
Neuronale Netze leicht gemacht (Teil 80): Graph Transformer Generative Adversarial Model (GTGAN)

Einführung
Der anfängliche Zustand der Umgebung wird am häufigsten mit Modellen analysiert, die Faltungsschichten oder verschiedene Aufmerksamkeitsmechanismen verwenden. Bei Faltungsarchitekturen fehlt jedoch das Verständnis für langfristige Abhängigkeiten in den Originaldaten aufgrund inhärenter induktiver Verzerrungen. Architekturen, die auf Aufmerksamkeitsmechanismen beruhen, ermöglichen die Kodierung langfristiger oder globaler Beziehungen und das Erlernen hoch expressiver Merkmalsrepräsentationen. Andererseits nutzen die Modelle der Graphenfaltung lokale und benachbarte Vertex-Korrelationen, die auf der Topologie des Graphen basieren. Daher ist es sinnvoll, Graphenfaltungsnetze und Transformer zu kombinieren, um lokale und globale Interaktionen zu modellieren und so die Suche nach optimalen Handelsstrategien zu realisieren.
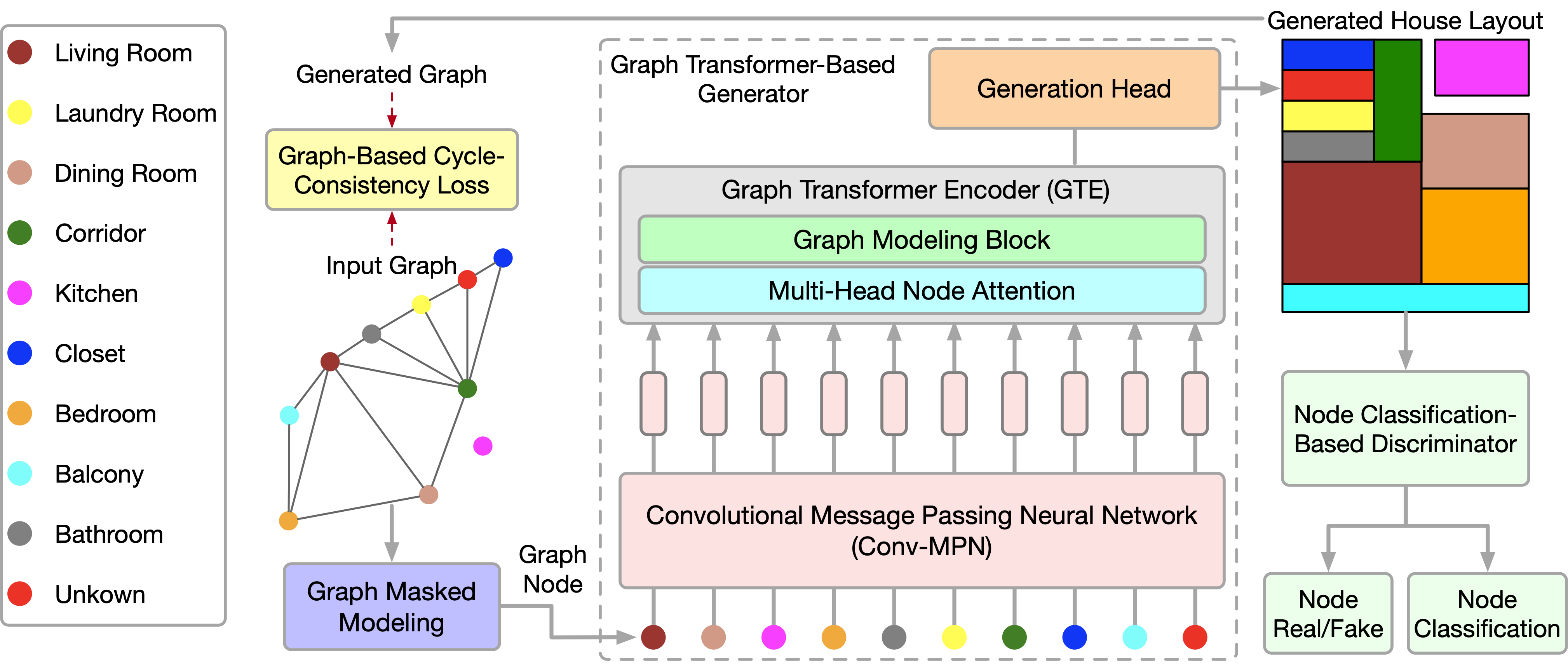
Die kürzlich veröffentlichte Arbeit „Graph Transformer GANs with Graph Masked Modeling for Architectural Layout Generation“ stellt den Algorithmus für das Graph Transformer Generative Adversarial Model (GTGAN) vor, der diese beiden Ansätze auf prägnante Weise kombiniert. Die Autoren des GTGAN-Algorithmus befassen sich mit dem Problem der Erstellung eines realistischen architektonischen Entwurfs eines Hauses aus einem Eingabegraphen. Das von ihnen vorgestellte Generatormodell besteht aus drei Komponenten: einem Message Passing (Conv-MPN), einem Graph-Transformer-Encoder (GTE) und einem Generierungskopf.
Qualitative und quantitative Experimente an drei komplexen, grafisch eingeschränkten architektonischen Layout-Generationen mit drei Datensätzen, die in dem Papier vorgestellt wurden, zeigen, dass die vorgeschlagene Methode Ergebnisse erzielen kann, die den bisher vorgestellten Algorithmen überlegen sind.
1. GTGAN-Algorithmus
Um die Methode zu beschreiben, wollen wir die Erstellung eines Hausgrundrisses als Beispiel nehmen. Generator G erhält den Rausch-Vektor für jeden Raum und das Blasendiagramm als Eingabe. Anschließend wird ein Hausgrundriss erstellt, in dem jeder Raum als achsenorientiertes Rechteck dargestellt wird. Die Autoren der Methode stellen jedes Blasendiagramm als einen Graphen dar, bei dem jeder Knoten einen Raum eines bestimmten Typs und jede Kante die räumliche Nachbarschaft von Räumen repräsentiert. Konkret erstellen sie für jeden Raum ein Rechteck. Zwei Räume mit einer Graphenkante sollten räumlich benachbart sein, während zwei Räume ohne Graphenkante räumlich nicht benachbart sein sollten.
Bei einem Blasendiagramm erzeugen sie zunächst einen Knoten für jeden Raum und initialisieren ihn mit einem 128-dimensionalen Rauschvektor, der aus einer Normalverteilung abgetastet wird. Dann kombinieren sie den Rausch-Vektor mit einem 10-dimensionalen One-Hot-Raumtyp-Vektor (tr). Daher können sie einen 138-dimensionalen Vektor gr erhalten, um das ursprüngliche Blasendiagramm darzustellen.
![]()
Beachten Sie, dass in diesem Fall die Knoten des Graphen als Eingabedaten für den vorgeschlagenen Transformer verwendet werden.
Der Faltungsnachrichtenblock Conv-MPN stellt einen 3D-Tensor im Ausgabedesignraum dar. Sie wenden eine allgemeine Linienschicht an, um gr in ein Merkmalsvolumen gr,l=1 der Größe 16×8×8 zu erweitern, wobei l=1 das aus der ersten Conv-MPN-Schicht extrahierte Objekt ist. Es wird zweimal durch eine transponierte Faltung zu einem Objekt gr,l=3 der Größe 16x32x32 hochgerechnet.
Die Conv-MPN-Schicht aktualisiert den Merkmalsgraphen durch die Weitergabe von Faltungsnachrichten. Konkret aktualisieren sie gr,l=1 in den folgenden Schritten:
- Sie verwenden ein GTE, um langfristige Korrelationen zwischen Räumen zu erfassen, die im Eingabegraphen verbunden sind;
- Die Verwendung eines anderen GTE, um langfristige Abhängigkeiten zwischen nicht verbundenen Räumen im Eingabegraphen zu erfassen;
- Sie kombinieren Funktionen über verbundene Räume im Eingabegraphen;
- Sie kombinieren Funktionen in nicht miteinander verbundenen Räumen;
- Wir wenden einen Faltungsblock (CNN) auf das kombinierte Merkmal an.
Dieser Prozess kann wie folgt formuliert werden:
![]()
wobei N(r) Mengen von Räumen bezeichnet, die verbunden bzw. nicht verbunden sind; „+“ und „;“ bezeichnen die pixelweise Addition bzw. kanalweise Verkettung.
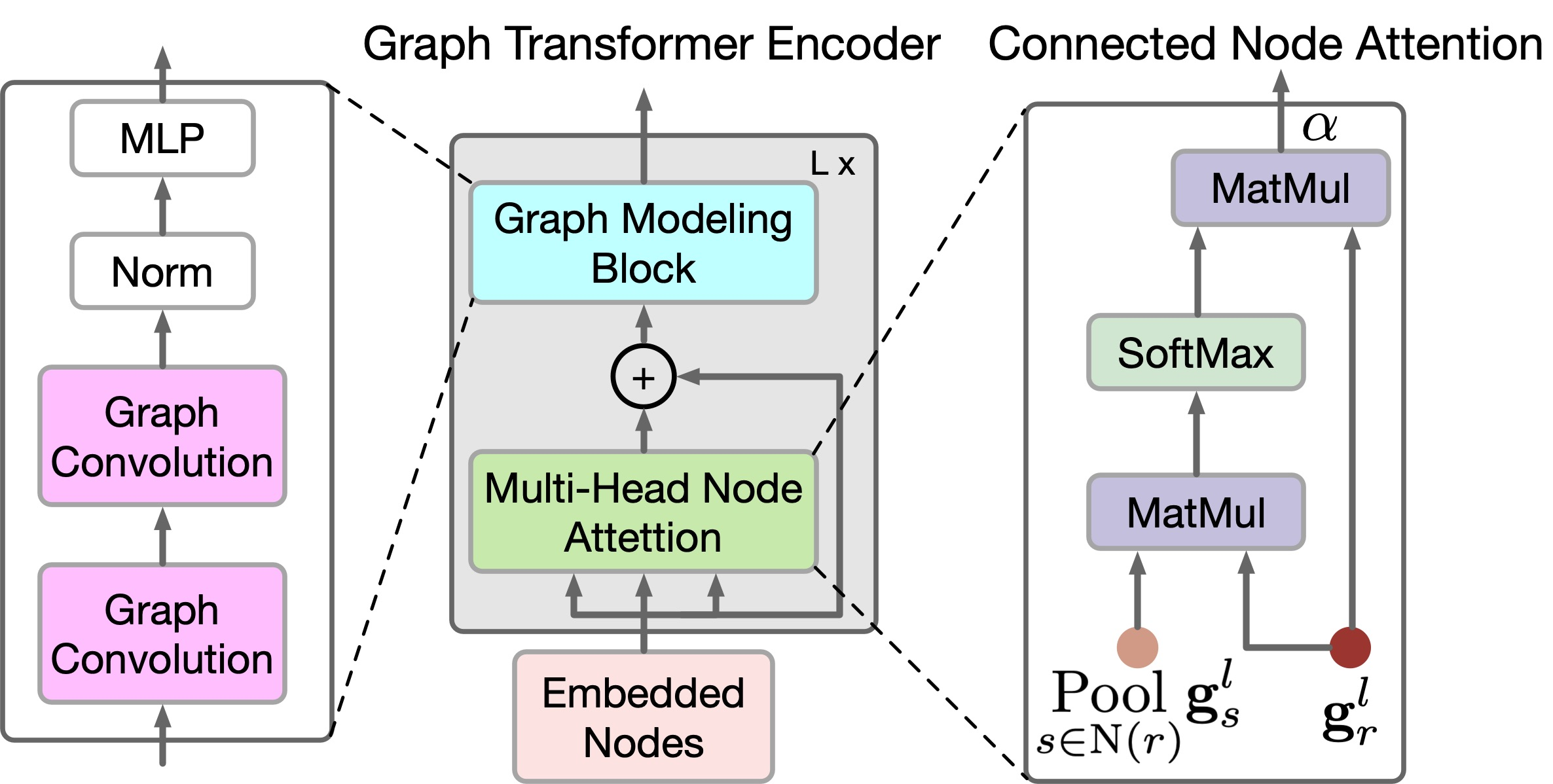
Um lokale und globale Beziehungen zwischen den Knoten des Graphen widerzuspiegeln, schlagen die Autoren der Methode einen neuen GTE-Encoder vor. GTE kombiniert die Modelle Selbstaufmerksamkeit von Transformers und Graph Convolution, um globale bzw. lokale Korrelationen zu erfassen. Bitte beachten Sie, dass GTGAN keine Positionseinbettungen verwendet, da das Ziel der Aufgabe darin besteht, die Positionen der Knoten im generierten Hauslayout anzugeben.
GTGAN erweitert die Multi-Head-Self-Attention um die Multi-Head-Node-Attention, die darauf abzielt, globale Korrelationen zwischen verbundenen Räumen/Knoten und globale Abhängigkeiten zwischen unverbundenen Räumen/Knoten zu erfassen. Zu diesem Zweck schlagen die Autoren der Methode zwei neue Module für die Aufmerksamkeit auf Graphenknoten vor, nämlich: Aufmerksamkeit auf verbundene Knoten (CNA) und Aufmerksamkeit auf nicht verbundene Knoten (NNA). Beide Module haben die gleiche Netzarchitektur.
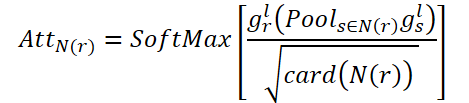
Das Ziel von CNA ist die Modellierung globaler Korrelationen zwischen verbundenen Räumen. AttN(r) misst den Einfluss eines Knotens auf andere verbundene Knoten. Dann führen sie die Matrixmultiplikation gr,l mit dem transponierten AttN(r) durch. Anschließend multiplizieren sie das Ergebnis mit dem Skalierungsparameter ɑ.
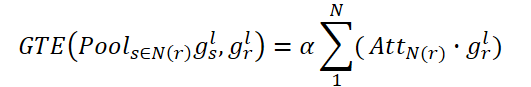
Dabei ist ɑ ein lernbarer Parameter.
Jeder verbundene Knoten in N(r) stellt die gewichtete Summe aller verbundenen Knoten dar. Auf diese Weise erhält CNA einen globalen Überblick über die Struktur des räumlichen Graphen und kann die Räume entsprechend der Karte der verbundenen Aufmerksamkeit selektiv anpassen, wodurch die Darstellung des Hausgrundrisses und die semantische Konsistenz auf hoher Ebene verbessert werden.
In ähnlicher Weise zielt der NNA darauf ab, globale Beziehungen in nicht miteinander verbundenen Räumen zu erfassen. Er verwendet seinen lernbaren Parameter ß.
Schließlich führen sie eine elementweise Summe von gr,l durch, sodass das aktualisierte Knotenmerkmal sowohl verbundene als auch unverbundene räumliche Beziehungen erfassen kann.
![]()
Während CNA und NNA nützlich sind, um langfristige und globale Abhängigkeiten zu extrahieren, sind sie weniger effektiv bei der Erfassung feinkörniger lokaler Informationen in komplexen Heimatdatenstrukturen. Um diese Einschränkung zu beheben, schlagen die Autoren der Methode einen neuen Graphmodellierungsblock vor.
Konkret verbessern sie angesichts der in der obigen Gleichung erzeugten Merkmale gr,l die lokalen Korrelationen mit Hilfe von Faltungsgraphen-Netzwerken weiter.
![]()
Dabei bezeichnet A die Adjazenzmatrix des Graphen, G.C.(•) die Faltung des Graphen und P die lernbaren Parameter. σ ist die lineare Gaußsche Fehlereinheit (GeLU).
Die Bereitstellung von Informationen über die Beziehungen zwischen den Knoten im globalen Diagramm hilft bei der Erstellung genauerer Hausgrundrisse. Um diesen Prozess zu differenzieren, schlagen die Autoren der Methode eine neue Verlustfunktion vor, die auf einer Adjazenzmatrix basiert, die den räumlichen Beziehungen zwischen der Bodenwahrheit und den generierten Graphen entspricht. Die Graphen erfassen die Adjazenzbeziehungen zwischen den einzelnen Knoten in den verschiedenen Räumen und gewährleisten dann die Übereinstimmung zwischen der Grundwahrheit und den generierten Graphen durch die vorgeschlagene Schleifen-Konsistenzverlustfunktion. Diese Verlustfunktion zielt darauf ab, die gegenseitigen Beziehungen zwischen den Knoten genau zu erhalten. Einerseits müssen sich nicht überschneidende Teile als nicht überschneidend vorausgesagt werden. Andererseits müssen benachbarte Knoten als Nachbarn vorhergesagt werden und den Proximity-Koeffizienten entsprechen.
Im Folgenden wird die Visualisierung von GTGAN durch die Autoren vorgestellt.
2. Implementierung mit MQL5
Nach der Betrachtung der theoretischen Aspekte der GTGAN-Methode gehen wir zum praktischen Teil unseres Artikels über, in dem wir die vorgeschlagenen Ansätze mit MQL5 umsetzen.
Bitte beachten Sie jedoch den Unterschied zwischen den Problemen, die von den Autoren der Methode gelöst wurden, und denen, die wir gelöst haben. Unser Ziel ist es nicht, ein Diagramm der Kursentwicklung zu erstellen. Unser Ziel ist es, die optimale Verhaltensstrategie für den Agenten zu finden. Am Ausgang des Modells wollen wir die optimale Aktion des Agenten in einem bestimmten Zustand der Umgebung erhalten. Auf den ersten Blick sind unsere Aufgaben grundverschieden.
Wenn Sie sich jedoch die GTGAN-Methodik genauer ansehen, werden Sie feststellen, dass sich die Autoren der Methode hauptsächlich auf den Encoder (GTE) konzentrieren. Sie schenken sowohl der Architektur des Encoders als auch seinem Training große Aufmerksamkeit.
Die Autoren der Methode schlagen ein vorheriges Training des Encoders mit zufälliger Maskierung sowohl der Knoten als auch der Verbindungen vor. Sie schlagen vor, bis zu 40 % der Originaldaten zu maskieren, sodass jeder Knoten und jede Kante potenzielle Lücken in den benachbarten Verbindungen aufweist. Um fehlende Daten wiederherzustellen, muss jeder Knoten und jede Kanteneinbettung seinen lokalen Kontext konsumieren und interpretieren. Das bedeutet, dass jede Investition spezifische Details ihres unmittelbaren Umfelds verstehen muss. Der vorgeschlagene Ansatz der Maskierung nach dem Zufallsprinzip mit hohem Verhältnis und der anschließenden Rekonstruktion überwindet die Beschränkungen, die sich aus der Größe und Form der für die Vorhersage verwendeten Teilgraphen ergeben. Daher werden Knoten- und Kanteneinbettungen gefördert, um lokale kontextuelle Details zu verstehen.
Wenn Knoten oder Kanten mit hohen Koeffizienten entfernt werden, können die verbleibenden Knoten und Kanten als Teilgraphen betrachtet werden, deren Aufgabe es ist, den gesamten Graphen vorherzusagen. Dies stellt eine komplexere Aufgabe zur Vorhersage pro Graph dar, verglichen mit anderen Aufgaben zum Selbsttraining, bei denen in der Regel globale Graphdetails erfasst werden, indem kleinere Graphen oder Kontext als Vorhersageziele verwendet werden. Die vorgeschlagene „intensive“ Pre-Training-Aufgabe der Maskierung und Graphenrekonstruktion bietet eine breitere Perspektive für das Erlernen überlegener Knoten-Kanten-Einbettungen, die in der Lage sind, komplexe Details sowohl auf der Ebene der einzelnen Knoten/Kanten als auch auf der Ebene des gesamten Graphen zu erfassen.
Der Kodierer im vorgeschlagenen System fungiert als Brücke, indem er die ursprünglichen Attribute der sichtbaren, unmaskierten Knoten und Kanten in ihre entsprechenden Einbettungen in latenten Merkmalsräumen umwandelt. Dieser Prozess umfasst die Knoten- und Kantenaspekte des Kodierers, zu denen der vorgeschlagene Block für die Graphenmodellierung und der Multi-Head-Knoten-Attention-Mechanismus gehören. Diese Funktionen wurden in Anlehnung an die Transformer-Architektur entwickelt, eine Technik, die für ihre Fähigkeit bekannt ist, sequentielle Daten effizient zu modellieren. Dieser Block hilft bei der Erstellung robuster Darstellungen, die die ganzheitliche Dynamik der Beziehungen innerhalb eines Graphen erfassen.
Folglich können wir den vorgeschlagenen Encoder verwenden, um lokale und globale Abhängigkeiten in den Quelldaten zu untersuchen. Wir werden den vorgeschlagenen Encoder-Algorithmus in einer neuen Klasse namens CNeuronGTE implementieren.
2.1 Die Encoder.Klasse GTE
Die GTE-Encoderklasse CNeuronGTE erbt von der Basisklasse der neuronalen Schicht CNeuronBaseOCL. Die Struktur des vorgeschlagenen Encoders unterscheidet sich deutlich von den bisher betrachteten Transformer-Optionen. Daher haben wir uns trotz der großen Anzahl bereits erstellter neuronaler Schichten, die Aufmerksamkeitsmechanismen nutzen, dazu entschlossen, eine dieser Schichten nicht zu übernehmen. Im Laufe der Arbeit werden wir jedoch auf bereits erstellte Entwicklungen zurückgreifen.
Die Struktur der neuen Klasse ist unten dargestellt.
class CNeuronGTE : public CNeuronBaseOCL { protected: uint iHeads; ///< Number of heads uint iWindow; ///< Input window size uint iUnits; ///< Number of units uint iWindowKey; ///< Size of Key/Query window //--- CNeuronConvOCL cQKV; CNeuronSoftMaxOCL cSoftMax; int ScoreIndex; CNeuronBaseOCL cMHAttentionOut; CNeuronConvOCL cW0; CNeuronBaseOCL cAttentionOut; CNeuronCGConvOCL cGraphConv[2]; CNeuronConvOCL cFF[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionInsideGradients(void); public: CNeuronGTE(void) {}; ~CNeuronGTE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronGTE; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
Sie können hier bereits bekannte lokale Variablen sehen:
- iHeads;
- iWindow;
- iUnits;
- iWindowKey.
Ihr funktioneller Zweck bleibt derselbe. Wir werden uns bei der Implementierung der Methoden mit dem Zweck der internen Schichten vertraut machen.
Wir haben alle internen Objekte als statisch deklariert, was uns erlaubt, den Konstruktor und den Destruktor der Klasse leer zu lassen. Bitte beachten Sie, dass wir im Klassenkonstruktor nicht einmal den Wert der lokalen Variablen angeben.
Wie immer wird die vollständige Initialisierung der Klasse in der Methode Init durchgeführt. In den Parametern dieser Methode erhalten wir alle notwendigen Informationen, um die richtige Klassenarchitektur zu erstellen. Im Hauptteil der Methode rufen wir die entsprechende Methode der übergeordneten Klasse auf, die die minimal notwendige Kontrolle über die erhaltenen Anfangsparameter und die Initialisierung der geerbten Objekte implementiert.
bool CNeuronGTE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Nach der erfolgreichen Ausführung der Methode der übergeordneten Klasse speichern wir die empfangenen Daten in lokalen Variablen.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); activation = None;
Initialisieren Sie dann die hinzugefügten Objekte. Zunächst initialisieren wir die innere Faltungsschicht cQKV. In dieser Schicht planen wir, eine Darstellung aller 3 Entitäten (Abfrage, Schlüssel und Wert) in parallelen Threads zu erzeugen. Die Größe des Quelldatenfensters und seiner Stufe entspricht der Größe der Beschreibung eines Sequenzelements. Die Anzahl der Faltungsfilter ist gleich dem Produkt aus der Größe des Beschreibungsvektors einer Entität eines Elements der Sequenz, multipliziert mit der Anzahl der Aufmerksamkeitsköpfe und mit 3 (der Anzahl der Entitäten). Die Anzahl der Elemente ist gleich der Größe der analysierten Sequenz.
if(!cQKV.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * 3 * iHeads, iUnits, optimization, iBatch)) return false;
Um die Stabilität des Blocks zu erhöhen, normalisieren wir die erzeugten Entitäten mit einer SoftMax-Schicht.
if(!cSoftMax.Init(0, 1, OpenCL, iWindowKey * 3 * iHeads * iUnits, optimization, iBatch)) return false; cSoftMax.SetHeads(3 * iHeads * iUnits);
Der nächste Schritt besteht darin, einen Abhängigkeitskoeffizientenpuffer im OpenCL-Kontext zu erstellen. Die Größe ist 2 mal größer als üblich — dies ist notwendig, um die Koeffizienten für verbundene und nicht verbundene Knotenpunkte getrennt zu erfassen.
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits * 2 * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Wir speichern die Ergebnisse der Mehrkopfaufmerksamkeit in der lokalen Schicht cMHAttentionOut.
if(!cMHAttentionOut.Init(0, 2, OpenCL, iWindowKey * 2 * iHeads * iUnits, optimization, iBatch)) return false;
Bitte beachten Sie, dass die Schicht der Ergebnisse der Mehrkopfaufmerksamkeit ebenfalls doppelt so groß ist wie die ähnliche Schicht der zuvor betrachteten Transformer-Implementierungen. Dies geschieht auch, um das Schreiben von Daten sowohl von verbundenen als auch von nicht verbundenen Knotenpunkten zu ermöglichen.
Darüber hinaus ist es bei diesem Ansatz nicht erforderlich, eine separate Funktion für das Training der Skalierungsparameter ɑ und ß zu implementieren. Stattdessen werden wir die Funktionalität der W0-Schicht nutzen. In diesem Fall werden die Aufmerksamkeitsköpfe sowie der Einfluss von verbundenen und nicht verbundenen Knotenpunkten kombiniert.
if(!cW0.Init(0, 3, OpenCL, 2 * iWindowKey * iHeads, 2 * iWindowKey* iHeads, iWindow, iUnits, optimization, iBatch)) return false;
Nach dem Aufmerksamkeitsblock müssen wir die Ergebnisse mit den Originaldaten addieren und die Ergebnisse normalisieren. Die resultierenden Werte werden in die Schicht cAttentionOut geschrieben.
if(!cAttentionOut.Init(0, 4, OpenCL, iWindow * iUnits, optimization, iBatch)) return false;
Es folgen 2 Blöcke mit je 2 Schichten. Dazu gehören ein Block mit Graphenfaltung und FeedForward. Wir initialisieren die Objekte der angegebenen Blöcke in einer Schleife.
for(int i = 0; i < 2; i++) { if(!cGraphConv[i].Init(0, 5 + i, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cFF[i].Init(0, 7 + i, OpenCL, (i == 0 ? iWindow : 4 * iWindow), (i == 0 ? iWindow : 4 * iWindow), (i == 1 ? iWindow : 4 * iWindow), iUnits, optimization, iBatch)) return false; }
Schließlich ersetzen wir den Puffer für den Fehlergradienten.
if(cFF[1].getGradient() != Gradient) { if(!!Gradient) delete Gradient; Gradient = cFF[1].getGradient(); } //--- return true; }
Damit ist die Methode beendet.
Nach der Initialisierung der Klasse wird der Algorithmus für den Feed-Forward-Durchlauf der Klasse entwickelt. Hier beginnen wir mit unserem OpenCL-Programm, in dem wir einen neuen Kernel GTEFeedForward erstellen müssen. Innerhalb dieses Kerns werden wir die Abhängigkeiten sowohl von verbundenen als auch von nicht verbundenen Knotenpunkten analysieren. In der Methodik der GTGAN-Methode implementieren wir im GTEFeedForward-Kernelkörper die Funktionalität von CNA und NNA.
Bevor wir jedoch zur Implementierung übergehen, sollten wir festlegen, welche Knoten als verbunden und welche als nicht verbunden gelten sollen. Das erste, was Sie wissen müssen, ist, dass die Knoten in unserer Implementierung Beschreibungen der Parameter eines Balkens sind. Wir befassen uns mit der Zeitreihenanalyse. Daher können nur 2 benachbarte Balken direkt miteinander verbunden sein. Für den Balken Xt sind also nur die Balken Xt-1 und Xt+1 verbunden. Die Balken Xt-1 und Xt+1 sind nicht miteinander verbunden, da zwischen ihnen der Balken Xt liegt.
Nein, wir können mit der Umsetzung fortfahren. In den Parametern erhält der Kernel Zeiger auf die Datenaustauschpuffer.
__kernel void GTEFeedForward(__global float *qkv, __global float *score, __global float *out, int dimension) { const size_t cur_q = get_global_id(0); const size_t units_q = get_global_size(0); const size_t cur_k = get_local_id(1); const size_t units_k = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
Im Kernelkörper identifizieren wir einen Thread im Aufgabenbereich. In diesem Fall haben wir es mit einem 3-dimensionalen Raum von Aufgaben zu tun, von denen eine zu einer lokalen Gruppe zusammengefasst wird.
Der nächste Schritt ist die Bestimmung der Mischungen in den Datenpuffern.
int shift_q = dimension * (cur_q + h * units_q); int shift_k = (cur_k + h * units_k + heads * units_q); int shift_v = dimension * (h * units_k + heads * (units_q + units_k)); int shift_score_con = units_k * (cur_q * 2 * heads + h) + cur_k; int shift_score_notcon = units_k * (cur_q * 2 * heads + heads + h) + cur_k; int shift_out_con = dimension * (cur_q + h * units_q); int shift_out_notcon = dimension * (cur_q + units_q * (h + heads));
Hier werden wir ein 2-dimensionales lokales Array deklarieren. Die zweite Dimension hat 2 Elemente für verbundene und nicht verbundene Knoten.
const uint ls_score = min((uint)units_k, (uint)LOCAL_ARRAY_SIZE); __local float local_score[LOCAL_ARRAY_SIZE][2];
Der nächste Schritt ist die Bestimmung der Abhängigkeitskoeffizienten. Zunächst multiplizieren wir die entsprechenden Abfrage- und Schlüsseltensoren. Teilen Sie ihn durch die Wurzel der Dimension und nehmen Sie den Exponentialwert.
//--- Score float scr = 0; for(int d = 0; d < dimension; d ++) scr += qkv[shift_q + d] * qkv[shift_k + d]; scr = exp(min(scr / sqrt((float)dimension), 30.0f));
Dann stellen wir fest, ob die analysierten Sequenzelemente miteinander verbunden sind, und speichern das Ergebnis in dem gewünschten Pufferelement.
if(cur_q == cur_k) { score[shift_score_con] = scr; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = scr; } } else { if(abs(cur_q - cur_k) == 1) { score[shift_score_con] = scr; score[shift_score_notcon] = 0; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = 0; } } else { score[shift_score_con] = 0; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = 0; local_score[cur_k][1] = scr; } } } barrier(CLK_LOCAL_MEM_FENCE);
Nun können wir die Summe der Koeffizienten für jedes der Elemente der Folge ermitteln.
for(int k = ls_score; k < units_k; k += ls_score) { if((cur_k + k) < units_k) { local_score[cur_k][0] += score[shift_score_con + k]; local_score[cur_k][1] += score[shift_score_notcon + k]; } } barrier(CLK_LOCAL_MEM_FENCE); //--- int count = ls_score; do { count = (count + 1) / 2; if(cur_k < count) { if((cur_k + count) < units_k) { local_score[cur_k][0] += local_score[cur_k + count][0]; local_score[cur_k][1] += local_score[cur_k + count][1]; local_score[cur_k + count][0] = 0; local_score[cur_k + count][1] = 0; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); barrier(CLK_LOCAL_MEM_FENCE);
Dann bringen wir die Summe der Abhängigkeitskoeffizienten für jedes Element der Sequenz auf 1. Dazu teilen Sie einfach den Wert jedes Elements durch die entsprechende Summe.
score[shift_score_con] /= local_score[0][0]; score[shift_score_notcon] /= local_score[0][1]; barrier(CLK_LOCAL_MEM_FENCE);
Sobald die Abhängigkeitskoeffizienten gefunden sind, können wir die Auswirkungen von verbundenen und nicht verbundenen Knoten bestimmen.
shift_score_con -= cur_k; shift_score_notcon -= cur_k; for(int d = 0; d < dimension; d += ls_score) { if((cur_k + d) < dimension) { float sum_con = 0; float sum_notcon = 0; for(int v = 0; v < units_k; v++) { sum_con += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_con + v]; sum_notcon += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_notcon + v]; } out[shift_out_con + cur_k + d] = sum_con; out[shift_out_notcon + cur_k + d] = sum_notcon; } } }
Nachdem alle Iterationen erfolgreich abgeschlossen wurden, beenden wir die Kernel-Operation und kehren zur Arbeit am Hauptprogramm zurück. Hier erstellen wir zunächst die Methode AttentionOut, um den oben erstellten Kernel aufzurufen. Dies ist eine Methode, die von einer anderen Methode der gleichen Klasse aufgerufen wird. Es funktioniert nur mit internen Objekten und enthält keine Parameter.
Im Hauptteil der Methode wird zunächst geprüft, ob der Zeiger auf das Klassenobjekt für die Arbeit mit dem OpenCL-Kontext relevant ist.
bool CNeuronGTE::AttentionOut(void) { if(!OpenCL) return false;
Dann bestimmen wir den Aufgabenbereich und die Größe der Arbeitsgruppen. In diesem Fall verwenden wir einen 3-dimensionalen Aufgabenraum mit 1-dimensionaler Gruppierung in Arbeitsgruppen.
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits, 1};
Dann übergeben wir die notwendigen Parameter an den Kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_qkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_out, cAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_GTEFeedForward, def_k_gteff_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Den Kernel stellen wir in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_GTEFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Vergessen Sie nicht, die Vorgänge bei jedem Schritt zu kontrollieren. Und nach Abschluss der Methode geben wir einen logischen Wert der Ergebnisse der Methode zurück, der es uns ermöglicht, den Prozess im aufrufenden Programm zu steuern.
Nach Abschluss der vorbereitenden Arbeiten erstellen wir eine Top-Level-Feed-Forward-Pass-Methode unserer Klasse CNeuro.nGTE::feedForward. In den Parametern dieser Methode erhalten wir, ähnlich wie bei den entsprechenden Methoden in anderen zuvor besprochenen Klassen, einen Zeiger auf ein Objekt der vorherigen Schicht, dessen Puffer die Ausgangsdaten für die Methodenoperation enthält.
bool CNeuronGTE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.FeedForward(NeuronOCL)) return false;
Im Hauptteil der Methode wird jedoch nicht die Relevanz des empfangenen Zeigers geprüft, sondern sofort die analoge Feedforward-Methode für das Objekt aufgerufen, das die Entitäten Abfrage, Schlüssel und Wert bildet. Alle notwendigen Kontrollen sind bereits im Hauptteil der aufgerufenen Methode implementiert.1 Nach der erfolgreichen Bildung von Entitäten, die wir anhand des Ergebnisses der aufgerufenen Methode beurteilen können, normalisieren wir die empfangenen Daten in der SoftMax-Schicht.
if(!cSoftMax.FeedForward(GetPointer(cQKV))) return false;
Als Nächstes verwenden wir die oben erstellte AttentionOut-Methode und bestimmen den Einfluss von verbundenen und nicht verbundenen Knoten.
if(!AttentionOut()) return false;
Wir werden die Dimension der Ergebnisse der Mehrkopfaufmerksamkeit auf den Wert des Tensors der Originaldaten reduzieren.
if(!cW0.FeedForward(GetPointer(cMHAttentionOut))) return false;
Dann addieren und normalisieren wir die Daten.
if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cAttentionOut.getOutput(), iWindow, true)) return false;
In diesem Stadium haben wir den Block der Mehrkopfaufmerksamkeit abgeschlossen und gehen zum graphischen Faltungsblock GC über. Hier verwenden wir 2 Schichten des CrystalGraph Convolutional Network. Um die Funktionalität zu implementieren, müssen wir nur nacheinander ihre Direktübergabemethoden aufrufen.
if(!cGraphConv[0].FeedForward(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].FeedForward(GetPointer(cGraphConv[0]))) return false;
Als Nächstes kommt der Vorwärtsdurchgangs-Block.
if(!cFF[0].FeedForward(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].FeedForward(GetPointer(cFF[0]))) return false;
Und am Ende der Methode werden die Ergebnisse noch einmal addiert und normalisiert.
if(!SumAndNormilize(cAttentionOut.getOutput(), cFF[1].getOutput(), Output, iWindow, true)) return false; //--- return true; }
Nach der Implementierung des Vorwärtsdurchgangs gehen wir dazu über, den Prozess des Rückwärtsdurchgangs zu organisieren. Auch hier beginnen wir mit der Erstellung eines neuen Kernels GTEInsideGradients auf der OpenCL-Programmseite. In den Parametern erhält der Kernel Zeiger auf die für den Betrieb notwendigen Datenpuffer. Wir erhalten alle Dimensionen aus dem Aufgabenbereich.
__kernel void GTEInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const uint u = get_global_id(0); const uint d = get_global_id(1); const uint h = get_global_id(2); const uint units = get_global_size(0); const uint dimension = get_global_size(1); const uint heads = get_global_size(2);
Ähnlich wie beim Vorwärtsdurchgangs-Kernel werden wir diesen Kernel in einem 3-dimensionalen Aufgabenraum ausführen. Dieses Mal werden wir jedoch keine Arbeitsgruppen organisieren. Im Hauptteil des Kernels wird der aktuelle Thread im Aufgabenraum in allen Dimensionen identifiziert.
Der Algorithmus unseres Kernels kann in 3 Blöcke unterteilt werden:
- Gradient des Wertes
- Gradient der Abfrage
- Gradient des Schlüssels
Wir organisieren den Rückwärtsdurchgang in umgekehrter Reihenfolge wie den Vorwärtsdurchgang. Wir definieren also zunächst den Fehlergradienten für die Entität Wert. In diesem Block werden zunächst die Offsets in den Datenpuffern bestimmt.
//--- Calculating Value's gradients { int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units + u) + d;
Dann organisieren wir einen Zyklus zur Erfassung von Fehlergradienten für verbundene und nicht verbundene Knoten. Das Ergebnis wird im entsprechenden Element des globalen Puffers der Entitätsfehlergradienten qkv_g gespeichert.
float sum = 0; for(uint i = 0; i <= units; i ++) { sum += gradient[shift_out_con + i * dimension] * scores[shift_score_con + i * step_score]; sum += gradient[shift_out_notcon + i * dimension] * scores[shift_score_notcon + i * step_score]; } qkv_g[shift_v] = sum; }
Im zweiten Schritt berechnen wir die Fehlergradienten für die Entität Abfrage. Ähnlich wie beim ersten Block berechnen wir zunächst die Offsets in den Datenpuffern.
//--- Calculating Query's gradients { int shift_q = dimension * (u + h * units) + d; int shift_out_con = dimension * (h * units + u) + d; int shift_out_notcon = dimension * (u + units * (h + heads)) + d; int shift_score_con = units * h; int shift_score_notcon = units * (heads + h); int shift_v = dimension * (h * units + 2 * heads * units);
Die Berechnung des Fehlergradienten ist jedoch etwas komplizierter. Zunächst müssen wir den Fehlergradienten auf der Ebene der Abhängigkeitskoeffizientenmatrix bestimmen und seine Ableitung mit der SoftMax-Funktion anpassen. Erst dann können wir den Fehlergradienten auf die Ebene der gewünschten Einheit übertragen. Zu diesem Zweck müssen wir ein System von verschachtelten Schleifen erstellen.
float grad = 0; for(int k = 0; k < units; k++) { int shift_k = (k + h * units + heads * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + k]; float sc_notcon = scores[shift_score_notcon + k]; for(int v = 0; v < units; v++) for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_con + dim] * ((float)(k == v) - sc_con); sc_g += scores[shift_score_notcon + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_notcon + dim] * ((float)(k == v) - sc_notcon); } grad += sc_g * qkv[shift_k]; }
Nachdem alle Iterationen des Schleifensystems abgeschlossen sind, übertragen wir den Gesamtfehlergradienten in das entsprechende Element des globalen Datenpuffers.
qkv_g[shift_q] = grad; }
Im letzten Block unseres Kernels definieren wir den Fehlergradienten für die Entität Key. In diesem Fall erstellen wir einen Algorithmus ähnlich dem vorherigen Block. In diesem Fall nehmen wir jedoch den Fehlergradienten aus der Abhängigkeits-Koeffizientenmatrix in einer anderen Dimension.
//--- Calculating Key's gradients { int shift_k = (u + (h + heads) * units) + d; int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units); float grad = 0; for(int q = 0; q < units; q++) { int shift_q = dimension * (q + h * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + u + q * step_score]; float sc_notcon = scores[shift_score_notcon + u + q * step_score]; for(int g = 0; g < units; g++) { for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_con + g * dimension + dim] * ((float)(u == g) - sc_con); sc_g += scores[shift_score_notcon + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_notcon + g * dimension+ dim] * ((float)(u == g) - sc_notcon); } } grad += sc_g * qkv[shift_q]; } qkv_g[shift_k] = grad; } }
Um den beschriebenen Kernel aufzurufen, werden wir die Methode CNeuronGTE::AttentionInsideGradients erstellen. Der Algorithmus für seine Konstruktion ähnelt dem der Methode CNeuronGTE::AttentionOut. Deshalb werden wir sie jetzt nicht im Detail betrachten. Ich schlage vor, Sie studieren sie im Anhang, wo Sie den vollständigen Code aller in diesem Artikel verwendeten Programme finden.
Der gesamte Prozess der Fehlergradientenverteilung wird in der Methode CNeuronGTE::calcInputGradients beschrieben. In den Parametern erhält diese Methode einen Zeiger auf das Objekt der vorherigen neuronalen Schicht, an das der Fehlergradient übergeben werden soll.
bool CNeuronGTE::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cFF[1].calcInputGradients(GetPointer(cFF[0]))) return false;
Dank unseres bereits mehrfach angewandten Ansatzes mit der Ersetzung von Datenpuffern haben wir bei der Backpropagation-Methode der nachfolgenden neuronalen Schicht den Fehlergradienten direkt in den Puffer der letzten Schicht des FeedForward-Blocks erhalten. Daher müssen wir nicht übermäßig viele Daten kopieren. Bei der Backpropagation-Methode beginnt man sofort mit der Weitergabe des Fehlergradienten durch die Schichten des FeedForward-Blocks.
if(!cFF[0].calcInputGradients(GetPointer(cGraphConv[1]))) return false;
Danach propagieren wir den Fehlergradienten in ähnlicher Weise durch den Graphfaltungsblock.
if(!cGraphConv[1].calcInputGradients(GetPointer(cGraphConv[0]))) return false; if(!cGraphConv[1].calcInputGradients(GetPointer(cAttentionOut))) return false;
In diesem Schritt wird der Fehlergradient aus den 2 Threads kombiniert.
if(!SumAndNormilize(cAttentionOut.getGradient(), Gradient, cW0.getGradient(), iWindow, false)) return false;
Dann verteilen wir den Fehlergradienten auf die Aufmerksamkeitsköpfe.
if(!cW0.calcInputGradients(GetPointer(cMHAttentionOut))) return false;
Und propagieren sie durch den Aufmerksamkeitsblock.
if(!AttentionInsideGradients()) return false;
Der Fehlergradient für alle 3 Entitäten (Abfrage, Schlüssel, Wert) ist in einem verketteten Puffer enthalten, der es uns ermöglicht, alle Entitäten parallel auf einmal zu verarbeiten. Zunächst wird der Fehlergradient durch die Ableitung der SoftMax-Funktion angepasst, die wir zur Normalisierung der Daten verwendet haben.
if(!cSoftMax.calcInputGradients(GetPointer(cQKV))) return false;
Dann propagieren wir den Fehlergradienten auf die Ebene der vorherigen Schicht.
if(!cQKV.calcInputGradients(prevLayer)) return false;
Hier müssen wir nur den Fehlergradienten aus dem zweiten Datenstrom hinzufügen.
if(!SumAndNormilize(cW0.getGradient(), prevLayer.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
Vervollständigen wir die Methode.
Nach der Verteilung des Fehlergradienten müssen wir nur noch die Modellparameter aktualisieren, um den Fehler zu minimieren. Alle lernbaren Parameter unserer Klasse sind in internen Objekten enthalten. Um die Parameter anzupassen, werden wir daher nacheinander die entsprechenden Methoden der internen Objekte aufrufen.
bool CNeuronGTE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; if(!cW0.UpdateInputWeights(GetPointer(cMHAttentionOut))) return false; if(!cGraphConv[0].UpdateInputWeights(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].UpdateInputWeights(GetPointer(cGraphConv[0]))) return false; if(!cFF[0].UpdateInputWeights(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].UpdateInputWeights(GetPointer(cFF[0]))) return false; //--- return true; }
Damit ist die Beschreibung der Methoden unserer neuen Klasse CNeuronGTE abgeschlossen. Alle Methoden der Klassendienste, einschließlich der Methoden für den Dateibetrieb, sind in den Anhängen zu sehen. Wie immer enthält der Anhang den vollständigen Code aller Programme, die bei der Erstellung des Artikels verwendet wurden.
2.2 Modellarchitektur
Nachdem wir eine neue Klasse erstellt haben, gehen wir zur Arbeit an unseren Modellen über. Wir werden ihre Architektur entwerfen und sie ausbilden. Nach der GTGAN-Methode müssen wir den Encoder vortrainieren. Daher werden wir 2 Methoden für die Beschreibung der Modellarchitektur erstellen. In der ersten Methode, CreateEncoderDescriptions, erstellen wir die Beschreibungen der Encoder- und Decoder-Architekturen, die nur für das Pre-Training verwendet werden.
bool CreateEncoderDescriptions(CArrayObj *encoder, CArrayObj *decoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; }
Wir füttern den Encoder mit der Beschreibung eines Balkens.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Wir normalisieren die resultierenden Daten mit einer Batch-Normalisierungsschicht.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Danach erstellen wir die Einbettung des letzten Balkens und fügen ihn dem Stapel hinzu.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
Hier ist anzumerken, dass wir im Gegensatz zu früheren Arbeiten, in denen die Einbettung in einer Schicht erstellt wurde, die Vorschläge der Autoren der GTGAN-Methode in Bezug auf den Conv-MPN-Nachrichtenübertragungsblock genutzt und den Prozess der Erstellung der Einbettung in zwei Stufen unterteilt haben. Auf die Einbettungsschicht folgt also eine weitere Faltungsschicht, die die Arbeit der Erzeugung von Zustandseinbettungen abschließt.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes fügen wir eine DropOut-Schicht hinzu, um Daten während des Repräsentationstrainings in der Pre-Trainingsphase zu maskieren.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count*prev_wout; descr.probability= 0.4f; descr.activation=None; if(!encoder.Add(descr)) { delete descr; return false; }
Im nächsten Schritt werden wir ein wenig von dem vorgeschlagenen Algorithmus abweichen und eine Positionskodierung hinzufügen. Dies ist auf erhebliche Unterschiede bei den zugewiesenen Aufgaben zurückzuführen.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Danach werden wir 8 Schichten eines neuen Encoders in einer Schleife hinzufügen.
//--- layer 6 - 14 for(int i = 0; i < 8; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronGTE; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!encoder.Add(descr)) { delete descr; return false; } }
Die Decoder-Architektur wird deutlich kürzer sein. Die Ergebnisse des Encoders werden in den Eingang des Modells eingespeist.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count * prev_wout; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Lassen wir sie durch die Faltungsschicht laufen.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count=prev_count; descr.window = prev_wout; descr.step=prev_wout; descr.window_out=EmbeddingSize/4; descr.optimization = ADAM; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
Normalisierung mit SoftMax.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Am Ausgang des Decoders wird eine vollständig verknüpfte Schicht erstellt, deren Anzahl der Elemente den Ergebnissen der Einbettungsschicht entspricht.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count*EmbeddingSize/2; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Als Ergebnis haben wir einen asymmetrischen Autoencoder aus den Modellen zusammengestellt, der trainiert wird, um Daten im Stapel der Einbettungsschicht wiederherzustellen. Die Wahl des latenten Zustands der Einbettungsschicht wurde absichtlich getroffen. Während des Trainingsprozesses möchten wir die Aufmerksamkeit des Encoders auf den gesamten Satz historischer Daten richten und nicht nur auf den letzten Candlestick.
Lassen Sie uns die Architektur von Actor und Critic in der Methode CreateDescriptions beschreiben.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Bei der Architektur des Akteurs habe ich auch beschlossen, ein wenig Experimentierfreude einzubringen. Wir füttern das Modell mit einer Beschreibung des aktuellen Zustands des Kontos.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die vollständig verknüpfte Schicht wird für uns eine Art Einbettung des resultierenden Zustands erstellen.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Als Nächstes fügen wir einen Block von 3 Cross-Attention-Schichten hinzu, in denen wir die Abhängigkeiten zwischen dem aktuellen Zustand unseres Kontos und dem Zustand der Umgebung bewerten.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die erhaltenen Ergebnisse werden von 2 vollständig verbundenen Schichten verarbeitet.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Am Ausgang des Akteurs erzeugen wir seine stochastische Politik.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Modell Critic wurde praktisch unverändert aus dem Vorgängerwerk übernommen. Die Ergebnisse der Encoder-Operation werden in den Eingang des Modells eingespeist.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = GPTBars*EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Fügen Sie den empfangenen Daten die Actor-Aktionen hinzu.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type=defNeuronConcatenate; descr.window=prev_count; descr.step = NActions; descr.count=LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; }
Und setzen Sie einen Entscheidungsblock aus 2 vollständig verbundenen Schichten zusammen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.3 Berater für Repräsentationslernen
Nachdem wir die Modellarchitektur erstellt haben, gehen wir dazu über, einen EA zu erstellen, um sie zu trainieren. Zunächst erstellen wir den Repräsentations-Vorübungs-EA „...\Experts\GTGAN\StudyEncoder.mq5“. Die Struktur des EA ist weitgehend von früheren Arbeiten übernommen. Um den Artikel nicht zu lang werden zu lassen, beschränken wir uns auf die Modellbildungsmethode Train.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Im Hauptteil der Methode wird zunächst ein Vektor von Wahrscheinlichkeiten für die Auswahl von Pässen aus dem Erfahrungswiedergabepuffer auf der Grundlage ihrer Leistung erstellt.
Als Nächstes deklarieren wir lokale Variablen.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Dann organisieren wir ein System von Modelltrainingsschleifen. Im Hauptteil der äußeren Schleife werden die Trajektorie und der anfängliche Zustand des Lernens auf dieser Trajektorie untersucht.
int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - batch)); if(state <= 0) { iter--; continue; }
Wir löschen den Encoder-Puffer und bestimmen den Endzustand des Trainingspakets.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total);
Nach Abschluss der vorbereitenden Arbeiten organisieren wir eine verschachtelte Schleife des direkten Trainings der Modelle.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
Hier laden wir eine Beschreibung des aktuellen Zustands der Umgebung aus dem Erfahrungswiedergabepuffer und rufen die Vorwärtsdurchgangs-Methode des Encoders auf.
//--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Danach folgt der Vorwärtsdurchgang des Decoders.
if(!Decoder.feedForward((CNet*)GetPointer(Encoder),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Nach dem Vorwärtsdurchgang müssen wir Trainingsziele für das Modell festlegen. Der Autoencoder lernt selbst, um die ursprünglichen Daten wiederherzustellen. Wie wir bereits besprochen haben, werden wir beim Training des View-Modells den versteckten Zustand der Einbettungsschicht verwenden. Lassen Sie uns diese Daten in einen lokalen Puffer laden.
Encoder.GetLayerOutput(LatentLayer,Result);
Und geben sie als Zielwerte für die Optimierung der Parameter unserer Modelle weiter.
if(!Decoder.backProp(Result,(CBufferFloat*)NULL) || !Encoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Jetzt müssen wir den Nutzer nur noch über den Fortschritt des Lernprozesses informieren und zur nächsten Iteration des Schleifensystems übergehen.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nach erfolgreichem Abschluss des Modelltrainings wird das Kommentarfeld im Diagramm gelöscht.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Decoder", Decoder.getRecentAverageError()); ExpertRemove(); //--- }
Ausdruck der Trainingsergebnisse in das Protokoll und Einleitung des Prozesses zur Beendigung der EA-Arbeit ein.
In diesem Stadium können wir den Trainingsdatensatz aus früheren Arbeiten verwenden und mit dem Training des Repräsentationsmodells beginnen. Während das Modell trainiert, gehen wir dazu über, den EA für das Training der Akteurspolitik zu erstellen.
2.4 Trainings-EA der Akteurspolitik
Um die Verhaltensregeln des Akteurs zu trainieren, erstellen wir den EA „...\Experts\GTGAN\Study.mq5“. An dieser Stelle sei angemerkt, dass wir während des Trainingsprozesses 3 Modelle verwenden und nur 2 trainieren (Akteur und Kritiker). Das Encoder-Modell wurde im vorherigen Schritt trainiert.
CNet Encoder; CNet Actor; CNet Critic;
Bei der EA-Initialisierungsmethode laden wir zunächst das Beispielarchiv hoch.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Dann versuchen wir, die vortrainierten Modelle zu laden. In diesem Fall ist der Fehler beim Laden eines vortrainierten Encoders kritisch für das Funktionieren des Programms.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Can't load pretrained Encoder"); return INIT_FAILED; }
Wenn jedoch ein Fehler beim Laden des Akteurs und/oder Kritikers auftritt, erstellen wir neue Modelle, die mit zufälligen Parametern initialisiert werden.
if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor) || !Critic.Create(critic)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Wir übertragen alle Modelle in einen einzigen OpenCL-Kontext.
OpenCL = Encoder.GetOpenCL(); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
Stellen Sie sicher, dass der Encoder-Trainingsmodus ausgeschaltet ist.
Encoder.TrainMode(false);
Seine Architektur verwendet eine DropOut-Ebene, die die Daten nach dem Zufallsprinzip ausblendet. Während des Betriebs des Modells müssen wir die Maskierung deaktivieren, indem wir den Trainingsmodus des Modells deaktivieren.
Als Nächstes implementieren wir die minimal notwendige Kontrolle der Modellarchitektur.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Wir initialisieren die Hilfsdatenpuffer.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
Und erzeugen Sie ein Ereignis, um das Modelltraining zu starten.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Der Prozess der Ausbildung von Modellen ist wie üblich in der Methode Train organisiert.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Im Hauptteil der Methode wird, wie im vorherigen EA, zunächst ein Vektor von Wahrscheinlichkeiten für die Auswahl von Trajektorien aus dem Erfahrungswiederholungspuffer auf der Grundlage ihrer Rentabilität erstellt. Wir initialisieren auch lokale Variablen. Dann organisieren wir ein System von Modelltrainingsschleifen.
Im Hauptteil der äußeren Schleife wird die Trajektorie aus dem Erfahrungswiedergabepuffer und dem Anfangszustand des Lernprozesses abgerufen.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand()*MathRand() / MathPow(32767, 2))*(Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Wir löschen den Encoder-Stapel und ermitteln den letzten Status des Trainingspakets.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
Nach Abschluss der vorbereitenden Arbeiten organisieren wir eine verschachtelte Schleife des direkten Trainings der Modelle.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Im Hauptteil der verschachtelten Schleife laden wir die Beschreibung des analysierten Zustands des Kontos aus dem Erfahrungswiedergabepuffer und implementieren einen direkten Durchlauf durch den Encoder.
Als Nächstes müssen wir eine Beschreibung des Kontostandes aus dem Erfahrungswiedergabepuffer laden, um den Vorwärtsdurchgang des Akteurs zu implementieren.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Hier fügen wir einen Zeitstempel des aktuellen Zustands hinzu.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Als Nächstes führen wir einen Vorwärtsdurchgang des Akteurs durch.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount),1,false,GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Feedback des Kritikers:
//--- Critic if(!Critic.feedForward((CNet *)GetPointer(Encoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Wir entnehmen die Zielwerte für beide Modelle aus dem Erfahrungswiedergabepuffer. Zunächst führen wir einen Rückwärtsdurchgang auf dem Akteur durch.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Dann führen wir den umgekehrten Durchlauf des Kritikers durch und übertragen den Fehlergradienten an den Akteur.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
In beiden Fällen werden die Encoder-Parameter nicht aktualisiert.
Sobald der Rückwärtsdurchlauf beider Modelle erfolgreich abgeschlossen ist, informieren wir den Nutzer über den Trainingsfortschritt und fahren mit der nächsten Iteration des Schleifensystems fort.
//--- if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Sobald der Schulungsprozess abgeschlossen ist, löschen wir das Feld für die Kommentare auf dem Chart.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Wir zeigen die Trainingsergebnisse in einem Protokoll an und leiten den Prozess der Beendigung des EA ein.
Damit ist das Thema des Modelltrainings abgeschlossen. Die Programme zur Interaktion mit der Umwelt wurden mit minimalen Anpassungen aus dem vorherigen Artikel übernommen. Im Anhang finden Sie den vollständigen Code aller in diesem Artikel verwendeten Programme.
3. Test
In den vorangegangenen Abschnitten dieses Artikels haben wir uns mit der neuen GTGAN-Methode vertraut gemacht und viel Arbeit in die Implementierung der vorgeschlagenen Ansätze mit MQL5 gesteckt. In diesem Teil des Artikels testen wir, wie üblich, die geleistete Arbeit und werten die Ergebnisse aus, die auf realen Daten im MetaTrader 5 Strategietester erzielt wurden. Die Modelle werden anhand historischer Daten für EURUSD H1 trainiert und getestet. Dazu gehört auch ein Modelltraining mit historischen Daten für die ersten 7 Monate des Jahres 2023. Auf die Schulung folgt ein Test mit Daten vom August 2023.
Die in diesem Artikel erstellten Modelle arbeiten mit Quelldaten, ähnlich wie die Modelle aus früheren Artikeln. Die Vektoren der Aktionen des Akteurs und der Belohnungen für abgeschlossene Übergänge in einen neuen Zustand sind ebenfalls identisch mit den vorherigen Artikeln. Daher können wir zum Trainieren von Modellen den Erfahrungswiedergabepuffer verwenden, der während des Modelltrainings aus früheren Artikeln gesammelt wurde. Wir benennen die Datei einfach in „GTGAN.bd“ um.
Die Modelle werden in zwei Stufen trainiert. Zunächst trainieren wir den Encoder (Repräsentationsmodell). Und dann trainieren wir die Verhaltensregeln des Akteurs. Die Aufteilung des Lernprozesses in zwei Phasen hat eine positive Wirkung. Die Modelle trainieren recht schnell und stabil.
Ausgehend von den Trainingsergebnissen können wir sagen, dass das Modell schnell gelernt hat, zu verallgemeinern und die Handlungsrichtlinien aus dem Erfahrungswiedergabepuffer zu befolgen. Leider gab es nicht viele positive Durchgänge in meinem Erfahrungswiederholungspuffer. Das Modell hat also eine Strategie erlernt, die nahe am Durchschnitt der Trainingsstichprobe liegt, was aber leider kein positives Ergebnis liefert. Ich denke, es ist einen Versuch wert, das Modell auf positive Pässe zu trainieren.
Schlussfolgerung
In diesem Artikel haben wir den GTGAN-Algorithmus erörtert, der im Januar 2024 zur Lösung komplexer Architekturprobleme eingeführt wurde. Für unsere Zwecke haben wir versucht, die Ansätze einer umfassenden Analyse des aktuellen Stands im Encoder GTE zu übernehmen, der die Vorteile von Aufmerksamkeitsmethoden und Faltungsgraphenmodellen auf prägnante Weise kombiniert.
Im praktischen Teil des Artikels haben wir die vorgeschlagenen Ansätze mit MQL5 implementiert und die resultierenden Modelle auf realen Daten im MetaTrader 5 Strategietester getestet.
Die Testergebnisse deuten darauf hin, dass zusätzliche Arbeiten in Bezug auf die vorgeschlagenen Ansätze erforderlich sind.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA-Beispielsammlung |
| 2 | ResearchRealORL.mq5 | EA | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | EA | Modelltraining EA |
| 4 | StudyEncoder.mq5 | EA | Repräsentationsmodell lernen EA |
| 4 | Test.mq5 | EA | Testmodel des EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14445
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.