Características del Wizard MQL5 que debe conocer (Parte 13): DBSCAN para la clase experta de señales
Introducción
Esta serie de artículos sobre el Wizard MQL5 es una introducción a cómo las ideas abstractas en matemáticas u otros campos de la vida pueden cobrar vida como sistemas de trading y ser probadas o validadas antes de realizar cualquier compromiso serio basado en ellas. Esta capacidad de tomar ideas simples y no del todo implementadas o previstas y explorar su potencial como sistemas de trading es una de las joyas que presenta el conjunto de asistentes Wizard MQL5 para asesores expertos. Las clases expertas del asistente proporcionan muchas de las características mundanas requeridas por cualquier asesor experto, especialmente en lo que se refiere a la apertura y cierre de operaciones, pero también en aspectos pasados por alto como la ejecución de decisiones sólo en una nueva formación de barras.
Así pues, al mantener esta librería de procesos como un aspecto independiente de un asesor experto, con Wizard MQL5 cualquier idea no sólo puede probarse de forma independiente, sino que también puede compararse en cierto modo en pie de igualdad con cualquier otra idea (o método) que pudiera estar considerándose. En esta serie, hemos examinado métodos alternativos de agrupamiento, como el agrupamiento aglomerativo y el agrupamiento k-means.
En cada uno de estos enfoques, antes de generar los conglomerados respectivos, uno de los parámetros de entrada requeridos era el número de conglomerados que debían crearse. Esto supone, en esencia, que el usuario conoce bien el conjunto de datos y no está explorando o mirando un conjunto de datos desconocido. Con Density Based Spatial Clustering for Applications with Noise (DBSCAN) el número de clusters a formar es una incógnita «respetada». Esto ofrece más flexibilidad no sólo para explorar conjuntos de datos desconocidos y descubrir sus principales rasgos de clasificación, sino que también puede permitir comprobar los «sesgos» existentes o las opiniones más extendidas sobre cualquier conjunto de datos para saber si el número de conglomerados asumido puede verificarse.
Tomando sólo dos parámetros, a saber, épsilon, que es la distancia espacial máxima entre los puntos de un conglomerado, y el número de puntos mínimos necesarios para constituir un conglomerado, DBSCAN es capaz no sólo de generar conglomerados a partir de los datos muestreados, sino también de determinar el número adecuado de estos conglomerados. Para apreciar sus notables proezas, puede resultar útil examinar algunos agrupamientos que puede realizar frente a enfoques alternativos.
Según este artículo público en Medium, DBSCAN y k-means clustering darían, por su definición, estos resultados de clustering separados.
Para la agrupación k-means tendríamos:

Mientras que DBSCAN daría:

Además de estos, este artículo también comparó DBSCAN con otro enfoque de clustering llamado CLARANS que arrojó los siguientes resultados. Para CLARANS la reclasificación fue:

Sin embargo, DBSCAN con las mismas formas dio la siguiente agrupación:
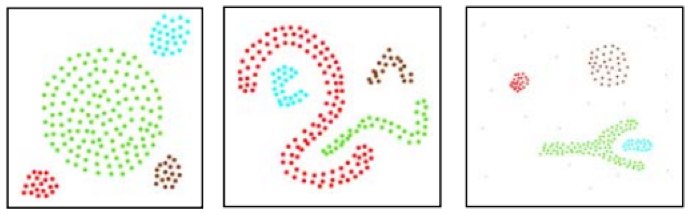
El primer ejemplo puede ser una presentación ficticia, pero el segundo es definitivo. El argumento es que, sin un número preestablecido de conglomerados necesarios para la clasificación, DBSCAN utiliza la densidad o el espaciado medio de los puntos para obtener agrupaciones adecuadas y, por tanto, conglomerados.
Como puede observarse en las imágenes anteriores, k-means se ocupa de la partición territorial, que en este caso se rige por las coordenadas de los ejes `x` e `y`. Así que lo que hace k-means es repartir los puntos dentro de las restricciones de los ejes (en este caso `x` e `y`) como mejor ajuste. DBSCAN introduce una «dimensión» adicional de densidad en la que no basta con abundar en las áreas de los ejes de coordenadas, sino que también se tiene en cuenta la intraproximidad de todos los puntos; el resultado es que los clusters pueden extenderse por regiones más extensas de lo que se consideraría su loci medio o mejor ajuste.
Por lo tanto, en este artículo veremos cómo DBSCAN puede ayudar a refinar las decisiones de compra y venta de la clase de señal experta utilizada en el asistente Wizard MQL5. Ya hemos visto cómo el clustering puede ser informativo en este tipo de decisiones en los dos artículos anteriores sobre los temas enlazados anteriormente, así que vamos a basarnos en ello a la hora de construir clases de señales para DBSCAN.
Para ello, contaremos con 3 ilustraciones de diferentes clases de señales expertas que utilizan DBSCAN de diferentes maneras principalmente a partir del procesamiento de diferentes conjuntos de datos. Por último, como se mencionó al principio estas ideas se presentan aquí para las pruebas preliminares y de selección y no son nada cerca de lo que debe ser utilizado en cuentas reales. Siempre se espera una diligencia independiente por parte del lector.
Desmitificando DBSCAN
Para «desmitificar» DBSCAN, puede ser una buena idea proporcionar algunas ilustraciones, fuera del comercio, que estamos obligados a encontrar en el día a día. Veamos 3 ejemplos.
Ejemplo 1: Imagine una situación en la que usted es propietario de un supermercado y tiene que analizar un conjunto de datos sobre algunos compradores e intentar ver si hay algún patrón que se pueda extraer y utilizar en el futuro con fines de planificación. Este análisis puede adoptar varias formas, pero en nuestro caso nos centraremos principalmente en la agrupación. Con k-means, habría que empezar por presuponer un número fijo de tipos de clientes, por ejemplo, consumidores discrecionales, que sólo compran bienes de consumo o electrónicos de gran valor y sólo cuando hay rebajas, y consumidores habituales, a los que se ve a menudo en la tienda comprando alimentos una vez a la semana. Con esta dosificación establecida, usted procedería a desglosar lo que compran y a planificar adecuadamente sus inventarios para poder hacer frente a su demanda en el futuro. Ahora bien, como ha preestablecido sus grupos (tipos de clientes) en 2, está obligado a tener 2 desembolsos de gastos importantes (posicionados en el tiempo como centroides medios) para reponer su inventario, y esto puede no ser tan favorable para la tesorería como le gustaría, ya que más gastos, pero de menor tamaño, podrían ser más manejables. Si, por el contrario, hubiera utilizado DBSCAN para la segmentación de sus clientes, el número de tipos de clientes que obtendría vendría determinado por su densidad o por la proximidad en el tiempo a la que estos clientes suelen realizar sus compras. Antes hemos utilizado la analogía de los ejes `x` e `y` para cuantificar el épsilon (proximidad de los puntos de datos), pero para el caso del tiempo con los clientes del supermercado bastaría un calendario en el que la «proximidad» de los clientes se cuantificaría por la distancia temporal entre sus compras y una fecha del calendario. Esto permite agrupar a los clientes de forma más flexible, lo que a su vez podría dar lugar a gastos más manejables a la hora de reponer existencias, entre otras ventajas.
Ejemplo 2: Considere una situación en la que, como planificador urbanístico de una ciudad, se le encarga reevaluar el número máximo de residencias que debería permitirse en cada distrito de la ciudad a partir del estudio de los patrones de tráfico urbano. Mientras que en el ejemplo 1 utilizamos el tiempo como dominio espacial para la agrupación, en este ejemplo nos limitamos a las rutas físicas que atraviesan la ciudad y quizá conectan los distritos. La agrupación de k-means comenzaría utilizando el número existente de distritos como agrupaciones y, a continuación, determinaría la ponderación o el umbral de población de cada distrito basándose en la cantidad media de tráfico matutino y vespertino en sus rutas de conexión. Con la nueva proporción de ponderación, cada municipio vería reducido o aumentado proporcionalmente su límite residencial. Sin embargo, los distritos no son inamovibles. Algunos pueden estar muriendo, otros prosperando y, lo que es más importante, algunos pueden estar emergiendo, por lo que utilizando DBSCAN sólo con las rutas de tráfico y sin suposiciones sobre el número de distritos, podemos agrupar las rutas en diferentes formas de conglomerados que, a su vez, mapearían nuestros nuevos distritos. En este caso, nuestro épsilon registraría el número de coches que circulan por cada ruta (en las horas punta de la mañana y de la tarde), por ejemplo, por kilómetro. Esto podría implicar que las rutas más densas se agrupasen más que las menos densas, lo que crea problemas en los casos en que las rutas conducen a zonas geográficas diferentes. La forma de resolver este problema o de entender los datos sería que esas rutas, aunque correspondan a zonas físicas diferentes, representan el mismo «tipo de municipio» (podría deberse al nivel de renta, etc.) y, por tanto, a efectos de planificación, se pueden prever de forma similar.
Ejemplo 3: Por último, las redes sociales son una mina de datos de oro para muchas empresas y la clave para entenderlas mejor podría estar en la capacidad de clasificar o en nuestro caso clusterizar a los usuarios en grupos dispares. Ahora bien, como los usuarios de las redes sociales forman sus propios grupos por ocio o trabajo, pueden tener intereses comunes o no, e incluso pueden interactuar esporádicamente, es una tarea hercúlea para k-means dar con un número aceptable de conglomerados de buenas a primeras al iniciar el proceso de agrupación. Por otro lado, DBSCAN, al centrarse en la densidad, puede centrarse en el número de interacciones de los usuarios, por ejemplo, mediante la enumeración en un periodo de tiempo determinado. Así, este número de interacciones de un usuario con otro puede guiar al parámetro épsilon en la formación y definición de los distintos clusters que podrían ser posibles en una determinada plataforma de medios sociales.
Además de los puntos planteados en estos ejemplos, también merece la pena señalar que DBSCAN es más hábil a la hora de manejar el ruido e identificar valores atípicos, especialmente en situaciones de aprendizaje no supervisado como es el caso de DBSCAN. El parámetro de entrada número mínimo de puntos también es importante a la hora de llegar al número ideal de conglomerados para un conjunto de datos muestreados, sin embargo, no es tan sensible (o importante) como épsilon porque su función en esencia es establecer el umbral de «ruido». Con DBSCAN, cualquier dato que no entre en los clusters designados es ruido.
Implementación en MQL5
Por lo tanto, la estructura básica del asistente Wizard MQL5 montado asesores expertos ya se ha cubierto en artículos anteriores. El manual oficial al respecto puede encontrarse aquí. Sin embargo, para recapitular los asesores expertos ensamblados dependen de la clase experta definida en el archivo '<include\Expert\Expert.mqh>'. Esta clase de experto define principalmente cómo se gestionan las funciones típicas del asesor experto relacionadas con la apertura y el cierre de posiciones. Este, a su vez, depende de la clase base de expertos que está definida en el archivo ‘<include\Expert\ExpertBase.mqh>’, y este último archivo maneja la recuperación y el almacenamiento en búfer de la información de precios actuales para el símbolo al que está adjunto el asesor experto. Desde la clase de expertos, que podemos considerar como el ancla, se derivan por herencia otras 3 clases, a saber: la clase de señales de expertos, la clase de trailing de expertos y la clase de gestión de dinero de expertos. Las implementaciones personalizadas de cada una de estas clases ya se han compartido en artículos anteriores. No obstante, es importante reiterar que la clase de señales se encarga de las decisiones de compra y venta, la clase de trailing determina cuándo y en qué medida ajustar el stop de arrastre en las posiciones abiertas, y finalmente, la clase de gestión de dinero define qué proporción del margen disponible se puede utilizar para el dimensionamiento de las posiciones.
Los pasos para montar un asesor experto a partir de las clases disponibles en la librería son realmente sencillos y existen artículos aquí además del enlace compartido arriba sobre cómo hacerlo. La preparación de los datos es gestionada por la clase base de expertos; sin embargo, para que esto sea confiable, las pruebas deberían realizarse idealmente con los datos de precios de su corredor previsto, y se deben descargar los ticks reales de su servidor en la mayor medida posible.
Al codificar la función DBSCAN este documento público comparte algunos códigos fuente útiles en los que nos basamos para definir nuestras funciones. Si comenzamos con la más básica de estas, hay un total de 4 funciones simples; nos centraríamos en la función de distancia.
//+------------------------------------------------------------------+ //| Function for Euclidean Distance between points | //+------------------------------------------------------------------+ double CSignalDBSCAN::Distance(Spoint &A, Spoint &B) { double _d = 0.0; for(int i = 0; i < int(fmin(A.key.Size(), B.key.Size())); i++) { _d += pow(A.key[i] - B.key[i], 2.0); } _d = sqrt(_d); return(_d); }
El artículo citado y la mayoría del código fuente público sobre DBSCAN utilizan la distancia euclidiana como la métrica principal para cuantificar la distancia entre puntos en cualquier conjunto de puntos. Sin embargo, dado que nuestros puntos están en forma de vector, MQL5 ofrece varias alternativas para medir esta distancia entre puntos, como la similitud del coseno, entre otras. El lector podría explorar estas opciones, ya que son sub-funciones del tipo de datos vectorial. Codificamos la función euclídea desde cero ya que no he sido capaz de encontrarla en las funciones Pérdida o Regresión métrica.
Lo siguiente entre los bloques de construcción que necesitamos es una función 'RegionQuery'. Devuelve una lista de puntos dentro del umbral definido por el parámetro de entrada epsilon que pueden considerarse dentro del mismo cluster que el punto en cuestión.
//+------------------------------------------------------------------+ //| Function that returns neighbouring points for an input point &P[]| //+------------------------------------------------------------------+ void CSignalDBSCAN::RegionQuery(Spoint &P[], int Index, CArrayInt &Neighbours) { Neighbours.Resize(0); int _size = ArraySize(P); for(int i = 0; i < _size; i++) { if(i == Index) { continue; } else if(Distance(P[i], P[Index]) <= m_epsilon) { Neighbours.Resize(Neighbours.Total() + 1); Neighbours.Add(i); } } P[Index].visited = true; }
Normalmente, para cada punto dentro de un conjunto de datos en consideración, tratamos de llegar a una lista de puntos, para que nada se pase por alto, y esta lista es útil para la siguiente función que es la función 'ExpandCluster'.
//+------------------------------------------------------------------+ //| Function that extends cluster for identified cluster IDs | //+------------------------------------------------------------------+ bool CSignalDBSCAN::ExpandCluster(Spoint &SetOfPoints[], int Index, int ClusterID) { CArrayInt _seeds; RegionQuery(SetOfPoints, Index, _seeds); if(_seeds.Total() < m_min_points) // no core point { SetOfPoints[Index].cluster_id = -1; return(false); } else { SetOfPoints[Index].cluster_id = ClusterID; for(int ii = 0; ii < _seeds.Total(); ii++) { int _current_p = _seeds[ii]; CArrayInt _result; RegionQuery(SetOfPoints, _current_p, _result); if(_result.Total() > m_min_points) { for(int i = 0; i < _result.Total(); i++) { int _result_p = _result[i]; if(SetOfPoints[_result_p].cluster_id == -1) { SetOfPoints[_result_p].cluster_id = ClusterID; } } } } } return(true); }
Esta función, que toma un ID de clúster y un índice de punto, determina si el ID de clúster necesita ser asignado a nuevos puntos en función de los resultados de la función de consulta de región mencionada anteriormente. Si el resultado es verdadero, el clúster aumenta de tamaño; en caso contrario, se mantiene. En esta función se comprueban los puntos ya agrupados para evitar repeticiones y, como se ha indicado anteriormente, los puntos no agrupados (que mantienen el ID de agrupación: -1) se consideran ruido.
La función principal de DBSCAN, que recorre todos los puntos de un conjunto de datos para determinar si es necesario ampliar el ID del clúster actual, se encarga de reunir todos estos datos. El ID del cluster actual es un número entero que se incrementa cada vez que se establece un nuevo cluster y en cada incremento se consulta la vecindad de todos los puntos pertenecientes a este cluster a través de la función de consulta de región como ya se ha mencionado y esto se llama a través de la función expandir cluster. A continuación figura el listado correspondiente:
//+------------------------------------------------------------------+ //| Main clustering function | //+------------------------------------------------------------------+ void CSignalDBSCAN::DBSCAN(Spoint &SetOfPoints[]) { int _cluster_id = -1; int _size = ArraySize(SetOfPoints); for(int i = 0; i < _size; i++) { if(SetOfPoints[i].cluster_id == -1) { if(ExpandCluster(SetOfPoints, i, _cluster_id)) { _cluster_id++; SetOfPoints[i].cluster_id = _cluster_id; } } } }
Del mismo modo, la estructura que maneja el conjunto de datos denominado «SetOfPoints» en el listado anterior, se define en la cabecera de la clase del siguiente modo:
struct Spoint { vector key; bool visited; int cluster_id; Spoint() { key.Resize(0); visited = false; cluster_id = -1; }; ~Spoint() {}; };
DBSCAN como método de clustering se enfrenta a retos de memoria dependiendo del tamaño del conjunto de datos. Además, existe una corriente de pensamiento que considera que épsilon, el parámetro de entrada clave que mide la densidad de los conglomerados, no debería ser uniforme para todos los conglomerados. En la implementación que estamos utilizando para este artículo, este es el caso; sin embargo, existen variantes de DBSCAN, como HDBSCAN, que podríamos cubrir en futuros artículos. Estas variantes ni siquiera requieren epsilon como parámetro de entrada, sino que solo dependen del número mínimo de puntos en un clúster, un parámetro menos crítico y sensible, lo que hace que sea un enfoque más versátil para el agrupamiento.
Clases de señales
Si nos basamos en lo que hemos definido anteriormente en la aplicación podemos presentar una serie de enfoques diferentes en la agrupación de datos de precios de valores para generar señales de comercio. Así pues, los tres enfoques de ejemplo prometidos al principio del artículo serán agrupaciones:
- Datos brutos de la barra de precios OHLC.
- Cambios en los datos del indicador RSI.
- Cambios en el indicador Moving Average Price.
En artículos anteriores sobre agrupación teníamos un modelo rudimentario en el que etiquetábamos póstumamente valores agrupados con cambios eventuales en el precio y utilizábamos medias ponderadas actuales de estos cambios para hacer nuestra siguiente previsión. Adoptaremos un enfoque similar, pero la principal diferencia entre cada método será principalmente el conjunto de datos introducido en nuestra función DBSCAN. Dado que estos conjuntos de datos varían, los parámetros de entrada para cada clase de señal también pueden ser diferentes.
Si partimos de los datos brutos de OHLC, nuestro conjunto de datos estará constituido por 4 puntos clave. Así, el vector que definimos como 'key' en la estructura 'Spoint' que contiene nuestros datos tendrá un tamaño de 4. Estos 4 puntos serán los cambios respectivos en los precios de apertura, máximo, mínimo y cierre. Así pues, rellenamos una estructura «Spoint» con la información sobre el precio actual de la siguiente manera:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CSignalDBSCAN::GetOutput() { double _output = 0.0; ... ... for(int i = 0; i < m_set_size; i++) { for(int ii = 0; ii < m_key_size; ii++) { if(ii == 0) { m_model.x[i].key[ii] = (m_open.GetData(StartIndex() + i) - m_open.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } else if(ii == 1) { m_model.x[i].key[ii] = (m_high.GetData(StartIndex() + i) - m_high.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } else if(ii == 2) { m_model.x[i].key[ii] = (m_low.GetData(StartIndex() + i) - m_low.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } else if(ii == 3) { m_model.x[i].key[ii] = (m_close.GetData(StartIndex() + i) - m_close.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } } if(i > 0) //assign classifier only for data points for which eventual bar range is known { m_model.y[i - 1] = (m_close.GetData(StartIndex() + i - 1) - m_close.GetData(StartIndex() + i)) / m_symbol.Point(); } } ... return(_output); }
Si ensamblamos esta señal a través del asistente y realizamos pruebas en EURUSD para el año 2023 en el marco temporal diario, nuestra mejor ejecución nos da el siguiente informe y curva de renta variable.


A partir de los informes se podría decir que hay potencial, sin embargo, en este caso no hemos hecho una prueba de avance como habíamos intentado a pequeña escala en artículos anteriores, por lo que se invita al lector a hacerla antes de seguir adelante.
Siguiendo con los valores absolutos del RSI como conjunto de datos, implementaríamos esto de manera similar con la principal diferencia de cómo estamos contabilizando los 3 diferentes periodos de retardo a los que tomamos las lecturas del RSI. Así, con este conjunto de datos estamos obteniendo 4 puntos de datos por tiempo como con los precios OHLC en bruto, pero estos puntos de datos son valores del indicador RSI. Los retardos a los que se toman se establecen mediante 3 parámetros de entrada que hemos etiquetado como A, B y C. El conjunto de datos se rellena del siguiente modo:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CSignalDBSCAN::GetOutput() { double _output = 0.0; ... RSI.Refresh(-1); for(int i = 0; i < m_set_size; i++) { for(int ii = 0; ii < m_key_size; ii++) { if(ii == 0) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i); } else if(ii == 1) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i + m_lag_a); } else if(ii == 2) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i + m_lag_a + m_lag_b); } else if(ii == 3) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i + m_lag_a + m_lag_b + m_lag_c); } } if(i > 0) //assign classifier only for data points for which eventual bar range is known { m_model.y[i - 1] = (m_close.GetData(StartIndex() + i - 1) - m_close.GetData(StartIndex() + i)) / m_symbol.Point(); } } int _o[]; ... ... return(_output); }
Así, cuando realizamos pruebas para el mismo símbolo durante el mismo periodo 2023 en el marco temporal diario obtenemos los siguientes resultados de nuestra mejor ejecución:


Un informe prometedor pero, una vez más, no concluyente a la espera de la propia diligencia. Todos los expertos reunidos para este artículo realizan sus operaciones mediante órdenes limitadas y no utilizan precios Take Profit o Stop Loss para cerrar posiciones. Esto implica que las posiciones se mantienen hasta que se invierte una señal y entonces se abre una nueva posición a la inversa.
Por último, con los cambios en la media móvil rellenaríamos un conjunto de datos casi como hicimos con el RSI, con la diferencia principal de que aquí buscamos cambios en las lecturas del indicador MA, mientras que con el RSI nos interesaban los valores absolutos. Otra diferencia importante serían los valores clave, el tamaño del vector 'key' dentro de la estructura 'Spoint' es sólo 3 y no 4 ya que nos estamos centrando en cambios de lag y no en lecturas absolutas.
La ejecución de las pruebas arroja el siguiente informe para su mejor ejecución.


Conclusión
En conclusión, DBSCAN es una forma no supervisada de clasificar datos que requiere unos parámetros de entrada mínimos, a diferencia de otros enfoques más convencionales como k-means. Requiere sólo dos parámetros, de los cuales sólo uno, épsilon, es crítico, lo que conduce a una excesiva dependencia o sensibilidad hacia esta entrada.
A pesar de esta dependencia excesiva de épsilon, el hecho de que para cualquier clasificación el número de conglomerados se determine orgánicamente hace que sea bastante versátil en varios conjuntos de datos y más capaz de manejar el ruido.
Cuando se utiliza dentro de una instancia personalizada de la clase de señal experta, se puede utilizar una amplia variedad de conjuntos de datos de entrada, desde precios brutos hasta valores indicadores, como base para clasificar un valor.
Además de crear una instancia personalizada de la clase de señal experta, el lector puede crear implementaciones personalizadas similares de la clase `Trailing` o de la clase `Money` que también utilizan DBSCAN, tal y como hemos tratado en artículos anteriores de esta serie.
Otra vía que merece la pena estudiar y para la que creo que DBSCAN y el clustering en general están preparados es la normalización de datos. Muchos modelos de previsión suelen requerir una forma de normalización de los datos de entrada antes de poder utilizarlos en la previsión. Por ejemplo, un algoritmo Random Forest o una red neuronal necesitarían datos normalizados, sobre todo si se trata de precios de valores. En los grandes modelos lingüísticos, ahora en boga, que utilizan la arquitectura de transformadores, el paso equivalente es la incrustación, en la que todo el texto, incluido el numérico, se reasigna a un número con el fin de procesarlo mediante una red neuronal. Sin esta normalización de textos y números sería imposible que la red procesara de forma viable las ingentes cantidades de datos que utiliza para desarrollar algoritmos de IA. Pero además, esta normalización se ocupa de los valores atípicos, que pueden ser un quebradero de cabeza cuando se intenta entrenar una red y dar con pesos y sesgos aceptables. Podría haber otros usos pertinentes del clustering y DBSCAN, pero estos son mis dos centavos. Feliz cacería.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/14489
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso