d + count][i] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); }
A los valores obtenidos se añadirán los parámetros de desplazamiento y se normalizarán con la función SoftMax.
if(d == 0) { float sum = 0; for(uint i = 0; i <= (stop - start); i++) { temp[0][i] = exp(temp[0][i] + rpb[shift_score + i]); sum += temp[0][i]; } for(uint i = 0; i <= (stop - start); i++) { temp[0][i] = temp[0][i] / sum; score[shift_score + i] = temp[0][i]; } } barrier(CLK_LOCAL_MEM_FENCE);
Guardaremos el resultado en el búfer de coeficientes de dependencia.
Ahora podremos multiplicar los coeficientes resultantes por los elementos correspondientes de la entidad Value para determinar los resultados del bloque Self-attention multicabeza con ventanas.
int shift_out = dimension * (u * heads + h) + d; int shift_v = dimension * (heads * (u * 3 + 2) + h); float sum = 0; for(uint i = 0; i <= (stop - start); i++) sum += qkv[shift_v + i] * temp[0][i]; out[shift_out] = sum; }
Luego guardaremos los valores obtenidos en los elementos correspondientes del búfer de resultados y finalizaremos la operación del kernel.
Después de crear el kernel, volveremos a nuestro programa principal donde creamos los métodos de nuestra nueva clase CNeuronDOTOCL. Primero crearemos un método DOT, que se encargará de poner en la cola de ejecución el kernel creado anteriormente.
El algoritmo del método es bastante sencillo: Todo lo que haremos es transferir parámetros externos al kernel.
bool CNeuronDOTOCL::DOT(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iUnits, iHeads}; uint local_work_size[3] = {iDimension, 1, 1}; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_qkv, cQKV.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_score, iScoreBuffer)) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_out, MHAttentionOut.getOutputIndex())) return false;
Después de lo cual enviamos el kernel a la cola de ejecución.
ResetLastError(); if(!OpenCL.Execute(def_k_DOTFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Al mismo tiempo, no nos olvidaremos de controlar el proceso de las operaciones en cada fase.
Una vez completado el trabajo preparatorio, pasaremos a crear el método CNeuronDOTOCL::feedForward, donde definiremos a nivel superior el algoritmo de pasada directa de nuestra capa.
En los parámetros del método, obtendremos el puntero a la capa de la capa neuronal anterior. Por comodidad, guardaremos el puntero obtenido en una variable local.
bool CNeuronDOTOCL::feedForward(CNeuronBaseOCL *NeuronOCL)
{
CNeuronBaseOCL* inputs = NeuronOCL;
A continuación comprobaremos si el tamaño de los datos de origen difiere de los parámetros de la capa actual. De ser necesario, escalaremos los datos de origen y calcularemos las entidades Query, Key y Value.
Si hay búferes de datos iguales, omitiremos el paso del escalado y generaremos las entidades Query, Key y Value directamente.
if(iPrevWindowSize != iWindowSize) { if(!cProjInput.FeedForward(inputs) || !cQKV.FeedForward(GetPointer(cProjInput))) return false; inputs = GetPointer(cProjInput); } else if(!cQKV.FeedForward(inputs)) return false;
El siguiente paso será llamar al método Self-Attention creado anteriormente con ventanas.
if(!DOT()) return false;
Después reduciremos la dimensionalidad de los datos.
if(!cProj.FeedForward(GetPointer(MHAttentionOut))) return false;
Y añadiremos el resultado al búfer de datos de origen.
if(!SumAndNormilize(inputs.getOutput(), cProj.getOutput(), AttentionOut.getOutput(), iWindowSize, true)) return false;
Pasaremos el resultado por el bloque FeedForward.
if(!cFF1.FeedForward(GetPointer(AttentionOut))) return false; if(!cFF2.FeedForward(GetPointer(cFF1))) return false;
Nuevamente, sumaremos los búferes de resultados. Esta vez mostrando el bloque Self-Attention con ventanas.
if(!SumAndNormilize(AttentionOut.getOutput(), cFF2.getOutput(), SAttenOut.getOutput(), iWindowSize, true)) return false;
Al final del bloque vendrá la etapa de Self-attention global. Para ello utilizaremos la capa CNeuronXCiTOCL.
if(!cCAtten.FeedForward(GetPointer(SAttenOut))) return false; //--- return true; }
Luego comprobaremos los resultados de las operaciones y finalizaremos el método.
Con esto damos por concluida nuestra panorámica de la implementación de la pasada directa de nuestra clase y pasamos a trabajar en los métodos de pasada inversa. Aquí también comenzaremos nuestro trabajo creando un kernel de pasada inversa del bloque de Self-Attention con ventanas DOTInsideGradients. Al igual que el kernel de pasada directa, ejecutaremos el nuevo kernel en un espacio de tareas tridimensional, solo que esta vez sin crear grupos locales.
En los parámetros, el kernel obtendrá los punteros a todos los búferes de datos necesarios.
__kernel void DOTInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *rpb, __global float *rpb_g, __global float *gradient) { //--- init const uint u = get_global_id(0); const uint d = get_global_id(1); const uint h = get_global_id(2); const uint units = get_global_size(0); const uint dimension = get_global_size(1); const uint heads = get_global_size(2);
Y en el cuerpo del kernel, identificaremos directamente el hilo en las 3 dimensiones. Y definiremos un espacio de tareas que nos indique la dimensionalidad de los búferes resultantes.
Aquí es también donde determinaremos el desplazamiento en los búferes de datos.
uint step = 3 * dimension * heads; uint start = max((int)u - 1, 0); uint stop = min((int)u + 1, (int)units - 1); const uint shift_q = u * step + dimension * h + d; const uint shift_k = u * step + dimension * (heads + h) + d; const uint shift_v = u * step + dimension * (2 * heads + h) + d;
Después pasaremos directamente a la distribución del gradiente. En primer lugar, definiremos el gradiente de error para el elemento Value. Para ello, multiplicaremos el gradiente resultante por el coeficiente de influencia correspondiente.
//--- Calculating Value's gradients float sum = 0; for(uint i = start; i <= stop; i ++) { int shift_score = i * 3 * heads; if(u == i) { shift_score += (uint)(u > 0); } else { if(u > i) shift_score += (uint)(start > 0) + 1; } uint shift_g = dimension * (i * heads + h) + d; sum += gradient[shift_g] * scores[shift_score]; } qkv_g[shift_v] = sum;
El siguiente paso será determinar el gradiente de error para la entidad de Query. Aquí el algoritmo será un poco más complicado. Primero tendremos que determinar el gradiente de error para el correspondiente vector de coeficientes de dependencia. Luego ajustaremos el gradiente resultante usando la derivada de la función SoftMax. Solo entonces podremos multiplicar el gradiente de error resultante de los coeficientes de dependencia por el elemento correspondiente del tensor de entidades Key.
Cabe señalar aquí que, antes de normalizar los coeficientes de dependencia, los hemos sumado con los elementos de desplazamiento posicional de la atención. Como sabemos, al añadir el gradiente, transferimos totalmente el gradiente en ambas direcciones. El recuento doble se nivelará fácilmente gracias a la pequeña tasa de aprendizaje. En consecuencia, transferiremos el gradiente de error al nivel de la matriz de los coeficientes de dependencia al búfer de gradiente de error de desplazamiento posicional.
//--- Calculating Query's gradients float grad = 0; uint shift_score = u * heads * 3; for(int k = start; k <= stop; k++) { float sc_g = 0; float sc = scores[shift_score + k - start]; for(int v = start; v <= stop; v++) for(int dim=0;dim<dimension;dim++) sc_g += scores[shift_score + v - start] * qkv[v * step + dimension * (2 * heads + h) + dim] * gradient[dimension * (u * heads + h) + dim] * ((float)(k == v) - sc); grad += sc_g * qkv[k * step + dimension * (heads + h) + d]; if(d == 0) rpb_g[shift_score + k - start] = sc_g; } qkv_g[shift_q] = grad;
A continuación, solo nos quedará determinar el gradiente de error para la entidad Key de forma similar. El algoritmo es similar al de Query, pero en una dimensión diferente de la matriz de coeficientes.
//--- Calculating Key's gradients grad = 0; for(int q = start; q <= stop; q++) { float sc_g = 0; shift_score = q * heads * 3; if(u == q) { shift_score += (uint)(u > 0); } else { if(u > q) shift_score += (uint)(start > 0) + 1; } float sc = scores[shift_score]; for(int v = start; v <= stop; v++) { shift_score = v * heads * 3; if(u == v) { shift_score += (uint)(u > 0); } else { if(u > v) shift_score += (uint)(start > 0) + 1; } for(int dim=0;dim<dimension;dim++) sc_g += scores[shift_score] * qkv[shift_v-d+dim] * gradient[dimension * (v * heads + h) + d] * ((float)(d == v) - sc); } grad += sc_g * qkv[q * step + dimension * h + d]; } qkv_g[shift_k] = grad; }
Esto completará el kernel y nos llevará de nuevo a trabajar con nuestra clase CNeuronDOTOCL, donde crearemos un método DOTInsideGradients para llamar al kernel creado anteriormente. El algoritmo seguirá siendo el mismo:
- definimos el espacio de tareas
bool CNeuronDOTOCL::DOTInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iUnits, iDimension, iHeads};
- transmitimos los parámetros
if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_qkv, cQKV.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_qkv_g, cQKV.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_scores, iScoreBuffer)) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_rpb_g, cRelativePositionsBias.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_gradient, MHAttentionOut.getGradientIndex())) return false;
- colocamos en la cola de ejecución
ResetLastError(); if(!OpenCL.Execute(def_k_DOTInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
- comprobamos el resultado de las operaciones y finalizamos el método.
El propio algoritmo de pasada inversa lo escribiremos en el método calcInputGradients. En los parámetros, este método obtendrá el puntero al objeto de la capa anterior al que se debe transmitir el gradiente de error. En el cuerpo del método comprobaremos directamente la relevancia del puntero recibido. Después de todo, con un puntero no válido, no tendremos a dónde transmitir el gradiente de error. Y el significado lógico de todas las operaciones se aproximará a "0".
bool CNeuronDOTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
A continuación, repetiremos las operaciones de pasada directa en orden inverso. Al inicializar nuestra clase CNeuronDOTOCL, hemos tenido la precaución de intercambiar los búferes. Y ahora, al recibir el gradiente de error de la capa neuronal descendente, lo obtendremos directamente en la capa de atención global. En consecuencia, omitiremos la ya redundante operación de copiado de datos y llamaremos inmediatamente al método de la capa interna de atención global del mismo nombre.
if(!cCAtten.calcInputGradients(GetPointer(SAttenOut))) return false;
Aquí también hemos utilizado la técnica de intercambio de búferes y pasaremos inmediatamente el gradiente de error a través del bloque FeedForward.
if(!cFF2.calcInputGradients(GetPointer(cFF1))) return false; if(!cFF1.calcInputGradients(GetPointer(AttentionOut))) return false;
A continuación, resumiremos el gradiente de error de los 2 hilos.
if(!SumAndNormilize(AttentionOut.getGradient(), SAttenOut.getGradient(), cProj.getGradient(), iWindowSize, false)) return false;
Y lo distribuiremos a las cabezas de atención.
if(!cProj.calcInputGradients(GetPointer(MHAttentionOut))) return false;
Luego llamaremos a nuestro método de distribución de gradiente de error a través del bloque de Self-attention con ventanas.
if(!DOTInsideGradients()) return false;
A continuación, comprobaremos si el tamaño de la capa anterior se corresponde con el tamaño de la capa actual. Cuando necesitemos escalar los datos, primero haremos descender el gradiente de error a la capa de escalado. Sumaremos los gradientes de error de los 2 hilos. Y solo entonces escalaremos el gradiente de error a la capa anterior.
if(iPrevWindowSize != iWindowSize) { if(!cQKV.calcInputGradients(GetPointer(cProjInput))) return false; if(!SumAndNormilize(cProjInput.getGradient(), cProj.getGradient(), cProjInput.getGradient(), iWindowSize, false)) return false; if(!cProjInput.calcInputGradients(prevLayer)) return false; }
En el caso de capas neuronales iguales, transmitiremos inmediatamente el gradiente de error a la capa anterior. Y luego lo aumentaremos con el gradiente de error del segundo hilo.
else { if(!cQKV.calcInputGradients(prevLayer)) return false; if(!SumAndNormilize(prevLayer.getGradient(), cProj.getGradient(), prevLayer.getGradient(), iWindowSize, false)) return false; } //--- return true; }
Tras distribuir el gradiente de error entre todas las capas neuronales, tendremos que actualizar los parámetros del modelo para minimizar el error. Y aquí todo sería trivial, si no fuera por un "pero". ¿Recuerda el búfer de parámetros de influencia posicional de los elementos? Tendremos que actualizar sus parámetros. Para implementar esta funcionalidad, crearemos el kernel RPBUpdateAdam. En los parámetros, transmitiremos los punteros al búfer de parámetros actuales y gradiente de error al kernel. Y también los tensores auxiliares y las constantes del método Adam.
__kernel void RPBUpdateAdam(__global float *target, __global const float *gradient, __global float *matrix_m, ///<[in,out] Matrix of first momentum __global float *matrix_v, ///<[in,out] Matrix of seconfd momentum const float b1, ///< First momentum multiplier const float b2 ///< Second momentum multiplier ) { const int i = get_global_id(0);
En el cuerpo del kernel, identificaremos el hilo que nos señala el desplazamiento en los búferes de datos.
A continuación, declararemos las variables locales y almacenaremos en ellas los valores necesarios de los búferes globales.
float m, v, weight; m = matrix_m[i]; v = matrix_v[i]; weight = target[i]; float g = gradient[i];
Según el método Adam, primero definiremos los momentos.
m = b1 * m + (1 - b1) * g; v = b2 * v + (1 - b2) * pow(g, 2);
A partir de los momentos obtenidos, calcularemos la corrección necesaria del parámetro.
float delta = m / (v != 0.0f ? sqrt(v) : 1.0f);
Y guardaremos todos los datos en los elementos correspondientes de los búferes globales.
target[i] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[i] = m; matrix_v[i] = v; }
Ahora regresaremos a nuestra clase CNeuronDOTOCL y crearemos el método updateRelativePositionsBias de la llamada al kernel siguiendo el patrón ya clásico. Aquí utilizaremos un espacio de tareas unidimensional.
bool CNeuronDOTOCL::updateRelativePositionsBias(void) { if(!OpenCL) return false; //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {cRelativePositionsBias.Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_gradient, cRelativePositionsBias.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_matrix_m, cRelativePositionsBias.getFirstMomentumIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_matrix_v, cRelativePositionsBias.getSecondMomentumIndex())) return false; if(!OpenCL.SetArgument(def_k_RPBUpdateAdam, def_k_rpbw_b1, b1)) return false; if(!OpenCL.SetArgument(def_k_RPBUpdateAdam, def_k_rpbw_b2, b2)) return false; ResetLastError(); if(!OpenCL.Execute(def_k_RPBUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Los trabajos preparatorios han concluido. Ahora podemos proceder a crear un método de nivel superior para actualizar los parámetros del bloque updateInputWeights. En los parámetros, el método obtendrá el puntero al objeto de la capa anterior. En este caso omitiremos la comprobación del puntero recibido, ya que se realizará en los métodos de la capa interna.
En primer lugar, comprobaremos si es necesario actualizar los parámetros de la capa de escalado. Y de ser necesario, llamaremos al método homónimo de la capa especificada.
if(iWindowSize != iPrevWindowSize) { if(!cProjInput.UpdateInputWeights(NeuronOCL)) return false; if(!cQKV.UpdateInputWeights(GetPointer(cProjInput))) return false; } else { if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; }
A continuación, actualizaremos los parámetros de la capa de generación de entidades Query, Key y Value.
Del mismo modo, actualizaremos los parámetros de todas las capas internas.
if(!cProj.UpdateInputWeights(GetPointer(MHAttentionOut))) return false; if(!cFF1.UpdateInputWeights(GetPointer(AttentionOut))) return false; if(!cFF2.UpdateInputWeights(GetPointer(cFF1))) return false; if(!cCAtten.UpdateInputWeights(GetPointer(SAttenOut))) return false;
Y al final del método actualizaremos los parámetros de desplazamiento posicional.
if(!updateRelativePositionsBias()) return false; //--- return true; }
Al mismo tiempo, no nos olvidaremos de controlar el proceso de las operaciones en cada paso.
Con esto concluimos nuestra revisión de los métodos de la nueva capa neuronal CNeuronDOTOCL. El código completo de la clase y todos sus métodos, incluidos los que no se han descrito en este artículo, se encuentran en el archivo adjunto.
Ahora procederemos a construir la arquitectura de nuestro nuevo modelo.
2.2 Arquitectura del modelo
Como es habitual, describiremos la arquitectura de nuestro modelo en el método CreateDescriptions. En los parámetros, el método obtendrá los punteros a 3 arrays dinámicos para almacenar la descripción de los modelos. En el cuerpo del método comprobaremos directamente la relevancia de los punteros recibidos y, de ser necesario, crearemos nuevos ejemplares de array.
bool CreateDescriptions(CArrayObj *dot, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Como habrá observado, crearemos 3 modelos:
- DOT
- Actor
- Critic.
El bloque DOT será proporcionado por la arquitectura DFFT, lo cual no será el caso del Actor y el Crítico. Pero queremos recordarle que el método DFFT propone crear un bloque TAE con salidas de clasificación y regresión. El uso coherente del Actor y el Crítico debería emular un bloque TAE. El Actor es un clasificador de acciones, mientras que el Crítico supone una regresión de recompensas.
Luego suministraremos a la entrada del modelo DOT la descripción del estado actual del entorno.
//--- DOT dot.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
Los datos "brutos" que procesamos en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
A continuación, crearemos una incorporación con los últimos datos y la añadiremos a la pila.
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!dot.Add(descr)) { delete descr; return false; }
Después añadiremos la codificación posicional de los datos.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!dot.Add(descr)) { delete descr; return false; }
Hasta ahora, hemos reproducido la arquitectura de incorporación de trabajos anteriores, pero más adelante empezará a producirse el cambio. Luego añadiremos el primer bloque DOT, que realizará el análisis estado por estado.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
En el siguiente bloque, comprimiremos los datos en un factor de 2, pero seguiremos analizando por estados individuales.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; prev_wout = descr.window = prev_wout / 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
A continuación, agruparemos los datos para el análisis en el tamaño de dos estados consecutivos.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; prev_count = descr.count = prev_count / 2; prev_wout = descr.window = prev_wout * 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
Y una vez más, comprimiremos los datos.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; prev_wout = descr.window = prev_wout / 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
La última capa del modelo DOT quedará fuera del alcance del método DFFT. Aquí es donde hemos añadido una capa de atención cruzada.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMH2AttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = prev_wout / descr.step; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
El modelo del Actor obtendrá como entrada los estados del entorno procesados en el modelo DOT.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count*prev_wout; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Los datos resultantes se combinarán con el estado actual de la cuenta.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
Los datos se procesarán en 2 capas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y en la salida generaremos la política estocástica del Actor.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El crítico también usará los estados del entorno procesados como datos de entrada.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; }
Complementaremos la descripción del entorno con las acciones del Agente.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; }
Los datos se procesarán en 2 capas totalmente conectadas con un vector de recompensas a la salida.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.3 Asesor de interacción con el entorno
Una vez compilada la arquitectura de los modelos, pasaremos a crear un asesor para interactuar con el entorno: "...\Experts\DFFT\Research.mq5". Este asesor está diseñado para recoger una muestra de entrenamiento inicial y luego actualizar el búfer de reproducción de experiencias. El asesor también puede utilizarse para probar el modelo entrenado. Aunque el asesor "...\Experts\DFFT\Test.mq5" se ofrece para cumplir con esta funcionalidad. Ambos asesores tienen un algoritmo similar. Solo este último no almacenará los datos en el búfer de reproducción de experiencias para un aprendizaje posterior. Esto se hará para lograr una prueba "justa" del modelo entrenado.
Permítanme decir de inmediato que ambos asesores han sido en gran parte copiados de trabajos anteriores. En el marco de este artículo, solo señalaremos los cambios relevantes para las especificidades de los modelos.
Como parte de la funcionalidad de recopilación de datos, no utilizaremos el modelo del Crítico.
CNet DOT; CNet Actor;
En el método de inicialización del asesor, primero conectaremos los indicadores necesarios.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- load models float temp;
Después intentaremos cargar los modelos preentrenados.
if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, actor, critic)) { delete dot; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Actor.Create(actor)) { delete dot; delete actor; delete critic; return INIT_FAILED; } delete dot; delete actor; delete critic; }
Si los modelos no han podido cargarse, inicializaremos los nuevos modelos con parámetros aleatorios. A continuación, transferimos ambos modelos a un único contexto OpenCL.
Actor.SetOpenCL(DOT.GetOpenCL());
Y realizaremos una verificación mínima de la arquitectura del modelo.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Y almacenaremos el estado de equilibrio en una variable local.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
La interacción directa con el entorno y la recogida de datos se realizará en el método OnTick. En el cuerpo del método primero comprobaremos si ha ocurrido un evento de apertura de nueva barra. Realizaremos todos los análisis solo en una vela nueva.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
A continuación, actualizaremos los datos históricos
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Y rellenaremos el búfer de la descripción del estado del entorno.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
El siguiente paso consistirá en recopilar los datos sobre el estado actual de la cuenta.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Luego consolidaremos los datos recogidos en el búfer de descripción del estado de la cuenta.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
Aquí también añadiremos una marca temporal del estado actual.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); //--- if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return;
Tras recoger los datos de origen, realizaremos una pasada directa del codificador.
if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
E inmediatamente efectuaremos una pasada directa del Actor.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(DOT), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Así, obtendremos los resultados del modelo.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions);
Y los descifraremos con la ejecución de las transacciones comerciales.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Después almacenaremos los datos del entorno en el búfer de reproducción de experiencias.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
El resto de los métodos del asesor se mantendrán sin cambios. Podrá leerlos usted mismo en el archivo adjunto.
2.4 Modelo de entrenamiento de modelos
Tras recoger la muestra de entrenamiento, pasaremos a construir el asesor de entrenamiento del modelo "...\Experts\DFFT\Study.mq5". Al igual que los asesores de interacción con el entorno, su algoritmo lo hemos tomado prestado en gran medida de trabajos anteriores. Por lo tanto, en lo referente al presente artículo, le propongo considerar únicamente el método de entrenamiento directo de modelos Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
En el cuerpo del método, primero generaremos un vector de probabilidades para seleccionar las trayectorias de la muestra de entrenamiento según sus retornos. Las pasadas más rentables se utilizarán con mayor frecuencia para entrenar el modelo.
A continuación, declararemos las variables locales necesarias.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Una vez concluido el trabajo preparatorio, organizaremos un sistema de ciclos de entrenamiento de modelos. Recordemos que hemos usado una pila de datos históricos en el modelo de Codificador. Un modelo de este tipo será muy sensible a la secuencia histórica de los datos suministrados. Por lo tanto, en un ciclo externo, muestrearemos una trayectoria del búfer de reproducción de experiencias y el estado inicial para entrenar en esa trayectoria.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Después eliminaremos la pila interna del modelo.
DOT.Clear();
Y organizaremos un ciclo anidado de recuperación de estados históricos secuenciales del búfer de reproducción de experiencias para entrenar el modelo. Fijaremos el paquete de entrenamiento del modelo en 2 días más que la profundidad de la pila interior del modelo.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
En el cuerpo del ciclo anidado, recuperaremos un estado del entorno del búfer de reproducción de experiencias y lo utilizaremos para una pasada directa del codificador.
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Para entrenar la política del Actor, primero necesitaremos llenar el búfer de descripción del estado de la cuenta como hicimos en el asesor de interacción con el entorno, solo que ahora no estaremos interrogando al entorno, sino extrayendo datos del búfer de reproducción de experiencias.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
También añadiremos una marca de tiempo.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Después haremos un pasada directa del Actor y el Crítico.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(DOT), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(DOT), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A continuación, entrenaremos al Actor para que actúe a partir del búfer de reproducción de experiencias con el gradiente transferido al modelo del Codificador. Clasificación de objetos en el bloque TAE propuesta por el método DFFT.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A continuación, determinaremos la recompensa para la siguiente transición al nuevo estado del entorno.
result.Assign(Buffer[tr].States[i+1].rewards); target.Assign(Buffer[tr].States[i+2].rewards); result=result-target*DiscFactor;
Y entrenaremos el modelo del Crítico con transferencia de gradiente de error a ambos modelos.
Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Aquí cabe señalar que en muchos algoritmos anteriores hemos intentado evitar la adaptación mutua de los modelos. Con cuidado de no obtener resultados indeseables. Los autores del método DFFT, por el contrario, argumentan que este enfoque permitirá un ajuste más completo de los parámetros del codificador para extraer la máxima información.
Tras entrenar los modelos, informaremos al usuario del progreso del proceso de entrenamiento y pasaremos a la siguiente iteración del ciclo.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez completadas con éxito todas las iteraciones del proceso de entrenamiento, borraremos el campo de comentarios del gráfico. Luego enviaremos los resultados del entrenamiento al registro. E inicializaremos la finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Con esto concluirá nuestra revisión de los métodos del asesor de entrenamiento de modelos. Podrá ver el código completo del asesor en el archivo adjunto. Ahí encontrará también todos los programas utilizados en la elaboración de este artículo.
3. Simulación
Con anterioridad, ya hemos trabajado bastante en la implementación del método Decoder-Free Fully Transformer-based (DFFT) usando MQL5. Y ahora ha llegado el momento de abordar la tercera parte de nuestro artículo; en ella, pondremos a prueba el trabajo realizado. Como siempre, el entrenamiento y las pruebas del nuevo modelo se realizarán con datos históricos del marco temporal EURUSD H1. Los parámetros de todos los indicadores se usarán por defecto.
Para entrenar el modelo, hemos recogido 500 trayectorias aleatorias a lo largo de los 7 primeros meses de 2023. Hemos puesto a prueba el modelo entrenado con datos históricos de agosto de 2023. Como podemos ver, el intervalo de prueba no ha formado parte de la muestra de entrenamiento, lo cual nos permite evaluar el rendimiento del modelo con nuevos datos.
Debo admitir que el modelo ha resultado bastante "ligero" en cuanto al consumo de recursos informáticos tanto durante el entrenamiento como en el modo operativo durante las pruebas.
El proceso de entrenamiento ha sido bastante estable, con un descenso suave tanto del error del Actor como del Crítico. Durante el entrenamiento, hemos obtenido un modelo capaz de generar ganancias marginales tanto con los datos de entrenamiento como con los de prueba. No obstante, me gustaría ver un mayor nivel de rendimiento y una línea de balance más plana.
Conclusión
En este artículo, nos hemos familiarizado con el método DFFT, un eficaz detector de objetos basado en transformadores sin uso de decodificador, que hemos introducido para resolver problemas de visión por computadora. Las principales características de este enfoque incluyen el uso de un transformador para la extracción de características y la predicción densa en un único mapa de características. El método propone nuevos módulos para mejorar la eficacia del entrenamiento y la explotación de los modelos.
Los autores del método han demostrado que el DFFT ofrece una gran precisión en la detección de objetos con un coste computacional relativamente bajo.
En la parte práctica de este artículo, hemos implementado los enfoques propuestos usando herramientas MQL5. Asimismo, hemos entrenamos y probado el modelo construido con datos históricos reales. Los resultados obtenidos confirman la eficacia de los algoritmos propuestos y merecen un estudio práctico más detallado.
Como siempre, quiero recordarles que todos los programas presentados en el artículo son de carácter puramente ilustrativo, y solo han sido creados para mostrar los enfoques propuestos, así como sus capacidades. Antes de utilizar los programas en mercados financieros reales, será necesario perfeccionarlos y probarlos a fondo.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de cobros de ejemplo Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14338
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso