
Нейросети — это просто (Часть 87): Сегментация временных рядов

Введение
Прогнозирование играет важную роль в анализе временных рядов. Глубокие модели привнесли значительное улучшение в эту область. Они не только успешно прогнозируют будущие значения, но и извлекают абстрактные представления, которые можно применять в других задачах, таких как классификация и обнаружение аномалий.
Архитектура Transformer, которая начала свое развитие в области обработки естественного языка (NLP), продемонстрировала свои преимущества в компьютерном зрении (CV) и успешно нашла применение в анализе временных рядов. Ее механизм Self-Attention, способный автоматически выявлять связи между элементами последовательности, стал основой для создания эффективных моделей прогнозирования.
Рост объемов доступных для анализа данных и улучшение методов машинного обучения позволяют разрабатывать более точные и эффективные модели для анализа временных данных. Однако с увеличением сложности временных рядов становится необходимо разрабатывать более эффективные и менее затратные методы анализа для достижения точных прогнозов и выявления скрытых паттернов.
Одним из таких методов является Transformer сегментирования временных рядов (Patch Time Series Transformer — PatchTST), который был представлен в статье "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers". В основу данного метода легли разделение временных рядов на сегменты (патчи) и использование Transformer для прогнозирования будущих значений.
Прогнозирование временных рядов направлено на понимание корреляции между данными на каждом временном этапе. Однако отдельный временной шаг не имеет семантического значения. Поэтому извлечение локальной семантической информации имеет важное значение для анализа их связей. В большинстве предыдущих работ используются только токены точечного временного шага исходных данных. PatchTST, напротив, улучшает локальность и собирает комплексную семантическую информацию, которая недоступна на уровне точек, путем агрегирования временных шагов в патчи на уровне подсерий.
Кроме того, многомерный временной ряд представляет собой многоканальный сигнал, и каждый токен исходных данных может представлять данными либо из одного канала, либо из нескольких каналов. В зависимости от структуры токенов исходных данных существуют разные варианты архитектуры Transformer. Смешивание каналов относится к последнему случаю, когда входной токен берет вектор всех функций временного ряда и проецирует его в пространство эмбединга для смешивания информации. С другой стороны, независимость канала означает, что каждый токен исходных данных содержит информацию только из одного канала. Ранее было доказано, что это хорошо работает в сверточных и линейных моделях. PatchTST демонстрирует эффективность подхода независимых каналов в моделях на основе Transformer.
Авторы PatchTST выделяют следующие преимущества предложенного метода:
- Сокращение сложности: Сегментация позволяет сократить временную и пространственную сложность модели, что повышает ее эффективность на больших наборах данных.
- Улучшение обучения на длинных периодах: Патчи позволяют модели изучать более длинные временные периоды, что потенциально повышает качество прогнозов.
- Обучение представлений: Предложенная модель не только эффективна для прогнозирования, но и способна извлекать более сложные абстрактные представления данных, что улучшает ее обобщающую способность.
Приведенные в авторской статье исследования демонстрируют эффективность предложенного метода и перспективность для различных прикладных задач анализа временных рядов.
1. Алгоритм PatchTST
Метод PatchTST разработан для анализа и прогнозирования многомерных временных рядов, в которых каждое состояние анализируемой системы описывается вектором параметров. При этом размер вектора описания каждого временного шага содержит одинаковое количество параметров с идентичной структурой данных. Таким образом, мы можем разделить общий многомерный временной ряд на несколько унитарных временных рядов по количеству параметров описания состояния системы.
Аналогично рассмотренным нами ранее методам, исходные данные, полученные на вход модели, сначала мы приводим к сопоставимому виду путем их нормализации. Этот шаг очень важен. Мы уже не раз говорили, что использование нормализованных данных на входе модели значительно повышает стабильность процесса её обучение. Кроме того, хотя метод PatchTST и подразумевает канально-независимый анализ унитарных временных рядов, их анализ осуществляется с единым набором обучаемых параметров. Поэтому очень важно чтобы анализируемые данные всех каналов находились в сопоставимом виде.
Следующим этапом осуществляется сегментация унитарных временных рядов, что позволяет моделировать локальные паттерны и повышает обобщающую способность модели. На этом шаге авторы метода PatchTST предлагают разделение временной последовательности на патчи фиксированного размера с фиксированным шагом. Метод одинаково хорошо работает как с перекрывающимися, так и не перекрывающимися сегментами. В первом случае шаг меньше размера патча, а во втором — оба гиперпараметра равны. Оба подхода к сегментации позволяют изучать локальную семантическую информацию. А выбор конкретного метода во многом зависит от поставленной задачи и размера анализируемого окна исходных данных.
Очевидно, что количество сегментов будет меньше длины последовательности. И разница тем больше, чем больше размер шага сегментации. Следовательно, максимальная разница между количеством сегментов и длиной последовательности достигается для не перекрывающихся патчей. В таком случае уменьшение осуществляется кратно величине шага. Это позволяет анализировать более длительный размер исходных данных временного ряда при тех же или даже меньших затратах памяти и вычислительных ресурсов.
При анализе малого окна исходных данных рекомендуется использовать перекрывающиеся патчи, что позволит более качественно изучить локальные семантические зависимости.
Ещё раз уточню, что мы создаем патчи для каждого отдельного унитарного временного ряда, но с едиными для всех параметрами сегментации.
Далее мы будем работать уже с созданными патчами. Формируем для них эмбединги. Добавляем обучаемое позиционное кодирование. И передаем в блок из нескольких слоев Энкодера ванильного Transformer.
Мы не будем подробно останавливаться на архитектуре Transformer, которая уже была детально представлена ранее. Но стоит обратить внимание, что Энкодере Transformer отдельно анализируются зависимости в рамках унитарных временных рядов. Однако для анализа всех унитарных временных рядов используются единые обучаемые параметры.
Transformer позволяет извлекать абстрактные представления из патчей исходных данных, учитывая их временную последовательность и контекст. Следовательно, представления, полученные на выходе Энкодера, содержат информацию о взаимосвязях между патчами и паттернах внутри каждого из них. Обработанные таким образом представления унитарных временных рядов конкатенируются. И полученный тензор может быть использован для решения различных задач. Он подается на "голову принятия решения" для генерации результатов работы модели.
Здесь надо сказать, что авторами метода предлагается использование одной модели для решения различных задач на одном наборе исходных данных. Это может быть поиск аномалий, классификация или прогнозирование последующих данных временных рядов на различный горизонт планирование. Достаточно лишь заменить "голову принятия решений" и провести тонкую настройку (дообучение) модели.
При прогнозировании последующих данных временных рядов на выходе модели мы осуществляем денормализацию данных, путем возвращения статистических характеристик, изъятых из исходных данных.
Авторская визуализация метода представлена ниже.
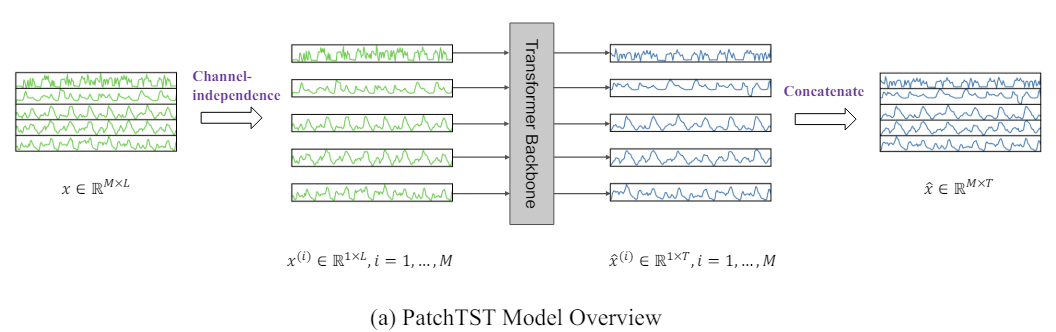
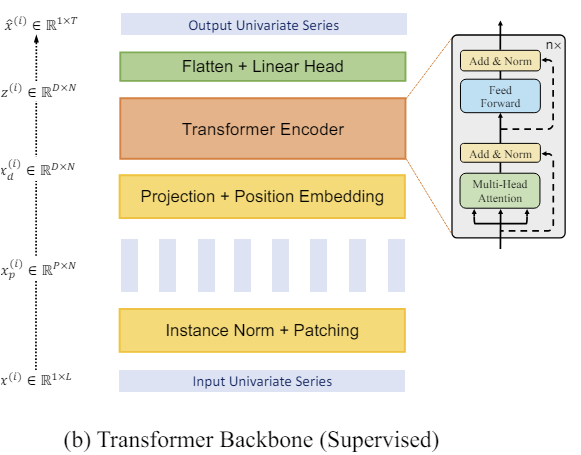
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода мы переходим к построению предложенных подходов средствами MQL5.
Здесь стоит уточнить, что мы будем имплементировать свое видение предложенных подходов. И оно может отличаться от авторского восприятия.
Как следует из представленного выше теоретического описания метода PatchTST в его основе лежат сегментация исходных данных и разделение многомерного временного ряда на отдельные унитарные последовательности.
Первой в потоке обработки данных идет сегментация, которая представляет собой разделение исходных данных на более мелкие блоки информации. В случае не перекрывающихся патчей это можно представить в виде переформатирования 2-мерного тензора исходных данных в 3-мерный. Для перекрывающихся патчей немного сложнее, так как потребуется копирование данных. Но в любом случае мы получаем на выходе 3-мерный тензор "количество переменных * количество патчей * размер патча".
Разумеется, что трансформирование тензора исходных данных подразумевает операции копирования информации. А нам бы хотелось исключить излишние операции, в том числе копирования. Ведь каждая дополнительная операция — это наши расходы времени и ресурсов.
Давайте обратим внимание на последующие операции. А далее в потоке операций следует эмбединг данных. И возникает законное желание совместить 2 операции. По существу мы выполним только операцию эмбединга данных, только для выполнения операции мы будем брать из тензора исходных данных отдельные блоки, соответствующие нашим патчам.
И здесь мы вспоминаем о сверточных слоях. В них мы так же берем блок исходных данных в размере заданного окна и после операции свертки с несколькими фильтрами получаем вектор проекции анализируемого окна данных в некое подпространство. Казалось бы, это то, что нам нужно. Но созданный нами ранее сверточный слой работает с одномерным тензором исходных данных. И не позволяет выделить отдельные унитарные временные ряды из общего тензора многомерного временного ряда. Поэтому нам предстоит создать нечто подобное, но с возможностью работы в рамках отдельных унитарных последовательностей.
2.1 Сегментация на стороне OpenCL
Вначале мы дополним программу OpenCL, создав в ней кернелы прямого и обратного проходов сегментации данных с проецированием их в некое подпространство эмбедингов. И начнем мы с кернела прямого прохода PatchCreate.
В параметрах кернелу мы будем передавать указатели на 3 буфера данных: исходные данные (inputs), матрица весовых коэффициентов (weights) и результатов (outputs). Кроме того, в параметры кернела добавим 4 константы. В них мы укажем полный размер тензора исходных данных для предотвращения ошибки выхода за его размеры. Укажем размер патча и шаг. А так же предоставим возможность пользователю добавления функции активации.
__kernel void PatchCreate(__global float *inputs, __global float *weights, __global float *outputs, int inputs_total, int window_in, int step, int activation ) { const int i = get_global_id(0); const int w = get_global_id(1); const int v = get_global_id(2); const int window_out = get_global_size(1); const int variables = get_global_size(2);
Мы планируем, что исполнение кернела будет осуществляться в 3-мерном пространстве задач: количество патчей, позиция элемента в векторе эмбединга анализируемого патча и идентификатор переменной в исходных данных. Напомню, что мы строим сегментацию в рамках независимых унитарных временных рядов.
В теле кернела мы осуществляем идентификацию потока по всем 3 измерениям пространства задач. А так же определяем размерности пространства задач.
Затем, на основании полученных данных мы модем определить смещение в буферах данных до анализируемых элементов.
const int shift_in = i * step * variables + v; const int shift_out = (i * variables + v) * window_out + w; const int shift_weights = (window_in + 1) * (v * window_out + w);
Обратите внимание, что при определении смещения в буфере исходных данных мы исходим из следующих допущений:
- Тензор исходных содержит последовательность векторов описаний состояния окружающей среды на отдельном временном шаге. Иными словами, тензор исходных данных представляет собой 2-мерную матрицу, строки которой содержат описания состояния окружающей среды на отдельном временном шаге. А столбы матрицы соответствуют отдельным параметрам (переменным) описания состояния анализируемой среды.
- Метод PatchTST анализирует отдельные унитарные временные ряды. Поэтому каждый параметр (переменная) описания состояния окружающей среды содержит только 1 элемент в векторе и сегментируется независимо от остальных (в рамках всего временного ряда).
Запомните эти допущения. В соответствии с ними нам предстоит подготовить исходные данные на стороне основной программы перед передачей их в модель.
Далее мы организуем цикл умножения вектора сегмента на соответствующий вектор весовых коэффициентов. В теле цикла мы контролируем смещение в буфере исходных данных с целью предотвращения обращений за пределами массива.
float res = weights[shift_weights + window_in]; for(int p = 0; p < window_in; p++) if((shift_in + p * variables) < inputs_total) res += inputs[shift_in + p * variables] * weights[shift_weights + p]; if(isnan(res)) res = 0;
Здесь обратите внимание, что при доступе к данным тензора исходных данных мы используем шаг, равный количество переменных в описании одного состояния окружающей среды. Т.е. мы двигаемся по столбцу матрицы исходных данных. Что соответствует требованию сегментации унитарного временного ряда.
В случае получения NaN в результате операции умножения векторов, мы заменяем его на "0".
Далее нам остается лишь выполнить заданную функцию активации и сохранить полученное значение в соответствующий буфер результатов.
switch(activation) { case 0: res = tanh(res); break; case 1: res = 1 / (1 + exp(-clamp(res, -20.0f, 20.0f))); break; case 2: if(res < 0) res *= 0.01f; break; defaultд: break; } //--- outputs[shift_out] = res; }
После реализации прямого прохода мы переходим к построению кернлов обратного прохода. И вначале мы создадим кернел распределения градиента ошибки на предыдущий слой PatchHiddenGradient. В параметрах данного кернела мы будем передавать уже 4 указателя на буферы данных:
- inputs — буфер исходных данных (необходим для корректировки градиентов ошибки на производную функции активации);
- inputs_gr — буфер градиентов ошибки на уровне исходных данных (в данном случае буфер для записи результатов);
- weights — матрица обучаемых параметров слоя;
- outputs_gr — тензор градиентов на уровне результатов слоя (в данном случае исходные данные для вычисления градиентов ошибки).
Кроме того, в кернел мы будем передавать 5 констант, о назначении которых легко догадаться из наименований переменных.
__kernel void PatchHiddenGradient(__global float *inputs, __global float *inputs_gr, __global float *weights, __global float *outputs_gr, int window_in, int step, int window_out, int outputs_total, int activation ) { const int i = get_global_id(0); const int v = get_global_id(1); const int variables = get_global_size(1);
Планируется использование кернела в 2-мерном пространстве задач: длины последовательности исходных данных и количества анализируемых параметров состояния окружающей среды (переменных).
Обратите внимание, что при построении кернелов пространство задач мы ориентируем в размерности тензора результатов. При прямом проходе мы ориентировались на 3-мерный тензор эмбедингов данных. А при обратном проходе на 2-мерный тензор исходных данных, точнее их градиентов ошибки. Такой подход позволяет настроить каждый отдельный поток на получение одного значения в буфере результатов работы кернела.
В теле кернела мы идентифицируем поток в пространстве задач и определяем необходимые размерности. После чего рассчитываем показатели смещений.
const int w_start = i % step; const int r_start = max((i - window_in + step) / step, 0); int total = (window_in - w_start + step - 1) / step; total = min((i + step) / step, total);
После чего мы организовываем систему вложенных циклов сбора градиентов ошибки.
float grad = 0; for(int p = 0; p < total; p ++) { int row = r_start + p; if(row >= outputs_total) break; for(int wo = 0; wo < window_out; wo++) { int shift_g = (row * variables + v) * window_out + wo; int shift_w = v * (window_in + 1) * window_out + w_start + (total - p - 1) * step + wo * (window_in + 1); grad += outputs_gr[shift_g] * weights[shift_w]; } }
Обратите внимание, что один элемент исходных данных оказывает влияние на значение всех элементов вектора эмбединга отдельно взятого патча с различными весовыми коэффициентами. Поэтому вложенный цикл собирает градиенты ошибки со всего вектора эмбединга отдельно взятого патча.
Кроме того, в случае перекрывающихся патчей, существует возможность попадания анализируемого элемента исходных данных в окно исходных данных нескольких патчей. Для сбора градиента ошибки с таких патчей служит внешний цикл нашей системы вложенных циклов.
Собранный (суммарный) градиент ошибки по анализируемому элементу исходных данных мы корректируем на производную функции активации.
float inp = inputs[i * variables + v]; if(isnan(grad)) grad = 0; //--- switch(activation) { case 0: grad = clamp(grad + inp, -1.0f, 1.0f) - inp; grad = grad * (1 - pow(inp == 1 || inp == -1 ? 0.99999999f : inp, 2)); break; case 1: grad = clamp(grad + inp, 0.0f, 1.0f) - inp; grad = grad * (inp == 0 || inp == 1 ? 0.00000001f : (inp * (1 - inp))); break; case 2: if(inp < 0) grad *= 0.01f; break; default: break; }
И результат операций запишем в соответствующий элемент буфера градиентов ошибки предшествующего нейронного слоя.
inputs_gr[i * variables + v] = grad; }
После распределения градиента ошибки нам предстоит скорректировать обучаемые параметры модели с целью минимизации ошибки. Для реализации этого функционала мы создадим кернел PatchUpdateWeightsAdam, в котором построим оптимизацию параметров по методу Adam.
В параметрах кернела мы будем передавать указатели на 5 буферов данных. Помимо уже знакомых нам буферов inputs, weights и output_gr добавляются вспомогательные буферы 1-го и 2-го моментов градиентов ошибки на уровне матрицы весов weights_m и weights_v, соответственно. Кроме того, в параметрах керенла мы будем передавать и коэффициенты обучения.
__kernel void PatchUpdateWeightsAdam(__global float *weights, __global const float *outputs_gr, __global const float *inputs, __global float *weights_m, __global float *weights_v, const int inputs_total, const float l, const float b1, const float b2, int step ) { const int c = get_global_id(0); const int r = get_global_id(1); const int v = get_global_id(2); const int window_in = get_global_size(0) - 1; const int window_out = get_global_size(1); const int variables = get_global_size(2);
Так как наш тензор весовых коэффициентов является 3-мерным, то и пространство задач будет формироваться в 3 измерениях:
- размер патча + bias,
- размер вектора эмбединга,
- количество переменных.
Здесь мы придерживаемся указанной выше логике, когда каждый отдельный поток корректирует значение 1 обучаемого параметра.
В теле кернела мы идентифицируем поток во всех 3 измерениях пространства задач. А так же определяем размерности измерений. После чего мы определяем константы смещений в буферах данных.
const int start_input = c * variables + v; const int step_input = step * variables; const int start_out = v * window_out + r; const int step_out = variables * window_out; const int total = inputs_total / (variables * step);
И организовываем цикл сбора градиентов ошибки на уровне корректируемого обучаемого параметра..
float grad = 0; for(int p = 0; p < total; p++) { int i = start_input + i * step_input; int o = start_out + i * step_out; grad += (c == window_in ? 1 : inputs[i]) * outputs_gr[0]; } if(isnan(grad)) grad = 0;
После определения градиента ошибки мы переходим к алгоритму корректировки параметра. Сначала определим моменты 1-го и 2-го порядка.
const int shift_weights = (window_in + 1) * (window_out * v + r) + c; //--- float weight = weights[shift_weights]; float mt = b1 * weights_m[shift_weights] + (1 - b1) * grad; float vt = b2 * weights_v[shift_weights] + (1 - b2) * pow(grad, 2);
Затем вычислим величину корректировки параметра.
float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight));
И в завершении скорректируем значения в буферах данных.
if(fabs(delta) > 0) weights[shift_weights] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); weights_m[shift_weights] = mt; weights_v[shift_weights] = vt; }
Обратите внимание, что изменение весового коэффициента в буфере данных мы осуществляем только если величина изменения параметра отлична от "0". С математической точки зрения прибавления "0" к текущему значению не изменяет параметра. Но мы вводим операцию дополнительной проверки локальной переменной, чтобы исключить излишнюю более затратную операцию доступа к глобальному буферу данных.
На этом мы завершаем работу на стороне OpenCL и переходим к работе на стороне основной программы.
2.2 Класс сегментации данных
Для вызова и обслуживания выше созданных кернелов на стороне основной программы мы создаем класс CNeuronPatching, который является наследником нашего базового класса всех нейронных слоев CNeuronBaseOCL.
В теле класса мы объявим переменные для сохранения основных параметров архитектуры объекта. А также буферы обучаемых параметров и соответствующих моментов. Все буферы мы объявляем статичными объектами, что позволяет нам оставить "пустыми" конструктор и деструктор класса.
class CNeuronPatching : public CNeuronBaseOCL { protected: uint iWindowIn; uint iStep; uint iWindowOut; uint iVariables; uint iCount; //--- CBufferFloat cPatchWeights; CBufferFloat cPatchFirstMomentum; CBufferFloat cPatchSecondMomentum; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPatching(void){}; ~CNeuronPatching(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronPatchingOCL; } virtual void SetOpenCL(COpenCLMy *obj); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
Набор переопределяемых методов класса довольно стандартный. Инициализация объектов и переменных класса осуществляется в методе Init. В параметрах метод получает всю необходимую информацию для создания объекта, требуемой архитектуры.
bool CNeuronPatching::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch ) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count * variables, optimization_type, batch)) return false;
В теле метода мы сначала вызываем одноименный метод родительского класса, в котором осуществляется минимально-необходимый контроль полученных значений и инициализации унаследованных объектов и переменных. Результат выполнения операций в методе родительского класса контролируем по возвращаемому логическому значению.
После успешного выполнения операций в методе родительского класса мы сохраняем полученные значения описания архитектуры объекта в локальные переменные.
iWindowIn = MathMax(window_in, 1); iWindowOut = MathMax(window_out, 1); iStep = MathMax(step, 1); iVariables = MathMax(variables, 1); iCount = MathMax(count, 1);
Инициализируем буфер обучаемых параметров.
int total = int((window_in + 1) * window_out * variables); if(!cPatchWeights.Reserve(total)) return false; float k = float(1 / sqrt(total)); for(int i = 0; i < total; i++) { if(!cPatchWeights.Add((2 * GenerateWeight()*k - k)*WeightsMultiplier)) return false; } if(!cPatchWeights.BufferCreate(OpenCL)) return false;
А также буферы моментов градиента ошибки на уровне обучаемых параметров.
if(!cPatchFirstMomentum.BufferInit(total, 0) || !cPatchFirstMomentum.BufferCreate(OpenCL)) return false; if(!cPatchSecondMomentum.BufferInit(total, 0) || !cPatchSecondMomentum.BufferCreate(OpenCL)) return false; //--- return true; }
После инициализации объекта мы переходим к построению метода прямого прохода CNeuronPatching::feedForward. В данном методе мы осуществляем постановку в очередь выше созданный кернел прямого прохода. Процедуры постановки кернала в очередь выполнения мы уже не один раз описывали в рамках данной серии статей. И основное внимание здесь стоит уделить корректному указанию размерности пространства задач и передаваемых параметров.
Как мы уже говорили при построении кернла, в данном случае мы используем 3-мерное пространство задач:
- количество патчей;
- размерность эмбединга 1 патча;
- количество анализируемых параметров в описании состояния окружающей среды.
bool CNeuronPatching::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iWindowOut, iVariables};
После создания массивов указания пространства задач и смещения в нем мы организовываем процесс передачи параметров кернелу.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchCreate, def_k_ptc_outputs, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_inputs_total, (int)NeuronOCL.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_window_in, (int)iWindowIn)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchCreate, def_k_ptc_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
При этом не забываем контролировать корректность выполнения операций. И после успешной передачи всех необходимых параметров мы осуществляем постановку кернела в очередь выполнения.
if(!OpenCL.Execute(def_k_PatchCreate, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Аналогичным образом осуществляем постановку в очередь кернела распределения градиента ошибки до элементов предшествующего слоя в соответствии с их влиянием на конечный результат работы модели в методе CNeuronPatching::calcInputGradients. Только вызов кернела PatchHiddenGradient осуществляется в 2-мерном пространстве задач.
bool CNeuronPatching::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {NeuronOCL.Neurons() / iVariables, iVariables};
Здесь следует обратить внимание, что размер исходной последовательности многомерного временного ряда мы определяем как отношение размера буфера результатов предшествующего слоя к количеству анализируемых переменных описания 1 состояния окружающей среды.
Напомню, что методом PatchTST предполагается использование в качестве исходных данных многомерного временного ряда, в котором каждое состояние окружающей среды описывается вектором фиксированной длины. И каждый элемент вектора содержит значение соответствующего параметра описания состояния системы.
Далее мы передаем параметры кернелу с контролем выполнения операций.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_inputs_gr, NeuronOCL.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchHiddenGradient, def_k_pthg_outputs_gr, Gradient.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_activation, (int)NeuronOCL.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_outputs_total, (int)iCount)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_window_in, (int)iWindowIn)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchHiddenGradient, def_k_pthg_window_out, (int)iWindowOut)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И осуществляем постановку кернела в очередь выполнения.
if(!OpenCL.Execute(def_k_PatchHiddenGradient, 2, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Последний метод построения основного функционала класса — метод корректировки обучаемых параметров модели CNeuronPatching::updateInputWeights. В данном методе осуществляется постановка в очередь кернела PatchUpdateWeightsAdam, алгоритм которого описан выше. Думаю, Вы уже понимаете, что алгоритм постановки кернела в очередь выполнения идентичен двум описанным выше методам. Разница в деталях. Здесь используется 3-мерное пространство задач.
bool CNeuronPatching::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowIn + 1, iWindowOut, iVariables};
В первом измерении мы к размеру патча добавляем 1 элемент байесовского смещения. Во втором и третьем измерении мы указываем размер эмбединга 1 патча и количество анализируемых независимых каналов, сохраненных в переменных нашего класса.
А далее мы осуществляем передачу параметров кернелу с контролем результатов выполнения операций.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_outputs_gr, getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights, cPatchWeights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights_m, cPatchFirstMomentum.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_weights_v, cPatchSecondMomentum.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_inputs_total, (int)NeuronOCL.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_step, (int)iStep)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PatchUpdateWeightsAdam, def_k_ptuwa_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
После чего осуществляется постановка кернела в очередь выполнения.
if(!OpenCL.Execute(def_k_PatchUpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Алгоритм методов работы с файлами максимально упрощен, и я предлагаю Вам самостоятельно ознакомиться с кодом данных методов во вложении. Там же Вы найдете полный код всех классов и их методов для создания и обучения моделей.
Выше был создан метод для создания эмбедингов патчей, создаваемых для независимых унитарных временных рядов, которые являются составными частями анализируемого многомерного временного ряда. Однако это только половина предложенного метода PatchTST. Второй, не менее важный блок данного метода — Transformer анализа зависимостей между патчами внутри унитарного временного ряда. И здесь есть важное уточнение, что анализ зависимостей осуществляется только в рамках независимых каналов. Без анализа перекрестных зависимостей между элементами разных унитарных каналов.
И тут надо вспомнить, что все рассмотренные нами ранее варианты реализации архитектуры Transformer использовали смешивание каналов, что противоречит принципам метода PatchTST. Но есть одно исключение — Conformer. Правда Conformer, в отличии от ванильного Transformer, используемого авторами метода PatchTST, имеете более сложную архитектуру. В нем используется Continuous-Attention и вводятся блоки NeuralODE для повышения эффективности модели, что в целом дает положительный результат. И это подтверждается проведенными нами ранее экспериментами. Поэтому в рамках своей реализации я смело заменил Transformer, используемый авторами метода PatchTST, на созданную нами ранее реализацию блока Conformer в классе CNeuronConformer.
2.3 Архитектура моделей
После проведения работы по реализации "кирпичиков" для имплементации метода PatchTST мы переходим к созданию архитектуры обучаемых моделей. Рассматриваемый метод был предложен для прогнозирования многомерных временных рядов. И думаю вполне очевидно, что мы реализуем данный метод в рамках Энкодера состояния окружающей среды. Архитектура данной модели описана в методе CreateEncoderDescriptions, в параметрах которой передается лишь один указатель на динамический массив для сохранения архитектуры модели.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы проверяем актуальность полученного указателя на объект и, при необходимости, создаем новый экземпляр динамического массива.
На вход модели мы подаем полный набор исторических данных.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь стоит обратить внимание, что процедура создания патчей не позволяет использовать в качестве исходных данных историю глубиной менее 1 патча. Конечно, мы можем подавать на вход модели при каждом вызове только исторические данные глубиной в 1 патч. При этом всю глубину анализируемой истории накапливать во внутреннем стеке, как мы это делали ранее в слое Эмбединга. Но такой подход имеет ряд ограничений. Прежде всего, в модели следует указывать шаг между патчами равный самому патчу (не перекрывающиеся патчи). В то время как фактический шаг будет равняться периодичности вызова модели.
Думаю очевидно, что здесь возникает некоторая путаница и сложности в согласовании программ сбора обучающих данных, обучения и эксплуатации моделей.
Второй момент, что при таком подходе при изменении размера патча или шага нам потребуется заново собирать обучающую выборку. Что внесет дополнительные ограничения и затраты в процессе обучения моделей.
Поэтому мы использовали более простой и универсальный метод подачи на вход модели полной глубины анализируемой. А размер патча и шага устанавливать параметрами в архитектуре соответствующего слоя модели.
Как всегда, на вход модели мы подаем "сырые" не обработанные данные, которые сразу нормализуем в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее следует обратить внимание, что в данной модели я поставил слой обучаемого позиционного кодирования на уровне исходных данных, а не эмбедингов, как это делалось ранее. Таким образом я хотел акцентировать внимание на позиции конкретных параметров. Ведь при использовании патчей с перекрытием, один параметр может попасть в несколько патчей.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count; if(!encoder.Add(descr)) { delete descr; return false; }
Следующим я добавил слой Dropout, который мы будем использовать для маскирования отдельных значений исходных данных в процессе обучения модели.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.4f; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Коэффициент маскирования данных я установил на уровне 40% аналогично предыдущей работе.
И далее мы добавляем слой генерации патчей. В своей работе я использовал не перекрывающиеся патчи с размером окна и шага равным 3.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPatchingOCL; descr.window = 3; prev_count = descr.count = (HistoryBars+descr.window-1)/descr.window; descr.step = descr.window; descr.layers=BarDescr; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь так же следует обратить внимание, что эмбединг патчей формируется в 2 этапа. Сначала мы генерируем эмбединги патчей с половинным размером. А затем в сверточном слое увеличиваем размер патча.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count*BarDescr; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Напомню, что позиционное кодирование мы внедрили на уровне исходных данных. Поэтому после генерации эмбедингов мы сразу данные в блок из 10 слоев Conformer.
//--- layer 6-16 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 8; descr.window_out = EmbeddingSize; descr.layers = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; } }
Далее идет голова принятия решений из 3 полносвязных слоев. Размер последнего слоя мы делаем достаточным для содержания восстановленной информации исторических данных и прогнозированию последующих состояний на заданную глубину.
//--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = BarDescr*(HistoryBars+NForecast); descr.activation=TANH; if(!encoder.Add(descr)) { delete descr; return false; }
В завершении модели мы осуществляем денормализацию восстановленных и прогнозных значений, путем добавления статистических показателей, изъятых из исходных данных.
//--- layer 20 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Обратите внимане, что размер исходных данных и результатов модели мы оставили аналогичный предыдущей работе. Это позволило нам полностью перенести архитектуру моделей Актера и Критика без изменений. Более того, в рамках нового эксперимента мы можем полностью использовать без изменений обучающую выборку и советники из предыдущей работы. Таким образом мы можем сравнить влияние различной архитектуры энкодера состояния окружающей среды на результаты обучения политики Актера.
С полным описанием архитектуры всех обучаемых моделей и программ, используемых при подготовке данной статьи, Вы можете самостоятельно ознакомиться во вложении.
3. Тестирование
В предыдущих разделах данной статьи мы познакомились с новым методом для прогнозирования многомерных временных рядов PatchTST. Мы реализовали свое видение предложенных подходов средствами MQL5. И теперь мы пришли к этапу тестирования проделанной работы. На данном этапе мы сначала обучаем модели с использованием реальных исторических данных. А затем проводим тестирование обученных моделей в тестере стратегий MetaTrader 5 на историческом отрезке, выходящим за рамки обучающей выборке.
Как и ранее, обучать модели мы будем на исторических данных за 2023 год инструмента EURUSD тайм-фрейм H1. Тестирование обученной модели осуществляется на исторических данных за Январь 2024 года с сохранением финансового инструмента и тайм-фрейма. Параметры всех анализируемых индикаторов в процессе сбора обучающей выборки и тестирования обученной политики использовались установленные по умолчанию.
Обучение моделей осуществляется в 2 этапа. На первом этапе мы обучаем энкодер состояния окружающей среды. Данная модель учится анализировать и обобщать только исторические данные многомерного временного ряда динамики цены инструмента и анализируемых индикаторов. Без учета состояния счета и открытых позиций. Поэтому мы обучаем модель на первичной обучающей выборки без сбора дополнительных данных до получения приемлемого результата восстановления маскированных данных и прогнозирования последующих состояний.
На втором этапе мы осуществляем обучение политики поведения Актера и корректность оценки действий Критиком. Данный этап является итерационным и включает 2 подпроцесса:
- Обучение моделей Актера и Критика.
- Сбор дополнительных данных об окружающей среде с учетом актуальной политики Актера.
После нескольких итераций обучения политики Актера мне удалось получить модель, способную генерировать прибыль как на исторических данных обучающей выборки, так и на новых данных. Результаты работы обученной модели на новых данных представлены ниже.
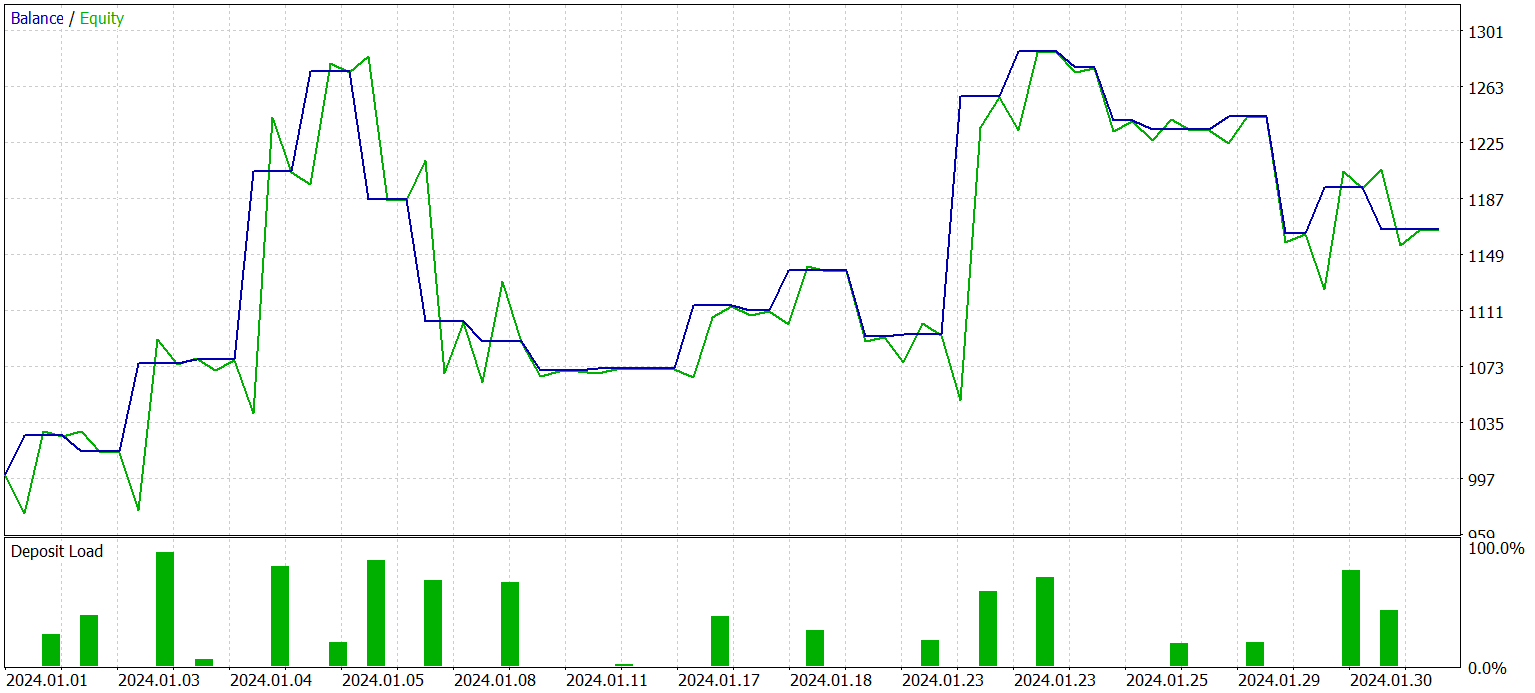
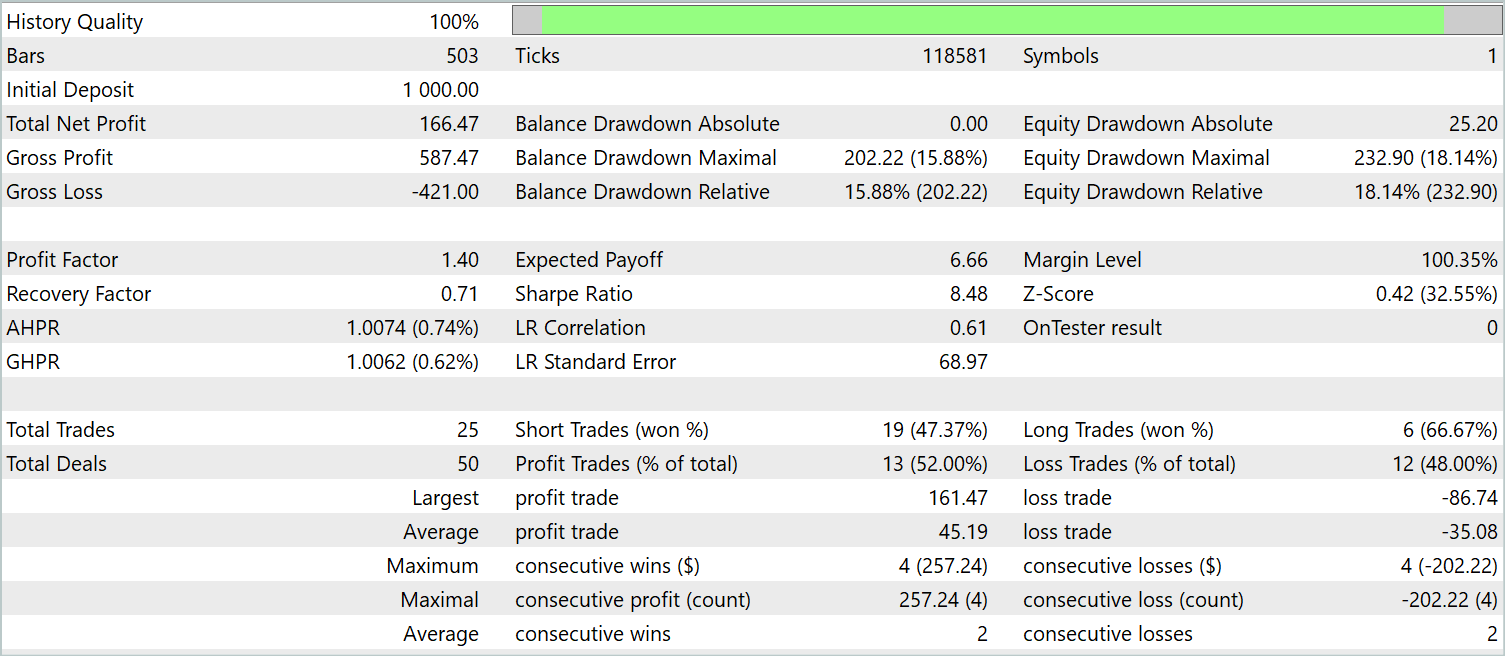
График баланса сложно назвать ровно возрастающим. Тем не менее, за период тестирования модель совершила 25 сделок, из которых 13 было закрыто с прибылью. Это составил 52.0% прибыльных сделок. Показатель близкий к паритету. Однако максимальная прибыльная сделка превышает максимальный убыток на 87.2%, а средняя прибыльная сделка превышает средний убыток на 28.6%. Как результат, за период тестирования профит-фактор составил 1.4.
Заключение
В данной статье мы познакомились с новым методом анализа и прогнозирования многомерных временных рядов PatchTST, который объединяет преимущества сегментации данных, использования трансформера и обучения представлений. Сегментация данных позволяет модели лучше улавливать локальные временные паттерны и контекст, что повышает качество анализа и прогнозирования. А использование трансформера позволяет извлекать абстрактные представления из данных, учитывать их временную последовательность и взаимосвязь.
В практической части статьи мы реализовали свое видение предложенных подходов средствами MQL5. Обучили модель на реальных исторических данных. И провели тестирование обученной политики Актера на новых данных, не входящих в обучающую выборку. Полученные результаты демонстрируют возможность использования метода PatchTST для построения и обучения моделей, способных генерировать прибыль.
Таким образом, метод PatchTST представляет собой мощный инструмент для анализа и прогнозирования многомерных временных рядов, который может быть успешно применен в различных практических задачах.
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Как разработать агент обучения с подкреплением на MQL5 с интеграцией RestAPI (Часть 2): Функции MQL5 для HTTP-взаимодействия с REST API игры "крестики-нолики"
Как разработать агент обучения с подкреплением на MQL5 с интеграцией RestAPI (Часть 2): Функции MQL5 для HTTP-взаимодействия с REST API игры "крестики-нолики"
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования