
Neuronale Netze leicht gemacht (Teil 82): Modelle für gewöhnliche Differentialgleichungen (NeuralODE)

Einführung
Machen wir uns mit einer neuen Modellfamilie vertraut: Gewöhnliche Differentialgleichungen. Anstatt eine diskrete Abfolge von versteckten Schichten festzulegen, parametrisieren sie die Ableitung des versteckten Zustands mit Hilfe eines neuronalen Netzes. Die Ergebnisse des Modells werden mit Hilfe einer „Black Box“, d. h. dem Differentialgleichungslöser, berechnet. Diese Modelle mit kontinuierlicher Tiefe verwenden eine konstante Speichermenge und passen ihre Schätzstrategie an jedes Eingangssignal an. Solche Modelle wurden erstmals in der Arbeit „Neural Ordinary Differential Equations“ vorgestellt. In dieser Arbeit demonstrieren die Autoren der Methode die Möglichkeit, Backpropagation mit jedem beliebigen Löser für gewöhnliche Differentialgleichungen (ODE) zu skalieren, ohne auf dessen interne Operationen zugreifen zu müssen. Dies ermöglicht ein durchgehendes Training von ODEs innerhalb größerer Modelle.
1. Der Algorithmus
Die größte technische Herausforderung beim Training von Modellen mit gewöhnlichen Differentialgleichungen ist die Durchführung der inversen Modendifferenzierung der Fehlerfortpflanzung mit Hilfe eines ODE-Lösers. Die Differenzierung mittels Feedforward-Operationen ist einfach, erfordert jedoch einen großen Speicherbedarf und führt zu zusätzlichen numerischen Fehlern.
Die Autoren der Methode schlagen vor, den ODE-Löser als Black Box zu behandeln und die Gradienten mit der Methode der konjugierten Empfindlichkeit zu berechnen. Mit diesem Ansatz können wir die Gradienten berechnen, indem wir eine zweite erweiterte ODE rückwärts in der Zeit lösen. Dies gilt für alle ODE-Löser. Es skaliert linear mit der Aufgabengröße und hat einen geringen Speicherbedarf. Außerdem kontrolliert sie eindeutig den numerischen Fehler.
Betrachten wir die Optimierung der skalaren Verlustfunktion L(), deren Eingangsdaten die Ergebnisse des ODE-Lösers sind:
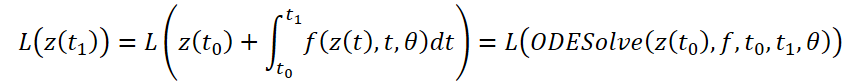
Um den Fehler L zu optimieren, benötigen wir Gradienten entlang θ. Der erste Schritt des von den Autoren der Methode vorgeschlagenen Algorithmus besteht darin, zu bestimmen, wie der Fehlergradient zu jedem Zeitpunkt von dem verborgenen Zustand z(t) abhängt a(t)=∂L/∂z(t). Ihre Dynamik wird durch eine andere ODE gegeben, die als Analogon der Regel betrachtet werden kann:
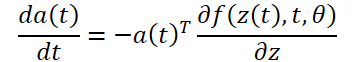
Wir können ∂L/∂z(t) mit einem weiteren Aufruf des ODE-Lösers berechnen. Dieser Solver muss rückwärts arbeiten, ausgehend von dem Anfangswert ∂L/∂z(t1). Eine der Schwierigkeiten besteht darin, dass wir zur Lösung dieser ODE die Werte von z(t) entlang der gesamten Trajektorie kennen müssen. Wir können jedoch einfach z(t) in der Zeit zurückverfolgen, ausgehend von seinem Endwert z(t1).
Zur Berechnung der Gradienten durch den Parameter θ müssen wir das dritte Integral bestimmen, das sowohl von z(t) als auch von a(t) abhängt:
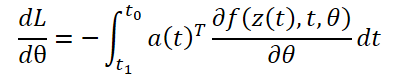
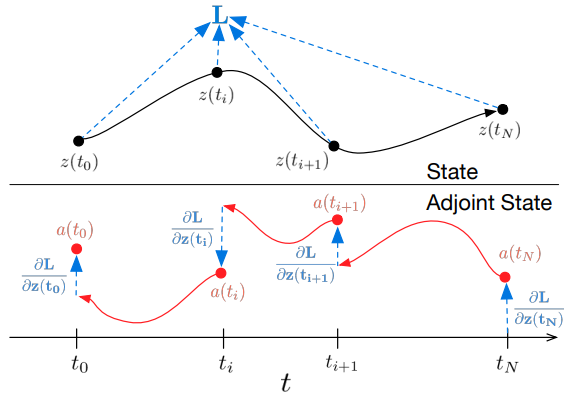
Alle Integrale zur Lösung von 𝐳, 𝐚 und ∂L/∂θ können in einem einzigen Aufruf eines ODE-Lösers berechnet werden, der den ursprünglichen Zustand, die konjugierte und andere partielle Ableitungen zu einem einzigen Vektor zusammenfasst. Nachfolgend finden Sie einen Algorithmus für die Konstruktion der erforderlichen Dynamik und den Aufruf eines ODE-Solvers, um alle Gradienten gleichzeitig zu berechnen.

Die meisten ODE-Löser sind in der Lage, den Zustand z(t) wiederholt zu berechnen. Wenn die Verluste von diesen Zwischenzuständen abhängen, muss die Ableitung des inversen Modus in eine Folge von Einzellösungen zerlegt werden, eine zwischen jedem aufeinanderfolgenden Paar von Ausgangswerten. Für jede Beobachtung muss die Konjugierte in Richtung der entsprechenden partiellen Ableitung ∂L/∂z(t) angepasst werden.
ODE-Löser können annähernd garantieren, dass die erzielten Ergebnisse innerhalb einer bestimmten Toleranz der wahren Lösung liegen. Eine Änderung der Toleranz verändert das Verhalten des Modells. Der Zeitaufwand für einen direkten Aufruf ist proportional zur Anzahl der Funktionsauswertungen, sodass die Anpassung der Toleranz einen Kompromiss zwischen Genauigkeit und Rechenkosten darstellt. Sie können mit hoher Genauigkeit trainieren, aber während des Betriebs auf niedrigere Genauigkeit umschalten.
2. Implementierung in MQL5
Um die vorgeschlagenen Ansätze zu implementieren, werden wir eine neue Klasse CNeuronNODEOCL erstellen, die die Grundfunktionalität von unserer vollständig verbundenen Schicht CNeuronBaseOCL erbt. Nachstehend finden Sie die Struktur der neuen Klasse. Zusätzlich zu den grundlegenden Methoden verfügt die Struktur über mehrere spezifische Methoden und Objekte. Wir werden ihre Funktionalität während des Implementierungsprozesses berücksichtigen.
class CNeuronNODEOCL : public CNeuronBaseOCL { protected: uint iDimension; uint iVariables; uint iLenth; int iBuffersK[]; int iInputsK[]; int iMeadl[]; CBufferFloat cAlpha; CBufferFloat cTemp; CCollection cBeta; CBufferFloat cSolution; CCollection cWeights; //--- virtual bool CalculateKBuffer(int k); virtual bool CalculateInputK(CBufferFloat* inputs, int k); virtual bool CalculateOutput(CBufferFloat* inputs); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool CalculateOutputGradient(CBufferFloat* inputs); virtual bool CalculateInputKGradient(CBufferFloat* inputs, int k); virtual bool CalculateKBufferGradient(int k); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronNODEOCL(void) {}; ~CNeuronNODEOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint variables, uint lenth, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronNODEOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); };
Bitte beachten Sie, dass wir, um mit Sequenzen mehrerer Umgebungszustände arbeiten zu können, die durch Einbettungen mehrerer Merkmale beschrieben werden, ein Objekt erstellen, das mit Ausgangsdaten arbeiten kann, die in 3 Dimensionen dargestellt werden:
- iDimension: die Größe des Einbettungsvektors eines Merkmals in einem separaten Umgebungszustand
- iVariables: die Anzahl der Merkmale, die einen Zustand der Umgebung beschreiben
- iLenth: die Anzahl der analysierten Systemzustände
Die ODE-Funktion wird in unserem Fall durch 2 vollständig verknüpfte Schichten mit der ReLU-Aktivierungsfunktion zwischen ihnen dargestellt. Wir räumen jedoch ein, dass die Dynamik jedes einzelnen Merkmals unterschiedlich sein kann. Daher werden wir für jedes Attribut unsere eigenen Gewichtungsmatrizen erstellen. Bei diesem Ansatz ist es nicht möglich, Faltungsschichten als interne Schichten zu verwenden, wie dies früher der Fall war. Daher zerlegen wir in unserer neuen Klasse die inneren Schichten der ODE-Funktion. Wir werden die Datenpuffer deklarieren, aus denen die internen Datenschichten bestehen. Dann werden wir Kernel und Methoden für die Implementierung von Prozessen erstellen.
2.1 Feedforward-Kernel
Bei der Konstruktion des Feedforward-Kerns für die ODE-Funktion gehen wir von den folgenden Einschränkungen aus:
- Jeder Zustand der Umgebung wird durch die gleiche feste Anzahl von Merkmalen beschrieben.
- Alle Merkmale haben die gleiche feste Einbettungsgröße.
Unter Berücksichtigung dieser Einschränkungen erstellen wir den Kernel FeedForwardNODEF auf der OpenCL-Programmseite. In den Parametern unseres Kernels werden wir Zeiger auf 3 Datenpuffer und 3 Variablen übergeben. Der Kernel wird in einem 3-dimensionalen Aufgabenraum gestartet.
__kernel void FeedForwardNODEF(__global float *matrix_w, ///<[in] Weights matrix __global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_o, ///<[out] Output tensor int dimension, ///< input dimension float step, ///< h int activation ///< Activation type (#ENUM_ACTIVATION) ) { int d = get_global_id(0); int dimension_out = get_global_size(0); int v = get_global_id(1); int variables = get_global_size(1); int i = get_global_id(2); int lenth = get_global_size(2);
Im Kernelkörper identifizieren wir zunächst den aktuellen Thread in allen 3 Dimensionen des Aufgabenraums. Dann werden wir die Verschiebung in den Datenpuffern zu den analysierten Daten bestimmen.
int shift = variables * i + v; int input_shift = shift * dimension; int output_shift = shift * dimension_out + d; int weight_shift = (v * dimension_out + d) * (dimension + 2);
Nach den Vorarbeiten berechnen wir in einer Schleife die Werte des aktuellen Ergebnisses, indem wir den Vektor der Ausgangsdaten mit dem entsprechenden Vektor der Gewichte multiplizieren.
float sum = matrix_w[dimension + 1 + weight_shift] + matrix_w[dimension + weight_shift] * step; for(int w = 0; w < dimension; w++) sum += matrix_w[w + weight_shift] * matrix_i[input_shift + w];
Dabei ist zu beachten, dass die ODE-Funktion nicht nur vom Zustand der Umgebung, sondern auch vom Zeitstempel abhängt. In diesem Fall gibt es einen Zeitstempel für den gesamten Umgebungszustand. Um die Duplizierung in Bezug auf die Anzahl der Merkmale und die Sequenzlänge zu vermeiden, fügten wir dem Quelldatentensor keinen Zeitstempel hinzu, sondern übergaben ihn einfach als Schrittparameter an den Kernel.
Als Nächstes müssen wir nur noch den resultierenden Wert durch die Aktivierungsfunktion propagieren und das Ergebnis in dem entsprechenden Pufferelement speichern.
if(isnan(sum)) sum = 0; switch(activation) { case 0: sum = tanh(sum); break; case 1: sum = 1 / (1 + exp(-clamp(sum, -20.0f, 20.0f))); break; case 2: if(sum < 0) sum *= 0.01f; break; default: break; } matrix_o[output_shift] = sum; }
2.2 Backpropagation-Kernel
Nach der Implementierung des Feedforward-Kerns erstellen wir die umgekehrte Funktionalität auf der OpenCL-Seite des Programms, den Fehlergradienten-Verteilungskern HiddenGradientNODEF.
__kernel void HiddenGradientNODEF(__global float *matrix_w, ///<[in] Weights matrix __global float *matrix_g, ///<[in] Gradient tensor __global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_ig, ///<[out] Inputs Gradient tensor int dimension_out, ///< output dimension int activation ///< Input Activation type (#ENUM_ACTIVATION) ) { int d = get_global_id(0); int dimension = get_global_size(0); int v = get_global_id(1); int variables = get_global_size(1); int i = get_global_id(2); int lenth = get_global_size(2);
Dieser Kernel wird ebenfalls in einem 3-dimensionalen Aufgabenraum gestartet, und wir identifizieren den Thread im Körper des Kernels. Wir bestimmen auch die Verschiebungen in den Datenpuffern zu den analysierten Elementen.
int shift = variables * i + v; int input_shift = shift * dimension + d; int output_shift = shift * dimension_out; int weight_step = (dimension + 2); int weight_shift = (v * dimension_out) * weight_step + d;
Dann summieren wir den Fehlergradienten für das analysierte Quelldatenelement.
float sum = 0; for(int k = 0; k < dimension_out; k ++) sum += matrix_g[output_shift + k] * matrix_w[weight_shift + k * weight_step]; if(isnan(sum)) sum = 0;
Bitte beachten Sie, dass der Zeitstempel im Wesentlichen eine Konstante für einen eigenen Zustand ist. Daher übertragen wir den Fehlergradienten nicht auf ihn.
Wir passen den resultierenden Betrag um die Ableitung der Aktivierungsfunktion an und speichern den resultierenden Wert in das entsprechende Element des Datenpuffers.
float out = matrix_i[input_shift]; switch(activation) { case 0: out = clamp(out, -1.0f, 1.0f); sum = clamp(sum + out, -1.0f, 1.0f) - out; sum = sum * max(1 - pow(out, 2), 1.0e-4f); break; case 1: out = clamp(out, 0.0f, 1.0f); sum = clamp(sum + out, 0.0f, 1.0f) - out; sum = sum * max(out * (1 - out), 1.0e-4f); break; case 2: if(out < 0) sum *= 0.01f; break; default: break; } //--- matrix_ig[input_shift] = sum; }
2.3 ODE-Löser
Wir haben die erste Phase der Arbeiten abgeschlossen. Schauen wir uns nun die Seite des ODE-Lösers an. Für meine Implementierung wählte ich die Dorman-Prince-Methode 5ter Ordnung.
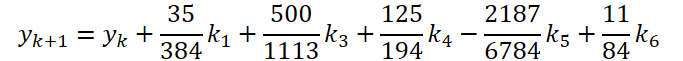
wobei
![]()
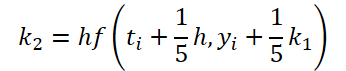
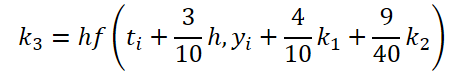
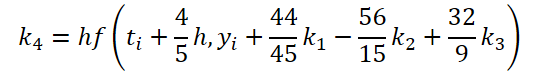
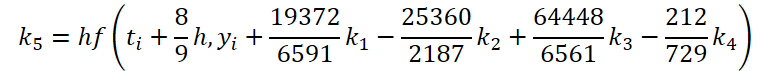
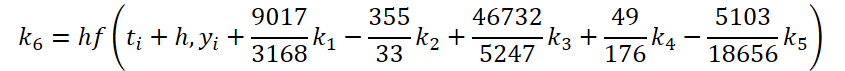
Wie Sie sehen können, unterscheiden sich die Funktion des Lösens und der Anpassung der Ausgangsdaten für die Berechnung der Koeffizienten k1..k6 nur in den numerischen Koeffizienten. Wir können die fehlenden Koeffizienten ki, multipliziert mit Null, addieren, was das Ergebnis nicht beeinflusst. Um den Prozess zu vereinheitlichen, werden wir daher einen Kernel FeedForwardNODEInpK auf der OpenCL-Seite des Programms erstellen. In den Kernelparametern übergeben wir Zeiger auf die Puffer der Quelldaten und alle Koeffizienten ki. Wir geben die erforderlichen Multiplikatoren im Puffer matrix_beta an.
__kernel void FeedForwardNODEInpK(__global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_k1, ///<[in] K1 tensor __global float *matrix_k2, ///<[in] K2 tensor __global float *matrix_k3, ///<[in] K3 tensor __global float *matrix_k4, ///<[in] K4 tensor __global float *matrix_k5, ///<[in] K5 tensor __global float *matrix_k6, ///<[in] K6 tenтor __global float *matrix_beta, ///<[in] beta tensor __global float *matrix_o ///<[out] Output tensor ) { int i = get_global_id(0);
Wir lassen den Kernel in einem eindimensionalen Aufgabenraum laufen und berechnen die Werte für jeden einzelnen Wert des Ergebnispuffers.
Nachdem wir den Fluss identifiziert haben, sammeln wir die Summe der Produkte in einer Schleife.
float sum = matrix_i[i]; for(int b = 0; b < 6; b++) { float beta = matrix_beta[b]; if(beta == 0.0f || isnan(beta)) continue; //--- float val = 0.0f; switch(b) { case 0: val = matrix_k1[i]; break; case 1: val = matrix_k2[i]; break; case 2: val = matrix_k3[i]; break; case 3: val = matrix_k4[i]; break; case 4: val = matrix_k5[i]; break; case 5: val = matrix_k6[i]; break; } if(val == 0.0f || isnan(val)) continue; //--- sum += val * beta; }
Der sich daraus ergebende Wert wird in dem entsprechenden Element des Ergebnispuffers gespeichert.
matrix_o[i] = sum; }
Für die Backpropagation-Methode erstellen wir den Kernel HiddenGradientNODEInpK, in dem wir den Fehlergradienten in die entsprechenden Datenpuffer propagieren, wobei wir die gleichen Beta-Koeffizienten berücksichtigen.
__kernel void HiddenGradientNODEInpK(__global float *matrix_ig, ///<[in] Inputs tensor __global float *matrix_k1g, ///<[in] K1 tensor __global float *matrix_k2g, ///<[in] K2 tensor __global float *matrix_k3g, ///<[in] K3 tensor __global float *matrix_k4g, ///<[in] K4 tensor __global float *matrix_k5g, ///<[in] K5 tensor __global float *matrix_k6g, ///<[in] K6 tensor __global float *matrix_beta, ///<[in] beta tensor __global float *matrix_og ///<[out] Output tensor ) { int i = get_global_id(0); //--- float grad = matrix_og[i]; matrix_ig[i] = grad; for(int b = 0; b < 6; b++) { float beta = matrix_beta[b]; if(isnan(beta)) beta = 0.0f; //--- float val = beta * grad; if(isnan(val)) val = 0.0f; switch(b) { case 0: matrix_k1g[i] = val; break; case 1: matrix_k2g[i] = val; break; case 2: matrix_k3g[i] = val; break; case 3: matrix_k4g[i] = val; break; case 4: matrix_k5g[i] = val; break; case 5: matrix_k6g[i] = val; break; } } }
Bitte beachten Sie, dass wir auch Nullwerte in die Datenpuffer schreiben. Dies ist notwendig, um eine doppelte Zählung von zuvor gespeicherten Werten zu vermeiden.
2.4 Gewichtsaktualisierung Kernel
Um die OpenCL-Programmseite zu vervollständigen, werden wir einen Kernel für die Aktualisierung der Gewichte der ODE-Funktion erstellen. Wie Sie aus den oben dargestellten Formeln ersehen können, wird die ODE-Funktion zur Bestimmung aller Koeffizienten ki verwendet. Daher müssen wir bei der Anpassung der Gewichte den Fehlergradienten aller Operationen erfassen. Keiner der von uns bisher erstellten Gewichtungsaktualisierungskerne arbeitete mit so vielen Gradientenpuffern. Wir müssen also einen neuen Kernel erstellen. Um das Experiment zu vereinfachen, werden wir nur den Kernel NODEF_UpdateWeightsAdam erstellen, um die Parameter mit der Adam-Methode zu aktualisieren, die ich am häufigsten verwende.
__kernel void NODEF_UpdateWeightsAdam(__global float *matrix_w, ///<[in,out] Weights matrix __global const float *matrix_gk1, ///<[in] Tensor of gradients at k1 __global const float *matrix_gk2, ///<[in] Tensor of gradients at k2 __global const float *matrix_gk3, ///<[in] Tensor of gradients at k3 __global const float *matrix_gk4, ///<[in] Tensor of gradients at k4 __global const float *matrix_gk5, ///<[in] Tensor of gradients at k5 __global const float *matrix_gk6, ///<[in] Tensor of gradients at k6 __global const float *matrix_ik1, ///<[in] Inputs tensor __global const float *matrix_ik2, ///<[in] Inputs tensor __global const float *matrix_ik3, ///<[in] Inputs tensor __global const float *matrix_ik4, ///<[in] Inputs tensor __global const float *matrix_ik5, ///<[in] Inputs tensor __global const float *matrix_ik6, ///<[in] Inputs tensor __global float *matrix_m, ///<[in,out] Matrix of first momentum __global float *matrix_v, ///<[in,out] Matrix of seconfd momentum __global const float *alpha, ///< h const int lenth, ///< Number of inputs const float l, ///< Learning rates const float b1, ///< First momentum multiplier const float b2 ///< Second momentum multiplier ) { const int d_in = get_global_id(0); const int dimension_in = get_global_size(0); const int d_out = get_global_id(1); const int dimension_out = get_global_size(1); const int v = get_global_id(2); const int variables = get_global_id(2);
Wie bereits erwähnt, übergeben Kernel-Parameter Zeiger auf eine große Anzahl von globalen Datenpuffern. Zu ihnen werden Standardparameter der gewählten Optimierungsmethode hinzugefügt.
Wir lassen den Kernel in einem 3-dimensionalen Aufgabenraum laufen, der die Dimension der Einbettungsvektoren der Quelldaten und Ergebnisse sowie die Anzahl der analysierten Merkmale berücksichtigt. Im Kernelkörper identifizieren wir den Fluss im Aufgabenraum entlang aller 3 Dimensionen. Dann bestimmen wir die Offsets in den Datenpuffern.
const int weight_shift = (v * dimension_out + d_out) * dimension_in; const int input_step = variables * (dimension_in - 2); const int input_shift = v * (dimension_in - 2) + d_in; const int output_step = variables * dimension_out; const int output_shift = v * dimension_out + d_out;
Als Nächstes wird in einer Schleife der Fehlergradient über alle Umgebungszustände hinweg erfasst.
float weight = matrix_w[weight_shift]; float g = 0; for(int i = 0; i < lenth; i++) { int shift_g = i * output_step + output_shift; int shift_i = i * input_step + input_shift; switch(dimension_in - d_in) { case 1: g += matrix_gk1[shift_g] + matrix_gk2[shift_g] + matrix_gk3[shift_g] + matrix_gk4[shift_g] + matrix_gk5[shift_g] + matrix_gk6[shift_g]; break; case 2: g += matrix_gk1[shift_g] * alpha[0] + matrix_gk2[shift_g] * alpha[1] + matrix_gk3[shift_g] * alpha[2] + matrix_gk4[shift_g] * alpha[3] + matrix_gk5[shift_g] * alpha[4] + matrix_gk6[shift_g] * alpha[5]; break; default: g += matrix_gk1[shift_g] * matrix_ik1[shift_i] + matrix_gk2[shift_g] * matrix_ik2[shift_i] + matrix_gk3[shift_g] * matrix_ik3[shift_i] + matrix_gk4[shift_g] * matrix_ik4[shift_i] + matrix_gk5[shift_g] * matrix_ik5[shift_i] + matrix_gk6[shift_g] * matrix_ik6[shift_i]; break; } }
Und dann passen wir die Gewichte nach dem bekannten Algorithmus an.
float mt = b1 * matrix_m[weight_shift] + (1 - b1) * g; float vt = b2 * matrix_v[weight_shift] + (1 - b2) * pow(g, 2); float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight));
Am Ende des Kernels speichern wir die Ergebnis- und Hilfswerte in den entsprechenden Elementen der Datenpuffer.
if(delta * g > 0) matrix_w[weight_shift] = clamp(matrix_w[weight_shift] + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[weight_shift] = mt; matrix_v[weight_shift] = vt; }
Damit ist die OpenCL-Programmseite abgeschlossen. Kommen wir zurück zur Implementierung unserer Klasse CNeuronNODEOCL.
2.5 Initialisierungsmethode der Klasse CNeuronNODEOCL
Die Initialisierung unseres Klassenobjekts wird in der Methode CNeuronNODEOCL::Init durchgeführt. In den Methodenparametern übergeben wir wie üblich die Hauptparameter der Objektarchitektur.
bool CNeuronNODEOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint variables, uint lenth, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, dimension * variables * lenth, optimization_type, batch)) return false;
Im Hauptteil der Methode rufen wir zunächst die entsprechende Methode der übergeordneten Klasse auf, die die empfangenen Parameter kontrolliert und die geerbten Objekte initialisiert. Wir können das verallgemeinerte Ergebnis der Durchführung von Operationen im Körper der übergeordneten Klasse durch den zurückgegebenen logischen Wert herausfinden.
Anschließend speichern wir die resultierenden Parameter der Objektarchitektur in lokalen Klassenvariablen.
iDimension = dimension; iVariables = variables; iLenth = lenth;
Wir deklarieren Hilfsvariablen und weisen ihnen die erforderlichen Werte zu.
uint mult = 2; uint weights = (iDimension + 2) * iDimension * iVariables;
Betrachten wir nun die Puffer des Koeffizienten ki und die angepassten Ausgangsdaten für ihre Berechnung. Wie Sie sich denken können, werden die Werte in diesen Datenpuffern vom Feedforward-Durchgang zum Backpropagation-Durchgang gespeichert. Beim nächsten Vorwärtsdurchlauf werden die Werte überschrieben. Um Ressourcen zu sparen, legen wir diese Puffer daher nicht im Hauptspeicher des Programms an. Wir erstellen sie nur auf der OpenCL-Seite des Kontexts. In der Klasse erstellen wir nur Arrays, um Zeiger auf sie zu speichern. In jedem Array werden dreimal mehr Elemente angelegt als k Koeffizienten verwendet werden. Dies ist notwendig, um Fehlergradienten zu erfassen.
if(ArrayResize(iBuffersK, 18) < 18) return false; if(ArrayResize(iInputsK, 18) < 18) return false;
Dasselbe machen wir mit den Zwischenwerten der Berechnung. Die Array-Größe ist jedoch geringer.
if(ArrayResize(iMeadl, 12) < 12) return false;
Um die Lesbarkeit des Codes zu erhöhen, werden wir Puffer in einer Schleife erstellen.
for(uint i = 0; i < 18; i++) { iBuffersK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; iInputsK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iInputsK[i] < 0) return false; if(i > 11) continue; //--- Initilize Meadl Output and Gradient buffers iMeadl[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iMeadl[i] < 0) return false; }
Der nächste Schritt besteht darin, Matrizen der Gewichtskoeffizienten des ODE-Funktionsmodells und der Momente zu erstellen. Wie oben erwähnt, werden wir 2 Ebenen verwenden.
//--- Initilize Weights for(int i = 0; i < 2; i++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(weights)) return false; float k = (float)(1 / sqrt(iDimension + 2)); for(uint w = 0; w < weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cWeights.Add(temp)) return false;
for(uint d = 0; d < 2; d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cWeights.Add(temp)) return false; } }
Als Nächstes erstellen wir konstante Multiplikatorpuffer:
- Zeitschritt Alpha
{
float temp_ar[] = {0, 0.2f, 0.3f, 0.8f, 8.0f / 9, 1, 1};
if(!cAlpha.AssignArray(temp_ar))
return false;
if(!cAlpha.BufferCreate(OpenCL))
return false;
}
- Anpassungen der Quelldaten
//--- Beta K1 { float temp_ar[] = {0, 0, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K2 { float temp_ar[] = {0.2f, 0, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K3 { float temp_ar[] = {3.0f / 40, 9.0f / 40, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K4 { float temp_ar[] = {44.0f / 44, -56.0f / 15, 32.0f / 9, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K5 { float temp_ar[] = {19372.0f / 6561, -25360 / 2187.0f, 64448 / 6561.0f, -212.0f / 729, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K6 { float temp_ar[] = {9017 / 3168.0f, -355 / 33.0f, 46732 / 5247.0f, 49.0f / 176, -5103.0f / 18656, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
- ODE-Lösungen
{
float temp_ar[] = {35.0f / 384, 0, 500.0f / 1113, 125.0f / 192, -2187.0f / 6784, 11.0f / 84};
if(!cSolution.AssignArray(temp_ar))
return false;
if(!cSolution.BufferCreate(OpenCL))
return false;
}
Am Ende der Initialisierungsmethode fügen wir einen lokalen Puffer für die Aufzeichnung von Zwischenwerten hinzu.
if(!cTemp.BufferInit(Output.Total(), 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
2.6 Organisation des Vorlaufs
Nach der Initialisierung des Klassenobjekts geht es an die Organisation des Feedforward-Algorithmus. Oben haben wir 2 Kernel auf der OpenCL-Programmseite erstellt, um den Feedforward-Durchlauf zu organisieren. Daher müssen wir Methoden erstellen, um sie aufzurufen. Wir beginnen mit einer recht einfachen Methode CalculateInputK, die die Ausgangsdaten für die Berechnung von k Koeffizienten vorbereitet
bool CNeuronNODEOCL::CalculateInputK(CBufferFloat* inputs, int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
In den Methodenparametern erhalten wir einen Zeiger auf den Puffer der Quelldaten, die wir von der vorherigen Schicht erhalten haben, und den Index des zu berechnenden Koeffizienten. Im Hauptteil der Methode wird geprüft, ob der angegebene Koeffizientenindex unserer Architektur entspricht.
Nachdem der Kontrollblock erfolgreich durchlaufen wurde, betrachten wir den Sonderfall k1.
![]()
In diesem Fall rufen wir nicht die Kernelausführung auf, sondern kopieren einfach den Zeiger auf den Quelldatenpuffer.
if(k == 0) { if(iInputsK[k] != inputs.GetIndex()) { OpenCL.BufferFree(iInputsK[k]); iInputsK[k] = inputs.GetIndex(); } return true; }
Im allgemeinen Fall rufen wir den FeedForwardNODEInpK-Kernel auf und schreiben die angepassten Quelldaten in den entsprechenden Puffer. Zu diesem Zweck definieren wir zunächst einen Aufgabenraum. In diesem Fall handelt es sich um einen eindimensionalen Raum.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Übergeben wir Pufferzeiger auf die Kernelparameter.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_beta, ((CBufferFloat *)cBeta.At(k)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_o, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Den Kernel stellen wir in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_FeedForwardNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Nach der Anpassung der Quelldaten berechnen wir den Wert der Koeffizienten. Dieser Prozess ist in der Methode CalculateKBuffer organisiert. Da die Methode nur mit internen Objekten arbeitet, müssen Sie nur den Index des gewünschten Koeffizienten in den Methodenparametern angeben, um Operationen durchzuführen.
bool CNeuronNODEOCL::CalculateKBuffer(int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
Im Hauptteil der Methode wird geprüft, ob der resultierende Index mit der Klassenarchitektur übereinstimmt.
Als Nächstes definieren wir einen 3-dimensionalen Problemraum.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iVariables, iLenth};
Dann übergeben wir Parameter an den Kernel, um die erste Schicht zu übergeben. Hier verwenden wir LReLU, um Nichtlinearität zu erzeugen.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_i, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_o, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_dimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_step, float(cAlpha.At(k)))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_activation, int(LReLU))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Wir stellen den Kernel in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_FeedForwardNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Der nächste Schritt ist ein Vorwärtsdurchlauf der zweiten Schicht. Der Aufgabenbereich bleibt derselbe. Daher ändern wir die entsprechenden Arrays nicht. Wir müssen die Parameter erneut an den Kernel übergeben. Diesmal ändern wir die Quelldaten, das Gewicht und die Ergebnispuffer.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_i, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_o, iBuffersK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Wir verwenden auch nicht die Aktivierungsfunktion.
if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_activation, int(None))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Andere Parameter ändern sich nicht.
if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_dimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_step, cAlpha.At(k))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Wir senden den Kernel an die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_FeedForwardNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
Nachdem wir alle k Koeffizienten berechnet haben, können wir das Ergebnis der Lösung der ODE bestimmen. In der Praxis werden wir für diese Zwecke den Kernel FeedForwardNODEInpK verwenden. Ihr Aufruf ist bereits in der Methode CalculateInputK implementiert. In diesem Fall müssen wir jedoch die verwendeten Datenpuffer ändern. Daher werden wir den Algorithmus in der CalculateOutput-Methode umschreiben.
bool CNeuronNODEOCL::CalculateOutput(CBufferFloat* inputs) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
In den Parametern dieser Methode erhalten wir nur einen Zeiger auf den Quelldatenpuffer. Im Hauptteil der Methode definieren wir sofort einen eindimensionalen Problemraum. Dann übergeben wir Zeiger auf die Quelldatenpuffer an die Kernelparameter.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Für die Multiplikatoren geben wir einen Puffer von ODE-Lösungskoeffizienten an.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_beta, cSolution.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Wir schreiben die Ergebnisse in den Ergebnispuffer unserer Klasse.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_o, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Den Kernel stellen wir in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_FeedForwardNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Wir kombinieren die erhaltenen Werte mit den Quelldaten und normalisieren sie.
if(!SumAndNormilize(Output, inputs, Output, iDimension, true, 0, 0, 0, 1)) return false; //--- return true; }
Wir haben Methoden für den Aufruf von Kernels vorbereitet, um den Prozess des Vorwärtsdurchgangs zu organisieren. Jetzt müssen wir den Algorithmus nur noch in der Top-Level-Methode CNeuronNODEOCL::feedForward formalisieren.
bool CNeuronNODEOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { for(int k = 0; k < 6; k++) { if(!CalculateInputK(NeuronOCL.getOutput(), k)) return false; if(!CalculateKBuffer(k)) return false; } //--- return CalculateOutput(NeuronOCL.getOutput()); }
In den Parametern erhält die Methode einen Zeiger auf das Objekt der vorherigen Ebene. Im Hauptteil der Methode organisieren wir eine Schleife, in der wir nacheinander die Quelldaten anpassen und alle k Koeffizienten berechnen. Bei jeder Iteration steuern wir den Prozess der Durchführung von Operationen. Nach erfolgreicher Berechnung der erforderlichen Koeffizienten rufen wir die ODE-Lösungsmethode auf. Wir haben viel Vorarbeit geleistet, und so ist der Algorithmus der Top-Level-Methode recht prägnant ausgefallen.
2.7 Organisation des Backpropagation-Durchgangs
Der Feedforward-Algorithmus sorgt für den Betrieb des Modells. Das Modelltraining ist jedoch untrennbar mit dem Backpropagation-Verfahren verbunden. Während dieses Prozesses werden die trainierten Parameter angepasst, um den Fehler des Modells zu minimieren.
Ähnlich wie bei den Feedforward-Kerneln haben wir 2 Backpropagation-Kerne auf der OpenCL-Programmseite erstellt. Nun müssen wir auf der Seite des Hauptprogramms Methoden für den Aufruf der Backpropagation-Kerne erstellen. Da wir einen Rückwärtsprozess implementieren, arbeiten wir mit Methoden in der Reihenfolge des Backpropagation-Durchgangs.
Nachdem wir den Fehlergradienten von der nächsten Schicht erhalten haben, verteilen wir den resultierenden Gradienten zwischen der Quelldatenschicht und k Koeffizienten. Dieser Prozess ist in der Methode CalculateOutputGradient implementiert, die den Kernel HiddenGradientNODEInpK aufruft.
bool CNeuronNODEOCL::CalculateOutputGradient(CBufferFloat *inputs) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
In den Methodenparametern erhalten wir einen Zeiger auf den Fehlergradientenpuffer der vorherigen Schicht. Im Hauptteil der Methode organisieren wir den Prozess des Aufrufs des Programmkernels OpenCL. Zunächst definieren wir einen eindimensionalen Aufgabenraum. Dann übergeben wir Zeiger auf Datenpuffer und Kernelparameter.
Bitte beachten Sie, dass die Kernel-Parameter HiddenGradientNODEInpK die Kernel-Parameter von FeedForwardNODEInpK vollständig replizieren. Der einzige Unterschied besteht darin, dass beim Vorwärtsdurchgang Puffer für die Quelldaten und k Koeffizienten verwendet werden. Der Backpropagation-Durchgang verwendet Puffer für die entsprechenden Gradienten. Aus diesem Grund habe ich die Konstanten des Kernel-Puffers nicht umdefiniert, sondern die Konstanten für den Vorwärtsdurchgang verwendet.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_beta, cSolution.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_o, Gradient.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Achten Sie auch auf folgende Dinge. Zur Erfassung von k Koeffizienten wurden Puffer mit dem entsprechenden Index im Bereich [0, 5] verwendet. In diesem Fall verwenden wir Puffer mit einem Index im Bereich [6, 11], um Fehlergradienten zu erfassen.
Nachdem wir alle Parameter erfolgreich an den Kernel übergeben haben, stellen wir sie in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_HiddenGradientNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Betrachten wir nun die Methode CalculateInputKGradient, die denselben Kernel aufruft. Die Konstruktion des Algorithmus weist einige Nuancen auf, denen wir besondere Aufmerksamkeit schenken sollten.
Das erste sind natürlich die Methodenparameter. Hier wird der Index des Koeffizienten k hinzugefügt.
bool CNeuronNODEOCL::CalculateInputKGradient(CBufferFloat *inputs, int k) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Im Hauptteil der Methode definieren wir denselben eindimensionalen Aufgabenraum. Dann übergeben wir die Parameter an den Kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Um die Fehlergradienten der k Koeffizienten zu schreiben, werden diesmal jedoch Puffer mit einem Index im Bereich [12, 17] verwendet. Dies ist darauf zurückzuführen, dass die Fehlergradienten für jeden Koeffizienten akkumuliert werden müssen.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[13])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[14])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[15])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[16])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[17])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Darüber hinaus verwenden wir Multiplikatoren aus dem Array cBeta.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_beta, ((CBufferFloat *)cBeta.At(k)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_o, iInputsK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Nach erfolgreicher Übergabe aller erforderlichen Parameter an den Kernel stellen wir ihn in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_HiddenGradientNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Als Nächstes müssen wir den aktuellen Fehlergradienten mit dem zuvor akkumulierten Fehlergradienten für den entsprechenden Koeffizienten k aufsummieren. Zu diesem Zweck organisieren wir eine Rückwärtsschleife, in der wir nacheinander Fehlergradienten hinzufügen, beginnend mit dem analysierten k-Koeffizienten bis zum Minimum.
for(int i = k - 1; i >= 0; i--) { float mult = 1.0f / (i == (k - 1) ? 6 - k : 1); uint global_work_offset[1] = {0}; uint global_work_size[1] = {iLenth * iVariables}; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix1, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix2, iBuffersK[k + 12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix_out, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_dimension, iDimension)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_in1, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_in2, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_out, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_multiplyer, mult)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MatrixSum, 1, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
Beachten Sie, dass wir nur die Fehlergradienten für k Koeffizienten mit einem Index kleiner als der aktuelle addieren. Dies ist darauf zurückzuführen, dass der Multiplikator ß für Koeffizienten mit einem größeren Index offensichtlich gleich 0 ist. Denn solche Koeffizienten werden nach dem aktuellen berechnet und nehmen nicht an seiner Bestimmung teil. Dementsprechend ist ihr Fehlergradient gleich Null. Für ein stabileres Training werden die kumulierten Fehlergradienten gemittelt.
Der letzte Kernel, der an der Ausbreitung des Fehlergradienten beteiligt ist, ist der Kernel, der den Fehlergradienten durch die innere Schicht der ODE-Funktion HiddenGradientNODEF propagiert. Sie wird in der Methode CalculateKBufferGradient aufgerufen. Bei den Parametern erhält die Methode nur den Index des k-Koeffizienten, für den der Gradient verteilt wird.
bool CNeuronNODEOCL::CalculateKBufferGradient(int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
Im Hauptteil der Methode wird geprüft, ob der resultierende Index mit der Architektur des Objekts übereinstimmt. Dann definieren wir einen 3-dimensionalen Problemraum.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iVariables, iLenth};
Wir implementieren die Übergabe von Parametern an den Kernel. Da wir den Fehlergradienten innerhalb des Backpropagation-Durchgangs verteilen, legen wir zunächst die Puffer der Schicht 2 der Funktion fest.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_i, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_ig, iMeadl[k * 2 + 1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_g, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_dimension_out, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_activation, int(LReLU))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Wir stellen den Kernel in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_HiddenGradientNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Im nächsten Schritt übertragen wir, sofern die Arrays, die den Taskraum definieren, unverändert bleiben, die Daten der 1. Schicht der Funktion in die Kernel-Parameter.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_i, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_ig, iInputsK[k + 12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_g, iMeadl[k * 2 + 1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_dimension_out, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_activation, int(None))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Aufruf der Kernel-Ausführung.
if(!OpenCL.Execute(def_k_HiddenGradientNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
Wir haben Methoden zum Aufrufen von Kerneln für die Verteilung des Fehlergradienten zwischen den Ebenenobjekten entwickelt. In diesem Zustand sind es jedoch nur verstreute Teile des Programms, die keinen einzigen Algorithmus bilden. Wir müssen sie zu einem Ganzen verbinden. Wir organisieren den allgemeinen Algorithmus für die Verteilung des Fehlergradienten innerhalb unserer Klasse mit der Methode calcInputGradients.
bool CNeuronNODEOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!CalculateOutputGradient(prevLayer.getGradient())) return false; for(int k = 5; k >= 0; k--) { if(!CalculateKBufferGradient(k)) return false; if(!CalculateInputKGradient(GetPointer(cTemp), k)) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getOutput(), iDimension, false, 0, 0, 0, 1.0f / (k == 0 ? 6 : 1))) return false; } //--- return true; }
In den Parametern erhält die Methode einen Zeiger auf das Objekt der vorherigen Schicht, an das wir den Fehlergradienten übergeben müssen. In der ersten Stufe verteilen wir den Fehlergradienten, den wir von der nachfolgenden Schicht erhalten, auf die vorherige Schicht und k Koeffizienten entsprechend den Faktoren der ODE-Lösung. Wie Sie sich erinnern, haben wir diesen Prozess in der Methode CalculateOutputGradient implementiert.
Anschließend führen wir eine Rückwärtsschleife durch, um bei der Berechnung der entsprechenden Koeffizienten Gradienten durch die ODE-Funktion zu propagieren. Hier propagieren wir zunächst den Fehlergradienten durch unsere 2 Schichten in der Methode CalculateKBufferGradient. Dann verteilen wir den resultierenden Fehlergradienten zwischen den entsprechenden k Koeffizienten und den Ausgangsdaten in der Methode CalculateInputKGradient. Anstelle eines Puffers mit Fehlergradienten aus der vorherigen Schicht erhalten wir jedoch Daten in einem temporären Puffer. Anschließend wird der resultierende Gradient mit Hilfe der Methode SumAndNormilize zu dem zuvor im Gradientenpuffer der vorherigen Schicht angesammelten Gradienten addiert. Bei der letzten Iteration wird der Mittelwert des kumulierten Fehlergradienten gebildet.
In diesem Stadium haben wir den Fehlergradienten auf alle Objekte, die das Ergebnis beeinflussen, entsprechend ihrem Beitrag vollständig verteilt. Alles, was wir tun müssen, ist die Aktualisierung der Modellparameter. Um diese Funktion auszuführen, haben wir zuvor den Kernel NODEF_UpdateWeightsAdam erstellt. Nun müssen wir auf der Seite des Hauptprogramms einen Aufruf an den angegebenen Kernel organisieren. Diese Funktion wird in der Methode updateInputWeights ausgeführt.
bool CNeuronNODEOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension + 2, iDimension, iVariables};
In den Parametern erhält die Methode einen Zeiger auf das Objekt der vorherigen neuronalen Schicht, der in diesem Fall nominal ist und nur für die Virtualisierung der Methode benötigt wird.
Bei den Vorwärts- und Rückwärtsdurchläufen haben wir nämlich die Daten der vorherigen Schicht verwendet. Wir brauchen sie also, um die Parameter der ersten Schicht der ODE-Funktion zu aktualisieren. Während des Vorwärtsdurchlaufs haben wir den Zeiger auf den Ergebnispuffer der vorherigen Schicht im Array iInputsK mit dem Index 0 gespeichert. Verwenden wir sie also in unserer Implementierung.
Im Hauptteil der Methode definieren wir zunächst einen 3-dimensionalen Problemraum. Dann übergeben wir die erforderlichen Parameter an den Kernel. Zunächst aktualisieren wir die Parameter der Schicht 1.
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik1, iInputsK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk1, iMeadl[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik2, iInputsK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk2, iMeadl[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik3, iInputsK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk3, iMeadl[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik4, iInputsK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk4, iMeadl[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik5, iInputsK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk5, iMeadl[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik6, iInputsK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk6, iMeadl[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_m, ((CBufferFloat*)cWeights.At(1)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_v, ((CBufferFloat*)cWeights.At(2)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_alpha, cAlpha.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_lenth, int(iLenth))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Den Kernel stellen wir in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_NODEF_UpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Dann wiederholen wir die Vorgänge, um den Prozess der Aktualisierung der Parameter von Schicht 2 zu organisieren.
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik1, iMeadl[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk1, iBuffersK[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik2, iMeadl[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk2, iBuffersK[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik3, iMeadl[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk3, iBuffersK[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik4, iMeadl[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk4, iBuffersK[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik5, iMeadl[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk5, iBuffersK[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik6, iMeadl[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk6, iBuffersK[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_m, ((CBufferFloat*)cWeights.At(4)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_v, ((CBufferFloat*)cWeights.At(5)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_alpha, cAlpha.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_lenth, int(iLenth))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_NODEF_UpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
2.8 Dateioperationen
Wir haben uns Methoden zur Organisation des Hauptprozesses der Klasse angesehen. Ich möchte jedoch noch ein paar Worte zu den Methoden für die Arbeit mit Dateien sagen. Wenn Sie sich die Struktur der internen Objekte der Klasse genau ansehen, können Sie nur die Sammlung cWeights zum Speichern auswählen, die die Gewichte zu den Zeitpunkten ihrer Anpassung enthält. Sie können auch 3 Parameter speichern, die die Architektur der Klasse bestimmen. Speichern wir sie mit der Methode Save.
bool CNeuronNODEOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; if(!cWeights.Save(file_handle)) return false; if(FileWriteInteger(file_handle, int(iDimension), INT_VALUE) < INT_VALUE || FileWriteInteger(file_handle, int(iVariables), INT_VALUE) < INT_VALUE || FileWriteInteger(file_handle, int(iLenth), INT_VALUE) < INT_VALUE) return false; //--- return true; }
In den Parametern erhält die Methode ein Dateihandle zum Speichern der Daten. Unmittelbar im Körper der Methode rufen wir die Methode der übergeordneten Klasse mit demselben Namen auf. Dann speichern wir die Sammlung und die Konstanten.
Die Methode zum Speichern von Klassen ist sehr übersichtlich und ermöglicht es Ihnen, maximalen Speicherplatz zu sparen. Die Einsparungen werden jedoch durch die Methode des Datenladens erkauft.
bool CNeuronNODEOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; if(!cWeights.Load(file_handle)) return false; cWeights.SetOpenCL(OpenCL); //--- iDimension = (int)FileReadInteger(file_handle); iVariables = (int)FileReadInteger(file_handle); iLenth = (int)FileReadInteger(file_handle);
Hier laden wir zunächst die gespeicherten Daten. Dann organisieren wir den Prozess der Erstellung fehlender Objekte in Übereinstimmung mit den geladenen Parametern der Objektarchitektur.
//--- CBufferFloat *temp = NULL; for(uint i = 0; i < 18; i++) { OpenCL.BufferFree(iBuffersK[i]); OpenCL.BufferFree(iInputsK[i]); //--- iBuffersK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; iInputsK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; if(i > 11) continue; //--- Initilize Output and Gradient buffers OpenCL.BufferFree(iMeadl[i]); iMeadl[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iMeadl[i] < 0) return false; } //--- cTemp.BufferFree(); if(!cTemp.BufferInit(Output.Total(), 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
Damit ist die Diskussion über die Methoden unserer neuen Klasse CNeuronNODEOCL abgeschlossen. Und im Anhang finden Sie den vollständigen Code aller hier verwendeten Methoden und Programme.
2.9 Modellarchitektur für das Training
Wir haben eine neue neuronale Schichtklasse geschaffen, die auf dem ODE-Löser CNeuronNODEOCL basiert. Fügen wir der Architektur des Encoders, den wir im vorherigen Artikel erstellt haben, ein Objekt dieser Klasse hinzu.
Wie immer wird die Architektur der Modelle in der Methode CreateDescriptions festgelegt, in deren Parametern wir Zeiger auf 3 dynamische Arrays übergeben, um die Architektur der zu erstellenden Modelle anzugeben.
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Im Methodenrumpf werden die empfangenen Zeiger überprüft und gegebenenfalls neue Array-Objekte erstellt.
Wir geben Rohdaten, die den Zustand der Umgebung beschreiben, in das Encoder-Modell ein.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die empfangenen Daten werden in der Batch-Normalisierungsschicht vorverarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Anschließend erzeugen wir Einbettungen der resultierenden Zustände mit Hilfe einer Einbettungsschicht und einer anschließenden Faltungsschicht.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Die erzeugten Einbettungen werden durch eine Positionskodierung ergänzt.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Dann verwenden wir eine komplexe, kontextgesteuerte Datenanalyseschicht.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCCMROCL; descr.count = prev_count; descr.window = prev_wout; descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Bis zu diesem Punkt haben wir das Modell aus den vorherigen Artikeln vollständig kopiert. Als Nächstes wollen wir 2 Ebenen einer neuen Klasse hinzufügen.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronNODEOCL; descr.count = prev_count; descr.window = EmbeddingSize/4; descr.step = 4; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronNODEOCL; descr.count = prev_count; descr.window = EmbeddingSize/4; descr.step = 4; if(!encoder.Add(descr)) { delete descr; return false; }
Die Modelle Akteur und Kritiker wurden unverändert aus dem vorherigen Artikel übernommen. Daher werden wir diese Modelle jetzt nicht berücksichtigen.
Das Hinzufügen neuer Schichten hat keinen Einfluss auf die Prozesse der Interaktion mit der Umgebungs und der Modellbildung. Folglich werden auch alle früheren EAs ohne Änderungen verwendet. Auch hier finden Sie den vollständigen Code aller Programme im Anhang. Wir gehen nun zur nächsten Phase über, um die geleistete Arbeit zu testen.
3. Tests
Wir haben eine neue Familie von Modellen für gewöhnliche Differentialgleichungen betrachtet. Unter Berücksichtigung der vorgeschlagenen Ansätze haben wir die neue Klasse CNeuronNODEOCL mit MQL5 implementiert, um die neuronale Schicht in unseren Modellen zu organisieren. Jetzt gehen wir zu Phase 3 unserer Arbeit über: Training und Testen der Modelle auf realen Daten im MetaTrader 5 Strategie-Tester.
Wie zuvor werden die Modelle anhand historischer Daten für EURUSD H1 trainiert und getestet. Wir haben die Modelle offline trainiert. Zu diesem Zweck haben wir eine Trainingsstichprobe aus verschiedenen 500 Trajektorien auf der Grundlage historischer Daten für die ersten 7 Monate des Jahres 2023 zusammengestellt. Die meisten Trajektorien wurden in zufälligen Durchgängen erfasst. Der Anteil der gewinnbringenden Pässe ist recht gering. Um die durchschnittliche Rentabilität der Durchgänge während des Trainingsprozesses auszugleichen, verwenden wir Trajektorien-Sampling mit Priorisierung ihrer Ergebnisse. Auf diese Weise können rentable Durchgänge höher gewichtet werden. Dadurch erhöht sich die Wahrscheinlichkeit, dass solche Durchgänge ausgewählt werden.
Die trainierten Modelle wurden im Strategietester mit historischen Daten vom August 2023 mit demselben Symbol und Zeitrahmen getestet. Mit diesem Ansatz können wir die Leistung des trainierten Modells auf neuen Daten (die nicht in der Trainingsstichprobe enthalten sind) bewerten, wobei die Statistiken der Trainings- und Testdatensätze erhalten bleiben.
Die Testergebnisse deuten darauf hin, dass es möglich ist, Strategien zu erlernen, die sowohl in den Trainings- als auch in den Testzeiträumen Gewinne erzielen. Nachstehend finden Sie die Screenshots der Tests.


Basierend auf den Testergebnissen für August 2023 tätigte das trainierte Modell 160 Handelsgeschäfte, von denen 84 mit Gewinn abgeschlossen wurden. Dies entspricht 52,5 %. Daraus lässt sich schließen, dass die Handelsparität leicht in Richtung Gewinn gekippt ist. Der durchschnittliche Gewinn ist 4 % höher als der durchschnittliche Verlust. Die durchschnittliche Serie von gewinnbringenden Geschäften ist gleich der durchschnittlichen Serie von Verlustgeschäften. Die maximal gewinnbringende Serie durch die Anzahl der Handelsgeschäfte ist gleich der maximal verlustbringenden Serie durch diesen Parameter. Allerdings übersteigen der maximal gewinnbringende Handel und die maximal gewinnbringende Serie an Beträgen ähnliche Variablen von Verlustgeschäften. Infolgedessen wies das Modell während des Testzeitraums einen Gewinnfaktor von 1,15 und eine Sharpe Ratio von 2,14 auf.
Schlussfolgerung
In diesem Artikel haben wir eine neue Klasse von Modellen für gewöhnliche Differentialgleichungen (ODEs) untersucht. Die Verwendung von ODEs als Komponenten von Modellen des maschinellen Lernens hat eine Reihe von Vorteilen und Möglichkeiten. Sie ermöglichen die Modellierung von dynamischen Prozessen und Datenänderungen, was insbesondere für Probleme im Zusammenhang mit Zeitreihen, Systemdynamik und Prognosen wichtig ist. Neuronale ODEs können erfolgreich in verschiedene neuronale Netzwerkarchitekturen integriert werden, einschließlich tiefer und rekurrenter Modelle, was den Anwendungsbereich dieser Methoden erweitert.
Im praktischen Teil unseres Artikels haben wir die vorgeschlagenen Ansätze in MQL5 implementiert. Wir haben das Modell mit realen Daten im MetaTrader 5 Strategie-Tester trainiert und getestet. Die Testergebnisse sind oben dargestellt. Sie zeigen die Wirksamkeit der vorgeschlagenen Ansätze zur Lösung unserer Probleme.
Ich möchte Sie jedoch daran erinnern, dass alle in diesem Artikel vorgestellten Programme informativen Charakter haben und nur dazu dienen, die vorgeschlagenen Ansätze zu demonstrieren.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA-Beispielsammlung |
| 2 | ResearchRealORL.mq5 | EA | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | EA | Modelltraining EA |
| 4 | Test.mq5 | EA | Testmodel des EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14569
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.