Artikel über maschinelles Lernen im Handel.
Erstellen von KI-basierten Handelsrobotern: native Integration der Bibliotheken für Python, Matrizen und Vektoren, Mathematik und Statistik und vieles mehr.
Finden Sie heraus, wie Sie maschinelles Lernen im Handel einsetzen können. Neuronen, Perzeptronen, Faltungs- und rekurrente Netze, Vorhersagemodelle – beginnen Sie mit den Grundlagen und arbeiten Sie sich bis zur Entwicklung Ihrer eigenen KI vor. Sie lernen, wie man neuronale Netze für den algorithmischen Handel auf Finanzmärkten trainiert und anwendet.
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Gradient Boosting (CatBoost) für die Entwicklung von Handelssystemen. Ein naiver Zugang
Trainieren des Klassifikators CatBoost in Python und Exportieren des Modells nach mql5, sowie Parsen der Modellparameter und eines nutzerdefinierten Strategietesters. Die Python-Sprache und die MetaTrader 5-Bibliothek werden zur Vorbereitung der Daten und zum Training des Modells verwendet.
Datenwissenschaft und maschinelles Lernen (Teil 10): Ridge-Regression
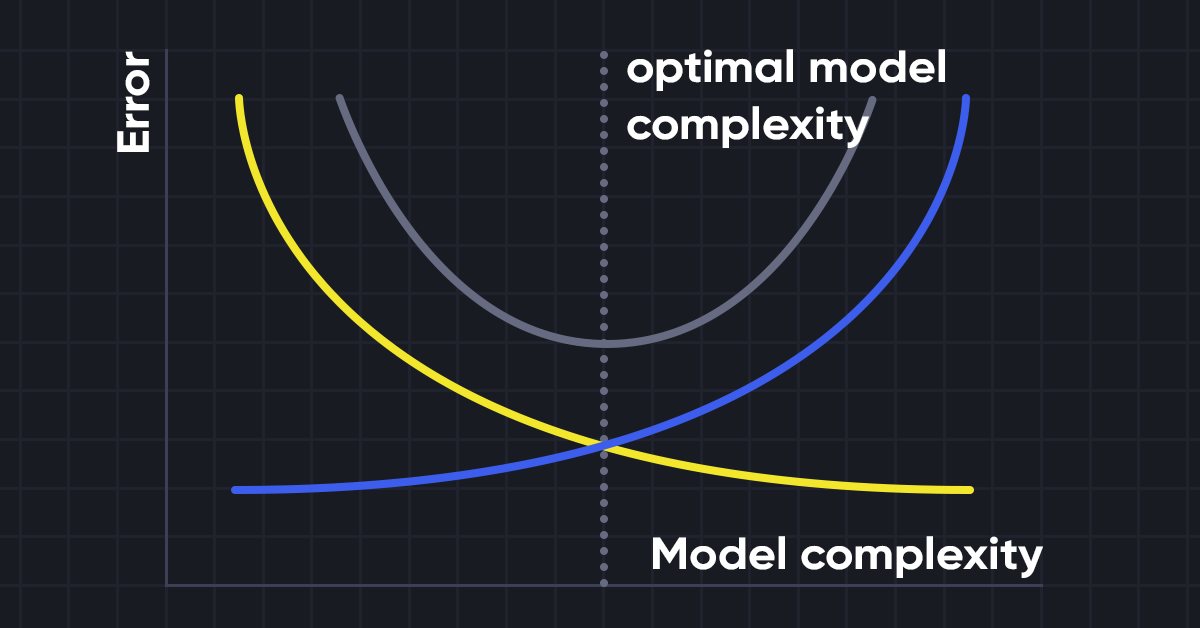
Die Ridge-Regression ist ein einfaches Verfahren zur Reduzierung der Modellkomplexität und zur Vermeidung einer Überanpassung, die bei einer einfachen linearen Regression auftreten kann.
Datenwissenschaft und maschinelles Lernen - Neuronales Netzwerk (Teil 01): Entmystifizierte Feed Forward Neurale Netzwerke
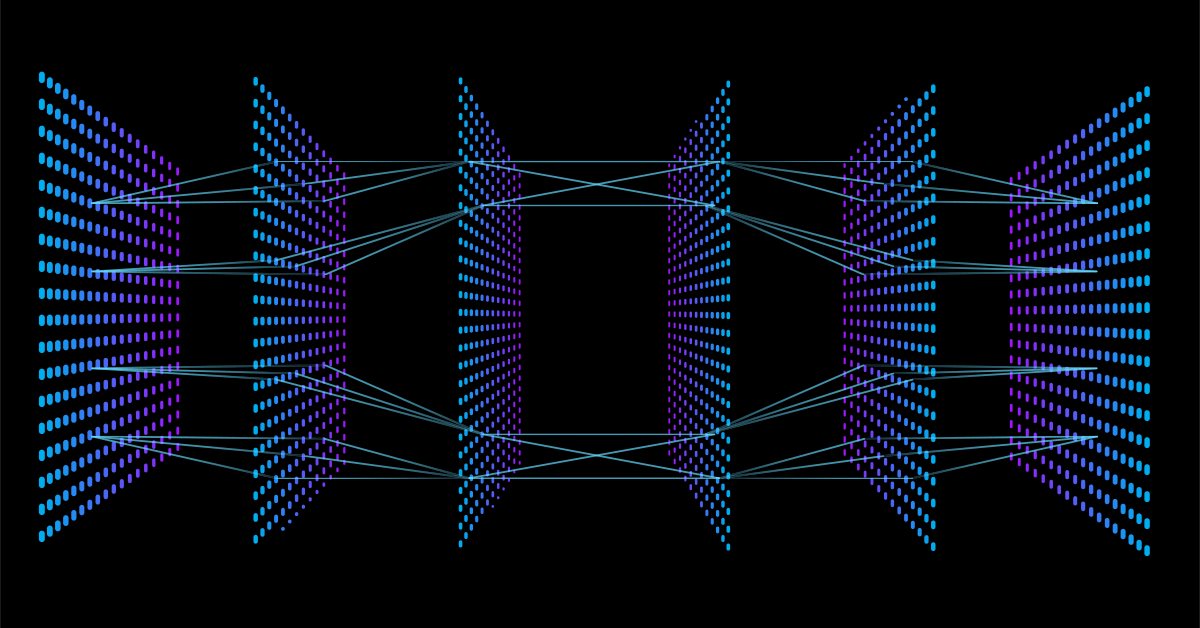
Viele Menschen lieben sie, aber nur wenige verstehen die gesamte Funktionsweise neuronaler Netze. In diesem Artikel werde ich versuchen, alles, was hinter den verschlossenen Türen einer mehrschichtigen Feed-Forward-Wahrnehmung vor sich geht, in einfacher Sprache zu erklären.

Techniken des MQL5-Assistenten, die Sie kennen sollten (Teil 04): Die Lineare Diskriminanzanalyse
Der Händler von heute ist ein Philomath, der fast immer (entweder bewusst oder unbewusst...) nach neuen Ideen sucht, sie ausprobiert, sich entscheidet, sie zu modifizieren oder zu verwerfen; ein explorativer Prozess, der einiges an Sorgfalt kosten sollte. Diese Artikelserie wird vorschlagen, dass der MQL5-Assistent eine Hauptstütze für Händler sein sollte.

Fortschrittliches Resampling und Auswahl von CatBoost-Modellen durch die Brute-Force-Methode
Dieser Artikel beschreibt einen der möglichen Ansätze zur Datentransformation mit dem Ziel, die Verallgemeinerbarkeit des Modells zu verbessern, und erörtert auch die Stichprobenziehung und Auswahl von CatBoost-Modellen.

Wie man ONNX-Modelle in MQL5 verwendet
ONNX (Open Neural Network Exchange) ist ein offenes Format, das zur Darstellung von Modellen des maschinellen Lernens entwickelt wurde. In diesem Artikel wird untersucht, wie ein CNN-LSTM-Modell zur Vorhersage von Finanzzeitreihen erstellt werden kann. Wir werden auch zeigen, wie man das erstellte ONNX-Modell in einem MQL5 Expert Advisor verwendet.
Gradient Boosting beim transduktiven und aktiven maschinellen Lernen
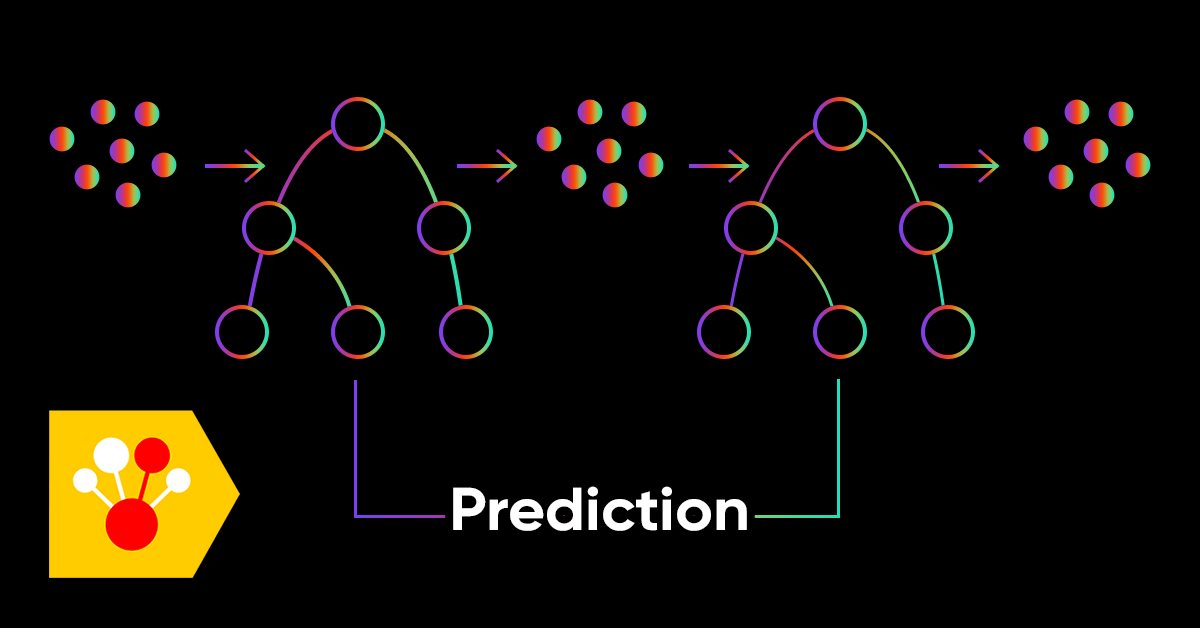
In diesem Artikel werden wir aktive Methoden des maschinellen Lernens anhand von realen Daten betrachten und ihre Vor- und Nachteile diskutieren. Vielleicht helfen Ihnen diese Methoden und Sie werden sie in Ihr Arsenal an maschinellen Lernmodellen aufnehmen. Die Transduktion wurde von Vladimir Vapnik eingeführt, der Miterfinder der Support-Vector Machine (SVM) ist.

Datenwissenschaft und maschinelles Lernen (Teil 05): Entscheidungsbäume
Entscheidungsbäume imitieren die Art und Weise, wie Menschen denken, um Daten zu klassifizieren. Schauen wir mal, wie man so einen Baum erstellt und ihn zur Klassifizierung und Vorhersage einiger Daten verwenden kann. Das Hauptziel des Entscheidungsbaum-Algorithmus ist es, die Daten mit Fremdanteilen und die reinen oder knotennahen Daten abzutrennen.

Neuronale Netze leicht gemacht (Teil 20): Autoencoder
Wir untersuchen weiterhin Modelle und Algorithmen für unüberwachtes Lernen. Einige Leser haben vielleicht Fragen zur Relevanz der jüngsten Veröffentlichungen zum Thema neuronale Netze. In diesem neuen Artikel befassen wir uns wieder mit neuronalen Netzen.

Algorithmen zur Optimierung mit Populationen Cuckoo-Optimierungsalgorithmus (COA)
Der nächste Algorithmus, den ich besprechen werde, ist die Optimierung der Kuckuckssuche (Cockoo) mit Levy-Flügen. Dies ist einer der neuesten Optimierungsalgorithmen und ein neuer Spitzenreiter in der Rangliste.

Algorithmen zur Optimierung mit Populationen Ameisenkolonie-Optimierung (ACO)
Dieses Mal werde ich den Algorithmus der Ameisenkolonie-Optimierung analysieren. Der Algorithmus ist sehr interessant und komplex. In diesem Artikel versuche ich, eine neue Art von ACO zu schaffen.
Datenwissenschaft und maschinelles Lernen (Teil 08): K-Means Clustering in reinem MQL5
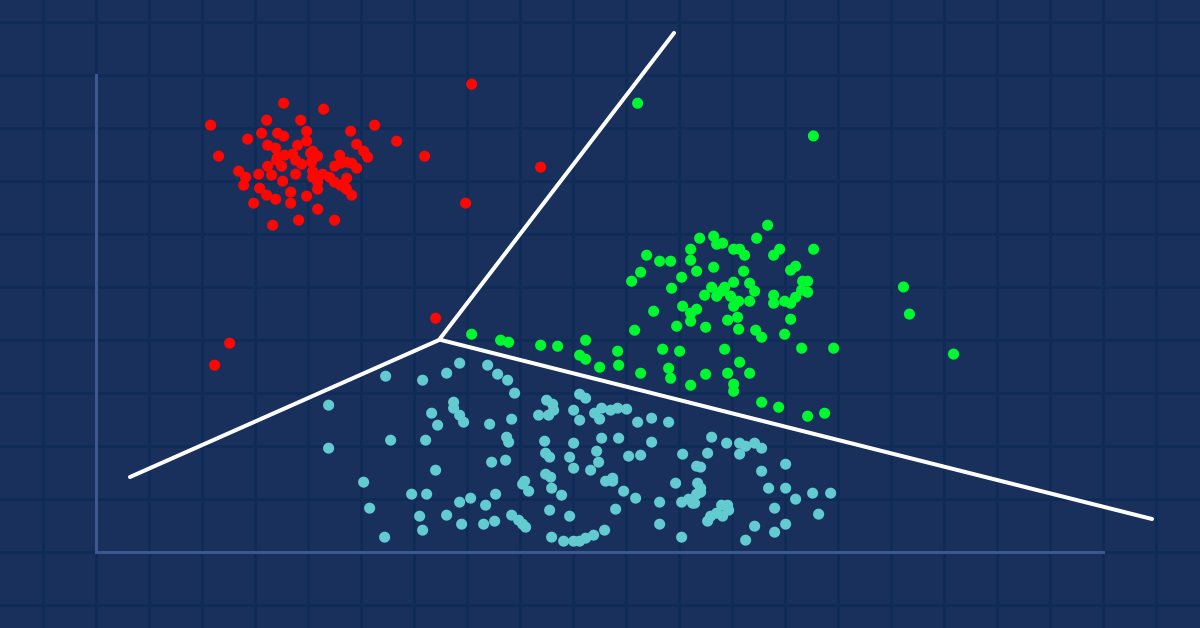
Data Mining ist für Datenwissenschaftler und Händler von entscheidender Bedeutung, da die Daten oft nicht so einfach sind, wie wir denken. Das menschliche Auge kann die kleinen zugrundeliegenden Muster und Beziehungen im Datensatz nicht erkennen, vielleicht kann uns der Algorithmus K-Means dabei helfen. Finden wir es heraus...
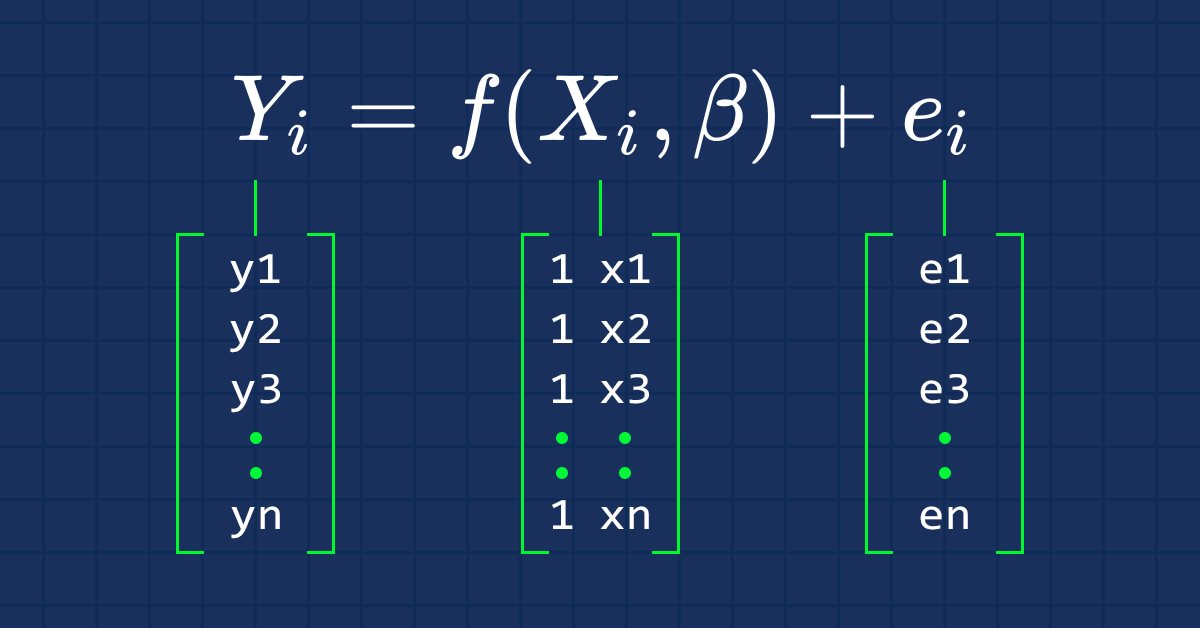
Datenwissenschaft und maschinelles Lernen (Teil 03): Matrix-Regression
Diesmal werden unsere Modelle mit Hilfe von Matrizen erstellt, was uns eine gewisse Flexibilität ermöglicht, während wir gleichzeitig leistungsstarke Modelle erstellen können, die nicht nur mit fünf unabhängigen Variablen, sondern auch mit vielen Variablen umgehen können, solange wir innerhalb der Berechnungsgrenzen eines Computers bleiben.
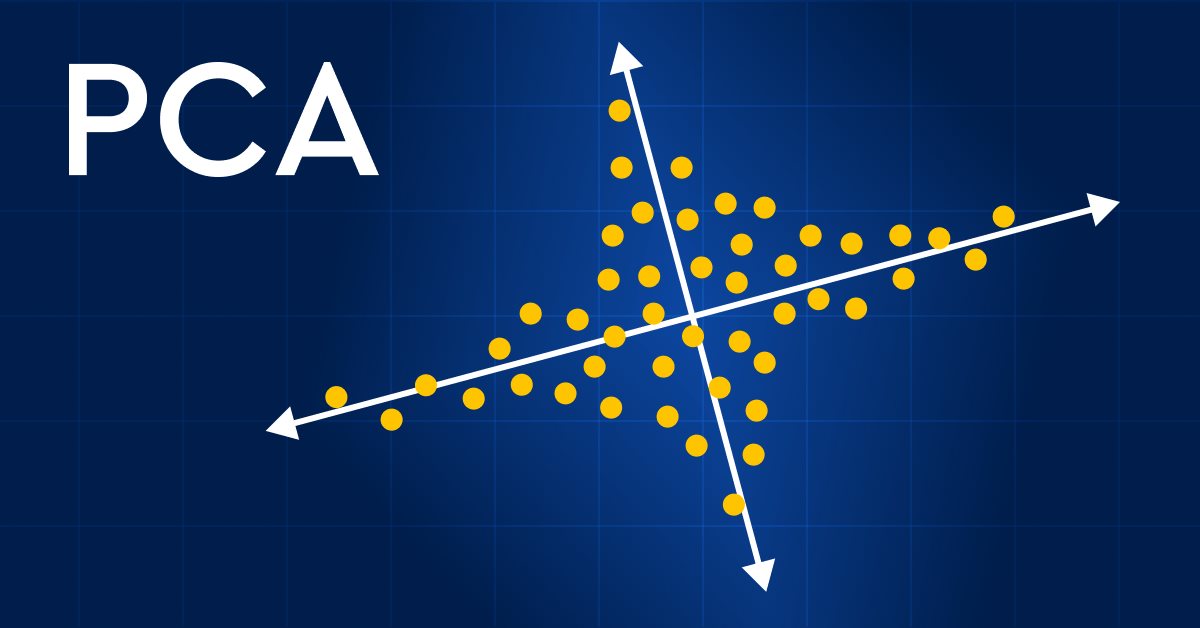
Datenwissenschaft und maschinelles Lernen (Teil 13): Verbessern Sie Ihre Finanzmarktanalyse mit der Principal Component Analysis (PCA)
Revolutionieren Sie Ihre Finanzmarktanalyse mit der Principal Component Analysis (PCA, Hauptkomponentenanalyse)! Entdecken Sie, wie diese leistungsstarke Technik verborgene Muster in Ihren Daten entschlüsseln, latente Markttrends aufdecken und Ihre Anlagestrategien optimieren kann. In diesem Artikel untersuchen wir, wie die PCA eine neue Sichtweise für die Analyse komplexer Finanzdaten bieten kann, die Erkenntnisse zutage fördert, die bei herkömmlichen Ansätzen übersehen würden. Finden Sie heraus, wie die Anwendung von PCA auf Finanzmarktdaten Ihnen einen Wettbewerbsvorteil verschaffen und Ihnen helfen kann, der Zeit voraus zu sein

ONNX meistern: Der Game-Changer für MQL5-Händler
Tauchen Sie ein in die Welt von ONNX, dem leistungsstarken offenen Standardformat für den Austausch von Modellen für maschinelles Lernen. Entdecken Sie, wie der Einsatz von ONNX den algorithmischen Handel in MQL5 revolutionieren kann, indem er es Händlern ermöglicht, hochmoderne KI-Modelle nahtlos zu integrieren und ihre Strategien auf ein neues Niveau zu heben. Entdecken Sie die Geheimnisse der plattformübergreifenden Kompatibilität und lernen Sie, wie Sie das volle Potenzial von ONNX in Ihren MQL5-Handelsbestrebungen ausschöpfen können. Verbessern Sie Ihr Trading-Spiel mit diesem umfassenden Leitfaden zur Beherrschung von ONNX:

Neuronale Netze leicht gemacht (Teil 35): Modul für intrinsische Neugier
Wir untersuchen weiterhin Algorithmen für das verstärkte Lernen. Alle bisher betrachteten Algorithmen erfordern die Erstellung einer Belohnungspolitik, die es dem Agenten ermöglicht, jede seiner Aktionen bei jedem Übergang von einem Systemzustand in einen anderen zu bewerten. Dieser Ansatz ist jedoch ziemlich künstlich. In der Praxis gibt es eine gewisse Zeitspanne zwischen einer Handlung und einer Belohnung. In diesem Artikel werden wir einen Algorithmus zum Trainieren eines Modells kennenlernen, der mit verschiedenen Zeitverzögerungen zwischen Aktion und Belohnung arbeiten kann.

Experimente mit neuronalen Netzen (Teil 5): Normalisierung der Eingaben zur Weitergabe an ein neuronales Netz
Neuronale Netze sind ein ultimatives Instrument im Werkzeugkasten der Händler. Prüfen wir, ob diese Annahme zutrifft. MetaTrader 5 ist als autarkes Medium für den Einsatz neuronaler Netze im Handel konzipiert. Dazu gibt es eine einfache Erklärung.

Neuronale Netze leicht gemacht (Teil 16): Praktische Anwendung des Clustering
Im vorigen Artikel haben wir eine Klasse für das Clustering von Daten erstellt. In diesem Artikel möchte ich Varianten für die mögliche Anwendung der gewonnenen Ergebnisse bei der Lösung praktischer Handelsaufgaben vorstellen.

ONNX-Modelle in Klassen packen
Die objektorientierte Programmierung ermöglicht die Erstellung eines kompakteren Codes, der leicht zu lesen und zu ändern ist. Hier sehen wir uns das Beispiel für drei ONNX-Modelle an.

Algorithmen zur Populationsoptimierung Partikelschwarm (PSO)
In diesem Artikel werde ich den beliebten Algorithmus der Partikelschwarm-Optimierung (PSO) besprechen. Zuvor haben wir wichtige Eigenschaften von Optimierungsalgorithmen wie Konvergenz, Konvergenzrate, Stabilität und Skalierbarkeit erörtert, einen Prüfstand entwickelt und den einfachsten RNG-Algorithmus betrachtet.
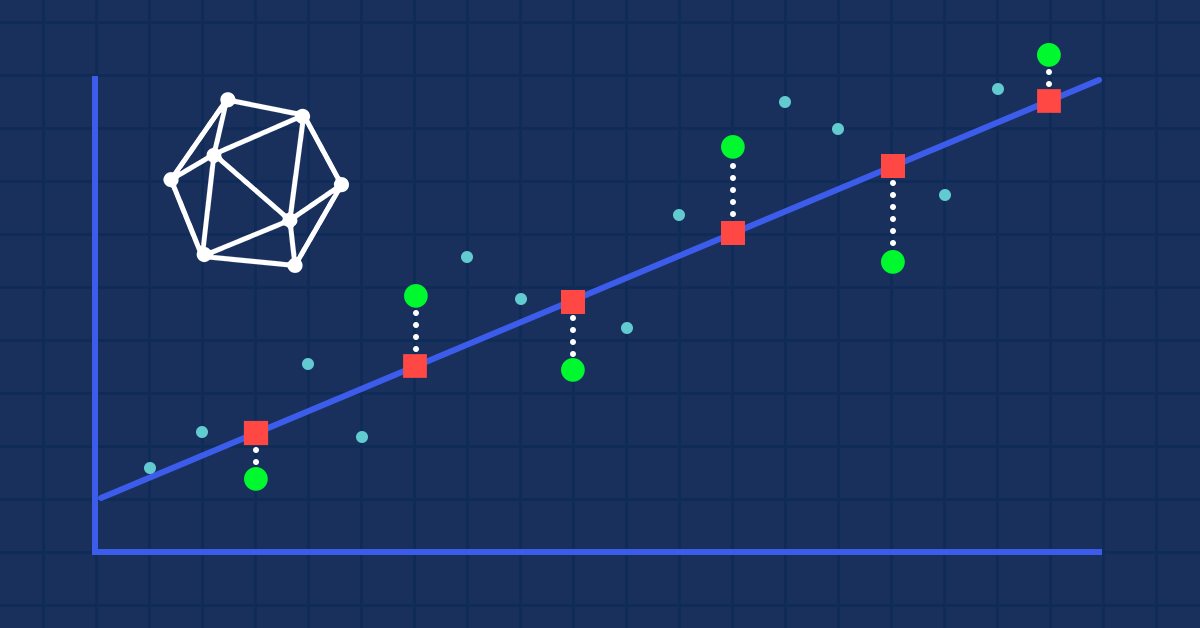
Bewertung von ONNX-Modellen anhand von Regressionsmetriken
Bei der Regression geht es um die Prognose eines realen Wertes anhand eines unbekannten Beispiels. Die so genannten Regressionsmetriken werden verwendet, um die Genauigkeit der Vorhersagen des Regressionsmodells zu bewerten.

Ein Beispiel für die Zusammenstellung von ONNX-Modellen in MQL5
ONNX (Open Neural Network eXchange) ist ein offenes Format zur Darstellung neuronaler Netze. In diesem Artikel zeigen wir Ihnen, wie Sie zwei ONNX-Modelle gleichzeitig in einem Expert Advisor verwenden können.

Einführung in MQL5 (Teil 1): Ein Leitfaden für Einsteiger in den algorithmischen Handel
Tauchen Sie ein in die faszinierende Welt des algorithmischen Handels mit unserem einsteigerfreundlichen Leitfaden zur MQL5-Programmierung. Entdecken Sie die Grundlagen von MQL5, der Sprache, die den MetaTrader 5 antreibt, während wir die Welt des automatisierten Handels entmystifizieren. Vom Verständnis der Grundlagen bis hin zu den ersten Schritten in der Programmierung ist dieser Artikel Ihr Schlüssel, um das Potenzial des algorithmischen Handels auch ohne Programmierkenntnisse zu erschließen. Begleiten Sie uns auf eine Reise, auf der Einfachheit und Raffinesse im aufregenden Universum von MQL5 aufeinandertreffen.

Algorithmen zur Optimierung mit Populationen Grauer-Wolf-Optimierung (GWO)
Betrachten wir einen der neuesten modernen Optimierungsalgorithmen - die Grey-Wolf-Optimierung. Das originelle Verhalten bei Testfunktionen macht diesen Algorithmus zu einem der interessantesten unter den zuvor besprochenen Algorithmen. Dies ist einer der besten Algorithmen für das Training neuronaler Netze, glatte Funktionen mit vielen Variablen.

Neuronale Netze leicht gemacht (Teil 14): Datenclustering
Es ist mehr als ein Jahr her, dass ich meinen letzten Artikel veröffentlicht habe. Das ist eine ganze Menge Zeit, um Ideen zu überarbeiten und neue Ansätze zu entwickeln. In dem neuen Artikel möchte ich von der bisher verwendeten Methode des überwachten Lernens abweichen. Diesmal werden wir uns mit Algorithmen des unüberwachten Lernens beschäftigen. Wir werden insbesondere einen der Clustering-Algorithmen - K-Means - betrachten.

Neuronale Netze leicht gemacht (Teil 29): Der Algorithmus Advantage Actor Critic
In den vorangegangenen Artikeln dieser Reihe haben wir zwei Algorithmen des verstärkten Lernens (Reinforcement Learning) kennengelernt. Jede von ihnen hat seine eigenen Vor- und Nachteile. Wie so oft in solchen Fällen kommt man dann auf die Idee, beide Methoden in einem Algorithmus zu kombinieren und das Beste aus beiden zu verwenden. Dies würde die Unzulänglichkeiten eines jeden von ihnen ausgleichen. Eine dieser Methoden wird in diesem Artikel erörtert.

Neuronale Netze leicht gemacht (Teil 49): Soft Actor-Critic
Wir setzen unsere Diskussion über Algorithmen des Verstärkungslernens zur Lösung von Problemen im kontinuierlichen Aktionsraum fort. In diesem Artikel werde ich den Soft Actor-Critic (SAC) Algorithmus vorstellen. Der Hauptvorteil von SAC ist die Fähigkeit, optimale Strategien zu finden, die nicht nur die erwartete Belohnung maximieren, sondern auch eine maximale Entropie (Vielfalt) von Aktionen aufweisen.
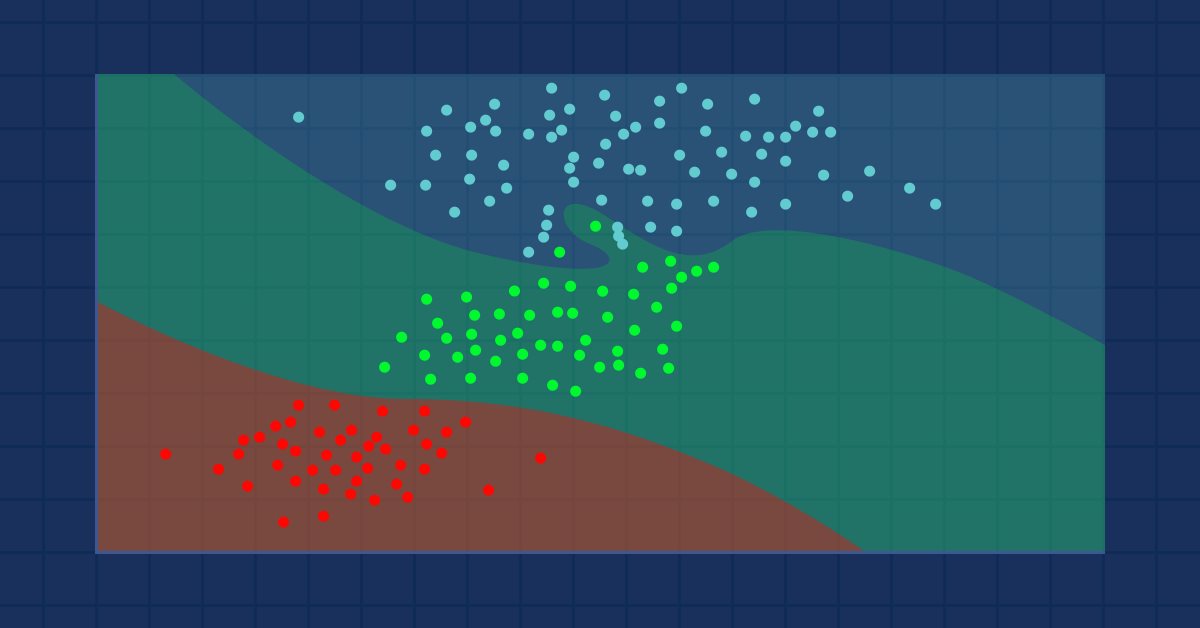
Datenwissenschaft und maschinelles Lernen (Teil 09): Der Algorithmus K-Nächste-Nachbarn (K-Nearest Neighbors, KNN)
Dies ist ein fauler Algorithmus, der nicht aus dem Trainingsdatensatz lernt, sondern den Datensatz speichert und sofort reagiert, wenn er eine neue Probe erhält. So einfach er auch ist, er wird in einer Vielzahl von Anwendungen in der Praxis eingesetzt

Neuronale Netze leicht gemacht (Teil 50): Soft Actor-Critic (Modelloptimierung)
Im vorigen Artikel haben wir den Algorithmus Soft Actor-Critic (Akteur-Kritiker) implementiert, konnten aber kein profitables Modell trainieren. Hier werden wir das zuvor erstellte Modell optimieren, um die gewünschten Ergebnisse zu erzielen.

Deep Learning, Vorhersage und Aufträge mit Python, dem MetaTrader5 Python-Paket und ONNX-Modelldatei
Im Rahmen des Projekts wird Python für Deep Learning-basierte Prognosen auf den Finanzmärkten eingesetzt. Wir werden die Feinheiten des Testens der Leistung des Modells anhand von Schlüsselkennzahlen wie dem mittleren absoluten Fehler (MAE), dem mittleren quadratischen Fehler (MSE) und dem R-Quadrat (R2) erkunden und lernen, wie man alles in eine ausführbare Datei verpackt. Wir werden auch eine ONNX-Modelldatei mit seinem EA erstellen.

Algorithmen zur Optimierung mit Populationen: Nelder-Mead- oder Simplex-Suchverfahren (NM)
Der Artikel stellt eine vollständige Untersuchung der Nelder-Mead-Methode vor und erklärt, wie das Simplex (Funktionsparameterraum) bei jeder Iteration geändert und neu angeordnet wird, um eine optimale Lösung zu erreichen, und beschreibt, wie die Methode verbessert werden kann.
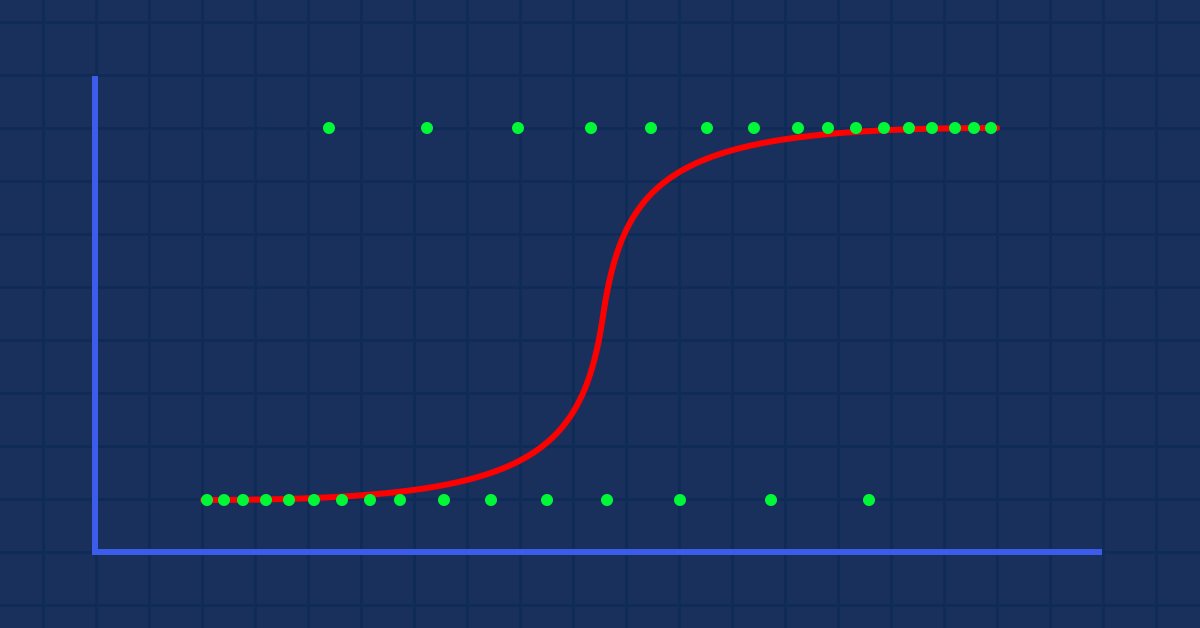
Datenwissenschaft und maschinelles Lernen (Teil 02): Logistische Regression
Die Klassifizierung von Daten ist für einen Algo-Händler und einen Programmierer von entscheidender Bedeutung. In diesem Artikel werden wir uns auf einen logistischen Klassifizierungsalgorithmus konzentrieren, der uns wahrscheinlich helfen kann, die Ja- oder Nein-Stimmen, die Höhen und Tiefen, Käufe und Verkäufe zu identifizieren.

Datenwissenschaft und maschinelles Lernen (Teil 04): Vorhersage des aktuellen Börsenkrachs
In diesem Artikel werde ich versuchen, unser logistisches Modell zu verwenden, um den Börsencrash auf der Grundlage der Fundamentaldaten der US-Wirtschaft vorherzusagen. NETFLIX und APPLE sind die Aktien, auf die wir uns konzentrieren werden, wobei wir die früheren Börsencrashs von 2019 und 2020 nutzen werden, um zu sehen, wie unser Modell in der aktuellen Krise abschneiden wird.

Neuronale Netze leicht gemacht (Teil 21): Variierter Autoencoder (VAE)
Im letzten Artikel haben wir uns mit dem Algorithmus des Autoencoders vertraut gemacht. Wie jeder andere Algorithmus hat auch dieser seine Vor- und Nachteile. In seiner ursprünglichen Implementierung wird der Autoencoder verwendet, um die Objekte so weit wie möglich von der Trainingsstichprobe zu trennen. Dieses Mal werden wir darüber sprechen, wie man mit einigen ihrer Nachteile umgehen kann.

Klassifizierungsmodelle in der Bibliothek Scikit-Learn und ihr Export nach ONNX
In diesem Artikel werden wir die Anwendung aller in der Bibliothek Scikit-Learn verfügbaren Klassifizierungsmodelle untersuchen, um die Klassifizierungsaufgabe im Iris-Datensatz von Fisher, zu lösen. Wir werden versuchen, diese Modelle in das ONNX-Format zu konvertieren und die resultierenden Modelle in MQL5-Programmen zu verwenden. Außerdem werden wir die Genauigkeit der Originalmodelle mit ihren ONNX-Versionen auf dem vollständigen Iris-Datensatz vergleichen.

Neuronale Netze leicht gemacht (Teil 43): Beherrschen von Fähigkeiten ohne Belohnungsfunktion
Das Problem des Verstärkungslernens liegt in der Notwendigkeit, eine Belohnungsfunktion zu definieren. Sie kann komplex oder schwer zu formalisieren sein. Um dieses Problem zu lösen, werden aktivitäts- und umweltbasierte Ansätze zum Erlernen von Fähigkeiten ohne explizite Belohnungsfunktion erforscht.

Neuronale Netze leicht gemacht (Teil 51): Behavior-Guided Actor-Critic (BAC)
Die letzten beiden Artikel befassten sich mit dem Soft Actor-Critic-Algorithmus, der eine Entropie-Regularisierung in die Belohnungsfunktion integriert. Dieser Ansatz schafft ein Gleichgewicht zwischen Umwelterkundung und Modellnutzung, ist aber nur auf stochastische Modelle anwendbar. In diesem Artikel wird ein alternativer Ansatz vorgeschlagen, der sowohl auf stochastische als auch auf deterministische Modelle anwendbar ist.

Datenkennzeichnung für Zeitreihenanalyse (Teil 2): Datensätze mit Trendmarkern mit Python erstellen
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!

Matrizen und Vektoren in MQL5: Die Aktivierungsfunktionen
Hier wird nur einer der Aspekte des maschinellen Lernens beschrieben — die Aktivierungsfunktionen. In künstlichen neuronalen Netzen berechnet eine Neuronenaktivierungsfunktion einen Ausgangssignalwert auf der Grundlage der Werte eines Eingangssignals oder eines Satzes von Eingangssignalen. Wir werden uns mit den inneren Abläufen des Prozesses befassen.

Algorithmen zur Optimierung mit Populationen: Der Algorithmus intelligenter Wassertropfen (IWD)
Der Artikel befasst sich mit einem interessanten, von der unbelebten Natur abgeleiteten Algorithmus - intelligente Wassertropfen (IWD), die den Prozess der Flussbettbildung simulieren. Die Ideen dieses Algorithmus ermöglichten es, den bisherigen Spitzenreiter der Bewertung - SDS - deutlich zu verbessern. Der neue Führende (modifizierter SDSm) befindet sich wie üblich im Anhang.