Artikel über maschinelles Lernen im Handel.
Erstellen von KI-basierten Handelsrobotern: native Integration der Bibliotheken für Python, Matrizen und Vektoren, Mathematik und Statistik und vieles mehr.
Finden Sie heraus, wie Sie maschinelles Lernen im Handel einsetzen können. Neuronen, Perzeptronen, Faltungs- und rekurrente Netze, Vorhersagemodelle – beginnen Sie mit den Grundlagen und arbeiten Sie sich bis zur Entwicklung Ihrer eigenen KI vor. Sie lernen, wie man neuronale Netze für den algorithmischen Handel auf Finanzmärkten trainiert und anwendet.
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Algorithmen zur Optimierung mit Populationen Fledermaus-Algorithmus (BA)
In diesem Artikel werde ich den Fledermaus-Algorithmus (Bat-Algorithmus, BA) betrachten, der gute Konvergenz bei glatten Funktionen zeigt.

Neuronale Netze leicht gemacht (Teil 54): Einsatz von Random Encoder für eine effiziente Forschung (RE3)
Wann immer wir Methoden des Verstärkungslernens in Betracht ziehen, stehen wir vor dem Problem der effizienten Erkundung der Umgebung. Die Lösung dieses Problems führt häufig dazu, dass der Algorithmus komplizierter wird und zusätzliche Modelle trainiert werden müssen. In diesem Artikel werden wir einen alternativen Ansatz zur Lösung dieses Problems betrachten.

Algorithmen zur Optimierung mit Populationen: Differenzielle Evolution (DE)
In diesem Artikel werden wir uns mit dem Algorithmus befassen, der von allen bisher diskutierten Algorithmen die umstrittensten Ergebnisse zeigt - der Algorithmus der differentiellen Evolution (DE).
Kategorientheorie in MQL5 (Teil 16): Funktoren mit mehrschichtigen Perceptrons
In diesem Artikel, dem 16. in unserer Reihe, geht es weiter mit einem Blick auf Funktoren und wie sie mit künstlichen neuronalen Netzen implementiert werden können. Wir weichen von unserem bisherigen Ansatz der Volatilitätsprognose ab und versuchen, eine nutzerdefinierte Signalklasse zum Setzen von Ein- und Ausstiegssignalen zu implementieren.

Integrieren Sie Ihr eigenes LLM in Ihren EA (Teil 1): Die bereitgestellte Hardware und Umgebung
Angesichts der rasanten Entwicklung der künstlichen Intelligenz sind Sprachmodelle (language models, LLMs) heute ein wichtiger Bestandteil der künstlichen Intelligenz, sodass wir darüber nachdenken sollten, wie wir leistungsstarke LLMs in unseren algorithmischen Handel integrieren können. Für die meisten Menschen ist es schwierig, diese leistungsstarken Modelle auf ihre Bedürfnisse abzustimmen, sie lokal einzusetzen und sie dann auf den algorithmischen Handel anzuwenden. In dieser Artikelserie werden wir Schritt für Schritt vorgehen, um dieses Ziel zu erreichen.

Algorithmen zur Optimierung mit Populationen: der Gravitationssuchalgorithmus (GSA)
GSA ist ein von der unbelebten Natur inspirierter Populationsoptimierungsalgorithmus. Dank des in den Algorithmus implementierten Newton'schen Gravitationsgesetzes können wir dank der hohen Zuverlässigkeit der Modellierung der Interaktion physikalischer Körper den bezaubernden Tanz von Planetensystemen und Galaxienhaufen beobachten. In diesem Artikel möchte ich einen der interessantesten und originellsten Optimierungsalgorithmen vorstellen. Der Simulator für die Bewegung von Raumobjekten ist ebenfalls vorhanden.

Neuronale Netze leicht gemacht (Teil 58): Decision Transformer (DT)
Wir setzen das Studium der Methoden des Reinforcement Learning bzw. des Verstärkungslernens fort. In diesem Artikel werde ich mich auf einen etwas anderen Algorithmus konzentrieren, der die Politik des Agenten im Paradigma der Konstruktion einer Sequenz von Aktionen betrachtet.

Neuronale Netze leicht gemacht (Teil 66): Explorationsprobleme beim Offline-Lernen
Modelle werden offline mit Daten aus einem vorbereiteten Trainingsdatensatz trainiert. Dies bietet zwar gewisse Vorteile, hat aber den Nachteil, dass die Informationen über die Umgebung stark auf die Größe des Trainingsdatensatzes komprimiert werden. Das wiederum schränkt die Möglichkeiten der Erkundung ein. In diesem Artikel wird eine Methode vorgestellt, die es ermöglicht, einen Trainingsdatensatz mit möglichst unterschiedlichen Daten zu füllen.

Neuronale Netze leicht gemacht (Teil 46): Goal-conditioned reinforcement learning (GCRL, zielgerichtetes Verstärkungslernen)
In diesem Artikel werfen wir einen Blick auf einen weiteren Ansatz des Reinforcement Learning. Es wird als Goal-conditioned reinforcement learning (GCRL, zielgerichtetes Verstärkungslernen) bezeichnet. Bei diesem Ansatz wird ein Agent darauf trainiert, verschiedene Ziele in bestimmten Szenarien zu erreichen.
Neuronale Netze leicht gemacht (Teil 22): Unüberwachtes Lernen von rekurrenten Modellen
Wir untersuchen weiterhin Modelle und Algorithmen für unüberwachtes Lernen. Diesmal schlage ich vor, dass wir die Eigenschaften von AutoAutoencodern bei der Anwendung auf das Training rekurrenter Modelle diskutieren.

Experimente mit neuronalen Netzen (Teil 6): Das Perzeptron als autarkes Instrument zur Preisprognose
Der Artikel liefert ein Beispiel für die Verwendung eines Perzeptrons als autarkes Preisprognoseinstrument, indem er allgemeine Konzepte und den einfachsten vorgefertigten Expert Advisor vorstellt und anschließend die Ergebnisse seiner Optimierung zeigt.

Neuronale Netze leicht gemacht (Teil 41): Hierarchische Modelle
Der Artikel beschreibt hierarchische Trainingsmodelle, die einen effektiven Ansatz für die Lösung komplexer maschineller Lernprobleme bieten. Hierarchische Modelle bestehen aus mehreren Ebenen, von denen jede für verschiedene Aspekte der Aufgabe zuständig ist.
Algorithmen zur Optimierung mit Populationen: Spiralförmige Dynamische Optimization (SDO) Algorithmus
In diesem Artikel wird ein Optimierungsalgorithmus vorgestellt, der auf den Mustern der Konstruktion spiralförmiger Trajektorien in der Natur, wie z. B. bei Muschelschalen, basiert - der Algorithmus der spiralförmigen dynamischen Optimierung (SDO). Ich habe den von den Autoren vorgeschlagenen Algorithmus gründlich überarbeitet und verändert. Der Artikel befasst sich mit der Notwendigkeit dieser Änderungen.

Neuronale Netze leicht gemacht (Teil 37): Sparse Attention (Verringerte Aufmerksamkeit)
Im vorigen Artikel haben wir relationale Modelle erörtert, die in ihrer Architektur Aufmerksamkeitsmechanismen verwenden. Eines der besonderen Merkmale dieser Modelle ist die intensive Nutzung von Computerressourcen. In diesem Artikel wird einer der Mechanismen zur Verringerung der Anzahl von Rechenoperationen innerhalb des Self-Attention-Blocks betrachtet. Dadurch wird die allgemeine Leistung des Modells erhöht.
Datenwissenschaft und maschinelles Lernen — Neuronales Netzwerk (Teil 02): Entwurf von Feed Forward NN-Architekturen
Bevor wir fertig sind, müssen wir noch einige kleinere Dinge im Zusammenhang mit dem neuronalen Feed-Forward-Netz behandeln, unter anderem den Entwurf. Sehen wir uns an, wie wir ein flexibles neuronales Netz für unsere Eingaben, die Anzahl der verborgenen Schichten und die Knoten für jedes Netz aufbauen und gestalten können.

Messen der Information von Indikatoren
Maschinelles Lernen hat sich zu einer beliebten Methode für die Strategieentwicklung entwickelt. Während die Maximierung der Rentabilität und der Vorhersagegenauigkeit stärker in den Vordergrund gerückt wurde, wurde der Bedeutung der Verarbeitung der Daten, die zur Erstellung von Vorhersagemodellen verwendet werden, nicht viel Aufmerksamkeit geschenkt. In diesem Artikel befassen wir uns mit der Verwendung des Konzepts der Entropie zur Bewertung der Eignung von Indikatoren für die Erstellung von Prognosemodellen, wie sie in dem Buch Testing and Tuning Market Trading Systems von Timothy Masters dokumentiert sind.

Neuronale Netze leicht gemacht (Teil 42): Modell der Prokrastination, Ursachen und Lösungen
Im Kontext des Verstärkungslernens kann die Prokrastination (Zögern) eines Modells mehrere Ursachen haben. Der Artikel befasst sich mit einigen der möglichen Ursachen für Prokrastination bei Modellen und mit Methoden zu deren Überwindung.

Neuronale Netze leicht gemacht (Teil 61): Optimismusproblem beim Offline-Verstärkungslernen
Während des Offline-Lernens optimieren wir die Strategie des Agenten auf der Grundlage der Trainingsdaten. Die daraus resultierende Strategie gibt dem Agenten Vertrauen in sein Handeln. Ein solcher Optimismus ist jedoch nicht immer gerechtfertigt und kann zu erhöhten Risiken während des Modellbetriebs führen. Heute werden wir uns mit einer der Methoden zur Verringerung dieser Risiken befassen.

Neuronale Netze leicht gemacht (Teil 44): Erlernen von Fertigkeiten mit Blick auf die Dynamik
Im vorangegangenen Artikel haben wir die DIAYN-Methode vorgestellt, die einen Algorithmus zum Erlernen einer Vielzahl von Fertigkeiten (skills) bietet. Die erworbenen Fertigkeiten können für verschiedene Aufgaben genutzt werden. Aber solche Fertigkeiten können ziemlich unberechenbar sein, was ihre Anwendung schwierig machen kann. In diesem Artikel wird ein Algorithmus zum Erlernen vorhersehbarer Fertigkeiten vorgestellt.
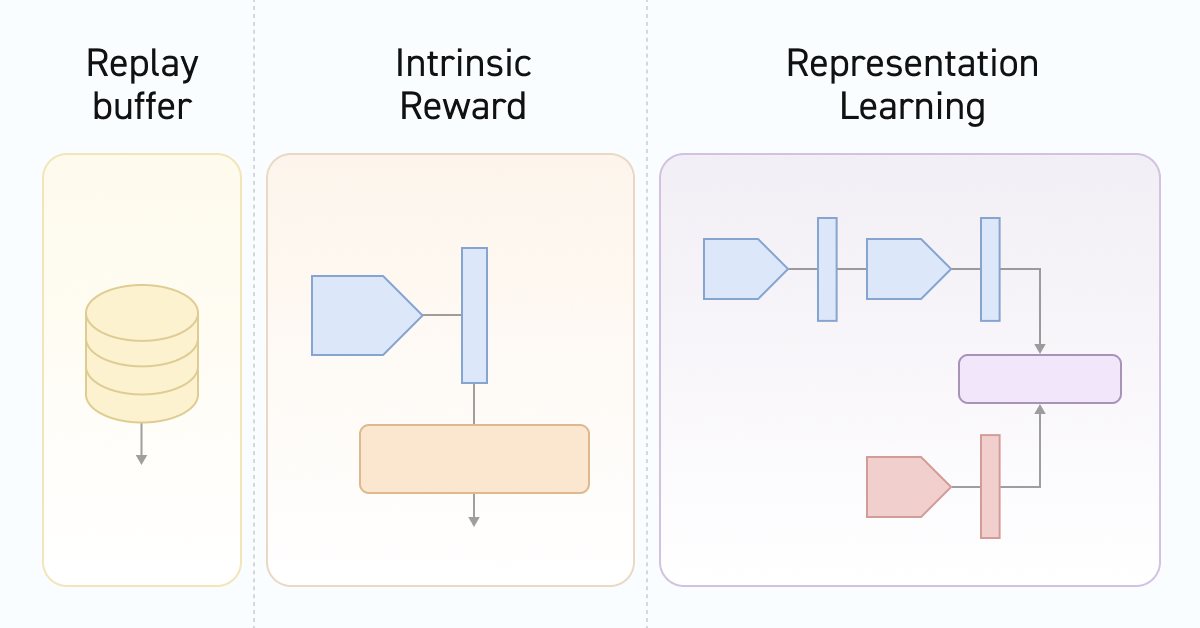
Neuronale Netze leicht gemacht (Teil 55): Contrastive Intrinsic Control (CIC)
Das kontrastive Training ist eine unüberwachte Methode zum Training der Repräsentation. Ziel ist es, ein Modell zu trainieren, das Ähnlichkeiten und Unterschiede in Datensätzen aufzeigt. In diesem Artikel geht es um die Verwendung kontrastiver Trainingsansätze zur Erkundung verschiedener Fähigkeiten des Akteurs (Actor skills).

Neuronale Netze leicht gemacht (Teil 52): Forschung mit Optimismus und Verteilungskorrektur
Da das Modell auf der Grundlage des Erfahrungswiedergabepuffers trainiert wird, entfernt sich die aktuelle Strategie oder Politik des Akteurs immer weiter von den gespeicherten Beispielen, was die Effizienz des Trainings des Modells insgesamt verringert. In diesem Artikel befassen wir uns mit einem Algorithmus zur Verbesserung der Effizienz bei der Verwendung von Stichproben in Algorithmen des verstärkten Lernens.

Datenwissenschaft und maschinelles Lernen (Teil 18): Der Kampf um die Beherrschung der Marktkomplexität, verkürzte SVD versus NMF
Die verkürzte Singulärwertzerlegung (Truncated Singular Value Decomposition, SVD) und die nicht-negative Matrixzerlegung (Non-Negative Matrix Factorization, NMF) sind Verfahren zur Dimensionsreduktion. Beide spielen eine wichtige Rolle bei der Entwicklung von datengesteuerten Handelsstrategien. Entdecken Sie die Kunst der Dimensionalitätsreduzierung, der Entschlüsselung von Erkenntnissen und der Optimierung quantitativer Analysen für einen fundierten Ansatz zur Navigation durch die Feinheiten der Finanzmärkte.

Frequenzbereichsdarstellungen von Zeitreihen: Das Leistungsspektrum
In diesem Artikel erörtern wir Methoden zur Analyse von Zeitreihen im Frequenzbereich. Hervorhebung des Nutzens der Untersuchung der Leistungsspektren von Zeitreihen bei der Erstellung von Vorhersagemodellen. In diesem Artikel werden wir einige der nützlichen Perspektiven erörtern, die sich aus der Analyse von Zeitreihen im Frequenzbereich unter Verwendung der diskreten Fourier-Transformation (dft) ergeben.
Neuronale Netze leicht gemacht (Teil 34): Vollständig parametrisierte Quantilfunktion
Wir untersuchen weiterhin verteilte Q-Learning-Algorithmen. In früheren Artikeln haben wir verteilte und Quantil-Q-Learning-Algorithmen besprochen. Im ersten Algorithmus haben wir die Wahrscheinlichkeiten für bestimmte Wertebereiche trainiert. Im zweiten Algorithmus haben wir Bereiche mit einer bestimmten Wahrscheinlichkeit trainiert. In beiden Fällen haben wir a priori Wissen über eine Verteilung verwendet und eine andere trainiert. In diesem Artikel wenden wir uns einem Algorithmus zu, der es dem Modell ermöglicht, für beide Verteilungen trainiert zu werden.

Neuronale Netze leicht gemacht (Teil 60): Online Decision Transformer (ODT)
Die letzten beiden Artikel waren der Decision-Transformer-Methode gewidmet, die Handlungssequenzen im Rahmen eines autoregressiven Modells der gewünschten Belohnungen modelliert. In diesem Artikel werden wir uns einen weiteren Optimierungsalgorithmus für diese Methode ansehen.

Algorithmen zur Optimierung mit Populationen: Der Algorithmus Charged System Search (CSS)
In diesem Artikel werden wir einen weiteren Optimierungsalgorithmus betrachten, der von der unbelebten Natur inspiriert ist - den CSS-Algorithmus (Charged System Search, Suche geladener Systeme). In diesem Artikel wird ein neuer Optimierungsalgorithmus vorgestellt, der auf den Prinzipien der Physik und Mechanik beruht.

Neuronale Netze leicht gemacht (Teil 64): Die Methode konservativ gewichtetes Klonen von Verhaltensweisen (CWBC)
Aufgrund von Tests, die in früheren Artikeln durchgeführt wurden, kamen wir zu dem Schluss, dass die Optimalität der trainierten Strategie weitgehend von der verwendeten Trainingsmenge abhängt. In diesem Artikel werden wir uns mit einer relativ einfachen, aber effektiven Methode zur Auswahl von Trajektorien für das Training von Modellen vertraut machen.
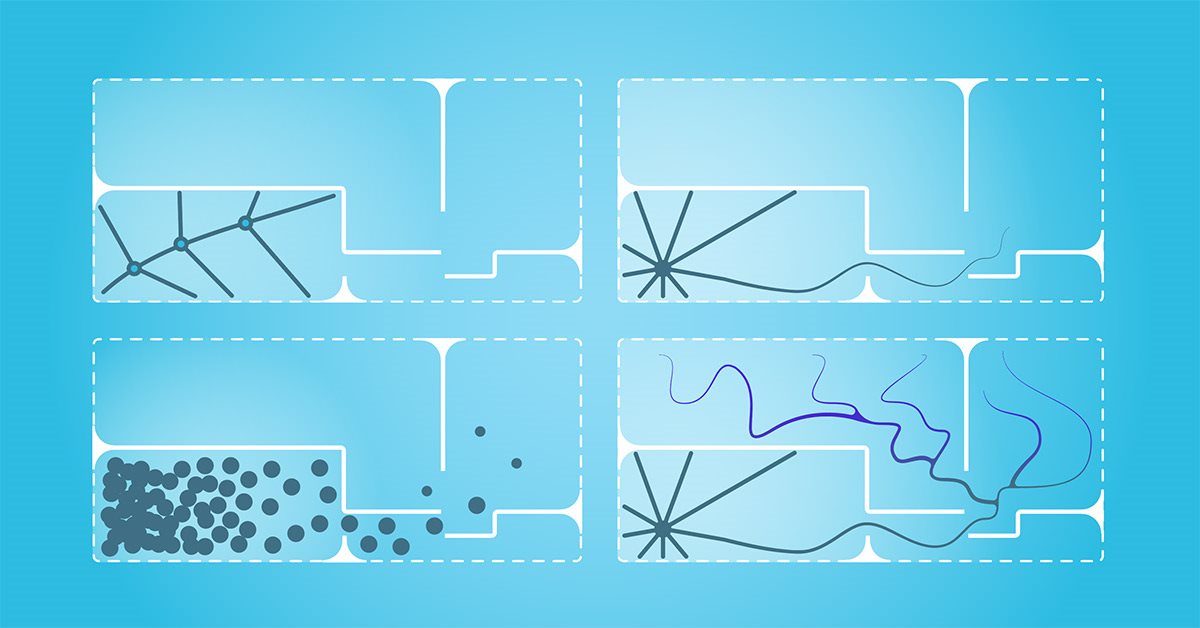
Neuronale Netze leicht gemacht (Teil 45): Training von Fertigkeiten zur Erkundung des Zustands
Das Training nützlicher Fertigkeiten ohne explizite Belohnungsfunktion ist eine der größten Herausforderungen beim hierarchischen Verstärkungslernen. Zuvor haben wir bereits zwei Algorithmen zur Lösung dieses Problems kennengelernt. Die Frage nach der Vollständigkeit der Umweltforschung bleibt jedoch offen. In diesem Artikel wird ein anderer Ansatz für das Training von Fertigkeiten vorgestellt, dessen Anwendung direkt vom aktuellen Zustand des Systems abhängt.

Datenwissenschaft und maschinelles Lernen (Teil 19): Überladen Sie Ihre AI-Modelle mit AdaBoost
AdaBoost, ein leistungsstarker Boosting-Algorithmus, der die Leistung Ihrer KI-Modelle steigert. AdaBoost, die Abkürzung für Adaptive Boosting, ist ein ausgeklügeltes Ensemble-Lernverfahren, das schwache Lerner nahtlos integriert und ihre kollektive Vorhersagestärke erhöht.

Algorithmen zur Optimierung mit Populationen Firefly-Algorithmus (FA)
In diesem Artikel werde ich die Optimierungsmethode des Firefly-Algorithmus (FA) betrachten. Dank der Änderung hat sich der Algorithmus von einem Außenseiter zu einem echten Tabellenführer entwickelt.

Neuronale Netze leicht gemacht (Teil 18): Assoziationsregeln
Als Fortsetzung dieser Artikelserie betrachten wir eine andere Art von Problemen innerhalb der Methoden des unüberwachten Lernens: die Ermittlung von Assoziationsregeln. Dieser Problemtyp wurde zuerst im Einzelhandel, insbesondere in Supermärkten, zur Analyse von Warenkörben eingesetzt. In diesem Artikel werden wir über die Anwendbarkeit solcher Algorithmen im Handel sprechen.

Neuronale Netze leicht gemacht (Teil 23): Aufbau eines Tools für Transfer Learning
In dieser Artikelserie haben wir bereits mehr als einmal über Transfer Learning berichtet. In diesem Artikel schlage ich vor, diese Lücke zu schließen und einen genaueren Blick auf Transfer Learning zu werfen.

MQL5-Assistent-Techniken, die Sie kennen sollten (Teil 09): K-Means-Clustering mit fraktalen Wellen
Das K-Means-Clustering verfolgt den Ansatz, Datenpunkte als einen Prozess zu gruppieren, der sich zunächst auf die Makroansicht eines Datensatzes konzentriert und zufällig generierte Clusterzentren verwendet, bevor er heranzoomt und diese Zentren anpasst, um den Datensatz genau darzustellen. Wir werden uns dies ansehen und einige Anwendungsfälle ausnutzen.
Die Kategorientheorie in MQL5 (Teil 1)
Die Kategorientheorie ist ein vielfältiger und expandierender Zweig der Mathematik, der in der MQL-Gemeinschaft noch relativ unentdeckt ist. In dieser Artikelserie sollen einige der Konzepte vorgestellt und untersucht werden, mit dem übergeordneten Ziel, eine offene Bibliothek einzurichten, die zu Kommentaren und Diskussionen anregt und hoffentlich die Nutzung dieses bemerkenswerten Bereichs für die Strategieentwicklung der Händler fördert.

Kategorientheorie in MQL5 (Teil 15) : Funktoren mit Graphen
Dieser Artikel über die Implementierung der Kategorientheorie in MQL5 setzt die Serie mit der Betrachtung der Funktoren fort, diesmal jedoch als Brücke zwischen Graphen und einer Menge. Wir greifen die Kalenderdaten wieder auf und plädieren trotz der Einschränkungen bei der Verwendung von Strategy Tester für die Verwendung von Funktoren zur Vorhersage der Volatilität mit Hilfe der Korrelation.

Kategorientheorie in MQL5 (Teil 17): Funktoren und Monoide
Dieser Artikel, der letzte in unserer Reihe zum Thema Funktoren, befasst sich erneut mit Monoiden als Kategorie. Monoide, die wir in dieser Serie bereits vorgestellt haben, werden hier zusammen mit mehrschichtigen Perceptrons zur Unterstützung der Positionsbestimmung verwendet.

Algorithmen zur Optimierung mit Populationen: Der Algorithmus Simulated Isotropic Annealing (SIA). Teil II
Der erste Teil war dem bekannten und beliebten Algorithmus des Simulated Annealing gewidmet. Wir haben ihre Vor- und Nachteile gründlich abgewogen. Der zweite Teil des Artikels ist der radikalen Umgestaltung des Algorithmus gewidmet, die ihn zu einem neuen Optimierungsalgorithmus macht, dem Simulated Isotropic Annealing (SIA).

Neuronale Netze leicht gemacht (Teil 40): Verwendung von Go-Explore bei großen Datenmengen
In diesem Artikel wird die Verwendung des Go-Explore-Algorithmus über einen langen Trainingszeitraum erörtert, da die Strategie der zufälligen Aktionsauswahl mit zunehmender Trainingszeit möglicherweise nicht zu einem profitablen Durchgang führt.

Datenkennzeichnung für die Zeitreihenanalyse (Teil 4):Deutung der Datenkennzeichnungen durch Aufgliederung
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung (labeling) von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!

Neuronale Netze leicht gemacht (Teil 36): Relationales Verstärkungslernen
In den Verstärkungslernmodellen, die wir im vorherigen Artikel besprochen haben, haben wir verschiedene Varianten von Faltungsnetzwerken verwendet, die in der Lage sind, verschiedene Objekte in den Originaldaten zu identifizieren. Der Hauptvorteil von Faltungsnetzen ist die Fähigkeit, Objekte unabhängig von ihrer Position zu erkennen. Gleichzeitig sind Faltungsnetzwerke nicht immer leistungsfähig, wenn es zu verschiedenen Verformungen von Objekten und Rauschen kommt. Dies sind die Probleme, die das relationale Modell lösen kann.