
Neuronale Netze leicht gemacht (Teil 87): Zeitreihen-Patching

Einführung
Die Vorhersage spielt eine wichtige Rolle in der Zeitreihenanalyse. Tiefe Modelle haben in diesem Bereich erhebliche Verbesserungen gebracht. Neben der erfolgreichen Vorhersage zukünftiger Werte extrahieren sie auch abstrakte Darstellungen, die für andere Aufgaben wie die Klassifizierung und die Erkennung von Anomalien verwendet werden können.
Die Architektur des Transformers, die ursprünglich aus dem Bereich der Verarbeitung natürlicher Sprache (NLP) stammt, hat ihre Vorteile in der Computer Vision (CV) bewiesen und wird erfolgreich in der Zeitreihenanalyse eingesetzt. Sein Self-Attention-Mechanismus, der automatisch Beziehungen zwischen Elementen einer Zeitreihe erkennen kann, ist zur Grundlage für die Erstellung effektiver Prognosemodelle geworden.
In dem Maße, in dem die für die Analyse verfügbaren Datenmengen wachsen und die Methoden des maschinellen Lernens verbessert werden, wird es möglich, genauere und effizientere Modelle für die Analyse von Zeitdaten zu entwickeln. Da die Komplexität der Zeitreihen jedoch zunimmt, müssen wir effizientere und weniger kostspielige Analysemethoden entwickeln, um genaue Prognosen zu erstellen und verborgene Muster zu erkennen.
Eine dieser Methoden ist Patch Time Series Transformer, PatchTST, die in dem Artikel „A Time Series is Worth 64 Words: Long-term Forecasting with Transformers“. Diese Methode basiert auf der Unterteilung von Zeitreihen in Segmente (Patches) und der Verwendung von Transformer zur Vorhersage zukünftiger Werte.
Die Zeitreihenprognose zielt darauf ab, die Korrelation zwischen den Daten in jedem Zeitschritt zu verstehen. Ein einzelner Zeitschritt hat jedoch keine semantische Bedeutung. Daher ist die Extraktion lokaler semantischer Informationen wichtig für die Analyse von Datenbeziehungen. Die meisten früheren Arbeiten verwenden nur Eingabe-Token für Punkt-Zeit-Schritte. PatchTST hingegen verbessert die Lokalisierung und erfasst komplexe semantische Informationen, die auf Punktebene nicht verfügbar sind, indem es Zeitschritte zu Patches auf Unterserienebene zusammenfasst.
Außerdem ist eine multivariate Zeitreihe ein Mehrkanalsignal, und jedes Eingabe-Token kann Daten von einem oder mehreren Kanälen darstellen. Je nach der Struktur des Eingabe-Tokens gibt es verschiedene Optionen für die Architektur des Transformers. Die Kanalmischung bezieht sich auf den letzteren Fall, bei dem das Eingabe-Token einen Vektor aller Zeitreihenmerkmale nimmt und ihn in den Einbettungsraum projiziert, um die Informationen zu mischen. Auf der anderen Seite bedeutet Kanalunabhängigkeit, dass jedes Eingangs-Token Informationen nur einem Kanal enthält. Dies hat sich bereits bei Faltungsmodellen und linearen Modellen bewährt. PatchTST demonstriert die Wirksamkeit des Ansatzes der unabhängigen Kanäle in Transformator-basierten Modellen.
Die Autoren von PatchTST heben die folgenden Vorteile der vorgeschlagenen Methode hervor:
- Reduktion der Komplexität: Patching ermöglicht die Verringerung der zeitlichen und räumlichen Komplexität eines Modells und erhöht damit seine Effizienz bei größeren Datensätzen.
- Verbessertes Lernen durch längeres Rückblicksfenster: Patches ermöglichen es dem Modell, über längere Zeiträume zu lernen, was die Qualität der Vorhersagen verbessern kann.
- Repräsentationslernen: Das vorgeschlagene Modell ist nicht nur effektiv in der Vorhersage, sondern auch in der Lage, komplexere abstrakte Darstellungen von Daten zu extrahieren, was seine Generalisierungsfähigkeit verbessert.
Die in der Arbeit des Autors vorgestellten Studien zeigen die Wirksamkeit der vorgeschlagenen Methode und ihr Potenzial für verschiedene angewandte Probleme der Zeitreihenanalyse.
1. Der PatchTST-Algorithmus
Die Methode PatchTST wurde für die Analyse und Vorhersage multivariater Zeitreihen entwickelt, bei denen jeder Zustand des analysierten Systems durch einen Vektor von Parametern beschrieben wird. In diesem Fall enthält die Größe des Beschreibungsvektors jedes Zeitschritts die gleiche Anzahl von Parametern mit einer identischen Datenstruktur. So können wir die allgemeine multivariate Zeitreihe in mehrere univariate Zeitreihen unterteilen, je nach der Anzahl der Parameter, die den Zustand des Systems beschreiben.
Wie bei den zuvor betrachteten Methoden bringen wir zunächst die Eingangsdaten des Modells in eine vergleichbare Form, indem wir sie normalisieren. Dieser Schritt ist sehr wichtig. Wir haben bereits mehrfach diskutiert, dass die Verwendung normalisierter Daten am Modelleingang die Stabilität des Trainingsprozesses deutlich erhöht. Obwohl die PatchTST-Methode eine kanalunabhängige Analyse von univariaten Zeitreihen impliziert, wird die Analyse mit einem einzigen Satz von Trainingsparametern durchgeführt. Daher ist es sehr wichtig, dass die analysierten Daten aus allen Kanälen in einer vergleichbaren Form vorliegen.
Der nächste Schritt ist das Patchen univariater Zeitreihen, was die Modellierung lokaler Muster ermöglicht und die Verallgemeinerungsfähigkeit des Modells erhöht. In diesem Schritt schlagen die Autoren der PatchTST-Methode vor, die Zeitreihe in Patches fester Größe mit einem festen Schritt zu unterteilen. Die Methode funktioniert sowohl bei überlappenden als auch bei nicht überlappenden Patches gleichermaßen gut. Im ersten Fall ist der Schritt kleiner als die Patch-Größe, und im zweiten Fall sind beide Hyperparameter gleich. Beide Patching-Ansätze ermöglichen die Erkundung lokaler semantischer Informationen. Die Wahl einer bestimmten Methode hängt weitgehend von der Aufgabe und der Größe des analysierten Eingabefensters ab.
Natürlich ist die Anzahl der Patches kleiner als die Länge der Zeitreihe. Je größer der Patching-Schritt ist, desto größer ist der Unterschied. Daher wird die maximale Differenz zwischen der Anzahl der Patches und der Länge der Zeitreihe bei nicht überlappenden Patches erreicht. In diesem Fall wird die Verkleinerung in Vielfachen der Schrittweite vorgenommen. Dadurch können längere Zeitreihen mit denselben oder sogar geringeren Speicher- und Rechenressourcen analysiert werden.
Bei der Analyse eines kleinen Eingabefensters empfiehlt es sich, überlappende Patches zu verwenden, die eine qualitativere Untersuchung der lokalen semantischen Abhängigkeiten ermöglichen.
Wir erstellen Patches für jede einzelne univariate Zeitreihe, aber mit denselben Patching-Parametern für alle.
Danach arbeiten wir mit den bereits erstellten Patches. Wir erstellen Einbettungen für sie. Wir fügen eine trainierbare Positionskodierung hinzu und geben sie an einen Block aus mehreren Vanilla-Transformer-Encoder-Schichten weiter.
Wir werden nicht näher auf die Transformer-Architektur eingehen, da wir sie bereits zuvor besprochen haben. Bitte beachten Sie, dass der Transformer Encoder Abhängigkeiten innerhalb univariater Zeitreihen separat analysiert. Für die Analyse aller univariaten Zeitreihen werden jedoch die gleichen Lernparameter verwendet.
Ein Transformer ermöglicht die Extraktion abstrakter Darstellungen aus Eingabepatches unter Berücksichtigung ihrer zeitlichen Abfolge und ihres Kontexts. Daher enthalten die am Ausgang des Encoders erhaltenen Darstellungen Informationen über die Beziehungen zwischen den Patches und die Muster innerhalb jedes Feldes. Die auf diese Weise verarbeiteten univariaten Zeitreihendarstellungen werden verkettet. Der resultierende Tensor kann zur Lösung verschiedener Probleme verwendet werden. Sie werden in den „Entscheidungskopf“ eingespeist, um den Output des Modells zu erzeugen.
Bitte beachten Sie, dass die Autoren der Methode vorschlagen, ein Modell zu verwenden, um verschiedene Probleme mit einem Eingabedatensatz zu lösen. Dies kann die Suche nach Anomalien, die Klassifizierung oder die Vorhersage von Zeitreihendaten über verschiedene Planungshorizonte sein. Zum Feinabstimmen (neu trainieren) des Modells muss nur der „Entscheidungskopf“ ausgetauscht werden.
Bei der Vorhersage nachfolgender Zeitreihendaten denormalisieren wir die Daten am Modellausgang, indem wir statistische Merkmale zurückgeben, die aus den Eingabedaten extrahiert wurden.
Im Folgenden wird die Visualisierung der Methode durch den Autor vorgestellt.
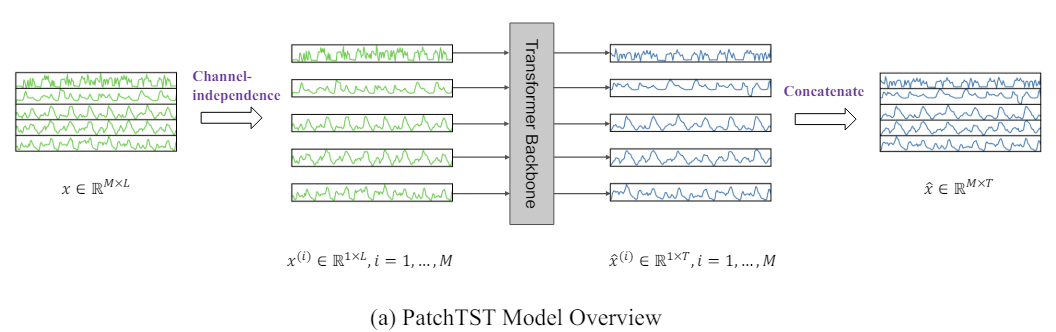
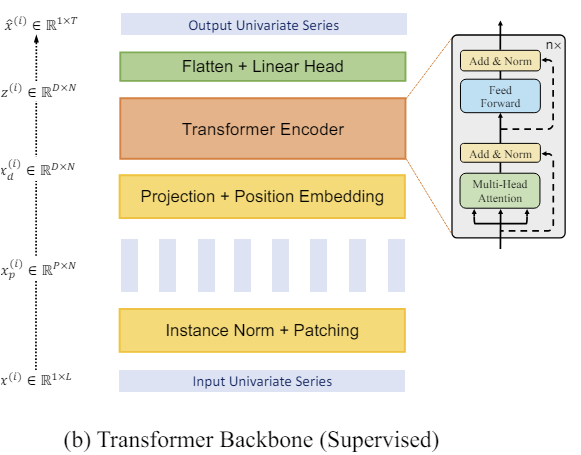
2. Implementierung in MQL5
Wir haben uns mit den theoretischen Aspekten der Methode befasst. Nun können wir uns der praktischen Umsetzung der vorgeschlagenen Ansätze mit MQL5 zuwenden.
Auch hier werden wir unsere Vorstellung von den vorgeschlagenen Ansätzen umsetzen, die sich von der Idee der ursprünglichen Autoren unterscheiden kann.
Wie aus der oben dargestellten theoretischen Beschreibung der PatchTST-Methode hervorgeht, basiert sie auf dem Input-Patching und der Aufteilung der multivariaten Zeitreihen in separate univariate Sequenzen.
Der erste Schritt im Datenverarbeitungsfluss ist das Patching, also die Aufteilung der Eingabedaten in kleinere Informationsblöcke. Bei nicht überlappenden Patches kann man sich dies als Umformatierung eines 2-dimensionalen Eingabetensors in einen 3-dimensionalen Tensor vorstellen. Bei sich überschneidenden Patches ist es etwas komplizierter, da Daten kopiert werden müssen. Aber in jedem Fall erhalten wir am Ausgang einen 3-dimensionalen Tensor: „Anzahl der Variablen * Anzahl der Patches * Patchgröße“.
Die Transformation des Eingabedatentensensors impliziert Datenkopiervorgänge. Wir möchten unnötige Vorgänge, einschließlich des Kopierens, abschaffen. Denn jeder zusätzliche Vorgang kostet uns Zeit und Ressourcen.
Achten wir auf die folgenden Vorgänge. Der nächste Schritt im Arbeitsablauf ist die Dateneinbettung. Eine logische Lösung wäre es, die beiden Vorgänge zu kombinieren. Eigentlich führen wir nur den Vorgang der Dateneinbettung durch. Um die Operation durchzuführen, werden wir jedoch einzelne Blöcke aus dem Eingabedatentensor nehmen, die unseren Patches entsprechen.
Wir haben uns bereits mit Faltungsschichten beschäftigt. In diesen Schichten nehmen wir ebenfalls einen Eingabeblock in der Größe eines bestimmten Fensters und erhalten nach einer Faltungsoperation mit mehreren Filtern einen Projektionsvektor des analysierten Datenfensters in einen bestimmten Unterraum. Sieht aus wie das, was wir brauchen. Die Faltungsschicht, die wir zuvor erstellt haben, arbeitet jedoch mit einem eindimensionalen Eingabetensor. Sie erlaubt es uns nicht, einzelne univariate Zeitreihen aus dem allgemeinen Tensor einer multivariaten Zeitreihe zu isolieren. Wir müssen also etwas Ähnliches schaffen, aber mit der Möglichkeit, innerhalb einzelner univariater Sequenzen zu arbeiten.
2.1 OpenCL-seitiges Patchen
Zunächst ergänzen wir das OpenCL-Programm, indem wir Kernel für die Feed-Forward- und Backward-Data-Patching-Durchgänge mit ihrer Projektion in einen bestimmten Unterraum von Einbettungen erstellen. Beginnen wir mit dem Feedforward-Pass Kernel PatchCreate.
In den Kernel-Parametern werden Zeiger auf 3 Datenpuffer übergeben: Eingaben, Gewichtungsmatrix und Ausgaben. Zusätzlich werden wir 4 Konstanten zu den Kernel-Parametern hinzufügen. In diesen Konstanten geben wir die volle Größe des Eingabedatentensensors an, um einen Fehler zu vermeiden, der außerhalb des Bereichs liegt. Wir spezifizieren die Patchgröße und den Schritt. Wir werden dem Nutzer auch die Möglichkeit geben, eine Aktivierungsfunktion hinzuzufügen.
__kernel void PatchCreate(__global float *inputs, __global float *weights, __global float *outputs, int inputs_total, int window_in, int step, int activation ) { const int i = get_global_id(0); const int w = get_global_id(1); const int v = get_global_id(2); const int window_out = get_global_size(1); const int variables = get_global_size(2);
Wir gehen davon aus, dass der Kernel in einem dreidimensionalen Aufgabenraum ausgeführt wird: die Anzahl der Patches, die Position des Elements im Einbettungsvektor des analysierten Patches und die Kennung der Variablen in den Quelldaten. Ich möchte Sie daran erinnern, dass wir die Segmentierung im Rahmen unabhängiger univariater Zeitreihen konstruieren.
Im Kernelkörper identifizieren wir den Thread über alle 3 Dimensionen des Aufgabenraums. Wir bestimmen auch die Dimensionen des Aufgabenraums.
Auf der Grundlage der empfangenen Daten können wir dann die Verschiebung in den Datenpuffern zu den analysierten Elementen bestimmen.
const int shift_in = i * step * variables + v; const int shift_out = (i * variables + v) * window_out + w; const int shift_weights = (window_in + 1) * (v * window_out + w);
Bei der Bestimmung einer Verschiebung (shift) im Eingangspuffer gehen wir von folgenden Annahmen aus:
- Der Eingabetensor enthält eine Folge von Vektoren, die den Zustand der Umgebung in einem bestimmten Zeitschritt beschreiben. Mit anderen Worten: Der Eingabetensor ist eine 2-dimensionale Matrix, deren Zeilen Beschreibungen des Zustands der Umgebung zu einem bestimmten Zeitschritt enthalten. Die Spalten der Matrix entsprechen den einzelnen Parametern (Variablen), die den Zustand der analysierten Umgebung beschreiben.
- Mit der PatchTST-Methode werden einzelne univariate Zeitreihen analysiert. Daher enthält jeder Parameter (Variable), der den Zustand der Umgebung beschreibt, nur ein Element des Vektors und wird unabhängig von den anderen (innerhalb der gesamten Zeitreihe) geändert.
Denken Sie an diese Annahmen. Dementsprechend müssen wir die Eingabedaten auf der Seite des Hauptprogramms vorbereiten, bevor wir sie an das Modell übertragen.
Anschließend wird eine Schleife organisiert, um den Segmentvektor mit dem entsprechenden Gewichtsvektor zu multiplizieren. Im Schleifenkörper kontrollieren wir die Verschiebung im Eingabedatenpuffer, um Zugriffe außerhalb der Array-Grenzen zu verhindern.
float res = weights[shift_weights + window_in]; for(int p = 0; p < window_in; p++) if((shift_in + p * variables) < inputs_total) res += inputs[shift_in + p * variables] * weights[shift_weights + p]; if(isnan(res)) res = 0;
Dabei ist zu beachten, dass wir beim Zugriff auf die Tensordaten einen Schritt verwenden, der der Anzahl der Variablen in der Beschreibung eines Zustands der Umgebung entspricht. Das heißt, wir bewegen uns entlang der Spalte der Eingabematrix. Dies entspricht der Anforderung an eine univariate Zeitreihe.
Wenn wir NaN als Ergebnis der Vektor-Multiplikationsoperation erhalten, ersetzen wir es durch „0“.
Als Nächstes müssen wir nur noch die gegebene Aktivierungsfunktion ausführen und den resultierenden Wert im entsprechenden Ergebnispuffer speichern.
switch(activation) { case 0: res = tanh(res); break; case 1: res = 1 / (1 + exp(-clamp(res, -20.0f, 20.0f))); break; case 2: if(res < 0) res *= 0.01f; break; defaultд: break; } //--- outputs[shift_out] = res; }
Nach der Implementierung des Feed-Forward-Passes gehen wir dazu über, die Backpropagation-Kerne zu konstruieren. Zunächst wird ein Kernel erstellt, um den Fehlergradienten an die vorherige Schicht weiterzugeben - PatchHiddenGradient. In den Parametern dieses Kernels werden wir 4 Zeiger auf Datenpuffer übergeben:
- inputs — Eingangsdatenpuffer (notwendig für die Anpassung der Fehlergradienten durch die Ableitung der Aktivierungsfunktion);
- inputs_gr — Puffer für Fehlergradienten auf der Ebene der Eingabedaten (in diesem Fall ein Puffer zum Schreiben der Ergebnisse);
- weights — Matrix der trainierbaren Parameter der Schicht;
- outputs_gr — Tensor der Gradienten auf der Ausgangsebene der Schicht (in diesem Fall die Eingabedaten für die Berechnung der Fehlergradienten).
Außerdem werden wir 5 Konstanten an den Kernel übergeben. Ihr Zweck lässt sich leicht aus den Namen der Variablen ableiten.
__kernel void PatchHiddenGradient(__global float *inputs, __global float *inputs_gr, __global float *weights, __global float *outputs_gr, int window_in, int step, int window_out, int outputs_total, int activation ) { const int i = get_global_id(0); const int v = get_global_id(1); const int variables = get_global_size(1);
Wir planen, den Kernel in einem 2-dimensionalen Aufgabenraum zu verwenden: die Länge der Eingabesequenz und die Anzahl der analysierten Parameter des Zustands der Umgebung (Variablen).
Beachten Sie, dass wir bei der Konstruktion von Kerneln den Aufgabenraum an den Dimensionen des Ausgangstensors orientieren. Im Feed-forward-Durchgang orientieren wir uns am 3-dimensionalen Tensor der Dateneinbettungen. Während des Backpropagation-Durchgangs handelt es sich um den 2-dimensionalen Tensor der Eingaben bzw. deren Fehlergradienten. Mit diesem Ansatz kann jeder einzelne Thread so konfiguriert werden, dass er einen einzigen Wert im Ausgabepuffer des Kernels empfängt.
Im Kernelkörper identifizieren wir den Thread im Aufgabenraum und definieren die erforderlichen Dimensionen. Danach berechnen wir die Verschiebungen.
const int w_start = i % step; const int r_start = max((i - window_in + step) / step, 0); int total = (window_in - w_start + step - 1) / step; total = min((i + step) / step, total);
Dann organisieren wir ein System von verschachtelten Schleifen, um Fehlergradienten zu sammeln.
float grad = 0; for(int p = 0; p < total; p ++) { int row = r_start + p; if(row >= outputs_total) break; for(int wo = 0; wo < window_out; wo++) { int shift_g = (row * variables + v) * window_out + wo; int shift_w = v * (window_in + 1) * window_out + w_start + (total - p - 1) * step + wo * (window_in + 1); grad += outputs_gr[shift_g] * weights[shift_w]; } }
Ein Eingangselement beeinflusst den Wert aller Elemente des Einbettungsvektors eines einzelnen Patches mit unterschiedlichen Gewichten. Daher sammelt die verschachtelte Schleife Fehlergradienten aus dem gesamten Einbettungsvektor eines einzelnen Patches.
Darüber hinaus besteht bei sich überlappenden Patches die Möglichkeit, dass die analysierten Daten der Eingabeelemente in das Eingabefenster mehrerer Patches fallen. Die äußere Schleife unseres verschachtelten Schleifensystems wird verwendet, um den Fehlergradienten von solchen Patches zu sammeln.
Wir passen den gesammelten (Gesamt-)Fehlergradienten für das analysierte Eingangselement durch die Ableitung der Aktivierungsfunktion an.
float inp = inputs[i * variables + v]; if(isnan(grad)) grad = 0; //--- switch(activation) { case 0: grad = clamp(grad + inp, -1.0f, 1.0f) - inp; grad = grad * (1 - pow(inp == 1 || inp == -1 ? 0.99999999f : inp, 2)); break; case 1: grad = clamp(grad + inp, 0.0f, 1.0f) - inp; grad = grad * (inp == 0 || inp == 1 ? 0.00000001f : (inp * (1 - inp))); break; case 2: if(inp < 0) grad *= 0.01f; break; default: break; }
Wir schreiben das Ergebnis der Operationen in das entsprechende Element des Fehlergradientenpuffers der vorherigen neuronalen Schicht.
inputs_gr[i * variables + v] = grad; }
Nach der Ausbreitung des Fehlergradienten müssen wir die Trainingsparameter des Modells anpassen, um den Fehler zu minimieren. Um diese Funktionalität zu implementieren, erstellen wir den Kernel PatchUpdateWeightsAdam, in dem wir die Parameter mithilfe der Methode Adam optimieren.
In den Kernel-Parametern werden wir Zeiger auf 5 Datenpuffer übergeben. Zusätzlich zu den bekannten Puffern inputs, weights und output_gr gibt es Hilfspuffer für das 1. und 2. Moment der Fehlergradienten auf der Ebene der Gewichtsmatrix weights_m bzw. weights_v. Darüber hinaus werden wir in den Kernel-Parametern auch Lernraten angeben.
__kernel void PatchUpdateWeightsAdam(__global float *weights, __global const float *outputs_gr, __global const float *inputs, __global float *weights_m, __global float *weights_v, const int inputs_total, const float l, const float b1, const float b2, int step ) { const int c = get_global_id(0); const int r = get_global_id(1); const int v = get_global_id(2); const int window_in = get_global_size(0) - 1; const int window_out = get_global_size(1); const int variables = get_global_size(2);
Da unser Gewichtungstensor dreidimensional ist, wird auch der Aufgabenraum in drei Dimensionen gebildet:
- Patchgröße + Bias,
- Größe des Einbettungsvektors,
- Anzahl der Variablen.
Hier folgen wir der oben erwähnten Logik, bei der jeder einzelne Thread den Wert von 1 trainierbaren Parameter anpasst.
Im Kernelkörper identifizieren wir den Thread in allen 3 Dimensionen des Aufgabenraums. Wir bestimmen auch die Größen der Dimensionen. Danach definieren wir Verschiebungskonstanten in Datenpuffern.
const int start_input = c * variables + v; const int step_input = step * variables; const int start_out = v * window_out + r; const int step_out = variables * window_out; const int total = inputs_total / (variables * step);
Wir führen eine Schleife aus, um Fehlergradienten auf der Ebene des korrigierten Lernparameters zu sammeln.
float grad = 0; for(int p = 0; p < total; p++) { int i = start_input + i * step_input; int o = start_out + i * step_out; grad += (c == window_in ? 1 : inputs[i]) * outputs_gr[0]; } if(isnan(grad)) grad = 0;
Nach der Bestimmung des Fehlergradienten gehen wir zum Algorithmus für die Parameterkorrektur über. Zunächst definieren wir die Momente 1. und 2. Ordnung.
const int shift_weights = (window_in + 1) * (window_out * v + r) + c; //--- float weight = weights[shift_weights]; float mt = b1 * weights_m[shift_weights] + (1 - b1) * grad; float vt = b2 * weights_v[shift_weights] + (1 - b2) * pow(grad, 2);
Dann berechnen wir den Wert der Parameteranpassung.
float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight));
Und schließlich werden wir die Werte in den Datenpuffern anpassen.
if(fabs(delta) > 0) weights[shift_weights] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); weights_m[shift_weights] = mt; weights_v[shift_weights] = vt; }
Bitte beachten Sie, dass wir das Gewicht im Datenpuffer nur dann ändern, wenn der Wert für die Parameteränderung von „0“ verschieden ist. Mathematisch gesehen ändert das Hinzufügen von „0“ zum aktuellen Wert den Parameter nicht. Wir führen jedoch einen zusätzlichen Vorgang zur Überprüfung lokaler Variablen ein, um den unnötigen und teureren Vorgang des Zugriffs auf den globalen Datenpuffer zu vermeiden.
Damit ist unsere Arbeit auf der Seite von OpenCL abgeschlossen. Kommen wir nun zur Hauptseite des Programms.
2.2 Klasse Daten-Patching
Um die oben erstellten Kernel auf der Seite des Hauptprogramms aufzurufen und zu bedienen, erstellen wir die Klasse CNeuronPatching, die von unserer Basisklasse für alle neuronalen Schichten CNeuronBaseOCL geerbt wird.
Im Klassenkörper werden wir Variablen deklarieren, um die Hauptparameter der Architektur des Objekts sowie Puffer für Trainingsparameter und entsprechende Momente zu speichern. Wir deklarieren alle Puffer als statische Objekte, was uns erlaubt, den Konstruktor und Destruktor der Klasse „leer“ zu lassen.
class CNeuronPatching : public CNeuronBaseOCL { protected: uint iWindowIn; uint iStep; uint iWindowOut; uint iVariables; uint iCount; //--- CBufferFloat cPatchWeights; CBufferFloat cPatchFirstMomentum; CBufferFloat cPatchSecondMomentum; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPatching(void){}; ~CNeuronPatching(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronPatchingOCL; } virtual void SetOpenCL(COpenCLMy *obj); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
Die Menge der überschreibbaren Klassenmethoden ist ziemlich standardisiert. Die Initialisierung von Objekten und Klassenvariablen erfolgt in der Methode Init. In den Parametern erhält die Methode alle notwendigen Informationen, um ein Objekt der gewünschten Architektur zu erstellen.
bool CNeuronPatching::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch ) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count * variables, optimization_type, batch)) return false;
Im Körper der Methode rufen wir zunächst dieselbe Methode der Elternklasse auf, die die minimal notwendige Kontrolle der empfangenen Werte und die Initialisierung der geerbten Objekte und Variablen durchführt. Das Ergebnis der Ausführung von Operationen in der Methode der übergeordneten Klasse wird durch den zurückgegebenen logischen Wert gesteuert.
Nach erfolgreicher Ausführung der Operationen in der übergeordneten Klassenmethode speichern wir die erhaltenen Werte der Objektarchitekturbeschreibung in lokalen Variablen.
iWindowIn = MathMax(window_in, 1); iWindowOut = MathMax(window_out, 1); iStep = MathMax(step, 1); iVariables = MathMax(variables, 1); iCount = MathMax(count, 1);
Wir initialisieren den Puffer mit den Trainingsparametern.
int total = int((window_in + 1) * window_out * variables); if(!cPatchWeights.Reserve(total)) return false; float k = float(1 / sqrt(total)); for(int i = 0; i < total; i++) { if(!cPatchWeights.Add((2 * GenerateWeight()*k - k)*WeightsMultiplier)) return false; } if(!cPatchWeights.BufferCreate(OpenCL)) return false;
Wir initialisieren auch die Puffer für Momente des Fehlergradienten auf der Ebene der Trainingsparameter.
if(!cPatchFirstMomentum.BufferInit(total, 0) || !cPatchFirstMomentum.BufferCreate(OpenCL)) return false; if(!cPatchSecondMomentum.BufferInit(total, 0) || !cPatchSecondMomentum.BufferCreate(OpenCL)) return false; //--- return true; }
Nach der Initialisierung des Objekts gehen wir zur Konstruktion der Feed-Forward-Methode CNeuronPatching::feedForward über. Bei dieser Methode wird der oben erstellte Feed-Forward-Pass-Kernel in die Warteschlange gestellt. In früheren Artikeln haben wir bereits mehrfach beschrieben, wie man einen Kernel in die Ausführungswarteschlange stellt. Das Hauptaugenmerk sollte hier auf der korrekten Angabe der Größe des Aufgabenbereichs und der übergebenen Parameter liegen.
Wie wir bereits bei der Konstruktion des Kerns erwähnt haben, verwenden wir in diesem Fall einen 3-dimensionalen Aufgabenraum:
- Anzahl der Patches
- 1 Patch-Einbettungsgröße
- Anzahl der Parameter, die bei der Beschreibung des Zustands der Umgebung analysiert werden
bool CNeuronPatching::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iWindowOut, iVariables};
Nach der Erstellung der Indikationsarray des Aufgabenraums und der darin befindlichen Schichten organisieren wir den Prozess der Parameterübergabe an den Kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_outputs, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_inputs_total, (int)NeuronOCL.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_window_in, (int)iWindowIn)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Vergessen Sie nicht, die Korrektheit der Vorgänge zu kontrollieren. Nach erfolgreicher Übergabe aller erforderlichen Parameter wird der Kernel in die Ausführungswarteschlange gestellt.
if(!OpenCL.Execute(def_k_PatchCreate, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
In ähnlicher Weise platzieren wir den Kernel der Fehlergradientenverteilung in der Warteschlange vor den Elementen der vorherigen Schicht entsprechend ihrem Einfluss auf das Endergebnis des Modells in der Methode CNeuronPatching::calcInputGradients. Der Kernel PatchHiddenGradient wird in einem 2-dimensionalen Aufgabenraum aufgerufen.
bool CNeuronPatching::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {NeuronOCL.Neurons() / iVariables, iVariables};
An dieser Stelle sei darauf hingewiesen, dass wir die Größe der Eingangssequenz einer multivariaten Zeitreihe als das Verhältnis zwischen der Größe des Ergebnispuffers der vorhergehenden Schicht und der Anzahl der analysierten Variablen, die den Zustand der Umgebung beschreiben, definieren.
Ich möchte Sie daran erinnern, dass nach der Methode PatchTST die Eingabe eine multivariate Zeitreihe sein sollte, in der jeder Zustand der Umgebung durch einen Vektor fester Länge beschrieben wird. Jedes Element des Vektors enthält den Wert des entsprechenden Parameters, der den Zustand des Systems beschreibt.
Anschließend übergeben wir die Parameter an den Kernel und steuern die Ausführung der Operationen.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_inputs_gr, NeuronOCL.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_outputs_gr, Gradient.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_activation, (int)NeuronOCL.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_outputs_total, (int)iCount)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_window_in, (int)iWindowIn)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_window_out, (int)iWindowOut)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Wir stellen den Kernel in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_PatchHiddenGradient, 2, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Die letzte Methode in dieser Klasse ist die Methode, die die trainierbaren Parameter des Modells anpasst CNeuronPatching::updateInputWeights. Diese Methode wird verwendet, um den Kernel PatchUpdateWeightsAdam in eine Warteschlange zu stellen. Ihr Algorithmus ist oben beschrieben. Der Algorithmus für die Aufnahme des Kernels in die Ausführungswarteschlange ist identisch mit den beiden oben beschriebenen Methoden. Der Unterschied liegt jedoch in den Details. Hier wird ein 3-dimensionaler Aufgabenraum verwendet.
bool CNeuronPatching::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowIn + 1, iWindowOut, iVariables};
In der ersten Dimension fügen wir 1 Element der Bayes'schen Verzerrung zur Patchgröße hinzu. In der zweiten und dritten Dimension legen wir die Einbettungsgröße von 1 Patch und die Anzahl der analysierten unabhängigen Kanäle fest, die in unseren Klassenvariablen gespeichert sind.
Dann übergeben wir Parameter an den Kernel und kontrollieren die Ergebnisse der Operationen.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_outputs_gr, getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights_m, cPatchFirstMomentum.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights_v, cPatchSecondMomentum.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_inputs_total, (int)NeuronOCL.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Danach wird der Kernel in die Ausführungswarteschlange gestellt.
if(!OpenCL.Execute(def_k_PatchUpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Die Klasse verfügt auch über Datei-Operationsmethoden, die Sie anhand der unten angefügten Codes studieren können. Zusätzlich zu den Dateioperationen enthalten die Anhänge alle Klassen und Methoden zum Erstellen und Trainieren von Modellen.
Wir haben eine Methode zur Erzeugung von Patch-Embeddings entwickelt, die für unabhängige univariate Zeitreihen erstellt werden, die Bestandteil der analysierten multivariaten Zeitreihen sind. Dies ist jedoch nur die Hälfte der vorgeschlagenen Methode PatchTST. Der zweite wichtige Baustein dieser Methode ist der Transformer zur Analyse von Abhängigkeiten zwischen Patches innerhalb einer univariaten Zeitreihe. Bitte beachten Sie, dass die Analyse von Abhängigkeiten nur im Rahmen von unabhängigen Kanälen durchgeführt wird. Es gibt keine Analyse der gegenseitigen Abhängigkeiten zwischen Elementen verschiedener univariater Kanäle.
Alle bisher betrachteten Implementierungsoptionen der Transformer-Architektur verwendeten eine Kanalmischung, was den Prinzipien der Methode PatchTST widerspricht. Die einzige Ausnahme ist der Conformer. Allerdings hat der Conformer, anders als der von den Autoren der PatchTST-Methode verwendete Vanilla Transformer, eine komplexere Architektur. Er verwendet kontinuierliche Aufmerksamkeit und NeuralODE-Blöcke, um die Effizienz des Modells zu verbessern, was im Allgemeinen zu einem positiven Ergebnis führt. Dies wurde durch unsere Experimente bestätigt. Daher habe ich im Rahmen meiner Implementierung den von den Autoren von PatchTST verwendeten Transformer durch die Implementierung des zuvor erstellten Conformer-Blocks in der Klasse CNeuronConformer ersetzt.
2.3 Modellarchitektur
Nach der Implementierung der „Blöcke“ für die PatchTST-Methode gehen wir dazu über, die Architektur der trainierbaren Modelle zu erstellen. Die untersuchte Methode wurde für die Vorhersage multivariater Zeitreihen vorgeschlagen. Natürlich werden wir diese Methode innerhalb des Environment State Encoders implementieren. Die Architektur dieses Modells wird in der Methode CreateEncoderDescriptions beschrieben. In den Parametern wird nur ein Zeiger auf ein dynamisches Array übergeben, um die Modellarchitektur zu erhalten.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Im Methodenrumpf wird die Relevanz des empfangenen Zeigers auf das Objekt geprüft und gegebenenfalls eine neue Instanz des dynamischen Arrays erstellt.
Wir füttern das Modell mit einem vollständigen Satz an historischen Daten.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
An dieser Stelle ist anzumerken, dass das Verfahren zur Erstellung von Patches keine History-Tiefe von weniger als 1 Eingabe-Patch zulässt. Natürlich können wir bei jedem Aufruf nur historische Daten von 1 Patch-Tiefe einspeisen. Dann würde die gesamte Tiefe des analysierten Verlaufs im internen Stapel akkumuliert werden, wie wir es zuvor in der Einbettungsschicht getan haben. Dieser Ansatz hat jedoch eine Reihe von Einschränkungen. Zunächst einmal müssten wir einen Abstand zwischen den Patches festlegen, der dem Patch selbst entspricht (nicht überlappende Patches). Der tatsächliche Schritt wäre jedoch gleich der Häufigkeit des Modellaufrufs.
Die Angleichung der Programme für die Erhebung von Ausbildungsdaten, für das Training und für Betriebsmodelle wäre also etwas verwirrend und komplex.
Der zweite Punkt ist, dass wir bei diesem Ansatz bei einer Änderung der Patch-Größe oder des Schrittes die Trainingsstichprobe neu sammeln müssten. Dies würde zusätzliche Einschränkungen und Kosten für das Training von Modellen mit sich bringen.
Daher verwenden wir eine einfachere und universellere Methode, um dem Modell die gesamte Tiefe der analysierten Geschichte zuzuführen. Das Feld und die Schrittweite werden durch Parameter in der Architektur der entsprechenden Modellebene festgelegt.
Wie immer füttern wir das Modell mit „rohen“, unverarbeiteten Daten, die wir sofort in der Batch-Normalisierungsschicht normalisieren.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes ist anzumerken, dass in diesem Modell die Ebene der trainierbaren Positionskodierung auf der Eingabeebene liegt und nicht auf der Ebene der Einbettungen, wie dies zuvor der Fall war. Auf diese Weise wollte ich mich auf die Position bestimmter Parameter konzentrieren. Wenn Sie überlappende Patches verwenden, kann ein Parameter in mehreren Patches enthalten sein.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes fügte ich eine Dropout-Schicht hinzu, mit der wir einzelne Eingabewerte während des Modelltrainings ausblenden können.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.4f; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Ich habe den Datenmaskierungskoeffizienten auf 40 % festgesetzt, ähnlich wie in dem vorherigen Artikel.
Dann fügen wir eine Ebene zur Patch-Erzeugung hinzu. In meiner Arbeit habe ich nicht überlappende Patches mit einer Fenstergröße und einer Schrittweite von 3 verwendet.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPatchingOCL; descr.window = 3; prev_count = descr.count = (HistoryBars+descr.window-1)/descr.window; descr.step = descr.window; descr.layers=BarDescr; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
In diesem Zusammenhang ist auch erwähnenswert, dass die Patch-Einbettung in 2 Stufen erfolgt. Zunächst erzeugen wir Patch-Einbettungen in halber Größe. In der Faltungsschicht wird dann die Größe des Patches erhöht.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count*BarDescr; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Wie Sie sich erinnern, haben wir die Positionskodierung auf der Eingabeebene implementiert. Daher werden die Daten nach der Erzeugung der Einbettungen sofort in den 10-schichtigen Conformer-Block eingegeben.
//--- layer 6-16 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 8; descr.window_out = EmbeddingSize; descr.layers = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; } }
Danach folgt der Entscheidungskopf, der aus 3 vollständig verknüpften Schichten besteht. Wir legen die Größe der letzten Schicht so fest, dass sie die rekonstruierten Informationen der historischen Daten enthält und die nachfolgenden Zustände bis zu einer bestimmten Tiefe vorhersagen kann.
//--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = BarDescr*(HistoryBars+NForecast); descr.activation=TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Am Ende des Modells werden die rekonstruierten und vorhergesagten Werte durch Hinzufügen von statistischen Indikatoren, die aus den Originaldaten gewonnen wurden, denormalisiert.
//--- layer 20 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Bitte beachten Sie, dass wir den Umfang der Eingabedaten und der Modellergebnisse gleich belassen haben wie im vorherigen Artikel. Daher können wir die Modelle Akteur (Actor) und Kritiker (Critic) ohne Änderungen kopieren. Außerdem können wir in dem neuen Experiment den Trainingsdatensatz und die EAs aus den früheren Artikeln verwenden. Auf diese Weise können wir die Auswirkungen verschiedener Umgebungszustands-Encoder-Architekturen auf die Lernergebnisse von Akteurspolitk vergleichen.
Die Anhänge enthalten die vollständige Architekturbeschreibung für alle hier verwendeten trainierbaren Modelle.
3. Tests
In den vorangegangenen Abschnitten dieses Artikels haben wir eine neue Methode zur Vorhersage multivariater Zeitreihen, PatchTST, vorgestellt. Wir haben unsere Vision der vorgeschlagenen Ansätze mit MQL5 umgesetzt. Nun ist es an der Zeit, die geleistete Arbeit zu überprüfen. Wir trainieren die Modelle zunächst anhand echter historischer Daten. Anschließend testen wir die trainierten Modelle im MetaTrader 5 Strategie-Tester auf einem historischen Zeitraum, der über den Trainingsdatensatz hinausgeht.
Wie zuvor wird das Modell mit historischen EURUSD-H1-Daten trainiert. Das trainierte Modell wird anhand historischer Daten für Januar 2024 mit demselben Finanzinstrument und Zeitrahmen getestet. Beim Sammeln der Trainingsstichprobe und beim Testen der erlernten Strategie haben wir Indikatoren mit Standardparametern verwendet.
Die Modelle werden in zwei Stufen trainiert. Im ersten Schritt trainieren wir den Umgebungszustandscodierer. Dieses Modell lernt, nur historische Daten von multivariaten Zeitreihen der Symbolpreisdynamik und der analysierten Indikatoren zu analysieren und zu verallgemeinern. Der Prozess berücksichtigt nicht den Kontostand und die offenen Positionen. Daher trainieren wir das Modell auf dem anfänglichen Trainingsdatensatz, ohne zusätzliche Daten zu sammeln, bis wir ein akzeptables Ergebnis bei der Rekonstruktion der maskierten Daten und der Vorhersage der nachfolgenden Zustände erzielen.
In der zweiten Stufe trainieren wir die Verhaltenspolitik des Akteurs und die Korrektheit der Bewertungen der Handlungen durch den Kritiker. Diese Phase ist iterativ und umfasst 2 Teilprozesse:
- Training der Modelle von Akteur und Kritiker.
- Erhebung zusätzlicher Umgebungsdaten unter Berücksichtigung der aktuellen Politik des Akteurs.
Nach mehreren Trainingsiterationen von Actor erhielt ich ein Modell, das sowohl mit historischen Trainingsdaten als auch mit neuen Daten Gewinne erzielen kann. Die Ergebnisse des trainierten Modells auf neuen Daten werden im Folgenden vorgestellt.
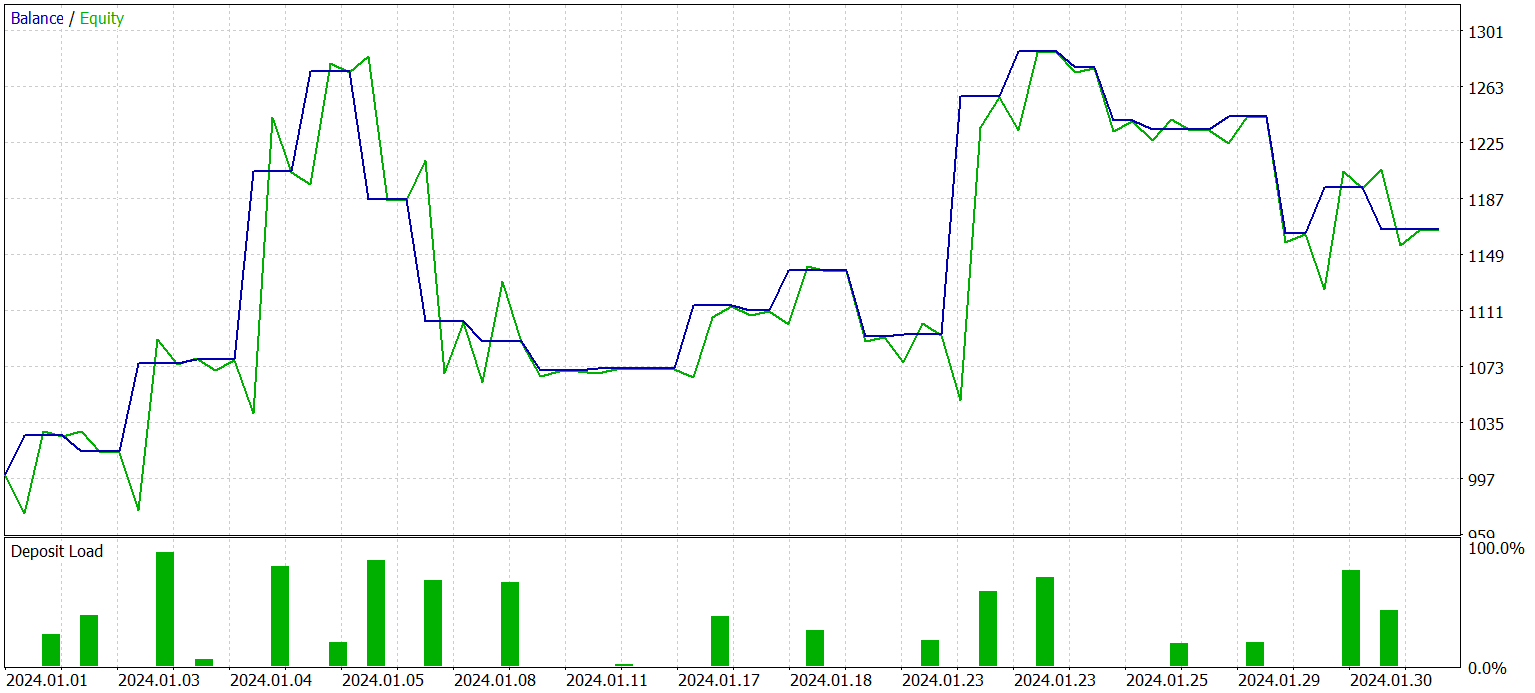
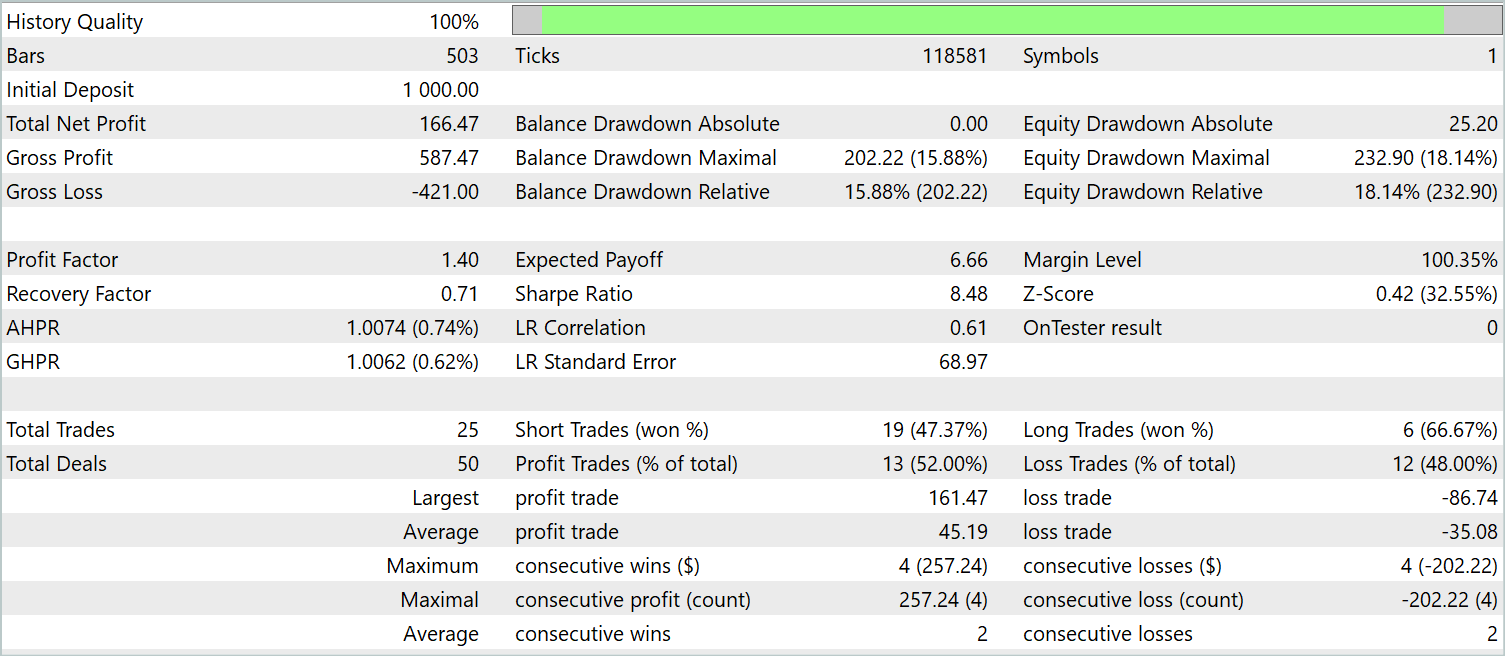
Die Saldenkurve kann nicht als gleichmäßig ansteigend betrachtet werden. Dennoch hat das Modell während des Testzeitraums 25 Geschäfte getätigt, von denen 13 mit Gewinn abgeschlossen wurden. Dies entsprach 52,0 % der gewinnbringenden Geschäfte. Der Wert liegt nahe der Parität. Der maximale Gewinn übersteigt jedoch den maximalen Verlust um 87,2 %, und der durchschnittliche Gewinn übersteigt den durchschnittlichen Verlust um 28,6 %. Infolgedessen lag der Gewinnfaktor während des Testzeitraums bei 1,4.
Schlussfolgerung
In diesem Artikel haben wir eine neue Methode zur Analyse und Vorhersage mehrdimensionaler Zeitreihen, PatchTST, erörtert, die die Vorteile von Datenpatching, Transformatoreinsatz und Repräsentationslernen kombiniert. Durch die Anpassung der Daten kann das Modell lokale zeitliche Muster und den Kontext besser erfassen, was die Qualität der Analyse und Vorhersage verbessert. Die Verwendung eines Transformators ermöglicht es uns, abstrakte Darstellungen aus den Daten zu extrahieren, wobei ihre zeitliche Abfolge und ihre Zusammenhänge berücksichtigt werden.
Im praktischen Teil des Artikels haben wir unsere Vision der vorgeschlagenen Ansätze mit MQL5 umgesetzt. Wir haben das Modell anhand echter historischer Daten trainiert. Dann testeten wir die trainierte Actor-Politik mit neuen Daten, die nicht in der Trainingsstichprobe enthalten waren. Die erzielten Ergebnisse zeigen, dass es möglich ist, mit der Methode PatchTST Modelle zu erstellen und zu trainieren, die einen Gewinn erzielen können.
Die Methode PatchTST ist ein leistungsfähiges Werkzeug für die Analyse und Vorhersage multivariater Zeitreihen, das bei verschiedenen praktischen Problemen erfolgreich eingesetzt werden kann.
- A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
- Andere Artikel dieser Serie
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA-Beispielsammlung |
| 2 | ResearchRealORL.mq5 | EA | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | EA | Trainings-EA des Modells |
| 4 | StudyEncoder.mq5 | EA | Trainings-EA der Kodierung |
| 5 | Test.mq5 | EA | Modeltest-EA |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14798
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.