
Neuronale Netze leicht gemacht (Teil 66): Explorationsprobleme beim Offline-Lernen

Einführung
Im weiteren Verlauf der Artikelserie über Methoden des Verstärkungslernens stellt sich die Frage nach dem Gleichgewicht zwischen der Erkundung der Umgebung und der Ausnutzung der erlernten Strategien. Wir haben uns bereits verschiedene Methoden überlegt, um den Agenten zur Erkundung anzuregen. Aber oft sind Algorithmen, die beim Online-Lernen hervorragende Ergebnisse erzielen, offline nicht so effektiv. Das Problem ist, dass im Offline-Modus die Informationen über die Umgebung durch die Größe des Trainingsdatensatzes begrenzt sind. In den meisten Fällen sind die für das Modelltraining ausgewählten Daten eng gefasst, da sie in einem kleinen Teilbereich der Aufgabe gesammelt werden. Dies vermittelt ein noch begrenzteres Bild von der Umgebung. Um jedoch die optimale Lösung zu finden, benötigt der Agent ein möglichst umfassendes Verständnis der Umgebung und ihrer Muster. Wir haben bereits festgestellt, dass die Lernergebnisse häufig von den Trainingsdaten abhängen.
Außerdem trifft der Agent während des Trainingsprozesses häufig Entscheidungen, die über den Unterraum des Trainingsdatensatzes hinausgehen. In solchen Fällen ist es schwierig, die späteren Ergebnisse vorherzusagen. Deshalb sammeln wir nach dem vorläufigen Modelltraining zusätzlich Trajektorien im Trainingsdatensatz, die den Lernprozess anpassen können.
Die Online-Schulung von Umgebungsmodellen kann die oben genannten Probleme manchmal entschärfen. Leider ist es jedoch aus verschiedenen Gründen nicht immer möglich, ein Umgebungsmodell zu trainieren. Oft ist die Ausbildung eines Modells sogar teurer als die Ausbildung eines Agenten. Manchmal ist es einfach unmöglich.
Die zweite offensichtliche Richtung ist die Erweiterung des Trainingsdatensatzes. Aber hier sind wir in erster Linie durch die Größe der verfügbaren Ressourcen und die Kosten für die Untersuchung der Umgebung begrenzt.
In diesem Artikel werden wir uns mit dem Rahmenwerk Exploratory Data for Offline RL (ExORL) vertraut machen, das in dem Artikel „Don't Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning“. Die in diesem Artikel vorgestellten Ergebnisse zeigen, dass die richtige Vorgehensweise bei der Datenerfassung einen erheblichen Einfluss auf die endgültigen Lernergebnisse hat. Diese Auswirkungen sind vergleichbar mit denen der Wahl des Lernalgorithmus und der Modellarchitektur.
1. Sondierungsdaten für die Offline-RL-Methode (ExORL)
Die Autoren der Methode Exploratory data for Offline RL (ExORL) bieten keine neuen Lernalgorithmen oder Architekturlösungen für Modelle an. Stattdessen liegt der Schwerpunkt auf dem Prozess der Datenerfassung zum Trainieren von Modellen. Sie führen Experimente mit fünf verschiedenen Lernmethoden durch, um den Einfluss des Inhalts des Trainingsdatensatzes auf das Lernergebnis zu bewerten.
Die ExORL-Methode kann in 3 Hauptphasen unterteilt werden. Die erste Stufe ist die Sammlung von nicht gekennzeichneten Sondierungsdaten. In dieser Phase können verschiedene unüberwachte Lernalgorithmen eingesetzt werden. Die Autoren der Methode schränken die Bandbreite der anwendbaren Algorithmen nicht ein. Darüber hinaus verwenden wir im Prozess der Interaktion mit der Umgebung in jeder Episode eine Strategie π, die von der Geschichte der vorherigen Interaktionen abhängt. Jede Episode wird im Datensatz als Folge eines Zustands St, einer Aktion At und des darauf folgenden Zustands St+1 gespeichert. Die Sammlung von Trainingsdaten wird fortgesetzt, bis der Trainingsdatensatz vollständig gefüllt ist. Die Größe dieses Trainingsdatensatzes ist durch die technischen Spezifikationen oder die verfügbaren Ressourcen begrenzt.
In der Praxis bewerten die Autoren dieses Papiers neun verschiedene Algorithmen zur unüberwachten Datenerfassung:
- Eine einfache Basislinie, die immer eine gleichmäßig zufällige Politik ausgibt.
- Methoden, die den Fehler eines Vorhersagemodells maximieren: ICM, Disagreement und RND;
- Algorithmen, die eine gewisse Schätzung der Abdeckung des Zustandsraums maximieren: APT und Proto-RL;
- Kompetenzbasierte Algorithmen, die eine Vielzahl von Fähigkeiten erlernen: DIAYN, und APS.
Nach dem Sammeln eines Datensatzes von Zuständen und Aktionen besteht der nächste Schritt darin, die Daten anhand einer vorgegebenen Belohnungsfunktion zu vergleichen. In dieser Phase wird die Belohnung für jedes Tupel im Datensatz bewertet.
In Experimenten verwenden die Autoren der Methode Standard- oder manuelle Belohnungsfunktionen. Der vorgeschlagene Rahmen ermöglicht auch das Training der Belohnungsfunktion. Das heißt, sie ermöglicht die Umsetzung der inversen RL.
Der letzte Schritt in ExORL ist das Training des Modells. Die Strategie wird mit Offline-Verstärkungslernalgorithmen auf einem markierten Datensatz trainiert. Das Offline-Training wird vollständig mit Offline-Daten aus dem Trainingsdatensatz durchgeführt, indem Tupel zufällig ausgewählt werden. Die endgültige Strategie wird dann in einer realen Umgebung bewertet.
Im Folgenden stellen die Autoren die Methode vor.
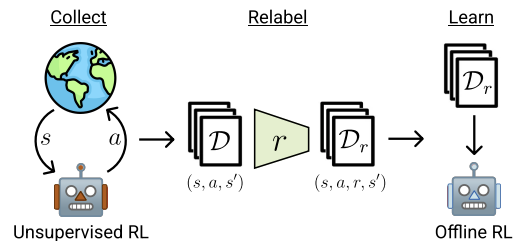
In dem Papier demonstrieren die Autoren die Ergebnisse von fünf verschiedenen Offline-Verstärkungslernalgorithmen. Die grundlegende Option ist das einfache Klonen von Verhalten. Sie präsentieren auch die Ergebnisse von drei Offline-Verstärkungslernalgorithmen, von denen jeder unterschiedliche Mechanismen verwendet, um eine Extrapolation über die Aktionen in den Daten hinaus zu verhindern. Der klassische TD3 wird auch als Basistest vorgestellt, um die Auswirkung des Offline-Modus auf Methoden zu bewerten, die ursprünglich für das Online-Lernen entwickelt wurden und keinen Mechanismus haben, der explizit die Extrapolation über den Trainingsdatensatz hinaus verhindert.
Auf der Grundlage der Ergebnisse der Experimente kommen die Autoren der Methode zu dem Schluss, dass die Verwendung diverser Daten Offline-Algorithmen für das Verstärkungslernen erheblich vereinfachen kann, da das Extrapolationsproblem nicht mehr gelöst werden muss. Die Ergebnisse zeigen, dass explorative Daten die Leistung des Offline-Verstärkungslernens bei einer Vielzahl von Problemen verbessern. Darüber hinaus erbringen zuvor entwickelte Offline-RL-Algorithmen gute Leistungen bei aufgabenspezifischen Daten, sind aber TD3 bei nicht beschrifteten ExORL-Daten unterlegen. Idealerweise sollten sich Offline-Algorithmen zum verstärkenden Lernen automatisch an den verwendeten Datensatz anpassen, um das Beste aus beiden Welten zu erhalten.
2. Implementierung mit MQL5
Die Autoren der Methode Exploratory Data for Offline RL (ExORL) geben die allgemeine Richtung für den Aufbau des Rahmens vor. In diesem Papier experimentieren die Autoren mit verschiedenen Methoden der Modellschulung. Im praktischen Teil meines Artikels beschloss ich, eine ExORL-Implementierung zu erstellen, die dem Modell aus den vorherigen Artikeln so nahe wie möglich kommt. Bitte beachten Sie jedoch einen konstruktiven Punkt. Der DWSL-Algorithmus impliziert eine Gewichtung der Aktionen aus dem S-Zustand nach ihrem Vorteil. In unserer Implementierung haben wir die nächstgelegenen Zustände aller Trajektorien durch ihre Einbettung ermittelt. Die Maßnahmen wurden in den ausgewählten Staaten nach ihren Auswirkungen auf das Ergebnis gewichtet.
Die ExORL-Methode geht jedoch von einer maximalen Vielfalt des Agentenverhaltens aus. In diesem Zusammenhang müssen wir den Abstand zwischen den Aktionen in den einzelnen Zuständen bestimmen. Die Verwendung der Entfernung zum nächstgelegenen Zustands-Aktions-Paar als Belohnung wird den Agenten ermutigen, die Umgebung zu erkunden. Daher werden wir die Zustandseinbettung auf der Grundlage der Aktion bestimmen.
Alternativ ist es möglich, den Abstand zwischen aufeinanderfolgenden Zuständen zu bestimmen. Dies erscheint recht logisch, wenn man mit einem stochastischen Umfeld arbeitet. In diesem Umfeld kann die Ausführung einer Handlung mit einer gewissen Wahrscheinlichkeit zu verschiedenen Folgezuständen führen. Aber die Verwendung solcher Algorithmen führt uns weiter weg von der DWSL-Methode, die wir als Grundlage für unsere Implementierung verwenden. Minimale Anpassungen des Basisalgorithmus werden es uns ermöglichen, die Auswirkungen des ExORL-Rahmens auf das Ergebnis der Modellschulung besser zu beurteilen.
Daher entschied ich mich für die erste Option und erhöhte die Größe der Quelldatenebene im Encoder-Modell um den Aktionsvektor des Akteurs. Ansonsten blieb die Architektur der Modelle unverändert. Sie finden sie in der Anlage. Datei „...\ExORL\Trajectory.mqh“, Methode CreateDescriptions.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor ........ ........ //--- Critic ........ ........ //--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr + NActions; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 ........ ........ //--- return true; }
Der Prozess der Sammlung von Trainingsdaten ist in dem Expert Advisor „...\ExORL\ResearchExORL.mq5“ implementiert.
Achten Sie auf die Angabe des Rahmens im Dateinamen. Der Anhang enthält die Datei „...\ExORL\Research.mq5“, die aus dem vorherigen Artikel übernommen wurde. Daher werden wir seinen Algorithmus nicht weiter erörtern.
Diese beiden Expert Advisors sind dazu gedacht, den Trainingsdatensatz aufzufüllen. Seltsamerweise werden wir den EA während des Trainingsprozesses verwenden. Aber darüber werden wir später noch sprechen. Betrachten wir nun den Algorithmus des Expert Advisors „...\ExORL\ResearchExORL.mq5“.
Die externen Parameter des EA wurden vom Basis-EA für die Interaktion mit der Umgebung übernommen.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = 10; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price input int Agent = 1;
Im Zuge der Interaktion werden wir die Umgebungsstudienpolitik für den Akteur trainieren. Für den Lernprozess benötigen wir die Modelle Kritiker (Critic) und Encoder. Um die Kosten für das Training der Sondierungspolitik zu senken und damit die Geschwindigkeit der Sammlung von Trainingsdaten zu erhöhen, habe ich beschlossen, nur einen Kritiker zu verwenden.
CNet Actor; CNet Critic; CNet Convolution;
Außerdem werden wir eine Markierung zum Laden zuvor übergebener Trajektorien und eine Matrix ihrer Einbettungen in die Liste der globalen Variablen aufnehmen.
bool BaseLoaded; matrix<float> state_embeddings;
In der Initialisierungsmethode OnInit EA werden zunächst die von uns analysierten Indikatoren initialisiert.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Geben wir die Art des Füllens des Handelsgeschäfts an.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Wir laden die vortrainierten Modelle. Wenn es keine vortrainierten Modelle gibt, erstellen wir neue Modelle, die mit zufälligen Gewichten initialisiert werden. In diesem EA habe ich beschlossen, das Laden des Modells in verschiedene Blöcke aufzuteilen, was es mir ermöglicht, einen zuvor trainierten Kritiker zu verwenden, während kein trainierter Akteur (Actor) oder Encoder vorhanden ist.
Bitte beachten Sie, dass wir bisher immer von der Notwendigkeit gesprochen haben, einen vollständigen Satz von synchronisierten Modellen zu haben. In diesem Fall verwenden wir absichtlich einen Kritiker, der getrennt vom Akteur ausgebildet wurde. Dafür gibt es einen Grund. Ich hatte die Idee, einen Algorithmus zur Synchronisierung von Gewichtungskoeffizienten zwischen Modellen in verschiedenen MetaTrader 5-Testagenten zu entwickeln. Stattdessen beschloss ich, mehrere parallel trainierte Akteurs-Sondierungsmodelle zu erstellen. Solche Modelle werden, nachdem sie mit Zufallsparametern initialisiert wurden, parallel auf historischen Daten trainiert. Obwohl sie das gleiche historische Segment verwenden, hat jedes explorative Akteursmodell seinen eigenen Lernpfad. Dadurch wird der erforschte Unterraum der Umgebung erweitert. Durch die Verwendung eines Puffers mit bereits abgeschlossenen Flugbahnen wird die Wiederholung von Trajektorien minimiert.
Um explorative Akteurs-Modelle zu identifizieren, fügen wir dem Namen der Modelldatei das Suffix „Ex“ und die Agentennummer aus den externen Parametern hinzu. Die Optimierung dieses Parameters ermöglicht es uns, im MetaTrader 5 Strategietester mehrere Sondierungsakteure parallel laufen zu lassen.
//--- load models float temp; if(!Actor.Load(StringFormat("%sAct%d.nnw", FileName, Agent), temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- }
Gleichzeitig verwenden wir ein einziges Kritikermodell, um identische Trainingsbedingungen für alle explorativen Akteure zu schaffen. Deshalb ist es wichtig, das vortrainierte Kritiker-Modell zu laden, auch wenn keine explorativen Akteurs-Modelle vorhanden sind.
if(!Critic.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Critic.Create(critic)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
Die Verwendung eines einzigen Encoder-Modells für alle Agenten ermöglicht es uns auch, einen Vergleich von Zuständen und Aktionen in einem einzigen Unterraum zu organisieren. Dies ist jedoch für den Lernprozess nicht entscheidend, da jeder Agent die zuvor durchlaufenen Bahnen unabhängig voneinander kodiert. So kann er Entfernungen richtig einschätzen und das Verhalten des Akteurs diversifizieren.
if(!Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Convolution.Create(convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
Ich stimme zu, dass der vorgestellte Code umständlich aussieht. Wahrscheinlich wäre es logisch, die Beschreibung der Modellarchitektur nach verschiedenen Methoden aufzuteilen. Aber das würde den Code nur für diesen EA vereinfachen. Andererseits würde dies den Code anderer Programme, die in dem Artikel verwendet werden, verkomplizieren. Aus diesem Grund habe ich beschlossen, die Methode zur Beschreibung der Modellarchitektur nicht zu fragmentieren.
Wir übertragen alle Modelle in einen einzigen OpenCL-Kontext. Dadurch können wir ihren Betrieb synchronisieren und die Menge der Datenkopien zwischen dem Hauptspeicher und dem OpenCL-Kontextspeicher reduzieren.
Critic.SetOpenCL(Actor.GetOpenCL());
Convolution.SetOpenCL(Actor.GetOpenCL());
Critic.TrainMode(false);
Bitte beachten Sie, dass wir den Trainingsmodus des Kritikers deaktivieren. Wir haben bereits erörtert, wie wichtig es ist, für alle Agenten, die die Umgebung erkunden, die gleichen Trainingsbedingungen zu schaffen. Dabei spielt es eine wichtige Rolle, den Kritiker in einem festen Zustand zu halten.
Danach implementieren wir die Standard-Minimalsteuerung der Modellarchitektur.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Dann initialisieren wir die globalen Variablen.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); BaseLoaded = false; bGradient.BufferInit(MathMax(AccountDescr, NActions), 0); //--- return(INIT_SUCCEEDED); }
Nach erfolgreichem Abschluss aller oben genannten Vorgänge ist die EA-Initialisierungsmethode abgeschlossen.
Bei der Programminitialisierungsmethode werden keine bereits abgeschlossenen Trajektorien geladen. Wir erstellen auch nicht ihre Einbettungen. Der Grund dafür ist, dass die Erstellung von Einbettungen früherer Zustände recht teuer und zeitaufwändig sein kann. Ihre Dauer hängt von der Anzahl der besuchten Zustände ab.
Wie bereits erwähnt, trainieren wir im Gegensatz zu den zuvor diskutierten EAs, die mit der Umgebung interagieren, in diesem Fall den explorierenden Akteur. Nach Abschluss jedes Durchgangs wird das trainierte Modell gespeichert.
void OnDeinit(const int reason) { //--- ResetLastError(); if(!Actor.Save(StringFormat("%sActEx%d.nnw", FileName, Agent), 0, 0, 0, TimeCurrent(), true)) PrintFormat("Error of saving Agent %d: %d", Agent, GetLastError()); delete Result; }
Lassen Sie uns nun kurz die erstellten Hilfsmethoden betrachten. Die Methode CreateEmbeddings implementiert den Prozess der Kodierung von Zuständen und Aktionen. Diese Methode hat keine Parameter und liefert eine Zustandseinbettungsmatrix.
Im Hauptteil der Methode werden zunächst lokale Variablen angelegt.
matrix<float> CreateEmbeddings(void) { vector<float> temp; CBufferFloat State; Convolution.getResults(temp); matrix<float> result = matrix<float>::Zeros(0, temp.Size());
Dann versuchen wir, die zuvor gesammelte Trajektorendatenbank zu laden. Wenn das Laden der Daten fehlschlägt, wird eine leere Matrix an den Aufrufer zurückgegeben.
BaseLoaded = LoadTotalBase(); if(!BaseLoaded) { PrintFormat("%s - %d => Error of load base", __FUNCTION__, __LINE__); return result; }
Wenn die Trajektoriendatenbank erfolgreich geladen ist, zählen wir die Gesamtzahl der Zustände in allen Trajektorien und ändern die Größe der zu füllenden Matrix.
int total_tr = ArraySize(Buffer); //--- int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; result.Resize(total_states, temp.Size());
Es folgt ein System von verschachtelten Schleifen zur Codierung von Zuständen und Aktionen. In der äußeren Schleife wird über die geladenen Trajektorien iteriert. In der verschachtelten Schleife werden die Zustände durchlaufen.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
Im Hauptteil des spezifizierten Schleifensystems erstellen wir zunächst einen Puffer mit Rohdaten, die den Zustand der Umgebung beschreiben. Wir übertragen historische Preis- und Indikatordaten in den angegebenen Puffer.
Dann fügen wir eine Beschreibung des Kontostands und der offenen Positionen hinzu.
float prevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float prevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - prevBalance) / prevBalance); State.Add(Buffer[tr].States[st].account[1] / prevBalance); State.Add((Buffer[tr].States[st].account[1] - prevEquity) / prevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / prevBalance); State.Add(Buffer[tr].States[st].account[5] / prevBalance); State.Add(Buffer[tr].States[st].account[6] / prevBalance);
Hinzufügen eines Zeitstempels in Form eines harmonischen Vektors.
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Fügen Sie den Aktionsvektor des Akteurs hinzu.
State.AddArray(Buffer[tr].States[st].action);
Wir übergeben den zusammengesetzten Tensor an den Encoder und rufen die Vorwärtsdurchgangs-Methode (feed-forward) auf. Die daraus resultierende Einbettung wird der Ergebnismatrix hinzugefügt.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp); if(!result.Row(temp, state)) continue; state++; } } }
Dann geht es weiter zum nächsten Zustand aus dem Trajektorienpuffer.
Nach Abschluss aller Iterationen der Zustandscodierungsschleife reduzieren wir die Größe der Ergebnismatrix auf die tatsächliche Anzahl der gespeicherten Einbettungen und löschen den Puffer der zuvor geladenen Trajektorien. Danach werden wir nur noch mit Einbettungen arbeiten.
if(state != total_states) result.Reshape(state, result.Cols()); ArrayFree(Buffer);
Jetzt geben wir das Ergebnis an das aufrufende Programm zurück und beenden die Methode.
//--- return result; }
Als Nächstes haben wir eine Methode zur Erzeugung interner Belohnungen entwickelt: ResearchReward. Um ein System zur effektiven Erkundung der Umgebung zu schaffen, wenn wir explorative Akteure trainieren, werden wir nur interne Belohnungen verwenden, die den Akteur dazu ermutigen sollen, verschiedene und sich nicht wiederholende Aktionen durchzuführen. Daher benötigen wir in diesem Stadium keine gekennzeichneten Daten oder extrinsischen Belohnungen, die den Umgebungsraum einschränken könnten. In diesem Zusammenhang sollte der Bildung von internen Belohnungen besondere Aufmerksamkeit gewidmet werden.
In den Parametern der Methode ResearchReward übergeben wir:
- Quantil der nächstgelegenen Zustände und Handlungen, die zur Bildung interner Belohnungen verwendet werden
- Einbettung des analysierten Zustands
- Zustandseinbettungsmatrix, die nach der oben vorgestellten Methode gebildet wurde
Im Hauptteil der Methode bereiten wir einen Null-Ergebnisvektor vor und prüfen, ob die Einbettungsgrößen des analysierten Zustands mit den Einbettungen in der zuvor erstellten Matrix übereinstimmen.
vector<float> ResearchReward(double quant, vector<float> &embedding, matrix<float> &state_embedding) { vector<float> result = vector<float>::Zeros(NRewards); if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
Nach erfolgreicher Übergabe des Steuerblocks initialisieren wir die lokalen Variablen.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * quant); matrix<float> temp = matrix<float>::Zeros(states, size); vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S;
Im nächsten Schritt berechnen wir den Abstand zwischen dem analysierten Zustands-Aktions-Paar, das zuvor im Erfahrungswiedergabepuffer gespeichert wurde. Um eine weiche Schätzung der Entfernungen zu erhalten, verwenden wir die Funktion LogSumExp, die von den Autoren der Methode DWSL vorgeschlagen wurde.
for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha = temp.Max(); if(alpha == 0) alpha = 1; vector<float> dist = MathLog(MathExp(temp / (-alpha)).Sum(1)) * (-alpha);
Als Nächstes wählen wir die erforderliche Anzahl von Einbettungen der nächstgelegenen Zustands-Aktions-Paare aus.
float max = dist.Quantile(quant); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
Mit Hilfe des Algorithmus der Kernnormen erzeugen wir eine interne Belohnung für die gewählte Handlung des Akteurs und den latenten Zustand.
k_embedding.SVD(U, V, S); result[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result[NRewards - 1] = EntropyLatentState(Actor); //--- return result; }
Das Ergebnis wird an das aufrufende Programm zurückgegeben.
Beachten Sie, dass im Ergebnisvektor die Elemente der extrinsischen Belohnung mit Nullwerten belassen wurden. Dies steht im Einklang mit dem ExORL-Rahmen. Der betreffende EA soll eine unkontrollierte Erkundung der Umgebung ermöglichen. Wie bereits erwähnt, wird die Verwendung von extrinsischen Belohnungen in dieser Phase den zu untersuchenden Unterraum nur einengen.
Der Prozess der Interaktion mit der Umgebung und das explorative Training des Akteurs ist in der OnTick-Tick-Verarbeitungsmethode implementiert. Bitte beachten Sie, dass der Lernprozess in dieser Phase vereinfacht wurde. Nur 1 Kritiker wird im Lernprozess eingesetzt. Darüber hinaus verzichten wir auf die Verwendung des Erfahrungswiederholungspuffers im explorativen Akteurs-Modell-Trainingsprozess. Möglicherweise wird das Fehlen dieses Puffers durch zusätzliche Durchläufe im Strategietester kompensiert.
Für jede Kerze wird ein Rückwärtsdurchgang (backpropagation) durchgeführt. Die Parameter werden auf der Grundlage der letzten Aktion des Akteurs angepasst.
Dieser Ansatz ist vielleicht nicht der wirksamste oder am einfachsten umzusetzende. Für die Bewertung der Wirksamkeit der Methode ist sie jedoch durchaus geeignet.
Prüfen Sie im Hauptteil der Methode zunächst das Auftauchen eines neuen Balkens.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Dann laden wir die historischen Daten.
//--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Als Nächstes erstellen wir die Quelldatenpuffer unseres explorativen Akteurs. Hier füllen wir zunächst den Puffer für die Beschreibung des Umgebungszustands mit den empfangenen historischen Daten auf.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Als Nächstes überprüfen wir den aktuellen Kontostand und die offenen Positionen.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Auf der Grundlage der empfangenen Daten erstellen wir einen Puffer, der den Kontostatus beschreibt.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
Zu diesem Puffer fügen wir den harmonischen Zeitstempelvektor hinzu.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Die generierten Daten reichen aus, um einen Feedforward-Durchlauf des Akteurs durchzuführen.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
Als Ergebnis eines erfolgreichen Vorwärtsdurchgangs des Akteurs erhalten wir einen Vektor prädiktiver Aktionen, den wir entschlüsseln und an die Umgebung weiterleiten.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Erstens interagieren wir mit der Umgebung als Teil einer langfristigen Position.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Wiederholen Sie den Vorgang für die kurze Position.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Die Ergebnisse der Interaktion mit der Umgebung werden dann in einer Struktur zur Beschreibung von Zuständen und Handlungen zusammengefasst. Dann fügen wir die extrinsische Belohnung hinzu. Danach fügen Sie all dies der Trajektorie hinzu, die auf der Grundlage der Durchgangsergebnisse in den Erfahrungswiedergabepuffer aufgenommen wird.
//--- sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove();
Achten Sie auf den Belohnungsvektor. Bisher haben wir von unkontrollierter Erkundung gesprochen, während der Vektor mit externen Belohnungen gefüllt ist. Die Elemente der internen Belohnung werden dagegen mit Nullwerten belassen. Beachten Sie, dass die gespeicherten Trajektorien verwendet werden, um die Hauptakteurspolitik in Stufe 3 des ExORL-Rahmens zu trainieren. Die Population des Belohnungspuffers ist jedoch die Umsetzung von Stufe 2, die sich auf die Neubewertung von Zuständen und Aktionen bezieht. Daher passen alle unsere Aktionen in den Rahmen des ExORL-Algorithmus.
Wie Sie sehen können, ist der oben vorgestellte Algorithmus fast identisch mit den Methoden der Interaktion mit der Umgebung, die wir zuvor besprochen haben. Aber hier schließen wir den Vorgang der Methode nicht ab, wie zuvor. Stattdessen gehen wir zur Umsetzung des Lernprozesses für die explorative Akteurspolitik über.
Zunächst brauchen wir die Einbettung des aktuellen Zustands und der abgeschlossenen Aktion. Um sie zu erhalten, fügen wir Informationen über den Kontostatus und die von dem Akteur durchgeführte Aktion in den Puffer des aktuellen Umgebungsstatus ein. Der resultierende Puffer wird in den Encoder-Eingang eingespeist und die Feedforward-Methode aufgerufen.
bState.AddArray(GetPointer(bAccount)); bState.AddArray(temp); bActions.AssignArray(temp); if(!Convolution.feedForward(GetPointer(bState), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Convolution.getResults(temp);
Als Ergebnis erfolgreicher Operationen erhalten wir eine Einbettung des aktuellen Zustands.
Als Nächstes prüfen wir, ob es geladene Daten über zuvor zurückgelegte Trajektorien gibt, und kodieren sie gegebenenfalls, indem wir die oben vorgestellte Methode CreateEmbeddings aufrufen.
if(!BaseLoaded) { state_embeddings = CreateEmbeddings(); BaseLoaded = true; }
Bitte beachten Sie, dass wir unabhängig vom Ergebnis der Operationen das Datenladeflag auf true setzen. Dadurch können wir in Zukunft wiederholte Versuche, die Datenbank mit den übergebenen Zuständen zu laden, vermeiden.
Als Nächstes prüfen wir die Größe der Zustandseinbettungsmatrix. Ist die Gröse der Matrix Null, kann das darauf hinweisen, dass es keine zuvor zurückgelegten Wege gibt. In diesem Fall haben wir keine Daten, um die Modellparameter in diesem Stadium zu aktualisieren. Daher fügen wir der Matrix einfach die Einbettung des aktuellen Zustands hinzu. Dann gehen wir dazu über, die Eröffnung der nächsten Kerze abzuwarten.
ulong total_states = state_embeddings.Rows(); if(total_states <= 0) { ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError()); return; }
Wenn in der übergebenen Zustandseinbettungsmatrix Daten vorhanden sind, erzeugen wir eine interne Belohnung und fügen die aktuelle Zustandseinbettung zur Matrix hinzu.
vector<float> rewards = ResearchReward(Quant, temp, state_embeddings); ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError());
Es ist sehr wichtig, dass die aktuelle Zustandseinbettung erst nach der Generierung einer internen Belohnung zur Matrix der übergebenen Zustandseinbettungen hinzugefügt wird. Andernfalls wird die aktuelle Einbettung bei der Berechnung der internen Belohnung zweimal berücksichtigt, was zu einer Verzerrung der Daten führen kann.
Andererseits ist es bei einem vollständigen Ausschluss des Prozesses des Hinzufügens von Einbettungen zur Matrix nicht möglich, den aktuellen Passstatus bei der Generierung interner Belohnungen zu berücksichtigen.
Wir übertragen die erzeugte interne Belohnung in den Datenpuffer. Danach führen wir die Vorwärts- und Rückwärtsdurchgänge für den Kritiker durch. Danach folgt der Rückwärtsdurchgang für die Erkundung des Akteur.
Result.AssignArray(rewards); if(!Critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(bActions)) || !Critic.backProp(Result, GetPointer(bActions), GetPointer(bGradient)) || !Actor.backPropGradient(GetPointer(bAccount), GetPointer(bGradient), LatentLayer)) PrintFormat("%s -> %d: Error of backpropagation %", __FUNCTION__, __LINE__, GetLastError()); }
Bitte beachten Sie, dass wir in diesem Fall innerhalb eines Vorgangs sequenzielle Aufrufe der Methoden der Vorwärts- und Rückwärtsdurchgänge des Kritiker implementieren. Das liegt daran, dass wir in diesem Fall den Kritiker nicht trainieren und die Ergebnisse seines Vorwärtsdurchgang nicht auswerten. Wir brauchen ihn nur, um den Fehlergradienten an den Akteur zu übertragen. Daher werden beide Methoden als Teil des Rückwärtsdurchgangs-Verfahrens des Akteurs aufgerufen. Dies führte zu einer so ungewöhnlichen Anordnung der Methodenaufrufe, die im Übrigen keine Auswirkungen auf das Endergebnis hat.
Damit ist die Beschreibung der Methode der Interaktion mit der Umgebung und des Online-Lernens der explorativen Akteurspolitik abgeschlossen. Andere EA-Methoden werden ohne Änderungen verwendet. Sie finden sie in der Anlage.
Wir gehen nun dazu über, den Expert Advisor für die Modellschulung anzupassen. Auch wenn die Autoren der Methode in ihren Experimenten grundlegende Methoden für das Training von Modellen verwendeten, erforderte die Umsetzung unseres Ansatzes einige Änderungen an der Trainings-EA aus dem vorherigen Artikel. Die Änderungen waren hauptsächlich auf Änderungen in der Encoder-Architektur zurückzuführen, die zu Änderungen im Zusammenhang mit der Interaktion mit dem Modell führten. Aber das Wichtigste zuerst.
Die vorgenommenen Änderungen sind nicht global. Daher werden wir uns nur auf die Betrachtung der Modelltrainingsmethode „Train“ konzentrieren. Im Hauptteil der Methode wird die Anzahl der geladenen Trajektorien überprüft.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Dann zählen wir die Gesamtzahl der Zustände in diesen Trajektorien.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total;
Als Nächstes bereiten wir lokale Variablen vor.
vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
Danach organisieren wir ein System von Schleifen, um die zuvor übergebenen Zustände zu kodieren und eine Einbettungsmatrix zu erstellen. Dieser Prozess ähnelt dem oben beschriebenen Verfahren. Es gibt jedoch einen Vorbehalt.
Wie zuvor füllen wir im Hauptteil des Schleifensystems den Puffer für den aktuellen Umgebungszustand.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
Fügen wir den Kontostatus und die offenen Positionen hinzu.
float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance);
Wir fügen einen Zeitstempel in Form eines harmonischen Vektors hinzu.
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Anstelle eines Aktionsvektors übergeben wir jedoch einen Nullvektor mit der entsprechenden Länge.
State.AddArray(vector<float>::Zeros(NActions));
Diese Lösung eliminiert den Einfluss abgeschlossener Aktionen auf die Zustandseinbettung. Damit kehren wir zur Implementierung der DWSL-Methode aus dem vorherigen Artikel zurück und gleichen die Änderungen in der Encoder-Architektur aus. In Übereinstimmung mit den Empfehlungen der Autoren der ExORL-Methode verwenden wir daher unveränderte Methoden für das Training der Modelle. In diesem Fall verwenden wir beim Training aller Modelle einen State-Action-Encoder. Dies ermöglicht ein korrektes Training sowohl der Sondierungs- als auch der Hauptakteurs-Politik.
Als Nächstes führen wir einen Feedforward-Durchlauf des Encoders durch. Das Ergebnis der Operationen in Form der Zustandseinbettung wird der Matrix hinzugefügt.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); if(!state_embedding.Row(temp, state)) continue;
Gleichzeitig füllen wir die Aktions- und Belohnungsmatrizen, die im Lernprozess verwendet werden, gemäß dem DWSL-Algorithmus auf. Wie zuvor wird die Belohnungsmatrix mit den Werten der Vorteile der durchgeführten Aktionen gefüllt.
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue; state++;
Wir informieren den Nutzer über den Fortschritt der Zustandscodierung und fahren mit der nächsten Iteration des Schleifensystems fort.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
Nach erfolgreichem Abschluss aller Iterationen der Zustandscodierung reduzieren wir die Matrixgrößen auf die tatsächlich gespeicherte Datenmenge. Anders als bei der oben beschriebenen CreateEmbeddings-Kodierungsmethode wird das Trajektorien-Array jedoch nicht gelöscht, da es beim Training der Modelle weiterhin benötigt wird.
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
}
Als Nächstes müssen wir den Lernprozess organisieren. Zunächst erstellen wir lokale Variablen und bilden einen Vektor von Trajektorienauswahlwahrscheinlichkeiten.
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr;
Dann erstellen wir eine Trainingsschleife. Im Hauptteil der Schleife werden die Trajektorie und der Zustand auf ihr abgetastet.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Dann prüfen wir, ob die Belohnung vor dem Ende der Episode generiert werden muss. Wenn er generiert werden muss, füllen wir den Puffer mit dem nachfolgenden Zustand der Umgebung.
target_reward = vector<float>::Zeros(NRewards); //--- Target if(iter >= StartTargetIter) { State.AssignArray(Buffer[tr].States[i + 1].state);
Wir füllen sofort den Puffer mit der Beschreibung des nachfolgenden Kontostands und der offenen Positionen.
float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
Fügen wir harmonisierte Zeitstempels hinzu.
double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Die generierten Daten reichen aus, um den Vorwärtsdurchgang des Akteurs durchzuführen, der eine Aktion in Übereinstimmung mit der aktualisierten Politik erzeugt.
//--- if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Die resultierende Aktion wird von 2 Zielkritikern bewertet.
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2);
Wir verwenden die niedrigere der beiden Schätzungen als erwartete Belohnung und addieren die Entropie des latenten Zustands dazu.
target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
Im nächsten Schritt trainieren wir das Kritiker-Modell. Zu diesem Zweck bilden wir einen Vektor, der den aktuellen Zustand der Umgebung beschreibt.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
Wir bilden einen Vektor, der den Kontostand und die offenen Positionen beschreibt, ergänzt durch harmonisierte Zeitstempel.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Danach der Vorwärtsdurchgang für den Akteur.
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wie Sie sich vielleicht erinnern, verwenden wir tatsächliche Handlungen, die während der Interaktion mit der Umgebung ausgeführt werden, um Kritiker zu trainieren. Aber wir brauchen den Vorwärtsdurchlauf des Akteurs, um den latenten Zustand zu bilden.
Als Nächstes kopieren wir die tatsächlichen Aktionen aus der Trainingsmenge in den Datenpuffer und führen einen Vorwärtsdurchgang der Kritiker durch.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Danach nehmen wir den Puffer mit der aktuellen Umgebungszustandsbeschreibung und fügen ihm Daten über den Kontostand und einen Nullvektor hinzu, um die Aktionen des Akteurs zu ersetzen. Dann erzeugen wir eine Einbettung des analysierten Zustands der Umgebung.
if(!State.AddArray(GetPointer(Account)) || !State.AddArray(vector<float>::Zeros(NActions)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
Auf der Grundlage der empfangenen Einbettung erstellen wir eine Struktur von Zielen, um Modelle zu trainieren. Der Algorithmus der Methode, die die Zielwerte erzeugt, wurde im vorherigen Artikel beschrieben.
target = GetTargets(Quant, temp, state_embedding, rewards, actions);
In diesem Schritt haben wir alle notwendigen Daten für den Rückwärtsdurchgang der Kritiker. Da wir jedoch den Fehlergradientenvektor mit der Methode CAGrad korrigieren werden, müssen wir die Modelle nacheinander trainieren.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
In diesem Schritt trainieren wir die grundlegende Strategie des Akteurs. Wie bisher werden wir eine Kombination von Ansätzen zur Schulung der Politik verwenden. Zunächst verwenden wir den DWSL-Algorithmus und trainieren den Akteur auf die Wiederholung von Aktionen, gewichtet nach ihrem Einfluss auf das Endergebnis.
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Danach passen wir die Aktionen des Akteurs in Richtung Ergebniserhöhung an. Die zweite Stufe des Trainings wird nur dann eingesetzt, wenn wir von der Richtigkeit der Beurteilung der Handlungen durch den Kritiker überzeugt sind.
//--- CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
Am Ende der Iterationen des Trainingsprozesses passen wir die Parameter der Zielmodelle an.
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
Wir informieren den Nutzer über den Fortschritt des Lernprozesses und gehen zur nächsten Iteration der Lernschleife über.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nach Abschluss der gesamten Modelltrainingsschleife löschen wir den Kommentar im Chart. Wir geben die Trainingsergebnisse im Protokoll aus und leiten den Prozess zur Beendigung des EA-Vorgangs ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Damit ist die Beschreibung der Algorithmen der verwendeten Programme abgeschlossen. Der vollständige Code aller in diesem Artikel verwendeten Programme ist im Anhang verfügbar. Wir gehen jetzt dazu über, die geleistete Arbeit zu testen.
3. Tests
In den vorangegangenen Abschnitten dieses Artikels haben wir uns mit der Methode Exploratory Data for Offline RL vertraut gemacht und unsere Vision der vorgestellten Methode mit MQL5 umgesetzt. Nun ist es an der Zeit, die Ergebnisse zu bewerten. Wie immer wird das Training und Testen der Modelle auf EURUSD H1 durchgeführt. Die Indikatoren werden mit Standardparametern verwendet. Die Modelle werden mit historischen Daten für die ersten 7 Monate des Jahres 2023 trainiert. Um das trainierte Modell zu testen, verwenden wir historische Daten vom August 2023.
Der in diesem Artikel vorgestellte Algorithmus ermöglicht das Training völlig neuer Modelle. Das ist eine Ausbildung von Grund auf. Die Methode ermöglicht jedoch auch eine Feinabstimmung der zuvor trainierten Modelle. Also beschloss ich, die zweite Option zu testen. Wie ich bereits zu Beginn des Artikels sagte, habe ich die EAs aus dem vorherigen Artikel als Grundlage für diese Arbeit verwendet. Wir werden dieses Modell optimieren. Zunächst müssen wir die Modelldateien umbenennen.
| DWSL.bd | ==> | ExORL.bd |
| DWSLAct.nnw | ==> | ExORLAct.nnw |
| DWSLCrt1.nnw | ==> | ExORLCrt1.nnw |
| DWSLCrt2.nnw | ==> | ExORLCrt2.nnw |
Wir übertragen das Encoder-Modell nicht, weil wir seine Architektur geändert haben.
Nach der Umbenennung der Dateien starten wir den EA ResearchExORL.mq5 zur weiteren Untersuchung der Umgebung anhand der Trainingsdaten. Bei meiner Arbeit habe ich 100 zusätzliche Durchgänge von 5 Prüfern gesammelt.
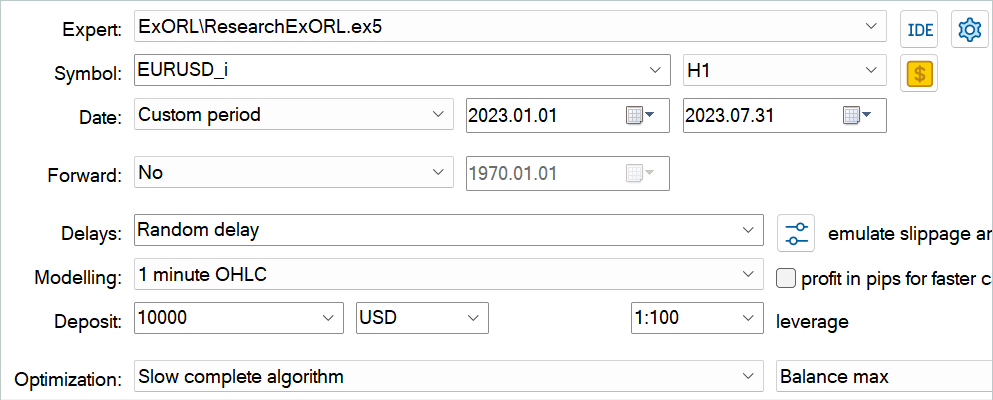
Die praktische Erfahrung zeigt die Möglichkeit der parallelen Nutzung in einem Wiedergabepuffer, der mit verschiedenen Methoden gesammelt wird. Ich habe sowohl die Trajektorien verwendet, die von der zuvor besprochenen EA Research.mq5 gesammelt wurden, als auch die EA ResearchExORL.mq5. Der erste zeigt die Vor- und Nachteile der erlernten Akteurspolitik auf. Die zweite ermöglicht es uns, die Umgebung so weit wie möglich zu erkunden und die noch nicht berücksichtigten Möglichkeiten zu bewerten.
Im Laufe des iterativen Modelltrainings ist es mir gelungen, seine Leistung zu verbessern.


Während die Anzahl der Handelsgeschäfte während des Testzeitraums generell auf ein Drittel zurückging (56 gegenüber 176), stiegen die Gewinne um fast das Dreifache. Der Betrag des maximal profitablen Handelsgeschäfts hat sich mehr als verdoppelt. Und das durchschnittliche, profitable Handelsgeschäft stieg um das Fünffache. Außerdem ist ein Anstieg des Saldos während des gesamten Testzeitraums zu beobachten. Infolgedessen hat sich der Gewinnfaktor des Modells von 1,3 auf 2,96 erhöht.
Schlussfolgerung
In diesem Artikel stellen wir eine neue Methode vor, die Explorationsdaten für Offline-RL, die sich hauptsächlich auf den Ansatz zur Sammlung von Daten für den Trainingsdatensatz für das Offline-Modelltraining konzentriert. Die von den Autoren der Methode durchgeführten Experimente machen das Problem der Auswahl der Quelldaten zu einem der wichtigsten, das das Ergebnis ebenso beeinflusst wie die Wahl der Modellarchitektur und der Trainingsmethode.
Im praktischen Teil unseres Artikels haben wir unsere Vision der vorgeschlagenen Methode umgesetzt und sie mit historischen Daten aus dem MetaTrader 5 Strategietester getestet. Die Tests bestätigen die Schlussfolgerungen der Autoren der Methode hinsichtlich des Einflusses des Algorithmus zur Sammlung von Übungsproben auf das Ergebnis der Modellschulung. Durch eine Änderung des Ansatzes für die Sammlung von Trainingstrajektorien konnten wir also die Leistung des im vorherigen Artikel vorgestellten Modells optimieren.
Ich möchte Sie jedoch noch einmal daran erinnern, dass alle in diesem Artikel vorgestellten Programme nur der Demonstration der Technologie dienen und nicht für den Einsatz im realen Handel vorbereitet sind.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | Beispielsammlung EA |
| 2 | ResearchExORL.mq5 | EA | EA für die Sammlung von Beispielen mit der ExORL-Methode |
| 3 | Study.mq5 | EA | Trainings-EA des Agenten |
| 4 | Test.mq5 | EA | Modeltraining-EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13819
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.