
Inferência causal em problemas de classificação de séries temporais

Conteúdo do artigo:
- Introdução
- História da inferência causal
- Noções básicas de inferência causal em aprendizado de máquina
- Escada de Evidências na inferência causal
- Notação na inferência causal
- Viés
- Experimentos randomizados
- Correspondência
- Incerteza
- Meta learners
- Um exemplo de construção de um sistema de negociação
No artigo anterior, examinamos minuciosamente o treinamento via meta learner e validação cruzada, bem como a salvaguarda de modelos no formato ONNX. Eu também observei que os modelos de aprendizado de máquina não são capazes de encontrar padrões diretamente em dados díspares e contraditórios. Nesse caso, é muito importante o que exatamente é enviado para a entrada e saída de uma rede neural ou qualquer outro algoritmo de aprendizado de máquina.
Por outro lado, nem sempre podemos preparar os dados de treinamento necessários, cuja estrutura já contém relações causais. Como regra, isso é um conjunto de indicadores e exemplos de cenários de compra e venda. O sinal incremental, zigue-zague ou a posição das médias móveis relativas entre si são frequentemente usados para definir a direção de uma negociação futura. Todos esses tipos de marcações não são especialistas e, como regra, não contêm verdadeiras relações causais.
A marcação de dados é talvez o processo mais caro e que consome mais tempo e recursos no mundo do aprendizado de máquina, pois requer a participação de especialistas na área de estudo (os chamados anotadores). Até mesmo redes neurais poderosas de linguagem, como o GPT e seus análogos, treinadas em grandes quantidades de dados, são capazes apenas de classificar padrões de linguagem que formam um contexto semântico. No entanto, eles não respondem à questão de se alguma declaração particular é realmente verdadeira ou falsa. Equipes de anotadores trabalham com esses modelos, ajustando suas respostas para que se tornem úteis ao usuário final.
Nesse caso, o trader tem uma pergunta razoável: se eu sei como marcar dados, então por que preciso de uma rede neural? Afinal, eu posso simplesmente escrever a lógica baseada no meu conhecimento e usá-la efetivamente. Essa ideia está certa e errada ao mesmo tempo. Está errada no sentido de que a rede neural lida bem com a tarefa de previsão, então é suficiente treiná-la em dados bem marcados e depois receber previsões em novos dados, sem se preocupar em escrever a lógica da estratégia de negociação. Além disso, a funcionalidade embutida permite avaliar a confiabilidade das previsões usando novos dados. E está certa no sentido de que, sem saber o que alimentar na entrada da rede neural ou fornecendo dados incorretamente rotulados como saída, ela não será capaz de criar uma estratégia de negociação lucrativa por padrão.
A compreensão dos problemas acima de aprendizado de máquina não chegou aos comerciantes imediatamente. Inicialmente, até mesmo os criadores dos primeiros algoritmos simples de aprendizado de máquina acreditavam firmemente que o análogo matemático de um neurônio copia o trabalho dos neurônios do cérebro, o que significa que uma rede neural suficientemente grande será capaz de desempenhar totalmente as funções do cérebro e aprender a analisar informações de forma independente. Mais tarde, entendo que o cérebro possui um grande número de departamentos altamente especializados Cada um deles processa certas informações e as transmite para outros departamentos. Foi assim que surgiram as arquiteturas de redes neurais multicamadas, graças às quais os pesquisadores chegaram mais perto de desvendar os mistérios de como o cérebro funciona. Essas arquiteturas aprenderam a processar perfeitamente informações específicas, como dados visuais, de texto, de áudio ou tabulares
Como se descobriu mais tarde, essas redes neurais também não têm a capacidade de tirar conclusões independentes sobre padrões verdadeiros, enquanto envolvidas em aprendizado supervisionado. Elas são propensas ao overtraining e à subjetividade.
O próximo passo no caminho para entender a estrutura e o funcionamento do cérebro foi a descoberta de que as redes neurais naturais são baseadas no aprendizado por reforço, e não apenas no aprendizado a partir de amostras prontas Este é um tipo de aprendizado, no qual um sistema complexo é recompensado por decisões subjetivamente corretas e penalizado por decisões incorretas Após receber tais recompensas várias vezes, dependendo da tarefa em questão, a experiência é acumulada e opções de respostas subjetivamente corretas são aprendidas. O cérebro ou rede neural começa a cometer menos erros em certos casos se já os encontrou antes.
Isso levou ao surgimento do aprendizado por reforço, quando os próprios pesquisadores definiram a função de recompensa (algum tipo de função de aptidão em algoritmos de otimização), recompensando ou punindo a rede neural por respostas corretas ou incorretas. Agora, o algoritmo de aprendizado de máquina não é mais treinado em dados prontos e bem rotulados, mas age por tentativa e erro, tentando maximizar a função de recompensa. Atualmente, há um grande número de algoritmos de aprendizado por reforço para diferentes tarefas, e essa área está se desenvolvendo bastante ativamente.
Isso parecia uma grande descoberta até começar a ser usado, entre outras coisas, para problemas de classificação de séries temporais financeiras Ficou claro que esse aprendizado é muito difícil de controlar, pois agora tudo se resume a definir a função de recompensa correta e escolher a arquitetura da rede. Enfrentamos o mesmo problema trivial: se não conhecemos a verdadeira função objetivo, que descreve as relações causais reais entre os estados do sistema e suas respostas, então é improvável que a encontremos através de inúmeras buscas tanto da própria função objetivo quanto de vários algoritmos de aprendizado por reforço, a menos que tenhamos sorte.
História semelhante aconteceu com modelos generativos que aprendem condicionalmente sem um supervisor. Construídos com base no princípio de um codificador-decodificador ou gerador-discriminador, eles aprendem a compactar informações, destacando características importantes, ou distinguir amostras reais de fictícias (no caso de redes neurais adversárias) e, em seguida, gerar exemplos plausíveis, como imagens. Enquanto tudo é mais ou menos claro com imagens e elas são uma espécie de "nonsense" plausível de uma rede neural, é muito mais complicado com a geração de respostas consistentes precisas. O elemento de aleatoriedade inerente à geração de uma resposta específica não nos permite tirar conclusões inequívocas sobre relações causais, o que não é adequado para uma atividade tão arriscada quanto o comércio, onde o comportamento aleatório do algoritmo é sinônimo de perdas.
O autor do artigo experimentou todos esses algoritmos para problemas de classificação de séries temporais, em particular pares de moedas Forex, e não ficou muito satisfeito com os resultados.
Recentemente, podemos encontrar cada vez mais publicações sobre o tema da chamada aprendizagem de máquina "confiável" ou "digna de confiança". Em geral, o conjunto de abordagens ainda não está totalmente formado e varia de área para área. É importante entender que isso aborda o problema da inferência causal por meio de algoritmos de aprendizado de máquina. Pesquisadores aprenderam a entender e confiar tanto no aprendizado de máquina que estão prontos para confiar a ele a tarefa de buscar relações causais nos dados, o que, claro, leva o aprendizado de máquina a um nível completamente novo. A inferência causal é amplamente utilizada em campos como medicina, econometria e marketing.
Este artigo descreve uma tentativa de entender algumas técnicas de inferência causal em relação ao comércio algorítmico.
História da inferência causal
A causalidade tem uma longa história e foi considerada na maioria, senão em todas, as culturas avançadas conhecidas por nós.
Aristóteles, um dos filósofos mais prolíficos da Grécia antiga, argumentou que entender a estrutura causal de um processo é um componente necessário para conhecer esse processo. Além disso, ele argumentou que a capacidade de responder a perguntas do tipo "por quê" é a essência da explicação científica Aristóteles identifica quatro tipos de causas (material, formal, eficiente e final). Essa ideia pode refletir alguns aspectos interessantes da realidade, embora possa soar contra-intuitiva para uma pessoa moderna.
David Hume, o famoso filósofo escocês do século XVIII, propôs uma estrutura mais unificada para as relações causais. Hume começou argumentando que nunca observamos relações causais no mundo. A única coisa que observamos é que alguns eventos estão conectados entre si: apenas encontramos que um deles realmente segue o outro. O impulso de uma bola de bilhar é acompanhado pelo movimento da segunda. Isso é tudo o que aparece aos sentidos externos. A mente não experimenta sentimentos ou impressões internas dessa sucessão de objetos: portanto, não há nada em cada fenômeno particular que sugira qualquer força ou conexão necessária.
Uma interpretação da teoria da causalidade de Hume é a seguinte:
- Nós apenas observamos como o movimento ou a aparência do objeto A precede o movimento ou a aparência do objeto B.
- Se vemos essa sequência um número suficiente de vezes, desenvolvemos um senso de antecipação.
- Esse sentimento de expectativa é a essência do nosso conceito de causalidade (não se trata do mundo, mas do sentimento que desenvolvemos).
Essa teoria é muito interessante, pelo menos, de dois pontos de vista. Primeiro, elementos dessa teoria são muito semelhantes a uma ideia chamada condicionamento na psicologia. Condicionamento é uma forma de aprendizado. Existem muitos tipos de condicionamento, mas todos se baseiam em uma base comum – associação (daí o nome desse tipo de aprendizado - aprendizado associativo). Em qualquer tipo de condicionamento, pegamos algum evento ou objeto (geralmente chamado de estímulo) e o associamos a um comportamento ou resposta específicos. O aprendizado associativo funciona em diferentes espécies animais. Pode ser encontrado em humanos, macacos, cães e gatos, bem como em organismos muito mais simples, como caracóis.
Em segundo lugar, a maioria dos algoritmos clássicos de aprendizado de máquina também funciona com base em associações. No caso de aprendizado supervisionado, tentamos encontrar uma função que mapeie entradas para saídas. Para fazer isso de forma eficiente, precisamos descobrir quais elementos da entrada são úteis para prever a saída. Na maioria dos casos, a associação é suficiente para esse propósito.
Informações adicionais sobre as possibilidades de estudar relações causais vêm da psicologia infantil.
Alison Gopnik é uma psicóloga infantil americana que estuda como bebês desenvolvem modelos do mundo. Ela também colabora com cientistas da computação para ajudá-los a entender como os bebês humanos constroem conceitos de senso comum sobre o mundo externo. As crianças usam o aprendizado associativo ainda mais do que os adultos, mas também são experimentadores insaciáveis. Você já viu um pai tentando convencer seu filho a parar de jogar brinquedos ao redor? Alguns pais tendem a interpretar esse comportamento como rude, destrutivo ou agressivo, mas as crianças frequentemente têm outros motivos. Elas realizam experimentos sistemáticos que lhes permitem estudar as leis da física e as regras da interação social (Gopnik, 2009). Bebês com apenas 11 meses preferem experimentar com objetos que exibem propriedades imprevisíveis do que com objetos que se comportam de forma previsível (Stahl & Feigenson, 2015). Essa preferência permite que eles construam modelos do mundo de forma eficaz.
O que podemos aprender com os bebês é que não estamos limitados a observar o mundo, como Hume supôs. Também podemos interagir com ele. No contexto da inferência causal, essas interações são chamadas de intervenções. Intervenções estão no centro do que muitos consideram o Santo Graal do método científico: o ensaio controlado randomizado (RCT).
Mas como podemos distinguir uma associação de uma relação causal real? Vamos tentar descobrir.
Noções básicas de inferência causal em aprendizado de máquina
O principal objetivo da inferência causal em aprendizado de máquina é determinar se podemos tomar decisões com base em um algoritmo de aprendizado de máquina treinado. Aqui, não estamos sempre interessados na precisão e frequência das previsões, embora isso também seja importante, mas estamos mais interessados na sua estabilidade e no nosso nível de confiança nelas.
A principal tese da inferência causal é: "Correlação não implica causação". Isso significa que a correlação não prova a influência de um evento sobre outro, mas apenas determina a relação linear desses dois ou mais eventos.
Portanto, uma relação causal é determinada pela influência de uma variável sobre outra. A variável influente é frequentemente chamada de instrumental no caso de intervenção de terceiros, ou simplesmente uma das covariáveis (características no aprendizado de máquina). Ou através de uma ação para outra ação. Em geral, o evento A é sempre seguido pelo evento B? Ou o evento A realmente causa o evento B? É por isso que também é chamado de teste A/B. É exatamente isso que vamos tratar mais adiante, mas usando algoritmos de aprendizado de máquina.
Existem várias abordagens para lidar com a inferência de causalidade, tanto usando experimentos randomizados quanto usando variáveis instrumentais e aprendizado de máquina. Não faz sentido listar todos os métodos aqui, pois outros trabalhos são dedicados a isso. Estamos interessados em como podemos aplicar isso a um problema de classificação de séries temporais.
É importante notar que quase todos esses métodos são baseados no modelo causal de Neumann-Rubin, ou modelos de resultados potenciais. Esta é uma abordagem estatística que ajuda a determinar se um evento é realmente consequência de outro.
Por exemplo, um classificador treinado mostra lucros nas subamostras de treinamento e validação, enquanto seus sinais levam a perdas na subamostra de teste. Para medir o efeito causal em novos dados usando este classificador, precisamos comparar os resultados em novos dados no caso de ele ter sido realmente treinado e no caso de não ter sido treinado. Como é impossível ver os resultados de um classificador não treinado, pois ele não gera nenhum sinal de compra ou venda, esse resultado potencial é desconhecido. Temos apenas o resultado real após treiná-lo, e o resultado desconhecido sem treinamento é contrafactual. Em outras palavras, precisamos descobrir se treinar um classificador leva a lucros aumentados ou a fazer um lucro em novos dados comparado, por exemplo, a abrir negociações aleatoriamente. Ou seja, treinar um classificador tem algum efeito positivo?
Este dilema é um "problema fundamental da inferência causal", quando não sabemos qual seria o resultado real se o classificador não tivesse sido treinado, mas apenas sabemos o resultado real após ele ter sido treinado.
Devido ao problema fundamental da inferência causal, os efeitos causais ao nível da unidade (um único exemplo de treinamento) não podem ser observados diretamente. Não podemos dizer com certeza se nossas previsões melhoraram porque não temos nada com o que compará-las. No entanto, experimentos randomizados nos permitem avaliar os efeitos causais no nível populacional. Em um experimento randomizado, os classificadores são treinados aleatoriamente em diferentes subamostras. Devido a essa distribuição aleatória dos exemplos de treinamento, os resultados de previsão dos classificadores são (em média) equivalentes, e a diferença nas previsões do classificador para exemplos específicos pode ser atribuída ao caso de os exemplos do conjunto de teste serem incluídos ou não nos exemplos de treinamento. Podemos então obter uma estimativa do efeito causal médio (também chamado de efeito médio do tratamento) calculando a diferença nos resultados médios entre as amostras tratadas (com um classificador treinado nos dados) e de controle (com um classificador não treinado nos dados).
Ou imagine que existe um multiverso e em cada um dos subuniversos vive a mesma pessoa, que toma decisões diferentes que levam a resultados diferentes. A pessoa em cada subuniverso conhece apenas sua própria versão do futuro e não conhece as opções para o futuro de seus outros "eus" em outros subuniversos.
No exemplo do multiverso, assumimos que todas as pessoas têm contrapartes em outros universos. Todas as pessoas são, em média, semelhantes. Isso significa que podemos comparar as razões para as decisões que elas tomam com os resultados dessas decisões. Assim, com base nesse conhecimento, será possível tirar uma conclusão causal sobre o que aconteceria com uma pessoa específica em outro universo se ela agisse de uma forma ou de outra que ela nunca agiu lá antes. Se, é claro, esses universos forem semelhantes.
Escada de Evidências na inferência causal
Há alguma sistematização dos métodos de inferência causal, que representa uma hierarquia de métodos de acordo com sua capacidade de evidência. Isso ajudará a descobrir qual poder de evidência nosso método escolhido terá. Abaixo estão citações do artigo, cujo link é fornecido acima.

- No primeiro degrau da escada estão os experimentos científicos típicos.
Do tipo que provavelmente te ensinaram no ensino fundamental ou até no ensino médio. Para explicar como um experimento científico deve ser conduzido, meu professor de biologia nos fez pegar sementes de uma caixa, dividir em dois grupos e plantar em dois frascos. O professor insistiu que fizéssemos as condições nos dois frascos completamente idênticas: mesmo número de sementes, mesma umidade do solo, etc. O objetivo era medir o efeito da luz no crescimento das plantas, então colocamos um de nossos frascos perto de uma janela e trancamos o outro em um armário. Duas semanas depois, todos os nossos frascos próximos à janela tinham pequenos brotos bonitos, enquanto os que deixamos no armário mal tinham crescido. A exposição à luz sendo a única diferença entre os dois frascos, explicou o professor, estávamos autorizados a concluir que a privação de luz causou o não crescimento das plantas.
Isso é basicamente o mais rigoroso que você pode ser quando deseja atribuir causa. A má notícia é que essa metodologia só se aplica quando você tem um certo nível de controle sobre seu grupo de tratamento (o que recebe luz) e seu grupo de controle (o que está no armário). Controle suficiente pelo menos para que todas as condições sejam estritamente idênticas, exceto o parâmetro que você está experimentando (luz neste caso). Obviamente, isso não se aplica às ciências sociais nem à ciência de dados.
Então por que o autor inclui isso no artigo, você pode perguntar? Bem, basicamente porque este é o método de referência. Todos os métodos de inferência causal são de certa forma hacks projetados para reproduzir essa metodologia simples em condições onde você não deveria ser capaz de tirar conclusões se seguisse estritamente as regras explicadas pelo seu professor de ciências do ensino médio.
- Experimentos Estatísticos (também conhecidos como testes A/B)
Provavelmente o método de inferência causal mais conhecido na tecnologia: testes A/B, também conhecidos como Ensaios Controlados Randomizados. A ideia por trás dos experimentos estatísticos é confiar na aleatoriedade e no tamanho da amostra para mitigar a incapacidade de colocar seus grupos de tratamento e controle nas mesmas condições exatas. Teoremas estatísticos fundamentais, como a lei dos grandes números, o teorema do limite central ou a inferência bayesiana, dão garantias de que isso funcionará e uma maneira de deduzir estimativas e sua precisão a partir dos dados que você coleta.
- Quase-Experimentos
Um quase-experimento é a situação em que seu grupo de tratamento e controle é dividido por um processo natural que não é verdadeiramente aleatório, mas pode ser considerado próximo o suficiente para calcular estimativas. Na prática, isso significa que você terá métodos diferentes que corresponderão a diferentes suposições sobre quão "próximo" você está da situação de teste A/B. Entre os exemplos famosos de experimentos naturais: usar a loteria do draft da guerra do Vietnã para estimar o impacto de ser um veterano nos seus ganhos, ou a fronteira entre Nova Jersey e Pensilvânia para estudar o efeito do salário mínimo na economia.
- Métodos Contrafactuais
Aqui abandonamos a ideia de grupos de tratamento e controle (na verdade, não completamente), e, de fato, modelamos a série temporal Y a partir de dados históricos sem a participação de X no futuro, onde X já entra em jogo. Assim, durante o experimento, podemos comparar os dados reais de Y (onde X participou) com o modelo (previsão de Y sem X) e estimar o tamanho do efeito, ajustando-o para a precisão do modelo para Y. No entanto, para que essa suposição seja próxima da verdade, precisamos fazer o maior número de testes para a estabilidade do método. O efeito resultante dependerá criticamente não apenas da qualidade do modelo, mas também, em geral, da aplicação correta do método escolhido.
Ao construir um modelo de classificação de séries temporais, só podemos usar métodos contrafactuais. Em outras palavras, precisamos inventar uma variável instrumental ou tratamento nós mesmos, aplicá-lo às nossas observações e, em seguida, realizar os testes apropriados para a estabilidade do método, que é o que faremos no futuro. Obviamente, esta é a abordagem mais complexa e tem a menor força evidencial de acordo com a Escada de Evidências.
Notação na inferência causal
Concordamos que "tratamento" T se refere a algum impacto em um objeto, seja um paciente de clínica, uma pessoa sob a influência de uma campanha publicitária ou alguma amostra do conjunto de treinamento. Então, há duas opções. Ou o sujeito recebeu tratamento ou não.

Também já sabemos que cada objeto (unidade) não pode ser tratado e não tratado ao mesmo tempo. Ou seja, pode ser uma das duas coisas.
Portanto,
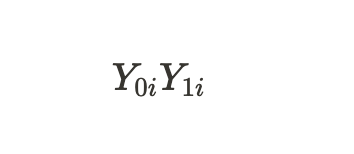
indicam os resultados potenciais para uma unidade sem tratamento e para uma unidade com tratamento. Podemos calcular o efeito do tratamento individual através da diferença desses resultados potenciais:
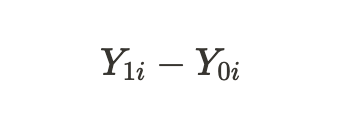
Devido ao problema fundamental da inferência causal mencionado acima, não podemos obter um efeito de tratamento individual porque apenas um dos resultados é conhecido, mas podemos calcular o efeito médio do tratamento em todos os sujeitos semelhantes, alguns dos quais receberam o tratamento enquanto outros não:
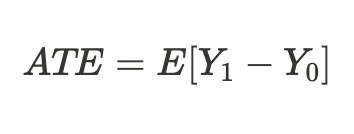
Ou podemos obter um efeito médio do tratamento apenas para unidades que foram tratadas:
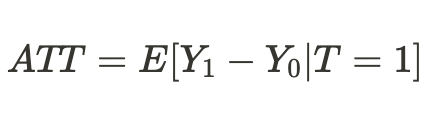
Viés
O viés é o que distingue correlação (associação) de causalidade (causa e efeito). E se, em outro universo, nossos "eus" se encontrassem em condições de existência completamente diferentes, e os resultados das decisões que eles tomassem não corresponderiam mais aos que estamos acostumados neste universos Então, as conclusões sobre os possíveis resultados se revelariam errôneas, e as suposições seriam apenas associativas, mas não relacionamentos causais.
Isso também é verdade para classificadores treinados quando eles param de lucrar com novos dados que não viram antes ou simplesmente param de prever corretamente.
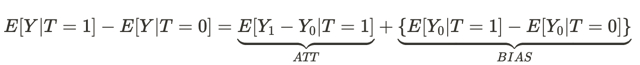
Esta equação responde à pergunta de por que um relacionamento associativo não é um causal. O viés aqui é o quão diferentes são as condições de vida das pessoas em diferentes universos antes de terem qualquer efeito em ambos os universos. Isso ocorre porque existem muitas outras variáveis que influenciam o resultado da decisão que eles tomam. Como resultado, as populações de pessoas em um universo e em outro diferem não apenas nas diferentes decisões tomadas, mas também nas diferentes condições de existência.
Acontece que, se as condições de nossa existência em diferentes universos se mostrassem comparáveis, então nossa conclusão sobre os resultados de nossas ações (em média) em outro universo se revelaria causal:
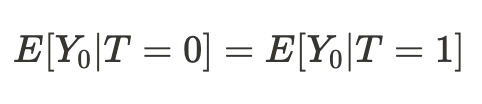
Consequentemente, a diferença de médias agora se torna o efeito causal médio:
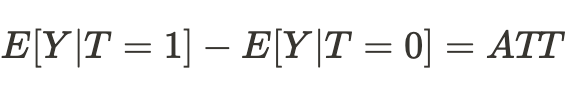
Podemos simplesmente concluir que, para estimar um efeito causal, uma amostra de um universo deve ser comparável a uma amostra de outro universo. Se for assim, então seremos capazes de determinar a verdadeira relação e, com um alto grau de probabilidade, seremos capazes de prever o resultado das ações de nossos "eus" em outro universo.
Em outras palavras, uma associação se torna uma relação causal quando o viés é igual a zero.
Traduzindo o acima para termos de aprendizado de máquina, geralmente lidamos com dados de treinamento e validação, bem como dados de teste. O modelo de treinamento da máquina aprende usando dados de treinamento com participação parcial dos dados de validação. Se as subamostras forem comparáveis, teremos aproximadamente os mesmos erros de previsão nos dados de treinamento e validação. Se as subamostras diferirem por um viés condicional, o erro de previsão nos dados de validação será maior. Sem mencionar a subamostra de teste, cuja distribuição de dados pode não ser de todo semelhante às distribuições das duas primeiras.
Mas como podemos então fazer uma inferência causal se as distribuições das subamostras forem diferentes? A resposta já foi parcialmente dada na seção anterior: podemos fazer inferências causais através de experimentos randomizados.
Experimentos randomizados
Como já ficou claro, a randomização nos permite dividir os dados aleatoriamente em grupos, um dos quais recebeu "tratamento" (no nosso caso, treinamento de modelo), enquanto o outro não. Além disso, devemos fazer isso várias vezes e treinar muitos modelos Isso é necessário para eliminar o viés de nossas estimativas. Randomizar e treinar vários classificadores remove a dependência de resultados potenciais de um modelo específico de aprendizado de máquina.
Isso pode ser um pouco confuso a princípio. Podemos pensar que a falta de dependência de resultados (previsões) de um modelo particular torna o treinamento desse modelo inútil. Do ponto de vista das previsões desse modelo particular, a resposta é sim. No entanto, estamos lidando com resultados potenciais (previsões).
Resultado potencial é o que o resultado seria se o modelo fosse treinado ou não treinado. Em experimentos randomizados, não queremos que o resultado (previsão) seja independente do treinamento, pois o treinamento do modelo afeta diretamente o resultado.
Mas queremos que os resultados potenciais sejam independentes do treinamento de qualquer classificador específico, que é tendencioso!
Dizendo isso, queremos dizer que queremos que os resultados potenciais sejam os mesmos para os grupos de controle e de teste. Nossos dados de treinamento e teste precisam ser comparáveis porque queremos remover o viés das estimativas. as cada classificador individual dá pesos diferentes a diferentes exemplos de treinamento, mesmo que estejam misturados, o que torna a quantidade de tratamento diferente para cada observação. Isso complica a inferência causal.
A randomização dos exemplos de treinamento nos permite avaliar o efeito do tratamento (treinamento) obtendo a diferença nos erros do modelo nas amostras de teste e treinamento. No entanto, no caso de classificação, as características dos algoritmos de aprendizado de máquina devem ser levadas em consideração. Nesse caso, a estimativa do efeito ainda é tendenciosa porque cada classificador individual é treinado em metade ou mais dos exemplos originais, dando a cada exemplo pesos diferentes (tratamento). Usando vários classificadores (um conjunto deles), minimizamos o viés ao fazer a média das pontuações dos classificadores, tornando o tratamento mais igual para cada unidade. Isso coloca todos os exemplos de treinamento nas mesmas condições, dando-lhes o mesmo valor.
Nesta seção, aprendemos que experimentos randomizados ajudam a remover o viés dos dados para fazer inferências causais mais confiáveis. Conjuntos de modelos nos ajudam a dar estimativas equivalentes do efeito do treinamento.
Correspondência
Experimentos randomizados nos permitem estimar o efeito médio do treinamento de um conjunto de modelos. No entanto, estamos interessados em obter efeitos individuais para cada exemplo de treinamento. Isso é necessário para entender em quais situações a estratégia de negociação, em média, traz lucro e quais situações devem ser ajustadas ou excluídas da negociação. Em outras palavras, queremos obter estimativas condicionais dos efeitos do treinamento, dependendo das características individuais de cada objeto.
A correspondência é uma maneira de comparar amostras individuais da amostra total para garantir que sejam semelhantes em todas as outras características, exceto se foram incluídas no conjunto de treinamento ou não. Isso nos permite derivar pontuações individuais para cada exemplo de treinamento.
Há correspondência exata e imprecisa (aproximada).
Na correspondência grosseira, por exemplo, podemos comparar todas as unidades com base em critérios de proximidade, como distância Euclidiana, bem como distâncias de Minkowski e Mahalanobis. Mas como estamos lidando com séries temporais, temos a opção de comparar unidades posicionalmente, por tempo. Se treinarmos um conjunto de modelos, então as previsões de cada modelo em qualquer momento já estão associadas ao conjunto de características presentes naquele ponto na linha do tempo. Tudo o que temos a fazer é comparar as previsões de todos os modelos para um ponto específico no tempo. A complexidade computacional de tal comparação é mínima em comparação com outros métodos, o que permitirá mais experimentos. Além disso, isso será uma correspondência precisa.
Incerteza
Na negociação algorítmica, não é suficiente para nós determinar os efeitos médios e individuais do tratamento, porque queremos construir o modelo de classificador final. Precisamos aplicar ferramentas de inferência causal para estimar a incerteza no conjunto de dados e dividir as unidades em aquelas que respondem ao tratamento condicional (treinamento de um classificador) e aquelas que não respondem. Em outras palavras, aquelas que, na grande maioria dos casos, são corretas e incorretamente. Dependendo do grau de incerteza, que é calculado como a soma das diferenças entre os resultados potenciais para todos os modelos.
Como estamos estimando a incerteza dos dados do ponto de vista do classificado, as ordens de compra e venda serão avaliadas separadamente, pois sua distribuição conjunta irá confundir a estimativa final.
Meta learners
Meta learners em inferência causal são modelos de aprendizagem de máquina que ajudam a estimar efeitos causais.
Já nos familiarizamos com os conceitos de ATE e ATT, que fornecemos informações sobre o efeito causal médio em uma população. No entanto, é importante lembrar que pessoas e outros organismos complexos (por exemplo, animais, grupos sociais, empresas ou países) podem responder de maneira diferente ao mesmo tratamento. Quando lidamos com uma situação como essa, a ATE pode ocultar informações importantes de nós.
Uma solução para esse problema é calcular o CATE (efeito médio condicional do tratamento), também conhecido como HTE. Ao calcular o CATE, não olhamos apenas para o tratamento, mas para um conjunto de variáveis que definem as características individuais de cada unidade que podem alterar como o tratamento afeta o resultado.
No caso de tratamento binário, o CATE pode ser definido como:
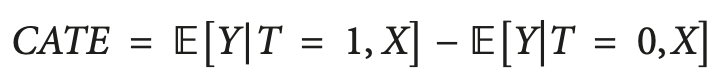
onde X são as características que descrevem cada objeto individual (unidade). Assim, fazemos uma transição de um efeito de tratamento homogêneo para um heterogêneo.
A ideia de que pessoas ou outras unidades podem reagir de maneira diferente ao mesmo tratamento é frequentemente representada na forma de uma matriz, às vezes chamada de matriz de elevação, que você pode ver na figura.
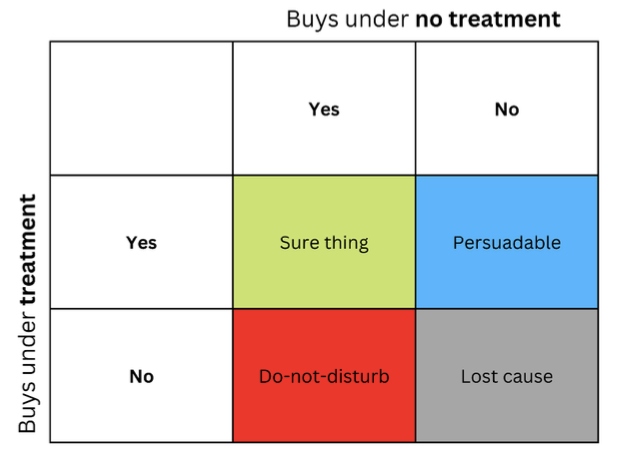
As linhas representam a resposta ao conteúdo quando a mensagem (como um anúncio) é enviada ao destinatário. As colunas representam respostas quando nenhum tratamento é dado.
As quatro células coloridas representam a dinâmica do efeito do tratamento. Compradores confiantes (verde) compram independentemente do tratamento. Os vermelhos (Não Perturbe) podem comprar sem tratamento, mas não comprarão se tratados. Aqueles que perderam o interesse (cinza) não comprarão independentemente do status do tratamento, e os azuis não comprarão sem tratamento, mas podem comprar se participarem.
Se você é um profissional de marketing com orçamento limitado, convém focar o marketing no grupo azul (Persuadíveis) e evitar o marketing para o grupo vermelho (Não Perturbe), se possível.
O marketing nos grupos "Caso Certo" e "Causa Perdida" não causará prejuízo direto, mas também não fornecerá nenhum benefício.
Da mesma forma, se você for um médico, gostaria de prescrever um medicamento para pessoas que possam se beneficiar dele e evitar prescrevê-lo para aqueles que possam ser prejudicados por ele. Em muitos cenários do mundo real, uma variável de resultado pode ser probabilística (por exemplo, a probabilidade de uma compra) ou contínua (por exemplo, o valor do gasto). Nesses casos, não podemos identificar grupos discretos e focar em encontrar unidades com o maior aumento esperado na variável de resultado entre as condições sem tratamento e com tratamento. Essa diferença entre o resultado com tratamento versus sem tratamento é às vezes chamada de uplift.
Traduzindo isso para a linguagem de classificação de séries temporais, precisamos determinar quais exemplos do conjunto de treinamento respondem melhor ao tratamento (treinamento do classificador) e colocá-los em um grupo separado.
Uma maneira simples de estimar um efeito de tratamento heterogêneo é construir um modelo substituto que preveja a variável de tratamento com base nos preditores que você usa, formalmente representado como segue:
T ~ X
O desempenho desse modelo deve ser essencialmente aleatório. Se não for aleatório, isso significa que o tratamento depende das características, ou que significa que há alguma variável ausente que não consideramos, e isso afeta nossas inferências causais, introduzindo confusão. Isso geralmente acontece devido ao mau design de testes controlados aleatoriamente, onde o tratamento não é realmente direcionado aleatoriamente.
S-Learner
S-Learner é o nome de uma abordagem simples para modelagem de CATE. O S-Learner pertence à categoria dos chamados meta-alunos. Note que meta aprendizes causais não estão diretamente relacionados ao conceito de meta aprendizado usado no aprendizado de máquina tradicional. Eles usam um ou mais modelos básicos (tradicionais) de aprendizado de máquina e os usam para calcular o efeito causal. Em geral, você pode usar qualquer modelo de aprendizagem de máquina de complexidade suficiente (árvore, rede neural, etc.) como um aluno básico para ser compatível com seus dados.
O S-Learner é o metamodelo mais simples que usa apenas um learner básico (daí seu nome: S(ingle)-Learner). A ideia por trás do S-Learner é surpreendentemente simples: treinar um modelo no conjunto de dados completo de treinamento, incluindo a variável de tratamento como uma característica, prever ambos os resultados potenciais e subtrair os resultados para obter o CATE.
Após o treinamento, o procedimento passo a passo de previsão para o S-Learner é o seguinte:
- Selecione a observação de interesse.
- Defina o valor do tratamento para essa observação como 1 (ou Verdadeiro).
- Preveja o resultado usando o modelo treinado.
- Pegue a mesma observação novamente.
- Desta vez, defina o valor do tratamento como 0 (ou Falso).
- Faça uma previsão.
- Subtraia o valor de previsão sem tratamento do valor de previsão com tratamento.
T-Learner
A principal motivação do T-Learner é superar as principais limitações do S-Learner. Se o S-Learner pode aprender a ignorar o tratamento, por que não torná-lo impossível de ignorar?
É exatamente isso que o T-Learner faz. Em vez de ajustar um modelo a todas as reclamações (tratadas e não tratadas), agora ajustamos dois modelos — um apenas para as unidades tratadas e um apenas para as unidades não tratadas.
De certa forma, isso é equivalente a forçar a primeira divisão em um modelo baseado em árvore a ser uma divisão pela variável de tratamento.
O processo de aprendizagem do T-Learner é o seguinte:
- Divida os dados pela variável de tratamento em dois subconjuntos
- Treine dois modelos - um em cada subconjunto.
- Para cada observação, veja os resultados usando ambos os modelos.
- Subtraia os resultados do modelo sem tratamento dos resultados do modelo com tratamento.
Observe que agora não há chance de que os tratamentos sejam ignorados porque codificamos a divisão do tratamento como dois modelos separados.
O T-Learner foca em melhorar apenas um aspecto onde o S-Learner pode (mas não precisa) falhar. Essa melhoria tem um custo. Ajustar dois algoritmos a dois subconjuntos diferentes de dados significa que cada algoritmo é treinado com menos dados, o que pode reduzir a qualidade do ajuste.
Isso também torna o T-Learner menos eficiente em termos de uso de dados (precisamos de duas vezes mais dados para treinar cada aluno básico do T-Learner para produzir uma representação em qualidade ao S-Learner). Isso geralmente resulta em uma variação maior na pontuação do T-Learner em comparação com a do S-Learner. Em particular, a variação pode se tornar muito grande nos casos em que um grupo de tratamento tem muito menos observações do que o outro.
Em particular, a variação pode se tornar muito grande nos casos em que um grupo de tratamento tem muito menos observações do que o outro. Uma coisa a ter em mente é que este meta learner é geralmente mais intensivo em dados do que o S-Learner, mas a diferença diminui à medida que o tamanho geral do conjunto de dados aumenta.
X-Learner
O X-Learner é um meta-aprendizado projetado para fazer uso mais eficiente das informações disponíveis nos dados.
X-Learner busca estimar o CATE diretamente e, ao fazer isso, utiliza informações que o S-Learner e o T-Learner descartaram anteriormente. Que tipo de dados são esses? S-Learner e T-Learner estudaram o que é chamado de função de resposta, ou como as unidades respondem ao tratamento (em outras palavras, a função de resposta é o mapeamento da característica X e do tratamento T para o resultado y). Ao mesmo tempo, nenhum dos modelos usou o resultado real para simular o CATE.
- O primeiro passo é simples, e você já o conhece. Isso é exatamente o que fizemos com o T-Learner. Dividimos nossos dados pela variável de tratamento para obter dois subconjuntos separados: o primeiro contendo apenas as unidades que receberam o tratamento, e o segundo contendo apenas as unidades que não receberam o tratamento. Em seguida, treinamos dois modelos: um em cada subconjunto.
- Introduzimos um modelo adicional chamado "modelo de escore de propensão" (no caso mais simples, é a regressão logística) e o treinamos para prever o tratamento para as características X.
- Em seguida, calculamos o efeito do tratamento e treinamos dois modelos nas características e nos valores do CATE.
- Os resultados do uso dos dois modelos são adicionados com o peso obtido do escore de propensão do modelo.
Por outro lado, se o seu conjunto de dados for muito pequeno, o X-Learner pode não ser a melhor escolha, pois cada modelo adicional vem com ruído adicional ao ajustar, e podemos não ter dados suficientes para usar esse modelo. Nesse caso, o S-Learner é mais adequado.
Existem meta learners mais avançados. Eu não vou usá-los, então não há muito sentido em discuti-los neste breve artigo. Estes são o aprendizado de máquina Desviesado/ortogonal e o R-learner, que você pode estudar por conta própria.
Conclusão sobre os meta learners existentes
Os algoritmos propostos, apesar de uma parte teórica bastante extensa, são apenas estimadores do efeito CATE. A literatura sobre inferência causal dificilmente aborda todo o ciclo de detecção e avaliação dos efeitos do tratamento, a menos que sejam casos muito óbvios, e a situação com a implementação dos modelos resultantes em processos de negócios também é bastante fraca. É afirmado que cabe ao pesquisador formular os experimentos e, em seguida, usar esses estimadores. Decidi ir um pouco além e incorporei elementos desses estimadores na criação de um sistema de negociação, que ocorre automaticamente. Os sinais e rótulos são fornecidos na entrada e saída do algoritmo, como antes, então o algoritmo tenta identificar relações causais na parte dos dados onde isso é possível e excluir o restante da lógica de tomada de decisões de negociação.
Implementação da função meta learner para construir um algoritmo de negociação.
Munido do mínimo necessário de conhecimento, proponho considerar meu próprio algoritmo. Muitos experimentos foram realizados com diferentes meta learners e maneiras de usá-los para analisar efeitos causais. No momento, o algoritmo proposto é um dos melhores do arsenal, embora possa ser melhorado.
Como determinamos que não é prático usar um único classificador, que é tendencioso, para avaliar os resultados potenciais, o primeiro argumento da função é um número especificado de classificadores. Usei o algoritmo CatBoost. Em seguida, vêm os hiperparâmetros do aprendiz, como o número de iterações e a profundidade da árvore, bem como a bad_samples_fraction - um parâmetro conhecido desde o primeiro artigo dedicado aos meta learners. Esta é a porcentagem de exemplos mal classificados que devem ser excluídos do conjunto de treinamento final. Devemos tentar não negociar nesses momentos.
BAD_BUY e BAD_SELL são coleções de índices de maus exemplos que são reabastecidos a cada iteração.
A cada nova iteração, cujo número é igual ao número especificado de aprendizes, o conjunto de dados é dividido em subamostras de treinamento e validação aleatoriamente em uma proporção dada (aqui é 50/50). Isso impede que cada algoritmo individual superestime. A partição aleatória permite que cada classificador seja treinado e validado em subamostras exclusivas, enquanto todo o conjunto de dados é usado para produzir estimativas. Isso elimina o viés nas estimativas, permitindo-nos avaliar com mais precisão quais exemplos são realmente pouco suscetíveis ao tratamento (treinamento do classificador).
Após cada treinamento, os rótulos de classe reais são comparados com os previstos. Os rótulos previstos incorretamente juntam-se às coleções de maus exemplos. Esperamos que, à medida que o número de classificadores aumenta, as estimativas de amostras realmente ruins se tornem menos tendenciosas.
Depois que as coleções de maus exemplos são formadas, calculamos o número médio de amostras ruins em todos os índices. Depois disso, selecionamos aqueles índices nos quais o número de maus exemplos excede a média por uma certa quantidade. Isso nos permite variar o número de maus exemplos incluídos no treinamento do modelo final, pois com um grande número de re-treinamentos há uma probabilidade de que cada índice caia em maus exemplos pelo menos uma vez. Nesse caso, acaba que todos os exemplos serão excluídos do conjunto de treinamento final, então esse algoritmo não funcionará.
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float): dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] BAD_BUY = pd.DatetimeIndex([]) BAD_SELL = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] diff_negatives_b = coreset_b['labels'] != coreset_b['labels_pred'] diff_negatives_s = coreset_s['labels'] != coreset_s['labels_pred'] BAD_BUY = BAD_BUY.append(diff_negatives_b[diff_negatives_b == True].index) BAD_SELL = BAD_SELL.append(diff_negatives_s[diff_negatives_s == True].index) to_mark_b = BAD_BUY.value_counts() to_mark_s = BAD_SELL.value_counts() marked_idx_b = to_mark_b[to_mark_b > to_mark_b.mean() * bad_samples_fraction].index marked_idx_s = to_mark_s[to_mark_s > to_mark_s.mean() * bad_samples_fraction].index data.loc[data.index.isin(marked_idx_b), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_s), 'meta_labels'] = 0.0 return data[data.columns[1:]]
As funções restantes não foram alteradas e são descritas no artigo anterior. Você pode baixá-las lá, enquanto a função meta learner pode ser substituída pela proposta. No restante deste artigo, focaremos nos experimentos e tentaremos tirar conclusões finais.
Testando o algoritmo de inferência causal
Vamos supor que usamos otimização genética de estratégias de negociação de acordo com algum critério (a chamada função de aptidão). Estamos interessados não apenas no melhor resultado de otimização, mas também em garantir que os resultados de todas as passagens, em média, sejam bons. Se a estratégia de negociação for ruim ou a variação dos parâmetros for muito grande, haverá um grande número de passagens de otimização com resultados insatisfatórios, o que afetará negativamente a estimativa média. Gostaríamos de evitar isso, então treinaremos nosso algoritmo muitas vezes, depois faremos a média dos resultados e compararemos o melhor resultado com a média.
Para isso, escrevi uma modificação de um testador personalizado que testa todos os modelos treinados da lista de uma só vez:
def test_all_models(result: list): pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] pr_tst['labels'] = 0.5 pr_tst['meta_labels'] = 0.5 for i in range(len(result)): pr_tst['labels'] += result[i][1].predict_proba(X)[:,1] pr_tst['meta_labels'] += result[i][2].predict_proba(X)[:,1] pr_tst['labels'] = pr_tst['labels'] / (len(result)+1) pr_tst['meta_labels'] = pr_tst['meta_labels'] / (len(result)+1) pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(pr_tst, plot=plt)
Agora faremos inferência causal 25 vezes (treinaremos 25 modelos independentes, altamente randomizados em termos de divisão aleatória em subamostras):
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(15, 25, 2, 0.3)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
test_all_models(options) Primeiro, vamos testar o melhor modelo de acordo com a versão R^2:
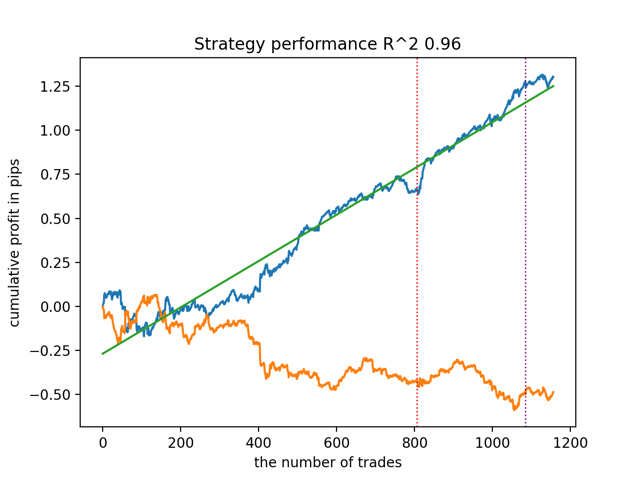
Agora vamos testar todos os modelos de uma vez:
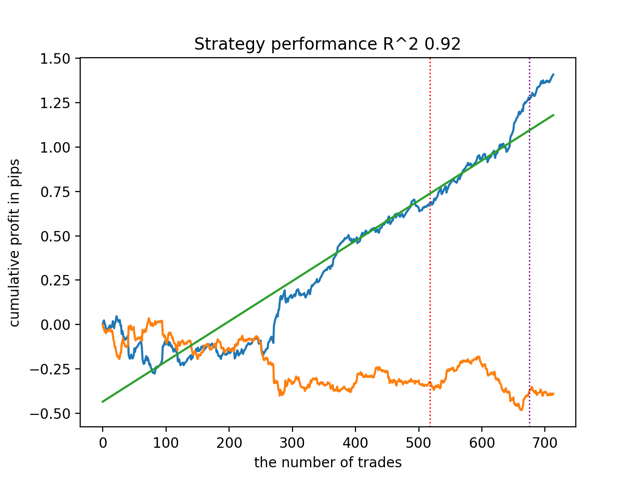
O resultado médio não é muito diferente do melhor. Isso significa que, no decorrer de um experimento randomizado controlado, é possível se aproximar das verdadeiras relações causais.
Vamos treinar e testar o algoritmo com outros parâmetros de entrada do meta learner.
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(5, 10, 1, 0.4)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
test_all_models(options) Os resultados são os seguintes:
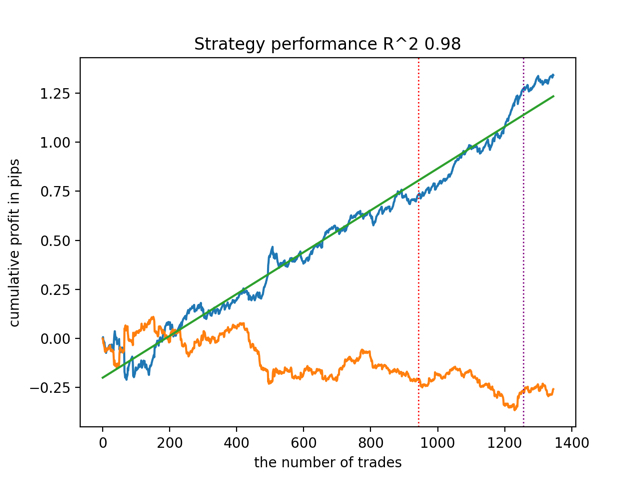
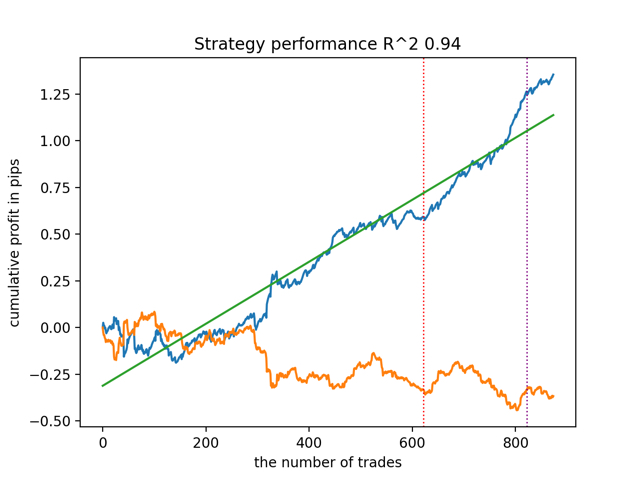
Também foi notado que a profundidade do histórico de treinamento (destacada por linhas verticais nos gráficos) afeta a qualidade dos resultados, assim como o número de características e outros hiperparâmetros dos modelos (o que, em geral, não é surpreendente), enquanto a variação na qualidade dos modelos permanece pequena. Acredito que a estabilidade resultante é uma propriedade ou característica importante do algoritmo proposto, o que nos permite ter uma confiança adicional na qualidade das estratégias de negociação resultantes.
Resumo
Este artigo apresentou a você os conceitos básicos de inferência causal. Este é um tópico bastante amplo e complexo para cobrir todos os seus aspectos em um único artigo. A inferência causal e o pensamento causal têm suas raízes na filosofia e psicologia e desempenham um papel importante na nossa compreensão da realidade. Portanto, grande parte do que é escrito é bem percebido em um nível intuitivo. No entanto, sendo um pouco agnóstico, tentei dar um exemplo prático e ilustrativo para demonstrar o poder da chamada inferência causal em problemas de classificação de séries temporais. Você pode usar este algoritmo para conduzir vários experimentos. Basta substituir algumas funções no código apresentado no artigo anterior. Os experimentos não terminam aqui. Talvez novas informações interessantes apareçam, que mais tarde compartilharei com você.
Referências úteis
- Aleksander Molak "Causal inference and discovery in Python"
- Matheus Facure "Causal inference for the Brave and True"
- Miguel A. Hernan, James M. Robins "Causal inference: What If"
- Gabriel Okasa "Meta-learners for estimation of causal effects: finite sample cross-fit performance"
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13957
 Compreendendo os Paradigmas de Programação (Parte 2): Uma Abordagem Orientada a Objetos para Desenvolver um Expert Advisor de Ação de Preço
Compreendendo os Paradigmas de Programação (Parte 2): Uma Abordagem Orientada a Objetos para Desenvolver um Expert Advisor de Ação de Preço
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso