
ニューラルネットワークが簡単に(第81回):Context-Guided Motion Analysis (CCMR)

はじめに
本連載の一環として、環境の状態を分析するためのさまざまな方法と、得られたデータを利用するためのアルゴリズムに触れました。過去の値動きデータから安定したパターンを見つけるために畳み込みモデルを使用しました。また、Attentionモデルを用いて、異なる局所的な環境状態間の依存関係を発見しました。環境の状態は常にある時点のある断面として評価しましたが、環境指標のダイナミクスを評価したことはありません。モデルが環境条件を分析し比較する過程で、何らかの形で重要な変化に注意を払うと仮定しましたが、そのようなダイナミクスを明示的に定量的に表現することはしませんでした。
コンピュータビジョンの分野では、オプティカルフロー推定という根本的な問題があります。この問題の解決策は、シーン内のオブジェクトの動きに関する情報を提供します。この問題を解決するために、多くの興味深いアルゴリズムが提案され、現在広く使用されています。オプティカルフロー推定の結果は、自律走行からオブジェクト追跡、監視まで様々な分野で利用されています。
現在のアプローチのほとんどは畳み込みニューラルネットワークを使用していますが、大域的文脈を欠いています。このため、オブジェクトのオクルージョンや大きな変位を推論するのは難しくなります。別の方法は、Transformerやその他のAttentionテクニックを使用することです。これにより、古典的なCNNの固定された受容野をはるかに超えることができます。
特に興味深いCCMRという手法が論文「CCMR:High Resolution Optical Flow Estimation via Coarse-to-Fine Context-Guided Motion Reasoning」で発表されました。これはオプティカルフロー推定へのアプローチであり、モーション集約概念と高解像度マルチスケールアプローチのAttention指向手法の利点を組み合わせたものです。CCMR法は、文脈に基づくモーショングルーピング概念を、高解像度の粗い推定フレームワークに一貫して統合しています。これにより、オクルージョン領域でも高精度の詳細なフローフィールドが得られます。この文脈において、この手法の著者は、まず大域的なSelf-Attention文脈特徴量を計算し、それを用いてすべてのスケールにわたって反復的にモーション特徴量を導くという、2段階のモーショングルーピング戦略を提案しています。このように、XCiTベースのモーションに関する文脈指向の推論は、あらゆる粗いスケールでの処理を提供します。この手法の著者がおこなった実験は、提案されたアプローチの強力な性能とその基本概念の利点を実証しています。
1. CCMRアルゴリズム
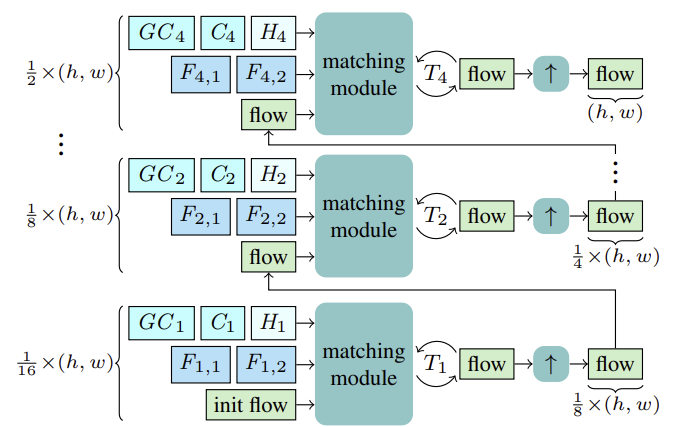
CCMR法は、共通のゲート付き回帰型ユニット(Gated Recurrent Unit: GRU)を用いて、粗いスケールと細かいスケールで回帰型更新をおこない、オプティカルフローを推定します。推定を開始する前に、各スケールSについて、マッチングのための特徴量Fs,1, Fs,2が計算されます。さらに、文脈特徴量Csとそれに基づく大域的文脈特徴量GCsが計算され、回帰型ブロックの現在のスケールに対する初期隠れ状態Hsが参照状態I1から計算されます。
1/16の最も粗いスケールから始まり、上記の特徴量F1,1, F1,2, C1, GC1, H1に基づいてフローが計算されます。T1回帰型フロー更新の後、推定されたフローは、共有されたX2凸アップサンプラーを用いてアップサンプリングされます。ここで、フローは、次のより細かいスケールでのマッチングプロセスの初期化として機能します。このプロセスは、フローが最も細かい1/2スケールで計算され、元の解像度にアップサンプリングされるまで続けられます。
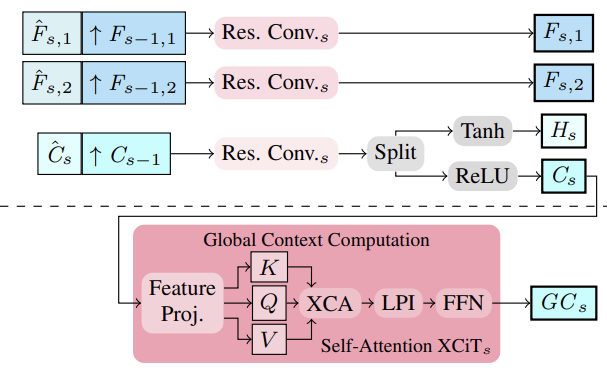
この手法の著者は、特徴量抽出器を用いてマルチスケール画像と文脈の特徴量を抽出することを提案しました。そのために、中間特徴量を上から下へ計算し、マルチスケール特徴量を得るために、より構造化された細かい特徴量Fs,1,Fs,2 and Csは、S∈ {2, 3, 4}に対して、より深く粗いスケールの特徴量Fs−1,1、Fs−1,2、Cs−1と組み合わせることで意味的に強化されます。このように、連結は、アップサンプリングされた粗い特徴量と中間的な細かい特徴量を積み重ね、それらを集約することによっておこなわれます。
マルチスケールCs文脈特徴量に基づいて、大域的文脈特徴量が計算されます。ここでは、より意味のある特徴量を得ることを目標とし、その特徴量を用いてモーションを制御します。そのために、XCiT層を使用して、チャネル統計を使用して文脈特徴量Csの集約をおこないます。これにより、トークンの数に対する線形複雑性が保証されます。このアーキテクチャの選択により、推定中に、すべての粗いスケールと細かいスケールで文脈の集約が可能になります。著者の提案するXCiTを使用したCCMRアプローチは、XCiT層が実際には入力データの粗い表現に適用され、明示的なパッチ適用によって実装され、その後元の解像度に再度アップサンプリングされるという元のアプローチとは異なることに注意することが重要です。一方、CCMRでは、XCiT層は、スケール固有のコンテンツを使用して、すべての粗いスケールと細かいスケールの特徴量に直接適用されます。大域的文脈を計算するために、まず文脈特徴量Csに位置符号化が加えられます。その後、層は正規化されます。この段階で、Self-Attentionを実装するために、すべてのQuery、Key、Value特徴量がCspから計算されます。クロス共分散Attentionステップを適用する前に、チャンネルKCs、QCs、VCsはh Headに再形成され、クロス共分散AttentionはXCA (KCs、QCs、VCs).として計算されます。その後、局地的パッチインタラクション層(LPI)そしてFFNブロックが適用されます。
交差共分散Attentionは各Head部のチャンネル間の大域的相互作用を提供しますが、LPIとFFNモジュールはそれぞれ局所的にトークン間の明示的な空間的相互作用と、全チャンネル間の接続を提供します。
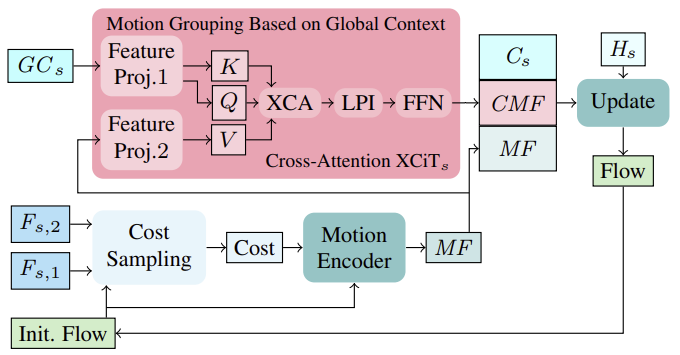
まず、最初の反復における初期フロー(またはそれ以降の反復における更新フロー)に基づいて、画像特徴量 (Fs,1、Fs,2)から近傍マッチングコストが計算されます。計算されたコストは、現在のフロー推定値とともに、モーションエンコーダを介して処理され、最終的にスレッド更新を計算するためにGRUによって使用されるモーション特徴量を出力します。
反復的なフロー更新を計算する際、文脈的特徴量に基づく大域的に集約されたモーション特徴量を取り入れることで、オクルージョン領域における曖昧さを解決することができます。これは論理的なことで、通常、部分的にオクルードされていないオブジェクトからのオクルードされたピクセルのモーションは、そのオクルードされていないピクセルのモーションから推測することができるからです。単一スケールの設定でモーションの特徴量を集約するために、この手法の著者は、すべての粗いスケールと細かいスケールで実行される大域的文脈計算からの大域的チャネル統計に基づく効率的な戦略に従っています。モーションのグルーピングは、大域的文脈特徴量GCとモーション特徴量MFに適用されるcross-attention層XCiTを用いておこなわれます。このように、パッチに明示的に分割することなく、各スケールにおいて、大域的な文脈特徴量GCからQueryとKeyを計算し、モーション特徴量から直接Valueを計算します。XCA、LPI、FFNを文脈のQuery、Key、Valueに適用した後、文脈駆動型モーション特徴量(Context-driven Motion Feature: CMF)、文脈駆動型モーション特徴量Cs、および初期モーション特徴量MFを組み合わせ、回帰型ブロックを通過させて更新フローを繰り返し計算します。
粗くおよび微調整されたスキームでモーション集約を実行するためにトークンcross-attentionを使用することは、メモリ使用量の点で実用的ではありません。
著者が発表したCCMR法の元の可視化を以下に示します。
2. MQL5を使用した実装
CCMR法の理論的側面について考察した後、本稿の実用的な部分に移りますが、そこではMQL5を使用して提案されたアプローチを実装します。ご覧の通り、提案されているアーキテクチャはかなり複雑です。そこで、提案するアルゴリズムの実装をいくつかのブロックに分けることにしました。
2.1 閉ループ畳み込みブロック
閉ループ畳み込みブロックから始めましょう。これを実装するために、CResidualConvクラスを作成しましょう。このクラスは全結合層のCNeuronBaseOCLクラスから基本機能を継承します。
新しいクラスの構造体を以下に示します。見ての通り、おなじみのメソッドのセットです。
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
クラスの機能は、畳み込み層の3つのブロックとバッチ正規化を使用します。内部層はすべて静的に宣言されているので、クラスのコンストラクタとデストラクタは空にしておくことができます。
クラスオブジェクトの初期化はInitメソッドでおこなわれます。メソッドのパラメータには、クラスのアーキテクチャを定義する定数を渡します。
bool CResidualConv::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
メソッド本体では、親クラスの同じ名前のメソッドを使用して、受け取ったパラメータを制御し、継承したオブジェクトを初期化します。
親クラスのメソッドが正常に実行された後、内部オブジェクトを初期化します。
if(!cConvs[0].Init(0, 0, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[0].Init(0, 1, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[0].SetActivationFunction(LReLU);
分析された環境の状態から特徴量を抽出するために、2ブロックの逐次畳み込み層を使用し、LReLU関数でバッチ正規化をおこない、それらの間に非線形性を作り出します。
if(!cConvs[1].Init(0, 2, OpenCL, window_out, window_out, window_out, count, optimization, iBatch)) return false; if(!cNorm[1].Init(0, 3, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[1].SetActivationFunction(None);
畳み込み層の3番目のブロックとバッチ正規化(活性化関数なし)を使用して、元のデータをCResidualConvの結果のサイズにスケーリングします。これで2つ目のデータフローを実装することができます。
if(!cConvs[2].Init(0, 4, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[2].Init(0, 5, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[2].SetActivationFunction(None);
2つの並列データフローを作成することは、誤差勾配を同様の並列フローで伝送することを意味します。誤差勾配を合計するために補助的な内部層を使用します。
if(!cTemp.Init(0, 6, OpenCL, window * count, optimization, batch)) return false;
不必要なデータコピーを避けるため、データバッファを置き換えます。
cNorm[1].SetGradientIndex(getGradientIndex()); cNorm[2].SetGradientIndex(getGradientIndex()); SetActivationFunction(None); iWindowOut = (int)window_out; //--- return true; }
CResidualConv::feedForwardメソッドでフィードフォワード機能を実装しています。メソッドのパラメータには、前のニューラル層へのポインタを受け取ります。
bool CResidualConv::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cConvs[0].FeedForward(NeuronOCL)) return false; if(!cNorm[0].FeedForward(GetPointer(cConvs[0]))) return false;
メソッド本体では、受信したポインタのチェックは行いません。なぜなら、そのようなチェックは内部層の関連メソッドですでに実装されているからです。したがって、すぐに内部層のフィードフォワードメソッドの呼び出しに進みます。
if(!cConvs[1].FeedForward(GetPointer(cNorm[0]))) return false; if(!cNorm[1].FeedForward(GetPointer(cConvs[1]))) return false;
上述したように、ブロック1とブロック3のフィードフォワードパスには、前のニューラル層から受け取ったデータを使用します。
if(!cConvs[2].FeedForward(NeuronOCL)) return false; if(!cNorm[2].FeedForward(GetPointer(cConvs[2]))) return false;
そして、その結果を加算し、正規化します。
if(!SumAndNormilize(cNorm[1].getOutput(), cNorm[2].getOutput(), Output, iWindowOut, true)) return false; //--- return true; }
誤差勾配バックプロパゲーションの逆プロセスはCResidualConv::calcInputGradientsメソッドで実装されています。そのアルゴリズムはフィードフォワードメソッドによく似ています。内部層の同名のメソッドを、逆の順序で呼び出すだけです。
bool CResidualConv::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cNorm[2].calcInputGradients(GetPointer(cConvs[2]))) return false; if(!cConvs[2].calcInputGradients(GetPointer(cTemp))) return false; //--- if(!cNorm[1].calcInputGradients(GetPointer(cConvs[1]))) return false; if(!cConvs[1].calcInputGradients(GetPointer(cNorm[0]))) return false; if(!cNorm[0].calcInputGradients(prevLayer)) return false;
ここで注意していただきたいのは、データバッファを置き換えることで、内部層への誤差勾配の初期コピーをなくしたことです。前の層には、2つのデータフローからの誤差勾配の合計を転送します。
if(!SumAndNormilize(prevLayer.getGradient(), cTemp.getGradient(), prevLayer.getGradient(), iWindowOut, false)) return false; //--- return true; }
クラスパラメータを更新するCResidualConv::updateInputWeightsメソッドも同様に構成されています。添付のコードを使用して、よく理解されることをお勧めします。CResidualConvクラスの全コードと全メソッドを以下に添付します。添付ファイルには、記事作成時に使用したすべてのプログラムのコードも含まれています。次に、次のブロックである特徴量エンコーダを構築するアルゴリズムの検討に移ります。
2.2 特徴量エンコーダ
CCMR法の著者によって提案された特徴量エンコーダアルゴリズムは、CCCMREncoderクラスで実装されます。このクラスは、全結合層の基本クラスCNeuronBaseOCLを継承しています。
class CCCMREncoder : public CNeuronBaseOCL { protected: CResidualConv cResidual[6]; CNeuronConvOCL cInput; CNeuronBatchNormOCL cNorm; CNeuronConvOCL cOutput; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CCCMREncoder(void) {}; ~CCCMREncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defCCMREncoder; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
このクラスでは、畳み込み層を使用して元データcInputを射影し、その結果をバッチ正規化層cNormで正規化します。また、エンコーダの演算結果の投影cOutputの畳み込み層を使用します。ソースデータと結果の投影層を使用するため、ソースデータのサイズや必要な特徴量数を参照することなく、いくつかのスケールでカスケード特徴量抽出を設定することができます。
データのスケーリングと特徴量抽出処理は、いくつかの逐次的な閉ループ畳み込みブロックの中でおこなわれます。便宜上、これを配列cResidualに結合しました。
前のクラスと同じように、クラスの内部オブジェクトをすべて静的に宣言したため、コンストラクタとデストラクタを空にしておくことができます。
クラスオブジェクトの初期化はCCCMREncoder::Initメソッドでおこなわれます。このメソッドのアルゴリズムは、すでにおなじみのロジックに従っています。パラメータとして、このメソッドはクラスアーキテクチャ定数を受け取ります。
bool CCCMREncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
メソッド本体では、まず親クラスの関連メソッドを呼び出し、受け取ったパラメータをチェックし、継承したオブジェクトを初期化します。親クラスのメソッドが完了した論理的な結果を用いて、その結果をコントロールします。
次に、ソースデータをスケーリングして正規化するためのブロックを初期化します。その操作結果に基づいて、32個のパラメータの記述という形で、環境の単一の状態の表現を取得する予定です。
if(!cInput.Init(0, 0, OpenCL, window, window, 32, count, optimization, iBatch)) return false; if(!cNorm.Init(0, 1, OpenCL, 32 * count, iBatch, optimization)) return false; cNorm.SetActivationFunction(LReLU);
次に、特徴量数{32, 64, 128}でデータスケーリングカスケードを作成します。
if(!cResidual[0].Init(0, 2, OpenCL, 32, 32, count, optimization, iBatch)) return false; if(!cResidual[1].Init(0, 3, OpenCL, 32, 32, count, optimization, iBatch)) return false;
if(!cResidual[2].Init(0, 4, OpenCL, 32, 64, count, optimization, iBatch)) return false; if(!cResidual[3].Init(0, 5, OpenCL, 64, 64, count, optimization, iBatch)) return false;
if(!cResidual[4].Init(0, 6, OpenCL, 64, 128, count, optimization, iBatch)) return false; if(!cResidual[5].Init(0, 7, OpenCL, 128, 128, count, optimization, iBatch)) return false;
そして最後に、データ次元をユーザーが指定した尺度に合わせます。
if(!cOutput.Init(0, 8, OpenCL, 128, 128, window_out, count, optimization, iBatch)) return false;
ブロック演算結果や誤差勾配の不要なコピー操作を排除するため、データバッファを置き換えます。
if(Output != cOutput.getOutput()) { if(!!Output) delete Output; Output = cOutput.getOutput(); } //--- if(Gradient != cOutput.getGradient()) { if(!!Gradient) delete Gradient; Gradient = cOutput.getGradient(); } //--- return true; }
すべての段階で、操作のプロセスを管理することを忘れてはなりません。そして、メソッドの結果を論理値で呼び出し元に知らせます。
次に、CCCMREncoder::feedForwardメソッドでフィードフォワードパスアルゴリズムを作成します。メソッドのパラメータには、いつものように、前の層のオブジェクトへのポインタを受け取ります。受け取ったポインタの妥当性のチェックは、入れ子オブジェクトのフィードフォワードパスのメソッド本体でおこなわれます。
bool CCCMREncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cInput.FeedForward(NeuronOCL)) return false; if(!cNorm.FeedForward(GetPointer(cInput))) return false;
まず、元のデータをスケーリングし、正規化します。次に、データを特徴量抽出を伴うスケーリングカスケードにかけます。
最初の閉ループ畳み込みブロックは、バッチ正規化層から初期データを受け取り、それに続くものは配列から前のブロックから受け取ります。これにより、ループの中でブロックを反復することができます。
if(!cResidual[0].FeedForward(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].FeedForward(GetPointer(cResidual[i - 1]))) return false;
操作の結果を所定のサイズに拡大縮小します。
if(!cOutput.FeedForward(GetPointer(cResidual[5]))) return false; //--- return true; }
誤差勾配は、逆の順序で内部のエンコーダオブジェクトを通して伝搬されます。
bool CCCMREncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cInput.UpdateInputWeights(NeuronOCL)) return false; if(!cNorm.UpdateInputWeights(GetPointer(cInput))) return false; if(!cResidual[0].UpdateInputWeights(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].UpdateInputWeights(GetPointer(cResidual[i - 1]))) return false; if(!cOutput.UpdateInputWeights(GetPointer(cResidual[5]))) return false; //--- return true; }
この記事では、クラスのすべてのメソッドについては詳しく説明しません。これらは、内部オブジェクトの対応するメソッドを順次呼び出すという同様のブロック構造を持っています。以下に添付する完全なコードを使用して、その構造を学ぶことができます。コードに関して質問があれば、フォーラムかプライベートメッセージでお答えします。ご希望のコミュニケーション形式をお選びください。
2.3 大域的文脈の動的グループ化
特徴量の変化のダイナミクスを考慮した大域的文脈をグループ化するために、CCRM法の著者はcross-attentionブロックXCiTを使用することを提案しました。このブロックでは、大域的文脈の特徴量からQueryエンティティとKeyエンティティが形成されます。Valueは、その後の2つの状態において形成される環境特性のダイナミクスから形成されます。このブロックの使い方は、以前検討したものとは少々異なります。提案されているブロックを使用するオプションを実装するには、いくつかの修正を加える必要があります。
新しいクラスCNeuronCrossXCiTOCLを作成しましょう。このクラスは、XCiTメソッドの以前の実装からほとんどの機能を継承します。
class CNeuronCrossXCiTOCL : public CNeuronXCiTOCL { protected: CCollection cConcat; CCollection cValue; CCollection cV_Weights; CBufferFloat TempBuffer; uint iWindow2; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool Concat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool DeConcat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); public: CNeuronCrossXCiTOCL(void) {}; ~CNeuronCrossXCiTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion); //--- virtual int Type(void) const { return defNeuronCrossXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
この実装では、以前に作成した機能を最大限に使用するよう試みます。3つのデータバッファコレクションと、中間データを保存するための補助バッファがクラス構造に追加されました。
先ほどと同様、内部オブジェクトはすべて静的に宣言されているので、クラスのコンストラクタとデストラクタは「空」です。
すべてのクラスオブジェクトの初期化は、CNeuronCrossXCiTOCL::Init メソッドで実行されます。
bool CNeuronCrossXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronXCiTOCL::Init(numOutputs, myIndex, open_cl, window1, lpi_window, heads, units_count, layers, optimization_type, batch)) return false;
パラメータでは、メソッドはクラス全体のアーキテクチャとその内部オブジェクトを決定する主要なパラメータを受け取ります。クラス本体では、親クラスの関連メソッドを呼び出し、受け取ったパラメータをチェックし、継承したオブジェクトをすべて初期化します。
親クラスのメソッドが正常に実行されたら、Valueエンティティの書き込み用バッファのパラメータと、その誤差勾配を定義します。また、指定されたエンティティの重み生成行列も定義します。
//--- Cross XCA iWindow2 = fmax(window2, 1); uint num = iWindowKey * iHeads * iUnits; //Size of V tensor uint v_weights = (iWindow2 + 1) * iWindowKey * iHeads; //Size of weights' matrix of V tensor
次に、XCiT cross-attention内部層の数によってループを編成し、ループ本体に必要なバッファを作成します。まず、生成されたValueエンティティとそれに対応する誤差勾配を書き込むためのバッファを追加します。
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize V tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cValue.Add(temp)) return false;
親クラスCNeuronXCiTOCLでは、Query、Key、Valueエンティティの連結バッファを使用しました。継承された機能をさらに使用できるようにするために、2つのソースから指定されたエンティティを1つのcConcatコレクションバッファに連結してみましょう。
//--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(3 * num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cConcat.Add(temp)) return false; }
次のステップは、Valueエンティティを生成するための重み行列バッファの作成です。
//--- XCiT //--- Initilize V weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(v_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < v_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false;
指定された重み行列の最適化処理のためのモーメントバッファ。
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(v_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false; } }
次に、中間データ格納バッファを初期化します。
TempBuffer.BufferInit(iWindow2 * iUnits, 0); if(!TempBuffer.BufferCreate(OpenCL)) return false; //--- return true; }
すべての段階で、操作のプロセスを管理することを忘れてはなりません。
フィードフォワードメソッドCNeuronCrossXCiTOCL::feedForwardは、大部分が親クラスからコピーされました。しかし、cross-attentionの特徴量は、その再定義を必要とします。特に、cross-attentionを実現するためには、2つの初期データソースが必要です。
bool CNeuronCrossXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(!NeuronOCL || !Motion) return false;
メソッド本体では、受け取ったポインタとソースデータオブジェクトとの関連性をチェックし、内部層を通るループを構成します。
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 2 * iWindowKey * iHeads, None)) return false;
ループの本体では、まず、前のニューラル層のデータからQueryとKeyエンティティを生成します。この情報の流れの中で、私たちはGCs大域的文脈を受け取ることになります。
レガシーコレクションQKV_TensorsとQKV_Weightsのバッファを使用していることに注意してください。ただし、生成されるのは2つのエンティティだけです。これは畳み込みフィルターの数「2 * iWindowKey * iHeads」からわかります。
同様に、他の初期データに基づいて、3つ目のエンティティValueを生成します。
CBufferFloat *v = cValue.At(i * 2); if(IsStopped() || !ConvolutionForward(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), Motion, v, iWindow, iWindowKey * iHeads, None)) return false;
前述したように、継承された機能を使用できるようにするために、3つのエンティティを1つのテンソルに連結します。
if(IsStopped() || !Concat(qkv, v, cConcat.At(2 * i), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
そして継承された機能を使用するのですが、1つだけ注意点があります。この実装では、どちらのフローでもシーケンス内の要素数は同じです。なぜなら、トップレベルでは、同じソースデータから両方のフローを生成するからです。このような理解から、配列の長さが等しいかどうかのチェックはおこないませんでした。しかし、その後の機能を正しく作動させるためには、このコンプライアンスは非常に重要です。したがって、このクラスを別々に使用する場合は、両方の配列の長さが等しくなるようにしてください。
Multi-Head Attentionの結果を見極めましょう。
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(cConcat.At(2 * i), temp, out)) return false;
データフローを集計し、正規化します。
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
その後、局地的なインタラクションが続きます。フローは合計され、正規化されます。
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false; out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false; temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false; //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
次にフィードフォワードブロックが来ます。
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false; //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
すべての内部ニューラル層を成功裏に反復した後、メソッドを完了します。
このメソッドでは、すべての内部ニューラル層に、元の特徴量ダイナミクスデータの1つのバッファが使用されることに注意してください。大域的文脈は徐々に変化し、文脈によってガイドされた大域的文脈Context-guided Motion Features (CMF)に変換されます。
内部オブジェクトを通して誤差勾配を伝播するプロセスは、逆の順序で同様に実装されます。そのアルゴリズムはCNeuronCrossXCiTOCL::calcInputGradientsメソッドに記述されています。このメソッドは、パラメータとして、対応する誤差勾配のバッファを持つ2つのソースデータオブジェクトへのポインタを受け取ります。
bool CNeuronCrossXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion) { if(!prevLayer || !Motion) return false;
メソッド本体では、まず受け取ったポインタの関連性を確認します。次に、内部層を逆の順序でループさせます。
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
ループ本体では、まずFeedForwardブロックを通して誤差勾配を伝播させます。
フィードフォワードパスの間に、各ブロックの入力データと出力データを加算して正規化したことを思い出してください。したがって、バックプロパゲーションパスの間に、両方のデータフローに沿って誤差勾配を伝播させる必要があります。誤差勾配をblockFeedForwardを通して伝播させた後、2つのフローからの誤差勾配を合計しなければなりません。
//--- Sum gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
同様にして、局所的な相互作用ブロックを介して誤差勾配を伝播させ、2つのデータフローにわたって誤差勾配を合計します。
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false; temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
最後のステップは、Attentionブロックを通して誤差勾配を伝播させることです。
//--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(cConcat.At(i * 2), cConcat.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
しかし、ここでは、3つのエンティティ(Query, Key、Value)の誤差勾配のバッファは連結されています。その実体はさまざまなデータソースから生成されたものであることを忘れてはなりません。誤差勾配を分配しなければなりません。まず、1つのバッファを2つに分割します。
if(IsStopped() || !DeConcat(QKV_Tensors.At(i * 2 + 1), cValue.At(i * 2 + 1), cConcat.At(i * 2 + 1), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
次に、対応するソースデータに勾配を伝播するメソッドを呼び出します。継承された機能をQueryとKeyに使用することができます。ただし、Valueの場合はもう少し複雑です。
//--- CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false;
フィードフォワードパスでは、すべての層で、特徴量変化のダイナミクスの1つのバッファを使用することを強調しました。誤差勾配をソースデータオブジェクトの勾配バッファに直接渡すと、それらは単に上書きされ、他の内部層の以前に書き込まれたデータは削除されます。そのため、最初のイテレーション(最後の内部層)でのみデータを直接書き込みます。
if(i > 0) out_grad = temp; if(i == iLayers - 1) { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), Motion.getGradient(), iWindow, iWindowKey * iHeads, None)) return false; }
その他の場合は、補助バッファを使用して一時的なデータを保存し、新しい勾配と以前に蓄積された勾配を合計します。
else { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), GetPointer(TempBuffer), iWindow, iWindowKey * iHeads, None)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(TempBuffer), Motion.getGradient(), Motion.getGradient(), iWindow2, false)) return false; }
2つのデータフローの誤差勾配を合計し、ループの次の反復に移ります。
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false; if(i > 0) out_grad = temp; } //--- return true; }
すべての内部層に誤差勾配を通すことに成功したら、メソッドを終了します。
すべての内部オブジェクトとソースデータの間で、最終結果に対する影響度に従って誤差勾配を分配した後、誤差を最小化するためにモデルのパラメータを調整する必要があります。この処理は、CNeuronCrossXCiTOCL::updateInputWeightsメソッドで整理されます。上述した2つのメソッドと同様に、内部のニューラル層を介したループで内部オブジェクトのパラメータを更新します。
bool CNeuronCrossXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization == SGD ? QKV_Weights.At(l * 2 + 1) : QKV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : QKV_Weights.At(l * 3 + 2)), iWindow, 2 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cV_Weights.At(l * (optimization == SGD ? 2 : 3)), cValue.At(l * 2 + 1), inputs, (optimization == SGD ? cV_Weights.At(l * 2 + 1) : cV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : cV_Weights.At(l * 3 + 2)), iWindow, iWindowKey * iHeads)) return false;
まず、Query、Key、Valueエンティティを生成するためのパラメータを更新します。LPI局地的通信ブロックが続きます。
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization == SGD ? cLPI_Weights.At(l * 5 + 3) : cLPI_Weights.At(l * 7 + 3)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization == SGD ? cLPI_Weights.At(l * 5 + 4) : cLPI_Weights.At(l * 7 + 4)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
FeedForwardブロックで処理を完了します。
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization == SGD ? FF_Weights.At(l * 4 + 2) : FF_Weights.At(l * 6 + 2)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 4 + 3) : FF_Weights.At(l * 6 + 3)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
以上で、CNeuronCrossXCiTOCLクラスのメソッドの説明を終了します。この記事の範囲では、クラスのすべてのメソッドについて詳しく説明することはできません。添付ファイルのコードを使用して、ご自分で勉強してください。添付ファイルには、すべてのクラスとそのメソッドの完全なコードが含まれています。また、記事作成に使用したすべてのプログラムも含まれています。
2.4 CCMRアルゴリズムの実装
新しいクラスを導入するために、かなり多くの作業をおこないましたが、これは準備作業でした。次に、CCMRアルゴリズムのビジョンを実装します。これは、提案されたアプローチに対する私たちのビジョンであることにご留意ください。本来の表現とは異なることがあります。それでも、提案されたアプローチを実装して、問題を解決しようと試みました。
このメソッドを実装するために、CNeuronBaseOCLクラスから基本機能を継承したCNeuronCCMROCLクラスを作成しましょう。新しいクラスの構造体を以下に示します。
class CNeuronCCMROCL : public CNeuronBaseOCL { protected: CCCMREncoder FeatureExtractor; CNeuronBaseOCL PrevFeatures; CNeuronBaseOCL Motion; CNeuronBaseOCL Temp; CCCMREncoder LocalContext; CNeuronXCiTOCL GlobalContext; CNeuronCrossXCiTOCL MotionContext; CNeuronLSTMOCL RecurentUnit; CNeuronConvOCL UpScale; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCCMROCL(void) {}; ~CNeuronCCMROCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronCCMROCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag virtual bool Clear(void); };
ここでは、伝統的な一連のメソッドと多くのオブジェクトを見ることができます。そのほとんどが上で作成されました。環境と局地的文脈の特徴量を抽出するために、CCCMREncoderクラスのオブジェクトを2つ作成します(それぞれFeatureExtractorと LocalContext)。
CNeuronXCiTOCLオブジェクトのインスタンスは、大域的文脈(GlobalContext)を取得するために使用されます。CNeuronCrossXCiTOCLを使用して、CMF (MotionContext)に特徴量のダイナミクスを考慮して調整します。
回帰型接続を実装するために、GRUの代わりにLSTMブロック(CNeuronLSTMOCL RecurrentUnit)を使用します。
すべての内部オブジェクトの機能については、クラスメソッドの実装で詳しく知ることになります。
前回同様、クラスの内部オブジェクトはすべて静的に宣言しました。したがって、クラスのコンストラクタとデストラクタは「空」のままです。
内部クラスオブジェクトはCNeuronCCMROCL::Initメソッドで初期化されます。
bool CNeuronCCMROCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
メソッドのパラメータでは、クラスアーキテクチャの主要な定数を取得します。メソッド本体では、すぐに親クラスの関連メソッドを呼び出し、そこで受け取ったパラメータをチェックし、継承したオブジェクトを初期化します。
親クラスのメソッドの実行に成功したら、内部オブジェクトの初期化に移ります。まず、現在の環境状態の特徴量エンコーダを初期化します。
if(!FeatureExtractor.Init(0, 0, OpenCL, window, 16, count, optimization, iBatch)) return false;
フローを推定するために、CCMR法はシステムの連続する2つの状態のスナップショットを使用します。ただし、この問題は少し違った角度から扱っています。フィードフォワードパスの各反復で、1つの環境状態のみの特徴量を生成し、ローカルバッファPrevFeaturesに保存します。このバッファの値を用いて、後続のフィードフォワードパスにおけるダイナミックフローを推定します。前の状態と特性の変化をローカルバッファオブジェクトに初期化します。
if(!PrevFeatures.Init(0, 1, OpenCL, 16 * count, optimization, iBatch)) return false; if(!Motion.Init(0, 2, OpenCL, 16 * count, optimization, iBatch)) return false;
不必要なデータコピーを避けるため、バッファの入れ替えをおこないます。
if(Motion.getGradientIndex() != FeatureExtractor.getGradientIndex())
Motion.SetGradientIndex(FeatureExtractor.getGradientIndex());
次に、環境の現在の状態に基づいて、LocalContextエンコーダを使用して文脈特徴量を生成します。ここで注意しなければならないのは、1セットのソースデータを2つのデータフローで使用していることです。その結果、2つのフローから誤差勾配を求める必要があります。勾配の合計を可能にするために、ローカルデータバッファを作成します。
if(!Temp.Init(0, 3, OpenCL, window * count, optimization, iBatch)) return false; if(!LocalContext.Init(0, 4, OpenCL, window, 16, count, optimization, iBatch)) return false;
Attentionメカニズムは、局地的文脈を大域的文脈にグループ化することを可能にします。
if(!GlobalContext.Init(0, 5, OpenCL, 16, 3, 4, count, 4, optimization, iBatch)) return false;
そして、大域的文脈はフローダイナミクスに合わせて調整されます。
if(!MotionContext.Init(0, 6, OpenCL, 16, 16, 3, 4, count, 4, optimization, iBatch)) return false;
最後に、回帰型ブロックのフローを更新します。
if(!RecurentUnit.Init(0, 7, OpenCL, 16 * count, optimization, iBatch) || !RecurentUnit.SetInputs(16 * count)) return false;
モデルサイズを小さくするため、かなり圧縮された状態の内部オブジェクトを使用しました。しかし、ユーザーは異なる次元のデータを必要とする場合があります。結果を希望のサイズにするために、スケーリング層を使用します。
if(!UpScale.Init(0, 8, OpenCL, 16, 16, window_out, count, optimization, iBatch)) return false;
不必要なデータのコピーを避けるため、データバッファの入れ替えを整理します。
if(UpScale.getGradientIndex() != getGradientIndex()) SetGradientIndex(UpScale.getGradientIndex()); if(UpScale.getOutputIndex() != getOutputIndex()) Output.BufferSet(UpScale.getOutputIndex()); //--- return true; }
フィードフォワードアルゴリズムはCNeuronCCMROCL::feedForwardメソッドに実装されています。フィードフォワードメソッドは、パラメータで、元のデータを含む前の層オブジェクトへのポインタを受け取ります。
bool CNeuronCCMROCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Delta Features if(!SumAndNormilize(FeatureExtractor.getOutput(), FeatureExtractor.getOutput(), PrevFeatures.getOutput(), 1, false, 0, 0, 0, -0.5f)) return false;
メソッド本体では、操作を開始する前に、環境状態符号エンコーダの結果バッファの内容を前の状態バッファに転送します。反復が始まる前に、バッファには前回のフィードフォワードパスの結果が格納されます。
データを転送する際、特徴量属性の符号を逆に変更することにご注意ください。
データを保存した後、ステートエンコーダにフィードフォワードパスを通します。
if(!FeatureExtractor.FeedForward(NeuronOCL)) return false;
FeatureExtractorのフィードフォワードパスが成功すると、後続の2つの条件の特徴量が得られ、偏差を決定することができます。分かりやすくするために、単純に特徴量の差を取ることにします。前の状態を保存する際、慎重に特徴量の符号を変更しました。さて、状態の違いを求めるには、バッファの内容を足します。
if(!SumAndNormilize(FeatureExtractor.getOutput(), PrevFeatures.getOutput(), Motion.getOutput(), 1, false, 0, 0, 0, 1.0f)) return false;
次のステップは、局地的文脈の特徴量を生成することです。
if(!LocalContext.FeedForward(NeuronOCL)) return false;
大域的文脈を抽出してみましょう。
if(!GlobalContext.FeedForward(GetPointer(LocalContext))) return false;
そして、変化のダイナミクスに合わせて調整します。
if(!MotionContext.FeedForward(GetPointer(GlobalContext), Motion.getOutput())) return false;
次に、回帰型ブロックのフローを調整します。
//--- Flow if(!RecurentUnit.FeedForward(GetPointer(MotionContext))) return false;
データを必要なサイズにスケーリングします。
if(!UpScale.FeedForward(GetPointer(RecurentUnit))) return false; //--- return true; }
実装中は、すべての段階でプロセスを管理することを忘れてはなりません。
バックプロパゲーションアルゴリズムはCNeuronCCMROCL::calcInputGradientsメソッドに実装されています。他のクラスの同名のメソッドと同様に、メソッドパラメータは前の層のオブジェクトへのインデックスを提供します。メソッド本体では、内部オブジェクトの対応するメソッドを順次呼び出します。ただし、オブジェクトの順序は直通とは逆になります。
bool CNeuronCCMROCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!UpScale.calcInputGradients(GetPointer(RecurentUnit))) return false;
まず、誤差勾配をスケーリング層を通して伝播させます。そして回帰型ブロックを通過します。
if(!RecurentUnit.calcInputGradients(GetPointer(MotionContext))) return false;
次に、文脈変換の全段階を通じて誤差勾配を順次伝播させます。
if(!MotionContext.calcInputGradients(GetPointer(GlobalContext), GetPointer(Motion))) return false; if(!GlobalContext.calcInputGradients(GetPointer(LocalContext))) return false; if(!LocalContext.calcInputGradients(GetPointer(Temp))) return false;
データバッファの置き換えにより、特徴量ダイナミクスからの誤差勾配は状態特徴量エンコーダに転送されます。誤差勾配はエンコーダを通して前の層のバッファに伝搬されます。
if(!FeatureExtractor.calcInputGradients(prevLayer)) return false;
文脈エンコーダから誤差勾配を加えます。
if(!SumAndNormilize(prevLayer.getGradient(), Temp.getGradient(), prevLayer.getGradient(), 1, false, 0, 0, 0, 1.0f)) return false; //--- return true; }
モデルのパラメータを更新するメソッドは難しくありません。内部オブジェクトのパラメータを順次更新していきます。
bool CNeuronCCMROCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!FeatureExtractor.UpdateInputWeights(NeuronOCL)) return false; if(!LocalContext.UpdateInputWeights(NeuronOCL)) return false; if(!GlobalContext.UpdateInputWeights(GetPointer(LocalContext))) return false; if(!MotionContext.UpdateInputWeights(GetPointer(GlobalContext), Motion.getOutput())) return false; if(!RecurentUnit.UpdateInputWeights(GetPointer(MotionContext))) return false; if(!UpScale.UpdateInputWeights(GetPointer(RecurentUnit))) return false; //--- return true; }
このクラスには、回帰型ブロックと前の状態を保存するためのバッファが含まれています。したがって、回帰型コンポーネントをクリアするCNeuronCCMROCL::Clearメソッドを再定義する必要があります。ここでは、同名の回帰型ブロックメソッドを呼び出し、FeatureExtractorの結果バッファをゼロ値で満たします。
bool CNeuronCCMROCL::Clear(void) { if(!RecurentUnit.Clear()) return false; //--- CBufferFloat *temp = FeatureExtractor.getOutput(); temp.BufferInit(temp.Total(), 0); if(!temp.BufferWrite()) return false; //--- return true; }
エンコーダの結果バッファをクリアしているのであって、前の状態バッファをクリアしているのではありません。フィードフォワードパスメソッドの最初に、エンコーダの結果バッファから前の状態バッファにデータをコピーします。
これで、CCMRアプローチのメインメソッドが終わりました。かなり多くの仕事をこなしましたが、記事のサイズは限られています。したがって、添付ファイルにある補助メソッドのアルゴリズムをよく理解することをお勧めします。そこには、CCMRアプローチを実装するためのすべてのクラスとそのメソッドの完全なコードがあります。また、添付ファイルには、記事作成に使用したすべてのプログラムの完全なコードが記載されています。次に、モデルの訓練アーキテクチャの検討に移ります。
2.5. モデルアーキテクチャ
モデルアーキテクチャの説明に移りますが、CCMRのアプローチは環境状態エンコーダのみに影響を与えたことを述べておきたいと思います。
CreateDescriptionsメソッドのパラメータには、Encoder、Actor、Criticのアーキテクチャを記録する3つの動的配列を指定します。
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
メソッド本体では、受け取ったポインタを確認し、必要であれば新しいオブジェクトインスタンスを生成します。
エンコーダには、現在の環境状態の生データを送ります。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
受信データはバッチ正規化層で前処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
その後、状態の埋め込みスタックを形成します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
その結果得られた埋め込みに位置エンコーディングを加えます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
そして、エンコーダアーキテクチャの最後のものは、新しいCNeuronCCMROCLブロックであり、これ自体が非常に複雑で、追加の処理を必要とします。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCCMROCL; descr.count = prev_count; descr.window = prev_wout; descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
ここでは、以前の記事で紹介したActorとCriticのアーキテクチャをそのまま使用します。モデルアーキテクチャの詳細については、こちらをご覧ください。加えて、モデルの完全なアーキテクチャは添付ファイルに示されています。次に、最終的なテスト段階に移ります。
3. 検証
今までのセクションでは、CCMR法を理解し、MQL5を使用して提案されたアプローチを実装しました。次に、上記の作業の結果を実際にテストしてみましょう。いつものように、EURUSDの履歴データ(時間枠 H1)を使用して、モデルの訓練とテストをおこないます。モデルは2023年の最初の7ヶ月間の履歴データで訓練されています。訓練済みモデルをMetaTrader 5ストラテジーテスターでテストするために、2023年8月の履歴データを使用します。
この記事では、以前の記事の一部として収集した訓練データセットを使用してモデルを訓練しました。訓練の過程で、訓練セットで利益を生み出すことができるモデルを得ることができました。
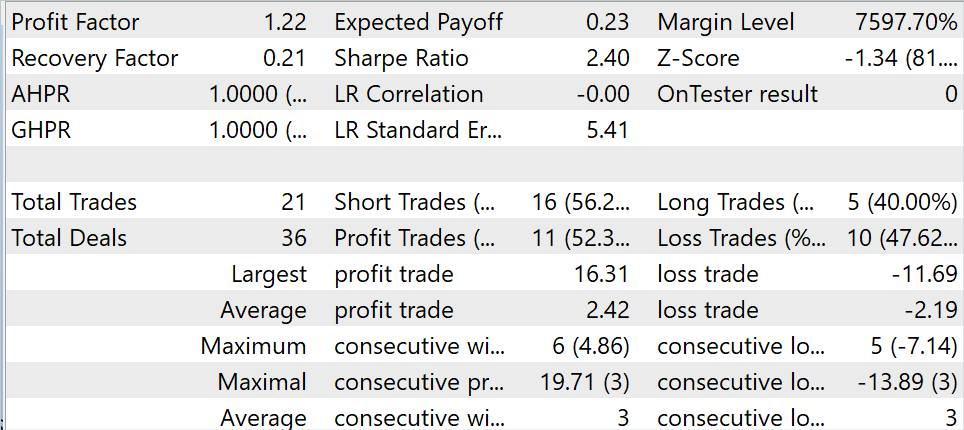
テスト期間中、このモデルは21件の取引をおこない、そのうち52.3%が利益を得て決済されました。最大利益取引と平均利益取引の両方が、負け取引の対応する指標を上回っています。その結果、利益率は1.22となりました。
結論
本稿では、CCMRと呼ばれるオプティカルフロー推定法について議論しました。CCMRは、文脈に基づくモーションの集約とマルチスケールのcoarse-to-fineアプローチの概念の利点を組み合わせたものです。これにより、障害物のある場所でも精度の高い詳細なフローマップが作成されます。
この手法の著者は2段階のモーショングループ化戦略を提案しています。まず大域的文脈特徴量を計算し、それを用いて、あらゆるスケールで反復的に運動特性を導いていきます。これにより、XCiTベースのアルゴリズムは、スケール固有の内容を保持したまま、粗いものから細かいものまですべてのスケールを処理することができます。
実用的な部分では、MQL5を使用して提案されたアプローチを実装しました。MetaTrader 5のストラテジーテスターで実際のデータを使用してモデルを訓練し、テストしました。得られた結果は、提案されたアプローチの有効性を示唆しています。
しかし、この記事で紹介されているすべてのプログラムは、あくまでも参考のためのものであり、提案されているアプローチを実証するためのものであることをお断りしておきます。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルをテストするEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14505
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索