
Redes neurais de maneira fácil (Parte 84): normalização reversível (RevIN)

Introdução
No artigo anterior, conhecemos o método Conformer, que foi desenvolvido para a previsão do tempo. Um método bastante interessante. E, ao testar o modelo treinado, obtivemos um resultado não ruim. Mas será que fizemos tudo certo? Ou podemos obter um resultado melhor? Vamos analisar o processo de treinamento. É fácil notar que estamos claramente usando o modelo de previsão dos próximos indicadores prováveis de séries temporais fora de seu propósito original. Alimentando a modelo com dados brutos da sequência temporal, treinamos-a, propagando o gradiente de erro a partir de modelos que utilizam os resultados da previsão. Primeiro, a partir do Crítico.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E depois a partir do Ator.
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E mais uma vez a partir do Ator, ao ajustar sua política com base na rentabilidade das operações.
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), -1, -1, false) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Isso, claro, não é um problema. E é uma prática amplamente utilizada no treinamento de diversos modelos. No entanto, neste caso, estamos focando no treinamento do Codificador do estado inicial do ambiente, não na previsão de estados subsequentes, mas sim na extração de características específicas que permitem otimizar o desempenho dos modelos subsequentes.
Claro, nosso principal objetivo é encontrar a política ótima do Ator. E, à primeira vista, não há nada de errado em adaptar o modelo do Codificador para os objetivos do Ator. Mas, nesse caso, o Codificador resolve uma tarefa ligeiramente diferente. Praticamente, ele se torna um bloco para os modelos subsequentes. E sua arquitetura pode não ser a mais otimizada para as tarefas em questão.
Além disso, ao treinar o Codificador com os gradientes de erro de 3 tarefas diferentes, podemos nos deparar com o problema de os gradientes de cada tarefa serem divergentes. Nesse caso, o modelo buscará o "meio-termo", que melhor satisfaça todas as tarefas definidas. E é bem provável que essa solução esteja longe do ideal.
Acredito que seja evidente que a lógica estruturada de uso dos modelos deve ser implementada também no processo de treinamento. E, dentro dessa abordagem, precisamos ensinar o Codificador a prever os próximos estados do ambiente. É precisamente no Codificador que os métodos do Conformer são usados. Depois, treinamos a política do Ator com base nos estados previstos do ambiente.
Teoricamente, tudo está claro. Mas, na prática, nos deparamos com uma grande diferença nas distribuições das características individuais que descrevem o estado do ambiente. Ao receber os dados "brutos" de descrição do estado do ambiente como entrada para o modelo, normalizamos esses dados para trazê-los a uma forma comparável. Mas como obter valores tão diferentes na saída do modelo?
Gostaria de lembrar que já enfrentamos esse problema ao treinar diversos modelos de autocodificadores. Então, encontramos uma solução ao usar os dados normalizados como metas. No entanto, neste caso, precisamos de dados que descrevem os próximos estados do ambiente, que diferem dos dados de entrada. Um dos métodos para resolver esse problema foi proposto no artigo "Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift".
Os autores do artigo propõem um método simples, mas eficaz, de normalização e desnormalização — a normalização instantânea reversível (RevIN), que primeiro normaliza as sequências de entrada e depois desnormaliza as sequências de saída do modelo para resolver problemas de previsão de séries temporais relacionados à mudança de distribuição. RevIN é simetricamente estruturada para devolver as informações originais de distribuição à saída do modelo por meio da reescalagem e deslocamento da saída na camada de desnormalização em uma magnitude equivalente ao deslocamento e reescalagem dos dados brutos na camada de normalização.
RevIN é uma camada flexível e treinável que pode ser aplicada a qualquer camada arbitrária, suprimindo eficazmente as informações não estacionárias (média e variância de cada instância) em uma camada e restaurando-as em outra camada de posição praticamente simétrica, como nas camadas de entrada e saída.
1. Algoritmo RevIN
Para nos familiarizarmos com o algoritmo RevIN, consideremos o problema de previsão multivariada de séries temporais em tempo discreto para um conjunto de dados brutos X = {xi}i=[1..N] e os respectivos dados de destino Y = {yi}i=[1..N], onde N denota o número de elementos na sequência.
Seja K, Tx e Ty o número de variáveis, o comprimento da sequência de entrada e o comprimento da previsão do modelo, respectivamente. Considerando a sequência de entrada Xi ∈ RKTx, nosso objetivo é resolver o problema de previsão de séries temporais, que consiste em prever os próximos valores Yi ∈ RKTy. No RevIN, o comprimento da sequência de entrada Tx e o comprimento da previsão Ty podem ser diferentes, uma vez que as observações são normalizadas e desnormalizadas com base na dimensão temporal. O método proposto, RevIN, consiste em camadas de normalização e desnormalização estruturadas simetricamente. Primeiro, normalizamos os dados brutos Xi usando sua média e desvio padrão, o que é amplamente aceito como normalização instantânea. A média e o desvio padrão são calculados para cada instância Xi dos dados brutos da seguinte forma:
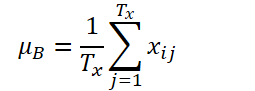
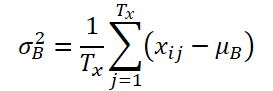

Sequências normalizadas podem ter uma média e desvio padrão mais consistentes, onde a informação não estacionária é reduzida. Como resultado, a camada de normalização permite que o modelo preveja com precisão a dinâmica local dentro da sequência ao receber dados de entrada com distribuições consistentes de média e desvio padrão.
O modelo recebe dados transformados na entrada e prevê seus valores futuros. No entanto, os dados de entrada possuem uma estatística diferente em comparação com a distribuição original, e, observando apenas a entrada normalizada, é difícil capturar a distribuição original dos dados de entrada. Assim, para simplificar essa tarefa para o modelo, restauramos explicitamente as propriedades não estacionárias, removidas dos dados de entrada, na saída do modelo, revertendo a normalização na posição simétrica na camada de saída. A etapa de denormalização pode trazer a saída do modelo de volta ao valor original da série temporal. Consequentemente, desnormalizamos a saída do modelo aplicando as operações inversas de normalização:

Os mesmos parâmetros estatísticos utilizados na etapa de normalização são aplicados para o escalonamento e o deslocamento. Agora, ŷi é a previsão final do modelo.
Simplesmente adicionada em posições virtualmente simétricas na rede, RevIN pode reduzir efetivamente a divergência na distribuição dos dados de séries temporais. Semelhante a uma camada de normalização treinável, que pode ser aplicada a redes neurais profundas arbitrárias. De fato, o método proposto é uma camada flexível e treinável, que pode ser aplicada a quaisquer camadas arbitrariamente escolhidas, até mesmo a várias camadas. Os autores do método confirmam sua eficácia como uma camada flexível, adicionando-a a camadas intermediárias em diversos modelos. No entanto, RevIN é mais eficaz quando aplicado a camadas virtualmente simétricas na estrutura Codificador-Decodificador. Em um modelo típico de previsão de séries temporais, a fronteira entre Codificador e Decodificador muitas vezes não é clara. Por isso, os autores do método aplicam RevIN às camadas de entrada e saída do modelo, pois estas podem ser vistas como uma estrutura Codificador-Decodificador, gerando valores subsequentes com base nos dados de entrada.
A visualização do método RevIN feita pelos autores é apresentada abaixo.

2. Implementação usando MQL5
Após discutir os aspectos teóricos do método, passamos para a implementação prática dos métodos propostos utilizando MQL5.
A partir da descrição teórica apresentada acima, é fácil perceber que a normalização dos dados de entrada proposta pelos autores do método replica completamente o algoritmo da camada de normalização em lote que implementamos anteriormente, CNeuronBatchNormOCL. Portanto, podemos usar a classe existente para normalizar os dados. No entanto, para a denormalização dos dados, precisamos criar uma nova camada neural, CNeuronRevINDenormOCL.
2.1 Criação da nova camada de Denormalização
É bastante óbvio que, no processo de denormalização dos dados, serão utilizados os objetos aplicados na normalização dos dados. Portanto, criaremos a nova camada CNeuronRevINDenormOCL como herdeira da camada de normalização CNeuronBatchNormOCL.
class CNeuronRevINDenormOCL : public CNeuronBatchNormOCL { protected: int iBatchNormLayer; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronRevINDenormOCL(void) : iBatchNormLayer(-1) {}; ~CNeuronRevINDenormOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, int NormLayer, CNeuronBatchNormOCL *normLayer); virtual int GetNormLayer(void) { return iBatchNormLayer; } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronRevInDenormOCL; } virtual CLayerDescription* GetLayerInfo(void); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) { return true; } };
É importante notar que o algoritmo do método RevIN prevê o uso de parâmetros treinados durante a etapa de denormalização, que foram ajustados na fase de normalização. Aqui, a lógica é que, na etapa de normalização, estudamos a distribuição dos dados brutos. Depois, ajustamos os dados brutos para uma forma comparável, removendo "lacunas". Em seguida, o modelo trabalha com os dados normalizados. Na saída do modelo, desnormalizamos os dados, restaurando seus parâmetros de distribuição originais. Assim, esperamos que a saída do modelo sejam dados previstos na distribuição "natural" dos dados brutos.
É evidente que, na etapa de denormalização, não há atualização dos parâmetros do modelo. Portanto, na estrutura da classe, redefinimos os métodos de atualização dos parâmetros do modelo como "placeholders" vazios. No entanto, ainda precisamos implementar o algoritmo de propagação para frente e a distribuição do gradiente de erro. Mas vamos abordar isso passo a passo.
Nesta classe, não declaramos objetos internos adicionais. Portanto, o construtor e o destrutor da classe permanecem vazios. No entanto, criaremos uma variável para armazenar o identificador da camada de normalização no modelo iBatchNormLayer. E, em seguida, criaremos um método público para obter o valor dessa variável GetNormLayer(void).
A inicialização do objeto da nossa nova classe é realizada no método CNeuronRevINDenormOCL::Init. Nos parâmetros, o método recebe todas as informações necessárias para a inicialização bem-sucedida dos objetos e variáveis internas. E aqui vale mencionar uma diferença significativa em relação aos métodos semelhantes de outras camadas neurais discutidas anteriormente. O ponto é que, nos parâmetros do método, além das constantes, passaremos um ponteiro para o objeto da camada de normalização em lote CNeuronBatchNormOCL.
bool CNeuronRevINDenormOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, int NormLayer, CNeuronBatchNormOCL *normLayer) { if(NormLayer > 0) { if(!normLayer) return false; if(normLayer.Type() != defNeuronBatchNormOCL) return false; if(BatchOptions == normLayer.BatchOptions) BatchOptions = NULL; if(!CNeuronBatchNormOCL::Init(numOutputs, myIndex, open_cl, numNeurons, normLayer.iBatchSize, normLayer.Optimization())) return false; if(!!BatchOptions) delete BatchOptions; BatchOptions = normLayer.BatchOptions; }
Outra diferença fundamental está no corpo do método. Aqui, criamos uma ramificação no algoritmo dependendo do identificador da camada de normalização em lote recebido. Se ele for maior que "0", verificamos o ponteiro recebido para a camada de normalização em lote. Além disso, verificamos o tipo do objeto recebido. Depois de passar por todos esses pontos de controle com sucesso, chamamos o método com o mesmo nome da classe pai. E somente após concluir todas essas verificações, realizamos a substituição do buffer dos parâmetros de otimização.
Vale destacar que não copiamos os dados. Em vez disso, substituímos completamente o ponteiro para o objeto buffer. Dessa forma, durante o treinamento do modelo, estaremos sempre trabalhando com os parâmetros de normalização atualizados.
A segunda ramificação do algoritmo é destinada à inicialização de um objeto vazio da classe durante o carregamento de um modelo previamente salvo. Aqui, apenas chamamos o método com o mesmo nome da classe pai, com parâmetros mínimos.
else if(!CNeuronBatchNormOCL::Init(numOutputs, myIndex, open_cl, numNeurons, 0, ADAM)) return false;
E então, independentemente do caminho escolhido, armazenamos o identificador da camada de normalização em lote recebida e encerramos a execução do método.
iBatchNormLayer = NormLayer; //--- return true; }
2.2 Propagação para frente
Começamos a implementação do algoritmo de propagação para frente criando o kernel RevInFeedForward no lado do programa OpenCL. De maneira semelhante à implementação do algoritmo da camada de normalização em lote, planejamos executar este kernel em um espaço de tarefas unidimensional.
Nos parâmetros do kernel, passaremos os ponteiros de 3 buffers de dados: dados brutos, parâmetros de normalização e resultados. Além disso, 2 constantes: o tamanho do buffer de parâmetros de normalização e o tipo de otimização dos parâmetros.
__kernel void RevInFeedForward(__global float *inputs, __global float *options, __global float *output, int options_size, int optimization) { int n = get_global_id(0);
Lembro que o tamanho do buffer de parâmetros de normalização depende do algoritmo de otimização de parâmetros escolhido. Esse buffer possui a seguinte estrutura.

No corpo do kernel, identificamos o fluxo analisado no espaço de tarefas. E imediatamente determinamos o deslocamento nos buffers para os dados analisados. Nos buffers de dados de entrada e de resultados, o deslocamento é igual ao identificador do fluxo. E o deslocamento no buffer de parâmetros de otimização é determinado conforme a estrutura do buffer e o método de otimização de parâmetros escolhido.
int shift = (n * optimization == 0 ? 7 : 9) % options_size;
Além disso, devemos considerar que o número de estados do ambiente analisados pode ser diferente da profundidade da nossa previsão. Nesse caso, partimos do princípio de que a estrutura dos estados do ambiente analisados e previstos é preservada. Em outras palavras, a quantidade e a ordem dos parâmetros analisados que descrevem um estado do ambiente são completamente preservadas ao prever os estados subsequentes. Portanto, para determinar o deslocamento no buffer de parâmetros de normalização, tomamos o restante da divisão do deslocamento calculado, levando em consideração o fluxo analisado e a estrutura do buffer, pelo tamanho do buffer de parâmetros de normalização.
O próximo passo é extrair os dados dos buffers globais para variáveis locais.
float mean = options[shift]; float variance = options[shift + 1]; float k = options[shift + 3];
Calcularemos o valor denormalizado do parâmetro previsto.
float res = 0; if(k != 0) res = sqrt(variance) * (inputs[n] - options[shift + 4]) / k + mean; if(isnan(res)) res = 0;
O resultado das operações será gravado no respectivo elemento do buffer de resultados.
output[n] = res; }
Após a implementação do algoritmo de denormalização de dados no lado do programa OpenCL, estabelecemos a chamada do kernel criado a partir do programa principal. Para isso, sobrescreveremos o método CNeuronRevINDenormOCL::feedForward.
bool CNeuronRevINDenormOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false; //--- PrevLayer = NeuronOCL; //--- if(!BatchOptions) iBatchSize = 0; if(iBatchSize <= 1) { activation = (ENUM_ACTIVATION)NeuronOCL.Activation(); return true; }
Assim como o método de mesmo nome da classe pai, os parâmetros do método receberão um ponteiro para o objeto da camada anterior, que contém os dados de entrada para nós.
No corpo do método, verificamos imediatamente o ponteiro recebido e o armazenamos na variável correspondente.
Em seguida, verificamos o tamanho do lote de normalização. Se não exceder "1", avaliamos isso como ausência de normalização e passamos os dados da camada anterior sem modificações. Obviamente, não copiaremos completamente os dados, mas apenas o identificador da função de ativação. E, ao acessar o buffer de resultados ou gradientes, retornamos os ponteiros para os buffers da camada anterior. Essa funcionalidade já foi implementada na classe pai.
Depois, implementamos o algoritmo de colocação do kernel na fila de execução. Primeiro, determinamos o espaço de tarefas.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Em seguida, passamos os parâmetros necessários para o kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffinputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffoptions, BatchOptions.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_RevInFeedForward, def_k_revffoutput, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_RevInFeedForward, def_k_revffoptions_size, (int)BatchOptions.Total())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_RevInFeedForward, def_k_revffoptimization, (int)optimization)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
E enviamos o kernel para a fila de execução.
if(!OpenCL.Execute(def_k_RevInFeedForward, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Não esquecemos de monitorar o processo de execução das operações em cada etapa.
2.3 Algoritmo de distribuição do gradiente de erro
Após a implementação da propagação para frente, precisamos implementar o algoritmo de propagação reversa. Como mencionado anteriormente, essa camada não contém parâmetros treináveis. Mais precisamente, ela utiliza os parâmetros treinados na fase de normalização. Portanto, todos os métodos de atualização de parâmetros são substituídos por "placeholders" vazios.
No entanto, a camada participa dos algoritmos de propagação reversa e o gradiente de erro é passado por ela para a camada anterior. Como antes, primeiro criamos o kernel RevInHiddenGradient no lado do programa OpenCL. Desta vez, o número de parâmetros do kernel aumentou. Passaremos 4 ponteiros para buffers de dados: os buffers de resultados e gradientes de erro da camada anterior, os parâmetros de otimização e o gradiente de erro nos resultados da camada atual. E 3 constantes: o tamanho do buffer de parâmetros de normalização, o tipo de otimização dos parâmetros e a função de ativação da camada anterior.
__kernel void RevInHiddenGraddient(__global float *inputs, __global float *inputs_gr, __global float *options, __global float *output_gr, int options_size, int optimization, int activation) { int n = get_global_id(0); int shift = (n * optimization == 0 ? 7 : 9) % options_size;
No corpo do kernel, primeiro identificamos o fluxo analisado e determinamos os deslocamentos nos buffers de dados. O algoritmo de determinação de deslocamento nos buffers foi descrito anteriormente durante a construção do kernel da propagação para frente.
Em seguida, carregamos os dados dos buffers globais de dados para variáveis locais.
float variance = options[shift + 1]; float inp = inputs[n]; float k = options[shift + 3];
Corrigimos o gradiente de erro com base na derivada da função de denormalização. Vale destacar que, na etapa de denormalização, todos os parâmetros de normalização são constantes e a derivada da função é consideravelmente simplificada.
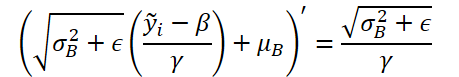
Implementamos a função apresentada no código.
float res = 0; if(k != 0) res = sqrt(variance) * output_gr[n] / k; if(isnan(res)) res = 0;
Depois disso, corrigimos o gradiente de erro com base na derivada da função de ativação da camada neural anterior.
switch(activation) { case 0: res = clamp(res + inp, -1.0f, 1.0f) - inp; res = res * (1 - pow(inp == 1 || inp == -1 ? 0.99999999f : inp, 2)); break; case 1: res= clamp(res + inp, 0.0f, 1.0f) - inp; res = res * (inp == 0 || inp == 1 ? 0.00000001f : (inp * (1 - inp))); break; case 2: if(inp < 0) res *= 0.01f; break; default: break; }
O resultado das operações será salvo no respectivo elemento do buffer de gradientes de erro da camada neural anterior.
//---
inputs_gr[n] = res;
}
O próximo passo é implementar a chamada desse kernel no lado do programa principal. Essa funcionalidade é executada no método CNeuronRevINDenormOCL::calcInputGradients. O próprio algoritmo de colocação do kernel na fila de execução é o mesmo que o descrito acima para o método de propagação para frente. Portanto, não vamos detalhá-lo agora.
Também não discutiremos detalhadamente os métodos auxiliares da classe. Seu algoritmo é bastante simples e acessível para análise independente no anexo, onde você encontrará o código completo de todos os métodos da nova classe e das classes previamente criadas. Lá, você pode revisar todos os programas usados na preparação do artigo.
2.4 Ajustes pontuais em classes de nível superior
É necessário mencionar algumas correções pontuais nos métodos das classes de nível superior, causadas pelas especificidades da nossa nova classe CNeuronRevINDenormOCL. Em primeiro lugar, isso se refere à inicialização e carregamento de objetos dessa classe.
Ao descrever o método de inicialização do objeto da nossa classe CNeuronRevINDenormOCL, mencionamos a particularidade de passar um ponteiro para o objeto da camada de normalização de dados. Aqui, é importante entender que, no momento de descrever a arquitetura do modelo, não temos um ponteiro para esse objeto por uma razão simples — o objeto ainda não foi criado. Podemos apenas indicar o número ordinal da camada, que sabemos com base na arquitetura descrita do modelo.
No entanto, sabemos claramente que a camada de normalização está localizada antes da camada de denormalização. Além disso, pode haver um número arbitrário de camadas neurais entre elas. Portanto, no momento da criação do objeto da camada de denormalização no modelo, a camada de normalização já deve ter sido criada. E podemos acessá-la, mas apenas dentro do modelo. Como o acesso às camadas neurais individuais é fechado para programas externos.
Portanto, no método CNet::Create, criamos um bloco separado para inicializar o objeto da camada de desnormalização CNeuronRevINDenormOCL.
case defNeuronRevInDenormOCL: if(desc.layers>=layers.Total()) { delete temp; return false; }
Aqui, primeiro verificamos se a camada com o identificador especificado já foi criada em nosso modelo.
Em seguida, verificamos o tipo da camada especificada. Ela deve ser uma camada de normalização em lote.
if(((CLayer *)layers.At(desc.layers)).At(0).Type()!=defNeuronBatchNormOCL) { delete temp; return false; }
Somente após a passagem bem-sucedida desses controles, criamos um novo objeto.
revin = new CNeuronRevINDenormOCL(); if(!revin) { delete temp; return false; }
Inicializamos o objeto.
if(!revin.Init(outputs, 0, opencl, desc.count, desc.layers, ((CLayer *)layers.At(desc.layers)).At(0))) { delete temp; delete revin; return false; }
E o adicionamos ao array de objetos.
if(!temp.Add(revin)) { delete temp; delete revin; return false; } break;
Além disso, há um detalhe ao carregar um modelo previamente treinado. Como você sabe, no método de inicialização de nossa nova classe, criamos uma bifurcação do algoritmo dependendo do identificador da camada de normalização. Isso foi feito com foco no processo de carregamento do modelo previamente treinado. O fato é que, antes de carregar o objeto, precisamos criar seu "esqueleto". Essa funcionalidade é realizada no método CLayer::CreateElement. E a complexidade do momento está no fato de que, antes de carregar os dados, não sabemos o identificador da camada de normalização. Portanto, indicamos "-1" como identificador e "NULL" em vez de um ponteiro para o objeto.
case defNeuronRevInDenormOCL: if(CheckPointer(OpenCL) == POINTER_INVALID) return false; revin = new CNeuronRevINDenormOCL(); if(CheckPointer(revin) == POINTER_INVALID) result = false; if(revin.Init(iOutputs, index, OpenCL, 1, -1, NULL)) { m_data[index] = revin; return true; } delete revin; break;
E, no processo de carregamento, todos os dados são carregados nos objetos internos e variáveis da nossa classe. Mas há mais um detalhe. No processo de carregamento dos dados, receberemos os parâmetros de normalização salvos após o pré-treinamento do modelo. No entanto, isso não nos satisfaz. Para o treinamento contínuo do modelo e sua operação, precisamos de uma sincronização dos parâmetros entre as camadas de normalização e desnormalização. Caso contrário, teremos uma discrepância entre a distribuição dos dados originais e nossas previsões. Portanto, passamos para o método CNet::Load, e, após carregar a próxima camada neural, verificamos seu tipo.
bool CNet::Load(const int file_handle) { ........ ........ //--- read array length num = FileReadInteger(file_handle, INT_VALUE); //--- read array if(num != 0) { for(i = 0; i < num; i++) { //--- create new element CLayer *Layer = new CLayer(0, file_handle, opencl); if(!Layer.Load(file_handle)) break; if(Layer.At(0).Type() == defNeuronRevInDenormOCL) { CNeuronRevINDenormOCL *revin = Layer.At(0); int l = revin.GetNormLayer(); if(!layers.At(l)) { delete Layer; break; }
No caso de detectar a camada de desnormalização CNeuronRevINDenormOCL, solicitamos o ponteiro para a camada de normalização e verificamos se essa camada foi carregada.
Também verificamos o tipo dessa camada.
CNeuronBaseOCL *neuron = ((CLayer *)layers.At(l)).At(0); if(neuron.Type() != defNeuronBatchNormOCL) { delete Layer; break; }
E, após a passagem bem-sucedida desses pontos de controle, inicializamos o objeto da camada, passando o ponteiro para a camada de normalização correspondente.
if(!revin.Init(revin.getConnections(), 0, opencl, revin.Neurons(), l, neuron)) { delete Layer; break; } } if(!layers.Add(Layer)) break; } } FileClose(file_handle); //--- result return (layers.Total() == num); }
E seguimos o algoritmo criado anteriormente.
O código completo de todas as classes e seus métodos, bem como todos os programas usados na preparação do artigo, pode ser encontrado em anexo.
2.5 Arquitetura dos Modelos Treináveis
Acima, implementamos abordagens propostas pelos autores do método RevIN usando MQL5. E agora é hora de incluí-las na arquitetura de nossos modelos. Conforme discutido anteriormente, utilizaremos a desnormalização no modelo Codificador para habilitar o aprendizado direto para previsão dos próximos estados do ambiente. O número de estados do ambiente a serem previstos (neste caso, as próximas velas) será determinado pela constante NForecast.
#define NForecast 6 //Number of forecast
Como planejamos treinar o Codificador separadamente do Ator e do Crítico, a descrição da arquitetura do Codificador será colocada em um método separado CreateEncoderDescriptions. Nos parâmetros, passaremos apenas um ponteiro para um array dinâmico para salvar a arquitetura do modelo criado. Aqui vale ressaltar que nossa implementação da classe CNeuronRevINDenormOCL não permite separar o Decodificador em um modelo distinto.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
No corpo do método, verificamos o ponteiro recebido e, se necessário, criamos uma nova instância do objeto de array dinâmico.
Na entrada do modelo, assim como anteriormente, fornecemos os dados "brutos" que descrevem o estado do ambiente.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados recebidos passam por um pré-processamento na camada de normalização em lote, e salvamos o número de ordem da camada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Após a normalização dos dados de entrada, criamos seu embedding e o adicionamos à pilha interna.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {4, 1, 1, 1, 2}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count * 5; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, adicionamos a codificação posicional dos dados.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout * 5; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados assim preparados são fornecidos como entrada para um bloco de 5 camadas CNeuronConformer.
//--- layer 5-10 for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 5; if(!encoder.Add(descr)) { delete descr; return false; } }
Para fins de verificação do método, usamos uma camada totalmente conectada como Decodificador, com o número correspondente de elementos. No entanto, para melhorar a qualidade da previsão, recomenda-se utilizar um Decodificador com uma arquitetura mais complexa.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NForecast*BarDescr; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Como estamos trabalhando com dados normalizados e presumimos que sua variância está próxima de "1" e a média em "0", utilizamos a função de ativação tangente hiperbólica (tanh) na saída do Decodificador. Como se sabe, seu intervalo de valores vai de "-1" a "1".
E, ao final, desnormalizamos os valores previstos.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Para completar a descrição da arquitetura dos modelos, sugiro que vejamos a construção do Ator e do Crítico de imediato. A arquitetura desses modelos é descrita no método CreateDescriptions. Ela é amplamente baseada no artigo anterior, mas com uma particularidade.
Nos parâmetros, o método recebe ponteiros para 2 arrays dinâmicos.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
No corpo do método, verificamos os ponteiros recebidos e, se necessário, criamos novas instâncias dos objetos.
Na entrada do Ator, fornecemos um tensor que descreve o estado da conta e das posições abertas.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Geramos o embedding dessa representação.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, temos um bloco de Atenção Cruzada, no qual o estado atual da conta é analisado à luz dos estados previstos do ambiente.
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
E o modelo do Ator é concluído com um bloco de tomada de decisão com política estocástica.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
De forma semelhante, construímos o modelo do Crítico. No entanto, em vez de descrever o estado da conta, o Crítico analisa as ações do Ator no contexto dos estados previstos do ambiente.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } }
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
E, na saída do Crítico, obtemos uma avaliação clara, e não estocástica, das ações do Agente.
2.6 Programas de treinamento dos modelos
Após descrever a arquitetura dos modelos treináveis, passamos à criação dos programas de treinamento. Para treinar o Encoder, criaremos o EA "...\Experts\RevIN\StudyEncoder.mq5". A arquitetura do EA é baseada em trabalhos anteriores, já revisados várias vezes nas séries de artigos. Portanto, focaremos apenas no método de treinamento da rede Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
No corpo do método, como de costume, geramos um vetor de probabilidades de escolha de trajetórias, dependendo de sua rentabilidade. Vale mencionar que para previsão dos estados futuros do ambiente, todos os ciclos são iguais. Afinal, o Codificador não analisa o estado da conta e as posições abertas. No entanto, mantivemos essa funcionalidade caso haja trajetórias de diferentes intervalos históricos no buffer de reprodução.
Em seguida, preparamos as variáveis locais e geramos o sistema de ciclos de treinamento do modelo.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - batch)); if(state <= 0) { iter--; continue; } Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - NForecast);
No corpo do ciclo externo, amostramos uma trajetória do buffer de reprodução de experiências e o estado inicial do treinamento. Em seguida, definimos o estado final do lote de treinamento e limpamos a pilha interna do modelo. Depois, criamos um ciclo interno de treinamento no intervalo selecionado de dados históricos.
for(int i = state; i < end && !IsStopped() && !Stop; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Aqui, primeiro carregamos o estado analisado do conjunto de treinamento. Transferimos-o para o buffer de dados. E realizamos a propagação para frente do Codificador, chamando o método correspondente do nosso modelo.
Na próxima etapa, precisamos preparar os dados-alvo. Para isso, criamos outro ciclo interno, no qual retiramos do conjunto de treinamento a quantidade necessária de estados subsequentes e os adicionamos ao buffer de dados.
//--- Collect target data bState.Clear(); for(int fst = 1; fst <= NForecast; fst++) { if(!bState.AddArray(Buffer[tr].States[i + fst].state)) break; }
Após a coleta dos valores-alvo, podemos realizar a propagação reversa no Codificador para minimizar o erro entre os valores previstos e os alvos.
if(!Encoder.backProp(GetPointer(bState), (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E, a seguir, resta apenas informar o usuário sobre o andamento do processo de treinamento e passar para a próxima iteração.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão bem-sucedida de todas as iterações de treinamento, limpamos o campo de comentários.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Registramos no diário as informações sobre os resultados alcançados durante o treinamento e iniciamos o encerramento do Expert Advisor.
O treinamento do modelo de previsão de estados futuros do ambiente é útil. Mas nosso objetivo é o treinamento da política do Ator. E o próximo passo é a criação do Expert Advisor para o treinamento do Ator e do Crítico, "...\Experts\RevIN\Study.mq5". O Expert Advisor é construído na mesma arquitetura, por isso tocaremos apenas em mudanças pontuais.
Primeiro, no processo de inicialização do Expert Advisor, a ausência de um Codificador previamente treinado gera um erro de inicialização incorreta do programa.
int OnInit() { //--- ........ ........ //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Error of load Encoder: %d", GetLastError()); return INIT_FAILED; } ........ ........ //--- return(INIT_SUCCEEDED); }
Segundo, o Codificador nesta versão do modelo não é treinado e, consequentemente, não é salvo.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
Além disso, há uma particularidade ao usar o Codificador como fonte de dados para o Ator e o Crítico. No início do artigo, falamos sobre a importância de utilizar dados normalizados para o treinamento e a operação dos modelos. A camada de desnormalização na saída do Codificador, ao contrário, retorna nossas previsões para a distribuição dos dados originais, tornando-os incompatíveis.
No entanto, já implementamos há algum tempo a funcionalidade de acessar as camadas ocultas do modelo para extrair os dados. Utilizaremos essa funcionalidade para obter dados normalizados de previsão da penúltima camada do Codificador. Esses dados serão usados como dados de entrada para o Ator e o Crítico. O ponteiro para a camada necessária será indicado na constante LatentLayer.
#define LatentLayer 11
Então, a chamada da propagação para frente do Crítico terá a seguinte forma:
if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
ou
if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Correspondentemente, a chamada da propagação para frente do Ator será escrita como
if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E não nos esqueceremos de indicar o identificador da camada ao chamar os métodos de propagação reversa dos nossos modelos.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder),LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder),LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Essas mesmas mudanças pontuais foram feitas nos Expert Advisors de interação com o ambiente. Mas sugiro que você explore esses detalhes por conta própria. O código completo de todos os programas utilizados na preparação deste artigo pode ser encontrado em anexo.
3. Testes
Após criar todos os programas necessários, podemos passar para o treinamento e teste dos modelos, o que nos permitirá avaliar a eficácia das soluções propostas.
Como de costume, treinamos e testamos os modelos em dados históricos reais do instrumento EURUSD, time frame H1.
O tempo não para. E com ele nossa base de dados históricos cresce. Durante a preparação deste artigo, decidi expandir o intervalo histórico do conjunto de treinamento para incluir todo o ano de 2023. Além disso, testaremos os modelos treinados nos dados de janeiro de 2024.
Para criar o conjunto de dados de treinamento inicial, usei o framework Real-ORL. A descrição detalhada pode ser encontrada no link. Eu carreguei dados de negociações a partir de 20 sinais reais. E executei o Expert Advisor "...\Experts\RevIN\ResearchRealORL.mq5" no modo de otimização lenta.


Como resultado, obtive 20 trajetórias. Nem todas foram lucrativas.

Nesta etapa, começamos primeiro o treinamento do Codificador. E, após sua conclusão, realizamos o treinamento inicial do Ator e do Crítico. Inicial porque 20 trajetórias são muito poucas para encontrar a política ideal do Ator.
O próximo passo é expandir nosso conjunto de dados de treinamento. Para isso, no modo de otimização lenta, executamos o Expert Advisor "...\Experts\RevIN\Research.mq5", que testará a política atual do Ator em dados históricos reais do período de treinamento e adicionará as passagens ao nosso conjunto de treinamento.

Neste estágio, não devemos esperar resultados impressionantes. Resultados negativos também são resultados. E uma boa experiência para o futuro treinamento dos modelos. Além disso, essa iteração nos permite conhecer melhor o ambiente em relação às ações da política atual do Ator.
Após várias iterações de treinamento da política do Ator e coleta de dados adicionais para o conjunto de treinamento, consegui treinar um modelo capaz de gerar lucro tanto no conjunto de treinamento quanto no conjunto de testes.


Durante o período de testes, o Expert Advisor realizou 424 negociações, das quais 210 foram fechadas com lucro. Isso representou 49,53%. No entanto, devido à superação dos valores máximos e médios das negociações lucrativas em relação aos valores das negociações com prejuízo, foi possível obter lucro durante o período de teste. A máxima redução no saldo e no equity foram próximas (9,14% e 10,36%, respectivamente). O fator de lucro durante o período de teste foi de 1,25. E o coeficiente de Sharpe atingiu 3,38.
Considerações finais
Neste artigo, conhecemos o método RevIN, que representa um passo importante no desenvolvimento de técnicas de normalização e desnormalização. Especialmente para modelos de aprendizado profundo no contexto de previsão de séries temporais. Ele permite preservar e restaurar informações estatísticas sobre séries temporais, o que é fundamental para previsões precisas. RevIN demonstra resistência à mudança na dinâmica dos dados ao longo do tempo. Isso o torna uma ferramenta eficaz para lidar com o problema de deslocamento de distribuição em séries temporais.
Uma das grandes vantagens do RevIN é sua flexibilidade e aplicabilidade em diferentes modelos de aprendizado profundo. Ele pode ser facilmente integrado em várias arquiteturas de redes neurais e até mesmo aplicado a múltiplas camadas, garantindo uma qualidade estável nas previsões.
Na parte prática do artigo, implementamos os métodos propostos usando MQL5. Treinamos os modelos com dados históricos reais. E os testamos em novos dados, que não faziam parte do conjunto de treinamento.
Os resultados dos testes mostraram que os modelos treinados são capazes de generalizar os dados do conjunto de treinamento e gerar lucro tanto em dados históricos do treinamento quanto fora dele.
No entanto, é importante lembrar que todos os programas apresentados no artigo são de caráter demonstrativo e se destinam apenas à verificação dos métodos propostos.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos usando o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para o treinamento de Modelos |
| 4 | StudyEncoder.mq5 | Expert Advisor | Expert Advisor para o treinamento do Codificador |
| 5 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código para o programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14673
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
 Desenvolvendo um Trading System com base no Livro de Ofertas (Parte I): o indicador
Desenvolvendo um Trading System com base no Livro de Ofertas (Parte I): o indicador
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso