
Entwicklung eines Expertenberaters für mehrere Währungen (Teil 11): Automatisieren der Optimierung (erste Schritte)
Einführung
Im vorangegangenen Artikel haben wir die Grundlage für die einfache Nutzung der aus der Optimierung gewonnenen Ergebnisse gelegt, um einen fertigen EA mit mehreren Instanzen von Handelsstrategien zu erstellen, die zusammenarbeiten. Jetzt müssen wir die Parameter aller verwendeten Instanzen nicht mehr manuell im Code oder in den EA-Eingaben eingeben. Wir müssen nur den Initialisierungsstring in einem bestimmten Format in einer Datei speichern oder ihn als Text in den Quellcode einfügen, damit der EA ihn verwenden kann.
Bislang wurde der Initialisierungsstring manuell erstellt. Nun ist es endlich an der Zeit, die automatische Bildung des EA-Initialisierungsstrings auf der Grundlage der erzielten Optimierungsergebnisse zu implementieren. Höchstwahrscheinlich werden wir im Rahmen dieses Artikels keine vollautomatische Lösung haben, aber zumindest werden wir einen bedeutenden Fortschritt in die beabsichtigte Richtung machen.
Erklärung des Problems
Ganz allgemein lassen sich unsere Ziele wie folgt formulieren: Wir möchten einen EA erhalten, der im Terminal läuft und eine EA-Optimierung mit einer Instanz einer Handelsstrategie auf mehreren Symbolen und Zeitrahmen durchführt. Dies sind EURGBP, EURUSD und GBPUSD, sowie die Zeitrahmen H1, M30 und M15. Wir müssen in der Lage sein, aus den in der Datenbank gespeicherten Ergebnissen jedes Optimierungsdurchgangs (pass) diejenigen auszuwählen, die sich auf ein bestimmtes Symbol und einen bestimmten Zeitraum beziehen (und später auf einige andere Kombinationen von Testparametern).
Aus jeder Gruppe von Ergebnissen für eine Symbol-Zeitrahmen-Kombination werden einige beste Ergebnisse nach verschiedenen Kriterien ausgewählt. Wir werden alle ausgewählten Instanzen in eine (vorerst) Instanzgruppe einordnen. Dann müssen wir den Gruppenmultiplikator bestimmen. Ein separater EA wird dies in Zukunft tun, aber im Moment können wir dies manuell tun.
Auf der Grundlage der gewählten Gruppe und des Multiplikators bilden wir eine Initialisierungszeichenfolge, die im endgültigen EA verwendet wird.
Konzepte
Wir wollen nun einige zusätzliche Konzepte zur weiteren Verwendung einführen:
- Universal EA ist ein Expert Advisor, der den Initialisierungsstring erhält, der ihn für die Arbeit auf einem Handelskonto bereit macht. Wir können den Initialisierungsstring aus einer Datei mit dem in den Eingaben angegebenen Namen lesen lassen oder ihn anhand des Projektnamens und der Version aus der Datenbank holen.
- Der optimierende EA ist ein EA, der für die Durchführung aller Maßnahmen zur Projektoptimierung verantwortlich ist. Wenn er auf einem Chart ausgeführt wird, sucht er in der Datenbank nach Informationen über die erforderlichen Optimierungsmaßnahmen und führt diese nacheinander aus. Das Endergebnis seiner Arbeit ist ein gespeicherter Initialisierungsstring für den universellen EA.
- Stage EAs sind die EAs, die direkt im Tester optimiert werden. Je nach der Anzahl der durchgeführten Phasen (stages) wird es mehrere davon geben. Der optimierende EA wird diese EAs zur Optimierung starten und deren Abschluss verfolgen.
In diesem Artikel beschränken wir uns auf eine Phase, in der die Parameter einer einzelnen Handelsstrategie optimiert werden. In der zweiten Phase werden einige der besten Fälle zu einer Gruppe zusammengefasst und normalisiert. Wir werden dies vorerst manuell durchführen.
Als universeller EA werden wir einen EA erstellen, der selbst einen Initialisierungsstring erstellen kann, indem er Informationen über gute Beispiele für Handelsstrategien aus der Datenbank auswählt.
Die Informationen über die erforderlichen Optimierungsmaßnahmen in der Datenbank sollten in einer praktischen Form gespeichert werden. Wir sollten in der Lage sein, diese Art von Informationen relativ einfach zu erstellen. Lassen wir einmal die Frage beiseite, wie diese Informationen in die Datenbank gelangen. Wir können später eine nutzerfreundliche Schnittstelle implementieren. Derzeit geht es vor allem darum, die Struktur dieser Informationen zu verstehen und eine entsprechende Tabellenstruktur in der Datenbank zu erstellen.
Beginnen wir mit der Identifizierung von allgemeineren Entitäten und gehen wir schrittweise zu einfacheren Entitäten über. Am Ende sollten wir zu der zuvor erstellten Entität kommen, die Informationen über einen einzelnen Testdurchlauf darstellt.
Projekt
Die oberste Ebene ist die Entität Projekt. Es handelt sich um eine zusammengesetzte Einheit: ein Projekt besteht aus mehreren Phasen. Die Entität der Phase (stange) wird im Folgenden betrachtet. Ein Projekt ist durch einen Namen und eine Version gekennzeichnet. Sie kann auch eine Beschreibung enthalten. Ein Projekt kann sich in verschiedenen Zuständen befinden: erstellt, in Warteschlange, läuft und abgeschlossen ( „created“, „queued for run“, „running“, „completed“). Es wäre auch logisch, den Initialisierungsstring für den universellen EA, den man als Ergebnis der Projektausführung erhält, in dieser Entität zu speichern.
Um die Verwendung von Informationen aus der Datenbank in MQL5-Programmen zu erleichtern, werden wir in Zukunft ein einfaches ORM implementieren, d.h. wir werden Klassen in MQL5 erstellen, die alle Entitäten darstellen, die wir in der Datenbank speichern werden.
Die Klassenobjekte für die Entität „Projekt“ werden Folgendes in der Datenbank speichern:
- id_project – Projekt-ID.
- name – Projektname, der im universellen EA für die Suche nach dem Initialisierungsstring verwendet wird.
- version – Projektversion, die z.B. durch die Versionen der Handelsstrategie-Instanzen definiert wird.
- description – Projektbeschreibung, beliebiger Text mit einigen wichtigen Details. Sie kann leer sein.
- params – Initialisierungsstring für den universellen EA, der nach Abschluss des Projekts ausgefüllt wird. Sie hat zunächst einen leeren Wert.
- status – Projektstatus (Created, Queued, Processing, Done). Zu Beginn wird das Projekt mit dem Status „Erstellt“ angelegt.
Die Liste der Felder kann später erweitert werden.
Wenn ein Projekt zur Ausführung bereit ist, wird es in die Warteschlange verschoben. Wir werden diesen Übergang zunächst manuell durchführen. Unser Optimierungs-EA sucht nach Projekten mit diesem Status und verschiebt sie in den Status „in Bearbeitung“.
Zu Beginn und am Ende jeder Phase prüfen wir, ob eine Aktualisierung des Projektstatus erforderlich ist. Wenn die erste Phase gestartet wird, geht das Projekt in den Bearbeitungszustand über. Wenn die letzte Phase abgeschlossen ist, geht das Projekt in den Status „Erledigt“ über. An dieser Stelle wird der Wert des Feldes params ausgefüllt, sodass wir eine Initialisierungszeichenfolge erhalten, die nach Abschluss des Projekts an den universellen EA übergeben werden kann.
Phase
Wie bereits erwähnt, ist die Durchführung eines jeden Projekts in mehrere Phasen unterteilt. Das Hauptmerkmal der Phase (stage) ist der EA, der im Rahmen dieser Phase zur Optimierung im Tester gestartet wird (stage EA). Auch für die Phase wird ein Testintervall festgelegt. Dieses Intervall ist für alle in dieser Phase durchgeführten Optimierungen identisch. Wir sollten auch die Speicherung anderer Informationen über die Optimierung vorsehen (anfängliches Depot, Tick-Simulationsmodus usw.).
Für eine Phase kann eine übergeordnete (vorherige) Phase angegeben werden. In diesem Fall beginnt die Ausführung der Phase erst nach Beendigung der übergeordneten Phase.
Objekte dieser Klasse speichern Folgendes in der Datenbank:
- id_stage – Phasen-ID.
- id_project – Projekt-ID, zu der die Phase gehört.
- id_parent_stage – ID der übergeordneten (vorherigen) Phase.
- name – Künstlername.
- expert – Name des EA, der in dieser Phase zur Optimierung eingesetzt wird.
- from_date – Startdatum des Optimierungszeitraums.
- to_date – Enddatum des Optimierungszeitraums.
- forward_date – Startdatum des Optimierungszeitraums. Das kann leer bleiben, sodass der Vorwärtsmodus nicht verwendet wird.
- other fields mit Optimierungsparametern (Anfangsablagerung, Tick-Simulationsmodus usw.), die Standardwerte haben, die in den meisten Fällen nicht geändert werden müssen
- status – Phasenstatus, der drei mögliche Werte annehmen kann: In Warteschlange, Bearbeitung, Erledigt (Queued, Processing, Done). Zu Beginn wird eine Phase mit dem Status „In Warteschlange“ erstellt.
Jede Phase besteht wiederum aus einem oder mehreren Aufträgen. Wenn der erste Jobbeginnt, geht die Phase in den Zustand „Verarbeitung“ über. Wenn alle Aufträge abgeschlossen sind, geht die Phase in den Zustand „Erledigt“ über.
Job
Die Durchführung jeder Phase besteht aus der sequentiellen Ausführung aller darin enthaltenen Aufträge. Die wichtigsten Merkmale des Jobs sind das Symbol, der Zeitrahmen und die Eingaben des EA, der in der Phase, die diesen Job enthält, optimiert wird.
Objekte dieser Klasse speichern Folgendes in der Datenbank:
- id_job – Job-ID.
- id_stage – ID der Phase, zu der der Jobgehört.
- symbol – Testsymbol (Handelsinstrument).
- period – Testzeitrahmen.
- tester_inputs – Einstellungen der EA-Optimierungseingänge.
- status – Jobstatus (in der Warteschlange, in Bearbeitung oder erledigt). Zu Beginn wird ein Jobmit dem Status „In Warteschlange“ erstellt.
Jeder Jobbesteht aus einer oder mehreren Optimierungsaufgaben. Wenn die erste Optimierungsaufgabe startet, geht der Jobin den Zustand Verarbeitung über. Wenn alle Optimierungsaufgaben abgeschlossen sind, geht der Jobin den Status „Erledigt“ über.
Optimierungsaufgabe
Die Ausführung jeder Aufgabe besteht aus der sequentiellen Ausführung aller in ihr enthaltenen Aufgaben. Das Hauptmerkmal des Problems ist das Optimierungskriterium. Der Rest der Einstellungen für den Tester wird von der Aufgabe aus dem Jobübernommen.
Objekte dieses Typs speichern Folgendes in der Datenbank:
- id_task – Aufgaben-ID.
- id_job – Job-ID, innerhalb derer der Job ausgeführt wird.
- optimization_criterion – Optimierungskriterium für eine bestimmte Aufgabe.
- start_date – Startzeit der Optimierungsaufgabe.
- finish_date – Endzeitpunkt der Optimierungsaufgabe.
- status – Status der Optimierungsaufgabe (In Warteschlange, In Bearbeitung, Erledigt). Zu Beginn wird eine Optimierungsaufgabe mit dem Status „In Warteschlange“ erstellt.
Jede Aufgabe besteht aus mehreren Optimierungsdurchgängen. Wenn der erste Optimierungsdurchlauf beginnt, geht die Optimierungsaufgabe in den Zustand Verarbeitung über. Wenn alle Optimierungsdurchläufe abgeschlossen sind, geht die Optimierungsaufgabe in den Zustand Erledigt über.
Optimierungsdurchgang
Wir haben dies bereits in einem der vorherigen Artikel berücksichtigt, in dem wir die automatische Speicherung der Ergebnisse aller Durchläufe während der Optimierung im Strategietester hinzugefügt haben. Nun fügen wir ein neues Feld hinzu, das die Aufgaben-ID enthält, innerhalb derer dieser Durchgang durchgeführt wurde.
Objekte dieses Typs speichern Folgendes in der Datenbank:
- id_pass – Durchgangs-ID.
- id_task – ID der Aufgabe, innerhalb derer der Durchgang durchgeführt wird.
- pass result fields – Gruppe von Feldern für alle verfügbaren Statistiken über den Durchgang (Durchgangsnummer, Anzahl der Transaktionen, Gewinnfaktor usw.).
- params – Initialisierungsstring mit Parametern der im Durchlauf verwendeten Strategieinstanzen.
- inputs – Übergabe der Eingabewerte.
- pass_date – Endzeit des Durchgangs.
Im Vergleich zur vorherigen Implementierung ändern wir die Zusammensetzung der gespeicherten Informationen über die Parameter der in jedem Durchgang verwendeten Strategien. Allgemeiner ausgedrückt, müssen wir Informationen über eine Gruppe von Strategien speichern. Deshalb werden wir dafür sorgen, dass eine Gruppe von Strategien, die eine Strategie enthält, auch für eine einzelne Strategie gespeichert wird.
Es gibt kein Statusfeld für den Durchgang, da die Einträge in der Tabelle erst nach Abschluss des Durchgangs und nicht vor dessen Beginn hinzugefügt werden. Daher bedeutet bereits das Vorhandensein eines Eintrags, dass der Durchgang vollständig ist.
Da die Struktur unserer Datenbank bereits erheblich erweitert wurde, werden wir Änderungen am Programmcode vornehmen, der für die Erstellung und die Arbeit mit der Datenbank zuständig ist.
Erstellung und Verwaltung der Datenbank
Während der Entwicklung müssen wir die Datenbank immer wieder mit einer aktualisierten Struktur neu erstellen. Daher werden wir ein einfaches Hilfsskript erstellen, das eine einzige Aktion ausführt - die Datenbank neu erstellen und mit den erforderlichen Anfangsdaten füllen. Die ersten Daten werden wir später in die leere Datenbank einfügen.
#include "Database.mqh" int OnStart() { DB::Open(); // Open the database // Execute requests for table creation and filling initial data DB::Create(); DB::Close(); // Close the database return INIT_SUCCEEDED; }
Wir speichern den Code in der Datei CleanDatabase.mq5 im aktuellen Ordner.
Zuvor enthielt die Tabellenerstellungsmethode CDatabase::Create() ein Array von Strings mit SQL-Abfragen, die eine Tabelle neu erstellten. Jetzt haben wir mehr Tabellen, sodass das Speichern von SQL-Abfragen direkt im Quellcode unpraktisch wird. Verschieben wir den Text aller SQL-Anfragen in eine separate Datei, aus der sie zur Ausführung in der Methode Create() geladen werden.
Zu diesem Zweck benötigen wir eine Methode, die alle Anfragen aus der Datei anhand ihres Namens liest und ausführt:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: ... // Make a request to the database from the file static bool ExecuteFile(string p_fileName); }; ... //+------------------------------------------------------------------+ //| Making a request to the database from the file | //+------------------------------------------------------------------+ bool CDatabase::ExecuteFile(string p_fileName) { // Array for reading characters from the file uchar bytes[]; // Number of characters read long len = 0; // If the file exists in the data folder, then if(FileIsExist(p_fileName)) { // load it from there len = FileLoad(p_fileName, bytes); } else if(FileIsExist(p_fileName, FILE_COMMON)) { // otherwise, if it is in the common data folder, load it from there len = FileLoad(p_fileName, bytes, FILE_COMMON); } else { PrintFormat(__FUNCTION__" | ERROR: File %s is not exists", p_fileName); } // If the file has been loaded, then if(len > 0) { // Convert the array to a query string string query = CharArrayToString(bytes); // Return the query execution result return Execute(query); } return false; }
Lassen Sie uns nun Änderungen an der Methode Create() vornehmen. Die Datei mit der Datenbankstruktur und den anfänglichen Daten erhält einen festen Namen: Die Zeichenkette .schema.sql wird an den Datenbanknamen angehängt:
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create() { string schemaFileName = s_fileName + ".schema.sql"; bool res = ExecuteFile(schemaFileName); if(res) { PrintFormat(__FUNCTION__" | Database successfully created from %s", schemaFileName); } }
Jetzt können wir eine beliebige SQLite-Datenbankumgebung verwenden, um alle Tabellen darin zu erstellen und sie mit den ersten Daten zu füllen. Danach können wir die resultierende Datenbank als eine Reihe von SQL-Abfragen in eine Datei exportieren und diese Datei in unseren MQL5-Programmen verwenden.
Die letzte Änderung, die wir in diesem Stadium an der Klasse CDatabase vornehmen müssen, steht im Zusammenhang mit der entstehenden Notwendigkeit, Anfragen nicht nur zum Einfügen von Daten, sondern auch zum Abrufen von Daten aus den Tabellen auszuführen. In Zukunft sollte der gesamte Code, der für die Datenbeschaffung verantwortlich ist, auf separate Klassen verteilt werden, die mit den einzelnen in der Datenbank gespeicherten Entitäten arbeiten. Aber bis wir diese Klassen haben, müssen wir uns mit provisorischen Lösungen begnügen.
Das Lesen von Daten mit den von MQL5 bereitgestellten Werkzeugen ist eine komplexere Aufgabe als das Hinzufügen von Daten. Um die Ergebniszeilen der Anfrage zu erhalten, müssen wir einen neuen Datentyp (Struktur) in MQL5 erstellen, der dazu bestimmt ist, Daten für diese spezifische Anfrage zu erhalten. Dann müssen wir eine Anfrage senden und das Ergebnis-Handle erhalten. Mit diesem Handle können wir dann in einer Schleife eine Zeichenkette nach der anderen aus den Abfrageergebnissen in eine Variable der gleichen, zuvor erstellten Struktur aufnehmen.
Daher ist es nicht einfach, innerhalb der Klasse CDababase eine generische Methode zu schreiben, die die Ergebnisse beliebiger Anfragen liest, die Daten aus den Tabellen abrufen. Deshalb sollten wir sie stattdessen der höheren Ebene zukommen lassen. Dazu müssen wir lediglich das Handle der Datenbankverbindung, das im Feld s_db gespeichert ist, an die höhere Ebene weitergeben:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: static int Id(); // Database connection handle ... }; ... //+------------------------------------------------------------------+ //| Database connection handle | //+------------------------------------------------------------------+ int CDatabase::Id() { return s_db; }
Wir speichern den erhaltenen Code in der Datei Database.mqh des aktuellen Ordners.
Der Optimierungs-EA
Jetzt können wir mit der Erstellung des optimierenden EA beginnen. Zunächst benötigen wir die Bibliothek, um mit dem Tester von fxsaber zu arbeiten, oder besser gesagt, diese Include-Datei:
#include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132
Unser Optimierungs-EA wird die Hauptarbeit in regelmäßigen Abständen - nach einem Timer - ausführen. Daher werden wir einen Timer erstellen und dessen Handler sofort zur Ausführung in der Initialisierungsfunktion starten. Da Optimierungsaufgaben in der Regel mehrere Dutzend Minuten in Anspruch nehmen, scheint die Auslösung des Timers alle fünf Sekunden völlig ausreichend:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create the timer and start its handler EventSetTimer(5); OnTimer(); return(INIT_SUCCEEDED); }
Im Timer-Handler prüfen wir, ob der Tester gerade nicht in Gebrauch ist. Wenn es tatsächlich nicht in Gebrauch ist, müssen wir Aktionen durchführen, um die aktuelle Aufgabe abzuschließen, falls vorhanden. Danach holen wir uns die Optimierungs-ID und die Eingaben aus der Datenbank für die nächste Aufgabe und starten diese durch Aufruf der Funktion StartTask():
//+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { PrintFormat(__FUNCTION__" | Current Task ID = %d", currentTaskId); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the tester is not in use if (MTTESTER::IsReady()) { // If the current task is not empty, if(currentTaskId) { // Complete the current task FinishTask(currentTaskId); } // Get the number of tasks in the queue totalTasks = TotalTasks(); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task currentTaskId = GetNextTask(currentSetting); // Launch the current task StartTask(currentTaskId, currentSetting); Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, currentTaskId)); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
In der Funktion zum Starten der Aufgabe verwenden wir die Methoden der Klasse MTTESTER, um die Eingaben in den Tester zu laden und den Tester im Optimierungsmodus zu starten. Wir aktualisieren auch die Informationen in der Datenbank, indem wir die Startzeit der aktuellen Aufgabe und ihren Status speichern:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", taskId, setting); // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Open(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
Die Funktion, die nächste Aufgabe aus der Datenbank zu erhalten, ist ebenfalls recht einfach. Im Wesentlichen veranlassen wir darin die Ausführung einer SQL-Abfrage und erhalten deren Ergebnisse. Beachten Sie, dass diese Funktion die ID der nächsten Aufgabe als Ergebnis zurückgibt und die Zeichenkette mit den Optimierungseingaben in die Einstellungsvariable schreibt, die der Funktion als Argument per Referenz übergeben wird:
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.from_date," " s.to_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status = 'Queued'" " ORDER BY s.id_stage, j.id_job LIMIT 1;"; // Open the database DB::Open(); if(DB::IsOpen()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; string from_date; string to_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=Articles\\2024-04-15.14741\\%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=2\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=0\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d||0||0||0||N\r\n" "%s\r\n", row.expert, row.symbol, row.period, row.from_date, row.to_date, row.optimization_criterion, row.id_task, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
Der Einfachheit halber werden die Werte einiger Optimierungseingaben direkt im Code angegeben. Zum Beispiel wird eine Einlage von 10.000 USD, eine Hebelwirkung von 1:200, USD usw. immer verwendet. Später können die Werte dieser Parameter bei Bedarf auch aus der Datenbank entnommen werden.
Der Code der Funktion TotalTasks(), die die Anzahl der Aufgaben in der Warteschlange zurückgibt, ist dem Code der vorherigen Funktion sehr ähnlich, sodass wir ihn hier nicht wiedergeben.
Wir speichern den resultierenden Code in der Datei Optimization.mq5 des aktuellen Ordners. Jetzt müssen wir noch ein paar kleine Änderungen an den zuvor erstellten Dateien vornehmen, um ein minimal autarkes System zu erhalten.
СVirtualStrategy und СSimpleVolumesStrategy
In diesen Klassen wird die Möglichkeit, den Wert des normalisierten Saldos der Strategie einzustellen, entfernt, sodass er immer einen Anfangswert von 10.000 hat. Er ändert sich jetzt nur noch, wenn eine Strategie in eine Gruppe mit einem bestimmten Normierungsfaktor aufgenommen wird. Auch wenn wir nur eine Instanz der Strategie ausführen wollen, müssen wir sie allein der Gruppe hinzufügen.
Legen wir also einen neuen Wert im Objektkonstruktor der Klasse CVirtualStrategy fest:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualStrategy::CVirtualStrategy() : m_fittedBalance(10000), m_fixedLot(0.01), m_ordersTotal(0) {}
Entfernen wir nun das Lesen des letzten Parameters aus der Initialisierungszeichenfolge im Konstruktor der Klasse CSimpleVolumesStrategy:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { // Save the initialization string m_params = p_params; // Read the parameters from the initialization string m_symbol = ReadString(p_params); m_timeframe = (ENUM_TIMEFRAMES) ReadLong(p_params); m_signalPeriod = (int) ReadLong(p_params); m_signalDeviation = ReadDouble(p_params); m_signaAddlDeviation = ReadDouble(p_params); m_openDistance = (int) ReadLong(p_params); m_stopLevel = ReadDouble(p_params); m_takeLevel = ReadDouble(p_params); m_ordersExpiration = (int) ReadLong(p_params); m_maxCountOfOrders = (int) ReadLong(p_params); m_fittedBalance = ReadDouble(p_params); // If there are no read errors, if(IsValid()) { ... } }
Wir speichern die an den Dateien VirtualStrategy.mqh und CSimpleVolumesStrategy.mqh vorgenommenen Änderungen im aktuellen Ordner.
СVirtualStrategyGroup
In dieser Klasse haben wir eine neue Methode hinzugefügt, die den Initialisierungsstring der aktuellen Gruppe mit einem anderen substituierten Wert des Normalisierungsfaktors zurückgibt. Dieser Wert wird erst ermittelt, wenn der Tester seinen Lauf abgeschlossen hat, sodass wir nicht sofort eine Gruppe mit dem richtigen Multiplikator erstellen können. Im Grunde ersetzen wir einfach die als Argument übergebene Zahl in der Initialisierungszeichenfolge vor der schließenden Klammer:
//+------------------------------------------------------------------+ //| Class of trading strategies group(s) | //+------------------------------------------------------------------+ class CVirtualStrategyGroup : public CFactorable { ... public: ... string ToStringNorm(double p_scale); }; ... //+------------------------------------------------------------------+ //| Convert an object to a string with normalization | //+------------------------------------------------------------------+ string CVirtualStrategyGroup::ToStringNorm(double p_scale) { return StringFormat("%s([%s],%f)", typename(this), ReadArrayString(m_params), p_scale); }Wir speichern Sie die an den Dateien VirtualStrategyGroup.mqh vorgenommenen Änderungen im aktuellen Ordner.
CTesterHandler
Fügen wir in der Klasse für die Speicherung der Ergebnisse von Optimierungsdurchläufen die statische Eigenschaft s_idTask hinzu, der wir die aktuelle ID der Optimierungsaufgabe zuweisen werden. In der Methode für die Verarbeitung eingehender Datenrahmen fügen wir sie zu der Gruppe von Werten hinzu, die an die SQL-Abfrage zum Speichern der Ergebnisse in der Datenbank übergeben werden:
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { ... public: ... static ulong s_idTask; }; ... ulong CTesterHandler::s_idTask = 0; ... //+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Open(); ... // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { ... // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s');", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); ... }
Wir speichern den erhaltenen Code in der Datei TesterHandler.mqh des aktuellen Ordners.
СVirtualAdvisor
Schließlich ist es Zeit für den letzten Schnitt. In der EA-Klasse fügen wir die automatische Normalisierung einer Strategie oder einer Gruppe von Strategien hinzu, die im EA während eines bestimmten Optimierungsdurchgangs verwendet wurden. Um dies zu tun, erstellen wir die Gruppe der verwendeten Strategien aus dem EA-Initialisierungsstring neu und bilden dann den Initialisierungsstring dieser Gruppe mit einem anderen normalisierenden Multiplikator, der nur auf der Grundlage der Ergebnisse des aktuellen Drawdowns des Durchgangs berechnet wird:
//+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Re-create the group of used strategies for subsequent normalization CVirtualStrategyGroup* group = NEW(ReadObject(m_params)); // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, // Normalized profit group.ToStringNorm(coeff) // Normalized group initialization string ); delete group; return fittedProfit; }
Wir speichern die Änderungen in der Datei VirtualAdvisor.mqh des aktuellen Ordners.
Start der Optimierung
Alles ist bereit, um mit der Optimierung zu beginnen. In der Datenbank haben wir insgesamt 81 Aufgaben erstellt (3 Symbole * 3 Zeitrahmen * 9 Kriterien). Zunächst wählten wir ein kurzes Optimierungsintervall von nur 5 Monaten und nur wenige mögliche Kombinationen von optimierten Parametern, da wir mehr an der Leistung des Autotests interessiert waren als an den Ergebnissen selbst in Form von gefundenen Kombinationen von Eingaben von funktionierenden Strategieinstanzen. Nach mehreren Testläufen und der Behebung kleinerer Mängel hatten wir das, was wir wollten. Die Tabelle der Durchgänge wurde mit den Durchgangsergebnissen gefüllt, die gefüllte Initialisierungszeichenfolgen von normalisierten Gruppen mit einer einzigen Strategieinstanz enthielten.
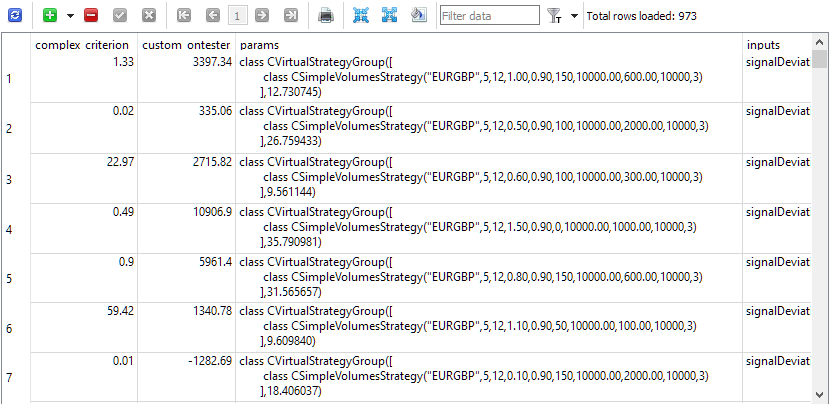
Abb. 1. Durchgänge mit deren Ergebnissen
Wenn sich die Struktur bewährt hat, können wir ihr eine komplexere Aufgabe übertragen. Lassen wir dieselben 81 Aufgaben über einen längeren Zeitraum und mit viel mehr Parameterkombinationen laufen. In diesem Fall werden wir noch einige Zeit warten müssen: 20 Agenten führen eine Optimierungsaufgabe etwa eine Stunde lang aus. Wenn wir also rund um die Uhr arbeiten, dauert es etwa 3 Tage, bis alle Aufgaben erledigt sind.
Danach wählen wir manuell die besten Durchgänge aus den Tausenden von erhaltenen Durchgängen aus und erstellen eine entsprechende SQL-Abfrage, die diese Durchgänge auswählt. Vorerst wird die Auswahl nur auf der Grundlage einer Sharpe Ratio von mehr als 5 erfolgen. Als Nächstes werden wir einen neuen EA erstellen, der in dieser Phase die Rolle eines universellen EAs spielen wird. Ihr Hauptbestandteil ist die Initialisierungsfunktion. In dieser Funktion extrahieren wir die Parameter der ausgewählten besten Durchgänge aus der Datenbank, bilden daraus einen Initialisierungsstring für den EA und erstellen ihn.
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency sinput double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input int count_ = 1000; // - Number of strategies in the group input group "::: Other parameters" sinput ulong magic_ = 27183; // - Magic input bool useOnlyNewBars_ = true; // - Work only at bar opening CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); string query = StringFormat( "SELECT DISTINCT p.custom_ontester, p.params, j.id_job " " FROM passes p JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE p.custom_ontester > 0 AND " " trades > 20 AND " " p.sharpe_ratio > 5" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC LIMIT %d;", count_); DB::Open(); int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return 0; } struct Row { double custom_ontester; string params; int id_job; } row; string strategiesParams = ""; while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Zur Optimierung haben wir ein Intervall gewählt, das zwei volle Jahre umfasst: 2021 und 2022. Werfen wir einen Blick auf die universellen EA-Ergebnisse in diesem Intervall. Um den maximalen Drawdown auf 10 % abzustimmen, wählen wir einen geeigneten Wert für den scale_ Multiplikator. Die Testergebnisse des universellen EA auf dem Intervall sind wie folgt:
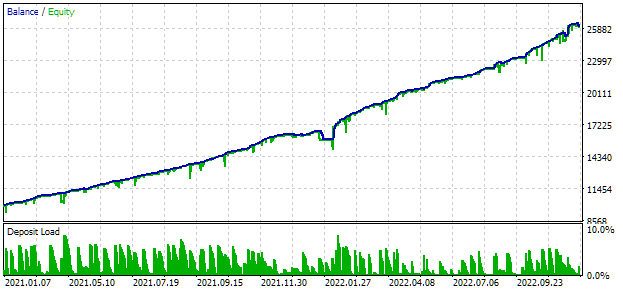
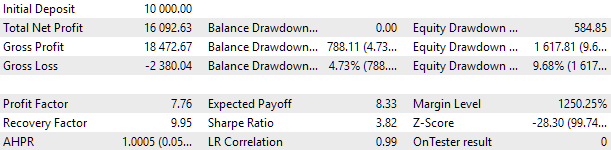
Abb. 2. Universelle EA-Testergebnisse für 2021-2022 (Skala_ = 2)
Etwa tausend Strategieinstanzen waren an der EA-Operation beteiligt. Diese Ergebnisse sollten als Zwischenergebnisse betrachtet werden, da wir viele der zuvor diskutierten Maßnahmen zur Verbesserung des Ergebnisses noch nicht durchgeführt haben. Insbesondere die Anzahl der Instanzen von EURUSD-Strategien erwies sich als wesentlich größer als für EURGBP, weshalb die Vorteile der Mehrwährungsstrategie noch nicht voll ausgeschöpft wurden. Es besteht also Hoffnung, dass wir noch ein gewisses Potenzial für Verbesserungen haben. Ich werde daran arbeiten, dieses Potenzial in den kommenden Artikeln umzusetzen.
Schlussfolgerung
Wir haben einen weiteren wichtigen Schritt in Richtung des angestrebten Ziels gemacht. Wir haben die Fähigkeit erlangt, die Optimierung von Handelsstrategie-Instanzen auf verschiedenen Symbolen, Zeitrahmen und anderen Parametern zu automatisieren. Jetzt müssen wir nicht mehr das Ende eines laufenden Optimierungsprozesses verfolgen, um die Parameter zu ändern und den nächsten Prozess zu starten.
Durch die Speicherung aller Ergebnisse in der Datenbank müssen wir uns keine Sorgen um einen möglichen Neustart des optimierenden EA machen. Wenn der Optimierungsvorgang des EA aus irgendeinem Grund unterbrochen wurde, wird er beim nächsten Start mit der nächsten Aufgabe in der Warteschlange fortgesetzt. Außerdem haben wir ein vollständiges Bild von allen Testdurchläufen während des Optimierungsprozesses.
Es gibt jedoch noch viel Raum für weitere Arbeiten. Wir haben die Aktualisierung von Phasen- und Projektstatus noch nicht implementiert. Derzeit gibt es nur die Aktualisierung von Aufgabenstatus. Auch die Optimierung von Projekten, die aus mehreren Phasen bestehen, wurde bisher nicht berücksichtigt. Es ist auch unklar, wie die Zwischenverarbeitung von DatenPhasen am besten umgesetzt werden kann, wenn sie z. B. eine Datenclusterung erfordert. Ich werde versuchen, all dies in den folgenden Artikeln zu behandeln.
Vielen Dank für Ihre Aufmerksamkeit! Bis bald!
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14741
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.