
Neuronale Netze leicht gemacht (Teil 64): Die Methode konservativ gewichtetes Klonen von Verhaltensweisen (CWBC)

Einführung
Der Decision Transformer (Entscheidungstransformierer) und alle seine Modifikationen, die wir in den letzten Artikeln besprochen haben, gehören zu den Methoden des Behavior Cloning (BC). Wir trainieren Modelle zur Wiederholung von Handlungen aus „Experten“-Trajektorien in Abhängigkeit vom Zustand der Umgebung und den Zielergebnissen. So bringen wir dem Modell bei, das Verhalten eines Experten im aktuellen Zustand der Umgebung zu imitieren, um das Ziel zu erreichen.
Unter realen Bedingungen weichen die Einschätzungen verschiedener Experten zum gleichen Zustand der Umgebung jedoch stark voneinander ab. Manchmal sind sie völlig gegensätzlich. Außerdem möchte ich Sie daran erinnern, dass wir in früheren Arbeiten keine Experten zur Erstellung unseres Trainingssets hinzugezogen haben. Wir haben verschiedene Methoden für das Sampling der Aktionen des Agenten verwendet und die besten Trajektorien ausgewählt. Diese Trajektorien waren nicht immer optimal.
Beim Sampling von Trajektorien in einem kontinuierlichen Raum von Aktionen und Episoden ist es fast unmöglich, alle möglichen Optionen zu speichern. Nur ein kleiner Teil der gesampelten Trajektorien kann unsere Anforderungen zumindest teilweise erfüllen. Solche Trajektorien sind eher Ausreißer, die das Modell während des Trainingsprozesses einfach verwerfen kann.
Um dieser Situation entgegenzuwirken, haben wir die Ansätze der Methode Go-Explore genutzt. Dann haben wir aus kleinen Stücken nach und nach eine erfolgreiche Trajektorie geformt. Solche Trajektorien können als suboptimal bezeichnet werden. Sie liegen nahe an unseren Erwartungen, aber ihre Optimalität bleibt unbewiesen.
Natürlich können wir die optimale Trajektorie anhand historischer Daten manuell markieren. Dieser Ansatz bringt uns dem überwachten Lernen näher, mit allen Vor- und Nachteilen dieses Ansatzes.
Gleichzeitig wird das Modell durch die Auswahl optimaler Durchgänge auf ideale Bedingungen eingestellt, was zu einer Überanpassung des Modells führen kann. In diesem Fall kann das Modell, nachdem es die Route der Trainingsstichprobe gelernt hat, die gewonnenen Erfahrungen nicht auf neue Umgebungszustände verallgemeinern.
Der zweite problematische Aspekt der Methoden zum Klonen von Verhalten ist die Festlegung von Zielen für das Modell (Return To Go, RTG). Wir haben dieses Thema bereits in früheren Arbeiten erörtert. In einigen Arbeiten wird empfohlen, den Koeffizienten für das maximale Ergebnis aus der Trainingsmenge zu verwenden, was oft zu besseren Ergebnissen führt. Dieser Ansatz ist jedoch nur für die Lösung statischer Probleme geeignet. Ein solcher Koeffizient wird für jede Aufgabe einzeln ausgewählt. Die Methode der Dichotomie der Kontrolle bietet eine weitere Lösung für dieses Problem. Es gibt aber auch andere Ansätze.
Die oben genannten Probleme werden von den Autoren des Artikels „Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning“ angesprochen. Um diese Probleme zu lösen, schlagen die Autoren eine recht interessante Methode vor, die Methode des Conservative Weighted Behavioral Cloning (CWBC), die nicht nur auf Modelle der Familie der Decision Transformer anwendbar ist.
1. Der Algorithmus
Um Faktoren zu identifizieren, die die Zuverlässigkeit von Methoden des Verstärkungslernens beeinflussen, die von Zielbelohnungen abhängen, haben die Autoren des Artikels „Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning“ zwei anschauliche Experimente entworfen.
Im ersten Experiment wurden Modelle verschiedener Architekturen auf einer Reihe von Trajektorien mit unterschiedlichen Ertragsniveaus ausgeführt, von praktisch zufällig bis fachmännisch und suboptimal. Die Ergebnisse des Experiments zeigen, dass die Zuverlässigkeit des Modells weitgehend von der Qualität des Trainingsdatensatzes abhängt. Beim Training des Modells auf Daten von Trajektorien mit durchschnittlichen und guten Renditen zeigt das Modell unter der Bedingung hoher Ziele zuverlässige Ergebnisse. Wird das Modell hingegen auf Trajektorien mit geringer Rendite trainiert, nimmt seine Leistung ab einem bestimmten Punkt mit steigendem RTG rapide ab. Das liegt daran, dass Daten von geringer Qualität nicht genügend Informationen liefern, um Strategien zu trainieren, die von großen Belohnungen abhängig sind. Dies wirkt sich negativ auf die Zuverlässigkeit des resultierenden Modells aus.
Die Datenqualität ist nicht der einzige Grund für die Zuverlässigkeit des Modells. Auch die Modellarchitektur spielt eine wichtige Rolle. In den durchgeführten Experimenten erweist sich DT in allen drei Datensätzen als zuverlässig. Es wird davon ausgegangen, dass die DT-Zuverlässigkeit durch die Verwendung einer Transformer-Architektur erreicht wird. Da die Strategie zur Vorhersage der nächsten Aktion des Agenten auf einer Abfolge von Umgebungszuständen und RTG-Etiketten basiert, können die Aufmerksamkeitsschichten RTG-Etiketten außerhalb der Verteilung des Trainingsdatensatzes ignorieren. Dies zeigt auch eine gute Vorhersagegenauigkeit. Gleichzeitig können auf der MLP-Architektur aufbauende Modelle, die den aktuellen Zustand und das RTG als Eingabedaten für die Generierung von Aktionen erhalten, die Informationen über die gewünschte Belohnung nicht ignorieren. Um diese Hypothese zu testen, experimentieren die Autoren mit einer leicht modifizierten Version von DT, bei der die Umgebungs- und RTG-Vektoren bei jedem Zeitschritt verkettet werden. Daher kann das Modell die RTG-Informationen in der Sequenz nicht ignorieren. Die Versuchsergebnisse zeigen, dass die Zuverlässigkeit eines solchen Modells schnell abnimmt, nachdem das FTE-Gerät die Verteilung der Trainingsmenge verlassen hat. Dies bestätigt die oben aufgestellte Vermutung.
Zur Optimierung des Modelltrainings und zur Minimierung des Einflusses der oben genannten Faktoren schlagen die Autoren des Artikels die Verwendung der Methode Conservative Weighted Behavioral Cloning Method (CWBC) vor, die eine relativ einfache, aber wirksame Methode zur Verbesserung der Zuverlässigkeit bestehender Methoden zum Training von Verhaltensklonmodellen darstellt. CWBC besteht aus zwei Komponenten:
- Gewichtung der Trajektorie
- Konservative RTG-Regulierung
Die Gewichtung von Trajektorien bietet eine systematische Möglichkeit, suboptimale Datenverteilungen umzuwandeln, um die optimale Verteilung genauer zu schätzen, indem die Gewichtung von Trajektorien mit hohem Ertrag erhöht wird. Der konservative Verlustregulierer ermutigt die Politik, nahe an der ursprünglichen Datenverteilung zu bleiben, vorbehaltlich großer Ziele.
1.1 Gewichtung der Trajektorie
Wir wissen, dass die optimale Offline-Verteilung der Trajektorien einfach die Verteilung der Demonstrationen ist, die durch die optimale Strategie erzeugt wird. In der Regel ist die Offline-Verteilung der Trajektorien im Vergleich zur optimalen Verteilung verzerrt. Während des Trainings führt dies zu einer Lücke zwischen Training und Test, da wir unseren Agenten so konditionieren wollen, dass er bei der Bewertung und dem Betrieb des Modells seinen Ertrag maximiert, aber gezwungen sind, das empirische Risiko bei einer verzerrten Datenverteilung während des Trainings zu minimieren.
Die Hauptidee der Methode besteht darin, die Trainingsstichprobe der Trajektorien in eine neue Verteilung umzuwandeln, die die optimale Trajektorie besser schätzt. Die neue Verteilung sollte sich auf Trajektorien mit hoher Rendite konzentrieren, was intuitiv die Diskrepanz zwischen Training und Test abschwächt. Da wir davon ausgehen, dass der ursprüngliche Datensatz nur sehr wenige Trajektorien mit hohem Rücklauf enthält, wird durch die bloße Eliminierung von Trajektorien mit niedrigem Rücklauf der Großteil der Trainingsdaten eliminiert. Dies führt zu einer schlechten Dateneffizienz. Die Autoren der Methode schlagen vor, die Trajektorien auf der Grundlage ihrer Erträge zu gewichten.
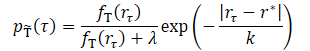
wobei λ, k zwei Hyperparameter sind, die die Form der transformierten Verteilung bestimmen.
Der Glättungsparameter k steuert, wie die Trajektorien auf der Grundlage ihrer Erträge gewichtet werden. Intuitiv bedeutet ein kleineres k eine stärkere Gewichtung renditestarker Trajektorien. Je höher der Parameterwert, desto gleichmäßiger wird die transformierte Verteilung. Die Autoren schlagen vor, den k-Wert als Differenz zwischen dem maximalen und dem z-ten Perzentilwert der Ergebnisse im Trainingsdatensatz festzulegen.
![]()
Dadurch kann der tatsächliche Wert von k an verschiedene Datensätze angepasst werden. Die Autoren der Methode testeten vier z-Werte aus der Menge {99, 90, 50, 0}, die vier steigenden k-Werten entsprechen. Nach den experimentellen Ergebnissen für jeden Datensatz ist die transformierte Verteilung mit kleinem k stark auf hohe Belohnungen konzentriert. Mit zunehmendem k nimmt die Dichte der Trajektorien mit geringen Ergebnis-Trajektorien zu und die Verteilung wird gleichmäßiger. Mit relativ kleinen Werten von k, die auf dem Perzentil der Menge {99, 90, 50} basieren, zeigt das Modell eine gute Leistung in allen Datensätzen. Große Werte von k auf der Grundlage des Perzentils 0 verschlechtern jedoch die Leistung für den Datensatz der Experten-Trajektorien.
Der Parameter λ beeinflusst auch die transformierte Verteilung. Wenn λ = 0 ist, konzentriert sich die transformierte Verteilung auf hohe Renditen. Mit zunehmendem λ nähert sich die transformierte Verteilung der ursprünglichen an, ist aber aufgrund des Einflusses des exponentiellen Terms immer noch in Richtung der Region mit hohen Erträgen gewichtet. Die tatsächliche Leistung der Modelle mit verschiedenen Werten von λ zeigt ähnliche Ergebnisse, die besser oder vergleichbar mit dem Training auf dem Originaldatensatz sind.
1.2 Konservative Regulierung
Wie bereits erwähnt, spielt auch die Architektur eine wichtige Rolle für die Zuverlässigkeit des trainierten Modells. Das idealisierte Szenario ist schwer oder gar nicht zu erreichen. Die Autoren der CWBC-Methode verlangen jedoch, dass ein Modell zumindest nahe an der ursprünglichen Datenverteilung bleibt, um ein katastrophales Versagen zu vermeiden, wenn ein RTG außerhalb der Verteilung angegeben wird. Mit anderen Worten: Die Politik muss konservativ sein. Die Konservativität muss jedoch nicht unbedingt von der Architektur herrühren, sondern kann auch aus einer geeigneten Verlustfunktion für das Modelltraining resultieren, wie dies typischerweise bei konservativen Methoden auf der Grundlage von Zustands- und Übergangskostenschätzungen der Fall ist.
Die Autoren der Methode schlagen einen neuen konservativen Regulierer für ergebnisabhängige Behavioral-Cloning-Methoden vor, der die Politik explizit ermutigt, nahe an der ursprünglichen Datenverteilung zu bleiben. Die Idee ist, die vorhergesagten Handlungen bei der Konditionierung auf große Out-of-Distribution-Renditen in die Nähe der In-Distribution-Handlungen zu bringen. Dies wird durch Hinzufügen von positivem Rauschen zu RTGs für Trajektorien mit hohem Rücklauf erreicht und bestraft den L2-Abstand zwischen der vorhergesagten Aktion und der Bodenwahrheit. Um zu gewährleisten, dass große Renditen außerhalb der Verteilung generiert werden, erzeugen wir Rauschen, sodass der angepasste RTG-Wert nicht kleiner ist als die höchste Rendite im Trainingssatz.
Die Autoren schlagen vor, eine konservative Regulierung auf Trajektorien anzuwenden, deren Renditen das q-te Perzentil der Belohnungen im Trainingssatz übersteigen. Dadurch wird sichergestellt, dass sich die Politik bei der Angabe eines RTG außerhalb der Trainingsverteilung ähnlich verhält wie bei Trajektorien mit hoher Rendite und nicht wie eine zufällige Trajektorie. Wir fügen Rauschen hinzu und verschieben das RTG bei jedem Zeitschritt.
Die von den Autoren der Methode durchgeführten Experimente zeigen, dass die Verwendung des 95. Perzentils im Allgemeinen in einer Vielzahl von Umgebungen und Datensätzen gut funktioniert.
Die Autoren der Methode stellen fest, dass sich der vorgeschlagene konservative Regulierer von anderen konservativen Komponenten für Offline-RL-Methoden unterscheidet, die auf der Schätzung der Kosten von Zuständen und Übergängen basieren. Während letztere in der Regel versuchen, die Schätzung der Kostenfunktion anzupassen, um Extrapolationsfehler zu vermeiden, verzerrt die vorgeschlagene Methode den Return-to-Go, um Bedingungen außerhalb der Verteilung zu schaffen, und passt die Vorhersage von Aktionen an.
Durch die Verwendung einer Trajektoriengewichtung in Verbindung mit einem konservativen Regulierer erhalten wir die Methode „Conservative Weighted Behavioral Cloning Method“ (CWBC), die das Beste aus beiden Welten vereint.
2. Implementierung mit MQL5
Nach der Besprechung der theoretischen Aspekte von Conservative Weighted Behavioral Cloning gehen wir dazu über, unsere Interpretation der vorgeschlagenen Ansätze umzusetzen. In dieser Arbeit werden wir 2 Modelle trainieren:
- Entscheidungstransformator für die Vorhersage von Aktionen.
- Modell zur Schätzung der Kosten des derzeitigen Zustands der Umgebung für die RTG-Erzeugung.
Um den Lernprozess zu optimieren, werden wir eine Trajektoriengewichtung und eine konservative Regulierung hinzufügen. Die Autoren der CWBC-Methode behaupten, dass die vorgeschlagenen Algorithmen die Effizienz des DT-Trainings um durchschnittlich 8% steigern können.
Beachten Sie, dass der Modellbildungsprozess unabhängig ist. Es ist möglich, ihre Ausbildung parallel zu organisieren. Das ist es, was wir verwenden werden. Doch zunächst wollen wir die Architektur der Modelle beschreiben. Wir werden den Prozess der Architekturbeschreibung in 2 separate Methoden unterteilen. In der Methode CreateDescriptions wird eine Beschreibung der Architektur des Agenten erstellt, die als Eingabe einen Schritt der analysierten Sequenz, bestehend aus 5 Entitäten, erhält:
- Historische Daten der енру Preisbewegung und der analysierten Indikatoren;
- Kontostand und offene Positionen;
- Zeitstempel;
- letzte Aktion des Agenten;
- RTG.
Dies spiegelt sich in der Quelldatenschicht des Modells wider.
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Wie üblich werden die empfangenen Daten in einer Batch-Normalisierungsschicht vorverarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Als Nächstes transformieren wir alle Entitäten in eine vergleichbare Form. Zu diesem Zweck verwenden wir zunächst eine Einbettungsschicht, die alles in einen einzigen N-dimensionalen Raum überträgt. Ich möchte Sie daran erinnern, dass unsere Einbettungsschicht im Speicher bereits gewonnene Daten in der Tiefe der analysierten Geschichte enthält. Neue Daten werden der gesammelten Sequenz hinzugefügt.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Dann verwenden wir die SoftMax-Schicht, um alle Einbettungen in eine vergleichbare Verteilung umzuwandeln. Bitte beachten Sie, dass SoftMax für jede einzelne Einbettung angewendet wird.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 5; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Nachdem wir alle Einbettungen in eine vergleichbare Form gebracht haben, verwenden wir einen Aufmerksamkeitsblock, der die resultierende Sequenz analysiert.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Danach folgt ein Block von 2 Faltungsschichten, der nach stabilen Mustern in den Daten sucht und gleichzeitig die Datendimension um das Zweifache reduziert.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass wir Daten im Rahmen einer separaten Einbettung verarbeitet haben. Zum Abschluss dieser Phase werden alle Entitäten mit der Funktion SoftMax in eine vergleichbare Form gebracht, die wir auch auf jede Entität der Sequenz einzeln anwenden.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Die verarbeiteten und vollständig vergleichbaren Daten werden an den Entscheidungsblock weitergeleitet, der aus vollständig verbundenen Schichten besteht. Am Ausgang erhalten wir die generierten prädiktiven Aktionen des Agenten.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Der nächste Schritt ist die Erstellung einer Beschreibung der Architektur des Umgebungskostenrechnungsmodells mit der Methode CreateRTGDescriptions. In dieses Modell wird eine bestimmte Abfolge historischer Preisänderungen und analysierter Indikatordaten eingegeben. In diesem Fall handelt es sich um eine Folge von mehreren Balken.
bool CreateRTGDescriptions(CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- RTG rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Die empfangenen Daten werden in der Batch-Normalisierungsschicht vorverarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Als Nächstes erstellen wir die Einbettung jedes Balkens mithilfe einer Faltungsschicht und der SoftMax-Funktion. In diesem Fall verwenden wir keine Einbettungsschicht, da die Datenstruktur jedes Balkens gleich ist und wir die empfangenen Daten nicht akkumulieren müssen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count + BarDescr - 1) / BarDescr; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Die verarbeiteten Daten werden an den Aufmerksamkeitsblock übertragen.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Dann gelangen die Daten in den Block der Faltungsschichten und werden dann von SoftMax normalisiert, ähnlich wie bei dem oben beschriebenen Modell.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Danach erstellen wir einen Entscheidungsblock aus vollständig verbundenen Schichten.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Am Ausgang des Modells erzeugen wir Stochastizität in der RTG-Erzeugungspolitik mit Hilfe eines Variations-Autoencoder-Blocks. So simulieren wir die Stochastizität der Umgebung und die Kosten möglicher Übergänge im Rahmen der erlernten Verteilung.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
Nachdem wir eine Beschreibung der Modellarchitektur erstellt haben, gehen wir zur Arbeit an den Expert Advisors für die Modellschulung über. Für die anfängliche Sammlung der Trainingsstichprobe werden wir die besten zufälligen Trajektorien auswählen, die mit dem Expert Advisor „...\CWBC\Faza1.mq5“ ermittelt wurden. Der Algorithmus dieses Expert Advisors und die Prinzipien der Datenerfassung sind im Artikel über den Control Transformer beschrieben.
Als Nächstes erstellen wir einen Expert Advisor zum Trainieren unseres Agenten „...\CWBC\StudyAgent.mq5“. Es muss gesagt werden, dass dieser EA weitgehend die Struktur des Trainings-EA des ursprünglichen Decision Transformer übernommen hat. Zusätzlich haben wir sie mit Ansätzen aus der CWBC-Methode ergänzt. Zunächst erstellen wir eine Methode zur Gewichtung von Trajektorien mit dem Namen GetProbTrajectories, die einen Vektor kumulativer Wahrscheinlichkeiten für Sampling-Trajektorien zurückgibt. Unmittelbar im Hauptteil der Methode bestimmen wir die maximale Rendite im Erfahrungswiedergabepuffer, das Niveau des erforderlichen Quantils und den Vektor der Standardabweichungen der Renditen. Wir benötigen diese Daten für die anschließende konservative Regulierung.
In den Parametern der Methode übergeben wir den Erfahrungswiedergholungspuffer (experience replay buffer) und die notwendigen Variablen.
vector<float> GetProbTrajectories(STrajectory &buffer[], float &max_reward, float &quantile, vector<float> &std, double quant, float lanbda) { ulong total = buffer.Size();
Im Hauptteil der Methode wird die Anzahl der Trajektorien im Wiederholungspuffer bestimmt und eine Matrix zum Sammeln von Belohnungen in Durchgängen erstellt.
matrix<float> rewards = matrix<float>::Zeros(total, NRewards); vector<float> result;
Beim Speichern der Trajektorien im Wiederholungspuffer wird die kumulative Belohnung bis zum Ende des Durchgangs neu berechnet. Daher wird die Gesamtbelohnung für den gesamten Durchgang in dem Element mit dem Index 0 gespeichert. Wir werden eine Schleife organisieren und die Gesamtbelohnung jedes Durchgangs in die vorbereitete Matrix kopieren.
for(ulong i = 0; i < total; i++) { result.Assign(buffer[i].States[0].rewards); rewards.Row(result, i); }
Mithilfe von Matrixoperationen erhalten wir die Standardabweichung für jedes Element des Belohnungsvektors.
std = rewards.Std(0);
Der Vektor der Gesamtbelohnungen für jeden Durchgang und der Wert der maximalen Belohnung.
result = rewards.Sum(1);
max_reward = result.Max();
Beachten Sie, dass ich eine einfache Summierung des Belohnungsvektors in jedem Durchgang verwendet habe. Es kann jedoch Abweichungen beim Durchschnittswert der zerlegten Belohnungen sowie bei den gewichteten Optionen für den Betrag oder den Durchschnitt geben. Die Vorgehensweise hängt von der jeweiligen Aufgabe ab.
Als Nächstes bestimmen wir die Höhe des erforderlichen Quantils. In der MQL5-Dokumentation zur Operation Quantilvektor heißt es, dass für eine korrekte Berechnung ein sortierter Sequenzvektor erforderlich ist. Wir erstellen eine Kopie des Vektors der Gesamtbelohnungen und sortieren ihn in aufsteigender Reihenfolge.
vector<float> sorted = result; bool sort = true; int iter = 0; while(sort) { sort = false; for(ulong i = 0; i < sorted.Size() - 1; i++) if(sorted[i] > sorted[i + 1]) { float temp = sorted[i]; sorted[i] = sorted[i + 1]; sorted[i + 1] = temp; sort = true; } iter++; } quantile = sorted.Quantile(quant);
Anschließend rufen wir die Vektorfunktion Quantil auf und speichern das Ergebnis.
Nach dem Sammeln der Daten, die für die nachfolgenden Operationen notwendig sind, gehen wir direkt zur Bestimmung der Gewichte für jede Trajektorie über. Um die Verwendung des Koeffizienten λ zu vereinheitlichen, benötigen wir einen Algorithmus, der alle möglichen Stichproben von Belohnungen auf eine einzige Verteilung bringt. Zu diesem Zweck normalisieren wir alle Belohnungen auf den Bereich (0, 1).
Achten Sie darauf, dass wir „0“ nicht in den Bereich der normierten Werte aufnehmen, da jede Trajektorie eine von „0“ verschiedene Wahrscheinlichkeit haben muss. Daher senken wir den Mindestwert des Belohnungsbereichs um 10 % der mittleren quadratischen Belohnung.
Die maximale Verwendung von relativen Werten ermöglicht es uns, unsere Berechnung wirklich zu vereinheitlichen.
float min = result.Min() - 0.1f * std.Sum();
Es besteht jedoch eine geringe Wahrscheinlichkeit, dass die Belohnungswerte in allen Durchgängen identisch sind. Hierfür kann es verschiedene Gründe geben. Trotz der geringen Wahrscheinlichkeit eines solchen Ereignisses werden wir eine Kontrolle durchführen. Im Hauptzweig unseres Algorithmus berechnen wir zunächst die Exponentialkomponente. Dann normalisieren wir die Belohnungen und berechnen die Gewichte der Trajektorien neu.
if(max_reward > min) { vector<float> multipl=exp(MathAbs(result - max_reward) / (result.Percentile(90)-max_reward)); result = (result - min) / (max_reward - min); result = result / (result + lanbda) * multipl; result.ReplaceNan(0); }
Für den Sonderfall gleicher Belohnungen füllen wir den Wahrscheinlichkeitsvektor mit einem konstanten Wert.
else result.Fill(1);
Dann reduzieren wir die Summe aller Wahrscheinlichkeiten auf „1“ und berechnen den Vektor der kumulativen Summen.
result = result / result.Sum(); result = result.CumSum(); //--- return result; }
Um die Trajektorie bei jeder Iteration abzutasten, verwenden wir die Methode SampleTrajectory, in deren Parametern wir den Vektor der oben ermittelten kumulativen Wahrscheinlichkeiten übergeben. Das Ergebnis der Iterationen ist der Trajektorienindex im Erfahrungswiederholungspuffer.
int SampleTrajectory(vector<float> &probability) { //--- check ulong total = probability.Size(); if(total <= 0) return -1;
Im Hauptteil der Methode wird die Größe des resultierenden Wahrscheinlichkeitsvektors überprüft, und wenn er leer ist, wird sofort der falsche Index „-1“ zurückgegeben.
Als Nächstes erzeugen wir eine Zufallszahl im Bereich [0, 1] aus einer Gleichverteilung und suchen nach einem Element, dessen Auswahlwahrscheinlichkeitsbereich in den resultierenden Zufallswert fällt.
Zunächst prüfen wir die Extrema (das erste und letzte Element des Wahrscheinlichkeitsvektors).
//--- randomize float rnd = float(MathRand() / 32767.0); //--- search if(rnd <= probability[0] || total == 1) return 0; if(rnd > probability[total - 2]) return int(total - 1);
Fällt der abgetastete Wert nicht in die Extrembereiche, werden die Elemente des Vektors auf der Suche nach dem gewünschten Wert durchlaufen.
Intuitiv kann man davon ausgehen, dass die Wahrscheinlichkeitsverteilung der Trajektorien tendenziell gleichmäßig ist. Wenn Sie in der Mitte des Vektors mit der Iteration über die Elemente beginnen und sich dabei in die gewünschte Richtung bewegen, ist dies wesentlich schneller als die Iteration über das gesamte Feld von Anfang an. Wir multiplizieren also den abgetasteten Wert mit der Größe des Vektors und erhalten einen Index des Elements. Wir überprüfen die Wahrscheinlichkeit des ausgewählten Elements anhand des Stichprobenwerts. Und wenn die Wahrscheinlichkeit geringer ist, dann erhöhen wir in der Schleife den Index, bis das gewünschte Element gefunden ist. Andernfalls machen wir das Gleiche mit einem reduzierten Index.
int result = int(rnd * total); if(probability[result] < rnd) while(probability[result] < rnd) result++; else while(probability[result - 1] >= rnd) result--; //--- return result return result; }
Das Ergebnis wird an das aufrufende Programm zurückgegeben.
Eine weitere Hilfsfunktion, die für die Implementierung der CWBC-Methode benötigt wird, ist die Rauscherzeugungsfunktion „Noise“. In den Funktionsparametern übergeben wir den Vektor der Standardabweichungen der Elemente des Belohnungsvektors und einen skalaren Koeffizienten, der den maximalen Lärmpegel bestimmt. Die Funktion gibt den Rauschvektor zurück.
vector<float> Noise(vector<float> &std, float multiplyer) { //--- check ulong total = std.Size(); if(total <= 0) return vector<float>::Zeros(0);
Im Hauptteil der Funktion wird zunächst die Größe des Vektors der Standardabweichung überprüft. Und wenn er leer ist, dann geben wir einen leeren Vektor des Rauschens zurück.
Nach erfolgreicher Übergabe des Kontrollblocks erstellen wir einen Vektor mit Nullwerten. Als Nächstes wird in einer Schleife für jedes Element des Belohnungsvektors ein separater Rauschwert erzeugt.
vector<float> result = vector<float>::Zeros(total); for(ulong i = 0; i < total; i++) { float rnd = float(MathRand() / 32767.0); result[i] = std[i] * rnd * multiplyer; } //--- return result return result; }
Wir haben separate Blöcke für die Implementierung der CWBC-Methode erstellt und gehen nun dazu über, den kompletten Trainingsalgorithmus des Agentenmodells zu implementieren, der in der Train-Methode implementiert ist.
Im Hauptteil der Methode werden die erforderlichen lokalen Variablen deklariert und die Methode GetProbTrajectories zum Wiegen der Trajektorien aufgerufen.
void Train(void) { float max_reward = 0, quantile = 0; vector<float> std; vector<float> probability = GetProbTrajectories(Buffer, max_reward, quantile, std, 0.95, 0.1f); uint ticks = GetTickCount();
Dann organisieren wir ein System von Modelltrainingsschleifen. Im Hauptteil der Schleifen rufen wir zunächst die SampleTrajectory-Methode auf, um die Trajektorie abzutasten, und wählen dann zufällig einen Zustand auf der ausgewählten Trajektorie aus, um den Lernprozess zu starten.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
Als Nächstes organisieren wir eine verschachtelte Schleife, in der das Modell auf aufeinanderfolgende Umgebungszustände trainiert wird. Für das korrekte Training und Funktionieren des Decision Transformer-Modells müssen wir die Ereignisse in strikter Übereinstimmung mit ihrer historischen Abfolge verwenden. Das Modell sammelt die empfangenen Daten, sobald sie in einem internen Puffer ankommen, und erstellt eine historische Sequenz für die Analyse.
Actions = vector<float>::Zeros(NActions); Agent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 1 - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Im Schleifenkörper sammeln wir Daten im Quelldatenpuffer. Zunächst laden wir historische Kursbewegungsdaten und analysierte Indikatorwerte herunter.
Es folgen Informationen über den Kontostand und die offenen Positionen.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Danach erzeugen wir einen Zeitstempel.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
Und wir fügen dem Puffer die Vektoren der letzten Aktionen des Agenten hinzu.
//--- Prev action if(state > 0) State.AddArray(Buffer[tr].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
Als nächstes müssen wir nur noch die Zielbezeichnung in Form von RTG in den Puffer einfügen. In diesem Block wird die Zielbezeichnung nicht bis zum Ende des Durchgangs verwendet, sondern nur für ein kleines lokales Segment. Hier schaffen wir auch einen Prozess der konservativen Regulierung. Dazu wird zunächst die Rentabilität der verwendeten Trajektorie überprüft und gegebenenfalls ein Rauschvektor erzeugt. Ich möchte Sie daran erinnern, dass nach der CWBC-Methode nur die Durchgänge mit den höchsten Erträgen mit Rauschen versehen werden.
//--- Return to go vector<float> target, result; vector<float> noise = vector<float>::Zeros(NRewards); target.Assign(Buffer[tr].States[0].rewards); if(target.Sum() >= quantile) noise = Noise(std, 100);
Anschließend berechnen wir die tatsächlichen Renditen für den lokalen historischen Zeitraum. Fügen wir den resultierenden Rauschvektor und die resultierenden Werte dem Quelldatenpuffer hinzu.
target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars) + noise; State.AddArray(target);
Nachdem wir nun einen vollständigen Satz der erforderlichen Daten generiert haben, führen wir einen Feedforward-Durchlauf des Agenten durch, um einen Vektor von Aktionen zu bilden.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Nach einem erfolgreichen Feed-Forward-Durchlauf rufen wir die Backpropagation-Methode des Agenten auf, um die Diskrepanzen zwischen den vorhergesagten und den tatsächlichen Aktionen des Agenten zu minimieren. Dieser Prozess ist ähnlich wie das Training des ursprünglichen DT.
//--- Policy study Result.AssignArray(Buffer[tr].States[state].action); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Am Ende müssen wir den Nutzer über den Fortschritt des Modelltrainings informieren und mit der nächsten Iteration unseres Modelltrainings-Schleifensystems fortfahren.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nachdem wir eine vollständige Schleife von Modell-Trainingsiterationen abgeschlossen haben, löschen wir das Kommentarfeld im Chart. Wir geben die Trainingsergebnisse in das Protokoll aus und starten die Abschaltung des Expert Advisors.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
Damit ist unsere Einführung in den Agenten-Trainingsalgorithmus abgeschlossen. Nach einem ähnlichen Prinzip wird im Expert Advisor „...\CWBC\StudyRTG.mq5“ ein Modell zur Bewertung des Umgebungszustände trainiert. Ich schlage vor, dass Sie sich in der Anlage mit dem Text vertraut machen. Die Anhänge enthalten auch alle in diesem Artikel verwendeten Programme.
Ich möchte noch auf einen weiteren Punkt eingehen. Wir haben den primären Trainingsdatensatz gebildet, indem wir die besten der gesampelten Trajektorien ausgewählt haben. Sie können bedingt als suboptimal eingestuft werden, da sie einige unserer Anforderungen erfüllen. Als Nächstes möchten wir die Strategie des Agenten optimieren, der auf diesen Daten trainiert wurde. Zu diesem Zweck müssen wir die Leistung des trainierten Modells anhand historischer Daten testen und gleichzeitig Informationen über die Möglichkeit der Optimierung der Politik sammeln. Während des nächsten Durchlaufs im Strategietester auf dem historischen Segment der Trainingsstichprobe führen wir also Aktionen innerhalb eines bestimmten Konfidenzintervalls der vom Agenten vorhergesagten Daten durch und fügen die Ergebnisse solcher Durchläufe zu unserem Erfahrungswiederholungspuffer hinzu. Danach führen wir die Iteration des nachgeschalteten Trainings der Modelle durch.
Die Funktion zum Sammeln nachgelagerter Pässe wird in den Expert Advisor „...\CWBC\Research.mq5“ implementiert. Im Rahmen dieses Artikels werden wir nicht auf alle Methoden des Expert Advisors im Detail eingehen. Betrachten wir nur die Verarbeitungsmethode der Ticks, OnTick, die die Interaktion mit der Umgebung implementiert.
Im Hauptteil der Methode wird geprüft, ob das Ereignis des Öffnens eines neuen Balkens eingetreten ist, und es werden gegebenenfalls historische Daten geladen.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Aus den gewonnenen Daten bilden wir zunächst einen Vektor von Eingabedaten zur Schätzung des Zustands und rufen den Feedforward-Durchgang des entsprechenden Modells auf.
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars - 1; b >= 0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!RTG.feedForward(GetPointer(bState), 1, false)) return;
Als nächstes bilden wir einen Tensor aus den Ausgangsdaten unseres Agenten. Achten Sie darauf, dass die Reihenfolge der Daten beim Training des Modells eingehalten wird. Hier verwenden wir anstelle des Erfahrungswiederholungspuffers Daten aus der Umgebung.
for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Parallel dazu sammeln wir die Daten in einer Struktur, die im Erfahrungswiederholungspuffer gespeichert wird.
Wir führen auch eine Umgebungserhebung durch (Anfragen an das Terminal), um Informationen über den Kontostand und offene Positionen zu sammeln.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Der Zeitstempel wird in voller Übereinstimmung mit dem Algorithmus des Lernprozesses erzeugt.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Am Ende der anfänglichen Datenvektorerfassung fügen wir die letzten Aktionen des Agenten hinzu und kehren zu „go“ von „Return-To-Go“ zurück, das von unserem Modell erzeugt wurde.
//--- Prev action bState.AddArray(AgentResult); //--- Latent representation RTG.getResults(Result); bState.AddArray(Result);
Die gesammelten Daten werden an die Feed-Forward-Methode unseres Agenten weitergeleitet, um einen Vektor von Folgeaktionen zu bilden.
//--- if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat *)NULL)) return;
Wir verzerren den Vektor der vorausschauenden Aktionen des Agenten leicht, indem wir zufälliges Rauschen hinzufügen. Damit fördern wir die Erkundung der Umgebung in einem bestimmten Umfeld von vorhersehbaren Aktionen.
Agent.getResults(AgentResult); for(ulong i = 0; i < AgentResult.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.03f; float t = AgentResult[i] + rnd; if(t > 1 || t < 0) t = AgentResult[i] - rnd; AgentResult[i] = t; } AgentResult.Clip(0.0f, 1.0f);
Danach speichern wir die für die nachfolgenden Kerzen benötigten Daten in lokalen Variablen.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Passen wir die Überschneidungsvolumina der multidirektionalen Positionen an.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(AgentResult[0] >= AgentResult[3]) { AgentResult[0] -= AgentResult[3]; AgentResult[3] = 0; } else { AgentResult[3] -= AgentResult[0]; AgentResult[0] = 0; }
Dann dekodieren wir den resultierenden Vektor der Agentenaktionen. Danach implementieren wir sie in die Umgebung.
//--- buy control if(AgentResult[0] < 0.9*min_lot || (AgentResult[1] * MaxTP * Symb.Point()) <= stops || (AgentResult[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(AgentResult[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + AgentResult[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - AgentResult[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(AgentResult[3] < 0.9*min_lot || (AgentResult[4] * MaxTP * Symb.Point()) <= stops || (AgentResult[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(AgentResult[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - AgentResult[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + AgentResult[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Als Nächstes müssen wir eine Belohnung von der Umgebung für den Übergang zum aktuellen Zustand (frühere Aktionen des Agenten) erhalten und die gesammelten Daten in den Erfahrungswiederholungspuffer übertragen.
int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Den vollständigen Code des Expert Advisors und alle seine Methoden finden Sie im Anhang.
Das trainierte Modell zum Testen des Expert Advisors „...\CWBC\Test.mq5“ folgt einem ähnlichen Algorithmus, mit Ausnahme der Verzerrung des Vektors der vom Agenten vorhergesagten Aktionen. Der Code ist auch im Anhang des Artikels enthalten.
Und nachdem wir alle notwendigen Programme erstellt haben, gehen wir dazu über, die geleistete Arbeit zu testen.
3. Tests
Im praktischen Teil unseres Artikels haben wir viel Arbeit investiert, um unsere Vision der Methode Conservative Weighted Behavioral Cloning mit MQL5 umzusetzen. Lassen Sie uns nun die Ergebnisse unserer Arbeit in der Praxis bewerten. Wie immer werden wir unsere Modelle anhand historischer EURUSD-H1-Daten trainieren und testen. Wir werden den historischen Zeitraum der ersten 7 Monate des Jahres 2023 als Trainingsdaten verwenden. Die Tests werden mit Daten vom August 2023 durchgeführt.
Wie bereits erwähnt, führen wir ein erstes Training mit den Daten durch, die im Artikel Control Transformer gesammelt wurden. Daher überspringen wir diesen Prozess und fahren sofort mit dem Modelltraining fort.
In diesem Artikel haben wir zwei Expert Advisors erstellt, um zwei Modelle zu trainieren. So können wir 2 Modelle parallel trainieren. Der Prozess kann auf verschiedenen Geräten unabhängig voneinander ausgeführt werden.
Nach dem anfänglichen Training der Modelle überprüfen wir die Leistung des trainierten Modells auf dem Trainingsdatensatz und sammeln zusätzliche Trajektorien, indem wir die Expert Advisors „...\CWBC\Research.mq5“ und „...\CWBC\Test.mq5“ im Strategietester auf dem historischen Zeitraum des Trainingsdatensatzes ausführen. Die Reihenfolge, in der die Expert Advisors in diesem Fall gestartet werden, hat keinen Einfluss auf den Prozess der Modellbildung.
Anschließend führen wir ein nachgelagertes Training mit den Daten aus dem aktualisierten Erfahrungswiederholungspuffer durch.
Hier ist anzumerken, dass in meinem Fall eine Verbesserung der Modellleistung erst nach der ersten Iteration des Downstream-Learnings zu beobachten war. Weitere Iterationen mit dem Ziel, zusätzliche Trajektorien zu sammeln und das Modell neu zu trainieren, brachten nicht das gewünschte Ergebnis. Dies könnte jedoch ein Sonderfall sein.
Während des Trainingsprozesses ist es mir gelungen, ein Modell zu erhalten, das auf dem historischen Segment der Trainingsstichprobe Gewinne erzielt.


Während des Trainingszeitraums tätigte das Modell 141 Abschlüsse. Etwa 40 % von ihnen endeten mit einem Gewinn. Der maximale Gewinn beträgt mehr als das Vierfache des maximalen Verlustes. Und der durchschnittliche Gewinn ist fast 2-mal höher als der durchschnittliche Verlust. Außerdem ist der durchschnittliche Gewinn um 13 % höher als der maximale Verlust. Daraus ergibt sich ein Gewinnfaktor von 1,11. Ähnliche Ergebnisse werden bei neuen Daten beobachtet.
Aber es gibt auch einen negativen Aspekt der erzielten Ergebnisse. Das Modell eröffnete nur Kaufpositionen, was im Allgemeinen dem globalen Trend in diesem historischen Zeitraum entspricht. Daher ist die Saldenlinie dem Chart des Handelsinstruments sehr ähnlich.


Die detaillierte Testanalyse zeigt Verluste im Februar und Mai 2023, die sich in den folgenden Monaten überschneiden. Der Monat März erwies sich als der rentabelste. Auf wöchentlicher Basis zeigte der Mittwoch die höchste Rentabilität.
Schlussfolgerung
In diesem Artikel stellen wir die Methode des konservativ gewichteten Klonens von Verhaltensweisen (CWBC) vor, das Trajektoriengewichtung und konservative Regulierung kombiniert, um die Robustheit der erlernten Strategien zu verbessern. Wir haben die vorgeschlagene Methode mit MQL5 implementiert und an realen historischen Daten getestet.
Unsere Ergebnisse zeigen, dass CWBC ein ziemlich hohes Maß an Stabilität beim Offline-Modelltraining aufweist. Die Methode ist insbesondere dann erfolgreich, wenn Trajektorien mit hohen Erträgen nur einen kleinen Teil des Trainingsdatensatzes ausmachen. Es ist jedoch zu beachten, dass die notwendigen Hyperparameter sorgfältig ausgewählt werden müssen, da sie eine wichtige Rolle für die Wirksamkeit der CWBC spielen.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Faza1.mq5 | EA | Beispielsammlung EA |
| 2 | Research.mq5 | EA | Expert Advisor für die Erfassung zusätzlicher Trajektorien |
| 3 | StudyAgentmq5 | EA | Expert Advisor zur Schulung des lokalen Politikmodells |
| 4 | StudyRTG.mq5 | EA | Expert Advisor zum Trainieren der Kostenfunktion |
| 5 | Test.mq5 | EA | Modeltest-EA |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13742
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.