
ニューラルネットワークが簡単に(第84回):RevIN (Reversible Normalization)

はじめに
前回の記事ではConformerメソッドについて説明しました。これは、もともと天気予報のために開発された、非常に興味深い手法です。訓練済みモデルをテストしたところ、かなり良好な結果が得られましたが、果たして私たちはすべてを正しくおこなったのでしょうか。もっと良い結果を得ることは可能でしょうか。学習プロセスを見てみましょう。明らかに、次に最も確率の高い時系列値を予測するモデルを、本来の目的には使用していません。時系列データをモデルの入力として与え、予測結果を用いてモデルに誤差勾配を伝播させることでモデルを訓練しました。まずはCriticの結果から始めました。
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
続いてActorの結果です。
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
そして再び、Actorからのデータです。操作の収益性のためにその方策を調整します。
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), -1, -1, false) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
もちろん、それは悪いことではありません。これは様々なモデルの訓練で広く使われている方法です。しかし、この場合、初期環境状態のエンコーダーモデルを訓練する際、その後の状態を予測するのではなく、その後のモデルの動作を最適化できる個々の特徴を特定することに重点が置かれます。
主な仕事は、もちろんActorの最適な方策を見つけることです。つまり、一見したところエンコーダーモデルをActorの目標に合わせることに問題はありませんが、この場合、エンコーダーは少し異なる問題を解決します。実際には、その後のモデルのブロックとなります。そのアーキテクチャは、必要なタスクを解決するのに最適とは限らないかもしれません。
さらに、3つの異なるタスクの誤差勾配を使ってエンコーダーを訓練する場合、個々のタスクの勾配の方向が異なるという問題が発生する可能性があります。この場合、モデルは設定されたすべてのタスクを最もよく満たす「黄金平均」を探しますが、このような解が最適解から大きく外れている可能性は十分にあります。
モデルを活用するという構造化されたロジックは、学習プロセスにも導入すべきだと明らかです。このパラダイムでは、まずエンコーダーを訓練し、その後、環境の状態を予測する必要があります。Conformerアプローチは、まさにエンコーダーに使用されており、予測された環境状態を基に、Actorの方策を訓練します。
理論的には明確ですが、実装では環境の状態を記述する個々の特徴の分布に大きな差異が生じます。このような生の環境状態を表すデータをモデルの入力として受け取り、それを比較可能な形に正規化します。しかし、モデルの出力で異なる値を得るにはどうすればよいのでしょうか。
これまでにも、様々なオートエンコーダーモデルを訓練する際に、同様の問題に直面してきました。その際は、正規化後のオリジナルデータをターゲットとして使用することで解決しましたが、このケースでは、入力データとは異なる環境のその後の状態を記述するデータが必要になります。この問題を解決する方法の1つが、論文「Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift」で提案されています。
この論文の著者は、シンプルで効果的な正規化と非正規化の方法であるReversible Instant Normalization (RevIN)を提案しています。このアルゴリズムでは、まず入力系列を正規化し、次にモデルの出力系列を非正規化することで、分布シフトに関連する時系列予測の問題を解決します。RevINは、正規化層でのシフトとスケーリングに相当する量を、非正規化層で逆にスケーリングおよびシフトする対称的な構造で、元の分布情報をモデル出力に戻します。
RevINRevINは柔軟かつ訓練可能な層で、任意の層に適用可能です。ある層で非定常な情報(インスタンスの平均と分散)を効果的に抑制し、入力層や出力層など対称的な位置にある別の層で復元します。
1. RevINアルゴリズム
RevINアルゴリズムを理解するために、入力データX = {xi}i=[1..N]と対応するターゲットY = {yi}i=[1..N]の集合に対する離散時間の時系列多変量予測問題を考えてみましょう。ここで、Nはシーケンス内の要素の数を表します。
K、Tx、Tyがそれぞれ変数の数、入力シーケンスの長さ、モデル予測値の長さを表すとします。入力系列Xi∈ RK*TxTxが与えられたとき、後続の値Yi∈ RK*Tyを予測する時系列予測問題を解くことが目的です。RevINでは、時間次元に沿って観測が正規化および非正規化されるため、入力シーケンスの長さTxと予測の長さTyは異なる可能性があります。提案手法であるRevINは、対称的に構造化された正規化層と非正規化層から構成されます。まず、入力Xiをその平均と標準偏差を使って正規化します。これは「インスタント正規化」として広く受け入れられており、各入力インスタンスXiの平均と標準偏差は以下のように計算されます。
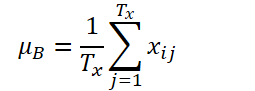
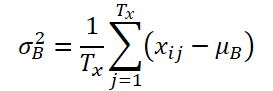

正規化された配列は、非定常な情報が抑えられ、より一貫した平均値と標準偏差を持つことが可能になります。その結果、正規化層は、平均と分散の点で一貫した分布の入力を受け取ることができ、モデルがシーケンス内の局所的なダイナミクスを正確に予測できるようになります。
モデルはこの変換されたデータを入力として受け取り、将来の値を予測します。しかし、入力データは元々の分布とは異なる統計量を持っており、正規化されたデータだけではその本来の分布を捉えるのは難しいです。そこで、モデルのタスクを容易にするために、出力層で対称的に正規化を反転させ、入力データから除去された非定常な特徴をモデルの出力に再び反映させます。非正規化のステップにより、モデル出力を元の時系列値に戻すことができるのです。この逆正規化操作を適用することで、モデル出力が非正規化され、元のデータの特徴を取り戻します。

正規化ステップで使用された統計量は、スケーリングとシフトにも使用されます。ここで、モデルの最終予測値をŷiとします。
RevINは、ネットワーク内の実質的に対称な位置に追加するだけで、訓練可能な正規化層として時系列データの分布の発散を効果的に低減することができ、一般的にあらゆるディープニューラルネットワークに適用可能です。提案された方法は非常に柔軟で、学習可能な層として機能し、任意に選択された層や複数の層に適用できます。この手法の著者は、この手法をさまざまなモデルの中間層に適用し、柔軟な層としての有効性を確認しています。ただし、RevINが最も効果を発揮するのは、エンコーダーデコーダー構造における対称的な層に適用した場合です。典型的な時系列予測モデルでは、エンコーダーとデコーダーの境界が不明確な場合が多いです。したがって、この手法の著者は、モデルの入力層と出力層にRevINを適用しています。これは、入力層と出力層が、エンコーダーデコーダー構造として入力データに基づいて後続の値を生成する役割を果たしているからです。
RevINメソッドの元の視覚化を以下に示します。

2. MQL5での実装
提案手法の理論的側面を考察したので、次にMQL5を使った実際の実装に進みましょう。
理論的な説明からわかるように、この手法の著者が提案した初期データの正規化は、以前に実装したCNeuronBatchNormOCLバッチ正規化層のアルゴリズムとほぼ同一であることがわかります。そのため、既存のクラスを使用してデータの正規化をおこなうことができます。しかし、データの非正規化には新しい層が必要です。これには、新しいニューラル層CNeuronRevINDenormOCLを作成します。
2.1 新しい非正規化層の作成
当然ながら、データの非正規化のプロセスでは、データの正規化で使用されたオブジェクトが使用されます。そのため、新しいCNeuronRevINDenormOCL層はCNeuronBatchNormOCL正規化層から派生しています。
class CNeuronRevINDenormOCL : public CNeuronBatchNormOCL { protected: int iBatchNormLayer; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronRevINDenormOCL(void) : iBatchNormLayer(-1) {}; ~CNeuronRevINDenormOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, int NormLayer, CNeuronBatchNormOCL *normLayer); virtual int GetNormLayer(void) { return iBatchNormLayer; } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronRevInDenormOCL; } virtual CLayerDescription* GetLayerInfo(void); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) { return true; } };
RevIN法に基づくアルゴリズムでは、正規化ステップで訓練したパラメータを使って非正規化をおこないます。ここでのロジックは、正規化ステップで入力データの分布を分析し、その後、入力データを比較可能な形に整え、「ギャップ」を取り除くというものです。このモデルは正規化されたデータで動作し、出力時にデータを非正規化して入力データの元の分布パラメータを返します。その結果、モデルの出力には、入力データの自然な分布における予測データが含まれることが期待されます。
明確にしておきたいのは、非正規化ステップではモデルのパラメータは更新されないという点です。そのため、クラス構造内では、モデルパラメータを更新するためのメソッドを「空のスタブ」でオーバーライドします。それでも、フィードフォワードパスアルゴリズムと誤差勾配の計算は実装する必要があります。まず、基本的な部分から実装を始めていきましょう。
このクラスでは、追加の内部オブジェクトは宣言しないため、クラスのコンストラクタとデストラクタは空の状態にしておきます。ただし、正規化層の識別子を格納する変数iBatchNormLayerを作成します。また、この変数の値を取得するためのpublicメソッドGetNormLayer(void)も作成します。
新しいクラスのオブジェクトはCNeuronRevINDenormOCL::Initメソッドで初期化されます。このメソッドのパラメータには、内部オブジェクトや変数の初期化を成功させるために必要なすべての情報が渡されます。ここで、従来のニューラル層の手法と大きな違いが生じます。このメソッドのパラメータには、定数に加えて、CNeuronBatchNormOCLバッチ正規化層のオブジェクトへのポインタを渡します。
bool CNeuronRevINDenormOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, int NormLayer, CNeuronBatchNormOCL *normLayer) { if(NormLayer > 0) { if(!normLayer) return false; if(normLayer.Type() != defNeuronBatchNormOCL) return false; if(BatchOptions == normLayer.BatchOptions) BatchOptions = NULL; if(!CNeuronBatchNormOCL::Init(numOutputs, myIndex, open_cl, numNeurons, normLayer.iBatchSize, normLayer.Optimization())) return false; if(!!BatchOptions) delete BatchOptions; BatchOptions = normLayer.BatchOptions; }
もう1つの根本的な違いは、メソッドの本体にあります。ここでは、受け取ったバッチ正規化層の識別子に応じた分岐アルゴリズムを構築します。もし識別子が0より大きければ、まず受信したバッチ正規化層へのポインタを確認し、そのオブジェクトの型もチェックします。その後、親クラスの同じメソッドを呼び出し、指定されたすべての制御ポイントを正常に通過した場合にのみ、最適化パラメータバッファを置き換えます。
データ自体はコピーしません。代わりに、バッファオブジェクトへのポインタを完全に変更します。この設計により、モデルの訓練プロセスでは常に関連する正規化パラメータを使用して作業できるようになります。
アルゴリズムの2番目のブランチは、以前に保存されたモデルを読み込む際に、空のクラスオブジェクトを初期化することを目的としています。この場合、親クラスのメソッドを最小限のパラメータで呼び出すだけで済みます。
else if(!CNeuronBatchNormOCL::Init(numOutputs, myIndex, open_cl, numNeurons, 0, ADAM)) return false;
次に、選択したパスにかかわらず、得られたバッチ正規化層の識別子を保存して、メソッドを完了します。
iBatchNormLayer = NormLayer; //--- return true; }
2.2 フィードフォワードパスの構成
OpenCLプログラム側でRevInFeedForwardカーネルを作成することで、フィードフォワードパスアルゴリズムの実装を開始します。バッチ正規化層アルゴリズムの実装と同様に、このカーネルを1次元のタスク空間で起動します。
カーネルパラメータでは、3つのデータバッファ(ソースデータ、正規化パラメータ、結果)へのポインタを渡します。また、2つの定数(正規化バッチパラメータを含むバッファのサイズと、パラメータの最適化タイプ)を渡します。
__kernel void RevInFeedForward(__global float *inputs, __global float *options, __global float *output, int options_size, int optimization) { int n = get_global_id(0);
正規化パラメータバッファのサイズは、選択されたパラメータ最適化アルゴリズムに依存することをお忘れなく。このバッファの構造は以下の通りです。

カーネル本体では、タスク空間内で各スレッドを識別し、分析データに対するバッファのシフトも決定します。ソースバッファと結果バッファにおいて、オフセットは各スレッドの識別子に基づいて決まります。最適化パラメータバッファのシフトは、与えられたバッファ構造と指定されたパラメータ最適化方法に従って決定されます。
int shift = (n * optimization == 0 ? 7 : 9) % options_size;
加えて、分析した環境状態の数が予測の深さとは異なる可能性があることも考慮しなければなりません。この場合、分析された環境状態と予測された状態の構造を一貫して維持する必要があります。言い換えれば、ある環境状態の記述に基づいて分析されたパラメータの数と順序は、後続の状態を予測する際に完全に保持されなければなりません。したがって、正規化パラメータバッファのシフトを決定するためには、解析されたスレッドとバッファ構造に基づいて計算されたシフト値を、正規化パラメータバッファのサイズで割った余りを取ることで求めます。
次のステップは、グローバルバッファからローカル変数にデータを抽出することです。
float mean = options[shift]; float variance = options[shift + 1]; float k = options[shift + 3];
予測パラメータの非正規化値を計算します。
float res = 0; if(k != 0) res = sqrt(variance) * (inputs[n] - options[shift + 4]) / k + mean; if(isnan(res)) res = 0;
演算結果は、結果バッファの対応する要素に書き込まれます。
output[n] = res; }
OpenCLプログラム側でデータ非正規化アルゴリズムを実装した後、メインプログラムから作成されたカーネル呼び出しを実装する必要があります。そのためには、CNeuronRevINDenormOCL::feedForwardメソッドをオーバーライドする必要があります。
bool CNeuronRevINDenormOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false; //--- PrevLayer = NeuronOCL; //--- if(!BatchOptions) iBatchSize = 0; if(iBatchSize <= 1) { activation = (ENUM_ACTIVATION)NeuronOCL.Activation(); return true; }
親クラスの同じメソッドと同様に、このメソッドは、入力データを含む前の層のオブジェクトへのポインタをパラメータとして受け取ります。
メソッド本体では、受け取ったポインタを確認し、対応する変数に保存します。
次に正規化バッチサイズを確認します。もしバッチサイズが「1」を超えない場合は、正規化をおこなわず、そのまま前の層のデータを渡します。この場合、すべてのデータをコピーするわけではなく、活性化関数の識別子だけをコピーします。結果や勾配バッファにアクセスする際には、前の層のバッファへのポインタを返します。この機能はすでに親クラスに実装されています。
次に、カーネルを直接実行キューに入れるアルゴリズムを実装します。ここでは、まずタスク空間を定義します。
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
その後、必要なパラメータをカーネルに渡します。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffinputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffoptions, BatchOptions.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffoutput, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_RevInFeedForward, def_k_revffoptions_size, (int)BatchOptions.Total())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_RevInFeedForward, def_k_revffoptimization, (int)optimization)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルを実行キューに送ります。
if(!OpenCL.Execute(def_k_RevInFeedForward, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
各ステップで操作を制御することを忘れないでください。
2.3 誤差勾配伝搬アルゴリズム
フィードフォワードパスを実装した後は、バックプロパゲーションアルゴリズムを実装する必要があります。前述のように、この層には学習可能なパラメータは含まれておらず、正規化の段階で訓練されたパラメータを使用します。そのため、すべてのパラメータ更新メソッドは「スタブ」として置き換えられます。
しかし、この層はバックプロパゲーションアルゴリズムに参加し、誤差勾配はこの層を通じて前のニューラル層に伝搬されます。これに対処するためには、前回と同様に、まずOpenCLプログラムの側でRevInHiddenGradientカーネルを作成します。今回のカーネルでは、パラメータの数が増加します。データバッファへの4つのポインタ(前の層の結果と誤差勾配、最適化パラメータ、現在の層の結果層での誤差勾配のバッファ)を渡します。また、3つの定数(正規化パラメータバッファのサイズ、パラメータ最適化タイプ、前の層の活性化関数)も渡します。
__kernel void RevInHiddenGraddient(__global float *inputs, __global float *inputs_gr, __global float *options, __global float *output_gr, int options_size, int optimization, int activation) { int n = get_global_id(0); int shift = (n * optimization == 0 ? 7 : 9) % options_size;
カーネル本体では、まずスレッドを特定し、データバッファのシフトを決定します。バッファのシフトを決定するアルゴリズムは、フィードフォワードカーネルに関連する部分で前述しました。
次に、グローバルデータバッファからローカル変数にデータを読み込みます。
float variance = options[shift + 1]; float inp = inputs[n]; float k = options[shift + 3];
次に、非正規化関数の微分によって誤差勾配を調整します。ここで注目すべきは、非正規化の段階で、正規化パラメータはすべて定数となり、関数の微分は大幅に簡略化されることです。
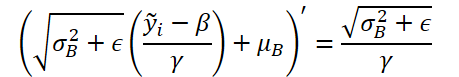
この関数をコードで実装してみましょう。
float res = 0; if(k != 0) res = sqrt(variance) * output_gr[n] / k; if(isnan(res)) res = 0;
その後、前のニューラル層の活性化関数の微分によって誤差勾配を調整します。
switch(activation) { case 0: res = clamp(res + inp, -1.0f, 1.0f) - inp; res = res * (1 - pow(inp == 1 || inp == -1 ? 0.99999999f : inp, 2)); break; case 1: res= clamp(res + inp, 0.0f, 1.0f) - inp; res = res * (inp == 0 || inp == 1 ? 0.00000001f : (inp * (1 - inp))); break; case 2: if(inp < 0) res *= 0.01f; break; default: break; }
演算結果を直前のニューラル層の誤差勾配バッファの対応する要素に保存します。
//---
inputs_gr[n] = res;
}
次のステップは、メインプログラム側でカーネル呼び出しを実装することです。この機能はCNeuronRevINDenormOCL::calcInputGradientsメソッドに実装されています。カーネルを実行キューに入れるアルゴリズムは、前述のフィードフォワード方式と同じです。従って、今はその詳細については触れません。
また、クラスの補助メソッドも考慮しません。アルゴリズムは非常にシンプルなので、添付ファイルを使って自分で勉強することができます。また、添付ファイルには、新しいクラスと以前に作成したクラスのすべてのメソッドの完全なコードが含まれているので、この記事で使われているすべてのプログラムを勉強することができます。
2.4 上級クラスでのスポット編集
新しいCNeuronRevINDenormOCLクラスの仕様に基づく、高レベルのクラスのメソッドに対する具体的な編集について説明します。これは、このクラスのオブジェクトの初期化と読み込みに関するものです。
CNeuronRevINDenormOCLクラスのオブジェクトを初期化する際には、データ正規化層のオブジェクトへのポインタを渡すという特殊な点があります。モデルアーキテクチャを説明する時点では、このオブジェクトがまだ作成されていないため、このポインタは存在しません。そのため、層の序数を示すことしかできませんが、これはモデルのアーキテクチャから推測することができます。
ただし、正規化層が非正規化層の前に存在することは明らかです。また、その間には任意の数のニューラル層を挟むことができます。つまり、非正規化層オブジェクトを作成する時点で、正規化層がすでにモデル内に作成されていなければなりません。正規化層に対するアクセスは可能ですが、これはモデル内部に限定されています。個々のニューラル層へのアクセスは、外部のプログラムには閉ざされているからです。
したがって、CNet::Createメソッドでは、CNeuronRevINDenormOCL非正規化層オブジェクトを初期化するための別のブロックを作成する必要があります。
case defNeuronRevInDenormOCL: if(desc.layers>=layers.Total()) { delete temp; return false; }
ここではまず、指定された識別子を持つ層がすでにモデルに作成されているかどうかを確認します。
次に、指定された層のタイプを確認します。バッチ正規化層であるべきです。
if(((CLayer *)layers.At(desc.layers)).At(0).Type()!=defNeuronBatchNormOCL) { delete temp; return false; }
指定されたコントロールが正常に渡された後にのみ、新しいオブジェクトを作成します。
revin = new CNeuronRevINDenormOCL(); if(!revin) { delete temp; return false; }
初期化します。
if(!revin.Init(outputs, 0, opencl, desc.count, desc.layers, ((CLayer *)layers.At(desc.layers)).At(0))) { delete temp; delete revin; return false; }
オブジェクトの配列に追加します。
if(!temp.Add(revin)) { delete temp; delete revin; return false; } break;
さらに、以前に訓練したモデルを読み込む際にも微妙なニュアンスがあります。ご存知のように、新しいクラスの初期化メソッドでは、正規化層の識別子に応じた分岐アルゴリズムを作成しました。これは、事前に訓練されたモデルを読み込めるようにするためです。重要なのは、オブジェクトを読み込む前に、そのオブジェクトの「ブランク」を作成する必要があるということです。この機能はCLayer::CreateElementメソッドで実行されます。問題は、データを読み込む前に正規化層の識別子がまだわからない点です。そのため、識別子には「-1」を、オブジェクトポインタにはNULLを指定します。
case defNeuronRevInDenormOCL: if(CheckPointer(OpenCL) == POINTER_INVALID) return false; revin = new CNeuronRevINDenormOCL(); if(CheckPointer(revin) == POINTER_INVALID) result = false; if(revin.Init(iOutputs, index, OpenCL, 1, -1, NULL)) { m_data[index] = revin; return true; } delete revin; break;
そして、読み込みの過程で、すべてのデータがクラスの内部オブジェクトと変数に読み込まれます。しかし、ここにもニュアンスがあります。データを読み込む際、モデルの事前訓練後に保存された正規化パラメータを取得しますが、これは実際には必要ありません。このモデルをさらに訓練して運用するには、正規化層と非正規化層の間でパラメータを同期させる必要があります。そうしないと、入力データの分布と予測との間にギャップが生じてしまいます。そこで、CNet::Loadメソッドに進み、次のニューラル層を読み込んだ後、そのタイプを確認します。
bool CNet::Load(const int file_handle) { ........ ........ //--- read array length num = FileReadInteger(file_handle, INT_VALUE); //--- read array if(num != 0) { for(i = 0; i < num; i++) { //--- create new element CLayer *Layer = new CLayer(0, file_handle, opencl); if(!Layer.Load(file_handle)) break; if(Layer.At(0).Type() == defNeuronRevInDenormOCL) { CNeuronRevINDenormOCL *revin = Layer.At(0); int l = revin.GetNormLayer(); if(!layers.At(l)) { delete Layer; break; }
CNeuronRevINDenormOCL非正規化層が検出された場合、正規化層へのポインタを要求し、そのような層が読み込まれているかどうかを確認します。
この層のタイプも確認します。
CNeuronBaseOCL *neuron = ((CLayer *)layers.At(l)).At(0); if(neuron.Type() != defNeuronBatchNormOCL) { delete Layer; break; }
指定された制御点が正常に渡されたら、対応する正規化層へのポインタを渡して層オブジェクトを初期化します。
if(!revin.Init(revin.getConnections(), 0, opencl, revin.Neurons(), l, neuron)) { delete Layer; break; } } if(!layers.Add(Layer)) break; } } FileClose(file_handle); //--- result return (layers.Total() == num); }
そして、先に作成したアルゴリズムに従います。
この記事の作成に使用したすべてのプログラムと同様に、すべてのクラスとそのメソッドの完全なコードは添付ファイルにあります。
2.5 訓練用モデルアーキテクチャ
RevIN法の著者が提案したアプローチをMQL5で実装しました。次に、それらをモデルのアーキテクチャに組み込む段階です。前述のように、エンコーダーモデルで非正規化を使用するのは、環境の後続状態を予測するための機能を実装するためです。NForecast定数を用いて、環境の予測状態(この場合、後続のローソクの数)を定義します。
#define NForecast 6 //Number of forecast
エンコーダーはActorやCriticとは別に訓練する予定なので、エンコーダーアーキテクチャの記述も別のメソッドCreateEncoderDescriptionsに移します。メソッドのパラメータには、作成されたモデルのアーキテクチャを保存するための動的配列へのポインタを1つだけ渡します。ここで注意しなければならないのは、CNeuronRevINDenormOCLクラスの実装では、デコーダーを別のモデルとして割り当てることができないということです。
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
メソッド本体では、受け取ったポインタを確認し、必要であれば動的配列オブジェクトの新しいインスタンスを生成します。
これまでと同様に、環境の状態を表す生の入力データをモデルに与えます。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
受信したデータはバッチ正規化層で一次処理を受けます。層の序数を保存する必要があります。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
入力データを正規化した後、データ埋め込みを作成し、内部スタックに追加します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {4, 1, 1, 1, 2}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count * 5; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
次に、データの位置エンコーディングを追加します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout * 5; if(!encoder.Add(descr)) { delete descr; return false; }
準備されたデータを5層のCNeuronConformerブロックに送り込みます。
//--- layer 5-10 for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 5; if(!encoder.Add(descr)) { delete descr; return false; } }
この方法をテストするために、適切な数の要素を持つ全結合層をデコーダーとして使用します。しかし、予測の質を向上させるためには、より複雑なアーキテクチャを持つデコーダーを使用することが推奨されます。
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NForecast*BarDescr; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
正規化されたデータを扱うので、分散は1に近く、平均は0に近いと仮定します。そこで、デコーダー出力の活性化関数として双曲線正接(tanh)を使用します。ご存知のように、その値の範囲は「-1」から1です。
そして最後に、予測値を非正規化します。
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
モデルの構造を説明する作業を終えるために、ActorとCriticの構造について考えてみましょう。指定されたモデルのアーキテクチャは、CreateDescriptionsメソッドに記述されます。前回の記事で説明したものとよく似ていますが、ニュアンスが違います。
パラメータの中で、このメソッドは2つの動的配列へのポインタを受け取ります。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
メソッド本体では、受け取ったポインタを確認し、必要であれば新しいオブジェクトインスタンスを生成します。
Actorには、口座状況と未決済ポジションを記述するテンソルを与えます。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
この表現の埋め込みを生成します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次にCross-Attentionブロックが登場し、口座の現在の状態と環境の予測状態を照らし合わせて分析します。
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
Actorモデルの最後には、確率的方策による意思決定ブロックがあります。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Criticのモデルも同じように構成されています。Criticは口座の状態を記述する代わりに、予測される環境の状態の文脈でActorの行動を分析します。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } }
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Criticの出力では、エージェントの行動に対する、確率的ではない明確な評価が得られます。
2.6 モデル訓練プログラム
訓練済みモデルのアーキテクチャを説明した後は、訓練プログラムの作成に移ります。エンコーダーを訓練するために、EA「...\Experts\RevIN\StudyEncoder.mq5」を作成します。EAのアーキテクチャは、以前の記事で紹介したものを踏襲しているので、この連載ではすでに何度も取り上げてきたものです。したがって、ここではTrainモデル訓練メソッドに焦点を当てます。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
メソッドの本体では、通常通り、収益性に応じて軌道を選択する確率のベクトルを生成します。将来の環境状態を予測する場合、すべてのパスは同じです。エンコーダーは口座状況と未決済ポジションを分析しないためです。しかし、異なる履歴間隔でのパスに基づく経験再生バッファがある場合、この機能は削除しません。
そして、ローカル変数を準備し、モデルの訓練ループのシステムを編成します。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - batch)); if(state <= 0) { iter--; continue; } Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - NForecast);
外側ループの本体では、経験再生バッファから軌跡をサンプリングし、その上で学習開始時の状態をサンプリングします。その後、訓練バッチの最終状態を決定し、内部モデルスタックをクリアします。その後、過去のデータから選択したセグメントに対して、入れ子の学習サイクルを実行します。
for(int i = state; i < end && !IsStopped() && !Stop; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
ここではまず、訓練セットから目的の状態を読み込みます。これをデータバッファに移します。次に、モデルの対応するメソッドを呼び出して、エンコーダーのフィードフォワードパスを実行します。
次のステップでは、ターゲットデータを準備します。そのために、訓練サンプルから必要な数の後続状態を取り出し、データバッファに追加する別の入れ子ループを構成します。
//--- Collect target data bState.Clear(); for(int fst = 1; fst <= NForecast; fst++) { if(!bState.AddArray(Buffer[tr].States[i + fst].state)) break; }
目標値を収集した後、予測値と目標値の誤差を最小化するためにエンコーダーのバックプロパゲーションパスを実行することができます。
if(!Encoder.backProp(GetPointer(bState), (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
その後、訓練の進捗状況をユーザーに通知し、次の訓練反復に移ります。
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
すべての訓練反復が成功したら、コメント欄をクリアします。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
達成された訓練結果の情報をログに出力し、EAの終了処理を初期化します。
将来の環境状態を予測するモデルを訓練することは有用です。しかし、私たちの目標はActor方策を訓練することです。次に、ActorとCriticを訓練するEA「....\Experts\RevIN\Study.mq5」を作成します。EAは同じアーキテクチャに基づいて構成されているので、具体的な変更点のみに触れます。
まず、EAの初期化において、事前に訓練されたエンコーダーがない場合、プログラムの初期化が正しくおこなわれていないというエラーが発生します。
int OnInit() { //--- ........ ........ //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Error of load Encoder: %d", GetLastError()); return INIT_FAILED; } ........ ........ //--- return(INIT_SUCCEEDED); }
第二に、このモデルのエンコーダーは訓練されていないので、保存すべきではありません。
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
さらに、ActorとCriticの入力データ源としてエンコーダーを使う場合、1つだけ注意点があります。記事の冒頭で、モデルの訓練と運用に正規化されたデータを使用することの重要性について述べました。一方、エンコーダー出力の非正規化層は予測を元のデータ分布に戻すため、両者を比較できなくなります。
しかし、モデルの隠れ層にアクセスしてデータを抽出する機能はすでに実装されています。この機能を利用して、エンコーダーの最後の層から正規化された予測データを取得します。このデータをActorとCriticの初期データとして使用します。LatentLayer定数に必要な層へのポインタを指定します。
#define LatentLayer 11
Criticへのフィードフォワード呼び出しは
if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
または
if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
のようになります。したがって、Actorのフィードフォワード呼び出しを次のように書きます。
if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
モデルのバックプロパゲーションメソッドを呼び出すときには、層識別子を指定するのを忘れないでください。
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder),LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
環境との相互作用のEAにも同様の変更を加えました。添付ファイルにあるコードを使って、自分で確認することができます。添付ファイルにはすべてのプログラムの完全なコードが含まれています。
3. テスト
必要なプログラムをすべて作成したら、いよいよモデルの訓練とテストをおこないます。これにより、提案された解決策の有効性を評価できます。
モデルの訓練とテストには、EURUSDのH1履歴データを使用します。
時間は止まっていません。データは時間とともに増えていくため、この記事の執筆に際し、訓練データセットの過去の区間を2023年全体にまで広げることにしました。2024年1月のデータは、訓練済みモデルのテストに使用されます。
主要な訓練データセットを作成するために、Real-ORLフレームワークを使用しました。このリンクに詳しい説明があります。20の実際のシグナルから取引データをダウンロードしました。そこで、EA「...\Experts\RevIN\ResearchRealORL.mq5」をFull Optimizationモードで動かしてみました。


その結果、20の軌道が得られました。そのすべてが利益を上げているわけではありません。

このステップでは、まずエンコーダーの訓練を開始します。エンコーダーの訓練が完了したら、ActorとCriticのプライマリ訓練を実行します。これは主に、Actorの最適な方策を得るには20の軌道では少なすぎるからです。
次のステップでは、訓練データセットを拡張します。そのために、低速完全最適化モードで、EA「...\Experts\RevIN\Research.mq5」を実行します。訓練期間内の実際の履歴データで現在のActor方策をテストし、訓練データセットにパスを追加します。

この段階では、突出した結果を期待してはいけません。ネガティブな結果もまた結果です。これはまた、さらなるモデル訓練実験のための良い経験にもなります。さらに、このような反復は、Actorの現在の方策の行動領域の環境を理解するのに役立ちます。
Actor方策の訓練を何度か繰り返し、訓練データセットに追加データを収集した結果、訓練データセットとテストデータセットの両方で利益を生み出せるモデルを訓練することができました。


テスト期間中、EAは424件の取引をおこない、うち210件は利益で決済されました。これは49.53%です。しかし、利益が最大で平均的な取引が、利益がない取引を上回ったため、テスト期間は利益で終わりました。最大残高とエクイティドローダウンは、それぞれ9.14%と10.36%という僅差の結果となりました。テスト期間のプロフィットファクターは1.25です。シャープレシオは3.38に達しました。
結論
この記事では、正規化非正規化技術の発展における重要なステップであるRevIN法について学びました。これは、時系列予測の文脈で深層学習モデルに特に関連しており、正確な予測に不可欠な時系列に関する統計情報を保存し、取り出すことができます。RevINは、経時的なデータダイナミクスの変化に対する頑健性を示しており、時系列における分布のずれの問題に対処するための効果的なツールとなります。
RevINの重要な利点の一つは、その柔軟性と様々な深層学習モデルへの適用性です。様々なニューラルネットワークアーキテクチャに簡単に実装でき、さらに多層に適用することも可能で、安定した予測品質を提供します。
実用的な部分では、MQL5を使って提案されたアプローチを実装しました。実際の過去のデータでモデルを訓練し、訓練データセットに含まれていない新しいデータでテストしました。
テスト結果は、訓練したモデルが訓練データを汎化し、過去の訓練セットとそれ以上のデータに対しても利益を生み出す能力を示しました。
ただし、この記事で紹介されているプログラムはすべてデモンストレーション用であり、提案されたアプローチをテストするためだけに設計されていることを忘れてはなりません。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | 訓練EAのエンコード |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14673

 エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索