
Redes neurais de maneira fácil (Parte 80): modelo generativo adversarial do transformador de grafos (GTGAN)

Introdução
Para analisar o estado inicial do ambiente, são frequentemente utilizadas modelos que empregam camadas convolucionais ou diversos mecanismos de atenção. No entanto, as arquiteturas convolucionais carecem de compreensão das dependências de longo prazo nos dados brutos, devido aos seus vieses indutivos inerentes. As arquiteturas baseadas em mecanismos de atenção permitem codificar relações de longo prazo ou globais e estudar representações de funções altamente expressivas. Por outro lado, os modelos de convolução de grafos utilizam bem as correlações de vértices locais e vizinhos com base na topologia do grafo, portanto, faz sentido combinar redes de convolução de grafos e Transformadores para modelar interações locais e globais para resolver a busca de estratégias de negociação ótimas.
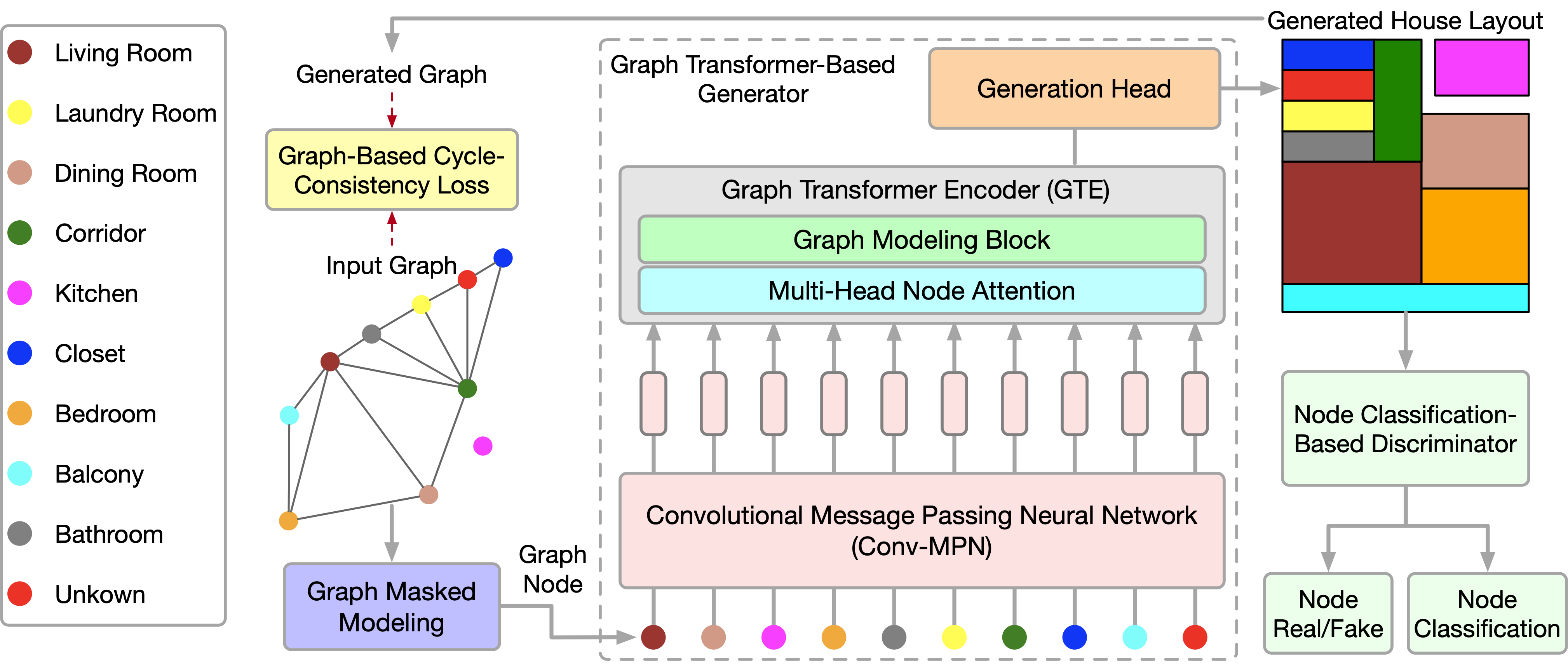
O algoritmo recentemente apresentado no artigo "Graph Transformer GANs with Graph Masked Modeling for Architectural Layout Generation" (GTGAN) combina concisamente ambas as abordagens mencionadas. Os autores do GTGAN resolvem a tarefa de criar um projeto arquitetônico realista de uma casa a partir de um grafo de entrada. E o modelo gerador apresentado consiste em três componentes: uma rede neural convolucional de transmissão de mensagens (Conv-MPN), um Codificador de transformador de grafos (GTE) e uma cabeça de geração.
Experimentos qualitativos e quantitativos em três gerações complexas de layout arquitetônico com restrições gráficas, utilizando três conjuntos de dados apresentados no artigo, demonstram que o método proposto pode fornecer resultados superiores aos algoritmos anteriormente apresentados.
1. Algoritmo GTGAN
Para descrever o método, tomamos como exemplo a criação de um layout de casa. O gerador G recebe um vetor de ruído para cada cômodo e um diagrama de bolhas como dados iniciais. Ele então gera um layout da casa em que cada cômodo é representado como um retângulo alinhado ao eixo. Os autores representam cada diagrama de bolhas como um grafo, em que cada nó representa um cômodo de um determinado tipo e cada aresta representa a adjacência espacial dos cômodos. Em particular, geramos um retângulo para cada cômodo. E dois cômodos conectados no grafo devem ser adjacentes espacialmente, enquanto cômodos não conectados devem ser espacialmente não adjacentes.
Dado o diagrama de bolhas, primeiro geramos um nó para cada cômodo e o inicializamos com um vetor de ruído de 128 dimensões, escolhido a partir de uma distribuição normal. Em seguida, combinamos o vetor de ruído com um vetor one-hot de 10 dimensões que representa o tipo de cômodo (tr). Assim, obtemos um vetor gr de 138 dimensões para representar o diagrama de bolhas inicial.
![]()
Note que, neste caso, os nós do grafo são utilizados como dados iniciais para o transformador proposto.
O bloco de transmissão de mensagens convolucionais (Conv-MPN) é representado por um tensor 3D no espaço de saída do design. Assim, aplicamos uma camada linear geral para expandir gr em um volume temático gr,l=1 de tamanho 16×8×8, onde l=1 é o objeto extraído da primeira camada Conv-MPN. Ele será submetido a duas upsamplings usando convolução transposta para se tornar um objeto gr,l=3 de tamanho 16×32×32.
A camada Conv-MPN atualiza o grafo de objetos espaciais através da transmissão de mensagens convolucionais. Em particular, atualizamos gr,l=1 nos seguintes passos:
- Usamos um GTE para registrar correlações de longo prazo entre cômodos conectados no grafo de entrada;
- Usamos outro GTE para capturar dependências de longo prazo entre cômodos não conectados no grafo de entrada;
- Combinamos as funções dos cômodos conectados no grafo de entrada;
- Combinamos as funções dos cômodos não conectados;
- Aplicamos um bloco convolucional (CNN) ao objeto combinado.
Este processo pode ser formulado da seguinte maneira:
![]()
onde N(r) denota os conjuntos de cômodos conectados e não conectados; "+" e ";" denotam soma pixel a pixel e concatenação por canal, respectivamente.
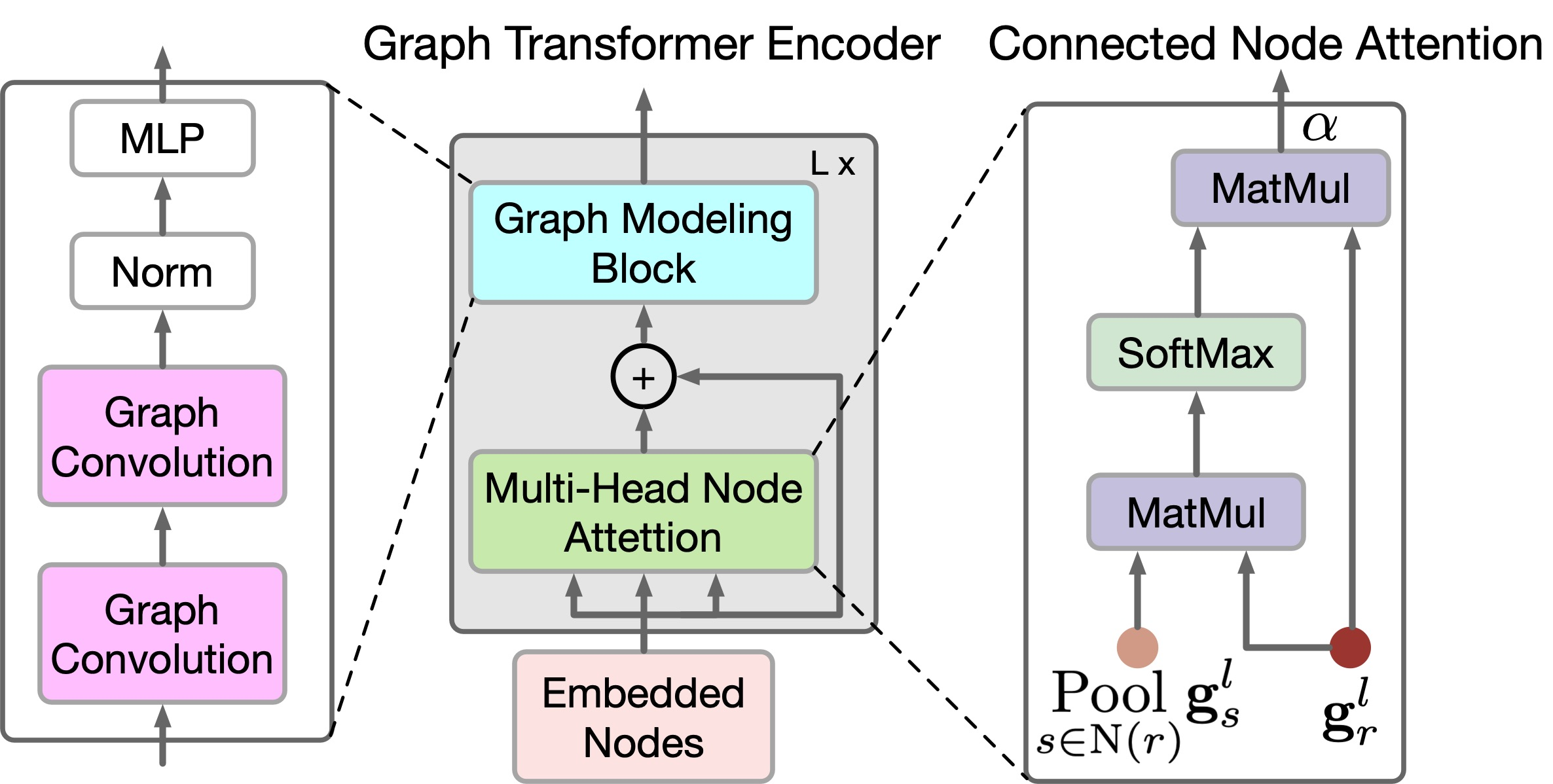
Para refletir as relações locais e globais entre os nós do grafo, os autores do método propõem um novo Codificador GTE. O GTE combina o mecanismo de Self-Attention dos modelos Transformer e a Graph Convolution para capturar correlações globais e locais, respectivamente. Note que no GTGAN não é utilizado codificação posicional, pois o objetivo da tarefa é indicar as posições dos nós no layout de casa gerado.
No GTGAN, o camada Self-Attention de várias cabeças é expandido para atenção de vários nós, com o objetivo de capturar correlações globais entre cômodos/nós conectados e dependências globais entre cômodos/nós não conectados. Para isso, os autores propõem dois novos módulos de atenção aos nós do grafo, a saber: atenção aos nós conectados (CNA) e atenção aos nós não conectados (NNA). Ambos os blocos possuem a mesma arquitetura de rede.
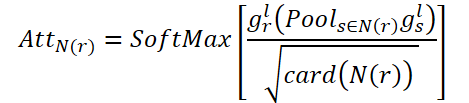
O objetivo do CNA é modelar correlações globais entre cômodos conectados. AttN(r) mede a influência de um nó sobre outros nós conectados. Em seguida, realizamos a multiplicação matricial de gr,l pelo AttN(r) transposto. Após isso, multiplicamos o resultado por um parâmetro de escala ɑ.
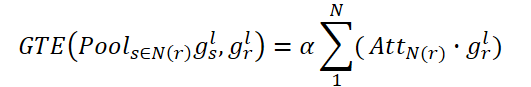
onde ɑ é um parâmetro treinável.
Dessa forma, cada nó conectado em N(r) representa uma soma ponderada de todos os nós conectados. Assim, o CNA obtém uma representação global da estrutura do grafo espacial e pode ajustar seletivamente os cômodos de acordo com o mapa de atenção conectado, melhorando a representação do layout da casa e a coerência semântica de alto nível.
De maneira similar, o NNA busca capturar as relações globais entre cômodos não conectados. Este também utiliza um parâmetro treinável ß.
Finalmente, realizamos a soma elementar de gr,l para que o objeto atualizado do nó possa fixar tanto as relações espaciais conectadas quanto as não conectadas.
![]()
Embora o CNA e o NNA sejam úteis para extrair dependências de longo prazo e globais, eles são menos eficazes na coleta de informações locais granulares em estruturas de dados complexas de uma casa. Para resolver essa limitação, os autores do método propõem um novo bloco de modelagem de grafos.
Em particular, dado o vetor gr,l gerado na equação anterior, este bloco adicionalmente aprimora as correlações locais utilizando redes convolucionais de grafos.
![]()
onde A denota a matriz de adjacência do grafo, GC(•) representa a convolução de grafo, e P denota os parâmetros treináveis. σ é a unidade linear gaussiana (GeLU).
Fornecer informações sobre as relações dos nós do grafo global ajuda a criar layouts de casas mais precisos. Para diferenciar este processo, os autores do método propõem uma nova função de perda baseada na matriz de adjacência, que corresponde às relações espaciais entre os grafos verdadeiros e os gerados. Mais precisamente, o grafo fixa as relações de adjacência entre cada nó em diferentes cômodos e, em seguida, garante a correspondência entre os grafos verdadeiros e gerados através da função de perda de consistência de ciclo proposta. Esta função de perda visa manter precisamente as relações mútuas entre os nós. Por um lado, as partes não adjacentes devem ser previstas como não adjacentes. Por outro lado, os nós vizinhos devem ser previstos como vizinhos e corresponder aos coeficientes de proximidade.
A visualização do GTGAN dos autores é apresentada abaixo.
2. Implementação com MQL5
Após considerar os aspectos teóricos do método GTGAN, passamos para a parte prática do nosso artigo, na qual implementamos as abordagens propostas utilizando MQL5.
Devemos notar imediatamente a diferença entre as tarefas resolvidas pelos autores do método e as nossas. Não buscamos gerar gráficos de movimento de preços. Nosso objetivo é encontrar a estratégia ótima de comportamento do Agente. E na saída do modelo, queremos obter a ação ótima do Agente em um determinado estado do ambiente. À primeira vista, nossas tarefas diferem radicalmente.
Mas, ao olhar mais de perto para a metodologia GTGAN, pode-se notar que a principal atenção dos autores é focada no Codificador (GTE). Aqui, grande atenção é dada tanto à arquitetura do Codificador quanto ao seu treinamento.
Os autores do método propõem o pré-treinamento do Codificador com mascaramento aleatório de nós e conexões. Propõe-se mascarar até 40% dos dados brutos, deixando cada nó e aresta com potenciais lacunas nas conexões vizinhas. Para restaurar os dados ausentes, cada incorporação de nó e aresta deve absorver e interpretar seu contexto local. Cada incorporação deve entender os detalhes específicos de seu ambiente imediato. A abordagem proposta de mascaramento aleatório com alto coeficiente e reconstrução subsequente elimina as limitações impostas pelo tamanho e forma dos subgrafos usados para previsão. Como resultado, as incorporações de nós e arestas são incentivadas a entender os detalhes contextuais locais.
Além disso, ao remover nós ou arestas com altos coeficientes, os nós e arestas restantes podem ser vistos como um conjunto de subgrafos cuja tarefa é prever todo o grafo. Isso representa uma tarefa de previsão mais complexa para cada grafo em comparação com outras tarefas de pré-treinamento autossupervisionado, que normalmente abrangem detalhes globais do grafo, usando grafos menores ou contexto como metas de previsão. A tarefa "intensa" proposta de pré-treinamento de mascaramento e reconstrução de grafo oferece uma perspectiva mais ampla para estudar incorporações superiores de nós e arestas, capazes de capturar detalhes complexos tanto no nível de nós/arestas individuais quanto no nível do grafo como um todo.
O Codificador no sistema proposto atua como uma ponte, transformando os atributos originais dos nós e arestas visíveis e não mascarados em suas respectivas incorporações em espaços de características ocultas. Esse processo inclui aspectos nodais e de bordas do Codificador, que incluem o bloco de modelagem de grafos proposto e o mecanismo de atenção de nós com várias cabeças. Essas funções são projetadas no espírito da arquitetura do Transformador, que é um método conhecido por sua capacidade de modelar dados sequenciais de maneira eficaz. Esse bloco ajuda a criar representações robustas que encapsulam a dinâmica integral das relações dentro do grafo.
Assim, podemos usar o Codificador proposto para explorar dependências locais e globais nos dados brutos. Implementamos o algoritmo do Codificador proposto em uma nova classe chamada CNeuronGTE.
2.1 Classe do Codificador GTE
A classe do Codificador GTECNeuronGTE será criada como herdeira de nossa classe base de camadas neurais CNeuronBaseOCL. A estrutura do Codificador proposto é tão diferente das variantes anteriores do Transformador que, apesar do grande número de camadas neurais anteriormente criadas utilizando mecanismos de atenção, decidimos não herdar uma delas. Embora utilizemos os desenvolvimentos anteriores no decorrer do trabalho.
A estrutura da nova classe é apresentada abaixo.
class CNeuronGTE : public CNeuronBaseOCL { protected: uint iHeads; ///< Number of heads uint iWindow; ///< Input window size uint iUnits; ///< Number of units uint iWindowKey; ///< Size of Key/Query window //--- CNeuronConvOCL cQKV; CNeuronSoftMaxOCL cSoftMax; int ScoreIndex; CNeuronBaseOCL cMHAttentionOut; CNeuronConvOCL cW0; CNeuronBaseOCL cAttentionOut; CNeuronCGConvOCL cGraphConv[2]; CNeuronConvOCL cFF[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionInsideGradients(void); public: CNeuronGTE(void) {}; ~CNeuronGTE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronGTE; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
Aqui vemos variáveis locais já familiares:
- iHeads;
- iWindow;
- iUnits;
- iWindowKey.
Sua função permanece a mesma. E nos familiarizaremos com o propósito das camadas internas no processo de implementação dos métodos.
Todos os objetos internos foram declarados estáticos, o que nos permite deixar o construtor e o destruidor da classe vazios. Note que, no construtor da classe, nem sequer especificamos o valor das variáveis locais.
A inicialização completa da classe, como sempre, é realizada no método Init. Nos parâmetros deste método, recebemos todas as informações necessárias para criar a arquitetura correta da classe. No corpo do método, chamamos imediatamente o método de mesmo nome da classe pai, onde é realizado o controle mínimo necessário dos parâmetros de entrada recebidos e a inicialização dos objetos herdados.
bool CNeuronGTE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Após a execução bem-sucedida do método da classe pai, salvamos os dados recebidos em variáveis locais.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); activation = None;
E inicializamos os objetos adicionados. Primeiro, inicializamos a camada convolucional interna cQKV. Nela, planejamos gerar a representação de todas as 3 entidades (Query, Key e Value) em fluxos paralelos. O tamanho da janela dos dados de entrada e seu passo são iguais ao tamanho da descrição de um elemento da sequência. E o número de filtros de convolução é igual ao produto do tamanho do vetor de descrição de uma entidade de um elemento da sequência multiplicado pelo número de cabeças de atenção e por 3 (número de entidades). O número de elementos é igual ao tamanho da sequência analisada.
if(!cQKV.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * 3 * iHeads, iUnits, optimization, iBatch)) return false;
Para aumentar a estabilidade do bloco, normalizamos as entidades geradas usando a camada SoftMax.
if(!cSoftMax.Init(0, 1, OpenCL, iWindowKey * 3 * iHeads * iUnits, optimization, iBatch)) return false; cSoftMax.SetHeads(3 * iHeads * iUnits);
O próximo passo é criar um buffer de coeficientes de dependência no contexto OpenCL. Seu tamanho é 2 vezes maior que o normal, para gravar separadamente os coeficientes para vértices conectados e não conectados.
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits * 2 * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Os resultados da atenção de várias cabeças serão armazenados na camada local cMHAttentionOut.
if(!cMHAttentionOut.Init(0, 2, OpenCL, iWindowKey * 2 * iHeads * iUnits, optimization, iBatch)) return false;
Observe que o tamanho da camada de resultados da atenção de várias cabeças também é 2 vezes maior que a camada equivalente das implementações anteriores do Transformador. Isso também é feito para permitir a gravação de dados de vértices conectados e não conectados.
Além disso, essa abordagem nos permite não criar um funcional separado para o aprendizado dos parâmetros de escala ɑ e ß. Em vez disso, usaremos a funcionalidade da camada W0. Nesse caso, ela combinará as cabeças de atenção, bem como a influência de vértices conectados e não conectados.
if(!cW0.Init(0, 3, OpenCL, 2 * iWindowKey * iHeads, 2 * iWindowKey* iHeads, iWindow, iUnits, optimization, iBatch)) return false;
Após o bloco de atenção, somaremos os resultados aos dados de entrada e normalizaremos os resultados. Os valores obtidos serão gravados na camada cAttentionOut.
if(!cAttentionOut.Init(0, 4, OpenCL, iWindow * iUnits, optimization, iBatch)) return false;
Em seguida, temos 2 blocos, cada um com 2 camadas. Esse é o bloco de convolução de grafos e o FeedForward. Os objetos desses blocos serão inicializados em um loop.
for(int i = 0; i < 2; i++) { if(!cGraphConv[i].Init(0, 5 + i, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cFF[i].Init(0, 7 + i, OpenCL, (i == 0 ? iWindow : 4 * iWindow), (i == 0 ? iWindow : 4 * iWindow), (i == 1 ? iWindow : 4 * iWindow), iUnits, optimization, iBatch)) return false; }
Por fim, substituímos o buffer de gradientes de erro.
if(cFF[1].getGradient() != Gradient) { if(!!Gradient) delete Gradient; Gradient = cFF[1].getGradient(); } //--- return true; }
E concluímos o método.
Após a inicialização da classe, passamos para a organização do algoritmo de propagação da classe. Aqui, primeiro focamos em nosso programa OpenCL, onde criaremos um novo kernel GTEFeedForward. Dentro desse kernel, analisaremos dependências de nós conectados e não conectados. Na metodologia do método GTGAN, no corpo do kernel GTEFeedForward, implementaremos as funcionalidades CNA e NNA.
Mas, antes de prosseguir com a implementação, vamos definir quais nós consideramos conectados e quais não. A primeira coisa a saber é que, em nossa implementação, os nós são descrições dos parâmetros de uma barra. Estamos lidando com a análise de séries temporais. Portanto, diretamente conectados só podem ser duas barras subsequentes. Assim, para a barra Xt, as barras conectadas são Xt-1 e Xt+1. No entanto, as barras X-1 e Xt+1 não são conectadas entre si, pois há uma barra Xt entre elas.
Com esse ponto esclarecido, passamos para a implementação. Nos parâmetros, o kernel recebe ponteiros para os buffers de troca de dados.
__kernel void GTEFeedForward(__global float *qkv, __global float *score, __global float *out, int dimension) { const size_t cur_q = get_global_id(0); const size_t units_q = get_global_size(0); const size_t cur_k = get_local_id(1); const size_t units_k = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
No corpo do kernel, identificamos o fluxo no espaço de tarefas. Neste caso, estamos lidando com um espaço de tarefas 3D, uma das quais é agrupada em um grupo local.
A próxima etapa é definir os deslocamentos nos buffers de dados.
int shift_q = dimension * (cur_q + h * units_q); int shift_k = (cur_k + h * units_k + heads * units_q); int shift_v = dimension * (h * units_k + heads * (units_q + units_k)); int shift_score_con = units_k * (cur_q * 2 * heads + h) + cur_k; int shift_score_notcon = units_k * (cur_q * 2 * heads + heads + h) + cur_k; int shift_out_con = dimension * (cur_q + h * units_q); int shift_out_notcon = dimension * (cur_q + units_q * (h + heads));
Aqui, também declaramos um array local 2D. Na segunda dimensão, há 2 elementos para os nós conectados e não conectados.
const uint ls_score = min((uint)units_k, (uint)LOCAL_ARRAY_SIZE); __local float local_score[LOCAL_ARRAY_SIZE][2];
A próxima etapa é determinar os coeficientes de dependência. Primeiro, multiplicamos os tensores correspondentes de Query e Key. Dividimos pela raiz da dimensionalidade e tomamos o valor exponencial.
//--- Score float scr = 0; for(int d = 0; d < dimension; d ++) scr += qkv[shift_q + d] * qkv[shift_k + d]; scr = exp(min(scr / sqrt((float)dimension), 30.0f));
Determinamos se os elementos da sequência analisados são conectados e salvamos o resultado no elemento necessário do buffer.
if(cur_q == cur_k) { score[shift_score_con] = scr; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = scr; } } else { if(abs(cur_q - cur_k) == 1) { score[shift_score_con] = scr; score[shift_score_notcon] = 0; if(cur_k < ls_score) { local_score[cur_k][0] = scr; local_score[cur_k][1] = 0; } } else { score[shift_score_con] = 0; score[shift_score_notcon] = scr; if(cur_k < ls_score) { local_score[cur_k][0] = 0; local_score[cur_k][1] = scr; } } } barrier(CLK_LOCAL_MEM_FENCE);
Agora podemos encontrar a soma dos coeficientes para cada um dos elementos da sequência.
for(int k = ls_score; k < units_k; k += ls_score) { if((cur_k + k) < units_k) { local_score[cur_k][0] += score[shift_score_con + k]; local_score[cur_k][1] += score[shift_score_notcon + k]; } } barrier(CLK_LOCAL_MEM_FENCE); //--- int count = ls_score; do { count = (count + 1) / 2; if(cur_k < count) { if((cur_k + count) < units_k) { local_score[cur_k][0] += local_score[cur_k + count][0]; local_score[cur_k][1] += local_score[cur_k + count][1]; local_score[cur_k + count][0] = 0; local_score[cur_k + count][1] = 0; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); barrier(CLK_LOCAL_MEM_FENCE);
E ajustamos a soma dos coeficientes de dependência para 1 para cada elemento da sequência. Para isso, basta dividir o valor de cada elemento pela soma correspondente.
score[shift_score_con] /= local_score[0][0]; score[shift_score_notcon] /= local_score[0][1]; barrier(CLK_LOCAL_MEM_FENCE);
Com os coeficientes de dependência encontrados, podemos determinar os resultados da influência dos nós conectados e não conectados.
shift_score_con -= cur_k; shift_score_notcon -= cur_k; for(int d = 0; d < dimension; d += ls_score) { if((cur_k + d) < dimension) { float sum_con = 0; float sum_notcon = 0; for(int v = 0; v < units_k; v++) { sum_con += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_con + v]; sum_notcon += qkv[shift_v + v * dimension + cur_k + d] * score[shift_score_notcon + v]; } out[shift_out_con + cur_k + d] = sum_con; out[shift_out_notcon + cur_k + d] = sum_notcon; } } }
Após a execução bem-sucedida de todas as iterações, concluímos o trabalho do kernel e retornamos ao trabalho no programa principal. Aqui, primeiro criamos o método AttentionOut para chamar o kernel criado acima. Este método será chamado de outro método da mesma classe. Ele trabalha apenas com objetos internos e não contém parâmetros.
No corpo do método, verificamos primeiro a atualidade do ponteiro para o objeto da classe que trabalha com o contexto OpenCL.
bool CNeuronGTE::AttentionOut(void) { if(!OpenCL) return false;
Em seguida, definimos o espaço de tarefas e o tamanho dos grupos de trabalho. Neste caso, usamos um espaço de tarefas 3D com união em 1 dimensão nos grupos de trabalho.
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits, 1};
Depois, passamos os parâmetros necessários para o kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_qkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_GTEFeedForward, def_k_gteff_out, cAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_GTEFeedForward, def_k_gteff_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
E colocamos o kernel na fila de execução.
if(!OpenCL.Execute(def_k_GTEFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Durante cada etapa, controlamos o processo de execução das operações. Após a conclusão do método, retornamos o valor lógico dos resultados do método, o que permitirá controlar o processo no programa chamador.
Após a conclusão do trabalho preparatório, criamos o método de alto nível de propagação da nossa classe CNeuronGTE::feedForward. Nos parâmetros deste método, similar a muitos métodos homônimos de outras classes discutidas anteriormente, recebemos um ponteiro para o objeto da camada anterior, cujo buffer contém os dados de entrada para o nosso método.
bool CNeuronGTE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.FeedForward(NeuronOCL)) return false;
No entanto, no corpo do método, não verificamos a atualidade do ponteiro recebido, mas chamamos imediatamente o método de propagação do objeto de formação das entidades Query, Key e Value. No corpo do método chamado, todos os controles necessários já estão implementados. Após a formação bem-sucedida das entidades, conforme podemos julgar pelo resultado do método chamado, normalizamos os dados obtidos na camada SoftMax.
if(!cSoftMax.FeedForward(GetPointer(cQKV))) return false;
Em seguida, usamos o método AttentionOut criado anteriormente e determinamos a influência dos vértices conectados e não conectados.
if(!AttentionOut()) return false;
A dimensão dos resultados da atenção de várias cabeças será reduzida ao tamanho do tensor dos dados brutos.
if(!cW0.FeedForward(GetPointer(cMHAttentionOut))) return false;
Em seguida, somamos e normalizamos os dados.
if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cAttentionOut.getOutput(), iWindow, true)) return false;
Nesse estágio, concluímos o bloco de atenção de múltiplas cabeças e passamos para o bloco de convolução de grafos GC. Aqui, usamos 2 camadas da CrystalGraph Convolutional Network. Para implementar a funcionalidade, basta chamar os métodos de propagação dessas camadas de forma sequencial.
if(!cGraphConv[0].FeedForward(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].FeedForward(GetPointer(cGraphConv[0]))) return false;
Em seguida, temos o bloco FeedForward.
if(!cFF[0].FeedForward(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].FeedForward(GetPointer(cFF[0]))) return false;
E, ao final do método, somamos e normalizamos os resultados mais uma vez.
if(!SumAndNormilize(cAttentionOut.getOutput(), cFF[1].getOutput(), Output, iWindow, true)) return false; //--- return true; }
Após a implementação da propagação, passamos a preparar o processo de propagação reversa. Começamos criando um novo kernel GTEInsideGradients no programa OpenCL. Nos parâmetros, o kernel recebe ponteiros para os buffers de dados necessários. Todas as dimensões são obtidas do espaço de tarefas.
__kernel void GTEInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const uint u = get_global_id(0); const uint d = get_global_id(1); const uint h = get_global_id(2); const uint units = get_global_size(0); const uint dimension = get_global_size(1); const uint heads = get_global_size(2);
Similar ao kernel de propagação, este kernel será executado em um espaço de tarefas 3D. Mas desta vez sem a organização de grupos de trabalho. No corpo do kernel, identificamos o fluxo atual no espaço de tarefas em todas as dimensões.
O algoritmo do nosso kernel pode ser dividido em 3 blocos:
- Gradiente de Value;
- Gradiente de Query;
- Gradiente de Key.
A propagação reversa é organizada na ordem inversa à da propagação. Primeiramente, determinamos o gradiente de erro para a entidade Value. Neste bloco, inicialmente calculamos os deslocamentos nos buffers de dados.
//--- Calculating Value's gradients { int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units + u) + d;
Em seguida, organizamos um ciclo para acumular os gradientes de erro dos nós conectados e não conectados. O resultado é salvo no elemento correspondente do buffer global de gradientes de erro das entidades qkv_g.
float sum = 0; for(uint i = 0; i <= units; i ++) { sum += gradient[shift_out_con + i * dimension] * scores[shift_score_con + i * step_score]; sum += gradient[shift_out_notcon + i * dimension] * scores[shift_score_notcon + i * step_score]; } qkv_g[shift_v] = sum; }
Na segunda etapa, calculamos os gradientes de erro para a entidade Query. Similar ao primeiro bloco, primeiro calculamos os deslocamentos nos buffers de dados.
//--- Calculating Query's gradients { int shift_q = dimension * (u + h * units) + d; int shift_out_con = dimension * (h * units + u) + d; int shift_out_notcon = dimension * (u + units * (h + heads)) + d; int shift_score_con = units * h; int shift_score_notcon = units * (heads + h); int shift_v = dimension * (h * units + 2 * heads * units);
O cálculo do gradiente de erro será um pouco mais complexo. Primeiro, precisamos determinar o gradiente de erro ao nível da matriz de coeficientes de dependência e ajustar sua derivada usando a função SoftMax. Só então transferimos o gradiente de erro para o nível da entidade desejada. Para isso, precisamos organizar um sistema de ciclos aninhados.
float grad = 0; for(int k = 0; k < units; k++) { int shift_k = (k + h * units + heads * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + k]; float sc_notcon = scores[shift_score_notcon + k]; for(int v = 0; v < units; v++) for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_con + dim] * ((float)(k == v) - sc_con); sc_g += scores[shift_score_notcon + v] * qkv[shift_v + v * dimension + dim] * gradient[shift_out_notcon + dim] * ((float)(k == v) - sc_notcon); } grad += sc_g * qkv[shift_k]; }
Após completar todas as iterações dos ciclos, transferimos o gradiente de erro acumulado para o elemento correspondente do buffer global de dados.
qkv_g[shift_q] = grad; }
No bloco final do nosso kernel, determinamos o gradiente de erro para a entidade Key. Neste caso, o algoritmo é similar ao bloco anterior. Mas pegamos o gradiente de erro da matriz de coeficientes de dependência em outra dimensão.
//--- Calculating Key's gradients { int shift_k = (u + (h + heads) * units) + d; int shift_out_con = dimension * h * units + d; int shift_out_notcon = dimension * units * (h + heads) + d; int shift_score_con = units * h + u; int shift_score_notcon = units * (heads + h) + u; int step_score = units * 2 * heads; int shift_v = dimension * (h * units + 2 * heads * units); float grad = 0; for(int q = 0; q < units; q++) { int shift_q = dimension * (q + h * units) + d; float sc_g = 0; float sc_con = scores[shift_score_con + u + q * step_score]; float sc_notcon = scores[shift_score_notcon + u + q * step_score]; for(int g = 0; g < units; g++) { for(int dim = 0; dim < dimension; dim++) { sc_g += scores[shift_score_con + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_con + g * dimension + dim] * ((float)(u == g) - sc_con); sc_g += scores[shift_score_notcon + g] * qkv[shift_v + u * dimension + dim] * gradient[shift_out_notcon + g * dimension+ dim] * ((float)(u == g) - sc_notcon); } } grad += sc_g * qkv[shift_q]; } qkv_g[shift_k] = grad; } }
Para chamar o kernel descrito, criamos o método CNeuronGTE::AttentionInsideGradients. O algoritmo de construção é similar ao método CNeuronGTE::AttentionOut. Não entraremos em detalhes agora, mas você pode encontrar o código completo de todos os programas utilizados na preparação deste artigo no anexo.
O processo completo de distribuição do gradiente de erro é descrito de forma abrangente no método CNeuronGTE::calcInputGradients. Nos parâmetros, este método recebe um ponteiro para o objeto da camada neural anterior, que receberá o gradiente de erro.
bool CNeuronGTE::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cFF[1].calcInputGradients(GetPointer(cFF[0]))) return false;
Aqui vale lembrar que, graças ao nosso já frequentemente utilizado método de substituição de buffers de dados. Ao executar o método de propagação reversa da camada neural subsequente, obtemos o gradiente de erro diretamente no buffer da última camada do bloco FeedForward. Portanto, não há necessidade de copiar dados desnecessariamente. No método de propagação reversa, começamos imediatamente com a distribuição do gradiente de erro pelas camadas do bloco FeedForward.
if(!cFF[0].calcInputGradients(GetPointer(cGraphConv[1]))) return false;
Em seguida, passamos o gradiente de erro pelo bloco de convolução de grafos de forma similar.
if(!cGraphConv[1].calcInputGradients(GetPointer(cGraphConv[0]))) return false; if(!cGraphConv[1].calcInputGradients(GetPointer(cAttentionOut))) return false;
Neste estágio, combinamos o gradiente de erro de dois fluxos.
if(!SumAndNormilize(cAttentionOut.getGradient(), Gradient, cW0.getGradient(), iWindow, false)) return false;
Depois, distribuímos o gradiente de erro pelas cabeças de atenção.
if(!cW0.calcInputGradients(GetPointer(cMHAttentionOut))) return false;
E passamos pelo bloco de atenção.
if(!AttentionInsideGradients()) return false;
Lembro que o gradiente de erro de todas as três entidades (Query, Key, Value) está contido em um buffer concatenado, o que nos permite processar todas as entidades em paralelo. Primeiro, ajustamos o gradiente de erro para a derivada da função SoftMax, que usamos para normalizar os dados.
if(!cSoftMax.calcInputGradients(GetPointer(cQKV))) return false;
Depois, reduzimos o gradiente de erro ao nível da camada anterior.
if(!cQKV.calcInputGradients(prevLayer)) return false;
Aqui, basta adicionar o gradiente de erro do segundo fluxo de dados.
if(!SumAndNormilize(cW0.getGradient(), prevLayer.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
E concluímos o método.
Após distribuir o gradiente de erro, resta apenas atualizar os parâmetros do modelo para minimizar o erro. Todos os parâmetros treináveis da nossa classe estão contidos em objetos internos. Portanto, para ajustar os parâmetros, chamaremos sequencialmente os métodos correspondentes dos objetos internos.
bool CNeuronGTE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; if(!cW0.UpdateInputWeights(GetPointer(cMHAttentionOut))) return false; if(!cGraphConv[0].UpdateInputWeights(GetPointer(cAttentionOut))) return false; if(!cGraphConv[1].UpdateInputWeights(GetPointer(cGraphConv[0]))) return false; if(!cFF[0].UpdateInputWeights(GetPointer(cGraphConv[1]))) return false; if(!cFF[1].UpdateInputWeights(GetPointer(cFF[0]))) return false; //--- return true; }
Com isso, concluímos a análise dos métodos da nossa nova classe CNeuronGTE. Os métodos de manutenção da classe, incluindo a manipulação de arquivos, podem ser encontrados no anexo. Lá, como sempre, você encontrará o código completo de todos os programas utilizados na preparação deste artigo.
2.2 Arquitetura dos Modelos
Após criar a nova classe, passamos a trabalhar em nossos modelos, criando sua arquitetura e treinando-os. Aqui, vale lembrar que o método GTGAN prevê o pré-treinamento do Codificador. Portanto, criaremos dois métodos para descrever a arquitetura dos modelos. No primeiro método, CreateEncoderDescriptions, criaremos as descrições da arquitetura do Codificador e do Decodificador, usado apenas para o pré-treinamento das representações.
bool CreateEncoderDescriptions(CArrayObj *encoder, CArrayObj *decoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; }
Na entrada do Codificador, fornecemos a descrição de uma vela.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados recebidos são normalizados usando uma camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, criamos o embedding da última barra e a adicionamos à pilha.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
Aqui, é importante notar que, ao contrário dos trabalhos anteriores, onde o embedding era criado em uma única camada, utilizamos as sugestões do método GTGAN para o bloco de mensagens Conv-MPN e dividimos o processo criação da incorporação em duas etapas. Após a camada de incorporação, adicionamos outra camada convolucional que finaliza a geração dos embeddings dos estados.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, adicionamos uma camada DropOut para mascarar dados durante o pré-treinamento das representações.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count*prev_wout; descr.probability= 0.4f; descr.activation=None; if(!encoder.Add(descr)) { delete descr; return false; }
No próximo passo, desviamos um pouco do algoritmo proposto e adicionamos a codificação posicional. Isso se deve às significativas diferenças nas tarefas propostas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, adicionamos 8 camadas do novo Codificador em um loop.
//--- layer 6 - 14 for(int i = 0; i < 8; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronGTE; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!encoder.Add(descr)) { delete descr; return false; } }
A arquitetura do Decodificador será significativamente mais curta. Na entrada do modelo, fornecemos os resultados do Codificador.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count * prev_wout; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Passamos esses resultados por uma camada convolucional.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count=prev_count; descr.window = prev_wout; descr.step=prev_wout; descr.window_out=EmbeddingSize/4; descr.optimization = ADAM; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
E normalizamos com a função SoftMax.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Na saída do Decodificador, criamos uma camada totalmente conectada com um número de elementos igual ao resultado da camada de embedding.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count*EmbeddingSize/2; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Como resultado, formamos um autocodificador assimétrico a partir dos modelos, que será treinado para restaurar os dados na pilha da camada de embedding. A escolha do estado latente da camada de embedding não é acidental. Durante o treinamento, queremos focar o Codificador no conjunto completo de dados históricos, e não apenas na última vela.
Descreveremos a arquitetura do Ator e do Crítico no método CreateDescriptions.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Na arquitetura do Ator, também decidi adicionar um pouco de experimentação. Na entrada do modelo, fornecemos a descrição do estado atual da conta.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Uma camada totalmente conectada criará um embedding do estado recebido.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, adicionamos um bloco de 3 camadas de Atenção Cruzada, nas quais avaliaremos as dependências entre o estado atual da conta e o estado do ambiente.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {prev_count,GPTBars}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os resultados obtidos são processados por 2 camadas totalmente conectadas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
E na saída do Ator, geramos sua política estocástica.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O modelo do Crítico foi transferido quase sem alterações do trabalho anterior. Na entrada do modelo, fornecemos os resultados do Codificador.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = GPTBars*EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Aos dados recebidos, adicionamos as ações do Ator.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type=defNeuronConcatenate; descr.window=prev_count; descr.step = NActions; descr.count=LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; }
E formamos um bloco de tomada de decisão com 2 camadas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.3 Expert Advisor de Treinamento de Representações
Após criar a arquitetura dos modelos, passamos para a construção dos Expert Advisors para seu treinamento. Primeiro, criaremos o Expert Advisor de pré-treinamento de representações "...\Experts\GTGAN\StudyEncoder.mq5". A estrutura do advisor é amplamente baseada em trabalhos anteriores. Para reduzir o volume do artigo, focaremos apenas no método de treinamento direto das modelos Train.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
No corpo do método, primeiro geramos um vetor de probabilidades para selecionar passagens do buffer de reprodução de experiências com base em sua eficácia.
Em seguida, declaramos variáveis locais.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Depois, organizamos um sistema de ciclos de treinamento dos modelos. No corpo do ciclo externo, amostramos a trajetória e o estado inicial do treinamento.
int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - batch)); if(state <= 0) { iter--; continue; }
Limpamos o buffer do Codificador e determinamos o estado final do lote de treinamento.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total);
Após concluir o trabalho preparatório, organizamos um ciclo aninhado de treinamento direto dos modelos.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
Aqui, carregamos a descrição do estado atual do ambiente a partir do buffer de reprodução de experiências e chamamos o método de propagação do Codificador.
//--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Depois disso, realizamos a propagação do Decodificador.
if(!Decoder.feedForward((CNet*)GetPointer(Encoder),-1,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Após a propagação, precisamos determinar as métricas alvo para o treinamento do modelo. O autocodificador se auto-treina restaurando os dados originais. Como discutido anteriormente, durante o treinamento do modelo de representações, usaremos o estado oculto da camada de embeddings. Carregamos esses dados no buffer local.
Encoder.GetLayerOutput(LatentLayer,Result);
E os passamos como valores-alvo para a otimização dos parâmetros dos nossos modelos.
if(!Decoder.backProp(Result,(CBufferFloat*)NULL) || !Encoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Agora, basta informar o usuário sobre o andamento do processo de treinamento e passar para a próxima iteração do sistema de ciclos.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão bem-sucedida do processo de treinamento do modelo de representação, limpamos o campo de comentários no gráfico.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Decoder", Decoder.getRecentAverageError()); ExpertRemove(); //--- }
Registramos no log os resultados do treinamento e iniciamos o processo de finalização do EA (Expert Advisor).
Neste ponto, podemos utilizar o conjunto de dados de treinamento de trabalhos anteriores e iniciar o processo de treinamento do modelo de representação. Enquanto o modelo está sendo treinado, passamos à criação do EA para o treinamento da política do Ator.
2.4 EA para o treinamento da política do Ator
Para treinar a política de comportamento do Ator, criaremos o EA "...\Experts\GTGAN\Study.mq5". Vale ressaltar que, durante o processo de treinamento, utilizaremos 3 modelos, mas treinaremos apenas 2 (Ator e Crítico). O modelo do Codificador foi treinado na etapa anterior.
CNet Encoder; CNet Actor; CNet Critic;
No método de inicialização do EA, primeiro carregamos a base de exemplos.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Em seguida, tentamos carregar os modelos previamente treinados. Neste caso, uma falha ao carregar o Codificador previamente treinado é crítica para o funcionamento do programa.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Can't load pretrained Encoder"); return INIT_FAILED; }
No entanto, em caso de falha ao carregar o Ator e/ou o Crítico, criamos novos modelos, inicializados com parâmetros aleatórios.
if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor) || !Critic.Create(critic)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Todos os modelos são transferidos para um único contexto OpenCL.
OpenCL = Encoder.GetOpenCL(); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
E desativamos o modo de treinamento do Codificador.
Encoder.TrainMode(false);
Lembro que sua arquitetura utiliza uma camada DropOut, que mascara dados aleatoriamente. Durante a utilização prática do modelo, precisamos desativar a mascaramento, o que é feito desativando o modo de treinamento do modelo.
Em seguida, realizamos o controle mínimo necessário da arquitetura dos modelos.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Inicializamos buffers de dados auxiliares.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
E geramos um evento de início do treinamento dos modelos.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
O processo de treinamento dos modelos é organizado, como de costume, no método Train.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
No corpo do método, assim como no EA anterior, primeiro geramos um vetor de probabilidades de seleção de trajetórias a partir do buffer de reprodução de experiências com base na rentabilidade delas. E inicializamos variáveis locais. Em seguida, organizamos o sistema de ciclos de treinamento dos modelos.
No corpo do ciclo externo, amostramos uma trajetória do buffer de reprodução de experiências e o estado inicial do processo de treinamento nela.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand()*MathRand() / MathPow(32767, 2))*(Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Limpamos a pilha do Codificador e determinamos o último estado do pacote de treinamento.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
Após concluir o trabalho preparatório, organizamos um ciclo aninhado de treinamento direto dos modelos.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- Trajectory if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
No corpo do ciclo interno, carregamos a descrição do estado analisado da conta a partir do buffer de reprodução de experiências e realizamos a propagação do Codificador.
Em seguida, para realizar a propagação do Ator, precisamos carregar a descrição do estado da conta a partir do buffer de reprodução de experiências.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Aqui adicionamos um carimbo de tempo ao estado atual.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
E realizamos a propagação do Ator.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount),1,false,GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E então do Crítico.
//--- Critic if(!Critic.feedForward((CNet *)GetPointer(Encoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Os valores-alvo para ambos os modelos são obtidos do buffer de reprodução de experiências. Primeiro, realizamos a propagação reversa do Ator.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E então do Crítico, transmitindo o gradiente de erro para o Ator.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Em ambos os casos, não atualizamos os parâmetros do Codificador.
Após a conclusão bem-sucedida da propagação reversa de ambos os modelos, informamos o usuário sobre o andamento do processo de treinamento e passamos para a próxima iteração do sistema de ciclos.
//--- if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão do processo de treinamento, limpamos o campo de comentários no gráfico.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Registramos no log os resultados do treinamento e iniciamos o processo de finalização do EA.
Com isso, concluímos a análise dos programas de treinamento dos modelos. Os programas de interação com o ambiente foram transferidos do artigo anterior com ajustes mínimos. Recomendo que você consulte o anexo, onde encontrará o código completo de todos os programas utilizados na preparação deste artigo.
3. Testes
Nas seções anteriores deste artigo, apresentamos o novo método GTGAN e realizamos um grande trabalho de implementação das abordagens propostas usando MQL5. Nesta parte do artigo, como de costume, realizamos testes do trabalho realizado com a avaliação dos resultados obtidos em dados reais no testador de estratégias do MetaTrader 5. O treinamento e teste dos modelos foram realizados com dados históricos do instrumento EURUSD, timeframe H1. O treinamento dos modelos foi feito no período histórico dos primeiros 7 meses de 2023. O teste do modelo treinado foi realizado com dados de agosto de 2023.
Os modelos criados neste artigo trabalham com dados brutos, de maneira semelhante aos modelos de artigos anteriores. Os vetores de ações do Ator e as recompensas pelas transições para um novo estado são idênticos aos dos artigos anteriores. Portanto, para o treinamento dos modelos, podemos usar o buffer de reprodução de experiências coletado durante o treinamento dos modelos de artigos anteriores. Para isso, basta renomear o arquivo para "GTGAN.bd".
O treinamento dos modelos é realizado em 2 etapas. Primeiro, treinamos o Codificador (modelo de representações). Em seguida, é treinada a política de comportamento do Ator. Vale mencionar que a divisão do processo de treinamento em 2 etapas tem um efeito positivo. Os modelos são treinados de forma bastante rápida e estável.
Os resultados do treinamento indicam que o modelo aprendeu rapidamente a generalizar e seguir a política de ações do buffer de reprodução de experiências. Infelizmente, meu buffer de reprodução de experiências continha poucos casos positivos. O modelo aprendeu uma política próxima à média do conjunto de treinamento, que, infelizmente, não resulta em um resultado positivo. Acho que vale a pena tentar treinar o modelo com passagens positivas.
Considerações finais
Neste artigo, apresentamos o algoritmo GTGAN, que foi introduzido em janeiro de 2024 para resolver complexas tarefas arquitetônicas. Para nossos objetivos, tentamos adotar abordagens de análise abrangente do estado atual no Codificador GTE, que combina de maneira concisa as vantagens dos métodos de atenção e dos modelos de grafos convolucionais.
Na parte prática do artigo, implementamos as abordagens propostas usando MQL5 e testamos os modelos obtidos em dados reais no testador de estratégias do MetaTrader 5.
Os resultados dos testes indicam a necessidade de trabalho adicional com as abordagens propostas.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA para coleta de exemplos usando o método Real-ORL |
| 3 | Study.mq5 | EA | EA para treinamento de modelos |
| 4 | StudyEncoder.mq5 | EA | EA para treinamento de modelo de representações |
| 4 | Test.mq5 | EA | EA para teste de modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14445
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
 Modelo GRU de Deep Learning com Python para ONNX com EA, e comparação entre modelos GRU e LSTM
Modelo GRU de Deep Learning com Python para ONNX com EA, e comparação entre modelos GRU e LSTM
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso