
Neuronale Netze leicht gemacht (Teil 78): Decoderfreier Objektdetektor mit Transformator (DFFT)

Einführung
In früheren Artikeln haben wir uns hauptsächlich auf die Vorhersage bevorstehender Kursbewegungen und die Analyse historischer Daten konzentriert. Auf der Grundlage dieser Analyse haben wir versucht, die wahrscheinlichste kommende Kursentwicklung auf verschiedene Weise vorherzusagen. Bei einigen Strategien wurde eine ganze Reihe von vorausgesagten Bewegungen konstruiert und versucht, die Wahrscheinlichkeit jeder einzelnen Vorhersage abzuschätzen. Die Training und der Betrieb solcher Modelle erfordern natürlich erhebliche Rechenressourcen.
Aber müssen wir wirklich die kommende Preisentwicklung vorhersagen? Außerdem ist die Genauigkeit der Vorhersagen bei weitem nicht so hoch wie gewünscht.
Unser oberstes Ziel ist es, einen Gewinn zu erwirtschaften, den wir aus dem erfolgreichen Handel mit unserem Vertreter erwarten. Der Agent wiederum wählt die optimalen Aktionen auf der Grundlage der vorhergesagten Preisverläufe (Trajektorie) aus.
Folglich führt ein Fehler bei der Erstellung von Vorhersagetrajektorien kann zu einem noch größeren Fehler bei der Auswahl von Aktionen durch den Agenten. Ich sage „kann dazu führen“, weil der Akteur sich während des Lernprozesses an Prognosefehler anpassen und den Fehler leicht ausgleichen kann. Eine solche Situation ist jedoch bei einem relativ konstanten Prognosefehler möglich. Im Falle eines stochastischen Vorhersagefehlers wird der Fehler in den Handlungen des Agenten nur zunehmen.
In einer solchen Situation suchen wir nach Möglichkeiten, den Fehler zu minimieren. Wie wäre es, wenn wir die Zwischenstufe der Vorhersage des Verlaufs der kommenden Kursbewegung eliminieren? Kehren wir zum klassischen Ansatz des Verstärkungslernens (reinforcement learning) zurück. Wir lassen den Akteur auf der Grundlage der Analyse historischer Daten Aktionen auswählen. Dies bedeutet jedoch keinen Schritt zurück, sondern eher einen Schritt zur Seite.
Ich schlage vor, dass Sie sich mit einer interessanten Methode vertraut machen, die zur Lösung von Problemen im Bereich der Computer Vision vorgestellt wurde. Dabei handelt es sich um die Decoder-freie, vollständig Transformer-basierte Methode (DFFT), die in dem Artikel „Efficient Decoder-free Object Detection with Transformers“ vorgestellt wurde.
Die hier vorgeschlagene Methode DFFT gewährleistet eine hohe Effizienz sowohl in der Trainings- als auch in der Verwendungsphase. Die Autoren der Methode vereinfachen die Objekterkennung zu einer einstufigen, dichten Vorhersageaufgabe, die nur einen Kodierer (encoder) benötigt. Sie konzentrieren ihre Bemühungen auf die Lösung von 2 Problemen:
- Eliminierung des ineffizienten Decoders und Verwendung von 2 leistungsstarken Kodierern, um die Vorhersagegenauigkeit der einstufigen Merkmalskarte beizubehalten;
- Lernen von semantischen Merkmalen auf niedriger Ebene für eine rechnerisch eingeschränkte Erkennungsaufgabe.
Insbesondere schlagen die Autoren der Methode ein neues, leichtgewichtiges, detektionsorientiertes Transformer-Backbone vor, das Low-Level-Merkmale mit reichhaltiger Semantik effektiv erfasst. Die in der Studie vorgestellten Experimente zeigen, dass der Rechenaufwand geringer ist und weniger Trainingsepochen erforderlich sind.
1. Der DFFT-Algorithmus
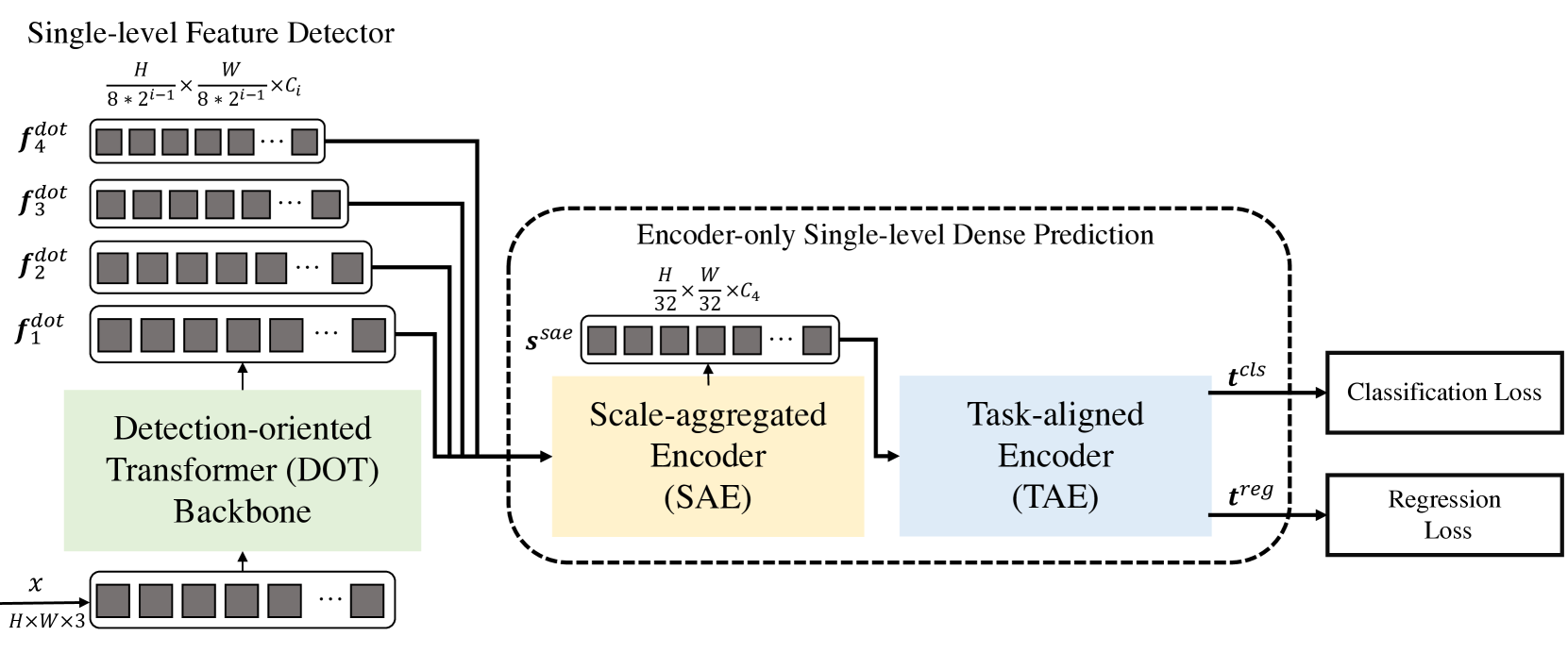
Die Decoder-freie, vollständig Transformer-basierte Methode (DFFT) ist ein effizienter Objektdetektor, der vollständig auf Decoder-freien Transformatoren basiert. Der Schwerpunkt des Transformer-Backbones liegt auf der Objekterkennung. Er extrahiert sie in vier Maßstäben und sendet sie an das nächste Modul zur Dichtevorhersage, das nur aus einem Kodierer besteht. Das Vorhersagemodul aggregiert zunächst das mehrskalige Merkmal zu einer einzigen Merkmalskarte unter Verwendung des skalierten Kodierers (Scale-Aggregated Encoder).
Anschließend schlagen die Autoren der Methode vor, den aufgabenorientierten Kodierer (Task-Aligned Encoder) für den gleichzeitigen Merkmalsabgleich bei Klassifikations- und Regressionsproblemen zu verwenden.
Der Backbone (DOT, Detection-Oriented Transformer) wurde entwickelt, um mehrstufige Merkmale mit strenger Semantik zu extrahieren. Es stapelt hierarchisch ein Einbettungsmodul und vier DOT-Stufen. Das neue semantisch erweiterte Aufmerksamkeitsmodul aggregiert die semantischen Informationen auf niedriger Ebene der beiden aufeinanderfolgenden Stufen von DOT.
Bei der Verarbeitung von hochauflösenden Merkmalskarten für Vorhersagen der Dichte reduzieren herkömmliche Transformationsblöcke die Rechenkosten, indem sie die mehrköpfige Selbstaufmerksamkeit (MSA) durch die Schicht der lokalen räumlichen Aufmerksamkeit und eine voreingenommene, fensterbasierte mehrköpfige Selbstaufmerksamkeit (SW-MSA) ersetzen. Diese Struktur verringert jedoch die Erkennungsleistung, da sie nur mehrskalige Objekte mit begrenzter Semantik auf niedriger Ebene extrahiert.
Um diesen Nachteil abzumildern, haben die Autoren der DFFT-Methode dem DOT-Block mehrere SW-MSA-Blöcke und einen kanalübergreifenden globalen Aufmerksamkeitsblock hinzugefügt. Beachten Sie, dass jeder Aufmerksamkeitsblock eine Aufmerksamkeitsschicht und eine FFN-Schicht enthält.
Die Autoren der Methode fanden heraus, dass die Platzierung einer leichten (light) Aufmerksamkeitsschicht auf Kanälen nach aufeinanderfolgenden lokalen räumlichen Aufmerksamkeitsschichten helfen kann, die Semantik eines Objekts auf jeder Skala zu erkennen.
Während der DOT-Block die semantischen Informationen in den Low-Level-Merkmalen durch globale kanalübergreifende Aufmerksamkeit verbessert, kann die Semantik weiter verbessert werden, um die Erkennungsaufgabe zu verbessern. Zu diesem Zweck schlagen die Autoren der Methode ein neues Modul der semantisch verstärkten Aufmerksamkeit (Semantic-Augmented Attention, SAA) vor, das semantische Informationen zwischen zwei aufeinanderfolgenden DOT-Schichten austauscht und deren Merkmale ergänzt. SAA besteht aus einer Upsampling-Schicht und einem kanalübergreifenden globalen Aufmerksamkeitsblock. Die Autoren der Methode fügen SAA zu allen zwei aufeinanderfolgenden DOT-Blöcken hinzu. Formal akzeptiert SAA die Ergebnisse des aktuellen DOT-Blocks und der vorherigen DOT-Stufe und gibt dann eine semantisch erweiterte Funktion zurück, die an die nächste DOT-Stufe gesendet wird und ebenfalls zu den endgültigen Multiskalenmerkmalen beiträgt.
Im Allgemeinen besteht die detektionsorientierte Stufe aus vier DOT-Schichten, wobei jede Stufe einen DOT-Block und ein SAA-Modul umfasst (außer der ersten Stufe). Insbesondere enthält die erste Stufe einen DOT-Block und kein SAA-Modul, da die Eingänge des SAA-Moduls aus zwei aufeinander folgenden DOT-Stufen stammen. Danach folgt eine Downsampling-Schicht zur Rekonstruktion der Eingangsdimension.
Das folgende Modul wurde entwickelt, um die Effizienz von DFFT sowohl bei Schlußfolgerung als auch beim Modelltraining zu verbessern. Zunächst wird ein Skalenaggregierter Kodierer (Scale-Aggregated Encoder, SAE) verwendet, um Objekte mit mehreren Maßstäben aus dem DOT-Backbone in einer Objektkarte Ssae zusammenzufassen.
Dann wird der aufgabenorientierte Kodierer (TAE) verwendet, um eine ausgerichtete Klassifizierungsfunktion 𝒕cls und eine Regressionsfunktion 𝒕reg gleichzeitig in einem Kopf zu erstellen.
Der aggregierte Skalenkodierer wird aus 3 SAE-Blöcken aufgebaut. Jeder SAE-Block nimmt zwei Objekte als Eingangsdaten und aggregiert sie schrittweise über alle SAE-Blöcke hinweg. Die Autoren der Methode nutzen den Maßstab der endlichen Aggregation von Objekten, um ein Gleichgewicht zwischen Erkennungsgenauigkeit und Rechenaufwand herzustellen.
Normalerweise führen Detektoren die Objektklassifizierung und -lokalisierung unabhängig voneinander mit zwei separaten Zweigen (unverbundenen Köpfen) durch. Diese zweigleisige Struktur berücksichtigt nicht die Interaktion zwischen den beiden Aufgaben und führt zu widersprüchlichen Vorhersagen. Beim Erlernen von Merkmalen für zwei Aufgaben kommt es jedoch in der Regel zu Konflikten im konjugierten Kopf. Die Autoren der Methode DFFT schlagen die Verwendung eines aufgabenspezifischen Kodierers vor, der ein besseres Gleichgewicht zwischen dem Erlernen interaktiver und aufgabenspezifischer Merkmale bietet, indem er Gruppenaufmerksamkeitseinheiten über Kanäle in einem verbundenen Kopf kombiniert.
Dieser Kodierer besteht aus zwei Arten von Kanalaufmerksamkeitsblöcken. Erstens, Multi-Level-Group-Attention-Blöcke über Kanäle ausrichten und trennen Ssae aggregierten Objekte in 2 Teile. Zweitens kodieren globale Aufmerksamkeitsblöcke über alle Kanäle hinweg eines der beiden getrennten Objekte für die anschließende Regressionsaufgabe.
Die Unterschiede zwischen dem Gruppenblock der Kanalaufmerksamkeit und dem globalen Block der Kanalaufmerksamkeit bestehen insbesondere darin, dass alle linearen Projektionen, mit Ausnahme der Projektionen für die Einbettungen von Query/Key/Value (Abfrage/Schlüssel/Wert) in einem Gruppenaufmerksamkeitsblock über Kanäle hinweg, in zwei Gruppen durchgeführt werden. So interagieren die Merkmale bei den Aufmerksamkeitsoperationen, während sie bei den Ausgabeprojektionen getrennt ausgegeben werden.
Das Original der von den Verfassern des Artikels vorgestellten Methode ist unter „visualization“ zu finden.
2. Implementierung mit MQL5
Nach der Betrachtung der theoretischen Aspekte der Methode DFFT (Decoder-Free Fully Transformer-based) wenden wir uns nun der Implementierung der vorgeschlagenen Ansätze mit MQL5 zu. Unser Modell wird sich jedoch leicht von der ursprünglichen Methode unterscheiden. Bei der Entwicklung des Modells berücksichtigen wir die Unterschiede zwischen den spezifischen Problemen der Computer Vision, für die die Methode vorgeschlagen wurde, und den Operationen auf den Finanzmärkten, für die wir unser Modell entwickeln.
2.1 DOT-Blockkonstruktion
Bevor wir beginnen, möchten wir darauf hinweisen, dass sich die vorgeschlagenen Ansätze deutlich von den Modellen unterscheiden, die wir zuvor entwickelt haben. Der DOT-Block unterscheidet sich auch von den Aufmerksamkeitsblöcken, die wir zuvor untersucht haben. Daher beginnen wir unsere Arbeit mit dem Aufbau einer neuen neuronalen Schicht CNeuronDOTOCL. Wir erstellen unsere neue Schicht als Abkömmling von CNeuronBaseOCL, unserer Basisklasse für neuronale Schichten.
Ähnlich wie bei anderen Aufmerksamkeitsblöcken werden wir Variablen hinzufügen, um wichtige Parameter zu speichern:
- iWindowSize — Fenstergröße eines Sequenzelements;
- iPrevWindowSize — Fenstergröße eines Elements der vorherigen Schichtenfolge;
- iDimension — Größe des Vektors der internen Entitäten Query, Key und Value (Abfrage, Schlüssel, Wert);
- iUnits — Anzahl der Elemente in der Sequenz;
- iHeads — Anzahl der Aufmerksamkeitsköpfe.
Ich glaube, Ihnen ist die Variable iPrevWindowSize aufgefallen. Durch die Hinzufügung dieser Variablen können wir die Fähigkeit zur Komprimierung von Daten von Schicht zu Schicht implementieren, wie es die DFFT-Methode bietet.
Um die Arbeit direkt in der neuen Klasse zu minimieren und die Nutzung bereits erstellter Entwicklungen zu maximieren, implementieren wir einen Teil der Funktionalität mit verschachtelten, neuronalen Schichten aus unserer Bibliothek. Wir werden ihre Funktionsweise bei der Implementierung von Feed-Forward- und Back-Propagation-Methoden im Detail besprechen.
class CNeuronDOTOCL : public CNeuronBaseOCL { protected: uint iWindowSize; uint iPrevWindowSize; uint iDimension; uint iUnits; uint iHeads; //--- CNeuronConvOCL cProjInput; CNeuronConvOCL cQKV; int iScoreBuffer; CNeuronBaseOCL cRelativePositionsBias; CNeuronBaseOCL MHAttentionOut; CNeuronConvOCL cProj; CNeuronBaseOCL AttentionOut; CNeuronConvOCL cFF1; CNeuronConvOCL cFF2; CNeuronBaseOCL SAttenOut; CNeuronXCiTOCL cCAtten; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool DOT(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool updateRelativePositionsBias(void); virtual bool DOTInsideGradients(void); public: CNeuronDOTOCL(void) {}; ~CNeuronDOTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint dimension, uint heads, uint units_count, uint prev_window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronDOTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Im Allgemeinen ist die Liste der überschriebenen Methoden Standard.
Im Klassenkörper verwenden wir statische Objekte. Dies ermöglicht es uns, den Konstruktor und den Destruktor der Klasse leer zu lassen.
Die Klasse wird in der Methode Init initialisiert. Die erforderlichen Daten werden in den Parametern an die Methode übergeben. Die minimal notwendige Kontrolle der Informationen wird in der entsprechenden Methode der übergeordneten Klasse implementiert. Hier initialisieren wir auch geerbte Objekte.
bool CNeuronDOTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint dimension, uint heads, uint units_count, uint prev_window, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Dann wird geprüft, ob die Größe der Quelldaten mit den Parametern der aktuellen Ebene übereinstimmt. Initialisieren Sie bei Bedarf die Datenskalierungsschicht.
if(prev_window != window) { if(!cProjInput.Init(0, 0, OpenCL, prev_window, prev_window, window, units_count, optimization_type, batch)) return false; }
Als Nächstes speichern wir die vom Aufrufer erhaltenen Basiskonstanten, die die Architektur der Schicht definieren, in internen Klassenvariablen.
iWindowSize = window; iPrevWindowSize = prev_window; iDimension = dimension; iHeads = heads; iUnits = units_count;
Dann initialisieren wir nacheinander alle internen Objekte. Zunächst initialisieren wir die Ebene, auf der wir die Ebenen Query, Key und Value erzeugen. Wir werden alle 3 Entitäten parallel im Körper einer neuronalen Schicht cQKV erzeugen.
if(!cQKV.Init(0, 1, OpenCL, window, window, dimension * heads, units_count, optimization_type, batch)) return false;
Als Nächstes erstellen wir den Puffer iScoreBuffer für die Aufzeichnung der Objektabhängigkeitskoeffizienten. Hier ist anzumerken, dass wir im DOT-Block zunächst die lokale Semantik analysieren. Zu diesem Zweck wird die Abhängigkeit zwischen einem Objekt und seinen 2 nächsten Nachbarn überprüft. Daher definieren wir die Größe des Score-Puffers als iUnits * iHeads * 3.
Darüber hinaus werden die im Puffer gespeicherten Koeffizienten bei jedem Vorwärtsdurchlauf neu berechnet. Sie werden erst beim nächsten Backpropagation-Durchgang verwendet. Daher werden wir die Pufferdaten nicht in der Modellspeicherdatei speichern. Außerdem werden wir nicht einmal einen Puffer im Speicher des Hauptprogramms anlegen. Wir müssen nur einen Puffer im Kontextspeicher von OpenCL erstellen. Auf der Seite des Hauptprogramms wird nur ein Zeiger auf den Puffer gespeichert.
//--- iScoreBuffer = OpenCL.AddBuffer(sizeof(float) * iUnits * iHeads * 3, CL_MEM_READ_WRITE); if(iScoreBuffer < 0) return false;
Im Gegensatz zum klassischen Transformator interagiert beim fensterbasierten Selbstaufmerksamkeits-Mechanismus jeder Token nur mit Token innerhalb eines bestimmten Fensters. Dadurch wird die Komplexität der Berechnungen erheblich reduziert. Diese Einschränkung bedeutet jedoch auch, dass die Modelle die relativen Positionen der Token innerhalb des Fensters berücksichtigen müssen. Um diese Funktionalität zu implementieren, führen wir trainierbare Parameter cRelativePositionsBias ein. Für jedes Tokenpaar (i, j) innerhalb des Fensters iWindowSize enthält cRelativePositionsBias ein Gewicht, das die Bedeutung der Interaktion zwischen diesen Token auf der Grundlage ihrer relativen Positionen bestimmt.
Die Größe dieses Puffers entspricht der Größe des Puffers für den Score-Koeffizienten. Um jedoch Parameter zu trainieren, benötigen wir neben dem Puffer für die Werte selbst zusätzliche Puffer. Um die Anzahl der internen Objekte zu verringern und die Lesbarkeit des Codes zu verbessern, wird für cRelativePositionsBias ein neuronales Schichtobjekt deklariert, das alle zusätzlichen Puffer enthält.
if(!cRelativePositionsBias.Init(1, 2, OpenCL, iUnits * iHeads * 3, optimization_type, batch)) return false;
In ähnlicher Weise fügen wir die übrigen Elemente des Mechanismus der Selbstaufmerksamkeit hinzu.
if(!MHAttentionOut.Init(0, 3, OpenCL, iUnits * iHeads * iDimension, optimization_type, batch)) return false; if(!cProj.Init(0, 4, OpenCL, iHeads * iDimension, iHeads * iDimension, window, iUnits, optimization_type, batch)) return false; if(!AttentionOut.Init(0, 5, OpenCL, iUnits * window, optimization_type, batch)) return false; if(!cFF1.Init(0, 6, OpenCL, window, window, 4 * window, units_count, optimization_type,batch)) return false; if(!cFF2.Init(0, 7, OpenCL, window * 4, window * 4, window, units_count, optimization_type, batch)) return false; if(!SAttenOut.Init(0, 8, OpenCL, iUnits * window, optimization_type, batch)) return false;
Als globalen Block der Aufmerksamkeit verwenden wir die Schicht CNeuronXCiTOCL.
if(!cCAtten.Init(0, 9, OpenCL, window, MathMax(window / 2, 3), 8, iUnits, 1, optimization_type, batch)) return false;
Um das Kopieren von Daten zwischen Puffern zu minimieren, werden wir Objekte und Puffer ersetzen.
if(!!Output) delete Output; Output = cCAtten.getOutput(); if(!!Gradient) delete Gradient; Gradient = cCAtten.getGradient(); SAttenOut.SetGradientIndex(cFF2.getGradientIndex()); //--- return true; }
Beenden der Ausführung der Methode.
Nach der Initialisierung der Klasse gehen wir zum Aufbau des Vorwärtsdurchgangs-Algorithmus über. Wir gehen nun dazu über, den Selbstaufmerksamkeits-Mechanismus auf der OpenCL-Programmseite zu organisieren. Hierfür erstellen wir den Kernel DOTFeedForward. In den Parametern übergeben wir dem Kernel Zeiger auf 4 Datenpuffer:
- qkv — die Puffer für Query, Key und Value (Abfrage, Schlüssel, Wert),
- score — Puffer der Abhängigkeitskoeffizienten,
- rpb — Positionsoffset-Puffer,
- aus — Puffer der Ergebnisse der mehrköpfigen, fenstergesteuerten Selbstaufmerksamkeit.
__kernel void DOTFeedForward(__global float *qkv, __global float *score, __global float *rpb, __global float *out) { const size_t d = get_local_id(0); const size_t dimension = get_local_size(0); const size_t u = get_global_id(1); const size_t units = get_global_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
Wir planen den Start des Kernels in einem 3-dimensionalen Aufgabenraum. Im Hauptteil des Kerns identifizieren wir den Thread in allen 3 Dimensionen. An dieser Stelle sei darauf hingewiesen, dass wir in der ersten Dimension der Abfrage-, Schlüssel- und Wertentitätsdimensionen eine Arbeitsgruppe mit Pufferaufteilung im lokalen Speicher erstellen.
Als Nächstes werden die Offsets in den Datenpuffern vor den zu analysierenden Objekten bestimmt.
uint step = 3 * dimension * heads; uint start = max((int)u - 1, 0); uint stop = min((int)u + 1, (int)units - 1); uint shift_q = u * step + h * dimension; uint shift_k = start * step + dimension * (heads + h); uint shift_score = u * 3 * heads;
Hier wird auch ein lokaler Puffer für den Datenaustausch zwischen Threads der gleichen Arbeitsgruppe angelegt.
const uint ls_d = min((uint)dimension, (uint)LOCAL_ARRAY_SIZE); __local float temp[LOCAL_ARRAY_SIZE][3];
Wie bereits erwähnt, bestimmen wir die lokale Semantik anhand der 2 nächsten Nachbarn eines Objekts. Zunächst ermitteln wir den Einfluss der Nachbarn auf das analysierte Objekt. Wir berechnen die Abhängigkeitskoeffizienten innerhalb der Arbeitsgruppe. Zunächst multiplizieren wir die Elemente der Entitäten Query und Key paarweise in parallelen Strömen.
//--- Score if(d < ls_d) { for(uint pos = start; pos <= stop; pos++) { temp[d][pos - start] = 0; } for(uint dim = d; dim < dimension; dim += ls_d) { float q = qkv[shift_q + dim]; for(uint pos = start; pos <= stop; pos++) { uint i = pos - start; temp[d][i] = temp[d][i] + q * qkv[shift_k + i * step + dim]; } } barrier(CLK_LOCAL_MEM_FENCE);
Dann fassen wir die resultierenden Produkte zusammen.
int count = ls_d; do { count = (count + 1) / 2; if(d < count && (d + count) < dimension) for(uint i = 0; i <= (stop - start); i++) { temp[d][i] += temp[d + count][i]; temp[d + count][i] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); }
Wir fügen den erhaltenen Werten Offset-Parameter hinzu und normalisieren sie mit der SoftMax-Funktion.
if(d == 0) { float sum = 0; for(uint i = 0; i <= (stop - start); i++) { temp[0][i] = exp(temp[0][i] + rpb[shift_score + i]); sum += temp[0][i]; } for(uint i = 0; i <= (stop - start); i++) { temp[0][i] = temp[0][i] / sum; score[shift_score + i] = temp[0][i]; } } barrier(CLK_LOCAL_MEM_FENCE);
Das Ergebnis wird im Puffer für die Abhängigkeitskoeffizienten gespeichert.
Nun können wir die sich ergebenden Koeffizienten mit den entsprechenden Elementen der Value-Entität multiplizieren, um die Ergebnisse eines mehrköpfigen, fenstergesteuerten Selbstaufmerksamkeits-Blocks zu ermitteln.
int shift_out = dimension * (u * heads + h) + d; int shift_v = dimension * (heads * (u * 3 + 2) + h); float sum = 0; for(uint i = 0; i <= (stop - start); i++) sum += qkv[shift_v + i] * temp[0][i]; out[shift_out] = sum; }
Wir speichern die resultierenden Werte in den entsprechenden Elementen des Ergebnispuffers und beenden den Kernel.
Nachdem wir den Kernel erstellt haben, kehren wir zu unserem Hauptprogramm zurück, wo wir die Methoden unserer neuen Klasse CNeuronDOTOCL erstellen. Zunächst erstellen wir die Methode DOT, bei der der oben erstellte Kernel in die Ausführungswarteschlange gestellt wird.
Der Algorithmus der Methode ist recht einfach. Wir übergeben dem Kernel einfach externe Parameter.
bool CNeuronDOTOCL::DOT(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iUnits, iHeads}; uint local_work_size[3] = {iDimension, 1, 1}; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_qkv, cQKV.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_score, iScoreBuffer)) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_out, MHAttentionOut.getOutputIndex())) return false;
Dann schicken wir den Kernel an die Ausführungswarteschlange.
ResetLastError(); if(!OpenCL.Execute(def_k_DOTFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Vergessen wir nicht, die Ergebnisse bei jedem Schritt zu kontrollieren.
Nach Abschluss der vorbereitenden Arbeiten gehen wir zur Erstellung der Methode CNeuronDOTOCL::feedForward über, in der wir den Vorwärtsdurchgangs-Algorithmus für unsere Schicht definieren werden.
In den Methodenparametern erhalten wir einen Zeiger auf die Schicht der vorherigen neuronalen Schicht. Der Einfachheit halber speichern wir den resultierenden Zeiger in einer lokalen Variablen.
bool CNeuronDOTOCL::feedForward(CNeuronBaseOCL *NeuronOCL)
{
CNeuronBaseOCL* inputs = NeuronOCL;
Als Nächstes wird geprüft, ob die Größe der Quelldaten von den Parametern der aktuellen Ebene abweicht. Falls erforderlich, skalieren wir die Quelldaten und berechnen Abfrage-, Schlüssel- und Werteinheiten.
Bei Gleichheit der Datenpuffer entfällt der Skalierungsschritt und es werden sofort die Entitäten Abfrage, Schlüssel und Wert erzeugt.
if(iPrevWindowSize != iWindowSize) { if(!cProjInput.FeedForward(inputs) || !cQKV.FeedForward(GetPointer(cProjInput))) return false; inputs = GetPointer(cProjInput); } else if(!cQKV.FeedForward(inputs)) return false;
Der nächste Schritt besteht darin, die oben erstellte Selbstaufmerksamkeits-Methode in einem Fenster aufzurufen.
if(!DOT()) return false;
Verkleinerung der Datendimension.
if(!cProj.FeedForward(GetPointer(MHAttentionOut))) return false;
Hinzufügen des Ergebnisses zum Quelldatenpuffer.
if(!SumAndNormilize(inputs.getOutput(), cProj.getOutput(), AttentionOut.getOutput(), iWindowSize, true)) return false;
Weitergabe des Ergebnisses durch den FeedForward-Block.
if(!cFF1.FeedForward(GetPointer(AttentionOut))) return false; if(!cFF2.FeedForward(GetPointer(cFF1))) return false;
Das Hinzufügen des Puffers führt erneut zu Ergebnissen. Diesmal addieren wir die Ergebnisse mit der Ausgabe des fenstergesteuerten Selbstaufmerksamkeits-Blocks.
if(!SumAndNormilize(AttentionOut.getOutput(), cFF2.getOutput(), SAttenOut.getOutput(), iWindowSize, true)) return false;
Am Ende des Blocks befindet sich die globale Selbstaufmerksamkeit. Für diese Phase verwenden wir die Schicht CNeuronXCiTOCL.
if(!cCAtten.FeedForward(GetPointer(SAttenOut))) return false; //--- return true; }
Wir überprüfen die Ergebnisse der Operationen und beenden die Methode.
Damit sind unsere Überlegungen zur Implementierung des Vorwärtsdurchgangs unserer Klasse abgeschlossen. Als Nächstes gehen wir zur Implementierung der Rückwärtsdurchgangs-Methoden über. Auch hier beginnen wir mit der Arbeit, indem wir einen Rückwärtsdurchgangs-Kernel für den fenstergesteuerten Selbstaufmerksamkeits-Block erstellen: DOTInsideGradients. Wie der Vorwärtsdurchgangs-Kernel wird auch der neue Kernel in einem 3-dimensionalen Aufgabenraum gestartet. Dieses Mal erstellen wir jedoch keine lokalen Gruppen.
In den Parametern erhält der Kernel Zeiger auf alle notwendigen Datenpuffer.
__kernel void DOTInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *rpb, __global float *rpb_g, __global float *gradient) { //--- init const uint u = get_global_id(0); const uint d = get_global_id(1); const uint h = get_global_id(2); const uint units = get_global_size(0); const uint dimension = get_global_size(1); const uint heads = get_global_size(2);
Im Hauptteil des Kerns identifizieren wir den Thread in allen 3 Dimensionen. Wir bestimmen auch den Aufgabenbereich, der die Größe der resultierenden Puffer angibt.
Hier bestimmen wir auch den Offset in den Datenpuffern.
uint step = 3 * dimension * heads; uint start = max((int)u - 1, 0); uint stop = min((int)u + 1, (int)units - 1); const uint shift_q = u * step + dimension * h + d; const uint shift_k = u * step + dimension * (heads + h) + d; const uint shift_v = u * step + dimension * (2 * heads + h) + d;
Dann gehen wir direkt zur Gradientenverteilung über. Zunächst definieren wir den Fehlergradienten für das Element Wert. Zu diesem Zweck multiplizieren wir den resultierenden Gradienten mit dem entsprechenden Einflusskoeffizienten.
//--- Calculating Value's gradients float sum = 0; for(uint i = start; i <= stop; i ++) { int shift_score = i * 3 * heads; if(u == i) { shift_score += (uint)(u > 0); } else { if(u > i) shift_score += (uint)(start > 0) + 1; } uint shift_g = dimension * (i * heads + h) + d; sum += gradient[shift_g] * scores[shift_score]; } qkv_g[shift_v] = sum;
Der nächste Schritt besteht darin, den Fehlergradienten für die Entität Abfrage zu definieren. Hier ist der Algorithmus ein wenig komplizierter. Zunächst müssen wir den Fehlergradienten für den entsprechenden Vektor der Abhängigkeitskoeffizienten bestimmen und den resultierenden Gradienten an die Ableitung der SoftMax-Funktion anpassen. Erst danach können wir den resultierenden Fehlergradienten der Abhängigkeitskoeffizienten mit dem entsprechenden Element des Tensors der Entität Schlüssel multiplizieren.
Bitte beachten Sie, dass wir vor der Normalisierung der Abhängigkeitskoeffizienten diese mit Elementen der positionalen Aufmerksamkeitsverzerrung addiert haben. Wie Sie wissen, übertragen wir beim Addieren den Gradienten vollständig in beide Richtungen. Die Doppelzählung von Fehlern wird durch einen kleinen Lernkoeffizienten leicht ausgeglichen. Daher übertragen wir den Fehlergradienten auf der Ebene der Abhängigkeits-Koeffizientenmatrix in den Puffer für den Positionsverschiebungs-Fehlergradienten.
//--- Calculating Query's gradients float grad = 0; uint shift_score = u * heads * 3; for(int k = start; k <= stop; k++) { float sc_g = 0; float sc = scores[shift_score + k - start]; for(int v = start; v <= stop; v++) for(int dim=0;dim<dimension;dim++) sc_g += scores[shift_score + v - start] * qkv[v * step + dimension * (2 * heads + h) + dim] * gradient[dimension * (u * heads + h) + dim] * ((float)(k == v) - sc); grad += sc_g * qkv[k * step + dimension * (heads + h) + d]; if(d == 0) rpb_g[shift_score + k - start] = sc_g; } qkv_g[shift_q] = grad;
Als Nächstes müssen wir nur noch den Fehlergradienten für die Entität Schlüssel auf ähnliche Weise definieren. Der Algorithmus ist ähnlich wie Abfrage, hat aber eine andere Dimension der Koeffizientenmatrix.
//--- Calculating Key's gradients grad = 0; for(int q = start; q <= stop; q++) { float sc_g = 0; shift_score = q * heads * 3; if(u == q) { shift_score += (uint)(u > 0); } else { if(u > q) shift_score += (uint)(start > 0) + 1; } float sc = scores[shift_score]; for(int v = start; v <= stop; v++) { shift_score = v * heads * 3; if(u == v) { shift_score += (uint)(u > 0); } else { if(u > v) shift_score += (uint)(start > 0) + 1; } for(int dim=0;dim<dimension;dim++) sc_g += scores[shift_score] * qkv[shift_v-d+dim] * gradient[dimension * (v * heads + h) + d] * ((float)(d == v) - sc); } grad += sc_g * qkv[q * step + dimension * h + d]; } qkv_g[shift_k] = grad; }
Damit beenden wir die Arbeit mit dem Kernel und kehren zur Arbeit mit unserer Klasse CNeuronDOTOCL zurück, in der wir die Methode DOTInsideGradients erstellen werden, um den oben erstellten Kernel aufzurufen. Der Algorithmus bleibt derselbe:
- Definition des Aufgabenbereichs
bool CNeuronDOTOCL::DOTInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iUnits, iDimension, iHeads};
- Übergabe der Parameter
if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_qkv, cQKV.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_qkv_g, cQKV.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_scores, iScoreBuffer)) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_rpb_g, cRelativePositionsBias.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_gradient, MHAttentionOut.getGradientIndex())) return false;
- In die Ausführungswarteschlange stellen
ResetLastError(); if(!OpenCL.Execute(def_k_DOTInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
- Dann prüfen wir das Ergebnis der Operationen und beenden die Methode.
Wir beschreiben den Rückwärtsdurchgangs-Algorithmus direkt in der Methode calcInputGradients. In den Parametern erhält die Methode einen Zeiger auf das Objekt der vorherigen Schicht, an das der Fehler weitergegeben werden soll. Im Hauptteil der Methode wird sofort die Relevanz des empfangenen Zeigers geprüft. Denn wenn der Zeiger ungültig ist, können wir den Fehlergradienten nirgendwo übergeben. Dann würde die logische Bedeutung aller Operationen nahe bei „0“ liegen.
bool CNeuronDOTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Als Nächstes wiederholen wir die Vorwärtsdurchgangs-Operationen in umgekehrter Reihenfolge. Bei der Initialisierung unserer Klasse CNeuronDOTOCL haben wir die Puffer vorsichtshalber ersetzt. Wenn wir nun den Fehlergradienten von der nachfolgenden neuronalen Schicht erhalten, empfangen wir ihn direkt in der globalen Aufmerksamkeitsschicht. Folglich entfällt das ohnehin unnötige Kopieren von Daten, und die entsprechende Methode wird sofort in der internen Schicht der globalen Aufmerksamkeit aufgerufen.
if(!cCAtten.calcInputGradients(GetPointer(SAttenOut))) return false;
Auch hier haben wir die Puffersubstitutionstechnik verwendet und den Fehlergradienten sofort durch den FeedForward-Block propagiert.
if(!cFF2.calcInputGradients(GetPointer(cFF1))) return false; if(!cFF1.calcInputGradients(GetPointer(AttentionOut))) return false;
Als Nächstes summieren wir den Fehlergradienten der 2 Threads.
if(!SumAndNormilize(AttentionOut.getGradient(), SAttenOut.getGradient(), cProj.getGradient(), iWindowSize, false)) return false;
Dann verteilen wir es auf die Köpfe der Aufmerksamkeit.
if(!cProj.calcInputGradients(GetPointer(MHAttentionOut))) return false;
Aufrufen unserer Methode zur Verteilung des Fehlergradienten durch den fenstergesteuerten Selbstaufmerksamkeits-Block.
if(!DOTInsideGradients()) return false;
Dann überprüfen wir die Größe der vorherigen und der aktuellen Ebene. Wenn wir Daten skalieren müssen, propagieren wir zunächst den Fehlergradienten auf die Skalierungsebene. Wir summieren die Fehlergradienten aus 2 Threads. Erst dann skalieren wir den Fehlergradienten auf die vorherige Schicht.
if(iPrevWindowSize != iWindowSize) { if(!cQKV.calcInputGradients(GetPointer(cProjInput))) return false; if(!SumAndNormilize(cProjInput.getGradient(), cProj.getGradient(), cProjInput.getGradient(), iWindowSize, false)) return false; if(!cProjInput.calcInputGradients(prevLayer)) return false; }
Wenn die neuronalen Schichten gleich sind, wird der Fehlergradient sofort auf die vorherige Schicht übertragen. Dann ergänzen wir ihn um den Fehlergradienten aus dem zweiten Thread.
else { if(!cQKV.calcInputGradients(prevLayer)) return false; if(!SumAndNormilize(prevLayer.getGradient(), cProj.getGradient(), prevLayer.getGradient(), iWindowSize, false)) return false; } //--- return true; }
Nachdem der Fehlergradient durch alle neuronalen Schichten propagiert wurde, müssen wir die Modellparameter aktualisieren, um den Fehler zu minimieren. Alles wäre so einfach, wenn da nicht eine Sache wäre. Erinnern Sie sich an den Parameterpuffer für die Positionierung der Elemente? Wir müssen seine Parameter aktualisieren. Um diese Funktion auszuführen, erstellen wir den Kernel RPBUpdateAdam. In den Parametern für den Kernel übergeben wir Zeiger auf den Puffer der aktuellen Parameter und den Fehlergradienten. Wir übergeben auch Hilfstensoren und Konstanten der Adam-Methode.
__kernel void RPBUpdateAdam(__global float *target, __global const float *gradient, __global float *matrix_m, ///<[in,out] Matrix of first momentum __global float *matrix_v, ///<[in,out] Matrix of seconfd momentum const float b1, ///< First momentum multiplier const float b2 ///< Second momentum multiplier ) { const int i = get_global_id(0);
Im Hauptteil des Kernels identifizieren wir einen Thread, der den Offset in den Datenpuffern angibt.
Als Nächstes deklarieren wir lokale Variablen und speichern die erforderlichen Werte der globalen Puffer in ihnen.
float m, v, weight; m = matrix_m[i]; v = matrix_v[i]; weight = target[i]; float g = gradient[i];
In Anlehnung an die Adam-Methode werden zunächst die Momente bestimmt.
m = b1 * m + (1 - b1) * g; v = b2 * v + (1 - b2) * pow(g, 2);
Auf der Grundlage der erhaltenen Impulse wird die erforderliche Anpassung der Parameter berechnet.
float delta = m / (v != 0.0f ? sqrt(v) : 1.0f);
Wir speichern alle Daten in den entsprechenden Elementen des globalen Puffers.
target[i] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[i] = m; matrix_v[i] = v; }
Kehren wir nun zu unserer Klasse CNeuronDOTOCL zurück und erstellen die Methode updateRelativePositionsBias, die den Kernel aufruft. Wir verwenden hier einen 1-dimensionalen Aufgabenraum.
bool CNeuronDOTOCL::updateRelativePositionsBias(void) { if(!OpenCL) return false; //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {cRelativePositionsBias.Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_gradient, cRelativePositionsBias.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_matrix_m, cRelativePositionsBias.getFirstMomentumIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_matrix_v, cRelativePositionsBias.getSecondMomentumIndex())) return false; if(!OpenCL.SetArgument(def_k_RPBUpdateAdam, def_k_rpbw_b1, b1)) return false; if(!OpenCL.SetArgument(def_k_RPBUpdateAdam, def_k_rpbw_b2, b2)) return false; ResetLastError(); if(!OpenCL.Execute(def_k_RPBUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Die vorbereitenden Arbeiten sind abgeschlossen. Als Nächstes erstellen wir die Top-Level-Methode updateInputWeights für die Aktualisierung der Blockparameter. In den Parametern erhält die Methode einen Zeiger auf das Objekt der vorherigen Ebene. In diesem Fall wird auf die Überprüfung des empfangenen Zeigers verzichtet, da die Überprüfung in den Methoden der internen Schichten durchgeführt wird.
Zunächst wird geprüft, ob die Parameter der Skalierungsebene aktualisiert werden müssen. Wenn eine Aktualisierung erforderlich ist, rufen wir die entsprechende Methode auf der angegebenen Ebene auf.
if(iWindowSize != iPrevWindowSize) { if(!cProjInput.UpdateInputWeights(NeuronOCL)) return false; if(!cQKV.UpdateInputWeights(GetPointer(cProjInput))) return false; } else { if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; }
Dann aktualisieren wir die Parameter der Abfrage-, Schlüssel- und Wert-Entitätserzeugungsschicht.
Auf ähnliche Weise aktualisieren wir die Parameter aller internen Schichten.
if(!cProj.UpdateInputWeights(GetPointer(MHAttentionOut))) return false; if(!cFF1.UpdateInputWeights(GetPointer(AttentionOut))) return false; if(!cFF2.UpdateInputWeights(GetPointer(cFF1))) return false; if(!cCAtten.UpdateInputWeights(GetPointer(SAttenOut))) return false;
Und am Ende der Methode aktualisieren wir die Parameter für den Positionsversatz.
if(!updateRelativePositionsBias()) return false; //--- return true; }
Auch hier sollten wir nicht vergessen, die Ergebnisse bei jedem Schritt zu kontrollieren.
Damit sind unsere Überlegungen zu den Methoden der neuen neuronalen Schicht CNeuronDOTOCL abgeschlossen. Den vollständigen Code der Klasse und ihrer Methoden, einschließlich derer, die in diesem Artikel nicht beschrieben werden, finden Sie im Anhang.
Wir machen weiter und bauen die Architektur unseres neuen Modells auf.
2.2 Modellarchitektur
Wie üblich werden wir die Architektur unseres Modells in der Methode CreateDescriptions beschreiben. In den Parametern erhält die Methode Zeiger auf 3 dynamische Arrays zur Speicherung von Modellbeschreibungen. Im Hauptteil der Methode prüfen wir sofort die Relevanz der empfangenen Zeiger und erstellen gegebenenfalls neue Instanzen der Arrays.
bool CreateDescriptions(CArrayObj *dot, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Wir müssen 3 Modelle erstellen:
- DOT
- Actor (Akteur)
- Critic (Kritiker).
Der DOT-Block wird von der DFFT-Architektur bereitgestellt. Es gibt jedoch nichts über den Akteur oder den Kritiker. Ich möchte Sie jedoch daran erinnern, dass die DFFT-Methode die Erstellung eines TAE-Blocks mit Klassifizierungs- und Regressionsausgaben vorschlägt. Die aufeinanderfolgende Verwendung von Akteur und Kritiker sollte den TAE-Block auslösen. Der Akteur ist der Aktionsklassifikator, und der Kritiker ist die Belohnungsregression.
Wir füttern das DOT-Modell mit einer Beschreibung des aktuellen Zustands der Umgebung.
//--- DOT dot.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
Wir verarbeiten die „rohen“ Daten in der Batch-Normalisierungsschicht.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
Dann erstellen wir eine Einbettung der neuesten Daten und fügen sie dem Stapel hinzu.
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!dot.Add(descr)) { delete descr; return false; }
Als Nächstes fügen wir die Positionskodierung der Daten hinzu.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!dot.Add(descr)) { delete descr; return false; }
Bis zu diesem Punkt haben wir die Einbettungsarchitektur aus früheren Arbeiten wiederholt. Dann haben wir Veränderungen. Wir fügen den ersten DOT-Block hinzu, in dem die Analyse im Kontext der einzelnen Staaten durchgeführt wird.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
Im nächsten Block komprimieren wir die Daten um das Doppelte, analysieren aber weiterhin im Kontext der einzelnen Zustände.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; prev_wout = descr.window = prev_wout / 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
Als Nächstes gruppieren wir die Daten für die Analyse in 2 aufeinander folgende Zustände.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; prev_count = descr.count = prev_count / 2; prev_wout = descr.window = prev_wout * 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
Auch hier komprimieren wir die Daten.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; prev_wout = descr.window = prev_wout / 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
Die letzte Schicht des DOT-Modells geht über die DFFT-Methode hinaus. Hier habe ich eine Kreuz-Aufmerksamkeits-Ebene hinzugefügt.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMH2AttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = prev_wout / descr.step; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
Das Akteursmodell erhält Input, der im DOT-Modell des Umweltzustands verarbeitet wird.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count*prev_wout; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die empfangenen Daten werden mit dem aktuellen Kontostand kombiniert.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
Die Daten werden von 2 vollständig verbundenen Schichten verarbeitet.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Am Ausgang erzeugen wir eine stochastische Akteurspolitik.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Der Kritiker verwendet auch verarbeitete Umweltzustände als Input.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; }
Wir ergänzen die Beschreibung des Umweltzustands durch die Aktionen des Agenten.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; }
Die Daten werden von 2 vollständig verknüpften Schichten mit einem Belohnungsvektor am Ausgang verarbeitet.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.3 EA für Umgebungsinteraktion
Nachdem wir die Architektur der Modelle erstellt haben, gehen wir dazu über, einen EA für die Interaktion mit der Umgebung „...\Experts\DFFT\Research.mq5“ zu erstellen. Dieser EA wurde entwickelt, um die anfängliche Trainingsprobe zu sammeln und anschließend den Erfahrungswiedergabepuffer zu aktualisieren. Der EA kann auch verwendet werden, um ein trainiertes Modell zu testen. Obwohl ein anderer EA „...\Experts\DFFT\Test.mq5“ zur Verfügung gestellt wird, um diese Funktion auszuführen. Beide EAs haben einen ähnlichen Algorithmus. Letzteres speichert jedoch keine Daten im Erfahrungswiedergabepuffer für späteres Training. Dies geschieht für einen „fairen“ Test des trainierten Modells.
Beide EAs sind hauptsächlich von früheren Arbeiten kopiert. Im Rahmen dieses Artikels werden wir uns nur auf die Änderungen konzentrieren, die mit den Besonderheiten der Modelle zusammenhängen.
Bei der Datenerhebung werden wir das Kritiker-Modell nicht verwenden.
CNet DOT; CNet Actor;
Bei der EA-Initialisierungsmethode verbinden wir zunächst die erforderlichen Indikatoren.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- load models float temp;
Dann versuchen wir, vortrainierte Modelle zu laden.
if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, actor, critic)) { delete dot; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Actor.Create(actor)) { delete dot; delete actor; delete critic; return INIT_FAILED; } delete dot; delete actor; delete critic; }
Wenn die Modelle nicht geladen werden konnten, werden neue Modelle mit zufälligen Parametern initialisiert. Danach übertragen wir beide Modelle in einen einzigen OpenCL-Kontext.
Actor.SetOpenCL(DOT.GetOpenCL());
Wir führen auch eine minimale Überprüfung der Modellarchitektur durch.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Wir speichern den Kontozustand in lokalen Variablen.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Die Interaktion mit der Umgebung und die Datenerfassung sind in der Methode OnTick implementiert. Im Hauptteil der Methode wird zunächst geprüft, ob ein neues Ereignis zur Öffnung eines Taktes eingetreten ist. Eine Analyse wird nur bei einer neuen Kerze durchgeführt.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Als Nächstes aktualisieren wir die historischen Daten.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Wir füllen den Puffer für die Beschreibung des Zustands der Umgebung.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
In einem nächsten Schritt werden Daten zum aktuellen Kontostand erhoben.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Wir konsolidieren die gesammelten Daten in einem Puffer, der den Kontostatus beschreibt.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
Hier fügen wir einen Zeitstempel des aktuellen Zustands hinzu.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); //--- if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return;
Nach der Erfassung der Ausgangsdaten führen wir einen Vorwärtsdurchlauf des Kodierers durch.
if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Wir implementieren sofort den Vorwärtsdurchgang des Akteurs.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(DOT), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Erhalt der Modellergebnisse.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions);
Sie werden bei der Durchführung von Handelsgeschäften entschlüsselt.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Wir speichern die von der Umgebung empfangenen Daten in den Erfahrungswiedergabepuffer.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
Die übrigen Methoden des EA wurden ohne Änderungen übernommen. Sie finden sie in der Anlage.
2.4 EA für das Modelltraining
Nach dem Sammeln des Trainingsdatensatzes fahren wir mit der Erstellung des Modelltrainings EA „...\Experts\DFFT\Study.mq5“ fort. Wie bei den Umweltinteraktions-EAs wurde der Algorithmus weitgehend aus früheren Artikeln übernommen. Daher schlage ich im Rahmen dieses Artikels vor, nur die Modellbildungsmethode Train zu betrachten.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Im Hauptteil der Methode wird zunächst ein Vektor von Wahrscheinlichkeiten für die Auswahl von Trajektorien aus dem Trainingsdatensatz in Abhängigkeit von ihrer Rentabilität erstellt. Die profitabelsten Durchgänge werden häufiger zum Trainieren von Modellen verwendet.
Als Nächstes deklarieren wir die notwendigen lokalen Variablen.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Nach Abschluss der vorbereitenden Arbeiten organisieren wir ein System von Modell-Trainingsschleifen. Ich möchte Sie daran erinnern, dass wir im Kodierer-Modell einen Stapel historischer Daten verwendet haben. Ein solches Modell ist sehr empfindlich gegenüber der historischen Abfolge der verwendeten Daten. Daher nehmen wir in der äußeren Schleife die Trajektorie aus dem Erfahrungswiedergabepuffer und den Anfangszustand für das Training auf dieser Trajektorie.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Danach löschen wir den internen Stapel des Modells.
DOT.Clear();
Erstellung einer verschachtelten Schleife, um die aufeinanderfolgenden historischen Zustände aus dem Erfahrungswiedergabepuffer zu extrahieren und das Modell zu trainieren. Wir setzen die Trainingscharge des Modells 2 Tage größer als die Tiefe der internen Spuren des Modells.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
Im Hauptteil der verschachtelten Schleife extrahieren wir einen Umgebungszustand aus dem Erfahrungswiedergabepuffer und verwenden ihn für den Kodierer-Vorwärtsdurchlauf.
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Um die Politik des Akteurs zu trainieren, müssen wir zunächst den Puffer für die Beschreibung des Kontostandes füllen, so wie wir es im Berater für die Interaktion mit der Umgebung getan haben. Jetzt wird jedoch nicht die Umgebung abgefragt, sondern es werden Daten aus dem Erfahrungswiedergabepuffer extrahiert.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Wir fügen auch einen Zeitstempel hinzu.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Danach führen wir den Vorwärtsdurchgang von Akteur und Kritiker aus.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(DOT), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(DOT), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Als Nächstes trainieren wir den Akteur, Aktionen aus dem Erfahrungswiedergabepuffer auszuführen und den Gradienten an das Kodierer-Modell zu übertragen. Die Objekte werden im TAE-Block gemäß der DFFT-Methode klassifiziert.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Als Nächstes bestimmen wir eine Belohnung für den nächsten Übergang in einen neuen Zustand der Umgebung.
result.Assign(Buffer[tr].States[i+1].rewards); target.Assign(Buffer[tr].States[i+2].rewards); result=result-target*DiscFactor;
Wir trainieren das Kritiker-Modell, indem wir den Fehlergradienten auf beide Modelle übertragen.
Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Beachten Sie, dass wir in vielen Algorithmen zuvor versucht haben, eine gegenseitige Anpassung der Modelle zu vermeiden. So haben wir versucht, unerwünschte Ergebnisse zu vermeiden. Die Autoren der DFFT-Methode hingegen erklären, dass dieser Ansatz eine bessere Konfiguration der Kodierer-Parameter ermöglicht, um ein Maximum an Informationen zu gewinnen.
Nach dem Training der Modelle informieren wir den Nutzer über den Fortschritt des Trainingsprozesses und fahren mit der nächsten Iteration der Schleife fort.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nach erfolgreichem Abschluss aller Iterationen des Trainingsprozesses löschen wir die Kommentare auf dem Chart. Die Lernergebnisse werden in der Journal abgedruckt. Dann initialisieren wir die Fertigstellung des EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Damit ist unser Überblick über die Methoden des EAs für das Modeltraining EA abgeschlossen. Den vollständigen Code des EA und alle seine Methoden finden Sie im Anhang. Der Anhang enthält auch alle in diesem Artikel verwendeten Programme.
3. Tests
Wir haben viel Arbeit investiert, um die DFFT-Methode (Decoder-Free Fully Transformer-based) mit MQL5 zu implementieren. Jetzt ist es Zeit für Teil 3 unseres Artikels: die Überprüfung der geleisteten Arbeit. Wie zuvor wird das neue Modell anhand historischer Daten für EURUSD H1 trainiert und getestet. Die Indikatoren werden mit Standardparametern verwendet.
Um das Modell zu trainieren, haben wir 500 zufällige Trajektorien über einen Zeitraum von den ersten 7 Monaten des Jahres 2023 gesammelt. Das trainierte Modell wurde mit historischen Daten für August 2023 getestet. Daher wurde das Testintervall nicht in die Trainingsmenge aufgenommen. Dies ermöglicht eine Leistungsbewertung anhand neuer Daten.
Ich muss zugeben, dass sich das Modell als recht „leicht“ erwiesen hat, was den Verbrauch an Rechenressourcen angeht, sowohl während des Trainings als auch im Betriebsmodus während der Tests.
Der Lernprozess verlief recht stabil mit einer gleichmäßigen Abnahme des Fehlers sowohl beim Akteur als auch beim Kritiker. Während des Trainingsprozesses erhielten wir ein Modell, das in der Lage war, sowohl bei Trainings- als auch bei Testdaten kleine Gewinne zu erzielen. Es wäre jedoch besser, ein höheres Rentabilitätsniveau und ein ausgeglichenen Saldo zu erreichen.
Schlussfolgerung
In diesem Artikel haben wir uns mit der DFFT-Methode vertraut gemacht, die ein effektiver Objektdetektor ist, der auf einem decoderfreien Transformator basiert und zur Lösung von Computer-Vision-Problemen vorgestellt wurde. Zu den wichtigsten Merkmalen dieses Ansatzes gehören die Verwendung eines Transformators für die Merkmalsextraktion und die dichte Vorhersage auf einer einzigen Merkmalskarte. Die Methode bietet neue Module zur Verbesserung der Effizienz von Modeltraining und -betrieb.
Die Autoren der Methode haben gezeigt, dass DFFT eine hohe Genauigkeit der Objekterkennung bei relativ geringem Rechenaufwand ermöglicht.
Im praktischen Teil dieses Artikels haben wir die vorgeschlagenen Ansätze mit MQL5 umgesetzt. Wir haben das konstruierte Modell auf realen historischen Daten trainiert und getestet. Die erzielten Ergebnisse bestätigen die Wirksamkeit der vorgeschlagenen Algorithmen und verdienen eine eingehendere praktische Forschung.
Ich möchte Sie daran erinnern, dass alle in diesem Artikel vorgestellten Programme nur zu Informationszwecken zur Verfügung gestellt werden. Sie wurden nur erstellt, um die vorgeschlagenen Ansätze und ihre Möglichkeiten zu demonstrieren. Bevor Sie ein Programm auf realen Finanzmärkten einsetzen, sollten Sie es fertig stellen und gründlich testen.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modelltraining EA |
| 4 | Test.mq5 | Expert Advisor | Modelltraining EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14338
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.