
ニューラルネットワークが簡単に(第87回):時系列パッチ

はじめに
時系列分析において、予測は非常に重要な役割を果たします。ディープラーニングモデルの導入により、この分野は大きな進展を遂げ、将来の値を正確に予測するだけでなく、分類や異常検知といった他のタスクにも応用できる抽象的な表現を抽出できるようになりました。
自然言語処理(NLP)分野で開発されたTransformerアーキテクチャは、コンピュータビジョン(CV)でもその優位性を発揮し、時系列解析にも成功を収めています。特に、Self-Attention(自己注意機構)は、時系列データの要素間の関係を自動的に識別する能力があり、効果的な予測モデルを構築する基盤となっています。
分析可能なデータ量の増加と機械学習手法の進化により、より正確かつ効率的な時系列データ分析モデルの開発が可能になっています。しかし、時系列データの複雑さが増す中で、正確な予測を実現し、隠れたパターンを見つけ出すためには、より効率的かつコストの低い分析手法が求められます。
このような課題に応える手法の一つが、パッチ時系列Transformer(PatchTST: Patch Time Series Transformer)です。この手法は「Time Series is Worth 64 Words:Long-term Forecasting with Transformers」で提案され、時系列データをパッチに分割し、Transformerを用いて将来の値を予測するという新しいアプローチを取っています。
時系列予測の目的は、各時間ステップ間の相関を捉えることにありますが、個々の時間ステップ自体には必ずしも意味がありません。そのため、局所的な意味情報を抽出することが、データの関係性を解析する上で重要です。それまでの多くの研究は、個々のタイムステップを入力トークンとして扱っていましたが、PatchTSTは時間ステップをサブシリーズ単位のパッチに集約することで局所性を改善し、個々のステップでは捉えられない複雑な意味情報を捉えることができます。
さらに、多変量時系列データは多チャンネル信号であり、各入力トークンは1つまたは複数のチャンネルのデータを表すことが可能です。入力トークンの構造に応じて、異なるTransformerアーキテクチャを選択することができます。チャネルミキシングは、複数チャンネルのデータを1つのベクトルに統合し、埋め込み空間でミキシングをおこなう方法を指します。一方、チャンネル独立性は、各入力トークンが1つのチャンネルのみの情報を含むことを意味し、従来の畳み込みモデルや線形モデルで有効性が示されています。PatchTSTは、Transformerベースのモデルにおいてもこのチャンネル独立アプローチが有効であることを証明しました。
PatchTSTの著者は、この手法の利点として次の点を強調しています。
- 複雑さの軽減:パッチ処理によりモデルの時間的および空間的な複雑さが軽減され、大規模データセットに対してより効率的に処理がおこなえます。
- 長いルックバックウィンドウによる学習の向上:パッチを使用することで、モデルがより長期間のデータから学習できるようになり、予測精度が向上する可能性があります。
- 表現学習:提案手法は予測に有効であるだけでなく、データの複雑な抽象表現を抽出できるため、モデルの汎化能力が向上します。
著者の論文で提示された研究結果は、PatchTSTの有効性を示すとともに、この手法が時系列分析における様々な応用問題に対して大きな可能性を持っていることを示しています。
1. PatchTSTアルゴリズム
PatchTST法は多変量時系列の分析と予測のために開発されたもので、分析システムの各状態はパラメータのベクトルで記述されます。この場合、各時間ステップの記述ベクトルのサイズは、同一のデータ構造を持つ同じ数のパラメータを含みます。したがって、一般的な多変量時系列を、システムの状態を記述するパラメータの数に応じて、いくつかの単変量時系列に分割することができます。
これまで検討してきた手法と同様に、まずモデルの入力データを正規化することで比較可能な形式にします。このステップは非常に重要です。モデルの入力に正規化されたデータを使用することで、その学習プロセスの安定性が大幅に向上することは、すでに何度も説明してきました。さらに、PatchTST法は一変量時系列のチャンネル非依存分析を意味しますが、分析は1セットの訓練パラメータで実行されます。したがって、すべてのチャンネルからの分析データが比較可能な形式であることが非常に重要です。
次のステップは、単変量時系列をパッチすることです。これは局所的なパターンをモデル化し、モデルの汎化能力を高めます。この段階で、PatchTST法の著者は、時系列を一定のステップで一定の大きさのパッチに分割することを提案しています。この方法は、重複しているパッチでも重複していないパッチでも同じように機能します。最初のケースでは、ステップはパッチサイズより小さく、2番目のケースでは、両方のハイパーパラメータは等しいです。パッチを当てるアプローチはどちらも、局所的な意味情報の探索を可能にします。特定の方法を選択するかどうかは、タスクと分析される入力ウィンドウのサイズに大きく依存します。
明らかに、パッチの数は時系列の長さより少なくなります。パッチのステップが大きければ大きいほど、その差は大きくなります。したがって、パッチ数と時系列長の差は、パッチが重複していない場合に最大となります。この場合、縮小はステップサイズの倍数で実行されます。これにより、より長い入力時系列を、同じかそれ以下のメモリと計算資源で分析することができます。
小さな入力ウィンドウを分析する場合、重複しているパッチを使用することが推奨され、これにより局所的な意味依存性をより定性的に調べることができます。
個々の一変量時系列ごとにパッチを作成しますが、すべてのパッチのパラメータは同じです。
その後、すでに作成されているパッチを使用します。そのために埋め込みを作成します。学習可能な位置符号化を追加し、いくつかのバニラTransformerエンコーダ層のブロックに渡します。
Transformerアーキテクチャについては、以前すでに説明したので、ここでは詳しく触れません。Transformerエンコーダは、一変量時系列内の依存関係を個別に分析しますが、すべての一変量時系列を分析するために同じ学習パラメータが使用されることに留意してください。
Transformerは、入力パッチから、その時系列と文脈を考慮した抽象的な表現を抽出することができます。したがって、エンコーダーの出力で得られる表現には、パッチ間の関係や各パッチ内のパターンに関する情報が含まれます。このようにして処理された一変量時系列表現は連結されます。こうして得られたテンソルは、さまざまな問題を解くのに利用できます。これは、モデルの出力を生成するための 「決定ヘッド」に供給されます。
この手法の著者は、1つの入力データセットで様々な問題を解くために1つのモデルを使うことを提案していることに注意してください。これは、異常の検索、分類、あるいは異なる計画期間にわたる後続の時系列データの予測です。ただ「決定ヘッド」を交換し、モデルを微調整(再訓練)するだけで済みます。
後続の時系列データを予測する際には、入力データから抽出した統計的特性を返すことで、モデル出力でデータを非正規化します。
以下は、筆者によるこの方法を視覚化したものです。
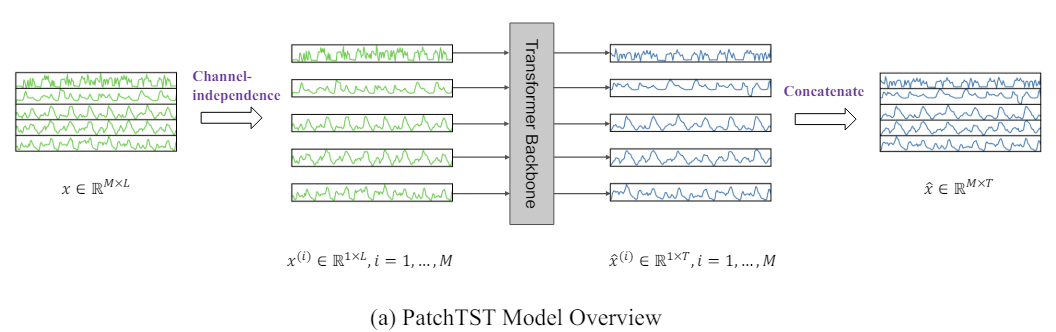
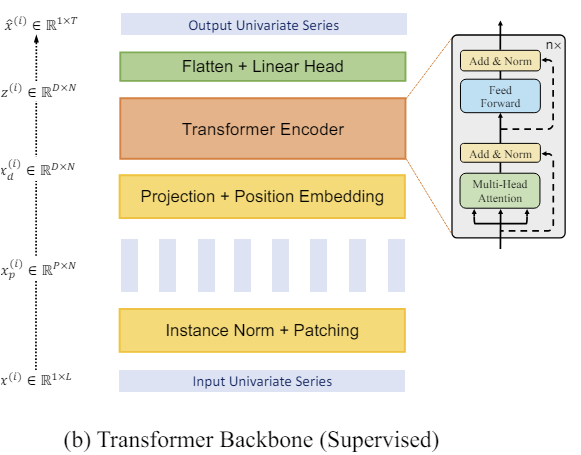
2. MQL5での実装
提案手法の理論的側面を考察したので、次に、MQL5を使った提案アプローチの実用的な実装に移りましょう。
繰り返しになりますが、提案されたアプローチについて、原著者たちの考えとは異なる私たちのビジョンを実行に移すことになります。
上に示したPatchTST法の理論的説明から導かれるように、PatchTST法は、入力パッチと多変量時系列を個別の単変量系列に分割することに基づいています。
データ処理の流れの最初のステップは、入力データをより小さな情報ブロックに分割するパッチ処理です。重複していないパッチの場合、これは2次元の入力テンソルを3次元のものに再フォーマットすると考えることができます。重複しているパッチの場合は、データをコピーする必要があるため、少し複雑になります。しかしいずれにせよ、3次元テンソル「変数の数*パッチの数*パッチのサイズ」が出力されます。
入力データテンソルの変換は、データのコピー操作を意味します。コピーも含め、無駄な作業は省きたいです。というのも、作業を増やすたびに、時間とリソースが費やされるからです。
以下の操作に注目してみましょう。操作フローの次は、データの埋め込みです。論理的な解決策は、2つの操作を組み合わせることでしょう。実際には、データを埋め込む操作だけをおこないます。しかし、演算を実行するには、入力データテンソルからパッチに対応する個々のブロックを取り出します。
以前、畳み込み層について考察しました。これらの層でも、与えられたウィンドウのサイズの入力ブロックを受け取り、いくつかのフィルタによる畳み込み演算の後、分析されたデータウィンドウのある部分空間への射影ベクトルを得ます。必要なもののようです。しかし、先に作った畳み込み層は、1次元の入力テンソルを扱います。多変量時系列の一般的なテンソルから個々の一変量時系列を分離することはできません。似たようなものを作らなければなりません、個々の一変量シーケンス内で作業できるようにしなければなりません。
2.1 OpenCL側のパッチ
まず、OpenCLプログラムを補足して、フィードフォワードとバックワードデータパッチパスのカーネルを、エンベッディングのある部分空間への射影で作成してみましょう。まずはフィードフォワードパスのカーネルPatchCreateからです。
カーネルパラメータには、3つのデータバッファ(入力、重み行列、出力)へのポインタを渡します。さらに、カーネルパラメーターに4つの定数を追加します。これらの定数では、範囲外のエラーを防ぐために、入力データテンソルのフルサイズを指定します。パッチサイズとステップを指定します。また、活性化関数を追加する機能も提供します。
__kernel void PatchCreate(__global float *inputs, __global float *weights, __global float *outputs, int inputs_total, int window_in, int step, int activation ) { const int i = get_global_id(0); const int w = get_global_id(1); const int v = get_global_id(2); const int window_out = get_global_size(1); const int variables = get_global_size(2);
カーネルが、パッチの数、分析されたパッチの埋め込みベクトルにおける要素の位置、ソースデータにおける変数の識別子の3次元のタスク空間で実行されることを期待しています。セグメンテーションは、独立一変量時系列の枠組みの中で構成されることを思い出してください。
カーネル本体では、タスク空間の3次元すべてにわたってスレッドを識別します。また、タスク空間の次元も決定します。
そして、受信したデータに基づいて、解析された要素へのデータバッファのシフトを決定することができます。
const int shift_in = i * step * variables + v; const int shift_out = (i * variables + v) * window_out + w; const int shift_weights = (window_in + 1) * (v * window_out + w);
入力バッファのシフトを決定する際、以下を仮定します。
- 入力テンソルには、個別の時間ステップにおける環境の状態を記述する一連のベクトルが含まれます。言い換えれば、入力テンソルは2次元の行列であり、その行には特定の時間ステップにおける環境の状態が記述されています。行列の列は、分析された環境の状態を記述する個々のパラメータ(変数)に対応します。
- PatchTST法は、個々の一変量時系列を分析します。したがって、環境の状態を記述する各パラメータ(変数)は、ベクトル内の1つの要素のみを含み、(全時系列内で)他のものから独立してパッチされます。
これらの前提を覚えておいてください。それに従って、入力データをモデルに転送する前に、メインプログラムの側で準備する必要があります。
次に、セグメントベクトルと対応する重みベクトルを掛け合わせるループを構成します。ループ本体では、入力データバッファのシフトを制御し、配列の境界外へのアクセスを防いでいます。
float res = weights[shift_weights + window_in]; for(int p = 0; p < window_in; p++) if((shift_in + p * variables) < inputs_total) res += inputs[shift_in + p * variables] * weights[shift_weights + p]; if(isnan(res)) res = 0;
ここでは、入力テンソルデータにアクセスするときは、環境の1つの状態を記述する変数の数に等しいステップを使用します。つまり、入力行列の列に沿って移動します。これは一変量時系列のパッチ要件を満たしています。
ベクトル乗算の結果としてNaNを受け取った場合、それを0に置き換えます。
次に、与えられた活性化関数を実行し、結果の値を対応する結果バッファに保存すれば済みます。
switch(activation) { case 0: res = tanh(res); break; case 1: res = 1 / (1 + exp(-clamp(res, -20.0f, 20.0f))); break; case 2: if(res < 0) res *= 0.01f; break; defaultд: break; } //--- outputs[shift_out] = res; }
フィードフォワードパスを実装した後、バックプロパゲーションカーネルの構築に移ります。まず、誤差勾配を前の層に伝搬するためのカーネル、PatchHiddenGradientを作ります。このカーネルのパラメータには、データバッファへの4つのポインターを渡します。
- inputs:入力データバッファ(活性化関数の微分による誤差勾配の調整に必要);
- inputs_gr:入力データレベルのエラー勾配のバッファ(この場合、結果を書き込むためのバッファ)
- weights:層の学習可能なパラメータの行列
- outputs_gr:層出力レベルの勾配のテンソル(この場合、誤差勾配を計算するための入力データ)
さらに、5つの定数をカーネルに渡す。その目的は、変数名から容易に推測できます。
__kernel void PatchHiddenGradient(__global float *inputs, __global float *inputs_gr, __global float *weights, __global float *outputs_gr, int window_in, int step, int window_out, int outputs_total, int activation ) { const int i = get_global_id(0); const int v = get_global_id(1); const int variables = get_global_size(1);
入力シーケンスの長さと、環境の状態を分析したパラメータの数(変数)という2次元のタスク空間でカーネルを使用する予定です。
カーネルを構築するとき、出力テンソルの次元でタスク空間を方向付けることに注意。フィードフォワードパスでは、データ埋込みの3次元テンソルを指向します。バックプロパゲーションパスの間、これは入力の2次元テンソル、つまり誤差勾配です。この方法によって、個々のスレッドがカーネルの出力バッファで単一の値を受け取るように設定できます。
カーネル本体では、タスク空間内のスレッドを特定し、必要な次元を定義します。その後、シフトを計算します。
const int w_start = i % step; const int r_start = max((i - window_in + step) / step, 0); int total = (window_in - w_start + step - 1) / step; total = min((i + step) / step, total);
そして、エラー勾配を収集するために、ネストされたループのシステムを編成します。
float grad = 0; for(int p = 0; p < total; p ++) { int row = r_start + p; if(row >= outputs_total) break; for(int wo = 0; wo < window_out; wo++) { int shift_g = (row * variables + v) * window_out + wo; int shift_w = v * (window_in + 1) * window_out + w_start + (total - p - 1) * step + wo * (window_in + 1); grad += outputs_gr[shift_g] * weights[shift_w]; } }
1つの入力要素は、1つのパッチの埋め込みベクトルの全要素の値に異なる重みで影響を与える。したがって、ネストされたループは、1つのパッチの埋め込みベクトル全体から誤差勾配を収集します。
また、重複しているパッチの場合、解析された入力要素データが複数のパッチの入力ウィンドウに入る可能性があります。ネストされたループシステムの外側のループは、このようなパッチから誤差勾配を収集するために使用されます。
分析された入力要素について、活性化関数の微分によって収集された(合計)誤差勾配を調整します。
float inp = inputs[i * variables + v]; if(isnan(grad)) grad = 0; //--- switch(activation) { case 0: grad = clamp(grad + inp, -1.0f, 1.0f) - inp; grad = grad * (1 - pow(inp == 1 || inp == -1 ? 0.99999999f : inp, 2)); break; case 1: grad = clamp(grad + inp, 0.0f, 1.0f) - inp; grad = grad * (inp == 0 || inp == 1 ? 0.00000001f : (inp * (1 - inp))); break; case 2: if(inp < 0) grad *= 0.01f; break; default: break; }
演算結果は、前のニューラル層の誤差勾配バッファの対応する要素に書き込まれます。
inputs_gr[i * variables + v] = grad; }
誤差勾配を伝播させた後、誤差を最小化するためにモデルの学習パラメータを調整する必要があります。この機能を実装するために、PatchUpdateWeightsAdamカーネルを作成します。 Adamメソッドを使ってパラメータを最適化します。
カーネルパラメーターには、5つのデータバッファへのポインターを渡す。おなじみのバッファinput、weights、output_grに加えて、それぞれ重み行列レベルweights_mと weights_vにおける誤差勾配の1次モーメントと2次モーメントの補助バッファがあります。さらに、カーネルパラメーターに学習率も渡す。
__kernel void PatchUpdateWeightsAdam(__global float *weights, __global const float *outputs_gr, __global const float *inputs, __global float *weights_m, __global float *weights_v, const int inputs_total, const float l, const float b1, const float b2, int step ) { const int c = get_global_id(0); const int r = get_global_id(1); const int v = get_global_id(2); const int window_in = get_global_size(0) - 1; const int window_out = get_global_size(1); const int variables = get_global_size(2);
重みのテンソルは3次元なので、タスク空間も3次元で形成される:
- パッチのサイズ+バイアス、
- 埋め込みベクトルのサイズ、
- 変数の数。
ここでは、前述のロジックに従い、各スレッドが1つの訓練可能なパラメーターの値を調整します。
カーネル本体では、タスク空間の3次元すべてでスレッドを識別します。寸法の大きさも決める。その後、データバッファにシフト定数を定義します。
const int start_input = c * variables + v; const int step_input = step * variables; const int start_out = v * window_out + r; const int step_out = variables * window_out; const int total = inputs_total / (variables * step);
補正された学習パラメータのレベルで誤差勾配を収集するループを実行します。
float grad = 0; for(int p = 0; p < total; p++) { int i = start_input + i * step_input; int o = start_out + i * step_out; grad += (c == window_in ? 1 : inputs[i]) * outputs_gr[0]; } if(isnan(grad)) grad = 0;
誤差勾配を決定した後、パラメータ補正アルゴリズムに移る。まず、1次と2次のモーメントを定義します。
const int shift_weights = (window_in + 1) * (window_out * v + r) + c; //--- float weight = weights[shift_weights]; float mt = b1 * weights_m[shift_weights] + (1 - b1) * grad; float vt = b2 * weights_v[shift_weights] + (1 - b2) * pow(grad, 2);
そして、パラメータ調整値を計算します。
float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight));
そして最後に、データバッファーの値を調整します。
if(fabs(delta) > 0) weights[shift_weights] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); weights_m[shift_weights] = mt; weights_v[shift_weights] = vt; }
パラメータ変更値が "0 "と異なる場合のみ、データバッファのウェイトを変更することに注意してください。数学的な観点からは、現在の値に "0 "を加えてもパラメータは変わらない。しかし、グローバルデータバッファへのアクセスという不必要でより高価な操作を排除するために、追加のローカル変数チェック操作を導入します。
これでOpenCL側の作業は終了です。メインプログラム側に話を移そう。
2.2 データパッチクラス
メインプログラム側で上記で作成したカーネルを呼び出してサービスするために、すべてのニューラル層の基本クラスCNeuronBaseOCLから継承したCNeuronPatchingクラスを作成します。
クラス本体では、オブジェクトのアーキテクチャの主要パラメータを格納する変数と、訓練パラメータと対応するモーメントのバッファを宣言します。すべてのバッファを静的オブジェクトとして宣言することで、クラスのコンストラクタとデストラクタを「空」にしておくことができます。
class CNeuronPatching : public CNeuronBaseOCL { protected: uint iWindowIn; uint iStep; uint iWindowOut; uint iVariables; uint iCount; //--- CBufferFloat cPatchWeights; CBufferFloat cPatchFirstMomentum; CBufferFloat cPatchSecondMomentum; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPatching(void){}; ~CNeuronPatching(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronPatchingOCL; } virtual void SetOpenCL(COpenCLMy *obj); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
オーバーライド可能なクラスメソッドのセットはごく標準的なものです。オブジェクトとクラス変数はInitメソッドで初期化されます。パラメータには、メソッドが必要なアーキテクチャのオブジェクトを作成するために必要なすべての情報を受け取ります。
bool CNeuronPatching::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch ) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count * variables, optimization_type, batch)) return false;
メソッド本体では、まず親クラスの同じメソッドを呼び出し、受け取った値の必要最小限の制御と、継承したオブジェクトや変数の初期化をおこないます。親クラスのメソッドで演算を実行した結果は、返される論理値によって制御されます。
親クラスのメソッドでの操作が成功したら、得られたオブジェクトアーキテクチャ記述の値をローカル変数に保存します。
iWindowIn = MathMax(window_in, 1); iWindowOut = MathMax(window_out, 1); iStep = MathMax(step, 1); iVariables = MathMax(variables, 1); iCount = MathMax(count, 1);
訓練パラメータのバッファを初期化します。
int total = int((window_in + 1) * window_out * variables); if(!cPatchWeights.Reserve(total)) return false; float k = float(1 / sqrt(total)); for(int i = 0; i < total; i++) { if(!cPatchWeights.Add((2 * GenerateWeight()*k - k)*WeightsMultiplier)) return false; } if(!cPatchWeights.BufferCreate(OpenCL)) return false;
また、誤差勾配のモーメントのバッファを訓練パラメータのレベルで初期化します。
if(!cPatchFirstMomentum.BufferInit(total, 0) || !cPatchFirstMomentum.BufferCreate(OpenCL)) return false; if(!cPatchSecondMomentum.BufferInit(total, 0) || !cPatchSecondMomentum.BufferCreate(OpenCL)) return false; //--- return true; }
オブジェクトを初期化した後、フィードフォワードメソッドCNeuronPatching::feedForwardの構築に移ります。このメソッドでは、上記で作成したフィードフォワードパスカーネルをキューに入れます。カーネルを実行キューに入れる手順については、以前の記事ですでに何度か説明しました。ここで注意しなければならないのは、タスクスペースと渡すパラメーターのサイズを正しく表示することです。
カーネルを構築するときにすでに述べたように、この場合は3次元のタスク空間を使用します。
- パッチ数
- 1パッチ埋め込みサイズ
- 環境状態の説明において分析されたパラメータの数
bool CNeuronPatching::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iWindowOut, iVariables};
タスクスペース指示配列とその中のシフトを作成した後、カーネルにパラメータを渡すプロセスを整理します。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_outputs, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_inputs_total, (int)NeuronOCL.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_window_in, (int)iWindowIn)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
操作の正確さを管理することを忘れてはいけません。必要なパラメータの転送に成功したら、カーネルを実行キューに入れます。
if(!OpenCL.Execute(def_k_PatchCreate, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
同様に、誤差勾配分布カーネルは、CNeuronPatching::calcInputGradientsメソッドにおいて、モデルの最終結果に対する影響度に従って、前の層の要素の前にキューに入れます。PatchHiddenGradientカーネルは2次元タスク空間で呼び出されます。
bool CNeuronPatching::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {NeuronOCL.Neurons() / iVariables, iVariables};
ここで注意すべきことは、多変量時系列の入力シーケンスのサイズを、環境の状態を記述する分析変数の数1に対する、前の層の結果バッファのサイズの比率として定義することです。
PatchTST法によれば、入力は多変量時系列であるべきで、環境の各状態は固定長のベクトルで記述されます。ベクトルの各要素は、システムの状態を記述する対応するパラメータの値を含みます。
次に、パラメータをカーネルに渡し、操作の実行を制御します。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_inputs_gr, NeuronOCL.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_outputs_gr, Gradient.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_activation, (int)NeuronOCL.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_outputs_total, (int)iCount)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_window_in, (int)iWindowIn)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_window_out, (int)iWindowOut)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルを実行キューに入れます。
if(!OpenCL.Execute(def_k_PatchHiddenGradient, 2, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
このクラスで考慮すべき最後のメソッドは、モデルの学習可能なパラメータを調整するメソッドCNeuronPatching::updateInputWeightsです。このメソッドは、PatchUpdateWeightsAdamカーネルをキューに入れるために使用されます。そのアルゴリズムは前述の通りです。カーネルを実行キューに入れるアルゴリズムは、前述の2つのメソッドと同じです。しかし、その違いは細部にあります。ここでは3次元のタスク空間を使用します。
bool CNeuronPatching::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowIn + 1, iWindowOut, iVariables};
最初の次元では、パッチサイズに1要素のベイズバイアスを加えます。2番目と3番目の次元では、1パッチの埋め込みサイズと、クラス変数に格納されている分析された独立チャンネルの数を指定します。
次に、パラメータをカーネルに転送し、演算結果を制御します。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_outputs_gr, getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights_m, cPatchFirstMomentum.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights_v, cPatchSecondMomentum.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_inputs_total, (int)NeuronOCL.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
その後、カーネルは実行キューに入れられます。
if(!OpenCL.Execute(def_k_PatchUpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
このクラスにはファイル操作メソッドもあるので、以下に添付するコードを使って勉強してください。ファイル操作に加えて、添付ファイルにはモデルを作成し訓練するためのすべてのクラスとメソッドが含まれています。
分析された多変量時系列の構成要素である独立した単変量時系列に対して作成されるパッチ埋め込みを生成する方法を開発しました。しかし、これは提案されているPatchTST法の半分でしかありません。この手法の2番目の重要なブロックは、一変量時系列内のパッチ間の依存関係を分析するためのTransformerです。なお、依存関係の分析は、独立したチャンネルの枠内でのみおこなわれます。異なる一変量チャネルの要素間の相互依存の分析はありません。
先に検討したTransformerアーキテクチャの実装オプションはすべてチャンネルミキシングを使用していましたが、これはPatchTST方式の原理と矛盾します。唯一の例外は Conformerです。しかし、Conformerは、PatchTST法の作者が使用したバニラTransformerとは異なり、より複雑なアーキテクチャを持っています。Continuous AttentionとNeuralODEブロックを使用し、モデルの効率を向上させています。これは私たちの実験でも確認されました。そこで、実装の一部として、PatchTSTの作者が使っていたTransformerを、CNeuronConformerクラスで以前に作成したConformerブロックの実装に大胆に置き換えてみました。
2.3 モデルアーキテクチャ
PatchTST法の「ブロック」を実装した後は、学習可能なモデルのアーキテクチャの作成に移ります。検討中のメソッドは、多変量時系列の予測のために提案されたものです。もちろん、このメソッドはEnvironment State Encoderの中に実装します。このモデルのアーキテクチャは、CreateEncoderDescriptionsメソッドで説明されています。パラメータには、モデルアーキテクチャを維持するために、動的配列へのポインタを1つだけ渡します。
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
メソッド本体では、受け取ったポインタとオブジェクトの関連性をチェックし、必要であれば動的配列の新しいインスタンスを作成します。
モデルには、過去のデータ一式を投入します。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
ここで注目すべきは、パッチ作成手順では、入力パッチ1枚未満の履歴の深さを使用することはできないということです。もちろん、各呼び出しの履歴データは1パッチの深さしか与えられません。そして、先ほど埋め込み層でおこなったように、分析された履歴の深さ全体が内部スタックに蓄積されます。しかし、このアプローチにはいくつかの限界があります。まず第一に、パッチ間の段差を、パッチそのものと等しく指定する必要があります(重複していないパッチ)。しかし、実際のステップはモデル呼び出しの頻度と同じになります。
そのため、訓練データの収集、訓練、モデルの運用のためのプログラムを調整する際に、混乱や複雑さが生じることになります。
2つ目のポイントは、このアプローチでは、パッチサイズやステップを変更する場合、訓練サンプルを収集し直す必要があるということです。そうなると、モデルを訓練するプロセスに新たな制約とコストが生じることになります。
そのため、よりシンプルで普遍的な方法を用いて、分析された履歴の全深さをモデルに与えます。パッチとステップサイズは、対応するモデル層のアーキテクチャのパラメータによって設定されます。
いつものように、「生」の未処理データをモデルに与え、バッチ正規化層ですぐに正規化します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次に、このモデルでは、訓練可能な位置符号化層は、以前のようにエンベッディングではなく、入力レベルに配置されていることに注意すべきです。こうすることで、特定のパラメーターの位置に集中したかったのです。(重複しているパッチを使用する場合、1つのパラメータを複数のパッチに含めることができます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count; if(!encoder.Add(descr)) { delete descr; return false; }
次にDropout層を追加しました。これは、モデルの訓練過程で個々の入力値をマスクするために使用します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.4f; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
データマスキング係数は前作と同様に40%に設定しました。
次にパッチ生成層を追加します。ウィンドウサイズとステップサイズを3に等しくして、重複していないパッチを使用しました。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPatchingOCL; descr.window = 3; prev_count = descr.count = (HistoryBars+descr.window-1)/descr.window; descr.step = descr.window; descr.layers=BarDescr; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
ここで、パッチ埋め込みが2段階で形成されることも注目に値します。まず、パッチ埋め込みを半分のサイズで生成します。次に、畳み込み層でパッチサイズを大きくします。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count*BarDescr; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
覚えているように、入力レベルで位置符号化を実装しました。そのため、埋め込みデータを生成した後、すぐに10層のConformerブロックにデータを入れます。
//--- layer 6-16 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 8; descr.window_out = EmbeddingSize; descr.layers = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; } }
次に、3つの全結合層からなる決定ヘッドが来ます。最後の層のサイズは、過去のデータから再構成された情報を含み、その後の状態を所定の深さまで予測するのに十分なものとします。
//--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = BarDescr*(HistoryBars+NForecast); descr.activation=TANH; if(!encoder.Add(descr)) { delete descr; return false; }
モデルの最後に、元のデータから抽出した統計的指標を加えて、再構成値と予測値を非正規化します。
//--- layer 20 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
なお、入力データとモデル結果のサイズは前回と同じにしてあります。したがって、ActorとCriticのモデルをそのままコピーすることができます。さらに、新しい実験では、以前の記事の訓練データセットとEAを使用することができます。このようにして、異なる環境状態エンコーダーアーキテクチャがActor方策の学習結果に与える影響を比較することができます。
添付ファイルには、本書で使用するすべての学習可能なモデルの完全なアーキテクチャ説明が含まれています。
3.テスト
本稿の前節では、多変量時系列を予測する新しい手法PatchTSTを紹介しました。MQL5を使用して、提案するアプローチのビジョンを実装しました。次に、出来上がった仕事をテストします。まず、実際の履歴データを使ってモデルを訓練します。次に、MetaTrader 5のストラテジーテスターで、訓練データセットを超えた過去の期間について、訓練したモデルをテストします。
前回と同様、モデルはEURUSD H1の履歴データで学習されます。訓練済みモデルは、同じ金融商品と時間枠で、2024年1月の履歴データを使ってテストされます。訓練サンプルの収集と学習した方策のテストでは、デフォルトのパラメータを持つ指標を使用しました。
モデルは2段階で学習されます。最初のステップでは、環境状態エンコーダーを訓練します。このモデルは、銘柄の価格ダイナミクスと分析指標の多変量時系列の履歴データのみを分析し、一般化することを学習します。このプロセスでは、口座の状態や未決済のポジションは考慮されません。したがって、マスクされたデータの再構築とその後の状態の予測において許容できる結果が得られるまで、追加のデータを収集することなく、最初の訓練データセットでモデルを訓練します。
第二段階では、Actorの行動方策とCriticの行動評価の正しさを訓練します。この段階は反復的で、2つのサブプロセスを含みます。
- ActorとCriticモデルの訓練
- Actorの現行方策を考慮した追加環境データの収集
Actorの訓練を何度か繰り返した後、過去の訓練データと新しいデータの両方で利益を生み出すことができるモデルを得ました。新しいデータに対する訓練済みモデルの結果を以下に示します。
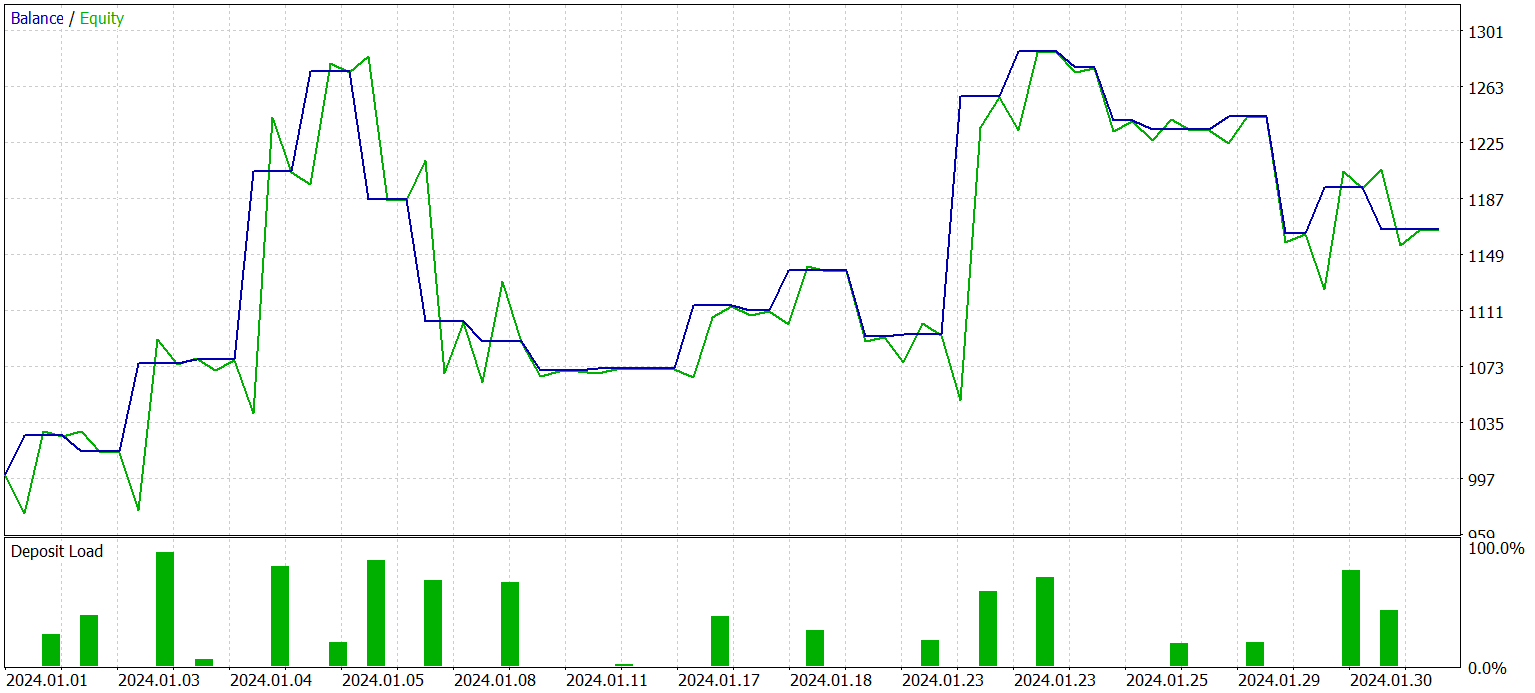
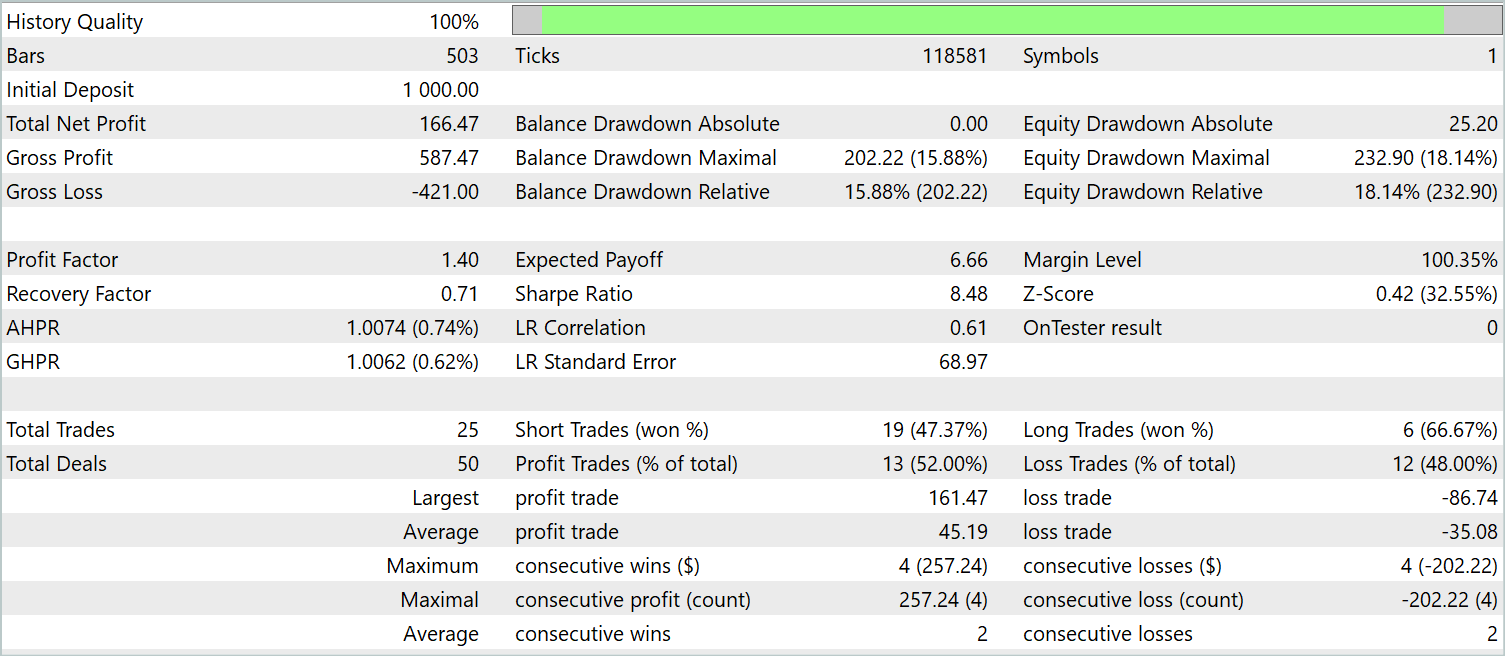
残高のグラフは滑らかに増加しているとは考えられません。とはいえ、テスト期間中、このモデルは25回の取引をおこない、うち13回は利益で決済しました。これは利益を上げた取引の52.0%に相当します。値はパリティに近いです。しかし、最大勝ちトレードは最大負けトレードを87.2%上回り、平均勝ちトレードは平均負けトレードを28.6%上回っています。その結果、テスト期間中のプロフィットファクターは1.4となりました。
結論
本稿では、多次元時系列データの分析と予測をおこなうための新しい手法であるPatchTSTを紹介しました。PatchTSTは、データパッチの生成、Transformerの利用、および表現学習の利点を組み合わせたアプローチです。データパッチを用いることで、モデルは局所的な時間的パターンや文脈をより的確に捉え、分析および予測精度が向上します。また、Transformerの使用により、時系列データの時間的順序や相互関係を考慮しながら、データから抽象的な表現を抽出できます。
本稿の実用的な部分では、MQL5を使用して提案されたアプローチのビジョンを実装しました。過去の実データを用いてモデルを訓練し、訓練サンプルに含まれていない新しいデータを使って、訓練済みのActor方策をテストしました。その結果、PatchTSTを用いることで、利益を生み出すモデルの構築と訓練が可能であることが確認されました。
PatchTST法は、多変量時系列データの分析・予測において強力なツールであり、さまざまな実用的問題に広く適用できる可能性があります。
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | 訓練EAのエンコード |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14798
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ここしばらくこのシリーズを追っているが、洞察に富んでいる。
しかし、1つ疑問があります。このシリーズは最後に1冊の本として出版されるのでしょうか?
しばらくこのシリーズを追っているが、洞察に満ちている。
しかし、1つ疑問があります。このシリーズは最後に1冊の本として出版されるのでしょうか?
こんにちは、
このシリーズの著者であるドミトリー・ギズリクは、トレーディングにおけるニューラルネットワークに関する本をすでに執筆しています。https://www.mql5.com/en/neurobook。 pdfまたはchmでご自由にダウンロードしてください。