Asesor Experto Grid-Hedge Modificado en MQL5 (Parte III): Optimización de una estrategia de cobertura simple (I)

Introducción
Bienvenido a la tercera parte de la serie de artículos sobre asesores expertos de cobertura. Empezaremos con un breve resumen de los avances de nuestro programa hasta la fecha. Hasta ahora, hemos desarrollado dos componentes clave: el Simple Hedge EA y el Simple Grid EA. En este artículo nos centraremos en la mejora del asesor experto Simple Hedge. Como objetivo, intentaremos mejorar su rendimiento combinando el análisis matemático y la fuerza bruta para encontrar la forma más eficaz de aplicar esta estrategia comercial.
En primer lugar, hablaremos de la optimización matemática de la estrategia de cobertura simple. Visto que el análisis necesario resulta complejo y profundo, no resultaría razonable describir en un solo artículo tanto la optimización matemática como la posterior optimización basada en código. Por lo tanto, dedicaremos este artículo a los aspectos matemáticos para explorar al máximo la teoría y los cálculos subyacentes al proceso de optimización. En posteriores artículos de esta serie abordaremos la optimización del código, aplicando técnicas prácticas de programación a los fundamentos teóricos aquí expuestos.
En el presente artículo, hablaremos de lo siguiente:
Profundizando en la optimización: un debate más detallado
¿Qué nos viene a la mente cuando decimos la palabra "optimización"? Es un término tan amplio como complejo. Pero, ¿qué es la optimización?
Vamos a aclarar la cuestión. En esencia, la optimización se refiere a la acción, el proceso o la metodología de perfeccionar algo -ya sea un diseño, un sistema o una solución- hasta alcanzar el máximo nivel de excelencia, funcionalidad o eficiencia. Pero admitámoslo: la idea de alcanzar la perfección absoluta no resulta del todo realista. ¿Cuál sería el verdadero objetivo? Superar los límites de lo posible con los recursos disponibles y esforzarnos por obtener el mejor resultado posible.
El campo de la optimización es muy amplio, por lo que disponemos de muchos métodos. En el contexto de nuestra discusión, nos centraremos en la "estrategia de cobertura clásica". Entre las numerosas técnicas de optimización, serán dos los enfoques que supondrán la piedra angular de nuestro estudio:
-
La optimización matemática: este enfoque aprovechará toda la potencia de las matemáticas. Imagine poder crear funciones de beneficio, funciones de reducción, etc., y utilizar estas para ajustar su estrategia basándose en datos fiables y cuantificables. Se trata de un método que no solo mejorará la precisión del esfuerzo de optimización, sino que también ofrecerá una vía matemática clara para mejorar la eficacia de la estrategia.
-
El método de la "fuerza bruta" : el método de la fuerza bruta es sencillo pero impresionante por su alcance. Este método consiste en probar todas las combinaciones imaginables de datos de entrada para encontrar la mejor configuración posible. ¿Cuál es el objetivo último de dicho planteamiento? Maximizar los beneficios o minimizar las reducciones, en función de las prioridades estratégicas. Pero también debemos considerar una complicación obvia: el enorme número de combinaciones de entrada. Esta complejidad hace que probar todos los escenarios posibles en la historia sea una tarea inasumible, especialmente con recursos y tiempo limitados.
Lo que sí nos puede beneficiar es la combinación de ambos enfoques. Aplicando primero la optimización matemática, podemos reducir sustancialmente el número de pasadas para la búsqueda bruta. Es una maniobra estratégica que nos permitirá centrarnos en las configuraciones más prometedoras, y hará que el proceso de fuerza bruta resulte mucho más manejable y económico.
En esencia, una ruta de optimización supone el equilibrio entre la precisión teórica y la viabilidad práctica. Partiendo de la optimización matemática, podremos filtrar muchas opciones, mientras que la fuerza bruta nos permitirá probar a fondo y perfeccionar las opciones restantes. Juntos, ambos métodos forman un poderoso dúo para optimizar eficazmente nuestra estrategia de cobertura clásica.
Optimización matemática
Al comenzar con la optimización matemática, el primer paso será crear una estructura clara y procesable. Y esto significará identificar las variables que afectan al resultado, en este caso, el beneficio. Vamos a analizar ahora los componentes que desempeñan un papel crucial en la configuración de la función de beneficio:
- Initial Position (IP) — posición inicial, es una variable binaria: 1 significa comprar, 0 significa vender. La selección inicial sentará las bases de la orientación de la estrategia comercial.
- Initial Lot Size (IL) — tamaño del lote inicial; tamaño de la primera orden en el ciclo comercial que sentará las bases para escalar las operaciones.
- Buy Take Profit (BTP) — take profit para las órdenes de compra; es un umbral predeterminado para el cierre de posiciones y la fijación de beneficios.
- Sell Take Profit (STP) — take profit similar para operaciones de venta; es un umbral predeterminado para cerrar posiciones de venta y fijar los beneficios.
- Buy-Sell Distance (D) — es un parámetro espacial que define el intervalo entre los niveles de las órdenes de compra y venta, afectando a los puntos de entrada de las operaciones.
- Lot Size Multiplier (M) — el multiplicador del tamaño del lote aumenta el tamaño del lote para las órdenes posteriores, introduciendo un ajuste dinámico según transcurra el ciclo comercial.
- Number of Orders (N) — número total de órdenes del ciclo; refleja la amplitud de la estrategia comercial.
Para mayor claridad, estos parámetros se presentarán de forma simplificada, pero en las ecuaciones algunas de estas variables se denotarán mediante índices.
Tomando estos parámetros como base, podremos proceder a formular la función de beneficio. La esencia de esta función consistirá en representar matemáticamente cómo un cambio en estas variables afecta a nuestro beneficio (o pérdidas). La función de beneficio es la piedra angular de nuestro proceso de optimización, ya que nos permitirá analizar cuantitativamente el rendimiento de las distintas estrategias comerciales en diferentes escenarios.
Vamos a escribir los parámetros de nuestra función de beneficio:
![]()
Así, la función de beneficio final tendrá el siguiente aspecto:
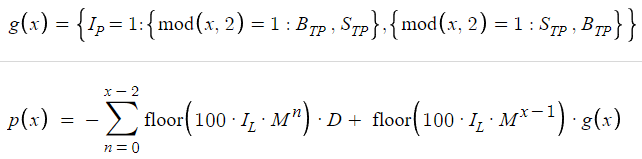
A primera vista, la función de beneficio puede parecer complicada debido a sus expresiones matemáticas y símbolos. Sin embargo, no debemos sentirnos intimidados. Cada componente de la ecuación desempeña un papel en la comprensión de cómo se generarán los beneficios dentro de nuestro sistema comercial.
También tenemos que entender la dinámica del cálculo de los beneficios. Aquí resulta fundamental la distinción entre la función de beneficio básica, denominada p(x), y su componente g(x), donde x representa el número total de órdenes o posiciones. Esta distinción es muy importante, porque nos permite entender cómo se generan los beneficios cuando el ciclo comercial termina en x posiciones. Vamos a desglosar este concepto para comprender plenamente su esencia.
Supongamos que hemos decidido cerrar el ciclo comercial con una sola orden. En este caso, tendremos este escenario:
![]()
Aquí, g(x) tomará un valor basado en la interacción entre el número de órdenes (N) y la posición inicial (PI). Por ejemplo, si establecemos el tamaño de lote inicial (IL) en 0,01 y (para facilitar la explicación) N en 1, y establecemos la posición inicial (IP) en comprar (IP = 1), entonces g(x) tomará el valor de Buy Take Profit (BTP). Como resultado, nuestra función de beneficio p(x) se convertirá en 100 multiplicado por 0,01 multiplicado por BTP = BTP, lo que simbólicamente indica que nuestro beneficio será igual a BTP. Tenga en cuenta que estamos calculando el beneficio en pips, no en divisa. Hemos elegido este enfoque deliberadamente para generalizar el cálculo de los beneficios para distintas divisas, garantizar la aplicabilidad independientemente del tipo de cuenta (micro o estándar) y simplificar el cálculo global. Aquí multiplicaremos el tamaño del lote por 100 para convertir el tamaño del lote en un valor de pip exacto, lo que nos permitirá calcular con precisión el beneficio.
Consideraremos ahora el caso en el que N aumenta a 2, es decir, introduciremos un nuevo nivel de complejidad:
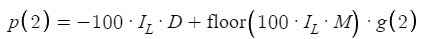
Este pequeño ajuste complicará el cálculo de los beneficios y exigirá un análisis más profundo de las causas subyacentes, que se ilustran mejor con ejemplos. El componente crítico aquí será la introducción de la función "floor", una operación matemática parecida a lo que conocemos como función de mayor número entero (GIF). La función Floor tiene un propósito específico: dado cualquier valor numérico, truncará el componente decimal hasta el mayor número entero precedente. Para valores positivos, esta operación es sencilla: Floor(1,54) = 1, Floor(4,52) = 4, etc. Este mecanismo formará parte integrante de la función de beneficio. Así, se garantizará que en los cálculos solo se tengan en cuenta valores enteros. Esta simplificación nos permitirá centrarnos en los valores positivos y evitar tener que considerar los valores negativos en este contexto.
El segmento inicial de la fórmula comenzará calculando el nivel mínimo como -100 veces el Impact Level (IL), lo cual ilustra el caso en el que el IL es 0,01. El resultado será un cálculo de -100 multiplicado por 0,01, lo cual equivaldrá a -1. Al integrarse con la distancia (D), la ecuación representará una pérdida de D pips por cada operación que no dé beneficios. El siguiente paso consistirá en añadir el límite inferior multiplicado por 100 veces IL multiplicado por un multiplicador (M) a la función g(x), que representará el valor del take profit (TP) para una orden de compra o de venta. El producto de IL y M determinará el tamaño del lote para la siguiente (segunda) orden, mientras que la multiplicación de este producto por 100 facilitará el cálculo exacto de los pips.
Aquí se nos plantea una cuestión clave en relación con la necesidad de utilizar la función Floor en nuestra ecuación. Para explicarlo, consideraremos un ejemplo en el que IL será 0,01 y M será 2, lo cual dará como resultado IL por 100 veces M, que será igual a 2. En este caso, aplicando la función Floor a 2 obtendremos 2, lo que parece hacer que la función sea redundante. Sin embargo, la utilidad de la función Floor se hará evidente en otro escenario: si IL se mantiene en 0,01 y M se fija en 1,5, el producto de 100 por IL por M será igual a 1,5. El tamaño de lote resultante de 0,015 es inaceptable porque los brókeres exigen que los tamaños de lote sean múltiplos de 0,01. Según la estrategia, el tamaño de la orden se fijará en 0,01 y los tamaños de lote posteriores aumentarán de forma controlada para garantizar que funcionen dentro de los requisitos del bróker. Por ejemplo, el siguiente tamaño de lote calculado como 0,01×1,5×1,5 será 0,0225, que en realidad se redondeará a 0,02 a efectos prácticos. Así, la función Floor se utilizará para ajustar la ecuación según la realidad operativa y obtener tamaños de lote procesables: 0,01 y luego 0,02. De este modo, se garantizará que el modelo cumpla las limitaciones prácticas del comercio. Queda claro que deberemos utilizar la función Floor para calcular los lotes. Por último, el valor ajustado se multiplicará por g(x), que se corresponderá con el TP de compra o el TP de venta, lo cual introducirá aún más los parámetros de la estrategia comercial en la fórmula de la ecuación. Espero que esto sea una justificación suficiente para cada componente de la ecuación, describiendo las consideraciones estratégicas para su construcción.
Ahora supongamos que N es igual a 3, entonces obtendremos un beneficio:
![]()
Cuando N es 3, la fórmula ilustrará una situación en la que se obtienen beneficios en determinadas condiciones, lo cual da lugar a un enfoque estructurado para calcular los resultados en función del número de órdenes denotado por N. El primer segmento representará las pérdidas en la primera orden. El segundo segmento adaptará el planteamiento sustituyendo g(x) por D, lo que también reflejará la pérdida de la segunda orden. La diferencia en el tercer segmento se debe a la introducción de M^2, que indicará un aumento exponencial del multiplicador dado el contexto.
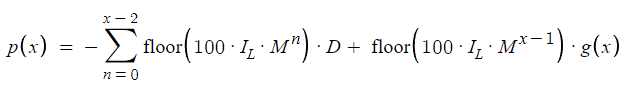
Como ampliación del marco para distintos valores de N, se presenta una ecuación generalizada que captará exhaustivamente la dinámica de esta estrategia comercial. Esta ecuación, adaptable a distintos casos de N, servirá de modelo básico para comprender el progreso y los posibles resultados a medida que aumente el número de órdenes.
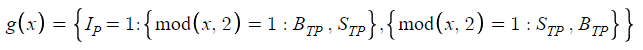
La determinación de g(x), que alterna entre buy take profit (BTP) y sell take profit (STP), dependerá de la posición inicial (IP) y de la paridad de N. Este proceso de decisión binario se presenta en una estructura condicional en la que tanto IP como la característica numérica de N, es decir, su paridad o imparidad, influirán en el resultado. Este mecanismo posibilitará la asignación lógica de los valores de g(x) según la posición en el mercado y la secuencia de órdenes.

El uso de la herramienta gráfica Desmos facilitará la comprensión de esta ecuación y permitirá ajustar los parámetros en tiempo real gracias a la información inmediata sobre los cambios. La capacidad de esta herramienta para mostrar resultados enteros resultará especialmente valiosa en contextos prácticos en los que el número de órdenes es intrínsecamente una variable discreta.
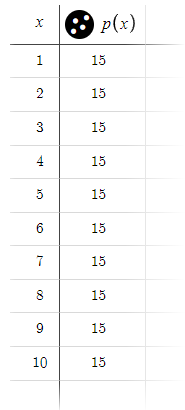
La demostración de Desmos con parámetros predefinidos mostrará el comportamiento del modelo en condiciones estándar. Asimismo, demostrará que podemos esperar un beneficio estable de 15 pips en un rango de hasta 10 órdenes.
Nota: para simplificar, por ahora hemos ignorado los spreads.
A la vista de los resultados, puede que le tiente invertir en esta estrategia, no obstante, quiero advertirle de que no tome decisiones precipitadas. Aún quedan muchas cuestiones por resolver antes de seguir adelante. Para comprender mejor la situación, sería útil introducir una columna adicional en nuestra tabla, pero antes, deberemos formular y escribir la ecuación que constituirá la base de esta nueva columna. Este paso preparatorio resulta esencial para analizar los datos y permite comprender mejor el propio proceso de toma de decisiones.
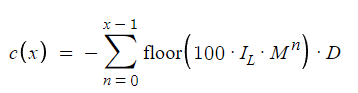
La ecuación ilustra la reducción máxima posible. Si el ciclo finaliza en la orden 10, la reducción máxima será igual a una cantidad muy próxima a la pérdida si la orden 10 ha sido una orden perdedora. Esto se muestra en la ecuación cuando n varía de 0 a x-1, mientras que antes n variaba entre 0 y x-2 para las pérdidas antes que el beneficio.
La ecuación presentada determinará la reducción máxima potencial, mostrando así los riesgos de esta estrategia. Por ejemplo, supongamos que el ciclo termina en la orden 10. En este contexto, la reducción máxima puede considerarse como una cantidad que se aproximará a las posibles pérdidas si la orden 10 hubiera dado lugar a pérdidas. El cálculo de la reducción se incluirá en la ecuación usando una variable n con valores de 0 a x-1. En esta sección se especificará el intervalo utilizado para calcular la reducción. Esto supondrá un cambio con respecto al método anterior de cálculo de las pérdidas, que implicaba recorrer un intervalo n de 0 a x-2 seguido de beneficio. Este ajuste de los parámetros ofrecerá una representación más precisa del perfil de riesgo de una estrategia, ya que de este modo tendremos en cuenta las pérdidas máximas posibles antes de que se materialice el beneficio potencial.
Para determinar la reducción máxima posible utilizando los parámetros de entrada por defecto, vamos a observar cómo se ajustan los valores de la nueva variable con los cambios en x. Este paso nos permitirá comprender el impacto directo del cambio de x en una reducción potencial, para entender el riesgo asociado a diferentes escenarios dentro de nuestra estrategia.
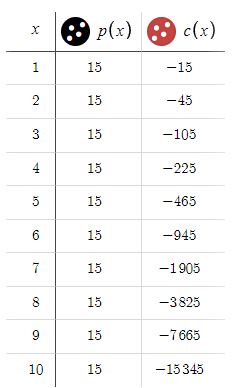
Como terminaremos el ciclo con beneficio en la orden 10, esperaremos una reducción máxima de 15.345 $. Esta cifra es bastante considerable, sobre todo si la comparamos con la relativamente modesta recompensa de 15 dólares. Dada esta dinámica, aumentaremos los parámetros BTP y STP de 15 pips a 50 pips.
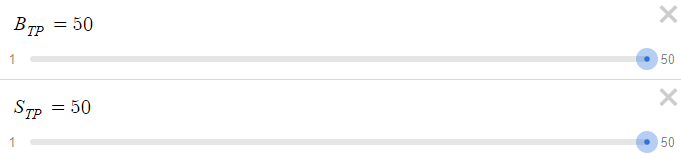
Ahora veamos el resultado:
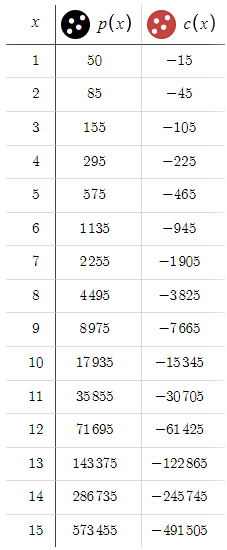
Aquí se observa una desviación significativa respecto al escenario anterior, en el que las pérdidas crecían exponencialmente. Ahora estamos en una posición en la que obtendremos rendimientos de forma sistemática, con una relación riesgo/beneficio muy favorable. Ante unos resultados tan alentadores, cabe preguntarse por qué limitarse a un objetivo de 50 puntos. Vamos a considerar la posibilidad de ampliar nuestro objetivo a 100 puntos.
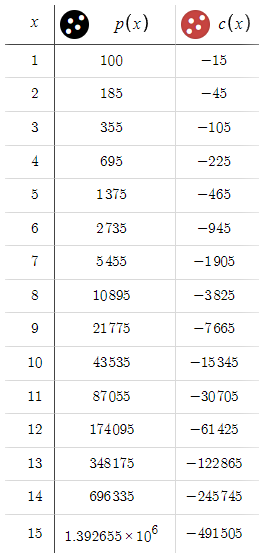
Obsérvese que los valores de c(x) permanecen constantes, mientras que p(x) aumentará para todos los valores de x. Esta desigualdad puede resultar desconcertante, dada la importante ventaja del beneficio potencial sobre las pérdidas. No obstante, aquí hay una trampa oculta. Para entenderlo, imagine que BTP y STP se fijan en, digamos, 10 000 puntos. En tales circunstancias, el precio tardará una eternidad en alcanzar estos objetivos. Esto nos lleva entonces a una conclusión importante: cuanto más elevados sean el BTP y el STP, menores serán las posibilidades de completar el ciclo, es decir, de alcanzar el BTP o el STP. Así, esto introduce un elemento oculto, que llamaremos p - la probabilidad de que el ciclo se complete en un x dado. Un aumento desmesurado de BTP y STP reducirá p, y cuanto menor sea p, menor será la probabilidad de que se complete el ciclo. Por ello, independientemente del beneficio potencial, si p es mínimo, es posible que el beneficio esperado nunca se materialice. Como estamos tratando principalmente con EURUSD, donde las fluctuaciones de 100 pips ya son significativas, usaremos un nivel preliminar de 50 pips tanto para BTP como para STP. Este nivel se basa en la intuición y podrá ajustarse según sea necesario para equilibrar eficazmente el riesgo y la recompensa.
Contabilizar p y calcular los beneficios esperados supone una tarea compleja. Aunque la optimización matemática ofrece un enfoque estructurado, no podrá determinar por sí sola la probabilidad de finalización del ciclo (p). Requiere un análisis gráfico para una comprensión más detallada. Además, surgirán complicaciones posteriores porque p es intrínsecamente inestable y se comporta como una variable aleatoria. Debemos entender que p es un vector de valores de probabilidad, donde cada elemento indica la probabilidad de cerrar el ciclo después de un cierto número de órdenes comunes. Por ejemplo, el primer elemento del vector representa la probabilidad de completar el ciclo con un solo pedido, y esta lógica se extenderá a los demás elementos para diferentes cantidades de órdenes. Un examen exhaustivo de este concepto, especialmente de su aplicación e implicaciones, será clave al pasar a la optimización basada en el código en el próximo artículo de esta serie.
En nuestro análisis, pasaremos por alto un factor importante: el spread. El spread juega un papel clave en nuestra estrategia (como en todas las estrategias), y afectará tanto al beneficio como a las pérdidas. Para tenerlo en cuenta, ajustaremos nuestros cálculos restando determinados valores de p(x) y c(x). Así que añadiremos la dispersión a nuestro análisis.
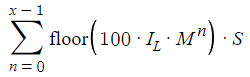
Es importante señalar que nuestro ajuste tiene en cuenta todas las operaciones de cero a x-1: el spread afectará a todas las operaciones, independientemente de que sean rentables o no. Para simplificar, actualmente tratamos el spread (denotado como S) como un valor constante. Esta decisión se toma para no complicar el análisis matemático con una variable adicional. Aunque dicha simplificación limita el realismo del modelo, nos permitirá centrarnos en los aspectos esenciales de la estrategia sin caer en una complejidad excesiva.
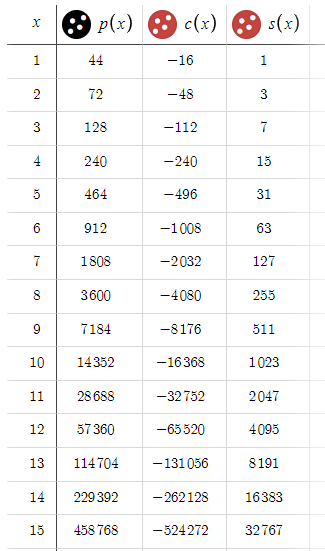
Después de introducir s(x) en los cálculos, tendremos que cuantificar el impacto real del spread en nuestros beneficios. El efecto es significativo: la pérdida asociada al spread aumentará a medida que se incremente x, pudiendo alcanzar los 32 000 puntos, es decir, unos 3 200 dólares. Este ajuste no solo reducirá nuestra ganancia potencial en s(x), sino que también aumentará nuestras pérdidas potenciales en la misma cantidad, alterando significativamente la relación riesgo/recompensa. Este cambio pone de relieve la importancia de considerar el spread en la planificación estratégica y la necesidad de gestionar cuidadosamente este factor a la hora de optimizar la estrategia.
Volviendo a la última tarea, cuando hablamos de reducir las opciones para aplicar la búsqueda de fuerza bruta, nos referimos al proceso de eliminación selectiva de ciertas combinaciones de parámetros que probablemente no produzcan resultados útiles para nuestra estrategia. Este paso resulta crucial para optimizar nuestro enfoque, especialmente cuando nos preparamos para la optimización en el código, ya que nos permitirá centrar los recursos computacionales en explorar las configuraciones más prometedoras.
Para dar un ejemplo, veremos un escenario en el que estableceremos los parámetros BTP (punto de activación de compra), STP (punto de activación de venta) y D (distancia) en 15 y M (multiplicador) en 1,5.
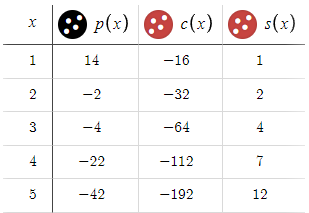
Al analizar estas configuraciones, podemos comprobar rápidamente que producen resultados insatisfactorios. Por ello, está claro que incorporar solo estos valores a la estrategia o realizar más esfuerzos de optimización será inútil.
Así que, en relación con esto, se nos plantea la siguiente pregunta: ¿cómo podemos identificar y eliminar de antemano estas combinaciones ineficaces de parámetros? Aunque el descubrimiento inicial de estos parámetros ha sido aleatorio, resulta difícil identificar y eliminar sistemáticamente todos los parámetros de entrada subóptimos. Esto requerirá un enfoque metódico, y tal vez un análisis preliminar para evaluar la viabilidad de utilizar diferentes conjuntos de parámetros antes de emprender una optimización de fuerza bruta a gran escala. De este modo, podremos simplificar el proceso de optimización y garantizar que todos los esfuerzos se centren únicamente en aquellas combinaciones de parámetros que puedan mejorar el rendimiento de nuestra estrategia comercial.
Abordar el problema derivado de la identificación y eliminación sistemática de las combinaciones de parámetros subóptimas en nuestro proceso de optimización es un reto que abordaremos en partes posteriores de esta serie. Este enfoque garantizará que nuestra investigación de las estrategias más prometedoras sea concreta y eficiente, mejorando así la eficacia general de nuestra metodología comercial. Por hoy, nos detendremos aquí. Continuaremos más tarde con la siguiente parte.
Conclusión
En esta tercera parte de nuestra serie, hemos explorado más a fondo la optimización de la estrategia de cobertura simple. Prestando especial atención al análisis matemático, hemos logrado comprender a un nivel básico el enfoque de "fuerza bruta" que utilizaremos en la siguiente parte.
De cara al futuro, en los próximos artículos de esta serie pasaremos de la investigación teórica a la optimización práctica basada en códigos. Asimismo, aplicaremos los principios e ideas aprendidos a escenarios comerciales reales. Este cambio promete hacer más clara la estrategia, ofreciendo mejoras tangibles y estrategias procesables para los tráders que buscan maximizar los beneficios al tiempo que gestionan eficazmente el riesgo.
Le agradezco cualquier comentario y opinión que haya dejado en artículos anteriores de esta serie. Siga compartiendo sus ideas y sugerencias. Juntos, no solo optimizaremos las estrategias comerciales, sino que facilitaremos el hallazgo de soluciones comerciales más eficaces que puedan soportar la prueba de la volatilidad y la incertidumbre del mercado.
¡Le deseo todos los éxitos en la programación y el comercio!
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13972
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.



 Paradigmas de programación (Parte 2): Enfoque orientado a objetos para el desarrollo de EA basados en la dinámica de precios
Paradigmas de programación (Parte 2): Enfoque orientado a objetos para el desarrollo de EA basados en la dinámica de precios
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso