
Entwicklung eines Expertenberaters für mehrere Währungen (Teil 9): Sammeln von Optimierungsergebnissen für einzelne Handelsstrategie-Instanzen
Einführung
In den vorangegangenen Artikeln haben wir bereits eine Menge interessanter Dinge umgesetzt. Wir haben eine Handelsstrategie oder mehrere Handelsstrategien, die wir in den EA implementieren können. Außerdem haben wir eine Struktur für die Verbindung vieler Instanzen von Handelsstrategien in einem einzigen EA entwickelt, Werkzeuge für die Verwaltung des maximal zulässigen Drawdowns hinzugefügt, Möglichkeiten für die automatische Auswahl von Strategieparametersätzen für ihre beste Arbeit in einer Gruppe untersucht und gelernt, wie man einen EA aus Gruppen von Strategieinstanzen und sogar aus Gruppen verschiedener Gruppen von Strategieinstanzen zusammenstellt. Der Wert der bereits erzielten Ergebnisse wird jedoch erheblich steigen, wenn es uns gelingt, sie miteinander zu kombinieren.
Versuchen wir, eine allgemeine Struktur im Rahmen des Artikels zu skizzieren: Einzelne Handelsstrategien werden in den Input eingespeist, während der Output ein fertiger EA ist, der ausgewählte und gruppierte Kopien der ursprünglichen Handelsstrategien verwendet, die die besten Handelsergebnisse liefern.
Nachdem wir einen groben Fahrplan erstellt haben, wollen wir uns einige Abschnitte davon genauer ansehen, analysieren, was wir für die Umsetzung der ausgewählten Etappe benötigen, und uns dann an die eigentliche Umsetzung machen.
Wichtigste Etappen
Lassen Sie uns die wichtigsten Phasen auflisten, die wir bei der Entwicklung des EA durchlaufen müssen:
- Umsetzung einer Handelsstrategie. Wir entwickeln die von CVirtualStrategy abgeleitete Klasse, die die Handelslogik der Eröffnung, Aufrechterhaltung und Schließung virtueller Positionen und Aufträge implementiert. Das haben wir in den ersten vier Teilen der Serie getan.
- Optimierung der Handelsstrategie. Wir wählen gute Inputs für eine Handelsstrategie aus, die bemerkenswerte Ergebnisse zeigen. Wenn keine gefunden werden, kehren wir zu Punkt 1 zurück.
In der Regel ist es für uns bequemer, die Optimierung für ein Symbol und einen Zeitrahmen durchzuführen. Bei der genetischen Optimierung müssen wir sie höchstwahrscheinlich mehrmals mit verschiedenen Optimierungskriterien, einschließlich einiger unserer eigenen, durchführen. Eine Brute-Force-Optimierung ist nur bei Strategien mit einer sehr geringen Anzahl von Parametern möglich. Selbst in unserer Modellstrategie ist eine erschöpfende Suche zu aufwendig. Wenn wir also über Optimierung sprechen, sollten wir weitergehen.
Ich werde die genetische Optimierung in den MetaTrader 5 Strategietester einbauen. Der Optimierungsprozess wurde in den Artikeln nicht detailliert beschrieben, da er ziemlich standardisiert ist. - Clustering von Gruppen. Dieser Schritt ist nicht zwingend erforderlich, spart aber Zeit für den nächsten Schritt. Hier reduzieren wir die Anzahl der Parametersätze von Handelsstrategie-Instanzen erheblich, aus denen wir geeignete Gruppen auswählen. Dies wird im sechsten Teil beschrieben.
- Auswahl von Gruppen von Parametersätzen. Wir führen auf der Grundlage der Ergebnisse der vorangegangenen Phase eine Optimierung durch, bei der wir
die am besten kompatiblen Parametersätze der Handelsstrategie-Instanzen auswählen, die die besten Ergebnisse liefern. Auch dies wird hauptsächlich im sechsten und siebten Teil beschrieben. - Auswahl von Gruppen aus Gruppen von Parametersätzen. Wir kombinieren nun die Ergebnisse der vorangegangenen Stufe in Gruppen nach dem gleichen Prinzip wie bei der Kombination der Sätze von Einzelinstanzparametern.
- Iteration durch Symbole und Zeitrahmen. Wir wiederholen die Schritte 2 - 5 für alle gewünschten Symbole und Zeitrahmen. Vielleicht ist es möglich, zusätzlich zu einem Symbol und einem Zeitrahmen eine separate Optimierung für bestimmte Klassen anderer Inputs für einige Handelsstrategien durchzuführen.
- Andere Strategien. Wenn Sie andere Handelsstrategien im Sinn haben, wiederholen Sie die Schritte 1 bis 6 für jede dieser Strategien.
- Zusammenbau des EA. Wir fassen alle besten Gruppen, die für verschiedene Handelsstrategien, Symbole, Zeitrahmen und andere Parameter gefunden wurden, in einem endgültigen EA zusammen.
Jede Stufe erzeugt nach Abschluss einige Daten, die gespeichert und in den nächsten Stufen verwendet werden müssen. Bisher haben wir provisorische, improvisierte Mittel verwendet, die bequem genug sind, um sie ein- oder zweimal zu nutzen, aber nicht besonders bequem für den wiederholten Gebrauch.
Zum Beispiel haben wir die Optimierungsergebnisse nach der zweiten Stufe in einer Excel-Datei gespeichert, dann die fehlenden Spalten manuell ergänzt und sie dann, nachdem wir sie als CSV-Datei gespeichert hatten, in der dritten Stufe verwendet.
Die Ergebnisse der dritten Stufe haben wir entweder direkt aus der Oberfläche des Strategietesters übernommen oder sie noch einmal in Excel-Dateien gespeichert, dort weiterverarbeitet und dann wieder die Ergebnisse aus der Tester-Interface verwendet.
Wir haben die fünfte Stufe nicht tatsächlich durchgeführt, sondern nur die Möglichkeit ihrer Durchführung vermerkt. Deshalb kam es nie zur Verwirklichung.
Für all diese empfangenen Daten möchten wir eine einzige Speicher- und Verwendungsstruktur einrichten.
Optionen für die Umsetzung
Die wichtigsten Daten, die wir speichern und verwenden müssen, sind die Optimierungsergebnisse mehrerer EAs. Wie Sie wissen, zeichnet der Strategietester alle Optimierungsergebnisse in einer separaten Cache-Datei mit der Endung *.opt auf, die dann im Tester oder sogar im Tester eines anderen MetaTrader 5 Terminals wieder geöffnet werden kann. Der Dateiname wird aus dem Hash ermittelt, der aus dem Namen des optimierten EA und den Optimierungsparametern berechnet wird. Auf diese Weise gehen keine Informationen über die bereits erfolgten Durchgänge (passes) verloren, wenn die Optimierung nach einer vorzeitigen Unterbrechung oder nach einer Änderung des Optimierungskriteriums fortgesetzt wird.
Daher ist eine der in Betracht gezogenen Optionen die Verwendung von Optimierungs-Cache-Dateien zur Speicherung von Zwischenergebnissen. Es gibt eine gute Bibliothek von fxsaber, die es uns ermöglicht, auf alle gespeicherten Informationen von MQL5-Programmen zuzugreifen.
Mit zunehmender Anzahl der durchgeführten Optimierungen steigt jedoch auch die Anzahl der Dateien mit ihren Ergebnissen. Um nicht durcheinander zu kommen, müssen wir uns eine zusätzliche Struktur für die Speicherung und die Arbeit mit diesen Cache-Dateien einfallen lassen. Wenn die Optimierung nicht auf einem Server durchgeführt wird, ist eine Synchronisierung oder Speicherung aller Cache-Dateien an einem Ort erforderlich. Darüber hinaus benötigen wir für die nächste Stufe noch einige Verarbeitungsschritte, um die erzielten Optimierungsergebnisse in den EA der nächsten Stufe zu exportieren.
Dann wollen wir uns die Speicherung aller Ergebnisse in der Datenbank ansehen. Auf den ersten Blick würde die Umsetzung dieses Vorhabens viel Zeit in Anspruch nehmen. Diese Arbeit kann jedoch in kleinere Schritte unterteilt werden, und wir können die Ergebnisse sofort nutzen, ohne auf die vollständige Umsetzung zu warten. Dieser Ansatz ermöglicht auch eine größere Freiheit bei der Wahl des geeignetsten Mittels zur Zwischenverarbeitung der gespeicherten Ergebnisse. Zum Beispiel können wir einen Teil der Verarbeitung einfachen SQL-Abfragen zuweisen, etwas wird in MQL5 berechnet, und etwas in Python- oder R-Programmen. Wir können verschiedene Verarbeitungsmöglichkeiten ausprobieren und die am besten geeignete auswählen.
MQL5 bietet integrierte Funktionen für die Arbeit mit der SQLite-Datenbank. Es gab auch Implementierungen von Bibliotheken von Drittanbietern, die z. B. die Arbeit mit MySQL ermöglichen. Es ist noch nicht klar, ob die Fähigkeiten von SQLite für uns ausreichen werden, aber höchstwahrscheinlich wird diese Datenbank für unsere Bedürfnisse ausreichend sein. Wenn dies nicht ausreicht, werden wir über eine Migration zu einem anderen DBMS nachdenken.
Beginnen wir mit dem Entwurf der Datenbank
Zunächst müssen wir die Entitäten identifizieren, deren Informationen wir speichern wollen. Ein Testlauf ist natürlich einer davon. Die Felder dieser Entität umfassen Testeingabedatenfelder und Testergebnisfelder. Im Allgemeinen können sie als separate Einheiten unterschieden werden. Das Wesentliche der Eingabedaten kann in noch kleinere Einheiten zerlegt werden: den EA, die Optimierungseinstellungen und die EA-Single-Pass-Parameter. Doch lassen wir uns weiterhin vom Grundsatz des geringsten Aufwands leiten. Für den Anfang reicht eine Tabelle mit Feldern für die Durchgangs-Ergebnisse, wie wir sie in früheren Artikeln verwendet haben, und ein oder zwei Textfelder, in denen die notwendigen Informationen über die Durchgangs-Inputs untergebracht werden.
Eine solche Tabelle kann mit der folgenden SQL-Abfrage erstellt werden:
CREATE TABLE passes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
pass INT, -- pass index
inputs TEXT, -- pass input values
params TEXT, -- additional pass data
initial_deposit REAL, -- pass results...
withdrawal REAL,
profit REAL,
gross_profit REAL,
gross_loss REAL,
max_profittrade REAL,
max_losstrade REAL,
conprofitmax REAL,
conprofitmax_trades REAL,
max_conwins REAL,
max_conprofit_trades REAL,
conlossmax REAL,
conlossmax_trades REAL,
max_conlosses REAL,
max_conloss_trades REAL,
balancemin REAL,
balance_dd REAL,
balancedd_percent REAL,
balance_ddrel_percent REAL,
balance_dd_relative REAL,
equitymin REAL,
equity_dd REAL,
equitydd_percent REAL,
equity_ddrel_percent REAL,
equity_dd_relative REAL,
expected_payoff REAL,
profit_factor REAL,
recovery_factor REAL,
sharpe_ratio REAL,
min_marginlevel REAL,
deals REAL,
trades REAL,
profit_trades REAL,
loss_trades REAL,
short_trades REAL,
long_trades REAL,
profit_shorttrades REAL,
profit_longtrades REAL,
profittrades_avgcon REAL,
losstrades_avgcon REAL,
complex_criterion REAL,
custom_ontester REAL,
pass_date DATETIME DEFAULT (datetime('now') )
NOT NULL
);
Erstellen wir die Hilfsklasse CDatabase, die Methoden für die Arbeit mit der Datenbank enthalten wird. Wir können es statisch machen, denn wir brauchen nicht viele Instanzen in einem Programm, eine einzige reicht aus. Da wir derzeit planen, alle Informationen in einer Datenbank zu sammeln, können wir den Namen der Datenbankdatei im Quellcode fest vorgeben.
Diese Klasse enthält das Feld s_db zum Speichern des offenen Datenbank-Handles. Die Methode Open() zum Öffnen der Datenbank setzt diesen Wert. Wenn die Datenbank zum Zeitpunkt des Öffnens noch nicht erstellt wurde, wird sie durch Aufruf der Methode Create() erstellt. Nach dem Öffnen können wir einzelne SQL-Abfragen an die Datenbank mit der Methode Execute() oder Massen-SQL-Abfragen in einer einzigen Transaktion mit der Methode ExecuteTransaction() ausführen. Zum Schluss schließen wir die Datenbank mit der Methode Close().
Wir können auch ein kurzes Makro deklarieren, das es uns ermöglicht, den langen Klassennamen CDatabase durch den kürzeren DB zu ersetzen.
#define DB CDatabase //+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { static int s_db; // DB connection handle static string s_fileName; // DB file name public: static bool IsOpen(); // Is the DB open? static void Create(); // Create an empty DB static void Open(); // Opening DB static void Close(); // Closing DB // Execute one query to the DB static bool Execute(string &query); // Execute multiple DB queries in one transaction static bool ExecuteTransaction(string &queries[]); }; int CDatabase::s_db = INVALID_HANDLE; string CDatabase::s_fileName = "database.sqlite";
Bei der Methode zur Erstellung der Datenbank erstellen wir einfach ein Array mit SQL-Abfragen zur Erstellung von Tabellen und führen sie in einer Transaktion aus:
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create() { // Array of DB creation requests string queries[] = { "DROP TABLE IF EXISTS passes;", "CREATE TABLE passes (" "id INTEGER PRIMARY KEY AUTOINCREMENT," "pass INT," "inputs TEXT," "params TEXT," "initial_deposit REAL," "withdrawal REAL," "profit REAL," "gross_profit REAL," "gross_loss REAL," ... "pass_date DATETIME DEFAULT (datetime('now') ) NOT NULL" ");" , }; // Execute all requests ExecuteTransaction(queries); }
Die Methode zum Öffnen der Datenbank „open“ versucht zunächst, eine vorhandene Datenbankdatei zu öffnen. Wenn sie nicht vorhanden ist, wird sie erstellt und geöffnet. Danach wird die Datenbankstruktur durch Aufruf der Methode Create() erstellt:
//+------------------------------------------------------------------+ //| Is the DB open? | //+------------------------------------------------------------------+ bool CDatabase::IsOpen() { return (s_db != INVALID_HANDLE); } ... //+------------------------------------------------------------------+ //| Open DB | //+------------------------------------------------------------------+ void CDatabase::Open() { // Try to open an existing DB file s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_COMMON); // If the DB file is not found, try to create it when opening if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | DATABASE_OPEN_COMMON); // Report an error in case of failure if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s open failed with code %d", s_fileName, GetLastError()); return; } // Create the database structure Create(); } PrintFormat(__FUNCTION__" | Database %s opened successfully", s_fileName); }
Bei der Methode zur Ausführung mehrerer Abfragen durch ExecuteTransaction() erstellen wir eine Transaktion und beginnen mit der Ausführung aller SQL-Abfragen in einer Schleife, eine nach der anderen. Wenn bei der Ausführung der nächsten Anfrage ein Fehler auftritt, unterbrechen wir die Schleife, melden den Fehler und brechen alle vorherigen Anfragen innerhalb dieser Transaktion ab. Wenn keine Fehler auftreten, bestätigen wir die Transaktion:
//+------------------------------------------------------------------+ //| Execute multiple DB queries in one transaction | //+------------------------------------------------------------------+ bool CDatabase::ExecuteTransaction(string &queries[]) { // Open a transaction DatabaseTransactionBegin(s_db); bool res = true; // Send all execution requests FOREACH(queries, { res &= Execute(queries[i]); if(!res) break; }); // If an error occurred in any request, then if(!res) { // Report it PrintFormat(__FUNCTION__" | ERROR: Transaction failed, error code=%d", GetLastError()); // Cancel transaction DatabaseTransactionRollback(s_db); } else { // Otherwise, confirm transaction DatabaseTransactionCommit(s_db); PrintFormat(__FUNCTION__" | Transaction done successfully"); } return res; }
Wir speichern die Änderungen in der Datei Database.mqh des aktuellen Ordners.
Modifizierung des EA zur Erfassung von Optimierungsdaten
Wenn nur Agenten auf dem lokalen Computer im Optimierungsprozess verwendet werden, können wir das Speichern der Durchgangsergebnisse in der Datenbank entweder in OnTester() oder OnDeinit() veranlassen. Bei der Verwendung von Agenten in einem lokalen Netzwerk oder im MQL5-Cloud-Netzwerk wird es sehr schwierig sein, wenn überhaupt, die Ergebnisse zu speichern. Glücklicherweise bietet MQL5 eine großartige Standardmethode, um beliebige Informationen von Testagenten zu erhalten, egal wo sie sich befinden, indem Datenrahmen erstellt, gesendet und empfangen werden.
Dieser Mechanismus ist in der Referenz und im AlgoBook hinreichend detailliert beschrieben. Um sie zu verwenden, müssen wir drei zusätzliche Ereignisbehandlungen zu den optimierten hinzufügen: OnTesterInit(), OnTesterPass() und OnTesterDeinit().
Die Optimierung wird immer von einem MetaTrader 5-Terminal aus gestartet, das wir im Folgenden bedingt als Hauptterminal bezeichnen werden. Wenn ein EA mit solchen Ereignisbehandlungen vom Hauptterminal aus zur Optimierung gestartet wird, wird ein neues Chart im Hauptterminal geöffnet und eine weitere Instanz des EA auf diesem Chart gestartet, bevor die EA-Instanzen an Testagenten verteilt werden, um normale Optimierungsdurchläufe mit verschiedenen Parametersätzen durchzuführen.
Diese Instanz wird in einem speziellen Modus gestartet: Die Standardfunktionen OnInit(), OnTick() und OnDeinit() werden dabei nicht ausgeführt. Stattdessen werden nur diese drei neuen Handler ausgeführt. Dieser Modus hat sogar einen eigenen Namen - der Modus des Sammelns von Daten der Optimierungsergebnisse. Falls erforderlich, können wir in den EA-Funktionen überprüfen, ob der EA in diesem Modus läuft, indem wir die Funktion MQLInfoInteger() wie folgt aufrufen:
// Check if the EA is running in data frame collection mode bool isFrameMode = MQLInfoInteger(MQL_FRAME_MODE);
Wie die Namen schon andeuten, wird OnTesterInit() im Frame-Collection-Modus einmal vor der Optimierung ausgeführt, OnTesterPass() wird jedes Mal ausgeführt, wenn einer der Testagenten seinen Durchlauf beendet hat, während OnTesterDeinit() einmal ausgeführt wird, nachdem alle geplanten Optimierungsdurchläufe abgeschlossen sind oder wenn die Optimierung unterbrochen wird.
Die EA-Instanz, die auf dem Hauptterminalchart im Frame-Sammelmodus gestartet wird, ist für das Sammeln von Datenframes von allen Testagenten zuständig. Datenrahmen („Data frame“) ist nur ein bequemer Name, um den Datenaustausch zwischen Testagenten und dem EA im Hauptterminal zu beschreiben. Er bezeichnet einen Datensatz mit einem Namen und einer numerischen ID, den der Testagent erstellt und nach Abschluss eines einzelnen Optimierungsdurchgangs an das Hauptterminal gesendet hat.
Es ist zu beachten, dass es sinnvoll ist, Datenrahmen nur in den EA-Instanzen zu erstellen, die im normalen Modus auf den Testagenten arbeiten, und Datenrahmen nur in der EA-Instanz im Hauptterminal zu sammeln und zu verarbeiten, die im Rahmensammelmodus arbeitet. Beginnen wir also mit dem Erstellung der „Frames“ bzw. Rahmen.
Wir können die Erstellung von Frames im EA in OnTester() oder in einer beliebigen Funktion oder Methode platzieren, die von OnTester() aus aufgerufen wird. Die Ereignisbehandlung wird nach Abschluss des Durchlaufs gestartet, und wir können in ihm die Werte aller statistischen Merkmale des abgeschlossenen Durchlaufs abrufen und ggf. den Wert des Nutzerkriteriums für die Bewertung der Durchlaufergebnisse berechnen.
Wir haben derzeit den Code, der ein nutzerdefiniertes Kriterium berechnet, das den voraussichtlichen Gewinn anzeigt, der bei einem maximal erreichbaren Drawdown von 10 % erzielt werden könnte:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Recalculate the profit double fittedProfit = profit * coeff; return fittedProfit; }
Verschieben wir diesen Code aus der EA-Datei SimpleVolumesExpertSingle.mq5 in die neue Methodenklasse CVirtualAdvisor, während der EA mit der Rückgabe des Ergebnisses des Methodenaufrufs beschäftigt ist:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { return expert.Tester(); }
Beim Verschieben sollten wir bedenken, dass wir die Variable fixedBalance_ innerhalb der Methode nicht mehr verwenden können, da sie in einem anderen EA möglicherweise nicht mehr vorhanden ist. Sein Wert kann jedoch von der statischen Klasse CMoney durch Aufruf der Methode CMoney::FixedBalance() ermittelt werden. Auf dem Weg dorthin werden wir eine weitere Änderung an der Berechnung unseres Nutzerkriteriums vornehmen. Nachdem wir den voraussichtlichen Gewinn ermittelt haben, berechnen wir ihn pro Zeiteinheit neu, zum Beispiel den Gewinn pro Jahr. Auf diese Weise können wir die Ergebnisse von Durchgängen über unterschiedlich lange Zeiträume grob vergleichen.
Dazu müssen wir uns das Startdatum des Tests im EA merken. Fügen wir die neue Eigenschaft m_fromDate hinzu, die dazu dient, die aktuelle Zeit im Konstruktor des EA-Objekts zu speichern.
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { protected: ... datetime m_fromDate; public: ... virtual double Tester() override; // OnTester event handler ... }; //+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, ~((CVirtualStrategy *) m_strategies[0])); return fittedProfit; }
Später werden wir vielleicht mehrere nutzerdefinierte Optimierungskriterien erstellen, und dann wird dieser Code wieder an eine neue Stelle verschoben werden. Aber lassen wir uns jetzt nicht von dem umfangreichen Thema der Untersuchung verschiedener Fitnessfunktionen zur Optimierung von EAs ablenken und lassen wir den Code so, wie er ist.
Die EA-Datei SimpleVolumesExpertSingle.mq5 erhält nun neue Ereignisbehandlungen durch OnTesterInit(), OnTesterPass() und OnTesterDeinit(). Da die Logik dieser Funktionen nach unserem Plan für alle EAs gleich sein soll, werden wir ihre Implementierung zunächst auf die EA-Ebene (CVirtualAdvisor-Klassenobjekt) herunterschrauben.
Es ist zu beachten, dass die Funktion OnInit(), in der die EA-Instanz erstellt wird, nicht ausgeführt wird, wenn der EA im Hauptterminal im Frame-Sammelmodus gestartet wird. Um die Erstellung/Löschung einer EA-Instanz nicht zu neuen Ereignisbehandlungen hinzuzufügen, sollten die Methoden zur Behandlung dieser Ereignisse in der Klasse CVirtualAdvisor statisch sein. Dann müssen wir den folgenden Code in den EA einfügen:
//+------------------------------------------------------------------+ //| Initialization before starting optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { return CVirtualAdvisor::TesterInit(); } //+------------------------------------------------------------------+ //| Actions after completing the next optimization pass | //+------------------------------------------------------------------+ void OnTesterPass() { CVirtualAdvisor::TesterPass(); } //+------------------------------------------------------------------+ //| Actions after optimization is complete | //+------------------------------------------------------------------+ void OnTesterDeinit(void) { CVirtualAdvisor::TesterDeinit(); }
Eine weitere Änderung, die wir für die Zukunft vornehmen können, ist die Abschaffung des separaten Aufrufs der Methode CVirtualAdvisor::Add() zum Hinzufügen von Handelsstrategien zum EA, nachdem dieser erstellt wurde. Stattdessen werden wir die Informationen über die Strategien sofort an den Konstruktor des EA übertragen, während dieser die Methode Add() selbständig aufruft. Dann kann diese Methode aus dem öffentlichen Teil entfernt werden.
Mit diesem Ansatz sieht die EA-Initialisierungsfunktion OnInit() wie folgt aus:
int OnInit() { CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor( new CSimpleVolumesStrategy( symbol_, timeframe_, signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_, ordersExpiration_, maxCountOfOrders_, 0), // One strategy instance magic_, "SimpleVolumesSingle", true); return(INIT_SUCCEEDED); }
Wir speichern die Änderungen in der Datei SimpleVolumesExpertSingle.mq5 des aktuellen Ordners.
Ändern der EA-Klasse
Um ein Überladen der EA-Klasse CVirtualAdvisor zu vermeiden, verschieben wir den Code der Ereignisbehandler TesterInit, TesterPass und OnTesterDeinit in die separate Klasse CTesterHandler, in der wir statische Methoden zur Behandlung der einzelnen Ereignisse erstellen. In diesem Fall müssen wir der Klasse CVirtualAdvisor ungefähr den gleichen Code wie in der Haupt-EA-Datei hinzufügen:
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { ... public: ... static int TesterInit(); // OnTesterInit event handler static void TesterPass(); // OnTesterDeinit event handler static void TesterDeinit(); // OnTesterDeinit event handler }; //+------------------------------------------------------------------+ //| Initialization before starting optimization | //+------------------------------------------------------------------+ int CVirtualAdvisor::TesterInit() { return CTesterHandler::TesterInit(); } //+------------------------------------------------------------------+ //| Actions after completing the next optimization pass | //+------------------------------------------------------------------+ void CVirtualAdvisor::TesterPass() { CTesterHandler::TesterPass(); } //+------------------------------------------------------------------+ //| Actions after optimization is complete | //+------------------------------------------------------------------+ void CVirtualAdvisor::TesterDeinit() { CTesterHandler::TesterDeinit(); }
Wir lassen uns auch einige Ergänzungen am Code des EA-Objektkonstruktors vornehmen. Verschiebung aller Aktionen aus dem Konstruktor in die neue Initialisierungsmethode Init() mit Blick auf zukünftige Verbesserungen. Dies ermöglicht es uns, mehrere Konstruktoren mit verschiedenen Parametersätzen hinzuzufügen, die alle dieselbe Initialisierungsmethode verwenden, nachdem die Parameter ein wenig vorverarbeitet wurden.
Fügen wir Konstruktoren hinzu, deren erstes Argument entweder ein Strategie-Objekt oder ein Strategie-Gruppen-Objekt sein wird. Dann können wir dem EA direkt im Konstruktor Strategien hinzufügen. In diesem Fall brauchen wir die Methode Add() in der EA-Funktion OnInit() nicht mehr aufzurufen.
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { protected: ... datetime m_fromDate; public: CVirtualAdvisor(CVirtualStrategy *p_strategy, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false); // Constructor CVirtualAdvisor(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false); // Constructor void CVirtualAdvisor::Init(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ); ... }; ... //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(CVirtualStrategy *p_strategy, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ) { CVirtualStrategy *strategies[] = {p_strategy}; Init(new CVirtualStrategyGroup(strategies), p_magic, p_name, p_useOnlyNewBar); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ) { Init(p_group, p_magic, p_name, p_useOnlyNewBar); }; //+------------------------------------------------------------------+ //| EA initialization method | //+------------------------------------------------------------------+ void CVirtualAdvisor::Init(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ) { // Initialize the receiver with a static receiver m_receiver = CVirtualReceiver::Instance(p_magic); // Initialize the interface with the static interface m_interface = CVirtualInterface::Instance(p_magic); m_lastSaveTime = 0; m_useOnlyNewBar = p_useOnlyNewBar; m_name = StringFormat("%s-%d%s.csv", (p_name != "" ? p_name : "Expert"), p_magic, (MQLInfoInteger(MQL_TESTER) ? ".test" : "") ); m_fromDate = TimeCurrent(); Add(p_group); delete p_group; };
Wir speichern die Änderungen in der VirtualExpert.mqh des aktuellen Ordners.
Klasse zur Behandlung von Optimierungsereignissen
Konzentrieren wir uns nun direkt auf die Durchführung von Aktionen, die vor dem Start, nach Abschluss des Durchlaufs und nach Abschluss der Optimierung durchgeführt werden. Wir erstellen die Klasse CTesterHandler und fügen ihr Methoden zur Behandlung der erforderlichen Ereignisse sowie einige Hilfsmethoden hinzu, die im geschlossenen Teil der Klasse untergebracht sind:
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { static string s_fileName; // File name for writing frame data static void ProcessFrames(); // Handle incoming frames static string GetFrameInputs(ulong pass); // Get pass inputs public: static int TesterInit(); // Handle the optimization start in the main terminal static void TesterDeinit(); // Handle the optimization completion in the main terminal static void TesterPass(); // Handle the completion of a pass on an agent in the main terminal static void Tester(const double OnTesterValue, const string params); // Handle completion of tester pass for agent }; string CTesterHandler::s_fileName = "data.bin"; // File name for writing frame data
Die Ereignishandler für das Hauptterminal sehen sehr einfach aus, da wir den Hauptcode in Hilfsfunktionen verschieben werden:
//+------------------------------------------------------------------+ //| Handling the optimization start in the main terminal | //+------------------------------------------------------------------+ int CTesterHandler::TesterInit(void) { // Open / create a database DB::Open(); // If failed to open it, we do not start optimization if(!DB::IsOpen()) { return INIT_FAILED; } // Close a successfully opened database DB::Close(); return INIT_SUCCEEDED; } //+------------------------------------------------------------------+ //| Handling the optimization completion in the main terminal | //+------------------------------------------------------------------+ void CTesterHandler::TesterDeinit(void) { // Handle the latest data frames received from agents ProcessFrames(); // Close the chart with the EA running in frame collection mode ChartClose(); } //+--------------------------------------------------------------------+ //| Handling the completion of a pass on an agent in the main terminal | //+--------------------------------------------------------------------+ void CTesterHandler::TesterPass(void) { // Handle data frames received from the agent ProcessFrames(); }
Die Aktionen, die nach Abschluss eines Durchgangs durchgeführt werden, existieren in zwei Versionen:
- Für das Testmittel. Dort werden nach der Passage die notwendigen Informationen gesammelt und ein Datenrahmen erstellt, der an das Hauptterminal gesendet wird. Diese Aktionen werden in der Ereignishandhabung Tester() gesammelt.
- Für das Hauptterminal. Hier können wir Datenrahmen von Testagenten empfangen, die im Rahmen empfangenen Informationen analysieren und in die Datenbank eingeben. Diese Aktionen werden in der Ereignisbehandlung durch TesterPass() gesammelt.
Die Generierung eines Datenrahmens für den Testagenten sollte im EA erfolgen, und zwar innerhalb von OnTester. Da wir seinen Code auf die EA-Objektebene (in die Klasse CVirtualAdvisor) verschoben haben, müssen wir hier die Methode CTesterHandler::Tester() hinzufügen. Als Methodenparameter übergeben wir den neu berechneten Wert des nutzerdefinierten Optimierungskriteriums und einen String, der die Parameter der Strategie beschreibt, die im optimierten EA verwendet wurde. Um eine solche Zeichenkette zu bilden, werden wir die bereits erstellte ~ (Tilde) für die Objekte der Klasse CVirtualStrategy verwenden.
//+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, ~((CVirtualStrategy *) m_strategies[0])); return fittedProfit; }
In der Methode CTesterHandler::Tester() gehen wir selbst alle möglichen Namen der verfügbaren statistischen Merkmale durch, ermitteln deren Werte, wandeln sie in Strings um und fügen diese Strings dem Array stats hinzu. Warum mussten wir reelle numerische Merkmale in Zeichenketten umwandeln? Nur so konnten sie in einem Rahmen mit einer Stringbeschreibung der Strategieparameter übergeben werden. In einem Frame können wir entweder ein Array von Werten eines der einfachen Typen (Strings gelten nicht) oder eine vorab erstellte Datei mit beliebigen Daten übergeben. Um zu vermeiden, dass zwei verschiedene Frames gesendet werden müssen (einer mit Zahlen, der andere mit Zeichenketten aus einer Datei), werden wir alle Daten in Zeichenketten umwandeln, sie in eine Datei schreiben und deren Inhalt in einem Frame senden:
//+------------------------------------------------------------------+ //| Handling completion of tester pass for agent | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Custom criteria string params // Description of EA parameters in the current pass ) { // Array of names of saved statistical characteristics of the pass ENUM_STATISTICS statNames[] = { STAT_INITIAL_DEPOSIT, STAT_WITHDRAWAL, STAT_PROFIT, ... }; // Array for values of statistical characteristics of the pass as strings string stats[]; ArrayResize(stats, ArraySize(statNames)); // Fill the array of values of statistical characteristics of the pass FOREACH(statNames, stats[i] = DoubleToString(TesterStatistics(statNames[i]), 2)); // Add the custom criterion value to it APPEND(stats, DoubleToString(custom, 2)); // Screen the quotes in the description of parameters just in case StringReplace(params, "'", "\\'"); // Open the file to write data for the frame int f = FileOpen(s_fileName, FILE_WRITE | FILE_TXT | FILE_ANSI); // Write statistical characteristics FOREACH(stats, FileWriteString(f, stats[i] + ",")); // Write a description of the EA parameters FileWriteString(f, StringFormat("'%s'", params)); // Close the file FileClose(f); // Create a frame with data from the recorded file and send it to the main terminal if(!FrameAdd("", 0, 0, s_fileName)) { PrintFormat(__FUNCTION__" | ERROR: Frame add error: %d", GetLastError()); } }
Betrachten wir schließlich eine Hilfsmethode, die Datenrahmen akzeptiert und die Informationen daraus in der Datenbank speichert. Bei dieser Methode erhalten wir in einer Schleife alle eingehenden Bilder, die zum aktuellen Zeitpunkt noch nicht bearbeitet wurden. Von jedem Frame erhalten wir Daten in Form eines Zeichenarrays und wandeln sie in eine Zeichenkette um. Anschließend wird eine Zeichenkette mit den Namen und Werten der Parameter des Durchlaufs mit dem angegebenen Index gebildet. Wir verwenden die erhaltenen Werte, um eine SQL-Abfrage zu erstellen, mit der wir eine neue Zeile in die Tabelle der Durchgänge in unserer Datenbank einfügen. Fügen wir die erstellte SQL-Abfrage zum SQL-Abfrage-Array hinzu.
Nachdem wir alle aktuell empfangenen Datenrahmen auf diese Weise bearbeitet haben, führen wir alle SQL-Abfragen aus dem Array in einer einzigen Transaktion aus.
//+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Open(); // Variables for reading data from frames string name; // Frame name (not used) ulong pass; // Frame pass index long id; // Frame type ID (not used) double value; // Single frame value (not used) uchar data[]; // Frame data array as a character array string values; // Frame data as a string string inputs; // String with names and values of pass parameters string query; // A single SQL query string string queries[]; // SQL queries for adding records to the database // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { // Convert the array of characters read from the frame into a string values = CharArrayToString(data); // Form a string with names and values of the pass parameters inputs = GetFrameInputs(pass); // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %s,\n'%s',\n'%s');", pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); // Close the database DB::Close(); }
Die Hilfsmethode GetFrameInputs() zur Bildung einer Zeichenkette mit den Namen und Werten der Eingabevariablen des Durchlaufs wurde aus dem AlgoBook übernommen und für unsere Bedürfnisse leicht ergänzt.
Wir speichern den erhaltenen Code in der Datei TesterHandler.mqh des aktuellen Ordners.
Operationskontrolle
Um die Funktionsweise zu testen, lassen wir die Optimierung mit einer kleinen Anzahl von Parametern laufen, die über einen relativ kurzen Zeitraum iteriert werden. Nachdem der Optimierungsprozess abgeschlossen ist, können wir die Ergebnisse im Strategietester und in der erstellten Datenbank betrachten.
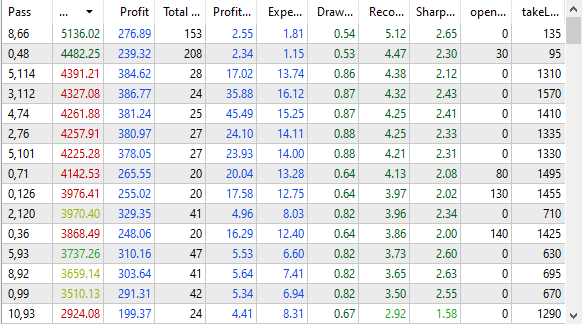
Abb. 1. Optimierungsergebnisse im Strategie-Tester
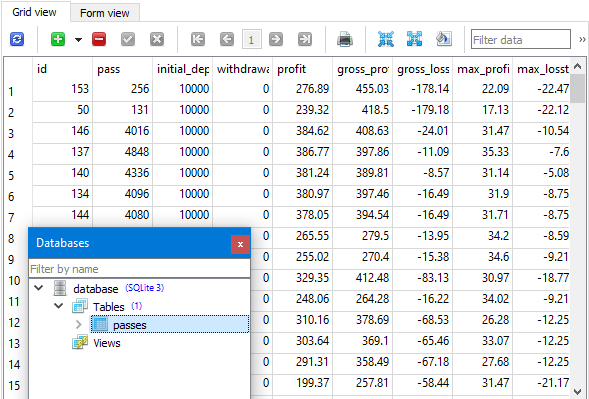
Abb. 2. Optimierungsergebnisse in der Datenbank
Wie wir sehen können, stimmen die Ergebnisse in der Datenbank mit den Ergebnissen im Testgerät überein: Bei gleicher Sortierung nach Nutzerkriterien beobachten wir in beiden Fällen die gleiche Reihenfolge der Gewinnwerte. Der beste Durchgang (pass) zeigt, dass der erwartete Gewinn bei einer Ersteinlage von 10.000 USD und einem maximal erreichbaren Drawdown von 10 % der Ersteinlage (1000 USD) innerhalb eines Jahres 5.000 USD übersteigen kann. Im Moment sind wir jedoch weniger an den quantitativen Eigenschaften der Optimierungsergebnisse interessiert als an der Tatsache, dass sie nun in einer Datenbank gespeichert werden können.
Schlussfolgerung
Wir sind also unserem Ziel einen Schritt näher gekommen. Es ist uns gelungen, die Ergebnisse der durchgeführten Optimierungen der EA-Parameter in unserer Datenbank zu speichern. Auf diese Weise haben wir die Grundlage für die weitere automatisierte Umsetzung der zweiten Stufe der EA-Entwicklung geschaffen.
Hinter den Kulissen sind noch viele Fragen offen. Viele Dinge mussten auf die Zukunft verschoben werden, da ihre Umsetzung mit erheblichen Kosten verbunden wäre. Aber mit den aktuellen Ergebnissen können wir die Richtung der weiteren Projektentwicklung klarer formulieren.
Die implementierte Speicherung funktioniert derzeit nur für einen Optimierungsprozess in dem Sinne, dass wir Informationen über die Durchgänge speichern, aber es ist immer noch schwierig, Gruppen von Zeichenfolgen, die sich auf einen Optimierungsprozess beziehen, daraus zu extrahieren. Zu diesem Zweck müssen wir Änderungen an der Datenbankstruktur vornehmen, was jetzt sehr einfach ist. In Zukunft werden wir versuchen, den Start mehrerer sequenzieller Optimierungsprozesse mit vorheriger Zuweisung verschiedener Optionen für die zu optimierenden Parameter zu automatisieren.
Vielen Dank für Ihre Aufmerksamkeit! Bis bald!
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14680
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.