Neuronale Netze leicht gemacht (Teil 86): U-förmiger Transformator

Einführung
Die Vorhersage langfristiger Zeitreihen ist insbesondere für den Handel von großer Bedeutung. Die Architektur des Transformers, die 2017 eingeführt wurde, hat in den Bereichen Natural Language Processing (NLP) und Computer Vision (CV) eine beeindruckende Leistung gezeigt. Der Einsatz von Self-Attention-Mechanismen ermöglicht die effektive Erfassung von Abhängigkeiten über lange Zeiträume hinweg, wobei wichtige Informationen aus dem Kontext extrahiert werden. Natürlich wurde recht schnell eine große Anzahl verschiedener Algorithmen auf der Grundlage dieses Mechanismus zur Lösung von Problemen im Zusammenhang mit Zeitreihen vorgeschlagen.
Jüngste Studien haben jedoch gezeigt, dass einfache mehrschichtige Perceptron-Netzwerke (MLP) die Genauigkeit von Transformator-basierten Modellen bei verschiedenen Zeitreihen-Datensätzen übertreffen können. Dennoch hat sich die Transformer-Architektur in mehreren Bereichen bewährt und sogar praktische Anwendung gefunden. Daher sollte seine Repräsentativität relativ hoch sein. Es muss Mechanismen für ihre Nutzung geben. Eine der Möglichkeiten zur Verbesserung des Vanilla-Transformer-Algorithmus wird im Artikel „U-shaped Transformer: Retain High Frequency Context in Time Series Analysis“ gezeigt, in dem der U-förmige Transformer-Algorithmus vorgestellt wird.
1. Der Algorithmus
Es sollte wohl gleich zu Beginn gesagt werden, dass die Autoren der U-förmigen Transformer-Methode eine umfassende Arbeit geleistet und nicht nur Wege zur Optimierung der klassischen Transformer-Architektur vorgeschlagen haben, sondern auch den Ansatz zum Training des Modells.
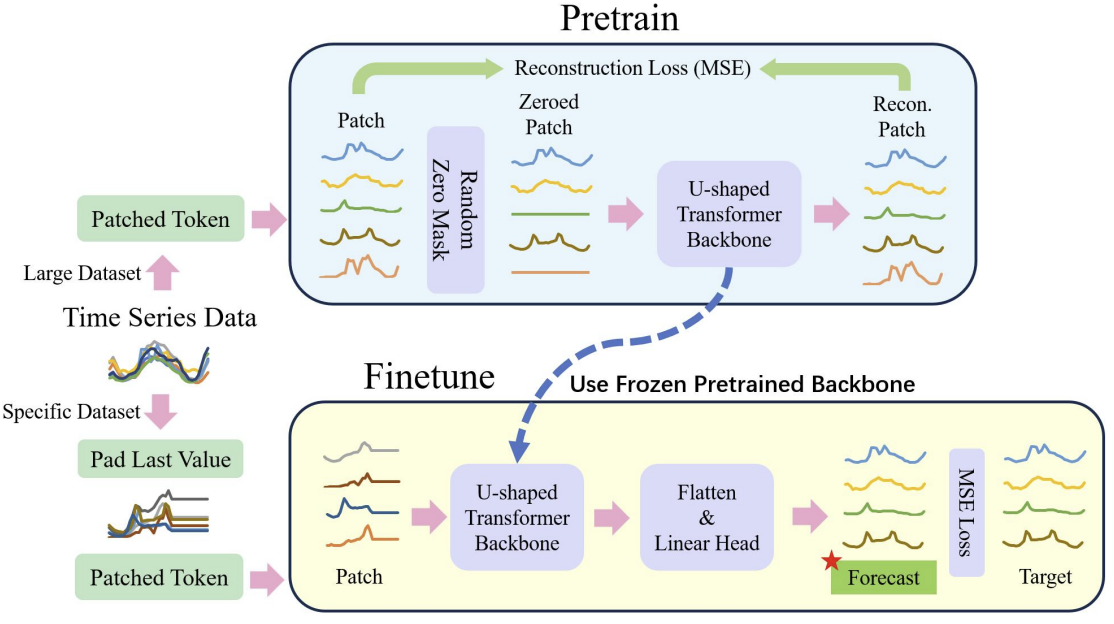
Wir haben bereits gesehen, dass das Training von Modellen, die auf der Transformer-Architektur basieren, erhebliche Rechenressourcen und eine große Trainingsstichprobe erfordert. Daher werden bei der Lösung von NLP- und CV-Problemen häufig verschiedene vortrainierte Modelle verwendet. Leider haben wir diese Möglichkeit bei der Lösung von Zeitreihenproblemen nicht, da die Art und Struktur von Zeitreihen sehr unterschiedlich ist. Aus diesem Grund schlagen die Autoren der U-förmigen Transformator-Methode vor, den Modellbildungsprozess in zwei Phasen zu unterteilen.
Zunächst wird vorgeschlagen, einen relativ großen Datensatz zu verwenden, um das U-förmige Transformatormodell für die Wiederherstellung zufällig maskierter Eingabedaten zu trainieren. Dadurch kann das Modell die Struktur der Eingabedaten, die Abhängigkeiten und den Kontext der Zeitreihen lernen. Dies ermöglicht auch eine effektive Filterung unterschiedlichen Rauschens. Darüber hinaus ergänzten die Autoren der Methode in ihrer Arbeit den Trainingsdatensatz mit Daten aus verschiedenen Zeitreihen, die nicht nur in unterschiedlichen Zeitintervallen, sondern auch aus unterschiedlichen Quellen erhoben wurden. So wollten sie den U-förmigen Transformer trainieren, um ganz andere Probleme zu lösen.
In der zweiten Stufe werden die Gewichte des U-förmigen Transformators eingefroren. Ihm wird ein „Entscheidungskopf“ hinzugefügt. Es ist auf die Lösung spezifischer Probleme in einem relativ kleinen Trainingsdatensatz abgestimmt.
Damit wird das Problem angegangen, dass 1 vortrainierter U-förmiger Transformator zur Lösung mehrerer Probleme verwendet wird.
Wie Sie sehen, geht die Feinabstimmung viel schneller und erfordert weniger Ressourcen als der vollständige U-förmige Transformator-Trainingsprozess.
Im Folgenden wird der allgemeine Prozess, wie er von den Autoren dargestellt wurde, beschrieben.
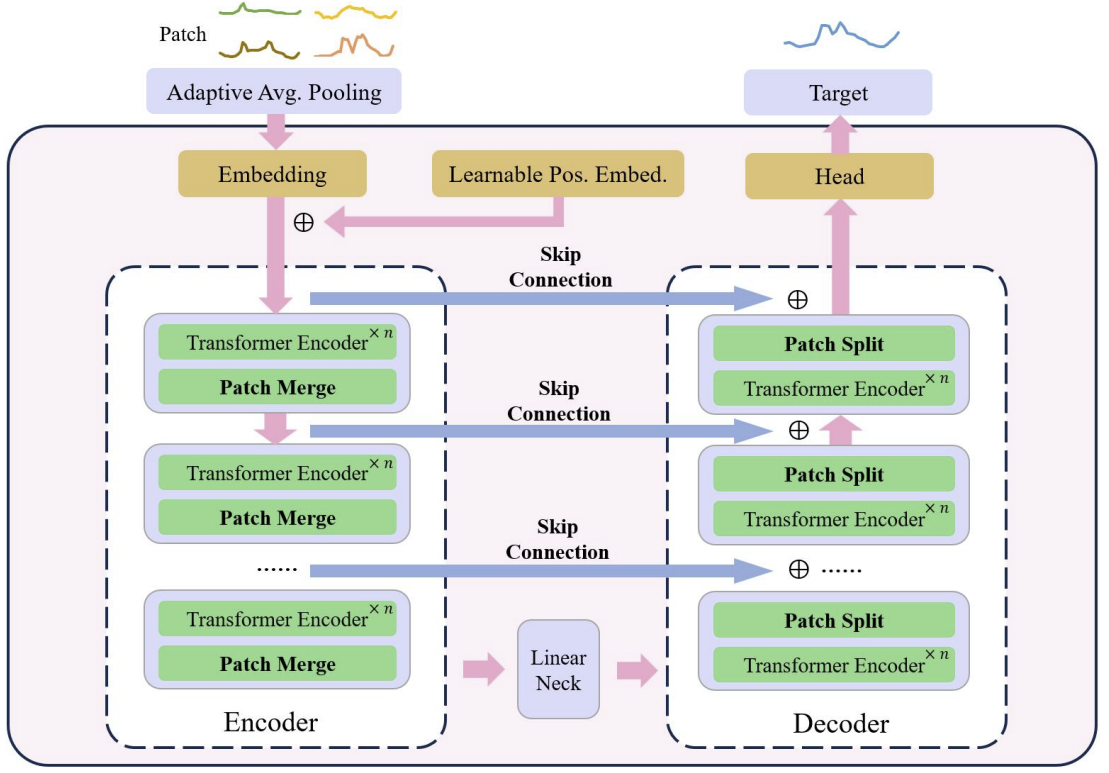
Das Herzstück des U-förmigen Transformators ist die Stapelung der Transformatorschichten. Mehrere Transformer-Ebenen bilden eine Gruppe. Nach der Bearbeitung der Gruppe werden die Patches zusammengeführt oder geteilt, um Merkmale unterschiedlicher Größenordnungen zu integrieren.
Mehrere Skip-Verbindungen werden für eine schnelle Datenübertragung vom Encoder zum Decoder verwendet. Auf diese Weise können hochfrequente Daten schnell und ohne unnötige Verarbeitung an den Ausgang des neuronalen Netzes gelangen. Die Eingangsdaten der Transformer-Gruppe werden in den Decoderausgang mit der gleichen Form eingespeist. Während der Codierung der Eingabedaten werden bei der Abwärtsbewegung des Modells kontinuierlich hochfrequente Merkmale herausgefiltert, während allgemeine Merkmale extrahiert werden. Während des Dekodierungsprozesses werden die allgemeinen Merkmale kontinuierlich mit den detaillierten Informationen aus der Skip-Connection rekonstruiert, was letztendlich zu einer zeitlichen Darstellung der Serie führt, die sowohl hochfrequente als auch niederfrequente Merkmale kombiniert.
Patch-Operationen sind entscheidende Komponenten für das U-förmige Transformatormodell, da sie die Erfassung von Merkmalen in verschiedenen Maßstäben ermöglichen. Die ausgewählten Merkmale wirken sich direkt auf die Informationen aus, die in den zugrunde liegenden Kontext der Aufmerksamkeitsberechnung einbezogen werden. Bei herkömmlichen Ansätzen werden Zeitreihen häufig in zwei Reihen aufgeteilt und als unabhängige Kanäle behandelt. Die Autoren der U-förmigen Transformer-Methode halten diesen Ansatz für unausgereift, da die Informationen über Patches aus verschiedenen Kanälen in einem Zeitschritt nicht aus benachbarten Regionen stammen. Daher schlagen sie vor, eine Faltung mit einer Fenstergröße und einem Stride von 2 als Patch-Pooling zu verwenden, wodurch sich die Anzahl der Kanäle verdoppelt. Dadurch wird sichergestellt, dass der vorherige Patch nicht fragmentiert wird und die Skalen besser zusammengeführt werden. Während des Dekodierungsprozesses verwenden die Autoren der Methode daher transponierte Faltungen als Patch-Separationsoperation.
Bei der U-förmigen Transformationsmethode wird die Faltung mit einem Punktkern als Einbettungsmethode verwendet, um jeden Patch in einem höherdimensionalen Raum abzubilden. Die Autoren der Methode erstellen dann einen trainierbaren relativen Positionskodierer für jedes Patch, der zu den einbettenden Patches hinzugefügt wird, um die Ansammlung von Vorwissen zwischen den Patches zu verbessern.
Wie bereits erwähnt, verwenden die Autoren der U-förmigen Transformer-Methode einen Patch-basierten Einbettungsansatz, um die Zeitreihendaten in kleinere Blöcke aufzuteilen. Sie verwenden die Patch-Wiederherstellung als Voraufgabe. Die Autoren der Methode glauben, dass die Wiederherstellung unmaskierter Patches die Robustheit des Modells gegenüber verrauschten Daten mit einem Wert von Null verbessern kann.
Nach dem Vortraining erfolgt die Feinabstimmung des Modells an einer bestimmten Kopfeinheit, die für die Generierung der Zielaufgaben zuständig ist. In diesem Stadium frieren sie alle Komponenten außer den Kopfnetzen ein.
Um die Verallgemeinerungsfähigkeit des Modells zu verbessern und das Potenzial des Transformators bei größeren Datensätzen auszuschöpfen, wird ein größerer Datensatz verwendet.
Um die Unausgewogenheit der Daten weiter abzuschwächen, verwenden sie gewichtete Zufallsstichproben, bei denen die Anzahl der Stichproben aus verschiedenen Datensätzen während des Trainings ausgeglichen ist.
Um das Problem der Trainingsinstabilität bei Transformator-basierten Modellen zu entschärfen, schlagen die Autoren der Methode vor, jeden Mini-Batch zu normalisieren, um die Eingabedaten auf eine Standard-Normalverteilung zu bringen.
Die vorgeschlagene Methode zur Datenvorverarbeitung ermöglicht eine effiziente Merkmalsextraktion aus verschiedenen Teilen des Datensatzes und überwindet effektiv das Problem des Datenungleichgewichts beim gemeinsamen Training auf mehreren Datensätzen.
2. Implementierung in MQL5
Nach der Betrachtung der theoretischen Aspekte der Methode gehen wir zum praktischen Teil unseres Artikels über, in dem wir die vorgeschlagenen Ansätze in MQL5 implementieren.
Wie bereits erwähnt, verwendet der U-förmige Transformator mehrere architektonische Lösungen, die wir umsetzen müssen. Beginnen wir mit dem Block der trainierbaren positionsbezogenen Kodierung.
2.1 Positionsbezogene Kodierung
Der Block für die Positionskodierung dient dazu, Informationen über die Position von Elementen in einer Zeitreihe in die Zeitreihe einzugeben. Wie Sie wissen, analysiert der Self-Attention-Algorithmus die Abhängigkeiten zwischen den Elementen unabhängig von ihrem Platz in der Reihe. Aber auch Informationen über die Position eines Elements in einer Reihe und über den Abstand zwischen den analysierten Elementen können eine wichtige Rolle spielen. Dies gilt insbesondere für zeitliche Datenreihen. Um diese Informationen hinzuzufügen, verwendet der klassische Transformator die Addition einer Sinusfolge zu den Eingangsdaten. Die Periodizität sinusförmiger Sequenzen ist fest und kann in verschiedenen Implementierungen je nach Größe der zu analysierenden Sequenz variieren.
Zeitreihen sind dadurch gekennzeichnet, dass sie eine gewisse Periodizität aufweisen. Manchmal haben sie mehrere Frequenzmerkmale. In solchen Fällen ist es notwendig, zusätzliche Arbeit zu leisten, um die Frequenzcharakteristiken des Positionskodierungstensors so auszuwählen, dass er die Originaldaten nicht verzerrt oder ihnen zusätzliche Informationen hinzufügt.
Das Originalpapier enthält keine detaillierte Beschreibung der Methode für die trainierbare Positionskodierung. Ich hatte den Eindruck, dass die Autoren der Methode während des Modelltrainings für jedes Element der Sequenz einen Positionskodierungskoeffizienten ausgewählt haben. Sie ist also während des gesamten Vorgangs fixiert.
In unserer Implementierung gehen wir noch einen Schritt weiter und machen die Koeffizienten der Positionskodierung von den Eingabedaten abhängig. Wir werden eine einfache, vollständig verbundene Schicht verwenden, um den Tensor für die Positionskodierung zu erzeugen. Natürlich werden wir diese Schicht während des Lernprozesses trainieren.
Um den vorgeschlagenen Mechanismus zu implementieren, werden wir eine neue Klasse CNeuronLearnabledPE erstellen. Wie in den meisten Fällen werden wir die Hauptfunktionalität von der Basisklasse CNeuronBaseOCL für neuronale Schichten erben.
class CNeuronLearnabledPE : public CNeuronBaseOCL { protected: CNeuronBaseOCL cPositionEncoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronLearnabledPE(void) {}; ~CNeuronLearnabledPE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronLearnabledPE; } virtual void SetOpenCL(COpenCLMy *obj); };
Die Klassenstruktur hat 1 verschachteltes Objekt der Basisschicht des neuronalen Netzes cPositionEncoder, das die trainierbaren Parameter unseres Tensors für die Positionskodierung enthält. Dieses Objekt ist statisch spezifiziert, und daher können wir den Konstruktor und den Destruktor der Klasse leer lassen.
Die Initialisierung einer Klasseninstanz erfolgt in der Methode Init. In den Methodenparametern übergeben wir alle notwendigen Informationen für die korrekte Initialisierung der verschachtelten Objekte.
bool CNeuronLearnabledPE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; if(!cPositionEncoder.Init(0, 1, OpenCL, numNeurons, optimization, iBatch)) return false; cPositionEncoder.SetActivationFunction(TANH); SetActivationFunction(None); //--- return true; }
Der Algorithmus der Methode ist recht einfach. Im Hauptteil der Methode rufen wir zunächst dieselbe Methode der übergeordneten Klasse auf, die die empfangenen externen Parameter überprüft und die geerbten Objekte initialisiert. Das Ergebnis der Operationen wird durch den logischen Wert bestimmt, der nach der Ausführung der aufgerufenen Methode zurückgegeben wird.
Der nächste Schritt besteht darin, das verschachtelte cPositionEncoder-Objekt zu initialisieren. Für das verschachtelte Objekt legen wir den hyperbolischen Tangens als Aktivierungsfunktion fest. Der Wertebereich dieser Funktion reicht von „-1“ bis „1“, was dem Wertebereich von Sinuswellen entspricht.
Für unsere Klasse der dynamischen Positionskodierung gibt es keine Aktivierungsfunktion.
Nachdem alle Iterationen erfolgreich abgeschlossen wurden, beenden wir die Methode mit dem Ergebnis true.
Beschreiben wir den Vorwärtsdurchgangs-Algorithmus unserer Methode in der Methode CNeuronLearnabledPE::feedForward. In Analogie zur gleichen Methode der Elternklasse erhält die Methode als Parameter einen Zeiger auf das Objekt der vorherigen neuronalen Schicht, das die Eingabedaten enthält.
bool CNeuronLearnabledPE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPositionEncoder.FeedForward(NeuronOCL)) return false; if(!SumAndNormilize(NeuronOCL.getOutput(), cPositionEncoder.getOutput(), Output, 1, false, 0, 0, 0, 1)) return false; //--- return true; }
Auf der Grundlage der erhaltenen Ausgangsdaten erstellen wir zunächst einen Tensor für die Positionskodierung. Dann fügen wir die erhaltenen Werte zum Tensor der Eingabedaten hinzu.
Die Ausführung aller Operationen wird anhand der Werte gesteuert, die von den aufgerufenen Methoden zurückgegeben werden.
Der Algorithmus CNeuronLearnabledPE::calcInputGradients der Methode der Fehlergradientenverteilung sieht etwas komplizierter aus. In den Parametern erhält sie auch einen Zeiger auf das Objekt der vorherigen neuronalen Schicht, an die wir den Fehlergradienten übergeben müssen.
bool CNeuronLearnabledPE::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!DeActivation(cPositionEncoder.getOutput(), cPositionEncoder.getGradient(), Gradient, cPositionEncoder.Activation())) return false; if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getGradient(), Gradient, NeuronOCL.Activation())) return false; //--- return true; }
Im Methodenrumpf wird zunächst die Relevanz des in den Parametern erhaltenen Zeigers geprüft.
Wir passen dann den Fehlergradienten, den wir von der nachfolgenden Schicht erhalten, an die Aktivierungsfunktion des internen Objekts an. Ich möchte Sie daran erinnern, dass wir während des Initialisierungsprozesses eine Aktivierungsfunktion für das interne Objekt angegeben haben, aber das CNeuronLearnabledPE-Objekt selbst ohne Aktivierungsfunktion gelassen haben. Daher wurde der Fehlergradient in unserem Schichtpuffer nicht durch die Aktivierungsfunktion korrigiert.
Der nächste Schritt ist die Wiederholung des Vorgangs der Korrektur des Fehlergradienten. Dieses Mal wird sie jedoch auf die Aktivierungsfunktion der vorherigen Schicht angewendet.
Beachten Sie, dass wir den Fehlergradienten nicht durch das interne Objekt, das den Positionskodierungstensor erzeugt, weitergeben. Um die Parameter dieser Schicht zu aktualisieren, brauchen wir nur einen Fehlergradienten an ihrem Ausgang zu haben. Es ist nicht notwendig, den Fehlergradienten durch das Objekt zur vorherigen Schicht zu propagieren, da der Block, der den Positionskodierungstensor erzeugt, die Eingabedaten oder deren Einbettung nicht beeinflussen sollte.
Um die Implementierung des Rückwärtsdurchgangs-Algorithmus der Klasse CNeuronLearnabledPE abzuschließen, erstellen wir eine Methode zur Aktualisierung der Lernparameter: updateInputWeights. Diese Methode ist sehr vereinfacht: Sie ruft die Methode des verschachtelten Objekts mit demselben Namen auf.
bool CNeuronLearnabledPE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return cPositionEncoder.UpdateInputWeights(NeuronOCL); }
Den vollständigen Code dieser Klasse und alle ihre Methoden finden Sie im Anhang.
2.2 U-förmige Transformatorenklasse
Fahren wir mit unserer Version der Umsetzung der von den Autoren der U-förmigen Transformer-Methode vorgeschlagenen Ansätze fort. Ich muss sagen, dass sich die Entscheidung über die Implementierungsarchitektur für die scip-connection zwischen Encoder und Decoder trotz ihrer scheinbaren Einfachheit als nicht so offensichtlich erwiesen hat. Einerseits könnten wir einen Verweis auf die Kennung der inneren Schicht verwenden und Daten vom Encoder an den Decoder weitergeben. Hier gibt es keine Schwierigkeiten. Es stellt sich jedoch die Frage nach der Ausbreitung des Fehlergradienten durch die scip-connection. Die gesamte Backpropagation-Architektur unserer Klassen basiert auf dem Umschreiben des Fehlergradienten während des nachfolgenden Rückwärtsdurchlaufs. Daher wird jeder Fehlergradient, den wir durch scip-connection propagieren, während der Gradientenfortpflanzungsoperationen durch neuronale Schichten zwischen scip-connection-Objekten entfernt.
Als Lösung können wir uns vorstellen, die gesamte U-förmige Transformatorarchitektur in einer Klasse zu erstellen. Wir brauchen jedoch einen Mechanismus, um eine unterschiedliche Anzahl von Encoder-Decoder-Blöcken mit einer unterschiedlichen Anzahl von Transformer-Schichten in jedem Block zu konstruieren. Die Lösung ist die wiederholte Erstellung von Objekten. Wir werden den gewählten Mechanismus im Laufe des Umsetzungsprozesses ausführlicher diskutieren.
Um unseren U-förmigen Transformer-Block zu implementieren, erstellen wir die Klasse CNeuronUShapeAttention, die, wie die vorhergehende, die Hauptfunktionalität von der Basisklasse CNeuronBaseOCL der neuronalen Schicht erbt.
class CNeuronUShapeAttention : public CNeuronBaseOCL { protected: CNeuronMLMHAttentionOCL cAttention[2]; CNeuronConvOCL cMergeSplit[2]; CNeuronBaseOCL *cNeck; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); //--- public: CNeuronUShapeAttention(void) {}; ~CNeuronUShapeAttention(void) { delete cNeck; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronUShapeAttention; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *net, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Im Klassenkörper erstellen wir ein Array mit 2 Elementen der mehrschichtigen, mehrköpfigen Aufmerksamkeitsklasse CNeuronMLMHAttentionOCL. Dies sind die Encoder und Decoder des aktuellen Blocks.
Wir erstellen auch ein Array mit 2 Faltungsschichtelementen, die wir für die Arbeit mit Patches verwenden werden.
Alle Elemente zwischen den Encodern und Decodern des aktuellen Blocks werden in das cNeck-Objekt der Basisklasse der neuronalen Schicht eingefügt, die in diesem Fall dynamisch ist. Aber wie kann eine unbestimmte Anzahl von Blöcken zu einem Block hinzugefügt werden? Um diese Frage zu beantworten, schlage ich vor, die Initialisierungsmethode des Objekts Init zu betrachten.
Wie immer erhalten wir in den Methodenparametern die wichtigsten Konstanten der Objektarchitektur:
- window — Größe des Eingangsdatenfensters (Beschreibungsvektor von 1 Element der Sequenz)
- window_key — die Größe des internen Vektors, der 1 Element einer Sequenz in den Entitäten Self-Attention Query, Key, Value (Abfrage, Schlüssel, Wert) beschreibt
- heads — Anzahl der Aufmerksamkeitsköpfe
- units_count — Anzahl der Elemente in der Sequenz
- Ebenen — Anzahl der Aufmerksamkeitsebenen in einem Block
- inside_bloks — Anzahl der verschachtelten U-förmigen Transformatorblöcke
Die Parameter window, window_key, heads und layers werden unverändert für die aktuellen und verschachtelten U-förmigen Transformer-Blöcke verwendet.
bool CNeuronUShapeAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Im Hauptteil der Methode rufen wir zunächst dieselbe Methode der Elternklasse auf, die die empfangenen Parameter kontrolliert und die geerbten Objekte initialisiert.
Als Nächstes werden die Objekte Encoder und Patch Split initialisiert.
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2 * window, 4 * window, (units_count + 1) / 2, optimization, iBatch)) return false;
Nun folgt der interessanteste Teil der Initialisierungsmethode. Zunächst wird die Anzahl der angegebenen verschachtelten Blöcke überprüft. Wenn es mehr als „0“ sind, erstellen und initialisieren wir den verschachtelten U-förmigen Transformator-Block, ähnlich wie die aktuelle Klasse. Die Anzahl der Elemente in der Sequenz wird jedoch um das Zweifache erhöht, was dem Ergebnis des Patch-Splittings entspricht. Wir verringern auch die Anzahl der verschachtelten Blöcke um „1“.
if(inside_bloks > 0) { CNeuronUShapeAttention *temp = new CNeuronUShapeAttention(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, 2 * units_count, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
Wir speichern den Zeiger auf das erstellte Objekt in der Variablen cNeck. Zu diesem Zweck haben wir ein dynamisches Objekt deklariert. Durch den wiederholten Aufruf der Initialisierungsfunktion wird also die erforderliche Anzahl von verschachtelten U-förmigen Transformer-Gruppen erzeugt.
Im letzten Block erstellen wir eine Faltungsschicht mit linearer Abhängigkeit zwischen dem Encoder und dem Decoder.
{
CNeuronConvOCL *temp = new CNeuronConvOCL();
if(!temp)
return false;
if(!temp.Init(0, 2, OpenCL, window, window, window, 2 * units_count, optimization, iBatch))
{
delete temp;
return false;
}
cNeck = temp;
}
Als Nächstes initialisieren wir die Decoder- und Patch-Merge-Objekte.
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, 2 * units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, 2 * window, 2 * window, window, units_count, optimization, iBatch)) return false;
Um unnötige Kopiervorgänge zu vermeiden, ersetzen wir den Fehlergradientenpuffer.
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
Ende der Methode.
Die anschließende Vorwärts-Methode ist viel einfacher. Darin rufen wir nur die gleichnamigen Methoden der internen Schichten nacheinander gemäß dem U-förmigen Transformer-Algorithmus auf. Zunächst durchlaufen die Eingangsdaten den Encoder-Block.
bool CNeuronUShapeAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
Dann teilen wir die Patches auf.
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
Und für verschachtelte Blöcke rufen wir die Vorwärts-Methode auf.
if(!cNeck.FeedForward(cMergeSplit[0].AsObject())) return false;
Die auf diese Weise verarbeiteten Daten werden dem Decoder zugeführt.
if(!cAttention[1].FeedForward(cNeck)) return false;
Gefolgt von der Patch-Merge-Ebene.
if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
Schließlich addieren wir die Ergebnisse des aktuellen U-förmigen Transformer-Blocks mit den empfangenen Eingangsdaten (scip-connection), um das Hochfrequenzsignal zu erhalten.
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), Output, 1, false)) return false; //--- return true; }
Ende der Methode.
Nach der Implementierung des Feed-Forward-Passes geht es an die Erstellung der Backpropagation-Methoden. Zunächst erstellen wir die Methode CNeuronUShapeAttention::calcInputGradients, in deren Parametern wir einen Zeiger auf das Objekt der vorherigen Schicht erhalten, an das wir den Fehlergradienten weitergeben müssen.
bool CNeuronUShapeAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Im Hauptteil der Methode wird sofort die Relevanz des empfangenen Zeigers geprüft.
Da wir die Datenpuffer ersetzen, ist der Fehlergradient bereits im Puffer der verschachtelten Patch-Mischschicht gespeichert. Wir können also die entsprechende Methode der Fehlergradientenverteilung aufrufen.
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
Als Nächstes propagieren wir den Fehlergradienten durch den Decoder.
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
Anschließend wird der Fehlergradient nacheinander durch die internen Blöcke des U-förmigen Transformators, die Patch-Splitting-Schicht und den Encoder geleitet.
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject())) return false; if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
Danach summieren wir die Fehlergradienten am Eingang und am Ausgang des aktuellen Blocks (scip-connection).
if(!SumAndNormilize(prevLayer.getGradient(), Gradient, prevLayer.getGradient(), 1, false)) return false; if(!DeActivation(prevLayer.getOutput(), prevLayer.getGradient(), prevLayer.getGradient(), prevLayer.Activation())) return false; //--- return true; }
Passen wir den Fehlergradienten an die Aktivierungsfunktion der vorherigen Schicht an und beenden die Methode.
Auf die Ausbreitung des Fehlergradienten folgt eine Anpassung der trainierbaren Parameter des Modells. Diese Funktionalität ist in der Methode CNeuronUShapeAttention::updateInputWeights implementiert. Der Algorithmus der Methode ist recht einfach. Wir rufen einfach die entsprechenden Methoden der verschachtelten Objekte nacheinander auf.
bool CNeuronUShapeAttention::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].UpdateInputWeights(NeuronOCL)) return false; if(!cMergeSplit[0].UpdateInputWeights(cAttention[0].AsObject())) return false; if(!cNeck.UpdateInputWeights(cMergeSplit[0].AsObject())) return false; if(!cAttention[1].UpdateInputWeights(cNeck)) return false; if(!cMergeSplit[1].UpdateInputWeights(cAttention[1].AsObject())) return false; //--- return true; }
Vergessen wir nicht, die Ergebnisse bei jedem Schritt zu kontrollieren.
Es sollten einige weitere Informationen zu den Dateiverarbeitungsmethoden gegeben werden. Die Operationen in der Datensicherungsmethode CNeuronUShapeAttention::Save sind recht einfach. Wir rufen die entsprechenden Methoden der übergeordneten Klasse und aller verschachtelten Objekte nacheinander auf.
bool CNeuronUShapeAttention::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; for(int i = 0; i < 2; i++) { if(!cAttention[i].Save(file_handle)) return false; if(!cMergeSplit[i].Save(file_handle)) return false; } if(!cNeck.Save(file_handle)) return false; //--- return true; }
Was die Datenlademethode CNeuronUShapeAttention::Load betrifft, so gibt es einige Nuancen. Sie beziehen sich darauf, wie das Laden von verschachtelten U-förmigen Transformatorblöcken organisiert ist. Zunächst rufen wir die Methode der übergeordneten Klasse auf, um die geerbten Objekte zu laden.
bool CNeuronUShapeAttention::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
Dann laden wir in einer Schleife die Daten des Encoders, des Decoders und der Patch-Schicht.
for(int i = 0; i < 2; i++) { if(!LoadInsideLayer(file_handle, cAttention[i].AsObject())) return false; if(!LoadInsideLayer(file_handle, cMergeSplit[i].AsObject())) return false; }
Dann müssen wir verschachtelte Blöcke laden. Wie Sie sich erinnern, verwenden wir hier einen dynamischen Zeiger auf ein Objekt. Daher gibt es einige Möglichkeiten. Der Zeiger in der Variablen kann ungültig sein oder auf ein Objekt einer anderen Klasse zeigen.
Wir lesen den Typ des gewünschten Objekts aus der Datei. Wir überprüfen auch den Typ des Objekts, auf das die Variable cNeck zeigt. Wenn sich die Typen unterscheiden, löschen wir das vorhandene Objekt.
int type = FileReadInteger(file_handle); if(!!cNeck) { if(cNeck.Type() != type) delete cNeck; }
Als Nächstes prüfen wir die Relevanz des Zeigers in der Variablen und erstellen gegebenenfalls ein neues Objekt des entsprechenden Typs.
if(!cNeck) { switch(type) { case defNeuronUShapeAttention: cNeck = new CNeuronUShapeAttention(); if(!cNeck) return false; break; case defNeuronConvOCL: cNeck = new CNeuronConvOCL(); if(!cNeck) return false; break; default: return false; } }
Nach Abschluss der vorbereitenden Arbeiten laden wir die Objektdaten aus der Datei.
cNeck.SetOpenCL(OpenCL); if(!cNeck.Load(file_handle)) return false;
Am Ende der Methode ersetzen wir die Puffer für die Fehlergradienten.
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
Ende der Methode.
Den vollständigen Code aller Klassen und ihrer Methoden sowie alle Programme, die bei der Erstellung des Artikels verwendet wurden, finden Sie im Anhang.
2.3 Modellarchitektur
Nachdem wir neue Klassen für die Erstellung unserer Modelle erstellt haben, gehen wir dazu über, die Architektur der trainierbaren Modelle zu beschreiben. Für sie erstellen wir die Datei „...\Experts\UShapeTransformer\Trajectory.mqh“.
Wie bereits erwähnt, schlagen die Autoren der U-förmigen Transformer-Methode vor, die Modelle in 2 Schritten zu trainieren. Im ersten Schritt wird der Encoder darauf trainiert, die maskierten Daten wiederherzustellen. Daher wird die Beschreibung der Architektur des Encoder-Modells in eine separate Methode namens CreateEncoderDescriptions ausgelagert. In den Methodenparametern übergeben wir einen Zeiger auf ein dynamisches Array-Objekt zur Aufzeichnung der Beschreibung der Modellarchitektur.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Im Methodenrumpf prüfen wir die Relevanz des empfangenen Zeigers und erstellen gegebenenfalls eine neue Instanz des dynamischen Arrays.
Als Nächstes erstellen wir eine Quelldatenschicht von ausreichender Größe.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die Eingabedaten werden dem Modell in „roher“ Form zugeführt. Vorverarbeitung in einer Batch-Normalisierungsschicht.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Wir speichern die Nummer der Batch-Normalisierungsebene, um sie in der inversen Normalisierungsebene anzugeben.
Um den Encoder zu trainieren, verwenden wir Datenmaskierung. Um die Maskierung durchzuführen, erstellen wir eine Dropout-Schicht.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.4f; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Die Maskierungswahrscheinlichkeit wird auf 0,4 gesetzt, was 40 % der Eingabedaten entspricht.
Bitte beachten Sie, dass wir die ursprünglichen Eingabedaten maskieren, nicht ihre Einbettungen.
Im nächsten Schritt verwenden wir 2 Faltungsschichten, um Einbettungen der maskierten Eingabedaten zu erzeugen.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = descr.window; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Dann fügen wir den Eingabedaten eine Positionskodierung hinzu. In diesem Fall verwenden wir eine erlernbare positionsbezogene Kodierung.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count*prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Jetzt fügen wir den U-förmigen Transformatorblock hinzu. Die folgenden Parameter werden in der Ebene verwendet.
- descr.count: Größe der Sequenz
- descr.window: Größe des Vektors mit einem Element Beschreibung
- descr.step: Anzahl der Aufmerksamkeitsköpfe
- descr.window_out: Größe des Elements der internen Aufmerksamkeitseinheiten
- descr.layers: Anzahl der Ebenen in jedem Transformer-Block
- descr.batch: Anzahl der verschachtelten U-förmigen Transformatorblöcke
Wie Sie sehen können, wurden die meisten Parameter aus den Aufmerksamkeitsblöcken übernommen.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronUShapeAttention; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 3; descr.batch = 2; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes kommt der Entscheidungsblock mit 3 vollständig verbundenen Schichten.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = BarDescr*(HistoryBars+NForecast); descr.activation=TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass wir am Ausgang des Encoders die rekonstruierten Eingabedaten plus mehrere vorhergesagte Werte erwarten. Auf diese Weise wollen wir den U-förmigen Transformator so trainieren, dass er nicht nur Abhängigkeiten in den Eingabedaten erfasst, sondern auch Bezugspunkte für die Konstruktion von Vorhersagewerten findet.
Um den Encoder zu vervollständigen, fügen wir eine umgekehrte Normalisierungsschicht hinzu, um die rekonstruierten und vorhergesagten Werte mit den ursprünglichen Eingabedaten vergleichbar zu machen.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Eine Änderung der Encoder-Architektur erfordert eine Änderung der Konstante der verborgenen Schicht, um Daten aus dem Modell zu erhalten.
#define LatentLayer 9
Darüber hinaus erfordert eine Änderung der Größe der Encoder-Ergebnisschicht auch eine Anpassung der Architektur der Modelle von Akteur und Kritiker, die diese Daten verwenden. Die Architektur dieser Modelle wird in der Methode CreateDescriptions beschrieben. In den Parametern erhält die Methode Zeiger auf 2 dynamische Arrays zur Erfassung der Architekturen der entsprechenden Modelle.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Im Hauptteil der Methode werden die empfangenen Zeiger überprüft und gegebenenfalls neue dynamische Arrays erstellt.
Zunächst beschreiben wir die Architektur des Akteurs. Wir füttern das Modell mit dem Vektor zur Beschreibung des Kontostandes.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die gewonnenen Daten werden von einer vollständig verknüpften Schicht verarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Als Nächstes fügen wir 5 Cross-Attention-Schichten hinzu, die Informationen über den Kontostand und die offenen Positionen mit den Daten der rekonstruierten und vorhergesagten Werte vergleichen, die vom Encoder generiert wurden.
for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, HistoryBars+NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
Beachten Sie, dass wir die Eingabedaten in der Trainings- und Betriebsphase der Akteurspolitik nicht maskieren werden. Es wird jedoch erwartet, dass der trainierte Encoder nicht nur spätere Zustände der Umgebung vorhersagt, sondern auch als eine Art Filter für historische Werte fungiert und verschiedene Störungen aus ihnen entfernt.
Am Ende des Modells befindet sich ein Entscheidungsblock mit einem stochastischen „Kopf“ (head).
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die Architektur des Kritikers wurde entsprechend angepasst. Ich werde diese Änderungen hier nicht beschreiben. Ich schlage vor, dass Sie sich anhand der Codes in der Anlage mit ihnen vertraut machen.
2.4 Kodierung des Trainings-EAs
Wir haben die Modellarchitektur beschrieben. Kommen wir nun zum Trainings-EA des Encoder-Modells. In dieser Arbeit verwenden wir den für den vorherigen Artikel gesammelten Trainingsdatensatz. In diesem Datensatz haben wir eine ganze Reihe von historischen Daten verwendet, um den Zustand der Umgebung zu beschreiben. Dieser Ansatz hat seine Vor- und Nachteile. Zu den Vorteilen gehören der Wegfall eines Stapels innerhalb des Modells für die Akkumulation historischer Daten und die Möglichkeit, Modelle anhand von Stichproben zu trainieren. Der Nachteil ist jedoch das beträchtliche Wachstum der Trainingsdatendatei, da sie Daten enthält, die viele Male wiederholt werden. Auch während des Betriebs wiederholt das Modell in jedem Schritt die Neuberechnung der historischen Daten für die gesamte Tiefe der analysierten Geschichte. In diesem Stadium ist es jedoch wichtig, die in das Modell eingespeisten Daten und die nach der Maskierung wiederhergestellten Daten eindeutig zu vergleichen. Daher habe ich mich für diese Lösung entschieden, um die vorgeschlagenen Ansätze zu testen.
Der neue EA „...\Experts\UShapeTransformer\StudyEncoder.mq5“ basiert hauptsächlich auf dem entsprechenden EA aus dem vorherigen Artikel. Daher werden wir nicht auf alle Methoden im Einzelnen eingehen. Betrachten wir nun die Methode der Modellbildung: Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Zu Beginn der Methode leisten wir ein wenig Vorbereitungsarbeit. Wir definieren die Wahrscheinlichkeiten von Stichproben-Trajektorien auf der Grundlage ihrer Erträge und deklarieren lokale Variablen.
Dann organisieren wir eine Modell-Trainingsschleife mit der vom Nutzer in den externen Parametern angegebenen Anzahl von Iterationen.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
Im Hauptteil der Schleife werden die Trajektorie und 1 Zustand abgetastet, um das Modell zu trainieren. Wir laden Informationen über den ausgewählten Zustand in den Datenpuffer.
bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Dann rufen wir die Vorwärtsdurchgangs-Methode für unser Modell auf und übergeben ihm die geladenen Daten.
Nach erfolgreicher Ausführung des Vorwärtsdurchgangs werden im Ergebnispuffer des Modells eine Darstellung der historischen Umgebungsparameter und ihre vorhergesagten Werte gespeichert. Das konkrete Ergebnis interessiert uns im Moment nicht.
Jetzt müssen wir echte Daten über die bevorstehenden und analysierten Umgebungszustände vorbereiten. Wie im vorherigen Artikel laden wir zunächst die nachfolgenden Umgebungszustände aus dem Erfahrungswiedergabepuffer.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
Ergänzen Sie diese mit Daten, die während des Vorwärtsdurchgangs in das Modell eingegeben werden. Wie wir gesehen haben, befinden sich unmaskierte Daten im Puffer.
if(!Result.AddArray(GetPointer(bState))) continue;
Nachdem wir nun einen Puffer mit Zielwerten vorbereitet haben, können wir einen Rückwärtsdurchgang des Modells durchführen und die Gewichte anpassen, um den Fehler zu minimieren.
if(!Encoder.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Nach der Aktualisierung der Modellparameter informieren wir den Nutzer über den Trainingsfortschritt und fahren mit der nächsten Iteration fort.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Überprüfen Sie immer das Ergebnis der Ausführung der Operation.
Sobald alle Iterationen der Modelltrainingsschleife erfolgreich abgeschlossen sind, wird das Kommentarfeld im Chart gelöscht.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Wir geben Informationen über die Ergebnisse des Modelltrainings an das MetaTrader 5-Protokoll aus und leiten die Beendigung des EA ein.
Den vollständigen Code des EA und alle seine Methoden finden Sie im Anhang.
Die Trainings-EAs der Politik von Akteur und Kritiker „...\Experts\RevIN\Study.mq5“ wurde nahezu unverändert aus dem vorherigen Artikel übernommen. Das Gleiche gilt für die Umgebungsinteraktions-EAs. Daher werden wir ihre Algorithmen in diesem Artikel nicht im Detail betrachten. Den vollständigen Code aller in diesem Artikel verwendeten Programme finden Sie im Anhang.
Ich möchte noch einmal betonen, dass in allen EAs, außer dem Encoder-Trainings-EA, der Trainingsmodus für das Encoder-Modell deaktiviert werden muss.
Encoder.TrainMode(false);
Dadurch wird die Maskierung der ursprünglichen Eingabedaten deaktiviert.
3. Tests
Wir haben die theoretischen Aspekte der U-förmigen Transformator-Methode erörtert und viel Arbeit in die Implementierung der vorgeschlagenen Ansätze mit MQL5 gesteckt. Nun ist es an der Zeit, die Ergebnisse unserer Arbeit anhand echter historischer Daten zu testen.
Wie bereits erwähnt, trainieren wir die Modelle mit dem für den vorherigen Artikel gesammelten Trainingsdatensatz. Auf eine detaillierte Beschreibung der Methoden zur Erhebung der Trainingsdatensätze wird an dieser Stelle verzichtet, da sie bereits ausführlich beschrieben wurden.
Das Modell wird mit historischen Daten von EURUSD, H1, für 2023 trainiert. Die trainierte Akteurspolitik wird im MetaTrader 5-Strategietester mit historischen Daten vom Januar 2024 getestet, mit demselben Symbol und Zeitrahmen.
In Übereinstimmung mit dem von den Autoren der U-förmigen Transformer-Methode vorgeschlagenen Ansatz trainieren wir die Modelle in 2 Stufen. Zunächst trainieren wir den Encoder mit zuvor gesammelten Trainingsdaten.
Dabei ist zu beachten, dass das Encoder-Modell nur historische Symboldaten analysiert. Daher müssen wir während des Encoder-Trainings keine zusätzlichen Durchgänge sammeln. Wir können sofort eine ausreichend große Anzahl von Modell-Trainingswiederholungen festlegen und warten, bis der Trainingsprozess abgeschlossen ist.
In dieser Phase konnte ich eine positive Veränderung der Qualität der Umgebungsprognosen feststellen.
Die zweite Phase des Lernens der Akteurspolitik ist iterativ. In dieser Phase wechseln wir das Training der Akteurspolitik mit der Sammlung zusätzlicher Informationen über die Umgebung ab, indem wir dem Trainingsdatensatz unter Verwendung der EA „...\Experts\UShapeTransformer\Research.mq5“ und der aktuellen Akteurspolitik neue Durchläufe hinzufügen.
Durch iteratives Lernen war ich in der Lage, ein Modell zu entwickeln, das sowohl in den Trainings- als auch in den Testdatensätzen Gewinne erzielen konnte.
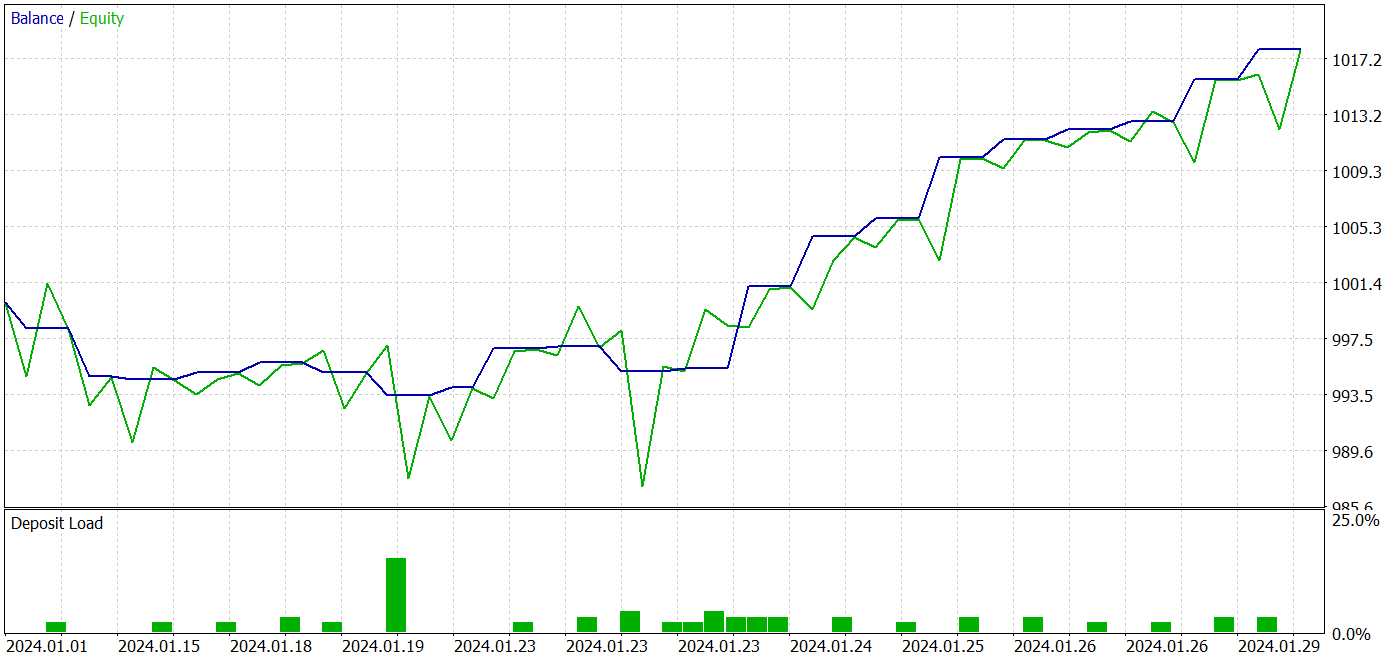
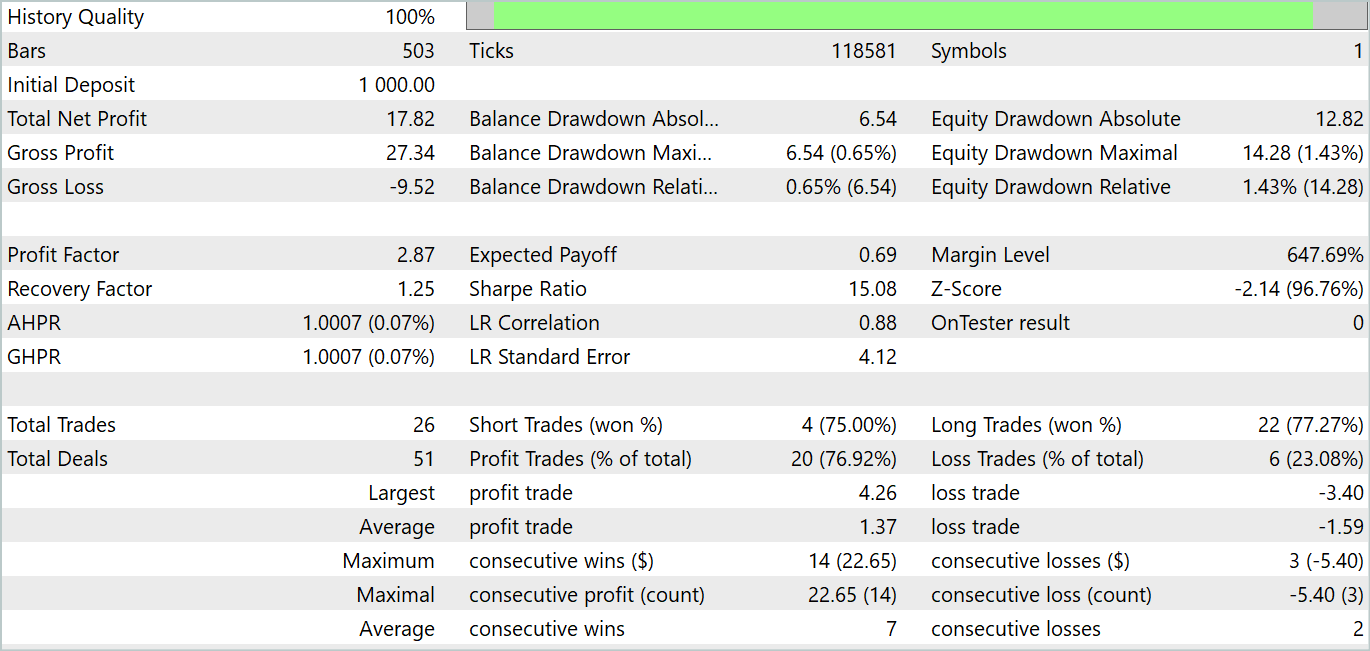
Während des Testzeitraums führte das Modell 26 Transaktionen durch. 20 davon wurden mit einem Gewinn abgeschlossen, was 76,92 % entspricht. Der Gewinnfaktor betrug 2,87.
Die erzielten Ergebnisse sind vielversprechend, aber der Testzeitraum von einem Monat ist zu kurz, um die Stabilität des Modells zuverlässig zu beurteilen.
Schlussfolgerung
In diesem Artikel haben wir uns mit der U-förmigen Transformer-Architektur vertraut gemacht, die speziell für Zeitreihenprognosen entwickelt wurde. Der vorgeschlagene Ansatz kombiniert die Vorteile von Transformatoren und vollständig verbundenen Perceptrons, was eine effektive Erfassung langfristiger Abhängigkeiten in Zeitdaten und die Verarbeitung hochfrequenter Zusammenhänge ermöglicht.
Eine der wichtigsten Errungenschaften des U-förmigen Transformators ist die Verwendung von scip-connectionen und trainierbaren Patch-Merge- und Splitting-Operationen. Dadurch kann das Modell effizient Merkmale in verschiedenen Maßstäben extrahieren und Informationen besser erfassen.
Im praktischen Teil des Artikels haben wir die vorgeschlagenen Ansätze mit MQL5 umgesetzt. Wir trainierten und testeten das resultierende Modell anhand echter historischer Daten. Wir haben recht gute Testergebnisse erhalten.
Ich möchte jedoch noch einmal betonen, dass alle in diesem Artikel vorgestellten Programme nur zur Demonstration der Technologie dienen und nicht für den Einsatz auf realen Märkten geeignet sind. Die Ergebnisse der Tests über einen Zeitraum von einem Monat können nur die Fähigkeiten des Modells aufzeigen, aber nicht seinen stabilen Betrieb über einen längeren Zeitraum bestätigen.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA-Beispielsammlung |
| 2 | ResearchRealORL.mq5 | EA | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | EA | Trainings-EA des Modells |
| 4 | StudyEncoder.mq5 | EA | Trainings-EA der Kodierung |
| 5 | Test.mq5 | EA | Modeltest-EA |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14766
 Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.