
Neuronale Netze leicht gemacht (Teil 88): Zeitreihen-Dense-Encoder (TiDE)

Einführung
Wahrscheinlich sind alle bekannten neuronalen Netzarchitekturen auf ihre Fähigkeit zur Lösung von Zeitreihenvorhersageproblemen hin untersucht worden, einschließlich rekurrenter, konvolutionärer und Graphmodelle. Die bemerkenswertesten Ergebnisse zeigen die Modelle, die auf der Architektur des Transformers basieren. Mehrere solcher Algorithmen wurden ebenfalls in dieser Artikelserie vorgestellt. Jüngste Forschungen haben jedoch gezeigt, dass Transformer-basierte Architekturen möglicherweise weniger leistungsfähig sind als erwartet. Bei einigen Benchmarks für Zeitreihenprognosen können einfache lineare Modelle eine vergleichbare oder sogar bessere Leistung zeigen. Leider haben solche linearen Modelle jedoch Mängel, da sie sich nicht für die Modellierung nichtlinearer Beziehungen zwischen einer Folge von Zeitreihen und zeitunabhängigen Kovariaten eignen.
Die weitere Forschung auf dem Gebiet der Zeitreihenanalyse und -prognose geht in zwei Richtungen. Einige sehen das Potenzial von Transformer, das noch nicht voll ausgeschöpft wurde, und arbeiten an der Verbesserung der Effizienz solcher Architekturen. Andere versuchen, die Unzulänglichkeiten der linearen Modelle zu minimieren. Der Artikel mit dem Titel „Long-term Forecasting with TiDE: Time-series Dense Encoder“ bezieht sich auf die zweite Richtung. In diesem Beitrag wird eine einfache und effiziente Deep-Learning-Architektur für Zeitreihenprognosen vorgeschlagen, die bei gängigen Benchmarks eine bessere Leistung als bestehende Deep-Learning-Modelle erzielt. Das vorgestellte Modell, das auf einem mehrschichtigen Perzeptron (MLP) basiert, ist erstaunlich einfach und enthält keine Mechanismen zur Selbstaufmerksamkeit, rekurrenten oder faltigen Schichten. Daher ist sie im Gegensatz zu vielen auf Transformer basierenden Lösungen in Bezug auf die Kontextlänge und den Vorhersagehorizont linear skalierbar.
Das Modell Time-series Dense Encoder (TiDE, Dense-Encoder von Zeitserien) verwendet MLP, um die vergangenen Zeitreihen zusammen mit Kovariaten zu kodieren und die prognostizierten Zeitreihen zusammen mit zukünftigen Kovariaten zu dekodieren.
Die Autoren der Methode analysieren ein vereinfachtes lineares Modell TiDE und zeigen, dass dieses lineare Modell nahezu optimale Fehler in linearen dynamischen Systemen (LDS) erreichen kann, wenn die LDS-Entwurfsmatrix einen maximalen Singulärwert ungleich 1 hat. Sie testen dies empirisch an simulierten Daten: Das lineare Modell übertrifft sowohl LSTMs als auch Tarnsformers.
Bei gängigen realen Zeitreihenvorhersage-Benchmarks erzielt TiDE im Vergleich zu früheren neuronalen Netzmodellen bessere oder ähnliche Ergebnisse. Gleichzeitig ist TiDE 5x schneller in der Produktion und über 10x schneller im Training als die besten Transformer-basierten Modelle.
1. TiDE-Algorithmus
Das TiDE-Modell (Time-series Dense Encoder) ist eine einfache und effiziente MLP-basierte Architektur für langfristige Zeitreihenprognosen. Die Autoren des Algorithmus fügen Nichtlinearität in Form eines MLP hinzu, sodass sie vergangene Daten und Kovariaten verarbeiten können. Das Modell wird auf unabhängige Datenkanäle angewandt, d. h., der Modellinput besteht aus der Vergangenheit und den Kovariaten einer Zeitreihe nach der anderen. In diesem Fall werden die Modellgewichte global anhand des gesamten Datensatzes trainiert, d. h. sie sind für alle unabhängigen Kanäle gleich.
Die Schlüsselkomponente des Modells ist der MLP-Block mit einem geschlossenem Regelkreis. Der MLP hat eine versteckte Schicht und ReLU-Aktivierung. Es gibt auch eine Skip-Verbindung, die völlig linear ist. Die Autoren der Methode verwenden Dropout auf der linearen Schicht, die die verborgene Schicht auf die Ausgabe abbildet, und verwenden auch die Normalisierungsschicht auf der Ausgabe.
Das TiDE-Modell ist logisch in Kodierungs- und Dekodierungsabschnitte unterteilt. Der Kodierungsabschnitt enthält einen Schritt der Merkmalsprojektion, gefolgt von einem Dense-Encoder MLP. Der Dekodierabschnitt besteht aus einem Dense-Dekodierer, gefolgt von einem zeitlichen Dekodierer. Dense-Encoder und Dense-Decoder können in einem Block kombiniert werden. Die Autoren der Methode trennen sie jedoch, weil sie in den beiden Blöcken unterschiedliche Größen von versteckten Schichten verwenden. Auch die letzte Schicht des Decoderblocks ist einzigartig: ihre Ausgangsgröße muss dem Planungshorizont entsprechen.
Ziel des Kodierungsschritts ist es, den Verlauf und die Kovariaten der Zeitreihe in einer dichten Merkmalsdarstellung abzubilden. Die Kodierung im TiDE-Modell umfasst zwei wichtige Schritte.
Zunächst wird ein Closed-Loop-Block verwendet, um die Kovariaten in jedem Zeitschritt (sowohl im historischen Kontext als auch im Prognosehorizont) in eine niedriger dimensionale Projektion zu übertragen.
Anschließend werden alle vergangenen und zukünftigen projizierten Kovariaten zusammengeführt und geglättet, indem sie mit den statischen Attributen und den vergangenen Zeitreihen kombiniert werden. Anschließend werden sie mit Hilfe eines Dense-Encoders, der mehrere geschlossene Blöcke enthält, in eine Einbettung übertragen. Die Dekodierung im TiDE-Modell bildet die kodierten latenten Repräsentationen in zukünftige Prognosewerte der Zeitreihe ab. Er umfasst auch zwei Operationen: den Dense-Decoder und den temporalen Decoder.
Ein Dense-Decoder ist ein Stapel aus mehreren geschlossenen Blöcken, die den Encoderblöcken ähnlich sind. Es nimmt die Ausgabe des Encoders als Eingabe und bildet sie in einen Vektor von vorhergesagten Zuständen ab.
Die Modellausgabe verwendet einen zeitlichen Decoder, um endgültige Vorhersagen zu erstellen. Ein zeitlicher Decoder ist derselbe Block mit geschlossenem Regelkreis, der den dekodierten Vektor des Zeitschritts t des Prognosehorizonts abbildet, kombiniert mit den projizierten Kovariaten des Prognosezeitraums. Durch diesen Vorgang wird eine Verbindung zwischen den zukünftigen Kovariaten und der Vorhersage der Zeitreihe hergestellt. Dies kann nützlich sein, wenn einige Kovariaten einen starken direkten Einfluss auf den tatsächlichen Wert in einem bestimmten Zeitschritt haben. Zum Beispiel der Nachrichtenhintergrund an einzelnen Kalendertagen.
Zu den Werten des temporalen Decoders addieren wir die Werte der globalen Residualverbindung, die die Vergangenheit der analysierten Zeitreihe linear auf den Planungshorizontvektor abbildet. Dadurch wird sichergestellt, dass ein rein lineares Modell immer eine Unterklasse des TiDE-Modells ist.
Im Folgenden wird die Visualisierung der Methode durch den Autor vorgestellt.
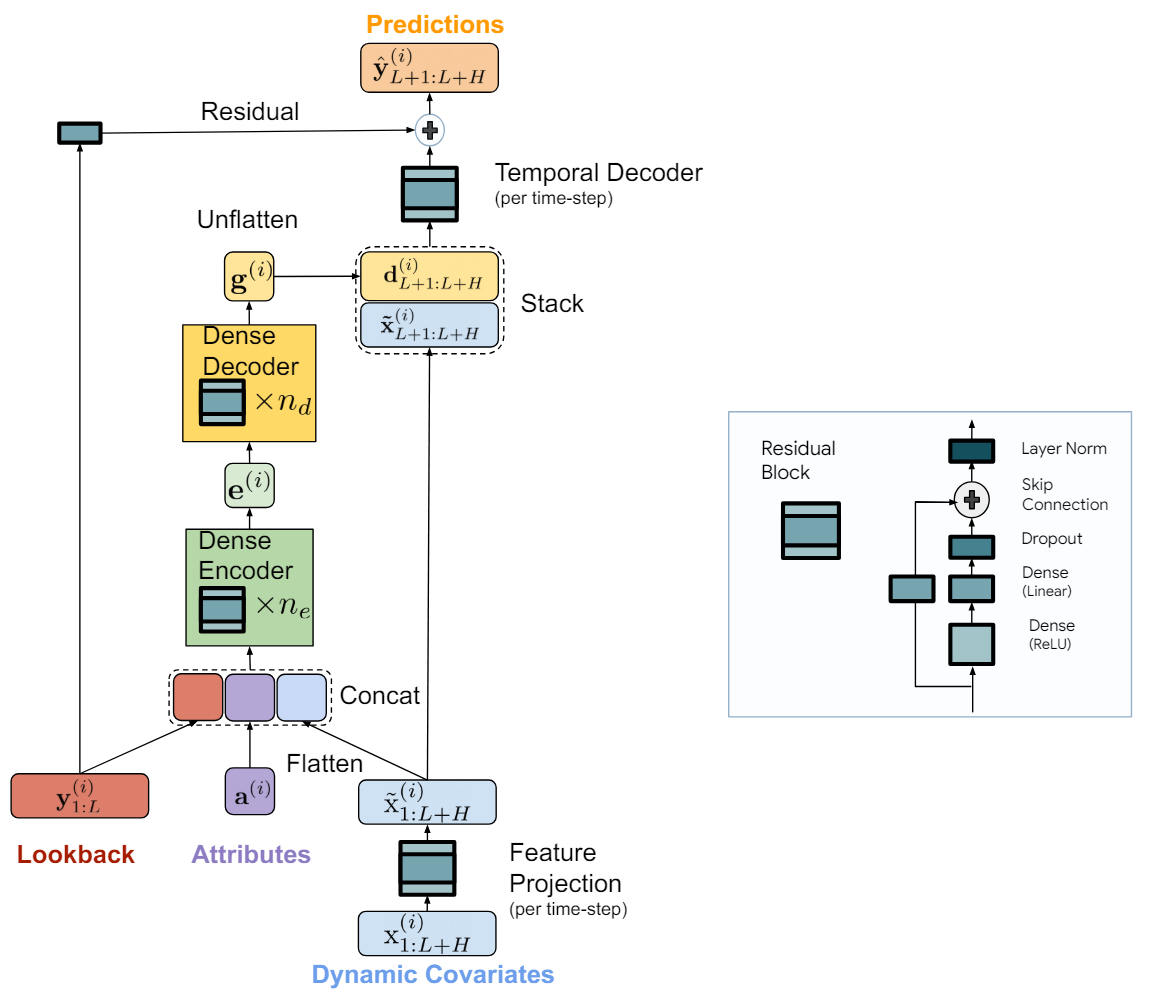
Das Modell wird mittels Mini-Batch-Gradientenabstieg trainiert. Die Autoren der Methode verwenden MSE als Verlustfunktion. Jede Epoche umfasst alle Paare von Vergangenheits- und Prognosehorizont, die aus dem Trainingszeitraum konstruiert werden können. So können sich die Zeitpunkte zweier Mini-Batches überschneiden.
2. Implementierung in MQL5
Wir haben die theoretischen Aspekte des TiDE-Algorithmus betrachtet. Nun können wir uns der praktischen Umsetzung dieser Ansätze mit MQL5 zuwenden.
Wie bereits oben erwähnt, ist der wichtigste „Baustein“ der TiDE-Methode, die wir hier betrachten, ein geschlossener Kreislauf. In diesem Block verwenden die Autoren der Methode vollständig verbundene Schichten. Es ist jedoch zu beachten, dass jeder dieser Blöcke in dem Modell auf einen separaten, unabhängigen Kanal angewendet wird. In diesem Fall werden die trainierbaren Parameter des Blocks global trainiert und sind für alle Kanäle der analysierten mehrdimensionalen Zeitreihe gleich.
Natürlich würden wir in unserer Implementierung gerne eine parallele Berechnung für alle unabhängigen Kanäle der mehrdimensionalen Zeitreihen, die wir analysieren, durchführen. In ähnlichen Fällen haben wir früher Faltungsschichten mit mehreren Faltungsfiltern verwendet. Die Fenstergröße einer solchen Faltungsschicht ist gleich ihrer Schrittweite und entspricht der Datenmenge eines Kanals. Ich denke, es ist offensichtlich, dass sie der Tiefe der analysierten Zeitreihenhistorie entspricht.
Da wir nun bei der Verwendung von Faltungsschichten angelangt sind, erinnern wir uns an den Closed-Loop-Faltungsblock, den wir bei der Implementierung des CCMR Methode erstellt haben. Wenn Sie aufmerksam lesen, werden Sie den Unterschied bemerken: Die CCMR-Implementierung verwendet Normalisierungsschichten. Im Rahmen dieses Artikels habe ich jedoch beschlossen, diesen Unterschied in der Blockarchitektur zu ignorieren. Daher werden wir die zuvor erstellte Block CResidualConv verwenden, um ein neues Modell zu erstellen.
Damit haben wir den grundlegenden „Baustein“ für den vorgeschlagenen TiDE-Algorithmus. Nun müssen wir den gesamten Algorithmus aus diesen Blöcken zusammensetzen.
2.1 TiDE-Algorithmusklasse
Implementieren wir die vorgeschlagenen Ansätze in der neuen Klasse CNeuronTiDEOCL, die von der Basisklasse der neuronalen Schicht CNeuronBaseOCL erbt. Die Architektur unserer neuen Klasse erfordert 4 Schlüsselparameter, für die wir lokale Variablen deklarieren werden:
- iHistory – die Tiefe der analysierten Zeitreihenhistorie
- iForecast – Zeitreihen-Vorhersagehorizont
- iVariables – die Anzahl der analysierten Variablen (Kanäle)
- iFeatures – die Anzahl der Kovariaten in der Zeitreihe
class CNeuronTiDEOCL : public CNeuronBaseOCL { protected: uint iHistory; uint iForecast; uint iVariables; uint iFeatures; //--- CResidualConv acEncoderDecoder[]; CNeuronConvOCL cGlobalResidual; CResidualConv acFeatureProjection[2]; CResidualConv cTemporalDecoder; //--- CNeuronBaseOCL cHistoryInput; CNeuronBaseOCL cFeatureInput; CNeuronBaseOCL cEncoderInput; CNeuronBaseOCL cTemporalDecoderInput; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); public: CNeuronTiDEOCL(void) {}; ~CNeuronTiDEOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint history, uint forecast, uint variables, uint features, uint &encoder_decoder[], ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronTiDEOCL; } virtual void SetOpenCL(COpenCLMy *obj); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
Wie Sie sehen können, enthalten die Variablen nicht die Anzahl der Blöcke im Encoder oder Decoder des Modells. In unserer Implementierung haben wir den Encoder und den Decoder in einem Array mit den Blöcken von acEncoderDecoder[] zusammengefasst. Die Größe dieses Arrays gibt die Gesamtzahl der Closed-Loop-Blöcke an, die zur Kodierung der historischen Daten und zur Dekodierung der vorhergesagten Zeitreihenwerte verwendet werden.
Darüber hinaus haben wir die Projektion der Zeitreihenkovariaten in 2 Blöcke unterteilt (acFeatureProjection[2]). In einer davon werden wir eine Projektion der Kovariaten erstellen, um historische Daten zu kodieren; in der zweiten – um vorhergesagte Werte zu dekodieren.
Wir werden auch einen temporalen Decoder-Block cTemporalDecoder hinzufügen. Für die globale Residualverbindung wird die Faltungsschicht cGlobalResidual verwendet.
Zusätzlich deklarieren wir 4 lokale, voll vernetzte Schichten zum Schreiben von Zwischenwerten. Der spezifische Zweck jeder Ebene wird während des Implementierungsprozesses erläutert.
Wir haben alle Objekte in unserer Klasse als statisch deklariert, was uns erlaubt, den Konstruktor und den Destruktor der Klasse „leer“ zu lassen.
Die Menge der überschreibbaren Methoden ist ziemlich standardisiert. Wie immer beginnen wir mit der Methode CNeuronTiDEOCL::Init, die das Klassenobjekt initialisiert.
bool CNeuronTiDEOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint history, uint forecast, uint variables, uint features, uint &encoder_decoder[], ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, forecast * variables, optimization_type, batch)) return false;
In den Parametern erhält die Methode alle notwendigen Informationen, um die gewünschte Architektur zu implementieren. Im Hauptteil der Methode rufen wir zunächst dieselbe Methode der Elternklasse auf, die die minimal notwendige Kontrolle der empfangenen Parameter und die Initialisierung der geerbten Objekte implementiert.
Nachdem die Operationen der Initialisierungsmethoden der übergeordneten Klasse erfolgreich ausgeführt wurden, werden die Werte der Schlüsselkonstanten gespeichert.
iHistory = MathMax(history, 1); iForecast = forecast; iVariables = variables; iFeatures = MathMax(features, 1);
Dann geht es an die Initialisierung der internen Objekte. Zunächst initialisieren wir die Kovariaten-Projektionsblöcke.
if(!acFeatureProjection[0].Init(0, 0, OpenCL, iFeatures, iHistory * iVariables, 1, optimization, iBatch)) return false; if(!acFeatureProjection[1].Init(0, 1, OpenCL, iFeatures, iForecast * iVariables, 1, optimization, iBatch)) return false;
Bitte beachten Sie, dass wir in unserem Experiment kein a priori Wissen über die Kovariaten der analysierten Zeitreihen verwenden. Stattdessen projizieren wir die Zeitharmonischen des Zeitstempels auf die Sequenz. Dabei erstellen wir unsere eigenen Projektionen für jeden Kanal (Variable) des analysierten mehrdimensionalen Zeitkanals.
Wir erhalten die Dimensionen der verborgenen Schichten des Dense-Encoders und Decoders in Form des Arrays encoder_decoder[]. Die Array-Größe gibt die Gesamtzahl der Closed-Loop-Blöcke im Encoder und Decoder an. Der Wert der Array-Elemente gibt die Dimension des entsprechenden Blocks an. Denken Sie daran, dass die Eingabe für den Encoder ein verketteter Vektor von historischen Zeitreihendaten mit einer Projektion von Kovariaten ist. Am Ausgang des Decoders müssen wir einen Vektor erhalten, der dem Prognosehorizont entspricht. Um Letzteres zu ermöglichen, fügen wir am Decoderausgang einen weiteren Block in der erforderlichen Größe hinzu.
int total = ArraySize(encoder_decoder); if(ArrayResize(acEncoderDecoder, total + 1) < total + 1) return false; if(total == 0) { if(!acEncoderDecoder[0].Init(0, 2, OpenCL, 2 * iHistory, iForecast, iVariables, optimization, iBatch)) return false; } else { if(!acEncoderDecoder[0].Init(0, 2, OpenCL, 2 * iHistory, encoder_decoder[0], iVariables, optimization, iBatch)) return false; for(int i = 1; i < total; i++) if(!acEncoderDecoder[i].Init(0, i + 2, OpenCL, encoder_decoder[i - 1], encoder_decoder[i], iVariables, optimization, iBatch)) return false; if(!acEncoderDecoder[total].Init(0, total + 2, OpenCL, encoder_decoder[total - 1], iForecast, iVariables, optimization, iBatch)) return false; }
Als Nächstes initialisieren wir den temporalen Decoderblock und die globale Rückkopplungsschicht.
if(!cGlobalResidual.Init(0, total + 3, OpenCL, iHistory, iHistory, iForecast, iVariables, optimization, iBatch)) return false; cGlobalResidual.SetActivationFunction(TANH); if(!cTemporalDecoder.Init(0, total + 4, OpenCL, 2 * iForecast, iForecast, iVariables, optimization, iBatch)) return false;
Achten Sie auf die folgenden beiden Punkte:
- Der zeitliche Decoder erhält als Eingabe eine verkettete Matrix von vorhergesagten Zeitreihenwerten und Projektionen von Vorhersagekovariaten. Am Ausgang des Blocks erhalten wir angepasste vorausberechnete Zeitreihenwerte.
- Am Ausgang jedes CResidualConv-Blocks werden die Daten normalisiert: Der Durchschnittswert jedes Kanals ist gleich „0“ und die Varianz ist gleich „1“. Um die Daten des globalen Closed-Loop-Blocks in eine vergleichbare Form zu bringen, werden wir den hyperbolischen Tangens (tanh) als Aktivierungsfunktion für die cGlobalResidual-Schicht verwenden.
Im nächsten Schritt initialisieren wir die Hilfsobjekte für die Speicherung von Zwischendaten. Wir speichern die historischen Daten der analysierten multivariaten Zeitreihen und die vom externen Programm erhaltenen Kovariaten in cHistoryInput bzw. cFeatureInput.
if(!cHistoryInput.Init(0, total + 5, OpenCL, iHistory * iVariables, optimization, iBatch)) return false; if(!cFeatureInput.Init(0, total + 6, OpenCL, iFeatures, optimization, iBatch)) return false;
Wir schreiben die verkettete Matrix aus historischen Daten und Kovariatenprojektionen in cEncoderInput.
if(!cEncoderInput.Init(0, total + 7, OpenCL, 2 * iHistory * iVariables, optimization,iBatch)) return false;
Die Ausgabe des Dense-Decoders wird mit den Kovariaten der vorhergesagten Werte verkettet und in cTemporalDecoderInput geschrieben.
if(!cTemporalDecoderInput.Init(0, total + 8, OpenCL, 2 * iForecast * iVariables, optimization, iBatch)) return false;
Am Ende der Initialisierungsmethode des Klassenobjekts werden wir die Datenpuffer austauschen, um das zusätzliche Kopieren von Fehlergradienten zwischen den Datenpuffern der einzelnen Elemente unserer Klasse zu vermeiden.
if(cGlobalResidual.getGradient() != Gradient) if(!cGlobalResidual.SetGradient(Gradient)) return false; if(cTemporalDecoder.getGradient() != getGradient()) if(!cTemporalDecoder.SetGradient(Gradient)) return false; //--- return true; }
Nachdem die Initialisierung der Klasseninstanz abgeschlossen ist, gehen wir zur Konstruktion des Feed-Forward-Algorithmus über, der in der Methode CNeuronTiDEOCL::feedForward beschrieben wird. In den Methodenparametern erhalten wir Zeiger auf 2 Objekte, die Eingabedaten enthalten. Dabei handelt es sich um historische multivariate Zeitreihendaten in Form eines Ergebnispuffers aus der vorherigen neuronalen Schicht und Kovariaten, die als separate Datenpuffer dargestellt werden.
bool CNeuronTiDEOCL::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!NeuronOCL || !SecondInput) return false;
Im Methodenkörper wird sofort geprüft, ob die empfangenen Zeiger relevant sind.
Als Nächstes müssen wir die empfangenen Eingabedaten in interne Objekte kopieren. Anstatt jedoch die gesamte Informationsmenge zu übertragen, werden nur die Zeiger auf die Datenpuffer überprüft und gegebenenfalls kopiert.
if(cHistoryInput.getOutputIndex() != NeuronOCL.getOutputIndex()) { CBufferFloat *temp = cHistoryInput.getOutput(); if(!temp.BufferSet(NeuronOCL.getOutputIndex())) return false; } if(cFeatureInput.getOutputIndex() != SecondInput.GetIndex()) { CBufferFloat *temp = cFeatureInput.getOutput(); if(!temp.BufferSet(SecondInput.GetIndex())) return false; }
Nach Durchführung der Vorarbeiten projizieren wir die historischen Daten in die Dimension der Prognosewerte. Dies ist eine Art autoregressives Modell.
if(!cGlobalResidual.FeedForward(NeuronOCL)) return false;
Wir erstellen Projektionen von Kovariaten auf historische und prognostizierte Werte.
if(!acFeatureProjection[0].FeedForward(NeuronOCL)) return false; if(!acFeatureProjection[1].FeedForward(cFeatureInput.AsObject())) return false;
Anschließend werden die historischen Daten mit der entsprechenden Kovariaten-Projektionsmatrix verknüpft.
if(!Concat(NeuronOCL.getOutput(), acFeatureProjection[0].getOutput(), cEncoderInput.getOutput(), iHistory, iHistory, iVariables)) return false;
Wir erstellen eine Schleife der Operationen des Dense-Encoder- und Decoderblocks.
uint total = acEncoderDecoder.Size(); CNeuronBaseOCL *prev = cEncoderInput.AsObject(); for(uint i = 0; i < total; i++) { if(!acEncoderDecoder[i].FeedForward(prev)) return false; prev = acEncoderDecoder[i].AsObject(); }
Dann verketten wir die Ausgabe des Decoders mit der Projektion der Kovariaten der vorhergesagten Werte.
if(!Concat(prev.getOutput(), acFeatureProjection[1].getOutput(), cTemporalDecoderInput.getOutput(), iForecast, iForecast, iVariables)) return false;
Die verkettete Matrix wird in den Zeitdecoderblock eingespeist.
if(!cTemporalDecoder.FeedForward(cTemporalDecoderInput.AsObject())) return false;
Am Ende der Vorwärtsoperationen summieren wir die Ergebnisse der beiden Datenströme und normalisieren das resultierende Ergebnis über die unabhängigen Kanäle.
if(!SumAndNormilize(cGlobalResidual.getOutput(), cTemporalDecoder.getOutput(), Output, iForecast, true)) return false; //--- return true; }
Auf den Feedforward-Durchgang folgt ein Backpropagation-Durchgang, der aus 2 Schichten besteht. Zunächst verteilen wir in der Methode CNeuronTiDEOCL::calcInputGradients den Fehlergradienten auf alle internen Objekte und externen Eingaben entsprechend ihrem Einfluss auf das Endergebnis. In den Parametern erhält die Methode Zeiger auf Objekte zum Schreiben der Fehlergradienten der Eingabedaten.
bool CNeuronTiDEOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!cTemporalDecoderInput.calcHiddenGradients(cTemporalDecoder.AsObject())) return false;
Da wir die Vertauschung von Datenpuffern nutzen, ist es nicht notwendig, Daten aus den Fehlergradienten unserer Klasse in die entsprechenden Puffer der verschachtelten Objekte zu kopieren. Wir rufen also die Methoden der Fehlergradientenverteilung unserer verschachtelten Blöcke in umgekehrter Reihenfolge auf.
Zunächst propagieren wir den Fehlergradienten durch den temporalen Decoderblock. Wir verteilen das Ergebnis der Operation auf den Dense-Decoder und die Projektion der vorhergesagten Kovariaten der Zeitreihe.
int total = (int)acEncoderDecoder.Size(); if(!DeConcat(acEncoderDecoder[total - 1].getGradient(), acFeatureProjection[1].getGradient(), cTemporalDecoderInput.getGradient(), iForecast, iForecast, iVariables)) return false;
Danach verteilen wir den Fehlergradienten auf den Dense-Encoder- und Decoderblock.
for(int i = total - 2; i >= 0; i--) if(!acEncoderDecoder[i].calcHiddenGradients(acEncoderDecoder[i + 1].AsObject())) return false; if(!cEncoderInput.calcHiddenGradients(acEncoderDecoder[0].AsObject())) return false;
Der Fehlergradient auf der Ebene der Eingangsdaten des Dense-Encoders ist über die historischen Daten der multivariaten Zeitreihen und die entsprechenden Kovariaten verteilt.
if(!DeConcat(cHistoryInput.getGradient(), acFeatureProjection[0].getGradient(), cEncoderInput.getGradient(), iHistory, iHistory, iVariables)) return false;
Als Nächstes wird der Fehlergradient der globalen Rückkopplungsschicht durch die Ableitung der Aktivierungsfunktion angepasst.
if(cGlobalResidual.Activation() != None) { if(!DeActivation(cGlobalResidual.getOutput(), cGlobalResidual.getGradient(), cGlobalResidual.getGradient(), cGlobalResidual.Activation())) return false; }
Wir senken den Fehlergradienten auf das Niveau der Eingangsdaten.
if(!NeuronOCL.calcHiddenGradients(cGlobalResidual.AsObject())) return false;
Auch hier wird der Fehlergradient des zweiten Datenstroms um die Ableitung der Aktivierungsfunktion der vorherigen Schicht angepasst.
if(NeuronOCL.Activation()!=None) if(!DeActivation(cHistoryInput.getOutput(),cHistoryInput.getGradient(), cHistoryInput.getGradient(),SecondActivation)) return false;
Danach summieren wir die Fehlergradienten aus beiden Datenströmen.
if(!SumAndNormilize(NeuronOCL.getGradient(), cHistoryInput.getGradient(), NeuronOCL.getGradient(), iHistory, false, 0, 0, 0, 1)) return false;
In diesem Stadium haben wir den Fehlergradienten auf die Ebene der historischen Daten der multivariaten Zeitreihen übertragen. Nun müssen wir den Fehlergradienten auf die Kovariaten übertragen.
An dieser Stelle sei darauf hingewiesen, dass dieses Verfahren im Rahmen des von uns durchgeführten Experiments nicht erforderlich ist. Für Kovariaten verwenden wir Zeitstempel-Harmonische, die durch die Formel gegeben sind. Diese Formel wird während des Lernprozesses nicht angepasst. Wir entwickeln jedoch ein Verfahren zur Übertragung des Gradienten auf die Ebene der Kovariaten, um eine „Zukunftssicherheit“ zu gewährleisten. In weiteren Experimenten können wir verschiedene Modelle zum Lernen von Zeitreihenkovariaten ausprobieren.
Wir propagieren also den Fehlergradienten aus den Kovariaten der historischen Daten. Die erhaltenen Werte werden in den Puffer der Kovariatengradienten übertragen.
if(!cFeatureInput.calcHiddenGradients(acFeatureProjection[0].AsObject())) return false; if(!SumAndNormilize(cFeatureInput.getGradient(), cFeatureInput.getGradient(), SecondGradient, iFeatures, false, 0, 0, 0, 0.5f)) return false;
Danach erhalten wir die Gradienten der Kovariaten der vorhergesagten Werte und summieren das Ergebnis der beiden Datenströme.
if(!cFeatureInput.calcHiddenGradients(acFeatureProjection[1].AsObject())) return false; if(!SumAndNormilize(SecondGradient, cFeatureInput.getGradient(), SecondGradient, iFeatures, false, 0, 0, 0, 1.0f)) return false;
Falls erforderlich, passen wir den Fehlergradienten für die Ableitung der Aktivierungsfunktion an.
if(SecondActivation!=None) if(!DeActivation(SecondInput,SecondGradient,SecondGradient,SecondActivation)) return false; //--- return true; }
Der zweite Schritt des Backpropagation-Durchgangs besteht darin, die Trainingsparameter des Modells anzupassen. Diese Funktionalität ist in der Methode CNeuronTiDEOCL::updateInputWeights implementiert. Der Algorithmus der Methode ist recht einfach. Wir rufen einfach die entsprechende Methode aller internen Objekte, die trainierbare Parameter haben, nacheinander auf.
bool CNeuronTiDEOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { //--- if(!cGlobalResidual.UpdateInputWeights(cHistoryInput.AsObject())) return false; if(!acFeatureProjection[0].UpdateInputWeights(cHistoryInput.AsObject())) return false; if(!acFeatureProjection[1].UpdateInputWeights(cFeatureInput.AsObject())) return false; //--- uint total = acEncoderDecoder.Size(); CNeuronBaseOCL *prev = cEncoderInput.AsObject(); for(uint i = 0; i < total; i++) { if(!acEncoderDecoder[i].UpdateInputWeights(prev)) return false; prev = acEncoderDecoder[i].AsObject(); } //--- if(!cTemporalDecoder.UpdateInputWeights(cTemporalDecoderInput.AsObject())) return false; //--- return true; }
Ich möchte noch ein paar Worte zu den Dateiverarbeitungsmethoden sagen. Um Speicherplatz zu sparen, speichern wir nur Schlüsselkonstanten und Objekte mit trainierbaren Parametern.
bool CNeuronTiDEOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; //--- if(FileWriteInteger(file_handle, (int)iHistory, INT_VALUE) < INT_VALUE) return false; if(FileWriteInteger(file_handle, (int)iForecast, INT_VALUE) < INT_VALUE) return false; if(FileWriteInteger(file_handle, (int)iVariables, INT_VALUE) < INT_VALUE) return false; if(FileWriteInteger(file_handle, (int)iFeatures, INT_VALUE) < INT_VALUE) return false; //--- uint total = acEncoderDecoder.Size(); if(FileWriteInteger(file_handle, (int)total, INT_VALUE) < INT_VALUE) return false; for(uint i = 0; i < total; i++) if(!acEncoderDecoder[i].Save(file_handle)) return false; if(!cGlobalResidual.Save(file_handle)) return false; for(int i = 0; i < 2; i++) if(!acFeatureProjection[i].Save(file_handle)) return false; if(!cTemporalDecoder.Save(file_handle)) return false; //--- return true; }
Dies führt jedoch zu einer gewissen Komplikation im Algorithmus der Datenlademethode CNeuronTiDEOCL::Load. Wie zuvor erhält die Methode als Parameter ein Dateihandle zum Laden von Daten. Zuerst laden wir die Daten des übergeordneten Objekts.
bool CNeuronTiDEOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
Dann lesen wir die Werte der Schlüsselkonstanten ab.
if(FileIsEnding(file_handle)) return false; iHistory = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false; iForecast = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false; iVariables = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false; iFeatures = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false;
Als Nächstes müssen wir die Daten aus dem Dense-Encoder- und Decoder-Block laden. Hier begegnet uns die erste Nuance. Wir lesen die Blockstapelgröße aus der Datendatei. Sie kann entweder größer oder kleiner als die aktuelle Größe des Arrays acEncoderDecoder sein. Falls erforderlich, passen wir die Größe des Arrays an.
int total = FileReadInteger(file_handle); int prev_size = (int)acEncoderDecoder.Size(); if(prev_size != total) if(ArrayResize(acEncoderDecoder, total) < total) return false;
Als Nächstes führen wir eine Schleife aus und lesen die Blockdaten aus der Datei. Bevor wir jedoch die Methode zum Laden der Daten der hinzugefügten Array-Elemente aufrufen, müssen wir sie initialisieren. Dies gilt nicht für zuvor erstellte Objekte, da diese in früheren Schritten initialisiert wurden.
for(int i = 0; i < total; i++) { if(i >= prev_size) if(!acEncoderDecoder[i].Init(0, i + 2, OpenCL, 1, 1, 1, ADAM, 1)) return false; if(!LoadInsideLayer(file_handle, acEncoderDecoder[i].AsObject())) return false; }
Als Nächstes laden wir die Objekte globales Residuum, Kovariantenprojektion und temporaler Decoder. Hier ist alles ganz einfach.
if(!LoadInsideLayer(file_handle, cGlobalResidual.AsObject())) return false; for(int i = 0; i < 2; i++) if(!LoadInsideLayer(file_handle, acFeatureProjection[i].AsObject())) return false; if(!LoadInsideLayer(file_handle, cTemporalDecoder.AsObject())) return false;
Zu diesem Zeitpunkt haben wir alle gespeicherten Daten geladen. Aber wir haben noch Hilfsobjekte, die wir ähnlich wie den Klasseninitialisierungsalgorithmus initialisieren.
if(!cHistoryInput.Init(0, total + 5, OpenCL, iHistory * iVariables, optimization, iBatch)) return false; if(!cFeatureInput.Init(0, total + 6, OpenCL, iFeatures, optimization, iBatch)) return false; if(!cEncoderInput.Init(0, total + 7, OpenCL, 2 * iHistory * iVariables, optimization,iBatch)) return false; if(!cTemporalDecoderInput.Init(0, total + 8, OpenCL, 2 * iForecast * iVariables,optimization, iBatch)) return false;
Gegebenenfalls tauschen wir die Datenpuffer aus.
if(cGlobalResidual.getGradient() != Gradient) if(!cGlobalResidual.SetGradient(Gradient)) return false; if(cTemporalDecoder.getGradient() != getGradient()) if(!cTemporalDecoder.SetGradient(Gradient)) return false; //--- return true; }
Der vollständige Code aller Methoden dieser neuen Klasse ist in der Anlage unten zu finden. Dort finden Sie auch Hilfsmethoden der Klasse, die in diesem Artikel nicht behandelt wurden. Ihr Algorithmus ist recht einfach, sodass Sie sie selbst studieren können. Betrachten wir nun die Architektur des Modelltrainings.
2.2 Modellarchitektur für das Training
Wie Sie vielleicht schon vermutet haben, wurde die neue TiDE-Methodenklasse zur Architektur des Environmental State Encoder hinzugefügt. Wir haben dasselbe für alle zuvor betrachteten Algorithmen getan, die zukünftige Zustände einer Zeitreihe vorhersagen. Wie Sie sich erinnern, beschreiben wir die Encoder-Architektur in der Methode CreateEncoderDescriptions. In den Methodenparametern erhalten wir einen Zeiger auf ein dynamisches Array-Objekt zum Schreiben der Architektur des zu erstellenden Modells.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Im Hauptteil der Methode wird der empfangene Zeiger überprüft und gegebenenfalls eine neue Instanz des dynamischen Array-Objekts erstellt.
Wir füttern das Modell mit historischen Rohdaten, die wir vom Terminal erhalten.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die Daten werden in der Batch-Normalisierungsschicht vorverarbeitet, wo sie in eine vergleichbare Form gebracht werden.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Beim Sammeln historischer Daten, die den Zustand der Umwelt beschreiben, bilden wir Daten im Kontext von Kerzenständern. Der Algorithmus der TiDE-Methode impliziert die Analyse von Daten im Zusammenhang mit unabhängigen Kanälen einzelner Merkmale. Um die Möglichkeit zu erhalten, bereits gesammelte Erfahrungswerte für das Training eines neuen Modells zu verwenden, haben wir den Datenerfassungsblock nicht umgestaltet. Stattdessen fügen wir eine Datentranspositionsschicht hinzu, die die Eingabedaten in die gewünschte Form umwandelt.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes kommt unsere neue Schicht, in der die Methode von TiDE implementiert ist.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTiDEOCL;
Die Anzahl der unabhängigen Kanäle in der Analyse ist gleich der Größe des Vektors, der eine Kerze des Umweltzustands beschreibt.
descr.count = BarDescr;
Die Tiefe der analysierten Historie und der Prognosehorizont werden durch die entsprechenden Konstanten bestimmt.
descr.window = HistoryBars; descr.window_out = NForecast;
Unser Zeitstempel wird als Vektor mit 4 Harmonischen dargestellt: als Jahr, Monat, Woche und Tag.
descr.step = 4;
Die Architektur des Dense-Encoder-Decoder-Blocks wird als Array von Werten angegeben, wie bei der Konstruktion der Klasse erläutert.
{
int windows[]={HistoryBars,2*EmbeddingSize,EmbeddingSize,2*EmbeddingSize,NForecast};
if(ArrayCopy(descr.windows,windows)<=0)
return false;
}
Alle Aktivierungsfunktionen werden in den internen Objekten der Klasse angegeben, sodass wir sie hier nicht aufführen.
descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Beachten Sie, dass die Daten innerhalb der CNeuronTiDEOCL-Schicht mehrfach normalisiert werden. Um die Verzerrung der vorhergesagten Werte zu korrigieren, wird eine Faltungsschicht ohne Aktivierungsfunktion verwendet, die eine einfache lineare Verzerrungsfunktion innerhalb unabhängiger Kanäle ausführt.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = NForecast; descr.step = NForecast; descr.window_out = NForecast; descr.activation=None; if(!encoder.Add(descr)) { delete descr; return false; }
Anschließend transponieren wir die vorhergesagten Werte in die Dimension der Eingabedatendarstellung.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Gibt die statistischen Variablen der Verteilung der Eingabedaten zurück.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr*NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Aufgrund der Änderung der Architektur des Environmental State Encoders sind 2 Punkte zu beachten. Der erste ist ein Zeiger auf die verborgene Zustands-Extraktionsschicht der vorhergesagten Werte der Umgebung.
#define LatentLayer 4
Der zweite ist die Größe dieses verborgenen Zustands. Im vorigen Artikel war die Ausgabe des State Encoders eine Beschreibung der historischen Daten und der vorhergesagten Werte. Dieses Mal haben wir nur vorhergesagte Werte. Daher müssen wir die Architekturen der Modelle Actor und Critic entsprechend anpassen.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- ........ ........ //--- Actor ........ ........ //--- layer 2-12 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } } ........ ........ //--- Critic ........ ........ //--- layer 2-12 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } } ........ ........ //--- return true; }
Bitte beachten Sie, dass wir in dieser Implementierung weiterhin die Transformer-Algorithmen in den Modellen Actor und Critic verwenden. Wir führen auch eine Querbeobachtung unabhängiger Kanäle für Prognosewerte durch. Sie können jedoch auch damit experimentieren, die Kreuz-Aufmerksamkeit auf vorhergesagte Werte im Zusammenhang mit Kerzen anzuwenden. Wenn Sie sich dafür entscheiden, vergessen Sie nicht, den Zeiger auf die verborgene Zustandsschicht des Encoders sowie die Anzahl der analysierten Objekte und die Größe des Beschreibungsfensters für ein Objekt zu ändern.
2.3 State Encoder Learning Advisor
Die nächste Phase besteht darin, die Modelle zu trainieren. Hier sind einige Verbesserungen im Algorithmus der Modelltraining EAs erforderlich. Dies betrifft vor allem die Arbeit mit dem Environmental State Encoder-Modell. Denn die neue Klasse wurde in dieses Modell aufgenommen. In diesem Artikel werde ich die Methoden des Modelltrainings EA „...\Experts\TiDE\StudyEncoder.mq5“ nicht näher erläutern. Konzentrieren wir uns nur auf die Modelltrainingsmethode „Train“.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Der Beginn der Methode folgt dem in früheren Artikeln besprochenen Algorithmus. Sie enthält vorbereitende Arbeiten.
Es folgt eine Modelltrainingsschleife. Im Hauptteil der Schleife werden die Trajektorie und der Zustand des Erfahrungswiedergabepuffers abgetastet.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
Wie zuvor laden wir historische Daten, die den Zustand der Umwelt beschreiben.
bState.AssignArray(Buffer[tr].States[i].state);
Jetzt brauchen wir aber mehr Kovariatendaten, um Vorhersagewerte zu generieren. Bei der Erstellung des Modells haben wir uns für die Verwendung der Harmonischen der Zeitstempel des Umweltzustands entschieden. Hoffen wir, dass das Modell seine Projektion auf historische und vorhergesagte Werte lernt.
Bereiten wir einen Puffer der Harmonischen der Zeitstempel vor.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Und nun können wir die Methode des Vorwärtsdurchgangs des Environment State Encoders aufrufen.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Als Nächstes bereiten wir, wie zuvor, die Zielwerte vor.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
Dann rufen wir die Backpropagation-Methode des Encoders auf.
if(!Encoder.backProp(Result, GetPointer(bTime), GetPointer(bTimeGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
An dieser Stelle sei darauf hingewiesen, dass in den Parametern der Backpropagation-Methode neben den Zielwerten auch Zeiger auf die Puffer der Zeitstempel-Harmonischen und deren Fehlergradienten angegeben werden. Auf den ersten Blick verwenden wir keine Fehlergradienten und könnten anstelle von Gradienten einen Puffer der Harmonischen selbst verwenden. Denn wir verwenden die Gradienten der harmonischen Fehler in der weiteren Arbeit nicht. Auch die Harmonischen selbst werden bei der nächsten Iteration umgeschrieben. Warum also einen zusätzlichen Puffer im Speicher anlegen?
Aber ich möchte Sie vor diesem überstürzten Schritt warnen. Nach der Ausbreitung des Fehlergradienten passen wir die Modellparameter an. Zur Anpassung der Gewichte verwendet jede Schicht den Fehlergradienten am Ausgang der Schicht und die Eingabedaten. Wenn wir also die Zeitstempel-Harmonischen mit Fehlergradienten überschreiben, erhalten wir bei der Aktualisierung der Projektionsparameter auf die Kovariaten der historischen Daten und der vorhergesagten Zustände verzerrte Gewichtsgradienten. Die Folge ist eine verzerrte Anpassung der Modellparameter. In diesem Fall wird das Modelltraining in eine unvorhersehbare Richtung gehen.
Nachdem die Vorwärts- und Rückwärtspassoperationen des Encoders erfolgreich abgeschlossen wurden, informieren wir den Nutzer über den Trainingsfortschritt und gehen zur nächsten Iteration der Trainingsschleife über.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Der Modellbildungsprozess wird so lange wiederholt, bis eine bestimmte Anzahl von Schleifeniterationen abgeschlossen ist. Diese Zahl wird in den externen Parametern der Schleife angegeben. Nach Abschluss der Training wird das Kommentarfeld in der Symboltabelle gelöscht.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Wir geben Informationen über die Trainingsergebnisse in das Terminalprotokoll aus und leiten die Beendigung von EA ein.
Die entsprechenden Änderungen werden auch in dem Model des Training EAs von Akteur (Actor) and Kritiker (Critic) „...\Experts\TiDE\Study.mq5“ vorgenommen. Wir werden jetzt aber nicht im Detail auf ihre Beschreibung eingehen. Anhand der obigen Beschreibung können Sie ähnliche Blöcke im EA-Code leicht finden. Der vollständige Code des EAs befindet sich im Anhang. Der Anhang enthält auch EAs für die Interaktion mit der Umwelt und die Sammlung von Trainingsdaten, die ähnliche Bearbeitungen enthalten.
3. Tests
Wir haben eine neue Methode zur Vorhersage von Zeitreihen kennengelernt: Time-series Dense Encoder (TiDE). Wir haben unsere Vision der vorgeschlagenen Ansätze mit MQL5 umgesetzt.
Wie bereits erwähnt, haben wir die Struktur der Eingabedaten aus früheren Modellen beibehalten, sodass wir die zuvor gesammelten Daten zum Trainieren neuer Modelle verwenden können.
Ich möchte Sie daran erinnern, dass alle Modelle mit historischen Daten des EURUSD-Symbols im H1-Zeitrahmen trainiert werden. Mit der Zeit ändert sich auch der Zeitraum für unsere EAs. Im Moment verwende ich echte historische Daten aus dem Jahr 2023, um meine Modelle zu trainieren. Die trainierten Modelle werden dann im MetaTrader 5 Strategie-Tester mit Daten vom Januar 2024 getestet. Die Testphase schließt sich an die Trainingsperiode an, um die Leistung des Modells anhand neuer Daten zu bewerten, die nicht im Trainingsdatensatz enthalten sind. Gleichzeitig wollen wir sehr ähnliche Bedingungen für den Betrieb des Modells schaffen, wenn es in Echtzeit auf neu eintreffenden Daten läuft, die zum Zeitpunkt des Modelltrainings physikalisch unbekannt sind.
Wie in einer Reihe von früheren Artikeln ist das Modell des Environment State Encoder unabhängig vom Kontostand und den offenen Positionen. Daher können wir das Modell sogar auf einer Trainingsstichprobe mit einem Durchgang der Interaktion mit der Umgebung trainieren, bis wir die gewünschte Genauigkeit der Vorhersage zukünftiger Zustände erreichen. Natürlich darf die „gewünschte Vorhersagegenauigkeit“ die Möglichkeiten des Modells nicht überschreiten. Keiner kann über seinen Schatten springen.
Nach dem Training des Modells zur Vorhersage von Umweltzuständen gehen wir zur zweiten Stufe über – dem Training der Verhaltenspolitik des Akteurs. In diesem Schritt trainieren wir iterativ die Modelle des Akteurs (Actor) und des Kritikers (Critic) und aktualisieren den Erfahrungswiedergabepuffer in bestimmten Zeiträumen.
Unter der Aktualisierung des Erfahrungswiedergabepuffers verstehen wir eine zusätzliche Sammlung der Umweltinteraktionserfahrung unter Berücksichtigung der aktuellen Verhaltenspolitik des Akteurs. Denn das von uns untersuchte Finanzmarktumfeld ist sehr vielschichtig. Wir können also nicht alle ihre Erscheinungsformen im Erfahrungswiedergabepuffer vollständig sammeln. Wir erfassen nur ein kleines Umfeld der aktuellen politischen Maßnahmen des Akteurs. Durch die Analyse dieser Daten machen wir einen kleinen Schritt zur Optimierung der Verhaltenspolitik unseres Akteurs. Wenn wir uns den Grenzen dieses Segments nähern, müssen wir zusätzliche Daten sammeln, indem wir den sichtbaren Bereich etwas über die aktualisierte Akteurspolitik hinaus erweitern.
Als Ergebnis dieser Iterationen habe ich eine Akteurspolitik trainiert, die in der Lage ist, sowohl in den Trainings- als auch in den Testdatensätzen Gewinne zu erzielen.


Im obigen Diagramm sehen wir einen Verlusthandel zu Beginn, der dann in einen klaren Gewinntrend übergeht. Der Anteil der Handelsgeschäfte mit Gewinn liegt bei unter 40 %. Auf 1 Handelsgeschäft mit Gewinn kommen fast 2 mit Verlust. Wir stellen jedoch fest, dass die unrentablen Handelsgeschäfte deutlich kleiner sind als die mit Gewinn. Der Durchschnitt der Handelsgeschäfte mit Gewinn ist fast 2-mal größer als der mit Verlust. All dies ermöglicht es dem Modell, während des Testzeitraums einen Gewinn zu erwirtschaften. Aus den Testergebnissen ergab sich ein Gewinnfaktor von 1,23.
Schlussfolgerung
In diesem Artikel haben wir das ursprüngliche TiDE-Modell (Time-series Dense Encoder) kennengelernt, das für die Langzeitprognose von Zeitreihen entwickelt wurde. Dieses Modell unterscheidet sich von klassischen linearen Modellen und Transformer, da es mehrschichtige Perceptrons (MLP) sowohl für die Kodierung vergangener Daten und Kovariaten als auch für die Dekodierung zukünftiger Vorhersagen verwendet.
Die von den Autoren der Methode durchgeführten Experimente zeigen, dass die Verwendung von MLP-Modellen ein großes Potenzial für die Lösung von Problemen der Zeitreihenanalyse und -prognose hat. Außerdem hat TiDE im Gegensatz zu Transformer eine lineare Berechnungskomplexität, was es bei der Arbeit mit großen Datenmengen effizienter macht.
Im praktischen Teil dieses Artikels haben wir unsere Vision der vorgeschlagenen Ansätze umgesetzt, die sich leicht von der ursprünglichen unterscheidet. Die erzielten Ergebnisse belegen jedoch, dass der vorgeschlagene Ansatz recht effizient sein kann. Außerdem ist der Prozess der Modellbildung viel schneller als bei den bereits erwähnten Transformer.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA-Beispielsammlung |
| 2 | ResearchRealORL.mq5 | EA | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | EA | Trainings-EA des Modells |
| 4 | StudyEncoder.mq5 | EA | Encode Training EA |
| 5 | Test.mq5 | EA | Modeltest-EA |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14812
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.