
Neuronale Netze leicht gemacht (Teil 81): Kontextgesteuerte Bewegungsanalyse (CCMR)

Einführung
Im Rahmen dieser Reihe lernten wir verschiedene Methoden zur Analyse des Umweltzustands und Algorithmen zur Nutzung der gewonnenen Daten kennen. Wir haben Faltungsmodelle verwendet, um stabile Muster in historischen Kursbewegungsdaten zu finden. Wir haben auch Aufmerksamkeitsmodelle verwendet, um Abhängigkeiten zwischen verschiedenen lokalen Umweltzuständen zu finden. Wir haben den Zustand der Umwelt immer als einen bestimmten Querschnitt zu einem bestimmten Zeitpunkt bewertet. Die Dynamik der Umweltindikatoren haben wir jedoch nie bewertet. Wir sind davon ausgegangen, dass das Modell bei der Analyse und dem Vergleich von Umweltbedingungen auf die wichtigsten Veränderungen achten würde. Wir haben jedoch keine explizite quantitative Darstellung einer solchen Dynamik verwendet.
Im Bereich der Computer Vision gibt es jedoch ein grundlegendes Problem bei der Schätzung des optischen Flusses. Die Lösung dieses Problems liefert Informationen über die Bewegung von Objekten in der Szene. Um dieses Problem zu lösen, wurde eine Reihe interessanter Algorithmen vorgeschlagen, die inzwischen weit verbreitet sind. Die Ergebnisse der optischen Flussschätzung werden in verschiedenen Bereichen eingesetzt, vom autonomen Fahren bis zur Objektverfolgung und Überwachung.
Die meisten aktuellen Ansätze verwenden faltbare neuronale Netze, denen jedoch der globale Kontext fehlt. Das macht es schwierig, über Objektverdeckungen oder große Verschiebungen nachzudenken. Ein alternativer Ansatz ist die Verwendung von Transformatoren und anderen Aufmerksamkeitstechniken. Sie ermöglichen es, weit über das feste rezeptive Feld der klassischen CNNs hinauszugehen.
Eine besonders interessante Methode mit der Bezeichnung CCMR wurde in dem Beitrag „CCMR: High Resolution Optical Flow Estimation via Coarse-to-Fine Context-Guided Motion Reasoning“ vorgestellt. Es handelt sich um einen Ansatz zur Schätzung des optischen Flusses, der die Vorteile aufmerksamkeitsorientierter Methoden von Bewegungsaggregationskonzepten und hochauflösender Multiskalenansätze kombiniert. Die CCMR-Methode integriert konsequent kontextbasierte Bewegungsgruppierungskonzepte in einen hochauflösenden, grobkörnigen Schätzungsrahmen. Dies ermöglicht detaillierte Strömungsfelder, die auch in verdeckten Bereichen eine hohe Genauigkeit bieten. In diesem Zusammenhang schlagen die Autoren der Methode eine zweistufige Strategie zur Bewegungsgruppierung vor, bei der zunächst globale kontextuelle Merkmale mit Selbstaufmerksamkeit berechnet werden, die dann dazu dienen, die Bewegungsmerkmale iterativ über alle Skalen hinweg zu steuern. Die kontextbezogene Argumentation über XCiT-basierte Bewegungen ermöglicht somit eine Verarbeitung auf allen grobkörnigen Skalen. Die von den Autoren der Methode durchgeführten Experimente zeigen die starke Leistung des vorgeschlagenen Ansatzes und die Vorteile seiner Grundkonzepte.
1. Der CCMR-Algorithmus
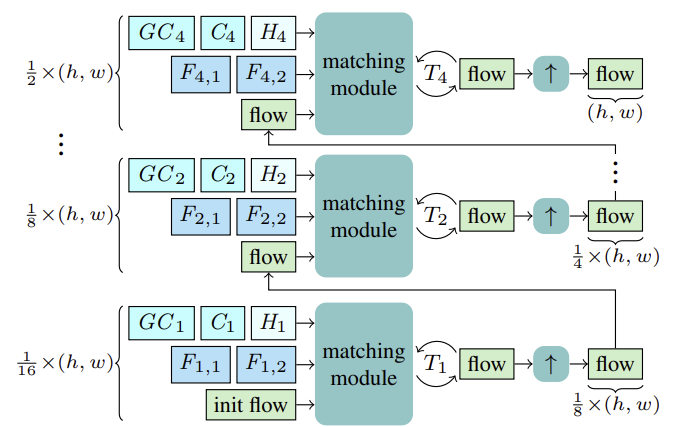
Die CCMR-Methode schätzt den optischen Fluss mithilfe von rekurrenten Aktualisierungen auf grober und feiner Ebene unter Verwendung einer gemeinsamen Gated Recurrent Unit (GRU). Bevor mit der Schätzung begonnen wird, werden für jede Skala S die Merkmale Fs,1, Fs,2 für den Abgleich berechnet. Außerdem werden Kontextmerkmale Cs und darauf aufbauend globale Kontextmerkmale GCs berechnet sowie der anfängliche verborgene Zustand Hs für die aktuelle Skala des rekurrenten Blocks aus dem Referenzzustand I1.
Ausgehend von der gröbsten Skala von 1/16 wird der Fluss auf der Grundlage der oben genannten Merkmale F1,1, F1,2, C1, GC1, H1 berechnet. Nach T1 rekurrenten Flussaktualisierungen wird der geschätzte Fluss mithilfe eines gemeinsamen X2 konvexen Upsamplers hochgerechnet, wobei der Fluss als Initialisierung für den Anpassungsprozess auf der nächst feineren Skala dient. Dieser Prozess wird so lange fortgesetzt, bis der Fluss in der feinsten 1/2-Skala berechnet und auf die ursprüngliche Auflösung hochgerechnet ist.
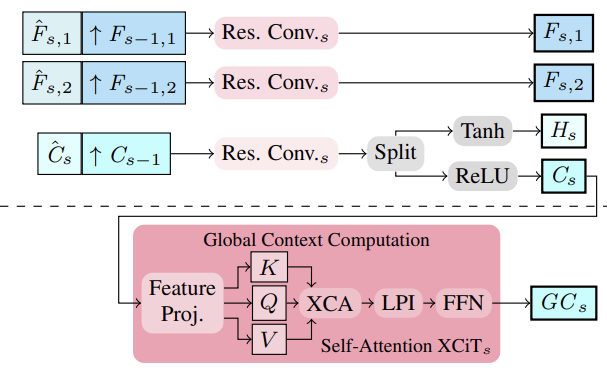
Die Autoren der Methode schlugen vor, Bild- und Kontextmerkmale in mehreren Maßstäben mit Hilfe eines Merkmalsextraktors zu extrahieren. Zu diesem Zweck werden Zwischenmerkmale von oben nach unten berechnet, und dann, um mehrstufige Merkmale zu erhalten, werden strukturiertere und feinere Merkmale Fs,1,Fs,2 and Cs semantisch verstärkt, indem sie mit tieferen, grobstufigen Merkmalen Fs−1,1,Fs−1,2 and Cs−1 for S∈ {2, 3, 4}. kombiniert werden. Die Konsolidierung erfolgt also durch Stapeln der hochabgetasteten gröberen Merkmale und der dazwischen liegenden feineren Merkmale und deren Aggregation.
Auf der Grundlage der multiskaligen Cs-Kontextmerkmale werden die globalen Kontextmerkmale berechnet. Hier geht es darum, aussagekräftigere Merkmale zu erhalten, die dann zur Steuerung der Bewegung verwendet werden. Zu diesem Zweck werden die kontextbezogenen Merkmale Cs unter Verwendung von Kanalstatistiken mit Hilfe der XCiT-Schicht aggregiert, die eine lineare Komplexität in Bezug auf die Anzahl der Token gewährleistet. Diese architektonische Entscheidung ermöglicht eine Kontextaggregation auf allen groben und feinen Skalen während der Schätzung. Der von den Autoren vorgeschlagene Ansatz CCMR zur Verwendung von XCiT unterscheidet sich von dem ursprünglichen Ansatz, bei dem die XCiT-Schicht auf eine gröbere Darstellung der Eingabedaten angewendet wird, die durch explizites Patching implementiert wird, und dann wieder auf die ursprüngliche Auflösung hochgerechnet wird. In CCMR hingegen wird die XCiT-Schicht direkt auf Merkmale in allen groben und feinen Maßstäben unter Verwendung maßstabsspezifischer Inhalte angewendet. Um den globalen Kontext zu berechnen, wird zunächst eine Positionskodierung zu den Kontextmerkmalen Cs hinzugefügt. Dann wird die Ebene normalisiert. In dieser Phase werden alle Merkmale von Abfrage, Schlüssel und Wert (Query, Key, Value) von Csp berechnet, um die Selbstaufmerksamkeit zu implementieren. Vor der Anwendung der Kreuzkovarianz-Attention werden die Kanäle KCs, QCs, VCs in h Köpfe umgewandelt. Die Kreuzkovarianz-Aufmerksamkeit wird dann als XCA (KCs, QCs, VCs) berechnet. Danach wird eine lokale Patch-Interaktionsschicht (LPI) und dann der FFN-Block angewendet.
Während die Kreuzkovarianz-Aufmerksamkeit für globale Interaktionen zwischen den Kanälen in jedem Kopf sorgt, bieten die LPI- und FFN-Module explizite räumliche Interaktionen zwischen Token vor Ort bzw. Verbindungen zwischen allen Kanälen.
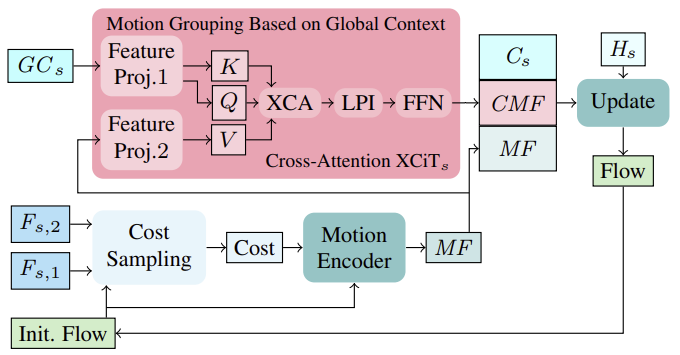
Zunächst werden auf der Grundlage des anfänglichen Flusses in der ersten Iteration (oder des aktualisierten Flusses in den nachfolgenden Iterationen) die Kosten für die Nachbarschaftsübereinstimmung anhand der Bildmerkmale (Fs,1, Fs,2) berechnet. Die berechneten Kosten werden dann zusammen mit der aktuellen Flussschätzung durch einen Bewegungsgeber verarbeitet, der Bewegungsmerkmale ausgibt, die schließlich von der GRU zur Berechnung einer Thread-Aktualisierung verwendet werden.
Bei der Berechnung iterativer Flussaktualisierungen kann die Einbeziehung global aggregierter Bewegungsmerkmale, die auf kontextuellen Merkmalen basieren, dazu beitragen, Mehrdeutigkeiten in verdeckten Regionen aufzulösen. Dies ist logisch, da die Bewegung verdeckter Pixel eines teilweise nicht verdeckten Objekts normalerweise aus der Bewegung seiner nicht verdeckten Pixel abgeleitet werden kann. Zur Aggregation von Bewegungsmerkmalen in einem einzigen Maßstab verfolgen die Autoren der Methode eine effiziente Strategie, die auf globalen Kanalstatistiken aus der globalen Kontextberechnung basiert, die auf allen groben und feinen Skalen durchgeführt wird. Die Gruppierung von Bewegungen erfolgt mit Hilfe einer Cross-Attention-Schicht XCiT, die auf globale kontextuelle Merkmale GCs und Bewegungsmerkmale MF angewendet wird. So berechnen wir Abfrage und Schlüssel aus globalen Kontextmerkmalen GCs und den Wert aus Bewegungsmerkmalen direkt auf jeder Skala ohne explizite Partitionierung in Patches. Nach der Anwendung von XCA, LPI und FFN auf die Abfrage, den Schlüssel und den Wert des Kontexts werden die kontextabhängigen Bewegungsmerkmale (CMFs), die kontextabhängigen Bewegungsmerkmale Cs und die ursprünglichen Bewegungsmerkmale MFs kombiniert und durch einen rekurrenten Block geleitet, um den Aktualisierungsfluss iterativ zu berechnen.
Beachten Sie, dass die Verwendung von Token-Kreuzaufmerksamkeit (cross-attention) zur Bewegungsaggregation in grobkörnigen und fein abgestimmten Schemata im Hinblick auf den Speicherverbrauch nicht praktikabel ist.
Die von den Autoren vorgestellte Visualisierung der CCMR-Methode ist unter dem Original zu finden.
2. Implementierung mit MQL5
Nach der Betrachtung der theoretischen Aspekte der CCMR-Methode gehen wir zum praktischen Teil unseres Artikels über, in dem wir die vorgeschlagenen Ansätze mit MQL5 umsetzen. Wie Sie sehen können, ist die vorgeschlagene Architektur recht komplex. Daher habe ich beschlossen, die Implementierung der vorgeschlagenen Algorithmen in mehrere Blöcke zu unterteilen.
2.1 Faltungsblock mit geschlossener Schleife
Wir beginnen mit dem Faltungsblock der geschlossenen Schleife. Um sie zu implementieren, erstellen wir die Klasse CResidualConv, die die Grundfunktionalität von der Klasse CNeuronBaseOCL der vollständig verbundenen Schicht erbt.
Die Struktur der neuen Klasse ist unten dargestellt. Wie Sie sehen können, enthält sie eine Reihe von bekannten Methoden.
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
Die Klassenfunktionalität wird 3 Blöcke einer Faltungsschicht und eine Stapelnormalisierung verwenden. Alle internen Schichten werden als statisch deklariert, was es uns ermöglicht, den Konstruktor und den Destruktor der Klasse leer zu lassen.
Die Initialisierung eines Klassenobjekts wird in der Methode Init durchgeführt. In den Methodenparametern werden wir Konstanten übergeben, die die Architektur der Klasse definieren.
bool CResidualConv::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
Im Hauptteil der Methode verwenden wir die gleichnamige Methode der abgeleitete Klasse, um die empfangenen Parameter zu kontrollieren und abgeleitete Objekte zu initialisieren.
Nachdem die Methode der übergeordneten Klasse erfolgreich ausgeführt wurde, werden die internen Objekte initialisiert.
if(!cConvs[0].Init(0, 0, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[0].Init(0, 1, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[0].SetActivationFunction(LReLU);
Um Merkmale aus dem analysierten Zustand der Umgebung zu extrahieren, verwenden wir 2 Blöcke sequentieller Faltungsschichten und eine Batch-Normalisierung mit der LReLU-Funktion, um eine Nichtlinearität zwischen ihnen zu erzeugen.
if(!cConvs[1].Init(0, 2, OpenCL, window_out, window_out, window_out, count, optimization, iBatch)) return false; if(!cNorm[1].Init(0, 3, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[1].SetActivationFunction(None);
Wir verwenden den dritten Block der Faltungsschicht und die Batch-Normalisierung (ohne Aktivierungsfunktion), um die Originaldaten auf die Größe der Ergebnisse unserer CResidualConv zu skalieren. Dadurch können wir einen zweiten Datenfluss implementieren.
if(!cConvs[2].Init(0, 4, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[2].Init(0, 5, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[2].SetActivationFunction(None);
Die Schaffung von 2 parallelen Datenflüssen zwingt uns, den Fehlergradienten in ähnlichen parallelen Flüssen zu übertragen. Wir verwenden eine innere Hilfsschicht, um die Fehlergradienten zu summieren.
if(!cTemp.Init(0, 6, OpenCL, window * count, optimization, batch)) return false;
Um unnötiges Kopieren von Daten zu vermeiden, ersetzen wir die Datenpuffer.
cNorm[1].SetGradientIndex(getGradientIndex()); cNorm[2].SetGradientIndex(getGradientIndex()); SetActivationFunction(None); iWindowOut = (int)window_out; //--- return true; }
Wir implementieren die Funktionsweise des Vorwärtsdurchgangs in der Methode CResidualConv::feedForward. In den Methodenparametern erhalten wir einen Zeiger auf die vorherige neuronale Schicht.
bool CResidualConv::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cConvs[0].FeedForward(NeuronOCL)) return false; if(!cNorm[0].FeedForward(GetPointer(cConvs[0]))) return false;
Im Hauptteil der Methode wird keine Prüfung des empfangenen Zeigers durchgeführt, da eine solche Prüfung bereits in den entsprechenden Methoden der internen Schichten implementiert ist. Daher gehen wir sofort dazu über, Vorwärtsdurchgangs-Methoden für interne Schichten aufzurufen.
if(!cConvs[1].FeedForward(GetPointer(cNorm[0]))) return false; if(!cNorm[1].FeedForward(GetPointer(cConvs[1]))) return false;
Wie bereits erwähnt, verwenden wir die von der vorhergehenden neuronalen Schicht erhaltenen Daten für den Vorwärtsdurchgangs der Blöcke 1 und 3.
if(!cConvs[2].FeedForward(NeuronOCL)) return false; if(!cNorm[2].FeedForward(GetPointer(cConvs[2]))) return false;
Dann addieren und normalisieren wir ihre Ergebnisse.
if(!SumAndNormilize(cNorm[1].getOutput(), cNorm[2].getOutput(), Output, iWindowOut, true)) return false; //--- return true; }
Der umgekehrte Prozess der Rückwärtsdurchgang mit den Fehlergradienten ist in der Methode CResidualConv::calcInputGradients implementiert. Der Algorithmus ist der Methode des Vorwärtsdurchgangs sehr ähnlich. Wir rufen einfach die gleichnamigen Methoden auf den internen Ebenen auf, aber in umgekehrter Reihenfolge.
bool CResidualConv::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cNorm[2].calcInputGradients(GetPointer(cConvs[2]))) return false; if(!cConvs[2].calcInputGradients(GetPointer(cTemp))) return false; //--- if(!cNorm[1].calcInputGradients(GetPointer(cConvs[1]))) return false; if(!cConvs[1].calcInputGradients(GetPointer(cNorm[0]))) return false; if(!cNorm[0].calcInputGradients(prevLayer)) return false;
Dabei ist zu beachten, dass durch das Ersetzen von Datenpuffern das anfängliche Kopieren von Fehlergradienten in interne Ebenen entfällt. An die vorherige Schicht wird die Summe der Fehlergradienten von 2 Datenströmen übertragen.
if(!SumAndNormilize(prevLayer.getGradient(), cTemp.getGradient(), prevLayer.getGradient(), iWindowOut, false)) return false; //--- return true; }
Die Methode CResidualConv::updateInputWeights zur Aktualisierung der Klassenparameter ist ähnlich aufgebaut. Ich schlage vor, dass Sie sich anhand des beigefügten Codes damit vertraut machen. Der vollständige Code der Klasse CResidualConv und alle ihre Methoden sind unten angefügt. Der Anhang enthält auch den vollständigen Code für alle Programme, die bei der Erstellung des Artikels verwendet wurden. Wir gehen nun dazu über, den Algorithmus für den Aufbau des nächsten Blocks zu betrachten: den Feature Encoder.
2.2 Der Feature-Encoder
Der von den Autoren der CCMR-Methode vorgeschlagene Feature-Encoder-Algorithmus wird in der Klasse CCCMREncoder implementiert, die ebenfalls von der Basisklasse der vollständig verbundenen neuronalen Schicht CNeuronBaseOCL erbt.
class CCCMREncoder : public CNeuronBaseOCL { protected: CResidualConv cResidual[6]; CNeuronConvOCL cInput; CNeuronBatchNormOCL cNorm; CNeuronConvOCL cOutput; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CCCMREncoder(void) {}; ~CCCMREncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defCCMREncoder; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
In dieser Klasse verwenden wir eine Faltungsschicht zur Projektion der Originaldaten cInput, deren Ergebnisse wir mit der Batch-Normalisierungsschicht cNorm normalisieren. Wir verwenden auch die Faltungsschicht der Projektion cOutput der Operationsergebnisse des Encoders. Da wir eine Projektionsschicht der Quelldaten und der Ergebnisse verwenden, können wir eine kaskadierte Merkmalsextraktion auf mehreren Skalen einrichten, ohne dass die Größe der Quelldaten und die gewünschte Anzahl von Merkmalen eine Rolle spielen.
Datenskalierung und Merkmalsextraktion werden in mehreren sequentiellen Faltungsblöcken mit geschlossener Schleife durchgeführt, die wir der Einfachheit halber in dem Array cResidual zusammengefasst haben.
Wie in der vorherigen Klasse haben wir alle internen Objekte der Klasse als statisch deklariert, was uns erlaubt, den Konstruktor und Destruktor der Klasse leer zu lassen.
Die Initialisierung der Klassenobjekte wird in der Methode CCCMREncoder::Init durchgeführt. Der Algorithmus dieser Methode folgt einer bereits bekannten Logik. Als Parameter erhält die Methode Konstanten der Klassenarchitektur.
bool CCCMREncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
Im Hauptteil der Methode rufen wir zunächst die entsprechende Methode der übergeordneten Klasse auf, die die empfangenen Parameter überprüft und die geerbten Objekte initialisiert. Wir kontrollieren das Ergebnis der Methode der übergeordneten Klasse anhand des logischen Ergebnisses ihrer Fertigstellung.
Als Nächstes wird der Block für die Skalierung und Normalisierung der Quelldaten initialisiert. Auf der Grundlage der Ergebnisse seiner Arbeit planen wir, eine Darstellung eines einzelnen Zustands der Umwelt in Form einer Beschreibung von 32 Parametern zu erhalten.
if(!cInput.Init(0, 0, OpenCL, window, window, 32, count, optimization, iBatch)) return false; if(!cNorm.Init(0, 1, OpenCL, 32 * count, iBatch, optimization)) return false; cNorm.SetActivationFunction(LReLU);
Wir erstellen dann eine Datenskalierungskaskade mit der Anzahl der Merkmale {32, 64, 128}.
if(!cResidual[0].Init(0, 2, OpenCL, 32, 32, count, optimization, iBatch)) return false; if(!cResidual[1].Init(0, 3, OpenCL, 32, 32, count, optimization, iBatch)) return false;
if(!cResidual[2].Init(0, 4, OpenCL, 32, 64, count, optimization, iBatch)) return false; if(!cResidual[3].Init(0, 5, OpenCL, 64, 64, count, optimization, iBatch)) return false;
if(!cResidual[4].Init(0, 6, OpenCL, 64, 128, count, optimization, iBatch)) return false; if(!cResidual[5].Init(0, 7, OpenCL, 128, 128, count, optimization, iBatch)) return false;
Und schließlich bringen wir die Datendimension auf den vom Nutzer angegebenen Maßstab.
if(!cOutput.Init(0, 8, OpenCL, 128, 128, window_out, count, optimization, iBatch)) return false;
Um unnötige Kopiervorgänge von Blockoperationsergebnissen und Fehlergradienten zu vermeiden, ersetzen wir Datenpuffer.
if(Output != cOutput.getOutput()) { if(!!Output) delete Output; Output = cOutput.getOutput(); } //--- if(Gradient != cOutput.getGradient()) { if(!!Gradient) delete Gradient; Gradient = cOutput.getGradient(); } //--- return true; }
Vergessen Sie nicht, den Arbeitsablauf bei jedem Schritt zu kontrollieren. Dann informieren wir den Aufrufer über die Ergebnisse der Methode mit einem logischen Wert.
Nun erstellen wir einen Feed-Forward-Pass-Algorithmus in der Methode CCCMREncoder::feedForward. In den Methodenparametern erhalten wir wie immer einen Zeiger auf das Objekt der vorherigen Ebene. Die Überprüfung der Relevanz des empfangenen Zeigers erfolgt im Körper der Methoden für die Weitergabe von verschachtelten Objekten.
bool CCCMREncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cInput.FeedForward(NeuronOCL)) return false; if(!cNorm.FeedForward(GetPointer(cInput))) return false;
Zunächst werden die Originaldaten skaliert und normalisiert. Anschließend werden die Daten durch eine Skalierungskaskade mit Merkmalsextraktion geleitet.
Man beachte, dass der erste Faltungsblock mit geschlossener Schleife seine Anfangsdaten von der Schicht für die Stapelnormalisierung erhält und die nachfolgenden Daten vom vorherigen Block aus dem Array. So können wir die Blöcke in einer Schleife durchlaufen.
if(!cResidual[0].FeedForward(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].FeedForward(GetPointer(cResidual[i - 1]))) return false;
Wir skalieren das Ergebnis der Operationen auf eine bestimmte Größe.
if(!cOutput.FeedForward(GetPointer(cResidual[5]))) return false; //--- return true; }
Der Fehlergradient wird durch die internen Encoder-Objekte in umgekehrter Reihenfolge weitergegeben.
bool CCCMREncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cInput.UpdateInputWeights(NeuronOCL)) return false; if(!cNorm.UpdateInputWeights(GetPointer(cInput))) return false; if(!cResidual[0].UpdateInputWeights(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].UpdateInputWeights(GetPointer(cResidual[i - 1]))) return false; if(!cOutput.UpdateInputWeights(GetPointer(cResidual[5]))) return false; //--- return true; }
In diesem Artikel werden wir uns nicht näher mit der Beschreibung aller Methoden der Klasse befassen. Sie haben eine ähnliche Blockstruktur, bei der die entsprechenden Methoden der internen Objekte nacheinander aufgerufen werden. Sie können die Struktur anhand des unten beigefügten vollständigen Codes studieren. Wenn Sie Fragen zum Code haben, beantworte ich sie gerne im Forum oder in privaten Nachrichten. Wählen Sie Ihr bevorzugtes Kommunikationsformat.
2.3 Dynamische Gruppierung des globalen Kontextes
Um den globalen Kontext zu gruppieren und dabei die Dynamik der Veränderungen in den Merkmalen zu berücksichtigen, schlugen die Autoren der CCRM-Methode die Verwendung eines Kreuzaufmerksamkeitsblocks XCiT vor. In diesem Block werden die Entitäten Abfrage und Schlüssel aus den Merkmalen des globalen Kontexts gebildet. Der Wert ergibt sich aus der Dynamik der gebildeten Umweltmerkmale von 2 aufeinanderfolgenden Zuständen. Diese Verwendung des Blocks unterscheidet sich etwas von der, die wir zuvor betrachtet haben. Um die vorgeschlagene Option für die Verwendung des Blocks umzusetzen, müssen wir einige Änderungen vornehmen.
Erstellen wir eine neue Klasse CNeuronCrossXCiTOCL, die den größten Teil der Funktionalität von der vorherigen Implementierung der XCiT-Methode erben wird.
class CNeuronCrossXCiTOCL : public CNeuronXCiTOCL { protected: CCollection cConcat; CCollection cValue; CCollection cV_Weights; CBufferFloat TempBuffer; uint iWindow2; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool Concat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool DeConcat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); public: CNeuronCrossXCiTOCL(void) {}; ~CNeuronCrossXCiTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion); //--- virtual int Type(void) const { return defNeuronCrossXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Beachten Sie, dass ich bei dieser Implementierung versucht habe, die zuvor erstellten Funktionen so weit wie möglich zu nutzen. Der Klassenstruktur wurden 3 Sammlungen von Datenpuffern und ein Hilfspuffer zur Speicherung von Zwischendaten hinzugefügt.
Wie zuvor werden alle internen Objekte als statisch deklariert, sodass der Konstruktor und der Destruktor der Klasse „leer“ sind.
Die Initialisierung aller Klassenobjekte wird in der Methode CNeuronCrossXCiTOCL::Init durchgeführt.
bool CNeuronCrossXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronXCiTOCL::Init(numOutputs, myIndex, open_cl, window1, lpi_window, heads, units_count, layers, optimization_type, batch)) return false;
In den Parametern erhält die Methode die wichtigsten Parameter, die die Architektur der gesamten Klasse und ihrer internen Objekte bestimmen. Im Körper der Klasse rufen wir die entsprechende Methode der übergeordneten Klasse auf, die die empfangenen Parameter überprüft und alle geerbten Objekte initialisiert.
Nach erfolgreicher Ausführung der Methode der übergeordneten Klasse definieren wir die Parameter der Puffer für das Schreiben von Wertentitäten und deren Fehlergradienten. Wir definieren auch Gewichtserzeugungsmatrizen für die angegebene Entität.
//--- Cross XCA iWindow2 = fmax(window2, 1); uint num = iWindowKey * iHeads * iUnits; //Size of V tensor uint v_weights = (iWindow2 + 1) * iWindowKey * iHeads; //Size of weights' matrix of V tensor
Als Nächstes organisieren wir eine Schleife nach der Anzahl der internen Schichten der Kreuzaufmerksamkeit XCiT und erstellen die erforderlichen Puffer im Hauptteil der Schleife. Zunächst fügen wir einen Puffer hinzu, um die erzeugten Werteinheiten und die entsprechenden Fehlergradienten zu schreiben.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize V tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cValue.Add(temp)) return false;
In der übergeordneten Klasse CNeuronXCiTOCL haben wir einen verketteten Puffer aus Abfrage-, Schlüssel- und Wertentitäten verwendet. Um die abgeleiteten Funktionsweisen weiter nutzen zu können, wollen wir die angegebenen Entitäten aus 2 Quellen in einen cConcat-Sammlungspuffer verketten.
//--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(3 * num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cConcat.Add(temp)) return false; }
Der nächste Schritt besteht darin, die Puffer für die Gewichtsmatrix zu erstellen, um die Entität Wert zu erzeugen.
//--- XCiT //--- Initilize V weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(v_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < v_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false;
Momentpuffer für den Optimierungsprozess der angegebenen Gewichtsmatrix.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(v_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false; } }
Dann initialisieren wir den Zwischenspeicher.
TempBuffer.BufferInit(iWindow2 * iUnits, 0); if(!TempBuffer.BufferCreate(OpenCL)) return false; //--- return true; }
Vergessen Sie nicht, den Arbeitsablauf bei jedem Schritt zu kontrollieren.
Die Vorwärtsdurchgangsmethode CNeuronCrossXCiTOCL::feedForward wurde weitgehend von der Elternklasse übernommen. Die aufmerksamkeitsübergreifenden Merkmale erfordern jedoch eine Neudefinition des Begriffs. Insbesondere für die Umsetzung der Kreuzaufmerksamkeit benötigen wir zwei Quellen von Ausgangsdaten.
bool CNeuronCrossXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(!NeuronOCL || !Motion) return false;
Im Hauptteil der Methode prüfen wir die Relevanz der empfangenen Zeiger auf die Quelldatenobjekte und organisieren eine Schleife durch die internen Ebenen.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 2 * iWindowKey * iHeads, None)) return false;
Im Hauptteil der Schleife erzeugen wir zunächst die Entitäten Abfrage und Schlüssel aus den Daten der vorherigen neuronalen Schicht. Es wird davon ausgegangen, dass wir in diesem Informationsfluss den globalen Kontext des GCs erhalten.
Bitte beachten Sie, dass wir Puffer aus den Legacy-Sammlungen QKV_Tensors und QKV_Weights verwenden. Wir erzeugen jedoch nur 2 Entitäten. Dies lässt sich an der Anzahl der Faltungsfilter „2 * iWindowKey * iHeads“ ablesen.
In ähnlicher Weise erzeugen wir die dritte Entität Wert, allerdings auf der Grundlage anderer Ausgangsdaten.
CBufferFloat *v = cValue.At(i * 2); if(IsStopped() || !ConvolutionForward(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), Motion, v, iWindow, iWindowKey * iHeads, None)) return false;
Wie oben erwähnt, werden alle 3 Entitäten zu einem einzigen Tensor verkettet, um die vererbte Funktionalität nutzen zu können.
if(IsStopped() || !Concat(qkv, v, cConcat.At(2 * i), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
Dann verwenden wir die geerbte Funktionalität, aber es gibt eine Sache. Bei dieser Implementierung ist die Anzahl der Elemente in der Sequenz in beiden Strömen identisch. Denn auf der obersten Ebene erzeugen wir beide Ströme aus denselben Quelldaten. In Anbetracht dieses Verständnisses habe ich keine Prüfung der Sequenzlängengleichheit vorgesehen. Für das korrekte Funktionieren der nachfolgenden Funktionen ist diese Einhaltung jedoch von entscheidender Bedeutung. Wenn Sie diese Klasse also separat verwenden wollen, achten Sie bitte darauf, dass die Länge der beiden Sequenzen gleich ist.
Lassen Sie uns die Ergebnisse der mehrköpfigen Aufmerksamkeit ermitteln.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(cConcat.At(2 * i), temp, out)) return false;
Wir summieren und normalisieren die Datenströme.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Es folgt ein Block mit lokaler Interaktion. Die Ströme werden dann summiert und normalisiert.
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false; out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false; temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false; //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Dann kommt der Block mit dem Vorwärtsdurchgang.
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false; //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
Nach erfolgreicher Iteration durch alle internen neuronalen Schichten ist die Methode abgeschlossen.
Bitte beachten Sie, dass bei dieser Methode ein Puffer der ursprünglichen Merkmalsdynamikdaten für alle internen neuronalen Schichten verwendet wird. Der globale Kontext ändert sich allmählich und verwandelt sich in den kontextgesteuerten globalen Kontext Context-guided Motion Features (CMF).
Der Prozess der Ausbreitung des Fehlergradienten durch interne Objekte wird auf ähnliche Weise in umgekehrter Reihenfolge durchgeführt. Sein Algorithmus ist in der Methode CNeuronCrossXCiTOCL::calcInputGradients beschrieben. In den Parametern erhält die Methode Zeiger auf 2 Quelldatenobjekte mit Puffern für die entsprechenden Fehlergradienten, die wir füllen müssen.
bool CNeuronCrossXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion) { if(!prevLayer || !Motion) return false;
Im Hauptteil der Methode wird zunächst die Relevanz der empfangenen Zeiger geprüft. Als Nächstes legen wir eine Schleife durch die internen Schichten in umgekehrter Reihenfolge an.
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
Im Hauptteil der Schleife propagieren wir zunächst den Fehlergradienten durch den Vorwärtsdurchgangsblock.
Ich möchte Sie daran erinnern, dass wir während des Vorwärtsdurchgangs die Eingangs- und Ausgangsdaten jedes Blocks addiert und normalisiert haben. Dementsprechend müssen wir während des Rückwärtsdurchgangs auch einen Fehlergradienten entlang beider Datenströme propagieren. Daher müssen wir nach der Weitergabe des Fehlergradienten durch den Block des Vorwärtsdurchgangs die Fehlergradienten der beiden Ströme summieren.
//--- Sum gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
Auf ähnliche Weise propagieren wir den Fehlergradienten durch den lokalen Interaktionsblock und summieren den Fehlergradienten über zwei Datenflüsse.
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false; temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
Der letzte Schritt besteht darin, den Fehlergradienten durch den Aufmerksamkeitsblock zu propagieren.
//--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(cConcat.At(i * 2), cConcat.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
Hier erhalten wir jedoch einen verketteten Puffer von Fehlergradienten für 3 Entitäten: Abfrage, Schlüssel und Wert. Aber wir erinnern uns, dass die Entitäten aus verschiedenen Datenquellen generiert wurden. Wir müssen den Fehlergradienten auf sie verteilen. Zunächst wird ein Puffer in 2 geteilt.
if(IsStopped() || !DeConcat(QKV_Tensors.At(i * 2 + 1), cValue.At(i * 2 + 1), cConcat.At(i * 2 + 1), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
Dann rufen wir Methoden zur Weitergabe von Gradienten an die entsprechenden Quelldaten auf. Wir können die geerbte Funktionalität für Abfrage und Schlüssel verwenden. Bei Wert sind die Dinge jedoch etwas komplizierter.
//--- CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false;
Während des Vorwärtsdurchgangs habe ich betont, dass wir für alle Schichten einen Puffer für die Dynamik der Merkmalsänderungen verwenden. Die direkte Übergabe des Fehlergradienten an den Gradientenpuffer des Quelldatenobjekts überschreibt diese einfach und löscht die zuvor geschriebenen Daten anderer interner Ebenen. Daher werden wir die Daten nur bei der ersten Iteration (der letzten internen Schicht) direkt schreiben.
if(i > 0) out_grad = temp; if(i == iLayers - 1) { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), Motion.getGradient(), iWindow, iWindowKey * iHeads, None)) return false; }
In anderen Fällen verwenden wir einen Hilfspuffer, um temporäre Daten zu speichern, und summieren dann die neuen und die zuvor akkumulierten Gradienten auf.
else { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), GetPointer(TempBuffer), iWindow, iWindowKey * iHeads, None)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(TempBuffer), Motion.getGradient(), Motion.getGradient(), iWindow2, false)) return false; }
Wir summieren die Fehlergradienten über die 2 Datenströme und fahren mit der nächsten Iteration der Schleife fort.
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false; if(i > 0) out_grad = temp; } //--- return true; }
Nachdem der Fehlergradient alle internen Schichten erfolgreich durchlaufen hat, beenden wir die Methode.
Nach der Verteilung des Fehlergradienten auf alle internen Objekte und Quelldaten entsprechend ihrem Einfluss auf das Endergebnis müssen wir die Modellparameter anpassen, um den Fehler zu minimieren. Dieser Vorgang ist in der Methode CNeuronCrossXCiTOCL::updateInputWeights geregelt. Ähnlich wie bei den beiden oben beschriebenen Methoden aktualisieren wir die Parameter der internen Objekte in einer Schleife durch die internen neuronalen Schichten.
bool CNeuronCrossXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization == SGD ? QKV_Weights.At(l * 2 + 1) : QKV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : QKV_Weights.At(l * 3 + 2)), iWindow, 2 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cV_Weights.At(l * (optimization == SGD ? 2 : 3)), cValue.At(l * 2 + 1), inputs, (optimization == SGD ? cV_Weights.At(l * 2 + 1) : cV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : cV_Weights.At(l * 3 + 2)), iWindow, iWindowKey * iHeads)) return false;
Zunächst aktualisieren wir die Parameter für die Erstellung der Entitäten Abfrage, Schlüssel und Wert. Es folgt der lokale Kommunikationsblock LPI.
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization == SGD ? cLPI_Weights.At(l * 5 + 3) : cLPI_Weights.At(l * 7 + 3)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization == SGD ? cLPI_Weights.At(l * 5 + 4) : cLPI_Weights.At(l * 7 + 4)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
Wir schließen den Prozess mit einem Vorwärtsdurchgangsblock ab.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization == SGD ? FF_Weights.At(l * 4 + 2) : FF_Weights.At(l * 6 + 2)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 4 + 3) : FF_Weights.At(l * 6 + 3)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
Damit ist die Beschreibung der Methoden der Klasse CNeuronCrossXCiTOCL abgeschlossen. Im Rahmen dieses Artikels können wir nicht auf alle Methoden der Klasse im Detail eingehen. Sie können sie mit Hilfe des Codes in der Anlage selbst untersuchen. Die Anhänge enthalten den vollständigen Code aller Klassen und ihrer Methoden. Sie enthalten auch alle Programme, die bei der Erstellung des Artikels verwendet wurden.
2.4 Implementierung des CCMR-Algorithmus
Wir haben eine Menge Arbeit investiert, um neue Klassen zu implementieren. Dies waren jedoch vorbereitende Arbeiten. Nun gehen wir dazu über, unsere Vision des Algorithmus CCMR umzusetzen. Bitte beachten Sie, dass dies unsere Vorstellung von den vorgeschlagenen Ansätzen ist. Sie kann von der ursprünglichen Darstellung abweichen. Dennoch haben wir versucht, die vorgeschlagenen Ansätze zur Lösung unserer Probleme umzusetzen.
Um die Methode zu implementieren, erstellen wir die Klasse CNeuronCCMROCL, die die grundlegende Funktionalität von der Klasse CNeuronBaseOCL erbt. Die Struktur der neuen Klasse ist unten dargestellt.
class CNeuronCCMROCL : public CNeuronBaseOCL { protected: CCCMREncoder FeatureExtractor; CNeuronBaseOCL PrevFeatures; CNeuronBaseOCL Motion; CNeuronBaseOCL Temp; CCCMREncoder LocalContext; CNeuronXCiTOCL GlobalContext; CNeuronCrossXCiTOCL MotionContext; CNeuronLSTMOCL RecurentUnit; CNeuronConvOCL UpScale; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCCMROCL(void) {}; ~CNeuronCCMROCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronCCMROCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag virtual bool Clear(void); };
Hier sehen Sie den traditionellen Methodensatz und eine Reihe von Objekten, von denen die meisten oben erstellt wurden. Wir erstellen 2 Instanzen der Klasse CCCMREncoder, um Merkmale der Umgebung und des lokalen Kontexts zu extrahieren (FeatureExtractor bzw. LocalContext).
Die CNeuronXCiTOCL-Objektinstanz wird verwendet, um den globalen Kontext (GlobalContext) zu erhalten. Mit CNeuronCrossXCiTOCL passen wir es unter Berücksichtigung der Dynamik der Merkmale an CMF (MotionContext) an.
Um rekurrente Verbindungen zu implementieren, verwenden wir anstelle von GRU einen LSTM-Block (CNeuronLSTMOCL RecurrentUnit).
Die Funktionalität aller internen Objekte werden wir bei der Implementierung der Klassenmethoden näher kennenlernen.
Wie zuvor haben wir alle internen Objekte der Klasse als statisch deklariert. Daher bleiben der Konstruktor und der Destruktor der Klasse „leer“.
Interne Klassenobjekte werden mit der Methode CNeuronCCMROCL::Init initialisiert.
bool CNeuronCCMROCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
In den Methodenparametern finden wir die wichtigsten Konstanten der Klassenarchitektur. Im Körper der Methode rufen wir sofort die entsprechende Methode der übergeordneten Klasse auf, in der die empfangenen Parameter überprüft und die geerbten Objekte initialisiert werden.
Nachdem die Methode der übergeordneten Klasse erfolgreich ausgeführt wurde, geht es an die Initialisierung der internen Objekte. Zunächst initialisieren wir den Feature Encoder mit dem aktuellen Zustand der Umgebung.
if(!FeatureExtractor.Init(0, 0, OpenCL, window, 16, count, optimization, iBatch)) return false;
Zur Schätzung des Flusses verwendet die CCMR-Methode Schnappschüsse von 2 aufeinander folgenden Zuständen des Systems. Wir behandeln dieses Thema jedoch aus einem etwas anderen Blickwinkel. Bei jeder Iteration des Vorwärtsdurchgangs erzeugen wir Merkmale von nur einem Umgebungszustand und speichern sie im lokalen Puffer PrevFeatures. Wir verwenden den Wert dieses Puffers, um den dynamischen Fluss im nachfolgenden Vorwärtsdurchgang zu schätzen. Wir initialisieren die lokalen Pufferobjekte des vorherigen Zustands und die Änderungen der Merkmale.
if(!PrevFeatures.Init(0, 1, OpenCL, 16 * count, optimization, iBatch)) return false; if(!Motion.Init(0, 2, OpenCL, 16 * count, optimization, iBatch)) return false;
Um unnötiges Kopieren von Daten zu vermeiden, organisieren wir den Austausch von Puffern.
if(Motion.getGradientIndex() != FeatureExtractor.getGradientIndex())
Motion.SetGradientIndex(FeatureExtractor.getGradientIndex());
Als Nächstes generieren wir auf der Grundlage des aktuellen Zustands der Umgebung Kontextmerkmale mithilfe des Encoders LocalContext. An dieser Stelle sei angemerkt, dass wir einen Satz von Quelldaten in 2 Datenströmen verwenden. Folglich müssen wir den Fehlergradienten aus 2 Strömen ermitteln. Um die Summierung von Gradienten zu ermöglichen, wird ein lokaler Datenpuffer angelegt.
if(!Temp.Init(0, 3, OpenCL, window * count, optimization, iBatch)) return false; if(!LocalContext.Init(0, 4, OpenCL, window, 16, count, optimization, iBatch)) return false;
Aufmerksamkeitsmechanismen werden es uns ermöglichen, lokale Kontexte zu einem globalen Kontext zusammenzufassen.
if(!GlobalContext.Init(0, 5, OpenCL, 16, 3, 4, count, 4, optimization, iBatch)) return false;
Der globale Kontext wird dann an die Strömungsdynamik angepasst.
if(!MotionContext.Init(0, 6, OpenCL, 16, 16, 3, 4, count, 4, optimization, iBatch)) return false;
Schließlich aktualisieren wir den Fluss im rekurrenten Block.
if(!RecurentUnit.Init(0, 7, OpenCL, 16 * count, optimization, iBatch) || !RecurentUnit.SetInputs(16 * count)) return false;
Um die Größe des Modells zu verringern, haben wir interne Objekte in einem ziemlich komprimierten Zustand verwendet. Der Nutzer kann jedoch Daten in einer anderen Dimension benötigen. Um die Ergebnisse auf die gewünschte Größe zu bringen, werden wir eine Skalierungsebene verwenden.
if(!UpScale.Init(0, 8, OpenCL, 16, 16, window_out, count, optimization, iBatch)) return false;
Um unnötiges Kopieren von Daten zu vermeiden, organisieren wir den Austausch von Datenpuffern.
if(UpScale.getGradientIndex() != getGradientIndex()) SetGradientIndex(UpScale.getGradientIndex()); if(UpScale.getOutputIndex() != getOutputIndex()) Output.BufferSet(UpScale.getOutputIndex()); //--- return true; }
Der Algorithmus des Vorwärtsdurchgangs ist in der Methode CNeuronCCMROCL::feedForward implementiert. Als Parameter erhält die Methode des Vorwärtsdurchgangs einen Zeiger auf das Objekt der vorherigen Ebene, das die ursprünglichen Daten enthält.
bool CNeuronCCMROCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Delta Features if(!SumAndNormilize(FeatureExtractor.getOutput(), FeatureExtractor.getOutput(), PrevFeatures.getOutput(), 1, false, 0, 0, 0, -0.5f)) return false;
Im Hauptteil der Methode wird der Inhalt des Ergebnispuffers des Environmental State Sign Encoders in den vorherigen Zustandspuffer übertragen, bevor irgendwelche Operationen gestartet werden. Bevor die Iterationen beginnen, enthält der Puffer die Ergebnisse des vorangegangenen Vorwärtsdurchlaufs.
Bitte beachten Sie, dass wir bei der Übertragung von Daten das Vorzeichen des Merkmalsattributs in das entgegengesetzte ändern.
Nach dem Speichern der Daten führen wir einen Vorwärtsdurchgang durch den State Encoder durch.
if(!FeatureExtractor.FeedForward(NeuronOCL)) return false;
Nach einem erfolgreichem Vorwärtsdurchgang von FeatureExtractor haben wir Merkmale von 2 nachfolgenden Bedingungen und können die Abweichung bestimmen. Der Einfachheit halber nehmen wir einfach die Differenz der Merkmale. Beim Speichern des vorherigen Zustands haben wir das Vorzeichen der Merkmale vorsichtig geändert. Um die Differenz der Zustände zu erhalten, können wir nun die Inhalte der Puffer addieren.
if(!SumAndNormilize(FeatureExtractor.getOutput(), PrevFeatures.getOutput(), Motion.getOutput(), 1, false, 0, 0, 0, 1.0f)) return false;
Der nächste Schritt besteht darin, lokale Kontextmerkmale zu erzeugen.
if(!LocalContext.FeedForward(NeuronOCL)) return false;
Lassen Sie uns den globalen Kontext extrahieren.
if(!GlobalContext.FeedForward(GetPointer(LocalContext))) return false;
Und passen Sie sie an die Dynamik der Veränderungen an.
if(!MotionContext.FeedForward(GetPointer(GlobalContext), Motion.getOutput())) return false;
Als Nächstes wird der Fluss im rekurrenten Block angepasst.
//--- Flow if(!RecurentUnit.FeedForward(GetPointer(MotionContext))) return false;
Wir skalieren die Daten auf die gewünschte Größe.
if(!UpScale.FeedForward(GetPointer(RecurentUnit))) return false; //--- return true; }
Vergessen wir bei der Umsetzung nicht, den Prozess bei jedem Schritt zu kontrollieren.
Der Algorithmus des Rückwärtsdurchgangs ist in der Methode CNeuronCCMROCL::calcInputGradients implementiert. Ähnlich wie bei den gleichnamigen Methoden in anderen Klassen liefern die Methodenparameter einen Index für das Objekt der vorherigen Ebene. Im Hauptteil der Methode rufen wir nacheinander die entsprechenden Methoden der internen Objekte auf. Die Reihenfolge der Objekte ist jedoch umgekehrt wie beim direkten Durchgang.
bool CNeuronCCMROCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!UpScale.calcInputGradients(GetPointer(RecurentUnit))) return false;
Zunächst propagieren wir den Fehlergradienten durch die Skalierungsschicht. Dann durch den rekurrenten Block.
if(!RecurentUnit.calcInputGradients(GetPointer(MotionContext))) return false;
Als Nächstes wird der Fehlergradient sequentiell durch alle Stufen der Kontexttransformation propagiert.
if(!MotionContext.calcInputGradients(GetPointer(GlobalContext), GetPointer(Motion))) return false; if(!GlobalContext.calcInputGradients(GetPointer(LocalContext))) return false; if(!LocalContext.calcInputGradients(GetPointer(Temp))) return false;
Mit der Ersetzung von Datenpuffern wird der Fehlergradient aus der Merkmalsdynamik an den State Feature Encoder übertragen. Wir propagieren den Fehlergradienten durch den Encoder zum Puffer der vorherigen Schicht.
if(!FeatureExtractor.calcInputGradients(prevLayer)) return false;
Fehlergradient aus dem Kontext-Encoder hinzufügen.
if(!SumAndNormilize(prevLayer.getGradient(), Temp.getGradient(), prevLayer.getGradient(), 1, false, 0, 0, 0, 1.0f)) return false; //--- return true; }
Die Methode zur Aktualisierung der Modellparameter ist nicht schwierig. Wir aktualisieren nacheinander die Parameter der internen Objekte.
bool CNeuronCCMROCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!FeatureExtractor.UpdateInputWeights(NeuronOCL)) return false; if(!LocalContext.UpdateInputWeights(NeuronOCL)) return false; if(!GlobalContext.UpdateInputWeights(GetPointer(LocalContext))) return false; if(!MotionContext.UpdateInputWeights(GetPointer(GlobalContext), Motion.getOutput())) return false; if(!RecurentUnit.UpdateInputWeights(GetPointer(MotionContext))) return false; if(!UpScale.UpdateInputWeights(GetPointer(RecurentUnit))) return false; //--- return true; }
Beachten Sie, dass diese Klasse einen wiederkehrenden Block und einen Puffer zum Speichern des vorherigen Zustands enthält. Daher müssen wir die Methode zum Löschen der wiederkehrenden Komponente CNeuronCCMROCL::Clear neu definieren. Hier rufen wir die gleichnamige rekurrente Blockmethode auf und füllen den Ergebnispuffer FeatureExtractor mit Nullwerten.
bool CNeuronCCMROCL::Clear(void) { if(!RecurentUnit.Clear()) return false; //--- CBufferFloat *temp = FeatureExtractor.getOutput(); temp.BufferInit(temp.Total(), 0); if(!temp.BufferWrite()) return false; //--- return true; }
Beachten Sie, dass wir den Ergebnispuffer des Encoders löschen, nicht den vorherigen Zustandspuffer. Zu Beginn der Vorwärtsdurchgangs-Methode werden Daten aus dem Ergebnispuffer des Encoders in den vorherigen Zustandspuffer kopiert.
Damit sind die wichtigsten Methoden zur Umsetzung von CCMR-Konzepten abgeschlossen. Wir haben eine ganze Menge Arbeit geleistet, aber der Umfang des Artikels ist begrenzt. Daher empfehle ich Ihnen, sich mit dem Algorithmus der Hilfsmethoden in der Anlage vertraut zu machen. Dort finden Sie den vollständigen Code aller Klassen und ihrer Methoden zur Implementierung von CCMR-Ansätzen. Darüber hinaus finden Sie im Anhang den vollständigen Code aller Programme, die bei der Erstellung des Artikels verwendet wurden. Wir gehen nun dazu über, die Architektur der Modellschulung zu betrachten.
2.5. Modell der Architektur
Bei der Beschreibung der Modellarchitektur möchte ich erwähnen, dass die CCMR-Ansätze nur den Environmental State Encoder betreffen.
Die Architektur der Modelle, die wir trainieren werden, wird in der Methode CreateDescriptions bereitgestellt, in deren Parametern wir 3 dynamische Arrays bereitstellen, um die Architektur von Encoder, Akteur und Kritiker zu erfassen.
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Im Hauptteil der Methode werden die empfangenen Zeiger überprüft und gegebenenfalls neue Objektinstanzen erstellt.
Wir füttern den Encoder mit Rohdaten über den aktuellen Zustand der Umgebung.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die empfangenen Daten werden in einer Batch-Normalisierungsschicht vorverarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Danach bilden wir einen Stapel von Zustandseinbettungen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Wir fügen den resultierenden Einbettungen eine Positionskodierung hinzu.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Und der letzte in der Encoder-Architektur ist der neue Block CNeuronCCMROCL, der an sich schon recht komplex ist und zusätzliche Verarbeitung erfordert.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCCMROCL; descr.count = prev_count; descr.window = prev_wout; descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Ich verwende hier die Architekturen von Akteur und Kritiker aus den vorherigen Artikeln ohne Änderungen. Eine detaillierte Beschreibung der Modellarchitektur finden Sie hier. Darüber hinaus wird im Anhang die vollständige Architektur der Modelle vorgestellt. Wir treten nun in die letzte Phase ein, um die geleistete Arbeit zu überprüfen.
3. Test
In den vorherigen Abschnitten dieses Artikels haben wir uns mit der CCMR-Methode vertraut gemacht und die vorgeschlagenen Ansätze mit MQL5 umgesetzt. Nun ist es an der Zeit, die Ergebnisse der oben beschriebenen Arbeit in der Praxis zu testen. Wie immer verwenden wir historische Daten von EURUSD, Zeitrahmen H1, zum Trainieren und Testen der Modelle. Die Modelle werden mit historischen Daten für die ersten 7 Monate des Jahres 2023 trainiert. Um das trainierte Modell im MetaTrader 5 Strategy Tester zu testen, verwende ich historische Daten vom August 2023.
In diesem Artikel habe ich das Modell mit dem Trainingsdatensatz trainiert, der im Rahmen der vorherigen Artikel gesammelt wurde. Während des Trainingsprozesses ist es mir gelungen, ein Modell zu erhalten, das in der Lage war, auf der Trainingsmenge Gewinne zu erzielen.
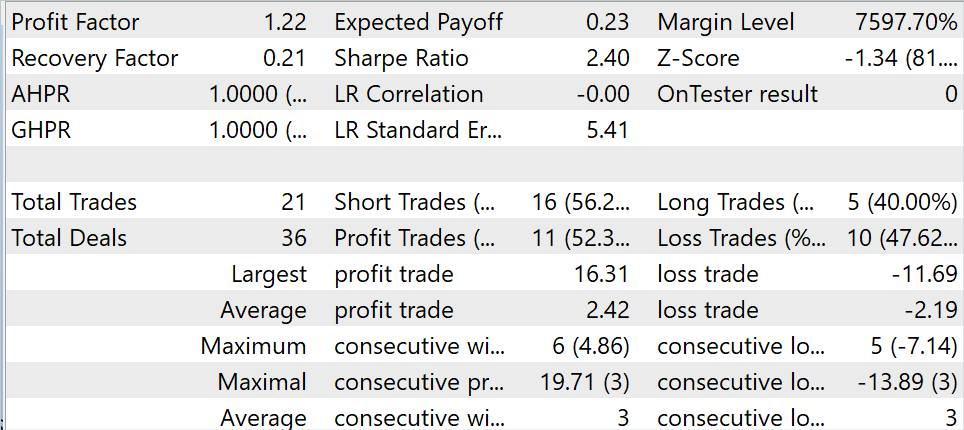
Während des Testzeitraums führte das Modell 21 Transaktionen durch, von denen 52,3 % mit Gewinn abgeschlossen wurden. Sowohl das Maximum als auch der Durchschnitt der gewinnbringenden Geschäfte übersteigen die entsprechenden Werte für die Verlustgeschäfte. Daraus ergibt sich ein Gewinnfaktor von 1,22
Schlussfolgerung
In diesem Artikel haben wir eine Methode zur Schätzung des optischen Flusses namens CCMR erörtert, die die Vorteile der Konzepte der kontextbasierten Bewegungsaggregation und eines mehrskaligen Grob-zu-Fein-Ansatzes kombiniert. So entstehen detaillierte Strömungskarten, die auch in verbauten Gebieten sehr genau sind.
Die Autoren der Methode schlugen eine zweistufige Strategie zur Bewegungsgruppierung vor, bei der zunächst globale Kontextmerkmale berechnet werden. Diese werden dann verwendet, um die Bewegungsmerkmale iterativ auf allen Skalen zu steuern. Dadurch können XCiT-basierte Algorithmen alle Skalen von grob bis fein verarbeiten, wobei skalenspezifische Inhalte erhalten bleiben.
Im praktischen Teil des Artikels haben wir die vorgeschlagenen Ansätze mit MQL5 umgesetzt. Wir haben das Modell mit realen Daten im MetaTrader 5 Strategie-Tester trainiert und getestet. Die erzielten Ergebnisse sprechen für die Wirksamkeit der vorgeschlagenen Ansätze.
Ich möchte Sie jedoch daran erinnern, dass alle in diesem Artikel vorgestellten Programme informativen Charakter haben und nur dazu dienen, die vorgeschlagenen Ansätze zu demonstrieren.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA-Beispielsammlung |
| 2 | ResearchRealORL.mq5 | EA | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | EA | Modelltraining EA |
| 4 | Test.mq5 | EA | Testmodel des EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14505
 Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.