
Redes neuronales: así de sencillo (Parte 73): AutoBots para predecir la evolución de los precios

Introducción
Predecir eficazmente el movimiento de los pares de divisas es un aspecto clave de la gestión segura de las operaciones. En este contexto, se presta especial atención al desarrollo de modelos eficientes que puedan aproximar con precisión la distribución conjunta de la información contextual y temporal necesaria para tomar decisiones comerciales. Como posible solución a tales tareas, vamos a discutir un nuevo método llamado "Latent Variable Sequential Set Transformers" (AutoBots) presentado en el artículo "Latent Variable Sequential Set Transformers For Joint Multi-Agent Motion Prediction". El método propuesto se basa en la arquitectura codificador-decodificador. Se desarrolló para resolver problemas de control seguro de sistemas robóticos. Permite generar secuencias de trayectorias para múltiples agentes coherentes con la escena. Los AutoBots pueden predecir la trayectoria de un ego-agente o la distribución de las trayectorias futuras de todos los agentes de la escena. En nuestro caso, intentaremos aplicar el modelo propuesto para generar secuencias de movimientos de precios de pares de divisas coherentes con la dinámica del mercado.
1. Algoritmos de AutoBots
"Latent Variable Sequential Set Transformers" (AutoBots) es un método basado en la arquitectura codificador-decodificador. Procesa secuencias de conjuntos. AutoBot se alimenta con una secuencia de conjuntos X1:t = (X1, ..., Xt), que en el problema de predicción del movimiento puede considerarse como el estado del entorno para t pasos de tiempo. Cada conjunto contiene M elementos (agentes, instrumentos financieros y/o indicadores) con K atributos (signos). Para procesar la información social y temporal en el codificador se utilizan las dos transformaciones siguientes.
Primero, el codificador AutoBots introduce información temporal en una secuencia de conjuntos utilizando una función de codificación posicional sinusoidal PE(.). En esta etapa, los datos se analizan como una colección de matrices, {X0, ..., XM}, que describen la evolución de los agentes a lo largo del tiempo. El codificador procesa las relaciones temporales entre conjuntos utilizando un bloque de atención multicabezal.
A continuación, se procesan los cortes S extrayendo conjuntos de estados del agente Sꚍ en un momento determinado ꚍ. Se procesan de nuevo en el bloque de atención múltiple.
Estas dos operaciones se repiten Lenc veces para obtener un tensor de contexto C de dimensión {dK, M, t}, que resume toda la representación de la escena de los datos originales, donde t es el número de pasos temporales en la escena de los datos de origen.
El objetivo del descodificador es generar predicciones que sean coherentes temporal y socialmente en el contexto de distribuciones de datos multimodales. Para generar c previsiones diferentes o la misma escena de los datos originales, el AutoBot decodificador utiliza c matrices de parámetros iniciales entrenables Qi que tienen la dimensión {dK, T}, donde T es el horizonte de planificación.
Intuitivamente, cada matriz de parámetros iniciales entrenables corresponde al ajuste de una variable latente discreta en AutoBot. Cada matriz entrenable Qi se repite entonces M veces a lo largo de la dimensión agente para obtener el tensor de entrada Q0i que tiene la dimensión {dK, M, T}.
El algoritmo ofrece la posibilidad de utilizar información contextual adicional, que se codifica mediante una red neuronal convolucional para crear un vector de características m<i. Para proporcionar información contextual a todos los pasos temporales futuros y a todos los elementos del conjunto, se propone copiar este vector a lo largo de las dimensiones M y T, creando un tensor Mi con la dimensión {dK, M, T}. A continuación, cada tensor Q0i se combina con Mi a lo largo de la dimensión dK. A continuación, este tensor se procesa mediante la capa totalmente conectada (rFFN) para obtener el tensor H de dimensión {dK, M, T}.
La descodificación comienza procesando la dimensión temporal determinada a la salida del codificador (C), así como los parámetros iniciales codificados y la información sobre el entorno (H). El decodificador procesa cada agente en H por separado, utilizando un bloque de atención de múltiples cabezas. Así, obtenemos un tensor que codifica la evolución temporal futura de cada elemento del conjunto de forma independiente.
Para garantizar la coherencia social de la escena futura entre los elementos del conjunto, procesamos cada trozo de tiempo H0, extrayendo conjuntos de estados del agente H0ꚍ en algún momento futuro ꚍ. Cada elemento de la secuencia es procesado por una unidad de atención multicabezal. Este bloque realiza la atención en cada paso temporal entre todos los elementos del conjunto.
Estas dos operaciones se repiten Ldec veces para crear el tensor de salida final para el agente <i. El proceso de descodificación se repite c veces con diferentes parámetros iniciales entrenados Qi e información contextual adicional mi. La salida del decodificador es un tensor O de dimensión {dK, M, T, c}, que puede procesarse mediante una red neuronal ф(.) para obtener la representación de salida deseada.
Una de las principales aportaciones que hace que el resultado y el tiempo de entrenamiento de AutoBot sean más rápidos en comparación con otros métodos es el uso de parámetros iniciales del decodificador Qr. Estas opciones tienen una doble finalidad. En primer lugar, tienen en cuenta la diversidad en la predicción del futuro, donde cada matriz Q<i corresponde a un ajuste de una variable latente discreta. En segundo lugar, ayudan a acelerar AutoBot al permitirle inferir a través de toda una escena con una sola pasada a través del decodificador sin selección secuencial.
A continuación se ofrece la visualización original del método presentada por los autores del artículo.
 proporcionada por los autores del artículo.")
2. Implementación utilizando MQL5
Hemos discutido los aspectos teóricos del método Latent Variable Sequential Set Transformers (AutoBots). Ahora pasemos a la parte práctica del artículo, en la que implementaremos nuestra visión del método presentado utilizando MQL5.
Para empezar, debe prestar atención a los dos puntos siguientes.
En primer lugar, el método proporciona codificación posicional. Sin embargo, ya hemos visto una codificación posicional similar utilizada dentro del método básico Self-Attention. Pero lo cierto es que antes, al estudiar los métodos de atención, la codificación posicional de los datos de origen se aplicaba en el lado del programa principal. Sin embargo, en AutoBot, la codificación posicional se implementa dentro del modelo tras el procesamiento preliminar y la creación de la incrustación de los datos de origen. Por supuesto, podríamos mover el preprocesamiento de datos a un modelo separado e implementar la codificación posicional en el lado del programa principal antes de transferir los datos al codificador. Pero esta opción requeriría operaciones adicionales de transferencia de datos entre la memoria del contexto OpenCL y el programa principal. Además, una implementación de este tipo limitaría nuestra flexibilidad a la hora de utilizar varias arquitecturas de modelos dentro de un mismo programa sin realizar ajustes adicionales en su código. Por ello, es preferible organizar todo el proceso en un solo modelo.
En segundo lugar, tanto en el codificador como en el decodificador, el método Latent Variable Sequential Set Transformers (AutoBots) requiere un uso alternativo de bloques de atención en el marco de varias dimensiones de los tensores analizados (análisis de dependencias temporales y sociales). Para cambiar la dimensión del foco de atención, necesitamos modificar la capa de atención multicabezal CNeuronMLMHAttentionOCL o transponer tensores. La transposición de tensores parece una tarea más sencilla en este caso. Para ello es necesario seguir ciertos pasos que ya se comentaron para la codificación posicional. No las repetiremos aquí. Es solo que necesitamos crear una capa de transposición de tensores en el lado del contexto OpenCL.
2.1 Capa de codificación posicional
Empezaremos por la capa de codificación posicional. Heredamos la clase de capa de codificación posicional CNeuronPositionEncoder de la clase base de capa neuronal de nuestra biblioteca CNeuronBaseOCL y sobrescribimos el conjunto básico de métodos:
- Init — inicialización
- feedForward — pase de avance
- calcInputGradients — propagación del gradiente de error a la capa anterior
- updateInputWeights — actualización de las ponderaciones
- Save y Load — operaciones de archivo
class CNeuronPositionEncoder : public CNeuronBaseOCL { protected: CBufferFloat PositionEncoder; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronPositionEncoder(void) {}; ~CNeuronPositionEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) { return true; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronPEOCL; } virtual void SetOpenCL(COpenCLMy *obj); };
Dejamos vacíos el constructor y el destructor de la clase.
Antes de pasar a otros métodos, vamos a discutir un poco la funcionalidad de la clase y la lógica de construcción. En el algoritmo Transformer, la codificación posicional se implementa añadiendo armónicos sinusoidales a los datos de origen mediante las siguientes funciones:
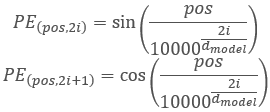
Tenga en cuenta que, en este caso, realizamos la codificación posicional de los elementos de la secuencia analizada. No se asocia con los armónicos de marca de tiempo utilizados anteriormente, que creamos en el lado del programa principal. El proceso es similar, pero el significado es diferente.
Obviamente, el tamaño de la secuencia analizada en el modelo siempre será constante. Por lo tanto, podemos simplemente crear y llenar un buffer armónico PositionEncoder en el método de inicialización de la clase Init. Durante el pase de avance, en el método feedForward, sólo añadimos los valores armónicos a los datos originales.
Se trata del pase de avance. ¿Y el pase de retropropagación? En el pase de avance realizamos la suma de dos tensores. En consecuencia, el gradiente de error durante el paso de retropropagación se distribuye uniformemente o se transfiere completamente a ambos términos. El tensor armónico de la codificación posicional en nuestro caso es una constante. Por lo tanto, transferiremos todo el gradiente de error a la capa anterior.
En cuanto a los pesos entrenables, simplemente no existen en la capa de codificación posicional. Por lo tanto, el método updateInputWeights se sobrescribe sólo por compatibilidad de clase y siempre devuelve true.
Esta es la lógica. Veamos ahora la aplicación. La clase se inicializa en el método Init. El método recibe en parámetros:
- numOutputs — número de conexiones a la capa siguiente
- open_cl — puntero al contexto OpenCL
- count — número de elementos de la secuencia
- window — número de parámetros para cada elemento de la secuencia
- optimization_type — método de optimización de parámetros.
bool CNeuronPositionEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false;
En el cuerpo del método, llamamos al método de inicialización de la clase padre, que implementa la funcionalidad básica. También comprobamos el resultado de las operaciones.
A continuación, tenemos que crear armónicos de codificación de posición. Para ello utilizaremos operaciones matriciales. En primer lugar, preparemos la matriz.
matrix<float> pe = matrix<float>::Zeros(count, window);
Creamos un vector para numerar las posiciones de los elementos en el tensor y un factor constante que se utiliza para todos los elementos.
vector<float> position = vector<float>::Ones(count); position = position.CumSum() - 1; float multipl = -MathLog(10000.0f) / window;
Como según la codificación posicional necesitamos alternar las fórmulas seno y coseno para los armónicos, rellenaremos la matriz en un bucle con un paso de 2. En el cuerpo del bucle, primero calculamos un vector de valores posicionales. Luego, en las columnas pares añadimos el seno del vector de valores posicionales. En las columnas impares escribimos el coseno del mismo vector.
for(uint i = 0; i < window; i += 2) { vector<float> temp = position * MathExp(i * multipl); pe.Col(MathSin(temp), i); if((i + 1) < window) pe.Col(MathCos(temp), i + 1); }
Copiaremos los armónicos posicionales resultantes en el búfer de datos y los transferiremos al contexto OpenCL.
if(!PositionEncoder.AssignArray(pe)) return false; //--- return PositionEncoder.BufferCreate(open_cl); }
Después de CNeuronPositionEncoder pasamos a organizar un pase feed-forward en el métodofeedForward. Como habrás notado, no hemos creado un núcleo de organización de procesos en el lado del contexto OpenCL. Pasamos directamente a la implementación del método. Esto se debe a que el núcleo para sumar 2 matrices SumMatrix ya fue creado anteriormente cuando implementamos el método Self-Attention.
Como es habitual, el método feedForward de los parámetros recibe un puntero a la capa neuronal anterior, que sirve como datos de origen. En el cuerpo del método comprobamos el puntero recibido.
bool CNeuronPositionEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!Gradient || Gradient != NeuronOCL.getGradient()) { if(!!Gradient) delete Gradient; Gradient = NeuronOCL.getGradient(); }
También reemplazamos inmediatamente el puntero al búfer de gradiente de error. Este sencillo método nos permitirá transferir directamente el gradiente de error de la capa siguiente a la anterior durante el paso de retropropagación, eliminando la copia innecesaria de datos en nuestra capa de codificación posicional.
A continuación, pasamos los datos necesarios a los parámetros del núcleo de suma vectorial.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = Neurons(); if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix1, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix2, PositionEncoder.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix_out, Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_dimension, (int)1)) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_multiplyer, 1.0f)) return false;
Coloca el núcleo en la cola de ejecución.
if(!OpenCL.Execute(def_k_MatrixSum, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel MatrixSum: %d", GetLastError()); return false; } //--- return true; }
Comprueba los resultados de las operaciones. Con esto, la aplicación del proceso de avance puede considerarse completa.
Como ya se ha mencionado, la capa de codificación posicional no contiene parámetros entrenables. Por lo tanto, el método updateInputWeights está "vacío" y siempre devuelve true. Al sustituir el puntero del búfer del gradiente de error, eliminamos por completo la capa de codificación posicional del proceso de propagación del gradiente de error. Por lo tanto, el método calcInputGradients, al igual que el método de actualización de parámetros, permanece "vacío" y se anula únicamente con fines de compatibilidad.
Con esto concluimos nuestro análisis de los métodos de capas de codificación posicional. El código completo de la clase está disponible en el archivo adjunto "...\Experts\NeuroNet_DNG\NeuroNet.mqh", que contiene todas las clases de nuestra biblioteca.
2.2 Transposición de tensores
La siguiente capa que acordamos crear es la capa de transposición tensorial CNeuronTransposeOCL. Al igual que con la capa de codificación posicional, al crear una clase heredamos de la clase base de la capa neuronal CNeuronBaseOCL. La lista de clases anuladas sigue siendo estándar. Sin embargo, también añadiremos 2 variables de clase para almacenar las dimensiones de la matriz transpuesta.
class CNeuronTransposeOCL : public CNeuronBaseOCL { protected: uint iWindow; uint iCount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronTransposeOCL(void) {}; ~CNeuronTransposeOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronTransposeOCL; } };
El constructor y el destructor de la clase permanecen vacíos. El método de inicialización de la clase Init está muy simplificado. En el cuerpo del método, sólo llamamos al método correspondiente de la clase padre y guardamos las dimensiones de la matriz transpuesta obtenida en los parámetros. No olvide comprobar los resultados de la operación.
bool CNeuronTransposeOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false; //--- iWindow = window; iCount = count; //--- return true; }
Para el método feed-forward, primero tenemos que crear un tensor de transposición de matrices Transpose. En los parámetros del núcleo, sólo pasaremos punteros a los búferes de los datos de origen y las matrices de resultados. Obtenemos los tamaños de las matrices a partir del espacio bidimensional del problema.
__kernel void Transpose(__global float *matrix_in, ///<[in] Input matrix __global float *matrix_out ///<[out] Output matrix ) { const int r = get_global_id(0); const int c = get_global_id(1); const int rows = get_global_size(0); const int cols = get_global_size(1); //--- matrix_out[c * rows + r] = matrix_in[r * cols + c]; }
El algoritmo del núcleo es bastante sencillo. Sólo determinamos la posición del elemento en la matriz de datos de origen y en la matriz de resultados. Después transferimos el valor.
El núcleo es llamado desde el método de pase feedForward. El algoritmo de llamada al núcleo es similar al indicado anteriormente. Primero definimos el espacio del problema, pero esta vez en un espacio bidimensional (número de elementos de la secuencia * número de características de cada elemento de la secuencia). A continuación, pasamos punteros a los búferes de datos a los parámetros del núcleo y lo ponemos en la cola de ejecución. No olvide comprobar el resultado de la operación.
bool CNeuronTransposeOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iCount, iWindow}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, Output.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
Durante el pase de retropropagación, necesitamos propagar el gradiente de error en la dirección opuesta. También necesitamos transponer la matriz del gradiente de error. Por lo tanto, utilizaremos el mismo núcleo. Sólo tenemos que invertir la dimensión del espacio del problema y especificar los punteros a los búferes de gradiente de error.
bool CNeuronTransposeOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iWindow, iCount}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, Gradient.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
Como se puede ver, la clase CNeuronTransposeOCL no contiene parámetros entrenables, por lo que el método updateInputWeights siempre devuelve true.
2.3 Arquitectura del AutoBot
Arriba hemos creado 2 nuevas capas bastante versátiles. Ahora podemos pasar directamente a la aplicación del método "Latent Variable Sequential Set Transformers" (AutoBots). Primero crearemos la arquitectura del modelo de previsión de movimiento de precios en el método CreateTrajNetDescriptions. Con el fin de reducir las operaciones por parte del programa principal, decidí organizar las operaciones del AutoBot en el marco de un modelo. Para describirlo, se pasa al método un puntero a un array dinámico. En el cuerpo del método, comprobamos el puntero recibido y, si es necesario, creamos una nueva instancia del objeto array dinámico.
bool CreateTrajNetDescriptions(CArrayObj *autobot) { //--- CLayerDescription *descr; //--- if(!autobot) { autobot = new CArrayObj(); if(!autobot) return false; }
El modelo se alimenta con el tensor de los datos originales. Como antes, para optimizar los cálculos durante el funcionamiento y el entrenamiento del modelo, sólo utilizaremos la descripción de la última barra como dato inicial. Todo el historial se acumula en el búfer de la capa de incrustación.
//--- Encoder autobot.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
El tratamiento primario de los datos de origen se realiza en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000,GPTBars); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Después generamos una incrustación de estado y la añadimos al búfer de datos históricos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!autobot.Add(descr)) { delete descr; return false; }
Tenga en cuenta que en este caso estamos incrustando sólo una entidad que describe el estado actual del entorno. La funcionalidad de esta capa es similar a la de la capa totalmente conectada. Sin embargo, utilizamos la capa CNeuronEmbeddingOCL ya que necesitamos crear un buffer de la secuencia histórica de incrustaciones. Sin embargo, el algoritmo no establece restricciones en el análisis de las barras de instrumentos. Podemos analizar tanto múltiples velas como múltiples instrumentos de negociación. Pero en este caso, tendrá que ajustar la matriz de incrustaciones.
A continuación, añadimos un tensor de codificación posicional a toda la secuencia de incrustación histórica.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; }
Ejecutamos el primer bloque de atención para evaluar las dependencias entre escenas en el tiempo.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
A continuación, tenemos que analizar las dependencias entre las características individuales. Para ello, transponemos el tensor y aplicamos un bloque de atención al tensor transpuesto.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Tenga en cuenta que después de la transposición, también cambiamos las dimensiones en el bloque de atención para que correspondan al tensor transpuesto.
Volvemos a transponer el tensor para devolverlo a su dimensión original. A continuación, volvemos a repetir los bloques de atención del codificador.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_wout; descr.window = prev_count; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
A la salida del codificador, recibimos un contexto para describir el estado actual del entorno. Necesitamos transferirlo al decodificador para predecir los parámetros futuros del movimiento de precios a la profundidad de planificación requerida. Sin embargo, según el algoritmo "Latent Variable Sequential Set Transformers", en esta etapa necesitamos añadir parámetros iniciales entrenables Q. Pero en la implementación actual de nuestra biblioteca, los parámetros entrenables sólo incluyen los pesos de las capas neuronales. Para no complicar el proceso existente, adopté una solución que puede no ser estándar, pero es eficaz. En este caso, utilizaremos la capa de concatenación de tensor СNeuronConcatenate. La primera parte de la capa sustituirá a la capa totalmente conectada para cambiar la representación contextual del estado ambiental actual recibida del codificador. Los pesos del segundo bloque actuarán como parámetros entrenables iniciales Q. Para no distorsionar los valores de los parámetros Q, alimentaremos un vector lleno de 1s a la segunda entrada.
A la salida de la capa, esperamos recibir un tensor de incrustación de estado para una profundidad de planificación determinada.
//--- Decoder //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = PrecoderBars * EmbeddingSize; descr.window = prev_count * prev_wout; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Como en el codificador, primero observamos las dependencias entre estados a lo largo del tiempo.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = PrecoderBars; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
A continuación, transponemos el tensor y analizamos la dependencia contextual entre las características individuales.
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Tras lo cual repetimos de nuevo las operaciones del decodificador.
//--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count * prev_wout; descr.window = descr.count; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Nótese que el uso del vector constante de 1s como segunda entrada del modelo nos permite iterar muchas veces la capa de concatenación en el decodificador. En este caso, los parámetros de peso entrenables desempeñan el papel de parámetros Q exclusivos de cada capa.
Para completar el descodificador, utilizamos una capa totalmente conectada que nos permite presentar los datos en el formato requerido.
//--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = PrecoderBars * 3; descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 Entrenamiento del AutoBot
Hemos analizado la arquitectura del modelo AutoBot para predecir los parámetros del próximo movimiento de precios en una profundidad de planificación determinada. El uso de los resultados del modelo entrenado sólo está limitado por tu imaginación. Teniendo una previsión del movimiento posterior del precio, puede construir un EA para realizar operaciones de acuerdo con la previsión recibida. Opcionalmente, puede pasarlo al modelo 'Actor' para generar directamente recomendaciones de acción. He utilizado la segunda opción. En este caso, la arquitectura de los modelos de 'Actor' y el establecimiento de objetivos se tomaron prestados de los anteriores artículos. Los cambios afectaron sólo a la capa de datos de origen para ajustarse a los resultados del modelo AutoBot anterior. No nos detendremos en ellos ahora. Se adjuntan a continuación (método CreateDescriptions) para que pueda estudiarlas usted mismo. Allí también podrá familiarizarse con los ajustes específicos en el EA para la interacción con el entorno "...\Experts\AutoBots\Research.mq5". Pasamos a organizar el proceso de entrenamiento del modelo para predecir el próximo movimiento de los precios. El proceso de entrenamiento se implementa en el EA "...\Experts\AutoBots\StudyTraj.mq5".
En este EA entrenamos un solo modelo.
CNet Autobot;
En el método de inicialización del EA OnInit cargamos primero el conjunto de datos de entrenamiento.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
A continuación, intentamos cargar el modelo AutoBot preentrenado y, si se produce un error, creamos un nuevo modelo inicializado con parámetros aleatorios.
//--- load models float temp; if(!Autobot.Load(FileName + "Traj.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *autobot = new CArrayObj(); if(!CreateTrajNetDescriptions(autobot)) { delete autobot; return INIT_FAILED; } if(!Autobot.Create(autobot)) { delete autobot; return INIT_FAILED; } delete autobot; //--- }
Después comprobamos que la arquitectura del modelo cumple los criterios principales.
Autobot.getResults(Result); if(Result.Total() != PrecoderBars * 3) { PrintFormat("The scope of the Autobot does not match the precoder bars (%d <> %d)", PrecoderBars * 3, Result.Total()); return INIT_FAILED; } //--- Autobot.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Autobot doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Creamos los búferes de datos necesarios.
OpenCL = Autobot.GetOpenCL(); if(!Ones.BufferInit(EmbeddingSize, 1) || !Gradient.BufferInit(EmbeddingSize, 0) || !Ones.BufferCreate(OpenCL) || !Gradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; } State.BufferInit(HistoryBars * BarDescr, 0);
Generamos un evento personalizado para el inicio del entrenamiento del modelo.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
En el método de desinicialización del EA, guardamos el modelo entrenado y borramos los objetos dinámicos de la memoria.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) Autobot.Save(FileName + "Traj.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; delete OpenCL; }
Como es habitual, el proceso de entrenamiento del modelo se implementa en el método Train. En el cuerpo del método, primero determinamos las probabilidades de elegir trayectorias en función de su rentabilidad.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
A continuación, declaramos e inicializamos los cambios locales.
vector<float> result, target, inp; matrix<float> targets; matrix<float> delta; STE = vector<float>::Zeros(PrecoderBars * 3); int std_count = 0; int batch = GPTBars + 50; bool Stop = false; uint ticks = GetTickCount(); ulong size = HistoryBars * BarDescr;
Como siempre, a la hora de entrenar un modelo de trayectoria, nos limitamos únicamente a los enfoques propuestos por los autores del método Latent Variable Sequential Set Transformers. En concreto, centraremos la formación en las desviaciones máximas, como en el método CFPI. Además, para garantizar la estabilidad del modelo en un mercado estocástico, "ampliaremos" el espacio muestral de entrenamiento añadiendo ruido a los datos originales, como se propone en el método SSWNP. Para implementar estas aproximaciones, en variable local declararemos una matriz de cambios de parámetros delta y un vector de errores cuadráticos medios MSE (Mean Square Errors).
Pero volvamos al algoritmo de nuestro método. En la arquitectura de nuestro AutoBot de previsión de trayectorias, utilizamos una capa de incrustación con un búfer incorporado para acumular datos históricos, lo que nos permite no tener que recalcular representaciones de datos que se repiten durante el funcionamiento del modelo. Sin embargo, este planteamiento también exige respetar la coherencia histórica al presentar los datos iniciales durante el proceso de aprendizaje. Por lo tanto, utilizaremos un sistema de bucles anidados para entrenar el modelo. El bucle exterior determina el número de iteraciones de entrenamiento.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
En el cuerpo del bucle, muestreamos la trayectoria desde la memoria intermedia teniendo en cuenta las probabilidades calculadas anteriormente. A continuación, determinamos aleatoriamente el estado inicial del aprendizaje en la trayectoria seleccionada.
También determinamos el estado final del paquete de formación. Limpiemos los búferes de historia de nuestro Autobot. y preparar una matriz para registrar los cambios de parámetros.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear(); delta = matrix<float>::Zeros(end - state - 1, Buffer[tr].States[state].state.Size());
A continuación, creamos un bucle anidado para trabajar con trayectorias limpias, en cuyo cuerpo llenamos el búfer de datos de origen.
for(int i = state; i < end; i++) { inp.Assign(Buffer[tr].States[i].state); State.AssignArray(inp);
Calculamos la desviación de los valores de los parámetros entre 2 estados ambientales posteriores.
if(i < (end - 1)) delta.Row(inp, row); if(row > 0) delta.Row(delta.Row(row - 1) - inp, row - 1);
Tras el trabajo preparatorio, realizamos un pase hacia delante de nuestro modelo.
if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tenga en cuenta que utilizamos un búfer lleno de valores constantes Ones como segundo flujo de datos de origen, tal y como se comentó al describir la arquitectura del modelo. Este búfer se preparó durante la inicialización del EA y no cambia durante todo el entrenamiento del modelo.
El pase de avance va seguido de un pase de retropropagación que actualiza los parámetros del modelo. Pero antes de llamarla, tenemos que preparar los valores de destino. Para ello, "miremos al futuro". Durante el proceso de formación, esta capacidad la proporciona el conjunto de datos de formación. Del búfer de repetición de experiencias, extraemos una descripción de los estados ambientales subsecuentes a una profundidad de planificación dada. Copia los datos necesarios en el vector de valores objetivo target.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Luego, cargamos los resultados del pase feed-forward de AutoBot y determinamos si es necesario realizar un paso de retropropagación en función del tamaño del error de predicción en el estado actual.
Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier;
El paso de retropropagación se realiza si hay un error de predicción en al menos uno de los parámetros por encima del valor umbral, que está relacionado por un coeficiente con el error de predicción cuadrático medio del modelo.
if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
A continuación, informamos al usuario del progreso del proceso de entrenamiento y pasamos a la siguiente iteración procesando el lote de trayectorias limpias.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Una vez completado el lote de entrenamiento de trayectorias limpias, pasamos al segundo bloque: un modelo de trayectoria sobre datos aumentados por ruido. Aquí definimos primero los parámetros de reparametrización del ruido.
//--- With noise vector<float> std_delta = delta.Std(0) * STD_Delta_Multiplier; vector<float> mean_delta = delta.Mean(0);
Y prepara un array y un vector para trabajar con ruido.
ulong inp_total = std_delta.Size(); vector<float> noise = vector<float>::Zeros(inp_total); double ar_noise[];
También muestreamos la trayectoria del conjunto de datos de entrenamiento, determinamos los estados inicial y final del lote de entrenamiento en él y borramos los búferes históricos de nuestro modelo.
tr = SampleTrajectory(probability); state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; } end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear();
A continuación, creamos un segundo bucle anidado.
for(int i = state; i < end; i++) { if(!Math::MathRandomNormal(0, 1, (int)inp_total, ar_noise)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } noise.Assign(ar_noise); noise = mean_delta + std_delta * noise;
En el cuerpo del bucle, generamos ruido y lo reparametrizamos utilizando los parámetros de distribución calculados anteriormente.
Añadimos el ruido resultante a los datos originales y realizamos el pase feed-forward del modelo.
inp.Assign(Buffer[tr].States[i].state); inp = inp + noise; State.AssignArray(inp); //--- if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Copiamos completamente el algoritmo para realizar un pase de retropropagación, incluyendo la preparación de los datos del objetivo y la determinación de la necesidad de los mismos, del bloque de operaciones con una trayectoria limpia.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0); Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Al final, sólo tenemos que informar al usuario sobre el progreso del entrenamiento y pasar a la siguiente iteración de entrenamiento.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter + 0.5) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez completadas todas las iteraciones del sistema de bucle de entrenamiento del modelo, borramos el campo de comentarios del gráfico. Imprime los resultados del entrenamiento en el registro y completa la operación del EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Autobot", Autobot.getRecentAverageError()); ExpertRemove(); //--- }
Hemos terminado de considerar los métodos del Asesor Experto para el modelo de entrenamiento de trayectorias "...\Experts\AutoBots\StudyTraj.mq5". El código completo de este EA se adjunta a continuación. Los archivos adjuntos también incluyen el entrenamiento de la política de 'Actor' "...\Experts\AutoBots\Study.mq5" y la prueba del modelo entrenado utilizando datos históricos "...\Experts\AutoBots\Test.mq5". En estos EAs, sólo hemos considerado ciertos cambios que afectan al funcionamiento del modelo AutoBot. Ahora pasamos a la fase de pruebas.
3. Prueba
Hemos realizado un trabajo bastante extenso para implementar los enfoques del método Latent Variable Sequential Set Transformers (AutoBots) en MQL5. Ahora es el momento de evaluar los resultados. Como en todos los casos anteriores, nuestro modelo se entrena utilizando los datos EURUSD H1 de los 7 primeros meses de 2023. Para probar el modelo entrenado de la política de 'Actor', utilizamos datos históricos de agosto de 2023. Como puede verse, el periodo de prueba sigue inmediatamente al de formación, lo que garantiza la máxima compatibilidad entre los datos de los conjuntos de datos de formación y de prueba.
Los parámetros de todos los indicadores utilizados para analizar la situación del mercado no se optimizaron durante el proceso de formación y prueba. Se utilizaron con parámetros por defecto.
Como habrás observado, la composición y estructura de los datos iniciales y los resultados de nuestro modelo de previsión de trayectorias se han copiado sin cambios del trabajo anterior. Por lo tanto, para entrenar el modelo, podemos utilizar la base de datos de ejemplos creada previamente. Esto nos permite evitar la etapa de recogida primaria de datos de entrenamiento y pasar directamente al proceso de entrenamiento del modelo.
Entrenaremos los modelos en 2 etapas:
- entrenamiento de un modelo de predicción de trayectoria
- entrenar la política del 'Actor'
El modelo de previsión de trayectorias sólo tiene en cuenta la dinámica del mercado y los indicadores analizados, sin hacer referencia al estado de las cuentas ni a las posiciones abiertas, que añaden variedad a las trayectorias de la muestra de entrenamiento. Como hemos recogido todas las trayectorias de un mismo instrumento y durante el mismo periodo histórico, para AutoBot todas las trayectorias son idénticas. Por lo tanto, podemos entrenar el modelo de previsión de movimientos de precios en un único conjunto de datos de entrenamiento sin actualizar las trayectorias hasta obtener resultados aceptables.
El proceso de entrenamiento resultó bastante estable y mostró una buena dinámica de reducción de errores casi constante. Aquí tengo que dar la razón a los autores del método cuando hablan de la velocidad de aprendizaje del modelo. Por ejemplo, los autores del método afirman que, durante su trabajo, todos los modelos fueron entrenados durante 48 horas en un único acelerador gráfico de escritorio 1080 Ti.
Inspirándome en el proceso de entrenamiento de un modelo de previsión de movimientos de precios, pensé que no era del todo correcto evaluar un algoritmo de previsión de trayectorias basándose en el rendimiento de una política 'Actor' entrenada. Aunque la política del 'Actor' se basa en los datos de la previsión recibida, se adapta a posibles errores en las previsiones generadas. La calidad de esa adaptación es otra cuestión, y está relacionada con la arquitectura del 'Actor' y el proceso de su formación. Sin embargo, no cabe duda de que dicha adaptación tiene repercusiones. Por lo tanto, he creado un pequeño EA para el comercio algorítmico clásico "...\Experts\AutoBots\Alternate.mq5".
El EA fue creado sólo para probar la calidad de previsión de los movimientos de precios en el probador de estrategias y su código, en mi opinión, no despierta mucho interés. Por lo tanto, no nos detendremos en ello en este artículo. Puede estudiar su código usted mismo en el archivo adjunto.
Este EA evalúa el movimiento previsto y abre operaciones con un lote mínimo en la dirección de una tendencia pronunciada en el horizonte de planificación. Los parámetros del EA no se han optimizado. Interesante es el resultado obtenido al probar el EA en el probador de estrategias hasta finales de 2023.
Tras entrenar un modelo de previsión de movimientos de precios con datos históricos de 7 meses, obtuvimos una tendencia estable de crecimiento del saldo en 2 meses.

Todas las operaciones se ejecutaron con un lote mínimo. Esto significa que el resultado obtenido depende únicamente de la calidad de la planificación de la trayectoria.
Conclusión
En este artículo nos familiarizamos con el método "Latent Variable Sequential Set Transformers" (AutoBots). Los enfoques propuestos por los autores del método se basan en la modelización de la distribución conjunta de la información contextual y temporal, lo que proporciona herramientas fiables para la previsión exacta (lo más exacta posible) del movimiento futuro de los precios.
AutoBots explota la arquitectura 'Codificador-Decodificador' y demuestra un funcionamiento eficiente mediante el uso de bloques de atención multifuncionales, así como mediante la introducción de una variable latente discreta para modelar distribuciones multimodales.
En la parte práctica del artículo, aplicamos los enfoques propuestos utilizando MQL5 y obtuvimos resultados prometedores en cuanto a la velocidad de aprendizaje del modelo y la calidad de las previsiones.
Así, el algoritmo AutoBots propuesto proporciona una herramienta prometedora para resolver problemas de previsión en el mercado FOREX, proporcionando precisión, robustez al cambio y la capacidad de modelar distribuciones multimodales para una comprensión más profunda de la dinámica de movimiento del mercado.
Referencias
Programas utilizados en este artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de recopilación de ejemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para la recopilación de ejemplos utilizando el método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA de entrenamiento de políticas |
| 4 | StudyTraj.mq5 | Expert Advisor | EA de entrenamiento del modelo de predicción de trayectorias |
| 5 | Test.mq5 | Expert Advisor | EA de prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema |
| 7 | NeuroNet.mqh | Biblioteca de clases | Una biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Código base | Biblioteca de código de programa OpenCL |
| 9 | Alternate.mq5 | Expert Advisor | EA de pruebas de calidad de predicción de trayectoria |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14095
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hay un enlace en la parte inferior de la Historia de cualquier página de la señal
Por alguna razón, todos los elogios son sólo en lenguas extranjeras. Ni una sola en el nuestro.
Es una peculiaridad de la mentalidad burguesa: tienden a alabar todo y cualquier cosa, a menos que sea una paliza evidente.
Entra en cualquier foro en inglés y lo comprobarás por ti mismo.
Parece que el archivo NeuroNet.mqh del adjunto no tiene las nuevas funciones que mencionas en 2.2 Transposición de tensores. ¿Me he perdido algo?
Hola Dmitriy,
Parece que el archivo NeuroNet.mqh del adjunto no tiene las nuevas funciones que mencionas en 2.2 Transposición de tensores. ¿Me he perdido algo?