
Redes neurais de maneira fácil (Parte 87): Segmentação de séries temporais

Introdução
A previsão desempenha um papel importante na análise de séries temporais. Os modelos profundos trouxeram melhorias significativas para esta área. Eles não apenas preveem com sucesso valores futuros, mas também extraem representações abstratas que podem ser aplicadas em outras tarefas, como classificação e detecção de anomalias.
A arquitetura Transformer, que começou seu desenvolvimento na área de processamento de linguagem natural (NLP), demonstrou suas vantagens na visão computacional (CV) e encontrou aplicação bem-sucedida na análise de séries temporais. Seu mecanismo de Self-Attention, capaz de identificar automaticamente conexões entre elementos da sequência, tornou-se a base para a criação de modelos de previsão eficazes.
O aumento dos volumes de dados disponíveis para análise e a melhoria dos métodos de aprendizado de máquina permitem desenvolver modelos mais precisos e eficientes para a análise de dados temporais. No entanto, à medida que a complexidade das séries temporais aumenta, torna-se necessário desenvolver métodos de análise mais eficientes e menos dispendiosos para alcançar previsões precisas e detectar padrões ocultos.
Um desses métodos é o Transformer de segmentação de séries temporais (Patch Time Series Transformer — PatchTST), que foi apresentado no artigo "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers". Este método baseia-se na divisão de séries temporais em segmentos (patches) e no uso do Transformer para prever valores futuros.
A previsão de séries temporais visa compreender a correlação entre os dados em cada estágio temporal. No entanto, um único passo temporal não possui significado semântico. Portanto, a extração de informações semânticas locais é de grande importância para a análise de suas conexões. Na maioria dos trabalhos anteriores, são usados apenas tokens de ponto temporal dos dados brutos. PatchTST, por outro lado, melhora a localidade e coleta informações semânticas complexas, que não estão disponíveis no nível de pontos, agregando passos temporais em patches no nível de sub-séries.
Além disso, uma série temporal multidimensional representa um sinal multicanal, e cada token dos dados brutos pode representar dados de um canal ou de vários canais. Dependendo da estrutura dos tokens dos dados brutos, existem diferentes variantes da arquitetura Transformer. A mistura de canais refere-se ao último caso, em que o token de entrada pega o vetor de todas as funções da série temporal e o projeta no espaço de embedding para misturar as informações. Por outro lado, a independência de canal significa que cada token dos dados brutos contém informações de apenas um canal. Anteriormente, foi comprovado que isso funciona bem em modelos convolucionais e lineares. PatchTST demonstra a eficácia da abordagem de canais independentes em modelos baseados em Transformer.
Os autores de PatchTST destacam as seguintes vantagens do método proposto:
- Redução da complexidade: A segmentação permite reduzir a complexidade temporal e espacial do modelo, aumentando sua eficiência em grandes conjuntos de dados.
- Melhoria do aprendizado em longos períodos: Os patches permitem que o modelo aprenda períodos temporais mais longos, o que potencialmente melhora a qualidade das previsões.
- Aprendizado de representações: O modelo proposto não é apenas eficaz para previsões, mas também é capaz de extrair representações abstratas mais complexas dos dados, o que melhora sua capacidade de generalização.
Os estudos apresentados no artigo dos autores demonstram a eficácia do método proposto e seu potencial para várias tarefas aplicadas na análise de séries temporais.
1. Algoritmo PatchTST
O método PatchTST foi desenvolvido para análise e previsão de séries temporais multidimensionais, em que cada estado do sistema analisado é descrito por um vetor de parâmetros. Nesse caso, o tamanho do vetor de descrição de cada passo temporal contém a mesma quantidade de parâmetros com estrutura de dados idêntica. Assim, podemos dividir a série temporal multidimensional em várias séries temporais unitárias consoante o número de parâmetros de descrição do estado do sistema.
Semelhante aos métodos que discutimos anteriormente, os dados brutos recebidos como entrada do modelo são normalizados para torná-los comparáveis. Este passo é muito importante. Já mencionamos várias vezes que o uso de dados normalizados na entrada do modelo aumenta significativamente a estabilidade do processo de treinamento. Além disso, embora o método PatchTST pressuponha uma análise canal-independente das séries temporais unitárias, sua análise é realizada com um conjunto unificado de parâmetros treináveis. Portanto, é crucial que os dados de todos os canais analisados estejam em um formato comparável.
Na próxima etapa, é realizada a segmentação das séries temporais unitárias, o que permite modelar padrões locais e aumentar a capacidade de generalização do modelo. Nesta etapa, os autores do método PatchTST propõem dividir a sequência temporal em patches de tamanho fixo com um passo fixo. O método funciona igualmente bem com segmentos sobrepostos e não sobrepostos. No primeiro caso, o passo é menor que o tamanho do patch, e no segundo, ambos os hiperparâmetros são iguais. Ambas as abordagens de segmentação permitem estudar informações semânticas locais. A escolha do método específico depende em grande parte da tarefa em questão e do tamanho da janela de dados brutos analisada.
É claro que o número de segmentos será menor que o comprimento da sequência. E a diferença aumenta conforme o tamanho do passo de segmentação. Portanto, a diferença máxima entre o número de segmentos e o comprimento da sequência é atingida para patches não sobrepostos. Nesse caso, a redução é feita proporcionalmente ao tamanho do passo. Isso permite analisar uma quantidade maior de dados brutos da série temporal com o mesmo ou até menor consumo de memória e recursos computacionais.
Ao analisar uma pequena janela de dados brutos, recomenda-se usar patches sobrepostos, o que permitirá estudar com mais qualidade as dependências semânticas locais.
Mais uma vez, esclareço que criamos patches para cada série temporal unitária separadamente, mas com parâmetros de segmentação unificados para todos.
A seguir, trabalharemos com os patches já criados. Formamos embeddings para eles. Adicionamos codificação posicional treinável. E enviamos para um bloco com várias camadas do codificador vanilla Transformer.
Não entraremos em detalhes sobre a arquitetura Transformer, que já foi detalhadamente apresentada anteriormente. No entanto, é importante observar que o codificador do Transformer analisa separadamente as dependências dentro de cada série temporal unitária. Entretanto, para a análise de todas as séries temporais unitárias, são usados parâmetros treináveis unificados.
O Transformer permite extrair representações abstratas dos patches dos dados brutos, levando em conta sua sequência temporal e contexto. Consequentemente, as representações obtidas na saída do codificador contêm informações sobre as inter-relações entre os patches e os padrões dentro de cada um deles. As representações processadas dessas séries temporais unitárias são concatenadas. E o tensor resultante pode ser usado para resolver várias tarefas. Ele é enviado para a "cabeça de tomada de decisão" para gerar os resultados do modelo.
Aqui é importante dizer que os autores do método propõem o uso de um único modelo para resolver várias tarefas com o mesmo conjunto de dados. Isso pode incluir a busca de anomalias, classificação ou previsão de dados subsequentes das séries temporais em diferentes horizontes de planejamento. Basta apenas substituir a "cabeça de tomada de decisão" e realizar o ajuste fino (re-treinamento) do modelo.
Ao prever dados subsequentes das séries temporais na saída do modelo, realizamos a desnormalização dos dados, retornando as características estatísticas extraídas dos dados brutos.
A visualização do método pelos autores é apresentada abaixo.
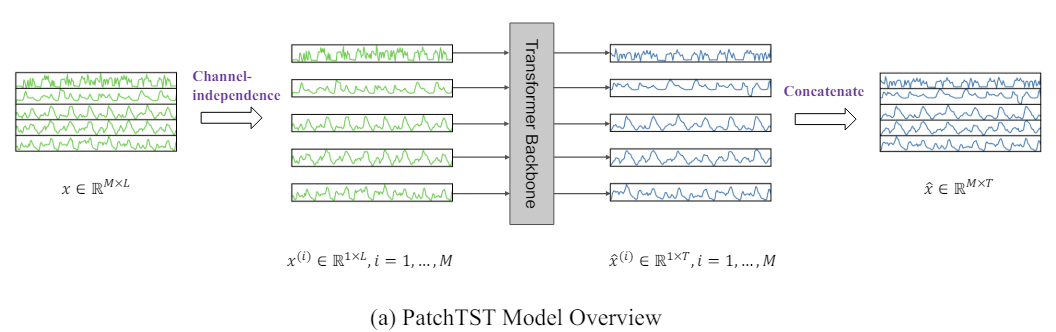
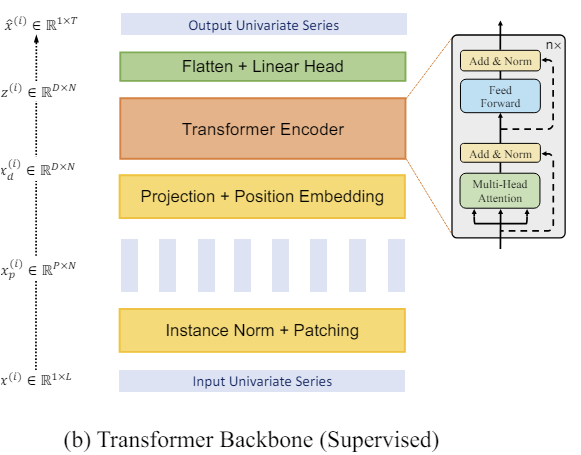
2. Implementação com MQL5
Após revisar os aspectos teóricos do método, passamos à construção das abordagens propostas com MQL5.
É importante esclarecer que iremos implementar nossa interpretação das abordagens propostas. E pode diferir da percepção dos autores.
Como mostrado na descrição teórica acima do método PatchTST, sua base é a segmentação dos dados brutos e a divisão da série temporal multidimensional em sequências unitárias separadas.
A primeira etapa no fluxo de processamento de dados é a segmentação, que consiste em dividir os dados brutos em blocos menores de informação. No caso de patches não sobrepostos, isso pode ser representado como o reformatamento de um tensor de dados 2D em um tensor 3D. Para patches sobrepostos, é um pouco mais complicado, pois exigirá a duplicação de dados. Mas, de qualquer forma, obtemos na saída um tensor 3D "número de variáveis * número de patches * tamanho do patch".
Claro, a transformação do tensor de dados brutos implica operações de cópia de informações. E gostaríamos de evitar operações desnecessárias, incluindo cópias de dados. Afinal, cada operação adicional representa custos de tempo e recursos para nós.
Vamos prestar atenção às operações subsequentes. Depois no fluxo de operações segue o embedding dos dados. E surge a vontade legítima de combinar essas duas operações. Essencialmente, realizaremos apenas a operação de embedding dos dados, mas para isso, retiraremos do tensor de dados brutos blocos separados que correspondem aos nossos patches.
E aqui lembramos dos camadas convolucionais. Nelas, também pegamos um bloco de dados brutos no tamanho da janela especificada e, após a operação de convolução com vários filtros, obtemos um vetor de projeção da janela de dados analisada em um subespaço. Parece que é exatamente o que precisamos. Porém, a camada convolucional que criamos anteriormente trabalha com um tensor unidimensional de dados brutos. E não permite identificar séries temporais unitárias separadas dentro do tensor geral da série temporal multidimensional. Portanto, teremos que criar algo semelhante, mas com a capacidade de trabalhar dentro de sequências unitárias separadas.
2.1 Segmentação no lado OpenCL
Primeiro, vamos complementar o programa OpenCL, criando nele kernels para as passagens para frente e reversa da segmentação de dados com projeção em um subespaço de embeddings. E começaremos com o kernel da passagem direta PatchCreate.
Nos parâmetros do kernel, passaremos ponteiros para três buffers de dados: dados brutos (inputs), matriz de coeficientes de peso (weights) e resultados (outputs). Além disso, adicionaremos quatro constantes aos parâmetros do kernel. Nelas, indicaremos o tamanho total do tensor de dados brutos para evitar erros de ultrapassagem dos limites. Indicaremos o tamanho do patch e o passo. E também forneceremos ao usuário a opção de adicionar uma função de ativação.
__kernel void PatchCreate(__global float *inputs, __global float *weights, __global float *outputs, int inputs_total, int window_in, int step, int activation ) { const int i = get_global_id(0); const int w = get_global_id(1); const int v = get_global_id(2); const int window_out = get_global_size(1); const int variables = get_global_size(2);
Planejamos que a execução do kernel ocorra em um espaço de tarefas 3D: número de patches, posição do elemento no vetor de embedding do patch analisado e identificador da variável nos dados brutos. Lembro que estamos construindo a segmentação dentro de séries temporais unitárias independentes.
No corpo do kernel, identificamos o fluxo em todas as três dimensões do espaço de tarefas. Também definimos as dimensões do espaço de tarefas.
Em seguida, com base nos dados obtidos, podemos determinar o deslocamento nos buffers de dados até os elementos analisados.
const int shift_in = i * step * variables + v; const int shift_out = (i * variables + v) * window_out + w; const int shift_weights = (window_in + 1) * (v * window_out + w);
Observe que, ao determinar o deslocamento no buffer de dados brutos, partimos das seguintes suposições:
- O tensor de dados brutos contém uma sequência de vetores de descrições do estado do ambiente em um determinado passo temporal. Em outras palavras, o tensor de dados brutos é representado por uma matriz 2D, cujas linhas contêm as descrições do estado do ambiente em um determinado passo temporal. E as colunas da matriz correspondem a parâmetros (variáveis) individuais que descrevem o estado do ambiente analisado.
- O método PatchTST analisa séries temporais unitárias separadas. Portanto, cada parâmetro (variável) que descreve o estado do ambiente contém apenas 1 elemento no vetor e é segmentado de forma independente dos demais (dentro de toda a série temporal).
Lembrem-se dessas suposições. De acordo com elas, teremos que preparar os dados brutos no lado do programa principal antes de enviá-los para o modelo.
Em seguida, organizamos o laço de multiplicação do vetor de segmento pelo vetor correspondente de coeficientes de peso. No corpo do laço, controlamos o deslocamento no buffer de dados brutos com o objetivo de evitar acessos fora dos limites do array.
float res = weights[shift_weights + window_in]; for(int p = 0; p < window_in; p++) if((shift_in + p * variables) < inputs_total) res += inputs[shift_in + p * variables] * weights[shift_weights + p]; if(isnan(res)) res = 0;
Aqui, observe que, ao acessar os dados do tensor de dados brutos, utilizamos um passo igual ao número de variáveis na descrição de um estado do ambiente. Ou seja, nos movemos pela coluna da matriz de dados brutos. Isso corresponde ao requisito de segmentação de uma série temporal unitária.
No caso de obtermos NaN como resultado da operação de multiplicação de vetores, o substituímos por "0".
Em seguida, resta apenas executar a função de ativação definida e salvar o valor obtido no buffer correspondente dos resultados.
switch(activation) { case 0: res = tanh(res); break; case 1: res = 1 / (1 + exp(-clamp(res, -20.0f, 20.0f))); break; case 2: if(res < 0) res *= 0.01f; break; defaultд: break; } //--- outputs[shift_out] = res; }
Após a implementação da propagação para frente, passamos à criação dos kernels de propagação reversa. Primeiro, criaremos o kernel de distribuição do gradiente de erro para a camada anterior PatchHiddenGradient. Nos parâmetros deste kernel, passaremos quatro ponteiros para buffers de dados:
- inputs — buffer de dados brutos (necessário para corrigir os gradientes de erro com base na derivada da função de ativação);
- inputs_gr — buffer de gradientes de erro no nível dos dados brutos (neste caso, o buffer para armazenar os resultados);
- weights — matriz de parâmetros treináveis da camada;
- outputs_gr — tensor de gradientes no nível dos resultados da camada (neste caso, os dados brutos para o cálculo dos gradientes de erro).
Além disso, no kernel passaremos cinco constantes, cujas funções são facilmente deduzidas pelos nomes das variáveis.
__kernel void PatchHiddenGradient(__global float *inputs, __global float *inputs_gr, __global float *weights, __global float *outputs_gr, int window_in, int step, int window_out, int outputs_total, int activation ) { const int i = get_global_id(0); const int v = get_global_id(1); const int variables = get_global_size(1);
O kernel será utilizado em um espaço de tarefas 2D: o comprimento da sequência de dados brutos e o número de parâmetros de estado do ambiente (variáveis) analisados.
Observe que, ao criar os kernels, o espaço de tarefas é orientado de acordo com as dimensões do tensor de resultados. Na propagação para frente, utilizamos um tensor tridimensional de embeddings de dados. Na propagação reversa, utilizamos um tensor bidimensional de dados brutos, mais especificamente, seus gradientes de erro. Essa abordagem permite ajustar cada fluxo individual para obter um valor no buffer de resultados do kernel.
No corpo do kernel, identificamos o fluxo no espaço de tarefas e determinamos as dimensões necessárias. Após isso, calculamos os deslocamentos.
const int w_start = i % step; const int r_start = max((i - window_in + step) / step, 0); int total = (window_in - w_start + step - 1) / step; total = min((i + step) / step, total);
Depois, organizamos o sistema de laços aninhados para coleta de gradientes de erro.
float grad = 0; for(int p = 0; p < total; p ++) { int row = r_start + p; if(row >= outputs_total) break; for(int wo = 0; wo < window_out; wo++) { int shift_g = (row * variables + v) * window_out + wo; int shift_w = v * (window_in + 1) * window_out + w_start + (total - p - 1) * step + wo * (window_in + 1); grad += outputs_gr[shift_g] * weights[shift_w]; } }
Observe que um elemento dos dados brutos influencia o valor de todos os elementos do vetor de embedding de um determinado patch com diferentes coeficientes de peso. Por isso, o laço aninhado coleta gradientes de erro de todo o vetor de embedding de um patch específico.
Além disso, no caso de patches sobrepostos, existe a possibilidade de o elemento dos dados brutos analisado estar presente na janela de dados brutos de vários patches. Para a coleta do gradiente de erro de tais patches, serve o laço externo do nosso sistema de laços aninhados.
O gradiente de erro coletado (somado) para o elemento analisado dos dados brutos é corrigido pela derivada da função de ativação.
float inp = inputs[i * variables + v]; if(isnan(grad)) grad = 0; //--- switch(activation) { case 0: grad = clamp(grad + inp, -1.0f, 1.0f) - inp; grad = grad * (1 - pow(inp == 1 || inp == -1 ? 0.99999999f : inp, 2)); break; case 1: grad = clamp(grad + inp, 0.0f, 1.0f) - inp; grad = grad * (inp == 0 || inp == 1 ? 0.00000001f : (inp * (1 - inp))); break; case 2: if(inp < 0) grad *= 0.01f; break; default: break; }
E o resultado das operações será registrado no elemento correspondente do buffer de gradientes de erro da camada neural anterior.
inputs_gr[i * variables + v] = grad; }
Após a distribuição do gradiente de erro, precisamos corrigir os parâmetros treináveis do modelo para minimizar o erro. Para implementar essa funcionalidade, criaremos o kernel PatchUpdateWeightsAdam, onde realizaremos a otimização dos parâmetros pelo método Adam.
Nos parâmetros do kernel, passaremos ponteiros para 5 buffers de dados. Além dos buffers já conhecidos inputs, weights e output_gr, são adicionados buffers auxiliares para o 1º e 2º momentos dos gradientes de erro ao nível da matriz de pesos weights_m e weights_v, respectivamente. Além disso, também passaremos os coeficientes de aprendizado nos parâmetros do kernel.
__kernel void PatchUpdateWeightsAdam(__global float *weights, __global const float *outputs_gr, __global const float *inputs, __global float *weights_m, __global float *weights_v, const int inputs_total, const float l, const float b1, const float b2, int step ) { const int c = get_global_id(0); const int r = get_global_id(1); const int v = get_global_id(2); const int window_in = get_global_size(0) - 1; const int window_out = get_global_size(1); const int variables = get_global_size(2);
Como nosso tensor de coeficientes de peso é tridimensional, o espaço de tarefas será estruturado em 3 dimensões:
- tamanho do patch + bias,
- tamanho do vetor de embedding,
- quantidade de variáveis.
Aqui seguimos a lógica mencionada anteriormente, em que cada fluxo individual corrige o valor de 1 parâmetro treinável.
No corpo do kernel, identificamos o fluxo em todas as 3 dimensões do espaço de tarefas. Também definimos as dimensões dessas medidas. Em seguida, determinamos as constantes de deslocamento nos buffers de dados.
const int start_input = c * variables + v; const int step_input = step * variables; const int start_out = v * window_out + r; const int step_out = variables * window_out; const int total = inputs_total / (variables * step);
E organizamos o laço de coleta de gradientes de erro no nível do parâmetro treinável corrigido.
float grad = 0; for(int p = 0; p < total; p++) { int i = start_input + i * step_input; int o = start_out + i * step_out; grad += (c == window_in ? 1 : inputs[i]) * outputs_gr[0]; } if(isnan(grad)) grad = 0;
Após determinar o gradiente de erro, passamos ao algoritmo de correção do parâmetro. Primeiro, determinamos os momentos de 1ª e 2ª ordens.
const int shift_weights = (window_in + 1) * (window_out * v + r) + c; //--- float weight = weights[shift_weights]; float mt = b1 * weights_m[shift_weights] + (1 - b1) * grad; float vt = b2 * weights_v[shift_weights] + (1 - b2) * pow(grad, 2);
Em seguida, calculamos o valor da correção do parâmetro.
float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight));
E, por fim, corrigimos os valores nos buffers de dados.
if(fabs(delta) > 0) weights[shift_weights] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); weights_m[shift_weights] = mt; weights_v[shift_weights] = vt; }
Observe que alteramos o coeficiente de peso no buffer de dados somente se o valor da correção do parâmetro for diferente de "0". Matematicamente, somar "0" ao valor atual não altera o parâmetro. No entanto, introduzimos a operação de verificação adicional da variável local para evitar uma operação mais custosa de acesso ao buffer de dados global.
Com isso, concluímos o trabalho no lado do OpenCL e passamos para o lado do programa principal.
2.2 Classe de segmentação de dados
Para chamar e gerenciar os kernels criados acima no programa principal, criamos a classe CNeuronPatching, que é uma herdeira da nossa classe base de todas as camadas neurais CNeuronBaseOCL.
No corpo da classe, declaramos variáveis para armazenar os principais parâmetros da arquitetura do objeto. Também declaramos os buffers dos parâmetros treináveis e dos momentos correspondentes. Todos os buffers são declarados como objetos estáticos, o que nos permite deixar o construtor e o destrutor da classe "vazios".
class CNeuronPatching : public CNeuronBaseOCL { protected: uint iWindowIn; uint iStep; uint iWindowOut; uint iVariables; uint iCount; //--- CBufferFloat cPatchWeights; CBufferFloat cPatchFirstMomentum; CBufferFloat cPatchSecondMomentum; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPatching(void){}; ~CNeuronPatching(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronPatchingOCL; } virtual void SetOpenCL(COpenCLMy *obj); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
O conjunto de métodos sobrescritos da classe é bastante padrão. A inicialização dos objetos e variáveis da classe é realizada no método Init. Nos parâmetros, o método recebe todas as informações necessárias para criar o objeto com a arquitetura requerida.
bool CNeuronPatching::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch ) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count * variables, optimization_type, batch)) return false;
No corpo do método, primeiro chamamos o método homônimo da classe mãe, onde ocorre o controle mínimo necessário dos valores recebidos e a inicialização dos objetos e variáveis herdados. O resultado das operações no método da classe mãe é controlado pelo valor lógico retornado.
Após a execução bem-sucedida das operações no método da classe mãe, armazenamos os valores recebidos da descrição da arquitetura do objeto em variáveis locais.
iWindowIn = MathMax(window_in, 1); iWindowOut = MathMax(window_out, 1); iStep = MathMax(step, 1); iVariables = MathMax(variables, 1); iCount = MathMax(count, 1);
Inicializamos o buffer dos parâmetros treináveis.
int total = int((window_in + 1) * window_out * variables); if(!cPatchWeights.Reserve(total)) return false; float k = float(1 / sqrt(total)); for(int i = 0; i < total; i++) { if(!cPatchWeights.Add((2 * GenerateWeight()*k - k)*WeightsMultiplier)) return false; } if(!cPatchWeights.BufferCreate(OpenCL)) return false;
Também inicializamos os buffers dos momentos do gradiente de erro no nível dos parâmetros treináveis.
if(!cPatchFirstMomentum.BufferInit(total, 0) || !cPatchFirstMomentum.BufferCreate(OpenCL)) return false; if(!cPatchSecondMomentum.BufferInit(total, 0) || !cPatchSecondMomentum.BufferCreate(OpenCL)) return false; //--- return true; }
Após a inicialização do objeto, passamos à construção do método de propagação para frente CNeuronPatching::feedForward. Neste método, colocamos na fila o kernel de propagação para frente criado anteriormente. Já discutimos várias vezes os procedimentos de enfileiramento de kernels ao longo desta série de artigos. Aqui, o principal ponto de atenção é a correta especificação da dimensionalidade do espaço de tarefas e dos parâmetros passados.
Como mencionado durante a criação do kernel, neste caso, utilizamos um espaço de tarefas tridimensional:
- quantidade de patches;
- dimensão do embedding de 1 patch;
- quantidade de parâmetros analisados na descrição do estado do ambiente.
bool CNeuronPatching::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iWindowOut, iVariables};
Após criar os arrays para a especificação do espaço de tarefas e seus deslocamentos, organizamos o processo de passagem de parâmetros para o kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_outputs, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_inputs_total, (int)NeuronOCL.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_window_in, (int)iWindowIn)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Aqui, não devemos esquecer de verificar a correção das operações realizadas. Após a transmissão bem-sucedida de todos os parâmetros necessários, colocamos o kernel na fila de execução.
if(!OpenCL.Execute(def_k_PatchCreate, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
De forma semelhante, colocamos na fila o kernel de distribuição do gradiente de erro para os elementos da camada anterior, de acordo com sua influência no resultado do modelo, no método CNeuronPatching::calcInputGradients. A única diferença é que a chamada do kernel PatchHiddenGradient é feita em um espaço de tarefas bidimensional.
bool CNeuronPatching::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {NeuronOCL.Neurons() / iVariables, iVariables};
Aqui, é importante observar que o tamanho da sequência original da série temporal multivariada é determinado pela relação entre o tamanho do buffer de resultados da camada anterior e o número de variáveis analisadas na descrição de um estado do ambiente.
Lembro que o método PatchTST pressupõe o uso de séries temporais multivariadas como dados de entrada, onde cada estado do ambiente é descrito por um vetor de comprimento fixo. Cada elemento do vetor contém o valor de um parâmetro correspondente à descrição do estado do sistema.
Depois, passamos os parâmetros para o kernel, com verificação do sucesso das operações.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_inputs_gr, NeuronOCL.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_outputs_gr, Gradient.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_activation, (int)NeuronOCL.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_outputs_total, (int)iCount)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_window_in, (int)iWindowIn)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_window_out, (int)iWindowOut)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
E colocamos o kernel na fila de execução.
if(!OpenCL.Execute(def_k_PatchHiddenGradient, 2, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
O último método de construção do funcional principal da classe é o método de ajuste dos parâmetros treináveis do modelo CNeuronPatching::updateInputWeights. Neste método, colocamos na fila o kernel PatchUpdateWeightsAdam, cujo algoritmo foi descrito anteriormente. Acredito que você já compreendeu que o algoritmo de enfileiramento do kernel para execução é idêntico aos dois métodos mencionados acima. A diferença está nos detalhes. Aqui, utilizamos um espaço de tarefas tridimensional.
bool CNeuronPatching::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowIn + 1, iWindowOut, iVariables};
Na primeira dimensão, somamos 1 elemento de viés ao tamanho do patch. Nas segunda e terceira dimensões, indicamos o tamanho da embedding de 1 patch e a quantidade de canais independentes analisados, armazenados nas variáveis da nossa classe.
Depois, transmitimos os parâmetros para o kernel, verificando os resultados das operações realizadas.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_outputs_gr, getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights_m, cPatchFirstMomentum.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights_v, cPatchSecondMomentum.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_inputs_total, (int)NeuronOCL.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Após isso, o kernel é colocado na fila de execução.
if(!OpenCL.Execute(def_k_PatchUpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
O algoritmo dos métodos de manipulação de arquivos foi simplificado ao máximo, e sugiro que você examine o código desses métodos de forma independente no anexo. Lá, você também encontrará o código completo de todas as classes e seus métodos para criação e treinamento de modelos.
Acima, foi criado um método para gerar os embeddings dos patches, gerados para séries temporais unitárias independentes, que são partes componentes da série temporal multivariada analisada. No entanto, isso é apenas metade do método proposto PatchTST. O segundo bloco, igualmente importante, desse método é o Transformer para análise das dependências entre os patches dentro de uma série temporal unitária. E aqui há uma importante ressalva: a análise das dependências é realizada apenas dentro de canais independentes. Sem analisar dependências cruzadas entre elementos de diferentes canais unitários.
Aqui vale lembrar que todas as variantes de implementação da arquitetura Transformer que analisamos anteriormente usavam a mistura de canais, o que contraria os princípios do método PatchTST. Mas há uma exceção — Conformer. Porém, Conformer, ao contrário do Transformer tradicional, usado pelos autores do método PatchTST, tem uma arquitetura mais complexa. Ele utiliza Continuous-Attention e introduz blocos de NeuralODE para aumentar a eficiência do modelo, o que, no geral, traz resultados positivos. Isso é confirmado pelos experimentos que realizamos anteriormente. Portanto, na minha implementação, substituí tranquilamente o Transformer, usado pelos autores do método PatchTST, pela implementação que criamos anteriormente do bloco Conformer na classe CNeuronConformer.
2.3 Arquitetura de modelos
Após implementar os "blocos" para a realização do método PatchTST, passamos à criação da arquitetura dos modelos treináveis. O método em questão foi proposto para a previsão de séries temporais multivariadas. Acredito que seja bastante óbvio que implementaremos esse método no âmbito do codificador de estado do ambiente. A arquitetura desse modelo é descrita no método CreateEncoderDescriptions, cujos parâmetros incluem apenas um ponteiro para um array dinâmico que armazena a arquitetura do modelo.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
No corpo do método, verificamos a validade do ponteiro para o objeto recebido e, se necessário, criamos uma nova instância do array dinâmico.
Alimentamos o modelo com o conjunto completo de dados históricos.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Aqui, é importante destacar que o procedimento de criação de patches não permite usar como dados de entrada um histórico menor que 1 patch de profundidade. Claro, podemos alimentar o modelo a cada chamada com dados históricos de apenas 1 patch de profundidade. No entanto, o histórico completo a ser analisado teria que ser acumulado em uma pilha interna, como fizemos anteriormente na camada de embedding. Esse método, no entanto, apresenta algumas limitações. Primeiro, é necessário que o passo entre os patches na modelagem seja igual ao próprio patch (patches não sobrepostos). Enquanto o passo real seria igual à periodicidade de chamadas ao modelo.
Acredito que é evidente que surge certa confusão e desafios na coordenação dos programas de coleta de dados de treinamento, treinamento e uso das modelos.
Outro ponto é que, com essa abordagem, ao alterar o tamanho do patch ou o passo, será necessário coletar novamente o conjunto de treinamento. Isso impõe limitações e custos adicionais no processo de treinamento das modelos.
Por isso, utilizamos um método mais simples e universal: alimentar o modelo com toda a profundidade dos dados analisados e definir o tamanho do patch e o passo como parâmetros na arquitetura da camada correspondente do modelo.
Como de costume, alimentamos o modelo com dados "brutos" não processados, que são normalizados imediatamente na camada de normalização por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, note que, nesta modelo, coloquei a camada de codificação posicional treinável no nível dos dados brutos, e não nos embeddings, como era feito anteriormente. Com isso, quis destacar a posição de parâmetros específicos. Afinal, ao usar patches sobrepostos, um parâmetro pode aparecer em vários patches.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count; if(!encoder.Add(descr)) { delete descr; return false; }
A seguir, adicionei a camada Dropout, que utilizamos para mascarar determinados valores dos dados brutos durante o treinamento do modelo.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.4f; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Defini a taxa de mascaramento em 40%, como na trabalho anterior.
Depois, adicionamos a camada de geração de patches. Utilizei patches não sobrepostos, com tamanho de janela e passo iguais a 3.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPatchingOCL; descr.window = 3; prev_count = descr.count = (HistoryBars+descr.window-1)/descr.window; descr.step = descr.window; descr.layers=BarDescr; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
Aqui, vale notar que o embedding dos patches ocorre em 2 etapas. Primeiro, geramos os embeddings dos patches com metade do tamanho. Depois, na camada convolucional, aumentamos o tamanho do patch.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count*BarDescr; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Lembro que implementamos a codificação posicional no nível dos dados brutos. Por isso, após a geração dos embeddings, passamos os dados diretamente para um bloco de 10 camadas Conformer.
//--- layer 6-16 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 8; descr.window_out = EmbeddingSize; descr.layers = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; } }
Em seguida, temos a camada de decisão, composta por 3 camadas totalmente conectadas. O tamanho da última camada é suficiente para conter as informações históricas recuperadas e prever os estados futuros com a profundidade estabelecida.
//--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = BarDescr*(HistoryBars+NForecast); descr.activation=TANH; if(!encoder.Add(descr)) { delete descr; return false; }
No final do modelo, realizamos a desnormalização dos valores recuperados e previstos, adicionando os indicadores estatísticos extraídos dos dados brutos.
//--- layer 20 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Note que mantivemos o tamanho dos dados brutos e os resultados do modelo iguais aos da trabalho anterior. Isso nos permitiu transferir a arquitetura dos modelos de Ator e Crítico sem modificações. Além disso, no novo experimento, podemos usar completamente o conjunto de treinamento e os EA da pesquisa anterior sem alterações. Assim, podemos comparar o impacto de diferentes arquiteturas de codificadores de estado do ambiente nos resultados do treinamento da política do Ator.
Você pode consultar a descrição completa da arquitetura de todos os modelos treináveis e dos programas utilizados na preparação deste artigo no anexo.
3. Testes
Nos capítulos anteriores deste artigo, exploramos um novo método para previsão de séries temporais multivariadas, o PatchTST. Implementamos nossa visão dos métodos propostos utilizando os recursos do MQL5. E agora chegamos à fase de testes do trabalho realizado. Nesta etapa, começamos treinando as modelos utilizando dados históricos reais. Em seguida, testamos os modelos treinadas no testador de estratégias do MetaTrader 5 em um período histórico que não faz parte do conjunto de treinamento.
Como antes, treinamos as modelos com dados históricos de 2023 do par EURUSD no time frame H1. O teste da modelo treinada é realizado com dados históricos de janeiro de 2024, mantendo o mesmo ativo financeiro e time frame. Os parâmetros de todos os indicadores analisados durante a coleta do conjunto de treinamento e no teste da política treinada foram mantidos em suas configurações padrão.
O treinamento das modelos é feito em duas etapas. Na primeira, treinamos o codificador de estado do ambiente. Este modelo aprende a analisar e generalizar apenas os dados históricos da série temporal multivariada que descrevem a dinâmica de preços do ativo e os indicadores analisados. Sem levar em consideração o saldo da conta ou as posições abertas. Portanto, treinamos a modelo com o conjunto de treinamento primário, sem coletar dados adicionais, até que seja alcançado um resultado aceitável na restauração dos dados mascarados e na previsão dos estados subsequentes.
Na segunda etapa, treinamos a política de comportamento do Ator e a precisão da avaliação das ações pelo Crítico. Esta fase é iterativa e inclui dois subprocessos:
- Treinamento dos modelos do Ator e do Crítico.
- Coleta de dados adicionais sobre o ambiente, considerando a política atual do Ator.
Após várias iterações de treinamento da política do Ator, consegui obter uma modelo capaz de gerar lucro tanto com os dados históricos do conjunto de treinamento quanto com novos dados. Os resultados do desempenho da modelo treinada com novos dados são apresentados a seguir.
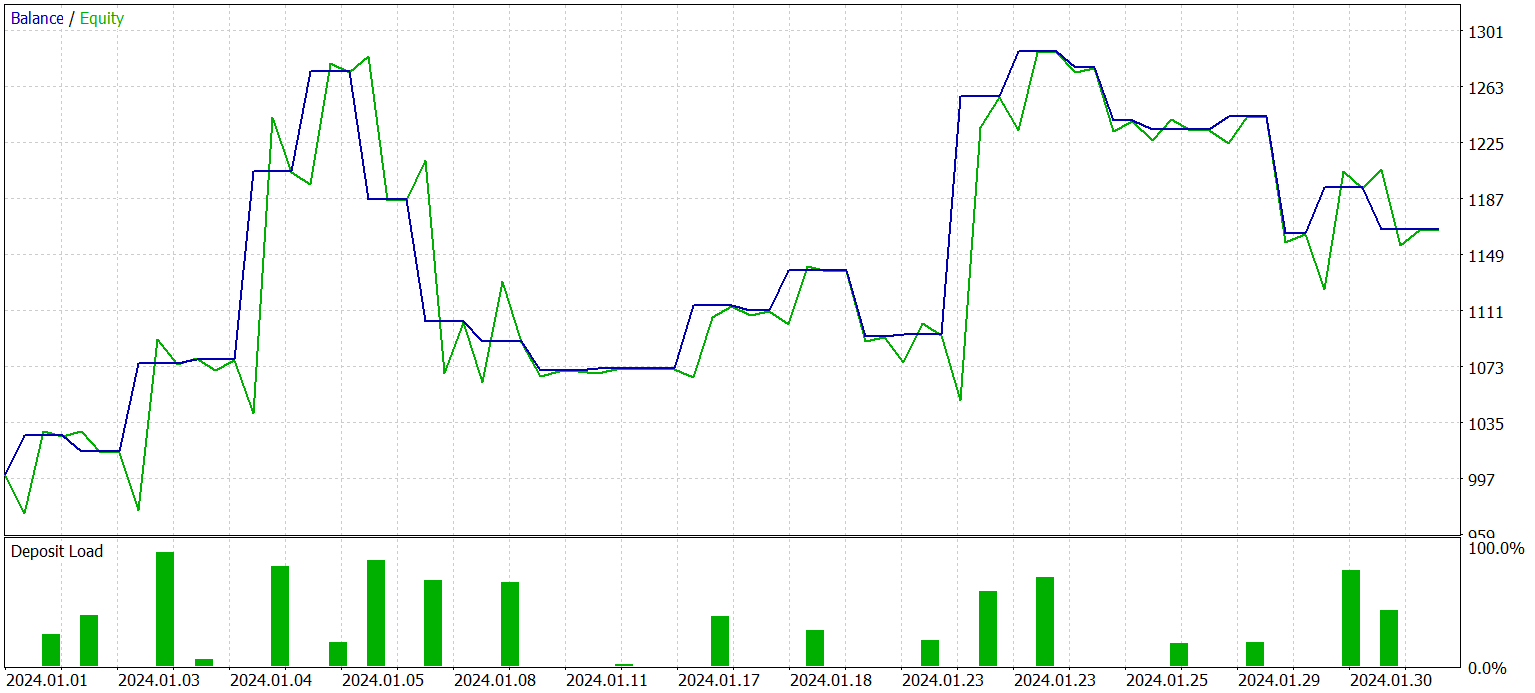
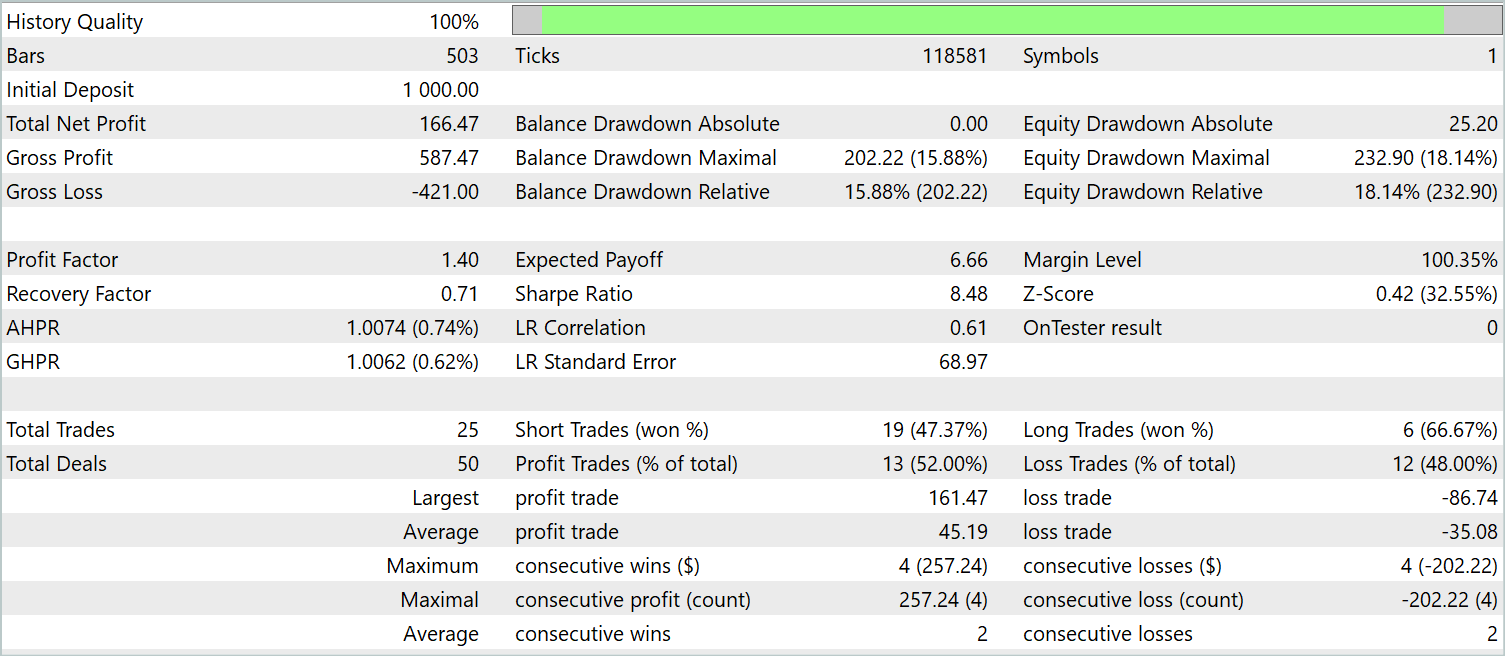
O gráfico de saldo não pode ser descrito como consistentemente crescente. No entanto, durante o período de teste, a modelo executou 25 operações, das quais 13 foram encerradas com lucro. Isso representou 52,0% de operações lucrativas um valor próximo do equilíbrio. Contudo, o maior lucro obtido em uma operação excedeu a maior perda em 87,2%, e o lucro médio por operação superou a perda média em 28,6%. Como resultado, o fator de lucro durante o período de teste foi de 1,4.
Considerações finais
Neste artigo, exploramos um novo método para análise e previsão de séries temporais multivariadas, o PatchTST, que combina as vantagens da segmentação de dados, do uso de transformers e do aprendizado de representações. A segmentação de dados permite que a modelo capture melhor os padrões temporais locais e o contexto, o que melhora a qualidade da análise e previsão. Além disso, o uso do transformer permite extrair representações abstratas dos dados, levando em consideração sua sequência temporal e inter-relações.
Na parte prática deste artigo, implementamos nossa visão dos métodos propostos usando os recursos do MQL5. Treinamos a modelo com dados históricos reais. E testamos a política do Ator treinada em novos dados que não faziam parte do conjunto de treinamento. Os resultados obtidos demonstram a viabilidade de usar o método PatchTST para construir e treinar modelos capazes de gerar lucro.
Assim, o método PatchTST se revela uma ferramenta poderosa para análise e previsão de séries temporais multivariadas, que pode ser aplicada com sucesso em diversas tarefas práticas.
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos utilizando o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de Modelos |
| 4 | StudyEncoder.mq5 | Expert Advisor | EA para treinamento de Codificador |
| 5 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14798
 Caminhe em novos trilhos: Personalize indicadores no MQL5
Caminhe em novos trilhos: Personalize indicadores no MQL5
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso