
Clústeres de series temporales en inferencia causal

Introducción
- ¿Qué es el clustering?
- Aplicación del clustering en la inferencia causal.
- Emparejamiento utilizando clustering.
- Determinación del efecto heterogéneo del tratamiento.
- Definición de los modos de mercado.
Clustering de volatilidad.
Emparejamiento de operaciones utilizando clustering.
Introducción
El clustering es una técnica de aprendizaje automático que divide un conjunto de datos en grupos de objetos (clusters) de manera que los objetos dentro del mismo grupo son similares entre sí, mientras que los objetos de diferentes grupos son distintos. El clustering puede ayudar a revelar la estructura de los datos, identificar patrones ocultos y agrupar objetos en función de su similitud.
El clustering se puede utilizar en la inferencia causal. Una forma de aplicar el clustering en este contexto es identificar grupos de objetos o eventos similares que puedan asociarse con una causa particular. Una vez que los datos están agrupados, se pueden analizar las relaciones entre los clusters y las causas para identificar posibles relaciones de causa y efecto.
Además, el clustering puede ayudar a identificar grupos de objetos que puedan estar sujetos a los mismos efectos o tener causas comunes, lo cual también puede ser útil para analizar relaciones de causa y efecto.
El uso del clustering en la inferencia causal puede ser especialmente útil para analizar datos e identificar posibles relaciones de causa y efecto. En este artículo analizaremos cómo puede utilizarse la agrupación en este contexto:
- Identificación de grupos de objetos similares: El clustering te permite identificar grupos de objetos que tienen características o comportamientos similares. Luego, puedes analizar estos grupos y buscar causas o factores comunes que puedan estar asociados con ellos.
- Determinación de relaciones de causa y efecto: Una vez que los datos se han dividido en clusters, se pueden explorar las relaciones entre ellos e identificar posibles relaciones de causa y efecto. Por ejemplo, si un determinado cluster de objetos muestra un cierto comportamiento o características, se puede realizar un análisis para averiguar qué factores pueden ser responsables de ello.
- Encontrar patrones ocultos: El clustering puede ayudar a revelar patrones ocultos en los datos que podrían estar relacionados con relaciones de causa y efecto. Al analizar la estructura de los clusters e identificar características comunes de los objetos dentro de ellos, es posible descubrir factores que pueden desempeñar un papel clave en la ocurrencia de ciertos fenómenos.
- Predicción de eventos futuros: Una vez que se han identificado los clusters y las relaciones de causa y efecto, el conocimiento obtenido puede utilizarse para predecir eventos o tendencias futuras. Con base en el análisis de datos y los patrones identificados, puedes hacer suposiciones sobre qué factores pueden influir en eventos futuros y qué medidas se pueden tomar para gestionarlos.
El clustering se puede utilizar para el emparejamiento en la inferencia causal. El emparejamiento es el proceso de hacer coincidir objetos de diferentes conjuntos de datos en función de su similitud o de su cumplimiento con ciertos criterios. En el contexto de la inferencia causal, el emparejamiento se puede utilizar para establecer relaciones entre causas y efectos, así como para identificar características o factores comunes que puedan ser responsables de ciertos fenómenos.
En el emparejamiento, el clustering puede ser útil para lo siguiente:
- Agrupación de objetos: El clustering te permite dividir un conjunto de datos en grupos de objetos que tienen características o comportamientos similares. Después de esto, puedes realizar el emparejamiento dentro de cada cluster para encontrar coincidencias entre los objetos y establecer conexiones entre ellos.
- Identificación de similitudes: Una vez que los objetos se han dividido en clusters, se pueden examinar las similitudes entre los objetos dentro de cada cluster y utilizarlas para el emparejamiento. Por ejemplo, si un determinado cluster de objetos presenta comportamientos o características similares, se puede realizar un emparejamiento para encontrar factores comunes que puedan estar asociados con estos objetos.
- Reducción de ruido: El clustering puede ayudar a reducir el ruido en los datos y resaltar los principales grupos de objetos, facilitando así el proceso de emparejamiento. Al dividir los datos en clusters, puedes centrarte en los objetos más significativos y similares, lo que mejora la calidad del emparejamiento y permite identificar relaciones de causa y efecto más claras.
Como resultado, el clustering de series temporales puede ayudar a identificar efectos heterogéneos del tratamiento, es decir, diferencias en los efectos entre diferentes grupos de series temporales. En el contexto del análisis de series temporales donde se realiza clasificación o pronóstico, el efecto heterogéneo del tratamiento significa que el comportamiento de la serie temporal puede variar según sus características u otros factores.
Así, al agrupar series temporales, se pueden lograr los siguientes efectos:
- Agrupación de series temporales: El clustering permite dividir las series temporales en grupos basados en sus características, tendencias u otros factores. Luego, se puede examinar el comportamiento de cada grupo por separado para determinar si existen diferencias en la predicción o clasificación entre los distintos clusters de series temporales.
- Identificación de subgrupos con efectos distintos: Al agrupar series temporales, se pueden identificar subgrupos con diferentes comportamientos o trayectorias de cambio. Esto permite a los investigadores determinar qué características o factores pueden influir en los resultados de clasificación o predicción e identificar subconjuntos de series temporales que puedan requerir enfoques de análisis diferentes.
- Personalización de modelos: Utilizando los resultados del clustering y los subgrupos de series temporales identificados con comportamientos diferentes, se pueden personalizar los modelos de clasificación o pronóstico y seleccionar las estrategias óptimas para cada grupo. Esto permite mejorar la precisión de las previsiones y la clasificación y adaptar los modelos a distintos tipos de series temporales.
El clustering también puede considerarse en términos de identificación de regímenes de mercado, por ejemplo, basándose en la volatilidad.
El análisis de la volatilidad del mercado es una herramienta clave para inversores y traders, ya que les permite comprender el estado actual del mercado y tomar decisiones informadas basadas en los movimientos de precios esperados. En el contexto del análisis financiero, los algoritmos de clustering basados en la volatilidad ayudan a destacar diferentes "regímenes" del mercado que pueden indicar distintas tendencias, fases de consolidación o períodos de alta incertidumbre.
¿Cómo funciona el algoritmo de clustering en problemas de determinación de regímenes de mercado basados en la volatilidad?
- Preparación de Datos: Las series temporales de volatilidad de precios para los activos se preprocesan, incluyendo el cálculo de la volatilidad basado en la desviación estándar de los precios o las variaciones en la distribución de precios.
- Aplicación del algoritmo de clustering: Luego se aplica el algoritmo de clustering a los datos de volatilidad para identificar estructuras ocultas y grupos de regímenes de mercado. Se pueden utilizar varios métodos como algoritmos de clustering, tales como K-Means, DBSCAN, o algoritmos específicamente diseñados para el análisis de series temporales, como aquellos que tienen en cuenta las dependencias temporales.
- Interpretación de los resultados: Los clusters resultantes representan diferentes regímenes de mercado que se pueden interpretar en el contexto de estrategias de trading. Por ejemplo, los clusters con baja volatilidad pueden corresponder a períodos de tendencia lateral, mientras que los clusters con alta volatilidad pueden indicar picos en el mercado o cambios en las tendencias.
Ventajas del algoritmo de clustering en problemas de determinación de regímenes de mercado basados en la volatilidad:
- Determinación de la estructura del mercado: Los algoritmos de clustering permiten resaltar la estructura del mercado e identificar modos ocultos, lo que ayuda a los inversores y traders a comprender el estado actual del mercado.
- Automatización del análisis: El uso de algoritmos de clustering permite automatizar el proceso de análisis de la volatilidad del mercado e identificación de diferentes modos, lo que ahorra tiempo y reduce la probabilidad de errores humanos.
- Apoyo a la toma de decisiones: Identificar patrones de mercado basados en la volatilidad ayuda a predecir movimientos futuros de precios y a tomar decisiones de trading e inversión informadas.
Desventajas del algoritmo de clustering en problemas de determinación de regímenes de mercado basados en la volatilidad:
- Sensibilidad a la selección de parámetros: Los resultados del clustering pueden depender de la selección de los parámetros del algoritmo, como el número de clusters o la métrica de distancia, lo que requiere una afinación cuidadosa.
- Limitaciones de los algoritmos: Algunos algoritmos de clustering pueden no ser eficientes al procesar grandes volúmenes de datos o pueden no tener en cuenta las dependencias temporales.
Tipos de algoritmos de clustering
Podemos utilizar diferentes algoritmos de clustering para nuestras tareas. Los principales tipos de clustering están disponibles como bibliotecas listas para usar, implementadas en Python. Entonces, la mejor manera de comenzar a experimentar con clustering es utilizar las bibliotecas, ya que no es necesario implementar cada algoritmo desde cero. Esto acelera significativamente el proceso de configuración y realización del experimento.
Vamos a revisar brevemente los principales algoritmos de clustering que pueden ser útiles para nosotros y luego los aplicaremos en nuestras tareas.
- K-Means destaca por su simplicidad y eficiencia, pero tiene limitaciones como la dependencia de las condiciones iniciales y la necesidad de conocer el número de clusters.
- Affinity Propagation no requiere predefinir el número de clusters y funciona bien con datos de diversas formas, pero puede ser computacionalmente complejo.
- Mean Shift es capaz de detectar clusters de forma arbitraria y no requiere especificar el número de clusters. Puede ser costoso desde el punto de vista informático cuando se trabaja con grandes cantidades de datos.
- Spectral Clustering es adecuado para datos con estructuras no lineales y es universal. Sin embargo, puede resultar difícil ajustar los parámetros y caro desde el punto de vista informático.
- Agglomerative Clustering crea clusters jerárquicos y es adecuado para manejar un número desconocido de clusters.
- GMM ofrece un enfoque probabilístico para el clustering, permitiendo modelar clusters con diferentes formas y densidades.
- HDBSCAN y BIRCH proporcionan un manejo eficiente de grandes volúmenes de datos y determinación automática del número de clusters, pero también tienen sus desventajas, como la complejidad computacional y la sensibilidad a los parámetros.
Implementación del clustering de series temporales (clustering de volatilidad)
Estamos interesados en la posibilidad de realizar clustering en series temporales financieras tanto como un medio para determinar regímenes de mercado como para hacer emparejamiento y determinar el efecto heterogéneo del tratamiento. Comenzamos intentando hacer clustering de los regímenes de mercado.
El siguiente código entrena el modelo de meta-aprendizaje y luego entrena el modelo final y el meta-modelo basado en los resultados del clustering, que se basa en la volatilidad de los datos financieros:
def meta_learner(models_number: int, iterations: int, depth: int, bad_samples_fraction: float, n_clusters: int, algorithm: int) -> pd.DataFrame: dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] X = X.loc[:, ~X.columns.str.contains('std')] meta_X = data.loc[:, data.columns.str.contains('std')] y = data['labels'] B_S_B = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark[to_mark > to_mark.mean() * bad_samples_fraction].index data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 if algorithm==0: data['clusters'] = KMeans(n_clusters=n_clusters).fit(meta_X).labels_ elif algorithm==1: data['clusters'] = AffinityPropagation().fit(meta_X).predict(meta_X) elif algorithm==2: data['clusters'] = SpectralClustering(n_clusters=n_clusters, assign_labels='discretize', random_state=0).fit_predict(meta_X) elif algorithm==3: data['clusters'] = MeanShift().fit_predict(meta_X) elif algorithm==4: data['clusters'] = AgglomerativeClustering(n_clusters=n_clusters).fit_predict(meta_X) elif algorithm==5: data['clusters'] = mixture.GaussianMixture(n_components=n_clusters, covariance_type='full').fit(meta_X).predict(meta_X) elif algorithm==6: data['clusters'] = HDBSCAN(min_cluster_size=150).fit_predict(meta_X) elif algorithm==7: data['clusters'] = Birch(threshold=0.01, n_clusters=n_clusters).fit_predict(meta_X) return data[data.columns[1:]]
Descripción de la función:
La función meta_learner está diseñada para meta-entrenar un modelo de clasificación con el fin de identificar y corregir muestras mal etiquetadas en un conjunto de datos. Utiliza un conjunto de modelos CatBoostClassifier para identificar dichas muestras y aplica algoritmos de agrupación para seguir procesando los datos. He aquí una descripción más detallada del proceso:
1. Preparación de los datos: La función comienza recuperando un conjunto de datos filtrado por marcas de tiempo (excluyendo los datos de determinados periodos). A continuación, los datos se dividen en características (X), meta-características (meta_X) basadas en desviaciones estándar y etiquetas objetivo (y).
2. Inicialización de la variable: Se crea un índice de fechas vacío B_S_B para almacenar los índices de las muestras mal etiquetadas.
3. Entrenamiento de modelos e identificación de etiquetas incorrectas: para cada uno de los modelos 'models_number', los datos se dividen en conjuntos de entrenamiento y validación. A continuación se entrena el modelo CatBoostClassifier con los parámetros dados. Una vez entrenado, el modelo se utiliza para predecir etiquetas en todo el conjunto de características X. Comparando las etiquetas predichas con las originales, la función identifica las muestras etiquetadas incorrectamente y añade sus índices a B_S_B.
4. Etiquetado de muestras erróneas: Después de entrenar todos los modelos, la función analiza los índices de muestras malas almacenados en B_S_B y marca las que se producen con más frecuencia de la determinada por bad_samples_fraction, marcándolas como 0,0 en la columna meta_labels de los datos de origen.
5. Clustering: Dependiendo del valor del parámetro 'algorithm', la función aplica uno de los algoritmos de clustering a las meta-características (meta_X) y añade las etiquetas de cluster resultantes a los datos originales.
6. Devuelve un resultado: La función devuelve un conjunto de datos actualizado con etiquetas y clusters asignados.
Este enfoque permite no sólo identificar y corregir errores en las etiquetas de los datos, sino también agruparlos para su posterior análisis o el entrenamiento de modelos, lo que puede ser especialmente útil en problemas en los que hay un número significativo de muestras etiquetadas incorrectamente.
La función de entrenamiento para los modelos finales tiene el siguiente aspecto:
def fit_final_models(dataset) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[:-3]] X = X[X.columns[:-3]] X = X.loc[:, ~X.columns.str.contains('std')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('std')] # labels for model\meta models y, y_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[-1]] y = y[y.columns[-3]] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.8, test_size=0.2, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.8, test_size=0.2, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=200, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU') meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model([model, meta_model]) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
La función 'fit_final_models' está diseñada para entrenar los modelos principal y meta en el conjunto de datos proporcionado. Aquí tienes una descripción detallada de su funcionamiento:
1. Preparación de datos:
- La función selecciona del conjunto de datos las filas en las que meta_labels es igual a 1 para entrenar el modelo principal (X, y).
- Todas las filas del conjunto de datos (X_meta, y_meta) se utilizan para entrenar el meta-modelo.
- Las columnas que contienen «std» en el nombre, así como las tres últimas columnas, se excluyen de las características para el entrenamiento del modelo principal.
- Para el meta-modelo, la función sólo utiliza las características que contienen «std» en el nombre.
- La variable objetivo (y) para el modelo principal se toma de la tercera columna desde el final y se convierte al tipo int16.
- La variable de destino para el meta-modelo (y_meta) se toma de la última columna y también se convierte a int16.
2. Dividir los datos en muestras de entrenamiento y de prueba:
- Para el modelo principal y el meta-modelo, los datos se dividen en muestras de entrenamiento y de prueba en una proporción del 80% al 20%.
3. Entrenamiento básico de modelos:
- Utilizamos el clasificador `CatBoostClassifier` con 200 iteraciones, la función de pérdida 'Accuracy' y la métrica de evaluación 'Accuracy'. No se muestra información sobre el progreso del entrenamiento, se selecciona el mejor modelo y el tipo de tarea se establece como 'CPU'.
- El modelo se entrena en el conjunto de datos de entrenamiento. También tiene parada temprana después de 25 rondas si la métrica no mejora.
4. Entrenamiento del meta-modelo:
- Similar al modelo principal, pero con 100 iteraciones, función de pérdida 'F1', métrica de evaluación 'F1' y parada anticipada tras 15 rondas.
5. Pruebas de modelos:
- Los modelos entrenados se prueban mediante la función test_model, que devuelve el valor de la métrica R2.
- Si el valor R2 resultante es NaN, se sustituye por -1,0 y se imprime el mensaje correspondiente.
6. Los valores de retorno son:
- La función devuelve una lista que contiene el valor R2, el modelo principal y el meta-modelo.
Esta característica forma parte de un proceso de aprendizaje automático en el que el modelo principal se entrena con datos filtrados (en los que se supone que las etiquetas se han validado o ajustado) y el meta-modelo se entrena para predecir grupos de volatilidad seleccionados.
Todo el algoritmo se entrena en un bucle:
Esta función entrena un modelo y un meta-modelo a partir del conjunto de datos de entrada. A continuación, devuelve una lista con el valor R2, el modelo principal y el meta-modelo.
# LEARNING LOOP models = [] for i in range(1): data = meta_learner(5, 25, 2, 0.9, n_clusters=N_CLUSTERS, algorithm=6) for clust in data['clusters'].unique(): print(f'Iteration: {i}, Cluster: {clust}') filtered_data = data.copy() filtered_data['clusters'] = filtered_data['clusters'].apply(lambda x: 1 if x == clust else 0) models.append(fit_final_models(filtered_data))
Este código es un bucle de entrenamiento que utiliza la función meta_learner para meta-entrenar el modelo y luego entrenar los modelos finales basados en los clusters resultantes. He aquí una descripción más detallada del proceso:
1. Inicialización de la lista de modelos: Se crea una lista vacía 'modelos' que se utilizará para almacenar los modelos finales entrenados.
2. Ejecución del bucle de entrenamiento: El bucle 'for' está configurado para una iteración (range(1)), lo que significa que todo el proceso se ejecutará una vez. Esto se hace con fines de demostración o prueba, ya que estos bucles suelen utilizar más iteraciones debido a la aleatorización de los algoritmos de aprendizaje.
3. Meta-aprendizaje mediante meta_learner: Se llama a la función meta_learner con los parámetros dados:
- models_number=5: Utilizamos 5 modelos básicos para el meta-aprendizaje.
- iterations=25: Cada modelo base se entrena con 25 iteraciones.
- depth=2: La profundidad del árbol clasificador para los modelos base se establece en 2.
- bad_samples_fraction=0.9: La fracción de muestras marcadas erróneamente es del 90%.
- n_clusters=N_CLUSTERS: El número de clusters para el algoritmo de clustering, donde N_CLUSTERS debe definirse de antemano.
- algorithm=6: Se utiliza el algoritmo de clustering HDBSCAN.
La función meta_learner devuelve un conjunto de datos actualizado con etiquetas y clusters asignados.
4. Iterar sobre clusters únicos: Para cada conglomerado único del conjunto de datos, se muestra un mensaje con la iteración y el número de conglomerado. A continuación, los datos se filtran de modo que todos los registros pertenecientes al clúster actual se marquen como 1 y todos los demás como 0. De este modo se crea una clasificación binaria para cada conglomerado.
5. Entrenamiento de modelos finales: Para cada clúster, se llama a la función fit_final_models, que entrena y devuelve un modelo basado en los datos filtrados. Los modelos entrenados se añaden a la lista 'models'.
Este enfoque permite entrenar una serie de modelos especializados, cada uno centrado en un clúster de datos específico, lo que puede mejorar el rendimiento general del modelado al tener en cuenta de manera más precisa las características de los diferentes grupos de datos.
Todos los algoritmos de clustering propuestos fueron analizados para determinar los regímenes del mercado. Algunos algoritmos tuvieron un buen desempeño, mientras que otros tuvieron un desempeño deficiente.
A continuación se presentan los resultados del entrenamiento utilizando diferentes algoritmos de clustering:
En primer lugar, me interesó la velocidad del clustering. Se encontró que los algoritmos Affinity Propagation, Spectral Clustering, Agglomerative Clustering y Mean Shift son muy lentos, por lo que todos se encuentran en la parte inferior del ranking. No pude obtener resultados de clustering utilizando configuraciones estándar, por lo que no se muestran resultados para estos algoritmos.
Encontré una confirmación de esto en la web:

Ejecuté 10 iteraciones de todo el proceso de entrenamiento para obtener resultados más informativos, ya que los resultados varían en diferentes iteraciones de entrenamiento debido a la aleatorización dentro de los algoritmos.
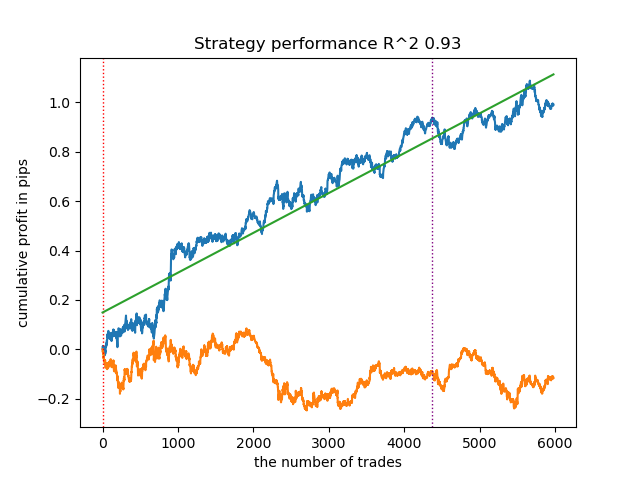
- La línea azul muestra el balance.
- La línea naranja muestra el instrumento financiero (en este caso EURUSD).
1. Entre los cuatro algoritmos restantes, decidí colocar a HDBSCAN en la parte superior del ranking. Separa bien los datos y no requiere especificar el número de clústeres.
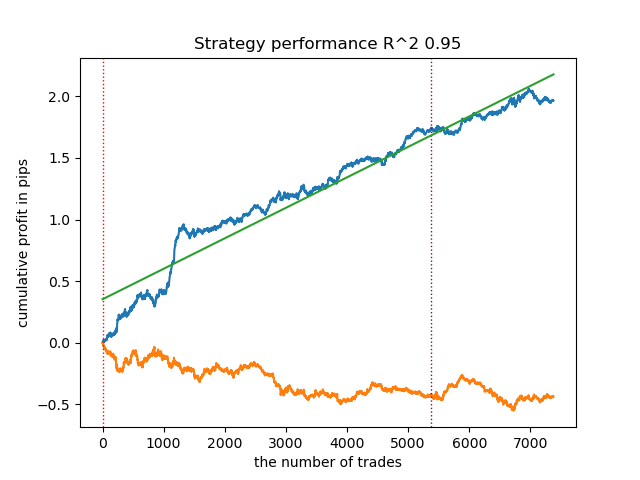
2. K-Means muestra un buen rendimiento y resultados de prueba bastante sólidos. La desventaja es la sensibilidad al número de clústeres, que en este caso es diez.
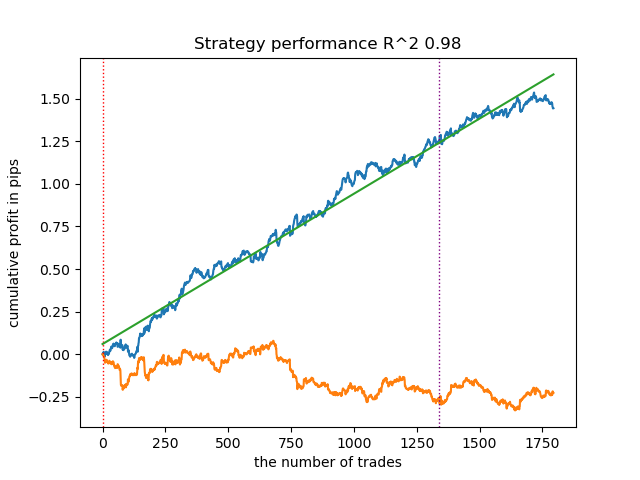
3. BIRCH muestra buenos resultados, pero calcula algo más lentamente que los algoritmos anteriores. Además, no hay requisito para un número inicial de clústeres.
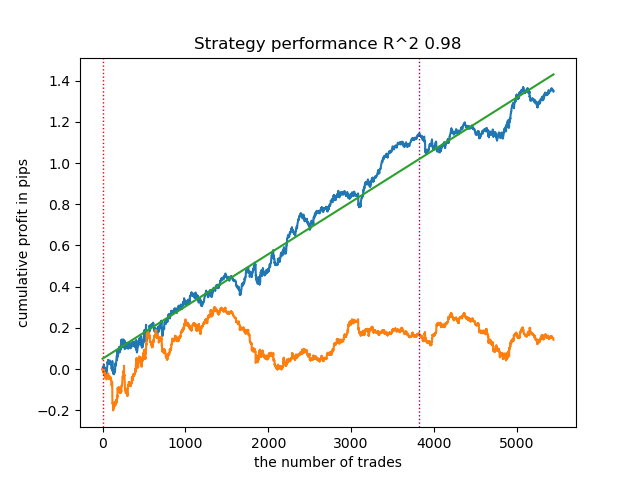
4. El modelo de mezcla gaussiana completa este ranking. Los resultados de las pruebas me parecieron peores que cuando se usaron otros algoritmos de clustering. Visualmente, esto se expresa en un gráfico de balance "más ruidoso". Al igual que con K-Means, definimos 10 clústeres.
Así, podemos obtener diferentes sistemas de trading dependiendo del régimen de mercado seleccionado. Durante el proceso de entrenamiento, los resultados de las pruebas del modelo se muestran para cada régimen, basándose en el número de clústeres especificado.
La calidad del clustering se ve afectada por el conjunto de parámetros de entrada. A continuación se presentan los parámetros que utilizamos:
- Par de divisas
- Marco temporal
- Fechas de inicio y fin del entrenamiento
- Número de características del modelo principal
- Número de características del meta-modelo (volatilidad)
- Número de clusters n_clusters
- Parámetros 'min' y 'max' de la función get_labels(min, max)
Por ejemplo, aquí hay otro conjunto de resultados de clustering con los siguientes parámetros:
SYMBOL = 'EURUSD' MARKUP = 0.00010 PERIODS = [i for i in range(10, 100, 10)] PERIODS_META = [20] BACKWARD = datetime(2019, 1, 1) FORWARD = datetime(2023, 1, 1) n_clusters = 40 def get_labels(dataset, min = 5, max = 5) Timeframe = H1
Dado que el algoritmo de búsqueda de clústeres también es aleatorio, es una buena práctica ejecutarlo varias veces.
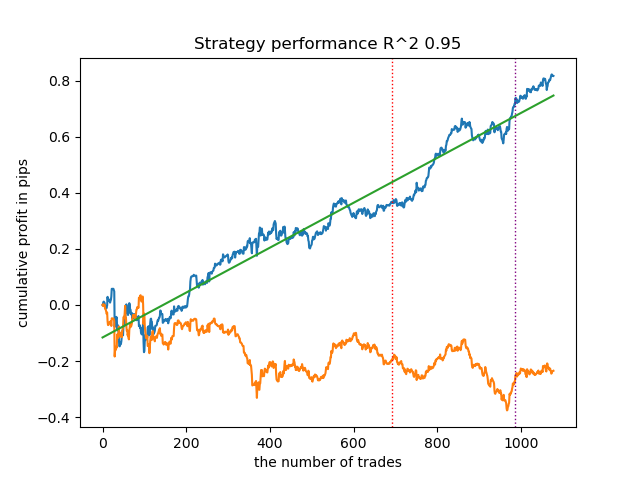
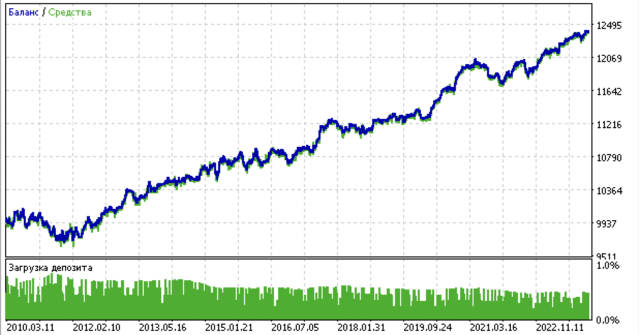
Emparejamiento de operaciones mediante clustering
Pasemos a la parte final, que es en realidad la parte principal del artículo. Quería profundizar en la comprensión de la inferencia causal al añadir un elemento de clustering. Este artículo explica qué es la inferencia causal, y este otro artículo cubre el emparejamiento mediante Propensity Score. Ahora reemplazaremos el emparejamiento a través del Propensity Score con nuestro propio enfoque, es decir, el emparejamiento mediante clustering. Para estos fines, utilizaremos el algoritmo del primer artículo y lo modificaremos.
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float, n_clusters: int): dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] clusters = KMeans(n_clusters=n_clusters).fit(X[X.columns[0:1]]).labels_ BAD_CLUSTERS = [] for _ in range(n_clusters): sublist = [pd.DatetimeIndex([]), pd.DatetimeIndex([])] BAD_CLUSTERS.append(sublist) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) coreset['clusters'] = clusters # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] for clust in range(n_clusters): diff_negatives_b = (coreset_b['labels'] != coreset_b['labels_pred']) & (coreset['clusters'] == clust) diff_negatives_s = (coreset_s['labels'] != coreset_s['labels_pred']) & (coreset['clusters'] == clust) BAD_CLUSTERS[clust][0] = BAD_CLUSTERS[clust][0].append(diff_negatives_b[diff_negatives_b == True].index) BAD_CLUSTERS[clust][1] = BAD_CLUSTERS[clust][ 1].append(diff_negatives_s[diff_negatives_s == True].index) for clust in range(n_clusters): to_mark_b = BAD_CLUSTERS[clust][0].value_counts() to_mark_s = BAD_CLUSTERS[clust][1].value_counts() marked_idx_b = to_mark_b[to_mark_b > to_mark_b.mean() * bad_samples_fraction].index marked_idx_s = to_mark_s[to_mark_s > to_mark_s.mean() * bad_samples_fraction].index data.loc[data.index.isin(marked_idx_b), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_s), 'meta_labels'] = 0.0 return data[data.columns[1:]]
Para quienes no hayan leído mis artículos anteriores, haré una breve descripción del algoritmo:
- Procesamiento de datos:
- Al principio, utilizamos las funciones get_prices() y get_labels() para obtener el conjunto de datos. Estas funciones devuelven información sobre precios y etiquetas de clase, respectivamente.
- get_labels() asocia datos de precios con etiquetas, que es una tarea común en ML relacionada con datos financieros.
- A continuación, los datos se filtran por intervalos de tiempo definidos por las constantes FORWARD y BACKWARD.
- Preparación de datos:
- Los datos se dividen en características (X) y etiquetas (y).
- A continuación, utilizamos el algoritmo de clustering K-Means para crear clusters de datos.
- Entrenamiento de modelos:
- En un bucle for, determinamos que el número de modelos es models_number. En cada iteración, el modelo se entrena con la mitad del conjunto de datos (train_size = 0,5) y se valida con la segunda mitad (conjunto de validación).
- Utilizamos el modelo CatBoostClassifier con determinados parámetros. Este método de refuerzo de gradiente está diseñado específicamente para trabajar con características categóricas.
- Ten en cuenta que el algoritmo utiliza la función de pérdida personalizada 'Accuracy' y la métrica de evaluación 'Accuracy'. Esto indica que nos centramos en la precisión de la predicción.
- A continuación, el meta-modelo se aplica para evaluar y ajustar las predicciones de los modelos primarios. Esto nos permite tener en cuenta posibles sesgos o errores en los modelos primarios.
- Identificación de muestras defectuosas:
- El algoritmo crea listas BAD_CLUSTERS que contienen qué información sobre las muestras malas de cada cluster. Las malas muestras se definen como aquellas en las que el modelo comete un número significativo de errores.
- En cada iteración de entrenamiento, el algoritmo identifica las muestras malas y guarda sus índices en la lista correspondiente.
- Meta-análisis y corrección:
- Los índices de las muestras erróneas identificadas en el paso anterior se agregan y se utilizan para marcar las muestras correspondientes en los datos maestros.
- Se supone que esto ayuda a mejorar la calidad del entrenamiento del modelo eliminando o corrigiendo las muestras erróneas.
- Retornar datos:
- La función devuelve los datos preparados sin la primera columna, que contiene las marcas de tiempo.
Este algoritmo trata de mejorar la calidad de los modelos de aprendizaje automático detectando y corrigiendo las muestras erróneas y utilizando un meta-modelo para tener en cuenta los errores de los modelos primarios. Es complejo y requiere un cuidadoso ajuste de los parámetros para funcionar con eficacia.
En el código presentado, el clustering ayuda a tener en cuenta la heterogeneidad en los datos de varias maneras:
- Identificación de clústeres de datos:
- El algoritmo de clustering K-Means permite dividir los datos en grupos de objetos similares. Cada conglomerado contiene datos con características similares. Esto es especialmente útil en el caso de datos heterogéneos, en los que los objetos pueden pertenecer a distintas categorías o tener estructuras diferentes.
- Análisis y procesamiento de los clústeres por separado:
- Cada clúster se procesa por separado de los demás, lo que permite tener en cuenta las características y la estructura de los datos dentro de cada grupo. Esto ayuda a comprender la heterogeneidad de los datos y a adaptar los algoritmos de aprendizaje a las condiciones específicas de cada clúster.
- Corrección de errores dentro de los clusters:
- Una vez entrenados los modelos, se analizan en bucle las muestras erróneas de cada clúster. Estas son las muestras para las que el modelo comete un número significativo de errores. Esto le permite localizar y centrar la corrección de errores en cada agrupación por separado, lo que puede resultar más eficaz que aplicar las mismas correcciones a todos los datos en conjunto.
- Tener en cuenta las características de los datos en el entrenamiento de meta-modelos:
- El clustering también se utiliza para tener en cuenta las diferencias entre clusters a la hora de entrenar un metamodelo. Esto permite que el meta-modelo se adapte mejor a la heterogeneidad de los datos al incorporar información sobre la estructura de los datos dentro de cada clúster.
Así pues, la agrupación desempeña un papel fundamental a la hora de tener en cuenta la heterogeneidad de los datos, lo que permite al algoritmo adaptarse con mayor eficacia a la diversidad de objetos y estructuras de datos.
A continuación se muestran los resultados del entrenamiento del modelo. Se puede ver que el modelo se ha vuelto más estable con los nuevos datos.
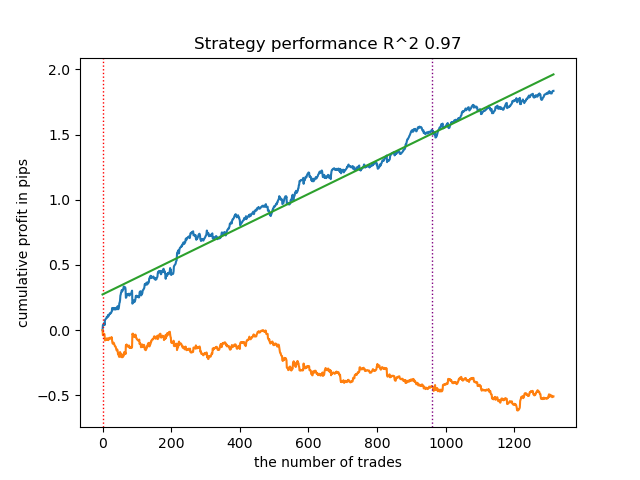
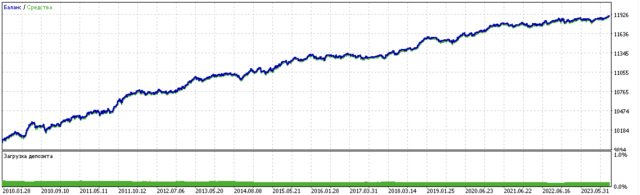
Este modelo puede exportarse a formato ONNX y es totalmente compatible con el ONNX Trader EA.
Conclusión
En este artículo, analizamos el enfoque original del autor sobre la agrupación de series temporales. Probé varios algoritmos para agrupar los regímenes de mercado en función de la volatilidad. Descubrí que los algoritmos complejos no siempre cumplen con las expectativas: a veces, algoritmos de clustering simples y rápidos como K-Means realizan un mejor trabajo. Al mismo tiempo, me gustó mucho el algoritmo HDBSCAN.
En la segunda parte, se utilizó la agrupación para determinar el efecto heterogéneo del tratamiento. Los experimentos han demostrado que tener en cuenta las malas operaciones mediante clustering reduce el rango de valores (la curva de balance se vuelve más suave) y mejora la capacidad del modelo para predecir en nuevos datos. En general, esta es una temática bastante compleja y profunda que requiere la configuración de hiperparámetros para ajustar finamente el algoritmo.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14548
 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso