
Características del Wizard MQL5 que debe conocer (Parte 20): Regresión simbólica
Introducción
Continuamos con estas series en las que examinamos algoritmos que pueden codificarse rápidamente, probarse y quizás incluso distribuirse, todo ello gracias al asistente MQL5, que no sólo cuenta con una biblioteca de funciones y clases de negociación estándar que acompañan a un Asesor Experto codificado, sino que también dispone de señales y métodos de negociación alternativos que pueden utilizarse en paralelo con cualquier implementación de clase personalizada.
La regresión simbólica es una variante del análisis de regresión que parte más de una «pizarra en blanco» que su prima tradicional, la regresión clásica. La mejor forma de ilustrar esto sería si consideramos el típico problema de regresión que consiste en buscar la pendiente y la intersección de una línea que se ajuste lo mejor posible a un conjunto de puntos de datos.

y = mx + c
Donde:
- 'y' es el pronóstico y el valor dependiente
- 'm' es la pendiente de la línea de mejor ajuste
- 'c' es la intersección con el eje 'y'
- y 'x' es la variable independiente
El problema anterior supone que los puntos de datos idealmente deberían ajustarse a una línea recta, por lo que se buscan soluciones para la intersección con el eje 'y' y la pendiente. Como alternativa, las redes neuronales también, en esencia, buscan encontrar el garabato o ecuación cuadrática que mejor represente 2 conjuntos de datos (también conocido como el modelo) asumiendo una red con una arquitectura preestablecida (número de capas, tamaños de capas, tipos de activación, etc.). Estos enfoques y otros similares tienen todos este sesgo de partida y hay casos en los que desde el aprendizaje profundo y (o) la experiencia, esto está justificado, sin embargo, la regresión simbólica permite que el modelo descriptivo que mapea dos conjuntos de datos se construya como un árbol de expresión comenzando con nodos asignados aleatoriamente.
Esto podría, en teoría, ser más hábil para descubrir complejas relaciones de mercado que podrían pasarse por alto con los medios convencionales. La regresión simbólica (SR, Symbolic Regression) tiene varias ventajas sobre los enfoques tradicionales. Es más adaptable a los nuevos datos del mercado y a las condiciones cambiantes, ya que cada análisis comienza sin sesgos, utilizando una asignación aleatoria de los nodos del árbol de expresión que luego se optimizan. Además, SR puede utilizar múltiples fuentes de datos, a diferencia de la regresión lineal, que supone que una sola variable "x" influye en el valor "y". Esta flexibilidad permite a SR proporcionar modelos más precisos y completos para escenarios de datos complejos. La adaptabilidad permite que más variables además de la 'x' solitaria se reúnan en un árbol de expresión que define mejor el valor de 'y'; es más flexible ya que el árbol de expresión ejerce más control sobre los datos de entrenamiento al desarrollar nodos sistemáticos que procesan los datos en una secuencia establecida con coeficientes definidos que le permiten capturar relaciones más complejas en oposición a, por ejemplo, la regresión lineal (como la anterior), donde solo se capturarían relaciones lineales. Incluso si 'y' dependiera únicamente de 'x', esta relación puede no ser lineal ya que podría ser cuadrática y SR permite establecer esto a partir de la optimización genética; y finalmente desmitificar la relación del modelo de caja negra entre los conjuntos de datos estudiados al introducir explicabilidad, ya que los árboles de expresión construidos inherentemente 'explican' en términos más precisos cómo los datos de entrada realmente se asignan al objetivo. La explicabilidad es inherente a la mayoría de las ecuaciones, sin embargo lo que SR añade quizás es la 'simplicidad' al realizar evoluciones genéticas a partir de expresiones más complejas y evolucionar hacia las más simples siempre que sus puntuaciones de mejor ajuste sean superiores.
Definición
SR representa el modelo de mapeo entre las variables independientes y la variable dependiente (o predicha) como un árbol de expresión. Así pues, una representación diagramática como la que figura a continuación:
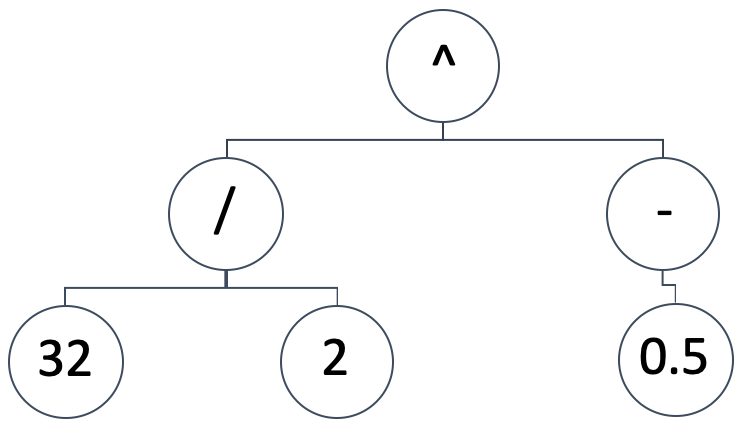
Se implicaría la expresión matemática:
(32/2) ^ (-0.5)
Eso equivaldría a: 0,25. Los árboles de expresión pueden adoptar una gran variedad de formas y diseños, queremos mantener la premisa fundacional de la RS, que es comenzar con una configuración aleatoria y no sesgada. Al mismo tiempo, necesitamos poder ejecutar optimizaciones genéticas en cualquier tamaño de un árbol de expresión generado inicialmente y, al mismo tiempo, poder comparar su resultado (o métrica de mejor ajuste) con árboles de expresión de diferentes tamaños.
Para lograr esto, ejecutaremos nuestras optimizaciones genéticas en "épocas". Si bien las épocas son comunes en la jerga del aprendizaje automático cuando se agrupan las sesiones de entrenamiento como con las redes neuronales, aquí usamos el término para referirnos a diferentes iteraciones de optimización genética donde cada ejecución usa árboles de expresión del mismo tamaño. ¿Por qué mantenemos el tamaño dentro de cada época? Debido a que la optimización genética utiliza cruces y los árboles de expresión tienen diferentes longitudes, esto complica innecesariamente el proceso. ¿Cómo mantenemos entonces aleatorios los árboles de expresión iniciales? Haciendo que cada época represente un tamaño particular de árboles. De esta manera, optimizamos todas las épocas y las comparamos todas con el mismo punto de referencia o métrica de mejor ajuste.
Las opciones de medición de la función de aptitud disponibles dentro de los tipos de datos vectoriales/matriciales de MQL5 que podríamos utilizar son regresión y pérdida. Estas funciones incorporadas serán aplicables porque compararemos la salida ideal del conjunto de datos de entrenamiento como un vector frente a las salidas producidas por el árbol de expresión probado también en formato vectorial. Por tanto, cuanto más largo/ o grande sea el conjunto de datos de prueba, mayores serán nuestros vectores comparados. Estos grandes conjuntos de datos diez a implicar que alcanzar el valor ideal de mejor ajuste a cero será muy difícil y, por lo tanto, es necesario permitir suficientes generaciones de optimización en cada época.
Para llegar al mejor árbol de expresión en función de la puntuación de mejor ajuste, evaluaremos los árboles de expresión desde el más largo (y por tanto más complejo) hasta el más simple y presumiblemente más fácil de "explicar". Nuestros formatos de árbol de expresión pueden adoptar una plétora de formas, sin embargo recurriremos a lo básico:
coeff, x-exponent, sign, coeff, x-exponent, sign, …
Donde:
- Coeff representa el coeficiente de x
- x-exponent es la potencia de x
- sign es un operador en la expresión que puede ser -, +, *, o /
El último valor de cualquier expresión no será un signo porque dicho signo no conectará con nada, lo que significa que los signos siempre serán menores que los valores x de cualquier expresión. El tamaño de una expresión de este tipo oscilará entre 1, cuando sólo proporcionemos un coeficiente x y un exponente sin signo, hasta 16 (16 se utiliza aquí estrictamente a efectos de prueba). Como se ha eludido anteriormente, este tamaño máximo se correlaciona directamente con el número de épocas que se utilizarán en la optimización genética. Esto implica simplemente que empezamos a optimizar para la expresión ideal con un árbol de expresión de 16 unidades de longitud. Estas 16 unidades implican 15 signos, como ya se ha mencionado, y "cada unidad" es simplemente un coeficiente x y el exponente de su x.
Así, al seleccionar los primeros árboles de expresión aleatorios seguiremos siempre el formato de 2 dígitos aleatorios "nodos" seguidos de un signo aleatorio "nodo", si el árbol de expresión tiene más de una unidad de longitud y no estamos terminando la expresión, es decir, tenemos una unidad que seguir. The listing that helps us achieve this is given below:
//+------------------------------------------------------------------+ // Get Expression Tree //+------------------------------------------------------------------+ void CSignalSR::GetExpressionTree(int Size, string &ExpressionTree[]) { if(Size < 1) { return; } ArrayFree(ExpressionTree); ArrayResize(ExpressionTree, (2 * Size) + Size - 1); int _digit[]; GetDigitNode(2 * Size, _digit); string _sign[]; if(Size >= 2) { GetSignNode(Size - 1, _sign); } int _di = 0, _si = 0; for(int i = 0; i < (2 * Size) + Size - 1; i += 3) { ExpressionTree[i] = IntegerToString(_digit[_di]); ExpressionTree[i + 1] = IntegerToString(_digit[_di + 1]); _di += 2; if(Size >= 2 && _si < Size - 1) { ExpressionTree[i + 2] = _sign[_si]; _si ++; } } }
Nuestra función anterior comienza verificando que el tamaño del árbol de expresión sea al menos uno. Si se aprueba esta prueba, entonces debemos determinar el tamaño real de la matriz del árbol. Desde arriba, hemos visto que los árboles siguen el formato coeficiente, exponente y luego signo, si corresponde. Esto implica que, dado un tamaño s, el número total de nodos de dígitos en ese árbol será 2 x s, ya que cada unidad de tamaño debe llevar un valor de coeficiente y exponente. Estos nodos se seleccionan al azar mediante la función get digit node, cuyo listado se comparte a continuación:
//+------------------------------------------------------------------+ // Get Digit //+------------------------------------------------------------------+ void CSignalSR::GetDigitNode(int Count, int &Digit[]) { ArrayFree(Digit); ArrayResize(Digit, Count); for(int i = 0; i < Count; i++) { Digit[i] = __DIGIT_NODE[MathRand() % __DIGITS]; } }
Los números se eligen al azar de la matriz de nodos de dígitos globales estáticos. Los nodos de señal, sin embargo, variarán dependiendo de si el tamaño del árbol excede uno. Si tenemos un árbol de tamaño único, entonces ningún signo sería aplicable ya que esto solo deja espacio para un coeficiente x y su exponente. Si tenemos más de uno, entonces el número de nodos de signo será equivalente al tamaño de entrada menos uno. Nuestra función para seleccionar aleatoriamente un signo para llenar el espacio de signo en la expresión se detalla a continuación:
//+------------------------------------------------------------------+ // Get Sign //+------------------------------------------------------------------+ void CSignalSR::GetSignNode(int Count, string &Sign[]) { ArrayFree(Sign); ArrayResize(Sign, Count); for(int i = 0; i < Count; i++) { Sign[i] = __SIGN_NODE[MathRand() % __SIGNS]; } }
Los signos, al igual que con la matriz de nodos de dígitos, se eligen al azar de la matriz de nodos de signos. Sin embargo, esta matriz puede adoptar varias variantes, pero para abreviar la acortaremos para acomodar solo los signos '+' y '-'. Se podría agregar el signo '*' (multiplicación), sin embargo, el signo de división '/' se omitió específicamente porque no manejamos divisiones de cero, que pueden ser bastante complicadas una vez que comenzamos la optimización genética y tenemos que hacer cruces, etc. El lector es libre de explorar esto, siempre y cuando se aborde adecuadamente el problema de la división cero, ya que podría distorsionar los resultados de optimización.
Una vez que tenemos una población inicial de árboles de expresión aleatoria, podemos comenzar el proceso de optimización genética para esa época particular. También es digna de mención la estructura simple que utilizamos para almacenar y acceder a la información del árbol de expresiones. Esencialmente es una matriz de cadenas con flexibilidad añadida de redimensionamiento (¿Características que debería proporcionar un tipo de datos estándar como la matriz que maneja dobles?). Esto también se enumera a continuación:
//+------------------------------------------------------------------+ //| //+------------------------------------------------------------------+ struct Stree { string tree[]; Stree() { ArrayFree(tree); }; ~Stree() {}; }; struct Spopulation { Stree population[]; Spopulation() {}; ~Spopulation() {}; };
Usamos esta estructura para crear y rastrear poblaciones en cada generación de optimización. Cada época utiliza un número determinado de generaciones para realizar su optimización. Como ya se mencionó, cuanto mayor sea el conjunto de datos de prueba, más generaciones de optimización se necesitarán. Por otro lado, si los datos de prueba son demasiado pequeños, esto puede generar árboles de expresión que se derivan principalmente del ruido blanco en lugar de los patrones subyacentes en los conjuntos de datos probados, por lo que es necesario lograr un equilibrio.
Una vez que comenzamos nuestra optimización en cada generación, necesitaremos obtener la aptitud de cada árbol y, como tenemos varios árboles, estos puntajes de aptitud se registran en un vector. Una vez que tenemos este vector, el siguiente paso es establecer un umbral para podar esta población, dado que este árbol se refina y se estrecha con cada generación subsiguiente dentro de una época determinada. Hemos llamado a este umbral '_fit' y se basa en un parámetro de entrada entero que actúa como un marcador percentil. El parámetro varía de 0 a 100.
Procedemos a crear otra población de muestra a partir de esta población inicial, en la que seleccionamos únicamente los árboles de expresión cuya aptitud sea inferior o igual al umbral. La función para calcular nuestra puntuación de aptitud utilizada anteriormente tendría el listado que figura a continuación:
//+------------------------------------------------------------------+ // Get Fitness //+------------------------------------------------------------------+ double CSignalSR::GetFitness(matrix &XY, vector &Y, string &ExpressionTree[]) { Y.Init(XY.Rows()); for(int r = 0; r < int(XY.Rows()); r++) { Y[r] = 0.0; string _sign = ""; for(int i = 0; i < int(ExpressionTree.Size()); i += 3) { double _yy = pow(XY[r][0], StringToDouble(ExpressionTree[i + 1])); _yy *= StringToDouble(ExpressionTree[i]); if(_sign == "+") { Y[r] += _yy; } else if(_sign == "-") { Y[r] -= _yy; } else if(_sign == "/" && _yy != 0.0)//un-handled { Y[r] /= _yy; } else if(_sign == "*") { Y[r] *= _yy; } else if(_sign == "") { Y[r] = _yy; } if(i + 2 < int(ExpressionTree.Size())) { _sign = ExpressionTree[i + 2]; } } } return(Y.RegressionMetric(XY.Col(1), m_regressor)); //return(_y.Loss(XY.Col(1),LOSS_MAE)); }
La función get fitness toma la matriz del conjunto de datos de entrada 'XY', y se centra en la columna x de la matriz (estamos utilizando datos de una sola dimensión tanto para las entradas como para las salidas) para elaborar el valor de previsión del árbol de expresión de entrada. La matriz de entrada tiene varias filas de datos, por lo que, basándose en el valor x de cada fila (la primera columna), se realiza una proyección y todas estas proyecciones, para cada fila, se almacenan en un vector 'Y'. Una vez procesadas todas las filas, este vector 'Y' se compara con los valores reales de la segunda columna utilizando la función incorporada de regresión o la función de pérdida. Elegimos la regresión, con el error cuadrático medio como métrica de regresión.
La magnitud de este valor es el valor de aptitud del árbol de expresión de entrada. Cuanto más pequeño sea, mejor se ajustará. Una vez obtenido este valor para cada una de las poblaciones muestreadas, primero debemos verificar que el tamaño de la muestra sea par; si no, reducimos el tamaño en uno. El tamaño debe ser uniforme porque en la siguiente etapa cruzamos estos árboles y los cruces generados se agregan en pares, y deben coincidir con la población original (las muestras) ya que solo reducimos la población al tomar muestras en cada generación. El cruce de árboles de expresión dentro de las muestras se realiza de forma aleatoria mediante selección de índices. La función responsable del cruce se enumera a continuación:
//+------------------------------------------------------------------+ // Set Crossover //+------------------------------------------------------------------+ void CSignalSR::SetCrossover(string &ParentA[], string &ParentB[], string &ChildA[], string &ChildB[]) { if(ParentA.Size() != ParentB.Size() || ParentB.Size() == 0) { return; } int _length = int(ParentA.Size()); ArrayResize(ChildA, _length); ArrayResize(ChildB, _length); int _cross = 0; if(_length > 1) { _cross = rand() % (_length - 1) + 1; } for(int c = 0; c < _cross; c++) { ChildA[c] = ParentA[c]; ChildB[c] = ParentB[c]; } for(int l = _cross; l < _length; l++) { ChildA[l] = ParentB[l]; ChildB[l] = ParentA[l]; } }
Esta función comienza verificando que las dos expresiones padres tengan el mismo tamaño y que ninguna de ellas sea cero. Si se pasa esto, las dos matrices secundarias de salida se redimensionan para que coincidan con las longitudes de las matrices principales y luego se seleccionará el punto de cruce. Este cruce también es aleatorio y solo es relevante cuando el tamaño del padre es mayor que uno. Una vez que se establece el punto de cruce, los valores de los dos padres se intercambian y se envían a las dos matrices secundarias. Aquí es donde las longitudes coincidentes resultan útiles porque, por ejemplo, si fueran diferentes, se necesitaría código adicional para manejar (o evitar) casos en los que los dígitos se intercambian por signos. Complicaciones claramente innecesarias cuando todos los tamaños pueden probarse independientemente, en su propia época, para lograr el mejor ajuste.
Una vez que hayamos terminado el cruce, podremos mutar a los niños. 'Puede' porque utilizamos un umbral de probabilidad del 5% para realizar estas mutaciones, ya que no están garantizadas pero normalmente son parte del proceso de optimización genética. Luego copiamos esta nueva población cruzada para sobrescribir nuestra población inicial de la cual habíamos tomado la muestra al comienzo y como marcador registramos el mejor puntaje de ajuste del mejor árbol de expresión de esta nueva población cruzada. Utilizamos la puntuación registrada no sólo para determinar el árbol de mejor ajuste, sino también en algunos casos excepcionales para detener la optimización en el caso de que obtengamos un valor cero.
Clase de señal personalizada
Al desarrollar la clase de señal, nuestros pasos principales no difieren mucho de lo que hemos hecho en clases de señal personalizadas anteriores a través de estas series. En primer lugar, necesitaríamos preparar el conjunto de datos para nuestro modelo. Estos son los datos que llenan nuestra matriz de entrada 'XY' para la función analizada anteriormente de obtención de aptitud. También es una entrada a la función que integra todos los pasos que hemos descrito anteriormente, llamada "GetBestTree". El código fuente de esta función se indica a continuación:
//+------------------------------------------------------------------+ // Get Best Fit //+------------------------------------------------------------------+ void CSignalSR::GetBestTree(matrix &XY, vector &Y, string &BestTree[]) { double _best_fit = DBL_MAX; for(int e = 1 + m_epochs; e >= 1; e--) { Spopulation _p; ArrayResize(_p.population, m_population); int _e_size = 2 * e; for(int p = 0; p < m_population; p++) { string _tree[]; GetExpressionTree(e, _tree); _e_size = int(_tree.Size()); ArrayResize(_p.population[p].tree, _e_size); for(int ee = 0; ee < _e_size; ee++) { _p.population[p].tree[ee] = _tree[ee]; } } for(int g = 0; g < m_generations; g++) { vector _fitness; _fitness.Init(int(_p.population.Size())); for(int p = 0; p < int(_p.population.Size()); p++) { _fitness[p] = GetFitness(XY, Y, _p.population[p].tree); } double _fit = _fitness.Percentile(m_fitness); Spopulation _s; int _samples = 0; for(int p = 0; p < int(_p.population.Size()); p++) { if(_fitness[p] <= _fit) { _samples++; ArrayResize(_s.population, _samples); ArrayResize(_s.population[_samples - 1].tree, _e_size); for(int ee = 0; ee < _e_size; ee++) { _s.population[_samples - 1].tree[ee] = _p.population[p].tree[ee]; } } } if(_samples % 2 == 1) { _samples--; ArrayResize(_s.population, _samples); } if(_samples == 0) { break; } Spopulation _g; ArrayResize(_g.population, _samples); for(int s = 0; s < _samples - 1; s += 2) { int _a = rand() % _samples; int _b = rand() % _samples; SetCrossover(_s.population[_a].tree, _s.population[_b].tree, _g.population[s].tree, _g.population[s + 1].tree); if (rand() % 100 < 5) // 5% chance { SetMutation(_g.population[s].tree); } if (rand() % 100 < 5) { SetMutation(_g.population[s + 1].tree); } } // Replace old population ArrayResize(_p.population, _samples); for(int s = 0; s < _samples; s ++) { for(int ee = 0; ee < _e_size; ee++) { _p.population[s].tree[ee] = _g.population[s].tree[ee]; } } // Print best individual for(int s = 0; s < _samples; s ++) { _fit = GetFitness(XY, Y, _p.population[s].tree); if (_fit < _best_fit) { _best_fit = _fit; ArrayCopy(BestTree,_p.population[s].tree); } } } } }
La matriz de entrada empareja valores x de dimensión única y valores y de dimensión única. Variables independientes y variables dependientes. La multidimensionalidad también podría acomodarse transformando el vector de entrada 'Y' en una matriz y un árbol de expresión para cada valor x en el vector de entrada, para cada valor y en el vector de salida. Estos árboles de expresión también tendrían que estar en un formato de almacenamiento matricial o de dimensión superior.
Sin embargo, utilizamos dimensiones únicas y nuestra fila de datos simplemente consta de precios de cierre consecutivos. Entonces, en la fila de datos superior o más reciente, tendríamos el penúltimo precio de cierre como nuestro valor x y el precio de cierre actual como nuestro y. La preparación y el llenado de nuestra matriz 'XY' con estos datos se gestiona mediante el código fuente que aparece a continuación:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalSR::LongCondition(void) { int result = 0; m_close.Refresh(-1); matrix _xy; _xy.Init(m_data_set, 2); for(int i = 0; i < m_data_set; i++) { _xy[i][0] = m_close.GetData(StartIndex()+i+1); _xy[i][1] = m_close.GetData(StartIndex()+i); } ... return(result); }
Una vez realizada la preparación de nuestros datos, es buena idea tener claro el método de evaluación de aptitud que se utilizará en nuestro modelo. Estamos optando por regresión frente a pérdida, pero incluso dentro de la regresión hay bastantes métricas para seleccionar. Por lo tanto, para permitir una selección óptima, el tipo de métrica de regresión que se utilizará es un parámetro de entrada, que podría optimizarse para adaptarse mejor a los conjuntos de datos probados. Sin embargo, nuestro valor predeterminado es el error cuadrático medio común.
La implementación del algoritmo genético está a cargo de la función de obtención del mejor árbol, cuyo código fuente ya figura arriba. Devuelve una serie de salidas principales entre las que se encuentra el mejor árbol de expresión. Con este árbol podemos procesar el precio de cierre actual como entrada (valor x) para obtener nuestro próximo cierre (valor y), utilizando la función obtener aptitud, ya que también devuelve algo más que la aptitud de una expresión consultada, puesto que el vector «Y» de entrada contiene nuestra previsión objetivo. Esto se maneja en el siguiente código:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalSR::LongCondition(void) { ... vector _y; string _best_fit[]; GetBestTree(_xy, _y, _best_fit); ... return(result); }
Con un precio indicativo del próximo cierre obtenido, el siguiente paso es convertir este precio en una señal utilizable para el Asesor Experto. A menudo, los valores previstos sólo son indicativos de una subida o una bajada, pero su valor absoluto está fuera de rango si se compara con los valores de los precios de cierre recientes. Esto significa que tendríamos que normalizarlos antes de poder utilizarlos. La normalización y la generación de señales se realizan en nuestro código a continuación:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalSR::LongCondition(void) { int result = 0; ... double _cond = (_y[0]-m_close.GetData(StartIndex()))/fmax(fabs(_y[0]),m_close.GetData(StartIndex())); _cond *= 100.0; //printf(__FUNCSIG__ + " cond: %.2f", _cond); //return(result); if(_cond > 0.0) { result = int(fabs(_cond)); } return(result); }
La salida entera de las condiciones larga y corta en una clase de señal Expert estándar tiene que estar en el rango 0 - 100 y esto es a lo que estamos convirtiendo nuestra señal en el código anterior.
La función de condición larga y la función de condición corta son espejos la una de la otra, y el montaje de clases de señales en Asesores Expertos se trata en los artículos aquí y aquí.
Pruebas retrospectivas y optimización
Al realizar una prueba con algunos de los "mejores ajustes" del Asesor Experto montado, obtenemos el siguiente informe y curva de renta variable:


Para cualquier configuración dada, dado que los árboles de expresión se obtienen a partir de una selección aleatoria y se cruzan y mutan también aleatoriamente, es poco probable que cualquier ejecución de prueba particular replique exactamente sus resultados, sin embargo, y curiosamente, si una ejecución de prueba es rentable, las ejecuciones posteriores con la misma configuración tendrán estadísticas de rendimiento diferentes pero, en conjunto, también serán rentables. Nuestra prueba se realiza para el año 2022, en el par EURJPY en el marco temporal de 4 horas. Como siempre, realizamos pruebas sin objetivos de precio para SL o TP, ya que esto podría ayudar a identificar mejor los ajustes ideales de Expert.
Conclusión
Para recapitular, hemos introducido la regresión simbólica como un modelo que podría utilizarse en una instancia personalizada de una clase de señal Experto para ponderar las condiciones largas y cortas. En este análisis utilizamos un conjunto de datos muy modesto, ya que tanto los valores de entrada como los de salida del modelo eran unidimensionales. Esto no significa que el modelo no pueda ampliarse para dar cabida a conjuntos de datos multidimensionales. Además, la naturaleza de optimización genética del algoritmo del modelo dificulta la obtención de resultados idénticos en cada prueba. Esto implica que los Asesores Expertos basados en este modelo deben utilizarse en marcos temporales bastante amplios y en tándem con otras señales comerciales para que puedan actuar como confirmación de señales ya generadas de forma independiente.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/14943
 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso