
Neuronale Netze leicht gemacht (Teil 79): Feature Aggregated Queries (FAQ) im Kontext des Staates

Einführung
Die meisten der zuvor besprochenen Methoden analysieren den Zustand der Umgebung als etwas Statisches, was der Definition eines Markov-Prozesses voll entspricht. Natürlich haben wir die Beschreibung des Umgebungszustands mit historischen Daten gefüllt, um das Modell mit so vielen notwendigen Informationen wie möglich zu versorgen. Das Modell bewertet jedoch nicht die Dynamik der Zustandsänderungen. Dies bezieht sich auch auf die im vorherigen Artikel vorgestellte Methode: DFFT wurde für die Erkennung von Objekten in statischen Bildern entwickelt.
Die Beobachtung von Kursbewegungen zeigt jedoch, dass die Dynamik von Veränderungen manchmal mit hinreichender Wahrscheinlichkeit die Stärke und Richtung der kommenden Bewegung anzeigen kann. Logischerweise wenden wir uns nun den Methoden zur Erkennung von Objekten in Videos zu.
Die Objekterkennung in Videos weist eine Reihe bestimmter Merkmale auf und muss das Problem der Veränderung von Objektmerkmalen durch Bewegung lösen, die im Bildbereich nicht vorkommen. Eine der Lösungen besteht darin, zeitliche Informationen zu nutzen und Merkmale aus benachbarten Bildern zu kombinieren. Der Artikel „ Feature Aggregated Queries for Transformer-based Video Object Detectors“ schlägt einen neuen Ansatz zur Erkennung von Objekten in Videos vor. Die Autoren des Artikels verbessern die Qualität von Abfragen (queries) für Transformator-basierte Modelle, indem sie diese aggregieren. Um dieses Ziel zu erreichen, wird eine praktische Methode vorgeschlagen, um Abfragen entsprechend den Merkmalen der Eingabeframes zu generieren und zu aggregieren. Ausführliche experimentelle Ergebnisse bestätigen die Wirksamkeit der vorgeschlagenen Methode. Die vorgeschlagenen Ansätze können auf eine Vielzahl von Methoden zur Erkennung von Objekten in Bildern und Videos ausgeweitet werden, um deren Effizienz zu verbessern.
1. Algorithmus für aggregierte Abfragen von Merkmalen
Die Methode FAQ ist nicht die erste, die die Transformer-Architektur zur Erkennung von Objekten in Videos verwendet. Bestehende Video-Objektdetektoren, die Transformer verwenden, verbessern jedoch die Darstellung von Objektmerkmalen durch die Zusammenfassung von Abfragen. Die naive Vanilla-Idee besteht darin, Abfragen aus benachbarten Frames zu mitteln. Die Abfragen werden nach dem Zufallsprinzip initialisiert und während des Trainingsprozesses verwendet. Angrenzende Abfragen werden zu Δ𝑸 für den aktuellen Rahmen 𝑰 zusammengefasst und wie folgt dargestellt:
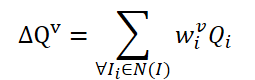
Wobei w lernbare Gewichte für die Aggregation sind.
Die einfache Idee, lernfähige Gewichte zu erstellen, basiert auf der Kosinusähnlichkeit der Merkmale des Eingabebildes. In Anlehnung an bestehende Video-Objekt-Detektoren erstellen die Autoren der FAQ-Methode Aggregationsgewichte nach der Formel:
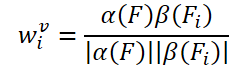
Dabei sind α und β Abbildungsfunktionen, und |⋅| bezeichnet die Normalisierung.
Relevante Merkmale des aktuellen Rahmens 𝑰 und seiner benachbarten 𝑰i werden als 𝑭 und 𝑭 bezeichneti. Die Wahrscheinlichkeit, ein Objekt zu identifizieren, lässt sich daher wie folgt ausdrücken:
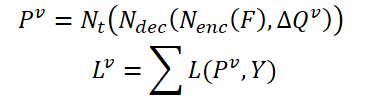
wobei 𝑷v die vorhergesagte Wahrscheinlichkeit unter Verwendung aggregierter Abfragen Δ𝑸v.
Es gibt ein Problem im Vanilla-Query-Aggregationsmodul: Diese benachbarten Queries 𝑸i werden zufällig initialisiert und sind nicht mit ihren entsprechenden Frames 𝑰i. Daher sind angrenzende Abfragen 𝑸i nicht genügend zeitliche oder semantische Informationen, um die durch schnelle Bewegungen verursachten Leistungseinbußen zu überwinden. Obwohl die für die Aggregation verwendeten Gewichte wi, die mit den Funktionen 𝑭 und 𝑭i in Bezug stehen, gibt es keine ausreichenden Beschränkungen für die Anzahl dieser zufällig initiierten Abfragen. Daher schlagen die Autoren der Methode FAQ vor, das Aggregationsmodul Query (Abfrage) zu einer dynamischen Version zu aktualisieren, die den Abfragen Einschränkungen hinzufügt und die Gewichte entsprechend den benachbarten Frames anpassen kann. Die einfache Umsetzung besteht darin, Abfragen 𝑸i direkt aus den Merkmalen 𝑭i des Eingaberahmens zu generieren. Die von den Autoren der Methode durchgeführten Experimente zeigen jedoch, dass diese Methode schwer zu trainieren ist und immer schlechtere Ergebnisse liefert. Im Gegensatz zu der oben erwähnten naiven Idee schlagen die Autoren der Methode vor, aus den zufällig initialisierten Abfragen neue Abfragen zu generieren, die an die ursprünglichen Daten angepasst sind. Zunächst definieren wir zwei Arten von Abfragevektoren: einfache und dynamische. Während des Lern- und Arbeitsprozesses werden dynamische Abfragen aus den Basisabfragen nach den Merkmalen 𝑭i, 𝑭 der Eingangsrahmen als:
![]()
Dabei ist M eine Abbildungsfunktion zur Herstellung einer Beziehung zwischen der Basisabfrage Qb und der dynamischen Abfrage Qd in Übereinstimmung mit den Merkmalen 𝑭 und 𝑭i.
Unterteilen wir zunächst die Basisabfragen in Gruppen nach r Abfragen. Dann verwenden wir für jede Gruppe dieselben Gewichte 𝑽, um den gewichteten Durchschnitt der Abfrage in der aktuellen Gruppe zu ermitteln:
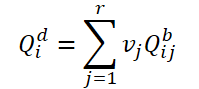
Um eine Beziehung zwischen dynamischen Abfragen 𝑸d und dem entsprechenden Rahmen 𝑰i herzustellen, schlagen die Autoren der Methode vor, Gewichte 𝑽 anhand globaler Merkmale zu erzeugen:
![]()
Dabei ist A eine globale Pooling-Operation, um die Dimension des Merkmalstensors zu ändern und Merkmale auf globaler Ebene zu erstellen,
G ist eine Abbildungsfunktion, mit der wir globale Merkmale in die Dimension des dynamischen Tensors Query projizieren können.
Somit kann der Prozess der dynamischen Abfrageaggregation auf der Grundlage der Quelldatenmerkmale wie folgt aktualisiert werden:
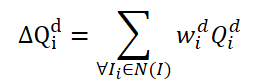
Die Autoren der Methode schlagen vor, während des Trainings sowohl dynamische Abfragen als auch einfache Abfragen zu aggregieren. Beide Arten von Abfragen werden mit denselben Gewichten und entsprechenden Vorhersagen 𝑷 aggregiertd und 𝑷b werden erzeugt. Hier berechnen wir auch den wechselseitigen Übereinstimmungsfehler für beide Vorhersagen. Der Hyperparameter γ wird verwendet, um die Auswirkungen von Fehlern auszugleichen.
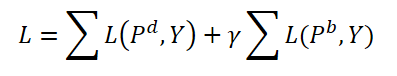
Während des Betriebs verwenden wir nur dynamische Abfragen 𝑸d und ihre entsprechenden Vorhersagen 𝑷d als Endergebnisse, die die ursprünglichen Modelle nur geringfügig verkomplizieren.
Nachstehend finden Sie eine Darstellung der Methode vom Autor der Methode zur Visualisierung:

2. Implementierung mit MQL5
Wir haben die theoretischen Aspekte der Algorithmen betrachtet. Kommen wir nun zum praktischen Teil unseres Artikels, in dem wir die vorgeschlagenen Ansätze mit Hilfe von MQL5 umsetzen werden.
Wie aus der obigen Beschreibung der FAQ-Methode ersichtlich ist, besteht ihr Hauptbeitrag in der Schaffung eines Moduls zur Erzeugung und Aggregation des dynamischen Abfragetensors im Decoder des Transformers. Ich möchte Sie daran erinnern, dass die Autoren der DFFT-Methode den Decoder wegen seiner Unwirksamkeit ausgeschlossen haben. Nun, in der aktuellen Arbeit werden wir einen Decoder hinzufügen und seine Effektivität im Zusammenhang mit der Verwendung von dynamischen Abfrageentitäten bewerten, die von den Autoren der FAQ-Methode vorgeschlagen wurden.
2.1 Dynamische Abfrageklasse
Um dynamische Abfragen zu generieren, erstellen wir die neue Klasse CNeuronFAQOCL. Das neue Objekt wird von der Basisklasse CNeuronBaseOCL der neuronalen Schicht abgeleitet.
class CNeuronFAQOCL : public CNeuronBaseOCL { protected: //--- CNeuronConvOCL cF; CNeuronBaseOCL cWv; CNeuronBatchNormOCL cNormV; CNeuronBaseOCL cQd; CNeuronXCiTOCL cDQd; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronFAQOCL(void) {}; ~CNeuronFAQOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronFAQOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
In der neuen Methode werden zusätzlich zu den grundlegenden Methoden, die überschrieben werden, 5 interne neuronale Schichten hinzugefügt. Wir werden ihren Zweck während der Durchführung erläutern. Wir haben alle internen Objekte als statisch deklariert, was uns erlaubt, den Konstruktor und den Destruktor der Klasse leer zu lassen.
Ein Klassenobjekt wird in der Methode CNeuronFAQOCL::Init initialisiert. In den Methodenparametern finden wir alle wichtigen Parameter für die Initialisierung interner Objekte. Im Hauptteil der Methode rufen wir die entsprechende Methode der übergeordneten Klasse auf. Wie Sie bereits wissen, implementiert diese Methode die minimal notwendige Kontrolle der empfangenen Parameter und die Initialisierung der geerbten Objekte.
bool CNeuronFAQOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Es ist keine Aktivierungsfunktion für unsere Klasse angegeben.
activation = None;
Als Nächstes initialisieren wir die internen Objekte. Hier wenden wir uns den von den Autoren der Abfrage-Methode vorgeschlagenen Ansätzen zur Erzeugung dynamischer Abfragen zu. Um Aggregationsgewichte für die Basisabfragen auf der Grundlage der Merkmale der Quelldaten zu erzeugen, erstellen wir 3 Ebenen. Zunächst leiten wir die Merkmale der Quelldaten durch eine Faltungsschicht, in der wir die Muster benachbarter Umgebungzustände analysieren.
if(!cF.Init(0, 0, OpenCL, 3 * window, window, 8, fmax((int)input_units - 2, 1), optimization_type, batch)) return false; cF.SetActivationFunction(None);
Um die Stabilität des Modelltrainings und -betriebs zu erhöhen, normalisieren wir die empfangenen Daten.
if(!cNormV.Init(8, 1, OpenCL, fmax((int)input_units - 2, 1) * 8, batch, optimization_type)) return false; cNormV.SetActivationFunction(None);
Dann komprimieren wir die Daten auf die Größe des Gewichtstensors der Basisabfrageaggregation. Um sicherzustellen, dass die resultierenden Gewichte im Bereich [0,1] liegen, verwenden wir eine sigmoide Aktivierungsfunktion.
if(!cWv.Init(units_count * window_out, 2, OpenCL, 8, optimization_type, batch)) return false; cWv.SetActivationFunction(SIGMOID);
Nach dem FAQ-Algorithmus müssen wir den resultierenden Vektor der Aggregationskoeffizienten mit der Matrix der Basisabfragen multiplizieren, die zu Beginn des Trainings zufällig generiert werden. Bei meiner Implementierung habe ich beschlossen, ein wenig weiter zu gehen und grundlegende Abfragen zu trainieren. Nun, mir ist nichts Besseres eingefallen, als eine vollständig verbundene neuronale Schicht zu verwenden. Wir füttern die Schicht mit einem Vektor von Aggregationskoeffizienten, während die Gewichtsmatrix der vollständig verknüpften Schicht ein Tensor der zu trainierenden Basisabfragen ist.
if(!cQd.Init(0, 4, OpenCL, units_count * window_out, optimization_type, batch)) return false; cQd.SetActivationFunction(None);
Als Nächstes folgt die Aggregation dynamischer Abfragen. Die Autoren der FAQ-Methode präsentieren in ihrem Papier die Ergebnisse von Experimenten mit verschiedenen Aggregationsmethoden. Am effektivsten war die dynamische Abfrageaggregation unter Verwendung der Transformer-Architektur. In Anlehnung an die obigen Ergebnisse verwenden wir das Klassenobjekt CNeuronXCiTOCL für die Aggregation dynamischer Abfragen.
if(!cDQd.Init(0, 5, OpenCL, window_out, 3, heads, units_count, 3, optimization_type, batch)) return false; cDQd.SetActivationFunction(None);
Um unnötige Datenkopiervorgänge zu vermeiden, ersetzen wir die Ergebnispuffer unserer Klassen- und Fehlergradienten.
if(Output != cDQd.getOutput()) { Output.BufferFree(); delete Output; Output = cDQd.getOutput(); } if(Gradient != cDQd.getGradient()) { Gradient.BufferFree(); delete Gradient; Gradient = cDQd.getGradient(); } //--- return true; }
Nach der Initialisierung des Objekts wird der Feed-Forward-Prozess in der Methode CNeuronFAQOCL::feedForward organisiert. Hier ist alles ganz einfach und überschaubar. In den Methodenparametern erhalten wir einen Zeiger auf die Quelldatenschicht mit Parametern zur Beschreibung des Zustands der Umgebung. Im Hauptteil der Methode rufen wir abwechselnd die entsprechenden Vorwärtsmethoden für interne Objekte auf.
bool CNeuronFAQOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cF.FeedForward(NeuronOCL)) return false;
Wir übertragen zunächst die Beschreibung der Umgebung durch eine Faltungsschicht und normalisieren die resultierenden Daten.
if(!cNormV.FeedForward(GetPointer(cF))) return false;
Dann erzeugen wir Aggregationskoeffizienten der Basisabfragen.
if(!cWv.FeedForward(GetPointer(cNormV))) return false;
Dynamische Abfragen (Queries) erstellen.
if(!cQd.FeedForward(GetPointer(cWv))) return false;
Sie werden in dem Klassenobjekt CNeuronXCiTOCL zusammengefasst.
if(!cDQd.FeedForward(GetPointer(cQd))) return false; //--- return true; }
Durch den Austausch von Datenpuffern werden die Ergebnisse der internen Schicht cDQd ohne unnötige Kopiervorgänge in den Ergebnispuffer unserer Klasse CNeuronFAQOCL übernommen. Daher können wir die Methode abschließen.
Als Nächstes erstellen wir die Backpropagation-Methoden CNeuronFAQOCL::calcInputGradients und CNeuronFAQOCL::updateInputWeights. Ähnlich wie bei der Vorwärtsdurchgangs-Methode rufen wir hier die entsprechenden Methoden auf internen Objekten auf, allerdings in umgekehrter Reihenfolge. Daher werden wir ihren Algorithmus in diesem Artikel nicht im Detail betrachten. Den vollständigen Code aller Methoden der dynamischen Abfragegenerierungsklasse CNeuronFAQOCL können Sie in den Anhängen zum Artikel studieren.
2.2 Die Klasse für die Kreuz-Aufmerksamkeit
Der nächste Schritt besteht darin, eine Klasse für die Kreuz-Aufmerksamkeit (Cross-Attention) zu erstellen. Im Rahmen der Implementierung der ADAPT-Methode haben wir bereits früher eine aufmerksamkeitsübergreifende Schicht geschaffen CNeuronMH2AttentionOCL. Damals analysierten wir jedoch die Beziehungen zwischen verschiedenen Dimensionen eines Tensors. Jetzt ist die Aufgabe ein wenig anders. Wir müssen die Abhängigkeiten der generierten dynamischen Abfragen aus der Klasse CNeuronFAQOCL zum komprimierten Zustand der Umgebung aus dem Encoder unseres Modells bewerten. Mit anderen Worten, wir müssen die Beziehung zwischen 2 verschiedenen Tensoren bewerten.
Um diese Funktionalität zu implementieren, werden wir eine neue Klasse CNeuronCrossAttention erstellen, die einen Teil der notwendigen Funktionalität von der oben erwähnten Klasse CNeuronMH2AttentionOCL erben wird.
class CNeuronCrossAttention : public CNeuronMH2AttentionOCL { protected: uint iWindow_K; uint iUnits_K; CNeuronBaseOCL *cContext; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); virtual bool attentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool AttentionInsideGradients(void); public: CNeuronCrossAttention(void) {}; ~CNeuronCrossAttention(void) { delete cContext; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); //--- virtual int Type(void) const { return defNeuronCrossAttenOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); };
Zusätzlich zum Standardsatz überschriebener Methoden sind hier 2 neue Variablen zu finden:
- iWindow_K — die Größe des Beschreibungsvektors für ein Element des zweiten Tensors;
- iUnits_K — die Anzahl der Elemente in der Folge des 2. Tensors.
Außerdem fügen wir einen dynamischen Zeiger auf die neuronale Hilfsschicht cContext hinzu, die bei Bedarf als Quellobjekt initialisiert wird. Da dieses Objekt eine optionale Hilfsfunktion erfüllt, bleibt der Konstruktor unserer Klasse leer. Aber im Destruktor der Klasse müssen wir das dynamische Objekt löschen.
~CNeuronCrossAttention(void) { delete cContext; }
Wie üblich wird das Objekt in der Methode CNeuronCrossAttention::Init initialisiert. In den Methodenparametern erhalten wir die notwendigen Daten über die Architektur der erstellten Schicht. Im Hauptteil der Methode rufen wir die entsprechende Methode der neuronalen Basisschichtklasse CNeuronBaseOCL::Init auf.
bool CNeuronCrossAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Bitte beachten Sie, dass wir die Initialisierungsmethode nicht von der direkten Elternklasse CNeuronMH2AttentionOCL aufrufen, sondern von der Basisklasse CNeuronBaseOCL. Dies ist auf Unterschiede in der Architektur der Klassen CNeuronCrossAttention und CNeuronMH2AttentionOCL zurückzuführen. Daher initialisieren wir im weiteren Verlauf der Methode nicht nur neue, sondern auch abgeleitete Objekte.
Zuerst speichern wir die Einstellungen unserer Schichten.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iWindow_K = fmax(window_k, 1); iUnits_K = fmax(units_k, 1); iHeads = fmax(heads, 1); activation = None;
Als Nächstes wird die Schicht zur Erzeugung von Abfrageentitäten initialisiert.
if(!Q_Embedding.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, optimization_type, batch)) return false; Q_Embedding.SetActivationFunction(None);
Wir führen dasselbe für die Entitäten Schlüssel und Wert durch.
if(!KV_Embedding.Init(0, 0, OpenCL, iWindow_K, iWindow_K, 2 * iWindowKey * iHeads, iUnits_K, optimization_type, batch)) return false; KV_Embedding.SetActivationFunction(None);
Bitte verwechseln Sie die hier erzeugten Abfrageentitäten nicht mit den dynamischen Abfragen, die in der Klasse CNeuronFAQOCL erzeugt werden.
Im Rahmen der Implementierung der FAQ-Methode werden wir die generierten, dynamischen Abfragen als Ausgangsdaten in diese Klasse eingeben. Wir können hier sagen, dass die Q_Embedding-Schicht sie auf die Aufmerksamkeitsköpfe verteilt. Und die KV_Embedding-Schicht erzeugt Entitäten aus einer komprimierten Darstellung des Umgebungszustands, die sie vom Encoder erhält.
Aber kehren wir zu unserer Klasseninitialisierungsmethode zurück. Nach der Initialisierung der Entity-Generierungsschichten erstellen wir einen Puffer für die Abhängigkeits-Koeffizientenmatrix Score.
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits_K * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Hier erstellen wir auch eine Ebene mit den Ergebnissen der mehrköpfigen Aufmerksamkeit.
if(!MHAttentionOut.Init(0, 0, OpenCL, iWindowKey * iUnits * iHeads, optimization_type, batch)) return false; MHAttentionOut.SetActivationFunction(None);
Und eine Ebene der Aggregation von Aufmerksamkeitsköpfen.
if(!W0.Init(0, 0, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, optimization_type, batch)) return false; W0.SetActivationFunction(None); if(!AttentionOut.Init(0, 0, OpenCL, iWindow * iUnits, optimization_type, batch)) return false; AttentionOut.SetActivationFunction(None);
Als nächstes kommt der Block mit dem Vorwärtsdurchgang.
if(!FF[0].Init(0, 0, OpenCL, iWindow, iWindow, 4 * iWindow, iUnits, optimization_type, batch)) return false; if(!FF[1].Init(0, 0, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, optimization_type, batch)) return false; for(int i = 0; i < 2; i++) FF[i].SetActivationFunction(None);
Am Ende der Initialisierungsmethode organisieren wir die Ersetzung von Puffern.
Gradient.BufferFree(); delete Gradient; Gradient = FF[1].getGradient(); //--- return true; }
Nach der Initialisierung der Klasse fahren wir wie üblich mit der Organisation des Vorwärtsdurchgangs fort. Innerhalb dieser Klasse werden wir keine neuen Kernel auf der Programmseite von OpenCL erstellen. In diesem Fall werden wir die Kernel verwenden, die zur Implementierung von Prozessen der übergeordneten Klasse erstellt wurden. Allerdings müssen wir einige kleinere Anpassungen an den Methoden zum Aufruf der Kernel vornehmen. In der Methode CNeuronCrossAttention::attentionOut zum Beispiel werden wir nur die Arrays ändern, die den Aufgabenbereich und die lokalen Gruppen in Bezug auf die Größe der Entitäts-Sequenz des Schlüssels angeben (im Code rot hervorgehoben).
bool CNeuronCrossAttention::attentionOut(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits_K/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits_K, 1}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, MHAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Der gesamte Algorithmus des Vorwärtsdurchgangs wird auf der obersten Ebene in der Methode CNeuronCrossAttention::feedForward beschrieben. Anders als die entsprechende Methode der übergeordneten Klasse erhält diese Methode in ihren Parametern Zeiger auf 2 Objekte neuronaler Schichten. Sie enthalten die Daten von 2 Tensoren für die Abhängigkeitsanalyse.
bool CNeuronCrossAttention::feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context) { //--- if(!Q_Embedding.FeedForward(NeuronOCL)) return false; //--- if(!KV_Embedding.FeedForward(Context)) return false;
Im Hauptteil der Methode werden zunächst Entitäten aus den empfangenen Daten erzeugt. Dann sprechen wir von der Methode der mehrköpfigen Aufmerksamkeit.
if(!attentionOut()) return false;
Wir fassen die Ergebnisse der Aufmerksamkeit zusammen
if(!W0.FeedForward(GetPointer(MHAttentionOut))) return false;
und summieren sie mit den Quelldaten. Danach normalisieren wir das Ergebnis innerhalb der Elemente der Sequenz. Im Rahmen der Implementierung der FAQ-Methode wird die Normalisierung im Kontext der einzelnen dynamischen Abfragen durchgeführt.
if(!SumAndNormilize(W0.getOutput(), NeuronOCL.getOutput(), AttentionOut.getOutput(), iWindow)) return false;
Die Daten werden dann durch den Vorwärtsdurchgangs-Block geleitet.
if(!FF[0].FeedForward(GetPointer(AttentionOut))) return false; if(!FF[1].FeedForward(GetPointer(FF[0]))) return false;
Dann summieren wir die Daten und normalisieren sie erneut.
if(!SumAndNormilize(FF[1].getOutput(), AttentionOut.getOutput(), Output, iWindow)) return false; //--- return true; }
Nachdem alle oben genannten Vorgänge erfolgreich abgeschlossen wurden, beenden wir die Methode.
Damit ist die Beschreibung der Vorwärtsdurchgangs-Methode abgeschlossen, und wir gehen zur Organisation des Rückwärtsdurchgangs über. Auch hier verwenden wir den Kernel, der als Teil der Implementierung der Elternklasse erstellt wurde, und nehmen spezifische Änderungen an der Kernel-Aufrufmethode CNeuronCrossAttention::AttentionInsideGradients vor.
bool CNeuronCrossAttention::AttentionInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindowKey, iHeads}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_qg, Q_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kvg, KV_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_outg, MHAttentionOut.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kunits, (int)iUnits_K)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Der Prozess der Ausbreitung des Fehlergradienten durch unsere Kreuz-Aufmerksamkeits-Schicht ist in der Methode CNeuronCrossAttention::calcInputGradients implementiert. Wie bei der Vorwärtsdurchgangs-Methode übergeben wir in den Parametern dieser Methode Zeiger auf 2 Schichten mit 2 Daten-Threads.
bool CNeuronCrossAttention::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context) { if(!FF[1].calcInputGradients(GetPointer(FF[0]))) return false; if(!FF[0].calcInputGradients(GetPointer(AttentionOut))) return false;
Dank der Ersetzung von Datenpuffern wird der von der nachfolgenden Schicht erhaltene Fehlergradient sofort in den Fehlergradientenpuffer der zweiten Schicht des Vorwärtsdurchgangs-Blocks übertragen. Daher brauchen wir die Daten nicht zu kopieren. Als Nächstes rufen wir sofort die Methoden zur Verteilung des Fehlergradienten der internen Schichten des Vorwärtsdurchgangs-Blocks auf.
In dieser Phase müssen wir den Fehlergradienten hinzufügen, den wir vom Block Vorwärtsdurchgang und von der nachfolgenden neuronalen Schicht erhalten haben.
if(!SumAndNormilize(FF[1].getGradient(), AttentionOut.getGradient(), W0.getGradient(), iWindow, false)) return false;
Als Nächstes wird der Fehlergradient auf die Aufmerksamkeitsköpfe verteilt.
if(!W0.calcInputGradients(GetPointer(MHAttentionOut))) return false;
Wir rufen die Methode auf, um den Fehlergradienten an die Entitäten Abfrage, Schlüssel und Wert weiterzugeben.
if(!AttentionInsideGradients()) return false;
Der Gradient der Schlüssel- und Wert-Entitäten wird auf die Kontext- (Encoder-) Ebene übertragen.
if(!KV_Embedding.calcInputGradients(Context)) return false;
Der Gradient aus der Abfrage wird in die vorherige Schicht übertragen.
if(!Q_Embedding.calcInputGradients(prevLayer)) return false;
Vergessen wir nicht, die Fehlergradienten zu summieren.
if(!SumAndNormilize(prevLayer.getGradient(), W0.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
Dann schließen wir die Methode ab.
Die Methode CNeuronCrossAttention::updateInputWeights zum Aktualisieren der internen Objektparameter ist recht einfach. Es ruft lediglich die entsprechenden Methoden der internen Objekte nacheinander auf. Sie finden sie in der Anlage. Außerdem enthält der Anhang die erforderlichen Dateiverarbeitungsmethoden. Darüber hinaus enthält sie den vollständigen Code aller in diesem Artikel verwendeten Programme und Klassen.
Damit ist die Erstellung der neuen Klassen abgeschlossen, und wir können zur Beschreibung der Modellarchitektur übergehen.
2.3 Modellarchitektur
Die Architektur der Modelle wird in der Methode CreateDescriptions dargestellt. Die derzeitige Architektur der Modelle ist weitgehend von der Implementierung der DFFT-Methode übernommen. Wir haben jedoch einen Decoder hinzugefügt. Daher erhalten der Akteur und der Kritiker Daten vom Decoder. Um eine Beschreibung der Modelle zu erstellen, benötigen wir also 4 dynamische Arrays.
bool CreateDescriptions(CArrayObj *dot, CArrayObj *decoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Das Modell des Encoders (Punkt) wurde ohne Änderungen aus dem vorherigen Artikel übernommen. Eine ausführliche Beschreibung des Programms finden Sie hier.
Der Decoder verwendet die latenten Daten des Encoders auf der Ebene der Positionskodierungsschicht als Eingangsdaten.
//--- Decoder decoder.Clear(); //--- Input layer CLayerDescription *po = dot.At(LatentLayer); if(!po || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = po.count * po.window; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Ich möchte Sie daran erinnern, dass wir auf dieser Ebene die Einbettungen mehrerer Umgebungszustände, die im lokalen Stapel gespeichert sind, mit hinzugefügten positionellen Kodierungsetiketten entfernen. Diese Einbettungen enthalten eine Folge von Zeichen, die den Zustand der Umgebung für die Kerzen GPTBars beschreiben. Dies kann mit den Bildern einer Videoserie verglichen werden. Auf der Grundlage dieser Daten erstellen wir dynamische Abfragen.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFAQOCL; { int temp[] = {QueryCount, po.count}; ArrayCopy(descr.units, temp); } descr.window = po.window; descr.window_out = 16; descr.optimization = ADAM; descr.step = 4; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
Und wir setzen die Kreuz-Aufmerksamkeit ein.
//--- layer 2 CLayerDescription *encoder = dot.At(dot.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {QueryCount, encoder.count}; ArrayCopy(descr.units, temp); } { int temp[] = {16, encoder.window}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Der Akteur empfängt Daten vom Decoder.
//--- Actor actor.Clear(); //--- Input layer encoder = decoder.At(decoder.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = encoder.units[0] * encoder.windows[0]; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Und kombiniert sie mit der Beschreibung des Kontostatus.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
Danach durchlaufen die Daten 2 vollständig verbundene Schichten.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Am Ausgang fügen wir der Politik des Akteurs Stochastizität hinzu.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Kritikermodell wurde fast unverändert übernommen. Die einzige Änderung besteht darin, dass die Quelle der Ausgangsdaten von Encoder auf Decoder geändert wurde.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(1)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 Umgebungs-Interaktions-EAs
Bei der Vorbereitung dieses Artikels habe ich 3 Umgebungs-Interaktions-EAs verwendet:
- Research.mq5
- ResearchRealORL.mq5
- Test.mq5
Der EA „...\Experts\FAQ\ResearchRealORL.mq5“ ist nicht mit der Modellarchitektur verknüpft. Da alle EAs durch die Analyse der gleichen Ausgangsdaten, die die Umgebung beschreiben, trainiert und getestet werden, wird dieser EA ohne Änderungen in verschiedenen Artikeln verwendet. Eine vollständige Beschreibung des Codes und der Verwendungsmöglichkeiten finden Sie hier.
Im Code des EA „...\Experts\FAQ\Research.mq5“ fügen wir ein Decoder-Modell hinzu.
CNet DOT; CNet Decoder; CNet Actor;
Dementsprechend fügen wir in der Initialisierungsmethode das Laden dieses Modells hinzu und initialisieren es ggf. mit zufälligen Parametern.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; //--- if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; } //--- Decoder.SetOpenCL(DOT.GetOpenCL()); Actor.SetOpenCL(DOT.GetOpenCL()); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Bitte beachten Sie, dass wir in diesem Fall nicht das Modell des Kritikers verwenden. Seine Funktionalität ist nicht in den Prozess der Interaktion mit der Umgebung und der Sammlung von Daten für das Training eingebunden.
Der eigentliche Prozess der Interaktion mit der Umgebung wird in der Methode OnTick organisiert. Im Hauptteil der Methode wird zunächst geprüft, ob ein neues Ereignis zur Öffnung eines Balkens eingetreten ist.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Der gesamte Prozess basiert auf der Analyse von geschlossenen Kerzen.
Wenn ein erforderliches Ereignis eintritt, laden wir zunächst historische Daten herunter.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Wir übertragen die Daten in den Puffer, der den aktuellen Zustand der Umgebung beschreibt.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Dann sammeln wir Daten über den Kontostand und die offenen Positionen.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Die empfangenen Daten werden im Kontostandspuffer gruppiert.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
Wir fügen hier auch die zeitbezogene Schwingungen (timestamp harmonics) hinzu.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Die gesammelten Daten werden zunächst dem Encoder-Eingang zugeführt.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Die Ergebnisse der Encoder-Operation werden an den Decoder übertragen.
if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer,(CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Dann werden sie an den Akteur übertragen.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } //--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Wir laden die vom Akteur vorhergesagten Aktionen und schließen Gegenoperationen aus.
vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Dann entschlüsseln wir die Prognosen und führen die erforderlichen Handelsmaßnahmen durch. Zunächst setzen wir Kauf-Positionen um.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Dann die Verkaufs-Positionen.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Am Ende der Methode speichern wir die Ergebnisse der Interaktion mit der Umgebung in den Erfahrungswiedergabepuffer.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
Die übrigen Methoden der EA wurden nicht geändert.
Ähnliche Änderungen wurden an dem EA „...\Experts\FAQ\Test.mq5“ vorgenommen. Sie können den vollständigen Code der beiden EAs selbst studieren, indem Sie die Codes aus dem Anhang verwenden.
2.5 Modelltraining EA
Die Modelle werden in dem EA „...\Experts\FAQ\Study.mq5“ trainiert. Wie bei den zuvor entwickelten EAs wurde die Struktur des EAs von früheren Arbeiten übernommen. In Übereinstimmung mit den Änderungen in der Modellarchitektur fügen wir einen Decoder hinzu.
CNet DOT; CNet Decoder; CNet Actor; CNet Critic;
Wie Sie sehen können, ist der auch Kritiker am Modelltraining beteiligt.
Bei der EA-Initialisierungsmethode laden wir zunächst die Trainingsdaten.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Dann versuchen wir, die vortrainierten Modelle zu laden. Wenn wir die Modelle nicht laden können, erstellen wir neue Modelle und initialisieren sie mit Zufallsparametern.
//--- load models float temp; if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Decoder.Load(FileName + "Dec.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor) || !Critic.Create(critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; }
Wir übertragen alle Modelle in einen OpenCL-Kontext.
OpenCL = DOT.GetOpenCL(); Decoder.SetOpenCL(OpenCL); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
Wir führen eine minimale Kontrolle über die Einhaltung der Modellarchitektur ein.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Wir erstellen Hilfsdatenpuffer.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
Für den Beginn des Lernprozesses erzeugen wir ein nutzerdefiniertes Ereignis.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Bei der EA-Deinitialisierungsmethode speichern wir die trainierten Modelle und löschen den Speicher der dynamischen Objekte.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); DOT.Save(FileName + "DOT.nnw", 0, 0, 0, TimeCurrent(), true); Decoder.Save(FileName + "Dec.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
Der Prozess des Trainings von Modellen ist in der Train-Methode implementiert. Im Hauptteil der Methode bestimmen wir zunächst die Wahrscheinlichkeit der Auswahl von Trajektorien in Abhängigkeit von ihrer Rentabilität.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Dann deklarieren wir lokale Variablen.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Dann erstellen wir ein System von verschachtelten Schleifen für den Lernprozess.
Die Encoder-Architektur bietet eine Einbettungsschicht mit einem internen Puffer für die Akkumulation historischer Daten. Diese Art der architektonischen Lösung ist sehr empfindlich gegenüber der historischen Abfolge der empfangenen Quelldaten. Um Modelle zu trainieren, organisieren wir daher ein System von verschachtelten Schleifen. Die äußere Schleife zählt die Anzahl der Trainings-Batches. In einer verschachtelten Schleife innerhalb des Trainings-Batches werden die Ausgangsdaten in historischer Chronologie eingespeist.
Im Hauptteil der äußeren Schleife werden eine Trajektorie und der Zustand abgetastet, um den Trainingslauf zu starten.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Löschen des internen Puffers, der für die Akkumulation von historischen Daten verwendet wird.
DOT.Clear();
Bestimmung des Stands am Ende des Ausbildungspakets.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
Dann organisieren wir eine verschachtelte Lernschleife. Im Hauptteil wird zunächst eine historische Beschreibung des Umgebungszustands aus dem Erfahrungswiedergabepuffer geladen.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
Mit den verfügbaren Daten führen wir einen Vorwärtsdurchgang durch den Encoder und Decoder durch.
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer, (CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Wir laden auch die entsprechende Beschreibung des Kontostandes aus dem Erfahrungswiedergabepuffer und übertragen die Daten in den entsprechenden Puffer
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Hinzufügen von zeitbezogenen Schwingungen.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Der Prozess wiederholt sich vollständig mit dem der EAs für die Interaktion mit der Umgebung. Wir fragen jedoch nicht das Terminal ab, sondern laden alle Daten aus dem Erfahrungswiedergabepuffer.
Nach Erhalt der Daten können wir einen sequentiellen Vorwärtsdurchgang für den Akteur und den Kritiker durchführen.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(Decoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Auf den Vorwärtsdurchgang folgt ein Rückwärtsdurchgang, bei dem die Modellparameter optimiert werden. Zunächst führen wir einen Rückwärtsdurchgang des Akteurs durch, um den Fehler bis zu den Aktionen aus dem Erfahrungswiedergabepuffer zu minimieren.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) ||
Der Fehlergradient vom Akteur wird an den Decoder weitergeleitet.
!Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) ||
Der Decoder überträgt seinerseits den Fehlergradienten an den Encoder. Achten Sie darauf, dass der Decoder die Ausgangsdaten von 2 Schichten des Encoders übernimmt und den Fehlergradienten an 2 entsprechende Schichten weiterleitet. Um die Modellparameter korrekt zu aktualisieren, müssen wir zunächst den Gradienten aus der latenten Schicht fortschreiben.
!DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) ||
Und nur dann - durch das gesamte Encoder-Modell.
!DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Als Nächstes bestimmen wir die Belohnung für den bevorstehenden Übergang.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result);
Und wir optimieren die Kritiker-Parameter mit anschließender Übertragung des Fehlergradienten auf alle beteiligten Modelle.
if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient), -1, false) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Am Ende der Operationen innerhalb des Schleifensystems informieren wir den Nutzer über den Trainingsfortschritt und fahren mit der nächsten Iteration fort.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nach erfolgreichem Abschluss aller Iterationen des Modelltrainingsschleifensystems wird das Kommentarfeld im Chart gelöscht.
Comment("");
Wir drucken auch die Ergebnisse des Modelltrainings in das Protokoll und leiten die Beendigung des EA ein.
PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Damit ist die Beschreibung der Algorithmen der verwendeten Programme abgeschlossen. Die vollständigen Codes dieser EAs sind unten beigefügt. Wir gehen nun zum letzten Teil des Artikels über, in dem wir den Algorithmus testen werden.
3. Tests
In diesem Artikel haben wir die Methode der aggregierte Abfragen von Merkmalen (Feature Aggregated Queries) kennengelernt und ihre Ansätze mit MQL5 umgesetzt. Jetzt ist es an der Zeit, die Ergebnisse unserer Arbeit zu bewerten. Wie immer habe ich mein Modell auf historischen Daten des EURUSD-Instruments mit dem H1-Zeitrahmen trainiert und getestet. Die Modelle werden auf der Grundlage eines historischen Zeitraums für die ersten 7 Monate des Jahres 2023 trainiert. Um die trainierten Modelle zu testen, verwenden wir historische Daten vom August 2023.
Das in diesem Artikel behandelte Modell analysiert Eingabedaten ähnlich wie die Modelle in den vorangegangenen Artikeln. Die Vektoren der Aktionen des Akteurs und der Belohnungen für abgeschlossene Übergänge in einen neuen Zustand sind ebenfalls identisch mit den vorherigen Artikeln. Daher können wir zum Trainieren von Modellen den Erfahrungswiedergabepuffer verwenden, der beim Trainieren der Modelle aus früheren Artikeln gesammelt wurde. Zu diesem Zweck benennen wir die Datei in „FAQ.bd“ um.
Wenn Sie jedoch keine Datei aus früheren Arbeiten haben oder aus bestimmten Gründen eine neue erstellen möchten, empfehle ich Ihnen, zunächst einige Durchläufe mit der Handelshistorie der echten Signale zu speichern. Dies wurde in dem Artikel beschrieben, der die RealORL-Methode beschreibt.
Dann kann man mit dem EA „...\Experts\FAQ\Research.mq5“ den Erfahrungswiedergabepuffer mit Zufallsdurchläufen ergänzen. Dazu führen wir eine langsame Optimierung dieses EA im MetaTrader 5 Strategy Tester auf historischen Daten aus dem Trainingszeitraum durch.
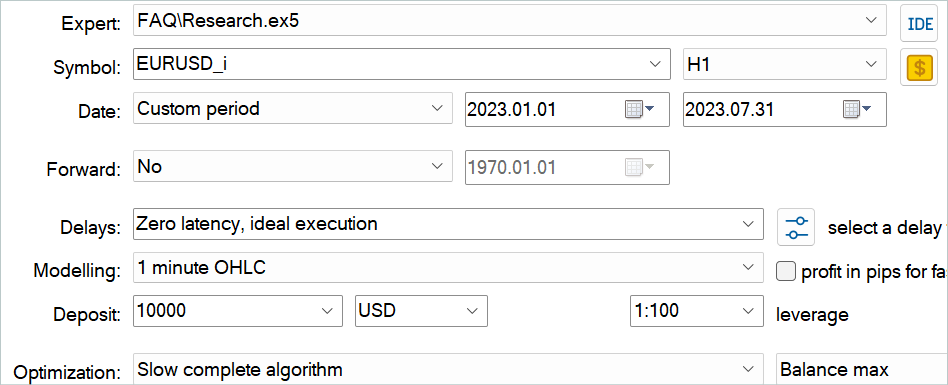
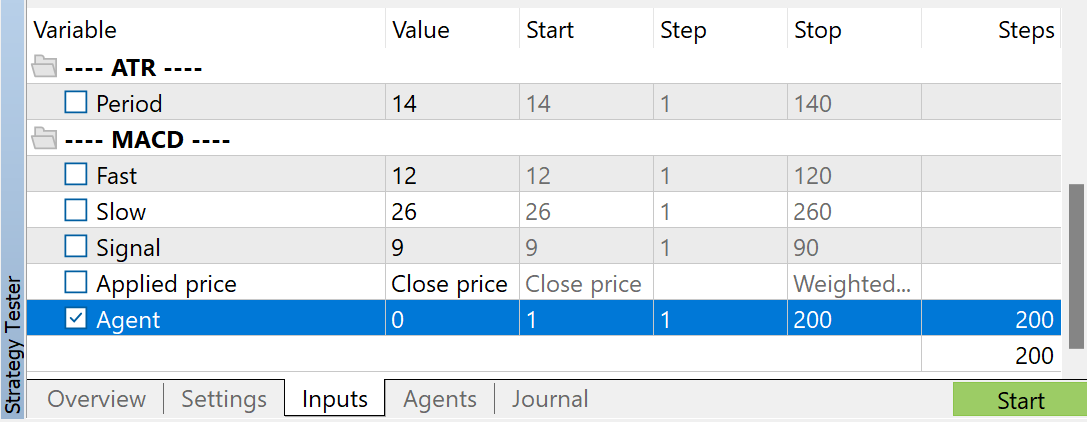
Sie können beliebige Indikatorparameter verwenden. Achten Sie jedoch darauf, dass Sie beim Sammeln eines Trainingsdatensatzes und beim Testen des trainierten Modells dieselben Parameter verwenden. Speichern Sie auch die Parameter für den Modellbetrieb. Bei der Erstellung dieses Artikels habe ich für alle Indikatoren die Standardeinstellungen verwendet.
Um die Anzahl der gesammelten Durchgänge zu regulieren, verwende ich eine Optimierung für den Parameter Agent. Dieser Parameter wurde dem EA nur hinzugefügt, um die Optimierungsläufe zu regeln, und wird im EA-Code nicht verwendet.
Nach dem Sammeln von Trainingsdaten lassen wir den EA „...\Experts\FAQ\Study.mq5“ in Echtzeit auf dem Chart laufen. Der EA trainiert Modelle anhand des gesammelten Trainingsdatensatzes, ohne Handelsoperationen durchzuführen. Daher hat der EA-Betrieb auf einem realen Chart keinen Einfluss auf Ihren Kontostand.
Normalerweise verwende ich einen iterativen Ansatz, um Modelle zu trainieren. Während dieses Prozesses trainiere ich abwechselnd Modelle und sammle zusätzliche Daten für den Trainingssatz. Mit diesem Ansatz ist die Größe unseres Trainingsdatensatzes begrenzt und kann nicht die gesamte Vielfalt des Agentenverhaltens in der Umgebung abdecken. Bei den nächsten Starts des EA „...\Experts\FAQ\Research.mq5“ wird er im Prozess der Interaktion mit der Umgebung nicht mehr von einer zufälligen Politik geleitet. Stattdessen wird unsere trainierte Politik verwendet. So füllen wir den Erfahrungswiederholungspuffer mit Zuständen und Aktionen auf, die unserer Politik nahe kommen. Auf diese Weise erkunden wir das Umfeld unserer Politik, ähnlich wie beim Online-Lernen. Das bedeutet, dass wir beim anschließenden Training echte Belohnungen für unsere Handlungen erhalten und keine interpolierten. Dies wird unserem Akteur helfen, die Politik in die richtige Richtung zu lenken.
Gleichzeitig überprüfen wir regelmäßig die Trainingsergebnisse auf Daten, die nicht im Trainingsdatensatz enthalten sind.
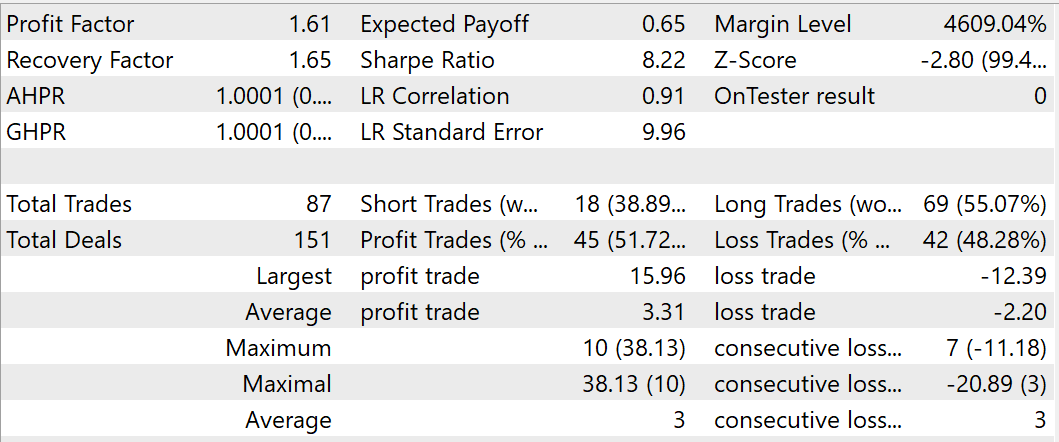
Während des Trainingsprozesses ist es mir gelungen, ein Modell zu erhalten, das in der Lage ist, auf den Trainings- und Testdatensätzen Gewinne zu erzielen. Während des Tests des trainierten Modells im August 2023 führte der EA 87 Handelsgeschäfte durch, von denen 45 mit Gewinn abgeschlossen wurden. Dies entspricht 51,72 %. Die Werte für die höchsten und die durchschnittlichen profitablen Positionen übersteigen die entsprechenden Werte der Verlustpositionen. Während des Testzeitraums erreichte der EA einen Gewinnfaktor von 1,61 und einen Erholungsfaktor von 1,65.
Schlussfolgerung
In diesem Artikel haben wir uns mit der Methode der Feature Aggregated Queries (FAQ) zur Erkennung von Objekten in Videos vertraut gemacht. Die Autoren dieser Methode konzentrierten sich auf die Initialisierung von Abfragen und deren Aggregation auf der Grundlage von Eingabedaten für Detektoren, die auf der Transformer-Architektur basieren, um die Effizienz und Leistung des Modells auszugleichen. Sie entwickelten ein Abfrageaggregationsmodul, das ihre Darstellung auf Objektdetektoren erweitert. Dadurch wird ihre Leistung bei Videoaufgaben verbessert.
Darüber hinaus haben die Autoren der FAQ-Methode das Abfrageaggregationsmodul zu einer dynamischen Version erweitert, die adaptiv Abfrageinitialisierungen erzeugen und Abfrageaggregationsgewichte entsprechend den Quelldaten anpassen kann.
Die vorgeschlagene Methode ist ein Plug-and-Play-Modul, das in die meisten modernen Transformator-basierten Objektdetektoren integriert werden kann, um Probleme in Videos und anderen Zeitsequenzen zu lösen.
Im praktischen Teil dieses Artikels haben wir die vorgeschlagenen Ansätze mit MQL5 umgesetzt. Wir haben das Modell anhand echter historischer Daten trainiert und es in einem Zeitraum außerhalb des Trainingssatzes getestet. Unsere Testergebnisse bestätigen die Wirksamkeit der vorgeschlagenen Ansätze. Der Trainings- und Testzeitraum ist jedoch recht kurz, um konkrete Schlussfolgerungen zu ziehen. Alle in diesem Artikel vorgestellten Programme dienen lediglich der Demonstration und dem Test der vorgeschlagenen Ansätze.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modelltraining EA |
| 4 | Test.mq5 | Expert Advisor | Modelltraining EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14394
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.