Econometría: previsión de un paso adelante
Usando el indicador KotirOut adjunto al artículo #2, muestro en D1
FECHA, kotir.
2011.08.01 00:00,1.4361
2011.08.02 00:00,1.4254
2011.08.03 00:00,1.4188
2011.08.04 00:00,1.4361
2011.08.05 00:00,1.4092
2011.08.08 00:00,1.4368
2011.08.09 00:00,1.4164
2011.08.10 00:00,1.4392
2011.08.11 00:00,1.4161
2011.08.12 00:00,1.4238
.
.
.
11.11.01 00:00,1.3842
2011.11.02 00:00,1.3662
2011.11.03 00:00,1.3725
2011.11.04 00:00,1.3824
2011.11.06 00:00,1.3828
2011.11.07 00:00,1.3816
2011.11.08 00:00,1.3766
2011.11.09 00:00,1.383
Hay 76 observaciones en total. La última fecha es la actual. Tendremos la previsión para mañana, 10 de noviembre.
Ecuación de regresión:
Ecuación de estimación:
=========================
KOTIR = C(1)*HP1(-1) + C(2)*HP1_D(-1) + C(3)*HP1_D(-2)
Coeficientes sustituidos:
=========================
KOTIR = 0,999499248852*HP1(-1) - 0,0151635132798*HP1_D(-1) - 0,176713388909*HP1_D(-2)
Ejecutamos el programa MOD2_T en EViews y obtenemos el resultado:

Así que: la previsión de mañana a partir de las 00:00 hp 1,3798
Pero hay una serie de fallos importantes: el error de previsión es de 97 pips. Un ejemplo de ejecución dio malos resultados: Factor de beneficio = 0,89
El resultado es repugnante y hay que buscar las razones.
Veamos los resultados de la estimación de la regresión:
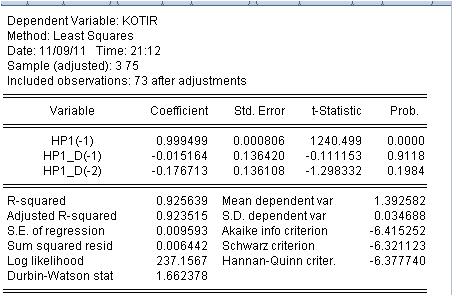
Bueno. No hizo falta indagar mucho. La probabilidad de que los dos últimos coeficientes sean iguales a cero es muy alta, es decir, no podemos rechazar la hipótesis de que los dos últimos coeficientes sean iguales a cero.
Esta ecuación de regresión no es buena y hay que cambiarla. Por cierto, se basa en el indicador Hedrick-Prescott. No tiene sentido discutir la rentabilidad de este modelo.
Estoy esperando sugerencias.
Creo que primero hay que averiguar el argumento mínimo requerido de f(x). Puede resultar que sólo los precios del marco temporal actual no sean suficientes. Podemos intentar otro enfoque, reescribamos su ecuación f(x)=a*X1+b*X2+c*X3.... Ahora utilizaremos la genética para encontrar el máximo optimizando los coeficientes a,b,c.
Me parece que su enfoque no es muy bueno. Intenta tomar la parte plana explícita del gráfico. Parece que el precio en esta zona está cerca de una variable aleatoria normalmente distribuida no creo que se pueda escribir la ecuación para el próximo águila o colas.
faa1947:
Итак первый прогноз.
Por cierto, se basa en el indicador Hedrick-Prescott. No tiene sentido discutir la rentabilidad de este modelo.
Estoy esperando una sugerencia.
Extrañamente no tienes forma de descartar este X-P... aunque no tenga sentido.... te aferras a este H-P como si estuvieras hipnotizado.... y ya lleva bastante tiempo...
Una sugerencia: si el siguiente modelo no funciona, tíralo a la basura, sin compasión ni arrepentimiento. Considere otras opciones: le dará la oportunidad de ver las similitudes y diferencias, los matices sutiles.
Lo sé por experiencia, y puedo decirte que en el futuro podrías volver a algunos modelos previamente descartados... pero desde una nueva perspectiva.
¿Cuál es la esencia de la ST del artículo 2? ¿Se prevé que el precio vuelva al valor suavizado?
Extrapolado suavizado + ruido
Creo que primero hay que averiguar el argumento mínimo requerido de f(x). Puede resultar que sólo los precios del marco temporal actual no sean suficientes. Podemos intentar otro enfoque, reescribamos su ecuación f(x)=a*X1+b*X2+c*X3.... Ahora utilizaremos la genética para encontrar el máximo optimizando los coeficientes a,b,c.
Me parece que su enfoque no es muy bueno. Intenta tomar la parte plana explícita del gráfico. Parece que el precio de esta parte se aproxima a una variable aleatoria de distribución normal No creo que sea posible escribir la ecuación para las próximas caras o colas.
En primer lugar es necesario encontrar el mínimo necesario de argumentos f(x). Puede resultar que sólo los precios del marco temporal actual no sean suficientes.
En mis términos: faltan variables. Debe investigarse si faltan variables. Lo haré a continuación.
Me parece que su enfoque no es muy bueno. Trata de tomar una sección de la carta de un plano obvio
La idea es diferente: cualquier sección. Ajustar una regresión y luego predecir para la siguiente vela. Llega una nueva vela, ajustamos de nuevo (desplazamos la ventana) y volvemos a pronosticar la siguiente vela, etc.
¿Has perdido la cabeza? ¿Has leído las noticias? (sólo se burla de la gente). ¡Compra! (3650 como máximo)
Extrañamente no tienes forma de renunciar a este X-P... aunque no tenga sentido.... te aferras a este H-P como si estuvieras hipnotizado.... y ha estado sucediendo durante mucho tiempo...
Hodrikt no tiene nada que ver.
El modelo que utilizamos tiene una idea: aislar el componente determinista y añadirle ruido
Hay otras ideas. ¿Y tú? ¿Hay gas en el piso? O tienes ideas, por favor, y te mostraré los cálculos.
El resultado de la previsión anterior.
La previsión era de un corto - tener un corto - previsión exitosa!
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Se ha publicado el artículo nº 2 con un título similar. Este artículo es una continuación del otro artículo #1. Estos artículos son un breve resumen de la econometría.
A partir de estos artículos propongo a los miembros del foro lo siguiente: trabajar colectivamente en la creación de modelos econométricos para predecir las cotizaciones de los pares de divisas con un paso de antelación. El tamaño de un paso corresponde al marco temporal, al que se adjunta el Asesor Experto descrito en el artículo #2.
Tomaré el modelo presentado en el artículo 2 y haré dos previsiones: sobre H1 y D1. Veremos el resultado. Luego, espero que el colectivo sugiera mejoras a este modelo o a sus propios modelos. Tomaré los modelos de otra persona y haré una previsión y publicaré el resultado. Estoy dispuesto a responder a las preguntas y a comentar los posts sobre la marcha.
El modelo es una función arbitraria (regresión) de la forma y = f(x1, x2, .... xn). La función y es, por ejemplo, el par EURUSD o cualquier otro par de divisas. xi son los argumentos de la función (variables independientes, regresores) - cualquier otra cotización disponible en el terminal. Por ejemplo, grabar:
EURUSD EURUSD(-1) GBRUSD(-1)
significa que calculamos el valor del EURUSD para otros dos pares de divisas, y tomamos los valores anteriores de estos pares en relación con la función (variable dependiente del EURUSD). Es obvio que podemos construir un modelo sobre un par de divisas, sobre sus valores de retraso - este es un enfoque clásico de AT, y podemos construir modelos multidivisas - en contraste con el AT no hay diferencia en términos de complejidad. Pero veremos en todo su esplendor qué es la correlación y su valor en el trading.
Los archivos en MQL4 y EViews se adjuntan a este artículo.