
Neuronale Netze leicht gemacht (Teil 42): Modell der Prokrastination, Ursachen und Lösungen

Einführung
Im Bereich des Verstärkungslernens stehen neuronale Netzmodelle oft vor dem Problem der Prokrastination, wenn der Lernprozess sich verlangsamt oder stecken bleibt. Modellhafte Prokrastination kann schwerwiegende Folgen für die Zielerreichung haben und erfordert geeignete Maßnahmen. In diesem Artikel werden wir die Hauptursachen für die Prokrastination von Modellen untersuchen und Methoden zur Lösung dieser Probleme vorschlagen.
1. Problem der Prokrastination
Einer der Hauptursachen für das Zögern von Modellen ist ein unzureichendes Ausbildungsumfeld. Das Modell kann auf einen begrenzten Zugang zu Trainingsdaten oder unzureichende Ressourcen stoßen. Um dieses Problem zu lösen, muss der Datensatz erstellt oder aktualisiert werden, die Vielfalt der Trainingsbeispiele muss erhöht werden und es müssen zusätzliche Trainingsressourcen eingesetztwerden, wie z. B. Rechenleistung oder vortrainierte Modelle für das Transfertraining.
Ein weiterer Grund für das Zögern eines Modells kann die Komplexität der Aufgabe sein, die es lösen soll, oder die Verwendung eines Trainingsalgorithmus, der viele Rechenressourcen erfordert. In diesem Fall kann die Lösung darin bestehen, das Problem oder den Algorithmus zu vereinfachen, die Berechnungsprozesse zu optimieren und effizientere Algorithmen oder verteiltes Lernen zu verwenden.
Ein Modell kann prokrastinieren, wenn ihm die Motivation fehlt, seine Ziele zu erreichen. Die Festlegung klarer und relevanter Ziele für das Modell, die Entwicklung einer Belohnungsfunktion, die Anreize für das Erreichen dieser Ziele schafft, und der Einsatz von Verstärkungstechniken, wie Belohnungen und Strafen, können zur Lösung dieses Problems beitragen.
Wenn das Modell kein Feedback erhält oder nicht auf der Grundlage neuer Daten aktualisiert wird, kann es zu einer Verzögerung seiner Entwicklung kommen. Die Lösung besteht darin, regelmäßige Modellaktualisierungszyklen auf der Grundlage neuer Daten und Rückmeldungen einzuführen und Mechanismen zur Kontrolle und Überwachung der Lernfortschritte zu entwickeln.
Es ist wichtig, die Fortschritte und Lernergebnisse des Modells regelmäßig zu bewerten. So können Sie die erzielten Fortschritte erkennen und mögliche Probleme oder Engpässe identifizieren. Regelmäßige Bewertungen ermöglichen rechtzeitige Anpassungen des Ausbildungsprozesses, um Verzögerungen zu vermeiden.
Die Bereitstellung eines Modells mit abwechslungsreichen Aufgaben und einer anregenden Umgebung kann helfen, Prokrastination zu vermeiden. Abwechslungsreiche Aufgaben tragen dazu bei, das Interesse und die Motivation des Modells aufrechtzuerhalten, und ein anregendes Umfeld, wie z. B. Wettbewerbe oder Spielelemente, können die aktive Teilnahme des Modells und seine Fortschritte fördern.
Die Prokrastination von Modellen kann durch unzureichende Aktualisierung und Verbesserung entstehen. Es ist wichtig, die Ergebnisse regelmäßig zu analysieren und das Modell auf der Grundlage von Feedback und neuen Ideen iterativ zu verbessern. Die allmähliche Entwicklung des Modells und sichtbare Fortschritte können helfen, die Prokrastination zu überwinden.
Ein wichtiger Aspekt bei der Ausbildung von Verstärkungsmodellen ist die Schaffung eines positiven und unterstützenden Lernumfelds für das Modell. Die Forschung zeigt, dass positive Beispiele zu einem effektiveren und gezielteren Modelllernen führen. Dies liegt daran, dass das Modell nach der optimalsten Wahl sucht und Strafen für falsche Handlungen zu einer Verringerung der Wahrscheinlichkeit der Wahl falscher Handlungen führen. Gleichzeitig zeigen positive Belohnungen dem Modell deutlich, dass die Wahl richtig war, und erhöhen die Wahrscheinlichkeit, solche Handlungen zu wiederholen, erheblich.
Wenn ein Modell für eine bestimmte Handlung eine positive Belohnung erhält, wird es ihr mehr Aufmerksamkeit schenken und geneigt sein, diese Handlung in Zukunft zu wiederholen. Dieser Motivationsmechanismus hilft dem Modell, die erfolgreichsten Strategien zur Erreichung seiner Ziele zu suchen und zu ermitteln.
Um die Prokrastination wirksam zu bekämpfen, müssen die Ursachen für die Prokrastination analysiert werden. Wenn Sie die spezifischen Ursachen der Prokrastination erkennen, können Sie gezielte Maßnahmen ergreifen, um sie zu beseitigen. Dies kann die Überprüfung von Schulungsprozessen, die Ermittlung von Engpässen, Ressourcenproblemen oder suboptimalen Modelleinstellungen umfassen.
Die Berücksichtigung und Anpassung an sich ändernde Bedingungen kann dazu beitragen, dass keine Verzögerungen auftreten. Regelmäßige Aktualisierungen des Modells auf der Grundlage neuer Daten und Änderungen der Lernaufgabe tragen dazu bei, dass es relevant und effektiv bleibt. Durch die Berücksichtigung von Faktoren wie neuen Anforderungen oder Zwängen kann sich das Modell anpassen und eine Stagnation vermeiden.
Das Setzen von kleinen Zielen und Meilensteinen kann helfen, eine größere Aufgabe in überschaubare und erreichbare Teile zu zerlegen. Dies wird dem Modell helfen, Fortschritte zu sehen und die Motivation während des Lernprozesses aufrechtzuerhalten.
Um die Prokrastination in einem Verstärkungslernmodell erfolgreich zu überwinden, müssen Sie eine Vielzahl von Ansätzen und Strategien anwenden. Dieser umfassende Ansatz wird dem Modell helfen, die Prokrastination wirksam zu überwinden und die besten Ergebnisse in der Ausbildung zu erzielen. Durch die Kombination verschiedener Techniken, wie z. B. die Verbesserung des Lernumfelds, die Festlegung klarer Ziele, die regelmäßige Bewertung der Fortschritte und den Einsatz von Motivation, wird das Modell in der Lage sein, die Prokrastination zu überwinden und Fortschritte bei der Erreichung seiner Lernziele zu machen.
2. Praktische Lösungsschritte
Nachdem wir die Theorie betrachtet haben, wollen wir uns nun der praktischen Anwendung dieser Ideen zuwenden.
Im vorangegangenen Artikel erwähnte ich die Notwendigkeit von Weiterbildungsmaßnahmen, um die Zahl der Verlustgeschäfte zu minimieren. Bei der Fortführung unserer Schulung sind wir jedoch auf eine Situation gestoßen, in der der EA während des gesamten Schulungszeitraums keine einzige Transaktion durchgeführt hat.
Dieses Phänomen, das als „Modell Prokrastination“ bezeichnet wird, ist ein ernstes Problem, das unsere Aufmerksamkeit und Lösungen erfordert.

2.1. Analyse der Ursachen
Um die Modellprokrastination beim Verstärkungslernen zu überwinden, ist es wichtig, zunächst die aktuelle Situation zu analysieren und die Ursachen für dieses Phänomen zu ermitteln. Die Analyse wird uns helfen zu verstehen, warum das Modell keine Handelsgeschäfte macht und was angepasst werden kann, um seine Leistung zu verbessern.
Das Testen des trainierten Modells erfolgt mit dem EA „Test.mq5“, der gierig einen Agenten und eine Aktion auswählt. Es ist wichtig zu beachten, dass jeder nachfolgende Start des EA mit denselben Parametern und demselben Testzeitraum zur Reproduktion des vorherigen Durchgangs mit hoher Genauigkeit führt. Auf diese Weise können wir Kontrollpunkte hinzufügen und die EA-Operation jedes Mal analysieren, wenn sie gestartet wird.
Das Hinzufügen von Kontrollpunkten und die Analyse der Arbeit des EA bei jedem Start bietet uns eine größere Zuverlässigkeit und Vertrauen in das Ergebnis des Trainings eines Verstärkungsmodells. Wir können besser verstehen, wie das Modell sein Wissen und seine Vorhersagen auf reale Daten anwendet, und entsprechende Schlussfolgerungen und Anpassungen zur Verbesserung seiner Leistung vornehmen.
Um die Arbeit des Schedulers zu bewerten, führen wir den Vektor ModelsCount ein, der die Anzahl der Auswahlen der einzelnen Agenten enthält. Dazu deklarieren wir den ModelsCount-Vektor im Block der globalen Variablen:
vector<float> ModelsCount;
In der Funktion OnInit wird dieser Vektor dann mit einer Größe initialisiert, die der Anzahl der verwendeten Agenten entspricht:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); //--- return(INIT_SUCCEEDED); }
In der Funktion OnTick wird nach jedem Vorwärtsdurchlauf des Schedulers der Zähler des entsprechenden Agenten im ModelsCount-Vektor erhöht:
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ....... //--- if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; Schedule.getResults(Result); int model = GetAction(Result, 0, 1); ModelsCount[model]++; //--- ........ ........ }
Zeigen Sie schließlich bei der Deinitialisierung des EA die Berechnungsergebnisse im Journal an:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Print(ModelsCount); delete Result; }
Daher fügen wir eine Funktion hinzu, die die Anzahl der Auswahlen der einzelnen Agenten zählt und die Zählergebnisse im Journal anzeigt, wenn der EA deinitialisiert wird. Auf diese Weise können wir die Leistung des Schedulers bewerten und erhalten Informationen darüber, wie oft jeder Agent während der EA-Ausführung ausgewählt wurde.
Nachdem wir unseren ersten Kontrollpunkt hinzugefügt haben, haben wir den EA im Strategietester gestartet, ohne die Parameter oder den Testzeitraum zu ändern. Die erzielten Ergebnisse bestätigten unsere Befürchtungen. Wir sehen, dass der Planer während der gesamten Testphase nur einen Agenten eingesetzt hat.

Diese Beobachtung deutet darauf hin, dass der Planer möglicherweise einen bestimmten Agenten bevorzugt und es vernachlässigt, andere verfügbare Agenten zu untersuchen. Eine solche Verzerrung kann die Leistung unseres Verstärkungslernmodells beeinträchtigen und seine Fähigkeit einschränken, effektivere Strategien zu entdecken.
Um dieses Problem zu lösen, müssen wir die Ursachen erforschen, warum der Planer sich für nur einen Agenten entscheidet.
Um die Ursachen für dieses Verhalten weiter zu analysieren, fügen wir zwei zusätzliche Kontrollpunkte hinzu. Wir konzentrieren uns nun auf die Dynamik der Veränderungen in den Verteilungen der Modellausgaben in Abhängigkeit von Veränderungen im Zustand der Umwelt. Zu diesem Zweck führen wir zwei zusätzliche Vektoren ein: prev_scheduler und prev_actor. In diesen Vektoren werden die Ergebnisse des vorherigen Vorwärtsdurchlaufs des Planers bzw. der Agenten gespeichert.
vector<float> prev_scheduler; vector<float> prev_actor;
Auf diese Weise können wir die aktuellen Verteilungen mit früheren vergleichen und ihre Veränderungen bewerten. Wenn wir feststellen, dass sich die Verteilungen im Laufe der Zeit oder als Reaktion auf Veränderungen in der Umwelt erheblich ändern, kann dies ein Hinweis darauf sein, dass das Modell zu empfindlich auf Veränderungen reagiert oder in seinen Strategien instabil ist.
Wenn wir diese Vektoren zu unserem Modell hinzufügen, erhalten wir detailliertere Informationen über die Dynamik der sich ändernden Strategien und Zuweisungen, was uns wiederum hilft, die Ursachen für die Präferenz eines bestimmten Agenten zu verstehen und Maßnahmen zur Lösung dieses Problems zu ergreifen.
Wie im vorherigen Fall werden die Vektoren in der OnInit-Methode initialisiert, um sie für die Datenkontrolle vorzubereiten.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); prev_scheduler.Init(Models); prev_actor.Init(Result.Total()); //--- return(INIT_SUCCEEDED); }
Die eigentliche Datensteuerung erfolgt in der Methode OnTick.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return; Actor.getResults(Result); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; vector<float> temp; Schedule.getResults(Result); Result.GetData(temp); float delta = MathAbs(prev_scheduler - temp).Sum(); int model = GetAction(Result, 0, 1); prev_scheduler = temp; Actor.getResults(Result); Result.GetData(temp); delta = MathAbs(prev_actor - temp).Sum(); prev_actor = temp; ModelsCount[model]++; //--- ........ ........ //--- }
In diesem Fall wollen wir bewerten, wie sich Veränderungen im Zustand der Umwelt auf das Ergebnis des Modells auswirken. Als Ergebnis dieses Experiments erwarten wir eine eindeutige Wahrscheinlichkeitsverteilung am Modellausgang für jede Kerze in der Teststichprobe. Mit anderen Worten, wir wollen beobachten, wie sich die Strategien des Modells in Abhängigkeit von veränderten Marktbedingungen verändern.
Wir werden die Ergebnisse der Analyse nicht protokollieren, da dies zu einer großen Datenmenge führen würde. Stattdessen werden wir den Debug-Modus verwenden, um die Veränderung der Werte zu beobachten. Um die Menge der zu vergleichenden Werte zu reduzieren, wird nur die Gesamtabweichung der Vektoren geprüft.
Leider haben wir bei dem Test keine Abweichungen festgestellt. Das bedeutet, dass die Wahrscheinlichkeitsverteilung der Modellausgabe in allen Umweltzuständen nahezu gleich bleibt.
Diese Beobachtung deutet darauf hin, dass sich das Modell nicht an das sich verändernde Umfeld anpasst und die unterschiedlichen Marktbedingungen nicht berücksichtigt. Es gibt mehrere mögliche Ursachen für dieses Verhalten des Modells und verschiedene Ansätze, um sie zu lösen:
- Beschränkungen des Trainingsdatensatzes: Wenn der Trainingsdatensatz nicht genügend unterschiedliche Situationen enthält, lernt das Modell möglicherweise nicht, angemessen auf neue Bedingungen zu reagieren. Die Lösung könnte darin bestehen, den Trainingsdatensatz zu erweitern und zu diversifizieren, um ein breiteres Spektrum an Szenarien und sich ändernden Marktbedingungen einzubeziehen.
- Unzureichende Modellschulung: Das Modell wird möglicherweise nicht ausreichend trainiert oder durchläuft nicht genügend Trainingsepochen, um sich an unterschiedliche Umgebungsbedingungen anzupassen. In diesem Fall kann die Erhöhung der Trainingszeit oder die Anwendung zusätzlicher Methoden, wie z. B. die Feinabstimmung, dazu beitragen, dass sich das Modell besser anpasst.
- Unzureichende Modellkomplexität: Das Modell ist möglicherweise nicht komplex genug, um subtile Unterschiede in den Umweltbedingungen zu erfassen. In diesem Fall kann eine Erhöhung des Umfangs und der Komplexität des Modells, z. B. durch Hinzufügen weiterer Schichten oder Erhöhung der Anzahl der Neuronen, dazu beitragen, dass Unterschiede in den Daten besser erfasst und verarbeitet werden.
- Falsche Wahl der Modellarchitektur: Die derzeitige Modellarchitektur ist möglicherweise nicht geeignet, das Problem der Anpassung an ein sich veränderndes Umfeld zu lösen. In einem solchen Fall kann eine Überarbeitung der Modellarchitektur die Anpassungsfähigkeit des Modells an Veränderungen im Umfeld verbessern.
- Falsche Belohnungsfunktion: Die Belohnungsfunktion des Modells ist möglicherweise nicht informativ genug oder entspricht nicht den gewünschten Zielen. In einem solchen Fall kann ein Überdenken der Belohnungsfunktion und die Einbeziehung relevanterer Faktoren dazu beitragen, dass das Modell in einem sich verändernden Umfeld intelligentere Entscheidungen trifft.
Alle diese Ansätze erfordern zusätzliche Experimente, Tests und Anpassungen des Modells, um eine bessere Anpassung an ein sich veränderndes Umfeld zu erreichen und seine Leistung zu verbessern.
Wir werden die Architektur der einzelnen Schichten analysieren, um herauszufinden, wo genau in unseren Modellen Informationen über Änderungen im Zustand des Systems verloren gehen. Im Debug-Modus überprüfen wir, ob sich die Ausgabe der einzelnen Schichten unserer Modelle geändert hat.
Wir beginnen mit der vollständig verbundenen Schicht CNeuronBaseOCL. In dieser Schicht wird geprüft, ob die Informationen über Änderungen des Systemzustands erhalten bleiben. Als Nächstes überprüfen wir die CNeuronBatchNormOCL-Batchdaten-Normalisierungsschicht, um sicherzustellen, dass sie die Zustandsänderungsdaten nicht verzerrt. Wir werden dann die Faltungsschicht CNeuronConvOCL analysieren, um zu sehen, wie sie Informationen über Systemzustandsänderungen verarbeitet. Schließlich werden wir die voll verknüpfte Schicht CNeuronMultiModel mit mehreren Modellen untersuchen, um festzustellen, wie sie Zustandsänderungen zwischen den Modellen berücksichtigt.
Mit Hilfe dieser Analyse können wir feststellen, auf welcher Ebene der Modellarchitektur Informationen über Änderungen des Systemzustands verloren gehen und welche Ebenen optimiert oder modifiziert werden können, um die Leistung des Modells bei der Anpassung an eine sich ändernde Umgebung zu verbessern.
Um die Ausgabe jeder Schicht im Modell zu kontrollieren und zu verfolgen, implementieren wir den prev_output-Vektor in der Klasse CNeuronBaseOCL. Wie Sie sich vielleicht erinnern, ist diese Klasse die Basisklasse für alle anderen Klassen neuronaler Schichten, und alle anderen Schichten erben von ihr. Durch das Hinzufügen eines Vektors zum Hauptteil dieser Klasse stellen wir sicher, dass er in allen Schichten des Modells vorhanden ist.
class CNeuronBaseOCL : public CObject { protected: ........ ........ vector<float> prev_output;
In der Klasseninitialisierungsmethode wird die Vektorgröße festgelegt, die der Anzahl der Neuronen in dieser Schicht entspricht.
bool CNeuronBaseOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { ........ ........ //--- prev_output.Init(numNeurons); //--- ........ ........ //--- return true; }
In der feedForward-Methode, die das Modell vorwärts durchläuft, fügen wir am Ende der Methode, nachdem alle Iterationen abgeschlossen sind, einen Kontrollpunkt hinzu. Beachten Sie, dass alle Operationen in dieser Methode im Kontext von OpenCL durchgeführt werden. Um Daten zu kontrollieren, müssen wir die Ergebnisse von Operationen in den Hauptspeicher laden, was jedoch sehr viel Zeit in Anspruch nehmen kann. Bisher haben wir versucht, diese Belastung zu minimieren, sodass nur die Ergebnisse des Modells belastet wurden. Im vorliegenden Fall ist es erforderlich, die Ergebnisse jeder neuronalen Schicht zu laden. Dieser Codeblock kann jedoch später entfernt oder auskommentiert werden, wenn die Datenkontrolle nicht erforderlich ist.
bool CNeuronBaseOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { ........ ........ //--- vector<float> temp; Output.GetData(temp); float delta=MathAbs(temp-prev_output).Sum(); prev_output=temp; //--- return true; }
Wir fügen auch ähnliche Kontrollen zu den Vorwärtsdurchlauf-Methoden aller analysierten Klassen von neuronalen Schichten hinzu. Auf diese Weise können wir die Ausgabewerte der einzelnen Schichten überwachen und feststellen, an welchen Stellen Änderungen des Systemzustands „verloren“ gehen können. Durch Hinzufügen geeigneter Codeblöcke zu den Vorwärtspassmethoden jeder Schichtklasse können wir die Ergebnisse der Schicht bei jeder Iteration des Modelltrainings speichern und analysieren.
Die Daten werden im Debugging-Modus überwacht.
Nach der Analyse der Ergebnisse stellten wir fest, dass der Datenvorverarbeitungsblock, der aus einer Rohdatenschicht, einer Batch-Normalisierungsschicht und zwei aufeinanderfolgenden Blöcken von Faltungsschichten und vollständig verknüpften neuronalen Schichten besteht, nicht richtig funktionierte. Wir haben festgestellt, dass das Modell nach der zweiten Faltungsschicht nicht mehr auf Änderungen im Zustand des analysierten Systems reagiert.
CNeuronBaseOCL -> CNeuronBatchNormOCL -> CNeuronConvOCL -> CNeuronBaseOCL -> CNeuronConvOCL -> CNeuronBaseOCL
Dies gilt sowohl für die Agenten als auch für den Planer, bei dem wir eine ähnliche Datenvorverarbeitungseinheit verwendet haben. Die Testergebnisse waren in beiden Fällen identisch.
Obwohl diese Architektur in früheren Versuchen positive Ergebnisse lieferte, erwies sie sich in diesem Fall als unwirksam. Daher müssen wir Änderungen an der Architektur der verwendeten Modelle vornehmen.
2.2. Ändern der Modellarchitektur
Die derzeitige Modellarchitektur hat sich als unwirksam erwiesen. Jetzt müssen wir einen Schritt zurückgehen und die zuvor erstellte Architektur aus einem neuen Blickwinkel betrachten, um mögliche Optimierungsmöglichkeiten zu bewerten.
Im aktuellen Modell geben wir die Marktsituation und den Stand unseres Kontos als Input für die Agenten ein, die die Situation analysieren und mögliche Aktionen vorschlagen. Wir addieren das Ergebnis der Arbeit der Agenten zu den zuvor gesammelten Ausgangsdaten und geben es als Eingabe an den Planer weiter, der einen Agenten auswählt, um die Aktion durchzuführen.
Stellen wir uns nun eine Investitionsabteilung vor, in der die Mitarbeiter die Marktlage analysieren und die Ergebnisse ihrer Analyse dem Leiter der Abteilung vorlegen. Der Abteilungsleiter kombiniert diese Ergebnisse mit den ursprünglichen Daten und führt eine zusätzliche Analyse durch, um einen Agenten auszuwählen, dessen Prognose mit seiner eigenen übereinstimmt. Dieser Ansatz kann jedoch die Effizienz der Abteilung beeinträchtigen.
In diesem Fall muss der Abteilungsleiter die Marktsituation selbst analysieren und auch die Arbeitsergebnisse der Mitarbeiter prüfen. Dies führt zu einer zusätzlichen Belastung und ist bei der Entscheidungsfindung nicht immer von praktischem Nutzen. Der Versuch, auf jeder Stufe so viele Informationen wie möglich bereitzustellen, kann dazu führen, dass der Hauptgedanke hierarchischer Modelle, nämlich die Aufteilung eines Problems in kleinere Komponenten, verfehlt wird.
In diesem Zusammenhang kann die Effizienz einer solchen Abteilung in Analogie zu unserem Modell geringer sein als die des Abteilungsleiters, da dieser sich nicht nur mit der Analyse der Marktsituation, sondern auch mit der Kontrolle der Leistung der Mitarbeiter befassen muss, was die Entscheidungsfindung beeinträchtigen kann.
Aus dem vorgestellten Szenario wird deutlich, dass die Effizienz der Investitionsabteilung verbessert wird, wenn wir die Analyse der Marktsituation zwischen den Agenten und dem Planer teilen. In diesem Modell spezialisieren sich die Agenten auf die Marktanalyse, während der Planer dafür verantwortlich ist, Entscheidungen auf der Grundlage der Prognosen der Agenten zu treffen, ohne eine eigene Analyse der Marktsituation durchzuführen.
Sie werden für die Analyse von Marktdaten zuständig sein, einschließlich der Durchführung technischer und grundlegender Analysen. Sie recherchieren und bewerten die aktuelle Marktsituation, ermitteln Trends und schlagen Handlungsmöglichkeiten vor. Sie werden jedoch bei ihrer Analyse den Saldo nicht berücksichtigen.
Der Planer hingegen ist für das Risikomanagement und die Entscheidungsfindung auf der Grundlage der Agentenanalyse zuständig. Er wird Prognosen und Empfehlungen von Vermittlern verwenden und zusätzliche Analysen der Kontolage und anderer Faktoren im Zusammenhang mit dem Risikomanagement durchführen. Auf der Grundlage dieser Informationen trifft der Planer die endgültige Entscheidung über bestimmte Maßnahmen im Rahmen der Investitionsstrategie.
Durch diese Aufgabenteilung können sich die Agenten auf die Marktanalyse konzentrieren, ohne durch den Kundenstatus abgelenkt zu werden, was ihre Spezialisierung und die Genauigkeit der Prognosen erhöht. Der Disponent wiederum kann sich auf die Risikobewertung und die Entscheidungsfindung auf der Grundlage von Agentenprognosen konzentrieren, was ihm eine effektive Verwaltung des Portfolios und eine Minimierung der Risiken ermöglicht.
Dieser Ansatz verbessert den Entscheidungsfindungsprozess des Investmentteams, da sich jedes Teammitglied auf sein Fachgebiet konzentriert, was zu genaueren Analysen und Prognosen führt. Dies kann die Leistung unseres Modells verbessern und zu fundierteren und erfolgreicheren Investitionsentscheidungen führen.
Auf der Grundlage dieser Informationen werden wir nun die Architektur unseres Modells überarbeiten. Zunächst werden wir die Quelldatenschicht des Agenten so verändern, dass sie sich ausschließlich auf die Analyse der Marktsituation konzentriert und die Neuronen, die für die Analyse des Kontostands zuständig sind, entfernt.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *scheduler) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * 12); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Im Datenvorverarbeitungsblock werden vollständig verbundene Schichten entfernt. Es bleiben nur die Batch-Normalisierungsschicht und 2 Faltungsschichten übrig.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Der Entscheidungsblock bleibt unverändert.
Wir haben beschlossen, die Architektur von Critic zu ändern. Wie bisher wird der Kritiker sowohl die Marktsituation als auch den Stand des Kontos analysieren. Das liegt daran, dass der Wert des nächsten Zustands nicht nur von der zuletzt durchgeführten Aktion abhängt, sondern auch von früheren Aktionen, die sich in offenen Positionen und kumulierten Gewinnen oder Verlusten ausdrücken.
Wir kamen auch zu dem Schluss, dass der Wert des nachfolgenden Zustands nicht von der gewählten Strategie abhängen sollte. Unser Ziel ist es, die potenziellen Gewinne zu maximieren, unabhängig von der spezifischen Strategie, die wir anwenden. Um dies zu berücksichtigen, haben wir einige Änderungen am Modell des Kritikers vorgenommen.
Konkret haben wir die Architektur von Critic vereinfacht, indem wir die voll vernetzten Schichten mit mehreren Modellen entfernt haben. Stattdessen haben wir ein vollständig parametrisiertes Entscheidungsmodell hinzugefügt. Dies ermöglicht uns einen allgemeineren und flexibleren Ansatz, bei dem die Strategie keinen direkten Einfluss auf die Bewertung des Zustandswertes hat.
Diese Änderung in der Architektur des Critic-Modells hilft uns, Marktanalyse und Entscheidungsfindung zu trennen, was den Prozess vereinfacht und es uns ermöglicht, uns auf die Gewinnmaximierung zu konzentrieren, unabhängig von der gewählten Strategie.
Darüber hinaus haben wir Änderungen am Datenvorverarbeitungsblock vorgenommen, die den Änderungen an der Agentenarchitektur ähneln. Im Block der Datenvorverarbeitung haben wir die Architektur vereinfacht, indem wir die vollständig verknüpften Schichten entfernt haben und nur eine Schicht zur Batch-Normalisierung und zwei Faltungsschichten übrig gelassen haben.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (int)(HistoryBars * 12 + 9); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 150; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.optimization = ADAM; descr.activation = TANH; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = TANH; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Als Nächstes haben wir die Architektur des Schedulers erheblich vereinfacht. Durch den Verzicht auf die Analyse der Marktsituation konnte der Umfang der Quelldatenschicht erheblich reduziert werden. Infolgedessen sind wir die Datenvorverarbeitungseinheit fast vollständig losgeworden, sodass nur noch die Schicht der Batch-Normalisierung übrig geblieben ist. Wir haben uns für die Batch-Normalisierung entschieden, um die absoluten Werte des Kontostands zu analysieren. Derzeit verwenden wir vollständig normalisierte Werte aus der Ausgabe des Agentenmodells. In Zukunft werden wir möglicherweise zu relativen Punktwerten übergehen und die Verwendung einer Datennormalisierungsebene überflüssig machen.
Im Entscheidungsblock haben wir ein einfaches Perceptron-Modell mit einer SoftMax-Schicht am Ausgang verwendet. Dieses Modell ermöglicht es uns, die Wahrscheinlichkeitsverteilung über verschiedene Agenten zu erhalten und auf der Grundlage dieser Wahrscheinlichkeiten die am besten geeignete Aktion auszuwählen.
Diese Vereinfachung der Scheduler-Architektur ermöglicht es uns, Entscheidungen effizienter zu treffen, indem nur die Ergebnisse der Agentenanalyse berücksichtigt werden. Dadurch wird die Komplexität der Berechnungen verringert und die Abhängigkeit von zusätzlichen Daten reduziert.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (9 + 40); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 10; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 10; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
Bei der Ausbildung des Modells verwenden wir drei EAs. Jede von ihnen erfüllt ihre eigene Funktion. Um Verwirrung zu vermeiden und die Möglichkeit von Fehlern zu verringern, haben wir beschlossen, die Funktion der Beschreibung der Modellarchitektur in die Datei „Trajectory.mqh“ zu verlagern, die Teil der Bibliothek ist, die die in unserem Modell verwendeten Klassen und Strukturen beschreibt. Dadurch können wir eine einzige Modellarchitektur in allen EAs verwenden und die automatische Synchronisierung von Änderungen in der Arbeit aller drei EAs gewährleisten.
Die Struktur der Modelle wurde geändert, einschließlich der Trennung des Quelldatenstroms, was Änderungen an der Struktur der Beschreibung des aktuellen Zustands erforderte. Für die Erfassung des Kontostandes haben wir ein eigenes Feld vorgesehen, damit dieser bei der Analyse und Entscheidungsfindung berücksichtigt werden kann. Diese Änderung ermöglicht uns eine effektivere Verwaltung und Nutzung von Kontoinformationen während der Modellschulung und des Betriebs.
struct SState { float state[HistoryBars * 12]; float account[9]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); } };
Infolge der Änderungen in der Struktur des Modells mussten wir auch die Methoden für die Arbeit mit Dateien ändern. Der vollständige Code der aktualisierten Struktur und der entsprechenden Methoden ist in der beigefügten Datei enthalten.
2.3. Änderungen im Datenerhebungsprozess
In der nächsten Phase haben wir Änderungen an der Datenerfassung vorgenommen, die in der EA „Research.mq5“ durchgeführt wird.
Wie bereits erwähnt, erhöht die Verwendung positiver Beispiele zum Trainieren eines Modells dessen Effizienz. Deshalb haben wir eine Beschränkung für die Mindestrentabilität eines Geschäfts eingeführt, um es in der Beispieldatenbank zu speichern. Die Höhe dieser Mindestrentabilität wird durch den externen Parameter ProfitToSave bestimmt.
Darüber hinaus haben wir externe Parameter zur Begrenzung der Take-Profit- und Stop-Loss-Niveaus eingeführt, um die Fälle des langfristigen Haltens von Positionen zu reduzieren. Die Werte dieser Parameter werden in der Einzahlungswährung festgelegt und ermöglichen es uns, die Dauer des Haltens einer Position zu begrenzen und indirekt das Volumen der offenen Positionen zu steuern.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input double ProfitToSave = 10; input double MoneyTP = 10; input double MoneySL = 5;
Änderungen in den Strukturen der Datenspeicherung und der Modellarchitekturen haben dazu geführt, dass die Datenerfassung und -aufbereitung für direkte Modellläufe geändert werden musste. Wie zuvor beginnen wir mit dem Sammeln von Marktzustandsdaten in dem Array „state“.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
Dann speichern wir die Kontoinformationen in dem Array „account“.
//--- sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
Für einen Vorwärtsdurchlauf mit der aktualisierten Agentenmodellarchitektur benötigen wir nur den Marktzustand aus dem Array „state“.
State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return;
Um Ausgangsdaten für den Vorwärtsdurchlauf des Schedulers zu erhalten, müssen Daten über den Kontostand und die Ergebnisse des Vorwärtsdurchlaufs des Agentenmodells kombiniert werden.
Actor.getResults(Result); State1.AssignArray(sState.account); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return;
Als Ergebnis eines direkten Durchlaufs durch die beiden Modelle wird eine Aktion ausgewählt. Dieser Prozess bleibt unverändert. Wir fügen jedoch die Analyse der kumulierten Gewinne und Verluste hinzu. Wenn der kumulierte Gewinn- oder Verlustwert die angegebenen Schwellenwerte erreicht, legen wir die Aktion zum Schließen aller Positionen fest.
Es ist wichtig zu beachten, dass unser Modell nur die Aktion das Schließen aller Positionen vorsieht. Bei der Analyse der kumulierten Gewinne und Verluste summieren wir daher den Wert aller Positionen, unabhängig von ihrer Richtung.
int act = GetAction(Result, Schedule.getSample(), Models); double profit = buy_profit + sell_profit; if(profit >= MoneyTP || profit <= -MathAbs(MoneySL)) act = 2;
Wir haben auch Änderungen an der Belohnungsfunktion vorgenommen. Die Entscheidung wurde getroffen, um die Auswirkungen von Aktienveränderungen zu eliminieren, die zu einer geringeren Belohnung führen. Wir sind uns jedoch darüber im Klaren, dass im Prozess des Handels auf den Finanzmärkten nur Veränderungen des Gleichgewichts einen endgültigen Wert haben. Diesem Umstand wurde bei der Anpassung der Belohnungsfunktion Rechnung getragen.
Den vollständigen Code aller EA-Methoden und -Funktionen finden Sie im Anhang.
2.4. Veränderungen im Lernprozess
Wir haben auch Änderungen am Modellschulungsprozess vorgenommen, wobei der Schwerpunkt auf der parallelen Schulung aller Modelle und Agenten liegt. Insbesondere haben wir den Ansatz für die Weitergabe von Belohnungen während des Rückwärtsdurchlaufs geändert. Bisher haben wir die Belohnung nur für den ausgewählten Agenten angegeben, jetzt möchten wir die gesamte Verteilung der Belohnungen an alle Agenten weitergeben. Dadurch kann der Planer die möglichen Auswirkungen jedes Agenten umfassender bewerten und die Wahrscheinlichkeit verringern, dass ein einziger Agent für alle Zustände ausgewählt wird, wie wir bereits beobachtet haben.
Aus der Wahrscheinlichkeitstheorie wissen wir, dass die Wahrscheinlichkeit des Eintretens eines komplexen Ereignisses gleich dem Produkt der Wahrscheinlichkeiten seiner Komponenten ist. In unserem Fall haben wir eine Wahrscheinlichkeitsverteilung für die Wahl der Agenten und eine Wahrscheinlichkeitsverteilung für die Wahl der Aktionen der einzelnen Agenten. In der Beispieldatenbank haben wir auch spezifische Aktionen und entsprechende Belohnungen vom System. Um die Daten für den Rückwärtsdurchlauf des Planers vorzubereiten, multiplizieren wir die Elemente des Vektors der Wahlwahrscheinlichkeiten der Agenten mit den Elementen des Vektors der Wahlwahrscheinlichkeiten der einzelnen Agenten für eine bestimmte Aktion.
Um die volle Belohnung an den Planer weiterzugeben, verwenden wir die SoftMax-Funktion, um die resultierenden Wahrscheinlichkeiten zu normalisieren und multiplizieren dann den resultierenden Vektor mit der externen Belohnung. Gleichzeitig passen wir die externe Belohnung auf der Grundlage des Zustandswertes an, wodurch wir die Abweichung von der optimalen Trajektorie abschätzen können.
void Train(void) { ........ ........ Actor.getResults(ActorResult); Critic.getResults(CriticResult); State1.AssignArray(Buffer[tr].States[i].account); State1.AddArray(ActorResult); if(!Scheduler.feedForward(GetPointer(State1), 12, false)) return; Scheduler.getResults(SchedulerResult); //--- ulong actions = ActorResult.Size() / Models; matrix<float> temp; temp.Init(1, ActorResult.Size()); temp.Row(ActorResult, 0); temp.Reshape(Models, actions); float reward=(Buffer[tr].Revards[i] - CriticResult.Max())/100; int action=Buffer[tr].Actions[i]; SchedulerResult=SchedulerResult*temp.Col(action); SchedulerResult.Activation(SchedulerResult,AF_SOFTMAX); SchedulerResult = SchedulerResult * reward; Result.AssignArray(SchedulerResult); //--- if(!Scheduler.backProp(GetPointer(Result))) return;
Um den Kritiker zu trainieren, geben wir einfach eine unkorrigierte externe Belohnung für die entsprechende Handlung weiter.
CriticResult[action] = Buffer[tr].Revards[i]; Result.AssignArray(CriticResult); //--- if(!Critic.backProp(GetPointer(Result), 0.0f, NULL)) return;
Bei der Arbeit mit Agentenmodellen berücksichtigen wir, dass der Einsatz jeder Strategie sowohl zu Gewinnen als auch zu Verlusten führen kann. In einigen Fällen ist es wichtig, nach einem erfolglosen Einstieg in eine Position die Entschlossenheit zu haben, diese rechtzeitig zu verlassen und die Verluste zu begrenzen. Daher können wir Handlungen mit negativen Belohnungen nicht völlig ausschließen, da in manchen Fällen andere Handlungen eine noch größere negative Wirkung haben können. Das Gleiche gilt für positive Belohnungen.
Bei der Vorbereitung von Daten für einen Rückwärtsdurchlauf von Agentenmodellen werden einfach die Ergebnisse des letzten Vorwärtsdurchlaufs angepasst, wobei die Wahrscheinlichkeit, dass jeder Agent eine Aktion wählt, und die externe Belohnung durch das System berücksichtigt werden. Um die Integrität der Wahrscheinlichkeitsverteilung für jeden Agenten zu erhalten, normalisieren wir die angepasste Verteilung mit Hilfe der SoftMax-Funktion.
//--- for(int r = 0; r < Models; r++) { vector<float> row = temp.Row(r); row[action] += row[action] * reward; row.Activation(row, AF_SOFTMAX); temp.Row(row, r); } temp.Reshape(1, ActorResult.Size()); Result.AssignArray(temp.Row(0)); //--- if(!Actor.backProp(GetPointer(Result))) return;
In den angehängten Dateien finden Sie den vollständigen Code aller EAs sowie die Funktionen, die bei ihrer Arbeit verwendet werden.
Um den Trainingsprozess für das Modell zu starten, starten wir den EA „Research.mq5“ im Optimierungsmodus des Strategietesters, ähnlich wie im Artikel über den Go-Explore Algorithmus beschrieben. Der Hauptunterschied besteht in der Festlegung des Mindestgewinns, der bestimmt, welche Beispiele in der Datenbank gespeichert werden. Dies trägt dazu bei, die Effizienz der Modellschulung zu verbessern, da wir uns auf positive Beispiele konzentrieren.
Es sei jedoch auf ein wichtiges Detail hingewiesen. Um eine vielfältigere Erkundung der Umgebung zu ermöglichen und die Abdeckung der Verhaltensstrategien zu erhöhen, können wir die Optimierung der Take-Profit- und Stop-Loss-Parameter in den Prozess der Stichprobenerhebung einbeziehen. Dadurch kann unser Modell mehr verschiedene Strategien untersuchen und optimale Ausstiegspunkte aus Positionen finden.

Nach der Erstellung einer Beispieldatenbank beginnen wir mit dem Training von Modellen mit dem EA „Study2.mq5“. Dazu müssen wir den EA auf dem Chart des ausgewählten Symbols starten und die Anzahl der Iterationen angeben, die bestimmt, wie oft die Modellparameter aktualisiert werden.
Wenn Sie den EA „Study2.mq5“ auf einem Chart starten, kann das Modell die gesammelten Beispiele zum Trainieren und Anpassen seiner Parameter verwenden. Während des Lernprozesses wird sich das Modell verbessern und an das Marktumfeld anpassen, um genauere Entscheidungen zu treffen und seine Effizienz zu steigern.
Wir überprüfen die Ergebnisse des Modelltrainings, indem wir einen einzigen Durchlauf des EA „Test.mq5“ im Strategietestprogramm durchführen. Es ist durchaus zu erwarten, dass nach der ersten Iteration des Modells das Ergebnis weit weg vom Erwarteten ist. Es kann ein Verlust auftreten.


Oder Gewinn erzielen. Aber die Saldenkurve wird weit von unseren Erwartungen sein.

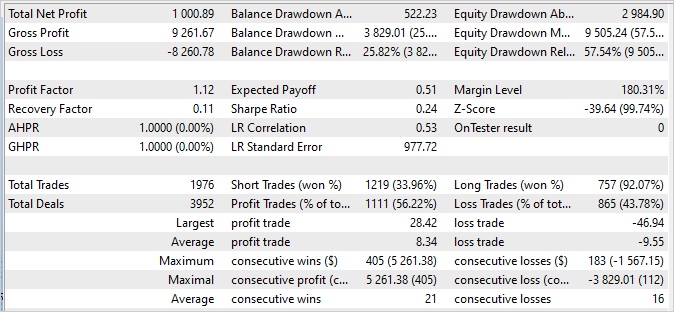
Gleichzeitig können wir aber feststellen, dass unser Scheduler fast alle Agenten auf die eine oder andere Weise nutzt.


Um fehlerhafte Aktionen des Modells zu erkennen, fügen wir einen Block zur Sammlung von Informationen über besuchte Zustände, abgeschlossene Aktionen und erhaltene externe Belohnungen zu unserem Test „Test.mq5“ EA hinzu. Dieser Datenerfassungsblock ähnelt dem, der im Expert Advisor zur Erfassung von Beispielen verwendet wird.
Beachten Sie, dass wir im Test-EA eine gierige Auswahl von Agenten und Aktionen verwenden. Das bedeutet, dass alle Schritte durch die Strategie unseres Modells bestimmt werden. Deshalb nehmen wir alle Durchläufe in die Beispieldatenbank auf, unabhängig von ihrer Rentabilität. Die Aufnahme dieser Daten in die Beispieldatenbank wird es uns ermöglichen, die Handelsstrategie unseres Modells anzupassen und zu optimieren.
Durch das Sammeln von Informationen über besuchte Zustände, durchgeführte Aktionen und erhaltene Belohnungen können wir die Leistung des Modells analysieren und feststellen, welche Aktionen zu gewünschten und welche zu unerwünschten Ergebnissen führen. Anhand dieser Informationen können wir die Effizienz des Modells und die Genauigkeit der Entscheidungsfindung in den folgenden Iterationen des Trainings verbessern.
Weitere Iterationen der Beispielsammlung EA im Optimierungsmodus des Strategietesters sind wichtig, um die Basis positiver Beispiele zu erweitern und mehr Daten für das Training unseres Modells bereitzustellen.
Es ist jedoch wichtig zu beachten, dass sich die Prozesse des Sammelns von Beispielen und des Trainings des Modells abwechseln müssen. Bei der Sammlung von Beispielen werden Aktionen aus der vom Modell generierten Wahrscheinlichkeitsverteilung ausgewählt. Das bedeutet, dass die Sammlung von Beispielen richtungsabhängig ist und neue Beispiele in kurzer Entfernung von der gierigen Aktionsauswahl liegen werden. Auf diese Weise können wir die Umgebung in einer bestimmten Richtung besser erkunden und die Beispieldatenbank mit nützlichen Daten anreichern.
Der Wechsel zwischen dem Sammeln von Beispielen und dem Training des Modells ermöglicht es dem Modell, neue Daten zu nutzen und seine Strategie auf der Grundlage der erhaltenen Informationen zu verbessern. Gleichzeitig wird das Modell mit jeder neuen Iteration immer erfahrener und an die gewünschte Handelsrichtung angepasst.
3. Test
Nach mehreren Iterationen des Sammelns von Beispielen, des Trainings und des Testens haben wir ein Modell erreicht, das in der Lage ist, mit einem Gewinnfaktor von 114,53 einen Gewinn auf der Trainingsmenge zu erzielen. In den ersten 4 Monaten des Jahres 2023, in denen das Modell trainiert wurde, wurden 286 Transaktionen abgeschlossen. Davon waren nur 16 unrentabel. Der Wiederherstellungsfaktor für den Trainingssatz betrug 1,3, was auf die Fähigkeit des Modells hinweist, sich schnell von Verlusten zu erholen.
Die Haltezeiten für offene Positionen lagen gleichmäßig zwischen 1 und 198 Stunden, mit einer durchschnittlichen Haltezeit von 72 Stunden und 59 Minuten. Dies zeigt, dass das Modell in Abhängigkeit von den aktuellen Marktbedingungen sowohl über kurz- als auch über langfristige Zeiträume Entscheidungen treffen kann.
Insgesamt deuten diese Ergebnisse darauf hin, dass das Modell einen hohen Gewinn, eine niedrige Verlustrate, die Fähigkeit, sich schnell zu erholen, und Flexibilität beim Timing der Positionen aufweist. Dies ist eine positive Bestätigung für die Wirksamkeit des Modells und sein Potenzial für die Anwendung unter realen Handelsbedingungen.



Es ist wichtig zu beachten, dass die Saldenkurve für die nächsten zwei Wochen, die nicht in der Trainingsmenge enthalten sind, Stabilität zeigt und keine signifikanten Unterschiede zum Diagramm der Trainingsmenge aufweist. Die Ergebnisse sind zwar etwas schlechter, aber immer noch anständig:
- Der Gewinnfaktor beträgt 15,64, was auf eine gute Rentabilität des Modells im Verhältnis zum Risiko hinweist.
- Der Erholungsfaktor beträgt 1,07, was die Fähigkeit des Modells angibt, sich von Verlustgeschäften zu erholen.
- Von den 89 abgeschlossenen Transaktionen wurden 80 mit einem Gewinn abgeschlossen, was auf einen hohen Anteil erfolgreicher Transaktionen hindeutet.
Diese Ergebnisse bestätigen die Stabilität und Robustheit des Modells in den nachfolgenden Handelsdaten. Auch wenn die Werte leicht vom Trainingsset abweichen, so sind sie doch beeindruckend und bestätigen das Potenzial des Modells für einen erfolgreichen Handel in der realen Welt.


Die Berichte der Strategietester finden Sie in der Anlage.
Schlussfolgerung
In diesem Artikel haben wir das Problem der Modellprokrastination untersucht und wirksame Ansätze zu seiner Überwindung vorgeschlagen. Mit Hilfe des Algorithmus Scheduled Auxiliary Control haben wir einen Ansatz für das Training von Modellen für den automatisierten Handel auf den Finanzmärkten entwickelt.
Wir haben eine hierarchische Architektur vorgestellt, die aus mehreren Modellen besteht, die miteinander interagieren. Jedes Modell ist für bestimmte Aspekte der Entscheidungsfindung zuständig. Diese modulare Struktur ermöglicht es uns, die Prokrastination wirksam zu überwinden, indem wir die Aufgabe in kleinere, aber miteinander verbundene Teilaufgaben aufteilen.
Wir haben auch Methoden zum Sammeln von Beispielen, zum Trainieren von Modellen und zum Testen behandelt, die es uns ermöglichen, Modelle effektiv auf realen Daten zu trainieren und an sich ändernde Marktsituationen anzupassen. Durch die Einbeziehung einer Vielzahl von Strategien und die Analyse der aufgelaufenen Gewinne und Verluste können wir fundierte Entscheidungen treffen und Risiken minimieren.
Die Ergebnisse unserer Experimente zeigen, dass der vorgeschlagene Ansatz tatsächlich in der Lage ist, die Prokrastination zu überwinden und einen stabilen und profitablen Handel zu erreichen. Unsere Modelle zeigen eine hohe Rentabilität und Stabilität bei Trainings- und Follow-up-Daten, was ihre Effektivität unter realen Bedingungen bestätigt.
Insgesamt ermöglicht unser Ansatz den Modellen, effektiv zu lernen, sich an Marktsituationen anzupassen und fundierte Entscheidungen zu treffen. Die Weiterentwicklung und Optimierung dieses Ansatzes könnte zu einer noch höheren Rentabilität und Stabilität des automatisierten Handels auf den Finanzmärkten führen.
Liste der Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study2.mql5 | Expert Advisor | Modelltraining EA |
| 3 | Test.mq5 | Expert Advisor | Modellversuche EA |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | FQF.mqh | Klassenbibliothek | Klassenbibliothek zur Organisation der Arbeit eines vollständig parametrisierten Modells |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek |
…
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/12638
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.