Neuronale Netze leicht gemacht (Teil 34): Vollständig parametrisierte Quantilfunktion

Inhalt
- Einführung
- 1. Theoretische Aspekte der vollständigen Parametrisierung
- 2. Implementation in MQL5
- 3. Tests
- Schlussfolgerung
- Referenzen
- Programme, die im diesem Artikel verwendet werden
Einführung
Wir untersuchen weiterhin verteilte Q-Learning-Algorithmen. Zuvor haben wir bereits zwei Algorithmen vorgestellt. Im ersten Fall[4] lernte unser Modell die Wahrscheinlichkeiten für den Erhalt einer Belohnung in einem bestimmten Wertebereich. Im zweiten Algorithmus[5] haben wir einen anderen Ansatz zur Lösung des Problems verwendet. Wir haben das Modell so trainiert, dass es den Belohnungsgrad mit einer bestimmten Wahrscheinlichkeit vorhersagt.
Offensichtlich benötigen wir bei beiden Algorithmen ein gewisses a priori Wissen über die Art der Belohnungsverteilung, um das Problem zu lösen. Beim ersten Algorithmus werden die erwarteten Belohnungen in das Modell eingespeist, während die Aufgabe des Nutzers beim zweiten Algorithmus etwas einfacher ist. Wir müssen in das Modell eine Reihe von Quantilen eingeben, deren Größe im Bereich von 0 bis 1 normalisiert ist und die in aufsteigender Reihenfolge angeordnet sind. Ohne die tatsächliche Verteilung der Belohnungswerte zu kennen, ist es jedoch schwierig, die Anzahl der benötigten Quantile und die Höhe der einzelnen Quantile zu bestimmen.
Hier ist anzumerken, dass wir von einer Gleichverteilung der untersuchten Sequenz ausgegangen sind. Wir haben also einheitliche Quantilsbereiche verwendet. Der wichtigste regulierende Hyperparameter war die Anzahl dieser Quantile. Sie wird empirisch anhand des Validierungsdatensatzes ermittelt.
1. Theoretische Aspekte der vollständigen Parametrisierung
Beide genannten Methoden erfordern die Voruntersuchung des Trainingsdatensatzes und die Optimierung der Hyperparameter. Dabei ist zu beachten, dass wir bei der Optimierung der Hyperparameter einige Durchschnittswerte wählen. Mit anderen Worten: Wir wählen etwas, das uns dem gewünschten Ziel so nahe wie möglich bringt. Die gewählten Parameter sollten möglichst alle möglichen Zustände des untersuchten Systems berücksichtigen. Wir haben auch die Annahme einer gleichmäßigen Verteilung gemacht. Es handelt sich also um ein Modell mit vielen Kompromissen. Natürlich ist ein solches Modell alles andere als optimal.
Um die Glaubwürdigkeit zu verbessern und den Vorhersagefehler zu minimieren, müssen wir die Anzahl der zu trainierenden Quantile erhöhen. Dies wiederum erhöht die Trainingszeit und die Größe des Modells. In den meisten Fällen ist dieser Ansatz unwirksam. Unser Ziel ist es jedoch, die Umwelt so gründlich wie möglich zu untersuchen. Daher erscheint es sinnvoll, im ersten Algorithmus auf feste Wertkategorien und im zweiten Algorithmus auf feste Quantile zu verzichten.
1.1. Implizite Quantilnetze (IQN)
Die Verwendung von Quantilen scheint hier vielversprechender zu sein. Denn um die Kategorien zu bestimmen, müssen wir die ursprüngliche Verteilung vollständig untersuchen und ihre Grenzen definieren. Auf Werte, die außerhalb des angegebenen Bereichs liegen, ist das Modell jedoch nicht vorbereitet. Das Kategorienmodell ist nicht allgemeingültig und variiert bei verschiedenen Aufgaben.
Gleichzeitig haben die Wahrscheinlichkeiten des Auftretens von Ereignissen klare Grenzen im Bereich von 0 bis 1. Die Verwendung einer gleichmäßigen Verteilung der Quantile schränkt jedoch unsere Freiheiten und den Bereich der optimierbaren Funktionen ein. Es wäre gut, einen solchen Algorithmus zu finden, bei dem das Modell selbst die optimale Quantilsverteilung bestimmen kann, ohne die Anzahl der Quantile zu erhöhen.
Der erste derartige Algorithmus wurde im Juli 2018 in dem Artikel Implicit Quantile Networks for Distributional Reinforcement Learning vorgeschlagen. Die Autoren sind das Problem der optimalen Quantile jedoch auf eine etwas andere Weise angegangen. Sie haben ihren Algorithmus auf der Grundlage des QR-DQN entwickelt, den wir bereits besprochen haben. Anstatt jedoch nach optimalen Quantilen zu suchen, beschlossen die Autoren, diese nach dem Zufallsprinzip zu generieren und sie zusammen mit den Ausgangsdaten, die den Zustand der Umwelt beschreiben, in das Modell einzuspeisen. Die Idee ist folgende: Während des Trainingsprozesses werden dieselben Systemzustände mit unterschiedlichen Quantilsverteilungen in das Modell eingegeben. Infolgedessen ist das Modell gezwungen, nicht einen bestimmten Ausschnitt der Quantilsfunktion zu verwenden, sondern ihre vollständige Approximation.
Dieser Ansatz ermöglicht die Ausbildung eines Modells, das weniger empfindlich auf den Hyperparameter „Anzahl der Quantile“ reagiert. Ihre Zufallsverteilung ermöglicht die Erweiterung des Bereichs der angenäherten Funktionen auf ungleichmäßig verteilte Funktionen.
Bevor die Daten in das Modell eingegeben werden, wird eine Einbettung von zufällig generierten Quantilen nach der folgenden Formel erstellt.
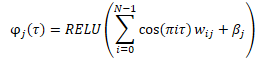
Es gibt verschiedene Möglichkeiten, die resultierende Einbettung mit dem Tensor der Originaldaten zu kombinieren. Dies kann entweder eine einfache Verkettung von zwei Tensoren oder eine Hadamard-Multiplikation (Element-für-Element) von zwei Matrizen sein.
Nachstehend finden Sie einen Vergleich der in Frage kommenden Architekturen, der von den Autoren des Artikels vorgestellt wurde.
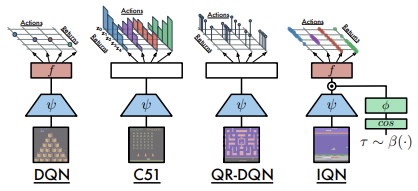
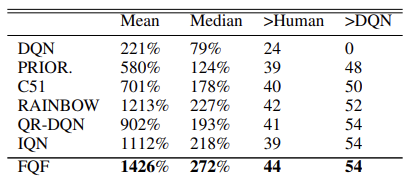
Die Wirksamkeit des Modells wird durch Tests bestätigt, die mit 57 Atari-Spielen durchgeführt wurden. Nachstehend finden Sie eine Vergleichstabelle aus dem Originalartikel [8]
Hypothetisch gesehen erlaubt dieser Ansatz, angesichts der unbegrenzten Größe des Modells, das Lernen einer beliebigen Verteilung der vorhergesagten Belohnung.
1.2. Vollständig parametrisierte Quantilsfunktion (FQF)
Das vorgestellte Modell der impliziten Quantilnetze ist in der Lage, verschiedene Funktionen zu approximieren. Dieser Prozess ist jedoch mit dem Wachstum des Modells verbunden. In der Praxis sind die Ressourcen jedoch begrenzt. Bei der Erzeugung von Zufallsquantilen besteht immer die Gefahr, nicht optimale Werte zu erhalten, sowohl beim Training als auch bei der Anwendung des Modells.
Im November 2019 wurde Fully Parameterized Quantile Function for Distributional Reinforcement Learning vorgeschlagen.
Im Wesentlichen handelt es sich um das gleiche IQN-Modell. Anstelle eines zufälligen Quantilgenerators wird jedoch eine vollständig verknüpfte neuronale Schicht verwendet, die die Verteilung der Quantile auf der Grundlage des aktuellen Zustands der Umgebung, der als Eingabe eingegeben wurde, zurückgibt. Das Modell erzeugt eine Quantilsverteilung für jedes Wertepaar „Zustand-Aktion“. Dies ermöglicht die Annäherung an die optimale Verteilung der erwarteten Belohnung für jede Aktion in einem bestimmten Systemzustand. Davon haben wir zu Beginn dieses Artikels gesprochen.
Die wichtigsten Anforderungen an Quantile bleiben erhalten. Diese liegen im Bereich von 0 bis 1. Um diesen Effekt zu erzielen, verwendet der Algorithmus eine Datennormalisierung am Ausgang der neuronalen Schicht. Die Daten werden mit der Funktion Softmax normalisiert und anschließend werden die Elemente des normalisierten Vektors kumulativ addiert.
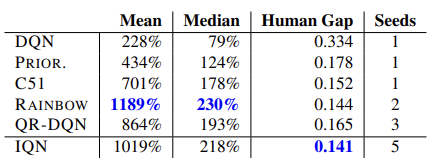
In dem Originalartikel stellen die Autoren die Ergebnisse von Algorithmustests an 55 Atari-Spielen vor. Nachfolgend finden Sie eine zusammenfassende Tabelle der Ergebnisse aus dem Originalartikel. Die vorgestellten Daten zeigen die Überlegenheit des Algorithmus zur vollständigen Parametrisierung der Quantilsfunktion gegenüber anderen verteilten Q-Learning-Algorithmen. Aber der Preis dafür ist die Leistung des Modells. Das zusätzliche Modell der Quantilgenerierung erfordert zusätzliche Rechenressourcen.
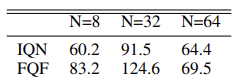
Die Autoren der Methode haben Experimente durchgeführt, um die optimale Anzahl von Quantilen zu ermitteln, und schlagen eine Verteilung mit 32 Quantilen vor.
Wir werden den Algorithmus der Methode bei der Umsetzung in weiteren Themen näher untersuchen.
2. Implementation in MQL5
In ihrem Artikel sprechen die Autoren der Methode über die Verwendung von zwei neuronalen Netzen: eines für die Generierung der Verteilung der Quantile und das andere für die Annäherung der Quantilfunktion. Der beschriebene Algorithmus verwendet jedoch auch ein drittes Faltungsnetz, das eine Einbettung des Umgebungszustands erzeugt. Diese Zustandseinbettung ist das Ausgangsmaterial für den betrachteten Algorithmus.
Die Bibliothek, die wir zuvor erstellt haben, ist jedoch auf die Erstellung sequenzieller Modelle ausgerichtet. Es enthält keinen Algorithmus zur Weitergabe eines Fehlergradienten zwischen Modellen, was bei der Ausbildung mehrerer sequenzieller Modelle erforderlich sein kann.
Natürlich können wir auch den Mechanismus des Transfer-Learnings verwenden und jedes einzelne Modell nacheinander trainieren. Ich beschloss jedoch, den gesamten Algorithmus in ein einziges Modell zu implementieren.
Um die Einbettung des Umgebungszustands zu erstellen, verwenden wir die bereits erwähnten Faltungsmodelle [1]. Daher können wir ein solches Modell mit den vorhandenen Werkzeugen leicht erstellen.
Als Nächstes müssen wir den FQF-Algorithmus implementieren. Meiner Meinung nach ist es am einfachsten, dies in unser Bibliothekskonzept zu implementieren, indem wir eine neue neuronale Schichtklasse erstellen. Wir geben die Einbettung des aktuellen Zustands des zu analysierenden Systems ein und die Schicht gibt die Agentenaktion aus. Innerhalb der neuen Klasse werden wir also einen Agenten unseres Modells erstellen.
Wir erstellen die neue Klasse CNeuronFQF, indem wir sie von der Basisklasse CNeuronBaseOCL für neuronale Schichten ableiten. Die neue Klasse wird unsere üblichen Methoden außer Kraft setzen. Im geschützten Block deklarieren wir die internen Objekte, die wir bei der Implementierung des FQF-Algorithmus verwenden werden. Wir werden mehr über den Zweck des Objekts erfahren, wenn wir den Algorithmus erstellen.
class CNeuronFQF : protected CNeuronBaseOCL { protected: //--- Fractal Net CNeuronBaseOCL cFraction; CNeuronSoftMaxOCL cSoftMax; //--- Cosine embeding CNeuronBaseOCL cCosine; CNeuronBaseOCL cCosineEmbeding; //--- Quantile Net CNeuronBaseOCL cQuantile0; CNeuronBaseOCL cQuantile1; CNeuronBaseOCL cQuantile2; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronFQF(); ~CNeuronFQF(); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronFQF; } virtual CLayerDescription* GetLayerInfo(void) override; };
In unserer Klasse verwenden wir statische interne Objekte, sodass der Konstruktor und der Destruktor der Klasse leer bleiben können.
Die Klasse und die internen Objekte werden in der Init-Methode initialisiert. Um interne Objekte zu initialisieren, benötigen wir die folgenden Parameter:
- numOutputs — die Anzahl der Neuronen in der nächsten Schicht
- myIndex — der Index des aktuellen Neurons in der Schicht
- open_cl — ein Zeiger auf das Objekt für die Arbeit mit dem OpenCL-Gerät
- Aktionen — die Anzahl der möglichen Aktionen des Agenten
- Quantile — die Anzahl der Quantile
- numInputs — die Größe der vorherigen neuronalen Schicht
- optimization_type — Funktion, die zur Optimierung der Modellparameter verwendet wird
- batch — Parameter zum Aktualisieren der Batchgröße
bool CNeuronFQF::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, actions, optimization, batch)) return false; SetActivationFunction(None);
Im Methodenrumpf wird kein Block zur Überprüfung der empfangenen Parameter definiert. Stattdessen rufen wir eine ähnliche Methode der übergeordneten Klasse auf, die bereits alle erforderlichen Steuerelemente enthält. Die Methode der Elternklasse steuert externe Parameter und initialisiert geerbte Objekte. Nach erfolgreicher Ausführung müssen wir also nur noch die neu deklarierten Objekte initialisieren.
Vergessen Sie auch nicht, die Objektaktivierungsfunktion zu deaktivieren. Alle notwendigen Aktivierungsfunktionen werden durch den Algorithmus definiert und für interne Objekte angegeben.
Nach dem FQF-Algorithmus wird die Einbettung des Systemzustands in das quantilgenerierende Netz eingegeben. Für diese Zwecke verwendeten die Autoren der Methode eine vollständig verknüpfte Schicht, während sie die Daten mithilfe der Funktion oftmax normalisierten. In unserer Implementierung werden dies zwei Objekte sein: eine voll verknüpfte Schicht ohne Aktivierungsfunktion und eine Softmax-Schicht.
Da wir die Verteilung der Quantile für jede mögliche Aktion generieren, wird die Größe der verwendeten Schichten als gleich dem Produkt aus der Anzahl der möglichen Aktionen und der gegebenen Anzahl der Quantile definiert. Im Falle von Softmax wird die Datennormalisierung auch im Kontext von Aktionen durchgeführt.
//--- if(!cFraction.Init(0, myIndex, open_cl, actions * quantiles, optimization, batch)) return false; cFraction.SetActivationFunction(None); //--- if(!cSoftMax.Init(0, myIndex, open_cl, actions * quantiles, optimization, batch)) return false; cSoftMax.SetHeads(actions); cSoftMax.SetActivationFunction(None);
Außerdem müssen wir gemäß dem Algorithmus eine Einbettung der erhaltenen Quantile erstellen. Sie wird in zwei Schritten verpackt. Zunächst bereiten wir die Daten vor und speichern sie im Puffer der neuronalen Schicht von cCosine. Dann wird es durch die voll verknüpfte Schicht cCosine Embedding mit der Aktivierungsfunktion ReLU geleitet. Darüber hinaus gleicht die Schicht cCosineEmbeding die Größe des Einbettungstensors mit der Größe der Quelldaten für die anschließende Hadamard-Multiplikation von Tensoren ab.
if(!cCosine.Init(numInputs, myIndex, open_cl, actions * quantiles, optimization, batch)) return false; cCosine.SetActivationFunction(None); //--- if(!cCosineEmbeding.Init(0, myIndex, open_cl, numInputs, optimization, batch)) return false; cCosineEmbeding.SetActivationFunction(LReLU);
Schließlich müssen wir die Daten durch das Modell der Quantilsfunktion leiten. Sie enthält eine versteckte, voll verknüpfte Schicht mit einer Anzahl von Neuronen, die dem Vierfachen des Produkts aus der Anzahl der Aktionen und der Anzahl der Quantile entspricht, sowie die Aktivierungsfunktion ReLU. Es gibt auch eine vollständig verbundene Schicht ohne Aktivierungsfunktion am Ausgang. Die Größe der Ergebnisschicht ist gleich dem Produkt aus der Anzahl der möglichen Aktionen und der Anzahl der Quantile.
if(!cQuantile0.Init(4 * actions * quantiles, myIndex, open_cl, numInputs, optimization, batch)) return false; cQuantile0.SetActivationFunction(None); //--- if(!cQuantile1.Init(actions * quantiles, myIndex, open_cl, 4 * actions * quantiles, optimization, batch)) return false; cQuantile1.SetActivationFunction(LReLU); //--- if(!cQuantile2.Init(0, myIndex, open_cl, actions * quantiles, optimization, batch)) return false; cQuantile2.SetActivationFunction(None); //--- return true; }
Vergessen Sie bei der Implementierung der Methode nicht, die Ausführung der Vorgänge zu kontrollieren. Nach erfolgreicher Initialisierung aller internen Objekte wird die Methode mit einem positiven Ergebnis beendet.
2.1. Feed-Forward
Nach der Initialisierung der Objekte geht es an den Aufbau des Feed-Forward-Prozesses. Bevor wir jedoch mit der Erstellung der Methode CNeuronFQF::feedForward fortfahren, müssen wir die erforderlichen Kernel im OpenCL-Programm erstellen. Wir haben eine fertige Implementierung neuronaler Schichten. Allerdings müssen wir die neue Funktionsweise noch implementieren.
Nach dem FQF-Algorithmus werden die Quelldaten als Einbettung des aktuellen Zustands in das quantilgenerierende Modell eingegeben. Die Operationen von zwei neuronalen Netzen (voll verbundenes cFraction und cSoftMax) wurden bereits implementiert. Softmax gibt jedoch einen Tensor aus, bei dem die Summe der Werte für jede Aktion gleich 1 ist. Wir brauchen zwar steigende Anteile an Quantilen. Danach müssen wir die Einbettung dieser Quantile mit Hilfe der folgenden Formel erstellen.
Die obige Formel wiederholt vollständig die Formel einer vollständig verbundenen neuronalen Schicht mit der Aktivierungsfunktion ReLU. Der Unterschied besteht hier darin, dass die Quelldaten cos(πi) sind. Wir werden also einen Tensor solcher Kosinuswerte im Puffer der Ergebnisse der neuronalen Schicht cCosine vorbereiten.
Um diese Funktionalität zu implementieren, werden wir den FQF_Cosine-Kernel erstellen. Wir werden zwei Zeiger auf Datenpuffer in den Kernel eingeben. Die eine gibt Daten aus der Softmax-Schicht aus, während die zweite die Ergebnisse der Kernel-Operationen aufzeichnet.
Nach dem FQF-Algorithmus sollten für jede mögliche Aktion Quantile erstellt werden. Daher werden wir den Kernel-Algorithmus unter Berücksichtigung des zweidimensionalen Problemraums entwickeln. Eine Dimension wird für Quantile verwendet, die zweite für mögliche Aktionen des Agenten.
Bestimmen Sie im Kernelkörper die Thread-ID in beiden Dimensionen. Fordern Sie auch die Gesamtzahl der Threads in der ersten Dimension an, anhand derer wir den Versatz in Tensoren zum ersten Quantil der analysierten Aktion bestimmen können.
Als Nächstes müssen wir den kumulativen Anteil des aktuellen Quantils berechnen. Dies wird in einer Schleife durchgeführt.
Bitte beachten Sie die folgenden Hinweise. Wie beim QR-DQN-Algorithmus bestimmen wir nicht die Obergrenze des Quantils, sondern seinen Durchschnittswert. Daher addieren wir den Anteil aller vorherigen Quantile, die im vorherigen Schritt von Softmax ermittelt wurden, und fügen die Hälfte des Anteils des aktuellen Quantils hinzu.
Dann schreiben wir den Kosinus aus dem Produkt des erhaltenen Durchschnittswertes des aktuellen Quantils, der Zahl Pi und der Ordnungszahl des Quantils auf.
__kernel void FQF_Cosine(__global float* softmax, __global float* output) { size_t i = get_global_id(0); size_t total = get_global_size(0); size_t action = get_global_id(1); int shift = action * total; //--- float result = 0; for(int it = 0; it < i; it++) result += softmax[shift + it]; result += softmax[shift + i] / 2.0f; output[shift + i] = cos(i * M_PI_F * result); }
Weitere Operationen zur Erstellung von Quantile Embedding werden mit Hilfe der Funktionalität der inneren Schicht von cCosine Embedding implementiert. Allerdings müssen wir dann eine Hadamard-Multiplikation des Quantil-Einbettungstensors mit dem Anfangsdatentensor (Systemzustandseinbettung) durchführen. Wir brauchen einen anderen Kernel, um diese Operation zu implementieren. Bevor ich jedoch einen neuen Kernel erstellt habe, habe ich mir die Kernel der zuvor erstellten neuronalen Netze angesehen. Und ich habe auf den Kernel geachtet, den wir für die Dropout-Schicht erstellt haben. Erinnern Sie sich daran, dass wir für diese Ebene einen Kernel erstellt haben, in dem wir den Koeffiziententensor Element für Element mit den Originaldaten multipliziert haben. Jetzt müssen wir eine ähnliche mathematische Operation durchführen, aber mit anderen Daten und der logischen Bedeutung der Operation. Dies hat jedoch keine Auswirkungen auf den Ablauf der mathematischen Operationen. Deshalb werden wir diese vorgefertigte Lösung verwenden.
Es folgen die Operationen des Quantilnetzes, das wir als Perzeptron mit einer versteckten Schicht implementiert haben. Das Perceptron gibt die Verteilung der erwarteten Belohnung ähnlich wie das QR-DQN-Modell aus. Anders als bei der zuvor betrachteten Methode wird jedoch für jede mögliche Aktion des Agenten eine eigene Wahrscheinlichkeitsverteilung verwendet. Um einen diskreten Belohnungswert zu erhalten, müssen wir das Belohnungsniveau für jedes Quantil mit seiner Wahrscheinlichkeit multiplizieren. Dann sollten wir die erhaltenen Werte im Zusammenhang mit den Aktionen des Agenten hinzufügen.
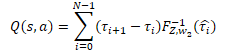
In unserem speziellen Fall wurden alle Wahrscheinlichkeitsdeltas bereits im cSoftMax-Puffer mit Schichtenergebnissen berechnet. Jetzt müssen wir nur noch Element für Element den Wert des angegebenen Puffers mit dem Ergebnispuffer des Quantilfunktions-Perzeptrons aus der neuronalen Schicht cQuantile2 multiplizieren. Wir fassen das Ergebnis der Operation im Zusammenhang mit den möglichen Handlungen des Agenten zusammen.
Um diese Operationen durchzuführen, erstellen wir einen neuen Kernel FQF_Output. In den Kernelparametern werden Zeiger auf drei Datenpuffer übergeben: Ergebnisse der Quantilfunktion, Wahrscheinlichkeitsdeltas und Ergebnispuffer. Wir geben auch die Anzahl der Quantile an.
Wir lassen den Kernel in einem eindimensionalen Aufgabenraum laufen, der der Anzahl der möglichen Agentenaktionen entspricht.
Im Kernelkörper wird zunächst ein Thread-Identifikator angefordert und die Verschiebung in den Datenpuffern zum entsprechenden Quantilverteilungsvektor bestimmt.
Anschließend wird der Wahrscheinlichkeitsvektor in einer Schleife mit dem Vektor der Quantilsverteilung multipliziert. Das Ergebnis der Operation wird in den entsprechenden Ergebnispuffer geschrieben.
Beachten Sie, dass der Ergebnispuffer deutlich kleiner ist als die ursprünglichen Datenpuffer, da er nur einen diskreten Wert für jede mögliche Aktion enthält. Im Gegensatz dazu enthalten die Quelldaten einen ganzen Vektor von Werten für jede Aktion. Dementsprechend ist der Offset im Ergebnispuffer gleich der Kennung des aktuellen Threads.
__kernel void FQF_Output(__global float* quantiles, __global float* delta_taus, __global float* output, uint total) { size_t action = get_global_id(0); int shift = action * total; //--- float result = 0; for(int i = 0; i < total; i++) result += quantiles[shift + i] * delta_taus[shift + i]; output[action] = result; }
Wir haben den gesamten Feed-Forward-Algorithmus FQF besprochen und die fehlenden Kernel erstellt. Jetzt können wir zu unserer Klasse zurückkehren und den gesamten Algorithmus mit MQL5 reproduzieren. Wie üblich überschreiben wir die Methode CNeuronFQF::feedForward, um den Vorwärtsdurchlauf durchzuführen.
Die Feed-Forward-Methode erhält als Parameter einen Zeiger auf die vorhergehende neuronale Schicht, deren Ergebnispuffer (entsprechend unseren Erwartungen) die Einbettung des aktuellen Systemzustands enthält.
Wir erstellen keinen Quelldaten-Kontrollblock im Methodenrumpf. Stattdessen nennen wir die Vorwärtsmethoden der inneren neuronalen Schichten cFraction und cSoftMax. Der Ausschluss des Quelldaten-Kontrollblocks birgt in diesem Fall keine Risiken, da jede der aufgerufenen Methoden ihren eigenen Kontrollblock hat. Wir müssen nur die Ergebnisse der aufgerufenen Methoden überprüfen.
bool CNeuronFQF::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cFraction.FeedForward(NeuronOCL)) return false; if(!cSoftMax.FeedForward(GetPointer(cFraction))) return false;
Als Nächstes müssen wir eine Einbettung der probabilistischen Ebenen der Quantile erstellen. Hier rufen wir zunächst den oben erstellten Datenaufbereitungskernel FQF_Cosine auf. Dieser Kernel läuft in einem zweidimensionalen Aufgabenraum. In der ersten Dimension geben wir die Anzahl der Quantile an. Die zweite Dimension ist die Anzahl der möglichen Aktionen des Agenten.
Beachten Sie, dass wir keine internen Variablen für die angegebenen Hyperparameter erstellt haben. Die Größe des Ergebnispuffers unserer CNeuronFQF-Schicht ist jedoch gleich der Anzahl der möglichen Agentenaktionen. Und wir können die Anzahl der Quantile als das Verhältnis zwischen der Schicht des Ergebnispuffers von cSoftMax und der Anzahl der Aktionen definieren.
Wir übergeben die Zeiger auf die Puffer an die Kernel-Parameter und fügen Sie den Kernel in die Ausführungswarteschlange ein. Vergessen Sie nicht, die Vorgänge bei jedem Schritt zu kontrollieren.
{
uint global_work_offset[2] = {0, 0};
uint global_work_size[2];
global_work_size[1] = Output.Total();
global_work_size[0] = cSoftMax.Neurons() / global_work_size[1];
OpenCL.SetArgumentBuffer(def_k_FQF_Cosine, def_k_fqf_cosine_softmax, cSoftMax.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_Cosine, def_k_fqf_cosine_outputs, cCosine.getOutputIndex());
if(!OpenCL.Execute(def_k_FQF_Cosine, 2, global_work_offset, global_work_size))
{
printf("Error of execution kernel FQF_Cosine: %d", GetLastError());
return false;
}
}
Als Nächstes rufen wir die Feed-Forward-Methode der inneren neuronalen Schicht cCosineEmbeding auf, die den Prozess der Quantileinbettung abschließt.
if(!cCosineEmbeding.FeedForward(GetPointer(cCosine))) return false;
Im nächsten Schritt des FQF-Algorithmus müssen wir die Einbettung des aktuellen Systemzustands (Ausgangsdaten) mit der Quantil-Einbettung kombinieren. Wie Sie sich erinnern, haben wir uns für diese Operation für die Verwendung der Dropout Kernel der neuronalen Schicht zu verwenden. Im Hauptteil dieses Kernels wurden Vektoroperationen für 40-Element-Vektoren verwendet. Daher wird die Anzahl der Threads viermal kleiner sein als die Größe der Datenpuffer.
Die erforderlichen Daten übergeben wir in den Kernel-Parametern. Dann stellen wir den Kernel in die Ausführungswarteschlange.
{
uint global_work_offset[1] = {0};
uint global_work_size[1] = {(cCosine.Neurons() + 3) / 4};
OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_input, NeuronOCL.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_map, cCosineEmbeding.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_out, cQuantile0.getOutputIndex());
OpenCL.SetArgument(def_k_Dropout, def_k_dout_dimension, (int)cCosine.Neurons());
if(!OpenCL.Execute(def_k_Dropout, 1, global_work_offset, global_work_size))
{
printf("Error of execution kernel Dropout: %d", GetLastError());
return false;
}
}
Nun müssen wir die Niveaus der Quantilsverteilung bestimmen. Zu diesem Zweck rufen wir nacheinander die Feed-Forward-Methoden der neuronalen Schichten in unserem Quantilfunktions-Perzeptron auf.
if(!cQuantile1.FeedForward(GetPointer(cQuantile0))) return false; //--- if(!cQuantile2.FeedForward(GetPointer(cQuantile1))) return false;
Nach der Feed-Forward-Pass-Methode rufen wir den Kernel zur Umwandlung der Quantilverteilung in einen diskreten Wert der erwarteten Belohnung für jede mögliche Agentenaktion FQF_Output auf. Das Verfahren, um den Kernel in die Ausführungswarteschlange zu stellen, ist dasselbe:
- den Aufgabenbereich definieren
- Zeiger auf Puffer und andere notwendige Informationen an die Kernel-Parameter übergeben
- Aufruf der Kernel-Ausführungsverfahren
Vergessen wir nicht, die Ergebnisse bei jedem Schritt zu kontrollieren.
{
uint global_work_offset[1] = {0};
uint global_work_size[1] = { Neurons() };
OpenCL.SetArgumentBuffer(def_k_FQF_Output, def_k_fqfout_quantiles, cQuantile2.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_Output, def_k_fqfout_delta_taus, cSoftMax.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_Output, def_k_fqfout_output, getOutputIndex());
OpenCL.SetArgument(def_k_FQF_Output, def_k_fqfout_total,
(uint)(cQuantile2.Neurons() / global_work_size[0]));
if(!OpenCL.Execute(def_k_FQF_Output, 1, global_work_offset, global_work_size))
{
printf("Error of execution kernel FQF_Output: %d", GetLastError());
return false;
}
}
//---
return true;
}
Damit sind die Operationen mit dem Feedforward-Kernel abgeschlossen. Als Nächstes werden die Backpropagation-Kernel erstellt. Sie wird durch zwei Methoden in unserer Klasse dargestellt: calcInputGradients und updateInputWeights.
2.2. Feed-Backward
Zunächst schauen wir uns die Methode calcInputGradients an, bei der der Gradient an alle internen Schichten und die vorherige neuronale Schicht weitergegeben wird.
Bei dieser Methode wird die Feed-Forward-Methode vollständig wiederholt, nur in umgekehrter Richtung. Dementsprechend müssen für alle Kernel, die wir während des direkten Durchgangs erstellt haben, Kernel mit „Spiegel“-Operationen erstellt werden. Da der gesamte Backpropagation-Prozess eine Umkehrung des Feedforward-Durchgangs ist, werden wir die Kernel in derselben Reihenfolge aufbauen.
Am Ausgang der Feed-Forward-Methode haben wir die Quantilsverteilung in einen diskreten Wert für jede mögliche Aktion des Agenten umgewandelt. Am Eingang der Backpropagation-Methode erwarten wir einen Fehlergradienten für jede Aktion. Dann müssen wir den resultierenden Gradienten sowohl durch den Wert der Quantilfunktion als auch durch die Wahrscheinlichkeitsdeltas der Quantilbereiche verteilen.
Wir werden all dies im FQF_OutputGradient-Kernel implementieren. In den Kernel-Parametern werden wir Zeiger auf fünf Datenpuffer übergeben. Drei davon enthalten die Quelldaten, die beiden anderen werden zum Schreiben der Ergebnisse der Kernel-Operationen verwendet.
Die Delta-Tensoren der Wahrscheinlichkeiten und die Ergebnisse der Quantilsfunktion werden mit tabellarischer Logik im Kontext von Quantilen und möglichen Agentenaktionen strukturiert. In ähnlicher Weise werden wir den Kernel in einem zweidimensionalen Aufgabenraum von Quantilen und Agentenaktionen ausführen.
Im Kernelkörper werden die Thread-IDs in beiden Dimensionen und die Anzahl der Stufen in der ersten Dimension abgefragt und ein Offset im Datenpuffer bestimmt.
__kernel void FQF_OutputGradient(__global float* quantiles, __global float* delta_taus, __global float* output_gr, __global float* quantiles_gr, __global float* taus_gr ) { size_t i = get_global_id(0); size_t total = get_global_size(0); size_t action = get_global_id(1); int shift = action * total;
Als Nächstes müssen wir den Fehlergradienten propagieren. Beim Vorwärtsdurchlauf erhalten wir das Ergebnis durch Multiplikation von 2 Variablen. Die Ableitung der Multiplikationsoperation ist der zweite Faktor. Um den Gradienten weiterzugeben, müssen wir daher den resultierenden Fehlergradienten mit dem entsprechenden Element des entgegengesetzten Tensors multiplizieren.
Beachten Sie, dass wir ein Element des Puffers der erhaltenen Gradienten mit den entsprechenden Elementen von zwei Tensoren multiplizieren müssen. Das heißt, wir müssen zweimal auf das gleiche Element des globalen Puffers zugreifen. Aber wir erinnern uns, dass der Zugriff auf die Elemente des globalen Speichers „teuer“ ist. Um die Gesamtausführungszeit der Operationen zu verringern, wird zunächst der Wert des globalen Pufferelements in die schnellere private Speichervariable übertragen. Die weiteren Operationen werden mit dieser schnellen Variablen durchgeführt.
Die Ergebnisse der Operationen werden in den entsprechenden Elementen von zwei Ergebnispuffern gespeichert.
float gradient = output_gr[action];
quantiles_gr[shift + i] = gradient * delta_taus[shift + i];
taus_gr[shift + i] = gradient * quantiles[shift + i];
}
Der nächste Kernel, den wir direkt aus unserer Feed Forward-Methode aufgerufen haben, ist Dropout. Wir haben darin die Hadamard-Multiplikation von zwei Einbettungstensoren durchgeführt: die Einbettung des Umgebungszustands und die Quantil-Einbettung. Für den Vorwärtsdurchlauf wurde der zuvor erstellte Dropout-Kernel verwendet. Um nun die Fehlergradienten in zwei Richtungen zu propagieren, müssten wir diesen Kernel zwei Mal hintereinander mit unterschiedlichen Eingaben aufrufen. Wir streben jedoch eine maximale Parallelisierung der Operationen an, um die Modelltrainingszeit zu minimieren. Nehmen wir uns also etwas Zeit und erstellen den neuen Kernel FQF_QuantileGradient.
Der Algorithmus dieses Kerns wiederholt den Algorithmus des vorherigen Kerns vollständig. Daran ist nichts Seltsames. Beide Kerne erfüllen eine ähnliche Funktion. Der Unterschied liegt nur im Offset im Puffer der resultierenden Gradienten. Im vorherigen Fall unterschied sich die Größe des Puffers für die erhaltenen Gradienten von den übrigen Puffern, da er nur einen diskreten Wert für jede mögliche Agentenaktion enthielt. In diesem Fall haben alle Puffer die gleiche Größe. Dementsprechend verwenden wir im Puffer für die empfangenen Gradienten einen Offset wie in den übrigen Puffern.
__kernel void FQF_QuantileGradient(__global float* state_embeding, __global float* taus_embeding, __global float* quantiles_gr, __global float* state_gr, __global float* taus_gr ) { size_t i = get_global_id(0); size_t total = get_global_size(0); size_t action = get_global_id(1); int shift = action * total; //--- float gradient = quantiles_gr[shift + i]; state_gr[shift + i] = gradient * taus_embeding[shift + i]; taus_gr[shift + i] = gradient * state_embeding[shift + i]; }
Der letzte Kernel, den wir besprechen müssen, ist FQF_CosineGradient, der ein umgekehrtes Verfahren zur Vorbereitung der Daten für die Quantil-Einbettung durchführt. Die Ableitung der Datenaufbereitungsoperation ist wie folgt:
![]()
Als Ergebnis der Operationen dieses Kernels erwarten wir einen Fehlergradienten am Ausgang der Softmax-Schicht des Quantilwahrscheinlichkeitsvorhersagemodells. Achten Sie darauf, dass jedes Quantil den kumulativen Wert des Ergebnistensors Softmax verwendet. Dies bedeutet, dass jedes Element des Tensors alle nachfolgenden Quantile beeinflusst. Es wäre logisch, dass jedes Element des Tensors seinen Anteil am Gradienten entsprechend seiner Beteiligung am Endergebnis erhält. Daher werden wir den Fehlergradienten aus allen Elementen des empfangenen Gradientenpuffers sammeln, die durch das analysierte Element des Softmax-Ergebnistensors beeinflusst wurden.
Betrachten wir nun die Implementierung des Kernels. In den Parametern übergeben wir Zeiger auf drei Datenpuffer:
- die Ergebnisse der Softmax-Schicht
- die erhaltene Fehlergradienten
- die Ergebnispuffer — Fehlergradienten auf der Ebene der Schicht des Ergebnispuffers von Softmax
Wie die meisten der in diesem Artikel besprochenen Kernel laufen auch diese Kernel in einem zweidimensionalen Aufgabenraum: einem für Quantile und einem für mögliche Agentenaktionen.
Im Hauptteil des Kernels fordern wir Thread-IDs in beiden Dimensionen an und bestimmen den Offset in den Datenpuffern. Alle Datenpuffer haben die gleiche Größe. Folglich ist der Offset für alle gleich groß.
__kernel void FQF_CosineGradient(__global float* softmax, __global float* output_gr, __global float* softmax_gr ) { size_t i = get_global_id(0); size_t total = get_global_size(0); size_t action = get_global_id(1); int shift = action * total;
Jedes Element wirkt sich nur auf sein eigenes und die nachfolgenden Quantile aus. Daher berechnen wir zunächst die Summe der vorangegangenen Elemente.
float cumul = 0; for(int it = 0; it < i; it++) cumul += softmax[shift + it];
Dann berechnen wir die Steigung aus dem entsprechenden Element.
Beachten Sie, dass wir beim Vorwärtsdurchlauf den Durchschnittswert des Quantils an die Einbettung weitergegeben haben. Dementsprechend berechnen wir den Fehlergradienten auf der Grundlage des Durchschnittswerts der Quantilwahrscheinlichkeit.
float result = -M_PI_F * i * sin(M_PI_F * i * (cumul + softmax[shift + i] / 2)) * output_gr[shift + i];
Anschließend wird in einer Schleife der Fehlergradient aus den nachfolgenden Quantilen bestimmt. Dabei wird auch der Einfluss des Gradienten entsprechend dem Anteil des aktuellen Elements an der Gesamtwahrscheinlichkeit des Gradientenquantils angepasst.
for(int it = i + 1; it < total; it++) { cumul += softmax[shift + it - 1]; float temp = cumul + softmax[shift + it] / 2; result += -M_PI_F * it * sin(M_PI_F * it * temp) * output_gr[shift + it] * softmax[shift + it] / temp; } softmax_gr[shift + i] += result; }
Nach allen Schleifeniterationen schreiben wir das Ergebnis in das entsprechende Element des Ergebnispuffers.
Wir haben alle Kernel für die Organisation des Backpropagation-Durchgangs unserer Klasse vorbereitet. Nun können wir mit der Erstellung der Gradienten-Backpropagation-Methode calcInputGradients fortfahren.
In den Parametern erhält die Methode einen Zeiger auf das Objekt der vorherigen neuronalen Schicht, auf die der Fehler übertragen werden soll. Der Kontrollblock ist in der Methode implementiert. Hier prüfen wir Zeiger auf das empfangene Objekt und interne Datenpuffer.
bool CNeuronFQF::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !Gradient || !Output) return false;
Bitte beachten Sie, dass wir im Gegensatz zur Feed-Forward-Methode hier einen Kontrollblock erstellen. Der Grund dafür ist, dass die Operationen dieser Methode mit dem Aufruf des OpenCL-Programmkerns beginnen. Wenn wir ihm Zeiger auf Datenpuffer übergeben, müssen wir sicher sein, dass sie existieren. Andernfalls kann es bei der Durchführung von Operationen zu einem kritischen Fehler kommen.
Nach dem erfolgreichen Durchlaufen des Kontrollblocks wird mit den Operationen der Fehlergradienten-Backpropagation fortgefahren. Zunächst rufen wir den FQF_OutputGradient-Kernel auf, in dem wir den Fehlergradienten an das Quantilfunktions-Perzeptron und den Quantile-Prognoseblock propagieren Das Verfahren, um den Kernel in die Ausführungswarteschlange zu stellen, ähnelt dem des Feed Forward: Der Kernel verwaltet einen zweidimensionalen Aufgabenraum. Die erste Dimension entspricht den Quantilen, die zweite den möglichen Aktionen des Agenten.
{
uint global_work_offset[2] = {0, 0};
uint global_work_size[2] = { cSoftMax.Neurons() / Neurons(), Neurons() };
OpenCL.SetArgumentBuffer(def_k_FQF_OutputGradient, def_k_fqfoutgr_quantiles,
cQuantile2.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_OutputGradient, def_k_fqfoutgr_taus,
cSoftMax.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_OutputGradient, def_k_fqfoutgr_output_gr,
getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_OutputGradient, def_k_fqfoutgr_quantiles_gr,
cQuantile2.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_OutputGradient, def_k_fqfoutgr_taus_gr,
cSoftMax.getGradientIndex());
if(!OpenCL.Execute(def_k_FQF_OutputGradient, 2, global_work_offset, global_work_size))
{
printf("Error of execution kernel FQF_OutputGradient: %d", GetLastError());
return false;
}
}
Als Nächstes wird der Fehlergradient durch das Perzeptron der Quantilfunktion geleitet. Zu diesem Zweck rufen wir nacheinander die Backpropagation-Methoden der inneren neuronalen Schichten des angegebenen Blocks auf.
if(!cQuantile1.calcHiddenGradients(GetPointer(cQuantile2))) return false; if(!cQuantile0.calcHiddenGradients(GetPointer(cQuantile1))) return false;
Wir müssen den Fehlergradienten aus der Quantilfunktion auf die Einbettung des aktuellen Systemzustands (vorherige neuronale Schicht) und die Einbettung der Quantilwahrscheinlichkeiten verteilen. Für diese Funktion wurde der Kernel FQF_QuantileGradient erstellt. Wir nennen diesen Kernel nach dem bereits erwähnten Verfahren.
{
uint global_work_offset[2] = {0, 0};
uint global_work_size[2] = { cCosineEmbeding.Neurons(), 1 };
OpenCL.SetArgumentBuffer(def_k_FQF_QuantileGradient, def_k_fqfqgr_state_enbeding,
NeuronOCL.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_QuantileGradient, def_k_fqfqgr_taus_embedding,
cCosineEmbeding.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_QuantileGradient, def_k_fqfqgr_quantiles_gr,
cQuantile0.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_QuantileGradient, def_k_fqfqgr_state_gr,
NeuronOCL.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_QuantileGradient, def_k_fqfqgr_taus_gr,
cCosineEmbeding.getGradientIndex());
if(!OpenCL.Execute(def_k_FQF_QuantileGradient, 2, global_work_offset, global_work_size))
{
printf("Error of execution kernel FQF_OutputGradient: %d", GetLastError());
return false;
}
}
Im nächsten Schritt wird der Fehlergradient durch Quantile Embedding geleitet. Hier nennen wir zunächst die Backpropagation-Methode der inneren neuronalen Schicht cCosine.
if(!cCosine.calcHiddenGradients(GetPointer(cCosineEmbeding))) return false;
Dann rufen wir FQF_CosineGradient auf.
{
uint global_work_offset[2] = {0, 0};
uint global_work_size[2] = { cSoftMax.Neurons() / Neurons(), Neurons() };
OpenCL.SetArgumentBuffer(def_k_FQF_CosineGradient, def_k_fqfcosgr_softmax,
cSoftMax.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_CosineGradient, def_k_fqfcosgr_output_gr,
cCosine.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_FQF_CosineGradient, def_k_fqfcosgr_softmax_gr,
cSoftMax.getGradientIndex());
if(!OpenCL.Execute(def_k_FQF_CosineGradient, 2, global_work_offset, global_work_size))
{
printf("Error of execution kernel FQF_CosineGradient: %d", GetLastError());
return false;
}
}
Am Ende der Methode propagieren wir den Fehlergradienten durch die innere Schicht cSoftMax, indem wir deren Backpropagation-Methode aufrufen.
if(!cSoftMax.calcInputGradients(GetPointer(cFraction))) return false; //--- return true;
Achten Sie darauf, dass wir den Fehlergradienten aus dem Quantilwahrscheinlichkeitsvorhersageblock nicht an die vorherige Schicht weitergeben. Dies ist darauf zurückzuführen, dass die Priorität der Aufgabe mit der Bestimmung der erwarteten Belohnung zusammenhängt und nicht mit der Wahrscheinlichkeitsverteilung.
Die zweite Backpropagation-Methode updateInputWeights, die wir außer Kraft setzen müssen, ist für die Aktualisierung der Modellparameter zuständig. Das ist ganz einfach. Wir rufen abwechselnd die entsprechenden Methoden der inneren neuronalen Schichten auf und überprüfen das Ergebnis der Operationen.
bool CNeuronFQF::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cFraction.UpdateInputWeights(NeuronOCL)) return false; if(!cCosineEmbeding.UpdateInputWeights(GetPointer(cCosine))) return false; if(!cQuantile1.UpdateInputWeights(GetPointer(cQuantile0))) return false; if(!cQuantile2.UpdateInputWeights(GetPointer(cQuantile1))) return false; //--- return true; }
Damit ist die Arbeit mit den wichtigsten Funktionen unserer neuen CNeuronFQF-Klasse abgeschlossen. Wir haben die Organisation der Vorwärts- und Rückwärtspropagationsprozesse berücksichtigt. Die Methoden zum Speichern von Daten in einer Datei und zum Wiederherstellen der Klasse wurden ebenfalls in der Klasse überschrieben. In diesen Methoden haben wir die entsprechenden Methoden der internen Objekte aufgerufen. Sie können sie selbst studieren. Den vollständigen Code aller verwendeten Klassen und ihrer Methoden finden Sie im Anhang.
Und wir machen weiter. Wir haben eine Klasse für die Organisation des Modelllernalgorithmus durch die Methode der vollständigen Parametrisierung der Quantilfunktion entwickelt. Dies ist jedoch nur ein Teil des Prozesses. Dies ist immer noch das gleiche Q-Learning mit dem Datenpuffer und dem Target Net (Zielnetz). Um die Anwendung der beschriebenen Methode direkt im Q-Learning-Prozess zu erleichtern, haben wir die Klasse CFQF geschaffen, die von der Basisklasse CNet unseres Modells abgeleitet ist.
class CFQF : protected CNet { private: uint iCountBackProp; protected: uint iUpdateTarget; //--- CNet cTargetNet; public: CFQF(void); CFQF(CArrayObj *Description) { Create(Description); } bool Create(CArrayObj *Description); ~CFQF(void); bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNet::feedForward(inputVals, window, tem); } bool backProp(CBufferFloat *targetVals, float discount = 0.9f, CArrayFloat *nextState = NULL, int window = 1, bool tem = true); void getResults(CBufferFloat *&resultVals); int getAction(void); int getSample(void); float getRecentAverageError() { return recentAverageError; } bool Save(string file_name, datetime time, bool common = true) { return CNet::Save(file_name, getRecentAverageError(), (float)iUpdateTarget, 0, time, common); } virtual bool Save(const int file_handle); virtual bool Load(string file_name, datetime &time, bool common = true); virtual bool Load(const int file_handle); //--- virtual int Type(void) const { return defFQF; } virtual bool TrainMode(bool flag) { return CNet::TrainMode(flag); } virtual bool GetLayerOutput(uint layer, CBufferFloat *&result) { return CNet::GetLayerOutput(layer, result); } //--- virtual void SetUpdateTarget(uint batch) { iUpdateTarget = batch; } virtual bool UpdateTarget(string file_name); };
Die Klasse ist ähnlich wie CQRDQN aus dem vorherigen Artikel. Seine Struktur ist fast identisch mit der Struktur dieser Klasse. Ich habe nicht verwendete Variablen und die Wahrscheinlichkeitsmatrix entfernt. All dies wird in separaten neuronalen Netzen durchgeführt. Ich habe auch die erforderlichen Änderungen an den Methoden der Klasse vorgenommen. Ich werde mich jetzt nicht mit allen Methoden der Klasse beschäftigen. Sie können sie im Anhang selbst überprüfen. Ich werde nur einige von ihnen erwähnen.
Beginnen wir mit der Backpropagation-Methode. Die Methode erhält als Parameter die Zielwerte und den nächsten Zustand des Systems. Der nächste Zustand ist ein optionaler Parameter. Sie kann beim Training eines neuen Modells verwendet werden, wenn die Verwendung eines nicht trainierten Modells zur Vorhersage zukünftiger Belohnungen zu Rauschen führt und den Lernprozess erschwert.
Im Methodenrumpf überprüfen wir das Vorhandensein eines obligatorischen Parameters in Form eines Puffers von Zielwerten.
bool CFQF::backProp(CBufferFloat *targetVals, float discount = 0.9f, CArrayFloat *nextState = NULL, int window = 1, bool tem = true) { //--- if(!targetVals) return false;
Dann prüfen wir auch, ob ein fakultativer Parameter vorhanden ist, und machen gegebenenfalls eine Vorhersage über künftige Belohnungen. Auch hier passen wir die Zielwerte für die Höhe der zukünftigen Belohnung unter Berücksichtigung des Diskontierungsfaktors an.
if(!!nextState) { vectorf target; if(!targetVals.GetData(target) || target.Size() <= 0) return false; if(!cTargetNet.feedForward(nextState, window, tem)) return false; cTargetNet.getResults(targetVals); if(!targetVals) return false; target = target + discount * targetVals.Maximum(); if(!targetVals.AssignArray(target)) return false; }
Danach prüfen wir, ob Target Net aktualisiert werden muss.
if(iCountBackProp >= iUpdateTarget) { #ifdef FileName if(UpdateTarget(FileName + ".nnw")) #else if(UpdateTarget("FQF.upd")) #endif iCountBackProp = 0; } else iCountBackProp++;
Am Ende der Methode rufen wir die Callback-Methode der übergeordneten Klasse auf.
return CNet::backProp(targetVals);
}
Die Methode zur Auswahl von „greedy actions“ wurde ebenfalls geändert. Hier bestimmen wir einfach das Element mit der höchsten Belohnung aus dem Ergebnispuffer des Modells.
int CFQF::getAction(void) { CBufferFloat *temp; CNet::getResults(temp); if(!temp) return -1; //--- return temp.Maximum(0, temp.Total()); }
Änderungen wurden auch an der Methode getSample für das Action Sampling vorgenommen. Bei dieser Methode erhalten wir zunächst das Ergebnis des letzten Vorwärtsdurchlaufs des Modells.
int CFQF::getSample(void) { CBufferFloat* resultVals; CNet::getResults(resultVals); if(!resultVals) return -1;
Wir kopieren die empfangenen Daten aus dem Puffer in einen Vektor und wenden die Softmax-Funktion auf sie an. Dann berechnen wir die kumulativen Summen der Vektorwerte.
vectorf temp; if(!resultVals.GetData(temp)) { delete resultVals; return -1; } delete resultVals; //--- if(!temp.Activation(temp, AF_SOFTMAX)) return -1; temp = temp.CumSum();
Der resultierende Vektor ist eine Art Quantil-Wahrscheinlichkeitsverteilung der Handlungen des Agenten. Dann nehmen wir einen Wert aus dieser Verteilung und geben ihn an den Aufrufer zurück.
int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(random >= 1) return (int)temp.Size() - 1; for(int i = 0; i < (int)temp.Size(); i++) if(random <= temp[i] && temp[i] > 0) return i; //--- return -1; }
Bei jedem Schritt überprüfen wir das Ergebnis der Operationen. Wenn ein Fehler auftritt, wird -1 an das aufrufende Programm zurückgegeben.
Damit ist die Diskussion der Klassen für die Implementierung des FQF-Algorithmus abgeschlossen. Der gesamte Code aller Klassen und Methoden befindet sich in der Anlage.
3. Tests
Um das Modell mit der Methode einer vollständig parametrisierten Quantilsfunktion zu trainieren, habe ich die EA FQF-learning.mq5 erstellt. Sein Algorithmus ist sehr ähnlich zu dem von QRDQN-learning.mq5 aus dem vorherigen Artikel. Ich habe nur den Dateinamen und die verwendeten Objekte geändert. Ich werde also nicht weiter auf die Architektur eingehen. Der vollständige Code des EA ist unten beigefügt.
Das Modell wurde auf den historischen Daten des EURUSD für die letzten 2 Jahre mit dem H1-Zeitrahmen trainiert. Alle Indikatoren wurden mit Standardparametern verwendet. Wie Sie sehen können, sind dies die gleichen Parameter, die wir bei der Prüfung aller Modelle in dieser Artikelserie verwenden.
Während des Trainingsprozesses zeigte das Modell eine recht gleichmäßige und stabile Dynamik der Fehlerreduzierung. Dies ist ein ziemlich guter Indikator für die Stabilität der Modellausbildung.
Das trainierte Modell wurde mit dem Strategietester getestet. Zu Testzwecken wurde eine separate EA FQF-learning-test.mq5 erstellt. Es ist eine Kopie von QRDQN-Lerntest.mq5 aus dem vorherigen Artikel. Daher werden wir seinen Algorithmus jetzt nicht besprechen. Nur der Dateiname und die Modellklasse haben sich geändert. Der vollständige Code des EAs befindet sich im Anhang.
Bei den Tests zeigte sich, dass das Modell in der Lage ist, Gewinne zu erzielen. Auf der Grundlage der Testergebnisse ergab das Modell einen Gewinnfaktor von 1,78 und einen Erholungsfaktor von 3,7. Der Anteil der erfolgreichen Geschäfte liegt bei über 57 %. Der größte Gewinn ist fast 2,5 Mal höher als der größte Verlust. Die längste Gewinnserie hatte 10 Abschlüsse, während die längste Verlustserie 4 Abschlüsse hatte. Im Allgemeinen ist die durchschnittliche Gewinnposition um ⅓ höher als eine durchschnittliche Verlustposition.


Schlussfolgerung
In diesem Artikel haben wir die Untersuchung von Algorithmen für verteiltes Verstärkungslernen fortgesetzt und Klassen zur Implementierung einer vollständig parametrisierten Quantilfunktions-Lernmethode im Verstärkungslernen erstellt. Wir haben das Modell mit dieser Methode trainiert und die Leistung des trainierten Modells im Strategietester überprüft. Während des Lernprozesses zeigte die Methode eine stetige Tendenz zur Fehlerreduzierung. Die Prüfung des trainierten Modells im Strategietester zeigte die Fähigkeit des Modells, Gewinne zu erzielen.
Ich möchte Sie noch einmal daran erinnern, dass der Finanzmarkthandel eine sehr riskante Anlagemethode ist. Die in diesem Artikel vorgestellten Programme dienen lediglich der Demonstration der Funktionsweise von Methoden und Algorithmen. Sie sind nicht für den Einsatz im Live-Handel bestimmt. Dennoch können sie als Grundlage für die Entwicklung funktionierender Handelsinstrumente verwendet werden. In jedem Fall müssen Sie die entwickelten Tools vor ihrer Verwendung gründlich und umfassend testen. Sie sollten die Risiken der Verwendung von Programmen im realen Handel kennen und akzeptieren.
Referenzen
- Neuronale Netze leicht gemacht (Teil 3): Convolutional Neurale Netzwerke
- Neuronale Netze leicht gemacht (Teil 12): Dropout
- Neuronale Netze leicht gemacht (Teil 26): Reinforcement-Learning
- Neuronale Netze leicht gemacht (Teil 27): Tiefes Q-Learning (DQN)
- Neuronale Netze leicht gemacht (Teil 28): Policy Gradient Algorithmus
- Neuronale Netze leicht gemacht (Teil 32): Verteiltes Q-Learning
- Neuronale Netze leicht gemacht (Teil 33): Quantilsregression im verteilten Q-Learning
- A Distributional Perspective on Reinforcement Learning
- Distributional Reinforcement Learning with Quantile Regression
- Implicit Quantile Networks for Distributional Reinforcement Learning
- Fully Parameterized Quantile Function for Distributional Reinforcement Learning
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | FQF-learning.mq5 | EA | EA zur Optimierung des Modells |
| 2 | FQF-learning-test.mq5 | EA | Ein Expert Advisor zum Testen des Modells im Strategy Tester |
| 3 | FQF.mqh | Klassenbibliothek | FQR-Modellklasse |
| 4 | NeuroNet.mqh | Klassenbibliothek | Bibliothek zur Erstellung neuronaler Netzmodelle |
| 5 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek zur Erstellung neuronaler Netzwerkmodelle |
| 6 | NetCreator.mq5 | EA | Tool für die Modellbildung |
| 7 | NetCreatotPanel.mqh | Klassenbibliothek | Klassenbibliothek zur Erstellung des Tools |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/11804
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.