
Нейросети — это просто (Часть 81): Анализ динамики данных с учетом контекста (CCMR)

Введение
В рамках данной серии мы познакомились с различными методами анализа состояния окружающей среды и алгоритмами использования полученных данных. С помощью сверточных моделей мы искали устойчивые паттерны в исторических данных ценового движения. Мы использовали модели внимания для поиска зависимостей между отдельными локальными состояниями окружающей среды. При этом мы всегда оценивали состояния окружающей среды как некий срез в момент времени. Но никогда не оценивали динамику показателей состояния окружающей среды. Мы предполагали, что модель в процессе анализа и сопоставления состояний окружающей среды как-то обратит внимание на ключевые изменения. Но явного количественного представления такой динамики мы не использовали.
Однако, в области компьютерного зрения существует фундаментальная задача оценки оптического потока, решение которой предоставляет информацию о движении объектов в сцене. И для решения этой задачи были предложены целый ряд интересных алгоритмов, которые получили широкое применение. Результаты оценки оптического потока используются в различных областях от автономного вождения, до отслеживания и наблюдения за объектами.
Большинство современных подходов используют сверточные нейронные сети, но они лишены глобального контекста. Это затрудняет рассуждения о заслонениях объектов или больших смещениях. Альтернативный подход — использование трансформеров и других методов внимания. Он позволяет выходить далеко за пределы фиксированного поля зрения классических CNN.
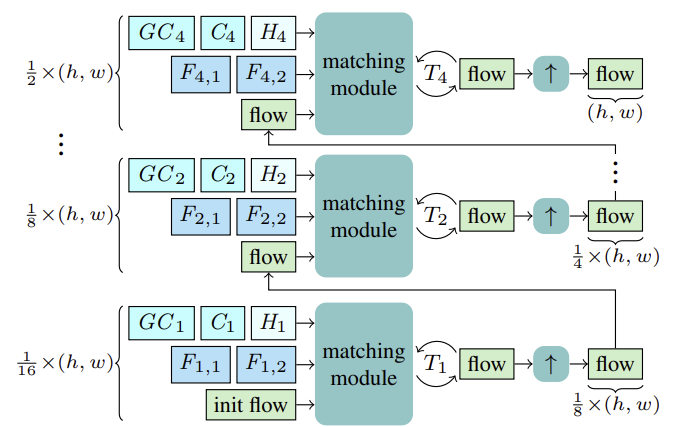
Особенно интересен в этом контексте метод CCMR, представленный в статье "CCMR: High Resolution Optical Flow Estimation via Coarse-to-Fine Context-Guided Motion Reasoning". Это подход к оценке оптического потока, который объединяет преимущества методов, направленных на внимание концепций агрегации движения, и высокоразрешающих многомасштабных подходов. В нем последовательно интегрируются концепции группировки движения на основе контекста в высокоразрешающую грубо-корректную оценочную схему. Это позволяет получать подробные потоковые поля, которые также обеспечивают высокую точность в заслоненных областях. В этом контексте предлагается двухэтапная стратегия группировки движения, где сначала вычисляется глобальное само-внимательные контекстных признаков, которые затем используются для направления признаков движения итеративно по всем масштабам. Таким образом, контекстно-направленное рассуждение о движении на основе XCiT обеспечивает обработку на всех грубо-корректных масштабах. Эксперименты, проведенные авторами метода, демонстрируют сильную производительность предложенного подхода и преимущества его основных концепций.
1. Алгоритм CCMR
Метод CCMR оценивает оптический поток с помощью рекуррентных обновлений в грубом и тонком масштабах с использованием общего вентильного рекуррентного блока (GRU). Перед началом оценки для каждого масштаба S вычисляются признаки двух последующих состояний Fs,1, Fs,2 для сопоставления. Кроме того, вычисляются контекстные признаки Cs и, на их основе, глобальные контекстные признаки GCs. А также начальное скрытое состояние Hs для текущего масштаба рекуррентного блока из опорного состояния I1.
Начиная с самого грубого масштаба 1/16, поток вычисляется на основе вышеуказанных признаков F1,1, F1,2, C1, GC1, H1. После T1 повторных обновлений оцененный поток повышается в разрешении с использованием общего 2-кратного выпуклого повышающего модуля, где поток служит инициализацией для процесса сопоставления на следующем более тонком масштабе. Этот процесс продолжается, пока поток не будет вычислен на самом тонком масштабе 1/2 и повышен до исходного разрешения.
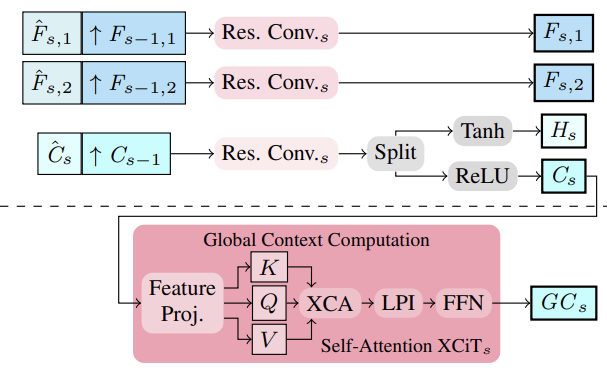
Авторы метода предложили извлекать многомасштабные признаки изображения и контекста с использованием извлекателя признаков. Для этого промежуточные признаки вычисляются сверху вниз, а затем, для получения многомасштабных признаков, более структурированные и тонкие признаки Fs,1, Fs,2 и Cs семантически усиливаются за счет объединения их с более глубокими признаками более грубого масштаба Fs−1,1, Fs−1,2 и Cs−1 для S ∈ {2, 3, 4}. Таким образом, консолидация осуществляется путем соединения повышенных более грубых признаков и промежуточных более тонких признаков и их агрегации.
На основе многомасштабных признаков контекста Cs, вычисляются глобальные контекстные признаки. Здесь целью является получение более значимых признаков, которые затем используются для управления движением. Для этого выполняется агрегация контекстных признаков Cs с использованием статистики каналов с помощью слоя XCiT, что обеспечивает линейную сложность относительно числа токенов. Этот архитектурный выбор позволяет осуществлять возможную агрегацию контекста на всех грубых и тонких масштабах во время оценки. Важно отметить, что предложенный авторами CCMR подход к использованию XCiT отличается от его исходного подхода, где слой XCiT фактически применяется к более грубому представлению его входных данных, реализованному через явное разбиение на патчи, а затем снова повышается до исходного разрешения. В рамках CCMR, напротив, применяется слой XCiT непосредственно к признакам на всех грубых и тонких масштабах, используя специфическое для масштаба содержимое. Для вычисления глобального контекста сначала к контекстным признакам Cs добавляется позиционное кодирование. Затем осуществляется нормализация слоя. На этом этапе для осуществления Self-Attention все Query, Key и Value вычисляются из Csp. Перед применением шага кросс-ковариационного внимания каналы KCs, QCs, VCs заново формируются в h головок. Затем вычисляется кросс-ковариационное внимание XCA(KCs, QCs, VCs). После чего применяется слой локального взаимодействия патчей (LPI), а затем блок FFN.
В то время как кросс-ковариационное внимание обеспечивает глобальные взаимодействия между каналами в каждой голове, модули LPI и FFN обеспечивают явное пространственное взаимодействие между токенами локально и связь между всеми каналами соответственно.
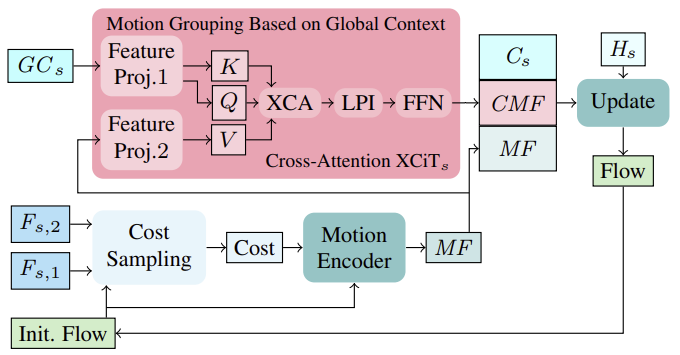
Сначала, основываясь на начальном потоке в первой итерации (или обновленном потоке в следующих итерациях), затраты на сопоставление в окрестности вычисляются из признаков изображения (Fs,1, Fs,2). Вычисленные затраты вместе с текущей оценкой потока затем обрабатываются через кодировщик движения, который выводит признаки движения, которые в конечном итоге используются в GRU для вычисления обновления потока.
При вычислении повторных обновлений потока включение глобально агрегированных признаков движения на основе контекстных признаков может помочь разрешить неоднозначности в закрытых областях. Это логично, потому что движение закрытых пикселей от частично незакрытого объекта обычно можно вывести из движения его незакрытых пикселей. Для агрегирования признаков движения в настройке одного масштаба авторы метода следуют своей эффективной стратегии на основе глобальной статистики каналов из вычисления глобального контекста, которое выполняется на всех грубых и тонких масштабах. Группировка движения выполняется с применением слоя кросс-внимания XCiT к глобальным контекстным признакам GCs и признакам движения MF. Таким образом, вычисляются Query и Key из глобальных контекстных признаков GCs и Value из признаков движения напрямую на каждом масштабе без явного разбиения на патчи. После применения XCA, LPI и FFN к Query, Key и Value контекста, контекстно-управляемые признаки движения (CMF), контекстные признаки Cs и начальные признаки движения MF объединяются и передаются через рекуррентный блок для итеративного вычисления обновления потока.
Обратите внимание, что применение токенного кросс-внимания для выполнения агрегирования движения в схемах грубой и тонкой настройки нецелесообразно с точки зрения использования памяти.
Авторская визуализация метода CCMR представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода CCMR мы переходим к практической части нашей статьи, в которой реализуем предложенные подходы средствами MQL5. Как можно заметить, предложенная архитектура довольно сложная и комплексная. Поэтому, реализацию предложенных алгоритмов было решено разделить на несколько блока.
2.1 Сверточный блок с обратной связью
И первым мы рассмотрим сверточный блок с обратной связью. Для его реализации мы создадим класс CResidualConv, который будет наследовать базовый функционал от класса полносвязного слоя CNeuronBaseOCL.
Структура нового класса представлена ниже. И, как можно заметить, она содержит уже привычный набор методов.
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
В функционале класса будут использоваться 3 блока из сверточного слоя и пакетной нормализации. Все внутренние слои объявлены статическими, что позволяет нам оставить пустыми конструктор и деструктор класса.
Инициализация объекта класса осуществляется в методе Init. В параметрах метода мы будем передавать константы, определяющие архитектуру класса.
bool CResidualConv::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
А в теле метода мы используем одноименный метод родительского класса для осуществления контроля полученных параметров и инициализации унаследованных объектов.
После успешного выполнения метода родительского класса мы инициализируем внутренние объекты.
if(!cConvs[0].Init(0, 0, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[0].Init(0, 1, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[0].SetActivationFunction(LReLU);
Для извлечения признаков из анализируемого состояния окружающей среды мы будем использовать 2 блока из последовательных сверточного слоя и пакетной нормализации с функцией LReLU для создания нелинейности между ними.
if(!cConvs[1].Init(0, 2, OpenCL, window_out, window_out, window_out, count, optimization, iBatch)) return false; if(!cNorm[1].Init(0, 3, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[1].SetActivationFunction(None);
Третий блок сверточного слоя и пакетной нормализации (без функции активации) мы будем использовать для масштабирования исходных данных до размера результатов нашего CResidualConv. Это позволит нам осуществить второй поток данных.
if(!cConvs[2].Init(0, 4, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[2].Init(0, 5, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[2].SetActivationFunction(None);
Создание 2 параллельных потоков данных обязывает нас осуществлять и передачу градиента ошибки в аналогичных параллельных потоках. Для суммирования градиентов ошибки мы будем использовать вспомогательный внутренний слой.
if(!cTemp.Init(0, 6, OpenCL, window * count, optimization, batch)) return false;
А для исключения излишнего копирования данных мы осуществим подмену буферов данных.
cNorm[1].SetGradientIndex(getGradientIndex()); cNorm[2].SetGradientIndex(getGradientIndex()); SetActivationFunction(None); iWindowOut = (int)window_out; //--- return true; }
Функционал прямого прохода мы реализуем в методе CResidualConv::feedForward. В параметрах метода мы получаем указатель на предшествующий нейронный слой.
bool CResidualConv::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cConvs[0].FeedForward(NeuronOCL)) return false; if(!cNorm[0].FeedForward(GetPointer(cConvs[0]))) return false;
В теле метода мы не организовываем проверку полученного указателя, так как такая проверка уже реализована в аналогичных методах внутренних слоев. Поэтому мы сразу переходим к вызову методов прямого прохода внутренних слоев.
if(!cConvs[1].FeedForward(GetPointer(cNorm[0]))) return false; if(!cNorm[1].FeedForward(GetPointer(cConvs[1]))) return false;
Как уже было сказано выше, данные, полученные от предыдущего нейронного слоя, мы будем использовать для прямого прохода 1 и 3 блоков.
if(!cConvs[2].FeedForward(NeuronOCL)) return false; if(!cNorm[2].FeedForward(GetPointer(cConvs[2]))) return false;
Чьи результаты мы сложим и нормализуем.
if(!SumAndNormilize(cNorm[1].getOutput(), cNorm[2].getOutput(), Output, iWindowOut, true)) return false; //--- return true; }
Обратный процесс распределения градиента ошибки организован в методе CResidualConv::calcInputGradients. Его алгоритм довольно схож с методом прямого прохода. Мы лишь осуществляем вызов одноименных методов внутренних слоев, но в обратном порядке.
bool CResidualConv::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cNorm[2].calcInputGradients(GetPointer(cConvs[2]))) return false; if(!cConvs[2].calcInputGradients(GetPointer(cTemp))) return false; //--- if(!cNorm[1].calcInputGradients(GetPointer(cConvs[1]))) return false; if(!cConvs[1].calcInputGradients(GetPointer(cNorm[0]))) return false; if(!cNorm[0].calcInputGradients(prevLayer)) return false;
Здесь стоит обратить внимание, что благодаря подмене буферов данных мы исключили первичное копирование градиентов ошибки на внутренние слои. А в предшествующий слой мы передаем сумму градиентов ошибки от 2 потоков данных.
if(!SumAndNormilize(prevLayer.getGradient(), cTemp.getGradient(), prevLayer.getGradient(), iWindowOut, false)) return false; //--- return true; }
Аналогично организован и метод обновления параметров класса CResidualConv::updateInputWeights, с которым я предлагаю Вам ознакомиться самостоятельно. Полный код класса CResidualConv и всех его методов Вы можете найти во вложении. Там же есть полный код всех программ, используемых при подготовке статьи. А мы переходим к рассмотрению алгоритма построения следующего блока — Энкодера признаков.
2.2 Энкодер признаков
Алгоритм, предложенного авторами метода CCMR, Энкодера признаком мы реализуем в классе CCCMREncoder, который также будет наследоваться от базового класса полносвязного нейронного слоя CNeuronBaseOCL.
class CCCMREncoder : public CNeuronBaseOCL { protected: CResidualConv cResidual[6]; CNeuronConvOCL cInput; CNeuronBatchNormOCL cNorm; CNeuronConvOCL cOutput; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CCCMREncoder(void) {}; ~CCCMREncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defCCMREncoder; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
В данном классе мы будем использовать сверточный слой для проекции исходных данных cInput, результаты работы которого мы нормализуем благодаря слою пакетной нормализации cNorm. И сверточный слой проекции результатов работы Энкоде cOutput. Благодаря использованию слое проекции исходных данных и результатов мы можем настроить каскадное извлечение признаков в нескольких масштабах без привязки к размеру исходных данных и желаемого количества признаков.
Непосредственное масштабирование данных и извлечение признаков осуществляется в нескольких последовательных сверточных блоках с обратной связью, которые для удобства мы объединили в массив cResidual.
Как и в предыдущем классе, все внутренние объекты класса мы объявили статическими, что позволяет нам оставить "пустыми" конструктор и деструктор класса.
Инициализация объектов класса осуществляется в методе CCCMREncoder::Init, алгоритм которого выполнен по уже знакомой схеме. В параметрах метод получает константы архитектуры класса.
bool CCCMREncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
А в теле метода мы сначала вызываем одноименный метод родительского класса, в котором осуществляется проверка полученных параметров и инициализация унаследованных объектов. Результат работы метода родительского класса мы контролируем по логическому результату его завершения.
Далее мы инициализируем блок масштабирования и нормализации исходных данных. По результатам работы которого мы планируем получать представление отдельно взятого состояния окружающей среды в виде описания из 32 параметров.
if(!cInput.Init(0, 0, OpenCL, window, window, 32, count, optimization, iBatch)) return false; if(!cNorm.Init(0, 1, OpenCL, 32 * count, iBatch, optimization)) return false; cNorm.SetActivationFunction(LReLU);
Затем мы создадим каскад масштабирования данных с количеством признаков {32, 64, 128}.
if(!cResidual[0].Init(0, 2, OpenCL, 32, 32, count, optimization, iBatch)) return false; if(!cResidual[1].Init(0, 3, OpenCL, 32, 32, count, optimization, iBatch)) return false;
if(!cResidual[2].Init(0, 4, OpenCL, 32, 64, count, optimization, iBatch)) return false; if(!cResidual[3].Init(0, 5, OpenCL, 64, 64, count, optimization, iBatch)) return false;
if(!cResidual[4].Init(0, 6, OpenCL, 64, 128, count, optimization, iBatch)) return false; if(!cResidual[5].Init(0, 7, OpenCL, 128, 128, count, optimization, iBatch)) return false;
И в завершении приведем размерность данных к масштабу, заданному пользователем.
if(!cOutput.Init(0, 8, OpenCL, 128, 128, window_out, count, optimization, iBatch)) return false;
Для исключения излишних операций копирования результатов работы блока и градиентов ошибки мы осуществляем подмену буферов данных.
if(Output != cOutput.getOutput()) { if(!!Output) delete Output; Output = cOutput.getOutput(); } //--- if(Gradient != cOutput.getGradient()) { if(!!Gradient) delete Gradient; Gradient = cOutput.getGradient(); } //--- return true; }
При этом не забываем контролировать процесс выполнения операций на каждом шаге. А о результатах работы метода мы проинформируем вызывающую программу логическим значением.
Алгоритм прямого прохода мы создадим в методе CCCMREncoder::feedForward. В параметрах метода, мы как всегда, получаем указатель на объект предшествующего слоя. Проверка актуальности полученного указателя осуществляется в теле методов прямого прохода вложенных объектов.
bool CCCMREncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cInput.FeedForward(NeuronOCL)) return false; if(!cNorm.FeedForward(GetPointer(cInput))) return false;
Сначала мы осуществляем масштабирование и нормализацию исходных данных. А затем проведем данные через каскад масштабирования с извлечением признаков.
Обратите внимание, что для первый сверточный блока с обратной связью получает исходными данными от слоя пакетной нормализации, а последующие от предыдущего блока из массива. Это позволяет нам осуществить перебор блоков в цикле.
if(!cResidual[0].FeedForward(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].FeedForward(GetPointer(cResidual[i - 1]))) return false;
Результат операций мы масштабируем до заданного размера.
if(!cOutput.FeedForward(GetPointer(cResidual[5]))) return false; //--- return true; }
Распределение градиента ошибки через внутренние объекты Энкодера осуществляется в обратном порядке.
bool CCCMREncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cInput.UpdateInputWeights(NeuronOCL)) return false; if(!cNorm.UpdateInputWeights(GetPointer(cInput))) return false; if(!cResidual[0].UpdateInputWeights(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].UpdateInputWeights(GetPointer(cResidual[i - 1]))) return false; if(!cOutput.UpdateInputWeights(GetPointer(cResidual[5]))) return false; //--- return true; }
В рамках данной статьи мы не будем более подробно останавливаться на описании всех методов класса. Они имеют аналогичную блочную структуру последовательного вызова соответствующих методов внутренних объектов. И Вы без труда сможете самостоятельно ознакомиться с ними во вложении, где, как Вы знаете, можно найти полный код всех программ, используемых при подготовке статьи. На все возможные вопросы я с удовольствием отвечу на форуме или в личных сообщениях. Выбор формата связи я оставляю за Вами.
2.3 Группировка глобального контекста с учетом динами
Для группировки глобального контекста с учетом динамики изменения признаков авторы метода CCRM предложили использовать блок кросс-внимания XCiT. В котором сущности Query и Key формируются из признаков глобального контекста. А Value — из динамики сформированных признаков окружающей среды 2 последующих состояний. Такое использование блока несколько отличается от рассмотренного нами ранее. И для реализации предложенного варианта использования блока нам потребуется внести некоторые доработки.
Мы создадим новый класс CNeuronCrossXCiTOCL, который будет наследовать большую часть функционала из прошлой реализации метода XCiT.
class CNeuronCrossXCiTOCL : public CNeuronXCiTOCL { protected: CCollection cConcat; CCollection cValue; CCollection cV_Weights; CBufferFloat TempBuffer; uint iWindow2; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool Concat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool DeConcat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); public: CNeuronCrossXCiTOCL(void) {}; ~CNeuronCrossXCiTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion); //--- virtual int Type(void) const { return defNeuronCrossXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Обратите внимание, что в данной реализации я постарался по максимуму использовать созданный ранее функционал. В структуре класса были добавлены 3 коллекции буферов данных и один вспомогательный буфер для хранения промежуточных данных.
Как и ранее, все внутренние объекты объявлены статическими, что позволяет нам оставить "пустыми" конструктор и деструктор класса.
Инициализация всех объекта класса осуществляется в методе CNeuronCrossXCiTOCL::Init.
bool CNeuronCrossXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronXCiTOCL::Init(numOutputs, myIndex, open_cl, window1, lpi_window, heads, units_count, layers, optimization_type, batch)) return false;
В параметрах метод получает основные параметры, определяющие архитектуру всего класса и его внутренних объектов. А в теле класса мы вызываем одноименный метод родительского класса, в котором осуществляется проверка полученных параметров и инициализация всех унаследованных объектов.
После успешного выполнения метода родительского класса мы определим параметры буферов для записи сущностей Value и их градиентов ошибки. А так же матрицы весов генерации указанной сущности.
//--- Cross XCA iWindow2 = fmax(window2, 1); uint num = iWindowKey * iHeads * iUnits; //Size of V tensor uint v_weights = (iWindow2 + 1) * iWindowKey * iHeads; //Size of weights' matrix of V tensor
Далее мы организуем цикл по числу внутренних слоев кросс-внимания XCiT и в теле цикла создадим необходимые нам буфера. Сначала мы добавляем буфер для записи сгенерированных сущностей Value и соответствующих градиентов ошибки.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize V tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cValue.Add(temp)) return false;
Здесь стоит напомнить, что в родительском классе CNeuronXCiTOCL мы использовали конкатенированный буфер сущностей Query, Key и Value. И, чтобы далее мы смогли использовать унаследованный функционал, давайте конкатенируем указанные сущности из 2 источников в один буфер коллекции cConcat.
//--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(3 * num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cConcat.Add(temp)) return false; }
Следующим шагом мы создадим буферы матрицы весов для генерации сущности Value.
//--- XCiT //--- Initilize V weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(v_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < v_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false;
И буферы моментов для процесса оптимизации указанной матрицы весов.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(v_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false; } }
И тут же мы инициализируем буфер хранения промежуточных данных.
TempBuffer.BufferInit(iWindow2 * iUnits, 0); if(!TempBuffer.BufferCreate(OpenCL)) return false; //--- return true; }
При этом не забываем контролировать процесс выполнения операций на каждом шаге.
Метод прямого прохода CNeuronCrossXCiTOCL::feedForward во многом был перенесен из родительского класса. Однако особенности кросс-внимания требуют его переопределения. В частности, для реализации кросс-внимания необходимо 2 источника исходных данных.
bool CNeuronCrossXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(!NeuronOCL || !Motion) return false;
В теле метода мы проверяем актуальность полученных указателей на объекты исходных данных и организовываем цикл последовательного перебора внутренних слоев.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 2 * iWindowKey * iHeads, None)) return false;
В теле цикла мы сначала генерируем сущности Query и Key из данных предшествующего нейронного слоя. Предполагается, что в данном потоке информации мы получаем глобальный контекст GCs.
Обратите внимание, что мы используем буфера из унаследованных коллекций QKV_Tensors и QKV_Weights, но при этом генерируем только 2 сущности. О чем свидетельствует количество фильтров свертки «2 * iWindowKey * iHeads».
Аналогичным образом мы генерируем третью сущность — Value, но уже из других исходных данных.
CBufferFloat *v = cValue.At(i * 2); if(IsStopped() || !ConvolutionForward(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), Motion, v, iWindow, iWindowKey * iHeads, None)) return false;
Как было сказано выше, для возможности использования унаследованного функционала мы конкатенируем все 3 сущности в единый тензор.
if(IsStopped() || !Concat(qkv, v, cConcat.At(2 * i), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
И далее мы смело используем унаследованный функционал, но есть один нюанс. В данной реализации количество элементов в последовательности в обоих потоках идентично. Ведь на верхнем уровне мы генерируем оба потока из одних исходных данных. С учетом этого понимания я не сделал проверку равенства длины последовательностей. Но для корректной работы последующего функционала это соответствие критично. Поэтому, если Вы захотите использовать данный класс отдельно, то, пожалуйста, позаботьтесь о равенстве длин обеих последовательностей.
Определим результаты много-голового внимания.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(cConcat.At(2 * i), temp, out)) return false;
Сложим и нормализируем потоки данных.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Далее следует блок локального взаимодействия с последующим суммированием и нормализацией потоков.
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false; out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false; temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false; //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
А так же блок FeedForward.
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false; //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
После успешного перебора всех внутренних нейронных слоевмы завершаем работу метода.
Обратите внимание, что в данном методе для всех внутренних нейронных слоев используется один буфер исходных данных динамики признаков. В то время как глобальный контекст постепенно изменяется и преобразуется в глобальный контекст с учетом динамики признаков — Context-guided Motion Features (CMF).
Процесс распределения градиента ошибки через внутренние объекты организован аналогичным образом в обратном порядке. Его алгоритм описан в методе CNeuronCrossXCiTOCL::calcInputGradients. В параметрах метод получает указатели на 2 объекта исходных данных с буферами соответствующих градиентов ошибки, которые нам предстоит заполнить.
bool CNeuronCrossXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion) { if(!prevLayer || !Motion) return false;
В теле метода мы сначала проверяем актуальность полученных указателей. А затем организовываем цикл перебора внутренних слоев в обратной последовательности.
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
В теле цикла первым делом мы проводим градиент ошибки через блок FeedForward.
Напомню, что в процессе прямого прохода мы осуществляли сложение и нормализацию данных входа и выхода каждого блока. Соответственно, при обратном проходе нам так же необходимо провести градиент ошибки по обоим потокам информации. Следовательно, после проведения градиента ошибки через блок FeedForward мы должны суммировать градиенты ошибки из 2 потоков.
//--- Sum gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
Аналогичным образом проводим градиент ошибки через блок локального взаимодействия и суммируем градиент ошибки по 2 потокам данных.
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false; temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
Заключительным этапом является проведение градиента ошибки через блок внимания.
//--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(cConcat.At(i * 2), cConcat.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
Однако, здесь мы получаем конкатенированный буфер градиентов ошибки для 3 сущностей: Query, Key и Value. Но мы же помним, что сущности были сгенерированы из различных источников данных. На них нам и предстоит распределить градиент ошибки. Сначала мы разделим один буфер на 2.
if(IsStopped() || !DeConcat(QKV_Tensors.At(i * 2 + 1), cValue.At(i * 2 + 1), cConcat.At(i * 2 + 1), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
А затем вызовем методы передачи градиентов на соответствующие исходные данные. Но если для Query и Key мы можем воспользоваться унаследованным функционалом, то с Value немного сложнее.
//--- CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false;
При прямом проходе я акцентировал внимание, что для всех слоев мы используем один буфер динамики изменений признаков. И прямая передача градиента ошибки в буфер градиентов объекта исходных данных просто перепишет их и удалит ранее записанные данные других внутренних слоев. Поэтому на прямую записывать мы будем только при первой итерации (последний внутренний слой).
if(i > 0) out_grad = temp; if(i == iLayers - 1) { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), Motion.getGradient(), iWindow, iWindowKey * iHeads, None)) return false; }
В других случаях мы воспользуемся вспомогательным буфером хранения временных данных с последующим суммированием нового и ранее накопленного градиентов.
else { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), GetPointer(TempBuffer), iWindow, iWindowKey * iHeads, None)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(TempBuffer), Motion.getGradient(), Motion.getGradient(), iWindow2, false)) return false; }
Суммируем градиенты ошибок по 2 потокам данных и преходим к следующей итерации цикла.
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false; if(i > 0) out_grad = temp; } //--- return true; }
После успешного проведения градиента ошибки через все внутренние слои мы завершаем работу метода.
За распределением градиента ошибки между всеми внутренними объектами и исходными данными в соответствии с их влиянием на конечный результат нам предстоит скорректировать параметры модели с целью минимизации ошибки. Этот процесс организован в методе CNeuronCrossXCiTOCL::updateInputWeights. По аналогии с 2 выше рассмотренными методами, обновлять параметры внутренних объектов мы будем в цикле последовательного перебора внутренних нейронных слоев.
bool CNeuronCrossXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization == SGD ? QKV_Weights.At(l * 2 + 1) : QKV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : QKV_Weights.At(l * 3 + 2)), iWindow, 2 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cV_Weights.At(l * (optimization == SGD ? 2 : 3)), cValue.At(l * 2 + 1), inputs, (optimization == SGD ? cV_Weights.At(l * 2 + 1) : cV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : cV_Weights.At(l * 3 + 2)), iWindow, iWindowKey * iHeads)) return false;
Сначала мы обновим параметры генерации сущностей Query, Key и Value. Затем наступает очередь блока локального взаимодействия LPI.
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization == SGD ? cLPI_Weights.At(l * 5 + 3) : cLPI_Weights.At(l * 7 + 3)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization == SGD ? cLPI_Weights.At(l * 5 + 4) : cLPI_Weights.At(l * 7 + 4)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
И завершаем блоком FeedForward.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization == SGD ? FF_Weights.At(l * 4 + 2) : FF_Weights.At(l * 6 + 2)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 4 + 3) : FF_Weights.At(l * 6 + 3)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
На этом мы завершаем рассмотрение методов класса CNeuronCrossXCiTOCL. Конечно, в рамках статьи мы не можем подробно останавливаться на всех методах класса. Но Вы можете самостоятельно ознакомиться с ними во вложении. Там Вы можете найти полный код всех классов и их методов. А так же все программ, используемых при подготовке статьи.
2.4 Реализация алгоритма CCMR
Выше была проведена довольно объемная работа по созданию новых классов. Но все же это была подготовительная работа. И теперь мы приступаем к реализации нашего видения алгоритма CCMR. Я обращаю внимание, что это наше видение предложенных подходов. И оно может отличаться от авторского представления. Тем не менее, мы попытались воплотить предложенные подходы для решения наших задач.
Для реализации метода мы создадим класс CNeuronCCMROCL, который унаследует базовый функционал от класса CNeuronBaseOCL. Структура нового класса представлена ниже.
class CNeuronCCMROCL : public CNeuronBaseOCL { protected: CCCMREncoder FeatureExtractor; CNeuronBaseOCL PrevFeatures; CNeuronBaseOCL Motion; CNeuronBaseOCL Temp; CCCMREncoder LocalContext; CNeuronXCiTOCL GlobalContext; CNeuronCrossXCiTOCL MotionContext; CNeuronLSTMOCL RecurentUnit; CNeuronConvOCL UpScale; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCCMROCL(void) {}; ~CNeuronCCMROCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronCCMROCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag virtual bool Clear(void); };
В ней мы видим привычный набор методов и целый ряд объектов, большая часть из которых была создана выше. Мы создаем 2 экземпляра объектов класса CCCMREncoder для экстракции признаков состояния окружающей среды и локального контекста (FeatureExtractor и LocalContext, соответственно).
Экземпляр объекта CNeuronXCiTOCL используется для получения глобального контекста (GlobalContext). А с помощью CNeuronCrossXCiTOCL корректируем его с учетом динамики признаков до CMF (MotionContext).
Для реализации рекуррентных связей вместо GRU мы используем LSTM-блок (CNeuronLSTMOCL RecurentUnit).
Более детально с функционалом всех внутренних объектов мы познакомимся в процессе реализации методов класса.
Как и ранее, все внутренние объекты класса мы объявили статичными. Следовательно, конструктор и деструктор класса остаются "пустыми".
Инициализация внутренних объектов класса осуществляется в методе CNeuronCCMROCL::Init.
bool CNeuronCCMROCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
В параметрах метода мы получаем ключевые константы архитектуры класса. А в теле метода мы сразу вызываем аналогичный метод родительского класса, в котором осуществляется проверка полученных параметров и инициализация унаследованных объектов.
После успешного выполнения метода родительского класса мы переходим к инициализации внутренних объектов. Первым мы инициализируем Энкодер признаков текущего состояния окружающей среды.
if(!FeatureExtractor.Init(0, 0, OpenCL, window, 16, count, optimization, iBatch)) return false;
Здесь стоит обратить внимание, что для оценки потока метод CCMR использует снимки 2 последовательных состояний системы. Мы же подошли к данному вопросу немного с другой стороны. На каждой итерации прямого прохода мы генерируем признаки только 1 состояния окружающей среды. И сохраняем его в локальный буфер PrevFeatures. Значение этого буфера мы используем для оценки динамического потока при последующем прямом проходе. Инициализируем объекты локального буфера предыдущего состояния и изменения признаков.
if(!PrevFeatures.Init(0, 1, OpenCL, 16 * count, optimization, iBatch)) return false; if(!Motion.Init(0, 2, OpenCL, 16 * count, optimization, iBatch)) return false;
С целью исключения излишнего копирования данных организуем подмену буферов.
if(Motion.getGradientIndex() != FeatureExtractor.getGradientIndex())
Motion.SetGradientIndex(FeatureExtractor.getGradientIndex());
Далее, на основании текущего состояния окружающей среды мы генерируем признаки контекста при помощи Энкодера LocalContext. Здесь следует обратить внимание, что мы используем один набор исходных данных в 2 потоках информации. Следовательно, и градиент ошибки нам предстоит получить из 2 потоков. Для возможности суммирования градиентов мы создадим буфер локальных данных.
if(!Temp.Init(0, 3, OpenCL, window * count, optimization, iBatch)) return false; if(!LocalContext.Init(0, 4, OpenCL, window, 16, count, optimization, iBatch)) return false;
Механизмы внимания позволят нам локальные контексты сгруппировать в глобальный контекст.
if(!GlobalContext.Init(0, 5, OpenCL, 16, 3, 4, count, 4, optimization, iBatch)) return false;
Который мы в последующем скорректируем на динамику потока.
if(!MotionContext.Init(0, 6, OpenCL, 16, 16, 3, 4, count, 4, optimization, iBatch)) return false;
В завершении мы обновляем поток в рекуррентном блоке.
if(!RecurentUnit.Init(0, 7, OpenCL, 16 * count, optimization, iBatch) || !RecurentUnit.SetInputs(16 * count)) return false;
С целью снижения объема модели мы использовали внутренние объекты довольно сжатого состояния. Однако, пользователю могут потребоваться данные в другой размерности. Для приведения результатов к нужной размерности мы воспользуемся слоем масштабирования.
if(!UpScale.Init(0, 8, OpenCL, 16, 16, window_out, count, optimization, iBatch)) return false;
И чтобы исключить излишнее копирование данных мы организуем подмену буферов данных.
if(UpScale.getGradientIndex() != getGradientIndex()) SetGradientIndex(UpScale.getGradientIndex()); if(UpScale.getOutputIndex() != getOutputIndex()) Output.BufferSet(UpScale.getOutputIndex()); //--- return true; }
Алгоритм прямого прохода реализован в методе CNeuronCCMROCL::feedForward. В параметрах метод прямого прохода получает указатель на объект предыдущего слоя, который содержит исходные данные.
bool CNeuronCCMROCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Delta Features if(!SumAndNormilize(FeatureExtractor.getOutput(), FeatureExtractor.getOutput(), PrevFeatures.getOutput(), 1, false, 0, 0, 0, -0.5f)) return false;
В теле метода, перед началом каких-либо операций мы перенесем содержимое буфера результатов Энкодера признаков состояния окружающей среды в буфер предыдущего состояния. Легко догадаться, что до начала итераций в буфере содержатся результаты предыдущего прямого прохода.
Обратите внимание, что при переносе данных мы изменяем знак признака на противоположный.
После сохранения данных мы осуществляем прямой проход Энкодера состояния.
if(!FeatureExtractor.FeedForward(NeuronOCL)) return false;
После успешного прямого прохода FeatureExtractor мы имеем признаки 2 последующих состояний и можем определить отклонение. Для простоты мы просто возьмем разницу признаков. При сохранении предыдущего состояния мы предусмотрительно изменили знак признаков. И теперь для получения разницы состояний мы можем сложить содержимое буферов.
if(!SumAndNormilize(FeatureExtractor.getOutput(), PrevFeatures.getOutput(), Motion.getOutput(), 1, false, 0, 0, 0, 1.0f)) return false;
Следующим этапом мы сгенерируем признаки локального контекста.
if(!LocalContext.FeedForward(NeuronOCL)) return false;
Извлечем глобальный контекст.
if(!GlobalContext.FeedForward(GetPointer(LocalContext))) return false;
И скорректируем его на динамику изменений.
if(!MotionContext.FeedForward(GetPointer(GlobalContext), Motion.getOutput())) return false;
Далее скорректируем поток в рекуррентном блоке.
//--- Flow if(!RecurentUnit.FeedForward(GetPointer(MotionContext))) return false;
И масштабируем данные до нужного размера.
if(!UpScale.FeedForward(GetPointer(RecurentUnit))) return false; //--- return true; }
В процессе реализации не забываем контролировать процесс на каждом шаге.
Алгоритм обратного прохода реализован в методе CNeuronCCMROCL::calcInputGradients. По аналогии с одноименными методами других классов, в параметрах метода мы получаем указатель на объект предыдущего слоя. В теле метода мы последовательно вызываем одноименные методы внутренних объектов. Только последовательность объектов будет обратная прямому проходу.
bool CNeuronCCMROCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!UpScale.calcInputGradients(GetPointer(RecurentUnit))) return false;
Сначала мы проведем градиент ошибки через слой масштабирования. А затем через рекуррентный блок.
if(!RecurentUnit.calcInputGradients(GetPointer(MotionContext))) return false;
Далее мы проведем градиент ошибки последовательно через все этапы преобразования контекста.
if(!MotionContext.calcInputGradients(GetPointer(GlobalContext), GetPointer(Motion))) return false; if(!GlobalContext.calcInputGradients(GetPointer(LocalContext))) return false; if(!LocalContext.calcInputGradients(GetPointer(Temp))) return false;
Благодаря подмене буферов данных, градиент ошибки с динамики признаков передается на Энкодер признаков состояния. И мы проводим градиент ошибки через Энкодер до буфера предыдущего слоя.
if(!FeatureExtractor.calcInputGradients(prevLayer)) return false;
И добавим градиент ошибки от Энкодера контекста.
if(!SumAndNormilize(prevLayer.getGradient(), Temp.getGradient(), prevLayer.getGradient(), 1, false, 0, 0, 0, 1.0f)) return false; //--- return true; }
Метод обновления параметров модели не выделяется сложностью алгоритма. Мы лишь последовательно обновляем параметры внутренних объектов.
bool CNeuronCCMROCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!FeatureExtractor.UpdateInputWeights(NeuronOCL)) return false; if(!LocalContext.UpdateInputWeights(NeuronOCL)) return false; if(!GlobalContext.UpdateInputWeights(GetPointer(LocalContext))) return false; if(!MotionContext.UpdateInputWeights(GetPointer(GlobalContext), Motion.getOutput())) return false; if(!RecurentUnit.UpdateInputWeights(GetPointer(MotionContext))) return false; if(!UpScale.UpdateInputWeights(GetPointer(RecurentUnit))) return false; //--- return true; }
Следует отметить, что данный класс содержит рекуррентный блок и буфер сохранения предыдущего состояния. Поэтому, нам нужно переопределить метод очистки рекуррентной составляющей CNeuronCCMROCL::Clear. Здесь мы вызываем одноименный метод рекуррентного блока и заполняем нулевыми значениями буфер результатов FeatureExtractor.
bool CNeuronCCMROCL::Clear(void) { if(!RecurentUnit.Clear()) return false; //--- CBufferFloat *temp = FeatureExtractor.getOutput(); temp.BufferInit(temp.Total(), 0); if(!temp.BufferWrite()) return false; //--- return true; }
Обратите внимание, что мы обнуляем буфер результатов Энкодера, а не буфер предыдущего состояния. Помните, в начале метода прямого прохода мы из буфера результатов Энкодера копируем данные в буфер предыдущего состояния?
На этом мы завершаем рассмотрение основных методов реализации подходов CCMR. Мы проделали довольно много работы, а размеры статьи ограничены. Поэтому с алгоритмом вспомогательных методов я предлагаю Вам познакомиться самостоятельно во вложении. Там Вы найдете полный код всех классов и их методов реализации подходов CCMR. Кроме того, во вложении Вы найдете полный код всех программ, используемых при подготовке статьи. А мы переходим к рассмотрению архитектуры обучаемых моделей.
2.5. Архитектура моделей
Переходя к описанию архитектуры моделей стоит сказать, что подходы CCMR затронули лишь Энкодер состояния окружающей среды.
Архитектура моделей, которые мы будем обучать представлена в методе CreateDescriptions, в параметрах которого мы будем предавать 3 динамических массива, для записи архитектуры Энкодера, Актера и Критика.
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
В теле метода мы проверяем полученные указатели и, при необходимости, создаем новые экземпляры массивов.
На вход Энкодера мы подаем необработанные данные текущего состояния окружающей среды.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полученные данные проходят предварительную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
После чего мы формируем стек эмбедингов состояний.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
К полученным эмбедингам мы добавляем позиционное кодирование.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
И завершает архитектуру Энкодера наш новый блок CNeuronCCMROCL, который сам по себе является довольно комплексным и требует дополнительной обработки.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCCMROCL; descr.count = prev_count; descr.window = prev_wout; descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Архитектуру Актера и Критика я перенес без изменений из предыдущей статьи. По ссылке представлено детальное описание архитектуры моделей. Кроме того, полная архитектура моделей представлена во вложении. А мы переходим к заключительному этапу — тестированию проделанной работы.
3. Тестирование
В предыдущих разделах данной статьи мы познакомились с методом CCMR и реализовали предложенные в нем подходы средствами MQL5. И теперь пришло время проверить на практике результаты проделанной выше работы. Как обычно, для обучения и тестирования моделей мы используем исторические данные инструмента EURUSD тайм-фрейм H1. Обучение моделей осуществляется на исторических данных за первые 7 месяцев 2023 года. Тестирование обученной модели осуществляется в тестере стратегий MetaTrader 5 на исторических данных Августа 2023 года.
В рамках данной статьи для обучения модели я использовал обучающую выборку, собранную в рамках работы над предыдущими статьями. И в процессе обучения была получена модель, способная генерировать прибыль как на обучающей выборке, так и в тестовом периоде.
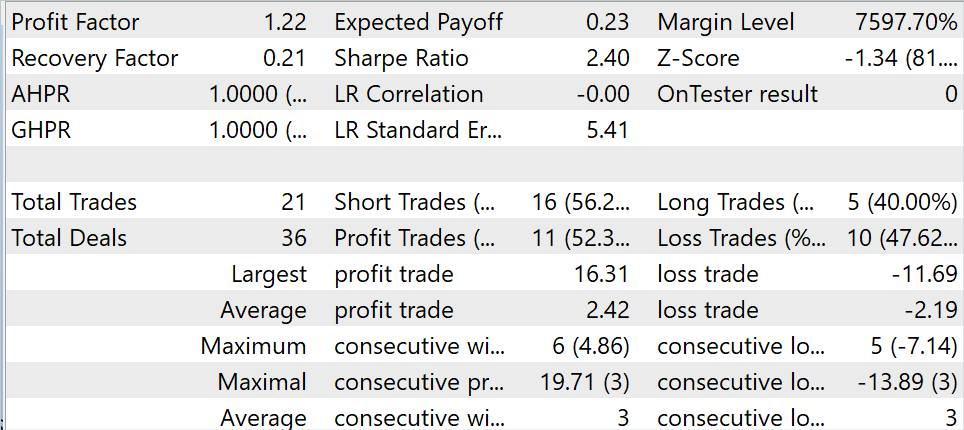
За период тестирования модель совершила 21 сделку, 52.3% которых были закрыты с прибылью. Как максимальная, так и средняя прибыльная сделка превышают соответствующий показатель для убыточных сделок. Что в целом позволило получить профит-фактор на уровне 1.22
Заключение
В данной статье мы познакомились c метод оценки оптического потока под названием CCMR, который объединяет преимущества концепций агрегации движения на основе контекста и многомасштабного подхода с грубого к точному. Это позволяет получать детализированные карты потока, которые также обладают высокой точностью в областях с заслонениями.
Авторами метода предложена двухэтапная стратегия группировки движения, в которой сначала вычисляются глобальные контекстные характеристики. Затем они используются для направления характеристик движения итеративно на всех масштабах. Это позволяет использовать алгоритмы на основе XCiT для обработки всех масштабов от грубого к точному, сохраняя масштабно-специфическое содержимое.
В практической части статьи мы реализовали предложенные подходы средствами MQL5. Обучили и протестировали модель на реальных данных в тестере стратегий MetaTrader 5. Полученные результаты позволяют говорить об эффективности предложенных подходов.
Однако напомню, что все программы, представленные в статье, носят информативный характер и предназначены только для демонстрации предложенных подходов.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования